
Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review





Abstract
:1. Introduction
- Reviews not only pedestrian or vehicle detection algorithms, but both of them. Since many pedestrian and vehicle detection algorithms used a modified version or techniques of generic object detection algorithms, these are also reviewed;
- Briefly presents the most important traditional techniques and focuses more on the DL techniques for generic objects, pedestrian, and vehicles detection algorithms;
- Reports works from 2012 until 2021 and works that were performed on different datasets, such as Caltech, KITTI, BDD100K and others;
- Summarises the main information acquired from the reviewed pedestrian and vehicle detection works in tables. The tables report the methods, the problem that the algorithms are trying to solve, the datasets used and the results acquired.
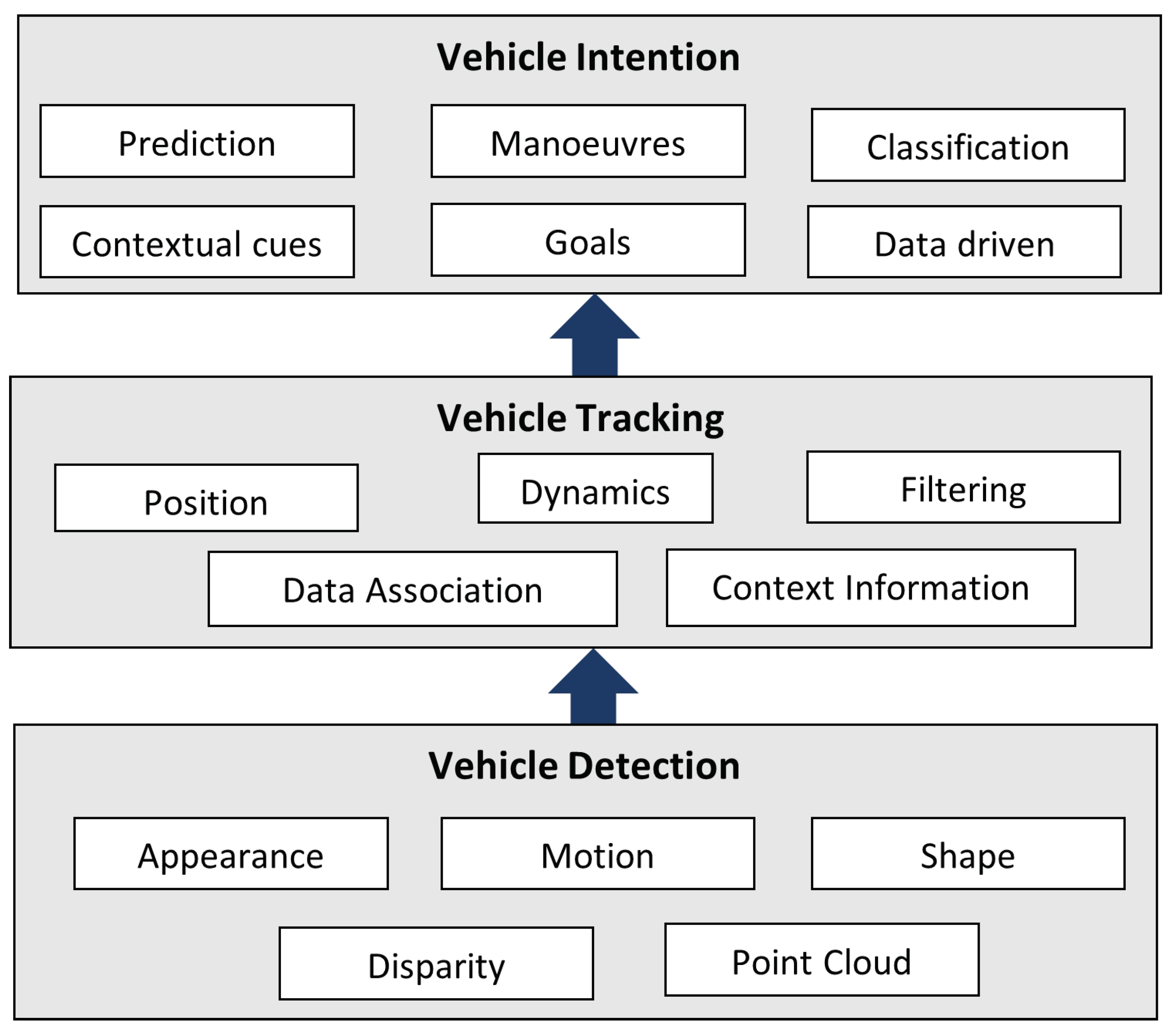
2. Autonomous Vehicle Systems
2.1. Benefits and Challenges
2.2. AV Taxonomy
2.3. AV System Architecture
2.3.1. Perception
2.3.2. Planning
2.3.3. Act
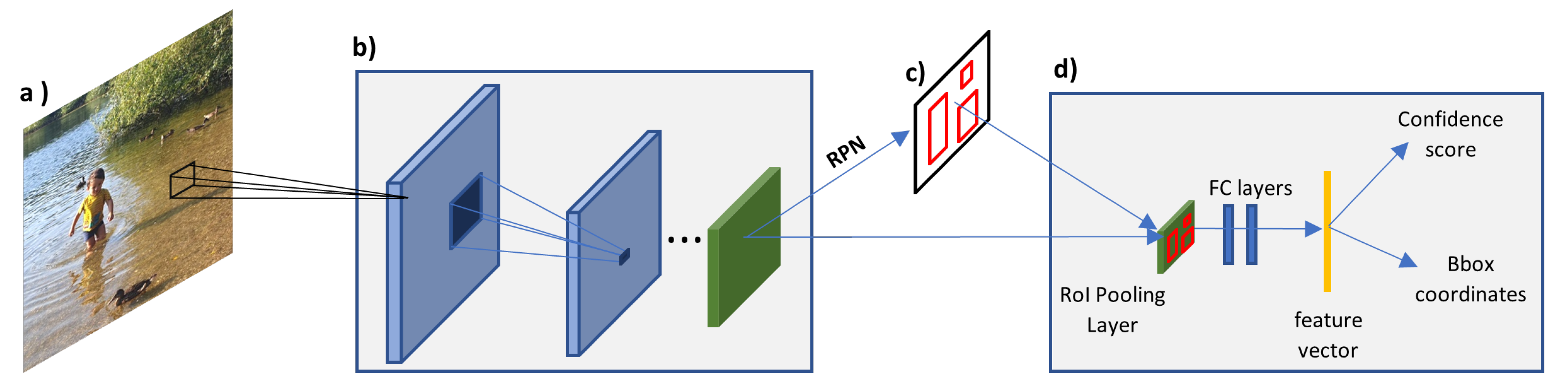
3. General Object Detection
- Image classification (Recognition): extracts features and information from an image to predict in which category it belongs to.
- Object detection: detects single or multiple objects in an image, surrounds each one of them with a bounding box and identify their locations.
- Object tracking: predicts the objects motions.
- Object segmentation: once each object is detected in an image, a pixel-wise mask for each object is created instead of separating them with surrounding boxes.
3.1. Traditional Techniques
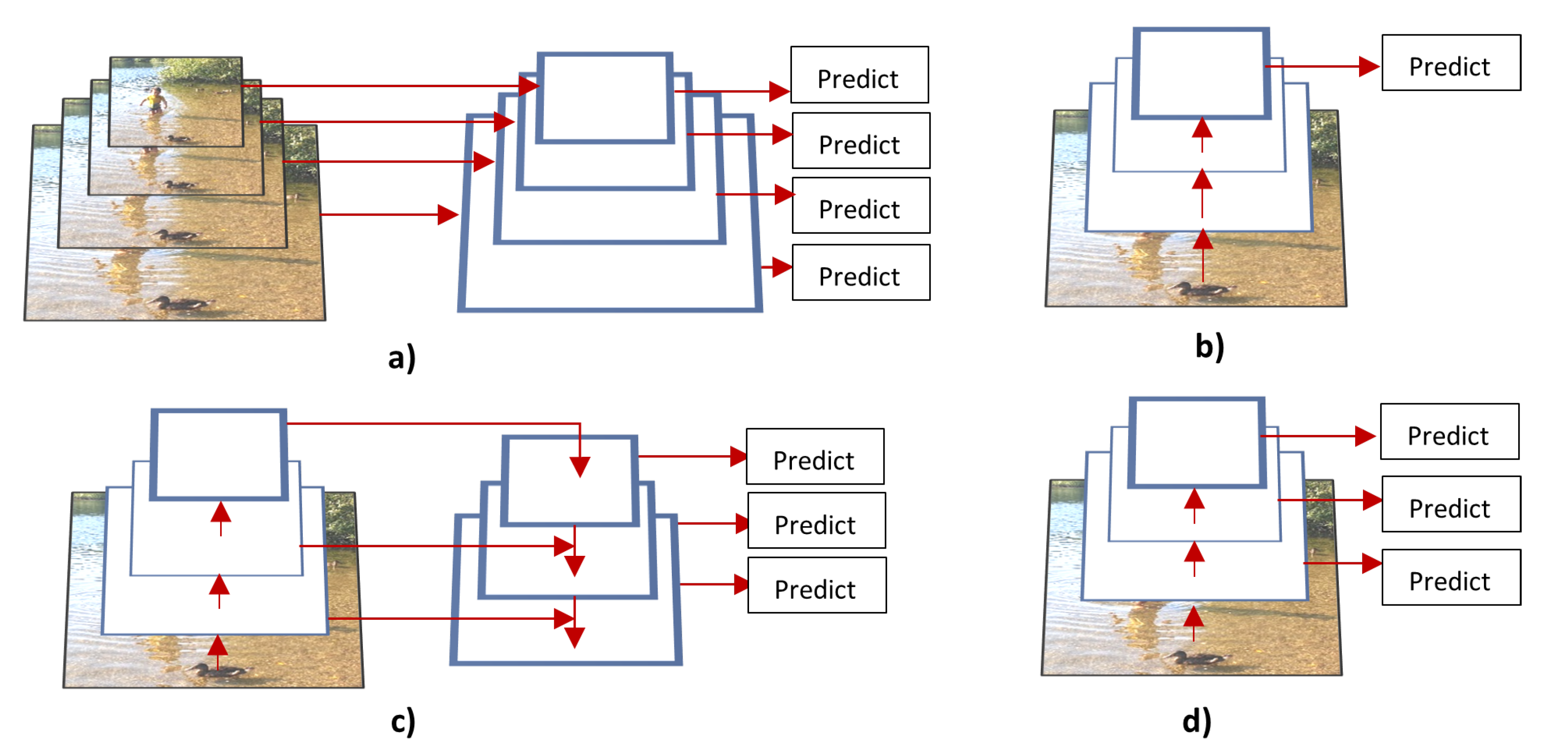
3.2. DL Techniques
4. Vehicle Detection
- Vehicle can belong to many classes (e.g., car, bus, truck, etc.).
- Vehicles belonging to the same class have varieties of shape, structure, colour, and size.
- Vehicles are viewed in different orientations (e.g., side-front view, side-back view, left-side, right side, etc.).
- One image might have several vehicles in different scales. Large size and small size vehicles have scale-variance, for instance, different visual characteristics and feature maps.
- Vehicles are more prone to be cluttered in complex traffic scenes.
- Vehicles are in environments that are dynamic due to different weather conditions (e.g., sunny, rainy, foggy and snow.), different times of the day (e.g., day, dusk, and night) and passing through tunnels. These factors affect the image background and illumination.
- For on-board vehicle detection, it is necessary to take into consideration the ego and target vehicle motion [21].
4.1. Traditional Techniques
4.2. DL Techniques
5. Pedestrian Detection
- Inconsistence of pedestrian appearance, for example, pedestrians wear different types and colours of clothes, have different heights, carry different objects in their hands, and constantly change their pose;
- They are more difficult to detect in environments that are cluttered (busy urban areas), have a high variance of illumination, are very dynamic and have poor weather conditions;
- One image might have several pedestrians in different scales. Pedestrian that are far away in the image does not have distinct boundaries and are obscure;
- Large size and small size pedestrians have scale-variance, for instance, different visual characteristics and features maps [122];
- Pedestrians change directions very quickly.
