
Locust Inspired Algorithm for Cloudlet Scheduling in Cloud Computing Environments

 ,
,  , and
, and 
Abstract
:1. Introduction
- The methodology provides for a more complete presentation of locust optimisation procedures.
- The design of the discrete version of the locust optimisation algorithm can be implemented for user task scheduling in cloud computing environments.
- Load balancing with efficient task allocation is achieved based on this locust optimisation algorithm, which can efficiently allocate and balance tasks on VMs.
- Allocating resources dynamically by utilising a novel hybrid algorithm using a meta-heuristic (locust-inspired) algorithm allows for efficient scheduling of cloud resources to serve the users’ tasks.
- Evaluation of the proposed method can be performed using resource utilisation, makespan, and waiting time among VMs as performance metrics.
2. Related Work
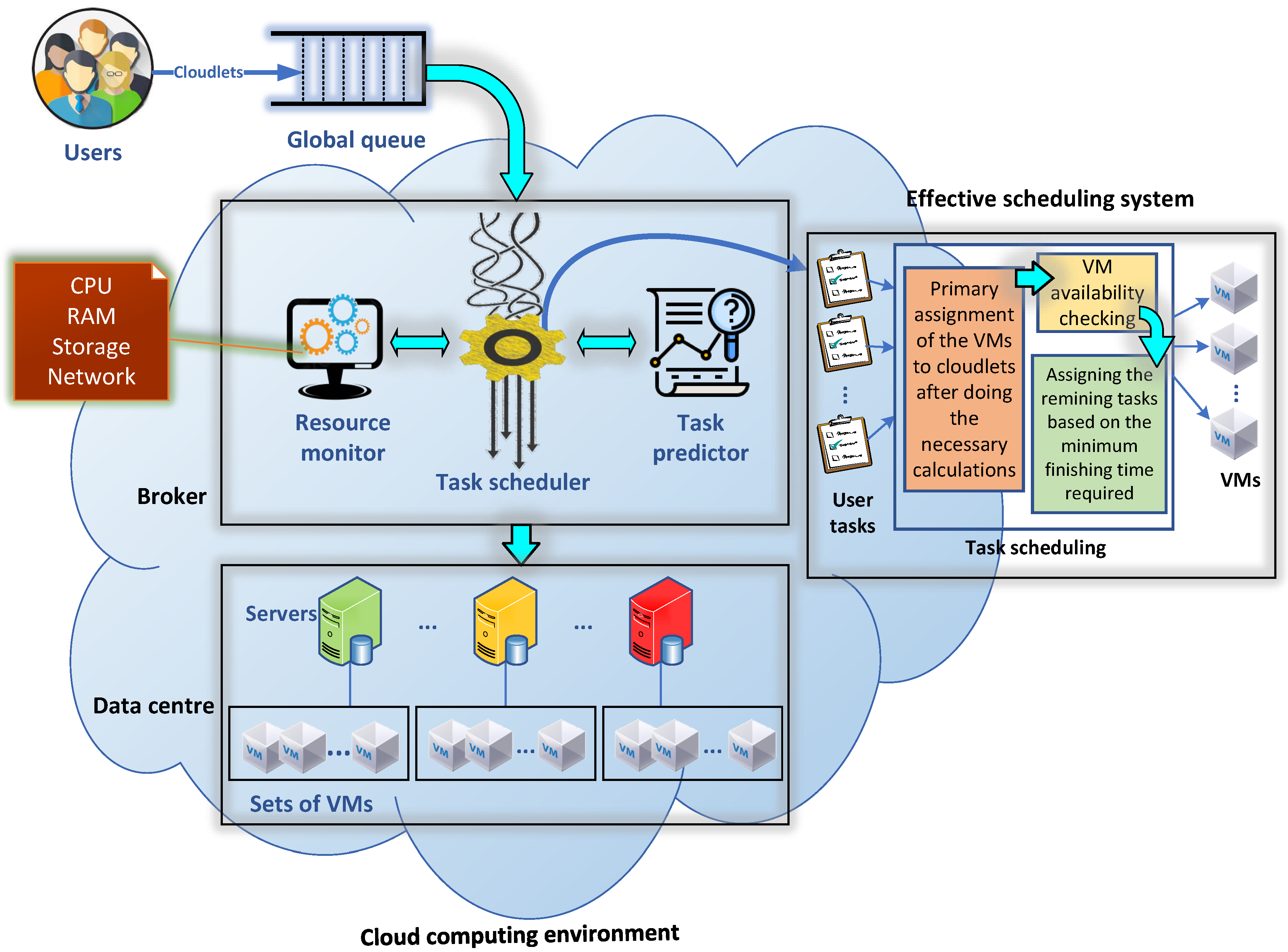
3. Methodology
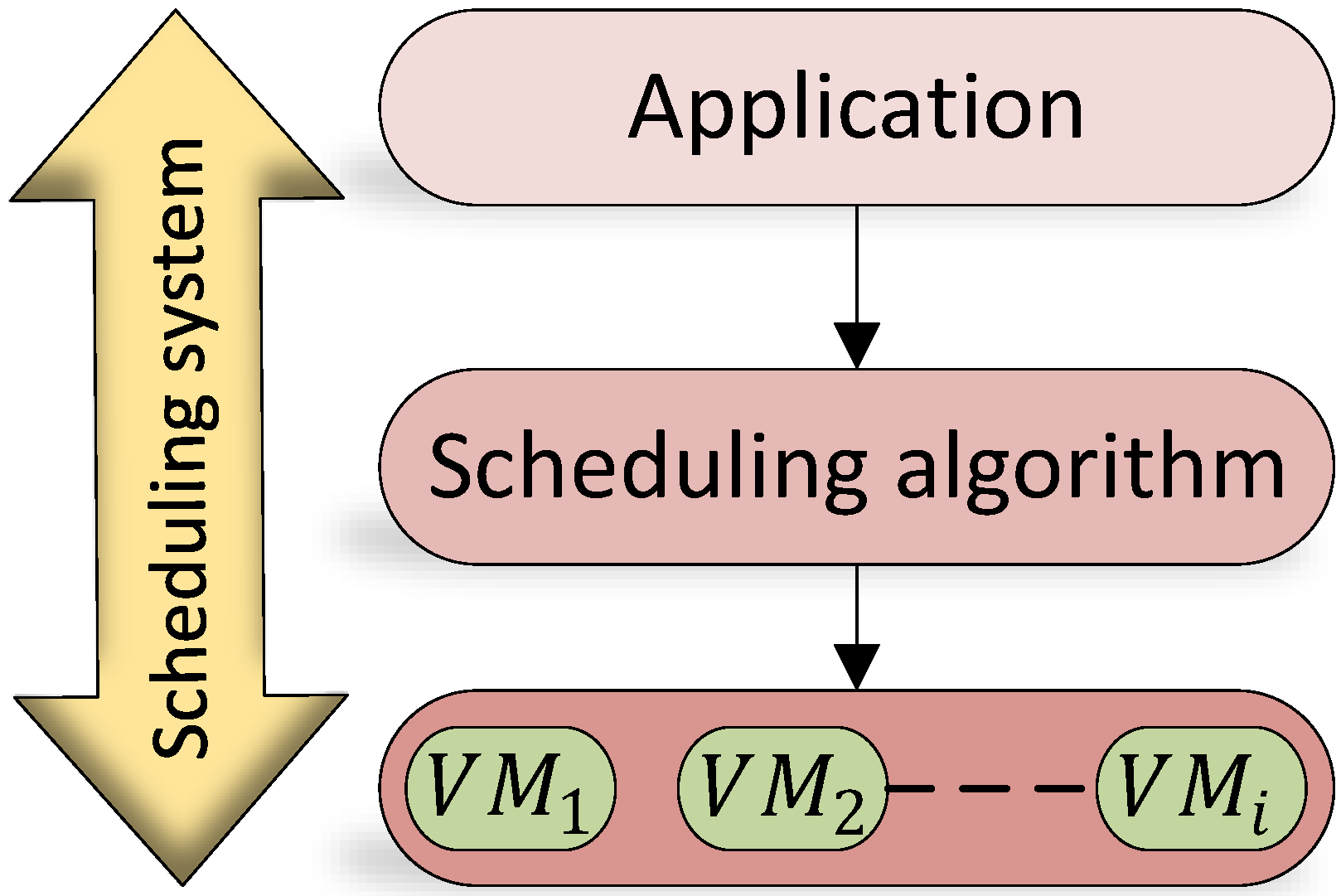
3.1. Algorithm Modelling
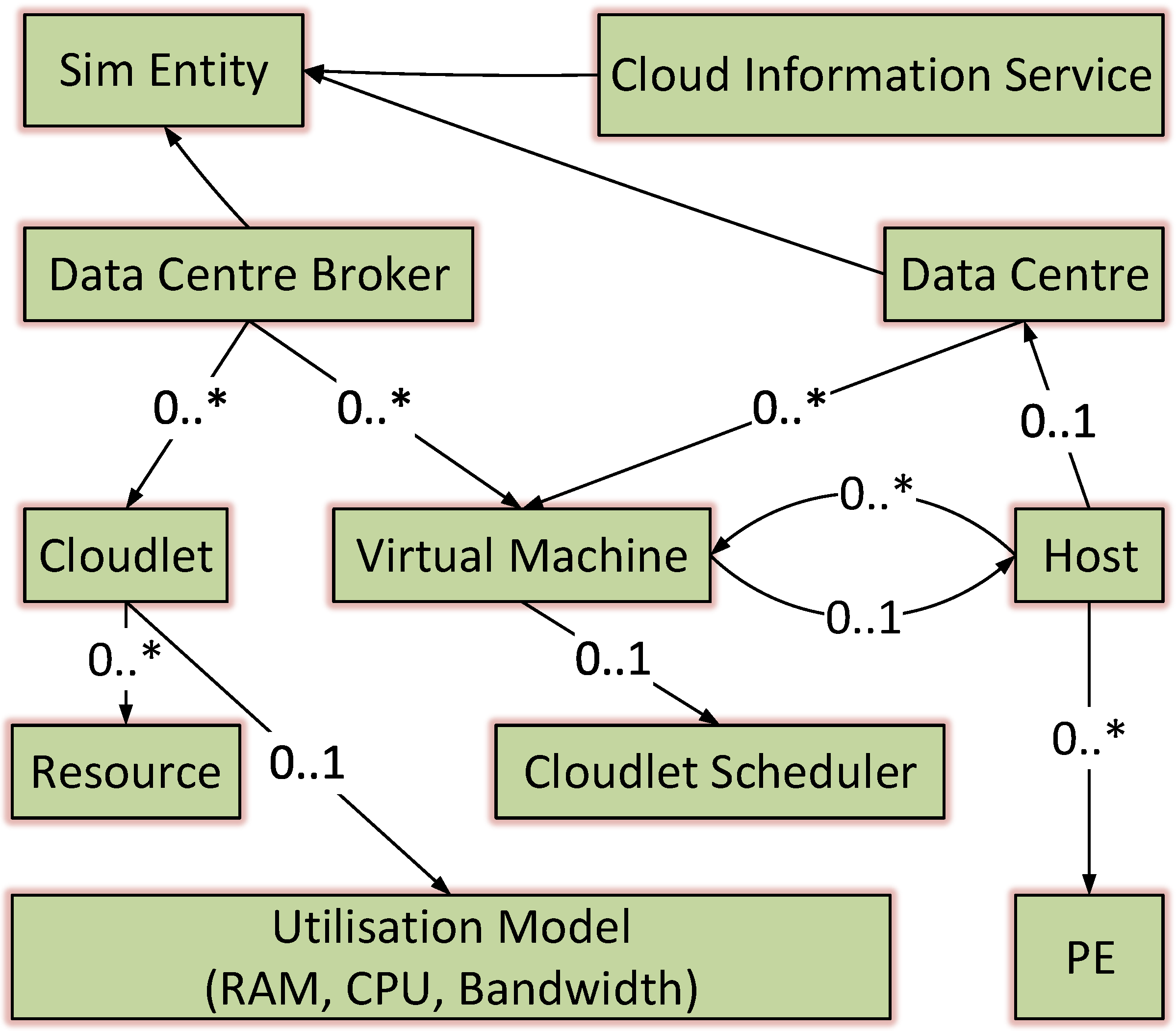
3.2. System Model
- Cloud Information Service (CIS): This is the main core entity involved as a registry created by default when the simulation in CloudSim is running. The data centre characteristics are saved in it such as resource availability. The CloudSim broker interacts with it to get resource updates.
