1. Introduction
Speech-to-text transcription has gained importance in many applications and benefits in research, the military, medical sector, smart homes, transportation systems, automatic transcription on lectures, conversations, record-making [
1]. Speech recognition technology (SRT) involves the identification of patterns in audio waves and matching them with phonetics of speech to convert them into text. The accuracy of SRT dramatically depends on the quality of audio. The presence of background noises, multiple speakers, or the speaker’s accent provides erroneous transcription. Speech enhancement is a significant problem in communications at airports, medical centers, and other familiar public places. The SRT requires enhancement of speech to improve the quality and intelligibility of the signal before translation. Various approaches have been proposed for improving the quality of speech, such as the spectral subtraction algorithm [
2], the signal subspace system [
3], and the adaptive wiener filtering approach [
4].
The spectral subtraction algorithm extracts the speech from additive noise. Enhancement of speech was achieved by estimating the spectrum of the noise-free signal and subtracting the estimated noisy signal from an available observed signal. The spectral subtraction algorithm suffered from residual noise [
2]. The signal subspace algorithm was used for enhancing uncorrelated additive noise. This approach decomposes the noisy signal’s vector space into signal plus subspace and orthogonal noise subspace using Karhunen–Loeve transforms (KLT) or eigenvalue decomposition. The signal plus slot is used for processing, and the noisy subspace is discarded [
3]. The noisy speech frames were classified into speech-dominated frames and noise-dominated frames using a signal KLT-based technique [
4]. A Weiner filter-based algorithm was proposed for enhancing the signals, and it had a drawback of fixed frequency that required estimation of the frequency spectrum of both clean signal and noise before filtering [
5]. An Adaptive Wiener filter method was proposed to overcome the disadvantage of the traditional Weiner filer that used an adaptation of the filter transfer function on sample to sample based on speech signal statistics [
6]. The adaptive Weiner Filter-based approach was found to provide the best improvement over the signal-to-noise ratio.
The neural networks that learn the statistical information automatically using non-linear processing units were introduced for noise reduction. The deeper networks are considered to be more efficient in learning than the shallow networks [
7]. A deep auto-encoder (DAE) algorithm was proposed for training the deep network architectures [
8]. The challenge with DAE is the difficulty in generalizing the algorithm for all types of speech signals. Over conventional minimum mean square error (MMSE) based statistical techniques, supervised methods using deep neural networks were proposed to enhance the large volume of speech data. These methods were found to handle non-stationary noises effectively [
9]. A voice activity detector (VAD) was introduced to estimate the noise during the non-speech, but it failed on encrypted speech signals [
10]. Recurrent neural network (RNN) based speech enhancement techniques were introduced. The RNNs are found to produce significant performance by taking advantage of the temporal information over the noisy spectrum. Long Short-Term Memory (LSTM) was implemented for optimal speech enhancement and produced optimal results [
11].
Generative adversarial networks (GAN) were used to construct the clear speech signals from the noise signals over RNNs [
12]. Multiple deep neural networks were recommended over the single neural network for speech enhancement with known and unknown sources of noise [
