
Coresets for the Average Case Error for Finite Query Sets


Abstract
1. Introduction
1.1. Approximation Techniques for the Sum of Losses
1.2. Coresets: A Data Summarization Technique for Approximating the Sum of Losses
1.3. Problem Statement: Average Case Analysis for Data Summarization
1.4. Our Contribution
- (i)
- Deterministic construction that returns a coreset of size in time ; see Theorem 2 and Corollary 4.
- (ii)
- Randomized construction that returns such a coreset (of size ) with probability at least in sub-linear time ; see Lemma 5.
1.5. Overview and Organization
2. On the Applications of Our Method and the Current State of the Art
- (i)
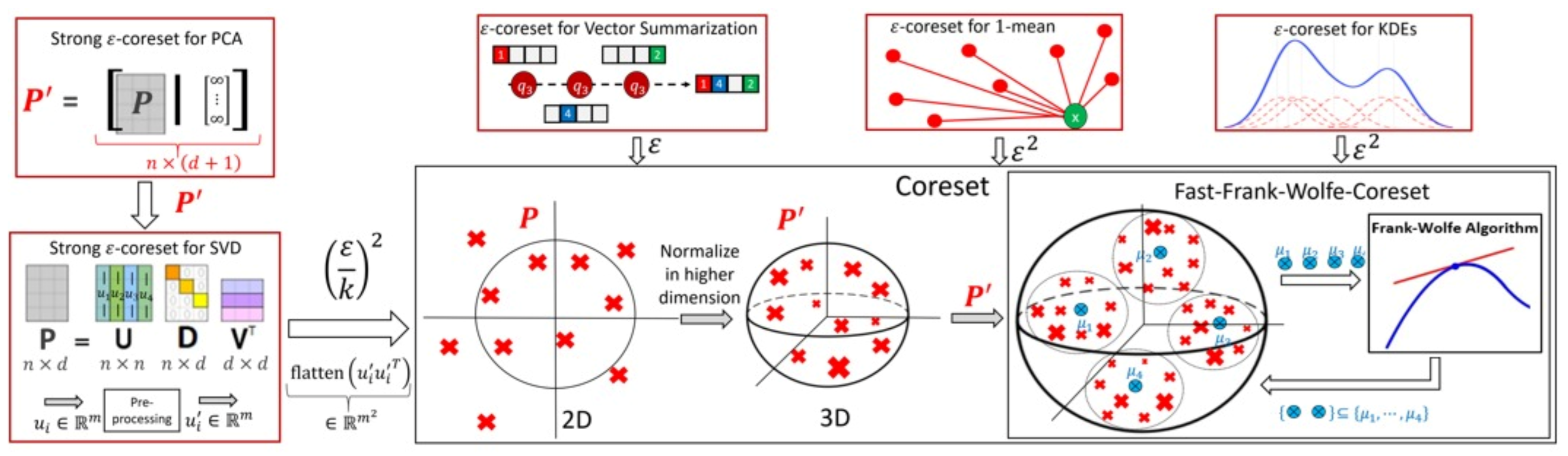
- Vector summarization: the goal is to maintain the sum of a (possibly infinite) stream of vectors in , up to an additive error of multiplied by their variance. This is a generalization of frequent items/directions [28].As explained in [29], the main real-world application is extractions and compactly representing groups and activity summaries of users from underlying data exchanges. For example, GPS traces in mobile networks can be exploited to identify meetings, and exchanges of information in social networks sheds light on the formation of groups of friends. Our algorithm tackles these application by providing provable solution to the heavy hitters problem in proximity matrices. The heavy hitters problem can be used to extract and represent in a compact way friend groups and activity summaries of users from underlying data exchanges.We propose a deterministic algorithm which reduces each subset of n vectors into weighted vectors in time, improving upon the of [29] (which is the current state of the art in terms of running time), for a sufficiently large n; see Corollary 4, and Figures 2 and 3. We also provide a non-deterministic coreset construction in Lemma 5. The merge-and-reduce tree can then be used to support streaming, distributed or dynamic data.
- (ii)
- Kernel Density Estimates (KDE): by replacing with for the vector summarization, we obtain fast construction of an -coreset for KDE of Euclidean kernels [17]; see more details in Section 4. Kernel density estimate is a technique for estimating a probability density function (continuous distribution) from a finite set of points to better analyse the studied probability distribution than when using a traditional [30,31].
