
Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors





Abstract
:1. Introduction
- 1.
- Identifying multiple concurrent noise sources that populate a given soundscape. Typically, in real-world environments, several sounds occur simultaneously. This complicates the task of building a reliable automatic sound classifier system specialized in identifying a predefined set of acoustic events [13].
- 2.
- Monitoring large-scale urban areas in a cost-effective way. Populating (with either automatic devices or human resources) extensive urban environments requires a considerable amount of resources. For instance, it has been reported [12] that the Department of Environmental Protection from New York City employs about 50 highly qualified sound inspectors. In addition, the starting price of autonomous nodes to continuously monitoring sound is usually around EUR 1000 [14].
- 3.
- Real-time processing. Although continuous exposure to noise is harmful, short-term exposure to sporadic noise shall not be neglected. In fact, sometimes noise violations are sporadic (i.e., they last a few minutes or hours at most). Therefore, human-based noise complaint assessment systems result in being ineffective due to the fact that technicians may arrive way after the disturbance has finished [12]. Furthermore, the large amount of data to be processed by autonomous acoustic sensors may make this kind of approach challenging.
- A new real-world 5 h length dataset (containing concurrent events) recorded simultaneously at four spots from a street intersection. This results in 4 × 5 h of acoustic data. A total of 5 h of audio data corresponding to 1 spot have been manually annotated. To the best of our knowledge, this is the first dataset with these characteristics.
- A software-assisted strategy to reduce the number of user interactions when labelling acoustic data to reduce the amount of time spent on this task.
- A two-stage acoustic classifier aimed at increasing the local classification robustness by taking into consideration the classification results of neighboring nodes (i.e., exploiting the nodes’ physical redundancy).
2. Related Work
2.1. Commercial Sensor Networks
2.2. Ad Hoc Developed Acoustic Sensor Networks
2.3. Sensor Deployment Strategies
3. Collection and Annotation of a Real-World Dataset
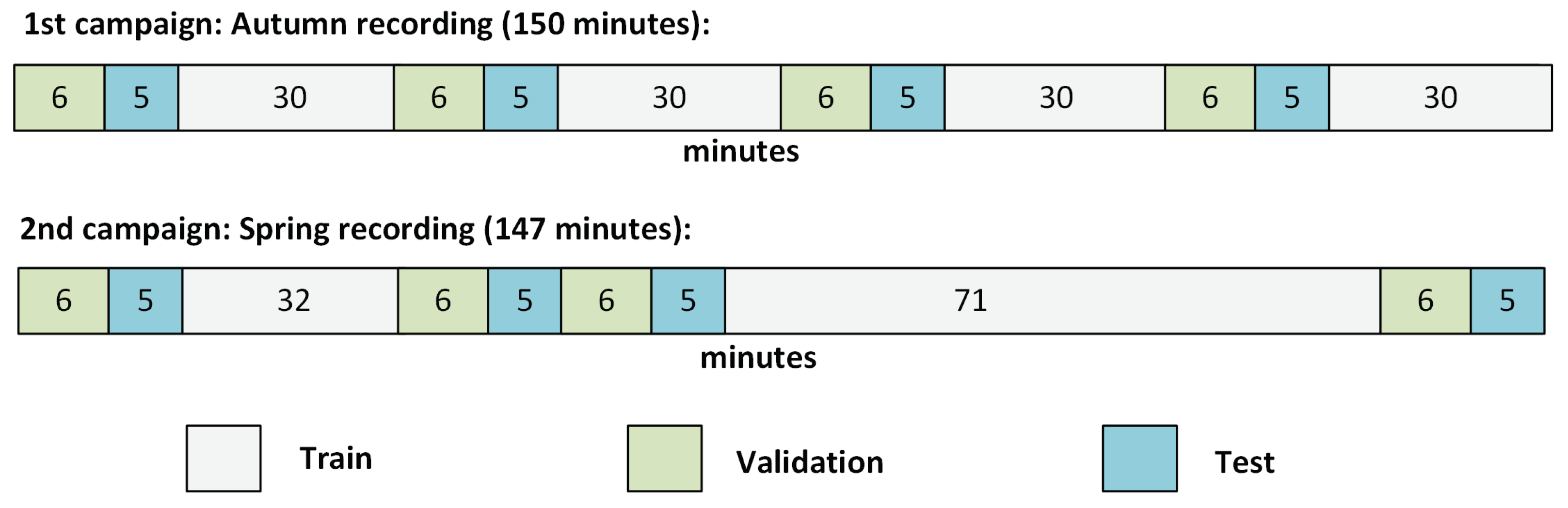
3.1. Recording Campaign
3.2. Data Labeling
- Input. The script reads the .wav files coming raw from the Zoom H5 recorders. This done with the module AudioSegment of the pydub library. This module loads the whole audio is input into a vector, which results in a very convenient solution when windowing it.
- Configuration file. Moreover, the script reads a configuration JSON file specifying (1) the window size in which the .wav file will be split, (2) all the possible labels that may appear in the recording, and (3) a key (one letter long) associated with each possible label.
