3.1. ECG Datasets
NSR and AF rhythms are collected from three datasets [
34]: MIT-BIH Normal Sinus Rhythm (NSR-DB), MIT-BIH Atrial Fibrillation (AF-DB), and MIT-BIH Arrhythmia (ARR-DB).
Using ambulatory ECG recorders, each record was acquired from patients referred to the Arrhythmia Laboratory at the Beth Israel Deaconess Medical Center, Massachusetts Institute of Technology. They are accessible via the Physiobank repository, a digital archive of well-characterized biomedical signals created by the United States National Institutes of Health for use by the research community [
35].
AF-DB consists of 23 two-channel ECG recordings (sampled at 250 Hz), from subjects with paroxysmal atrial fibrillation, atrial flutter, AV junctional rhythm, and normal rhythms, with a typical recording bandwidth of approximately 0.1 to 40 Hz. NSR-DB consists of 18 two-channel ECG recordings (sampled at 128 Hz) from subjects with no significant arrhythmia or heart abnormalities. ARR-DB consists of 48 records, each containing two-channel ambulatory ECG signals of 30-min duration. Lead 1 channel ECG signals, which record the right ventricle and right atrium, are used in this work.
The signals in AF-DB have rhythm annotations indicating NSR and AF. Meanwhile, the signals in NSR-DB and ARR-DB have heartbeat annotations as well, in addition to rhythm annotations for AF and NSR. The annotations are provided in terms of a distinct beginning and end label pertaining to particular regions of the signals. The heartbeats in NSR-DB and ARR-DB follow the recommended standards of the Association for the Advancement of Medical Instrumentation [
36]. Hence, the annotations/labels for each heartbeat in the NSR-DB and ARR-DB fall into multiple categories [
37]. The beat superclasses and their corresponding beat annotations of interest in this work are N: (
N,
L,
R,
B) and S:
A,
a,
J,
S,
j,
e,
n. While the primary focus is on heart rhythm classification, specific samples in the dataset are considered on a heartbeat segment basis for incorporating cases of atrial premature complexes (APC) [
38]. The rationale for incorporating heart rhythms with high saturation levels of anomalous heartbeats is to contribute stochasticity (diversity) to the AF class. The expectation is that the dataset consisting of contiguous AF rhythms and AF rhythms interspersed with normal and other types of beats will allow for the eventual detection of varying anomalous rhythms that differ considerably from the purely NSR training samples [
39,
40].
3.3. Preprocessing
Initially, the signals with rhythm annotations of NSR and AF from AF-DB, ARR-DB, and NSR-DB were divided into 30-s samples with no-overlapping windows. The segmented 30-s signals retained the respective label of NSR or AF as multiple 30-s samples can be obtained from a single longer signal with the same annotation. In the case of ARR-DB, all signals with annotations corresponding to non-atrial complications, such as paced rhythms, ventricular bigeminy, trigeminy, tachycardia, were ignored.
Most AF contiguous data samples originated from the AF-DB, with approximately 3.6% being from the ARR-DB dataset. From the NSR database, 15% of the total NSR rhythm records were arbitrarily selected. Most NSR data originated from NSR-DB, followed by ARR-DB while AF-DB contributed only 5% of the total NSR samples. All the signals accounted for had the highest resolution in terms of QRS complex certainty.
In addition, signals with ARR-DB were examined further in terms of heartbeat saturation to determine the presence of excessive supraventricular activity, which is associated with an increased risk of developing atrial fibrillation [
43]. The examined signals were annotated with APC, supraventricular tachyarrhythmia (SVTA), atrial couplets, or atrial flutter. As per AAMI standards, all considered heartbeats in the 30-s window derived from these signals belonged to the class N or S. The beats denoted by S can be referred to as supraventricular ectopic beats or premature beats. Although ectopic beats are mostly harmless, recent studies have shown that frequent repetitions of supraventricular ectopic behavior can indicate the presence of potential atrial abnormalities [
44].
