
Optimization-Based Approaches for Minimizing Deployment Costs for Wireless Sensor Networks with Bounded Estimation Errors

 , ,
, ,
Abstract
:1. Introduction
- Minimizing the deployment cost of temperature sensors.
- Data used in this research is from the Australian Climate Observation Reference Network-Surface Air Temperature.
- Data ranges from 2008–2019.
- Expected to significantly reduce the deployment cost while maintaining the error under threshold.
2. Related Work
2.1. Correlation-Aware Deployment Methods
2.2. Sensor Deployment Applications
2.3. Summary
- Focuses on the temperature data which can be widely applied in various fields, such as humidity monitoring, air quality sensing, GPS surveillance, or landslide detection.
- Uses optimization-based methods to achieve reliable results.
- The methods used in this work are suitable for data from other fields.
3. System Architecture and Problem Formulation
3.1. System Structure
3.2. Problem Formulation
4. Solution Approach
4.1. Lagrangian Relaxation-Based Method
4.1.1. Step 1: Reformulation for Relaxation
4.1.2. Steps 2 and 3: Decomposition and Solution of Subproblems
- Subproblem 1 (related to )Subproblem 1 is a minimization problem. It consists of continuous variable and logarithm, extremum will be found when differential equals zero or the boundaries of the decision variable, . Algorithm 1 shows the pseudo-code of Subproblem 1. First, we calculate the partial differential of the objective function by . Let the product is equal to zero to determine the value of . Secondly, the validity of the extremum must be checked. Setting the equal to , , or such that the objective value of (Sub 1) is minimum, correspondingly.
Algorithm 1 Subproblem 1 - Input: Given parameters and Lagrangian multipliers , .
- Output: Decision variable .
- Initialize:,
- for to do
- for to do
- if then
- continue
- end if
- if then
- , , or such that has minimum.
- else
- or such that has minimum.
- end if
- end for
- end for
- Subproblem 2 (related to )Subproblem 2 is further decomposed into independent minimization problems. For a location i, the decision variable is examined for two values which are or 1, such that has minimum, respectively. The pseudo-code is shown in Algorithm 2.
Algorithm 2 Subproblem 2 - Input: Given parameters and Lagrangian multiplier .
- Output: Decision variable .
- Initialize:,
- for to do
- for to do
- for to do
- if then
- continue
- else
- +
- end if
- end for
- end for
- or 1 such that has minimum.
- end for
- Subproblem 3 (related to )Subproblem 3 is also a minimization problem consisting continuous variable and logarithm. Since (Sub 3) is a logarithmic equation, the minimum of such equation lies at either one of the boundaries of . Therefore, Algorithm 3 simply checks either or has the minimum value. Algorithm 3 shows the pseudo-code of Subproblem 3.
Algorithm 3 Subproblem 3 - Input: Given Lagrangian multiplier .
- Output: Decision variable .
- Initialize:,
- for to do
- for to do
- for to do
- if then
- continue
- else
- or such that has minimum.
- end if
- end for
- end for
- end for
- Subproblem 4 (related to )Subproblem 4 aims at deriving the right such that has minimum. Since is given, can be determined by checking whether is negative. Algorithm 4 shows the pseudo-code of Subproblem 4.
Algorithm 4 Subproblem 4 - Input: Given parameters and Lagrangian multipliers , .
- Output: Decision variable .
- Initialize:,
- for to do
- for to do
- if then
- else
- end if
- end for
- end for
- Subproblem 5 (related to )Subproblem 5 is a quadratic equation of , so the minimum could be found by its differential. The boundary of lies between and . Algorithm 5 first checks whether the differential lies within the boundary. If so, the should be either , , or . Otherwise, the minimum happens at the one of boundaries, so should be either or . Algorithm 5 shows the pseudo-code of Subproblem 5.
Algorithm 5 Subproblem 5 - Input: Given parameters and Lagrangian multipliers , .
- Output: Decision variable .
- Initialize:,
- for to do
- for to do
- if min max then
- , , or such that has minimum.
- else
- or such that has minimum.