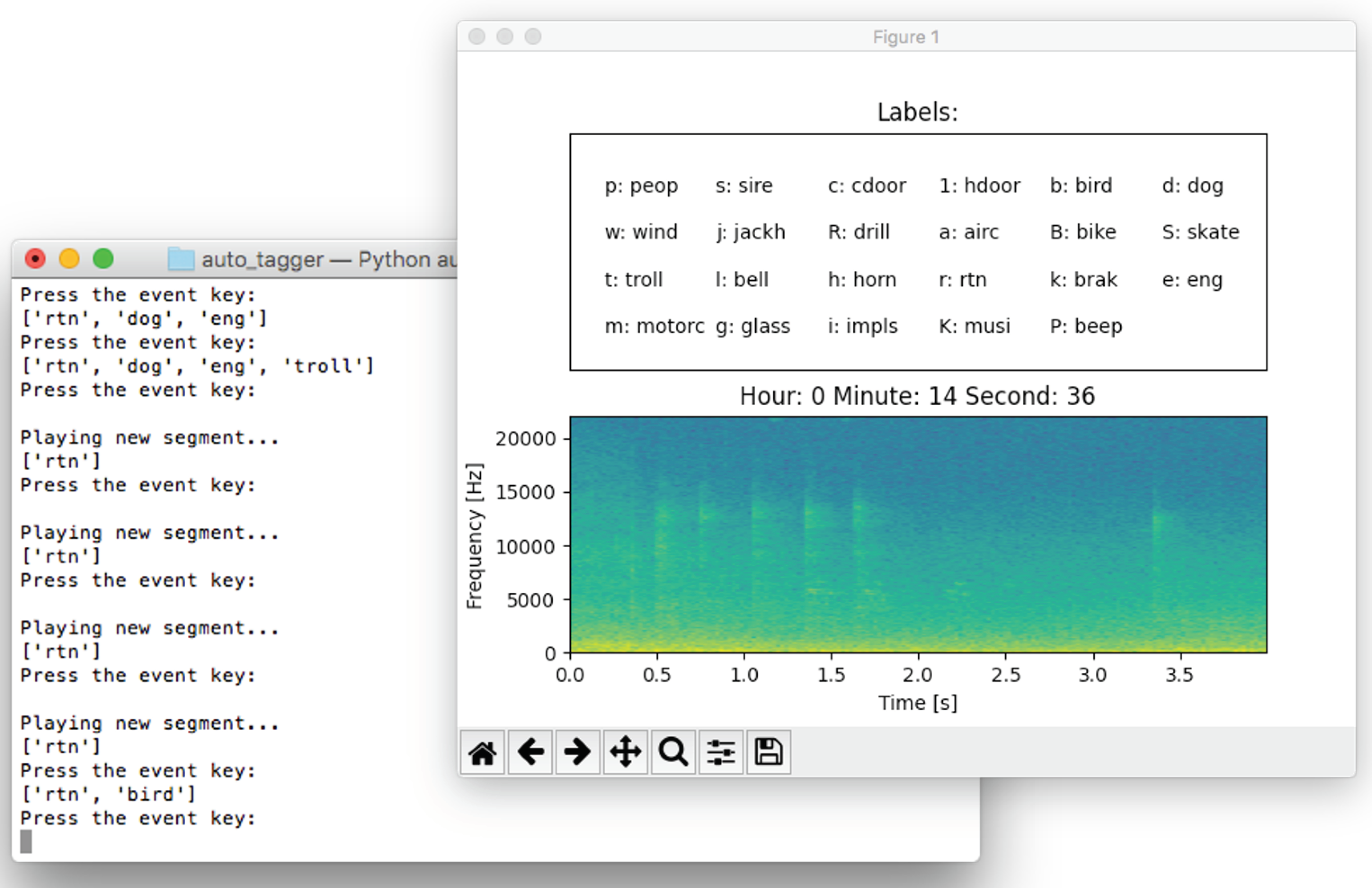
- User interaction. As shown in Figure 2, the script (1) displays a screen with the spectrogram—using the pyplot module of the matplotlib library—of the current window together with its start and finish times, (2) continuously reproduces the audio associated to the current window using the pyaudio library, and (3) shows the possible labels together with their associated keys in another screen. Then, each time the user presses a key corresponding to a label, the label is aggregated to the vector of labels associated with the current window. If the same key was pressed again, that event would be removed from the vector. Furthermore, the user can go to the following or previous acoustic window by using the arrow keys. Note that in this way, the user has a single interaction device (i.e., keyboard) and typos in labels are not possible.
- Output. The script writes a .csv file with (1) the start time of the window, (2) the finish time of the window, and (3) all the tags that have been selected for that window. For instance, a line in this .csv file would appear as follows:276.000000 280.000000 bike+dog+troll
280.000000 284.000000 bike+glass
284.000000 288.000000 dog+peop+drill
As a result, each line of the labels file derived from a recording contains the starting and ending time of the window and the different labels assigned to (i.e., appearing) that fragment.