13]. A de-reverberation method combining correlation-based blind de-convolution and modified spectral subtraction was presented for speech enhancement where inverse filtered reverberation was suppressed by the spectral subtraction [
14]. Though the conventional subtraction method reduces the noise level from speech, it introduces distortion noise in considerable spectral variation. The multiband spectral subtraction algorithm was proposed to overcome the distortion, maintaining the quality of speech signal [
15,
16]. Recent studies focus on the non-linear spectral subtraction algorithm for speech enhancements due to the significant variation in signal-to-noise ratio. The spectrum of real-world noise is irregular, and they have been affected more adversely at some frequencies. Non-linear spectral subtraction approaches are recommended to handle cleaning the speech signal [
17,
18]. The sub-space-based signal estimation method was proposed based on modified singular value decomposition (SVD) of data matrices that recovers speech signals from noisy observations [
19]. The technique focused on mapping the observed signal to a clean signal, suppressing the noise subspace. Though the subspace-based speech enhancement deals with noise distortion, it is also used to remove colored noise [
20].
Generalized sidelobe canceller (GSC) has been used for non-stationary broadband signals. GSC separates the desired signals from the interference by exploiting spatial information about the source location [
21]. Noise suppression techniques play a vital role in automatic voice recognition (AVR) strategies, aiming to provide a clear gap between the clean and noisy speech signals [
22]. Wiener filter and spectral subtraction combined noise estimator was proposed to control the noise energy in current frames and estimate noise from preceding frames by minimizing over subtraction [
23,
24,
25]. Iterative signal enhancement (ISE) algorithm based on truncated SVD was proposed to obtain improved selective frequency for filtering noises from speech signals. ISE performed better than other classical algorithms, especially with speech signals [
26,
27].
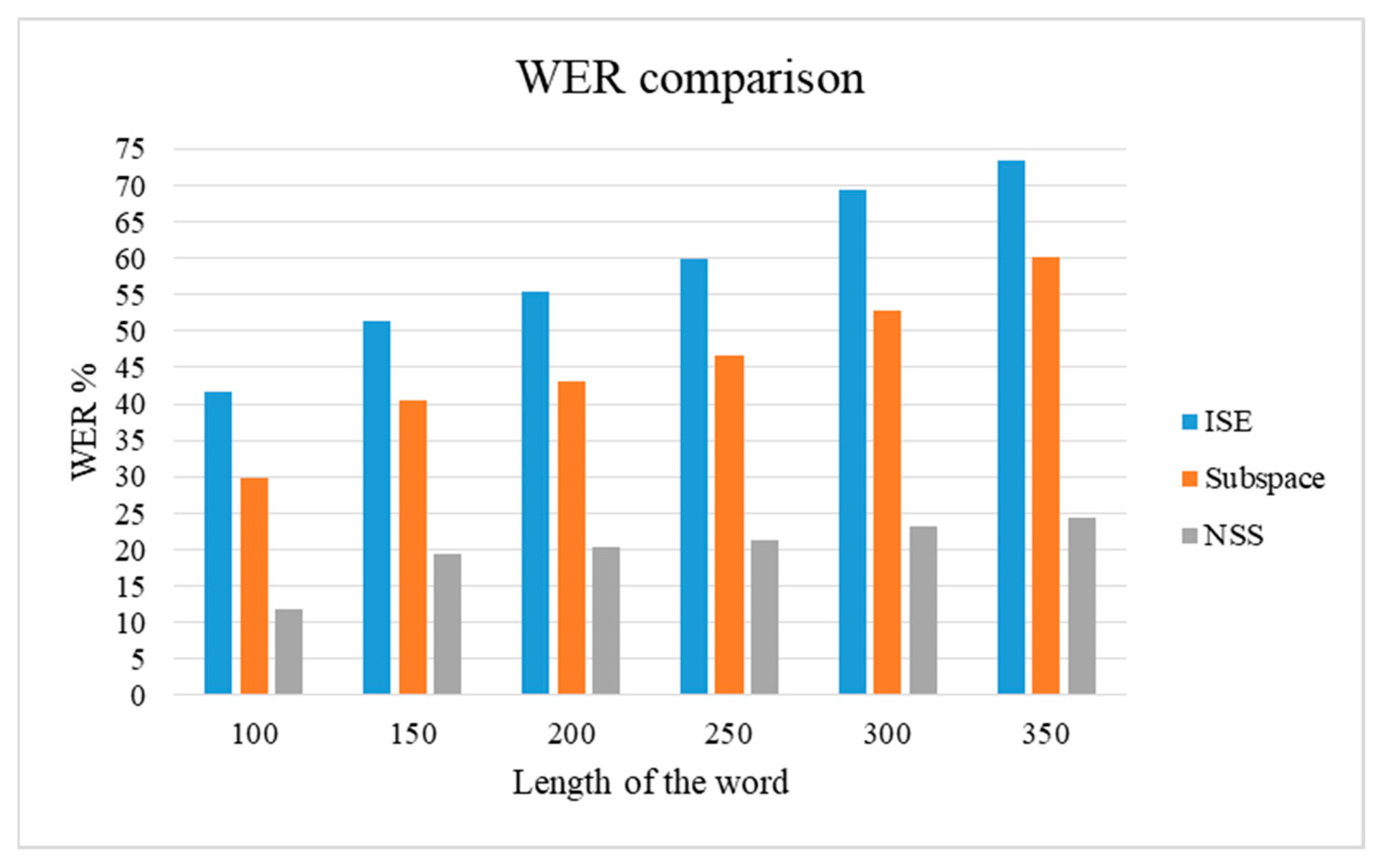
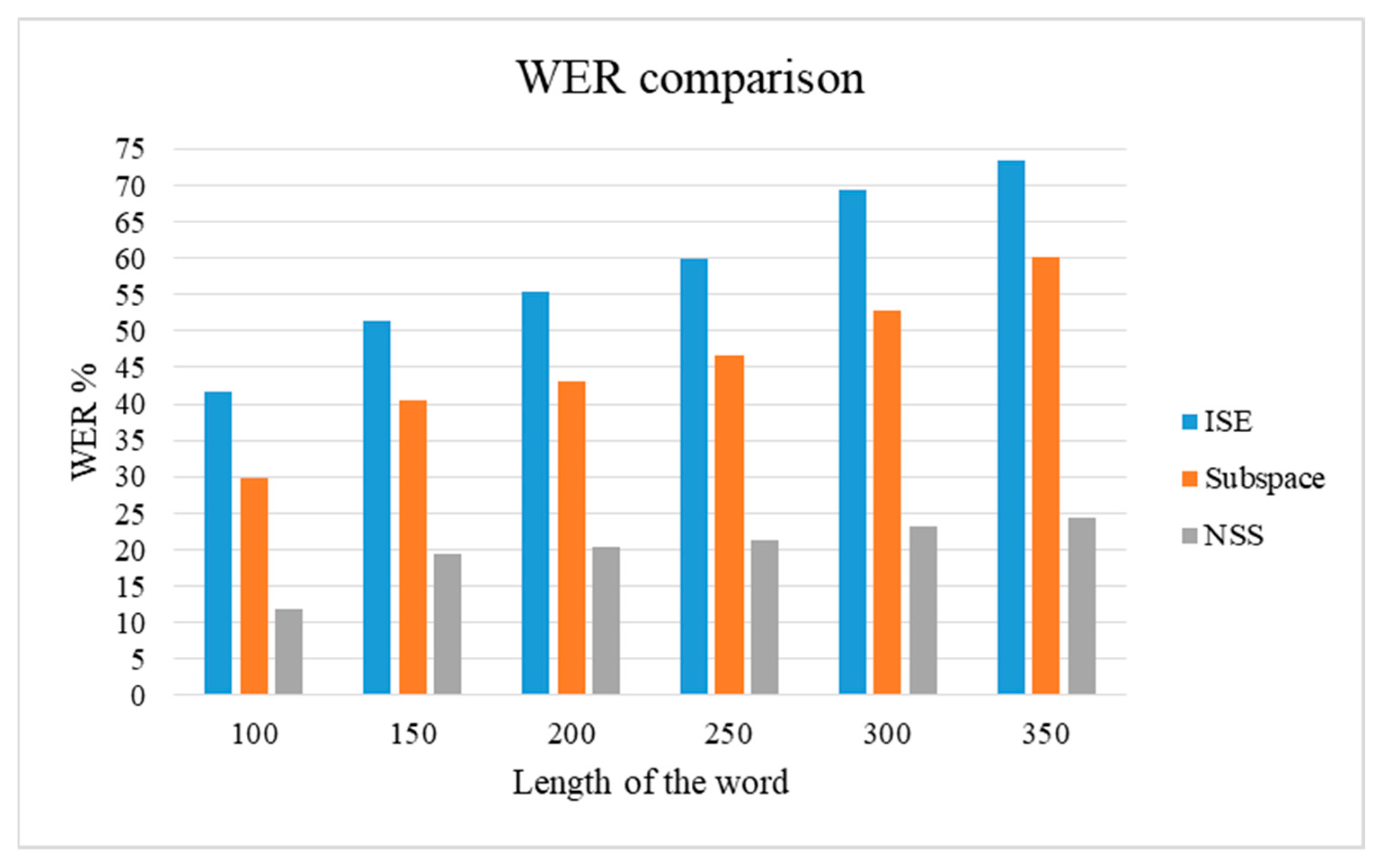
From the literature study, it is evident that Nonlinear Spectral Subtraction (NSS) and Iterative Signal Enhancement algorithm (ISE) are the most effective methods for speech enhancement [
28]. This paper proposes hybridization of NSS and ISE methods for further enhancing the speech signals. The performance of the hybrid algorithm is compared with the implementation of individual practices.
Dynamic time warping (DTW) is a dynamic programming algorithm technique used for determining the correspondence between two sequences of speech that may differ in time or speed [
29]. For example, resemblances in speaking a specific word would be identified, even if in one audio the person was speaking slowly and if in another the same person was talking more quickly, or even if there were hastening and slowing down during the course of one observation [
30]. DTW can be applied to audio, video, or any data that can be represented using a linear representation.
Table 1 gives the insights about the literature survey.
2. Proposed Methodology
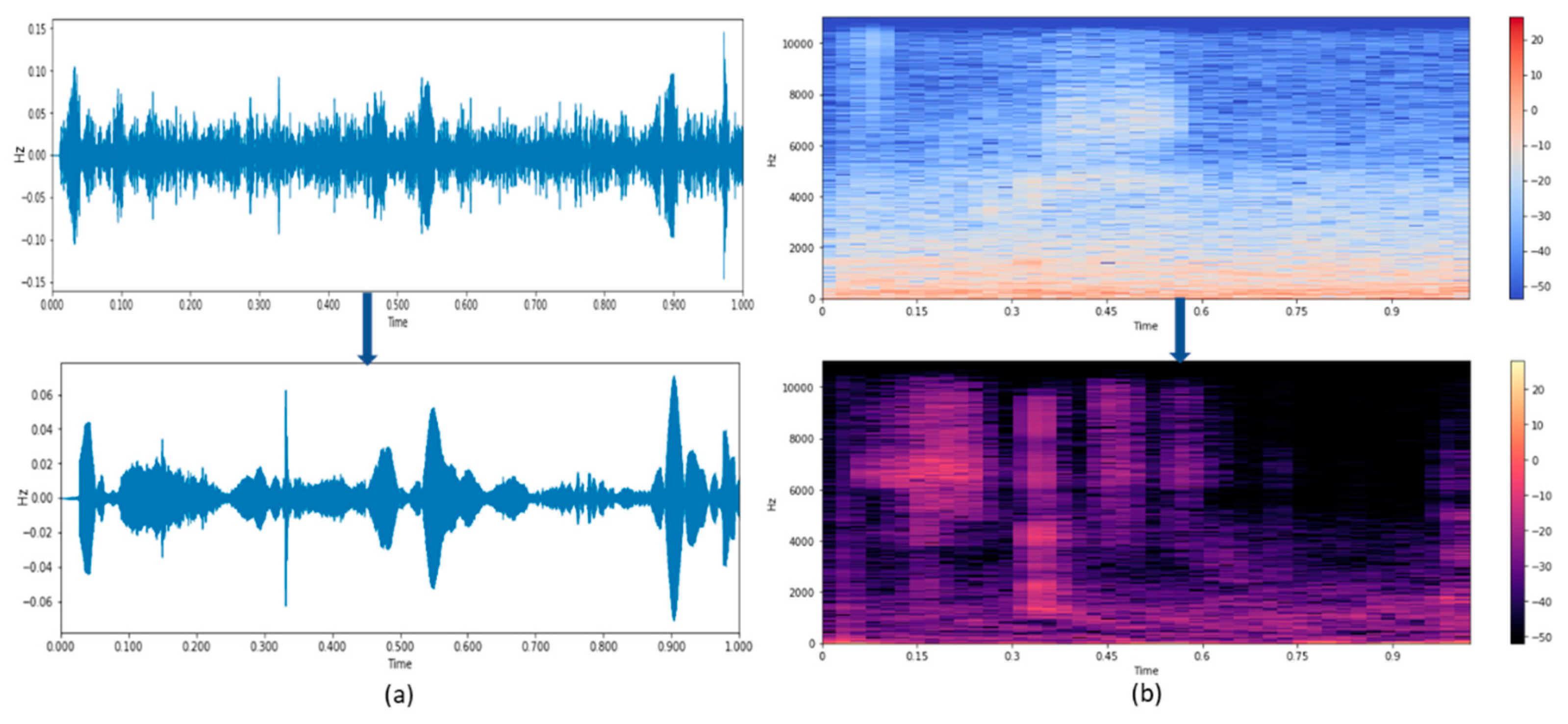
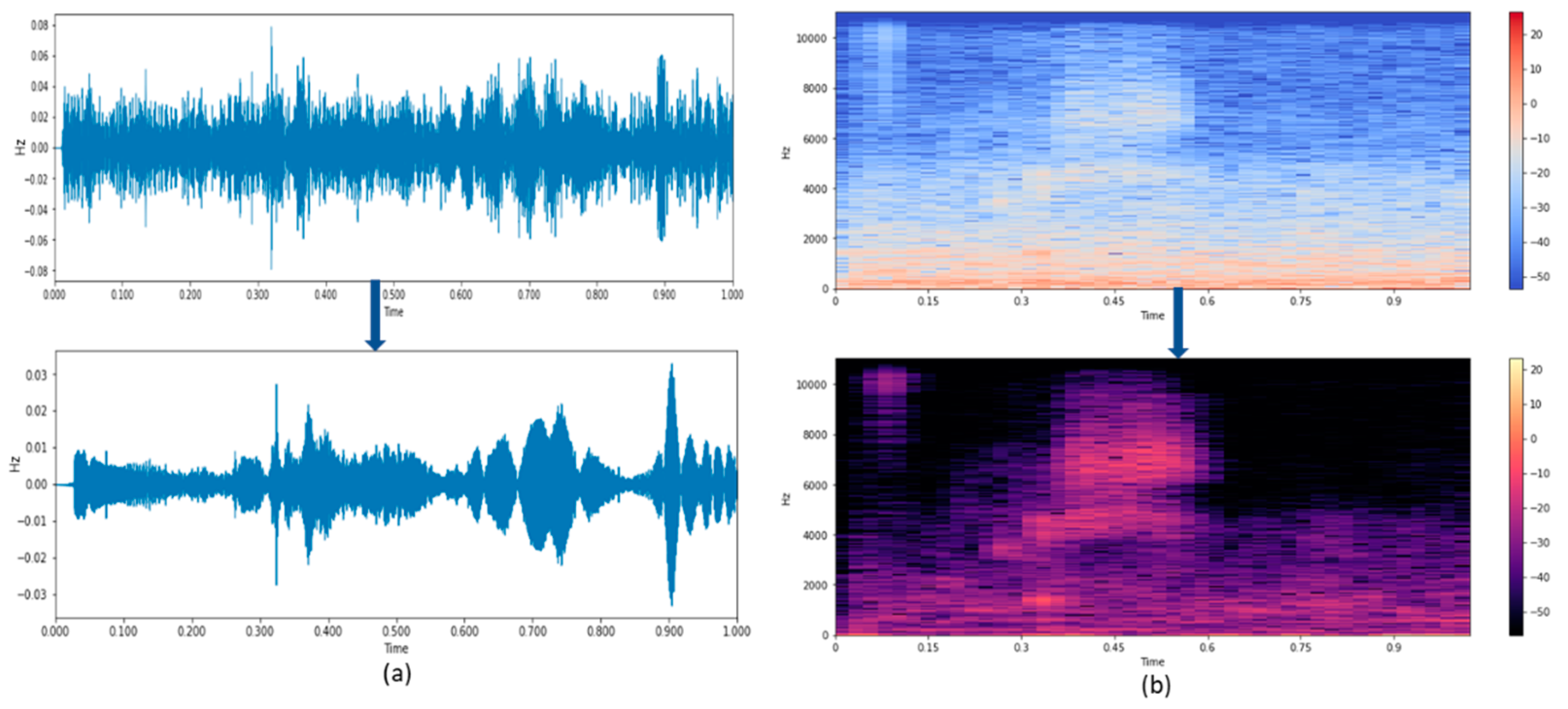
This work aims to enhance the speech signal by suppressing the noise signals involved in voice control applications. Speech enhancement is an essential factor in speech recognition as it can be used as a pre-processor to enhance speech. Generally, the source of the noise signals can be background noise, electromagnetically induced noise. Reducing these noises will result in increasing the intelligibility of the speech and agreeable speech recognition.