- end if
- end for
- end for
4.1.3. Steps 4 and 5: Dual Problem and Subgradient Method
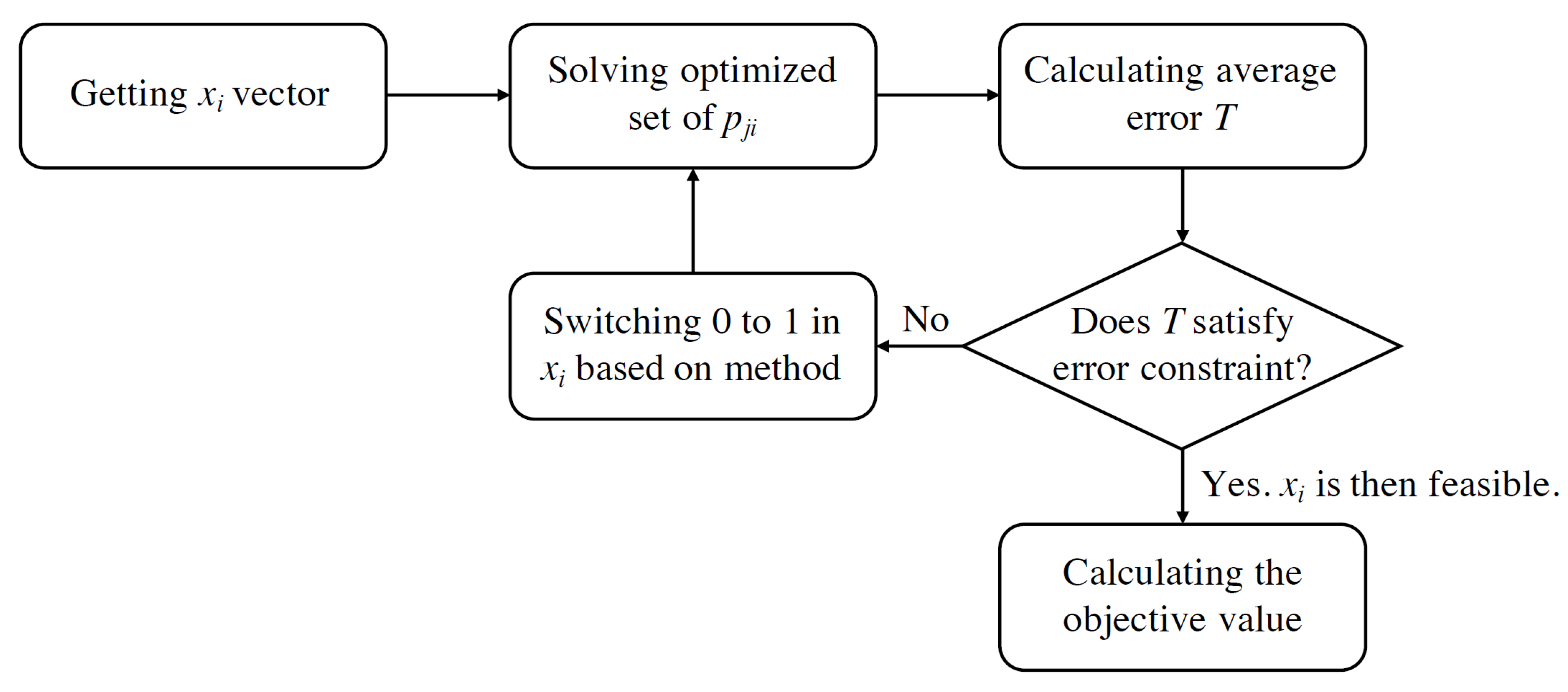
4.1.4. Step 6: Obtaining the Primal Feasible Solutions
- Referencing Capability Ranking (RCR)The primary goal of this study was to accurately estimate temperature measurement at locations without sensors. Equation (2) describes the estimation model; where can be calculated by a linear combination of the data series and coefficients . Thus, the problem is reduced to deriving an optimal series of such that in Equation (3) is minimized. To derive , we apply the steepest gradient descent method. The steepest gradient descent method, also known as the gradient method, was first described by Cauchy in 1847. Other analytic methods have been inspired by the method or derived from its deformation; the gradient method is thus fundamental to optimization methods. The method requires minimal work and few storage variables, and has low initial point requirements. However, it converges slowly, is inefficient, and sometimes is unable to yield an optimal solution. The goal of nonlinear programming is the numerical optimization of nonlinear functions. The theory and methods of nonlinear programming are used in military, economic, management, production process automation, engineering design and product optimization design applications. Nonlinear programming methods were used to calculate the optimal set of the coefficient in Equation (2). The objective function for gradient descent is Equation (20). In each LR iteration, the of each subproblems is used to optimize the corresponding . After several rounds of gradient descent, if the overall error of estimated measurements using optimized satisfies the average error threshold the set is considered feasible and the total cost is recorded. However, if is not satisfied, locations for deployed sensors are added to reduce the overall error. The addition is based on the ranking of of each location i; is the “referencing ability” of location i for other locations as presented in Equation (21).