- SimEntity: This entity is responsible for handling and sending messages to other entities for each event in the simulation.
- Data Centre (DC): A cloud resource comprising a pool of heterogeneous or homogeneous resources. A DC contains a set of hosts/servers, and its resources are provided to the VMs when required.
- Data Centre Broker: Defined as a VM management handler, the data centre broker acts on behalf of the user as a broker. It handles the processes of creation and destruction of VMs as well as handling task submissions to VMs.
- Physical Machine (PM): This represents a cloud computing server that executes actions related to VM management such as defining policies for bandwidth, memory, and VM processor provisions, and moreover, the creation and destruction processing for VMs.
- Virtual Machine (VM): This is a common means for cloud companies to increase the ability of their servers by running multiple systems on the same physical machine. A VM is given all the system functionalities to execute the end-users’ tasks (cloudlets) through a cloudlet scheduler.
- Processing Element (PE): This acts as a processor unit, which can be {1,2,3, ...}.
- Utilisation Model: This parameter is a determiner of the resource utilisation of the processor (e.g., if it is set to full, then the task will utilise all available resources of the VM, whereas if it is set to stochastic, then a random utilisation will be generated every time span).
3.3. The Proposed Algorithm
3.3.1. Preliminary Selection of VMs
- 1
- Computing the maximum and minimum cloudlet length ( and , respectively).
- 2
- Finding the total processing speed of all VMs represented in MIPS units as in Equation (7).
- 3
- 4
- If the VMs have different processing speeds, they will be sorted in increasing order based on their processing speeds (i.e., ).
- 5
- We will assume is a MIPS of to find the acceptance range, as illustrated in Figure 4.
- 6
3.3.2. Checking VM Utilisation
3.3.3. Earlier Cloudlet Handling
| Algorithm 1: Locust scheduling algorithm. |
| Input: VM configurations; cloudlet configurations |
| Output: Optimised allocation |
| 1 Precondition: Identify |
| ; |
 |
4. Experimental Results
4.1. Simulation Tool
- CloudSim allows the modelling of heterogeneous resources.
- The number of cloudlets that represent user applications is unlimited.
- Many of the cloud computing entities require simultaneous handling.
- CloudSim analysis methods can register all the required operations and calculate the statistics of the selected metrics.
- The simulator supports both static and dynamic schedulers.