The criteria for judging the label of a 30-s rhythm are based on the saturation level of class S beats. If zero S beats are present, then it is ignored, and if over 50% of the beats are S with an annotation of a, J, A, S, j, e, or n, it is treated as an AF rhythm. The passage from heartbeat types to heart rhythms is not necessarily direct. Thus, this rule is to ensure that only segments consisting of non-isolated beats are treated as AF samples.
Individuals in real scenarios may not always exhibit signs of sustained arrhythmia. It is possible for a fluctuating pattern between normal rhythms, where relatively shorter (<30 s) intermittent periods of abnormal heart behavior associated with AF can be observed, and thereby contributing to AF risk stratification. Excessive ectopic activity can cause palpitations, light-headedness, and increased awareness of heartbeats [
45]. For instance, patient 232 does not have any AF rhythm annotations, but has frequent ectopic runs. The cardiologists’ notes associated with the annotated record of patient 232 report the presence of sick sinus syndrome, which is an abnormality in the right atrium of the heart. To address this case of potential variability in patients and boost the robustness in classification performance of the developed model, instances that are not solely NSR but anomalous to a considerable degree were treated as an AF class instance.
As per the findings of [
27,
46], a second-order Butterworth filter was applied with the bandpass frequencies of 8Hz–20Hz for removing baseline drift, motion artifacts and minimizing other ECG features such as the P and T waves. The signals of the MIT-BIH Arrhythmia, MIT-BIH NSR, and MIT-BIH AF databases have sampling rates of 360 Hz, 128 Hz, 250 Hz, respectively. Fast Fourier (FFT) resampling is applied to down-sample the signals to 50 Hz, as the signals from the three MIT-BIH databases have different original sampling rates. It, therefore, must have the same frequency before any further processing. The method reported in [
46] achieves the highest signal-to-noise ratio and optimal QRS complex detection on the MIT-BIH databases instead of techniques such as the Pan Tompkins algorithm [
47], and the former method is utilized to produce a list of the peaks necessary to derive the time-domain HRV features.
PPG signal filtering was conducted with a 3rd order Butterworth filter with 0.5 Hz and 8 Hz cutoffs to remove powerline interference, motion artifacts, and other saturated noise [
48]. The UMass dataset signals were down-sampled from 128 Hz to 50 Hz using FFT resampling, similar to the approach executed in [
42]. Systolic peak detection in the PPG signals utilized the algorithm outlined in [
49], where two event-related moving averages with an offset threshold empirically yielded higher accuracy than the alternative techniques of Billauer [
50], Li [
48], and Zong [
51].
The decision for down-sampling all signals to 50 Hz, instead of up-sampling any acquired signals to 128 Hz is based on two key factors. Firstly, most PPG based devices do not have a high sampling rate (~128 Hz), and vary from 60 Hz to 100 Hz based on the quality of the sensor and the battery levels of the device the sensor is embedded in. However, the minimum sampling frequency required is 50 Hz to derive reasonably accurate HRV and PRV parameters with a low margin of error from ECG and PPG signals, respectively [
52,
53]. Secondly, the computational overhead is reduced without a significant effect on the signal acquisition or processing aspects, which can extend the deployment of the proposed model in this work to resource-constrained wearable devices.