- x Coefficient Ranking (xCR)xCR is similar to RCR. In this strategy, Equation (2) was also applied to estimate given by the LR procedure in each iteration. Moreover, steepest gradient descent was used to determine to minimize objective error (Equation (20)). If, after several rounds of gradient descent, if the overall estimated measurement error does not satisfy the average error threshold , locations are added to mitigate the error based on the ranking of the coefficients of in the LR objective formulation until a feasible set of is produced.
4.2. Pearson Correlation Coefficients and Linear Regression Methods
- The node is strongly associated with other nodes; the temperature can thus be accurately estimated by other nodes.
- The node is strongly associated with other nodes; it can be used to estimate temperatures at other nodes.
4.3. Extreme Gradient Boosting Method
5. Computational Experiments
5.1. XGBoost
5.2. RCR
5.3. xCR
5.4. Pearson Correlation and Linear Regression
5.5. Extended Application
5.5.1. Lifetime Enhancement
5.5.2. Other Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Albreem, M.A.; Sheikh, A.M.; Alsharif, M.H.; Jusoh, M.; Mohd Yasin, M.N. Green Internet of Things (GIoT): Applications, Practices, Awareness, and Challenges. IEEE Access 2021, 9, 38833–38858. [Google Scholar] [CrossRef]
- Janbi, N.; Katib, I.; Albeshri, A.; Mehmood, R. Distributed Artificial Intelligence-as-a-Service (DAIaaS) for Smarter IoE and 6G Environments. Sensors 2020, 20, 5796. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.C.; Cheng, P.; Ding, M.; Lopez-Perez, D.; Pathirana, P.N.; Li, J.; Seneviratne, A.; Li, Y.; Poor, H.V. Enabling AI in Future Wireless Networks: A Data Life Cycle Perspective. IEEE Commun. Surv. Tutor. 2021, 23, 553–595. [Google Scholar] [CrossRef]
- Su, X.; Liu, X.; Motlagh, N.H.; Cao, J.; Su, P.; Pellikka, P.; Liu, Y.; Petäjä, T.; Kulmala, M.; Hui, P.; et al. Intelligent and Scalable Air Quality Monitoring With 5G Edge. IEEE Internet Comput. 2021, 25, 35–44. [Google Scholar] [CrossRef]
- Sutjarittham, T.; Habibi Gharakheili, H.; Kanhere, S.S.; Sivaraman, V. Experiences With IoT and AI in a Smart Campus for Optimizing Classroom Usage. IEEE Internet Things J. 2019, 6, 7595–7607. [Google Scholar] [CrossRef]
- Khalifeh, A.; Abid, H.; Darabkh, K.A. Optimal Cluster Head Positioning Algorithm for Wireless Sensor Networks. Sensors 2020, 20, 3719. [Google Scholar] [CrossRef] [PubMed]
- Sugiura, K. SuMo-SS: Submodular Optimization Sensor Scattering for Deploying Sensor Networks by Drones. IEEE Robot. Autom. Lett. 2018, 3, 2963–2970. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.; Perillo, M.; Heinzelman, W.B. General Network Lifetime and Cost Models for Evaluating Sensor Network Deployment Strategies. IEEE Trans. Mob. Comput. 2008, 7, 484–497. [Google Scholar] [CrossRef]
- Liu, B.; Dousse, O.; Nain, P.; Towsley, D. Dynamic Coverage of Mobile Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 301–311. [Google Scholar] [CrossRef] [Green Version]
- Roy, V.; Simonetto, A.; Leus, G. Spatio-Temporal Sensor Management for Environmental Field Estimation. Signal Process. 2016, 128, 369–381. [Google Scholar] [CrossRef]