3.3. Obtained Dataset
3.4. Train/Validation/Test Split
4. Two-Stage Multilabel Classifier
4.1. Feature Extraction
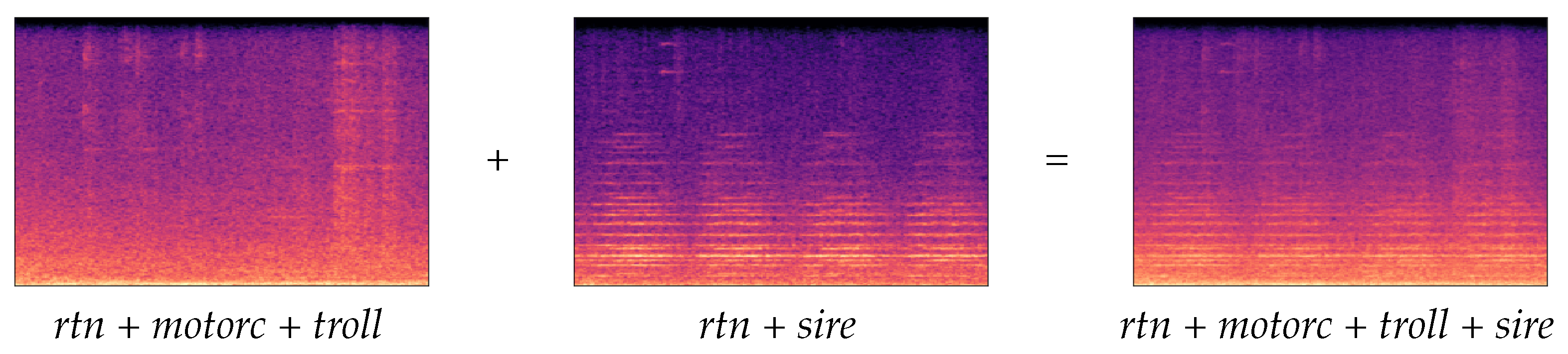
4.2. Data Augmentation
4.3. Multilabel Classification
- 1.
- The first layer (Section 4.3.1) is a Deep Neural Network (DNN) that classifies 4-s fragments in a single node.
- 2.
- The second layer (Section 4.3.2) aggregates the classification results of the deep neural networks running on the four corners of the intersection and makes a final decision on what events are actually happening on each corner by means of an ensemble of classifiers.
4.3.1. First Stage: Classification in One Node
4.3.2. Second Stage: Classification Using Physical Redundancy
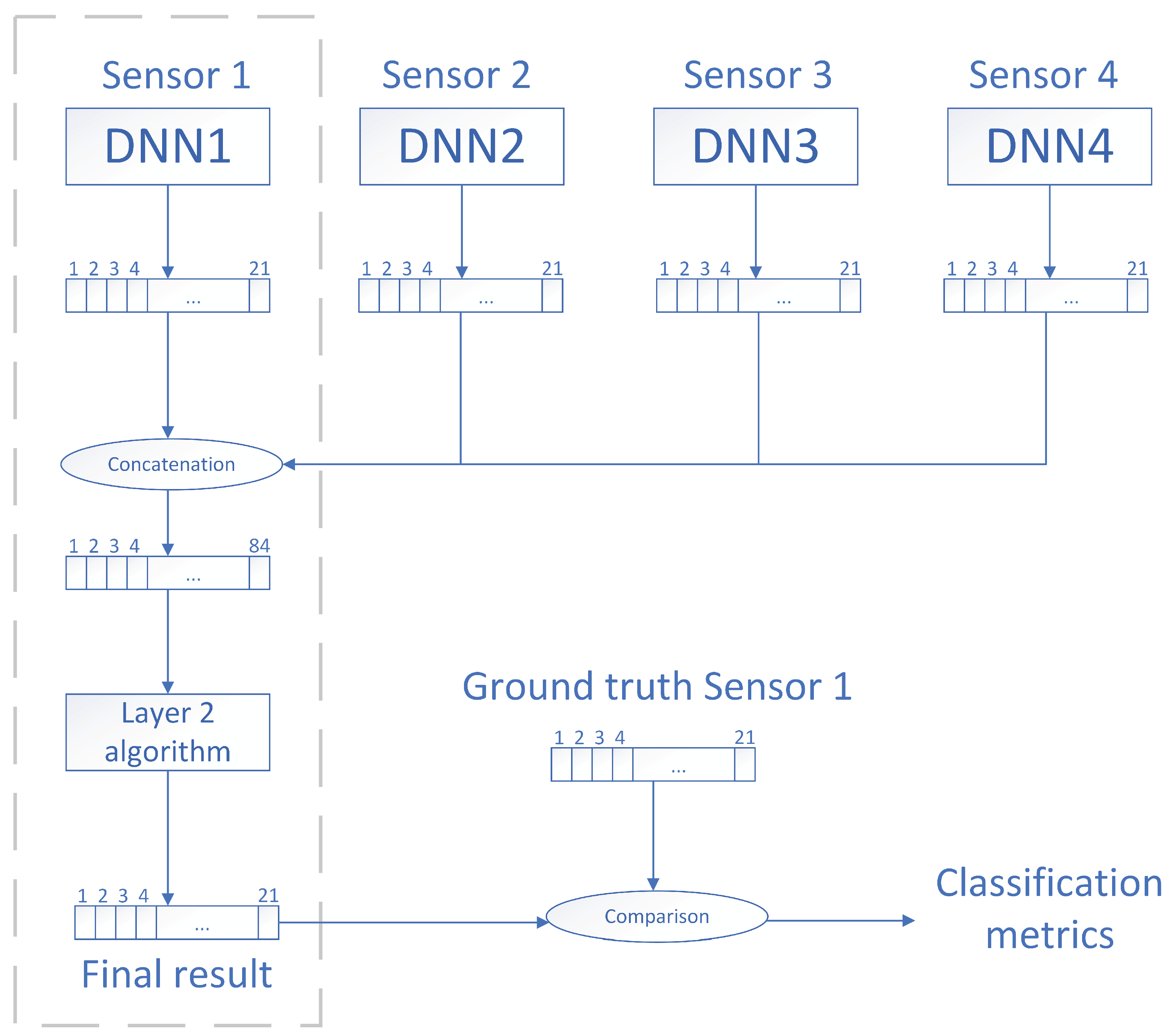
- 1.
