
Deep-Compact-Clustering Based Anomaly Detection Applied to Electromechanical Industrial Systems

 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
- The proposal of a novel methodological process to carry out the detection of anomalies applied to industrial electromechanical systems.
- The proposal consists of a hybrid scheme that combines the ability to characterize and extract features from DL with the ability to identify anomalies from an OCC-scheme based on ML. In addition, this scheme is adaptive since it can be applied to any environment of electromechanical systems.
- The deep embedding clustering proposed in [40] is extended and adapted to the OCC context. A compact representation for anomaly detection applied to electromechanical systems is learned and such representation ends up significantly increasing the final classification performance.
2. Theoretical Background
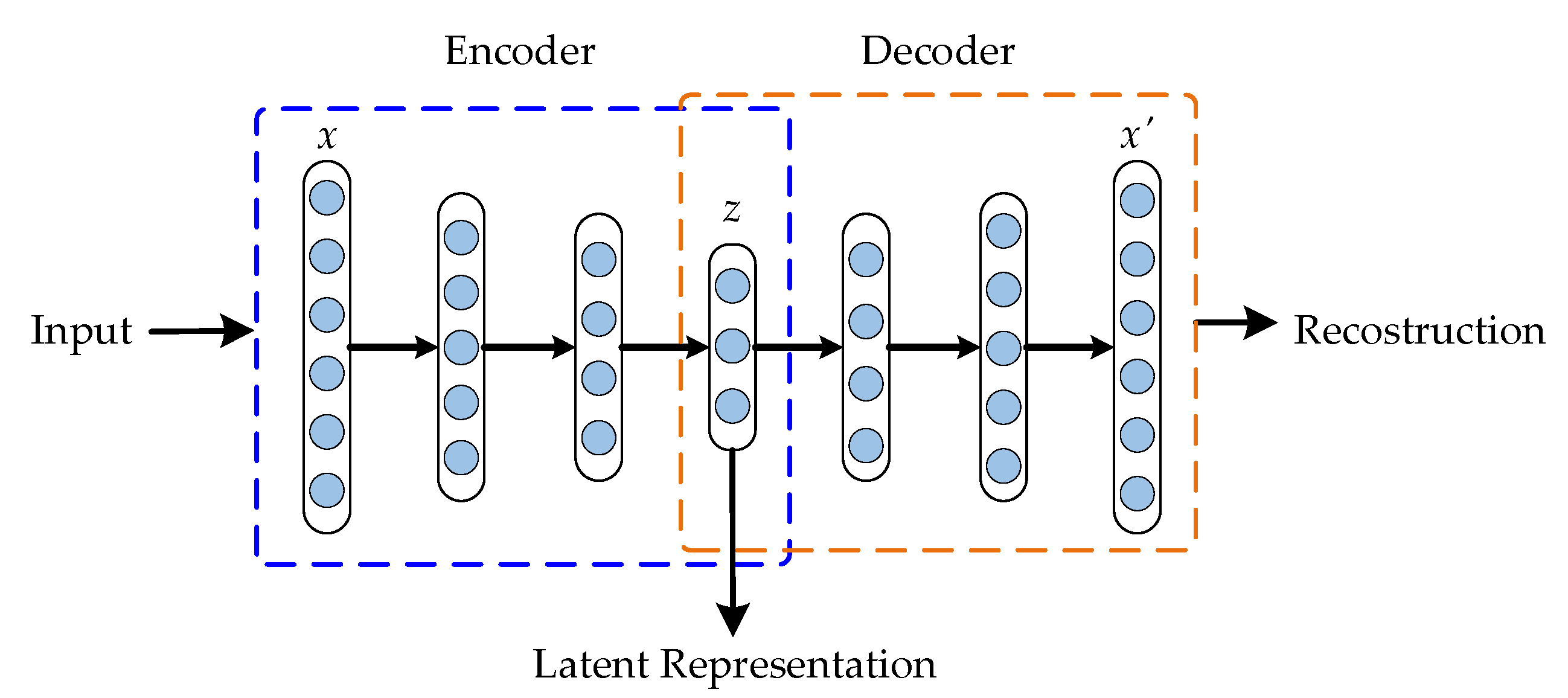
2.1. Deep-Autoencoder
2.2. Deep-Compact-Clustering
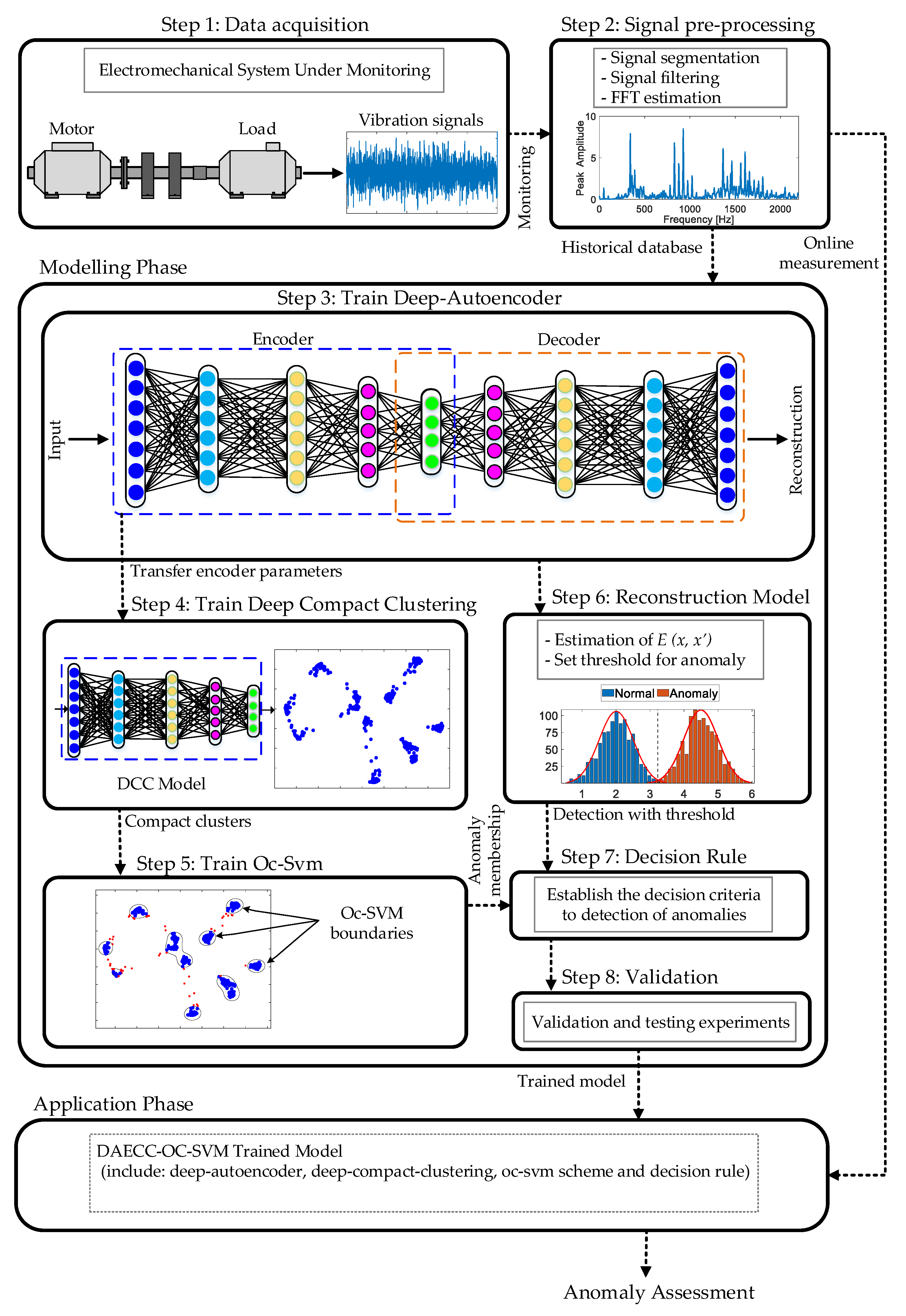
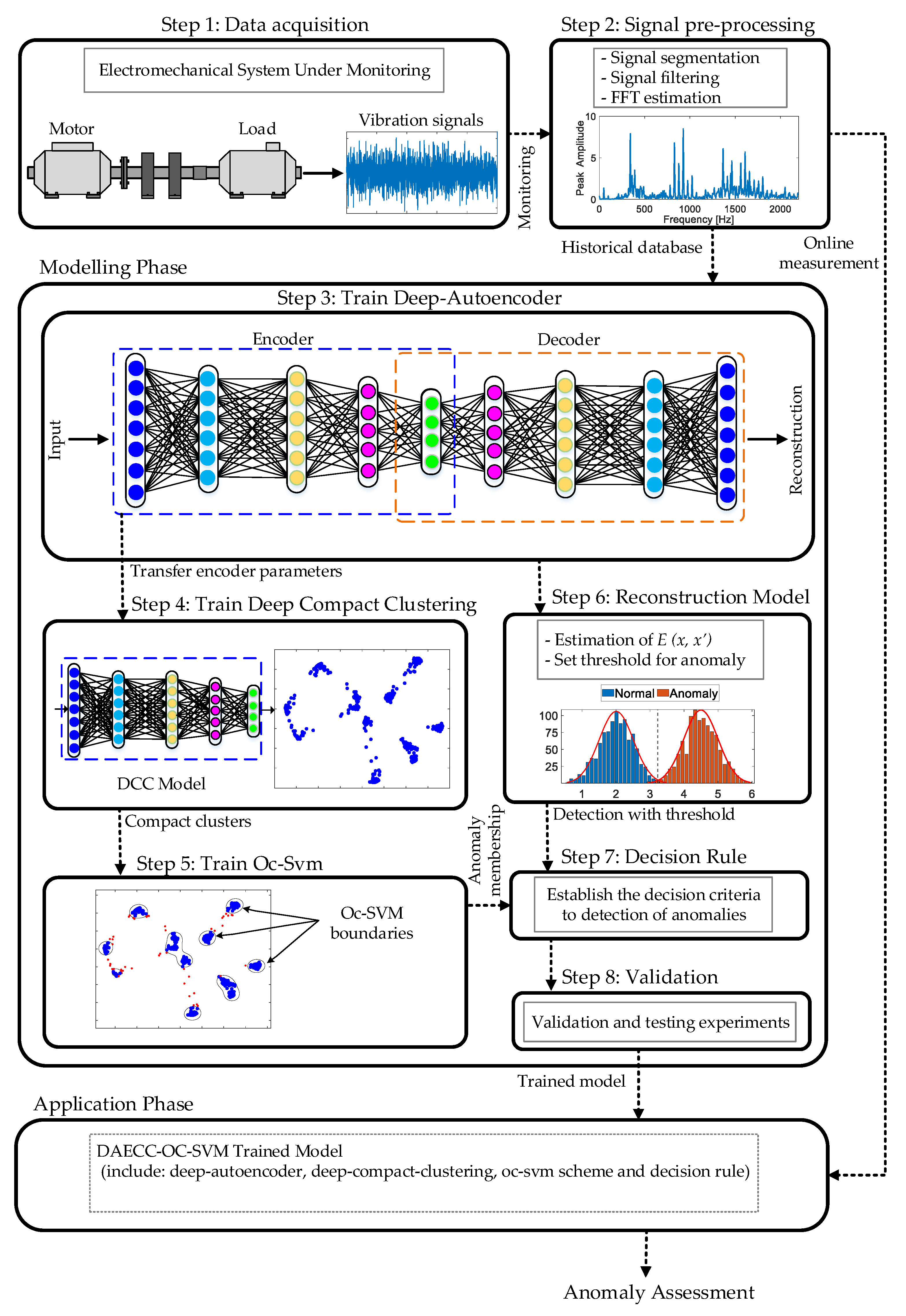
3. Methodology
3.1. Step 1: Data Acquisition
3.2. Step 2: Signal Pre-Processing
3.3. Step 3: Train Deep-Autoencoder
- Population initialization: the chromosomes of the GA are initially defined with a logical vector containing five elements: each one of the three hyperparameters and the number of neurons in the two hidden layers. Afterwards, a randomly initialization of the population is performed by assigning a specific value to each particular parameter; in fact, the values assigned to each parameter are within a predefined range of values. Once the initialization of the population is achieved the procedure continues in Step 2.
