
Prediction-Correction Techniques to Support Sensor Interoperability in Industry 4.0 Systems




Abstract
:1. Introduction
2. State of the Art on Sensor Interoperability in Industry 4.0 Scenarios
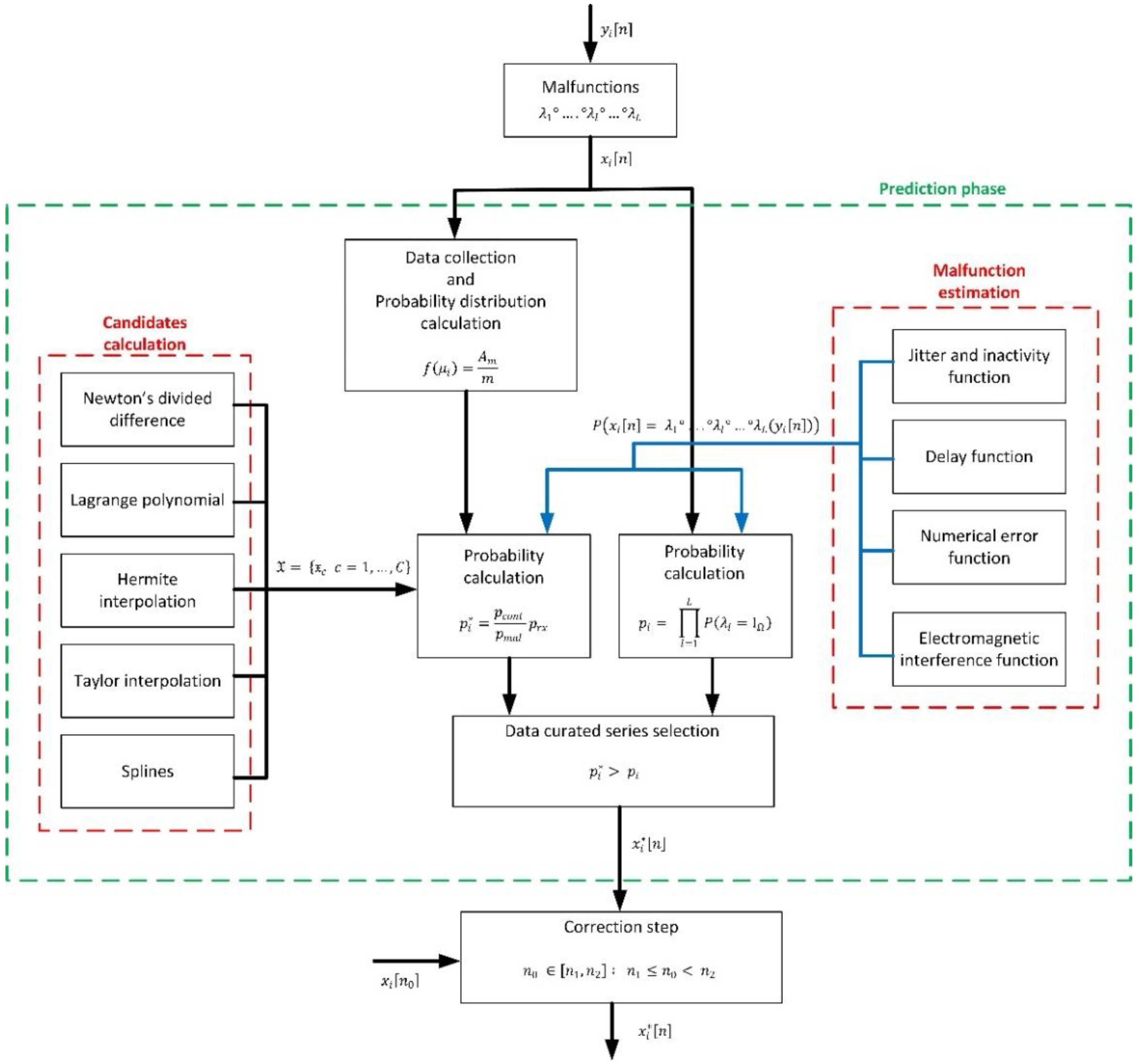
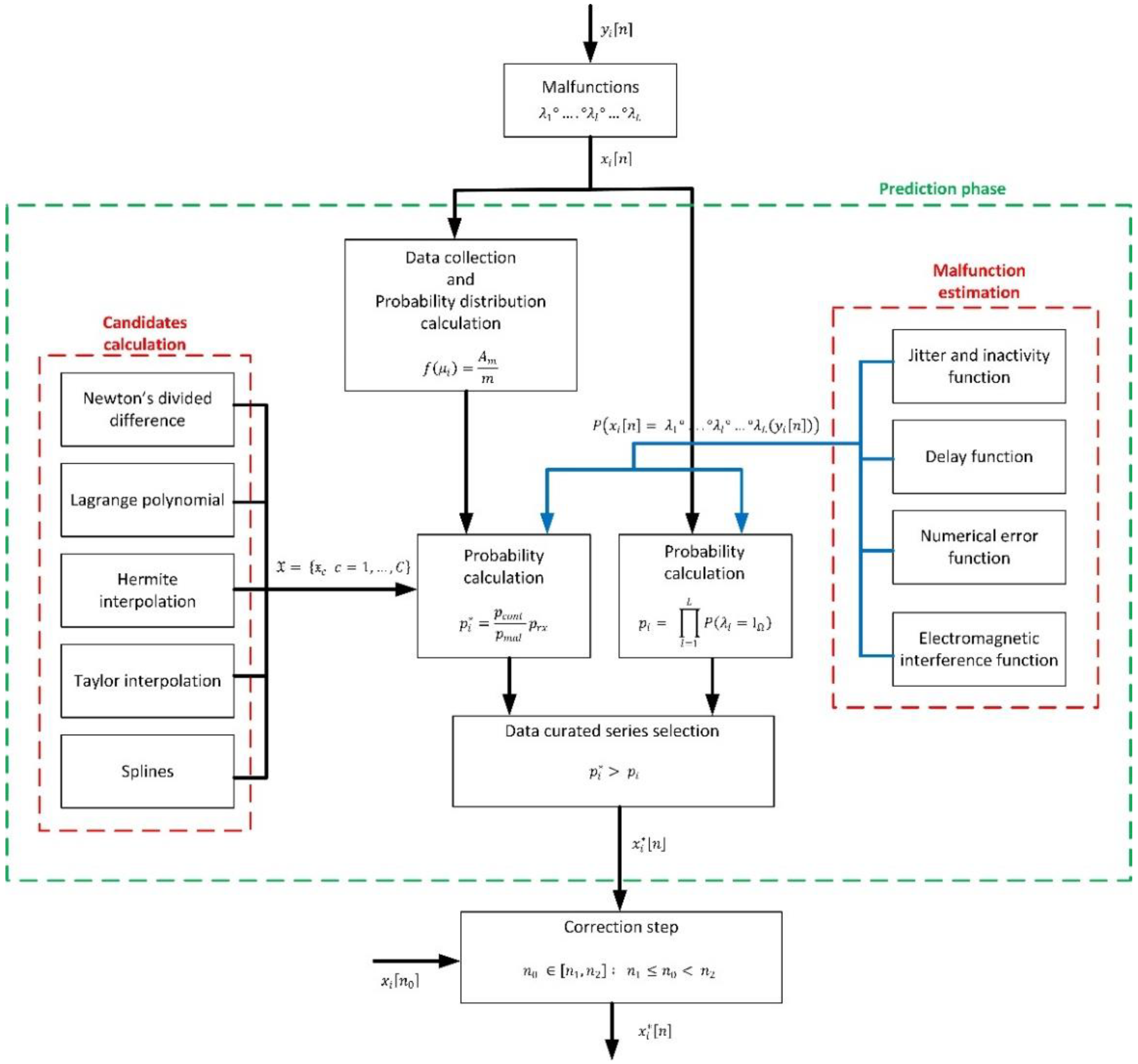
3. Proposed Predictor-Corrector Solution
3.1. General Mathematical Framework and Curation Strategy
3.2. Candidates to Curated Time Series: Calculation
3.3. Malfunction Modeling
3.4. Final Data Generation and Correction Step
- If probability is clearly higher than , candidate associated to this probability is selected as the curated data series and initially received information is deleted. In this proposal, we are considering a difference higher than 10% (66) as the limit to take this action.