- Once the deep neural network was trained, we used it to obtain a 21-component classification vector per each of the 4-s fragments of the original Eixample Dataset (see Section 3). Each component of the vector indicated the likelihood of an acoustic event being present on the fragment. The labels from the dataset associated with each fragment were kept as ground truth.
- 2.
- The previous stage was done with the simultaneous audio of the remaining three neighboring locations. Therefore, for each 4-s fragment of the Eixample Dataset, we obtained four 21-component vectors together with the ground-truth labels.
- 3.
- The four vectors were concatenated horizontally, thus obtaining a single 84-component vector.
- 4.
- The 84-component vector and ground truth labels were used to fit a machine learning model that would output the final classification results.
5. Experimental Evaluation
5.1. Classification Performance at the First Stage
- Experiment 0: We used the Training set of the Eixample Dataset and the entire BCNDataset without using data augmentation techniques.
- Experiment 1: We used the Training set of the Eixample Dataset and the entire BCNDataset using the data augmentation techniques detailed in Section 4.2 to have around 500 samples for each class.
- Experiment 2: We used the same data as in Experiment 1 and we also added data from the UrbanSound 8K dataset [43]. The sampling frequency of most of the audio files of the UrbanSound dataset is lower than the one used on the recording campaign (i.e., 44,100 Hz). In order to avoid having half of the spectrogram empty for the UrbanSound samples, each audio file was combined with an audio file from Experiment 1 using mix-up aggregation (that is, two spectrograms are aggregated, each of them having a different weight on the final image). Concretely, the audio files from the UrbanSound 8K dataset were only assigned between a random 10% to 30% on the final weight of the spectrogram.
- Experiment 3: We used the same data as in Experiment 2, but on this occasion, each audio file from the UrbanSound dataset was used 10 times to combine it with a different audio file randomly selected from the BCNDataset or the Eixample dataset. This way, we increased the size of the Training data.
5.2. Classification Performance at the Second Stage
- 1.
- Decision Tree (DT): The size of the model after training was 617 KB.
- 2.
- Random Forest (RF): The size of the model after training was 121 MB.
- 3.
- Logistic Regressor (LR): The size of the model after training was 20 KB.
- 4.
- XGBoost (XGB): The size of the model after training was 2.3 MB.
- Raspberry Pi Model 2B: Broadcom BCM2836 SoC (ARMv7), Quad-core ARM Cortex-A7, @ 900 MHz, 1GB LPDDR2 of RAM.
- Raspberry Pi model 3B+: Broadcom BCM2837B0 SoC (ARMv8), Cortex-A53, 64-bit @ 1.4GHz, 1GB LPDDR2 SDRAM.
- Raspberry Pi model 4: Broadcom BCM2711 SoC (ARMv8), Quad-core Cortex-A72 64-bit @ 1.5GHz, 4GB LPDDR4-3200 SDRAM.
6. Discussion
6.1. Location Perspective
6.2. Accuracy and Sample Availability
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DNN | Deep Neural Network |
| DT | Decision Tree |
| EEA | European Environment Agency |
| EU | European Union |
| LR | Logistic Regressor |
| RF | Random Forest |
| UASN | Underwater Acoustic Sensor Networks |
| WASN | Wireless Acoustic Sensor Network |
| XGB | XGBoost |
| WHO | World Health Organization |
References
- Moudon, A.V. Real noise from the urban environment: How ambient community noise affects health and what can be done about it. Am. J. Prev. Med. 2009, 37, 167–171. [Google Scholar] [CrossRef]
- Hurtley, C. Night Noise Guidelines for Europe; WHO Regional Office Europe: Bonn, Germany, 2009. [Google Scholar]
- World Health Organization. Environmental Health Inequalities in Europe: Second Assessment Report; World Health Organization; Regional Office for Europe: Bonn, Germany, 2019. [Google Scholar]
- World Health Organization. Burden of Disease from Environmental Noise: Quantification of Healthy Life Years Lost in Europe; World Health Organization; Regional Office for Europe: Bonn, Germany, 2011. [Google Scholar]
- World Health Organization. Data and Statistics. Available online: https://www.euro.who.int/en/health-topics/environment-and-health/noise/data-and-statistics (accessed on 9 November 2021).
