
Early Fault Diagnosis Method for Batch Process Based on Local Time Window Standardization and Trend Analysis



Abstract
:1. Introduction
2. Methods and Improvements
2.1. Local Adaptive Standardization
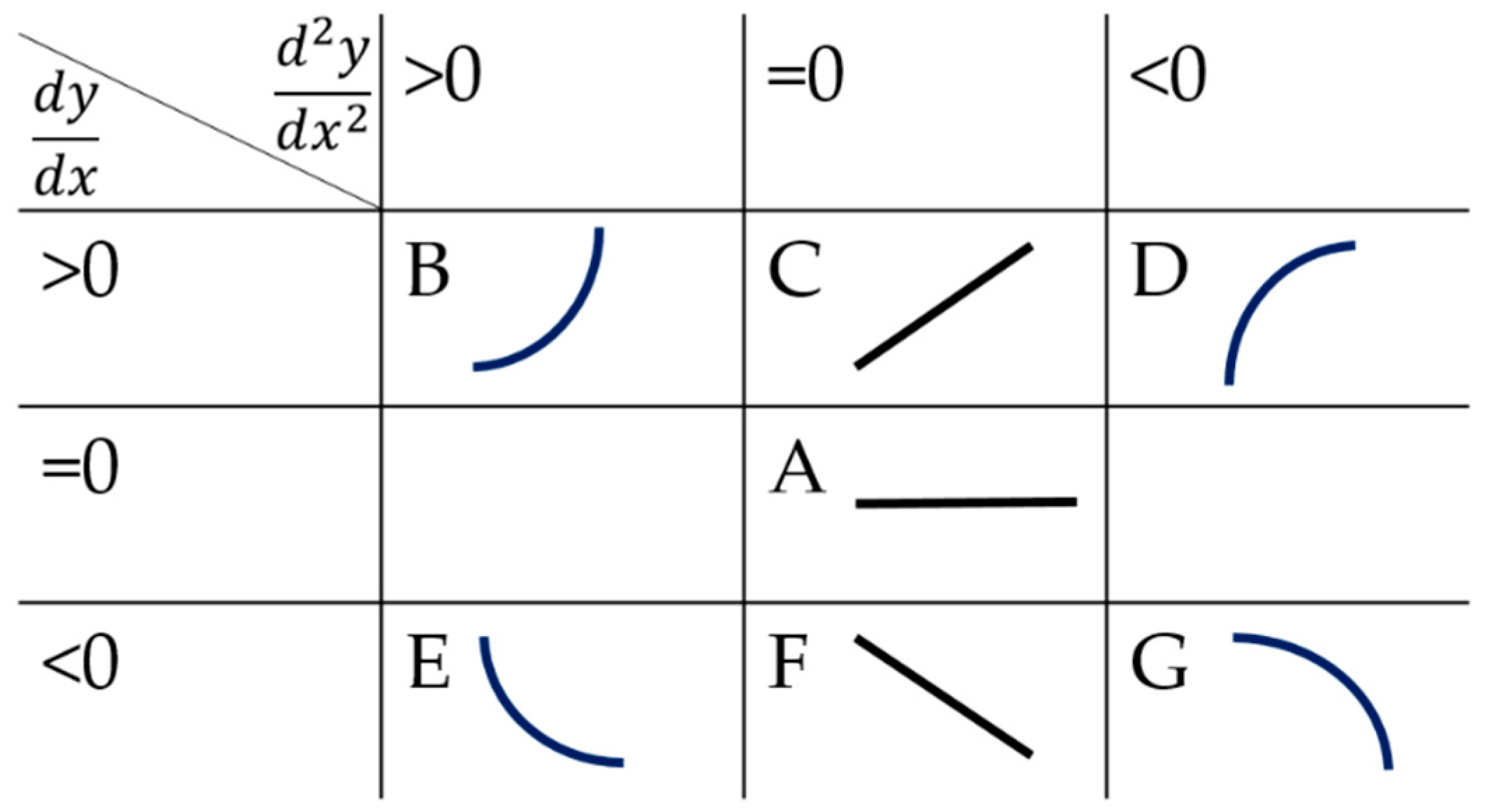
2.2. Qualitative Trend Analysis
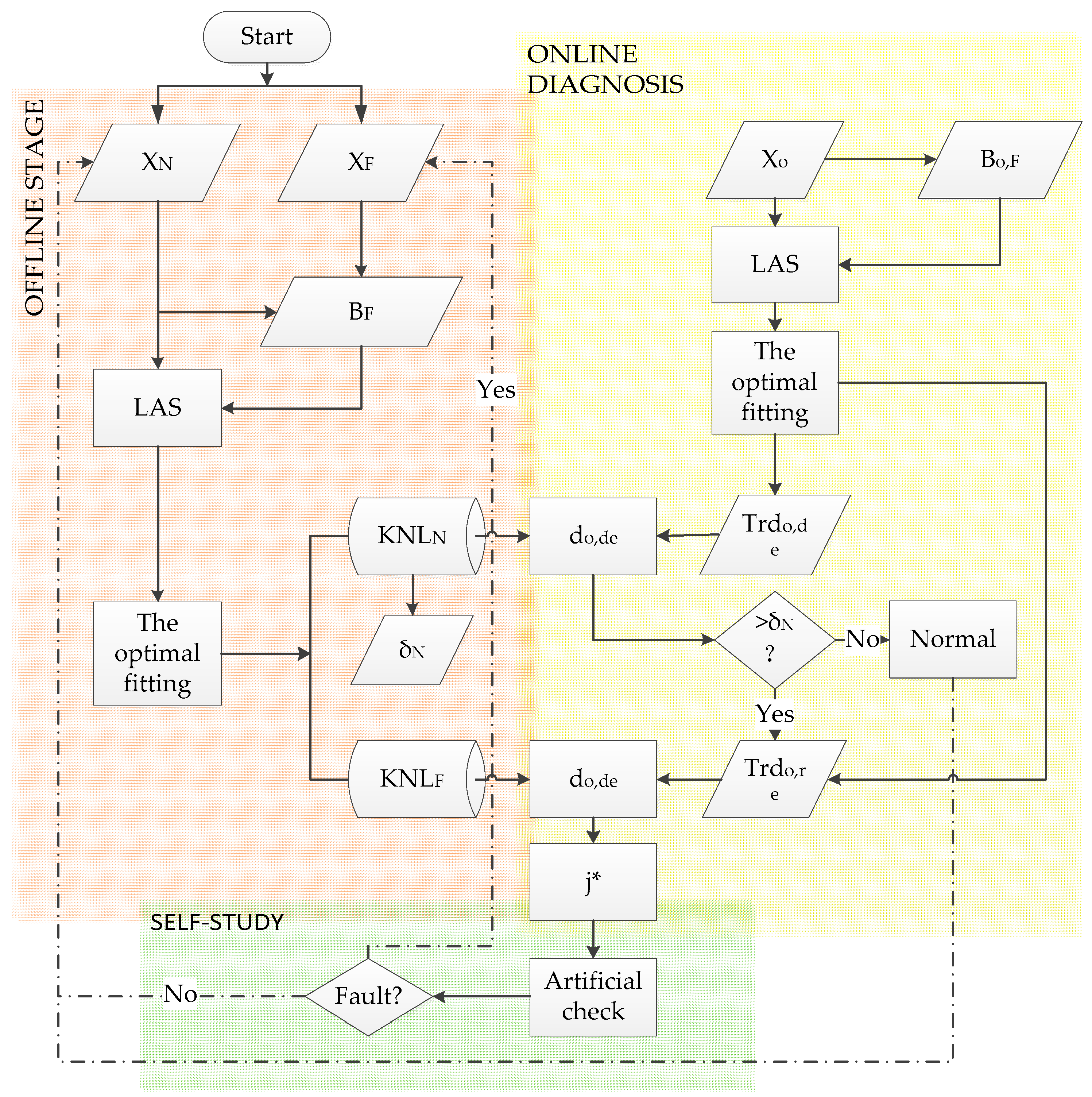
2.3. Fault Diagnosis Model
2.3.1. Offline Stage
2.3.2. Online Diagnosis Stage
2.3.3. Self-Study Stage
3. Application to the Fed-Batch Fermentation of Penicillin Process
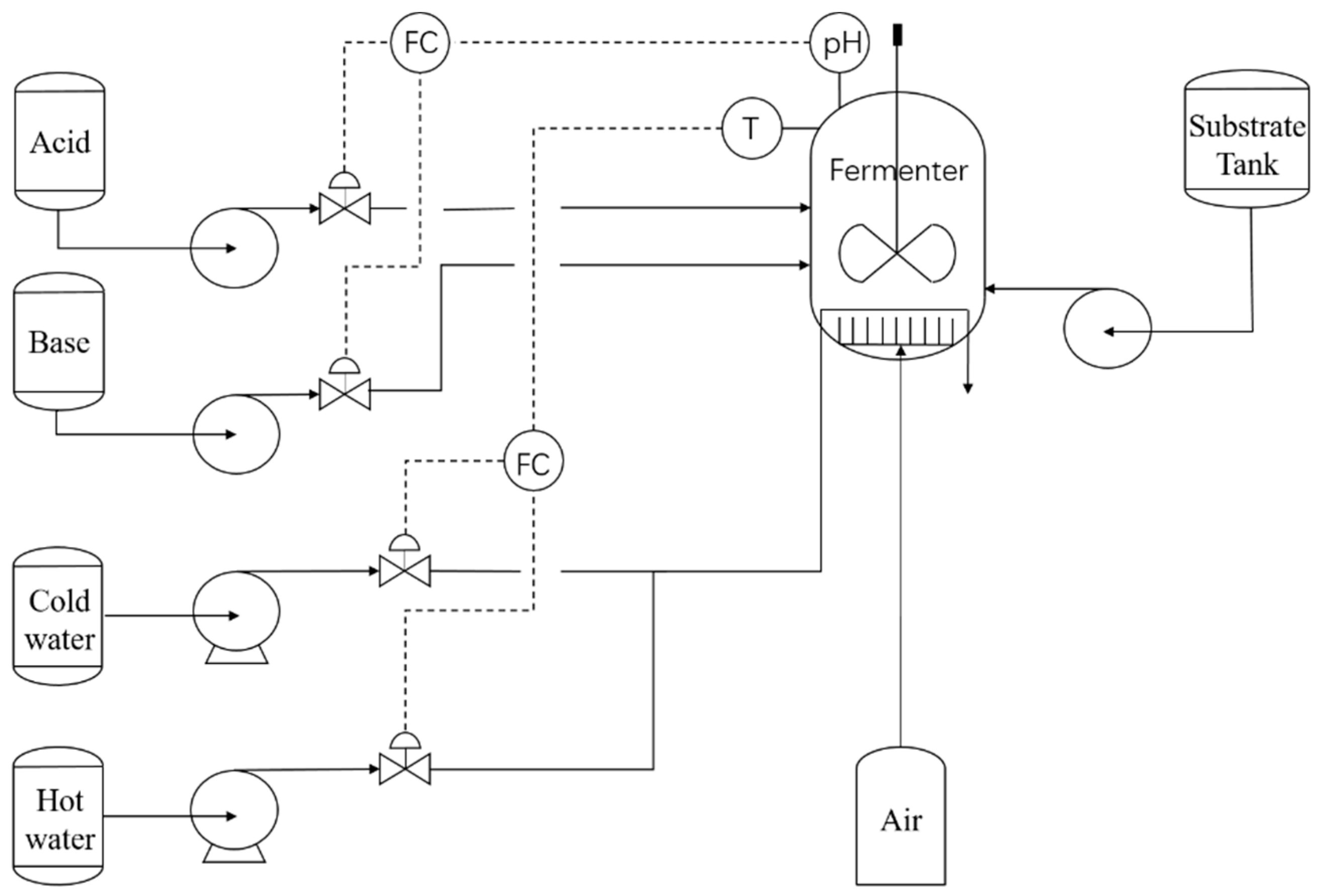
3.1. Process Description
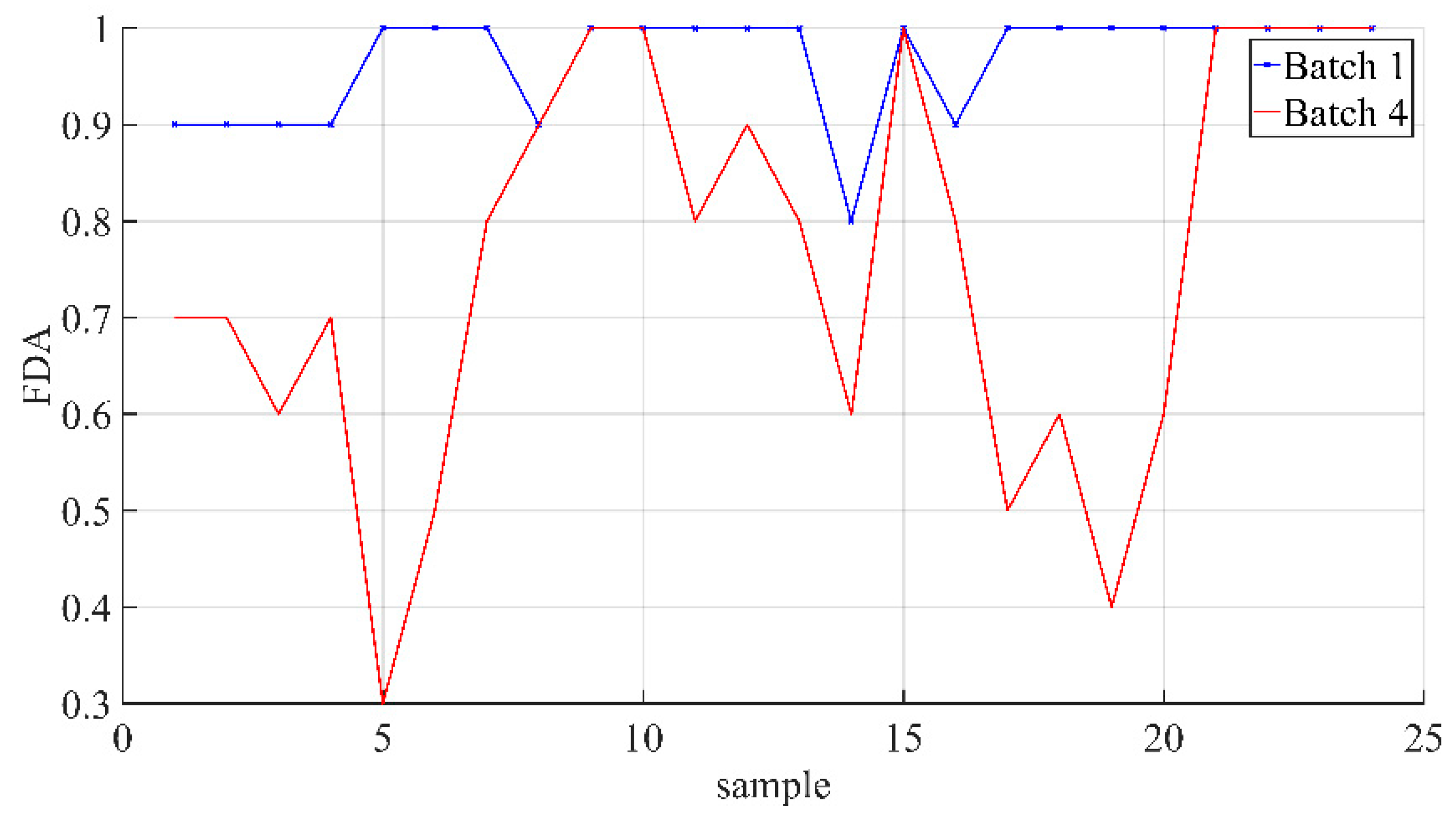
3.2. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nomikos, P.; Macgregor, J.F. Monitoring batch processes using multiway principal component analysis. AIChE J. 1994, 40, 1361–1375. [Google Scholar] [CrossRef]
- Md Nor, N.; Che Hassan, C.R.; Hussain, M.A. A review of data-driven fault detection and diagnosis methods: Applications in chemical process systems. Rev. Chem. Eng. 2020, 36, 513–553. [Google Scholar] [CrossRef]
- Shang, J.; Chen, M.; Ji, H.; Zhou, D. Recursive transformed component statistical analysis for incipient fault detection. Automatica 2017, 80, 313–327. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N. A review of process fault detection and diagnosis: Part II: Qualitative models and search strategies. Comput. Chem. Eng. 2003, 27, 313–326. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N.; Yin, K. A review of process fault detection and diagnosis: Part III: Process history based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Venkatasubramanian, V. The promise of artificial intelligence in chemical engineering: Is it here, finally? AIChE J. 2019, 65, 466–478. [Google Scholar] [CrossRef]