- (iii)
- 1-mean problem: a coreset for 1-mean which approximates the sum of squared distances over a set of n points to any given center (point) in . This problem arises in facility location problems (e.g., to compute the optimal location for placing an antenna such that all the customers are satisfied). Our deterministic construction computes such a weighted subset of size in time. Previous results of [19,32,33,34] suggested coresets for such problem. Unlike our results, these works are either non-deterministic, the coreset is not a subset of the input, or the size of the coreset is linear in d.
- (iv)
- Coreset for LMS solvers and dimensionality reduction: for example, a deterministic construction for singular value decomposition (SVD) that gets a matrix and returns a weighted subset of rows, such that their weighted distance to any k-dimensional non-affine (or affine in the case of PCA) subspace approximates the distance of the original points to this subspace. The SVD and PCA are very common algorithms (see [35]), and can be used for noise reduction, data visualization, cluster analysis, or as an intermediate step to facilitate other analyses. Thus, improving them might be helpful for a wide range of real-world applications. In this paper, we propose a deterministic coreset construction that takes time, improving upon the state of the art result of [35] which requires time; see Table 1. Many non-deterministic coresets constructions were suggested for those problems, the construction techniques apply non-uniform sampling [36,37,38], Monte-Carlo sampling [39], and leverage score sampling [23,40,41,42,43,44,45].
3. Vector Summarization Coreset
| Algorithm 1:FRANK–WOLFE; Algorithm 1.1 of [48] |