- Test, T.; Canfi, A.; Eyal, A.; Shoam-Vardi, I.; Sheiner, E.K. The influence of hearing impairment on sleep quality among workers exposed to harmful noise. Sleep 2011, 34, 25–30. [Google Scholar] [CrossRef] [Green Version]
- European Environment Agency. Noise. Available online: https://www.eea.europa.eu/themes/human/noise (accessed on 9 November 2021).
- Official Journal of the European Communities. Directive 2002/49/EC of the European Parliament and of the Council of 25 June 2002. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32002L0049&from=EN (accessed on 9 November 2021).
- Guski, R.; Schreckenberg, D.; Schuemer, R. WHO environmental noise guidelines for the European region: A systematic review on environmental noise and annoyance. Int. J. Environ. Res. Public Health 2017, 14, 1539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization. Environmental Noise Guidelines for the European Region; World Health Organization; Regional Office for Europe: Bonn, Germany, 2018. [Google Scholar]
- Abbaspour, M.; Karimi, E.; Nassiri, P.; Monazzam, M.R.; Taghavi, L. Hierarchal assessment of noise pollution in urban areas—A case study. Transp. Res. Part D Transp. Environ. 2015, 34, 95–103. [Google Scholar] [CrossRef]
- Bello, J.P.; Silva, C.; Nov, O.; Dubois, R.L.; Arora, A.; Salamon, J.; Mydlarz, C.; Doraiswamy, H. Sonyc: A system for monitoring, analyzing, and mitigating urban noise pollution. Commun. ACM 2019, 62, 68–77. [Google Scholar] [CrossRef]
- Fonseca, E.; Plakal, M.; Font, F.; Ellis, D.P.; Serra, X. Audio tagging with noisy labels and minimal supervision. arXiv 2019, arXiv:1906.02975. [Google Scholar]
- Mejvald, P.; Konopa, O. Continuous acoustic monitoring of railroad network in the Czech Republic using smart city sensors. In Proceedings of the 2019 International Council on Technologies of Environmental Protection (ICTEP), Starý Smokovec, Slovakia, 23–25 October 2019; pp. 181–186. [Google Scholar]
- Vidaña-Vila, E.; Navarro, J.; Borda-Fortuny, C.; Stowell, D.; Alsina-Pagès, R.M. Low-cost distributed acoustic sensor network for real-time urban sound monitoring. Electronics 2020, 9, 2119. [Google Scholar] [CrossRef]
- Vidaña-Vila, E.; Stowell, D.; Navarro, J.; Alsina-Pagès, R.M. Multilabel acoustic event classification for urban sound monitoring at a traffic intersection. In Proceedings of the Euronoise 2021, Madeira, Portugal, 25–27 October 2021. [Google Scholar]
- Polastre, J.; Szewczyk, R.; Culler, D. Telos: Enabling ultra-low power wireless research. In Proceedings of the 4th International Symposium on Information Processing in Sensor Networks, Boise, ID, USA, 15 April 2005; p. 48. [Google Scholar]
- Santini, S.; Vitaletti, A. Wireless sensor networks for environmental noise monitoring. In Proceedings of the 6. GI/ITG KuVS Fachgespräch Drahtlose Sensornetze, Aachen, Germany, 16–17 July 2007; pp. 98–101. [Google Scholar]
- Santini, S.; Ostermaier, B.; Vitaletti, A. First experiences using wireless sensor networks for noise pollution monitoring. In Proceedings of the 2008 Workshop on Real-World Wireless Sensor Networks (REALWSN), Glasgow, UK, 1 April 2008; pp. 61–65. [Google Scholar]
- Wang, C.; Chen, G.; Dong, R.; Wang, H. Traffic noise monitoring and simulation research in Xiamen City based on the Environmental Internet of Things. Int. J. Sustain. Dev. World Ecol. 2013, 20, 248–253. [Google Scholar] [CrossRef]
- Paulo, J.; Fazenda, P.; Oliveira, T.; Carvalho, C.; Félix, M. Framework to monitor sound events in the city supported by the FIWARE platform. In Proceedings of the Congreso Español de Acústica, Valencia, Spain, 21–23 October 2015; pp. 21–23. [Google Scholar]
- Paulo, J.; Fazenda, P.; Oliveira, T.; Casaleiro, J. Continuos sound analysis in urban environments supported by FIWARE platform. In Proceedings of the EuroRegio 2016/TecniAcústica, Porto, Portugal, 13–15 June 2016; pp. 1–10. [Google Scholar]
- Mietlicki, F.; Mietlicki, C.; Sineau, M. An innovative approach for long-term environmental noise measurement: RUMEUR network. In Proceedings of the EuroNoise 2015, Maastrich, The Netherlands, 3 June 2015; pp. 2309–2314. [Google Scholar]
- Mietlicki, C.; Mietlicki, F. Medusa: A new approach for noise management and control in urban environment. In Proceedings of the EuroNoise 2018, Heraklion, Crete, Greece, 31 May 2018; pp. 727–730. [Google Scholar]
- Botteldooren, D.; De Coensel, B.; Oldoni, D.; Van Renterghem, T.; Dauwe, S. Sound monitoring networks new style. In Acoustics 2011: Breaking New Ground: Annual Conference of the Australian Acoustical Society; Australian Acoustical Society: Queensland, Australia, 2011. [Google Scholar]
- Dominguez, F.; Dauwe, S.; Cuong, N.T.; Cariolaro, D.; Touhafi, A.; Dhoedt, B.; Botteldooren, D.; Steenhaut, K. Towards an environmental measurement cloud: Delivering pollution awareness to the public. Int. J. Distrib. Sens. Netw. 2014, 10, 541360. [Google Scholar] [CrossRef] [Green Version]
- Cense—Characterization of Urban Sound Environments. Available online: http://cense.ifsttar.fr/ (accessed on 8 November 2021).