4.2. Simulation Configurations and Parameters
4.3. Comparison Results
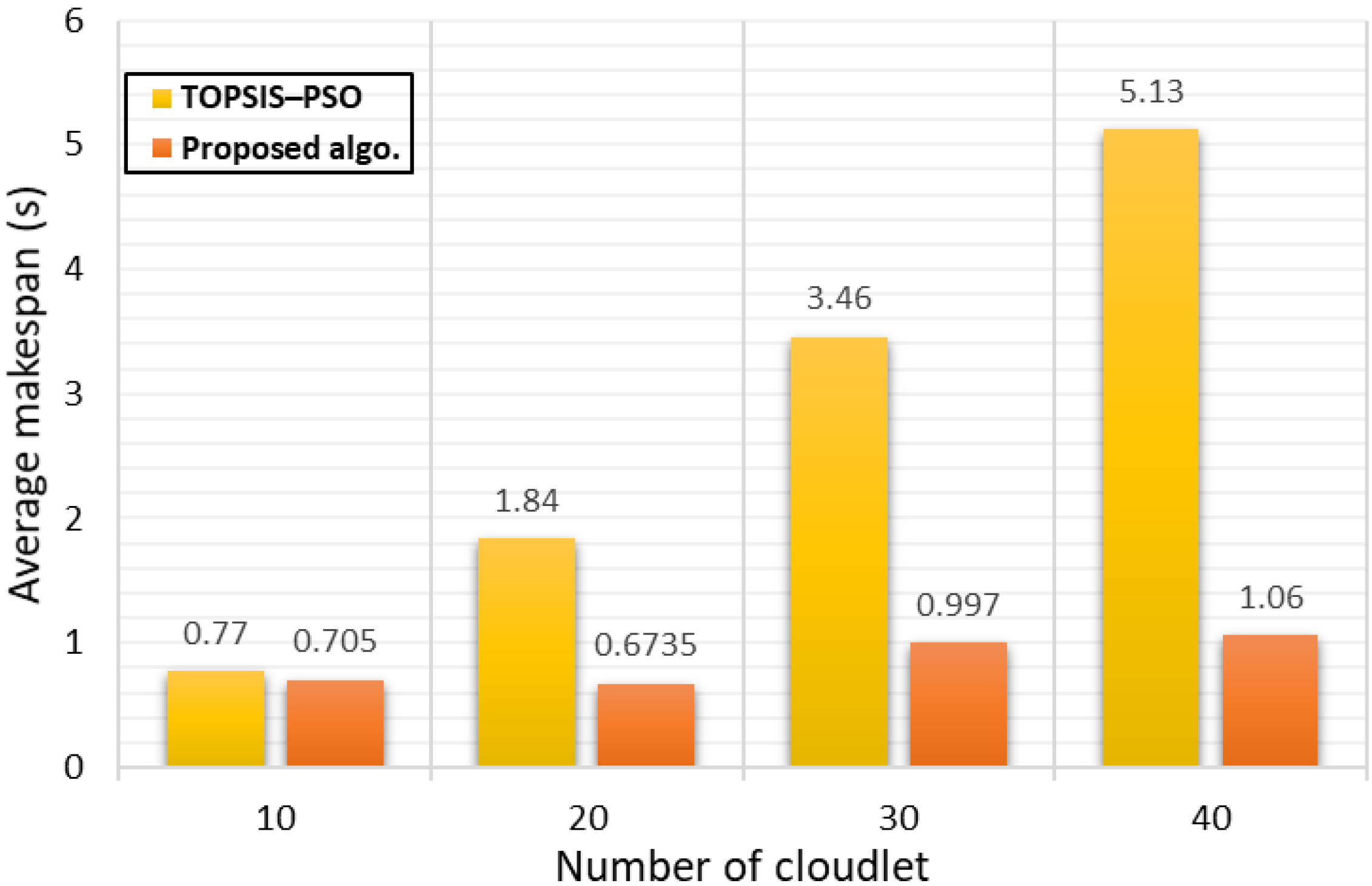
4.3.1. Type 1 Experiment (Locust Inspired Algorithm vs. TOPSIS–PSO)
Analysis of Makespan
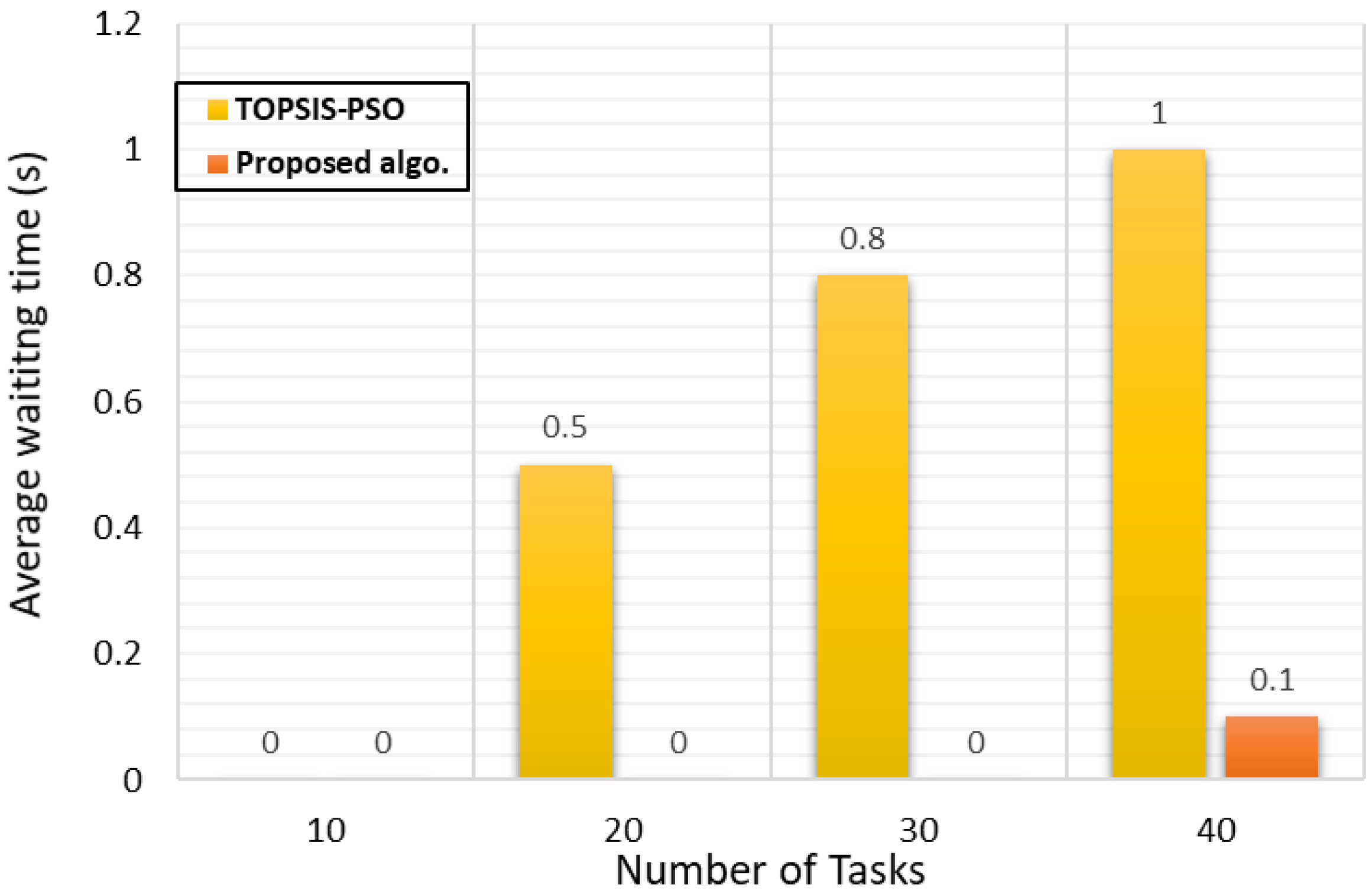
Analysis of Waiting Time
Analysis of Resource Utilisation
4.3.2. Type 2 Experiment (Locust Inspired Algorithm vs. State-of-the-Art Algorithms)
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Farid, M.; Latip, R.; Hussin, M.; Hamid, N.A.W.A. Scheduling scientific workflow using multi-objective algorithm with fuzzy resource utilization in multi-cloud environment. IEEE Access 2020, 8, 24309–24322. [Google Scholar] [CrossRef]
- Kamalinia, A.; Ghaffari, A. Hybrid task scheduling method for cloud computing by genetic and DE algorithms. Wirel. Pers. Commun. 2017, 97, 6301–6323. [Google Scholar] [CrossRef]
- Ms, S.; PM, J.P.; Alappatt, V. Profit maximization based task scheduling in hybrid clouds using whale optimization technique. Inf. Secur. J. Glob. Perspect. 2020, 29, 155–168. [Google Scholar] [CrossRef]
- Jena, R. Task scheduling in cloud environment: A multi-objective ABC framework. J. Inf. Optim. Sci. 2017, 38, 1–19. [Google Scholar] [CrossRef]
- Domanal, S.G.; Guddeti, R.M.; Buyya, R. A hybrid bio-inspired algorithm for scheduling and resource management in cloud environment. IEEE Trans. Serv. Comput. 2017, 13, 3–15. [Google Scholar] [CrossRef]
- Yu, S.; Wang, C.; Ren, K.; Lou, W. Achieving secure, scalable, and fine-grained data access control in cloud computing. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Duffield, N.G.; Goyal, P.; Greenberg, A.; Mishra, P.; Ramakrishnan, K.; Van der Merwe, J.E. Resource management with hoses: Point-to-cloud services for virtual private networks. IEEE/ACM Trans. Netw. 2002, 10, 679–692. [Google Scholar] [CrossRef]
- Alanzy, M.; Latip, R.; Muhammed, A. Range wise busy checking 2-way imbalanced algorithm for cloudlet allocation in cloud environment. JPhCS 2018, 1018, 012018. [Google Scholar] [CrossRef]
- Xiao, Z.; Song, W.; Chen, Q. Dynamic resource allocation using virtual machines for cloud computing environment. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 1107–1117. [Google Scholar] [CrossRef]
- Guan, B.; Wu, J.; Wang, Y.; Khan, S.U. CIVSched: A communication-aware inter-VM scheduling technique for decreased network latency between co-located VMs. IEEE Trans. Cloud Comput. 2014, 2, 320–332. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhani, M.F.; Boutaba, R.; Hellerstein, J.L. Dynamic heterogeneity-aware resource provisioning in the cloud. IEEE Trans. Cloud Comput. 2014, 2, 14–28. [Google Scholar] [CrossRef]
- Ala’anzy, M.; Othman, M. Load balancing and server consolidation in cloud computing environments: A meta-study. IEEE Access 2019, 7, 141868–141887. [Google Scholar] [CrossRef]
