2.1. Traditional Random Forest Algorithm
Random forest is a kind of ensemble learning whose core lies in random sample selection and random feature selection. It uses multiple decision trees as the base learner for learning, and applies voting laws to integrate the results of each learner to complete the learning task [
38,
39].
When the RF model is trained, the structure of the decision trees is determined, and the optimal characteristics of each split node and the sample size belonging to each category on each node can be obtained. Next, a single sample is input to get the split node that the sample has passed through in a certain decision tree, and the leaf node represents the final classification result of the sample in the decision tree. By arranging these split features in order, the decision path of a specific sample in a specific decision tree can be obtained.
For the features included in the decision path, the amount of information contained in each feature is different, resulting in different importance of each node for target prediction. Node importance is introduced to quantify it.
It is assumed that for a particular sample
, the label predicted by the
th decision tree in the random forest is
. It is defined that the training samples belonging to the
category at the
th node of the decision tree are positive samples. The proportion of positive samples in all training samples contained in this node is denoted as
, which can also be considered as the probability that the training sample contained in node
belongs to the predicted sample category
. The difference in proportion of positive samples in child node and its corresponding parent node can be viewed as the node importance of the child node [
40,
41,
42]. The larger the difference, the higher the purity of the sample split to the child node compared to that of the parent node, thus the higher the importance of the child node for the classification problem. Referring to the definition of local increment [
42], local importance (LI) of each node for the predicted label can be defined as follows:
where
represents the parent node of the
th node in the decision path of sample
in the tree
.
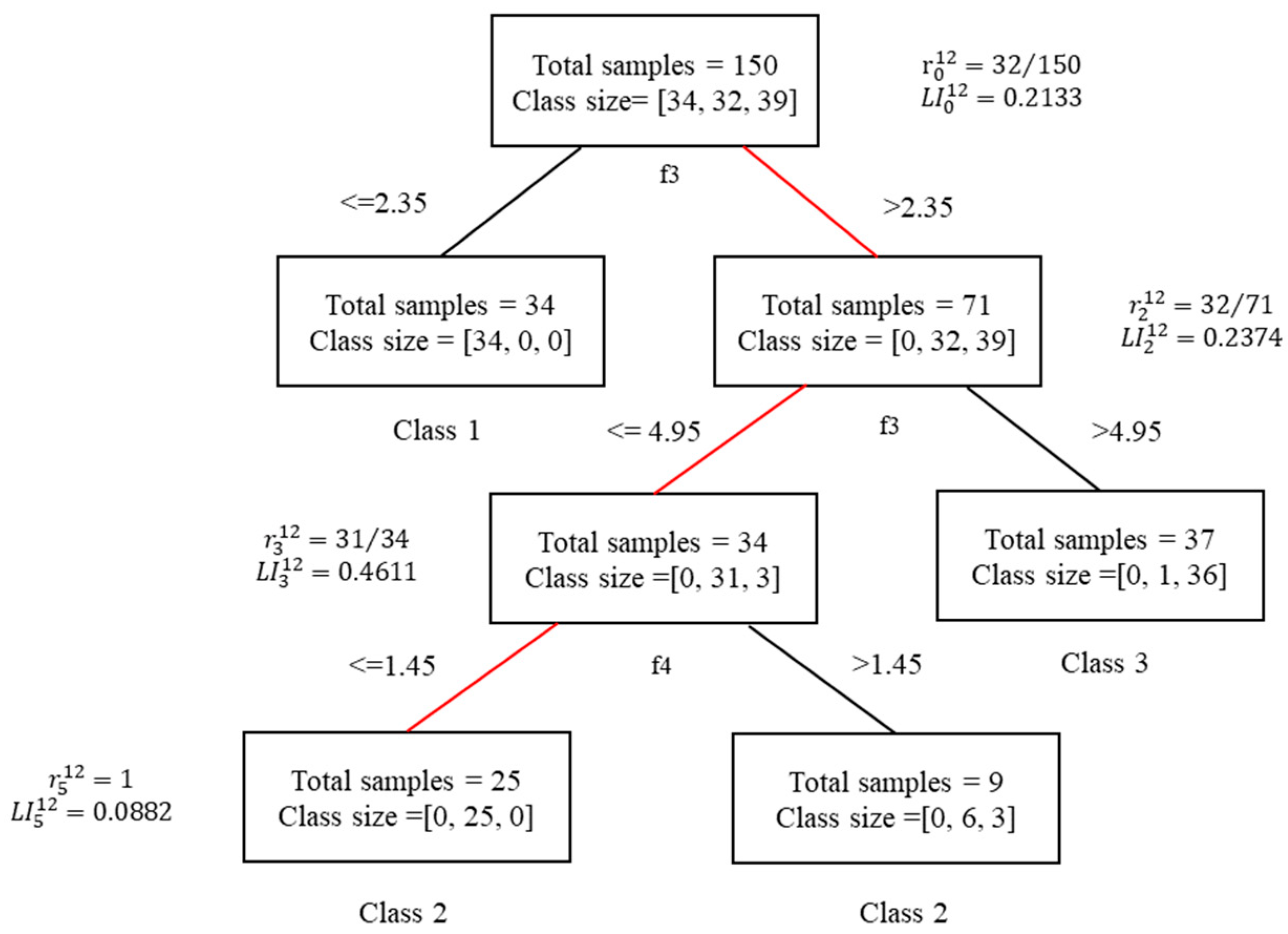
More specifically, the iris dataset (
https://www.kaggle.com/arshid/iris-flower-dataset, accessed on 14 September 2021) is used as a numerical example to better explain what the decision path is and to give the calculation process of local importance. The iris dataset contains 150 samples, which can be divided into Setosa (class 0), Versicolour (class 1), Virginica (class 2), each containing 50 samples. Each sample contains the following four characteristics: sepal length (
), sepal width (
), petal length (
), and petal width (
). For better training effects, 50 trees are trained and the minimum sample size for each category is set to 5 to prevent overfitting. Take the
th tree in the RF model for example, whose internal structure is shown in
Figure 1 below. Class size on each node represents the number of training samples belonging to each category; for example, class size at the root node equals [
32,
34,
39], which means that 34 samples belong to class 0, 32 samples belong to class 1, and 39 samples belong to class 2. At the root node,
is the optimal split feature based on the Gini coefficient, and if the value of the third feature of the input sample is no more than 2.35, it moves to the left node. Otherwise, it will move to the right node. Thus, all input samples are divided into two categories. Similarly, the left child nodes and right child nodes then select the optimal split characteristics to split collectively, and the split process will continue repeatedly until the classification pruning requirements with a minimum sample number of 5 are reached. The specific information for the test sample