- On the contrary, if probability is clearly higher than probability (67), all candidates are rejected and initially received data flow is accepted as the curated data series .
- If neither probability nor is clearly higher than the other (68), the final curate data series cannot be concluded to be the candidate or the originally received data . Thus, the curated data series is obtained as the arithmetic average of both series (69).
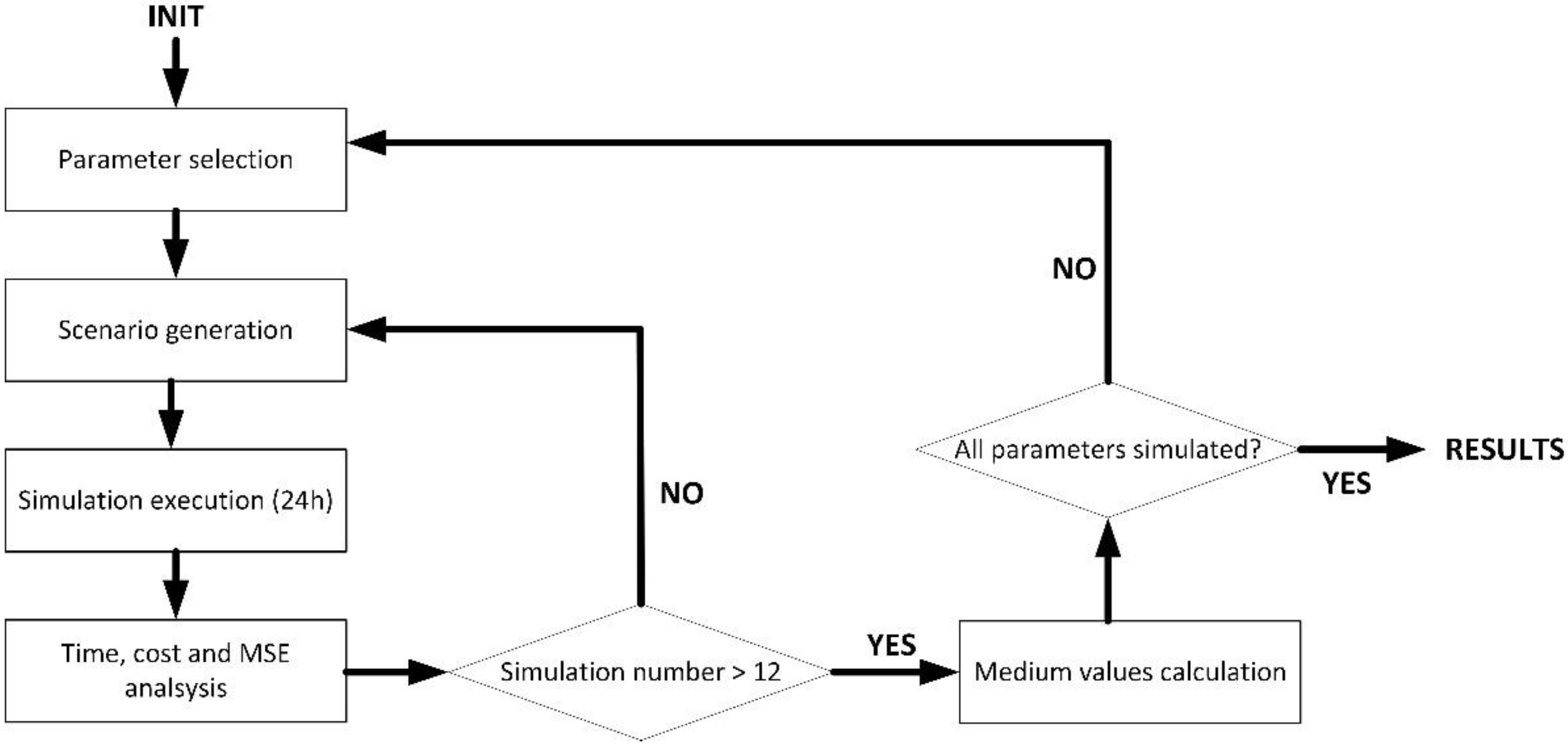
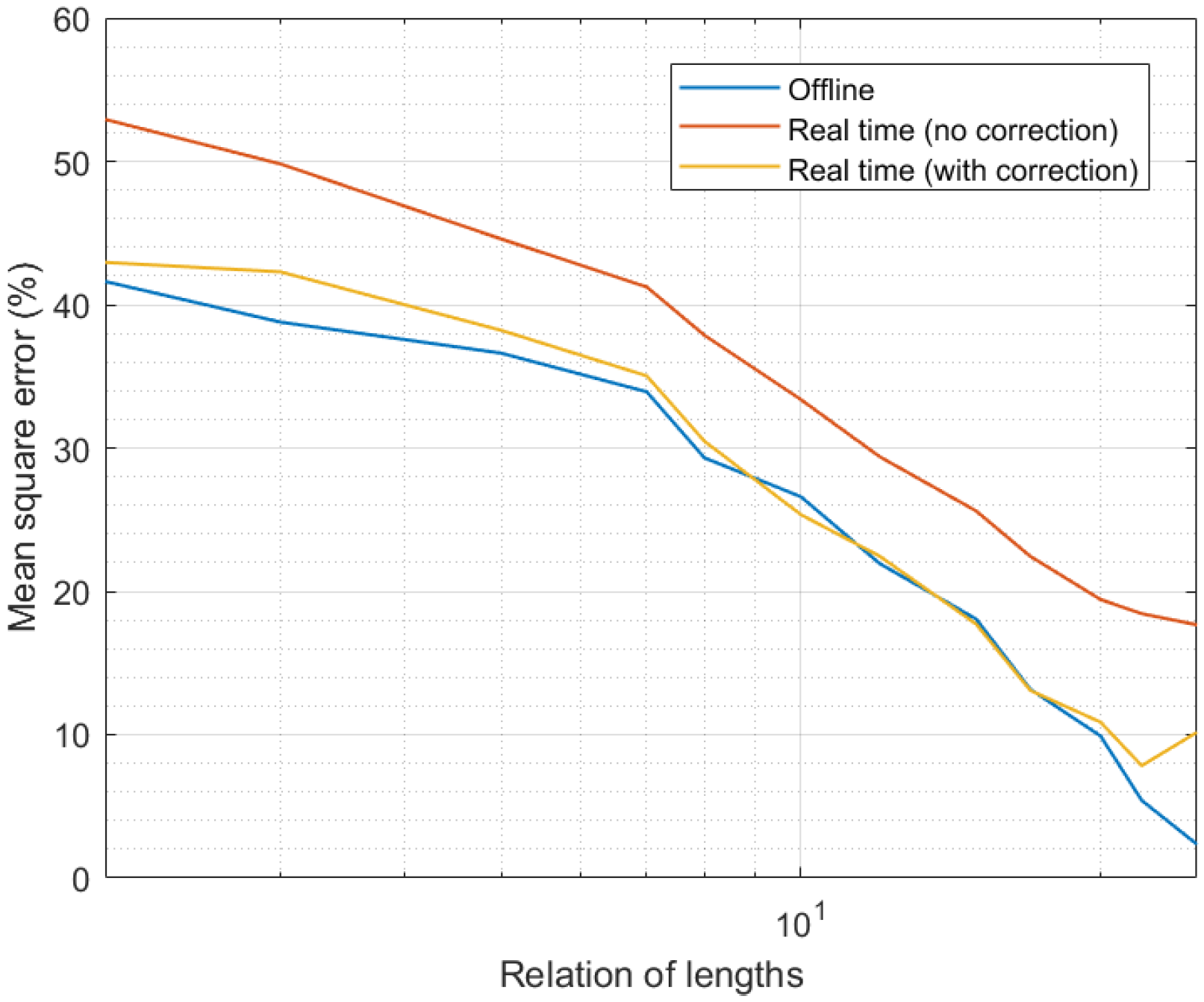
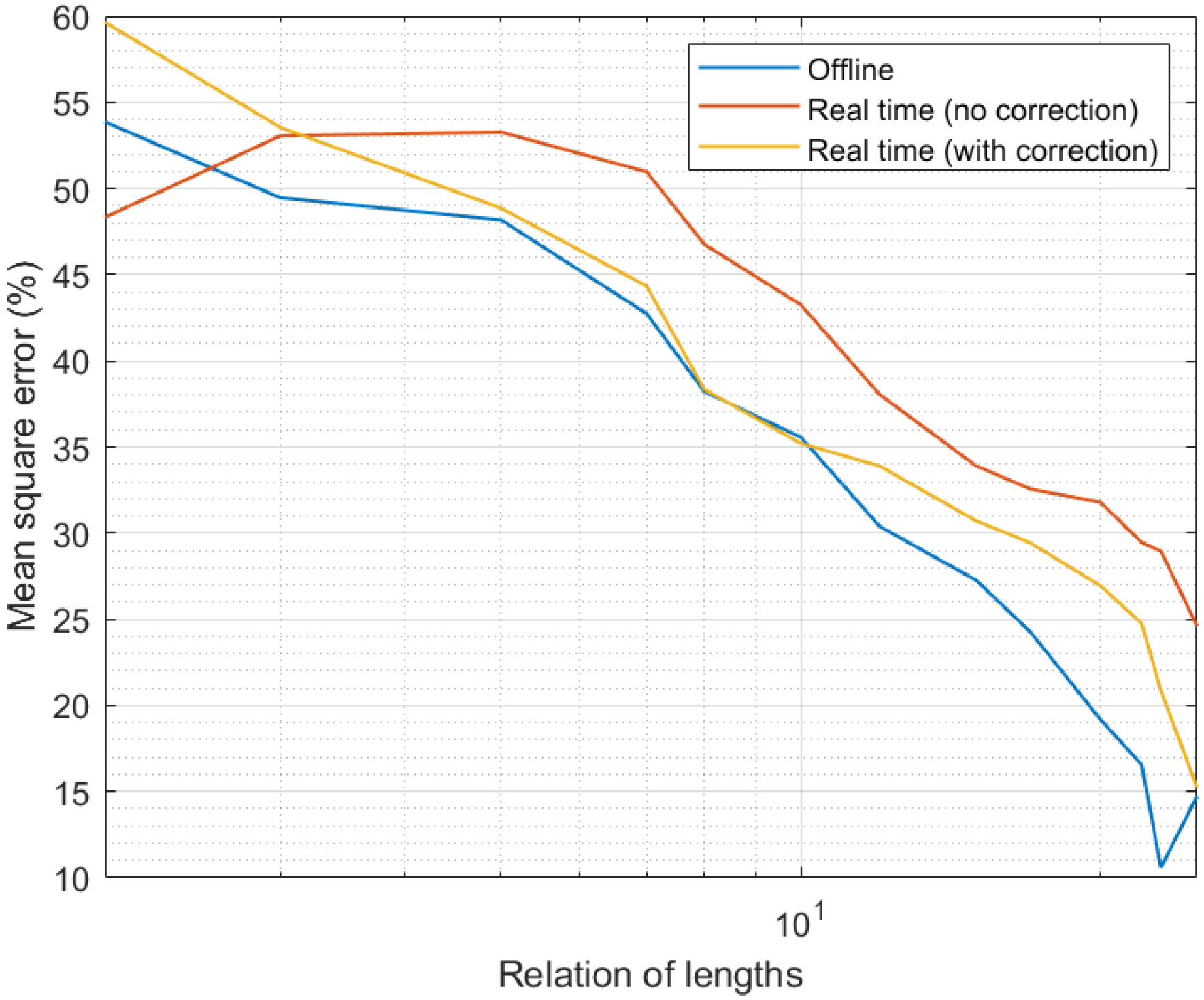
4. Experimental Validation and Results
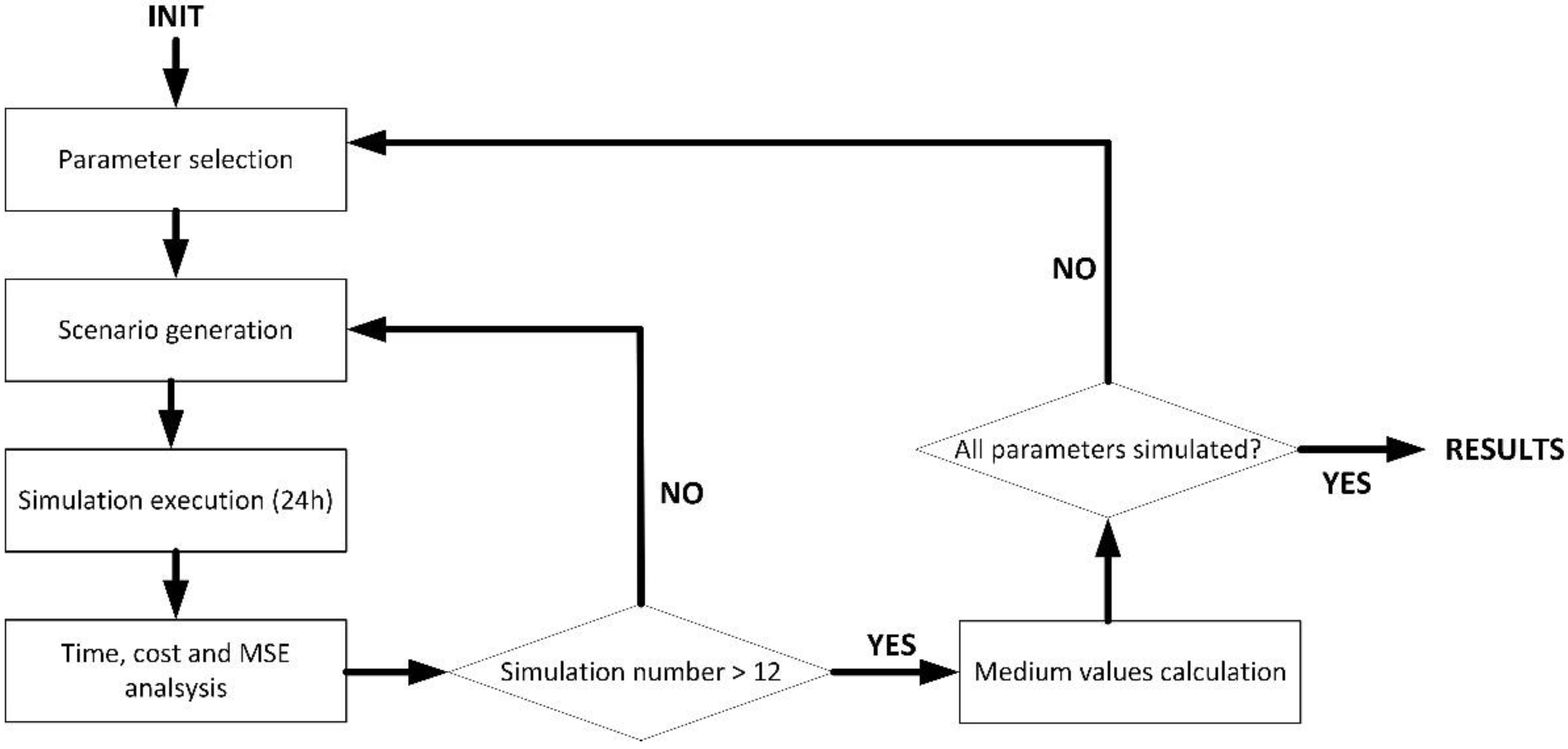
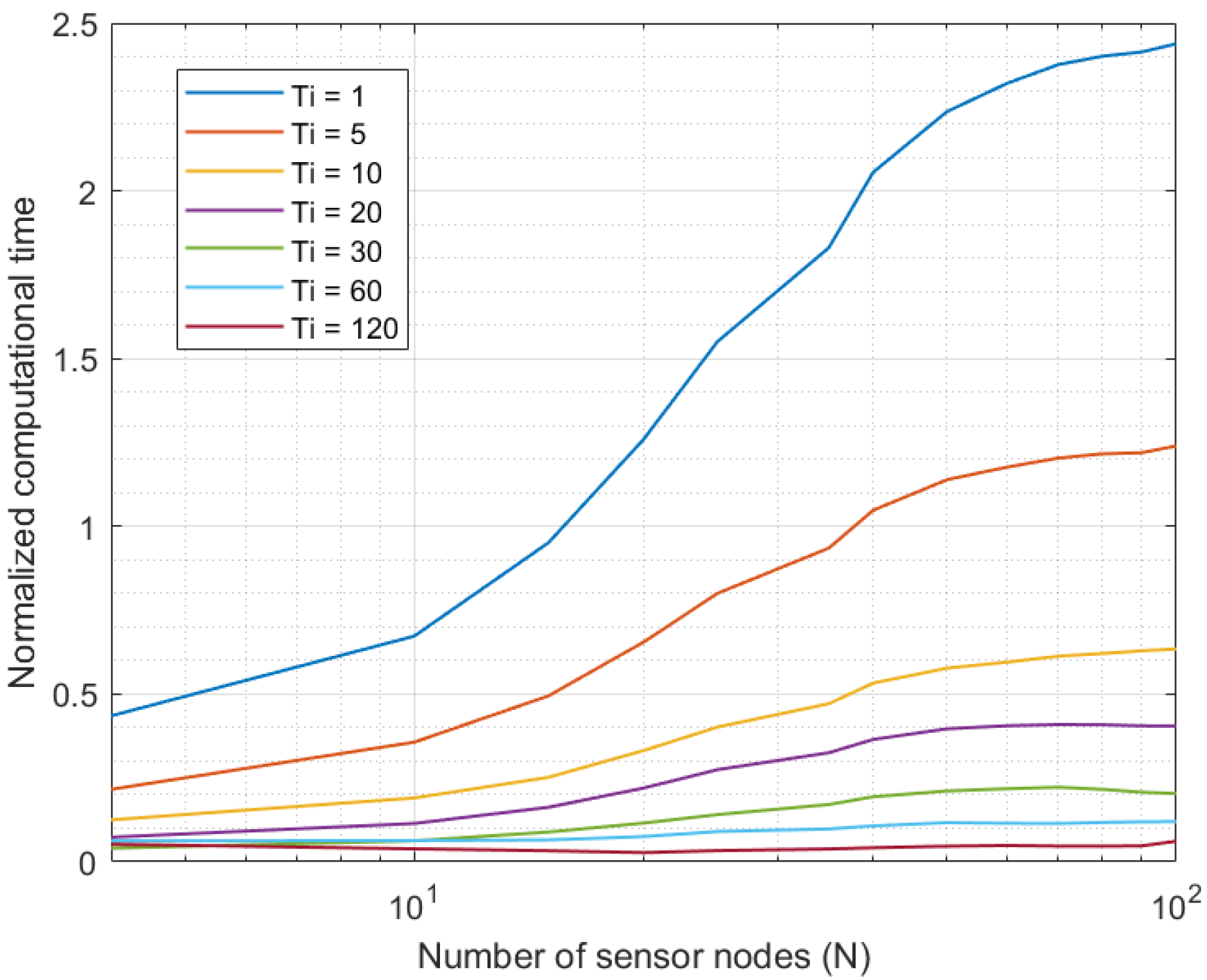
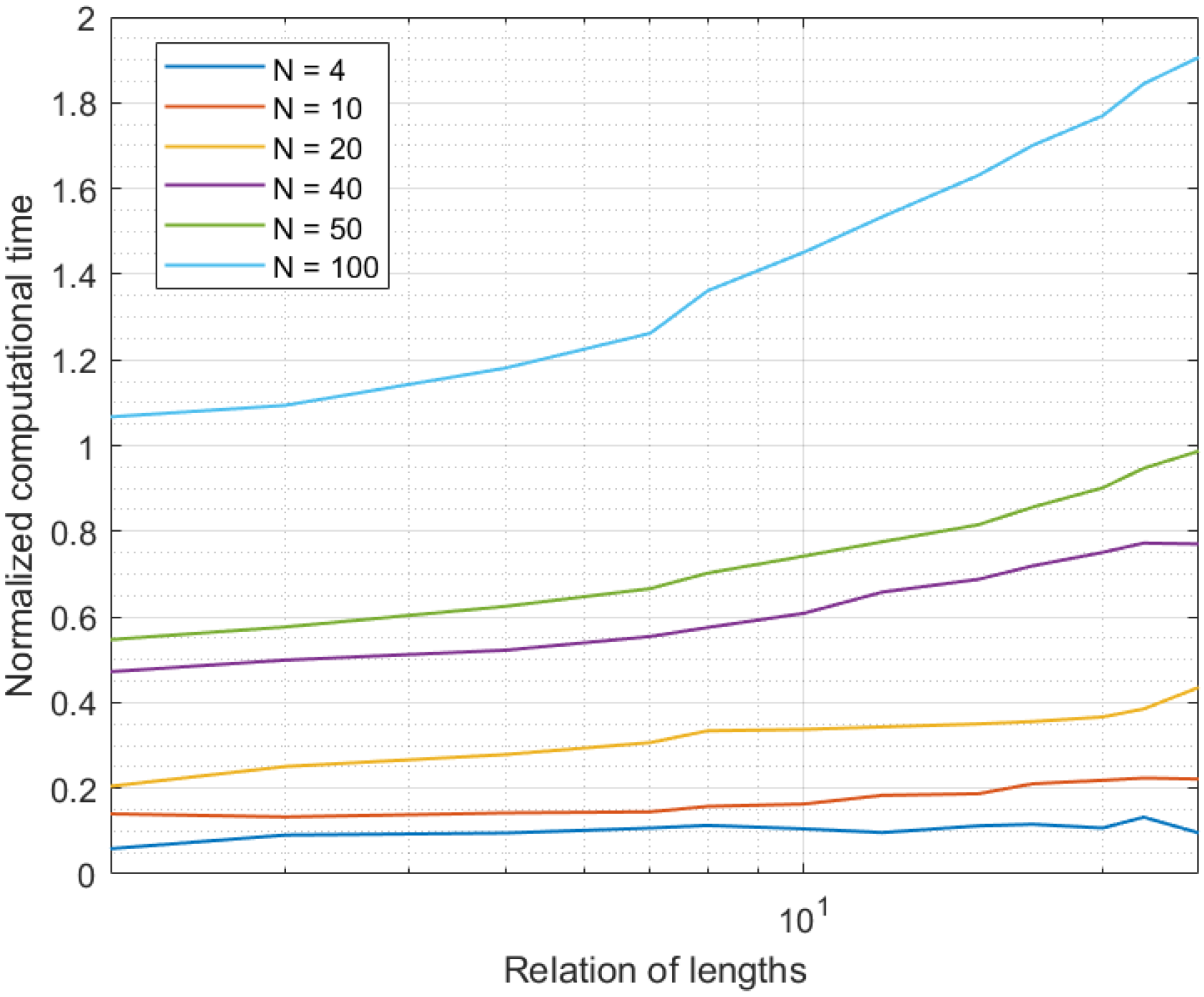
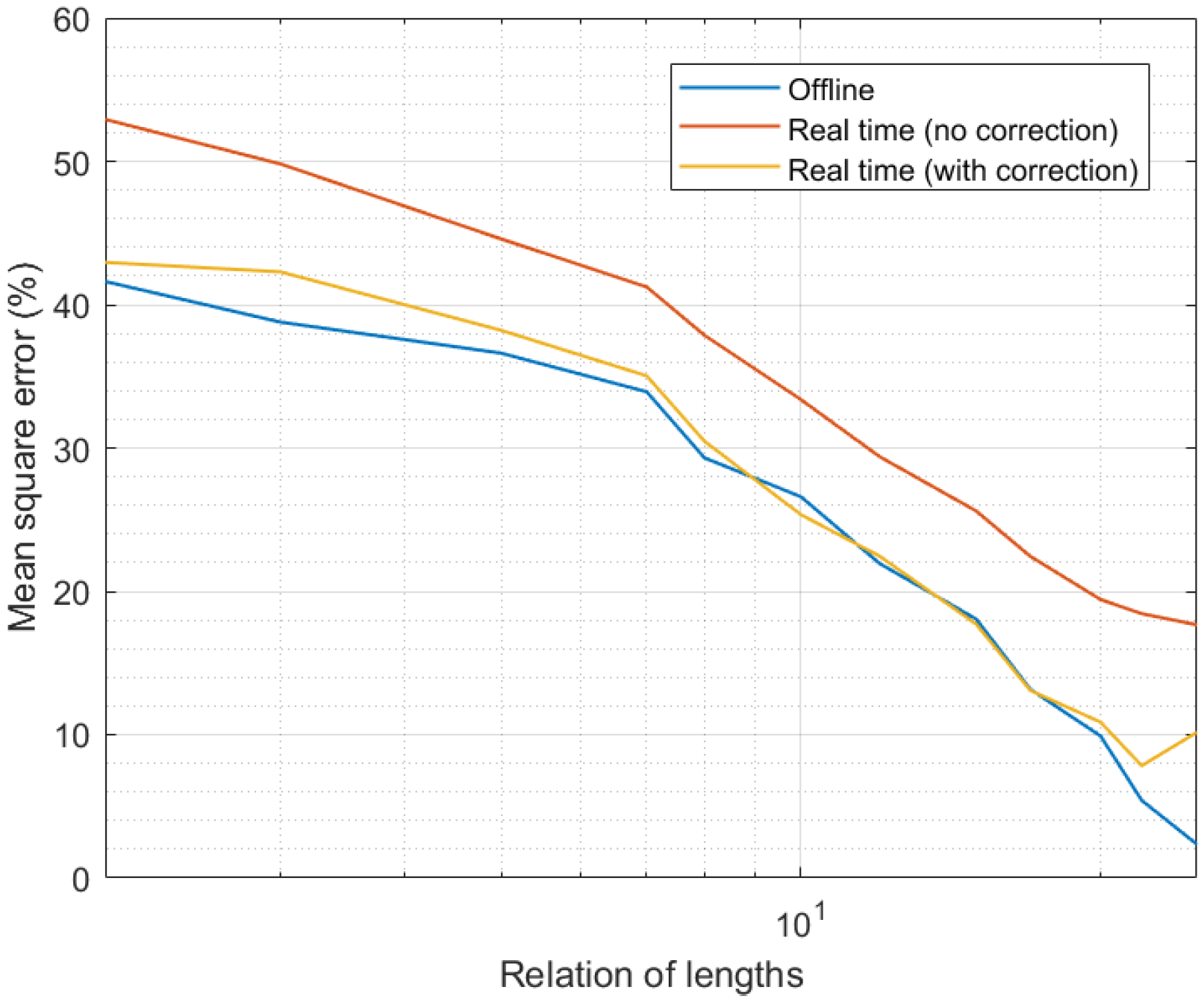
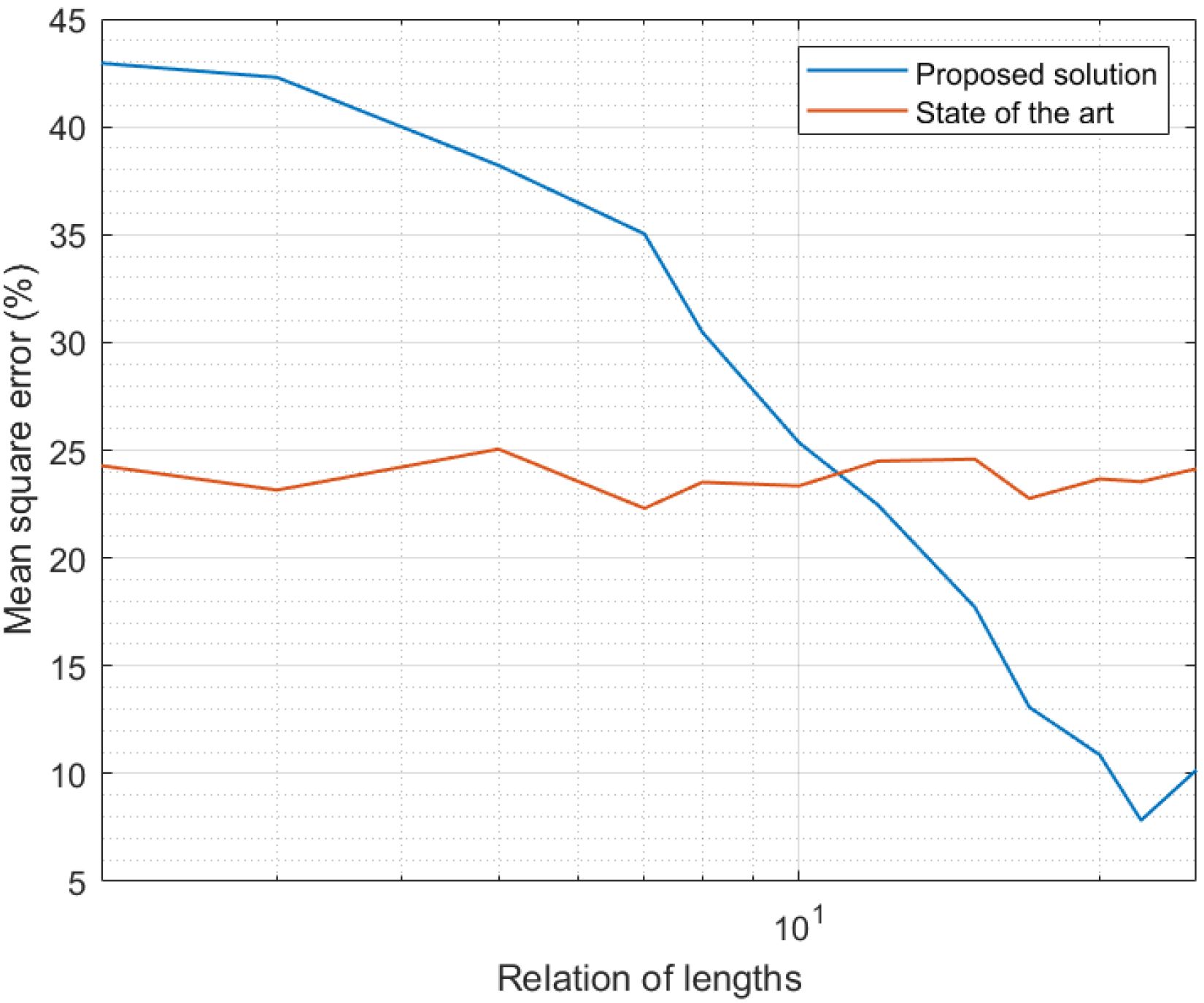
4.1. Experiments: Methods and Materials
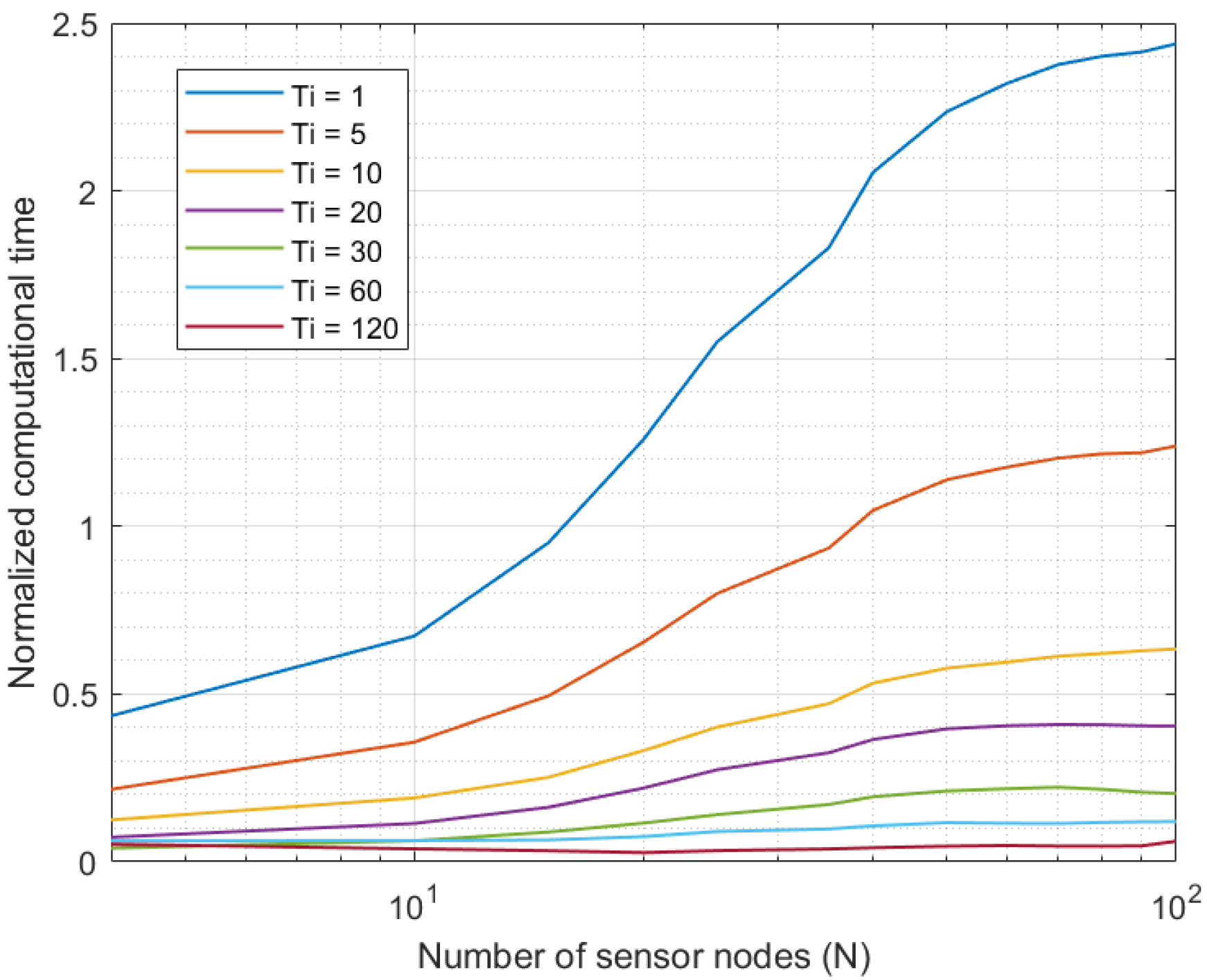
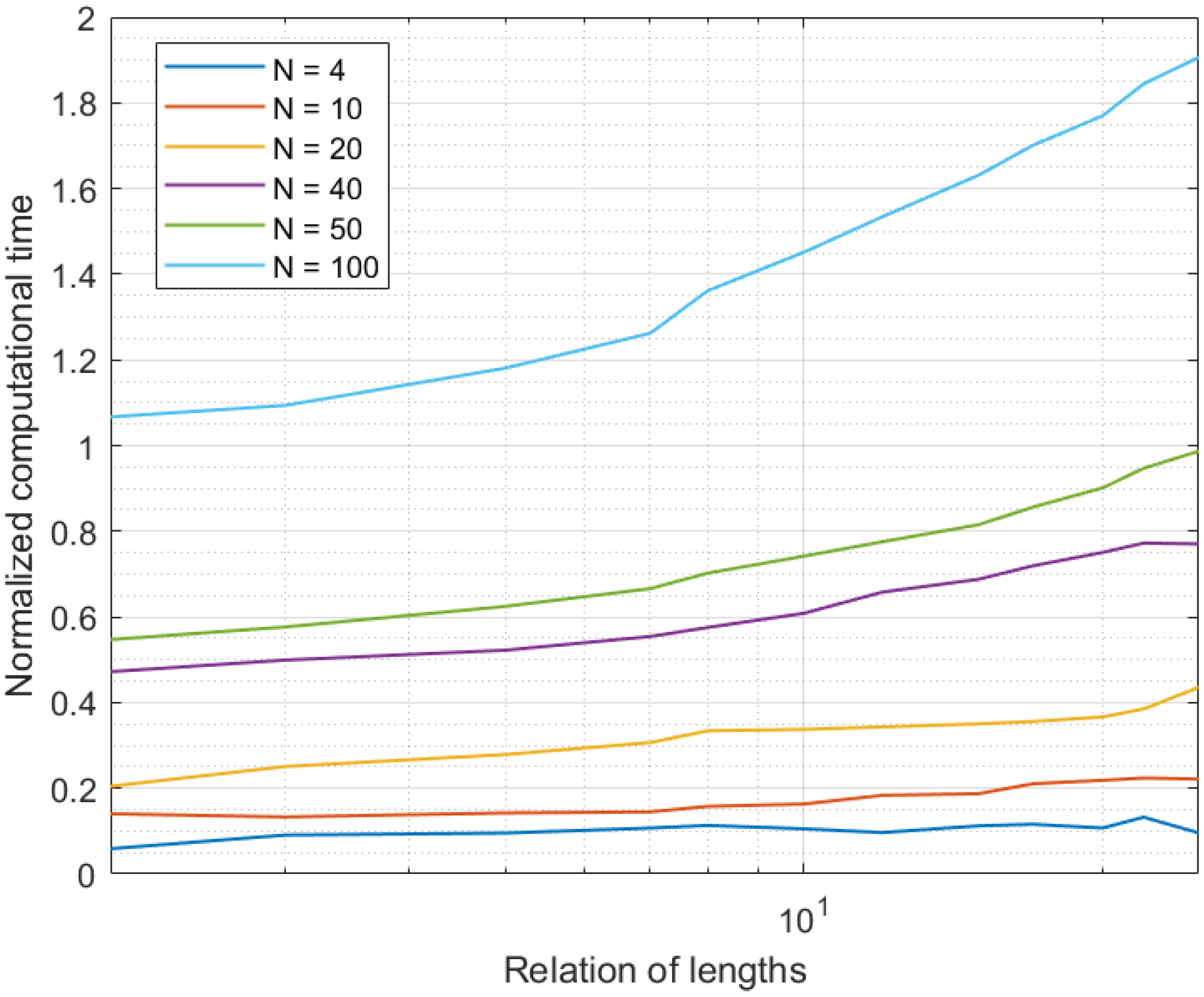
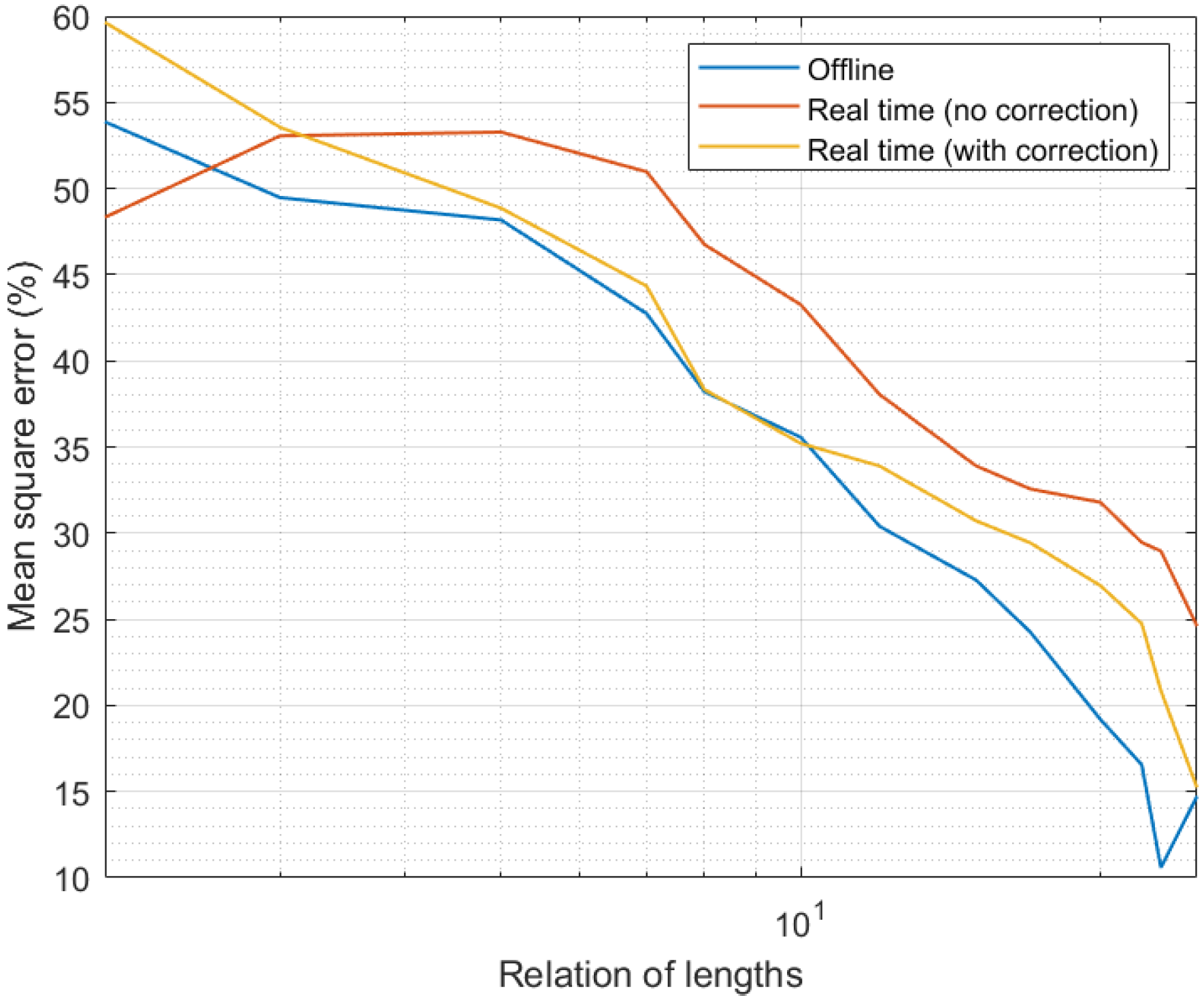
4.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Mendelsohn, R.; Neumann, J.E. (Eds.) The Impact of Climate Change on the United States Economy; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Chomsky, N.; Pollin, R.; Polychroniou, C.J. Climate Crisis and the Global Green New Deal: The Political Economy of Saving the Planet; Verso: London, UK, 2020. [Google Scholar]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Bordel, B.; Alcarria, R. Trust-enhancing technologies: Blockchain mathematics in the context of Industry 4.0. In Advances in Mathematics for Industry 4.0; Academic Press: Cambridge, UK, 2021; pp. 1–22. [Google Scholar]
- Bordel, B.; Alcarria, R.; Hernández, M.; Robles, T. People-as-a-Service Dilemma: Humanizing Computing Solutions in High-Efficiency Applications. Multidiscip. Digit. Publ. Inst. Proc. 2019, 31, 39. [Google Scholar] [CrossRef] [Green Version]
- Bordel, B.; Alcarria, R. Assessment of human motivation through analysis of physiological and emotional signals in Industry 4.0 scenarios. J. Ambient. Intell. Humaniz. Comput. 2017, 1–21. [Google Scholar] [CrossRef]
- Bordel, B.; Alcarria, R.; Robles, T.; Martín, D. Cyber–physical systems: Extending pervasive sensing from control theory to the Internet of Things. Pervasive Mob. Comput. 2017, 40, 156–184. [Google Scholar] [CrossRef]