- Ala’anzy, M.A.; Othman, M.; Hasan, S.; Ghaleb, S.M.; Latip, R. Optimising Cloud Servers Utilisation Based on Locust-Inspired Algorithm. In Proceedings of the 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 23–27. [Google Scholar]
- Kumar, P.M.; Manogaran, G.; Sundarasekar, R.; Chilamkurti, N.; Varatharajan, R. Ant colony optimization algorithm with internet of vehicles for intelligent traffic control system. Comput. Netw. 2018, 144, 154–162. [Google Scholar] [CrossRef]
- Yang, X.S. Nature-Inspired Optimization Algorithms; Elsevier, Mara Conner: London, UK, 2014. [Google Scholar]
- Kurdi, H.A.; Alismail, S.M.; Hassan, M.M. LACE: A locust-inspired scheduling algorithm to reduce energy consumption in cloud datacenters. IEEE Access 2018, 6, 35435–35448. [Google Scholar] [CrossRef]
- Alhassan, S.; Abdulghani, M. A bio-inspired algorithm for virtual machines allocation in public clouds. Procedia Comput. Sci. 2019, 151, 1072–1077. [Google Scholar] [CrossRef]
- Ala’anzy, M.A.; Othman, M. Mapping and Consolidation of VMs Using Locust-Inspired Algorithms for Green Cloud Computing. Neural Process. Lett. 2021, 1–17. [Google Scholar] [CrossRef]
- Davidović, T.; Šelmić, M.; Teodorović, D.; Ramljak, D. Bee colony optimization for scheduling independent tasks to identical processors. J. Heuristics 2012, 18, 549–569. [Google Scholar] [CrossRef]
- Rathore, M.; Rai, S.; Saluja, N. Load balancing of virtual machine using honey bee galvanizing algorithm in cloud. IJCSIT 2015, 6, 4128–4132. [Google Scholar]
- Awad, A.; El-Hefnawy, N.; Abdel_kader, H. Enhanced particle swarm optimization for task scheduling in cloud computing environments. Procedia Comput. Sci. 2015, 65, 920–929. [Google Scholar] [CrossRef] [Green Version]
- Dordaie, N.; Navimipour, N.J. A hybrid particle swarm optimization and hill climbing algorithm for task scheduling in the cloud environments. ICT Express 2018, 4, 199–202. [Google Scholar] [CrossRef]
- Zuo, L.; Shu, L.; Dong, S.; Zhu, C.; Hara, T. A multi-objective optimization scheduling method based on the ant colony algorithm in cloud computing. IEEE Access 2015, 3, 2687–2699. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Li, X.; Shi, X.; Huang, K.; Liu, Y. A multi-type ant colony optimization (MACO) method for optimal land use allocation in large areas. Int. J. Geogr. Inf. Sci. 2012, 26, 1325–1343. [Google Scholar] [CrossRef]
- Cho, K.M.; Tsai, P.W.; Tsai, C.W.; Yang, C.S. A hybrid meta-heuristic algorithm for VM scheduling with load balancing in cloud computing. Neural Comput. Appl. 2015, 26, 1297–1309. [Google Scholar] [CrossRef]
- Sun, W.; Ji, Z.; Sun, J.; Zhang, N.; Hu, Y. SAACO: A self adaptive ant colony optimization in cloud computing. In Proceedings of the 2015 IEEE Fifth International Conference on Big Data and Cloud Computing, Dalian, China, 26–28 August 2015; pp. 148–153. [Google Scholar]