5.1. Traditional Techniques
5.2. Hybrid and DL Techniques
6. Discussion
- Deeper networks to extract more features from different levels of abstraction. The downside is that the deeper network can suffer vanishing gradient issues, and it requires more memory and computational work [62];
- High-resolution input image approach which enables the network to extract more discriminative information, however, it requires more memory and computation power [56];
- Smaller receptive kernels to extract more information from the input image. However, smaller receptive kernels focus more on local information [59];
- Transfer learning technique, enables a network to transfer the parameters learnt from a task to another. This enables the network to learn in less time and to have better performance. However, the transferring of learning is only possible if the new task is closely related to the previously learned one;
- SSP to avoid warping, cropping, and accept images with different sizes and scales. It might affect accuracy performance, since the layers where the SPP is placed cannot be fine-tuned [66];
- Algorithms, such as WordTree, to combine multiple datasets. This enables the algorithm to improve performance and have better generalisation, but it can be complex to implement [71];
- Use different feature maps to predict bounding-box coordinates for multi-scale objects [73];
- Focal Loss Function to pay more attention to the positive sample (actual object) instead of the negative samples (background). This increases the algorithm efficiency and accuracy, however, it is required to fine-tune one more parameter [72];
- Multi-scale detection approaches such as multi-scale images, multi-scale features, anchor boxes, FPN, or using information from different layers of the network. An ideal multi-scale detector would be able to use various input images with different scales; however, this is very computationally expensive. The other cited options use methods to approximate the multi-scale feature map, therefore, the algorithm might be losing important information that could be used to better detect the objects [94];
- Region proposal algorithms that pay more attention to small objects. This increases the recall values of small objects, but it can be complex to devise [102];
- Multi-branch decision networks to deal with the intra-class distance. It increases the accuracy performance, however, it can be slightly more complex to implement because each branch needs to be designed according to the different scales of the object;
- Multitasking learning enables sharing of knowledge and can increase accuracy performance. However, it slightly increases the computation load [99];
- Ensemble network enable diversification but can make the algorithm computational expensive;
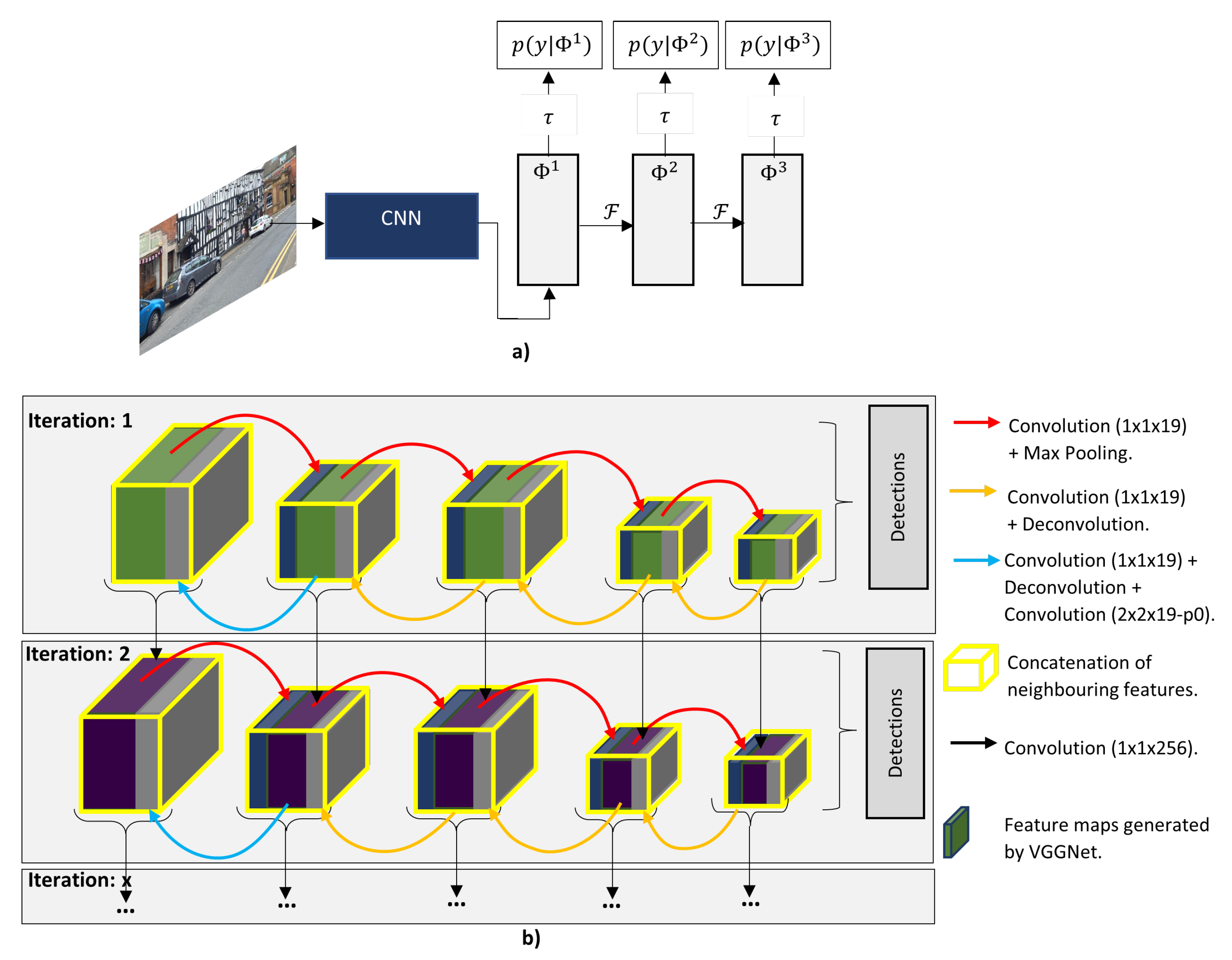
- Multiple levels of refinement, which increases the accuracy performance, but increases the detection speed as well [100];
- Disparity and point clouds estimation algorithms. They are used to extract 3D information which can increase the accuracy performance, however, they increase the algorithm complexity too [107];
- Part-aware RPN to increase the robustness of the algorithm to detect occluded objects. The drawback is that, it is complicated to combine the different detected parts to form the whole body [106];
- Techniques to transfer information from high-level layers to low-level layers to acquire high-quality region proposal [102];
- RNNs (LSTMs) to refine detection and localisation;
- RRC to improve accuracy detection and bounding box quality. After six iterations of the RRC, there is no further improvement because it needs an efficient memory mechanism [101].
- Stacks of small kernels instead of bigger ones to compute less variables [59];
- Share computation where feature maps are computed only once [66];
- Region proposal algorithm or RPN instead of densely apply sliding windows in the whole image [64];
- Feature pyramid instead of image pyramid [69];
- Decrease the number of RoI candidates [99].
7. Conclusions
- Nowadays, the preferred methods for object detection are based on DL techniques;
- Even though good results have been achieved for pedestrian and vehicle detection, the current algorithms are still struggling to detect small, occluded and truncated objects;
- There is limited work that investigates how to improve detection performance in bad illumination and weather conditions;
- From the authors’ point of view, the current algorithms are still not ready to be deployed in AV perception systems;
- Using only the traditional datasets (e.g., Caltech, KITTI, etc.) can make the algorithms have limited generalisation;
- It is not possible to make a fair comparison between the achieved detection speed of the algorithms, because they have been trained and tested in different hardware (e.g., GPUs, CPUs, etc.);
- Using techniques, such as ensemble and cascade architectures, to combine different detection algorithms has been shown to improve accuracy performance.
Suggested Future Research Directions
- Have more research that adopts ensemble techniques, since there is limited work that did this, and the ones reported in this review achieved improvement on the detection performance;
- Adopt cross-dataset evaluation and progressive training pipelines to increase generalisation performance, such as in Hasan et al. [151];
- Explore and improve detection algorithms in scenarios where weather and illumination conditions are challenging;
- Make a comparative study of the reviewed algorithms to report which one gives the best trade-off between accuracy and efficiency. In the comparative study, all the algorithms should be trained and tested on the same set of hardware. Although Haris and Glowacz [23] performed a comparative study of DL algorithms to detect road objects, they only compared the most known general object detection algorithms;
- Analyse if the reviewed algorithms meet AV real-time requirements. The authors would suggest adapting and implementing the reviewed algorithms in embedded devices, such as NVIDIA DRIVE Orin, NVIDIA DRIVE AGX Pegasus, and so forth.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AV | Autonomous Vehicle. |
| DL | Deep Learning. |
| KITTI | Karlsruhe Institute of Technology and Toyota Technological Institute |
| PIE | Pedestrian Intention Estimation. |
| BDD100K | Berkeley DeepDrive. |
| ADAS | Advanced Driver Assistance System. |
| HDAI | Hazard Detection System. |
| DARPA | Defence Advanced Research Projects Agency. |
| SAE | Society of Automotive Engineers. |
| V2V | Vehicle to Vehicle. |
| V2I | Vehicle to Infrastructure. |
| SLAM | Simultaneous Localisation and Mapping. |
| CDD | Charge-coupled Devices. |
| CMOS | Complementary Metal-oxide Semiconductors. |
| LIDAR | Light Detection and Ranging. |
| RADAR | Radio Detection and Ranging. |
| IMU | Inertial Measurement System. |
| GNSS | Global Navigation Satellite Systems. |
| ML | Machine Learning. |
| CNN | Convolutional Neural Network. |
| PID | Proportional Integral Derivative. |
| SIFT | Scale Invariant Feature Transform. |
| HOG | Histogram of Oriented Gradient. |
| EOH | Edge-Orientation-Histograms. |
| ISM | Implicit Shape Model. |
| SSC | Self-similarity Channels. |
| SURF | Speeded Up Robust Features. |
| MSER | Maximally Stable Extremal Regions. |
| ICF | Integral Channels Features. |
| ACF | Aggregated Channel Features. |
| SVM | Support-Vector-Machine. |
| AdaBoost | Adaptive Boosting. |
| ANN | Artificial Neural Network. |
| BBF | Best-Bin-First. |
| HT | Hough Transform. |
| ILSVRC | ImageNet Large-Scale Visual Recognition Challenge. |
| R-CNN | Region Convolutional Neural Network. |
| SPP-Net | Spatial Pyramid Pooling Network. |
| RoI | Region of Interest. |
| RPN | Region Proposal Network. |
| FPS | Frame Per Second. |
| FPN | Feature Pyramid Network. |
| YOLO | You Look Only Once. |
| SSD | Single Shot Multi-box Detection. |
| LIEM | Local Information Extraction Model |
| GIEM | Global Information Extraction Model |
| DNN | Deep Neural Network. |
| MSF | Multi-scale Features. |
| EMA | Exponential Moving Average. |
| IoU | Intersection Over Union. |
| ITS | Intelligent Transportation Systems. |
| LBP | Local Binary Patterns. |
| PCA | Principal Component Analysis. |
| 2D-DBN | 2D Deep Belief Network. |
| BFEN | Backward Feature Enhancement Network. |
| SLPN | Spatial Layout Preserving Network. |
| FC | Fully Connected Layer. |
| RRC | Recurrent Rolling Convolution. |
| mAP | mean Average Precision. |
| MS-CNN | Multi-scale CNN. |
| SDP + CRC | Scale Dependent Pooling and Cascade Rejection Classifiers. |
| DeepMANTA | Deep Many-Tasks. |
| monoFET | monocular Feature Enhancement Networks |
| DORN | Deep Ordinal Regression Network. |
| SS3D | Single Stage Monocular 3D. |
| TP | True Positive. |
| DR | Detection Rate. |
| AP | Average Precision. |
| FP | False Positive. |
| RE | Recognition Error. |
| ITVD | Imporving Tiny Vehicle Detection. |
| PAFs | Part Affinity Fields. |
| DPM | Deformable Part Model. |
| MR | Miss Rate. |
| RNN | Recurrent Neural Network. |
| LSTM | Long Short Term Memory. |
| SINet | Scale-insensitive Convolutional Neural Network. |
| LSVH | Large Scale Variance Highway. |
| RV-CNN | Region of Interest Voting CNN. |
| UTS | Urban Traffic Surveillance. |
| FVPN | Fast Vehicle Proposal Network. |
| ALN | Attributes Learning Network. |
| DCT | Discrete Cosine Transform. |
| CSS | Self-similarity on colour channels. |
| NNF | Non-Neighbouring Features. |
| SIDF | Sine-Inner Difference Features. |
| SSF | Symmetrical Similarity Features. |
| FSSS | Feature Selected Self-Similarity. |
| SDN | Switchable Deep Network. |
| BF | Boosted Forest. |
| SNF | Soft-rejection Network Fusion. |
| SDS | Simultaneous Detection and Segmentation. |
| MRF | Markov Random Field. |
| AG | Accuracy Gain. |
References
- WHO. Global Status Report on Road Safety 2018: Summary; Technical Report; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Maddox, J. Improving Driving Safety through Automation, Presentation at the Congressional Robotics Caucus; National Highway Traffic Safety Administration: Washington, DC, USA, 2012. [Google Scholar]
- IIHS-HLDI. Advanced Driver Assistance. 2019. Available online: https://www.iihs.org/topics/advanced-driver-assistance (accessed on 6 October 2020).