- Lee, J.; Davari, H.; Singh, J.; Pandhare, V. Industrial Artificial Intelligence for industry 4.0-based manufacturing systems. Manuf. Lett. 2018, 18, 20–23. [Google Scholar] [CrossRef]
- Robles, T.; Bordel, B.; Alcarria, R.; de Andrés, D.M. Mobile Wireless Sensor Networks: Modeling and Analysis of Three-Dimensional Scenarios and Neighbor Discovery in Mobile Data Collection. Ad Hoc Sens. Wirel. Netw. 2017, 35, 67–104. [Google Scholar]
- Bordel, B.; Alcarria, R.; Robles, T. Controlling Supervised Industry 4.0 Processes through Logic Rules and Tensor Deformation Functions. Informatica 2021, 32, 1–29. [Google Scholar]
- Martín, D.; Bordel, B.; Alcarria, R. Automatic detection of erratic sensor observations in Ami Platforms: A statistical approach. Multidiscip. Digit. Publ. Inst. Proc. 2019, 31, 55. [Google Scholar] [CrossRef] [Green Version]
- Martín, D.; Fuentes-Lorenzo, D.; Bordel, B.; Alcarria, R. Towards Outlier Sensor Detection in Ambient Intelligent Platforms—A Low-Complexity Statistical Approach. Sensors 2020, 20, 4217. [Google Scholar] [CrossRef]
- Bordel, B.; Miguel, C.; Alcarria, R.; Robles, T. A hardware-supported algorithm for self-managed and choreographed task execution in sensor networks. Sensors 2018, 18, 812. [Google Scholar] [CrossRef] [Green Version]
- Bordel, B.; Alcarria, R.; Robles, T.; You, I. A predictor-corrector algorithm based on Laurent series for biological signals in the Internet of Medical Things. IEEE Access 2020, 8, 109360–109371. [Google Scholar] [CrossRef]
- Burns, T.; Cosgrove, J.; Doyle, F. A Review of Interoperability Standards for Industry 4.0. Procedia Manuf. 2019, 38, 646–653. [Google Scholar] [CrossRef]
- De Melo, P.F.S.; Godoy, E.P. Controller Interface for Industry 4. In 0 based on RAMI 4.0 and OPC UA. In Proceedings of the 2019 II Workshop on Metrology for Industry 4.0 and IoT (MetroInd4. 0&IoT), Naples, Italy, 4–6 June 2019; IEEE: Naples, Italy, 2019; pp. 229–234. [Google Scholar]
- Kong, X.T.; Yang, X.; Peng, K.L.; Li, C.Z. Cyber physical system-enabled synchronization mechanism for pick-and-sort ecommerce order fulfilment. Comput. Ind. 2020, 118, 103220. [Google Scholar] [CrossRef]
