
Analysis of Graphomotor Tests with Machine Learning Algorithms for an Early and Universal Pre-Diagnosis of Dysgraphia

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
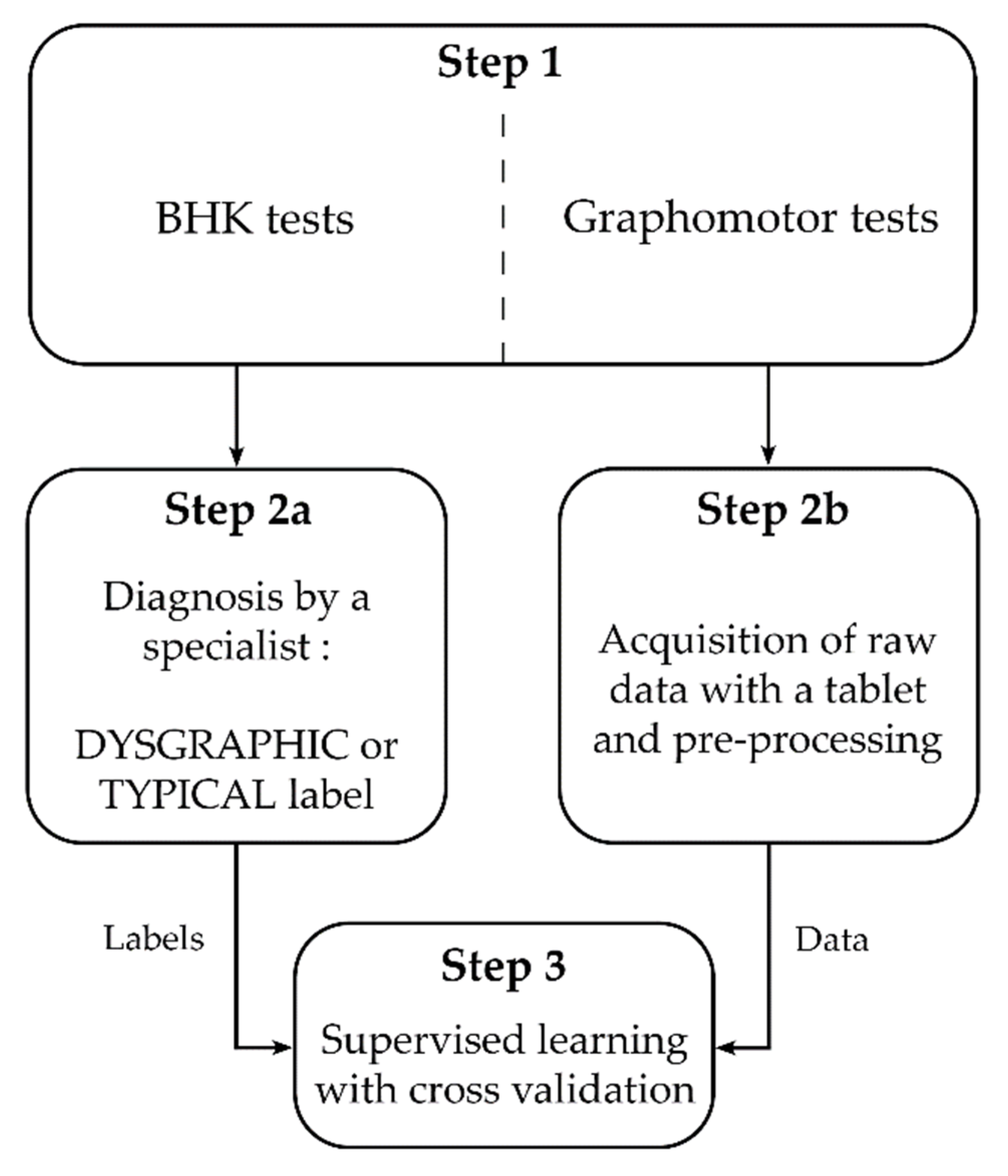
2. Materials and Methods
2.1. Participants
2.2. Approach & Procedure
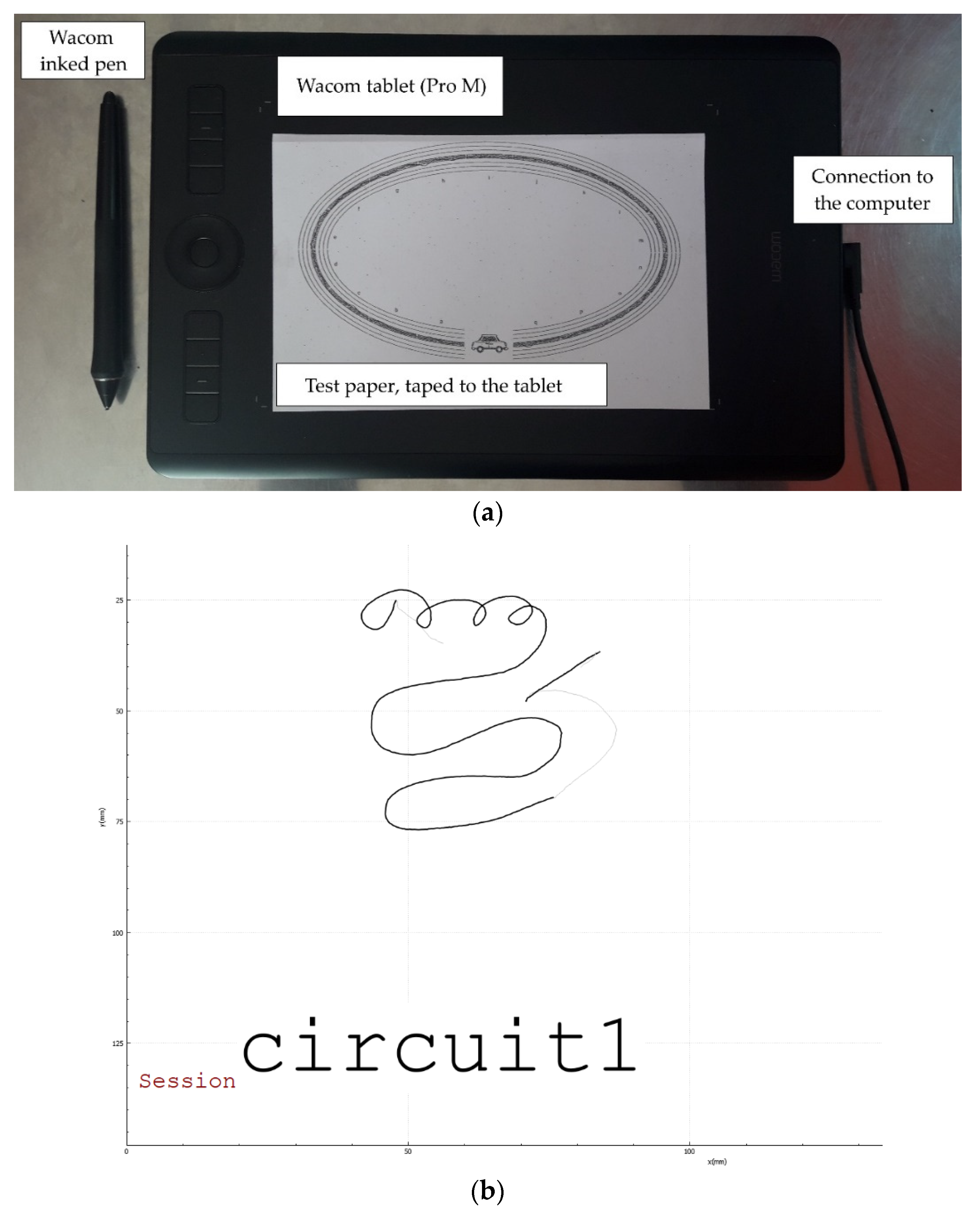
2.3. Tasks: The Graphomotor Tests
- 1.
- Circuit 1 (known as the lines): the child has to link the left drawing to the right one. There are 3 lines, getting