|
- (i)
- is a distribution vector with ,
- (ii)
- , and
- (iii)
- is computed in time.
| Algorithm 2:CORESET |
|
3.1. Boosting the Coreset’s Construction Running Time
- (i)
- and ,
- (ii)
- , and
- (iii)
- is computed in time.
| Algorithm 3:FAST-FW-CORESET |
|
- (i)
- and ,
- (ii)
- with probability at least we have , and
- (iii)
- S is computed in time.
| Algorithm 4:PROB-WEAK-CORESET |
|
4. Applications
| Algorithm 5:DIM-CORESET |
|
- (i)
- W is a diagonal matrix with non-zero entries,
- (ii)
- W is computed in time, and
- (iii)
- there is a constant c, such that for every and an orthogonal we haveHere, is the subtraction of ℓ from every row of A.
5. Experimental Results
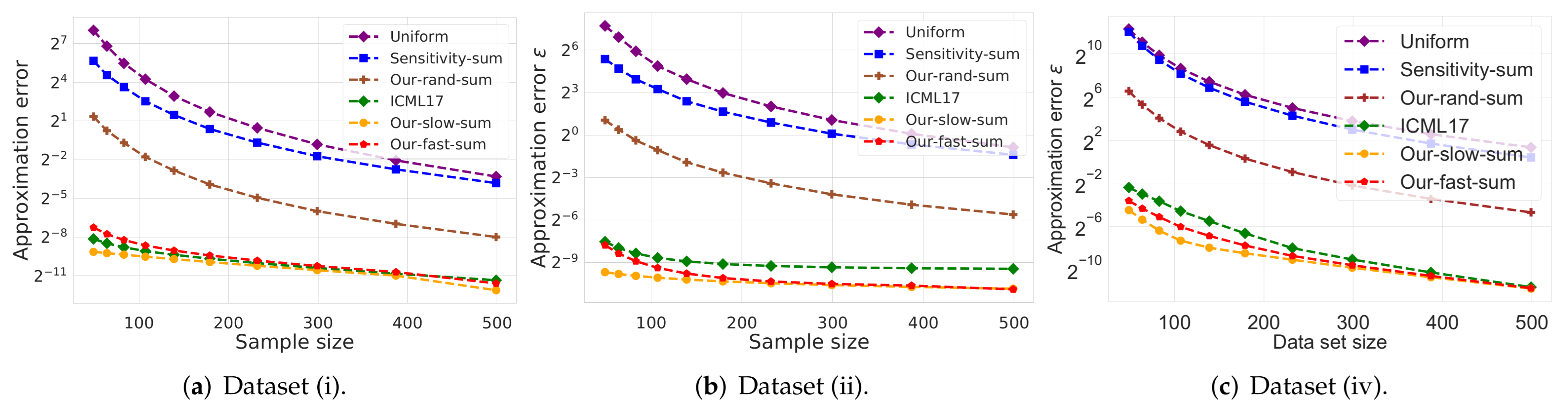
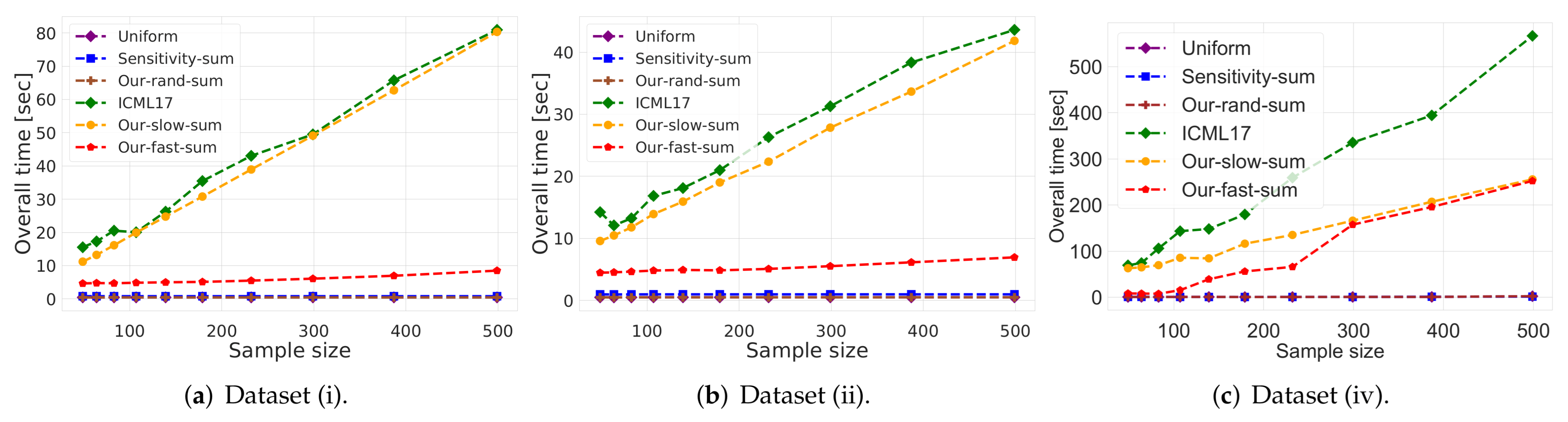
- (i)
- Uniform: Uniform random sample of the input Q, which requires sublinear time to compute.
- (ii)
- (ii)
- ICML17: The vector summarization coreset construction algorithm from [29] (see Algorithm 2 there), which runs in time.
- (iv)
- Our-rand-sum: Our coreset construction from Lemma 5, which requires time.
- (v)
- Our-slow-sum: Our coreset construction from Corollary 2, which requires time.
- (vi)
- Our-fast-sum: Our coreset construction from Corollary 4, which requires time.
- (vii)
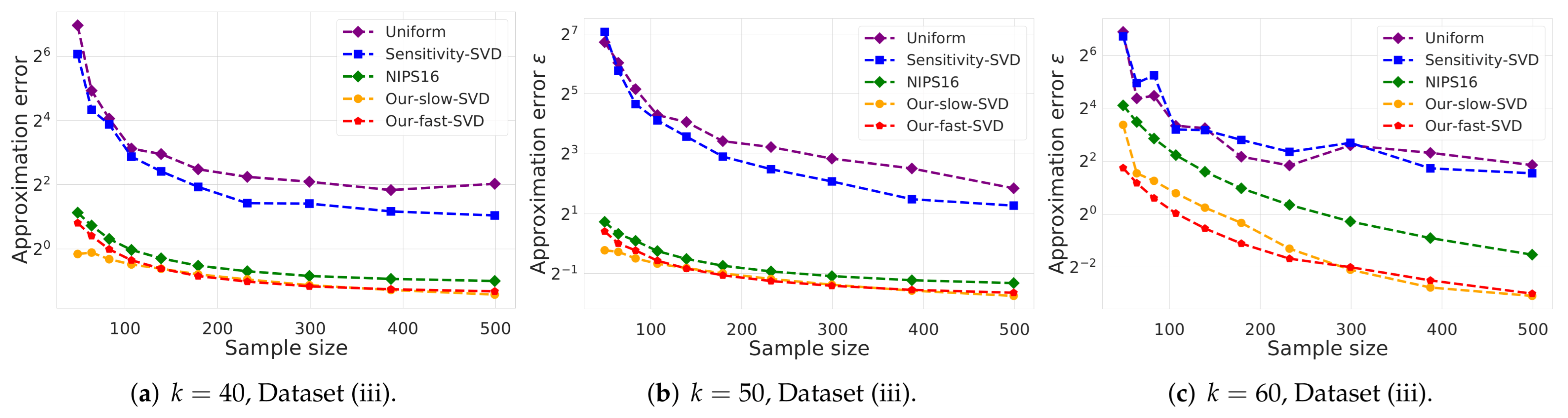
- Sensitivity-svd: Similar to Sensitivity-sum above, however, now the sensitivity is computed by projecting the rows of the input matrix A on the optimal k-subspace (or an approximation of it) that minimizes its sum of squared distances to the rows of A, and then computing the sensitivity of each row i in the projected matrix as , where is the ith row the matrix U from the SVD of ; see [37]. This takes time.