- Bell, M.C.; Galatioto, F. Novel wireless pervasive sensor network to improve the understanding of noise in street canyons. Appl. Acoust. 2013, 74, 169–180. [Google Scholar] [CrossRef]
- Bartalucci, C.; Borchi, F.; Carfagni, M.; Furferi, R.; Governi, L.; Lapini, A.; Bellomini, R.; Luzzi, S.; Nencini, L. The smart noise monitoring system implemented in the frame of the Life MONZA project. In Proceedings of the EuroNoise, Crete, Greece, 27–31 May 2018; pp. 783–788. [Google Scholar]
- Bartalucci, C.; Borchi, F.; Carfagni, M. Noise monitoring in Monza (Italy) during COVID-19 pandemic by means of the smart network of sensors developed in the LIFE MONZA project. Noise Mapp. 2020, 7, 199–211. [Google Scholar] [CrossRef]
- De Coensel, B.; Botteldooren, D. Smart sound monitoring for sound event detection and characterization. In Proceedings of the 43rd International Congress on Noise Control Engineering (Inter-Noise 2014), Melbourne, Australia, 16–19 November 2014; pp. 1–10. [Google Scholar]
- Brown, A.; Coensel, B.D. A study of the performance of a generalized exceedance algorithm for detecting noise events caused by road traffic. Appl. Acoust. 2018, 138, 101–114. [Google Scholar] [CrossRef] [Green Version]
- Mydlarz, C.; Salamon, J.; Bello, J.P. The implementation of low-cost urban acoustic monitoring devices. Appl. Acoust. 2017, 117, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Cramer, A.; Cartwright, M.; Pishdadian, F.; Bello, J.P. Weakly supervised source-specific sound level estimation in noisy soundscapes. arXiv 2021, arXiv:2105.02911. [Google Scholar]
- Cartwright, M.; Cramer, J.; Mendez, A.E.M.; Wang, Y.; Wu, H.H.; Lostanlen, V.; Fuentes, M.; Dove, G.; Mydlarz, C.; Salamon, J.; et al. SONYC-UST-V2: An urban sound tagging dataset with spatiotemporal context. arXiv 2020, arXiv:2009.05188. [Google Scholar]
- Sevillano, X.; Socoró, J.C.; Alías, F.; Bellucci, P.; Peruzzi, L.; Radaelli, S.; Coppi, P.; Nencini, L.; Cerniglia, A.; Bisceglie, A.; et al. DYNAMAP—Development of low cost sensors networks for real time noise mapping. Noise Mapp. 2016, 3, 172–189. [Google Scholar] [CrossRef]
- Bellucci, P.; Peruzzi, L.; Zambon, G. LIFE DYNAMAP project: The case study of Rome. Appl. Acoust. 2017, 117, 193–206. [Google Scholar] [CrossRef]
- Zambon, G.; Benocci, R.; Bisceglie, A.; Roman, H.E.; Bellucci, P. The LIFE DYNAMAP project: Towards a procedure for dynamic noise mapping in urban areas. Appl. Acoust. 2017, 124, 52–60. [Google Scholar] [CrossRef]
- Socoró, J.C.; Alías, F.; Alsina-Pagès, R.M. An anomalous noise events detector for dynamic road traffic noise mapping in real-life urban and suburban environments. Sensors 2017, 17, 2323. [Google Scholar] [CrossRef]
- Alsina-Pagès, R.M.; Alías, F.; Socoró, J.C.; Orga, F. Detection of anomalous noise events on low-capacity acoustic nodes for dynamic road traffic noise mapping within an hybrid WASN. Sensors 2018, 18, 1272. [Google Scholar] [CrossRef] [Green Version]
- Bellucci, P.; Cruciani, F.R. Implementing the Dynamap system in the suburban area of Rome. In Inter-Noise and Noise-Con Congress and Conference Proceedings; Institute of Noise Control Engineering: Hamburg, Germany, 2016; pp. 5518–5529. [Google Scholar]
- Gontier, F.; Lostanlen, V.; Lagrange, M.; Fortin, N.; Lavandier, C.; Petiot, J.F. Polyphonic training set synthesis improves self-supervised urban sound classification. J. Acoust. Soc. Am. 2021, 149, 4309–4326. [Google Scholar] [CrossRef] [PubMed]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia, Nice, France, 21–25 October 2014; pp. 1041–1044. [Google Scholar]