thinner and thinner, increasing the difficulty (see Figure 4).Figure 4. Circuit 1.
![Sensors 21 07026 g004]()

- 2.
- Circuit 2 (known as the labyrinth): likewise, the child links the bee and the flower. This task is more difficult to perform as there are a few abrupt turns (see Figure 5).
- 3.
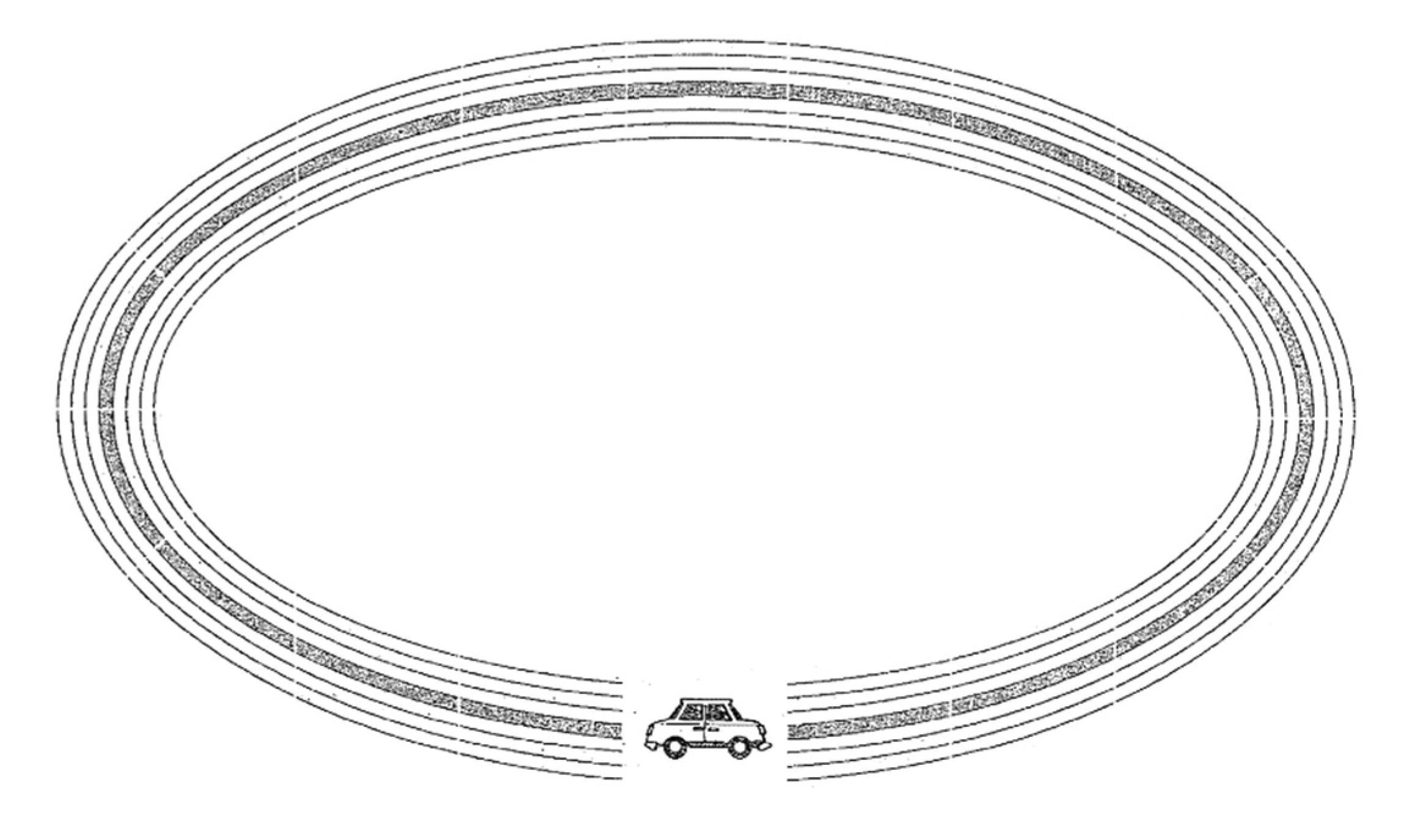
- Circuit 3 (known as the oval): the goal is the same, tracing a line from the left side of the car to the right side (see Figure 6).
