
Multi-Scale Capsule Attention Network and Joint Distributed Optimal Transport for Bearing Fault Diagnosis under Different Working Loads


Abstract
:1. Introduction
- A new transfer learning-based fault diagnosis approach called MSCAN-JDOT is proposed which accepts raw vibration signal as input and can effectively perform end-to-end fault diagnosis without the time-consuming and experience-dependent manual feature extraction.
- The proposed MSCAN-JDOT adopts multi-scale capsule attention networks as feature extraction networks, which can better extract fault features, and uses joint distribution optimal transport for domain adaptation, which can effectively align the fault features under different loads.
- MSCAN-JDOT achieves high accuracy and strong anti-noise performance for bearing fault diagnosis under different working loads.
2. Capsule Network and Optimal Transport
2.1. Capsule Network
2.2. Optimal Transport
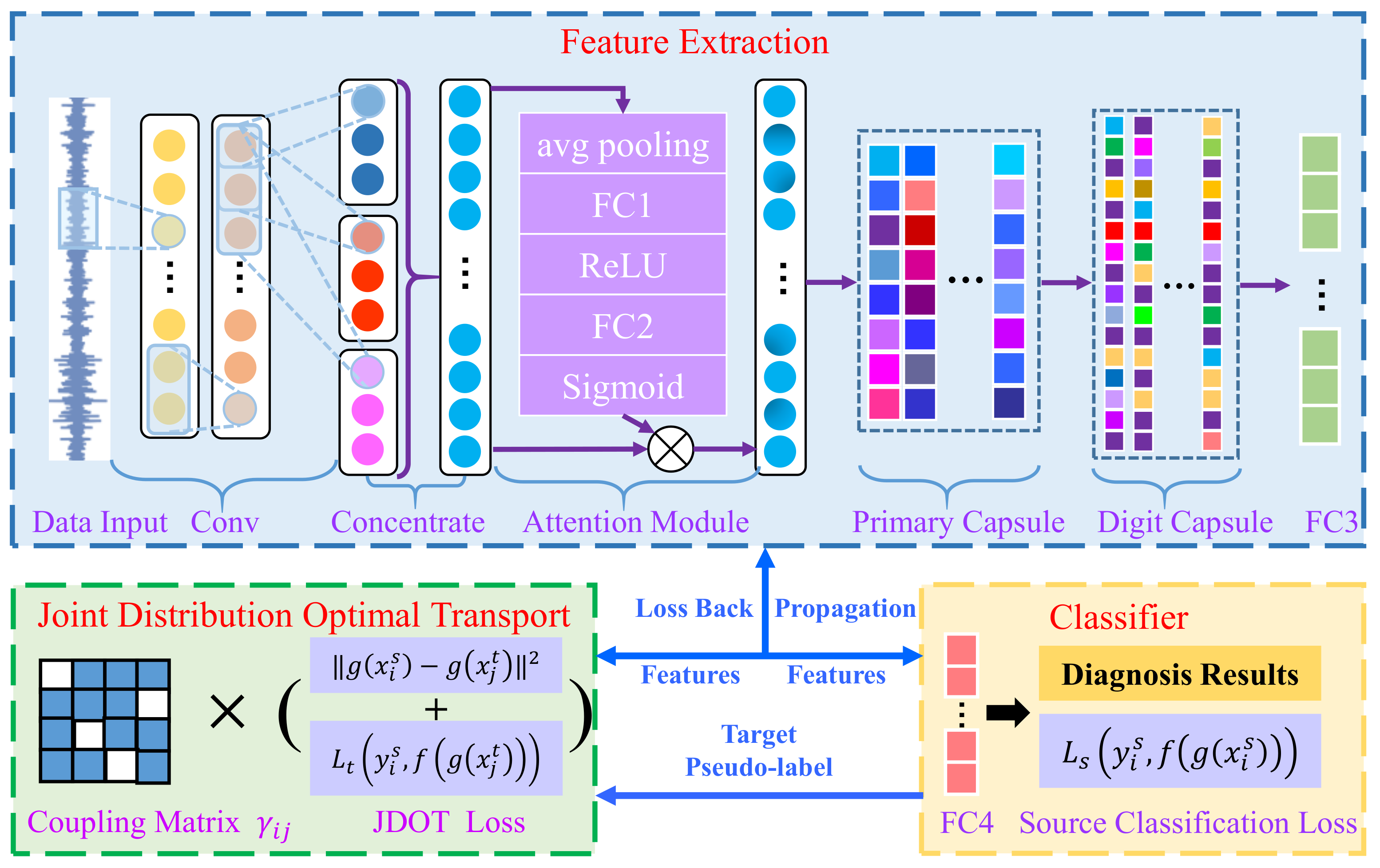
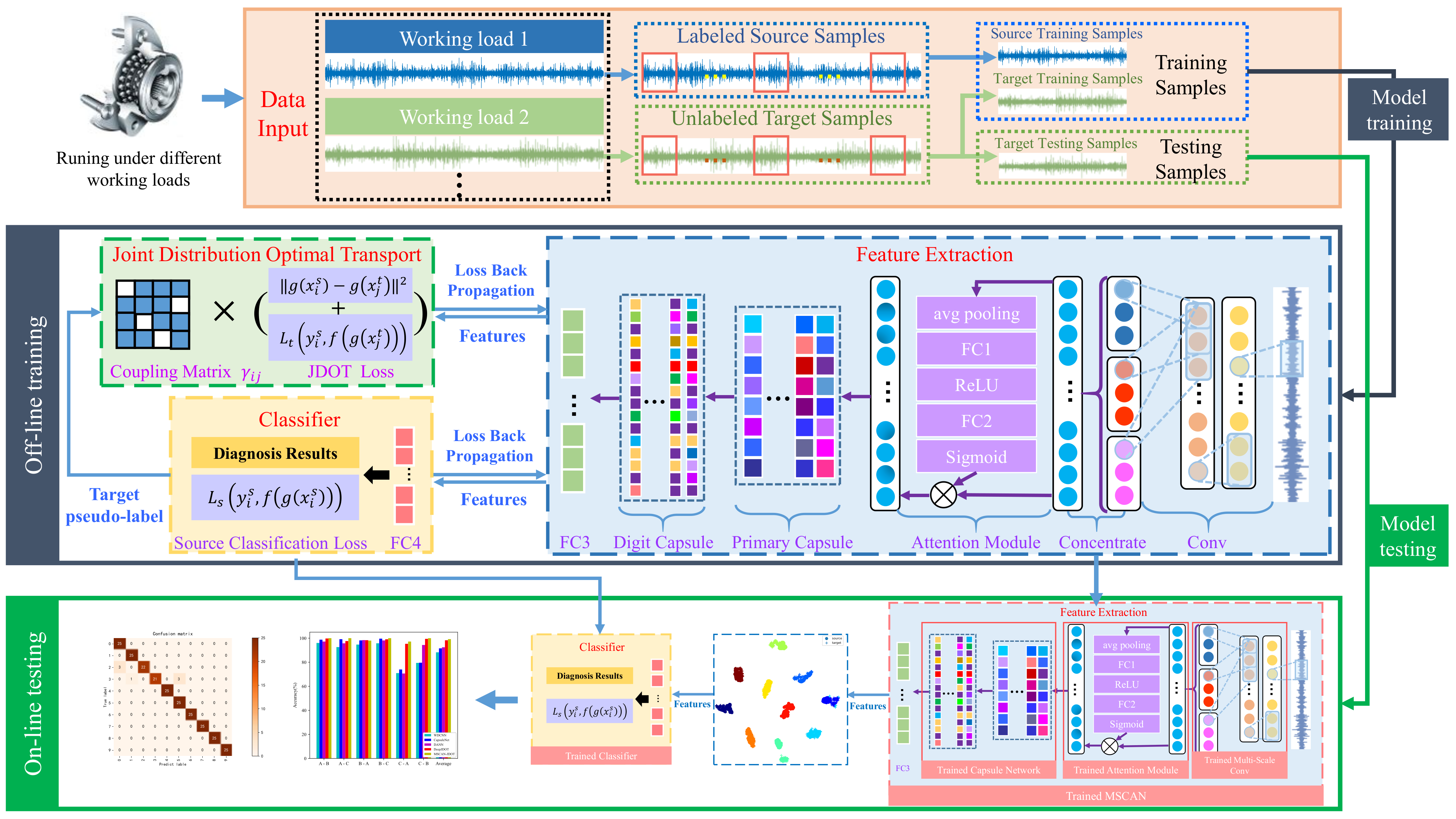
3. Proposed Method
3.1. Feature Extraction Details
| Algorithm 1 Dynamic routing algorithm |
| Procedure routing for all capsule in layer and capsule in layer : . for iterations do for all capsule in layer : for all capsule in layer : for all capsule in layer : for all capsule in layer and capsule in layer : return |