It is to be noted that the systolic peak detection algorithm for PPG signals proposed in [
48] is a modified variant of the QRS peak detection algorithm for MIT-BIH database ECG signals proposed in [
46]. This work performed filtering as per the recommended cutoff frequencies before applying the algorithm, as mentioned previously in this section. The general description of the algorithm reported in [
46,
48] is as follows:
- (i)
Consider a filtered signal , consisting of a sequence of samples over a sampling period s, as input to either the ECG variant of the algorithm or the PPG variant of the algorithm;
- (ii)
Detect R peaks in the ECG signals and systolic peaks in the PPG signals through a combination of potential block generation and thresholding;
- (iii)
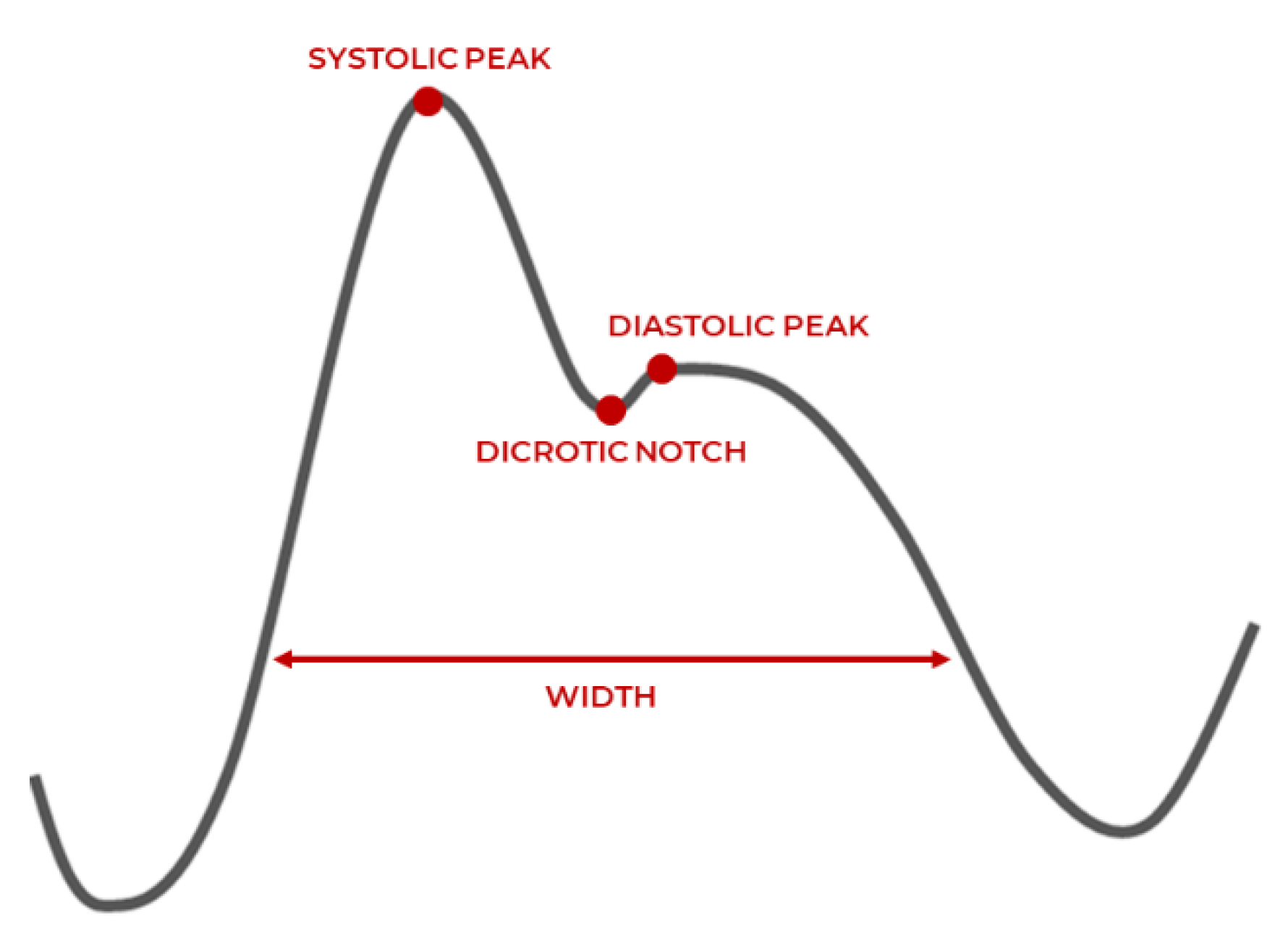
Preprocess PPG systolic peak detection (step skipped for ECG R peak detection in the squaring phase), where large differences resulting from the systolic peak are emphasized, while the small differences caused by the diastolic peak, dicrotic notch, and saturated noise are suppressed;
- (iv)
In the potential block generation phase, regions of the signal where peaks are likely to occur are demarcated in terms of the onset and offset points by two moving averages and ;
- (v)
estimates the possible regions of R peak or systolic peak amplitude and represents the amplitude in regions of a full heartbeat (RR peak, or systolic peak-to-systolic peak);
- (vi)
The window size
of the
is selected based on a healthy adult’s average duration of a QRS complex (100 milliseconds) or systolic peak (111 milliseconds) depending on the signal modality. The window size
for the
is selected based on the average duration of one full heartbeat (525 ms) or systolic peak (667 ms) in a healthy adult [
49]. The defined windows
bound the lower limit
and upper limits of the generated blocks, respectively;
- (vii)
The specific windowed regions where the amplitude values of are greater than , are selected as blocks of interest;
- (viii)