- Colonna, M. Urbanisation Worldwide. 2018. Available online: https://ec.europa.eu/knowledge4policy/foresight/topic/continuing-urbanisation/urbanisation-worldwide_en (accessed on 6 October 2020).
- Hart, A.; Cox, C. How Autonomous Vehicles Could Relive or Worsen Traffic Congestion; Technical Report. SBD HERE: Berlin, Germany, 2017. Available online: https://www.here.com/sites/g/files/odxslz166/files/2018-12/HERE_How_autonomous_vehicles_could_relieve_or_worsen_traffic_congestion_white_paper.pdf (accessed on 5 October 2020).
- Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Ten years of pedestrian detection, what have we learned? In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 613–627. [Google Scholar]
- Nguyen, D.T.; Li, W.; Ogunbona, P.O. Human detection from images and videos: A survey. Pattern Recognit. 2016, 51, 148–175. [Google Scholar] [CrossRef]
- Antonio, J.A.; Romero, M. Pedestrians’ Detection Methods in Video Images: A Literature Review. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 13–15 December 2018; pp. 354–360. [Google Scholar]
- Ragesh, N.K.; Rajesh, R. Pedestrian detection in automotive safety: Understanding state-of-the-art. IEEE Access 2019, 7, 47864–47890. [Google Scholar] [CrossRef]
- Gilroy, S.; Jones, E.; Glavin, M. Overcoming occlusion in the automotive environment—A review. IEEE Trans. Intell. Transp. Syst. 2019, 22, 23–35. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef] [Green Version]
- Mukhtar, A.; Xia, L.; Tang, T.B. Vehicle detection techniques for collision avoidance systems: A review. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2318–2338. [Google Scholar] [CrossRef]
- Abdulrahim, K.; Salam, R.A. Traffic surveillance: A review of vision based vehicle detection, recognition and tracking. Int. J. Appl. Eng. Res. 2016, 11, 713–726. [Google Scholar]
- Antony, J.J.; Suchetha, M. Vision based vehicle detection: A literature review. Int. J. Appl. Eng. Res. 2016, 11, 3128–3133. [Google Scholar]
- Shobha, B.S.; Deepu, R. A review on video based vehicle detection, recognition and tracking. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; pp. 183–186. [Google Scholar]
- Abbas, A.F.; Sheikh, U.U.; AL-Dhief, F.T.; Haji Mohd, M.N. A comprehensive review of vehicle detection using computer vision. Telkomnika 2021, 19, 838–850. [Google Scholar] [CrossRef]
- Manana, M.; Tu, C.; Owolawi, P.A. A survey on vehicle detection based on convolution neural networks. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1751–1755. [Google Scholar]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A comparative study of state-of-the-art deep learning algorithms for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Meng, C.; Bao, H.; Ma, Y. Vehicle Detection: A Review. J. Phys. Conf. Ser. 2020, 1634, 012107. [Google Scholar] [CrossRef]
- Kiran, V.K.; Parida, P.; Dash, S. Vehicle detection and classification: A review. In International Conference on Innovations in Bio-Inspired Computing and Applications; Springer: Cham, Switzerland, 2019; pp. 45–56. [Google Scholar]
- Yang, Z.; Pun-Cheng, L.S. Vehicle detection in intelligent transportation systems and its applications under varying environments: A review. Image Vis. Comput. 2018, 69, 143–154. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Haris, M.; Glowacz, A. Road Object Detection: A Comparative Study of Deep Learning-Based Algorithms. Electronics 2021, 10, 1932. [Google Scholar] [CrossRef]
- LaFrance, A. Your Grandmother’s Driverless Car. 2016. Available online: https://www.theatlantic.com/technology/archive/2016/06/beep-beep/489029/ (accessed on 7 October 2020).
- Pomerleau, D.A. Alvinn: An autonomous land vehicle in a neural network. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1989; pp. 305–313. [Google Scholar]
- Chen, Q.; Ozguner, U.; Redmill, K. Ohio state university at the 2004 darpa grand challenge: Developing a completely autonomous vehicle. IEEE Intell. Syst. 2004, 19, 8–11. [Google Scholar] [CrossRef]
- Tinto, R. Automated-Truck-Expansion-Pilbara. 2018. Available online: https://www.riotinto.com/news/releases/Automated-truck-expansion-Pilbara (accessed on 7 October 2020).
- Harris, M. How Google’s Autonomous Car Passed the First U.S. State Self-Driving Test. 2014. Available online: https://spectrum.ieee.org/how-googles-autonomous-car-passed-the-first-us-state-selfdriving-test (accessed on 7 October 2020).
- Perry, C. The Pathway to Driverless Cars: Summary Report and Action Plan; OCLC: London, UK , 2015. [Google Scholar]
- Agarwal, A.; Agarwal, K.; Misra, G.; Pabshetwar, O. Driverless Car for Next Generation Commuters-Key Factors and Future Issues. Am. J. Electr. Electron. Eng. 2019, 7, 62–68. [Google Scholar]
- Bagloee, S.A.; Tavana, M.; Asadi, M.; Oliver, T. Autonomous vehicles: Challenges, opportunities, and future implications for transportation policies. J. Mod. Transp. 2016, 24, 284–303. [Google Scholar] [CrossRef] [Green Version]
- EUR-Lex, E.L. EUR-Lex-32019R2144-EN-EUR-Lex. 2014. Available online: https://eur-lex.europa.eu/legal-content/en/ALL/?uri=CELEX%3A32019R2144 (accessed on 8 October 2020).
- Waymo, W. Waymo Safety Report. 2020. Available online: https://waymo.com/safety/ (accessed on 30 October 2020).
- Fagnant, D.J.; Kockelman, K. Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations. Transp. Res. Part A Policy Pract. 2015, 77, 167–181. [Google Scholar] [CrossRef]
- Creger, H.; Espino, J.; Sanchez, A.S. Autonomous Vehicle Heaven or Hell? Creating a Transportation Revolution that Benefits All. Greenlining Institute: Oakland, CA, USA, 2019. [Google Scholar]
- Nasseri, A.; Shlomit, H. 2020 Autonomous Vehicle Technology Report. Available online: https://www.wevolver.com/article/2020.autonomous.vehicle.technology.report (accessed on 12 October 2020).
- SAE International. J3016B: Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles; SAE International: New York, NY, USA, 2018. [Google Scholar]
- Durrant-Whyte, H. A Critical Review of the State-of-the-Art in Autonomous Land Vehicle Systems and Technology; Sandia National Laboratories: Albuquerque, NM, USA; Livermore, CA, USA, 2001; Volume 41, p. 242. [Google Scholar]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA; London, UK, 2011. [Google Scholar]
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Rosique, F.; Navarro, P.J.; Fernández, C.; Padilla, A. A systematic review of perception system and simulators for autonomous vehicles research. Sensors 2019, 19, 648. [Google Scholar] [CrossRef] [Green Version]
- Ben, D. Tesla AI Chief Explains Why Self-Driving Cars Don’t Need Lidar. 2021. Available online: https://venturebeat.com/2021/07/03/tesla-ai-chief-explains-why-self-driving-cars-dont-need-lidar/ (accessed on 9 July 2021).
- Davies, E.R. Computer Vision: Principles, Algorithms, Applications, Learning; Academic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Huang, T. Computer Vision: Evolution and Promise; CERN European Organization for Nuclear Research-Reports-CERN: Geneva, Switzerland, 1996; pp. 21–26. [Google Scholar]
- Chauhan, N.K.; Singh, K. A review on conventional machine learning vs deep learning. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 347–352. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Graz, Austria, 2006; pp. 404–417. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep learning vs. traditional computer vision. In Science and Information Conference; Springer: Cham, Switzerland, 2019; pp. 128–144. [Google Scholar]
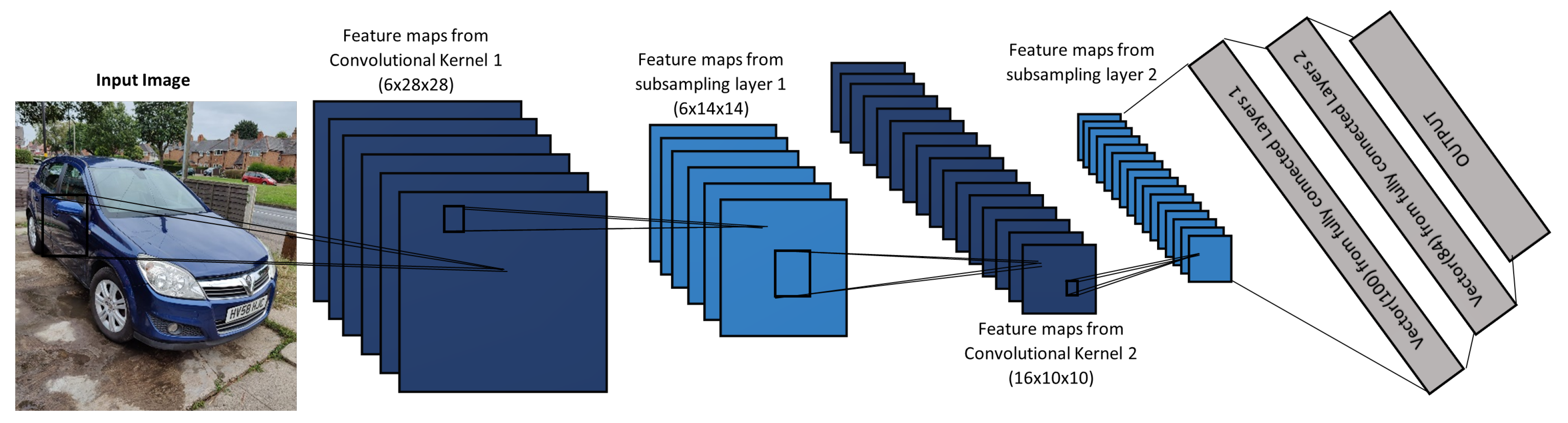
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.; Cai, L.; Lin, X.; Ji, R. Masked face detection via a modified LeNet. Neurocomputing 2016, 218, 197–202. [Google Scholar] [CrossRef]
- Xie, Y.; Jin, H.; Tsang, E.C. Improving the lenet with batch normalization and online hard example mining for digits recognition. In Proceedings of the 2017 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Ningbo, China, 9–12 July 2017; pp. 149–153. [Google Scholar]
- Li, W.; Li, X.; Qin, Y.; Song, W.; Cui, W. Application of improved LeNet-5 network in traffic sign recognition. In Proceedings of the 3rd International Conference on Video and Image Processing, New York, NY, USA, 30 July–2 August 2019; pp. 13–18. [Google Scholar]
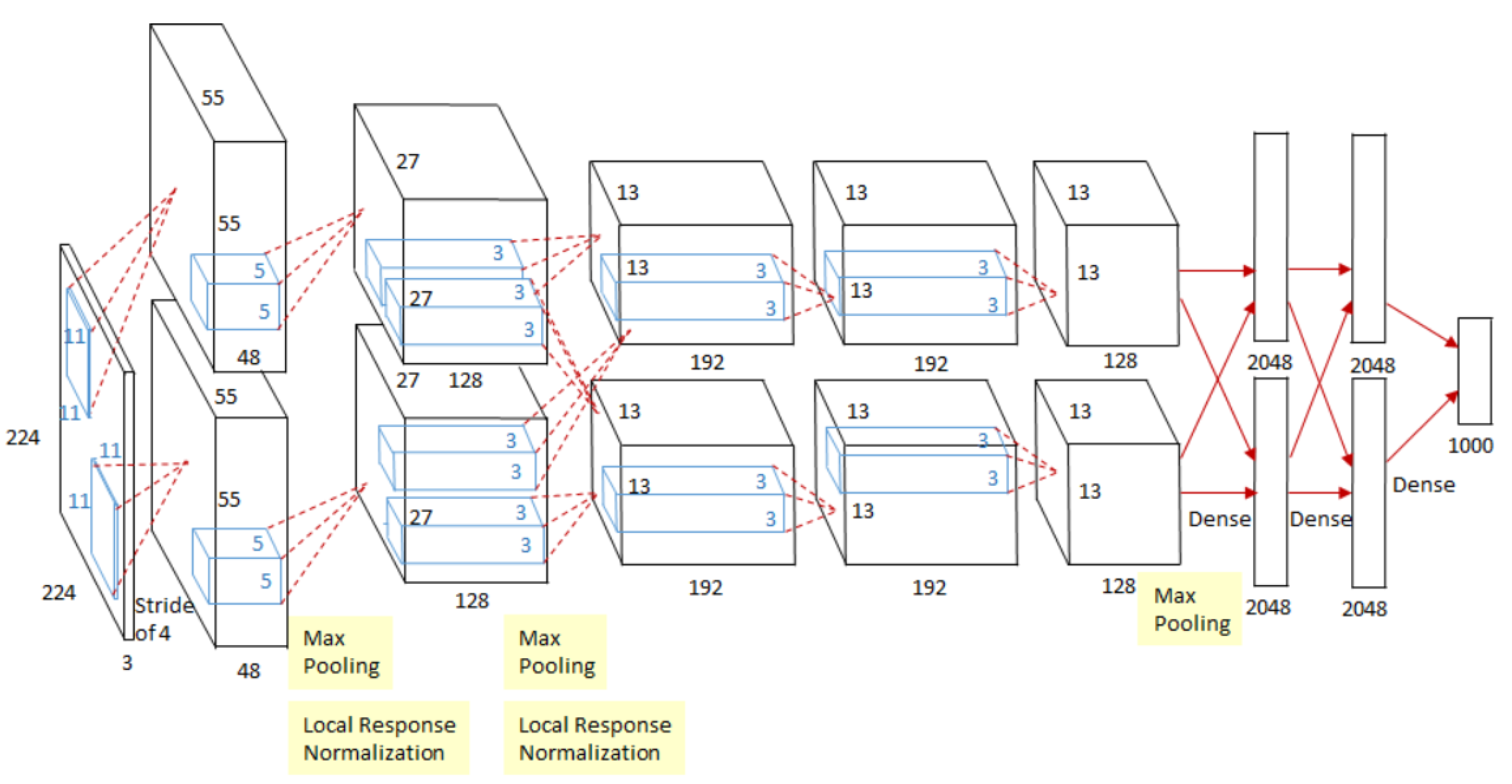
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Tsang, S.H. Review: AlexNet, CaffeNet—Winner of ILSVRC 2012 (Image Classification). 2020. Available online: https://medium.com/coinmonks/paper-review-of-alexnet-caffenet-winner-in-ilsvrc-2012-image-classification-b93598314160 (accessed on 6 October 2021).