3.2. JDOT Domain Adaptation
3.3. General Procedure of the Proposed Method
- Data Input: In this step, the raw data sampled under different working loads are split into target domain and source domain. The training sets contains the labeled source domain samples and the unlabeled target domain samples, while the testing sets only contains the unlabeled target samples.
- Training Stage: In this step, the training samples are input to the feature extraction network, and then the domain adaptation aligns the features of the source domain and target domain. Through the source prediction labels and target pseudo-labels generated by the classifier, the whole loss function of MSCAN-JDOT can be calculated by Equation (13). Finally, the model parameters can be updated with backward propagation.
- Testing Stage: In this step, testing samples are used to validate the performance of the MSCAN-JDOT, which is well trained after sufficient epochs. In this stage, the network only carries out forward propagation without backward propagation. The model is evaluated by label prediction results and features alignment effect.
4. Experimental Analysis
4.1. Dataset Introduction and Dataset Split
4.1.1. Dataset Introduction
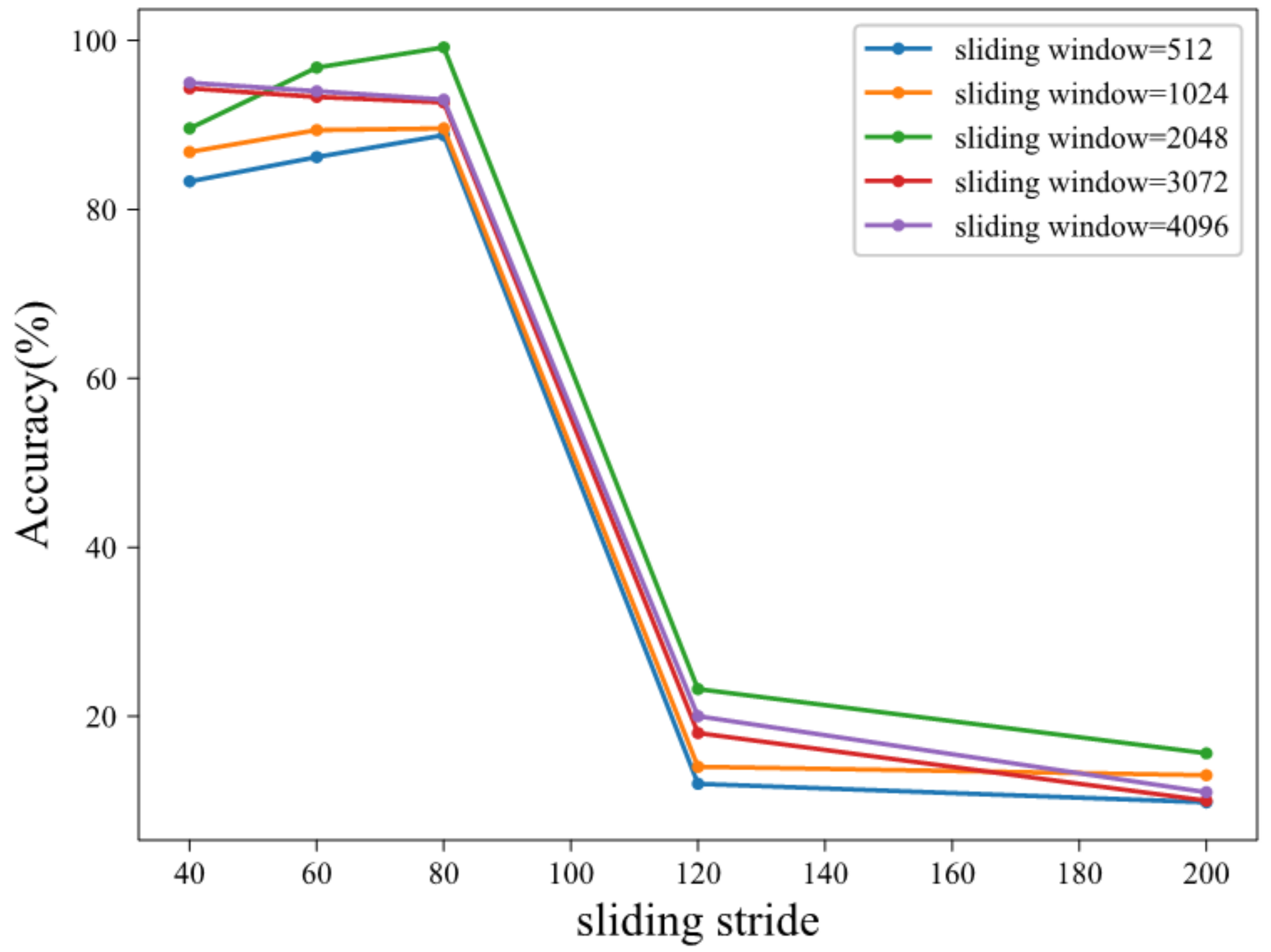