As a signal can be saturated with noise and motion artifacts during acquisition, the thresholding phase eliminates blocks that are likely to hinder accurate peak detection. The threshold specifies the anticipated width of a block, and any detected QRS complex or systolic peaks with width less than this threshold is rejected. An optional parameter can be added to the threshold to consider minor deviations in peak width and either tighten or loosen the constraints on a rejected block;
- (ix)
The output of the algorithm is a list of peak locations and their corresponding times in milliseconds.
After performing the peak detection algorithm summarized in Algorithm 1, a list of peak locations and their occurrence times enables the estimation of RR intervals or systolic peak-to-systolic peak intervals. From the intervals, the time-domain HRV and PRV features are derived in terms of their statistical characteristics as described in
Table 1.
| Algorithm 1. Pseudocode of peak detection algorithm and feature detection for dataset D. |
| FORin D (ECG or PPG data instance from dataset, where i = {0…size(D)) |
| Filtered signal = BandpassFilter( |
| Let (Peak amplitudes) |
| Let (Peak times) |
| Let |
| Let |
| Set = Average ECG or PPG peak duration |
| Set = Average ECG or PPG beat duration |
| Set = MovingAverage(, ) |
| Set = MovingAverage(, ) |
| Set threshold = |
| FOR n = 1 to length() |
| IF > THEN |
|
| ELSE |
|
| END IF |
| END FOR |
| FOR j = 0 to length(BlocksOfInterest) |
| IF THEN |
| = max(BlockOfInterest[j]) |
| = time(BlockOfInterest[j]) |
| ELSE; |
|
| END IF |
| END FOR |
| Calculate HRV/PRV (peaklist, timelist) |
| Transformed data instance = } |
| Save to updated dataset |
| END FOR |
Finally, Z-score normalization is performed on the derived features. All ECG and PPG datasets signal instances are fixed with zero mean (µ = 0), and unit standard deviation (σ = 1.) This step mitigates amplitude scaling issues, offset effects, and reduces drastic variability in the signal values.
Table 3 presents total data samples of NSR and AF classes after pre-processing.