- Population assessment: in this step is evaluated the fitness function which is based on the minimization of the reconstruction error between the input and the output features. Specifically, the Equation (1) in Section 2.1 is the GA’s optimization function. Thereby, GA’s aim is to achieve minimum reconstruction error. Therefore, the optimization problem to be solved by the GA involves the search of those specific parameter values that leads a high-performance feature mapping. Then, once the whole population is evaluated under a wide range of values, the condition of best parameter values is analyzed, and the procedure continues in Step 4.
- Mutation operation: the mutation of the GA produces a new value of the population by means of the roulette wheel selection, the new generated population takes into account the choosing of the best fitness value achieved by the previous evaluated population. Moreover, a mutation operation which is based on the Gaussian distribution is applied during the generation of the new population. Subsequently, the procedure continues in Step 2.
- Stop criteria: the stop criteria for the GA are two: (i) the obtention of a reconstruction error value lower than a predefined threshold, 5%, and/or, (ii) reaching the maximum number of iterations, 1000 epoch. In the case of the first stop criterion, (i), the procedure is repeated iteratively until those optimal parameter values are found until the GA evolve, then, the procedure continues in Step 3.
3.4. Step 4: Train Deep-Compact Clustering
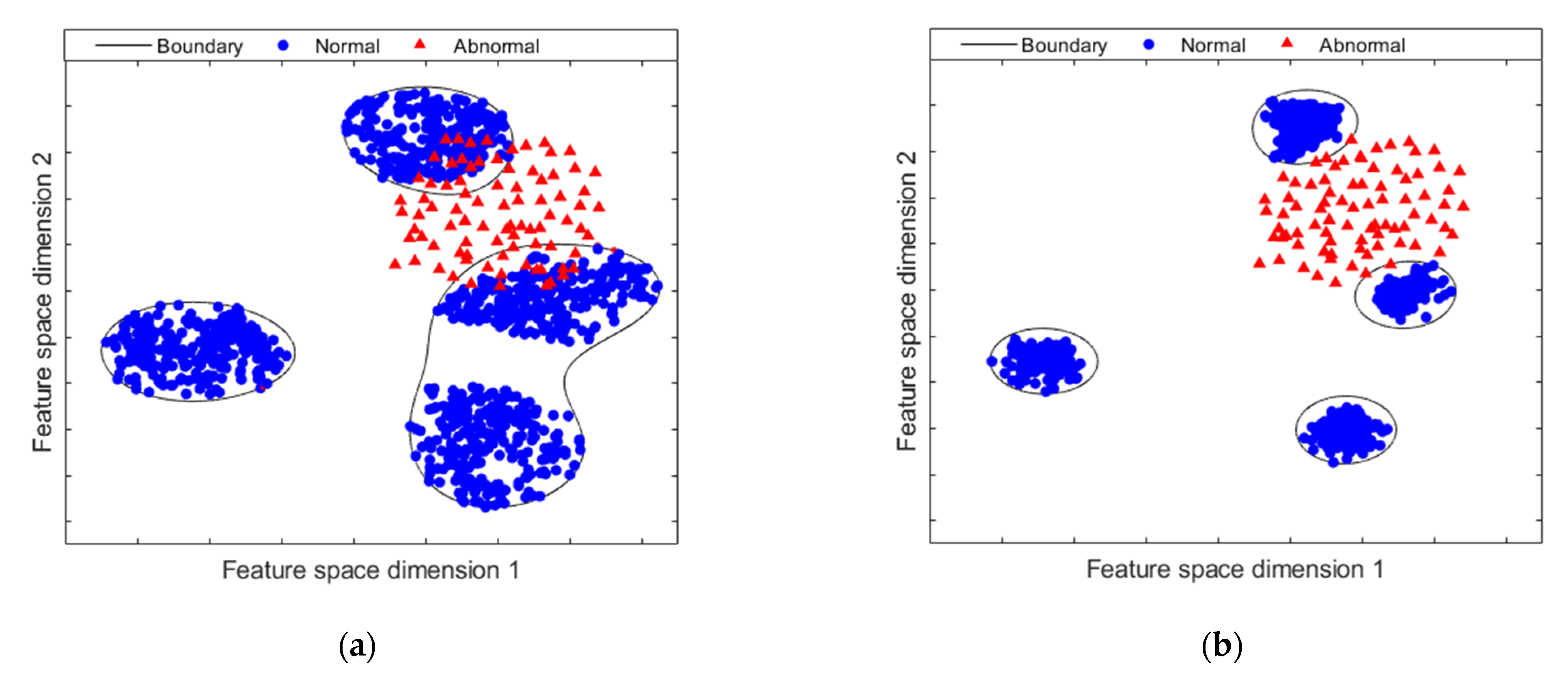
3.5. Step 5: Train Oc-Svm
3.6. Step 6: Reconstruction Model
3.7. Step 7: Decision Rule
3.8. Step 8: Valiadation