Figure 1 depicts the flow of the idea of enhancing the noisy speech signal.
In this article, a hybridized speech enhancement algorithm is proposed with experimental results.
Section 2.1 and
Section 2.2 present various speech enhancement and speech-to-text conversion algorithms used for various speech signals, respectively.
Section 3 represents the results obtained for the speech enhancement algorithms and their comparisons by using the word error rate values by converting the enhanced speech to text.
2.1. Speech Enhancement Algorithms
Enhancement of speech is essential when the terms involved are complex and involve external noises. There are various speech enhancement (SE) algorithms available, which are discussed in the following section.
2.1.1. Iterative Signal Enhancement Algorithm (ISE)
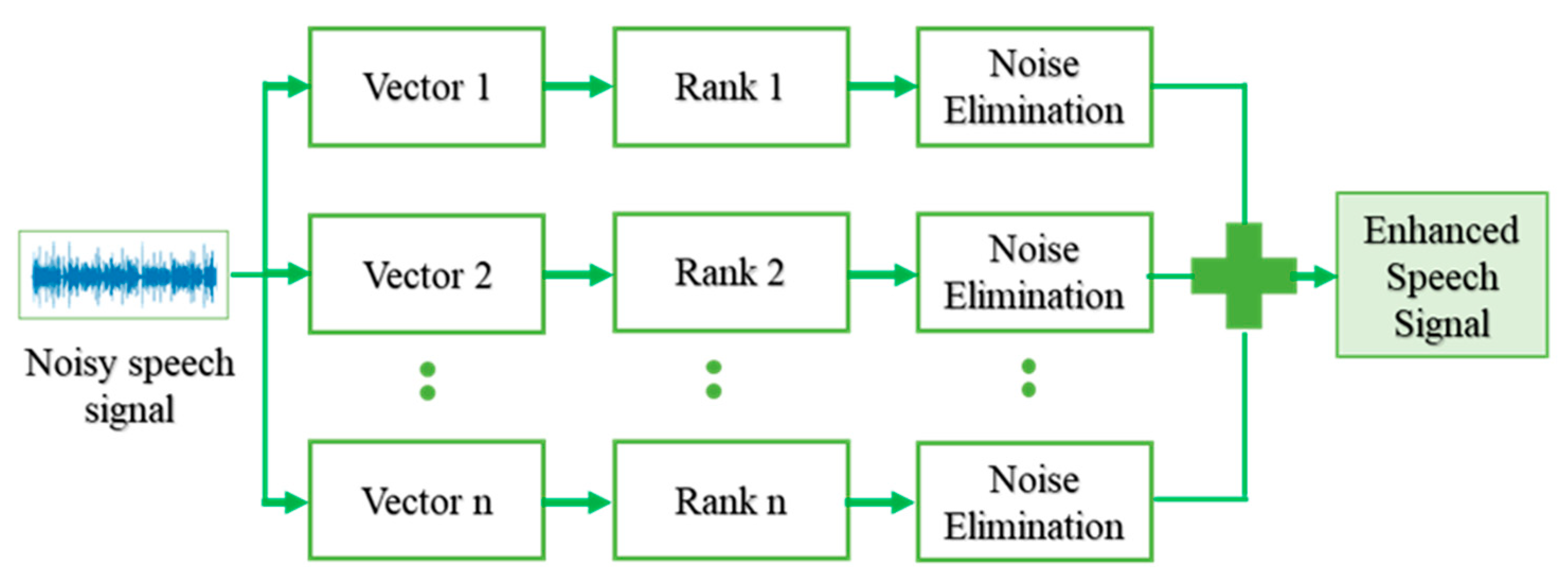
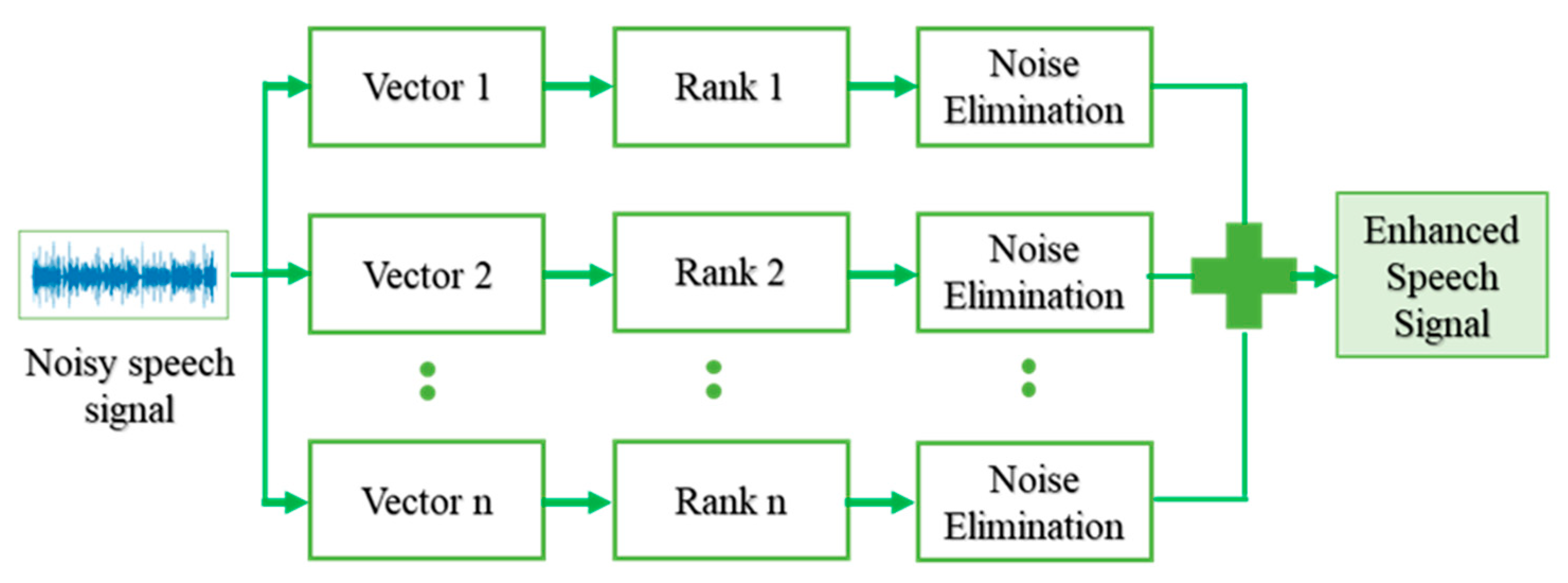
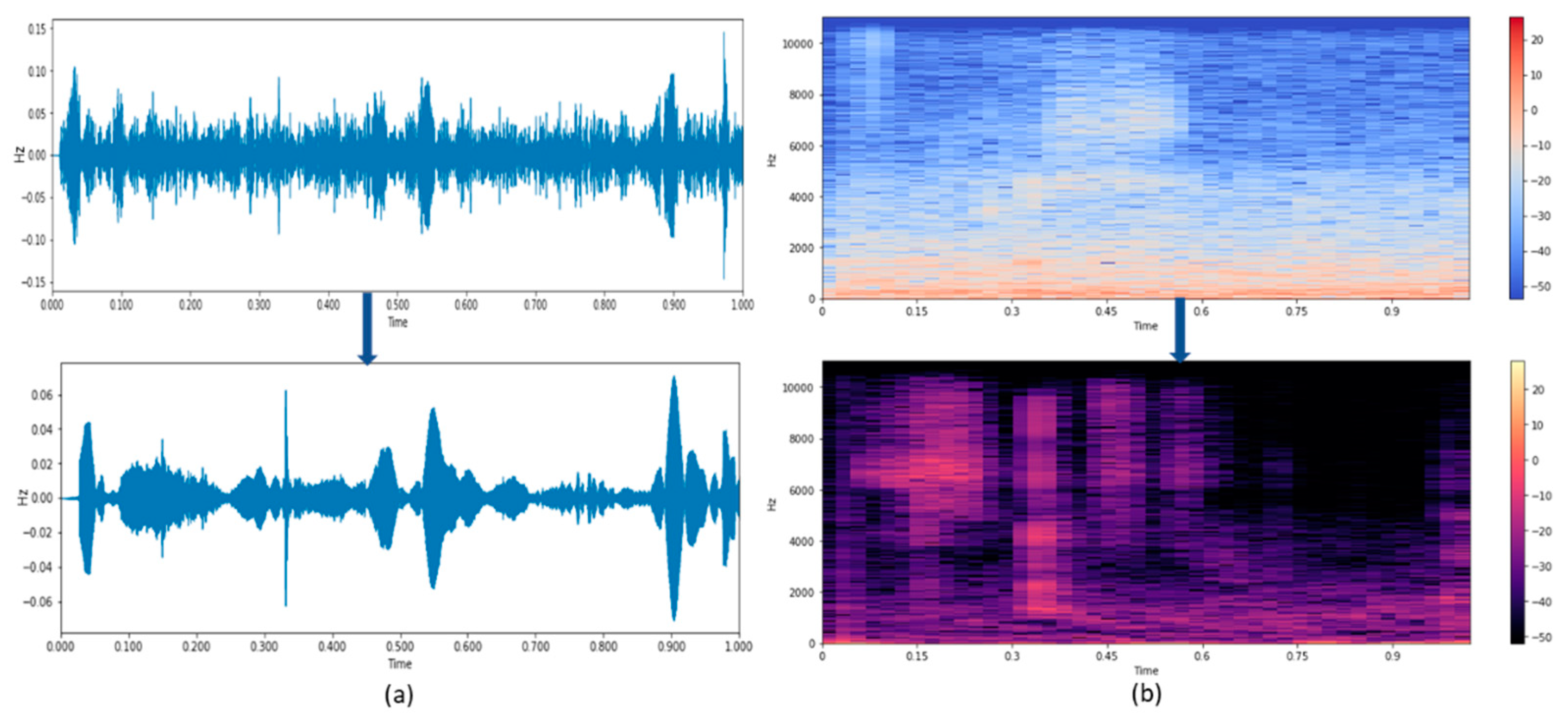
The iterative signal enhancement algorithm is used for reducing the noise in speech. The algorithm is designed based on a trimmed singular value decomposition (SVD) procedure and can be used as a tool for enhancing the noisy speech signal by suppressing the additive noise present in the signal. Compared to the classical algorithms, the ISE algorithm escalates similar improvements in Signal-to-Noise Ratio (SNR).
The ISE algorithm executes in two phases. The first phase produces an enhanced signal s[i] from the noisy signal ns[i]. The enhanced signal s[i], which comes from phase I, still contains some noise. So, the noise removal phase is repeated a certain number of times depending on the level of noise present in the signal. The signal decomposition of the enhanced signal at each level is given a rank ranging from 1 to level l. The first rank signal