
Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors


Abstract
:1. Introduction
2. Study Area and Data
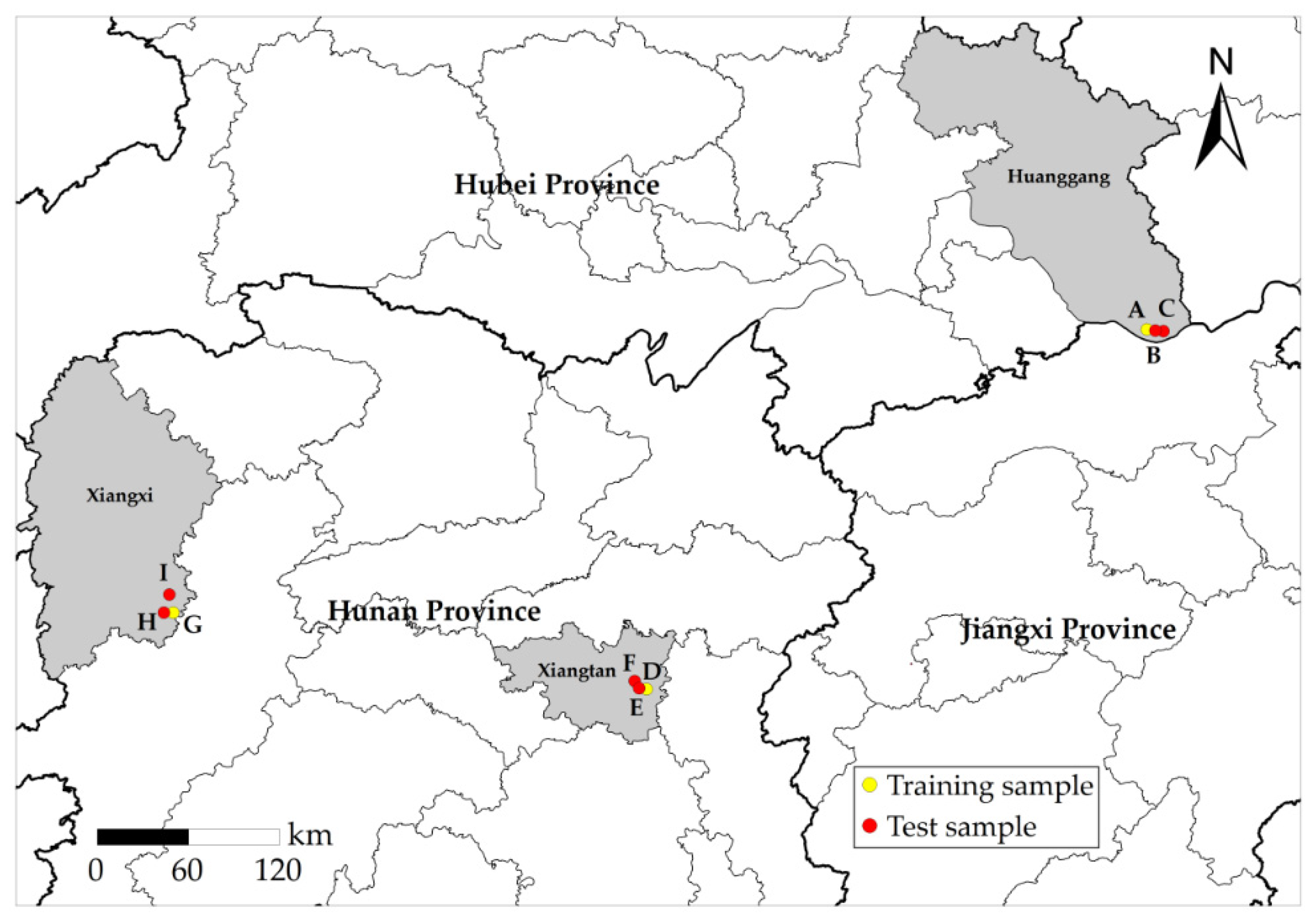
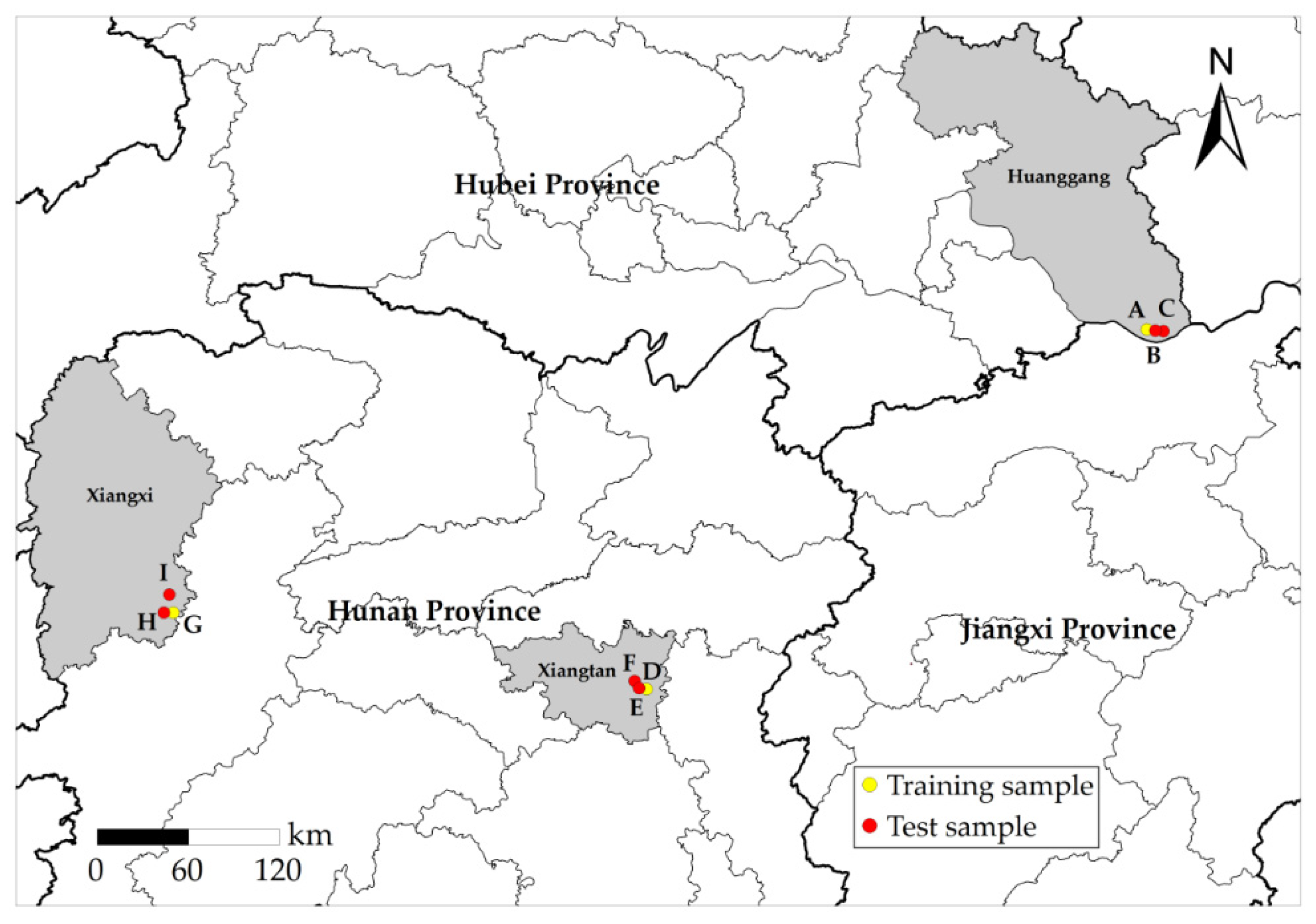
2.1. Study Area
2.2. Data Source and Preprocessing
3. Methods
3.1. Machine Learning Water Body Extraction Model for Remote Sensing Images
3.1.1. Support Vector Machine (SVM) Classification Model
3.1.2. Random Forest (RF) Classification Model
3.2. Deep Learning Water Body Extraction Model for Remote Sensing Images
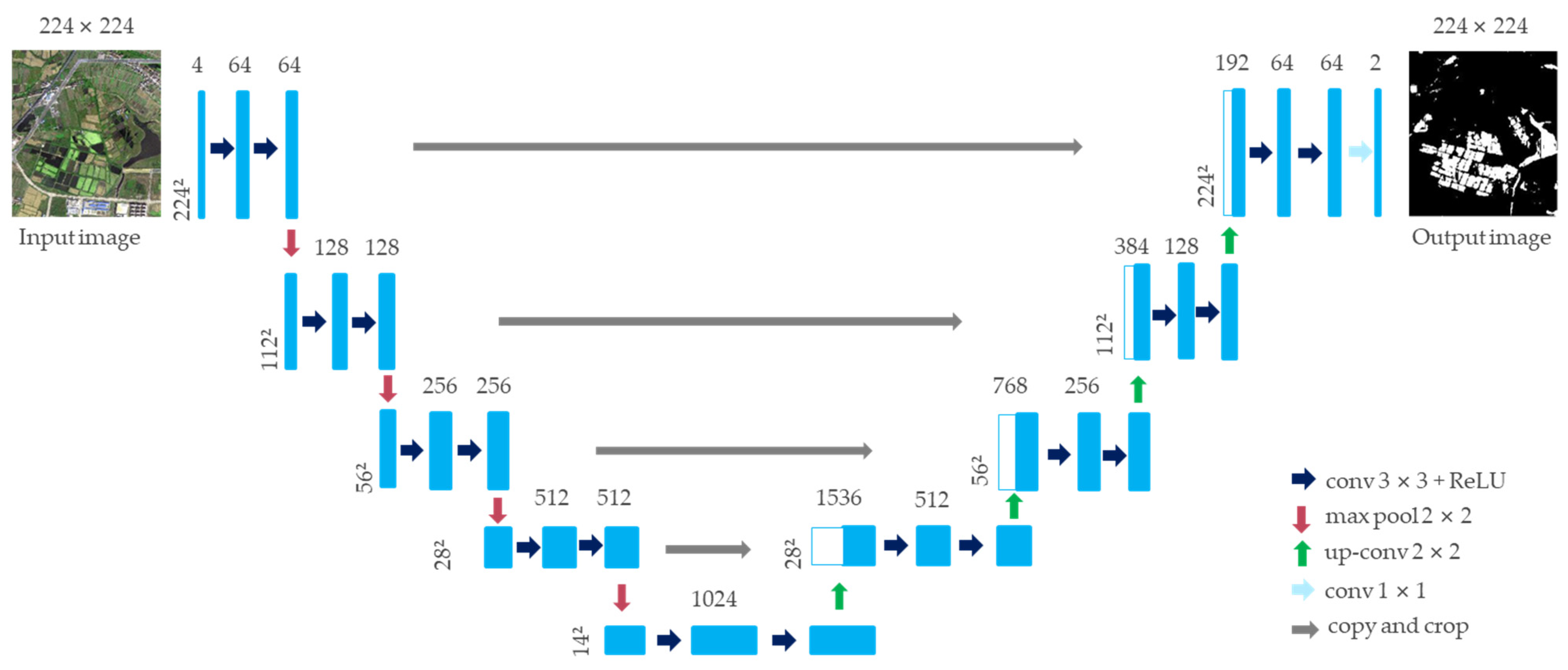
3.2.1. U-Net Model
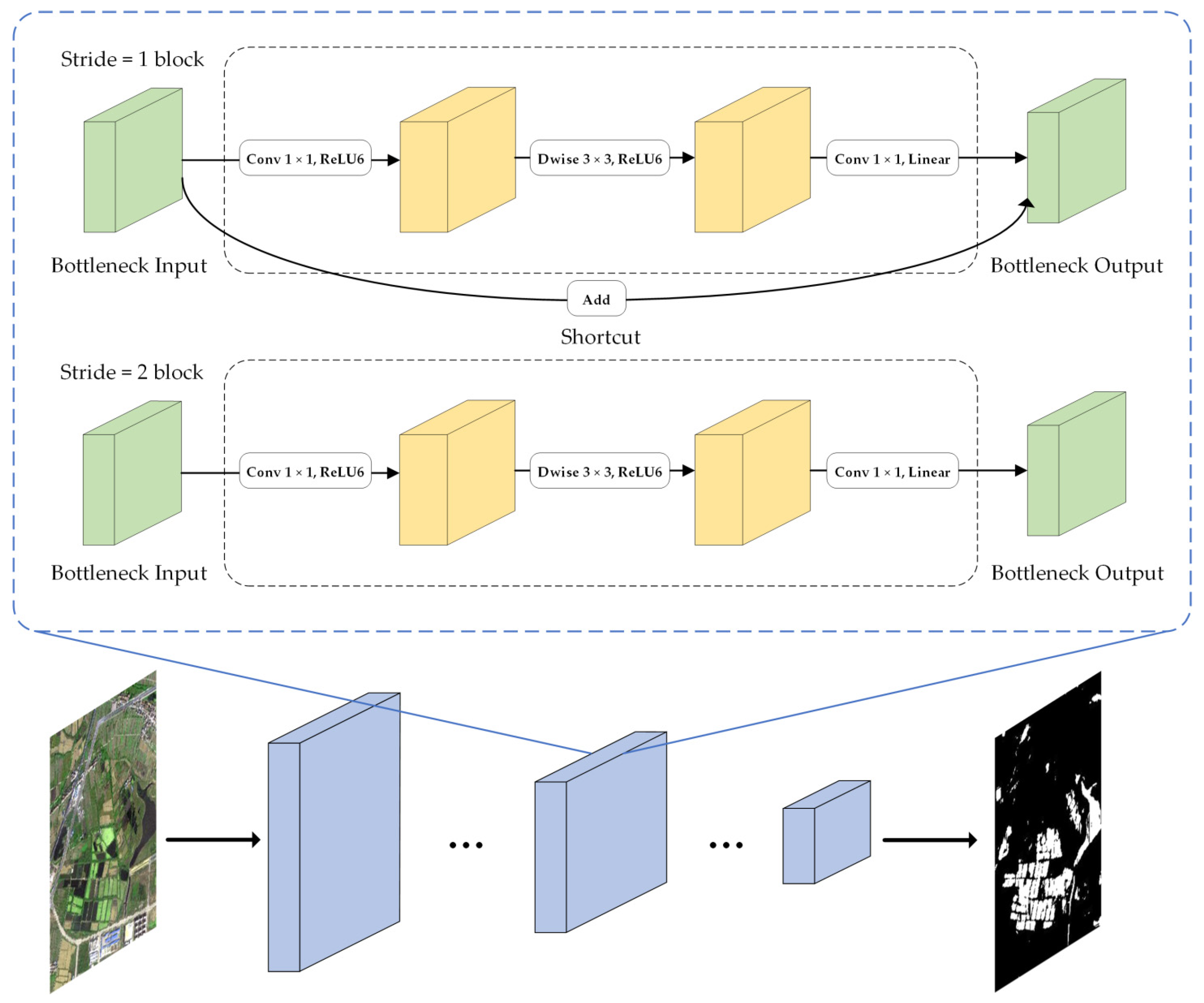
3.2.2. MobileNetV2 Model
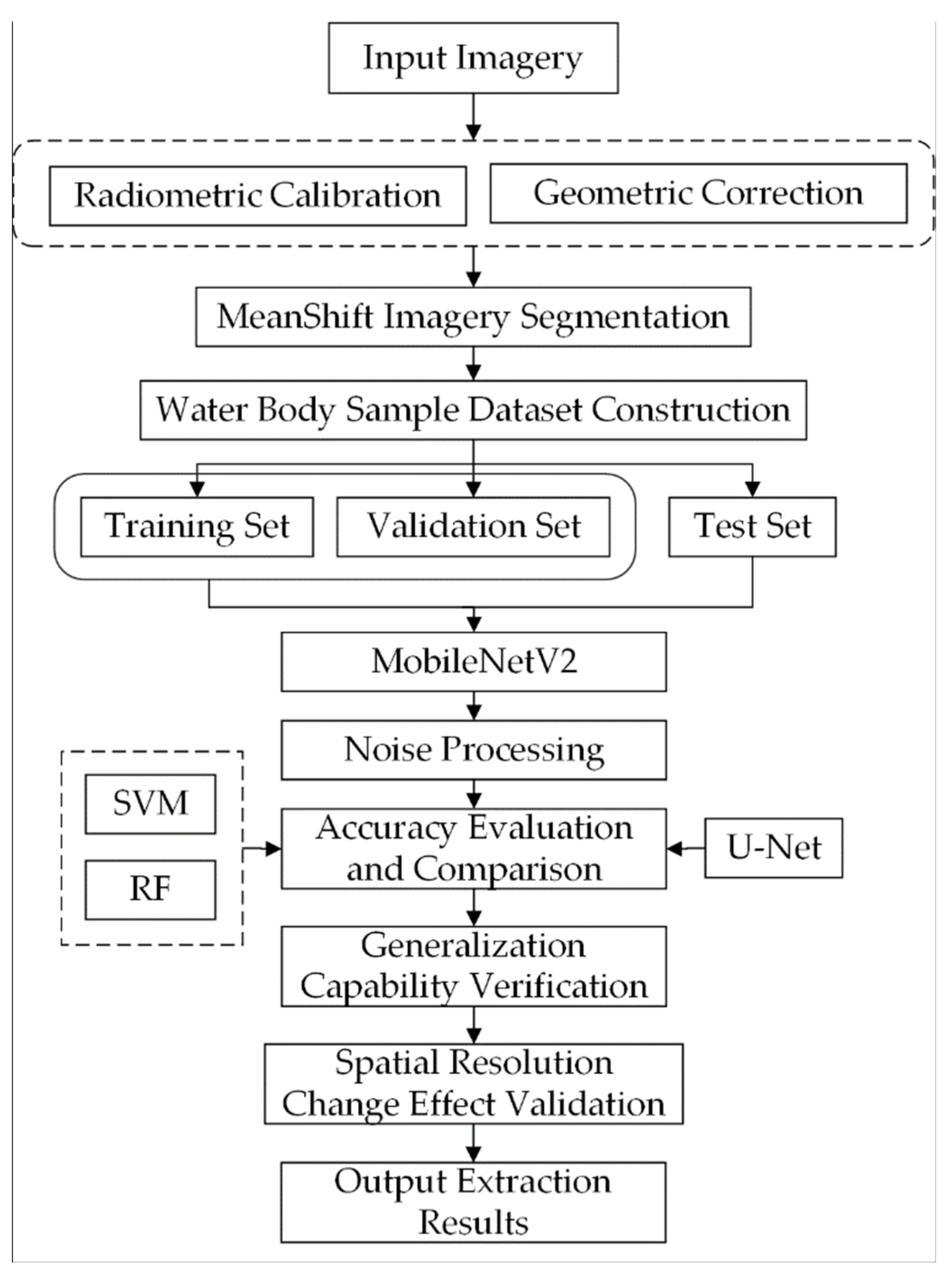
3.3. Construction of a Water Body Extraction Model Based on MobileNetV2
3.3.1. Hardware and Software Environment Configuration
3.3.2. Construction of the Water Body Extraction Sample Set
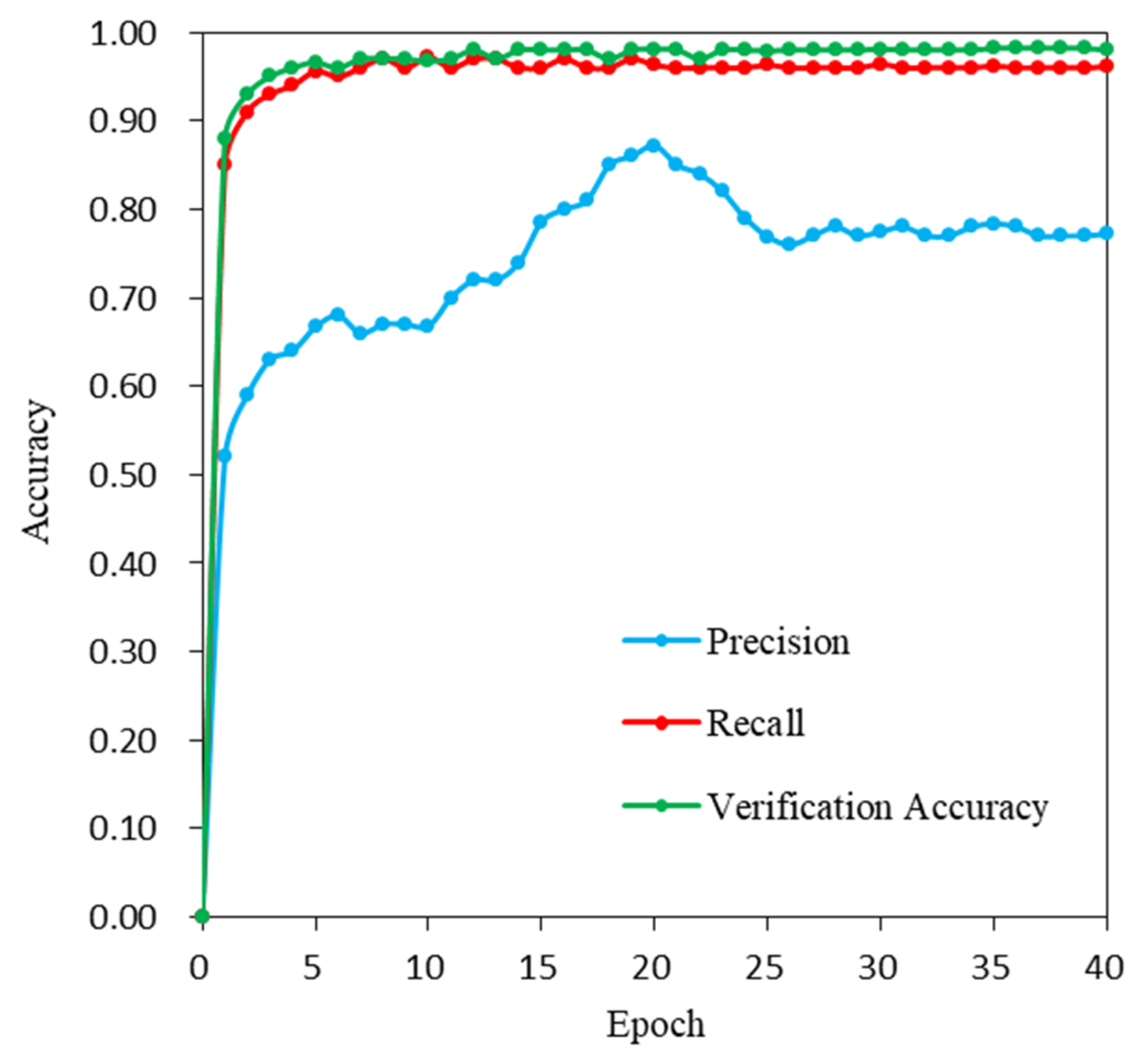
3.3.3. Deep Learning Water Body Extraction Model Training
3.4. Accuracy Evaluation Method
4. Results
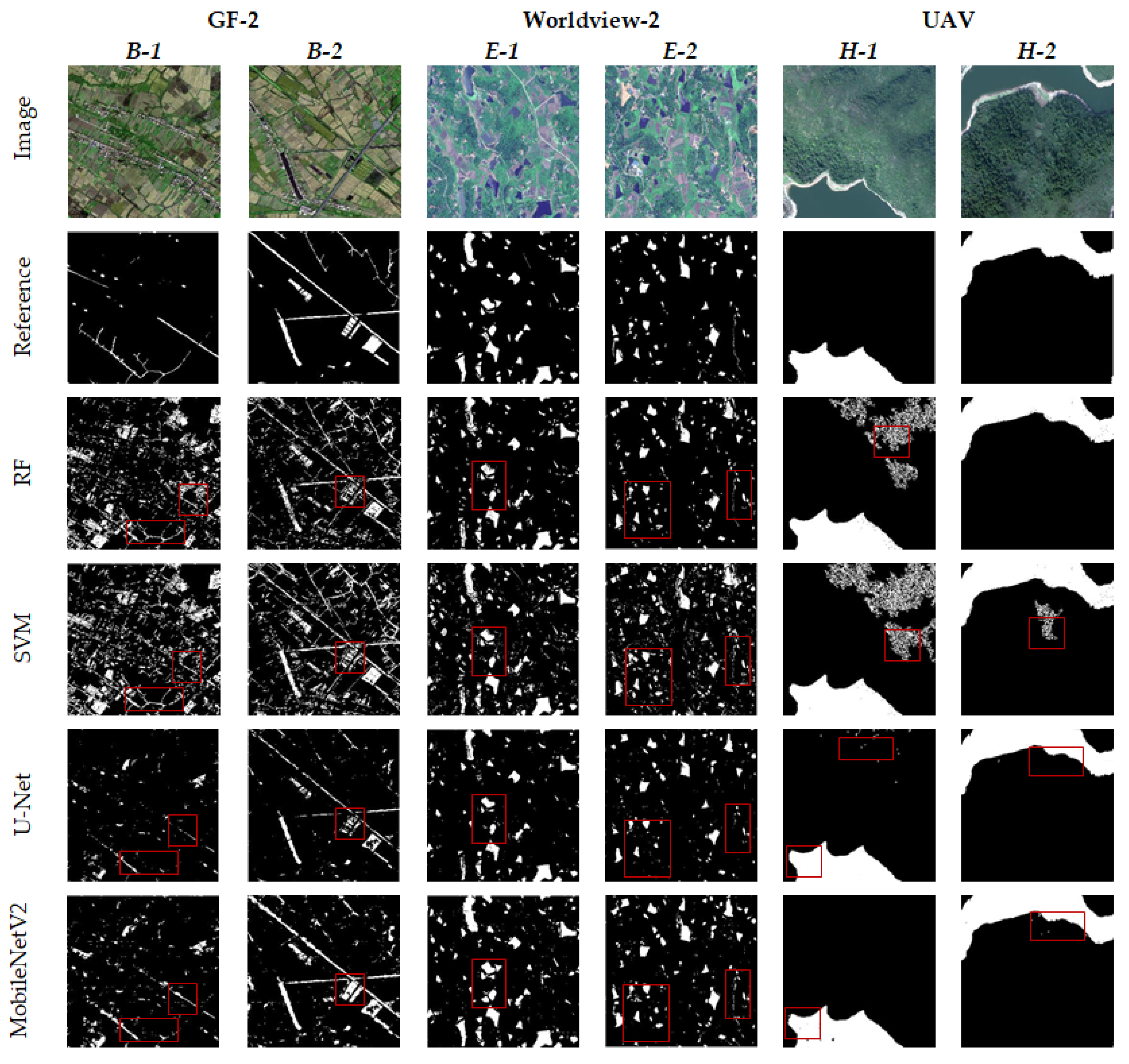
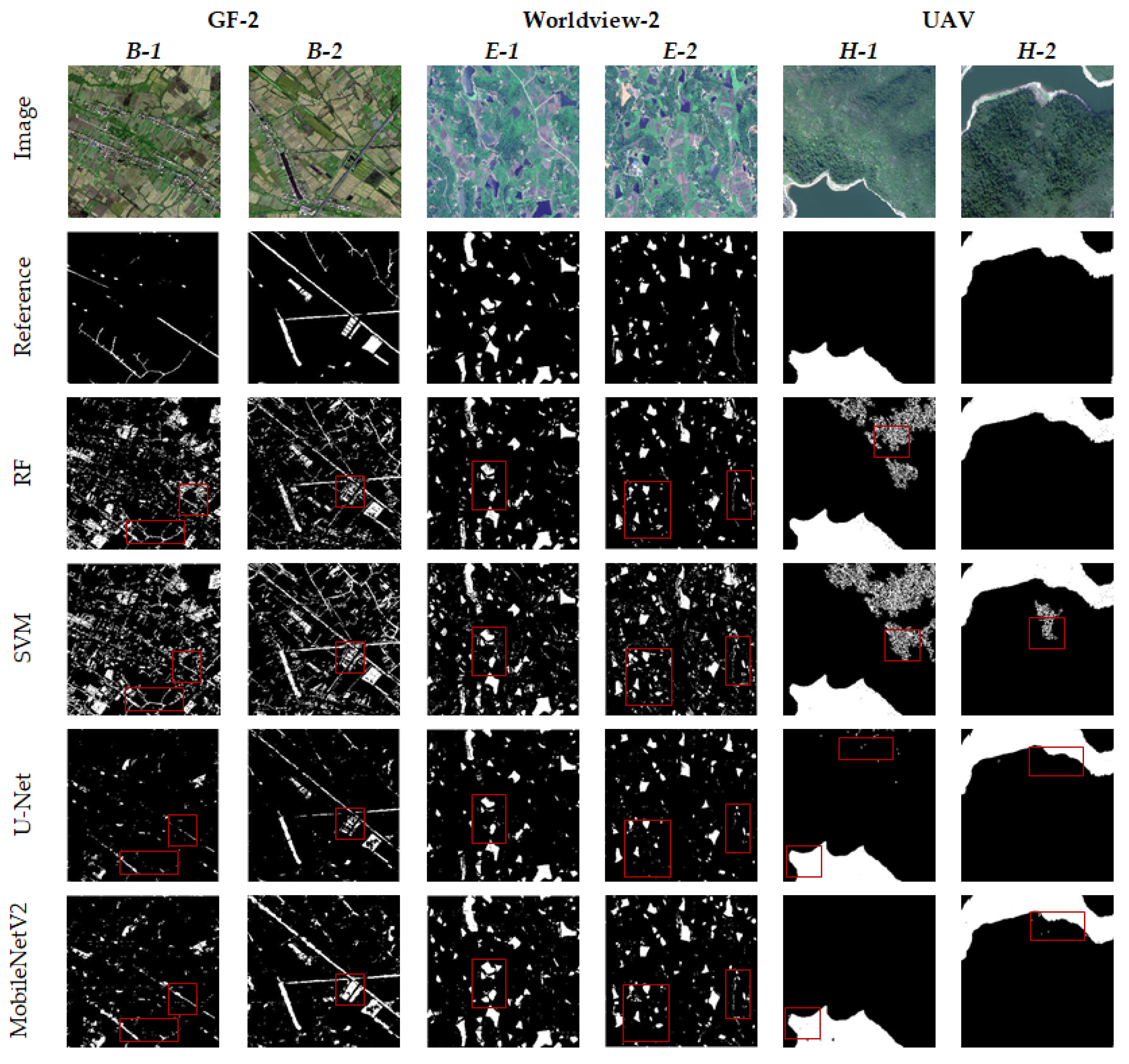
4.1. Comparison of Water Body Extraction Model Results
4.2. Accuracy Evaluation of Water Body Extraction Models
4.3. Water Body Extraction Generalization Verification of the MobileNetV2 Model
5. Discussion
5.1. Parameter Sensitivity Analysis
5.2. Efficiency Comparison of the Deep Learning Models
5.3. Influence of Spatial Resolution Change on the Accuracy of Water Body Extraction by the MobileNetV2 Model
5.4. Extraction Error Analysis of Mixed Water Bodies and Small Area Water Bodies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Wang, C.; Xu, L.; Wu, F.; Zhang, H.; Zhang, B. Multitemporal Water Extraction of Dongting Lake and Poyang Lake Based on an Automatic Water Extraction and Dynamic Monitoring Framework. Remote Sens. 2021, 13, 865. [Google Scholar] [CrossRef]
- Huang, C.; Chen, Y.; Zhang, S.; Wu, J. Detecting, extracting, and monitoring surface water from space using optical sensors: A review. Rev. Geophys. 2018, 56, 333–360. [Google Scholar] [CrossRef]