- Geraci, A. IEEE Standard Computer Dictionary: Compilation of IEEE Standard Computer Glossaries; IEEE Press: Piscataway, NJ, USA, 1991. [Google Scholar]
- Bartodziej, C.J. The concept industry 4.0. In The Concept Industry 4.0; Springer Gabler: Wiesbaden, Germany, 2017; pp. 27–50. [Google Scholar]
- Adolphs, P.; Bedenbender, H.; Dirzus, D.; Ehlich, M.; Epple, U.; Hankel, M.; Wollschlaeger, M. Reference Architecture Model Industrie 4.0 (Rami4. 0); Status report; ZVEI and VDI: Berlin, Germany, 2015. [Google Scholar]
- Pai, D.M. Interoperability between IIC Architecture & Industry 4.0 Reference Architecture for Industrial Assets; Tech. Rep.: Piscataway, NJ, USA, 2016. [Google Scholar]
- Villalonga, A.; Beruvides, G.; Castaño, F.; Haber, R.E. Cloud-based industrial cyber–physical system for data-driven reasoning: A review and use case on an industry 4.0 pilot line. IEEE Trans. Ind. Inform. 2020, 16, 5975–5984. [Google Scholar] [CrossRef]
- Xia, W.; Zhang, J.; Quek, T.Q.; Jin, S.; Zhu, H. Mobile edge cloud-based industrial internet of things: Improving edge intelligence with hierarchical SDN controllers. IEEE Veh. Technol. Mag. 2020, 15, 36–45. [Google Scholar] [CrossRef]
- Babbar, H.; Rani, S.; Singh, A.; Abd-Elnaby, M.; Choi, B.J. Cloud Based Smart City Services for Industrial Internet of Things in Software-Defined Networking. Sustainability 2021, 13, 8910. [Google Scholar] [CrossRef]
- Li, M.; Xu, G.; Lin, P.; Huang, G.Q. Cloud-based mobile gateway operation system for industrial wearables. Robot. Comput.-Integr. Manuf. 2019, 58, 43–54. [Google Scholar] [CrossRef]
- Tannahill, B.K.; Jamshidi, M. System of Systems and Big Data analytics–Bridging the gap. Comput. Electr. Eng. 2014, 40, 2–15. [Google Scholar] [CrossRef]
- Sun, S.; Zheng, X.; Villalba-Díez, J.; Ordieres-Meré, J. Data handling in industry 4.0: Interoperability based on distributed ledger technology. Sensors 2020, 20, 3046. [Google Scholar] [CrossRef]
- Negri, E.; Fumagalli, L.; Macchi, M. A Review of the Roles of Digital Twin in CPS-Based Production Systems. Value Based Intell. Asset Manag. 2020, 291–307. [Google Scholar]