decomposition sd[i] for the s[i] is obtained by averaging the anti-diagonals of the Hankel matrix to rank-1. Hankel matrices are square matrices with constant ascending skew-diagonals from left to right. Hankel matrix is constructed from the signal is helpful for decomposition of constant signals and time-frequency representation. The rank-1 signal decomposition covers most of the energetic spectral band of the noisy input signal in the frequency domain.
The signal decomposition sd[i] is subtracted from the input signal sn[i] to calculate the residual signal r[i], and the phase-I procedure is repeated by using the residual signal as the input for the upcoming iterations. The signal decomposition sd[i] is summed up throughout the iterations to obtain the enhanced signal s[i]. The iteration is stopped once the residual signal r[i] contains only the noise components. The phase-2 concentrates on the residual signal to maintain the number of iterations of phase-I. The working of the ISE algorithm is depicted in
Figure 2.
The ISE algorithm is advantageous over the typical enhancement algorithms as ISE has a better frequency selectivity for filtering out the noise than the standard algorithms.
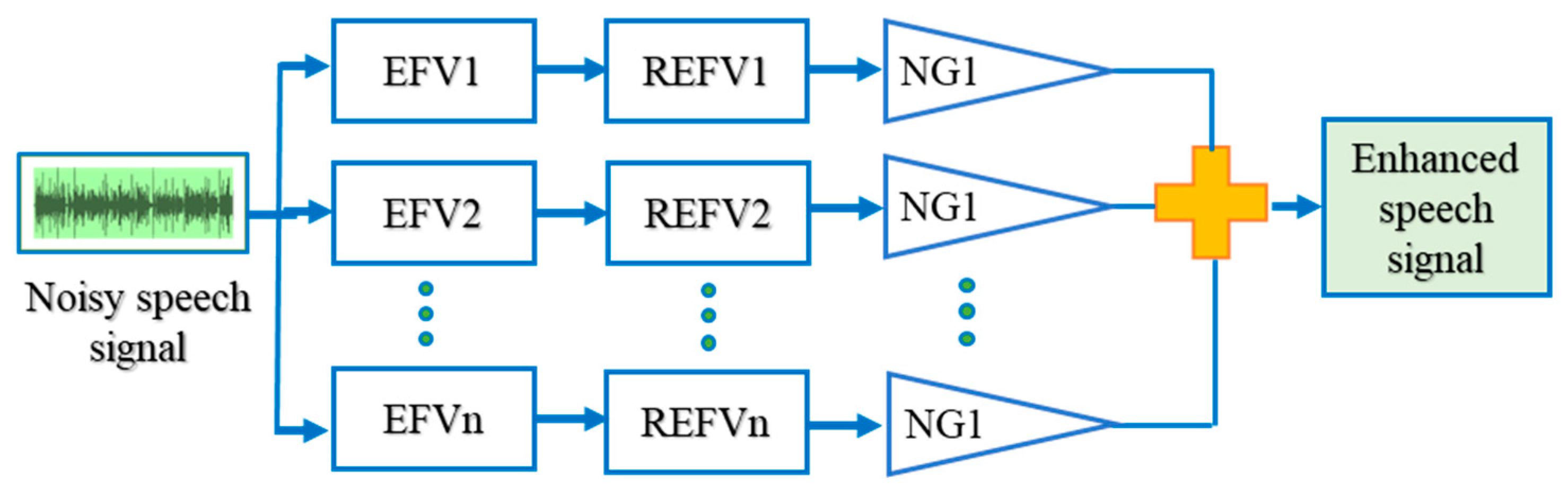
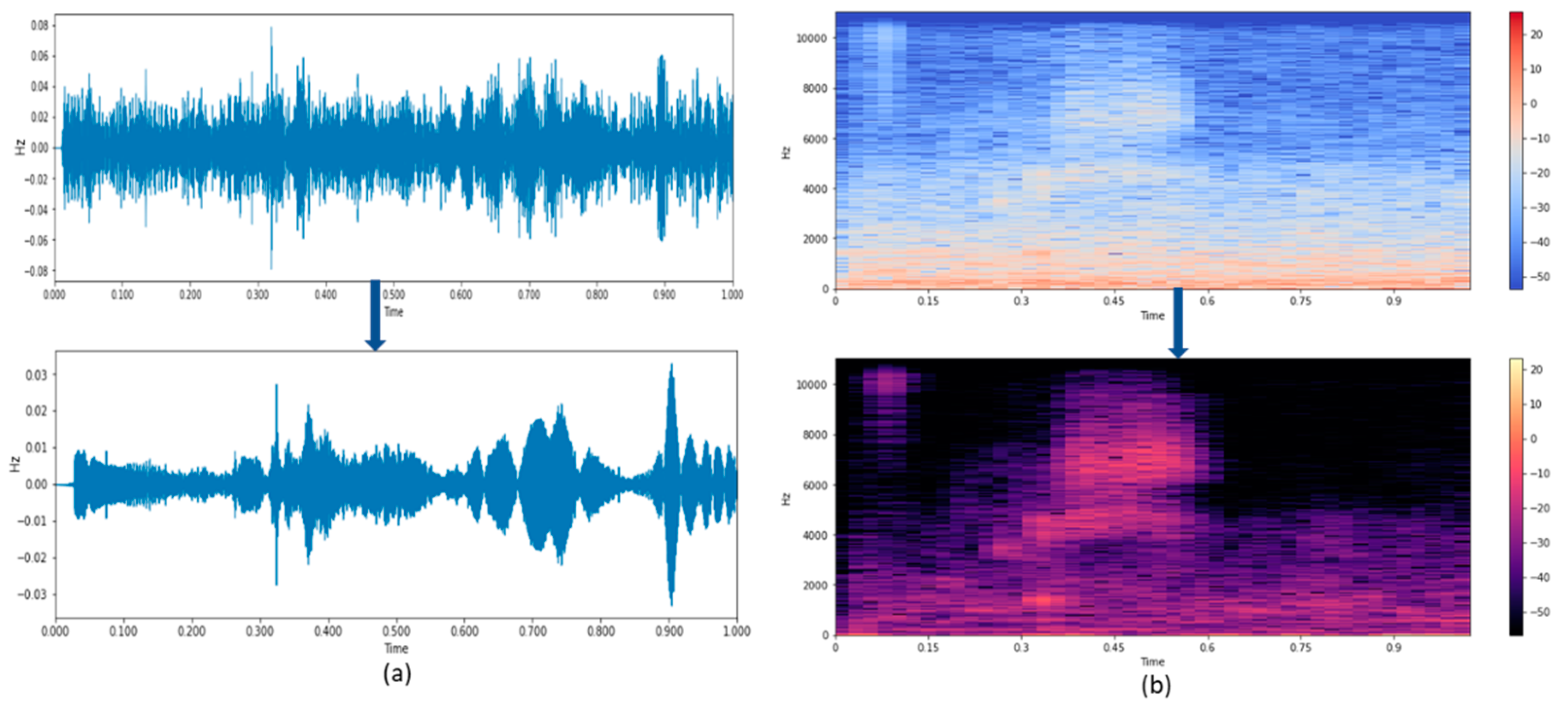
2.1.2. Subspace—Based Speech Enhancement
Subspace methods, also called high-resolution or super-resolution methods, use an eigenvalue analysis or eigendecomposition of the correlation matrix to derive frequency component values of a signal. The process for subspace-based speech enhancement can be stated as follows:
- (1)
Isolating the subspace as signal and noise subspaces from the original subspace
(noise mixed speech)
- (2)
Eliminating the noise-only subspace that has been isolated in step1.