- (viii)
- NIPS16: The coreset construction algorithm from [35] (see Algorithm 2 there) which requires time.
- (ix)
- Our-slow-svd: Corollary 7 offers a coreset construction for SVD using Algorithm 5, which utilizes Algorithm 2. However, Algorithm 2 either utilizes Algorithm 1 (see Theorem 2) or Algorithm 3 (see Theorem 4). Our-slow-svd applies the former option, which requires time.
- (x)
- Our-fast-svd: Corollary 7 offers a coreset construction for SVD using Algorithm 5, which utilizes Algorithm 2. However, Algorithm 2 either utilizes Algorithm 1 (see Theorem 2) or Algorithm 3 (see Theorem 4). Our-fast-svd uses the latter option, which requires time.
- (i)
- New York City Taxi Data [60]. The data covers the taxi operations at New York City. We used the data describing trip fares at the year of 2013. We used the numerical features (real numbers).
- (ii)
- US Census Data (1990) [61]. The dataset contains entries. We used the entire real-valued attributes of the dataset.
- (iii)
- Buzz in social media Data Set [62]. It contains examples of buzz events from two different social networks: Twitter, and Tom’s Hardware. We used the entire real-valued attributes.
- (iv)
- Gas Sensors for Home Activity Monitoring Data Set [63]. This dataset has recordings of a gas sensor array composed of 8 MOX gas sensors, and a temperature and humidity sensor. We used the last real-valued attributes of the dataset.
- (i)
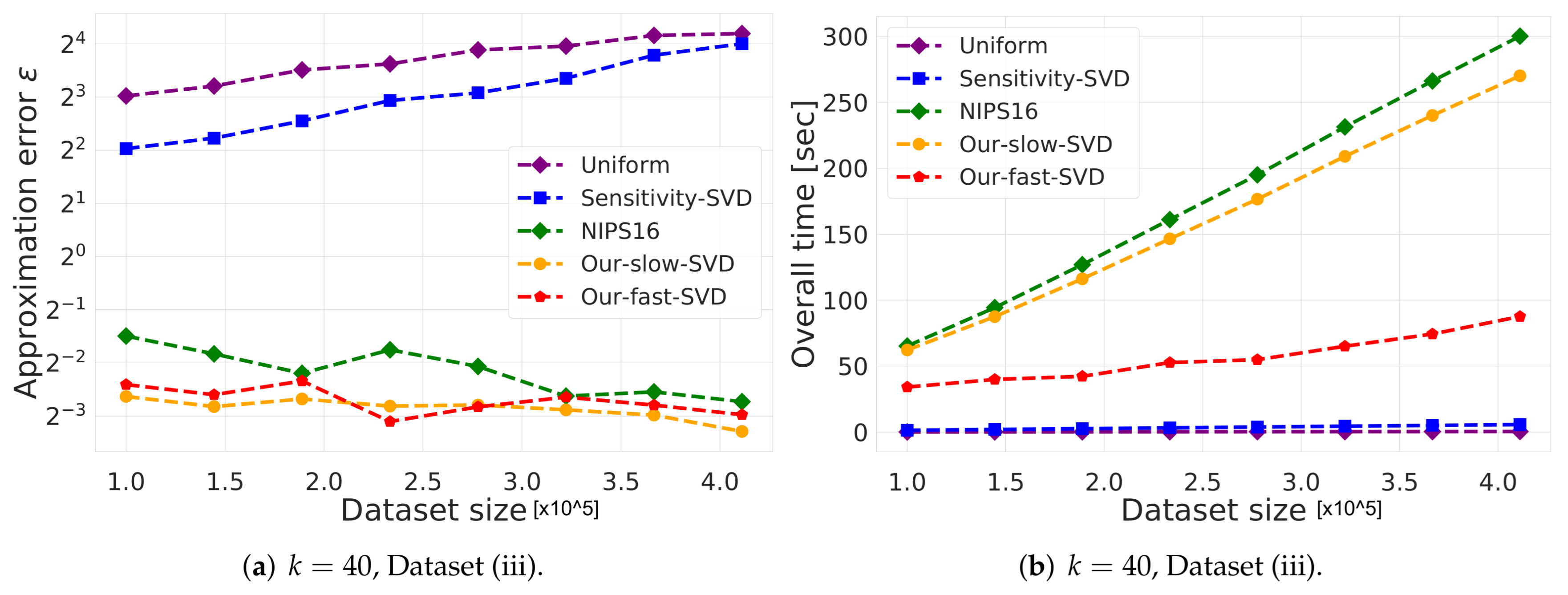
- Vector summarization:The goal is to approximate the mean of a huge input set, using only a small weighted subset of the input. The empirical approximation error is defined as , where is the mean of the full data and is the mean of the weighted subset computed via each compared algorithm; see Figure 2 and Figure 3.In Figure 2, we report the empirical approximation error as a function of the subset (coreset) size, for each of the datasets (i)–(ii), while in Figure 3 we report the overall computational time for computing the subset (coreset) and for solving the 1-mean problem on the coreset, as a function of the subset size.