4. Validation and Analysis
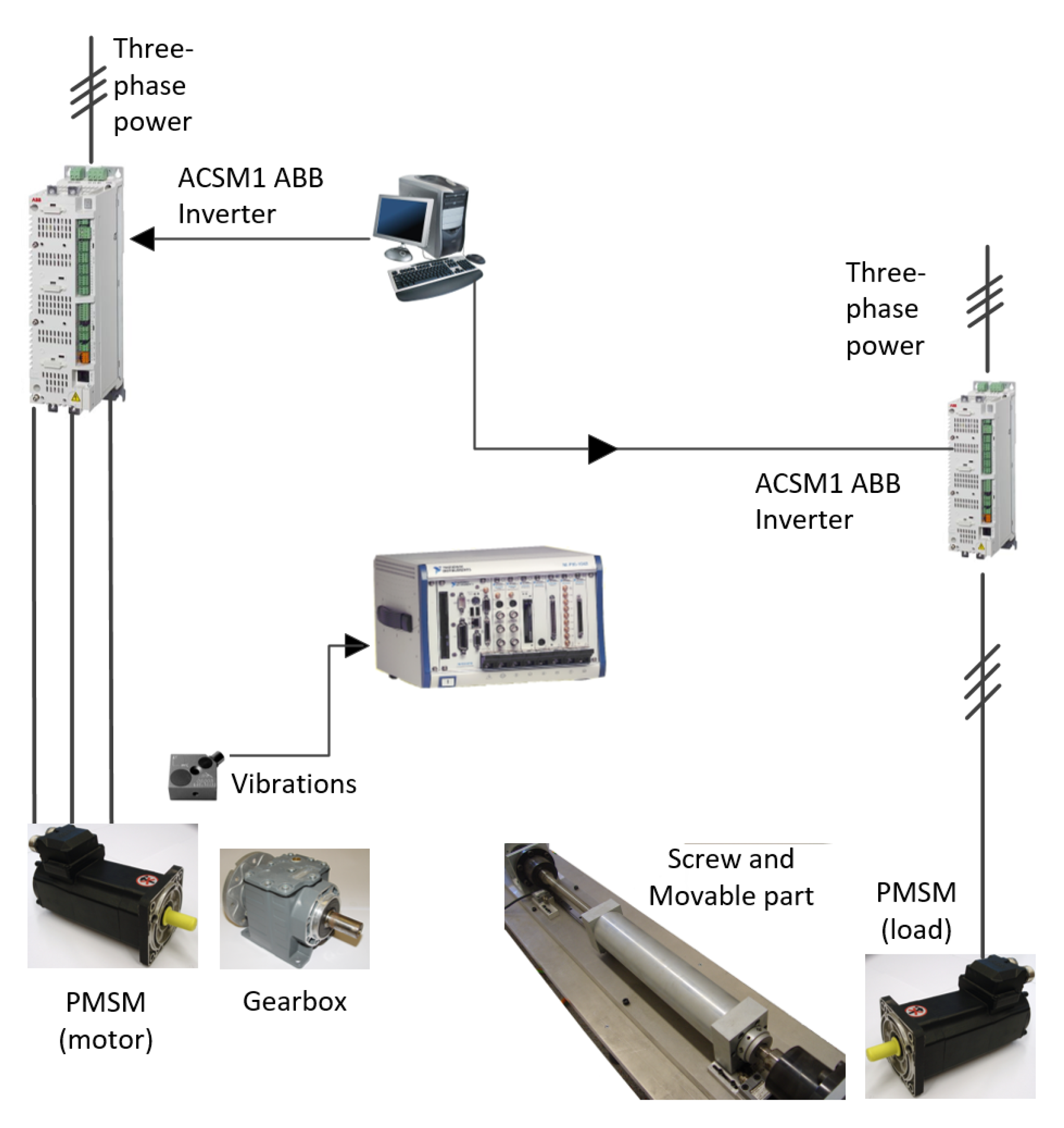
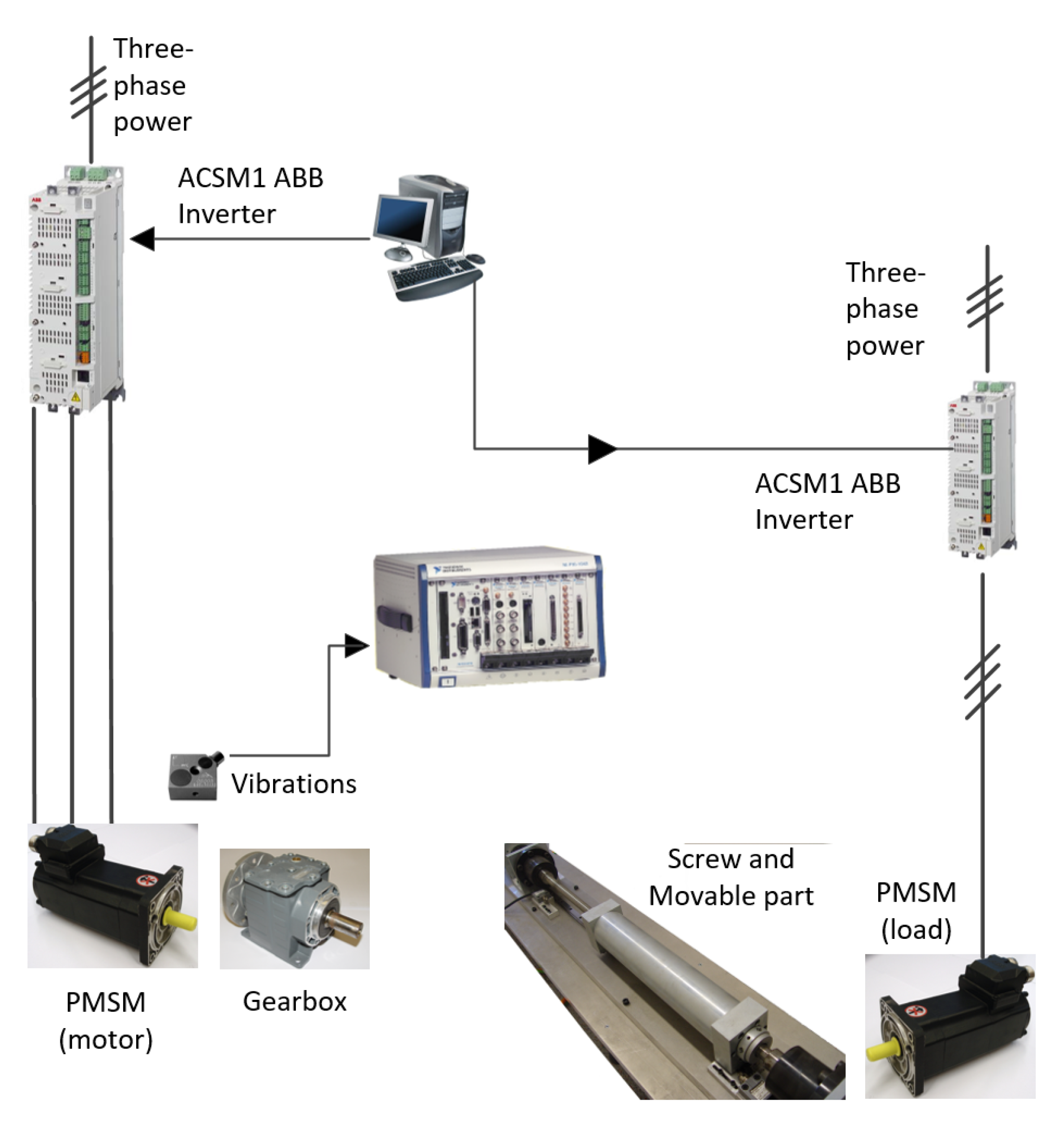
4.1. Test Benches Descriptions
4.1.1. Multi-Fault Experimental Test Bench
4.1.2. Rolling Bearing Faults Experimental Test Bench
4.1.3. Datasets Preprocessing and Methodology Adaption
- (1)
- First, the datasets were divided into three subsets, regarding the proposed methodology. Second, the data were selected randomly and a five-fold cross-validation approach is applied over the data in order to corroborate that the results are statistically significant.
- (2)
- Fast Fourier transform (FFT) is applied to every part of the windowed signals to obtain the corresponding frequency amplitude. The frequency amplitude of sample is scaled following the recommendations of [46].
- (3)
- For the multi-fault experimental test bench, the data of the plane perpendicular to the motor rotation are used. While for the bearing fault dataset, it takes the single-sided frequency amplitude calculated in the last step as the final input for the model. Therefore, the input dimension for the experimental test bench for the length of the input is 2048, and for the rolling bearing dataset, it is 1024.
- (4)
- Three autoencoders were used to build the deep-autoencoder. The hidden layers were established through search optimization using a GA. For the experimental test bench, the architecture of the deep-autoencoder is -850-120-2, for the encoder part, where is the dimension of input data. The decoder is a mirror of the encoder with dimensions 2-120-850-. While the encoder architecture of DAE for the rolling bearing dataset is -500-100-2, also is the dimension of input data.