Assume
s(i) represent the pure speech signals and let
n(i) indicates the zero-mean additive noises mixed in the pure speech. The observed noisy speech
x(i) can be given by
Allow Rx, Rs, and Rn to be (p × q) genuine autocorrelation matrices of x(i), s(i), and n(i), respectively, with q > p. Rx = Rs + Rn is obvious given the assumption of uncorrelated speech and noise. Regardless of the specific optimization criterion, speech enrichment is now obtained by
By nullifying the components in the noise subspace, the enhanced speech is constrained to inhabit only the signal subspace.
Changing (decreasing) the eigenvalues of the signal subspace.
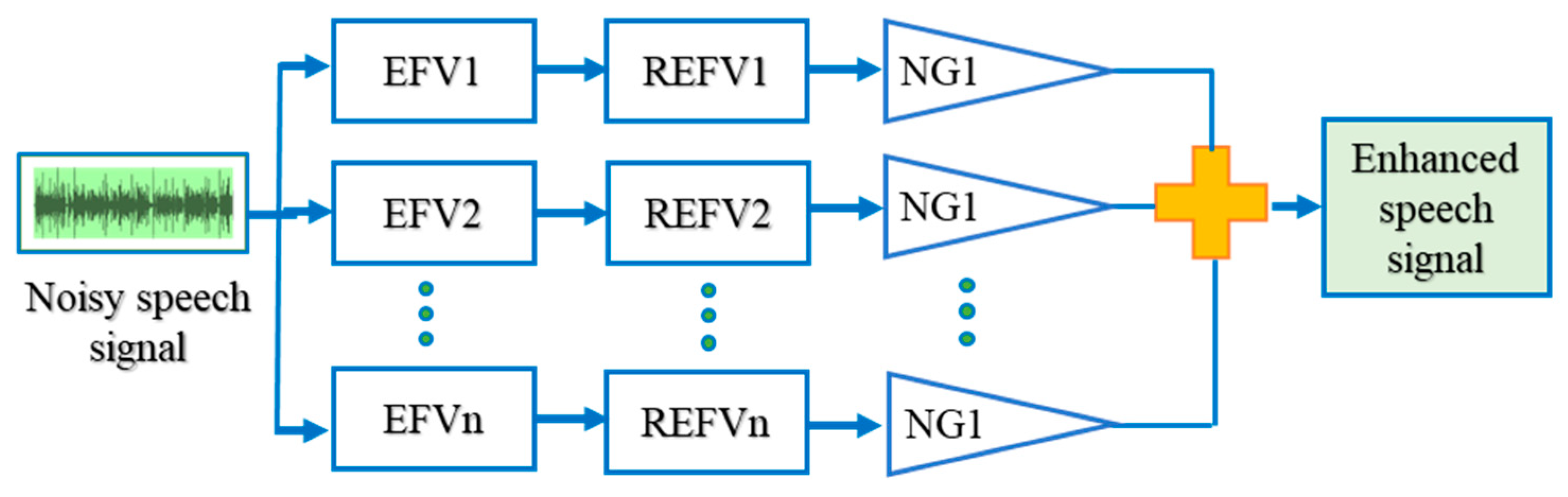
The input speech signal with noise is split into unique spaces. Each and every space is individually processed. In
Figure 3, the noisy input signal is fed as the input, whereas the individual subspaces are allocated with a vector value and rank, respectively. The filter bank output of each subspace is obtained by filtering the noisy signal
n(i) with its corresponding eigenfilter vector (EVF) and its reversed eigenfilter vector (REFV). This filtered output is fed to the not gate (NG) and their summation results in the enhanced speech signal.
2.1.3. Nonlinear Spectral Subtraction (NSS)
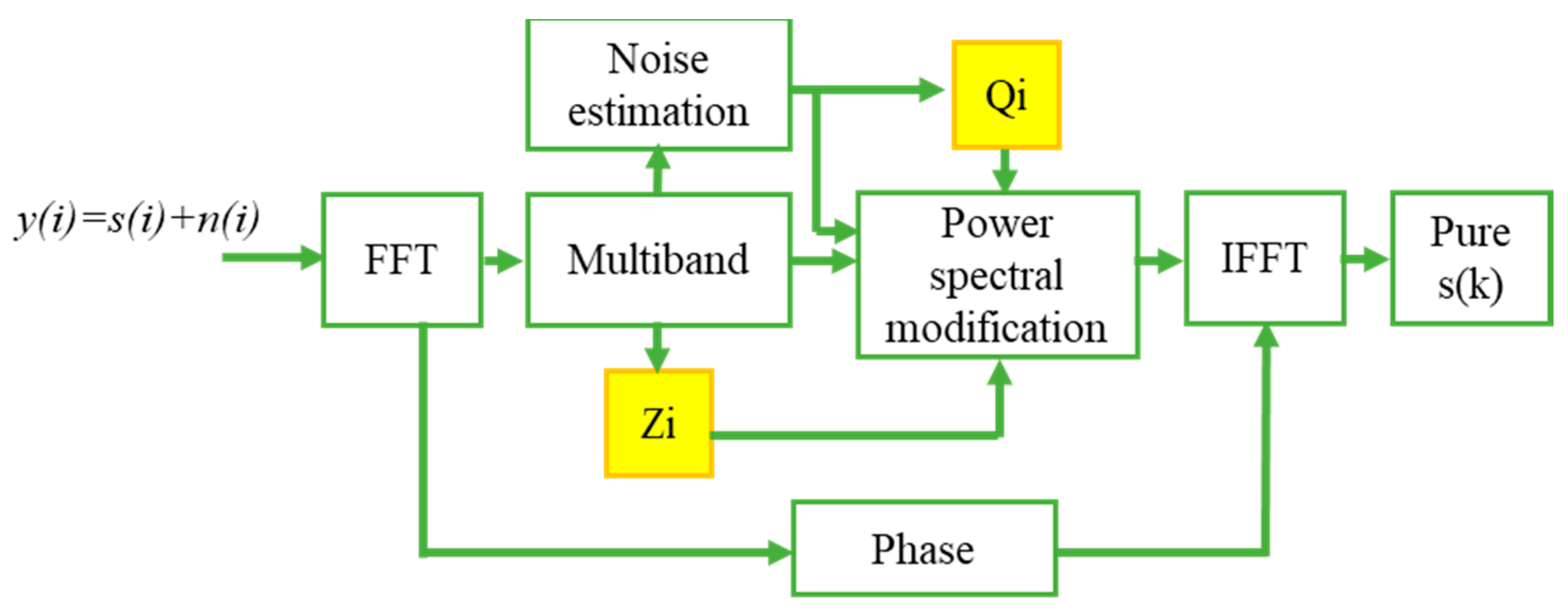
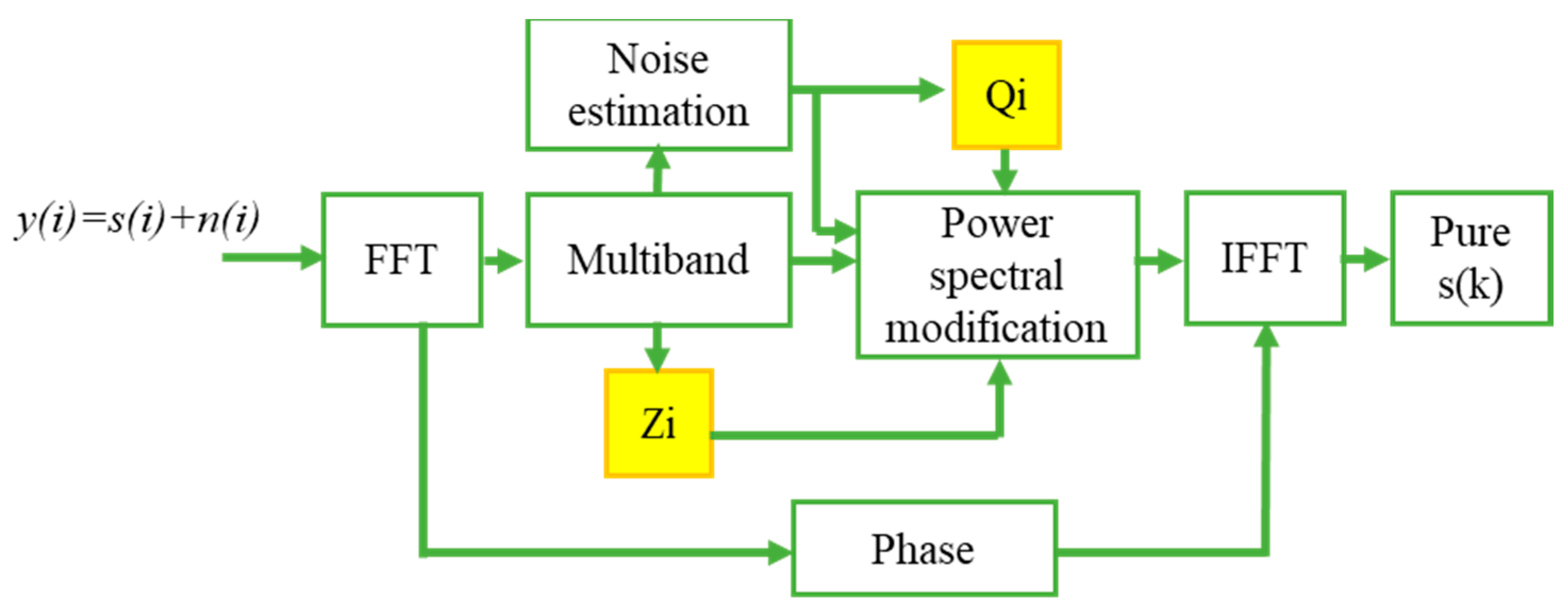
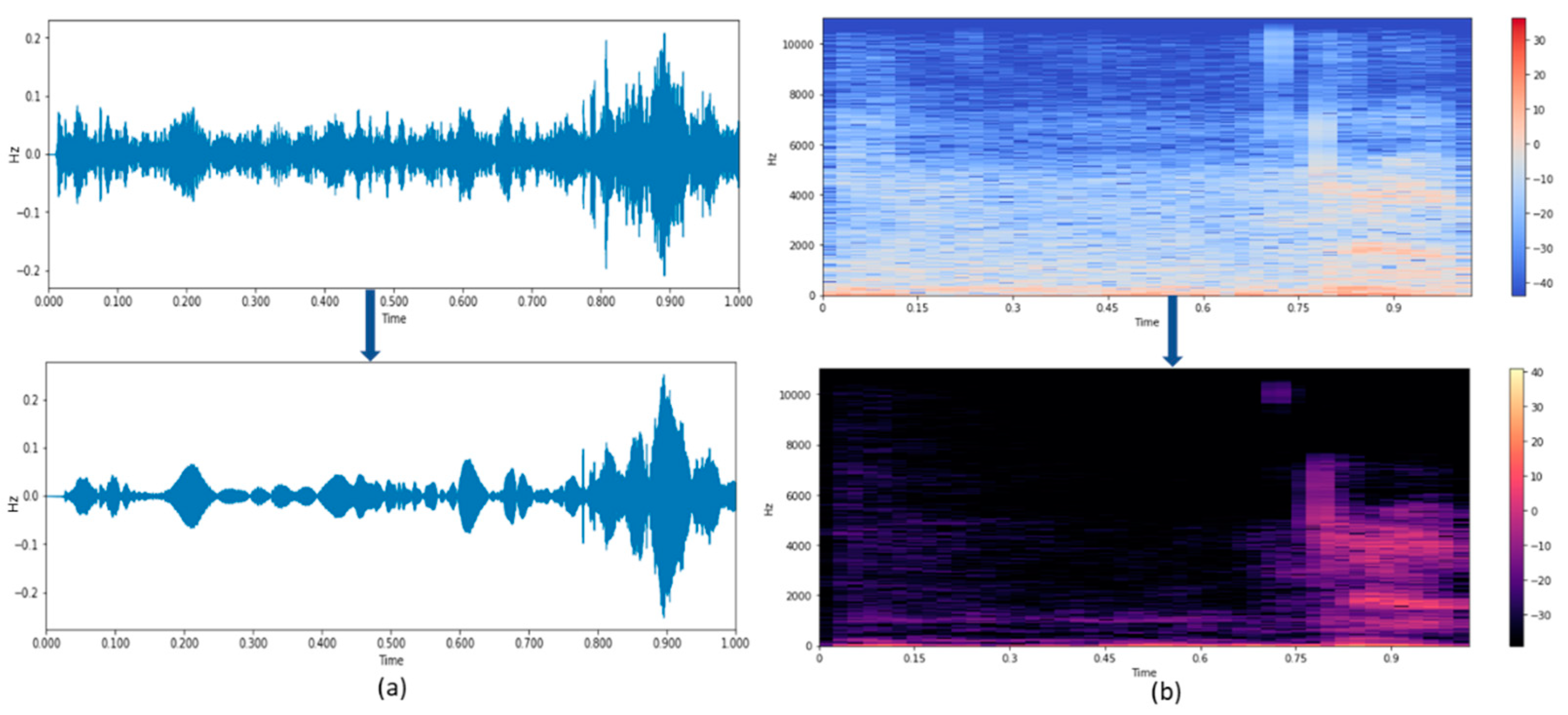
Nonlinear Spectral subtraction is one of the most primitive and notably the most famous speech enhancement methods. NSS can be predominantly valid in cases where a boisterous environment contaminates an original speech signal with the same bandwidth as that of speech. To decrease external noise, the NSS algorithm is developed, which considers the change of signal-to-noise ratio across the speech spectrum and uses a distinct over-subtraction factor in each frequency band.