- (ii)
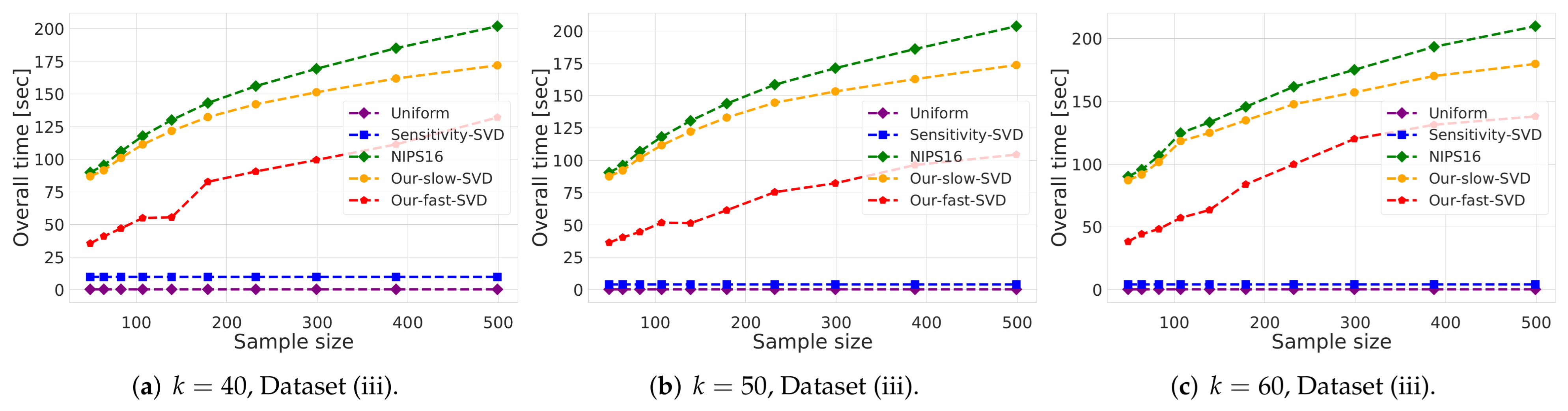
- k-SVD:The goal is to compute the optimal k-dimensional non-affine subspaces of a given input set. We can either compute the optimal subspace using the original (full) input set, or using a weighted subset (coreset) of the input. We denote by and the optimal subspace when computed either using the full data or using the subset at hand, respectively. The empirical approximation error is defined as the ratio , where and are the sum of squared distances between the points of original input set to and , respectively; see Figure 4, Figure 5 and Figure 6. Intuitively, this ratio represents the relative SSD error of recovering an optimal k-dimensional non-affine subspace on the compression, rather than using the full data.In Figure 4 we report the empirical error as a function of the coreset size. In Figure 5 we report the overall computational time in took to compute the coreset and to recover the optimal subspace using the coreset, as a function of the coreset size. In both figures we have three subfigures, each one for a different chosen value of k (the dimension of the subspace). Finally, in Figure 6 the x axis is the size of the dataset (which we compress to a subset of size 150), while the y-axis is the approximation error on the left hand side graph, and on the right hand side it is the overall computational time it took to compute the coreset and to recover the optimal subspace using the coreset.





5.1. Discussion
5.2. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Problem Reduction for Vector Summarization ε-Coresets
- (a)
- Weights sum to one: ,
- (b)
- The weighted sum is the origin: , and
- (c)
- Unit variance: .