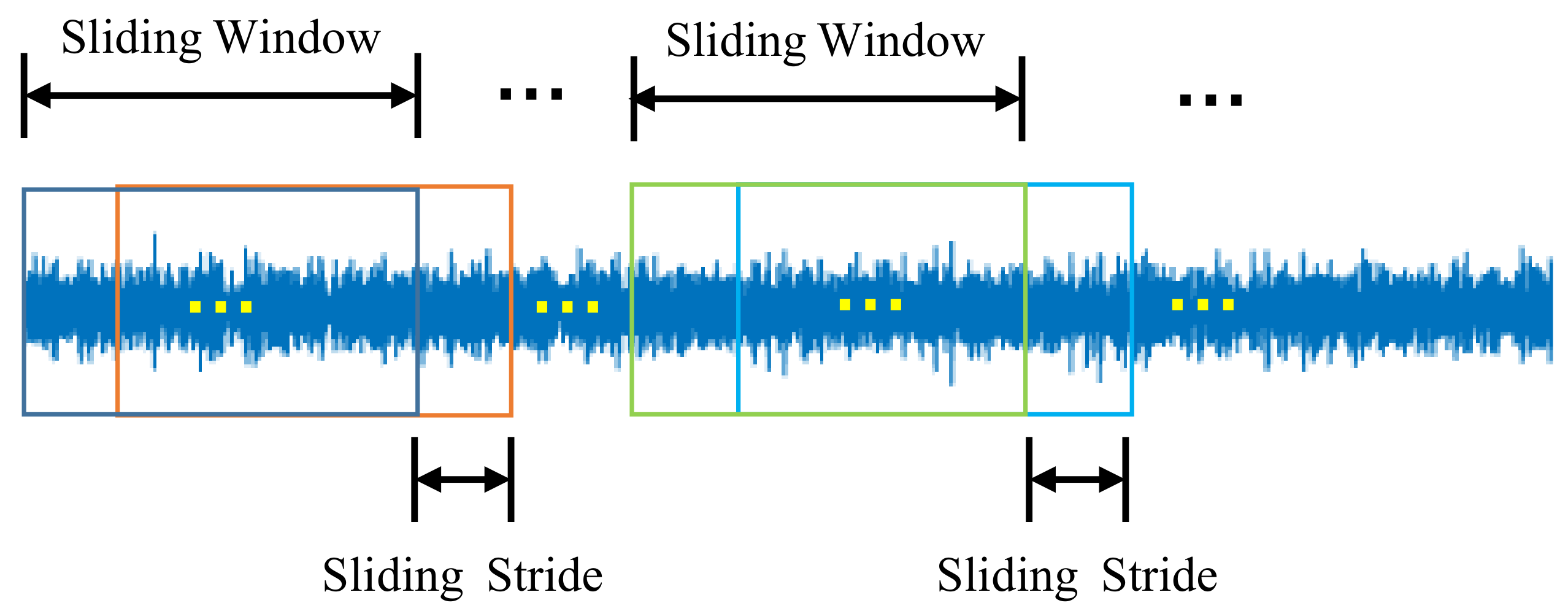
4.1.2. Dataset Split
4.2. Experimental Results and Performance Analysis
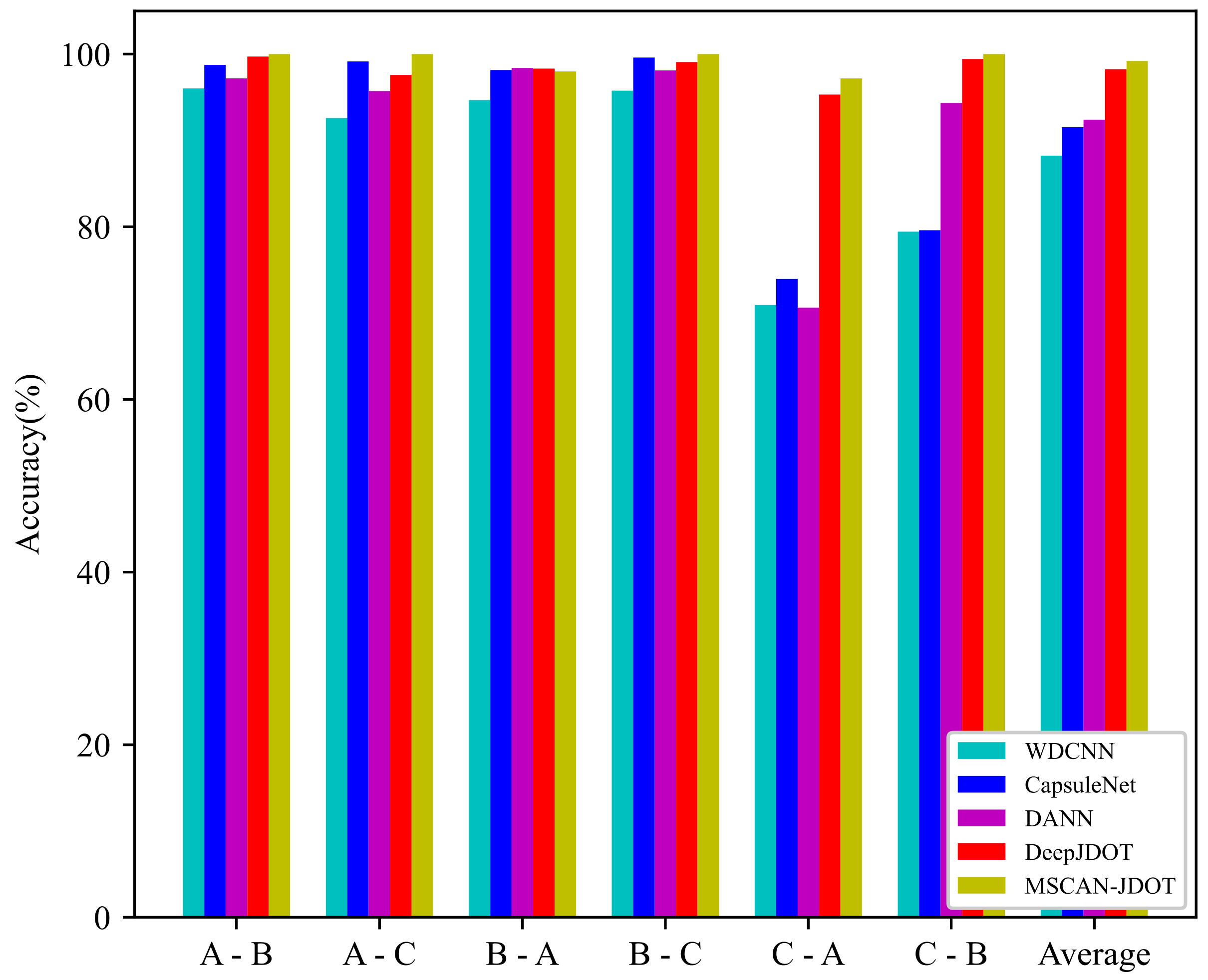
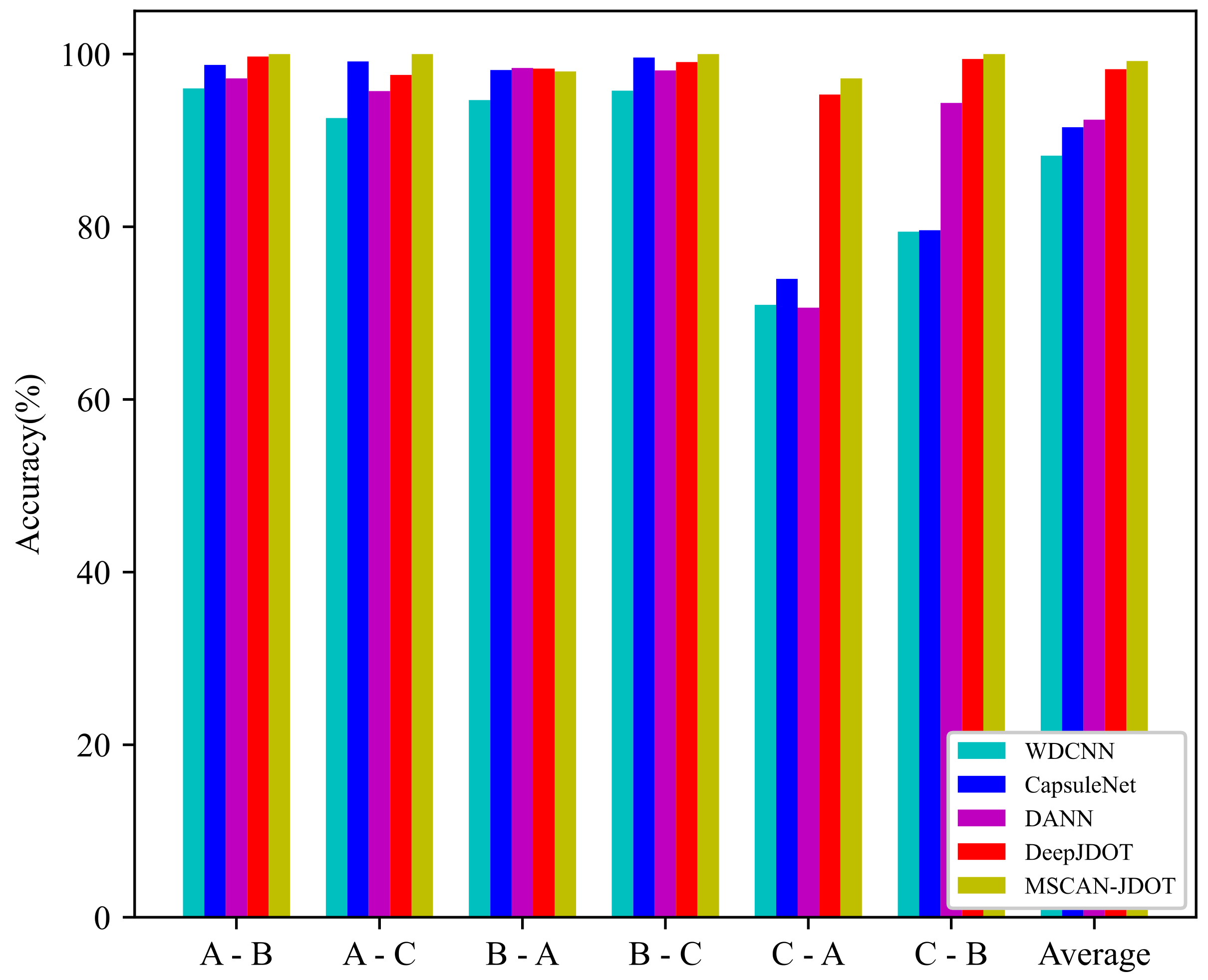
4.2.1. Fault Diagnosis Experiments under Different Loads
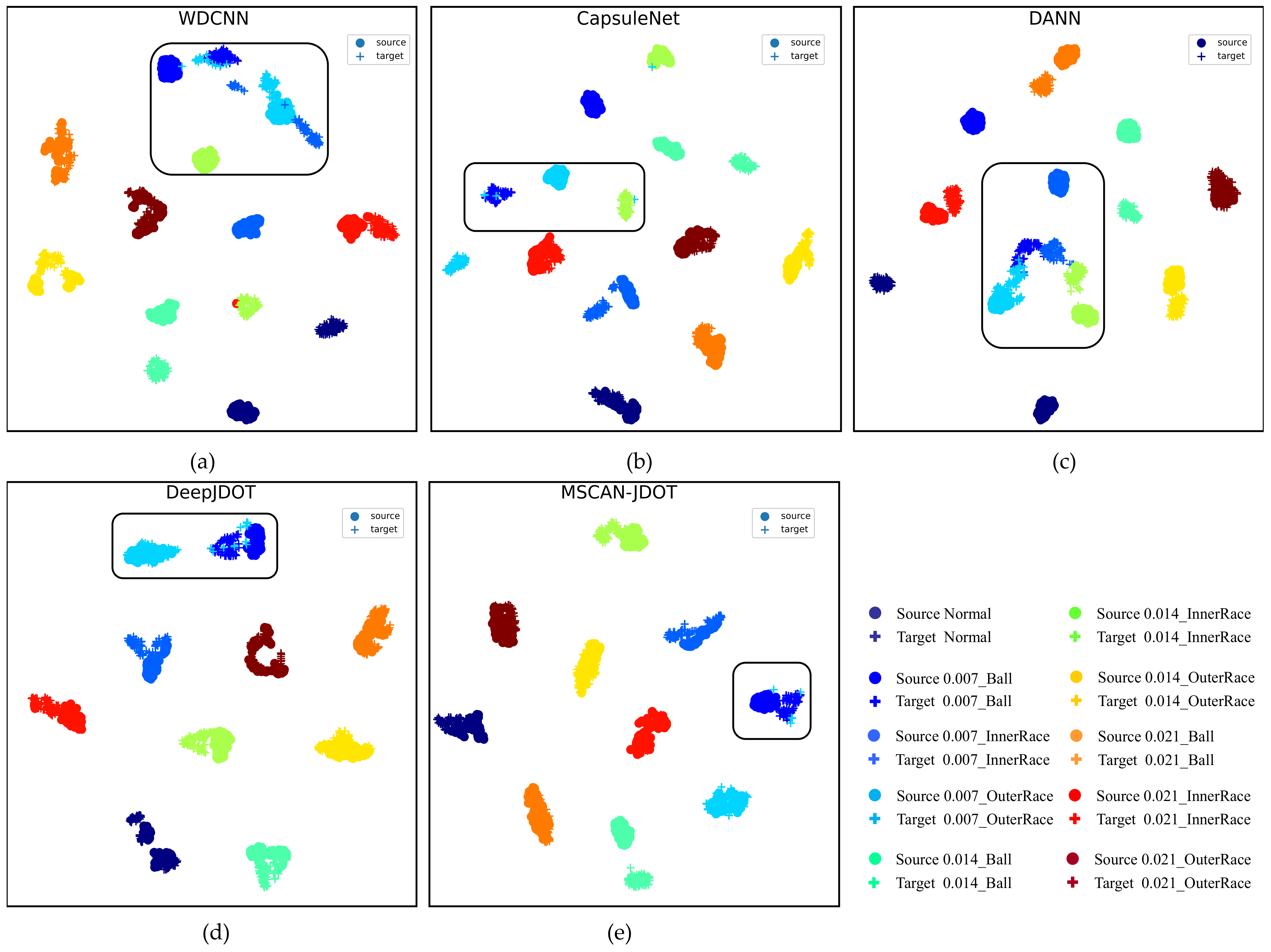
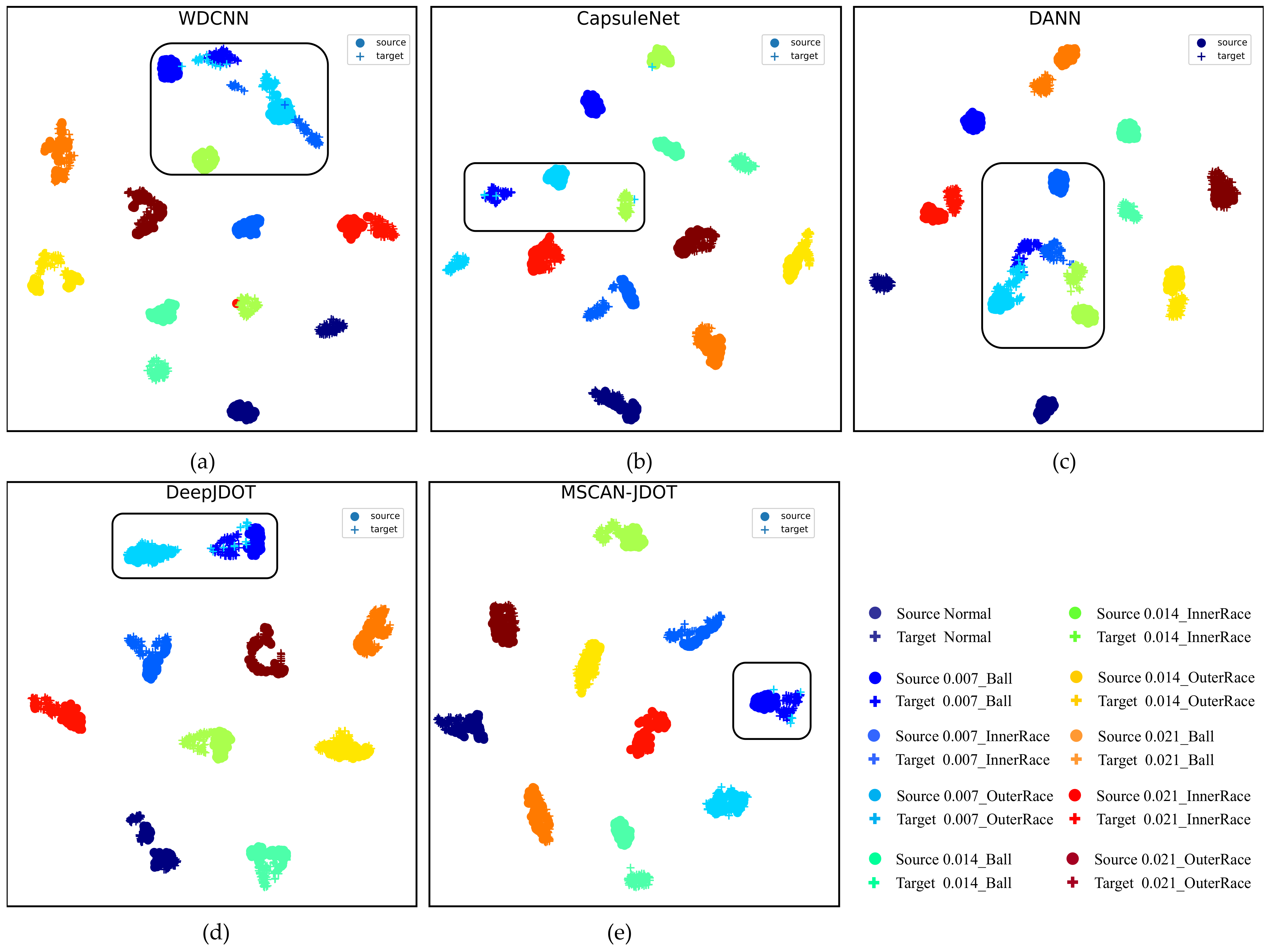
4.2.2. Analysis of Fault Diagnosis Experimental Results under Different Loads
4.2.3. Anti-Noise Experiments under Different Levels of Noise
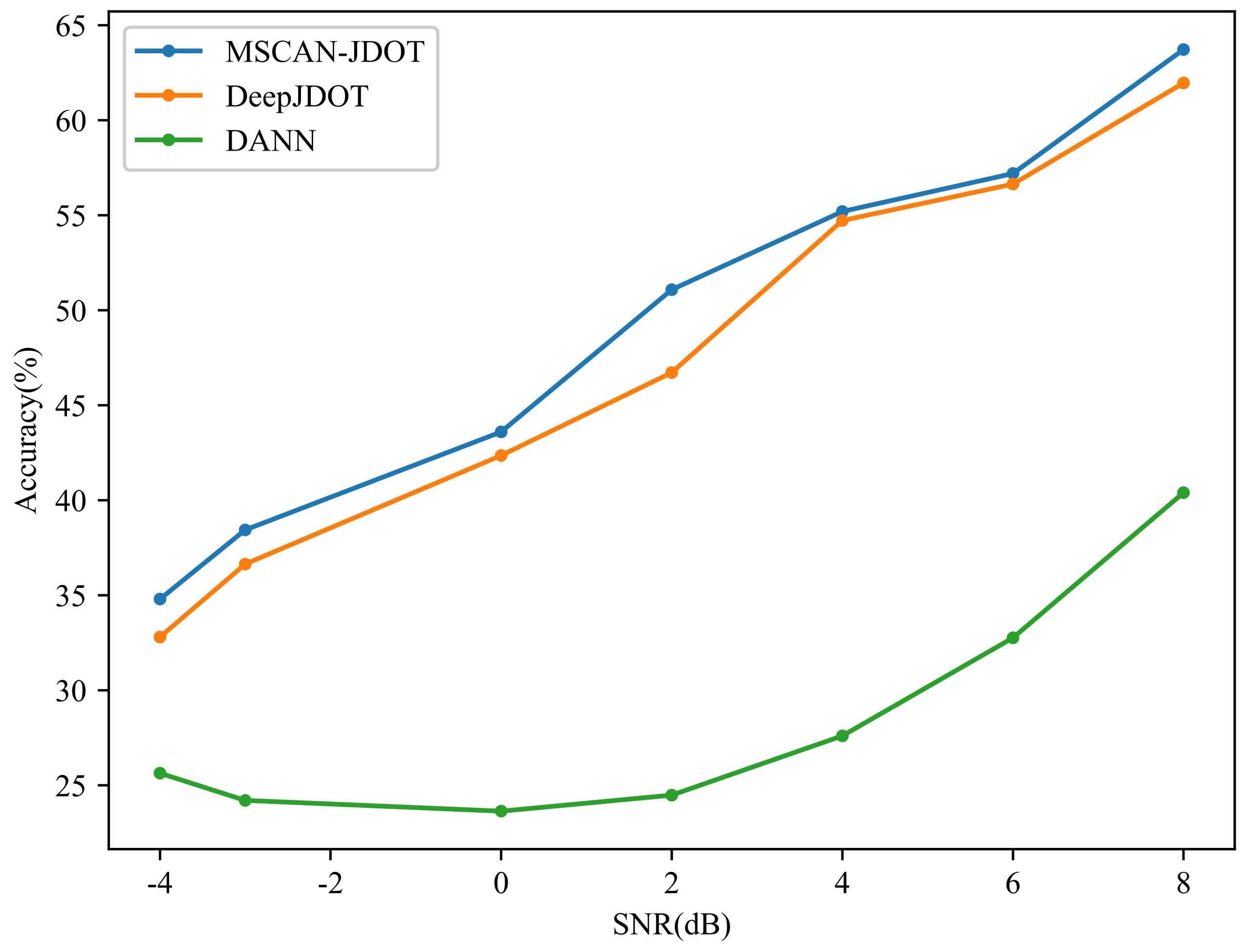
4.2.4. Anti-Noise Performance Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Gryllias, K.; Li, W. Mechanical fault diagnosis using Convolutional Neural Networks and Extreme Learning Machine. Mech. Syst. Signal Process. 2019, 133, 106272. [Google Scholar] [CrossRef]
- Shao, S.; Yan, R.; Lu, Y.; Wang, P.; Gao, R.X. DCNN-Based Multi-Signal Induction Motor Fault Diagnosis. IEEE Trans. Instrum. Meas. 2019, 69, 2658–2669. [Google Scholar] [CrossRef]
- Xu, G.; Liu, M.; Jiang, Z.; Shen, W.; Huang, C. Online Fault Diagnosis Method Based on Transfer Convolutional Neural Networks. IEEE Trans. Instrum. Meas. 2020, 69, 509–520. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep-Convolution-Based LSTM Network for Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2021, 17, 1658–1667. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Q.; Xiong, J.; Xiao, M.; Sun, G.; He, J. Fault Diagnosis of a Rolling Bearing Using Wavelet Packet De-noising and Random Forests. IEEE Sens. J. 2017, 17, 5581–5588. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, H. Fault Diagnosis of an Autonomous Vehicle with an Improved SVM Algorithm Subject to Unbalanced Datasets. IEEE Trans. Ind. Electron. 2021, 68, 6248–6256. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A re-view and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Wu, L.; Sarkar, S.; Jiang, D. An adaptive spatiotemporal feature learning approach for fault diagnosis in complex systems. Mech. Syst. Signal Process. 2019, 117, 170–187. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Ma, P.; Zhang, H.; Fan, W.; Wang, C.; Wen, G.; Zhang, X. A novel bearing fault diagnosis method based on 2D image representation and transfer learning-convolutional neural network. Meas. Sci. Technol. 2019, 30, 055402. [Google Scholar] [CrossRef]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2019, 15, 2446–2455. [Google Scholar] [CrossRef]
- Yan, R.; Shen, F.; Sun, C.; Chen, X. Knowledge Transfer for Rotary Machine Fault Diagnosis. IEEE Sens. J. 2020, 20, 8374–8393. [Google Scholar] [CrossRef]
- An, Z.; Li, S.; Wang, J.; Xin, Y.; Xu, K. Generalization of deep neural network for bearing fault diagnosis under different working conditions using multiple kernel method. Neurocomputing 2019, 352, 42–53. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Lu, B.-L.; Wei, H.-L.; Chen, L.; Li, X.-H.; Wang, C.-T. A Stacked Auto-Encoder Based Partial Adversarial Domain Adaptation Model for Intelligent Fault Diagnosis of Rotating Machines. IEEE Trans. Ind. Inform. 2021, 17, 6798–6809. [Google Scholar] [CrossRef]
- Li, Y.; Song, Y.; Jia, L.; Gao, S.; Li, Q.; Qiu, M. Intelligent Fault Diagnosis by Fusing Domain Adversarial Training and Maximum Mean Discrepancy via Ensemble Learning. IEEE Trans. Ind. Inform. 2021, 17, 2833–2841. [Google Scholar] [CrossRef]
- Wen, L.; Gao, L.; Li, X. A New Deep Transfer Learning Based on Sparse Auto-Encoder for Fault Diagnosis. IEEE Trans. Syst. Man, Cybern. Syst. 2017, 49, 136–144. [Google Scholar] [CrossRef]
- Li, L.; Zhang, M.; Wang, K. A fault diagnostic scheme based on capsule network for rolling bearing under different rotational speeds. Sensors 2020, 20, 1841. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; He, G.; Li, J.; Liao, Y.; Gryllias, K.; Li, W. Domain Adversarial Transfer Network for Cross-Domain Fault Diagnosis of Rotary Machinery. IEEE Trans. Instrum. Meas. 2020, 69, 8702–8712. [Google Scholar] [CrossRef]