3.4. Model Development
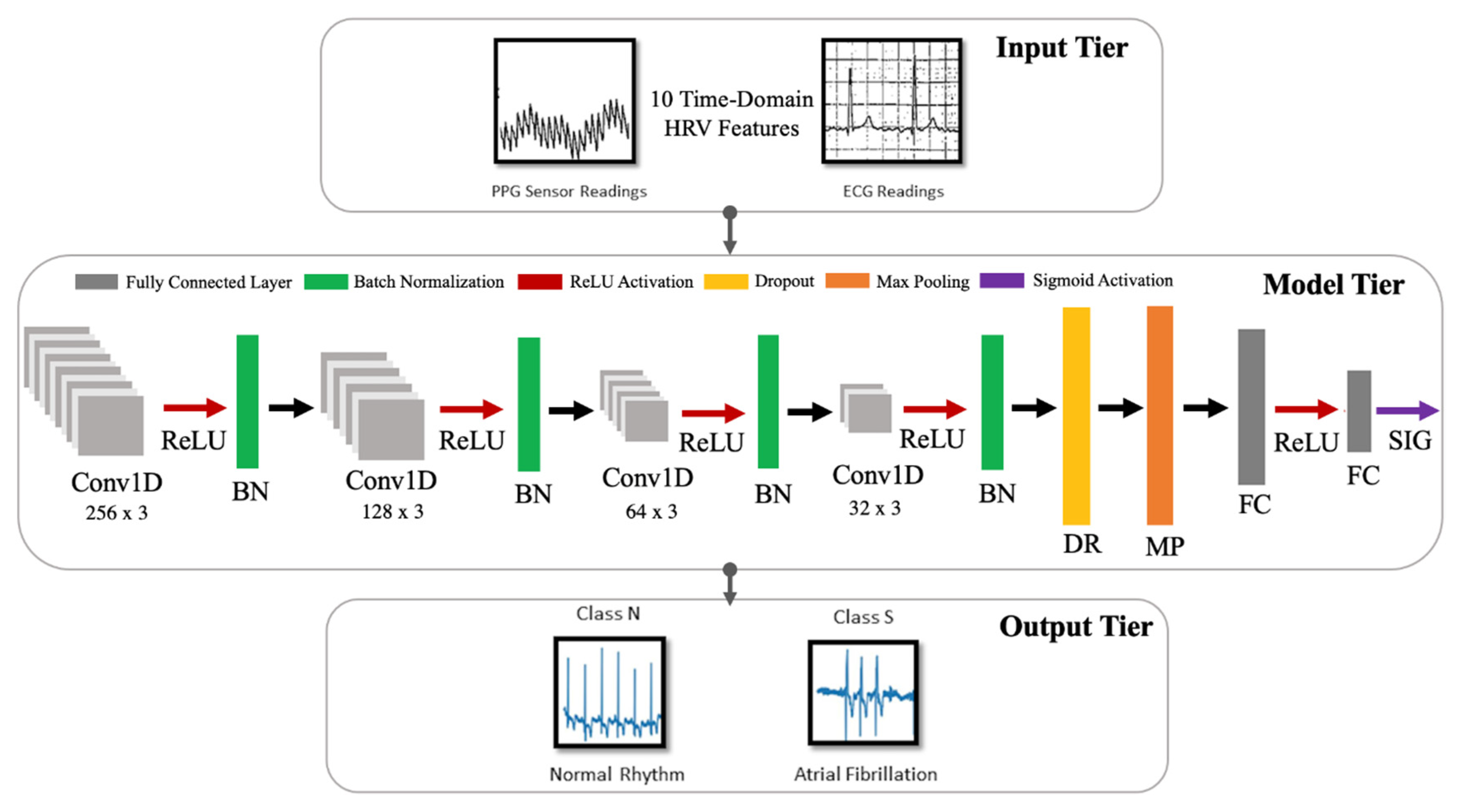
The model developed in this work is a one-dimensional 12-layer CNN for the classification of NSR and AF. The proposed architecture for the CNN is depicted in
Figure 5, outlining the input tier, model tier, and output tier. The model receives temporal HRV features extracted from ECG signals as input, propagates them through the neural network, and outputs a single output indicating whether the input instance belongs to NSR or AF class. A detailed summary of the CNN properties and parameters is listed in
Table 4. The configuration of the layers and their respective parameters reported were attained after hyperparameter tuning through GridSearch.
A single model is selected after training and evaluation. It is trained and tested using the HRV features derived from ECG, and finetuned to classify AF with PRV features derived from PPG. Due to the inherent similarities between the statistical properties of HRV and PRV, this approximation makes it possible for a unified AF representation across two wearable modalities.