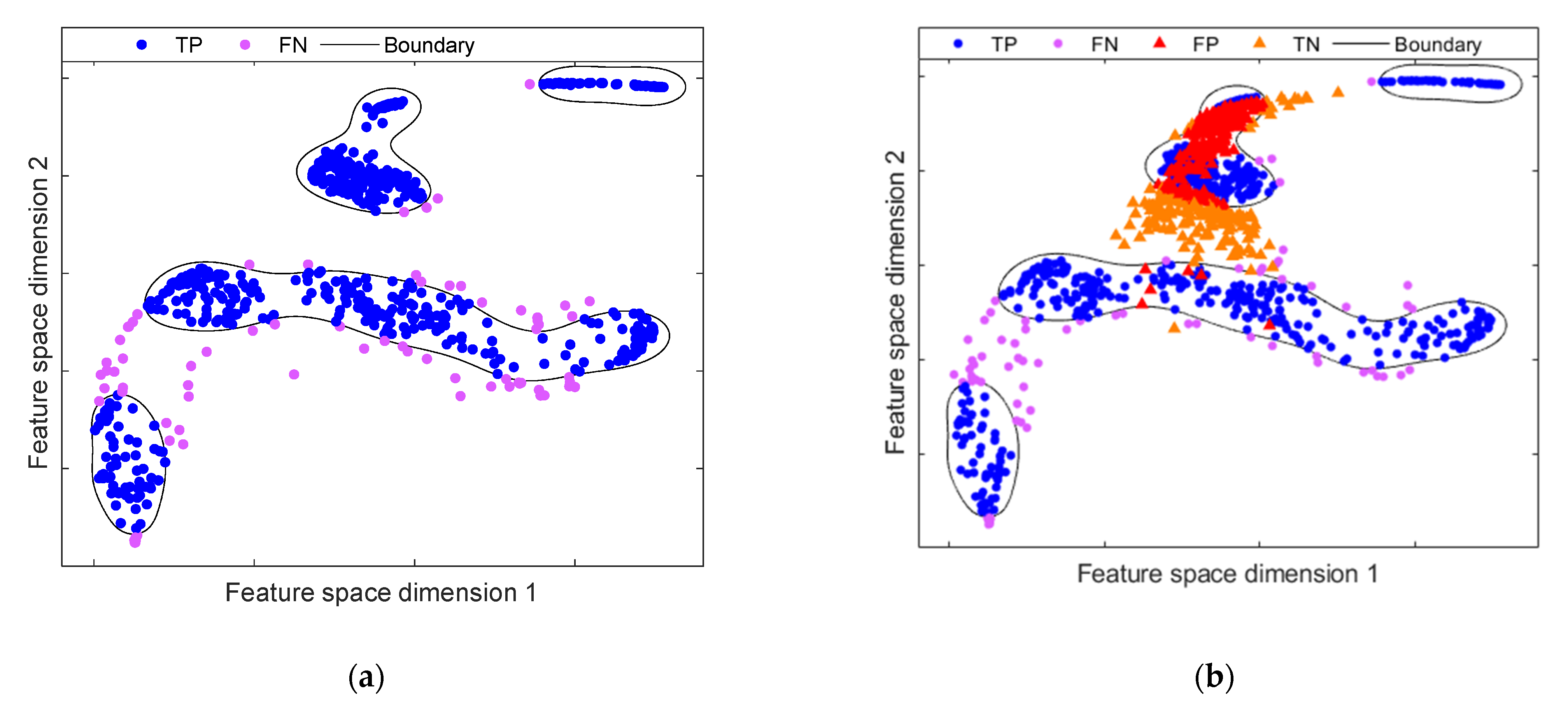
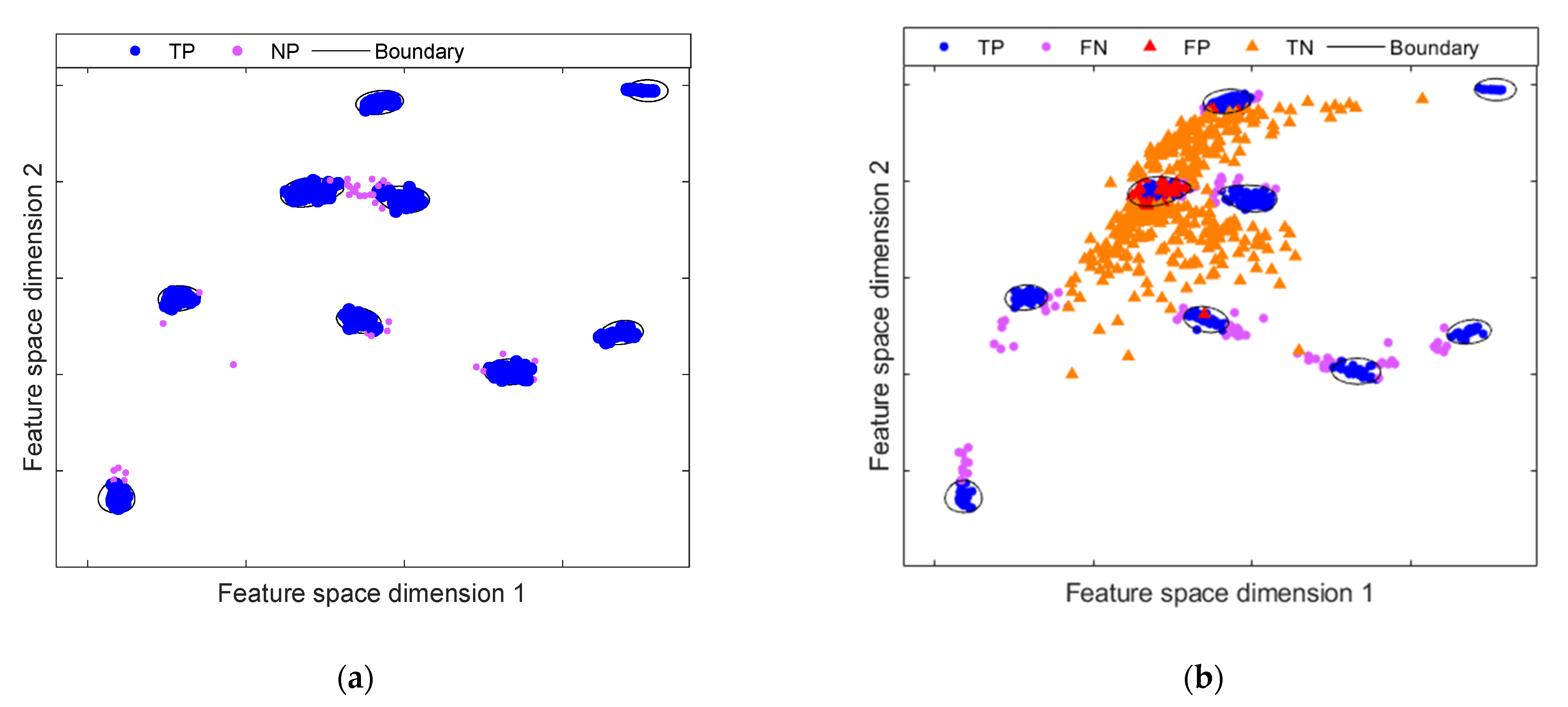
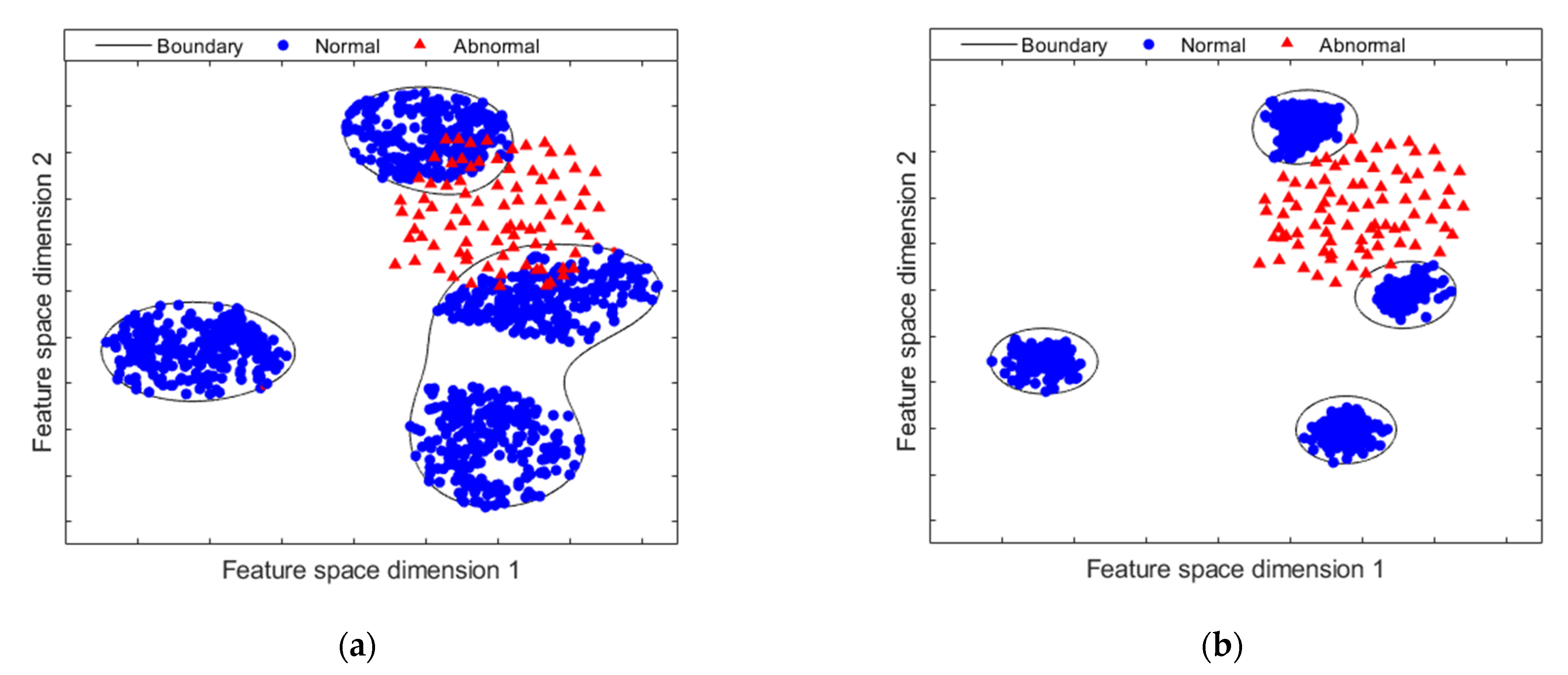
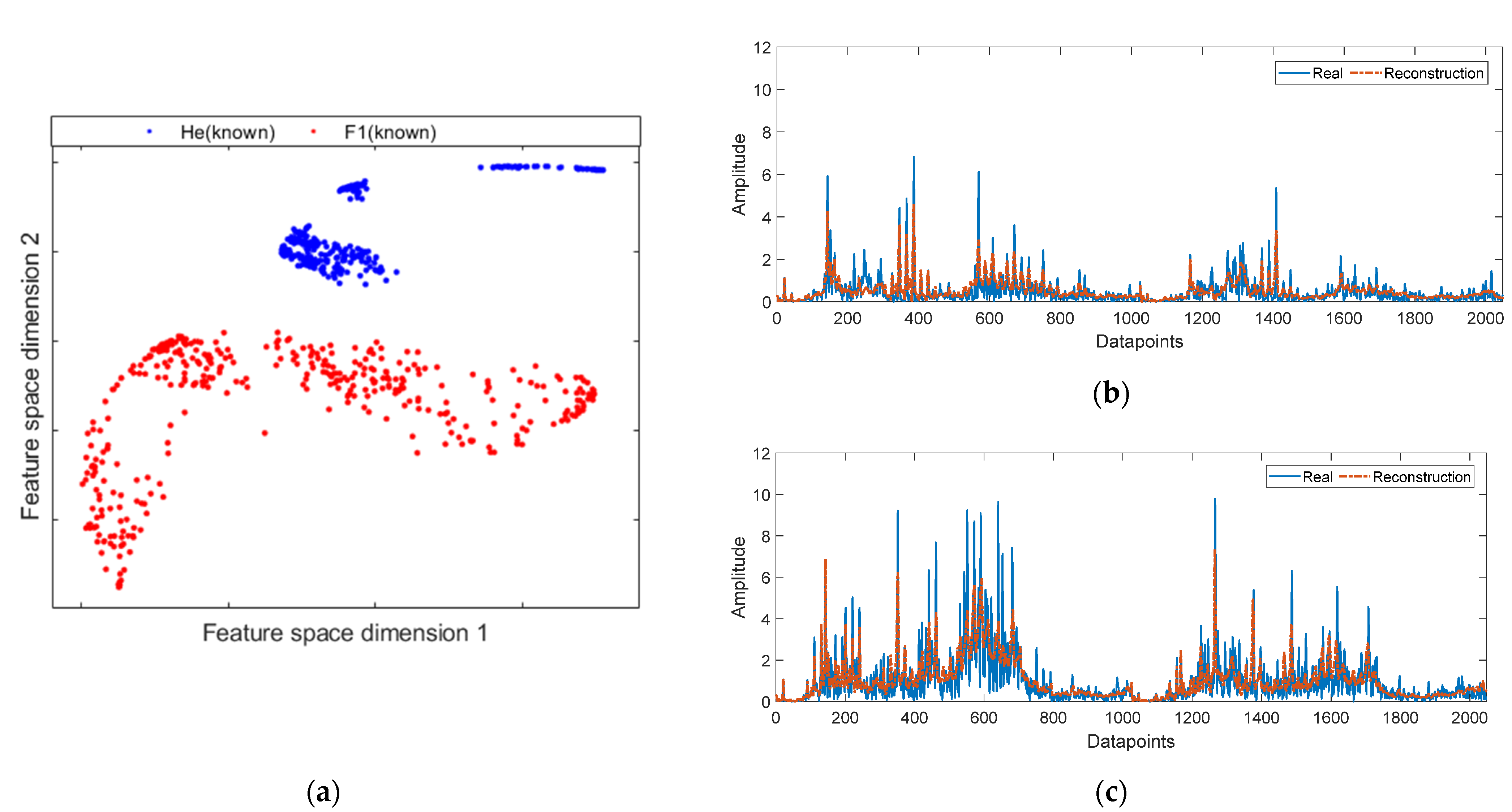