- Lei, Z.; Wen, G.; Dong, S.; Huang, X.; Zhou, H.; Zhang, Z.; Chen, X. An Intelligent Fault Diagnosis Method Based on Domain Adaptation and Its Application for Bearings Under Polytropic Working Conditions. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, X.; Li, J.; Yang, Y. Intelligent Fault Diagnosis with Deep Adversarial Domain Adaptation. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Yu, X.; Zhao, Z.; Zhang, X.; Sun, C.; Gong, B.; Yan, R.; Chen, X. Conditional Adversarial Domain Adaptation with Discrimination Embedding for Locomotive Fault Diagnosis. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Domain Adversarial Graph Convolutional Network for Fault Diagnosis Under Variable Working Conditions. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar]
- Huang, R.; Li, J.; Liao, Y.; Chen, J.; Wang, Z.; Li, W. Deep Adversarial Capsule Network for Compound Fault Diagnosis of Machinery Toward Multidomain Generalization Task. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, L.; Wei, H.; Chen, L.; Li, X. Optimal Transport Based Deep Domain Adaptation Approach for Fault Diagnosis of Rotating Machine. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. 2012, 2, 1097–1105. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G. Dynamic routing between capsules. In Proceedings of the 31st Conference on Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 3857–3867. [Google Scholar]
- Hinton, G.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ribeiro, F.D.S.; Leontidis, G.; Kollias, S. Capsule Routing via Variational Bayes. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3749–3756. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal Transport for Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Courty, N.; Flamary, R.; Habrard, A.; Rakotomamonjy, A. Joint distribution optimal transportation for domain adaptation. In Proceedings of the Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3731–3740. [Google Scholar]
- Damodaran, B.B.; Kellenberger, B.; Flamary, R.; Tuia, D.; Courty, N. DeepJDOT: Deep Joint Distribution Optimal Transport for Unsupervised Domain Adaptation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; Volume 11208, pp. 467–483. [Google Scholar]
- Case Western Reserve University Bearing Data Center Website. Available online: https://csegroups.case.edu/bearingdatacenter/pages/welcome-case-western-reserve-university-bearing-data-center-website (accessed on 29 March 2021).