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Arnault, A. About Convolutional Layer and Convolution Kernel. SICARA. Available online: https://www.sicara.ai/blog/2019-10-31-convolutional-layer-convolution-kernel (accessed on 9 December 2020).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
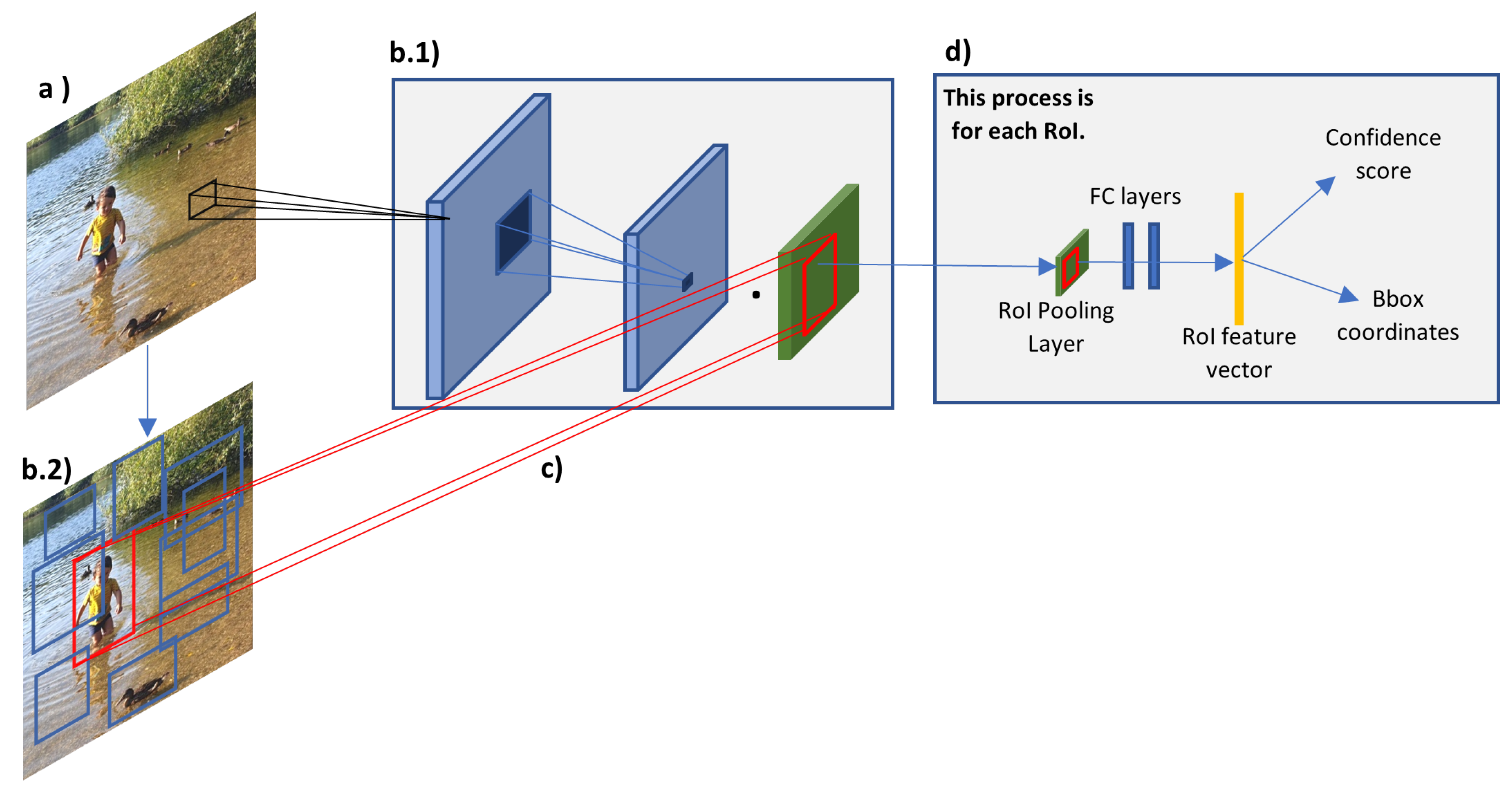
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
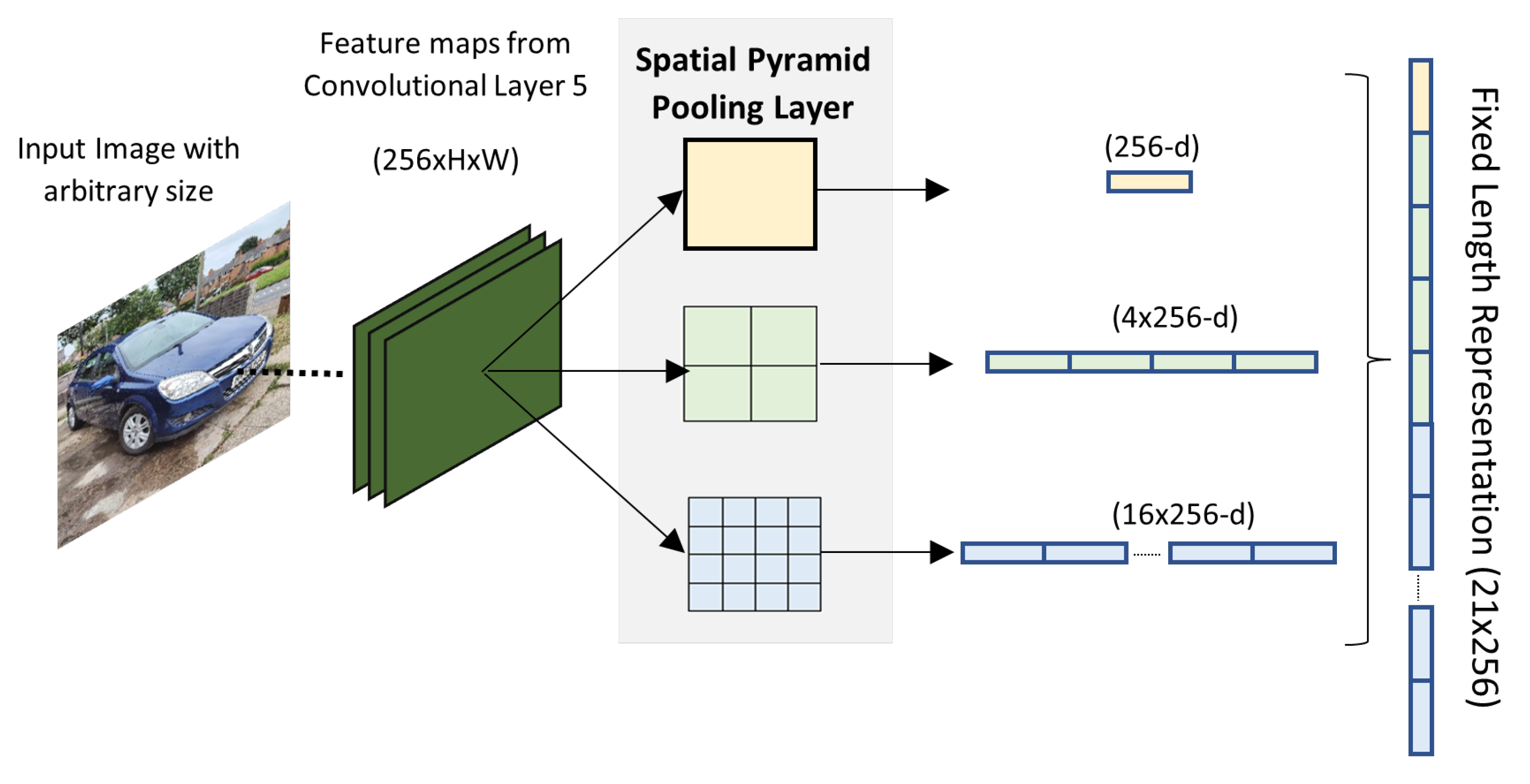
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kathuria, A. What’s New in YOLO v3? Towards Data Science 2018. Available online: https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b (accessed on 9 December 2020).
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Deng, H. GC-YOLOv3: You only look once with global context block. Electronics 2020, 9, 1235. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Glenn Jocher Ultralytics/Yolov5, GitHub, GitHub Repository. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 9 December 2020).
- Quang, T.N.; Lee, S.; Song, B.C. Object Detection Using Improved Bi-Directional Feature Pyramid Network. Electronics 2021, 10, 746. [Google Scholar] [CrossRef]
- Kandalkar, P.A.; Dhok, G.P. Review on Image Processing Based Vehicle Detection & Tracking System; IJSRSET: Gujarat, India, 2017; Volume 3, pp. 566–569.