- 4.
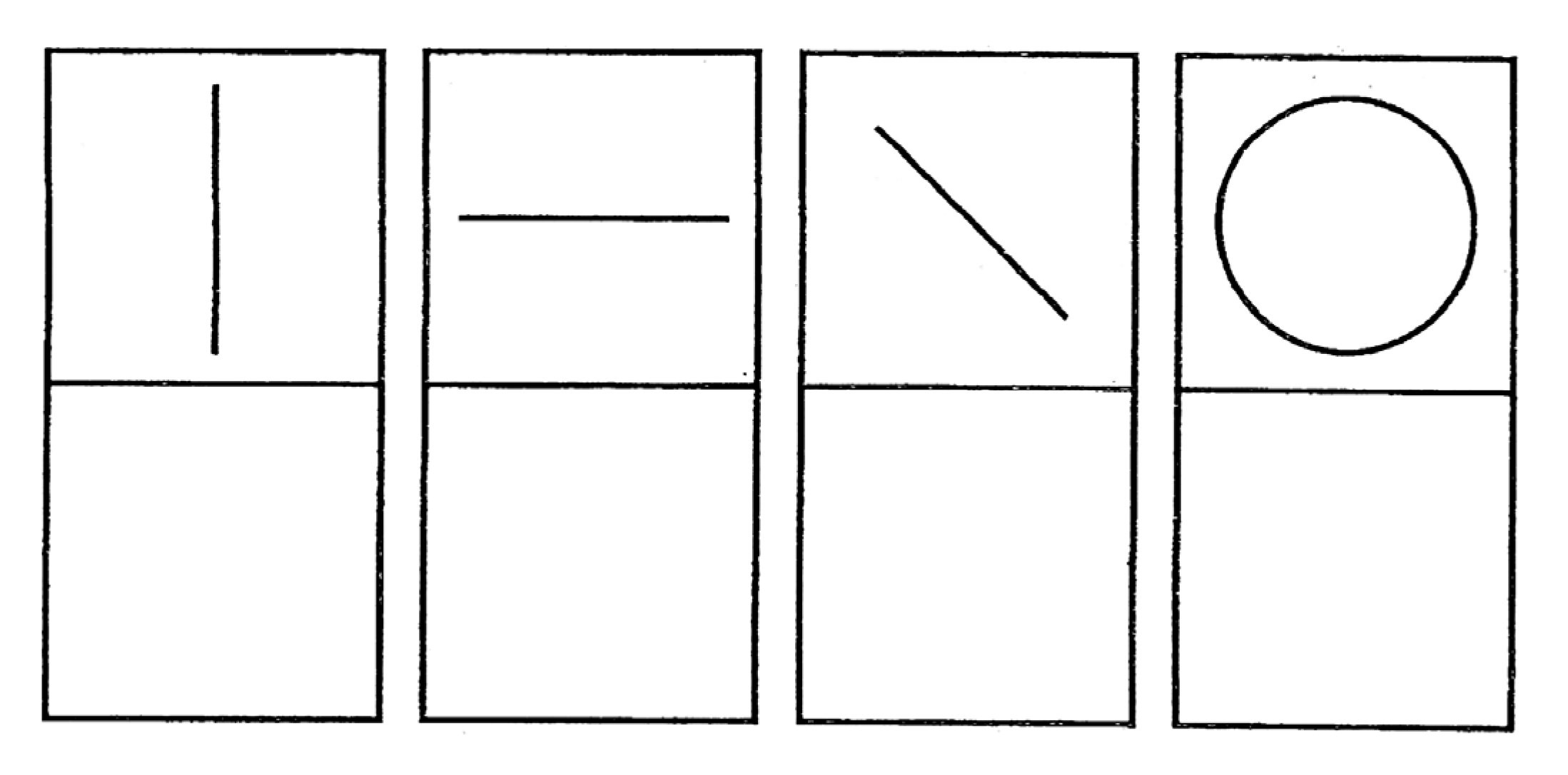
- Shapes 1: there are four simple shapes (one vertical line, one horizontal line, one sloping line, and a circle) for the child to reproduce. They must be drawn in only one stroke (see Figure 7).
- 5.