- Qi, Q.; Tao, F.; Hu, T.; Anwer, N.; Liu, A.; Wei, Y.; Nee, A.Y.C. Enabling technologies and tools for digital twin. J. Manuf. Syst. 2019, 58, 3–21. [Google Scholar] [CrossRef]
- Leng, J.; Zhang, H.; Yan, D.; Liu, Q.; Chen, X.; Zhang, D. Digital twin-driven manufacturing cyber-physical system for parallel controlling of smart workshop. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1155–1166. [Google Scholar] [CrossRef]
- Haag, S.; Anderl, R. Digital twin–Proof of concept. Manuf. Lett. 2018, 15, 64–66. [Google Scholar] [CrossRef]
- Raptis, T.P.; Passarella, A.; Conti, M. Data management in industry 4.0: State of the art and open challenges. IEEE Access 2019, 7, 97052–97093. [Google Scholar] [CrossRef]
- Reis, M.S.; Gins, G. Industrial process monitoring in the big data/industry 4.0 era: From detection, to diagnosis, to prognosis. Processes 2017, 5, 35. [Google Scholar] [CrossRef] [Green Version]
- De Vita, F.; Bruneo, D.; Das, S.K. On the use of a full stack hardware/software infrastructure for sensor data fusion and fault prediction in industry 4.0. Pattern Recognit. Lett. 2020, 138, 30–37. [Google Scholar] [CrossRef]
- Diez-Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Inf. Fusion 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Grangel-González, I. Semantic data integration for industry 4.0 standards. In European Knowledge Acquisition Workshop; Springer International Publishing: Cham, Switzerland, November 2016; pp. 230–237. [Google Scholar]
- Loures, E.D.F.R.; dos Santos, E.A.P.; Deschamps, F. Data Fusion for Industry 4.0: General Concepts and Applications. In Proceedings of the 25th International Joint Conference on Industrial Engineering and Operations Management–IJCIEOM: The Next Generation of Production and Service Systems, March 2020. Novi Sad, Serbia, 15–17 July 2019; Springer Nature: Basingstoke, UK, 2020; p. 362. [Google Scholar]
- Kabashkin, I.; Kundler, J. Reliability of sensor nodes in wireless sensor networks of cyber physical systems. Procedia Comput. Sci. 2017, 104, 380–384. [Google Scholar] [CrossRef]
- Hessner, K.G.; El Naggar, S.; von Appen, W.J.; Strass, V.H. On the reliability of surface current measurements by X-Band marine radar. Remote. Sens. 2019, 11, 1030. [Google Scholar] [CrossRef] [Green Version]