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Di, Z.; He, D. Forward Collision Warning system based on vehicle detection and tracking. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing (ICOIP), Warsaw, Poland, 10–12 June 2016; pp. 10–14. [Google Scholar]
- Hemmati, M.; Biglari-Abhari, M.; Niar, S. Adaptive vehicle detection for real-time autonomous driving system. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 1034–1039. [Google Scholar]
- Satzoda, R.K.; Trivedi, M.M. Multipart vehicle detection using symmetry-derived analysis and active learning. IEEE Trans. Intell. Transp. Syst. 2015, 17, 926–937. [Google Scholar] [CrossRef]
- Arunmozhi, A.; Park, J. Comparison of HOG, LBP and Haar-like features for on-road vehicle detection. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 0362–0367. [Google Scholar]
- Zhang, X.; Zheng, N.; He, Y.; Wang, F. Vehicle detection using an extended hidden random field model. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1555–1559. [Google Scholar]
- Truong, Q.B.; Lee, B.R. Vehicle detection algorithm using hypothesis generation and verification. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 534–543. [Google Scholar]
- Hsieh, J.W.; Chen, L.C.; Chen, D.Y. Symmetrical SURF and its applications to vehicle detection and vehicle make and model recognition. IEEE Trans. Intell. Transp. Syst. 2014, 15, 6–20. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Zhu, S.C. Learning and-or model to represent context and occlusion for car detection and viewpoint estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1829–1843. [Google Scholar] [CrossRef] [PubMed]
- Ming, Q.; Jo, K.H. Vehicle detection using tail light segmentation. In Proceedings of the 2011 6th International Forum on Strategic Technology, Harbin, China, 22–24 August 2011; Volume 2, pp. 729–732. [Google Scholar]
- Wang, H.; Cai, Y.; Chen, L. A vehicle detection algorithm based on deep belief network. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [Green Version]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 124–129. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 354–370. [Google Scholar]
- Zhou, Y.; Liu, L.; Shao, L.; Mellor, M. DAVE: A unified framework for fast vehicle detection and annotation. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 278–293. [Google Scholar]
- Yang, F.; Choi, W.; Lin, Y. Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar]
- Yuan, X.; Su, S.; Chen, H. A graph-based vehicle proposal location and detection algorithm. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3282–3289. [Google Scholar] [CrossRef]
- Gao, Y.; Guo, S.; Huang, K.; Chen, J.; Gong, Q.; Zou, Y.; Bai, T.; Overett, G. Scale optimization for full-image-CNN vehicle detection. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 785–791. [Google Scholar]
- Chu, W.; Liu, Y.; Shen, C.; Cai, D.; Hua, X.S. Multi-task vehicle detection with region-of-interest voting. IEEE Trans. Image Process. 2017, 27, 432–441. [Google Scholar] [CrossRef] [PubMed]
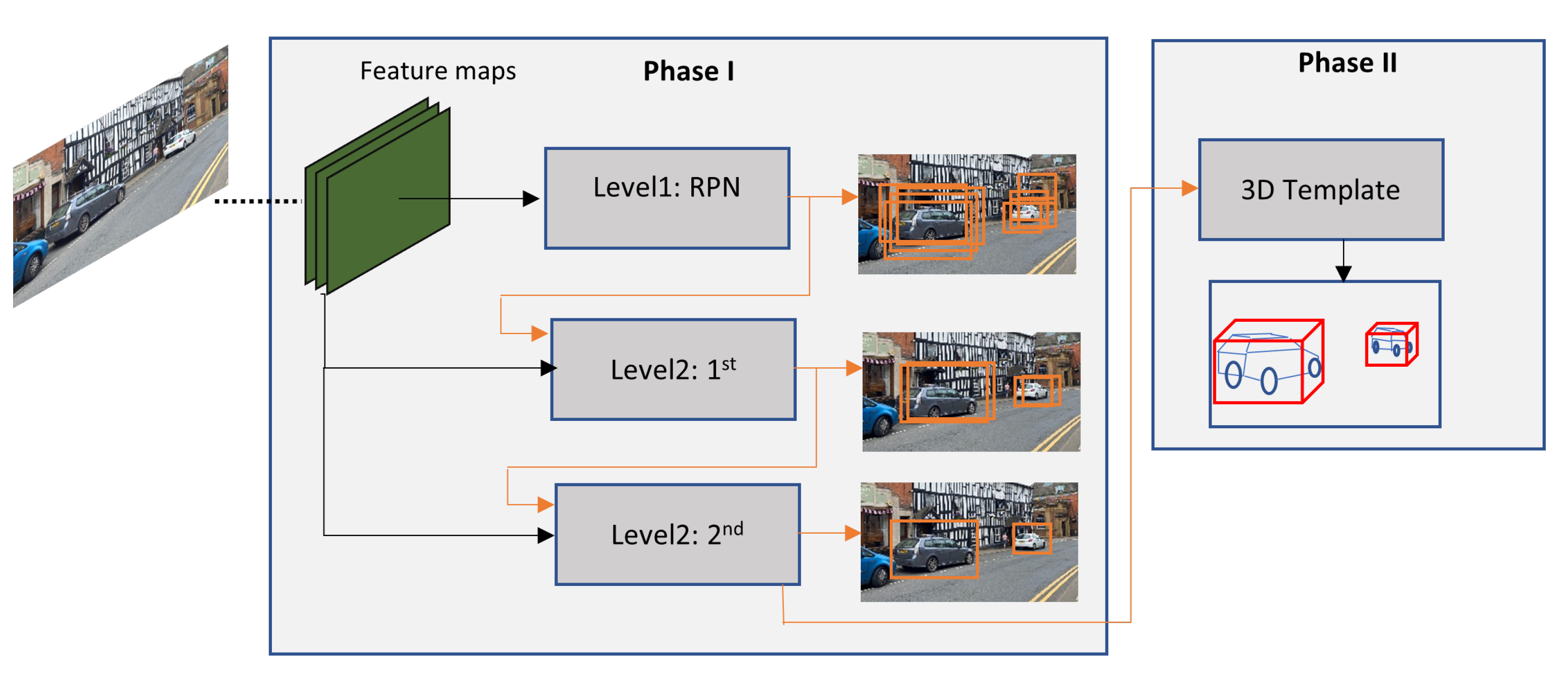
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teuliere, C.; Chateau, T. Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2040–2049. [Google Scholar]
- Ren, J.; Chen, X.; Liu, J.; Sun, W.; Pang, J.; Yan, Q.; Tai, Y.W.; Xu, L. Accurate single stage detector using recurrent rolling convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5420–5428. [Google Scholar]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Zhang, Y. Improving tiny vehicle detection in complex scenes. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-object detection in traffic scenes based on improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Zhang, W.; Wu, X.; Xiao, L.; Qian, Y.; Fang, Z. Real-time vehicle type classification with deep convolutional neural networks. J. Real-Time Image Process. 2019, 16, 5–14. [Google Scholar] [CrossRef]
- Zhang, W.; Zheng, Y.; Gao, Q.; Mi, Z. Part-aware region proposal for vehicle detection in high occlusion environment. IEEE Access 2019, 7, 100383–100393. [Google Scholar] [CrossRef]
- Bao, W.; Xu, B.; Chen, Z. Monofenet: Monocular 3d object detection with feature enhancement networks. IEEE Trans. Image Process. 2019, 29, 2753–2765. [Google Scholar] [CrossRef]
- Jörgensen, E.; Zach, C.; Kahl, F. Monocular 3d object detection and box fitting trained end-to-end using intersection-over-union loss. arXiv 2019, arXiv:1906.08070. [Google Scholar]
- Wang, T.; He, X.; Cai, Y.; Xiao, G. Learning a layout transfer network for context aware object detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4209–4224. [Google Scholar] [CrossRef]
- Chen, L.; Ding, Q.; Zou, Q.; Chen, Z.; Li, L. DenseLightNet: A light-weight vehicle detection network for autonomous driving. IEEE Trans. Ind. Electron. 2020, 67, 10600–10609. [Google Scholar] [CrossRef]
- Fan, J.; Huo, T.; Li, X.; Qu, T.; Gao, B.; Chen, H. Covered Vehicle Detection in Autonomous Driving Based on Faster RCNN. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7020–7025. [Google Scholar]
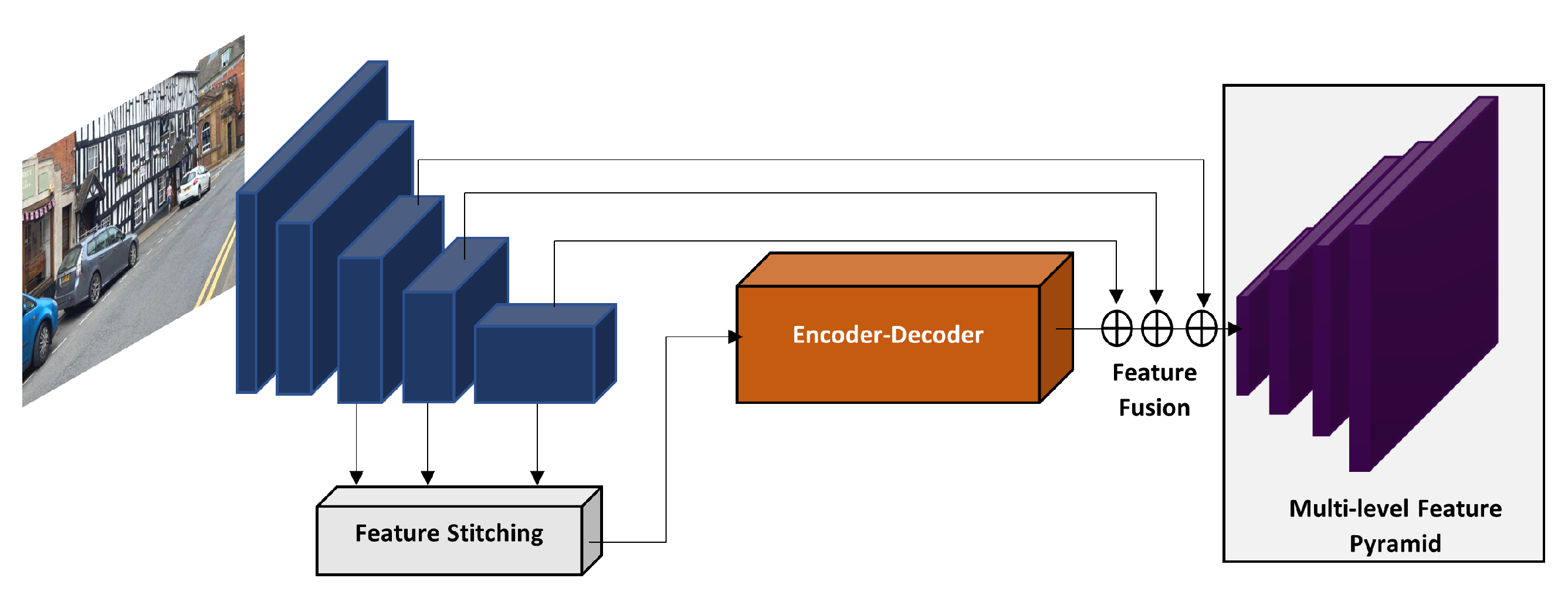
- Hong, F.; Lu, C.H.; Liu, C.; Liu, R.R.; Wei, J. A traffic surveillance multi-scale vehicle detection object method base on encoder-decoder. IEEE Access 2020, 8, 47664–47674. [Google Scholar] [CrossRef]
- Hu, J.; Sun, Y.; Xiong, S. Research on the Cascade Vehicle Detection Method Based on CNN. Electronics 2021, 10, 481. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2179–2195. [Google Scholar] [CrossRef] [Green Version]
- Gerónimo, D.; López, A.; Sappa, A.D. Computer vision approaches to pedestrian detection: Visible spectrum survey. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Girona, Spain, 2007; pp. 547–554. [Google Scholar]
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ogale, N.A. A survey of techniques for human detection from video. Surv. Univ. Md. 2006, 125, 19. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Ahmed, S.; Huda, M.N.; Rajbhandari, S.; Saha, C.; Elshaw, M.; Kanarachos, S. Pedestrian and cyclist detection and intent estimation for autonomous vehicles: A survey. Appl. Sci. 2019, 9, 2335. [Google Scholar] [CrossRef] [Green Version]
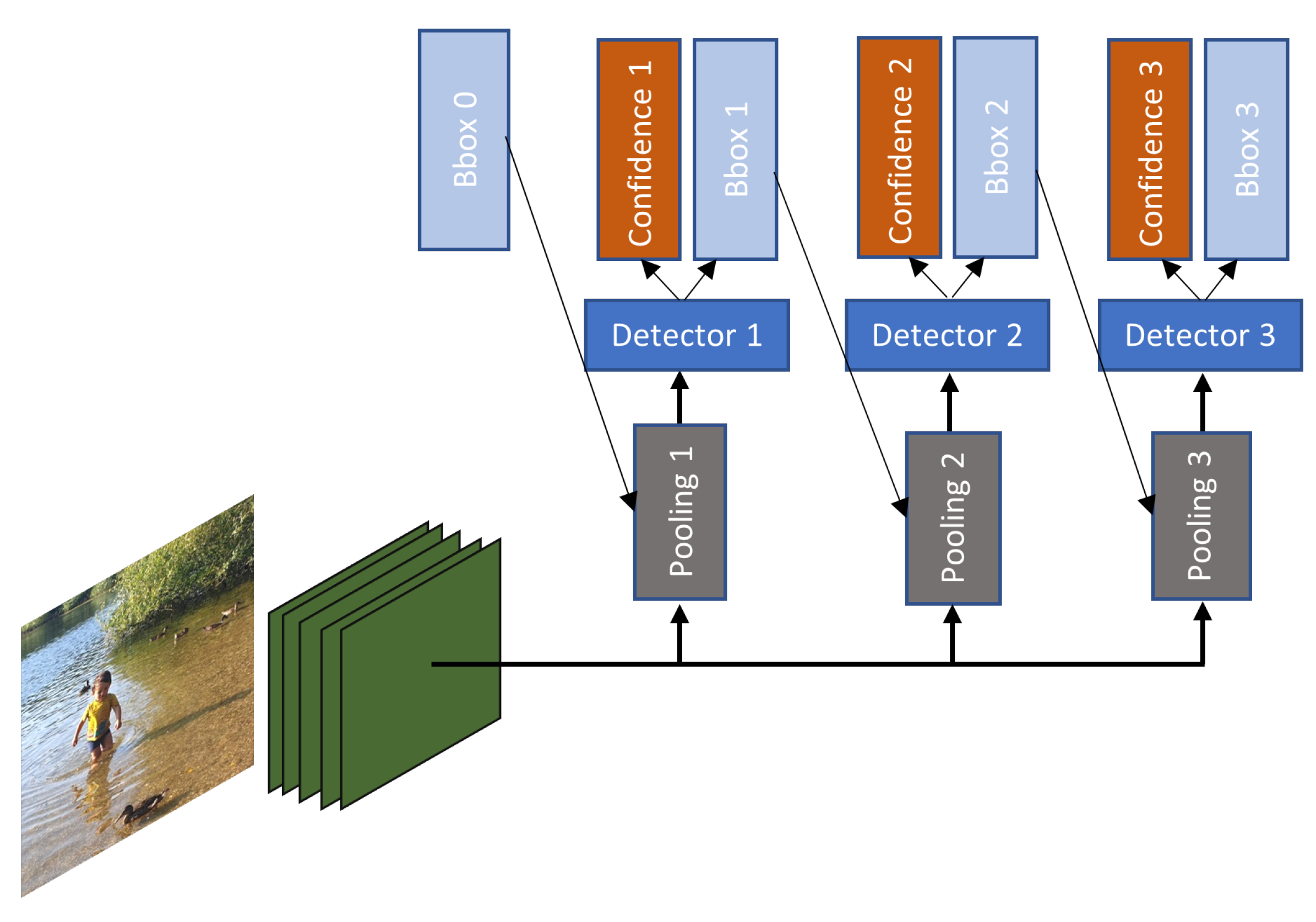
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Wang, X. Joint deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Wang, X. A discriminative deep model for pedestrian detection with occlusion handling. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3258–3265. [Google Scholar]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vis. 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Sabzmeydani, P.; Mori, G. Detecting pedestrians by learning shapelet features. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Maji, S.; Berg, A.C.; Malik, J. Classification using intersection kernel support vector machines is efficient. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Wojek, C.; Schiele, B. A performance evaluation of single and multi-feature people detection. In Joint Pattern Recognition Symposium; Springer: Munich, Germany, 2008; pp. 82–91. [Google Scholar]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral Channel Features; BMVC Press: London, UK, 2009. [Google Scholar]
- Dollár, P.; Belongie, S.; Perona, P. The Fastest Pedestrian Detector in the West; BMVA Press: Aberystwyth, UK, 2010. [Google Scholar]
- Walk, S.; Majer, N.; Schindler, K.; Schiele, B. New features and insights for pedestrian detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1030–1037. [Google Scholar]
- Nam, W.; Han, B.; Han, J.H. Improving object localization using macrofeature layout selection. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1801–1808. [Google Scholar]
- Dollár, P.; Appel, R.; Kienzle, W. Crosstalk cascades for frame-rate pedestrian detection. In European Conference on Computer Vision; Springer: Florence, Italy, 2012; pp. 645–659. [Google Scholar]
- Benenson, R.; Mathias, M.; Tuytelaars, T.; Van Gool, L. Seeking the strongest rigid detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3666–3673. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed haar-like features improve pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Nam, W.; Dollár, P.; Han, J.H. Local decorrelation for improved pedestrian detection. Adv. Neural Inf. Process. Syst. 2014, 27, 424–432. [Google Scholar]
- Chandra, R.; Randhavane, T.; Bhattacharya, U.; Bera, A.; Manocha, D. Deeptagent: Realtime Tracking of Dense Traffic Agents Using Heterogeneous Interaction. Technical Report, 2018. 2019. Available online: http://gamma.cs.unc.edu/HTI (accessed on 29 January 2021).