- Alauddin, M.; Khan, F.; Imtiaz, S.; Ahmed, S. A Bibliometric Review and Analysis of Data-Driven Fault Detection and Diagnosis Methods for Process Systems. Ind. Eng. Chem. Res. 2018, 57, 10719–10735. [Google Scholar] [CrossRef]
- Yang, M.; Wang, J.; Zhang, Y.; Bai, X.; Xu, Z.; Xia, X.; Fan, L. Fault Detection and Diagnosis for Plasticizing Process of Single-Base Gun Propellant Using Mutual Information Weighted MPCA under Limited Batch Samples Modelling. Machines 2021, 9, 166. [Google Scholar] [CrossRef]
- Hoo, K.; Piovoso, M.; Dahl, K.S.; MacGregor, J.F.; Nomikos, P. MultiWay PCA Applied to an Industrial Batch Process. In Proceedings of the 1994 American Control Conference-ACC’94, Baltimore, MD, USA, 29 June–1 July 1994; Volume 94, pp. 1294–1298. [Google Scholar]
- Nomikos, P.; MacGregor, J. Multi-Way Partial Least Squares in Monitoring Batch Processes. Chemom. Intell. Lab. Syst. 1995, 30, 97–108. [Google Scholar] [CrossRef]
- Zhang, J.; Luo, W.; Dai, Y. Integrated Diagnostic Framework for Process and Sensor Faults in Chemical Industry. Sensors 2021, 21, 822. [Google Scholar] [CrossRef] [PubMed]
- Cai, P.; Deng, X. Incipient fault detection for nonlinear processes based on dynamic multi-block probability related kernel principal component analysis. ISA Trans. 2020, 105, 210–220. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Yan, Y.; Ji, H.; Wang, Y. Recursive Correlative Statistical Analysis Method with Sliding Windows for Incipient Fault Detection. IEEE Trans. Ind. Electron. 2021, 1. [Google Scholar] [CrossRef]