There are three types of layers within a CNN: convolutional, pooling, and fully connected layers. An instantiated convolutional layer detects local conjunctions of features from a preceding layer which can be either an input layer or another convolutional layer. The convolutional layer merges semantically similar input features into a single learned representation. It is to be noted that features in the context of the neural network imply semantic similarities or overarching patterns detected across the provided inputs (a unified vector of HRV features). Receptive fields in each convolutional layer focus on different aspects of the derived features to create their internal representation of the inputs. The property of shared weights ensures that general features common to all data samples are learned once and shared with the other convolutional layers in the network. Subsampling reduces the dimensionality of the data to identify the most significant features. This can be related to size (spatial) or time sequence (temporal). A set of weighted vectors known as a filter/kernel outputs feature maps based on local receptive fields at each layer. These feature maps usually hold general characteristic information inferred from input feature data samples at a particular layer by the neural network [
54].
Each layer of the proposed CNN architecture and the components of activation and regularization presented in
Figure 5 are described as follows:
Convolutional Layer (Conv1D): In this layer, a convolution operation using Equation (3) is performed by sliding the filter/kernel over the input features to obtain a feature map as the output.
From Equation (3), k, c, f, and N denote the inputs, filter/kernel, the output feature map, and the number of elements in input k, respectively. In the CNN model developed for this work, there are four convolutional layers with 256, 128, 64 and 32 filters, respectively. The filter dimensions used in this layer are 5 × 5, which yielded the best result.
Fully Connected Layer (FC): This layer compiles the results obtained from the preceding convolution and pooling layers to estimate an output classification label using Equation (4) [
55]:
From Equation (4), w and b denote weights and biases, respectively. Here, y is the output from a previous layer j and x is the output of the current layer i. In the CNN model developed in this work, there are two fully connected layers, with 8 and 1 neurons, respectively.
Pooling Layer (MaxPooling1D): In this layer, the maxpooling operation is a type of spatial sub-sampling method that decreases the size of the feature maps derived by the convolutional layers. This is performed to retain only the features contributing significantly to the internal knowledge representation of the CNN, which is learned through the training process. In the CNN model developed for this work, there is 1 pooling layer, with 32 filters after the final convolutional layer and the following dropout layer. The filter dimensions of the pooling size used in this layer are 2 × 2.
Activation Functions: This determines the firing threshold of neurons in the hidden layer based on the weighted sum of input and biases.
Rectified Linear Unit (ReLU) [
56]: This is the activation function that is used in all three convolutional layers of the network. The Rectified Linear Unit produces 0, as an output
and then produces a linear output with slope 1, when
. It introduces non-linearity and mitigates the vanishing gradient problem, which is where the lower layers of the network train slowly as the gradient of optimization decreases exponentially. This leads to sparse neuron activation, more straightforward output, and makes computations easier while preserving the significant receptive fields of the convolution layers.
Sigmoid [
57]: An activation function used in the second fully connected layer, with 1 neuron. Sigmoid activation functions are monotonic and differentiable. Their mathematical property maps real number values to the [0, 1] range to render the output as a probability, given the particular set of transformed input HRV features. In this work, the binary classification output of 0 indicates that an instance belongs to the NSR class, and 1 means that it belongs to the AF class.
Regularization [
58]: This is a technique to prevent overfitting. Overfitting limits the ability of the model to predict new data, which means the network has learned only the specific features of the training set, like memorization, and cannot perform generalization on similar data. To mitigate this, the following two methods were used after all four convolutional layers.
Batch Normalization (BN) [
59]: This technique reduces the covariance shift, meaning that minor features differences that do not contribute heavily to the overall model performance will not be considered with high priority. Therefore, minor changes between the ranges of training data, validation data, or unseen data will not affect the classification performance and allow each layer to be more independent about certain input features.
Dropout (DP) [
60]: This technique randomly drops neurons and their connections to prevent neurons from co-adapting. This makes each neuron more responsible for capturing the overall data representation and contributing to the final output. The dropout rate, which reflects the percentage of random neurons to be dropped, was set to 0.2.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}