- Cao, J.; Pang, Y.; Li, X. Pedestrian detection inspired by appearance constancy and shape symmetry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1316–1324. [Google Scholar]
- Fu, X.; Yu, R.; Zhang, W.; Feng, L.; Shao, S. Pedestrian detection by feature selected self-similarity features. IEEE Access 2018, 6, 14223–14237. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Brazil, G.; Liu, X. Pedestrian detection with autoregressive network phases. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, 16–20 June 2019; pp. 7231–7240. [Google Scholar]
- Zhang, X.; Cheng, L.; Li, B.; Hu, H.M. Too far to see? Not really!—Pedestrian detection with scale-aware localization policy. IEEE Trans. Image Process. 2018, 27, 3703–3715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Cheng, J.; Liu, H.; Tang, M. Pcn: Part and context information for pedestrian detection with cnns. arXiv 2018, arXiv:1804.04483. [Google Scholar]
- Du, X.; El-Khamy, M.; Lee, J.; Davis, L. Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection. In Proceedings of the 2017 IEEE winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017; pp. 953–961. [Google Scholar]
- Du, X.; El-Khamy, M.; Morariu, V.I.; Lee, J.; Davis, L. Fused deep neural networks for efficient pedestrian detection. arXiv 2018, arXiv:1805.08688. [Google Scholar]
- Brazil, G.; Yin, X.; Liu, X. Illuminating pedestrians via simultaneous detection & segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable pedestrian detection: The elephant in the room. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Placed Virtually, 11–17 October 2021; pp. 11328–11337. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multi-stage feature learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3626–3633. [Google Scholar]
- Ouyang, W.; Zeng, X.; Wang, X. Modeling mutual visibility relationship in pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3222–3229. [Google Scholar]
- Zeng, X.; Ouyang, W.; Wang, X. Multi-stage contextual deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 121–128. [Google Scholar]
- Luo, P.; Tian, Y.; Wang, X.; Tang, X. Switchable deep network for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 899–906. [Google Scholar]
- Cai, Z.; Saberian, M.; Vasconcelos, N. Learning complexity-aware cascades for deep pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3361–3369. [Google Scholar]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 443–457. [Google Scholar]
- Cao, J.; Pang, Y.; Li, X. Learning multilayer channel features for pedestrian detection. IEEE Trans. Image Process 2017, 26, 3210–3220. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Lu, J.; Wang, G.; Zhou, J. Graininess-aware deep feature learning for pedestrian detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 732–747. [Google Scholar]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 536–551. [Google Scholar]
- Zhu, M.; Wu, Y. A Parallel Convolutional Neural Network for Pedestrian Detection. Electronics 2020, 9, 1478. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Luo, Y.; Zhang, C.; Zhao, M.; Zhou, H.; Sun, J. Where, What, Whether: Multi-modal learning meets pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 14065–14073. [Google Scholar]
- Wu, J.; Zhou, C.; Yang, M.; Zhang, Q.; Li, Y.; Yuan, J. Temporal-context enhanced detection of heavily occluded pedestrians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 13430–13439. [Google Scholar]
- Shao, X.; Wang, Q.; Yang, W.; Chen, Y.; Xie, Y.; Shen, Y.; Wang, Z. Multi-scale feature pyramid network: A heavily occluded pedestrian detection network based on ResNet. Sensors 2021, 21, 1820. [Google Scholar] [CrossRef]
- Xie, H.; Zheng, W.; Shin, H. Occluded Pedestrian Detection Techniques by Deformable Attention-Guided Network (DAGN). Appl. Sci. 2021, 11, 6025. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Rashtchian, C.; Zhang, H.; Salakhutdinov, R.; Chaudhuri, K. A closer look at accuracy vs. robustness. arXiv 2020, arXiv:2003.02460. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Kunic, T.; Tsotsos, J.K. Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6262–6271. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 2636–2645. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benefits | Challenges |
|---|---|
|
|
| Advantages | Disadvantages | |
|---|---|---|
| CAMERA | -Low cost. -Technology is mature. -High Resolution. -Possible to generate 3D stereoscopic view. -Detect RGB information. -Road markings and signs are design for human eyes. -Less chance to be affected by interference from another vehicles. -Wider field of view. | -Short range. -Performance decreases in poor weather and low light conditions. -Does not provide accurate distance and position of objects. -Usually does not provide depth information. Depth information can be acquired but make the system more complex (e.g., stereo camera and disparity estimation algorithms). |
| THERMAL | -Distinguish between hot and cold targets. -Can be used during the day and night. | -More expensive than cameras. -Main target is pedestrian but can get confused with hot air from the exhaust pipe or other objects that generates heat. -Cannot detect heat through glass, for example, detect drivers inside the car. |
| INFRARED | -Can be used during the day and night-time. -They are cheaper and small. | -It has short range. |
| SONAR | -Cheap. | -Affected by poor weather conditions. -Short range, it is commonly used for automated parking and blind spot detection features. |
| RADAR | -Its performance is not affected in bad weather or low light conditions. -Long range (up to 300 m). -Provide accurate distance, position, and speed. -Technology is mature. -Low cost | -Limited resolution. -Limited to recognise objects. |
| LIDAR | -360-degree view of the environment. -Wide field of view. -High accuracy. | -Low spatial resolution compared to cameras. -Performance decreases in poor weather. -Complex and requires high processing power. -Expensive. -Affected by interference and external light. -Does not provide colour information. -Acquired information are sparse. |
| Classifier | Advantages | Disadvantages |
|---|---|---|
| Linear-SVM | -Use less memory. -Fast to train and classify. | -Lower accuracy. |
| Non-linear SVM | -Good accuracy. | -Slow to train and test. -Considerable complexity. |
| Histogram Intersection Kernel SVM (HIKSVM) | -Same computational load as Linear SVM. | -Bad performance when using FPPI evaluation. -It has a short-range. |
| AdaBoost | -Fast classification. | -Slow to train. -Complexity increases as the number of classes increases. Hence, not suitable for challenging datasets. |
| MPL-Boost | -Learns Multiple classifiers in parallel. | -Still limited by the number of classes. |
| Work | Methods | Algorithm Objective | Dataset-Results | |
|---|---|---|---|---|
| Traditional Techniques | VeDAS [85] | Appearance based Multi-part based model. Active learning and Symmetry. Feature extractor: Haar Like. Classifier: AdaBoost. Hardware: i7 CPU with 4 cores. | Occlusion handling. | LISA True-Positve: 95% Detection-Rate: 87% Time: 15–25 fps. |
| [90] | Appearance based And-Or model to represent occlusion and context. Classifier: Weak-level Structural SVM Hardware: NVIDIA GPU. Evaluation: AP(%). | Occlusion handling. | KITTI: Easy: 84.80% Medium: 75.94% Hard: 60.70% Time: 2 to 3 s/img. | |
| [83] | Region proposal: Edges and Shadows. Feature extractor: HOG. Classifier: AdaBoost. Tracking: Feature points matching using Harris algorithm. Hardware:i5 3.2 GHz CPU 4 GB RAM. | Vehicle detection and Tracking for FCW. | OWN True Positive: 91.37 False-Positve: 3.09 Recognition Error: under 5% | |
| [86] | Feature extractor: Combination of HOG + LBP + Haar. Classifier: AdaBoost. Hardware: Intel Xeon 8 core 3.0 GHz. | Comparison of different feature extractors. | Udacity & KITTI Precision: 94.7% Detection Rate: 91% Time: 0.528 s/img. | |
| [84] | Feature extractor: HOG (for day-time and dusk). Classifier: SVM (for day-time and dusk). Detector: DBN (for night-time). Hardware: Zynq Soc. | Improve vehicle detection in different light conditions (day, dusk, and dark). | UPM & SYSU Accuracy: Day 91.56% Dusk 85.34%. Time: 50 fps/img. | |
| Deep Learning Techniques | [92] | Detector: 2D DBN. Hardware: Advantech industrial computer. | Improve vehicle detection performance by retaining more discriminative information. | OWN & Caltech Detection Rate: 96.05% Time: 53 ms/img. |
| Faster-RCNN [67] | Detector: original Faster R-CNN. Hardware: GPU 3.5 GHz. Evaluation: AP(%). | Generic object detection. | KITTI Easy: 88.97% Medium: 83.16% Hard: 72.62% Time: 2 s/img. | |