- Veiga, T.; Munch-Ellingsen, A.; Papastergiopoulos, C.; Tzovaras, D.; Kalamaras, I.; Bach, K.; Votis, K.; Akselsen, S. From a Low-Cost Air Quality Sensor Network to Decision Support Services: Steps towards Data Calibration and Service Development. Sensors 2021, 21, 3190. [Google Scholar] [CrossRef]
- Krause, A.; Singh, A.; Guestrin, C. Near-Optimal Sensor Placements in Gaussian Processes: Theory, Efficient Algorithms and Empirical Studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar] [CrossRef]
- Krause, A.; Guestrin, C.; Gupta, A.; Kleinberg, J. Robust Sensor Placements at Informative and Communication-Efficient Locations. Acm Trans. Sens. Netw. 2011, 7, 1–33. [Google Scholar] [CrossRef]
- Ranieri, J.; Chebira, A.; Vetterli, M. Near-Optimal Sensor Placement for Linear Inverse Problems. IEEE Trans. Signal Process. 2014, 62, 1135–1146. [Google Scholar] [CrossRef] [Green Version]
- Liaskovitis, P.G.; Schurgers, C. Leveraging Redundancy in Sampling-Interpolation Applications for Sensor Networks: A Spectral Approach. Acm Trans. Sens. Netw. 2010, 7, 12:1–12:28. [Google Scholar] [CrossRef]
- Forkuor, G.; Hounkpatin, O.K.L.; Welp, G.; Thiel, M. High Resolution Mapping of Soil Properties Using Remote Sensing Variables in South-Western Burkina Faso: A Comparison of Machine Learning and Multiple Linear Regression Models. PLoS ONE 2017, 12, e0170478. [Google Scholar] [CrossRef]
- Yan, X.; Xie, H.; Tong, W. A Multiple Linear Regression Data Predicting Method Using Correlation Analysis for Wireless Sensor Networks. In Proceedings of the 2011 Cross Strait Quad-Regional Radio Science and Wireless Technology Conference, Harbin, China, 26–30 July 2011; Volume 2, pp. 960–963. [Google Scholar] [CrossRef]
- He, D.; Liu, X.; Zheng, J.; Chan, S.; Zhu, S.; Min, W.; Guizani, N. A Lightweight and Intelligent Intrusion Detection System for Integrated Electronic Systems. IEEE Netw. 2020, 34, 173–179. [Google Scholar] [CrossRef]
- Ma, J.; Komuro, N.; SAkata, S. Sensors deployment for location estimation in wireless sensor networks. In Proceedings of the 2010 Second International Conference on Ubiquitous and Future Networks (ICUFN), Jeju, Korea, 16–18 June 2010; pp. 60–65. [Google Scholar] [CrossRef]
- Kim, H.; Han, S.W. An Efficient Sensor Deployment Scheme for Large-Scale Wireless Sensor Networks. IEEE Commun. Lett. 2015, 19, 98–101. [Google Scholar] [CrossRef]
- Han, G.; Zhang, C.; Shu, L.; Rodrigues, J.J.P.C. Impacts of Deployment Strategies on Localization Performance in Underwater Acoustic Sensor Networks. IEEE Trans. Ind. Electron. 2015, 62, 1725–1733. [Google Scholar] [CrossRef]
- Ramesh, M.V. Real-Time Wireless Sensor Network for Landslide Detection. In Proceedings of the 2009 Third International Conference on Sensor Technologies and Applications, Washington, DC, USA, 18–23 June 2009; pp. 405–409. [Google Scholar] [CrossRef]
- Solari, L.; Del Soldato, M.; Raspini, F.; Barra, A.; Bianchini, S.; Confuorto, P.; Casagli, N.; Crosetto, M. Review of Satellite Interferometry for Landslide Detection in Italy. Remote Sens. 2020, 12, 1351. [Google Scholar] [CrossRef]
- Huang, C.J.; Chu, C.R.; Yin, H.Y.; Chen, P.S. Calibration and Deployment of a Fiber-Optic Sensing System for Monitoring Debris Flows. Sensors 2012, 12, 5835. [Google Scholar] [CrossRef] [Green Version]
