
Selection of Essential Neural Activity Timesteps for Intracortical Brain–Computer Interface Based on Recurrent Neural Network

 , and
, and
Abstract
:1. Introduction
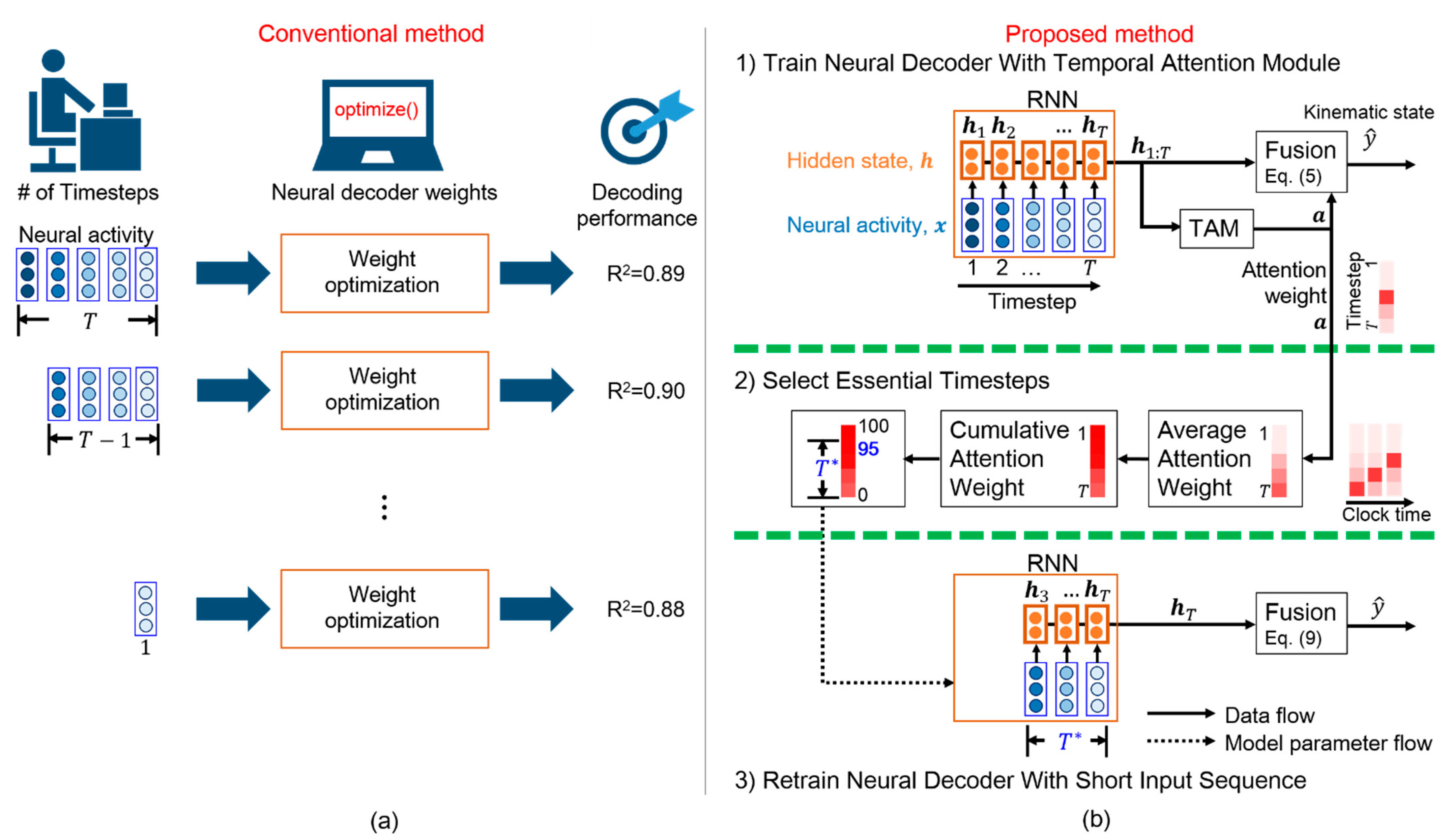
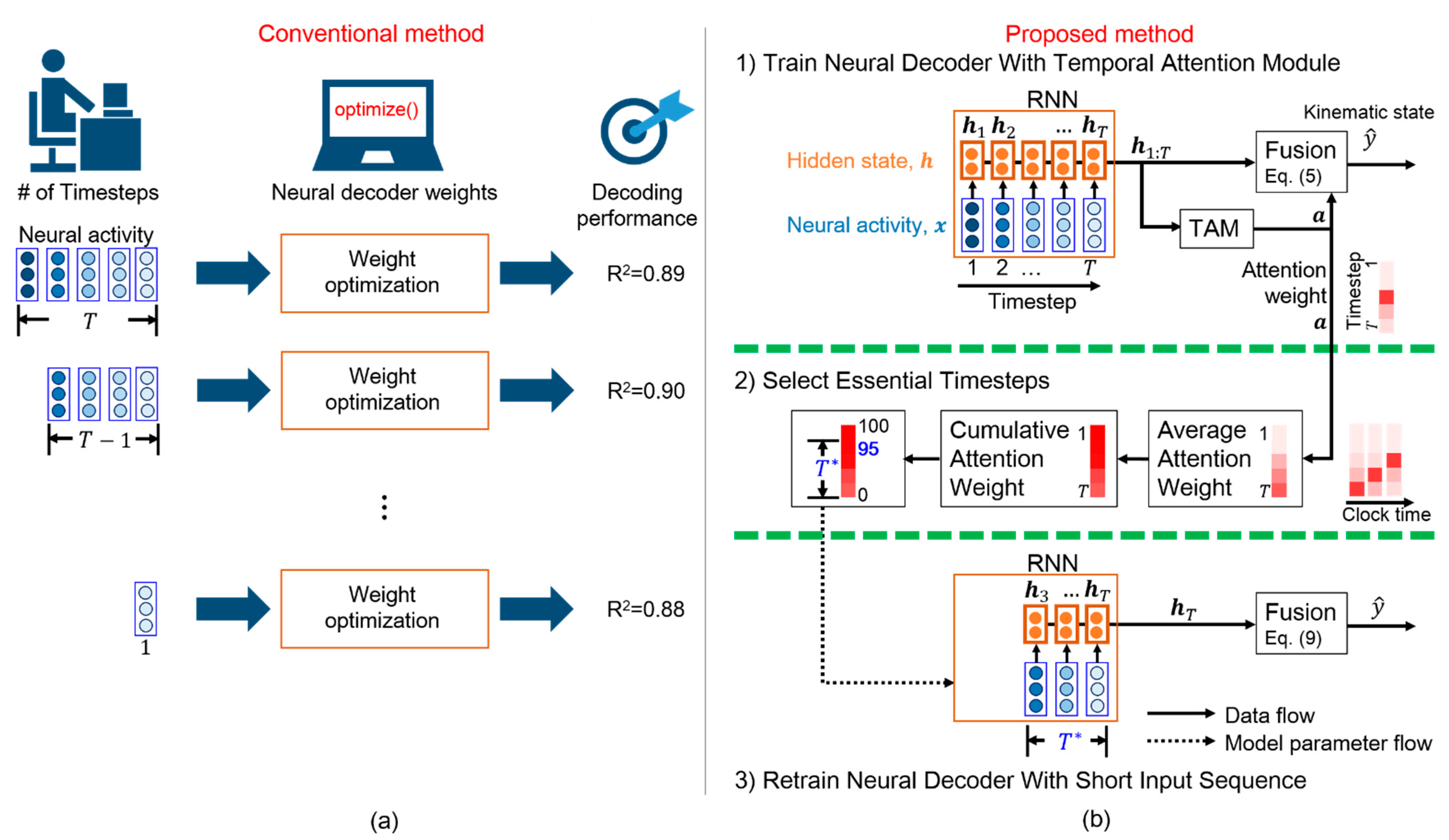
- We propose a scheme that efficiently determines the essential timesteps for a general RNN-based neural decoder, thus avoiding the time-consuming grid search;
- We adopt a TAM that interprets the salience of each timestep for predicting movement intention, leading to essential timestep selection;
- Experimental results reveal that the proposed TTS can determine the essential timesteps for three RNN-based neural decoders while reducing the computation time of offline training and online prediction;
- The RNN-based neural decoders with a few essential timesteps outperform state-of-the-art neural decoders on two nonhuman primate datasets;
- The visualization of attention weights demonstrates that only a few neural activity timesteps are emphasized for neural decoding during arm motion and resting.