| [93] | Detector: Faster R-CNN. Hardware: 32 Core server 3.1 GHz, 13 GB RAM, Tesla K40 GPU. Evaluation: AP(%). | Handle scale sensitivity. Improve vehicle detection by fine-tuning the Faster R-CNN detector. | KITTI Easy: 95.14%. Medium: 83.73%. Hard: 71.22%. Time: 0.32 and 0.47 s/img. | |
| MS-CNN [94] | Detector: MS-CNN. Feature up-sampling: Deconvolutional Layer. Hardware: Intel Xeon E5-2630 2.40 GHz 64 GB and NVIDIA Titan GPU. Evaluation: mAP(%). | Handle scale sensitivity and improve detection speed. | KITTI Easy: 90.03%. Medium: 89.02%. Hard: 76.11%. Time: 0.4 s/img. | |
| DAVE [95] | Region proposal: FVPN. Attributes: ALN (Based on GoogleNet). Detector: Combination of FVP + ALN. Hardware: NVIDIA Titan X GPU. | Vehicle detection and pose annotations. | UTS AP: 62.85%, 2 fps. PASCAL AP: 64.44%, 4 fps. LISA AP: 79.41%, 4 fps. | |
| SDP+CRC(ft) [96] | Multi-Scale method: Scale Dependent Pooling (SDP). Feature Extractor: VGG-16. Classifier: Cascade Rejection Classifier (CRC). Detector: SDP-CRC(ft). Hardware: NVIDIA K40 GPU. Evaluation: AP(%). | Handle scale variance and improve detection speed. | KITTI Easy: 90.33% Medium: 83.53% Hard: 71.13% Time: 0.6 s/img. | |
| [97] | Region proposal: Graph based algorithm + Super-pixels. Detector: VGG-16. Hardware: NVIDIA Titan GPU. Evaluation: AP(%). | Decrease the number of Region Proposal candidates. | KITTI: Easy: 80.53% Medium: 67.89% Hard: 58.23% Time: 1.57 s/img. | |
| [98] | Detector: R-CNN with modified anchor boxes and use of shallow features. Hardware: Not Specified. | Handle multi-scale vehicles. | KITTI AP: 83.6% Time: Not Specified. | |
| RV-CNN. [99] | Region proposal: RoI Voting. Feature extractor: AlexNet + GoogleNet + Res-50Net. Detector: RV-CNN a Multi-task learning and ensemble network. Evaluation: AP(%). | Improve vehicle detection robustness. | KITTI Easy: 91.28% Medium: 91.67% Hard: 85.43% Time: Not Specified. | |
| Deep Learning Techniques | Deep-MANTA [100] | Object Proposal: Coarse-to-Fine RPN. Feature extractor: GoogleNet or VGG16. Detector: Deep Course-to-fine Many task CNN. Hardware: Not Specified. Evaluation: AP(%). | Improve detection performance and robustness (occlusion and truncation) by performing 2D/3D vehicle analysis. | KITTI Easy: 96.40% Medium: 90.10% Hard: 80.79% Time: 0.7–2.1 s/img. |
| RRC [101] | Feature Extractor: VGGNet. Detector: RRC enables feature aggregation to extract more contextual information. Multi-scale feature pyramid. Hardware: Not specified. Evaluation: AP(%). | Improve mAP for single stage method. | KITTI Easy:N\ a Medium: 90.19%. Hard: 86.97%. Time: Not specified. | |
| ITVD [102] | Region Proposal: BFEN. Feature extractor: ResNet50. Detector:ITVD which is the combination of ResNet-50+ BFEN + STM + SLPN. Hardware: GPU 1080Ti. Evaluation: AP(%). | Improve detection of small vehicles by acquiring high-quality region proposals. | KTTI: Easy: 95.85% Medium: 91.73% Hard: 86.37% Time: 0.3 s/img. DETRAC: Easy: 92.95% Medium: 81.43% Hard: 63.73% Time: 0.2 s/img. | |
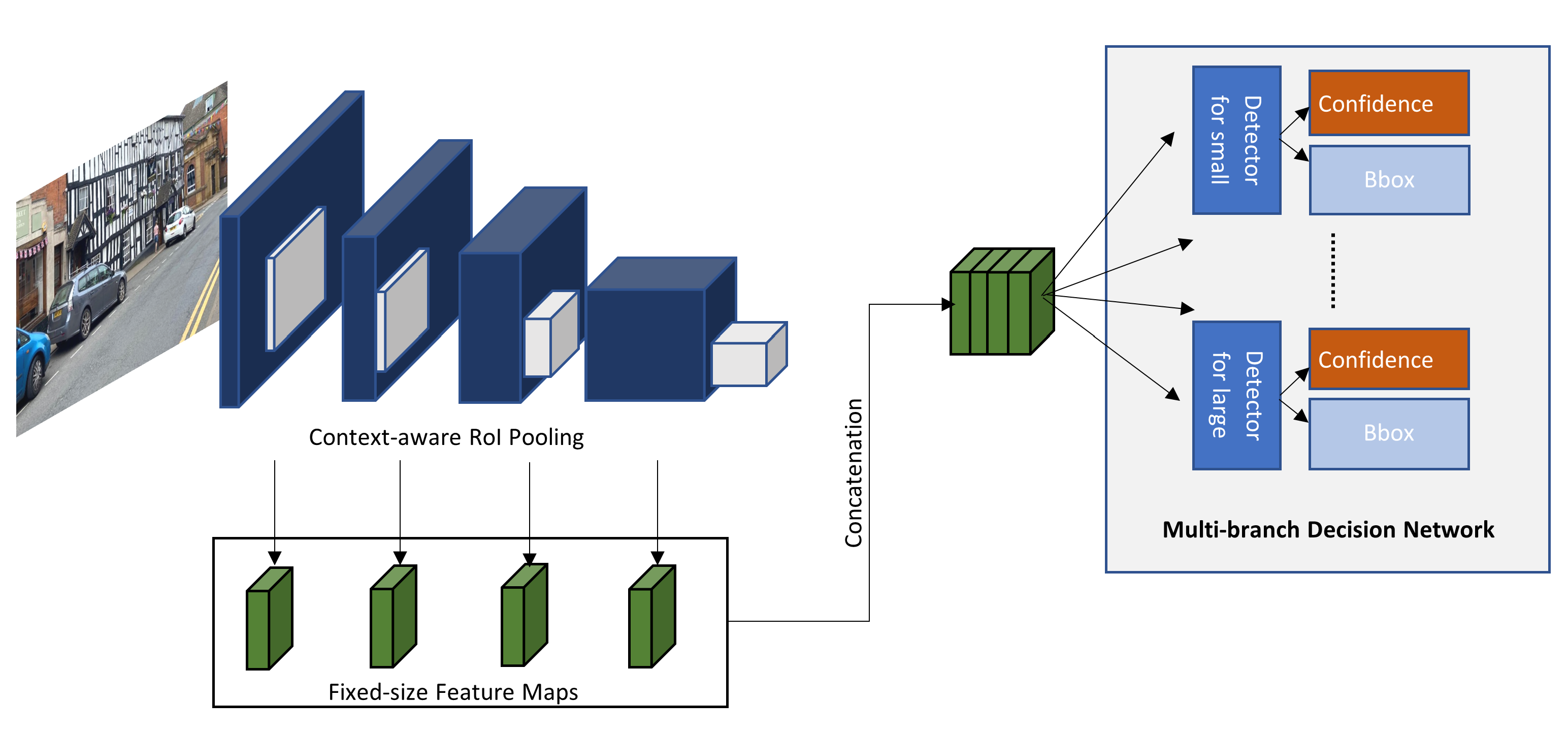
| SINet [82] | Region proposal: Context-aware pooling to conserve small object properties. Feature extractor: VGG or PVA. Detector: Multi-branch decision network called SINet. Hardware: Intel Xeon E5-1620 3.5 GHz and GPU NVIDIA Titan X. Evaluation: AP(%) and mAP(%). | Handle scale sensitivity. | KITTI: Easy: 90.60% Medium: 89.60% Hard: 77.75% Time: 0.11–0.2 s/img. OWN (LSVH): mAP: 70.17%. | |
| AP-SSD [103] | Feature extractor: multi-shape and colour Gabor. R-Net to generate AG map. Dynamic Region Enlargement to detect small objects. Detector: SSD. Hardware: Intel Xeon E5-2603 1.8 GHz and NVIDIA Quadro K620 GPU. | Improve detection accuracy. | KITTI: AP: 92.23% Time: 31.86 fps | |
| Cascade R-CNN [104] | RoI: RPN Detector: cascades of the Faster R-CNN detector. Hardware: Single Titan Xp GPU. | Improve detection quality (increase IoU threshold) by using multistage object detection. | KITTI Easy: 90.68%. Medium: 89.95%. Hard: 78.40%. Time: 0.14 s/img. | |
| [105] | Feature extractor: ZFNet Detector: Faster R-CNN Hardware: Intel Xeon E5-2630 2.40 GHz 64 GR RAM, NVIDIA GTX 1080 GPU. | Vehicle type classification. | OWN mAP: 81.05% Time: 0.354 s/img. | |
| Deep Learning Techniques | [106] | Region proposal: uses a novel part-aware RPN and PAFs to construct feature vectors for different parts of the vehicle. Feature extractor: VGG-16. Detector: Faster R-CNN. Part-aware NMS to reduce the number of box candidates. Hardware: NVIDIA Titan X GPU 12 GB memory. Evaluation: mAP(%). | Handle occlusion and truncation. | KITTI
Easy: 90.21% Medium: 89.01% Hard: 80.72% Time: 2.1 s/img. |
| MonoFENet [107] | Region proposal: RPN same as Faster R-CNN, RoI max pooling for the feature presentation, and RoI mean pooling for RoI point clouds. Disparity Estimation: DORN. Feature extractor: VGG-16 or ResNet-101 for image feature, and PointFE Network for point clouds features. Detector: MonoFENet. Hardware: Not specified. Evaluation: AP(%). | Feature enhancement by detecting 3D bounding boxes. | KITTI Easy: 91.42% Medium: 84.09% Hard: 75.93% Time: 0.06 s/img. | |
| SS3D [108] | Feature extractor: ResNet34 or drn_c_26 (Dilated Residual network) encoder. 3D boxes Estimator: non-linear least squares optimizer. Detector: SS3D. Hardware: Not specified. Evaluation: AP(%). | Improve inference time and detection accuracy for monocular 3D vehicle detection. | KITTI Easy: 92.72% Medium: 84.92% Hard: 70.35% Time: 0.048 s/img. | |
| [109] | Feature extractor: retrieve-and-transform LTN. Detector: Faster R-CNN. Hardware: Not specified. Evaluation: AP(%). | Trade-off between accuracy and speed. | KITTI: Easy: 90.12% Medium: 88.85% Hard: 79.62% Time: 0.4 s/img. | |
| DLNet [110] | Detector: DLNet is a combination of characteristics of DenseNet, YOLO and MobileNet. Hardware: GPu GeForce Titan X. | Improve speed and decrease resources requirements. | CITY AP: 78%. Time: 71 fps. Weight: 10.1MB. | |
| [111] | Feature extractor: VGG-16. Detector: Faster RCNN. Hardware: Not specified. | Improve detection accuracy by fine-tuning Faster RCNN. | CityScapes AP: 89.06% Time: Not specified. | |
| [112] | Feature extractor: DarkNet53. Multi-scale method: Multi-level feature pyramid. Detector: YOLOv3. Hardware: i7-9700 anbd NVIDIA GTX 1080ti. Evaluation: AP(%). | Handle multi-scale vehicles. | KITTI: Easy: 95.04% Medium: 92.39% Hard: 87.51% Time: 2.1 s/img. | |
| [113] | Feature extractor: HOG + LBP + Haar Like + VGG. Detector: SVM + Cascade CNN. Hardware: i7-8700 CPU 3.2 GHz 16 GB memory. | Improve detection accuracy and robustness. | BDD+Udacity+Other: Precision: 97.32% Recall: 98.69% Time: Not specified. |
| Work | Feature | Classification | MR |
|---|---|---|---|
| VJ [128] | Appearance + Motion (VJ-rectangles) | Cascade-AdaBoost | 94.73% |
| HOG [47] | HOG | Linear SVM | 68.46% |
| SHAPELET [129] | SHAPELET | AdaBoost | 91.37% |
| LatSvm-V1 [125] | HOG + DPM | Laten SVM | 79.78% |
| HIKSVM [130] | HOG | HIKSVM | 73.39% |
| MULTIFTR [131] | HOG + Shape Context + Haar Features | Linear SVM | 68.26% |
| LatSvm-V2 [126] | HOG + DPM | Latent SVM | 63.26% |
| ChnFtrs [132] | ICF | AdaBoost | 56.34% |
| FPDW [133] | Approximate Multiscale Gradient histograms + ICF | AdaBoost | 57.40% |
| MULTIFTR+MOTION [134] | HOG + Optical Flow + CSS | HIKSVM | 50.88% |
| MLS [135] | Macro-feature (Shapes) | AdaBoost | 61.03% |
| CorssTalk [136] | HOG + LUV + ICF | Crosstalk Cascade | 53.88% |
| SquaresChnFtrs [137] | HOG + LUV | Linear SVM | 50.17% |
| Roerei [137] | HOG + LUV + Multi-Scales + Global Normalisation | Linear SVM | 48.50% |
| ACF [138] | HOG + LUV + Normalised Gradient Magnitude | AdaBoost | 51.36% |
| InformedHaar [139] | Haar-Like + HOG + LUV | AdaBoost | 34.60% |
| LDCF [140] | Same as ACF | Same as ACF | 25.0% |
| Katamari-v1 [6] | HOG + LUV + DCT+ Optical Flow | Not Clear | 22.49% |
| Checkerboards [141] | HOG + LUV (Filtered channels feature) | AdaBoost | 18.50% |
| NNNF-L4 [142] | HOG + LUV NNF: SIDF and SSF | AdaBoost | 16.84% |
| FSSS [143] | ACF + FSSS | RealBoost L3 Decision tree | 13.96% |
| Work | Methods | Algorithm Objective | Dataset & Results |
|---|---|---|---|
| DBN-Isol [127] | Hybrid HOG + DPM + Scores of parts + Model-part Visibility Estimation Deep Model Hardware: Not specified. Evaluation: MR(%). | Occlusion handling and deformations. | Caltech Reasonable: 61.00% Heavy: 93.00% Time: Not specified. |
| ConvNet [152] | DL LeNet CNN. Unsupervised Multi-Stage Feature Learning Hardware: Not specified. Evaluation: MR(%). | Improve features. | Caltech Reasonable: 77.20% Time: Not specified. |