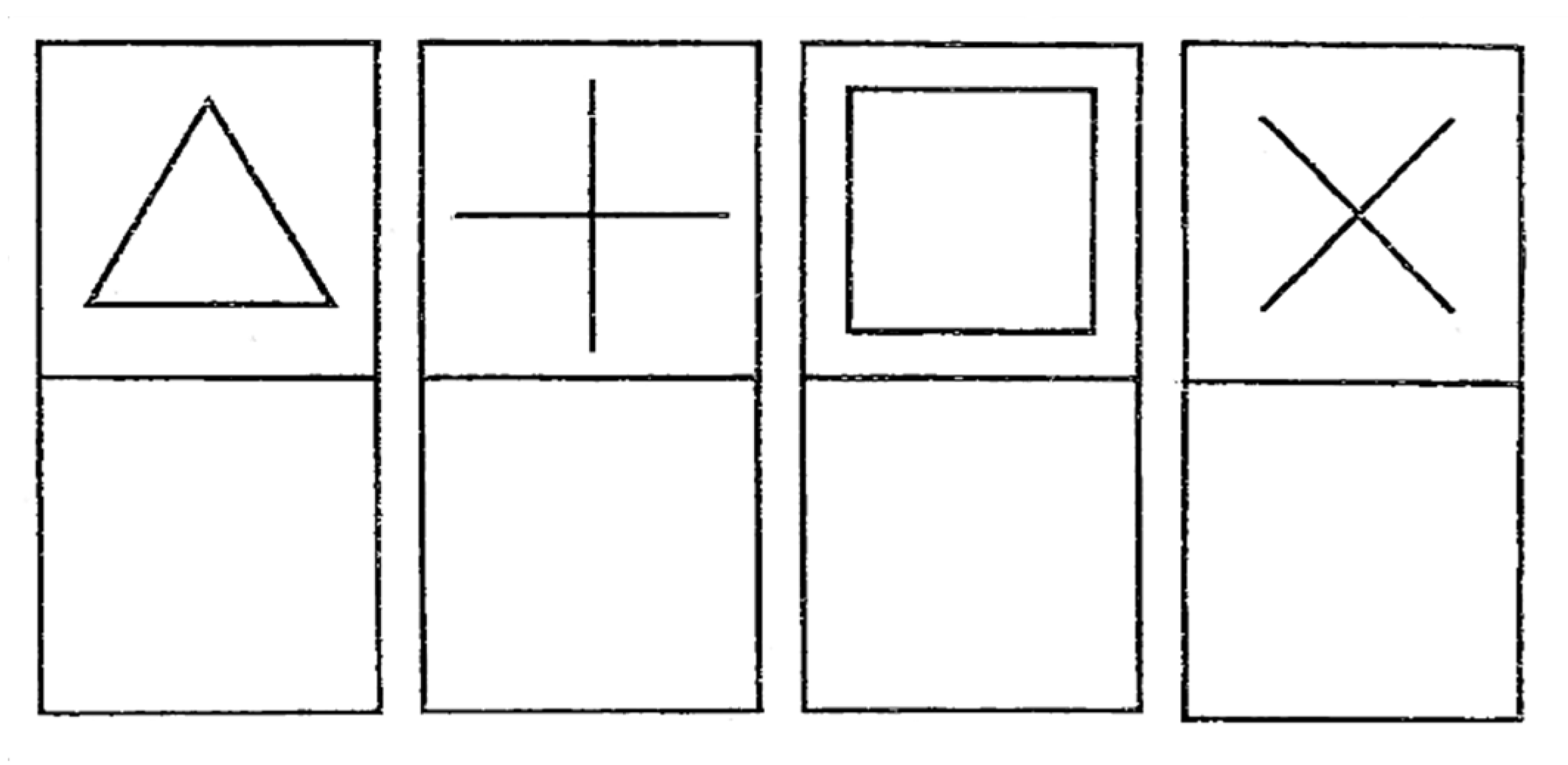
- Shapes 2: four other shapes that are slightly more complex: a triangle, a plus sign, a square and a cross (see Figure 8).
- 6.
- The Loops: two series of six alternated loops. This is the hardest exercise of these graphomotor tests, as it requires great visual-motor coordination (see Figure 9).