- Byun, Y.; Han, Y.; Chae, T. Image fusion-based change detection for flood extent extraction using bi-temporal very high-resolution satellite images. Remote Sens. 2015, 7, 10347–10363. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhao, S.; Qin, X.; Zhao, N.; Liang, L. Mapping of urban surface water bodies from Sentinel-2 MSI imagery at 10 m resolution via NDWI-based image sharpening. Remote Sens. 2017, 9, 596. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.n.; Luo, J.; Shen, Z.; Hu, X.; Yang, H. Multiscale water body extraction in urban environments from satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4301–4312. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of urban water bodies from high-resolution remote-sensing imagery using deep learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Gong, W.; Liu, T.; Jiang, Y.; Stott, P. Applicability of the Surface Water Extraction Methods Based on China’s GF-2 HD Satellite in Ussuri River, Tonghe County of Northeast China. Nat. Environ. Pollut. Technol. 2020, 19, 1537–1545. [Google Scholar] [CrossRef]
- Li, S.; Wang, S.; Zheng, Z.; Wan, D.; Feng, J. A new algorithm for water information extraction from high resolution remote sensing imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 4359–4363. [Google Scholar]
- Boonpook, W.; Tan, Y.; Xu, B. Deep learning-based multi-feature semantic segmentation in building extraction from images of UAV photogrammetry. Int. J. Remote Sens. 2021, 42, 1–19. [Google Scholar] [CrossRef]
- Boonpook, W.; Tan, Y.; Ye, Y.; Torteeka, P.; Torsri, K.; Dong, S. A deep learning approach on building detection from unmanned aerial vehicle-based images in riverbank monitoring. Sensors 2018, 18, 3921. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, Y.; Wang, S.; Xu, B.; Zhang, J. An improved progressive morphological filter for UAV-based photogrammetric point clouds in river bank monitoring. ISPRS J. Photogramm. Remote Sens. 2018, 146, 421–429. [Google Scholar] [CrossRef]
- Lin, A.Y.-M.; Novo, A.; Har-Noy, S.; Ricklin, N.D.; Stamatiou, K. Combining GeoEye-1 satellite remote sensing, UAV aerial imaging, and geophysical surveys in anomaly detection applied to archaeology. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 870–876. [Google Scholar] [CrossRef]