- Srivastava, S.; Roy, D.; Cartwright, M.; Bello, J.P.; Arora, A. Specialized embedding approximation for edge intelligence: A case study in urban sound classification. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8378–8382. [Google Scholar]
- Biagioni, E.S.; Sasaki, G. Wireless sensor placement for reliable and efficient data collection. In Proceedings of the 36th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 6–9 January 2003; p. 10. [Google Scholar]
- Han, G.; Zhang, C.; Shu, L.; Rodrigues, J.J. Impacts of deployment strategies on localization performance in underwater acoustic sensor networks. IEEE Trans. Ind. Electron. 2014, 62, 1725–1733. [Google Scholar] [CrossRef]
- Murad, M.; Sheikh, A.A.; Manzoor, M.A.; Felemban, E.; Qaisar, S. A survey on current underwater acoustic sensor network applications. Int. J. Comput. Theory Eng. 2015, 7, 51. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Wang, W.; Li, D.; Lee, J.L.; Wu, W.; Tokuta, A.O. A joint optimization of data ferry trajectories and communication powers of ground sensors for long-term environmental monitoring. J. Comb. Optim. 2016, 31, 1550–1568. [Google Scholar] [CrossRef]
- Ding, K.; Yousefi’zadeh, H.; Jabbari, F. A robust advantaged node placement strategy for sparse network graphs. IEEE Trans. Netw. Sci. Eng. 2017, 5, 113–126. [Google Scholar] [CrossRef]
- Bonet-Solà, D.; Martínez-Suquía, C.; Alsina-Pagès, R.M.; Bergadà, P. The Soundscape of the COVID-19 Lockdown: Barcelona Noise Monitoring Network Case Study. Int. J. Environ. Res. Public Health 2021, 18, 5799. [Google Scholar] [CrossRef]
- Zoom Corporation. H5 Handy Recorder-Operation Manual; Zoom Corporation: Tokyo, Japan, 2014. [Google Scholar]
- Vidaña-Vila, E.; Duboc, L.; Alsina-Pagès, R.M.; Polls, F.; Vargas, H. BCNDataset: Description and Analysis of an Annotated Night Urban Leisure Sound Dataset. Sustainability 2020, 12, 8140. [Google Scholar] [CrossRef]
- Vidaña-Vila, E.; Navarro, J.; Alsina-Pagès, R.M.; Ramírez, Á. A two-stage approach to automatically detect and classify woodpecker (Fam. Picidae) sounds. Appl. Acoust. 2020, 166, 107312. [Google Scholar] [CrossRef]
- Vidaña-Vila, E.; Navarro, J.; Alsina-Pagès, R.M. Towards automatic bird detection: An annotated and segmented acoustic dataset of seven picidae species. Data 2017, 2, 18. [Google Scholar] [CrossRef] [Green Version]
- Audacity, T. Audacity. 2014. Available online: https://audacity.es/ (accessed on 9 November 2021).
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Stowell, D.; Petrusková, T.; Šálek, M.; Linhart, P. Automatic acoustic identification of individuals in multiple species: Improving identification across recording conditions. J. R. Soc. Interface 2019, 16, 20180940. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Occurrences | ||||
|---|---|---|---|---|
| Label | Description | 1st Campaign | 2nd Campaign | Total |
| rtn | Background traffic noise | 2177 | 2118 | 4295 |
| peop | Sounds or noises produced by people | 300 | 612 | 912 |
| brak | Car brakes | 489 | 424 | 913 |
| bird | Bird vocalizations | 357 | 960 | 1317 |
| motorc | Motorcycles | 769 | 565 | 1334 |
| eng | Engine idling | 203 | 913 | 1116 |
| cdoor | Car door | 133 | 161 | 294 |
| impls | Undefined impulsional noises | 445 | 170 | 615 |
| cmplx | Complex noises that the labeler could not identify | 85 | 73 | 158 |
| troll | Trolley | 162 | 152 | 314 |
| wind | Wind | 8 | 23 | 31 |
| horn | Car or motorbike horn | 43 | 33 | 76 |
| sire | Sirens from ambulances, the police, etc. | 18 | 57 | 75 |