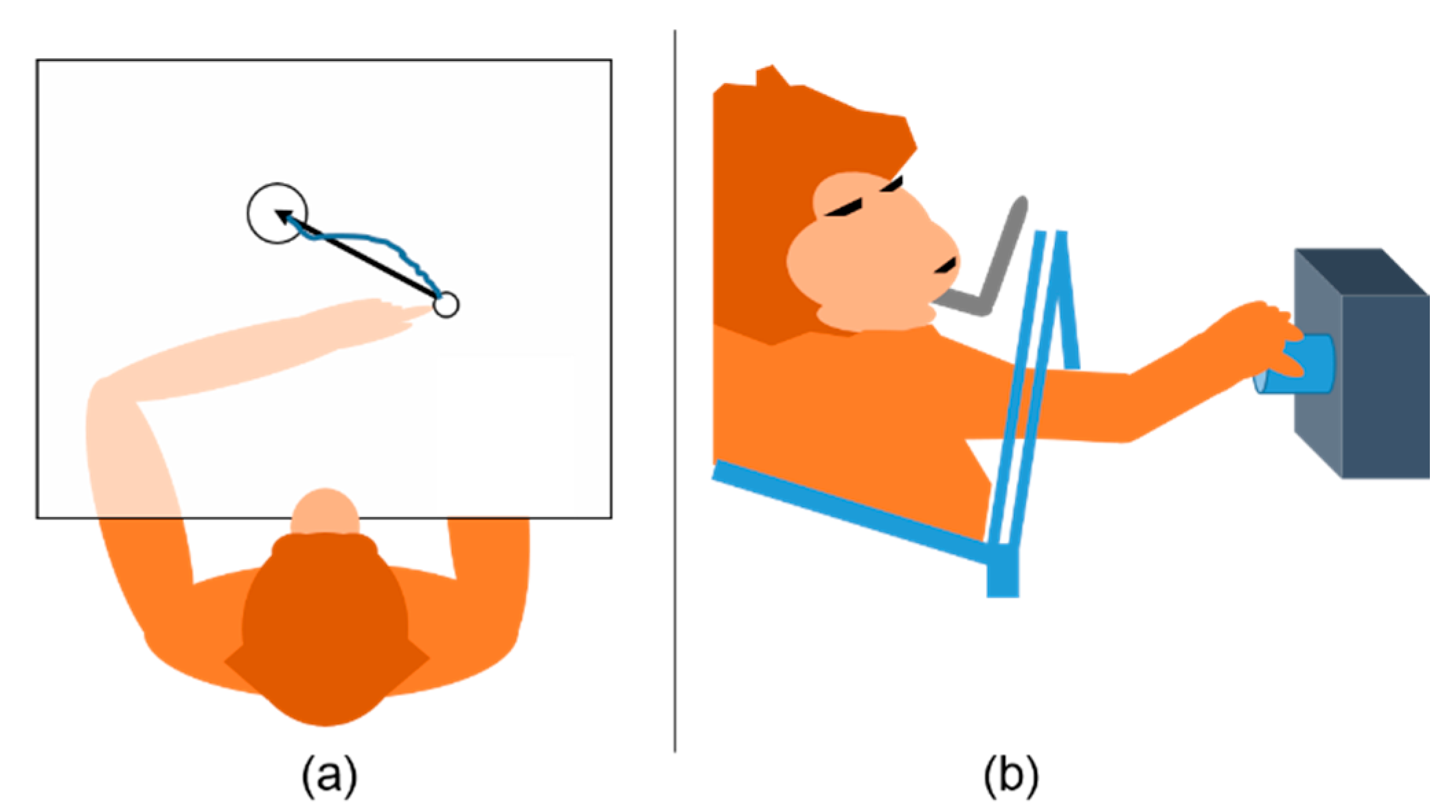
2. Behavioral Tasks and Neural Data Collection
2.1. Monkey Indy
2.2. Monkey N
3. Temporal Attention-Aware