- Haibo, Y.; Zongmin, W.; Hongling, Z.; Yu, G. Water body extraction methods study based on RS and GIS. Procedia Environ. Sci. 2011, 10, 2619–2624. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Du, Z.; Ling, F.; Zhou, D.; Wang, H.; Gui, Y.; Sun, B.; Zhang, X. A comparison of land surface water mapping using the normalized difference water index from TM, ETM+ and ALI. Remote Sens. 2013, 5, 5530–5549. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Li, P.; He, Y. A multi-band approach to unsupervised scale parameter selection for multi-scale image segmentation. ISPRS J. Photogramm. Remote Sens. 2014, 94, 13–24. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier—A case of Yuyao, China. Water 2015, 7, 1437–1455. [Google Scholar] [CrossRef]
- McKinney, D.C.; Cai, X. Linking GIS and water resources management models: An object-oriented method. Environ. Modell. Softw. 2002, 17, 413–425. [Google Scholar] [CrossRef]
- Sarp, G.; Ozcelik, M. Water body extraction and change detection using time series: A case study of Lake Burdur, Turkey. J. Taibah Univ. Sci. 2017, 11, 381–391. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.-Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [CrossRef]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water body extraction from very high-resolution remote sensing imagery using deep U-Net and a superpixel-based conditional random field model. IEEE Geosci. Remote Sens. Lett. 2018, 16, 618–622. [Google Scholar] [CrossRef]
- Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 189. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, Z.; Zeng, C.; Xia, G.-S.; Shen, H. An urban water extraction method combining deep learning and google earth engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 769–782. [Google Scholar] [CrossRef]