| musi | Music | 8 | 30 | 38 |
| bike | Non-motorized bikes | 51 | 24 | 75 |
| hdoor | House door | 25 | 60 | 85 |
| bell | Bells from a church | 24 | 27 | 51 |
| glass | People throwing glass in the recycling bin | 17 | 32 | 49 |
| beep | Beeps from trucks during reversing | 31 | 0 | 31 |
| dog | Dogs barking | 3 | 25 | 28 |
| drill | Drilling | 0 | 14 | 14 |
| Dataset | |||
|---|---|---|---|
| Label | Train | Validation | Test |
| rtn | 3029 | 583 | 683 |
| peop | 954 | 100 | 181 |
| brak | 627 | 137 | 149 |
| bird | 913 | 196 | 208 |
| motorc | 954 | 183 | 197 |
| eng | 864 | 73 | 179 |
| cdoor | 190 | 51 | 53 |
| impls | 457 | 67 | 91 |
| cmplx | 128 | 16 | 14 |
| troll | 229 | 53 | 32 |
| wind | 19 | 4 | 8 |
| horn | 49 | 17 | 10 |
| sire | 69 | 0 | 6 |
| musi | 34 | 0 | 4 |
| bike | 55 | 8 | 12 |
| hdoor | 65 | 12 | 8 |
| bell | 34 | 4 | 13 |
| glass | 40 | 6 | 3 |
| beep | 9 | 13 | 9 |
| dog | 23 | 4 | 1 |
| drill | 14 | 0 | 0 |
| Dataset Used | F1-Macro Average | F1-Micro Average |
|---|---|---|
| Experiment 0 | 12% | 46% |
| Experiment 1 | 39% | 70% |
| Experiment 2 | 36% | 75% |
| Experiment 3 | 33% | 67% |
| Algorithm Used | Micro Precision | Micro Recall | Micro F1 | Macro F1 |
|---|---|---|---|---|
| DT | 71.6% | 69.5% | 70.5% | 30.6 % |
| RF | 81.8% | 68.1% | 74.3% | 26.7 % |
| LR | 77.3% | 72% | 74.6 % | 37.8% |
| XGB | 78.5% | 70.2 % | 74.1 % | 39.3 % |
| Algorithms | RPi Model | Max. Time | Min. Time | Avg. Time |
|---|---|---|---|---|
| (seconds) | (seconds) | (seconds) | ||
| DNN + DT | Model 2B | 2.3 | 2.0 | 2.2 |
| DNN + RF | 2.9 | 2.4 | 2.6 | |
| DNN + LR | 2.4 | 2.0 | 2.2 | |
| DNN + XGB | 2.8 | 2.4 | 2.5 | |
| DNN + DT | Model 3B+ | 1.3 | 0.9 | 1.1 |
| DNN + RF | 1.5 | 1.2 | 1.3 | |
| DNN + LR | 1.3 | 1.1 | 1.2 | |
| DNN + XGB | 1.4 | 1.3 | 1.5 | |
| DNN + DT | Model 4B | 0.7 | 0.6 | 0.6 |
| DNN + RF | 0.8 | 0.7 | 0.7 | |
| DNN + LR | 0.8 | 0.6 | 0.6 | |
| DNN + XGB | 1.0 | 0.7 | 0.7 |
| Label | True Negative | False Positive | False Negative | True Positive | F1-Score |
|---|---|---|---|---|---|
| rtn | 0 | 37 | 11 | 672 | 0.97 |
| peop | 495 | 44 | 96 | 85 | 0.55 |
| brak | 513 | 58 | 80 | 69 | 0.50 |
| bird | 485 | 27 | 59 | 149 | 0.78 |
| motorc | 469 | 54 | 79 | 100 | 0.60 |
| eng | 502 | 39 | 41 | 138 | 0.78 |
| cdoor | 652 | 15 | 40 | 13 | 0.32 |
| impls | 598 | 31 | 61 | 30 | 0.39 |
| troll | 670 | 18 | 18 | 14 | 0.44 |
| wind | 709 | 3 | 5 | 3 | 0.43 |
| horn | 709 | 1 | 7 | 3 | 0.43 |
| sire | 701 | 13 | 5 | 1 | 0.10 |
| musi | 714 | 2 | 4 | 0 | 0 |
| bike | 707 | 1 | 12 | 0 | 0 |
| hdoor | 705 | 7 | 8 | 0 | 0 |
| bell | 707 | 0 | 6 | 7 | 0.70 |
| glass | 707 | 0 | 2 | 1 | 0.50 |
| beep | 711 | 0 | 9 | 0 | 0 |
| dog | 718 | 1 | 1 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vidaña-Vila, E.; Navarro, J.; Stowell, D.; Alsina-Pagès, R.M. Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors. Sensors 2021, 21, 7470. https://doi.org/10.3390/s21227470
Vidaña-Vila E, Navarro J, Stowell D, Alsina-Pagès RM. Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors. Sensors. 2021; 21(22):7470. https://doi.org/10.3390/s21227470
Chicago/Turabian StyleVidaña-Vila, Ester, Joan Navarro, Dan Stowell, and Rosa Ma Alsina-Pagès. 2021. "Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors" Sensors 21, no. 22: 7470. https://doi.org/10.3390/s21227470
APA StyleVidaña-Vila, E., Navarro, J., Stowell, D., & Alsina-Pagès, R. M. (2021). Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors. Sensors, 21(22), 7470. https://doi.org/10.3390/s21227470