- Marin-Perez, R.; Michailidis, I.T.; Garcia-Carrillo, D.; Korkas, C.D.; Kosmatopoulos, E.B.; Skarmeta, A. PLUG-N-HARVEST Architecture for Secure and Intelligent Management of Near-Zero Energy Buildings. Sensors 2019, 19, 843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wright, R. Intelligent Autonomous Ship Navigation using Multi-Sensor Modalities. Transnav Int. J. Mar. Navig. Saf. Sea Transp. 2019, 13, 503–510. [Google Scholar] [CrossRef]
- Du, W.; Xing, Z.; Li, M.; He, B.; Chua, L.H.C.; Miao, H. Sensor Placement and Measurement of Wind for Water Quality Studies in Urban Reservoirs. ACM Trans. Sens. Netw. 2015, 11, 1–27. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Xing, G.; Chen, J.; Lin, C.X.; Chen, Y. Intelligent Sensor Placement for Hot Server Detection in Data Centers. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 1577–1588. [Google Scholar] [CrossRef] [Green Version]
- Fisher, M.L. The Lagrangian Relaxation Method for Solving Integer Programming Problems. Manag. Sci. 2004, 50, 1861–1871. [Google Scholar] [CrossRef] [Green Version]
- Geoffrion, A.M. Lagrangean Relaxation for Integer Programming. In Approaches to Integer Programming; Balinski, M.L., Ed.; Springer: Berlin/Heidelberg, Germany, 1974; pp. 82–114. [Google Scholar] [CrossRef]
- Held, M.; Karp, R.M. The Traveling-Salesman Problem and Minimum Spanning Trees. Oper. Res. 1970, 18, 1138–1162. [Google Scholar] [CrossRef]
- Held, M.; Karp, R.M. The Traveling-Salesman Problem and Minimum Spanning Trees: Part II. Math. Program. 1971, 1, 6–25. [Google Scholar] [CrossRef]
- Held, M.; Wolfe, P.; Crowder, H.P. Validation of Subgradient Optimization. Math. Program. 1974, 6, 62–88. [Google Scholar] [CrossRef]
- Jiang, Y.; Tong, G.; Yin, H.; Xiong, N. A Pedestrian Detection Method Based on Genetic Algorithm for Optimize XGBoost Training Parameters. IEEE Access 2019, 7, 118310–118321. [Google Scholar] [CrossRef]
- Punmiya, R.; Choe, S. Energy Theft Detection Using Gradient Boosting Theft Detector With Feature Engineering-Based Preprocessing. IEEE Trans. Smart Grid 2019, 10, 2326–2329. [Google Scholar] [CrossRef]
- Lin, P.; Tang, L.; Ni, P. Field Evaluation of Subgrade Soils Under Dynamic Loads Using Orthogonal Earth Pressure Transducers. Soil Dyn. Earthq. Eng. 2019, 121, 12–24. [Google Scholar] [CrossRef]
- Li, X.; Zhuang, Z.; Qi, D.; Zhao, C. High Sensitive and Fast Response Humidity Sensor Based on Polymer Composite Nanofibers for Breath Monitoring and Non-Contact Sensing. Sens. Actuat. Chem. 2021, 330, 129239. [Google Scholar] [CrossRef]
- Liu, Y.; Nie, J.; Li, X.; Ahmed, S.H.; Lim, W.Y.B.; Miao, C. Federated Learning in the Sky: Aerial-Ground Air Quality Sensing Framework With UAV Swarms. IEEE Internet Things J. 2021, 8, 9827–9837. [Google Scholar] [CrossRef]
- Wang, S.; Ding, S.; Xiong, L. A New System for Surveillance and Digital Contact Tracing for COVID-19: Spatiotemporal Reporting Over Network and GPS. JMIR Mhealth Uhealth 2020, 8, e19457. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Related Work | Sensor Allocation | Cost/Energy Consumption | Data Collection | Correlation Aware | Deployment Strategy |
|---|---|---|---|---|---|---|
| Dynamic Coverage Measures | [9] | ✓ | ✓ | ✓ | ||
| Sparsity-Enforcing Sensor Management Methods | [10] | ✓ | ✓ | |||