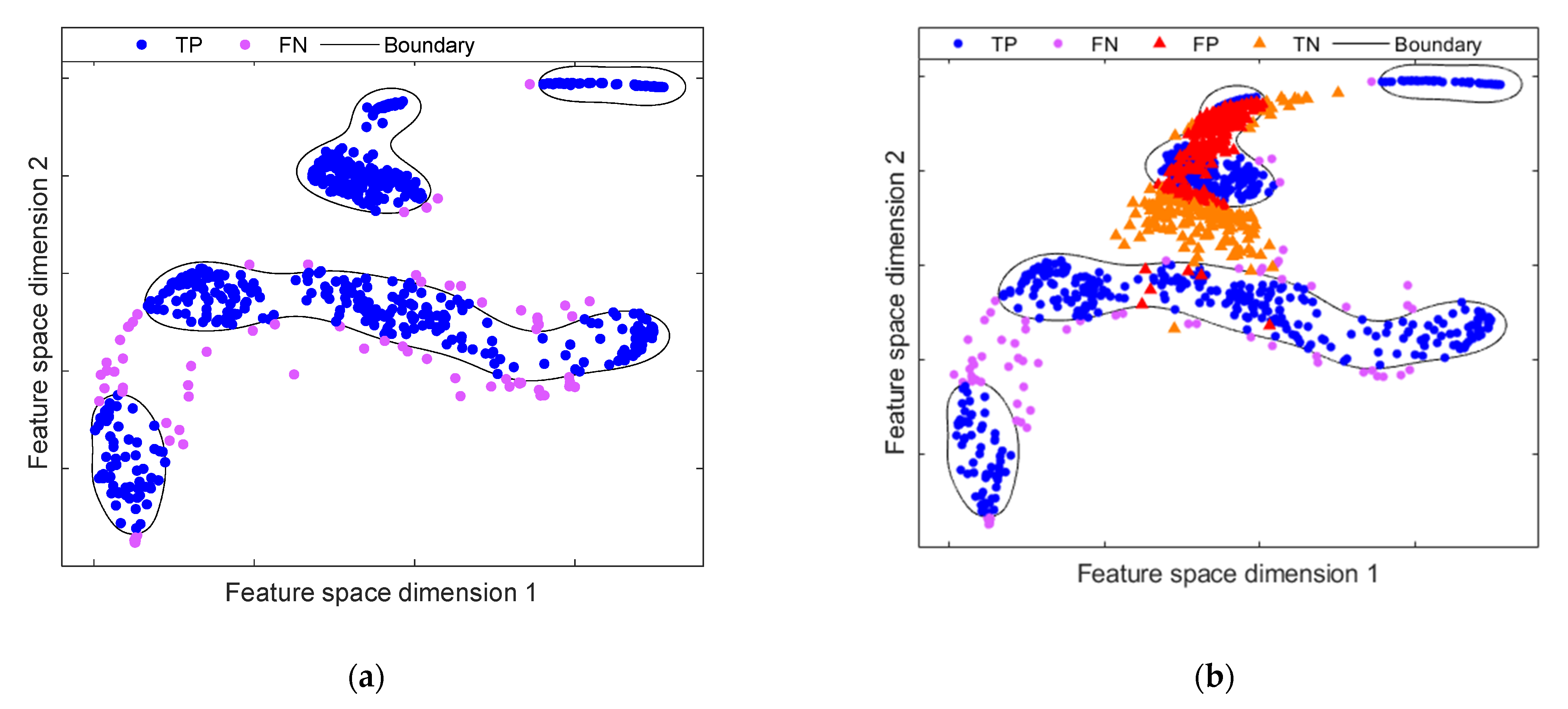
4.2. Experimental Results
- (1)
- (2)
- Variant simple Method 1: deep-autoencoder + OC-SVM;
- (3)
- Variant simple Method 2: deep compact clustering + OC-SVM.