2.4. Features Extraction
2.5. Z-Score Computing
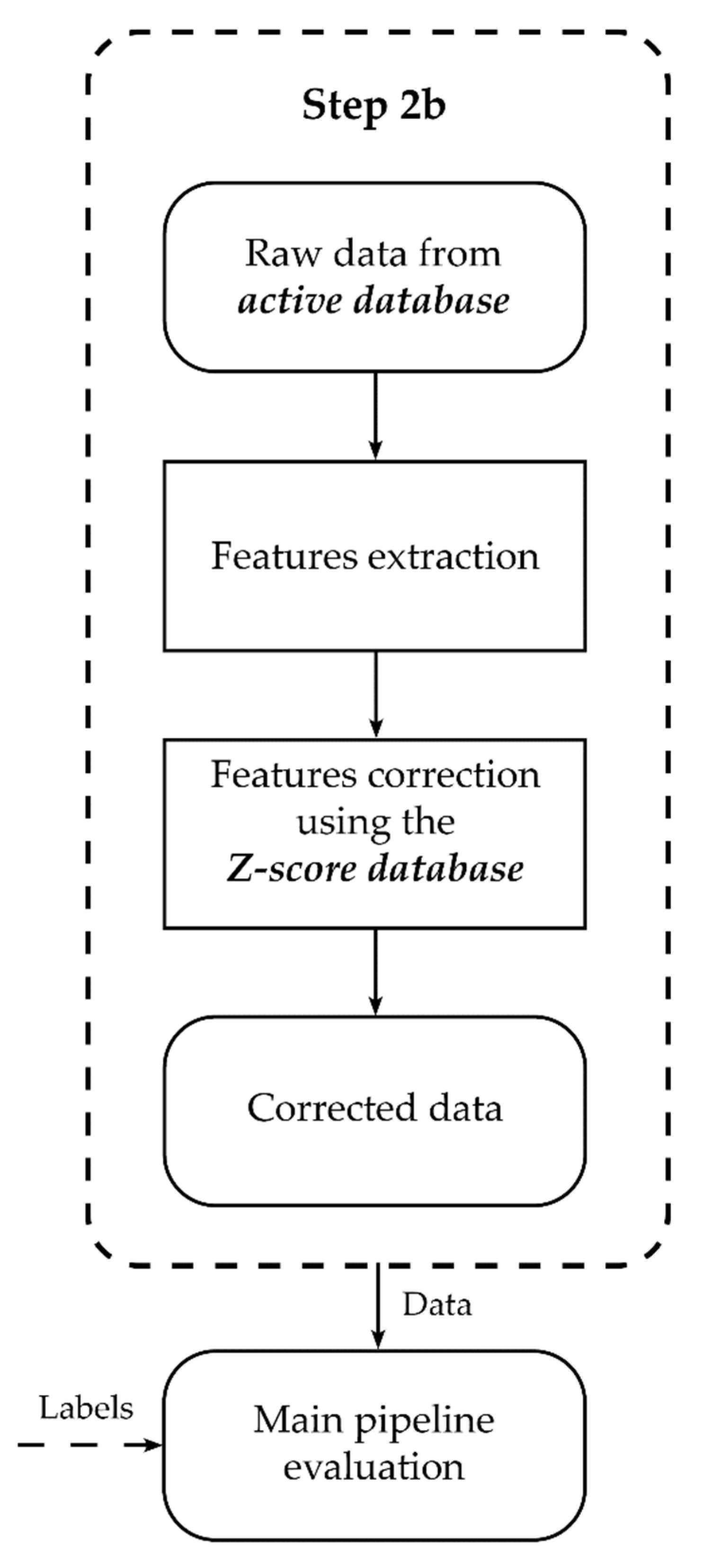
2.6. Preprocessing Steps
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMaster, E.; Roberts, T. Handwriting in 2015: A Main Occupation for Primary School–Aged Children in the Classroom? J. Occup. Ther. Sch. Early Interv. 2016, 9, 38–50. [Google Scholar] [CrossRef]
- McHale, K.; Cermak, S.A. Fine Motor Activities in Elementary School: Preliminary Findings and Provisional Implications for Children with Fine Motor Problems. Am. J. Occup. Ther. 1992, 46, 898–903. [Google Scholar] [CrossRef] [Green Version]
- Maeland, A.F. Handwriting and Perceptual-Motor Skills in Clumsy, Dysgraphic, and “Normal” Children. Percept. Mot. Skills 1992, 75, 1207–1217. [Google Scholar] [PubMed] [Green Version]
- Feder, K.P.; Majnemer, A. Handwriting Development, Competency, and Intervention. Dev. Med. Child Neurol. 2007, 49, 312–317. [Google Scholar] [CrossRef]
- Smits-Engelman, B.C.M.; Niemeijer, A.S.; van Galen, G.P. Fine Motor Deficiencies in Children Diagnosed as DCD Based on Poor Grapho-Motor Ability. Hum. Mov. Sci. 2001, 20, 161–182. [Google Scholar] [CrossRef]
- Charles, M.; Soppelsa, R.; Albaret, J.-M. BHK: Échelle D’évaluation Rapide de L’écriture Chez L’enfant; Les Editions du Centre de Psychologie Appliquée: Paris, France, 2004. [Google Scholar]
- Gargot, T.; Asselborn, T.; Pellerin, H.; Zammouri, I.; Anzalone, S.; Casteran, L.; Johal, W.; Dillenbourg, P.; Cohen, D.; Jolly, C. Acquisition of Handwriting in Children with and without Dysgraphia: A Computational Approach. PLoS ONE 2020, 15, e0237575. [Google Scholar] [CrossRef] [PubMed]
- Casteran, L.; Deschamps, L.; Boutet, J.; Aloui, S.; N’guyen-Morel, M.-A.; Labyt, E.; Jolly, C. Identification de deux sous-types de dysgraphies à partir de l’analyse de paramètres cinématiques et statiques de l’écriture d’enfants typiques et porteurs d’une dysgraphie. ANAE Approch. Neuropsychol. Apprentiss. Chez Enfant 2021. Available online: https://hal.univ-lorraine.fr/LPNC/hal-03101924v1 (accessed on 7 January 2021).