Appendix A.1. Reduction to Normalized Weighted Set
- (i)
- ,
- (ii)
- , and
- (iii)
- .
Appendix A.2. Vector Summarization Problem Reduction
Appendix B. Frank–Wolfe Theorem
Appendix C. Proof of Theorem 1
- is a point on a -dimensional face of S, i.e., , and . Hence, claim (i) of this theorem is satisfied.
- for every
Appendix D. Proof of Theorem 2
Appendix E. Proof of Theorem 3
- (a)
- ,
- (b)
- u(p) =1,
- (c)
- , and
- (d)
Appendix F. Proof of Corollary 4
Appendix G. Proof of Lemma 5
Appendix H. Proof of Theorem 6
1-Mean Problem Reduction
- ,
- , and
- .
Appendix I. Proof of Corollary 7
References
- Valiant, L.G. A theory of the learnable. Commun. ACM 1984, 27, 1134–1142. [Google Scholar] [CrossRef]
- Vapnik, V. Principles of risk minimization for learning theory. In Advances in Neural Information Processing Systems; Morgan-Kaufmann: Denver, CO, USA, 1992; pp. 831–838. [Google Scholar]
- Feldman, D.; Langberg, M. A unified framework for approximating and clustering data. In Proceedings of the Forty-Third Annual ACM Symposium on Theory of Computing, San Jose, CA, USA, 6–8 June 2011; pp. 569–578. [Google Scholar]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015; Volume 2018. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Bergman, S. The Kernel Function and Conformal Mapping; American Mathematical Soc.: Providence, RI, USA, 1970; Volume 5. [Google Scholar]
- Eggleston, H.G. Convexity. J. Lond. Math. Soc. 1966, 1, 183–186. [Google Scholar] [CrossRef]
- Phillips, J.M. Coresets and sketches. arXiv 2016, arXiv:1601.00617. [Google Scholar]
- Har-Peled, S. Geometric Approximation Algorithms; Number 173; American Mathematical Soc.: Providence, RI, USA, 2011. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Langberg, M.; Schulman, L.J. Universal ε-approximators for integrals. In Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms, Austin, TX, USA, 17 January 2010; pp. 598–607. [Google Scholar]
- Carathéodory, C. Über den Variabilitätsbereich der Koeffizienten von Potenzreihen, die gegebene Werte nicht annehmen. Math. Ann. 1907, 64, 95–115. [Google Scholar] [CrossRef]
- Cook, W.; Webster, R. Caratheodory’s theorem. Can. Math. Bull. 1972, 15, 293. [Google Scholar] [CrossRef]
- Phillips, J.M.; Tai, W.M. Near-optimal coresets of kernel density estimates. Discret. Comput. Geom. 2020, 63, 867–887. [Google Scholar] [CrossRef]
- Matousek, J. Approximations and optimal geometric divide-and-conquer. J. Comput. Syst. Sci. 1995, 50, 203–208. [Google Scholar] [CrossRef][Green Version]
- Braverman, V.; Feldman, D.; Lang, H. New frameworks for offline and streaming coreset constructions. arXiv 2016, arXiv:1612.00889. [Google Scholar]
- Bentley, J.L.; Saxe, J.B. Decomposable searching problems I: Static-to-dynamic transformation. J. Algorithms 1980, 1, 301–358. [Google Scholar] [CrossRef]
- Har-Peled, S.; Mazumdar, S. On coresets for k-means and k-median clustering. In Proceedings of the Thirty-Sixth Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, 13 June 2004; pp. 291–300. [Google Scholar]
- Maalouf, A.; Jubran, I.; Feldman, D. Fast and accurate least-mean-squares solvers. arXiv 2019, arXiv:1906.04705. [Google Scholar]
- Drineas, P.; Magdon-Ismail, M.; Mahoney, M.W.; Woodruff, D.P. Fast approximation of matrix coherence and statistical leverage. J. Mach. Learn. Res. 2012, 13, 3475–3506. [Google Scholar]
- Cohen, M.B.; Peng, R. Lp row sampling by lewis weights. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 4 June 2015; pp. 183–192. [Google Scholar]
- Ritter, K. Average-Case Analysis of Numerical Problems; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Juditsky, A.; Nemirovski, A.S. Large deviations of vector-valued martingales in 2-smooth normed spaces. arXiv 2008, arXiv:0809.0813. [Google Scholar]