Figure 4 describes the steps involved in extracting only the speech from the noisy speech signal. The speech signal with noise is given as input to the Fast Fourier Transform module. Let
y(i) denote the noisy speech, i.e., the pure speech signal
s(i) is polluted with the noise signal
n(i). Then in the time domain, their relationship is described as:
To obtain their relation in the spectral domain, take the Discrete Fourier Transform (DFT) and power magnitude for Equation (1) with the assumption that noise and speech signals are uncorrelated, then the relation is described as follows:
where r and f denote the frame and frequency values respectively. Now with the assumption that |N(r,f)| and |
(r,f)| can be estimated, the spectral subtraction can be formulated as follows:
The spectral subtraction algorithm adapts the damaged speech signal’s short-term spectral magnitude appropriately. The signal is modified so that the synthesized signal feels as near to the unbroken voice signal as possible. A noise power estimate and a subtraction rule are used to calculate the appropriate weighting of spectral magnitudes.
The Word Error Rate represents the amount of word error occurring during the speech. It can be calculated using the formula
where ‘Ns’ represents the number of substitutions, ‘Nd’ indicates the number of deletions, ‘Ni’ means the number of insertions, and ‘Nn’ stands for the number of words in a sentence.
2.2. Speech to Text Conversion
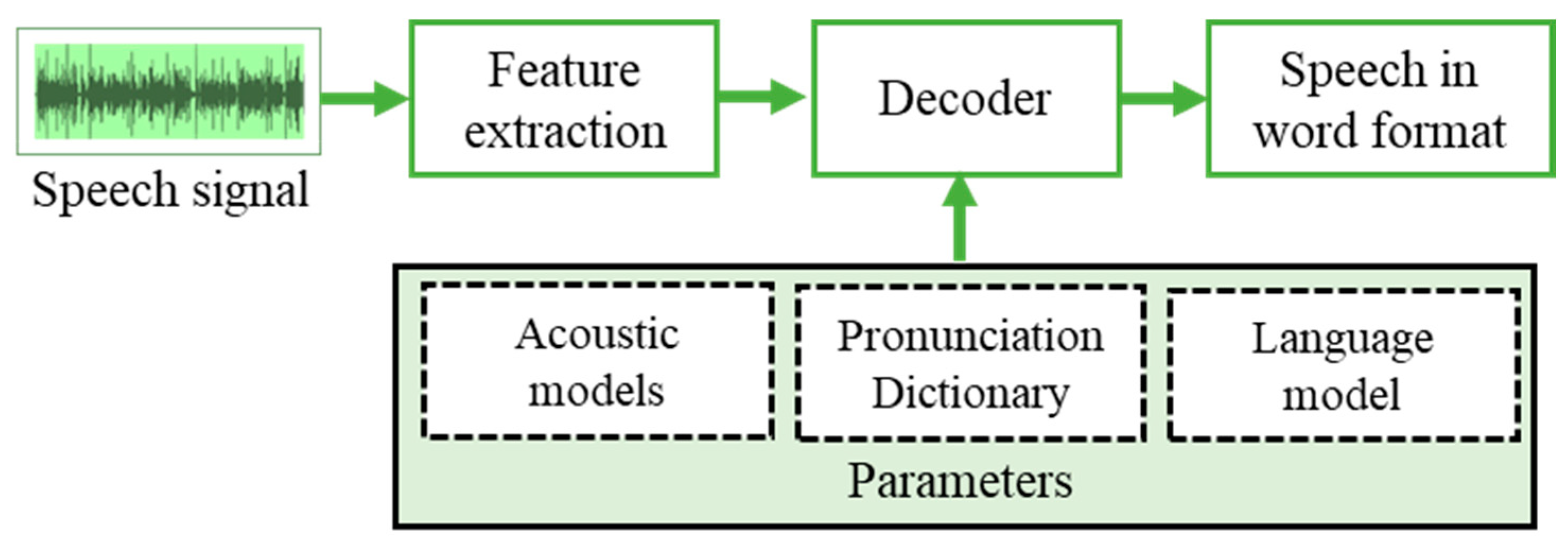
The primary purpose of speech to text (STT) or speech recognition is to enable a real-time dictation of audio signals into text. All the STT systems depend on the acoustic model and the language model. In the case of including the additional feature vocabulary systems, a pronunciation model can be used. It is challenging to construct a universal speech recognizer. To develop the best quality STT system, it needs to specialize in a specific language, idiom, application domain, speech type, and communication frequency.