| DBN-Multi [153] | Hybrid HOG + DPM + Part Detection Score Mutual Visibility Deep model Hardware: 2.27 GHz CPU. Evaluation: MR(%). | Cluttered background. | Caltech Reasonable: 48.00% Time: Not specified. |
| ContDeepNet or SDP [154] | Hybrid HOG + CSS + Feature Pyramid Deep Model Hardware: Not specified. Evaluation: MR(%). | Improve features. | Caltech Reasonable: 45.00% Time: Not specified. |
| UDN\JointDeep [123] | Hybrid Unify feature extraction, part deformation model, occlusion handling and classification. Standard CNN Back-propagation for Optimisation Hardware: Not specified. Evaluation: MR(%). | Improve features, deformation, occlusion, and classification. | Caltech Reasonable: 39.00% Time: Not specified. |
| SDN [155] | Hybrid HOG + CSS + SVM for pruning. Learn Features + Saliency Maps + Mixture Representations Switchable Restricted Boltzmann Machine + CNN Hardware: NVIDIA GTX 760 GPU. Evaluation: MR(%). | Cluttered background and occlusion. | Caltech Reasonable: 37.87% Time: <0.1 s/img. |
| CompACT-Deep [156] | Hybrid ACF + HOG + LUV Complexity aware cascade training (AdaBoost) Hardware: Intel Xeon E5-2620 64 GB RAM and NVIDIA Tesla K40m GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Trade-off between accuracy and complexity. | Caltech Reasonable: 11.7% KITTI Easy: 70.69% Medium: 58.74% Hard: 52.71% Time: 1 s/img. |
| MS-CNN [94] | DL Multi-Scale (Uses earlier layers of the Network since it is better to detect small objects) Proposal and Detection network. Deconvolutional Layer to increase feature map resolution. Hardware: Intel Xeon E5-2630 64 GB RAM and NVIDIA Titan GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Variance in instance scale and fast detection. | Caltech Reasonable: 9.95% KITTI Easy: 83.92% Medium: 73.70% Hard: 68.31% Time: 0.4 s/img. |
| RPN+BF [157] | DL. RPN region proposal BF to mine hard negative examples. Faster-RCNN for detection. Hardware: Tesla K40 GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Variance in instance scale. | Caltech Reasonable: 9.60% Time: 0.5 s/img. KITTI Easy: 77.12% Medium: 61.15% Hard: 55.12% Time: 0.6 s/img. |
| MCF [158] | Hybrid Multi-layer Channel features Integrates HOG+LUV channels + the CNN layers Multistage cascade AdaBoost as the learn and classification algorithm. Hardware: Intel Core i7-3700. Evaluation: MR(%). | Improve features. | Caltech Reasonable: 10.40% Time: 0.54 fps. |
| F-DNN and F-DNN+SS [148] | DL -Ensemble. SSD for pedestrian candidate generator. Multiple binary classification DNNs (Resnet and GoogLeNet). SNF for network fusion. Semantic Segmentation to refine object detection. Hardware: NVIDIA Titan X GPU. Evaluation: MR(%). | Fast and robust. | Caltech F-DNN: 8.65% F-DNN+SS: 8.18% Time: 2.48 s/img. |
| SA Fast-RCNN [122] | Hybrid ACF for region proposals. Combine a large-size and a small-size sub-network. Divide-and-conquer philosophy. Hardware: NVIDIA GeForce GTX Titan X GPU 12 GB. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Variance in instance scale. | Caltech Reasonable: 9.32% KITTI Easy: 77.93% Medium: 65.01% Hard: 60.42% Time: 0.59 s/img. |
| SDS-RCNN [150] | DL -Ensemble Semantic Segmentation. RPN+BF region proposal. Hardware: Titan X GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Detection accuracy. | Caltech Reasonable: 7.36% KITTI Medium: 63.05% Time: 0.21 s/img. |
| ADM [146] | DL -RNN Resnet to extract features R-CNN for pedestrian proposals. Active detector using RNN (LSTM) to improve bbox predictions. Hardware: Not specified. Evaluation: MR(%). | Variance in instance scale. | Caltech Reasonable: 9.0% Time: Not specified. |
| PCN [147] | DL -RNN Part and Context Network. RNN (LSTM) for semantic information. Hardware: Not specified. Evaluation: MR(%). | Occlusion handling. | Caltech Reasonable: 8.4% Time: Not specified. |
| GDFL [159] | DL VGG16 to extract feature. Scale-aware pedestrian attention module. Zoom-in-Zoom-out module using max-pooling and bi-linear interpolation. Hardware: Single GeForce GTX 1080Ti GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Improve feature extraction. | Caltech Reasonable: 7.84% KITTI Easy: 84.61% Medium: 68.62% Hard: 66.86% Time: 20 fps. |
| F-DNN2 SS [149] | DL -Ensemble SSD to generate pedestrian candidates. Soft-rejection to adjust confidence. Semantic Segmentation. Hardware: Single NVIDIA Titan X GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Detection accuracy and velocity. | Caltech Reasonable: 7.67% KITTI Easy: 74.05% Medium: 61.17% Hard: 57.15% Time: 2.48 s/img. |
| TLL-TFA [160] | Topological annotation to introduce less ambiguity. MRF to eliminate ambiguities in occlusion cases. Temporal feature aggregation as an extra feature. Hardware: Not specified. Evaluation: MR(%). | Variance in instance scale. | Caltech Reasonable: 7.40% Time: Not specified. |
| AR-Ped [145] | DL -Ensemble + Encoder-Decoder + Cascade + RNN Auto-regressive RPN. Decoder-encoder module for feature refinement. R-CNN classifier. Hardware: NVIDIA 1080Ti GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Improve features. | Caltech Reasonable: 6.45% KITTI Easy: 83.66% Medium: 73.44% Hard: 68.18% Time: 91ms/img. |
| Parallel-Net [161] | DL Fire modules to reduce parameters. Feature Fusion: Parallel convolutional layers are combined. Detector: Parallel-Net. Hardware: NVIDIA 2080Ti GPU. Evaluation: AP(%) for KITTI and MR(%) for Caltech. | Improve features and reduce parameters. | Caltech Reasonable: 54.61% Time: 35.71 fps. KITTI Combined: 77.90%. Time:2.26 fps. |
| Adaptive Perceive -SSD [103] | See Table 4 Evaluation: AP(%). | See Table 4 | KITTI Combined: 92.42%. |
| CSP Liu et al. [162] | Detector:Center Scale Prediction (CSP). Resnet to extract centre points that can represent heat and scale map of the pedestrians. Hardware: GTX 1080Ti GPU. Evaluation: MR(%). | Avoid the use of sliding windows or anchor boxes. | Caltech Reasonable: 4.5% Time: 0.33 s/img. |
| W-Net Luo et al. [163] | Feature Extractor: ResNet-50 + FPN. Detector: Where, what, and Whether Network (W-Net). GAN transforms 2D images to Bird-view-map. Transform from bird view to front view map to create a relationship between object scale and depth. Encoder-Decoder technique to re-encode body parts into full body. Hardware: NVIDIA GTX 1080Ti. Evaluation: MR(%). | Handling occlusion. | Caltech Reasonable: 6.37% Heavy: 28.33% CityPerson Reasonable: 9.3% Heavy: 18.7% Time: 0.31 s/img. |
| TFAN Wu et al. [164] | Feature Extractor: ResNet. Detector:Tube feature aggregation network (TFAN). Temporal feature fusion: temporally discriminative embedding module and part-based relation module. Hardware: Not specified. Evaluation: MR(%). | Make use of temporal context information to handle heavy occlusion. | Caltech Reasonable: 6.5% Heavy: 31.5% Time: Not specified. |
| MFPN [165] | Resnet to extract features. Feature Fusion: Bi-direction FPN to acquire more semantic information. Repulsion Loss of Minimum to increase detection quality. Hardware: i7-6500 CPU 2.5 GHz and NVIDIA GTX 1080Ti GPU. Evaluation: AP(%). | Handling occlusion. | CrowdHuman 90.96%. Time: Not specified. |
| DAGN and DAGN++ Xie et al. [166] | Detector: cascade R-CNN. Tone mapping to deal with poor illumination. Deformable Convolution with an Attention Module. DAGN++ uses progressive training pipeline. Hardware(Testing): Single GTX Titan X GPU. Evaluation: MR(%). | Handling occlusion. | Caltech DAGN: 6.03% DAGN++: 1.84% Time: 0.11 s/img. |
| Pedestron Hasan et al. [151] | Cross-dataset evaluation. Progressive training pipeline. Detector: cascade R-CNN. Hardware: Not specified. Evaluation: MR(%). | Handling generalisation limitations. | Caltech: Reasonable: 2.5% Small: 9.9% Heavy: 31.0% Cityperson: Reasonable: 9.7% Small: 11.8% Heavy: 31.0% Time: Not specified. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galvao, L.G.; Abbod, M.; Kalganova, T.; Palade, V.; Huda, M.N. Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review. Sensors 2021, 21, 7267. https://doi.org/10.3390/s21217267
Galvao LG, Abbod M, Kalganova T, Palade V, Huda MN. Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review. Sensors. 2021; 21(21):7267. https://doi.org/10.3390/s21217267
Chicago/Turabian StyleGalvao, Luiz G., Maysam Abbod, Tatiana Kalganova, Vasile Palade, and Md Nazmul Huda. 2021. "Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review" Sensors 21, no. 21: 7267. https://doi.org/10.3390/s21217267
APA StyleGalvao, L. G., Abbod, M., Kalganova, T., Palade, V., & Huda, M. N. (2021). Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review. Sensors, 21(21), 7267. https://doi.org/10.3390/s21217267