- He, Z.; Shardt, Y.; Wang, D.; Hou, B.; Zhou, H.; Wang, J. An incipient fault detection approach via detrending and denoising. Control Eng. Pract. 2018, 74, 1–12. [Google Scholar] [CrossRef]
- Jiang, P.; Hu, Z.; Liu, J.; Yu, S.; Wu, F. Fault Diagnosis Based on Chemical Sensor Data with an Active Deep Neural Network. Sensors 2016, 16, 1695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Liu, G.; Tang, X.; Lu, J.; Hu, J. An Ensemble Deep Convolutional Neural Network Model with Improved D-S Evidence Fusion for Bearing Fault Diagnosis. Sensors 2017, 17, 1729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, H.; Zhao, J.S. Deep convolutional neural network model based chemical process fault diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A Novel Deep Learning Method for Intelligent Fault Diagnosis of Rotating Machinery Based on Improved CNN-SVM and Multichannel Data Fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Jiang, Q. Data-Driven Nonlinear Chemical Process Fault Diagnosis Based on Hierarchical Representation Learning. Can. J. Chem. Eng. 2020, 98, 2150–2165. [Google Scholar] [CrossRef]
- Zhang, T.F.; Li, Z.; Deng, Z.H.; Hu, B. Hybrid Data Fusion DBN for Intelligent Fault Diagnosis of Vehicle Reducers. Sensors 2019, 19, 2504. [Google Scholar] [CrossRef] [Green Version]