- Guna, J.; Jakus, G.; Pogačnik, M.; Tomažič, S.; Sodnik, J. An analysis of the precision and reliability of the leap motion sensor and its suitability for static and dynamic tracking. Sensors 2014, 14, 3702–3720. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- AboElFotoh, H.M.; Iyengar, S.S.; Chakrabarty, K. Computing reliability and message delay for cooperative wireless distributed sensor networks subject to random failures. IEEE Trans. Reliab. 2005, 54, 145–155. [Google Scholar] [CrossRef]
- Castaño, F.; Strzelczak, S.; Villalonga, A.; Haber, R.E.; Kossakowska, J. Sensor reliability in cyber-physical systems using internet-of-things data: A review and case study. Remote. Sens. 2019, 11, 2252. [Google Scholar] [CrossRef] [Green Version]
- Pak, J.M.; Ahn, C.K.; Shmaliy, Y.S.; Lim, M.T. Improving reliability of particle filter-based localization in wireless sensor networks via hybrid particle/FIR filtering. IEEE Trans. Ind. Inform. 2015, 11, 1089–1098. [Google Scholar] [CrossRef]
- Nilsson, J.; Sandin, F. Semantic interoperability in industry 4.0: Survey of recent developments and outlook. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 127–132. [Google Scholar]
- Kumar, V.R.S.; Khamis, A.; Fiorini, S.; Carbonera, J.L.; Alarcos, A.O.; Habib, M.; Olszewska, J.I. Ontologies for industry 4.0. Knowl. Eng. Rev. 2019, 34, e17. [Google Scholar] [CrossRef] [Green Version]
- Kabugo, J.C.; Jämsä-Jounela, S.L.; Schiemann, R.; Binder, C. Industry 4.0 based process data analytics platform: A waste-to-energy plant case study. Int. J. Electr. Power Energy Syst. 2020, 115, 105508. [Google Scholar] [CrossRef]
- Bordel, B.; Alcarria, R.; Robles, T.; Sánchez-Picot, Á. Stochastic and information theory techniques to reduce large datasets and detect cyberattacks in Ambient Intelligence Environments. IEEE Access 2018, 6, 34896–34910. [Google Scholar] [CrossRef]
- Kaupp, L.; Beez, U.; Hülsmann, J.; Humm, B.G. Outlier detection in temporal spatial log data using autoencoder for industry 4.0. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Crete, Greece, May 24–26 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 55–65. [Google Scholar]