Hidden Markov Model
Hidden Markov Models (HMM) are mainly used for general-purpose speech recognition systems. In general, the speech signals are observed as a stationary signal whose amplitude and frequency remains constant. It takes a very short time scale for a speech to be estimated as a static process.
In HMM, it is possible to train the data set automatically, which makes it easy computationally, and hence it is extensively used. The HMM would generate a sequence of n-dimensional real-valued vectors every ten milliseconds (with ‘n’ being a small integer value such as 5 or 10) in speech recognition. The first coefficient of a Fourier transform of a small part of the speech is extracted and decorrelated with the cosine transform to calculate the cepstral coefficient vectors.
In each state of the HMM, a statistical distribution of a mixture of diagonal covariance Gaussians is performed to present the probability of each identified vector. In the current speech recognition systems, every word or phoneme has its output distribution, whereas, in HMM, the sequence of the terms or phonemes is constructed by cascading the individually trained cepstral vectors for the specific words and phonemes, respectively.
Modern voice recognition systems use diverse combinations of various common strategies to improve outcomes beyond the fundamental approach. Context dependency of the phonemes is required for the traditional large-sized vocabulary system to enable the phonemes with different pre and post contexts to have unique HMM states. These HMM states can be used to normalize different recordings and the speaker conditions using the cepstral normalization method. Vocal tract length normalization (VLTN) can be used to further normalize male-female or other speaker criteria. To capture the speech dynamics, linking and linear discriminant analysis (LDA) based projects can be used, which is followed by either the heteroscedastic LDA step or global semi-tied covariance transform method. To optimize the classification-related measure of the training data, many systems employ discriminative training strategies, which can be used to avoid the purely statistical approach to estimate the HMM parameter.
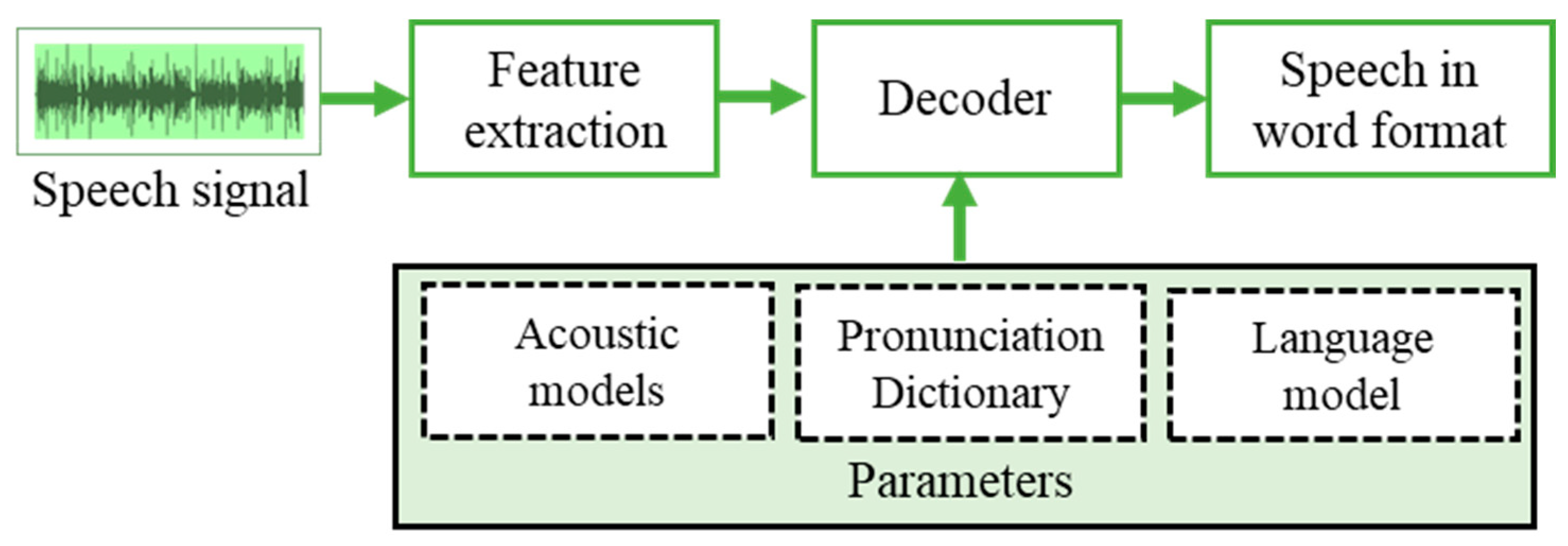