- Park, P.; Marco, P.D.; Shin, H.; Bang, J. Fault Detection and Diagnosis Using Combined Autoencoder and Long Short-Term Memory Network. Sensors 2019, 19, 4612. [Google Scholar] [CrossRef] [Green Version]
- Mallak, A.; Fathi, M. Sensor and Component Fault Detection and Diagnosis for Hydraulic Machinery Integrating LSTM Autoencoder Detector and Diagnostic Classifiers. Sensors 2021, 21, 433. [Google Scholar] [CrossRef]
- Jimenez, D.G.; Larraaga, J.; Poza, J.; Garramiola, F.; Madina, P. Data-Driven Fault Diagnosis for Electric Drives: A Review. Sensors 2021, 21, 4024. [Google Scholar] [CrossRef]
- Zhou, B.; Ye, H.; Zhang, H.; Li, M. A new qualitative trend analysis algorithm based on global polynomial fit. AIChE J. 2017, 63, 3374–3383. [Google Scholar] [CrossRef]
- Cheung, T.Y.; Stephanopoulos, G. Representation of Process Trends—Part I. A Formal Representation Framework. Comput. Chem. Eng. 1990, 14, 495–510. [Google Scholar] [CrossRef]
- Cheung, T.Y.; Stephanopoulos, G. Representation of Process Trends—Part II. The Problem of Scale and Qualitative Scaling. Comput. Chem. Eng. 1990, 14, 511–539. [Google Scholar] [CrossRef]
- Janusz, M.E.; Venkatasubramanian, V. Automatic generation of qualitative descriptions of process trends for fault detection and diagnosis. Eng. Appl. Artif. Intell. 1991, 4, 329–339. [Google Scholar] [CrossRef]
- Konstantinov, K.B.; Yoshida, T. Real-time qualitative analysis of the temporal shapes of (bio) process variables. AIChE J. 1992, 38, 1703–1715. [Google Scholar] [CrossRef]