- Bangira, T.; Alfieri, S.M.; Menenti, M.; Van Niekerk, A. Comparing thresholding with machine learning classifiers for mapping complex water. Remote Sens. 2019, 11, 1351. [Google Scholar] [CrossRef] [Green Version]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Fisher, A.; Danaher, T. A water index for SPOT5 HRG satellite imagery, New South Wales, Australia, determined by linear discriminant analysis. Remote Sens. 2013, 5, 5907–5925. [Google Scholar] [CrossRef] [Green Version]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Jia, K.; Jiang, W.; Li, J.; Tang, Z. Spectral matching based on discrete particle swarm optimization: A new method for terrestrial water body extraction using multi-temporal Landsat 8 images. Remote Sens. Environ. 2018, 209, 1–18. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, Y.; Zhou, M.; Zhang, S.; Zhan, W.; Sun, C.; Duan, Y. Landsat 8 OLI image based terrestrial water extraction from heterogeneous backgrounds using a reflectance homogenization approach. Remote Sens. Environ. 2015, 171, 14–32. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, J.; Wang, W.; Lin, C. A study for texture feature extraction of high-resolution satellite images based on a direction measure and gray level co-occurrence matrix fusion algorithm. Sensors 2017, 17, 1474. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Li, L.; Zhang, B.; Chen, D.; Gao, L. Soft urban water cover extraction using mixed training samples and support vector machines. Int. J. Remote Sens. 2015, 36, 3331–3344. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q.; Zhang, Y.; Du, X.; Wang, H. Two-step urban water index (TSUWI): A new technique for high-resolution mapping of urban surface water. Remote Sens. 2018, 10, 1704. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Zhang, H.; Xu, F. Water extraction in high resolution remote sensing image based on hierarchical spectrum and shape features. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Beijing, China, 22–26 April 2013; p. 012123. [Google Scholar]
- Huang, X.; Xie, C.; Fang, X.; Zhang, L. Combining pixel-and object-based machine learning for identification of water-body types from urban high-resolution remote-sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2097–2110. [Google Scholar] [CrossRef]