4.2.1. Results on Multi-Fault Experimental Test Bench
4.2.2. Results on Bearing Fault Experimental Test Bench
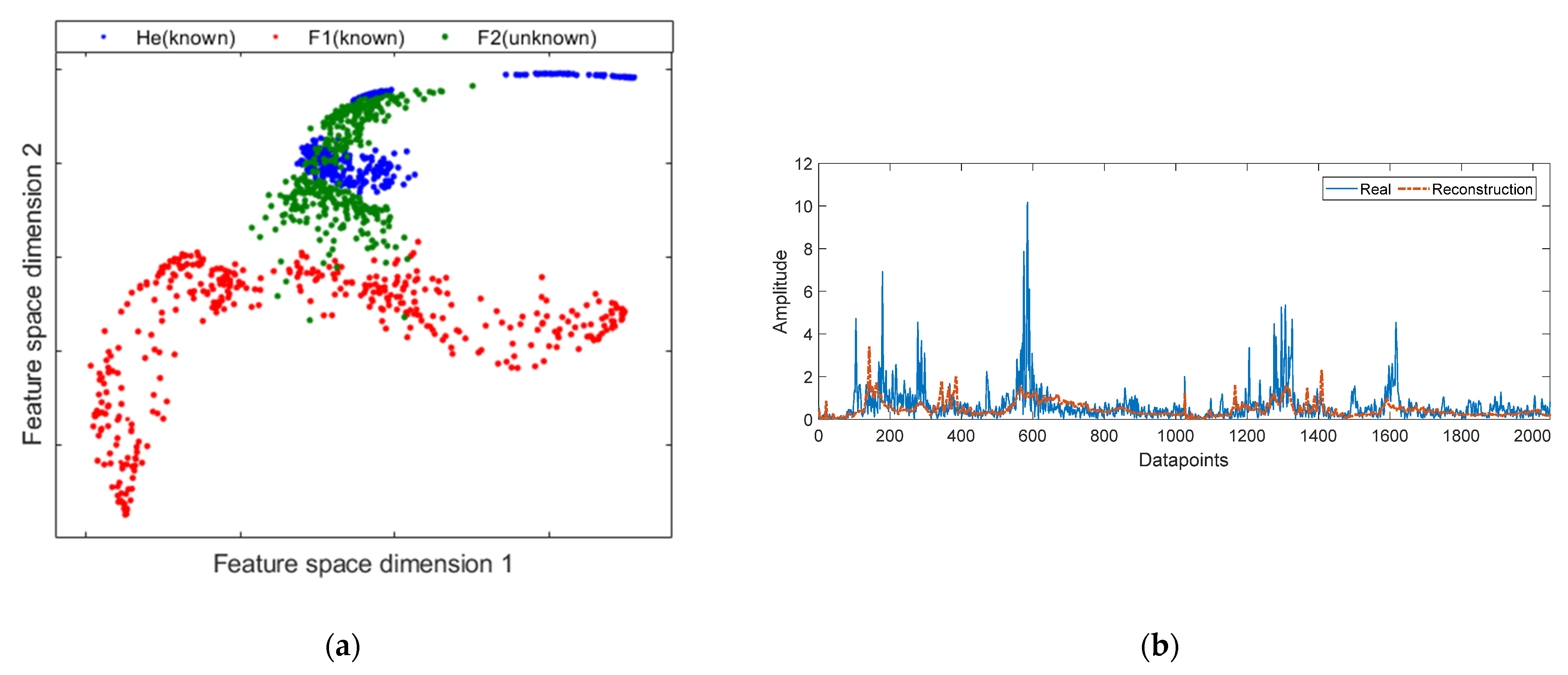
4.3. DAECC-OC-SVM Performance Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Munikoti, S.; Das, L.; Natarajan, B.; Srinivasan, B. Data-Driven Approaches for Diagnosis of Incipient Faults in DC Motors. IEEE Trans. Ind. Inform. 2019, 15, 5299–5308. [Google Scholar] [CrossRef]
- Manjurul-Islam, M.M.; Jong-Myon, K. Reliable multiple combined fault diagnosis of bearings using heterogeneous feature models and multiclass support vector Machines. Reliab. Eng. Syst. Saf. 2019, 184, 55–66. [Google Scholar] [CrossRef]
- Saucedo, J.J.; Delgado, M.; Osornio, R.A.; Romero, R.J. Multifault diagnosis method applied to an electric machine based on high-dimensional feature reduction. IEEE Trans. Ind. Appl. 2017, 53, 3086–3097. [Google Scholar] [CrossRef] [Green Version]
- Rauber, T.W.; Boldt, F.A.; Varejao, F.M. Heterogeneous feature models and feature selection applied to bearing fault diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 637–646. [Google Scholar] [CrossRef]
- Kumar, S.; Mukherjee, D.; Guchhait, P.K.; Banerjee, R.; Srivastava, A.K.; Vishwakarma, D.N.; Saket, R.K. A Comprehensive Review of Condition Based Prognostic Maintenance (CBPM) for Induction Motor. IEEE Access 2019, 7, 90690–90704. [Google Scholar] [CrossRef]
- Gonzalez-Jimenez, D.; del-Olmo, J.; Poza, J.; Garramiola, F.; Madina, P. Data-Driven Fault Diagnosis for Electric Drives: A Review. Sensors 2021, 21, 4024. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, S.; Zhu, Y. Convolutional neural network in intelligent fault diagnosis toward rotatory machinery. IEEE Access 2020, 8, 510–586. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale convolutional neural networks for fault diagnosis of wind turbine gearbox. IEEE Trans. Ind. Electron. 2018, 66, 3196–3207. [Google Scholar] [CrossRef]
- Chang, C.-H. Deep and shallow architecture of multilayer neural networks. IEEE Trans. Neural Netw. Learn. Systems. 2015, 26, 2477–2486. [Google Scholar] [CrossRef] [PubMed]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Li, H.; Hu, G.; Li, J.; Zhou, M. Intelligent fault diagnosis for largescale rotating machines using binarized deep neural networks and random forests. IEEE Trans. Autom. Sci. Eng. 2021. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, S.; Jin, B. Sequential Fault Diagnosis Based on LSTM Neural Network. IEEE Access 2018, 6, 12929–12939. [Google Scholar] [CrossRef]
- Li, X.; Jia, X.-D.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Intelligent cross-machine fault diagnosis approach with deep auto-encoder and domain adaptation. Neurocomputing 2020, 383, 235–247. [Google Scholar] [CrossRef]
- Li, C.; Zhang, W.; Peng, G.; Liu, S. Bearing fault diagnosis using fully-connected winner-take-all autoencoder. IEEE Access 2018, 6, 6103–6115. [Google Scholar] [CrossRef]
- Zhu, H.; Cheng, J.; Zhang, C.; Wu, J.; Shao, X. Stacked pruning sparse denoising autoencoder based intelligent fault diagnosis of rolling bearings. Appl. Soft Comput. 2020, 88, 106060. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Jiang, G.; Xie, P.; He, H.; Yan, J. Wind Turbine Fault Detection Using a Denoising Autoencoder with Temporal Information. IEEE/ASME Trans. Mechatron. 2018, 23, 89–100. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y.; Wang, J. Analytical investigation of autoencoder-based methods for unsupervised anomaly detection in building energy data. Appl. Energy 2018, 211, 1123–1135. [Google Scholar] [CrossRef]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep architecture for high-speed railway insulator surface defect detection: Denoising autoencoder with multitask learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H.; Luo, Z.; Li, X. Open-Set Domain Adaptation in Machinery Fault Diagnostics Using Instance-Level Weighted Adversarial Learning. IEEE Trans. Ind. Inform. 2021, 17, 7445–7455. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X. Federated Transfer Learning for Intelligent Fault Diagnostics Using Deep Adversarial Networks with Data Privacy. IEEE/ASME Trans. Mechatron. 2021. [Google Scholar] [CrossRef]
- Li, J.; Huang, R.; He, G.; Wang, S.; Li, G.; Li, W. A Deep Adversarial Transfer Learning Network for Machinery Emerging Fault Detection. IEEE Sens. J. 2020, 20, 8413–8422. [Google Scholar] [CrossRef]
- Zheng, H.; Yang, Y.; Yin, J.; Li, Y.; Wang, R.; Xu, M. Deep Domain Generalization Combining A Priori Diagnosis Knowledge Toward Cross-Domain Fault Diagnosis of Rolling Bearing. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar]
- Pimentel, M.A.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A review of novelty detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Chan, F.T.S.; Wang, Z.X.; Patnaik, S.; Tiwari, M.K.; Wang, X.P.; Ruan, J.H. Ensemble-learning based neural networks for novelty detection in multi-class systems. Appl. Soft Comput. 2020, 93, 106396. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Linear models for outlier detection. In Outlier Analysis, 2nd ed.; Springer Nature: New York, NY, USA, 2017; pp. 65–111. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Ramírez, M.; Ruíz-Soto, L.; Arellano-Espitia, F.; Saucedo, J.J.; Delgado-Prieto, M.; Romeral, L. Evaluation of Multiclass Novelty Detection Algorithms for Electric Machine Monitoring. In Proceedings of the IEEE 12th International Symposium on Diagnostics for Electrical Machines, Power Electronics and Drives (SDEMPED), Toulouse, France, 27–30 August 2019; pp. 330–337. [Google Scholar]