- Hamstra-Bletz, L.; Blöte, A.W. A Longitudinal Study on Dysgraphic Handwriting in Primary School. J. Learn. Disabil. 1993, 26, 689–699. [Google Scholar] [CrossRef] [PubMed]
- Gargot, T.; Asselborn, T.; Zammouri, I.; Brunelle, J.; Johal, W.; Dillenbourg, P.; Archambault, D.; Chetouani, M.; Cohen, D.; Anzalone, S.M. “It Is Not the Robot Who Learns, It Is Me.” Treating Severe Dysgraphia Using Child–Robot Interaction. Front. Psychiatry 2021, 12, 596055. [Google Scholar] [CrossRef] [PubMed]
- Mekyska, J.; Faundez-Zanuy, M.; Mzourek, Z.; Galaz, Z.; Smekal, Z.; Rosenblum, S. Identification and Rating of Developmental Dysgraphia by Handwriting Analysis. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 235–248. [Google Scholar] [CrossRef]
- Asselborn, T.; Gargot, T.; Kidziński, Ł.; Johal, W.; Cohen, D.; Jolly, C.; Dillenbourg, P. Automated Human-Level Diagnosis of Dysgraphia Using a Consumer Tablet. npj Digit. Med. 2018, 1, 42. [Google Scholar] [CrossRef] [Green Version]
- Sihwi, S.W.; Fikri, K.; Aziz, A. Dysgraphia Identification from Handwriting with Support Vector Machine Method. J. Phys. Conf. Ser. 2019, 1201, 012050. [Google Scholar] [CrossRef]
- Dankovičová, Z.; Hurtuk, J.; Feciľak, P. Evaluation of Digitalized Handwriting for Dysgraphia Detection Using Random Forest Classification Method. In Proceedings of the 2019 IEEE 17th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 12–14 September 2019; pp. 000149–000154. [Google Scholar]
- Drotár, P.; Dobeš, M. Dysgraphia Detection through Machine Learning. Sci. Rep. 2020, 10, 21541. [Google Scholar] [CrossRef] [PubMed]
- Zolna, K.; Asselborn, T.; Jolly, C.; Casteran, L.; Nguyen-Morel, M.-A.; Johal, W.; Dillenbourg, P. The Dynamics of Handwriting Improves the Automated Diagnosis of Dysgraphia. arXiv Prepr. 2019, arXiv:1906.07576. [Google Scholar]
- Dimauro, G.; Bevilacqua, V.; Colizzi, L.; Pierro, D.D. TestGraphia, a Software System for the Early Diagnosis of Dysgraphia. IEEE Access 2020, 8, 19564–19575. [Google Scholar] [CrossRef]
- Rosenblum, S. Development, Reliability, and Validity of the Handwriting Proficiency Screening Questionnaire (HPSQ). Am. J. Occup. Ther. 2008, 62, 298–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deschamps, L.; Gaffet, C.; Aloui, S.; Boutet, J.; Brault, V.; Labyt, E. Methodological Issues in the Creation of a Diagnosis Tool for Dysgraphia. npj Digit. Med. 2019, 2, 36. [Google Scholar] [CrossRef] [Green Version]
- Deschamps, L.; Devillaine, L.; Gaffet, C.; Lambert, R.; Aloui, S.; Boutet, J.; Brault, V.; Labyt, E.; Jolly, C. Development of a Pre-Diagnosis Tool Based on Machine Learning Algorithms on the BHK Test to Improve the Diagnosis of Dysgraphia. Adv. Artif. Intell. Mach. Learn. 2021, 1, 111–130. [Google Scholar]
- Galaz, Z.; Mucha, J.; Zvoncak, V.; Mekyska, J.; Smekal, Z.; Safarova, K.; Ondrackova, A.; Urbanek, T.; Havigerova, J.M.; Bednarova, J.; et al. Advanced Parametrization of Graphomotor Difficulties in School-Aged Children. IEEE Access 2020, 8, 112883–112897. [Google Scholar] [CrossRef]
- Galli, M.; Cimolin, V.; Stella, G.; De Pandis, M.F.; Ancillao, A.; Condoluci, C. Quantitative Assessment of Drawing Tests in Children with Dyslexia and Dysgraphia. Hum. Mov. Sci. 2019, 65, 51–59. [Google Scholar] [CrossRef]
- Harrington, G.S.; Farias, D.; Davis, C.H.; Buonocore, M.H. Comparison of the Neural Basis for Imagined Writing and Drawing. Hum. Brain Mapp. 2007, 28, 450–459. [Google Scholar] [CrossRef]
- Hammill, D.D.; Pearson, N.A.; Voress, J.K. Developmental Test of Visual Perception: DTVP-2, 2nd ed.; The Psychological Corporation USA: Austin, TX, USA, 1998. [Google Scholar]
- Alamargot, D.; Morin, M.-F. Does Handwriting on a Tablet Screen Affect Students’ Graphomotor Execution? A Comparison between Grades Two and Nine. Hum. Mov. Sci. 2015, 44, 32–41. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Raschka, S. MLxtend: Providing Machine Learning and Data Science Utilities and Extensions to Python’s Scientific Computing Stack. J. Open Source Softw. 2018, 3, 638. [Google Scholar] [CrossRef]
- Danna, J.; Paz-Villagrán, V.; Capel, A.; Pétroz, C.; Gondre, C.; Pinto, S.; Thoret, E.; Aramaki, M.; Ystad, S.; Kronland-Martinet, R.; et al. Movement Sonification for the Diagnosis and the Rehabilitation of Graphomotor Disorders. In Sound, Music, and Motion; Aramaki, M., Derrien, O., Kronland-Martinet, R., Ystad, S., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8905, ISBN 978-3-319-12976-1. [Google Scholar]