is shown in
Table 1.
satisfies the following:
Therefore, the decision path will be recorded as
as shown in the red path in
Figure 1. The corresponding decision nodes set is denoted as
. The final predicted sample category of sample
is 2, and the local importance of each node in the decision path of the sample
can be calculated according to
.
where
represents the local importance of the node
on the decision path of
in the decision tree
with predicted label
. All the results are shown in
Figure 1 where
indicates that in the classification process of sample
in the
th decision tree, node three is the most important with the largest increase in sample purity compared to the parent node. Node two has the second highest importance, and node five has the worst importance. It can be inferred that the data missing on node three will lead to the most significant error in the prediction result.
The corresponding classification result can be obtained on each decision tree similarly to the above procedure for each sample. The idea of the ensemble algorithm is to obtain the final classification results from the classification results of all weak sub-classifiers according to certain voting rules. In the RF model, there are the following two voting rules: soft voting rule and hard voting rule. A brief introduction is given.
Hard voting
Under the hard voting rule, each decision tree can give the classification result of a specific sample. According to the majority voting law, the result with the most occurrences is the final classification result. Its expression is as follows:
where
represents the test sample. Label value
belongs to
, and
represents a collection of all possible classification results.
represents the classification result of decision tree
for
.
is the voting variable and
represents the final classification results based on the hard voting.
Soft voting
The average value of the probabilities of all sub-classifiers predicting samples to be a certain category is used as the deciding criterion, and the category with the highest probability is selected as the final classification result. Its expression is as follows:
where
represents the probability of the prediction label belonging to
in the decision tree
.
2.2. Improved RF Algorithm Based on Decision Path
The traditional RF classification algorithm uses decision trees such as CART as the base learner and applies a certain voting rule to summarize the results of all base learners, so RF has good stability. In this way, even if there is a small amount of missing data in the sample, it will only affect the decision-making process and results of several specific decision trees, and the fault diagnosis results obtained generally remain accurate. Therefore, RF has strong robustness to a small amount of missing data caused by machine failure or bad operating conditions. When a large number of data are missing, it is common to fill the dataset with default or mean values. However, this processing method may change the distribution of data, introduce system bias, and thus reduce the classification accuracy of the RF algorithm.
Therefore, in order to make the most of the information available, to alleviate the adverse effect of the common filling methods on the RF when a large number of data go missing, this paper utilizes the decision path information to improve the accuracy of RF on the sample containing missing data.