- Guo, J.; Liu, G.; Zuo, Y.; Wu, J. An Anomaly Detection Framework Based on Autoencoder and Nearest Neighbor. In Proceedings of the 15th International Conference on Service Systems and Service Management (ICSSSM), Hang Zhou, China, 21–22 July 2018; pp. 1–6. [Google Scholar]
- Yang, Z.; Gjorgjevikj, D.; Long, J. Sparse Autoencoder-based Multi-head Deep Neural Networks for Machinery Fault Diagnostics with Detection of Novelties. Chin. J. Mech. Eng. 2021, 34, 54. [Google Scholar] [CrossRef]
- Carino, J.A.; Delgado-Prieto, M.; Iglesias, J.A.; Sanchis, A.; Zurita, D.; Millan, M.; Redondo, J.A.O.; Romero-Troncoso, R. Fault Detection and Identification Methodology under an Incremental Learning Framework Applied to Industrial Machinery. IEEE Access 2018, 6, 49755–49766. [Google Scholar] [CrossRef]
- Ergen, T.; Kozat, S.S. Unsupervised Anomaly Detection with LSTM Neural Networks. IEEE Trans. Neural Netw. Learn. Systems. 2020, 31, 3127–3141. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.; Gutoski, M.; Lazzaretti, A.E.; Lopes, H.S. One-Class Classification in Images and Videos Using a Convolutional Autoencoder with Compact Embedding. IEEE Access 2020, 8, 86520–86535. [Google Scholar] [CrossRef]
- Ribeiro, M.; Lazzaretti, A.E.; Lopes, H.S. A study of deep convolutional auto-encoders for anomaly detection in videos. Pattern Recognit. Lett. 2018, 105, 13–22. [Google Scholar] [CrossRef]
- Peng, X.; Xiao, S.; Feng, J.; Yau, W.Y.; Yi, Z. Deep subspace clustering with sparsity prior. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–16 July 2016; pp. 1925–1931. [Google Scholar]
- Tian, F.; Gao, B.; Cui, Q.; Chen, E.; Liu, T.-Y. Learning deep representations for graph clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1293–1299. [Google Scholar]
- Xie, J.; Girshick, R.B.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Gutoski, M.; Ribeiro, M.; Romero Aquino, N.M.; Lazzaretti, A.E.; Lopes, H.S. A clustering-based deep autoencoder for one-class image classification. In Proceedings of the IEEE Latin American Conference on Computational Intelligence (LA-CCI), Arequipa, Peru, 8–10 November 2017; pp. 1–6. [Google Scholar]
- Ren, Y.; Hu, K.; Dai, X.; Pan, L.; Hoi, S.; Xu, Z. Semi-supervised deep embedded clustering. Neurocomputing 2019, 325, 121–130. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Saków, M.; Marchelek, K. Design and optimisation of regression-type small phase shift FIR filters and FIR-based differentiators with optimal local response in LS-sense. Mech. Syst. Signal Process. 2021, 152, 107408. [Google Scholar] [CrossRef]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE Trans. Ind. Electron. 2017, 64, 2296–2305. [Google Scholar] [CrossRef]
- Arellano-Espitia, F.; Delgado-Prieto, M.; Martinez-Viol, V.; Saucedo-Dorantes, J.J.; Osornio-Rios, R.A. Deep-Learning-Based Methodology for Fault Diagnosis in Electromechanical Systems. Sensors 2020, 20, 3949. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations—ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Chen, Z.; Li, W. Multisensor Feature Fusion for Bearing Fault Diagnosis Using Sparse Autoencoder and Deep Belief Network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72, 303–315. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Wang, F.; Wang, Y. Rolling bearing fault diagnosis using adaptive deep belief network with dual-tree complex wavelet packet. ISA Trans. 2017, 69, 187–201. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Principi, E.; Rossetti, D.; Squartini, S.; Piazza, F. Unsupervised electric motor fault detection by using deep autoencoders. IEEE/CAA J. Autom. Sin. 2019, 6, 441–451. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
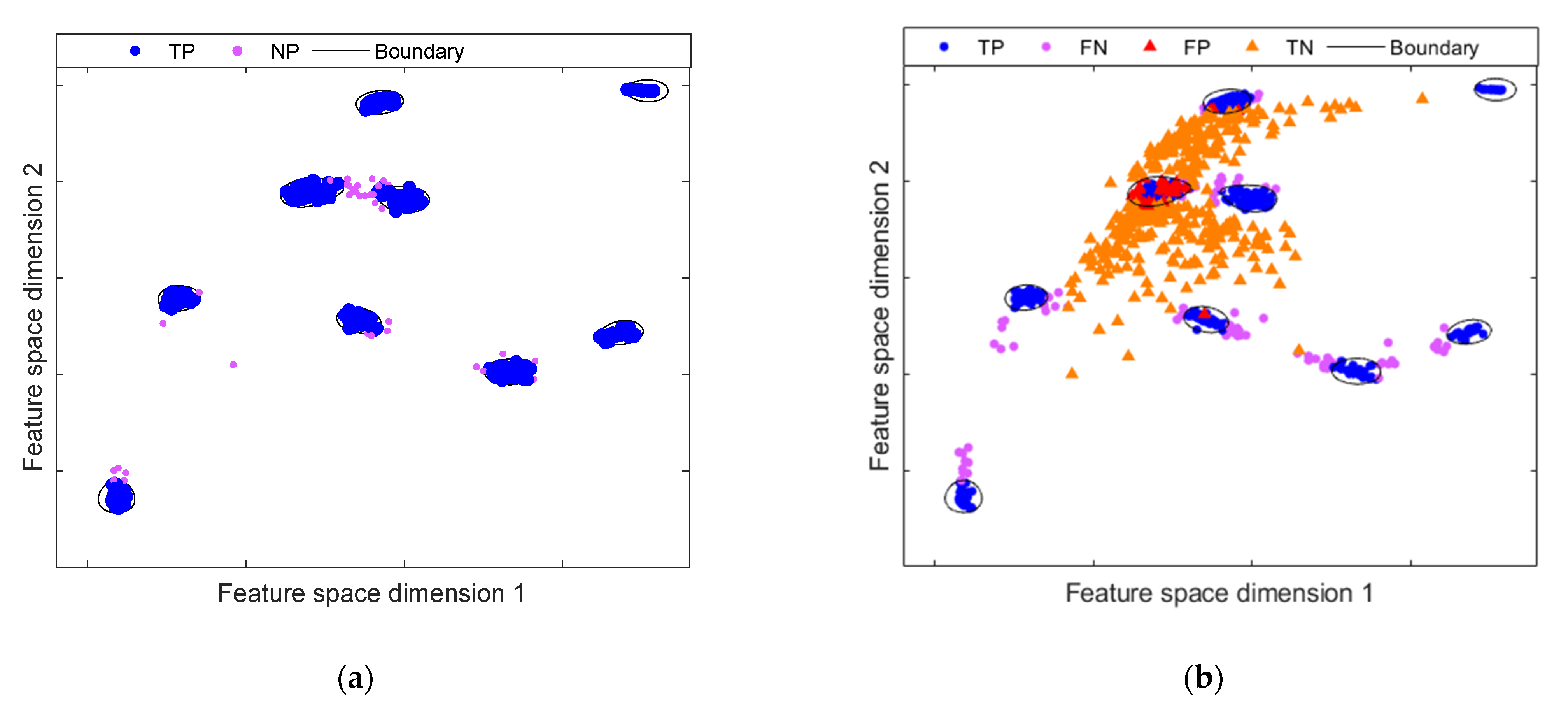{kind=link}
| Label | Training Set | Testing Set | |
|---|---|---|---|
| Known Set | Unknown Set | ||
| S1 | He | He | Bf, Df, Ef, Gf |
| S2 | He, Bf | He, Bf | Df, Ef, Gf |
| S3 | He, Df | He, Df | Bf, Ef, Gf |
| S4 | He, Ef | He, Ef | Bf, Df, Gf |
| S5 | He, Gf | He, Gf | Bf, Df, Ef |
| S6 | He, Bf, Df | He, Bf, Df | Ef, Gf |
| S7 | He, Bf, Ef | He, Bf, Ef | Df, Gf |
| S8 | He, Bf, Gf | He, Bf, Gf | Df, Ef |
| S9 | He, Df, Ef | He, Df, Ef | Bf, Gf |
| S10 | He, Df, Gf | He, Df, Gf | Bf, Ef |
| S11 | He, Ef, Gf | He, Ef, Gf | Bf, Df |
| S12 | He, Bf, Df, Ef | He, Bf, Df, Ef | Gf |
| S13 | He, Bf, Df, Gf | He, Bf, Df, Gf | Ef |
| S14 | He, Bf, Ef, Gf | He, Bf, Ef, Gf | Df |
| S15 | He, Df, Ef, Gf | He, Df, Ef, Gf | Bf |
| Label | Training Set | Testing Set | |
|---|---|---|---|
| Known Set | Unknown Set | ||
| SS1 | HE | HE | FB, FI, FO |
| SS2 | HE, FB | HE, FB | FI, FO |
| SS3 | HE, FI | HE, FI | FB, FO |
| SS4 | HE, FO | HE, FO | FB, FI |
| SS5 | HE, FB, FI | HE, FB, FI | FO |
| SS6 | HE, FB, FO | HE, FB, FO | FI |
| SS7 | HE, FI, FO | HE, FI, FO | FB |
| Label | DAE-MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | ||||
|---|---|---|---|---|---|---|---|---|
| TPR | TNR | TPR | TNR | TPR | TNR | TPR | TNR | |
| S1 | 0.982 | 0.607 | 0.891 | 0.409 | 0.936 | 0.662 | 0.936 | 0.894 |
| S2 | 0.908 | 0.003 | 0.931 | 0.573 | 0.862 | 0.797 | 0.862 | 0.801 |
| S3 | 0.988 | 0.672 | 0.888 | 0.145 | 0.908 | 0.542 | 0.908 | 0.877 |
| S4 | 0.933 | 0.770 | 0.911 | 0.138 | 0.873 | 0.677 | 0.873 | 0.922 |
| S5 | 0.983 | 0.370 | 0.892 | 0.402 | 0.869 | 0.558 | 0.869 | 0.874 |
| S6 | 0.922 | 0.020 | 0.917 | 0.459 | 0.852 | 0.797 | 0.852 | 0.797 |
| S7 | 0.920 | 0.013 | 0.909 | 0.278 | 0.870 | 0.811 | 0.870 | 0.811 |