- Teulings, H.-L.; Maarse, F.J. Digital Recording and Processing of Handwriting Movements. Hum. Mov. Sci. 1984, 3, 193–217. [Google Scholar] [CrossRef]
- Rosenblum, S. Using the Alphabet Task to Differentiate between Proficient and Nonproficient Handwriters. Percept. Mot. Skills 2005, 100, 629–639. [Google Scholar] [CrossRef]
- Rosenblum, S. The in air phenomenon: Temporal and spatial correlates of the handwriting process. Percept. Mot. Skills 2003, 96, 933–954. [Google Scholar] [CrossRef]
- Rosenblum, S. Inter-Relationships between Objective Handwriting Features and Executive Control among Children with Developmental Dysgraphia. PLoS ONE 2018, 13, e0196098. [Google Scholar] [CrossRef] [Green Version]
- Paz-Villagrán, V.; Danna, J.; Velay, J.-L. Lifts and Stops in Proficient and Dysgraphic Handwriting. Hum. Mov. Sci. 2014, 33, 381–394. [Google Scholar] [CrossRef]
- Silveri, G.; De Dea, F.; Perrone, I.; Accardo, A. Influence of Dysgraphia on Kinematic Characteristics of Handwriting in Italian Primary School Children. In World Congress on Medical Physics and Biomedical Engineering 2018; Lhotska, L., Sukupova, L., Lacković, I., Ibbott, G.S., Eds.; Springer: Singapore, 2019; Volume 68, pp. 241–245. ISBN 978-981-10-9037-0. [Google Scholar]
- Danna, J.; Paz-Villagrán, V.; Velay, J.-L. Signal-to-Noise Velocity Peaks Difference: A New Method for Evaluating the Handwriting Movement Fluency in Children with Dysgraphia. Res. Dev. Disabil. 2013, 34, 4375–4384. [Google Scholar] [CrossRef] [PubMed]
- Drotár, P.; Mekyska, J.; Rektorova, I.; Masarova, L.; Smekal, Z.; Faundez-Zanuy, M. Decision Support Framework for Parkinson’s Disease Based on Novel Handwriting Markers. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 23, 508–516. [Google Scholar] [CrossRef]
- Rueckriegel, S.M.; Blankenburg, F.; Burghardt, R.; Ehrlich, S.; Henze, G.; Mergl, R.; Hernáiz Driever, P. Influence of Age and Movement Complexity on Kinematic Hand Movement Parameters in Childhood and Adolescence. Int. J. Dev. Neurosci. 2008, 26, 655–663. [Google Scholar] [CrossRef]
- Accardo, A.P.; Genna, M.; Borean, M. Development, Maturation and Learning Influence on Handwriting Kinematics. Hum. Mov. Sci. 2013, 32, 136–146. [Google Scholar] [CrossRef] [PubMed]
- Glowacz, A. Ventilation Diagnosis of Angle Grinder Using Thermal Imaging. Sensors 2021, 21, 2853. [Google Scholar] [CrossRef] [PubMed]
- Saha, R.; Mukherjee, A.; Sarkar, A.; Dey, S. 5 Extraction of Common Feature of Dysgraphia Patients by Handwriting Analysis Using Variational Autoencoder; De Gruyter: Berlin, Germany, 2020; ISBN 978-3-11-067090-5. [Google Scholar]
- Letanneux, A.; Danna, J.; Velay, J.-L.; Viallet, F.; Pinto, S. From Micrographia to Parkinson’s Disease Dysgraphia. Mov. Disord. 2014, 29, 1467–1475. [Google Scholar] [CrossRef] [Green Version]
- Deuel, R.K. Developmental Dysgraphia and Motor Skills Disorders. J. Child. Neurol. 1995, 10, S6–S8. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | DYS/TD Repartition | Model Used | Score |
|---|---|---|---|
| [11] | 27/27 | Random Forest | 96.43% |
| [12] | 56/242 | Random Forest | 97.9% |
| [13] | 48/43 | SVM (RBF Kernel) | 82.51% |
| [16] | 24/971 | RNN | 90% 1 |
| [13] | 42/36 | Random Forest | 67% |
| [14] | 42/36 | SVM | 66% |
| [14] | 42/36 | AdaBoost | 64% |
| [15] | 57/63 | Random Forest | 77.6% 2 |
| [15] | 57/63 | SVM | 78.8% 2 |
| [15] | 57/63 | AdaBoost | 79.5% 2 |
| [20] | 122/458 | SVM (RBF Kernel) | 83% |
| Typical (n = 262) | Dysgraphic (n = 43) | p-Value | |
|---|---|---|---|
| Age (in years): mean (std) | 8.95 (1.22) | 9.20 (1.15) | 0.20 |
| Gender: Female/Male | 120/142 | 11/32 | <0.02 |
| Laterality: Left-Handed/Right-Handed | 33/229 | 2/41 | |
| Origin: School/Hospital | 252/10 | 13/30 | |
| BHK quality score: mean (std) | 12.2 (4.5) | 24.2 (5.8) | <1.10−13 |
| Grade 2: mean (std) | n = 89; 13.9 (5.3) | n = 7; 29.6 (7.2) | <0.02 |
| Grade 3: mean (std) | n = 66; 11.7 (4.0) | n = 13; 24.7 (3.6) | <1.10−7 |
| Grade 4: mean (std) | n = 57; 11.9 (3.3) | n = 15; 23.4 (6.1) | <1.10−4 |
| Grade 5: mean (std) | n = 50; 10.2 (3.8) | n = 8; 20.3 (2.9) | <1.10−3 |
| BHK speed score: mean (std) | 206 (79) | 161 (89) | <0.01 |
| Grade 2: mean (std) | n = 89; 134 (37) | n = 7; 123 (41) | 0.62 |
| Grade 3: mean (std) | n = 66; 190 (42) | n = 13; 131 (92) | 0.07 |
| Grade 4: mean (std) | n = 57; 245 (52) | n = 15; 148 (40) | <1.10−6 |