- Tropp, J.A. An introduction to matrix concentration inequalities. arXiv 2015, arXiv:1501.01571. [Google Scholar]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2002; pp. 693–703. [Google Scholar]
- Feldman, D.; Ozer, S.; Rus, D. Coresets for vector summarization with applications to network graphs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 17 July 2017; Volume 70, pp. 1117–1125. [Google Scholar]
- Węglarczyk, S. Kernel density estimation and its application. In ITM Web of Conferences; EDP Sciences: Les Ulis, France, 2018; Volume 23. [Google Scholar]
- Zheng, Y.; Jestes, J.; Phillips, J.M.; Li, F. Quality and efficiency for kernel density estimates in large data. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22 June 2013; pp. 433–444. [Google Scholar]
- Bachem, O.; Lucic, M.; Krause, A. Scalable k-means clustering via lightweight coresets. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19 July 2018; pp. 1119–1127. [Google Scholar]
- Barger, A.; Feldman, D. k-Means for Streaming and Distributed Big Sparse Data. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 30 June 2016; pp. 342–350. [Google Scholar]
- Feldman, D.; Schmidt, M.; Sohler, C. Turning Big data into tiny data: Constant-size coresets for k-means, PCA and projective clustering. arXiv 2018, arXiv:1807.04518. [Google Scholar]
- Feldman, D.; Volkov, M.; Rus, D. Dimensionality reduction of massive sparse datasets using coresets. Adv. Neural Inf. Process. Syst. 2016, 29, 2766–2774. [Google Scholar]
- Cohen, M.B.; Elder, S.; Musco, C.; Musco, C.; Persu, M. Dimensionality reduction for k-means clustering and low rank approximation. In Proceedings of the Forty-Seventh Annual ACM on Symposium on Theory of Computing, Portland, OR, USA, 14 June 2015; pp. 163–172. [Google Scholar]
- Varadarajan, K.; Xiao, X. On the sensitivity of shape fitting problems. arXiv 2012, arXiv:1209.4893. [Google Scholar]
- Feldman, D.; Tassa, T. More constraints, smaller coresets: Constrained matrix approximation of sparse big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10 August 2015; pp. 249–258. [Google Scholar]
- Frieze, A.; Kannan, R.; Vempala, S. Fast Monte-Carlo algorithms for finding low-rank approximations. J. ACM (JACM) 2004, 51, 1025–1041. [Google Scholar] [CrossRef]
- Yang, J.; Chow, Y.L.; Ré, C.; Mahoney, M.W. Weighted SGD for ℓp regression with randomized preconditioning. J. Mach. Learn. Res. 2017, 18, 7811–7853. [Google Scholar]
- Cohen, M.B.; Lee, Y.T.; Musco, C.; Musco, C.; Peng, R.; Sidford, A. Uniform sampling for matrix approximation. In Proceedings of the 2015 Conference on Innovations in Theoretical Computer Science, Rehovot, Israel, 11 January 2015; pp. 181–190. [Google Scholar]
- Papailiopoulos, D.; Kyrillidis, A.; Boutsidis, C. Provable deterministic leverage score sampling. In Proceedings of the 20th ACM SIGKDD iInternational Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24 August 2014; pp. 997–1006. [Google Scholar]
- Drineas, P.; Mahoney, M.W.; Muthukrishnan, S. Relative-error CUR matrix decompositions. SIAM J. Matrix Anal. Appl. 2008, 30, 844–881. [Google Scholar] [CrossRef]
- Cohen, M.B.; Musco, C.; Musco, C. Input sparsity time low-rank approximation via ridge leverage score sampling. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Barcelona, Spain, 16 January 2017; pp. 1758–1777. [Google Scholar]
- Maalouf, A.; Statman, A.; Feldman, D. Tight sensitivity bounds for smaller coresets. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23 August 2020; pp. 2051–2061. [Google Scholar]
- Batson, J.; Spielman, D.A.; Srivastava, N. Twice-ramanujan sparsifiers. SIAM J. Comput. 2012, 41, 1704–1721. [Google Scholar] [CrossRef]
- Cohen, M.B.; Nelson, J.; Woodruff, D.P. Optimal approximate matrix product in terms of stable rank. arXiv 2015, arXiv:1507.02268. [Google Scholar]
- Clarkson, K.L. Coresets, sparse greedy approximation, and the Frank-Wolfe algorithm. ACM Trans. Algorithms (TALG) 2010, 6, 63. [Google Scholar] [CrossRef]