| Gaussian and Non-Gaussian Process | [12,27] | ✓ | ✓ | |||
| FrameSense | [14] | ✓ | ✓ | ✓ | ✓ | |
| Lightweight and Intelligent Intrusion Detection Method | [18] | ✓ | ||||
| Proposed model | ✓ | ✓ | ✓ | ✓ | ✓ |
| Notation | Description |
|---|---|
| D | Index set of evaluation data, where |
| V | Index set of locations, where |
| Installation cost of sensor i, where | |
| Measurement is taken at location i in dataset k, where , | |
| Tolerance on the average estimation error | |
| Weight is associated with location i, where ( and ) |
| Notation | Description |
|---|---|
| Binary variable, 1 if sensor i is installed, and 0 otherwise | |
| Weighting factor is set from sensor j to estimate measurement at location i, where | |
| Maximum weighting factor for sensor j to estimate measurement at location i, where | |
| Measurement is estimated for location i using dataset k, where , | |
| Estimation error is calculated at location i using dataset k, where , | |
| Maximum estimation error calculated at location i using dataset k, where , | |
| T | Average estimation error () |
| Given Parameter | Value |
|---|---|
| Number of evaluation data () | 3650 |
| Number of locations () | 112 |
| 5∼1000 | |
| 12.1 °C∼47.9 °C | |
| 1.5 °C | |
| 0.000182∼0.018169, 1 |
| Cost | Topol. 1 | Topol. 2_1 | Topol. 2_2 | Topol. 4_1 | Topol. 4_2 | Topol. 4_3 | Topol. 4_4 |
|---|---|---|---|---|---|---|---|
| (# of Sensors) | (112) | (28) | (84) | (20) | (8) | (33) | (51) |
| XGBoost | 6108 | 3186 | 2779 | 2210 | 3002 | 3096 | 1051 |
| (23) | (11) | (15) | (9) | (5) | (11) | (9) | |
| RCR | 8264 | 3732 | 6272 | 2157 | 2035 | 2288 | 2820 |
| (30) | (10) | (25) | (7) | (3) | (9) | (16) | |
| xCR | 7434 | 3858 | 5383 | 2073 | 2035 | 1904 | 3602 |
| (39) | (10) | (30) | (6) | (3) | (6) | (17) | |
| PCC | 26,382 | 6578 | 17,673 | 3149 | 4349 | 4994 | 10,620 |
| (75) | (18) | (54) | (11) | (7) | (16) | (35) |
| Cycle | 1 | 2 | 3 | 4 | 5 | Remaining |
|---|---|---|---|---|---|---|
| of Active Sensors | 20 | 18 | 19 | 21 | 21 | 13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsiao, C.-H.; Lin, F.Y.-S.; Yang, H.-J.; Huang, Y.; Chen, Y.-F.; Tu, C.-W.; Zhang, S.-Y. Optimization-Based Approaches for Minimizing Deployment Costs for Wireless Sensor Networks with Bounded Estimation Errors. Sensors 2021, 21, 7121. https://doi.org/10.3390/s21217121
Hsiao C-H, Lin FY-S, Yang H-J, Huang Y, Chen Y-F, Tu C-W, Zhang S-Y. Optimization-Based Approaches for Minimizing Deployment Costs for Wireless Sensor Networks with Bounded Estimation Errors. Sensors. 2021; 21(21):7121. https://doi.org/10.3390/s21217121
Chicago/Turabian StyleHsiao, Chiu-Han, Frank Yeong-Sung Lin, Hao-Jyun Yang, Yennun Huang, Yu-Fang Chen, Ching-Wen Tu, and Si-Yao Zhang. 2021. "Optimization-Based Approaches for Minimizing Deployment Costs for Wireless Sensor Networks with Bounded Estimation Errors" Sensors 21, no. 21: 7121. https://doi.org/10.3390/s21217121
APA StyleHsiao, C.-H., Lin, F. Y.-S., Yang, H.-J., Huang, Y., Chen, Y.-F., Tu, C.-W., & Zhang, S.-Y. (2021). Optimization-Based Approaches for Minimizing Deployment Costs for Wireless Sensor Networks with Bounded Estimation Errors. Sensors, 21(21), 7121. https://doi.org/10.3390/s21217121