| S8 | 0.937 | 0.000 | 0.910 | 0.496 | 0.916 | 0.830 | 0.916 | 0.830 |
| S9 | 0.967 | 0.993 | 0.929 | 0.035 | 0.911 | 0.291 | 0.911 | 0.997 |
| S10 | 0.967 | 0.500 | 0.930 | 0.17 | 0.934 | 0.435 | 0.934 | 0.851 |
| S11 | 0.949 | 0.611 | 0.917 | 0.02 | 0.873 | 0.721 | 0.873 | 0.887 |
| S12 | 0.936 | 0.030 | 0.924 | 0.322 | 0.879 | 0.800 | 0.879 | 0.802 |
| S13 | 0.938 | 0.000 | 0.932 | 0.228 | 0.835 | 0.822 | 0.835 | 0.822 |
| S14 | 0.938 | 0.000 | 0.923 | 0.262 | 0.860 | 0.782 | 0.860 | 0.782 |
| S15 | 0.954 | 1.000 | 0.936 | 0.000 | 0.973 | 0.001 | 0.973 | 1.000 |
| Label | Balanced Accuracy | |||
|---|---|---|---|---|
| DAE MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | |
| S1 | 0.795 | 0.648 | 0.799 | 0.915 |
| S2 | 0.456 | 0.752 | 0.830 | 0.831 |
| S3 | 0.830 | 0.516 | 0.725 | 0.892 |
| S4 | 0.851 | 0.524 | 0.775 | 0.897 |
| S5 | 0.677 | 0.647 | 0.713 | 0.871 |
| S6 | 0.476 | 0.688 | 0.835 | 0.835 |
| S7 | 0.469 | 0.593 | 0.805 | 0.840 |
| S8 | 0.461 | 0.703 | 0.873 | 0.873 |
| S9 | 0.979 | 0.482 | 0.601 | 0.954 |
| S10 | 0.736 | 0.550 | 0.653 | 0.892 |
| S11 | 0.783 | 0.468 | 0.765 | 0.880 |
| S12 | 0.483 | 0.623 | 0.839 | 0.840 |
| S13 | 0.469 | 0.580 | 0.828 | 0.828 |
| SS4 | 0.469 | 0.592 | 0.821 | 0.821 |
| S15 | 0.977 | 0.468 | 0.487 | 0.986 |
| Average | 0.660 | 0.597 | 0.756 | 0.877 |
| Label | DAE MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | ||||
|---|---|---|---|---|---|---|---|---|
| PPV | NPV | PPV | NPV | PPV | NPV | PPV | NPV | |
| S1 | 0.777 | 0.947 | 0.595 | 0.760 | 0.740 | 0.909 | 0.907 | 0.932 |
| S2 | 0.646 | 0.000 | 0.857 | 0.821 | 0.908 | 0.720 | 0.908 | 0.720 |
| S3 | 0.888 | 0.860 | 0.677 | 0.415 | 0.763 | 0.704 | 0.934 | 0.821 |
| S4 | 0.909 | 0.820 | 0.682 | 0.461 | 0.834 | 0.721 | 0.957 | 0.784 |
| S5 | 0.783 | 0.578 | 0.789 | 0.709 | 0.870 | 0.609 | 0.981 | 0.745 |
| S6 | 0.740 | 0.101 | 0.869 | 0.704 | 0.992 | 0.644 | 0.922 | 0.644 |
| S7 | 0.739 | 0.085 | 0.800 | 0.563 | 0.920 | 0.670 | 0.922 | 0.672 |
| S8 | 0.734 | 0.000 | 0.836 | 0.636 | 0.938 | 0.777 | 0.938 | 0.777 |
| S9 | 0.997 | 0.968 | 0.746 | 0.195 | 0.791 | 0.426 | 0.998 | 0.796 |
| S10 | 0.872 | 0.457 | 0.792 | 0.541 | 0.811 | 0.334 | 0.942 | 0.745 |
| S11 | 0.894 | 0.755 | 0.740 | 0.129 | 0.827 | 0.605 | 0.940 | 0.763 |
| S12 | 0.790 | 0.028 | 0.845 | 0.516 | 0.954 | 0.633 | 0.955 | 0.634 |
| S13 | 0.789 | 0.000 | 0.828 | 0.460 | 0.974 | 0.557 | 0.974 | 0.557 |
| S14 | 0.789 | 0.000 | 0.833 | 0.462 | 0.916 | 0.598 | 0.916 | 0.598 |
| S15 | 1.000 | 0.840 | 0.789 | 0.000 | 0.795 | 0.018 | 1.000 | 0.885 |
| Label | DAEH MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | ||||
|---|---|---|---|---|---|---|---|---|
| TPR | TNR | TPR | TNR | TPR | TNR | TPR | TNR | |
| SS1 | 0.879 | 1.000 | 0.986 | 0.871 | 0.997 | 0.999 | 0.997 | 1.000 |
| SS2 | 0.950 | 0.862 | 0.984 | 0.376 | 0.963 | 0.884 | 0.963 | 0.980 |
| SS3 | 0.950 | 0.558 | 0.998 | 0.732 | 0.992 | 0.874 | 0.992 | 0.937 |
| SS4 | 0.950 | 0.854 | 0.985 | 0.552 | 0.964 | 0.960 | 0.964 | 0.983 |
| SS5 | 0.950 | 0.785 | 0.948 | 0.015 | 0.987 | 0.923 | 0.987 | 0.929 |
| SS6 | 0.950 | 1.000 | 0.891 | 0.594 | 0.982 | 0.690 | 0.982 | 1.000 |
| SS7 | 0.950 | 0.718 | 0.930 | 0.583 | 0.960 | 0.970 | 0.960 | 0.995 |
| Label | Balanced Accuracy | |||
|---|---|---|---|---|
| DAE MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | |
| SS1 | 0.939 | 0.928 | 0.998 | 0.998 |
| SS2 | 0.906 | 0.680 | 0.923 | 0.972 |
| SS3 | 0.754 | 0.865 | 0.933 | 0.965 |
| SS4 | 0.902 | 0.768 | 0.962 | 0.973 |
| SS5 | 0.868 | 0.481 | 0.955 | 0.958 |
| SS6 | 0.975 | 0.743 | 0.836 | 0.991 |
| SS7 | 0.834 | 0.756 | 0.965 | 0.978 |
| Average | 0.882 | 0.745 | 0.938 | 0.976 |
| Label | DAE MSE | DAE + OC-SVM | DCC + OC-SVM | DAECC-OC-SVM | ||||
|---|---|---|---|---|---|---|---|---|
| PPV | NPV | PPV | NPV | PPV | NPV | PPV | NPV | |
| SS1 | 1.000 | 0.892 | 0.912 | 0.963 | 0.999 | 0.997 | 1.000 | 0.997 |
| SS2 | 0.936 | 0.893 | 0.782 | 0.885 | 0.944 | 0.922 | 0.990 | 0.930 |
| SS3 | 0.834 | 0.767 | 0.896 | 0.991 | 0.940 | 0.984 | 0.970 | 0.985 |
| SS4 | 0.933 | 0.892 | 0.860 | 0.932 | 0.980 | 0.931 | 0.991 | 0.933 |
| SS5 | 0.930 | 0.839 | 0.742 | 0.088 | 0.974 | 0.961 | 0.976 | 0.961 |
| SS6 | 1.000 | 0.869 | 0.868 | 0.647 | 0.905 | 0.930 | 1.000 | 0.950 |
| SS7 | 0.910 | 0.827 | 0.870 | 0.735 | 0.989 | 0.892 | 0.998 | 0.894 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arellano-Espitia, F.; Delgado-Prieto, M.; Gonzalez-Abreu, A.-D.; Saucedo-Dorantes, J.J.; Osornio-Rios, R.A. Deep-Compact-Clustering Based Anomaly Detection Applied to Electromechanical Industrial Systems. Sensors 2021, 21, 5830. https://doi.org/10.3390/s21175830
Arellano-Espitia F, Delgado-Prieto M, Gonzalez-Abreu A-D, Saucedo-Dorantes JJ, Osornio-Rios RA. Deep-Compact-Clustering Based Anomaly Detection Applied to Electromechanical Industrial Systems. Sensors. 2021; 21(17):5830. https://doi.org/10.3390/s21175830
Chicago/Turabian StyleArellano-Espitia, Francisco, Miguel Delgado-Prieto, Artvin-Darien Gonzalez-Abreu, Juan Jose Saucedo-Dorantes, and Roque Alfredo Osornio-Rios. 2021. "Deep-Compact-Clustering Based Anomaly Detection Applied to Electromechanical Industrial Systems" Sensors 21, no. 17: 5830. https://doi.org/10.3390/s21175830
APA StyleArellano-Espitia, F., Delgado-Prieto, M., Gonzalez-Abreu, A.-D., Saucedo-Dorantes, J. J., & Osornio-Rios, R. A. (2021). Deep-Compact-Clustering Based Anomaly Detection Applied to Electromechanical Industrial Systems. Sensors, 21(17), 5830. https://doi.org/10.3390/s21175830