- Yao, F.; Wang, C.; Dong, D.; Luo, J.; Shen, Z.; Yang, K. High-resolution mapping of urban surface water using ZY-3 multi-spectral imagery. Remote Sens. 2015, 7, 12336–12355. [Google Scholar] [CrossRef] [Green Version]
- Sui, H.; Chen, G.; Hua, L. An Automatic integrated image segmentation, registration and change detection method for water-body extraction using HSR images and GIS data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 7, W2. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. (NIPS) 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Singh, P.; Verma, A.; Chaudhari, N.S. Deep convolutional neural network classifier for handwritten Devanagari character recognition. In Information Systems Design and Intelligent Applications; Springer: New Delhi, India, 2016; pp. 551–561. [Google Scholar] [CrossRef]
- Muhammad, U.; Wang, W.; Chattha, S.P.; Ali, S. Pre-trained VGGNet architecture for remote-sensing image scene classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1622–1627. [Google Scholar]
- Schuegraf, P.; Bittner, K. Automatic Building Footprint Extraction from Multi-Resolution Remote Sensing Images Using a Hybrid FCN. ISPRS Int. J. Geo-Inf. 2019, 8, 191. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Ma, M.; Ma, W.; Jiao, L.; Hong, S.; Shen, J.; Hou, B. A spatial-channel progressive fusion ResNet for remote sensing classification. Inf. Fusion 2021, 70, 72–87. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Wang, R.; Zhou, H.; Yang, J. A novel deep structure U-Net for sea-land segmentation in remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3219–3232. [Google Scholar] [CrossRef] [Green Version]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Yan, Z.; Shen, Q.; Cheng, G.; Gao, L.; Zhang, B. Water body extraction from very high spatial resolution remote sensing data based on fully convolutional networks. Remote Sens. 2019, 11, 1162. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Li, Y.; Gong, J.; Feng, Q.; Zhou, J.; Sun, J.; Shi, C.; Hu, W. Urban Water Extraction with UAV High-Resolution Remote Sensing Data Based on an Improved U-Net Model. Remote Sens. 2021, 13, 3165. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Sun, X.; Zhong, Y.; Zhang, L. High-resolution remote sensing image scene understanding: A review. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3061–3064. [Google Scholar]