| Grade 5: mean (std) | n = 50; 305 (62) | n = 8; 275 (100) | 0.53 |
| Feature | Reference |
|---|---|
| Duration of the Stimulus | [31] |
| Writing Time | [31] |
| Mean, Median and Maximum Duration of a Stroke | [32] |
| Mean, Median and Maximum Duration of a Lift | [32] |
| Number of Strokes | [33] |
| On Air/On Paper Time Ratio | [11] |
| Duration and Length of the Paths Performed at Low Velocity (less than 1 mm in 150 ms) | [11] |
| Mean on Paper Velocity | [11] |
| Average Normalized Jerk | [11] |
| Number and Duration of Abnormal Stops | [34] |
| Number of Peaks of Velocity | [35] |
| SNvpd | [36] |
| Rényi Entropy of order 2 | [37] |
| Signal-to-Noise Ratio | [37] |
| Estimator Used for the Feature Selection Step | ||
|---|---|---|
| Stimuli | Linear SVM | Extra Trees |
| Circuit 1 | Number of backtrackings in the third line (44.8%) Percentage of the third line completed after the first stop (41.4%) | Percentage of the third line completed after the first stop (50.8%) |
| Circuit 2 | Mean squared error during the short parts of the circuit (100%) Std of the slopes for the short parts of the circuit (99.6%) Std of the velocity peaks (96.2%) | Mean squared error during the short parts of the circuit (99.2%) Std of the velocity peaks (77.6%) Std of the slopes for the short parts of the circuit (65.2%) |
| Shapes 1 | Ratio between the horizontal and the vertical diameters of the circle (98.8%) | Ratio between the horizontal and the vertical diameters of the circle (58.8%) Length of horizontal diameter (42.2%) |
| The Loops | Std of the height of the loops (98%) SNR on the y axis (90.8%) Number of changes in angle (72%) Height without loops in the drawing (51.8%) Std of the velocity peaks (51.6%) | SNR on the y axis (77.8%) Height without loops in the drawing (72%) Std of the height of the loops (65.2%) |
| Circuit 3 | None | None |
| Shapes 2 | None | None |
| Model for Selection | |||||
|---|---|---|---|---|---|
| Extra Trees | Linear SVM | ||||
| Model for Estimation | Mean | Std | Mean | Std | |
| Acc. | 0.690 | 0.037 | 0.734 | 0.034 | |
| Random Forest | Sen. | 0.706 | 0.055 | 0.751 | 0.046 |
| Spe. | 0.674 | 0.052 | 0.717 | 0.043 | |
| Acc. | 0.700 | 0.038 | 0.730 | 0.033 | |
| MLP | Sen. | 0.708 | 0.054 | 0.739 | 0.040 |
| Spe. | 0.693 | 0.052 | 0.721 | 0.048 | |
| Acc. | 0.696 | 0.034 | 0.730 | 0.031 | |
| Extra Trees | Sen. | 0.735 | 0.047 | 0.761 | 0.039 |
| Spe. | 0.657 | 0.052 | 0.698 | 0.048 | |
| Acc. | 0.669 | 0.037 | 0.708 | 0.030 | |
| SVM (linear) | Sen. | 0.564 | 0.070 | 0.615 | 0.053 |
| Spe. | 0.773 | 0.057 | 0.801 | 0.041 | |
| Acc. | 0.506 | 0.012 | 0.506 | 0.010 | |
| SVM (polynomial) | Sen. | 0.432 | 0.059 | 0.423 | 0.049 |
| Spe. | 0.581 | 0.053 | 0.589 | 0.043 | |
| Acc. | 0.530 | 0.021 | 0.541 | 0.020 | |
| SVM (sigmoid) | Sen. | 0.495 | 0.048 | 0.512 | 0.046 |
| Spe. | 0.566 | 0.032 | 0.569 | 0.033 | |
| Acc. | 0.531 | 0.020 | 0.541 | 0.020 | |
| SVM (rbf) | Sen. | 0.496 | 0.047 | 0.513 | 0.046 |
| Spe. | 0.566 | 0.032 | 0.569 | 0.033 | |
| Acc. | 0.671 | 0.039 | 0.703 | 0.035 | |
| Gaussian Naïve Bayes | Sen. | 0.585 | 0.064 | 0.605 | 0.048 |
| Spe. | 0.757 | 0.049 | 0.802 | 0.046 | |
| Acc. | 0.646 | 0.048 | 0.690 | 0.041 | |
| Ada Boost | Sen. | 0.659 | 0.064 | 0.720 | 0.055 |
| Spe. | 0.633 | 0.063 | 0.659 | 0.054 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devillaine, L.; Lambert, R.; Boutet, J.; Aloui, S.; Brault, V.; Jolly, C.; Labyt, E. Analysis of Graphomotor Tests with Machine Learning Algorithms for an Early and Universal Pre-Diagnosis of Dysgraphia. Sensors 2021, 21, 7026. https://doi.org/10.3390/s21217026
Devillaine L, Lambert R, Boutet J, Aloui S, Brault V, Jolly C, Labyt E. Analysis of Graphomotor Tests with Machine Learning Algorithms for an Early and Universal Pre-Diagnosis of Dysgraphia. Sensors. 2021; 21(21):7026. https://doi.org/10.3390/s21217026
Chicago/Turabian StyleDevillaine, Louis, Raphaël Lambert, Jérôme Boutet, Saifeddine Aloui, Vincent Brault, Caroline Jolly, and Etienne Labyt. 2021. "Analysis of Graphomotor Tests with Machine Learning Algorithms for an Early and Universal Pre-Diagnosis of Dysgraphia" Sensors 21, no. 21: 7026. https://doi.org/10.3390/s21217026
APA StyleDevillaine, L., Lambert, R., Boutet, J., Aloui, S., Brault, V., Jolly, C., & Labyt, E. (2021). Analysis of Graphomotor Tests with Machine Learning Algorithms for an Early and Universal Pre-Diagnosis of Dysgraphia. Sensors, 21(21), 7026. https://doi.org/10.3390/s21217026