The HMM is used to convert speech features into HMM parameters and calculate all speech samples’ likelihood. Recognition of this likelihood of speech samples is used to recognize the spoken words.
Figure 5 represents the working model of the HMM that decodes the extracted features based on the parameters such as acoustic models, pronunciation dictionary, and the language model for which speech recognition is required.
5. Conclusions
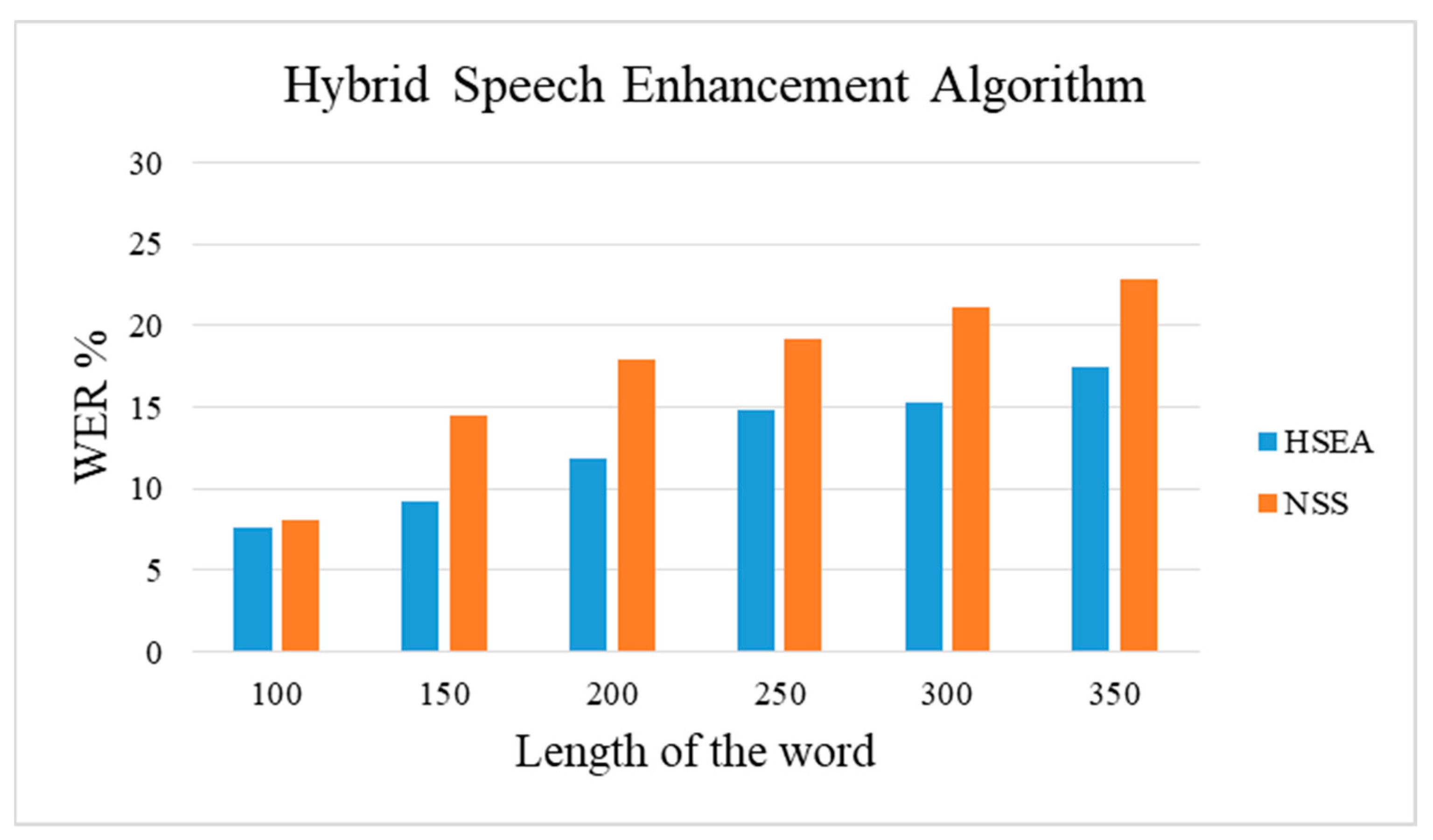
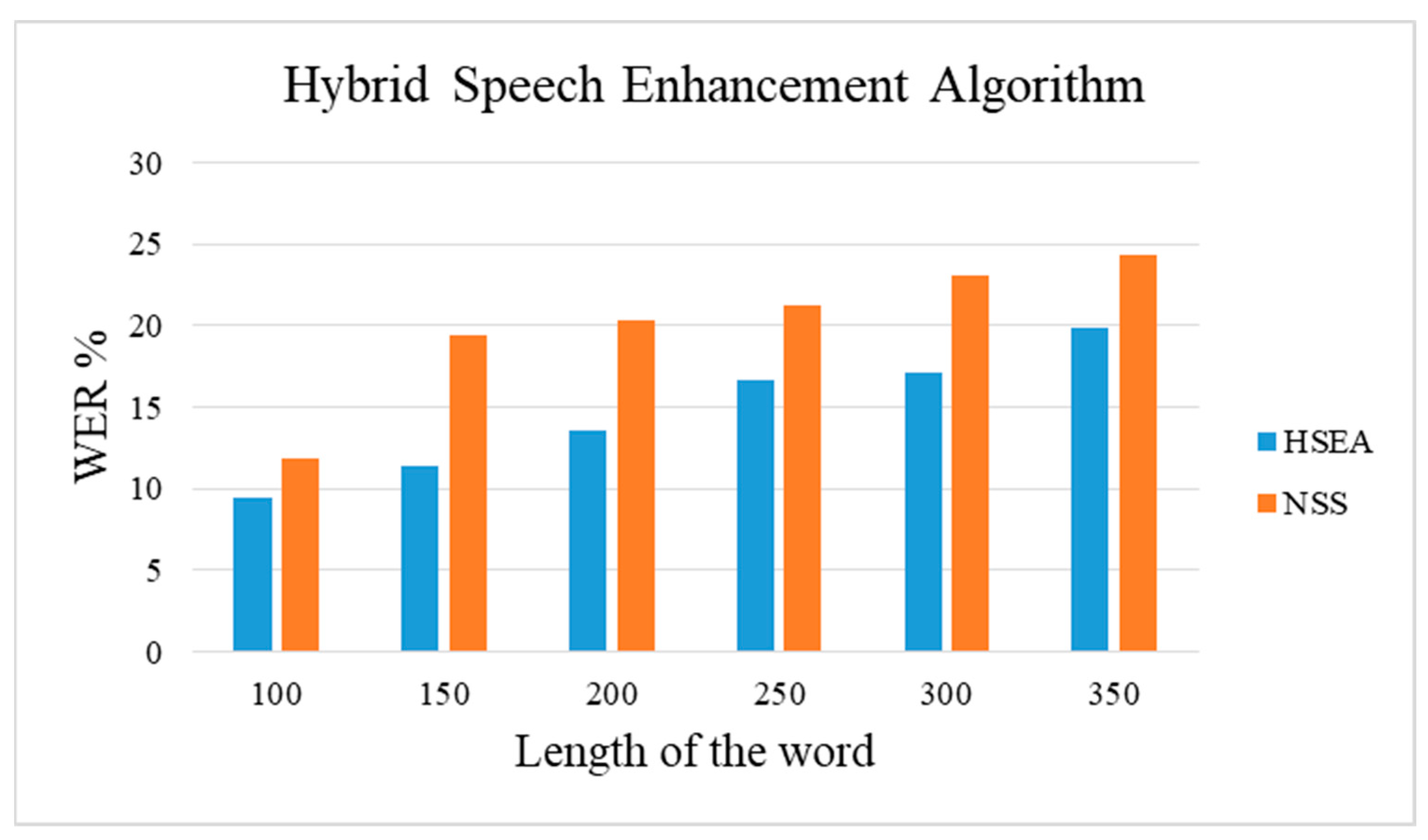
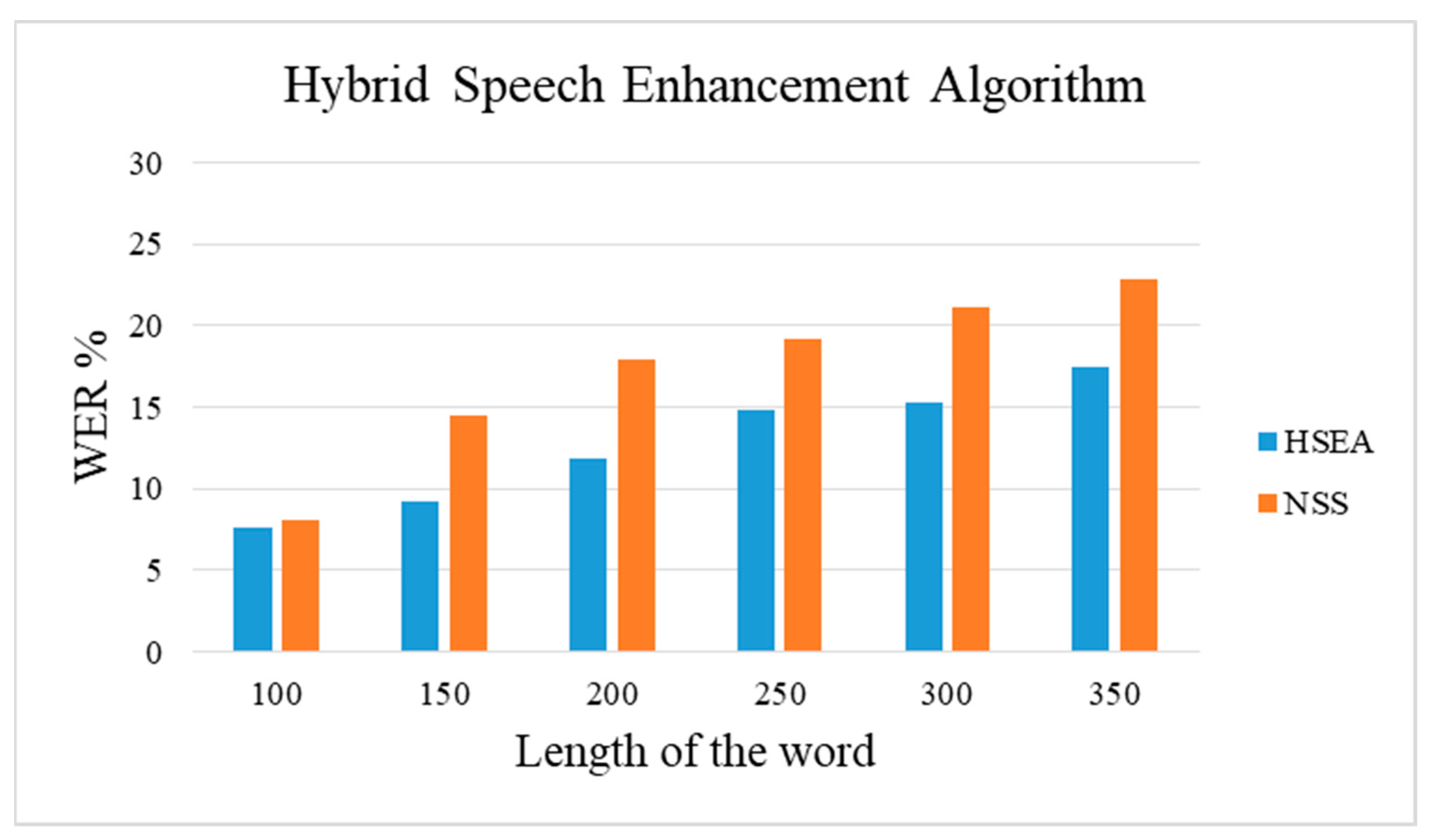
In this study, an HSEA is employed for medical audio data to reduce the word error rate. The entire procedure of the proposed method consists of the NSS and the HMM architecture with the medical data set. The typical NSS algorithm is optimized with least squares and minimum variance and then cascaded with the speech-to-text algorithm HMM to establish the proposed HSEA. In HSEA, the speech is enhanced using the NSS algorithm, and again the enhanced speech is optimized using the optimization criteria of the subspace method. As the double layer of enhancement is performed, HSEA can perform competitively with other typical speech enhancement models such as NSS, ISE, and Subspace. The proposed model has been validated with 6660 medical and 1440 RAVDESS audio data. The validation of the proposed HSEA architecture has proven to achieve maximum accuracy of 90.5% with a minimum word error rate of 9.5% for medical speech transcription and accuracy of 92.4%, the word error rate of 7.6% for the RAVDESS audio data. The validation of the proposed HSEA architecture has proven to achieve maximum accuracy of 90.5% with a minimum word error rate of 9.5%.
The proposed methodology can produce a clear speech signal as the output with reducing word error rate, making it efficient for all kinds of applications involving speech in open space. Despite the advantages, the methodology involves mathematical complexities as the layer of speech purification increases, which remains a limitation of the proposed method. Therefore, future work can concentrate on integrating the layers in such a way as to reduce the computational complexities and to achieve high efficiency.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}