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2017, 17, 1–35. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Kernel Size | Filters | Strides | Padding | Capsule Dimension | Capsules Number | Output Shape | ||
|---|---|---|---|---|---|---|---|---|---|
| Input | - | - | - | - | - | - | (2048,2) | ||
| Conv1 | 64 | 16 | 1 | same | - | - | (2048,16) | ||
| Conv2 | 32 | 32 | 8 | valid | - | - | (253,32) | ||
| Conv3(multi-scale conv) | 3/8/16 | 16/16/16 | 3 | same | - | - | (253,48) | ||
| Attention | avg_pooling | - | - | - | - | - | - | (253,48) | (1,48) |
| FC1 | (1,16) | ||||||||
| FC2 | (1,48) | ||||||||
| Primary Capsule | 3 | 256 | 1 | valid | 8 | 32 | (32,8) | ||
| Digit Capsule | - | - | - | 16 | 10 | (10,16) | |||
| Flatten | - | - | - | - | - | (160) | |||
| FC3 | - | - | - | - | - | (128) | |||
| FC4 | - | - | - | - | - | (10) | |||
| Dataset Name | Speed (rpm) | Load (HP) | Fault Diameter | Fault Location |
|---|---|---|---|---|
| A | 1772 | 1 | 0.007,0.014,0.021 | Ball, InnerRace, OuterRace |
| B | 1750 | 2 | 0.007,0.014,0.021 | Ball, InnerRace, OuterRace |
| C | 1730 | 3 | 0.007,0.014,0.021 | Ball, InnerRace, OuterRace |
| Health Conditions | Label |
|---|---|
| Normal | 0 |
| 0.007_Ball | 1 |
| 0.007_InnerRace | 2 |
| 0.007_OuterRace | 3 |
| 0.014_Ball | 4 |
| 0.014_InnerRace | 5 |
| 0.014_OuterRace | 6 |
| 0.021_Ball | 7 |
| 0.021_InnerRace | 8 |
| 0.021_OuterRace | 9 |
| CWRU | A-B | A-C | B-A | B-C | C-A | C-B | AVG |
|---|---|---|---|---|---|---|---|
| WDCNN | 96.04 | 92.60 | 94.68 | 95.76 | 70.96 | 79.44 | 88.25 |
| CapsuleNet | 98.76 | 99.16 | 98.16 | 99.60 | 73.96 | 79.60 | 91.54 |
| DANN | 97.20 | 95.72 | 98.40 | 98.12 | 70.64 | 94.36 | 92.41 |
| DeepJDOT | 99.72 | 97.60 | 98.32 | 99.08 | 95.32 | 99.44 | 98.25 |
| MSCAN-JDOT | 100 | 100 | 98.00 | 100 | 97.20 | 100 | 99.20 |
| SNR(dB) | −4 | −2 | 0 | 2 | 4 | 6 | 8 |
|---|---|---|---|---|---|---|---|
| DANN | 25.64 | 24.20 | 23.64 | 24.48 | 27.60 | 32.76 | 40.40 |
| DeepJDOT | 32.80 | 36.64 | 42.36 | 46.72 | 54.72 | 56.64 | 61.96 |
| MSCAN-JDOT | 34.80 | 38.44 | 43.60 | 51.08 | 55.20 | 57.20 | 63.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Yuan, X.; Fu, X.; Zhou, F.; Zhang, C. Multi-Scale Capsule Attention Network and Joint Distributed Optimal Transport for Bearing Fault Diagnosis under Different Working Loads. Sensors 2021, 21, 6696. https://doi.org/10.3390/s21196696
Sun Z, Yuan X, Fu X, Zhou F, Zhang C. Multi-Scale Capsule Attention Network and Joint Distributed Optimal Transport for Bearing Fault Diagnosis under Different Working Loads. Sensors. 2021; 21(19):6696. https://doi.org/10.3390/s21196696
Chicago/Turabian StyleSun, Zihao, Xianfeng Yuan, Xu Fu, Fengyu Zhou, and Chengjin Zhang. 2021. "Multi-Scale Capsule Attention Network and Joint Distributed Optimal Transport for Bearing Fault Diagnosis under Different Working Loads" Sensors 21, no. 19: 6696. https://doi.org/10.3390/s21196696
APA StyleSun, Z., Yuan, X., Fu, X., Zhou, F., & Zhang, C. (2021). Multi-Scale Capsule Attention Network and Joint Distributed Optimal Transport for Bearing Fault Diagnosis under Different Working Loads. Sensors, 21(19), 6696. https://doi.org/10.3390/s21196696