- Qin, Z.; Zhang, Z.; Chen, X.; Wang, C.; Peng, Y. Fd-mobilenet: Improved mobilenet with a fast downsampling strategy. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1363–1367. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Saly Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Kohv, M.; Sepp, E.; Vammus, L. Assessing multitemporal water-level changes with uav-based photogrammetry. Photogramm Rec. 2017, 32, 424–442. [Google Scholar] [CrossRef] [Green Version]
- Tsendbazar, N.-E.; de Bruin, S.; Mora, B.; Schouten, L.; Herold, M. Comparative assessment of thematic accuracy of GLC maps for specific applications using existing reference data. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 124–135. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, X.-N.; You, Y.-N.; Li, H. Research on water extraction technology of remote sensing image based on neural network. J. Phys. Conf. Ser. 2020, 1601, 032027. [Google Scholar] [CrossRef]
- Rabano, S.L.; Cabatuan, M.K.; Sybingco, E.; Dadios, E.P.; Calilung, E.J. Common garbage classification using mobilenet. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–4. [Google Scholar]
- Sae-Lim, W.; Wettayaprasit, W.; Aiyarak, P. Convolutional neural networks using mobilenet for skin lesion classification. In Proceedings of the 2019 16th international joint conference on computer science and software engineering (JCSSE), Amari Pattaya, Thailand, 10–12 July 2019; pp. 242–247. [Google Scholar]
- Li, Y.; Huang, H.; Xie, Q.; Yao, L.; Chen, Q. Research on a surface defect detection algorithm based on MobileNet-SSD. Appl. Sci. 2018, 8, 1678. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Q.; Wang, X.; Li, R.; Zhang, G.; Lai, J.; Hu, Q. Fruit image classification based on Mobilenetv2 with transfer learning technique. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–7. [Google Scholar]