- Kumar, A.; Sharma, D.K. An optimized multilayer outlier detection for internet of things (IoT) network as industry 4.0 automation and data exchange. In International Conference on Innovative Computing and Communications; Springer: Singapore, 2001; pp. 571–584. [Google Scholar]
- Sik, D.; Levendovszky, J. Detecting outliers and anomalies to prevent failures and accidents in Industry 4.0. In Proceedings of the 2020 11th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), online, 23–25 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 000355–000358. [Google Scholar]
- Hoppenstedt, B.; Reichert, M.; Kammerer, K.; Spiliopoulou, M.; Pryss, R. Towards a Hierarchical Approach for Outlier Detection in Industrial Production Settings. In Proceedings of the First International Workshop on Data Science for Industry 4.0. Workshop Proceedings of the EDBT/ICDT 2019 Joint Conference, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Polge, J.; Robert, J.; Le Traon, Y. A case driven study of the use of time series classification for flexibility in industry 4.0. Sensors 2020, 20, 7273. [Google Scholar] [CrossRef] [PubMed]
- McKinley, S.; Levine, M. Cubic spline interpolation. Coll. Redw. 1998, 45, 1049–1060. [Google Scholar]
- Underhill, M.J.; Brown, P.J. Estimation of total jitter and jitter probability density function from the signal spectrum. In Proceedings of the 18th European Frequency and Time Forum (EFTF 2004), Guildford, UK, 5–7 April 2004; pp. 502–508. [Google Scholar] [CrossRef]
- Popovski, P.; Stefanović, Č.; Nielsen, J.J.; De Carvalho, E.; Angjelichinoski, M.; Trillingsgaard, K.F.; Bana, A.S. Wireless access in ultra-reliable low-latency communication (URLLC). IEEE Trans. Commun. 2019, 67, 5783–5801. [Google Scholar] [CrossRef] [Green Version]
- Mukhopadhyay, S.; Panigrahi, D.; Dey, S. Data aware, low cost error correction for wireless sensor networks. In Proceedings of the 2004 IEEE Wireless Communications and Networking Conference (IEEE Cat. No. 04TH8733), Atlanta, GA, USA, 21–25 March 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 4, pp. 2492–2497. [Google Scholar]