- Bakshi, B.R.; Stephanopoulos, G. Representation of process trends—III. Multiscale extraction of trends from process data. Comput. Chem. Eng. 1994, 18, 267–302. [Google Scholar] [CrossRef]
- Guo, Q.; Li, S.; Gong, Y.; Wang, F.; Yu, G. Application of qualitative trend analysis in fault diagnosis of entrained-flow coal-water slurry gasifier. Control Eng. Pract. 2021, 112, 104835. [Google Scholar] [CrossRef]
- Zhou, X.; Mao, S.; Li, M. A Novel Anti-Noise Fault Diagnosis Approach for Rolling Bearings Based on Convolutional Neural Network Fusing Frequency Domain Feature Matching Algorithm. Sensors 2021, 21, 5532. [Google Scholar] [CrossRef] [PubMed]
- Dash, S.; Rengaswamy, R.; Venkatasubramanian, V. Fuzzy-logic based trend classification for fault diagnosis of chemical processes. Comput. Chem. Eng. 2003, 27, 347–362. [Google Scholar] [CrossRef]
- Bonet-Solà, D.; Alsina-Pagès, R. A Comparative Survey of Feature Extraction and Machine Learning Methods in Diverse Acoustic Environments. Sensors 2021, 21, 1274. [Google Scholar] [CrossRef]
- da Silva, P.R.N.; Gabbar, H.A.; Junior, P.V.; da Costa Junior, C.T. A new methodology for multiple incipient fault diagnosis in transmission lines using QTA and Nave Bayes classifier. Int. J. Electr. Power Energy Syst. 2018, 103, 326–346. [Google Scholar] [CrossRef]
- Ma, H.; Hu, Y.; Shi, H. A novel local neighborhood standardization strategy and its application in fault detection of multimode processe. Chemom. Intell. Lab. Syst. 2012, 118, 287–300. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Self-adaptive deep learning for multimode process monitoring. Comput. Chem. Eng. 2020, 141, 107024. [Google Scholar] [CrossRef]