According to the discussion of the decision path above, when sample
lacks several features, which are in the decision path corresponding to sample
in decision tree
, the classification results predicted by the decision tree are considered unreliable, that is, the missing feature nodes included in the decision path will reduce the credibility of the corresponding prediction results. To describe the adverse influence, the reliability score (RS) for the prediction results of each decision tree for a specific sample is defined. As is shown in the concept of local importance, the higher the local importance of a node containing missing data, the greater the adverse effect on the result. Since missing data occurs randomly, a decision path may consist of multiple split nodes that contain the same or different missing data, and the classification bias gets larger as the number of problem nodes increases. The sum of the local importance of all problem nodes in a decision path can indicate the degree of data loss that is unfavorable to the classification result. Considering that the length of the decision path of different samples in different decision trees is not the same, in order to compare the relative weakening effect on the classification accuracy, the ratio of the sum of the local importance of the reliable nodes to that of all nodes in the decision path can be calculated in the case of missing data. The reliability score of decision tree
can be denoted with respect to sample
as follows:
where
and
are a collection of all the nodes of the decision path in the decision tree
, and a collection of all the corresponding missing nodes, respectively.
The iris data are still used as an example to illustrate how RS is calculated. By analysis in
Section 2.1, the test sample
in the
th decision tree passes through
, and the predicted result is 2. If
is missing in
, then the nodes
and
containing the missing feature
are unreliable, as shown in
Figure 2.
According to the definition, the RS value of the
decision tree for sample
is as follows:
In the RF, the length of the decision path of the same sample
is not the same in different decision trees. In order to measure the RS of the decision trees with different decision path lengths, all the RS in the RF are normalized in this paper as follows:
where
and
represent the minimum and maximum values of RS values for all decision trees in a random forest, respectively, as follows:
For cases with missing data, this paper retains the original prediction results of each classifier because although some data in the test samples go missing, remaining data are still valid and retain important information. Besides, this paper uses reliability scores to revise the prediction results according to missing data contained in the decision path. The specific amendment process will be discussed according to two different voting rules.
When applying hard voting, the test sample
is inputted, and each decision tree can obtain the predicted label value
and the corresponding reliability scores, denoted as
. For different classifiers with the same prediction label, the sum of their reliability scores is used to obtain the total reliability predicted in the category. The label with the highest total reliability scores in all categories is taken as the final prediction result.
When applying soft voting, the test sample
is inputted, and each decision tree outputs the predicted probability of each category and the reliability scores of the classifier under the condition of missing data. The prediction probability of each category is multiplied by the reliability scores to obtain the revised predicted probability of each category, and the revised prediction probabilities of all sub-classifiers in the RF are added to obtain the total prediction of each category probability. The category with the highest predicted probability is taken as the final classification result of the sample
.
The soft voting rule summarizes the probabilities of all categories in all decision trees before voting, while the hard voting rule first votes in each decision tree and then aggregates the results. The former rule can better retain the classification probability information of each decision tree to the final result, while the latter one first votes in the decision tree, losing the probability information too early. Therefore, the diagnosis accuracy is theoretically higher under the soft voting rule.
By repeating the above procedures, the classification results for all the samples can be obtained.
The proposed DPRF algorithm is summarized as follows:
Stage 1: data collection and model training
- (1).
Collecting data: collect datasets for and : and ;
- (2).
Generating training and testing sets: Split the datasets of and into training and testing sets: and , of which the sample sizes correspond to and , respectively. Note that and do not contain any missing data;
- (3).
Training RF model: train the RF with complete data ;
- (4).
Obtaining nodes’ scores: calculate the scores for all the nodes on the trees in the RF according to the above .
Stage 2: classification with incomplete data
- (1).
Identifying decision paths for test sample: consider a test sample in with incomplete data, for each tree in the RF, identify the corresponding decision path and decision nodes set by and
;
- (2).
Calculating reliability scores for decision trees: for all the trees in the RF, calculate their normalized scores according to ;
- (3).
Obtaining final classification result for : calculate the final weighted result according to the hard or soft voting procedures in .
In short, the DPRF model firstly uses the complete industrial process dataset to train the RF model. Then, for the actual process samples that may contain missing data, DPRF automatically determines the location of the missing features of the sample, and completes the calculation of the decision paths, reliability scores and final FDD results on all decision trees. DPRF uses the information retained in the dataset to correct the judgment of RF, and alleviates the influence of subjective factors.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}