- Panwar, N.; Negi, S.; Rauthan, M.M.S.; Vaisla, K.S. Topsis–pso inspired non-preemptive tasks scheduling algorithm in cloud environment. Clust. Comput. 2019, 22, 1379–1396. [Google Scholar] [CrossRef]
- Chakravarthi, K.K.; Shyamala, L.; Vaidehi, V. TOPSIS inspired cost-efficient concurrent workflow scheduling algorithm in cloud. J. King Saud Univ. Comput. Inf. Sci. [CrossRef]
- Bhatt, A.; Dimri, P.; Aggarwal, A. Self-adaptive brainstorming for jobshop scheduling in multicloud environment. Softw. Pract. Exp. 2020, 50, 1381–1398. [Google Scholar] [CrossRef]
- El-Abd, M. Global-best brain storm optimization algorithm. Swarm Evol. Comput. 2017, 37, 27–44. [Google Scholar] [CrossRef]
- Shi, Y. Brain storm optimization algorithm. In International Conference in Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2011; pp. 303–309. [Google Scholar]
- Sanaj, M.; Prathap, P.J. Nature inspired chaotic squirrel search algorithm (CSSA) for multi objective task scheduling in an IAAS cloud computing atmosphere. Eng. Sci. Technol. Int. J. 2020, 23, 891–902. [Google Scholar] [CrossRef]
- Kumar, K.P.; Kousalya, K. Amelioration of task scheduling in cloud computing using crow search algorithm. Neural Comput. Appl. 2020, 32, 5901–5907. [Google Scholar] [CrossRef]
- Shojafar, M.; Javanmardi, S.; Abolfazli, S.; Cordeschi, N. FUGE: A joint meta-heuristic approach to cloud job scheduling algorithm using fuzzy theory and a genetic method. Clust. Comput. 2015, 18, 829–844. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ngadi, M.A. Symbiotic Organism Search optimization based task scheduling in cloud computing environment. Future Gener. Comput. Syst. 2016, 56, 640–650. [Google Scholar] [CrossRef]
- Changtian, Y.; Jiong, Y. Energy-aware genetic algorithms for task scheduling in cloud computing. In Proceedings of the 2012 Seventh ChinaGrid Annual Conference, Beijing, China, 20–23 September 2012; pp. 43–48. [Google Scholar]
- Dai, Y.; Lou, Y.; Lu, X. A task scheduling algorithm based on genetic algorithm and ant colony optimization algorithm with multi-QoS constraints in cloud computing. In Proceedings of the 7th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2015; Volume 2, pp. 428–431. [Google Scholar]
- Lee, Z.J.; Su, S.F.; Chuang, C.C.; Liu, K.H. Genetic algorithm with ant colony optimization (GA-ACO) for multiple sequence alignment. Appl. Soft Comput. 2008, 8, 55–78. [Google Scholar] [CrossRef]
- Milan, S.T.; Rajabion, L.; Darwesh, A.; Hosseinzadeh, M.; Navimipour, N.J. Priority-based task scheduling method over cloudlet using a swarm intelligence algorithm. Clust. Comput. 2020, 23, 663–671. [Google Scholar] [CrossRef]