- Desai, A.; Ghashami, M.; Phillips, J.M. Improved practical matrix sketching with guarantees. IEEE Trans. Knowl. Data Eng. 2016, 28, 1678–1690. [Google Scholar] [CrossRef]
- Madariaga, D.; Madariaga, J.; Bustos-Jiménez, J.; Bustos, B. Improving Signal-Strength Aggregation for Mobile Crowdsourcing Scenarios. Sensors 2021, 21, 1084. [Google Scholar] [CrossRef]
- Mahendran, N.; Vincent, D.R.; Srinivasan, K.; Chang, C.Y.; Garg, A.; Gao, L.; Reina, D.G. Sensor-assisted weighted average ensemble model for detecting major depressive disorder. Sensors 2019, 19, 4822. [Google Scholar] [CrossRef]
- Wu, L.; Xu, Q.; Heikkilä, J.; Zhao, Z.; Liu, L.; Niu, Y. A star sensor on-orbit calibration method based on singular value decomposition. Sensors 2019, 19, 3301. [Google Scholar] [CrossRef]
- Yang, W.; Hong, J.Y.; Kim, J.Y.; Paik, S.h.; Lee, S.H.; Park, J.S.; Lee, G.; Kim, B.M.; Jung, Y.J. A novel singular value decomposition-based denoising method in 4-dimensional computed tomography of the brain in stroke patients with statistical evaluation. Sensors 2020, 20, 3063. [Google Scholar] [CrossRef]
- Peri, E.; Xu, L.; Ciccarelli, C.; Vandenbussche, N.L.; Xu, H.; Long, X.; Overeem, S.; van Dijk, J.P.; Mischi, M. Singular value decomposition for removal of cardiac interference from trunk electromyogram. Sensors 2021, 21, 573. [Google Scholar] [CrossRef]
- Code. Open Source Code for All the Algorithms Presented in This Paper. 2021. Available online: https://github.com/alaamaalouf/vector-summarization-coreset (accessed on 29 September 2021).
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Oliphant, T.E. A Guide to NumPy; Trelgol Publishing USA, 2006; Volume 1, Available online: https://ecs.wgtn.ac.nz/foswiki/pub/Support/ManualPagesAndDocumentation/numpybook.pdf (accessed on 29 September 2021).
- Tremblay, N.; Barthelmé, S.; Amblard, P.O. Determinantal Point Processes for Coresets. J. Mach. Learn. Res. 2019, 20, 1–70. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 29 September 2021).
- Donovan, B.; Work, D. Using Coarse GPS Data to Quantify City-Scale Transportation System Resilience to Extreme Events. 2015. Available online: http://vis.cs.kent.edu/DL/Data/ (accessed on 29 September 2021).
- US Census Data (1990) Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/US+Census+Data+(1990) (accessed on 10 June 2021).
- Kawala, F.; Douzal-Chouakria, A.; Gaussier, E.; Dimert, E. Prédictions D’activité dans les Réseaux Sociaux en Ligne. 2013. Available online: https://archive.ics.uci.edu/ml/datasets/Buzz+in+social+media+ (accessed on 29 September 2021).
- Huerta, R.; Mosqueiro, T.; Fonollosa, J.; Rulkov, N.F.; Rodriguez-Lujan, I. Online decorrelation of humidity and temperature in chemical sensors for continuous monitoring. Chemom. Intell. Lab. Syst. 2016, 157, 169–176. [Google Scholar] [CrossRef]
- Chen, X. A new generalization of Chebyshev inequality for random vectors. arXiv 2007, arXiv:0707.0805. [Google Scholar]
- Minsker, S. Geometric median and robust estimation in Banach spaces. Bernoulli 2015, 21, 2308–2335. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maalouf, A.; Jubran, I.; Tukan, M.; Feldman, D. Coresets for the Average Case Error for Finite Query Sets. Sensors 2021, 21, 6689. https://doi.org/10.3390/s21196689
Maalouf A, Jubran I, Tukan M, Feldman D. Coresets for the Average Case Error for Finite Query Sets. Sensors. 2021; 21(19):6689. https://doi.org/10.3390/s21196689
Chicago/Turabian StyleMaalouf, Alaa, Ibrahim Jubran, Murad Tukan, and Dan Feldman. 2021. "Coresets for the Average Case Error for Finite Query Sets" Sensors 21, no. 19: 6689. https://doi.org/10.3390/s21196689
APA StyleMaalouf, A., Jubran, I., Tukan, M., & Feldman, D. (2021). Coresets for the Average Case Error for Finite Query Sets. Sensors, 21(19), 6689. https://doi.org/10.3390/s21196689