- Yan, J.; Zargaran-Yazd, A. IBIS-AMI modelling of high-speed memory interfaces. In Proceedings of the 2015 IEEE 24th Electrical Performance of Electronic Packaging and Systems (EPEPS), San Jose, CA, USA, 25–28 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 73–76. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Meaning | Parameter | Meaning |
|---|---|---|---|
| Industry 4.0 platform | Sensor node | ||
| Number of data flows | Malfunction function | ||
| Number of malfunctions | Original data series | ||
| Universe of values for data series | Sampling frequency | ||
| Current time instant | Limit in the expanded time interval | ||
| Curated time series | Probability of malfunction | ||
| Candidate to curated data series | Distance between distributions | ||
| Probability of data in reception | Real data generated by physical sensors | ||
| Number of candidates | Probability of original data | ||
| Identity function | Stationary time interval | ||
| Partition of the universe | Number of elements in a partition |
| Parameter | Value | Comments |
|---|---|---|
| 0.2 dBm | Typical value according to the hardware capabilities of ESP-32 microprocessor | |
| 4 | Standard value for the correction capacity of cyclic codes | |
| Associated to a 16-bit architecture | ||
| 4096 | Associated to a 12-bit ADC | |
| 1 h | Standard value in traffic theory | |
| 3 | Typical mathematical order for high-precision applications |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bordel, B.; Alcarria, R.; Robles, T. Prediction-Correction Techniques to Support Sensor Interoperability in Industry 4.0 Systems. Sensors 2021, 21, 7301. https://doi.org/10.3390/s21217301
Bordel B, Alcarria R, Robles T. Prediction-Correction Techniques to Support Sensor Interoperability in Industry 4.0 Systems. Sensors. 2021; 21(21):7301. https://doi.org/10.3390/s21217301
Chicago/Turabian StyleBordel, Borja, Ramón Alcarria, and Tomás Robles. 2021. "Prediction-Correction Techniques to Support Sensor Interoperability in Industry 4.0 Systems" Sensors 21, no. 21: 7301. https://doi.org/10.3390/s21217301
APA StyleBordel, B., Alcarria, R., & Robles, T. (2021). Prediction-Correction Techniques to Support Sensor Interoperability in Industry 4.0 Systems. Sensors, 21(21), 7301. https://doi.org/10.3390/s21217301