- Xavier, V.A.; Annadurai, S. Chaotic social spider algorithm for load balance aware task scheduling in cloud computing. Clust. Comput. 2019, 22, 287–297. [Google Scholar]
- Abrol, P.; Gupta, S.; Singh, S. A QoS Aware Resource Placement Approach Inspired on the Behavior of the Social Spider Mating Strategy in the Cloud Environment. Wirel. Pers. Commun. 2020, 113, 2027–2065. [Google Scholar] [CrossRef]
- Guttal, V.; Romanczuk, P.; Simpson, S.J.; Sword, G.A.; Couzin, I.D. Cannibalism can drive the evolution of behavioural phase polyphenism in locusts. Ecol. Lett. 2012, 15, 1158–1166. [Google Scholar] [CrossRef] [PubMed]
- Ariel, G.; Ayali, A. Locust collective motion and its modeling. PLoS Comput. Biol. 2015, 11, e1004522. [Google Scholar] [CrossRef] [Green Version]
- Topaz, C.M.; Bernoff, A.J.; Logan, S.; Toolson, W. A model for rolling swarms of locusts. Eur. Phys. J. Spec. Top. 2008, 157, 93–109. [Google Scholar] [CrossRef] [Green Version]
- Buyya, R.; Murshed, M. Gridsim: A toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. Concurr. Comput. Pract. Exp. 2002, 14, 1175–1220. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.; Liang, C.; Wang, J.Z.; Buyya, R. Bandwidth-aware divisible task scheduling for cloud computing. Softw. Pract. Exp. 2014, 44, 163–174. [Google Scholar] [CrossRef] [Green Version]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Al-Maamari, A.; Omara, F.A. Task scheduling using PSO algorithm in cloud computing environments. Int. J. Grid Distrib. Comput. 2015, 8, 245–256. [Google Scholar] [CrossRef]
- Alboaneen, D.; Tianfield, H.; Zhang, Y.; Pranggono, B. A metaheuristic method for joint task scheduling and virtual machine placement in cloud data centers. Future Gener. Comput. Syst. 2021, 115, 201–212. [Google Scholar] [CrossRef]
- Muthulakshmi, B.; Somasundaram, K. A hybrid ABC-SA based optimized scheduling and resource allocation for cloud environment. Clust. Comput. 2019, 22, 10769–10777. [Google Scholar] [CrossRef]
- Tawfeek, M.A.; El-Sisi, A.; Keshk, A.E.; Torkey, F.A. Cloud task scheduling based on ant colony optimization. In Proceedings of the 2013 8th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 26–28 November 2013; pp. 64–69. [Google Scholar]
- Yonggui, W.; Ruilian, H. Study on cloud computing task schedule strategy based on MACO algorithm. Comput. Meas. Control. 2011, 5, 1203–1204. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Algorithm Type | Improvement Types | Metrics | |||
|---|---|---|---|---|---|---|---|
| TS | SC | MS | WT | U | |||
| [19] | 2012 | BCO | ✓ | ✓ | |||
| [20] | 2015 | ABC | ✓ | ✓ | |||
| [21] | 2015 | PSO | ✓ | ✓ | ✓ | ||
| [22] | 2018 | PSO & hill-climbing | ✓ | ✓ | |||
| [23] | 2015 | ACO | ✓ | ✓ | ✓ | ||
| [24] | 2012 | MACO | ✓ | ✓ | ✓ | ||
| [25] | 2015 | ACO with PSO (ACOPS) | ✓ | ✓ | |||