- Birol, G.; Ündey, C.; Inar, A. A modular simulation package for fed-batch fermentation: Penicillin production. Comput. Chem. Eng. 2002, 26, 1553–1565. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Unit | Set Value | |||
|---|---|---|---|---|---|
| Batch 1 | Batch 2 | Batch 3 | Batch 4 | ||
| substrate conc. | g∙L−1 | 15 | 14 | 16 | 14 |
| dissolved oxygen | % saturation | 1.16 | 1.00 | 1.20 | 1.02 |
| carbon conc. | mol∙L−1 | 0.0005 | 0.0005 | 0.0006 | 0.00052 |
| culture volume | L | 100 | 100 | 100 | 100 |
| temperature | K | 298 | 298 | 298 | 298 |
| penicillin conc. | g∙L−1 | 0 | 0 | 0 | 0 |
| pH | - | 5.0 | 4.8 | 5.1 | 4.8 |
| biomass conc. | g∙L−1 | 0.1 | 0.1 | 0.1 | 0.1 |
| Variable Name | Unit | Set Value | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | ||
| fault type | aeration rate step increasing | agitator power step increasing | substrate feed rate step increasing | ||||||||||
| magnitude | % | 10 | 30 | 60 | 80 | 15 | 30 | 55 | 70 | 15 | 30 | 50 | 60 |
| occurrence moment | h | 80 | 90 | 100 | 110 | 111 | 90 | 150 | 65 | 80 | 90 | 70 | 105 |
| Variable Name | Unit | Set Value | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S13 | S14 | S15 | S16 | S17 | S18 | S19 | S20 | S21 | S22 | S23 | S24 | ||
| fault type | aeration rate step decreasing | agitator power step decreasing | substrate feed rate step decreasing | ||||||||||
| magnitude | % | 25 | 30 | 45 | 65 | 15 | 30 | 50 | 70 | 15 | 32 | 45 | 75 |