- Yu, J.; Yin, T.; Li, S.; Hong, S.; Peng, Y. Fast ship detection in optical remote sensing images based on sparse mobilenetv2 network. In Proceedings of the International Conference on Genetic and Evolutionary Computing, Qingdao, China, 1–3 November 2019; pp. 262–269. [Google Scholar]
- Wang, G.; Wu, M.; Wei, X.; Song, H. Water identification from high-resolution remote sensing images based on multidimensional densely connected convolutional neural networks. Remote Sens. 2020, 12, 795. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional neural networks for water body extraction from Landsat imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. [Google Scholar] [CrossRef]
- Li, M.; Wu, P.; Wang, B.; Park, H.; Yang, H.; Wu, Y. A Deep Learning Method of Water Body Extraction From High Resolution Remote Sensing Images With Multisensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3120–3132. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Cavallaro, G.; Falco, N.; Hedhli, I.; Krylov, V.A.; Moser, G.; Serpico, S.B.; Zerubia, J. Remote sensing data fusion: Markov models and mathematical morphology for multisensor, multiresolution, and multiscale image classification. In Mathematical Models for Remote Sensing Image Processing; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, H.S.; Ventura, S.J.; Mladenoff, D.J. Effects of spatial aggregation approaches on classified satellite imagery. Int. J. Geogr. Inf. Sci. 2002, 16, 93–109. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area | Sensor | Image Date | Spatial Resolution | Image Size |
|---|---|---|---|---|
| A–C | GF-2 | 2017.9.30 | 1 m | 10,080 × 10,080 |
| D–F | Worldview-2 | 2016.4.30 | 0.5 m | 13,440 × 10,080 |
| G–I | UAV | 2019.7.30 | 0.2 m | 13,440 × 10,080 |
| Input | Operation | Output |
|---|---|---|
| Sensor | Model | Precision | Recall | F1-Score | Kappa |
|---|---|---|---|---|---|
| GF-2 | RF | 49.6% | 80.9% | 0.61 | 0.57 |
| SVM | 34.3% | 87.9% | 0.49 | 0.44 | |
| U-Net | 58.1% | 69.5% | 0.63 | 0.59 | |
| MoblieNetV2 | 66.6% | 85.5% | 0.75 | 0.72 | |
| Worldview-2 | RF | 69.3% | 90.7% | 0.79 | 0.74 |