| [26] | 2015 | ACO & PSO to generate SA-ACO (self-adaptive) | ✓ | ✓ | |||
| [5] | 2017 | MPSO & CSO | ✓ | ✓ | ✓ | ||
| [27] | 2019 | TOPSIS (PSO based) | ✓ | ✓ | ✓ | ||
| [28] | 2020 | TOPSIS (PSO based) | ✓ | ✓ | |||
| [31] | 2011 | BSO | ✓ | ✓ | ✓ | ||
| [30] | 2017 | BSO | ✓ | ✓ | ✓ | ||
| [29] | 2020 | SA-BSO | ✓ | ✓ | ✓ | ||
| [32] | 2020 | CSSA | ✓ | ✓ | |||
| [33] | 2020 | CSA | ✓ | ✓ | |||
| [34] | 2015 | Fuzzy & SGA (FUGE) | ✓ | ✓ | |||
| [3] | 2020 | Bubble-net hunting of humpback wales (WOA) | ✓ | ✓ | ✓ | ||
| [35] | 2016 | DSOS | ✓ | ✓ | ✓ | ||
| [36] | 2012 | GA | ✓ | ✓ | |||
| [38] | 2008 | GA & ACO | ✓ | ✓ | |||
| [37] | 2015 | GA & ACO | ✓ | ✓ | |||
| [39] | 2020 | Bacteria & chemotactic phenomenon | ✓ | ✓ | |||
| [40] | 2019 | Chaotic social spider | ✓ | ✓ | ✓ | ||
| [41] | 2020 | social spider-mating (SSRPA) | ✓ | ✓ | ✓ | ✓ | |
| [16] | 2018 | Locust | ✓ | ✓ | |||
| [17] | 2019 | Locust | ✓ | ✓ | ✓ | ||
| [18] | 2021 | Locust | ✓ | ||||
| Our algorithm | 2021 | Locust | ✓ | ✓ | ✓ | ✓ | |
| #VM | Minimum T Length | Maximum T Length |
|---|---|---|
| . | . | . |
| . | . | . |
| . | . | . |
| Parameter | Value |
|---|---|
| No. of Cloudlets | 10–40 |
| Cloudlet length | (100–2500) MI |
| No. of VMs | 10 |
| VM MIPS | 2400 MIPS |
| Task scheduler | Time-shared |
| No. of hosts | 1 |
| Host(s) Storage | 1,000,000 MB |
| Host(s) memory | 4096 MB |
| No. of data centres | 1 |
| pesNumber (No. of CPUs) | 5 |
| num_user (No. of users) | 1 |
| Utilisation model | Full utilisation |
| System architecture | X86 |
| Operating system | Linux |
| VMM | Xen |
| Parameter | Value |
|---|---|
| Total number of tasks | 100–500 |
| Length of tasks | 1000–20,000 |
| Total number of VMs | 50 |
| VM memory (RAM) | 256–2048 |
| VM bandwidth | 500–1000 |
| Number of PEs required | 1–4 |
| Number of DCs | 10 |
| Number of hosts | 2–6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ala’anzy, M.A.; Othman, M.; Hanapi, Z.M.; Alrshah, M.A. Locust Inspired Algorithm for Cloudlet Scheduling in Cloud Computing Environments. Sensors 2021, 21, 7308. https://doi.org/10.3390/s21217308
Ala’anzy MA, Othman M, Hanapi ZM, Alrshah MA. Locust Inspired Algorithm for Cloudlet Scheduling in Cloud Computing Environments. Sensors. 2021; 21(21):7308. https://doi.org/10.3390/s21217308
Chicago/Turabian StyleAla’anzy, Mohammed Alaa, Mohamed Othman, Zurina Mohd Hanapi, and Mohamed A. Alrshah. 2021. "Locust Inspired Algorithm for Cloudlet Scheduling in Cloud Computing Environments" Sensors 21, no. 21: 7308. https://doi.org/10.3390/s21217308
APA StyleAla’anzy, M. A., Othman, M., Hanapi, Z. M., & Alrshah, M. A. (2021). Locust Inspired Algorithm for Cloudlet Scheduling in Cloud Computing Environments. Sensors, 21(21), 7308. https://doi.org/10.3390/s21217308