| occurrence moment | h | 68 | 90 | 130 | 100 | 90 | 78 | 80 | 70 | 100 | 180 | 150 | 111 |
| Sample No. | Occurrence Moment (h) | Detect Moment (h) | Result | Actual Fault Type | ||
|---|---|---|---|---|---|---|
| Batch 1 | Batch 4 | Batch 1 | Batch 4 | |||
| 1 | 80 | 80 | 80 | 1 | 1 | 1 |
| 2 | 90 | 90 | 90 | 1 | 1 | |
| 3 | 100 | 100 | 100 | 1 | 1 | |
| 4 | 110 | 110 | 110 | 1 | 1 | |
| 5 | 111 | 111.1 | 111.1 | 2 | 2 | 2 |
| 6 | 90 | 90.5 | 90.5 | 2 | 2 | |
| 7 | 150 | 150.3 | 150.3 | 2 | 2 | |
| 8 | 65 | 65.5 | 65.5 | 2 | 2 | |
| 9 | 80 | 80.4 | 80.4 | 3 | 3 | 3 |
| 10 | 90 | 90.5 | 90.5 | 3 | 3 | |
| 11 | 70 | 70.8 | 70.8 | 3 | 5 | |
| 12 | 105 | 105.1 | 105.1 | 3 | 5 | |
| 13 | 68 | 68 | 68 | 4 | 4 | 4 |
| 14 | 90 | 90.1 | 90.1 | 4 | 4 | |
| 15 | 130 | 130 | 130 | 4 | 4 | |
| 16 | 100 | 100 | 100 | 4 | 4 | |
| 17 | 90 | 90.7 | 90.7 | 5 | 3 | 5 |
| 18 | 78 | 78.1 | 78.1 | 5 | 5 | |
| 19 | 80 | 80.1 | 80.1 | 5 | 5 | |
| 20 | 70 | 70.2 | 70.2 | 5 | 5 | |
| 21 | 100 | 100.2 | 100.2 | 6 | 6 | 6 |
| 22 | 180 | 180.1 | 180.1 | 6 | 6 | |
| 23 | 150 | 150.2 | 150.2 | 6 | 6 | |
| 24 | 111 | 111.1 | 111.1 | 6 | 6 | |
| Sample No. | FDT (h) | FPR | ||
|---|---|---|---|---|
| LAS-QTA | MDKPCA | LAS-QTA | MDKPCA | |
| 1 | 0.0 | 6.9 | 0.0000 | 0.1708 |
| 2 | 0.0 | 5.2 | 0.0000 | 0.2011 |
| 3 | 0.0 | 0.9 | 0.0000 | 0.2051 |
| 4 | 0.0 | 2.0 | 0.0000 | 0.2312 |
| 5 | 0.1 | 1.0 | 0.0000 | 0.2218 |
| 6 | 0.5 | 5.2 | 0.0000 | 0.1932 |
| 7 | 0.3 | 3.1 | 0.0000 | 0.2308 |