| SVM | 53.9% | 90.4% | 0.68 | 0.65 | |
| U-Net | 88.1% | 67.6% | 0.77 | 0.75 | |
| MoblieNetV2 | 77.2% | 96.3% | 0.86 | 0.85 | |
| UAV | RF | 82.5% | 96.2% | 0.89 | 0.87 |
| SVM | 72.5% | 97.6% | 0.83 | 0.81 | |
| U-Net | 99.3% | 79.7% | 0.88 | 0.87 | |
| MoblieNetV2 | 97.3% | 99.5% | 0.98 | 0.98 |
| Sensor | Precision | Recall | F1-Score | Kappa |
|---|---|---|---|---|
| GF-2 | 51.4% | 84.9% | 0.64 | 0.61 |
| Worldview-2 | 80.2% | 84.7% | 0.82 | 0.81 |
| UAV | 96.3% | 99.5% | 0.98 | 0.98 |
| Model | Params (Million) | FLOPs (Million) | Average Training Time (Second) |
|---|---|---|---|
| U-Net | 7.76 | 685 | 903 |
| MobileNetV2 | 3.40 | 300 | 645 |
| Mode | Sensor | Precision | Recall | F1-Score | Kappa |
|---|---|---|---|---|---|
| Training I: GF-2 and Worldview-2 | GF-2 | −10% | 6.2% | −0.07 | −0.08 |
| Worldview-2 | 3.3% | 3.7% | 0.04 | 0.04 | |
| UAV | −61.5% | −0.1% | −0.46 | −0.56 | |
| Training II: GF-2 and UAV | GF-2 | 1.3% | −0.1% | 0.01 | 0.01 |
| Worldview-2 | −7.2% | −20.6% | −0.14 | −0.15 | |
| UAV | −0.5% | −1.6% | −0.01 | −0.02 | |
| Training III: Worldview-2 and UAV | GF-2 | −0.9% | −15.2% | −0.05 | −0.06 |
| Worldview-2 | 11.4% | −4.6% | 0.03 | 0.03 | |
| UAV | 1.3% | −2.3% | −0.01 | −0.01 | |
| Training IV: GF-2 and Worldview-2 and UAV | GF-2 | 5.2% | −1.1% | 0.04 | 0.04 |
| Worldview-2 | 12.7% | −1.3% | 0.06 | 0.06 | |
| UAV | −1.3% | −1.2% | −0.01 | −0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, S.; Lin, Y.; Wang, M. Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors. Sensors 2021, 21, 7397. https://doi.org/10.3390/s21217397
Wang Y, Li S, Lin Y, Wang M. Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors. Sensors. 2021; 21(21):7397. https://doi.org/10.3390/s21217397
Chicago/Turabian StyleWang, Yanjun, Shaochun Li, Yunhao Lin, and Mengjie Wang. 2021. "Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors" Sensors 21, no. 21: 7397. https://doi.org/10.3390/s21217397
APA StyleWang, Y., Li, S., Lin, Y., & Wang, M. (2021). Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors. Sensors, 21(21), 7397. https://doi.org/10.3390/s21217397