| 8 | 0.5 | 14.5 | 0.0000 | 0.2281 |
| 9 | 0.4 | 1.0 | 0.0000 | 0.2139 |
| 10 | 0.5 | 5.2 | 0.0000 | 0.2281 |
| 11 | 0.8 | 16.9 | 0.0000 | 0.2869 |
| 12 | 0.1 | 3.6 | 0.0000 | 0.3182 |
| 13 | 0.0 | 11.4 | 0.0000 | 0.2045 |
| 14 | 0.1 | 5.2 | 0.0000 | 0.1876 |
| 15 | 0.0 | 2.2 | 0.0000 | 0.2248 |
| 16 | 0.0 | 0.9 | 0.0000 | 0.2010 |
| 17 | 0.7 | 5.2 | 0.0000 | 0.2079 |
| 18 | 0.1 | 1.5 | 0.0000 | 0.1883 |
| 19 | 0.1 | 6.9 | 0.0000 | 0.1848 |
| 20 | 0.2 | 9.4 | 0.0000 | 0.2000 |
| 21 | 0.2 | 0.2 | 0.0000 | 0.1485 |
| 22 | 0.1 | 3.2 | 0.0000 | 0.2106 |
| 23 | 0.2 | 3.1 | 0.0000 | 0.1953 |
| 24 | 0.1 | 1.5 | 0.0000 | 0.1518 |
| mean | 0.2083 | 4.8042 | 0.0000 | 0.2098 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Dai, Y.; Luo, W. Early Fault Diagnosis Method for Batch Process Based on Local Time Window Standardization and Trend Analysis. Sensors 2021, 21, 8075. https://doi.org/10.3390/s21238075
Yao Y, Dai Y, Luo W. Early Fault Diagnosis Method for Batch Process Based on Local Time Window Standardization and Trend Analysis. Sensors. 2021; 21(23):8075. https://doi.org/10.3390/s21238075
Chicago/Turabian StyleYao, Yuman, Yiyang Dai, and Wenjia Luo. 2021. "Early Fault Diagnosis Method for Batch Process Based on Local Time Window Standardization and Trend Analysis" Sensors 21, no. 23: 8075. https://doi.org/10.3390/s21238075
APA StyleYao, Y., Dai, Y., & Luo, W. (2021). Early Fault Diagnosis Method for Batch Process Based on Local Time Window Standardization and Trend Analysis. Sensors, 21(23), 8075. https://doi.org/10.3390/s21238075