Timestep Selection for RNN-Based Neural Decoder
3.1. RNN-Based Neural Decoder
3.2. Temporal Attention Module
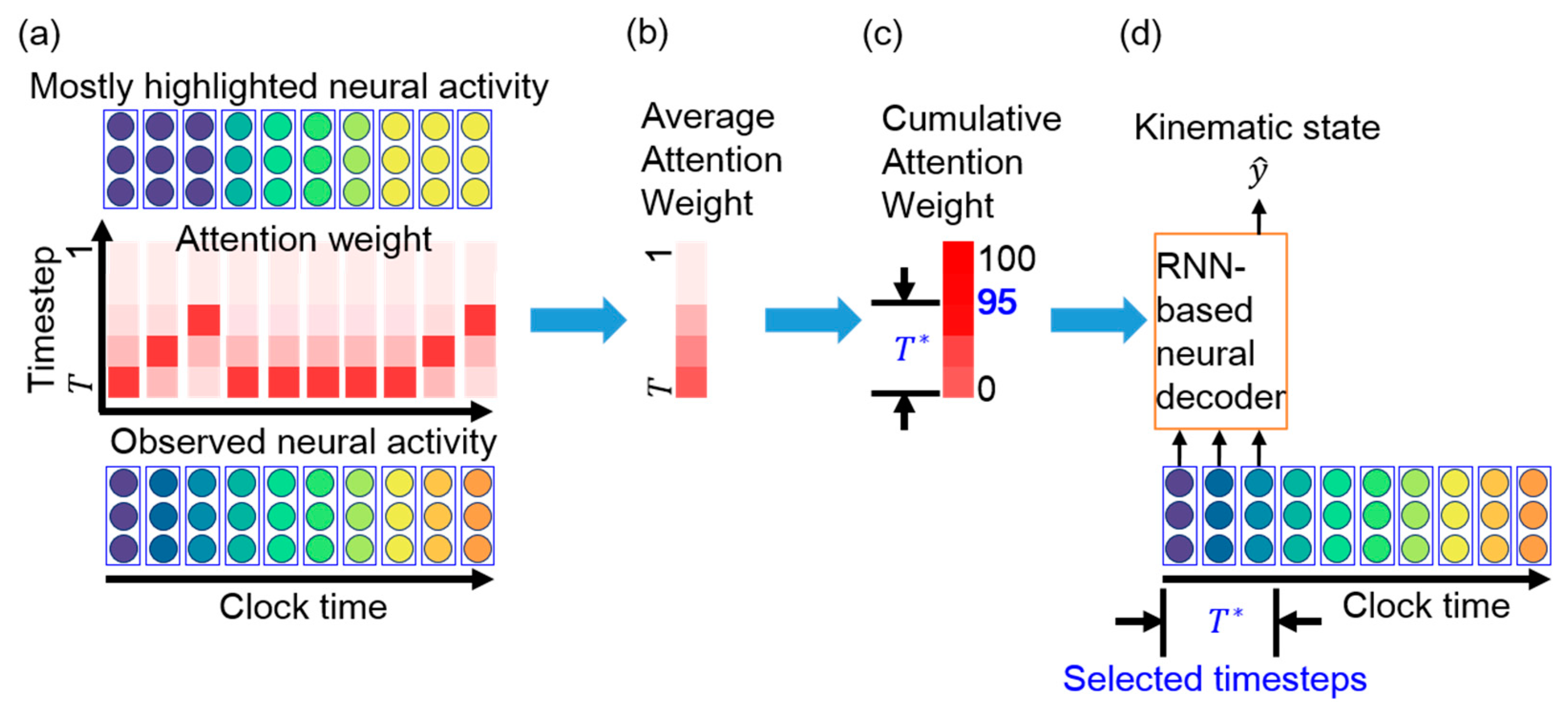
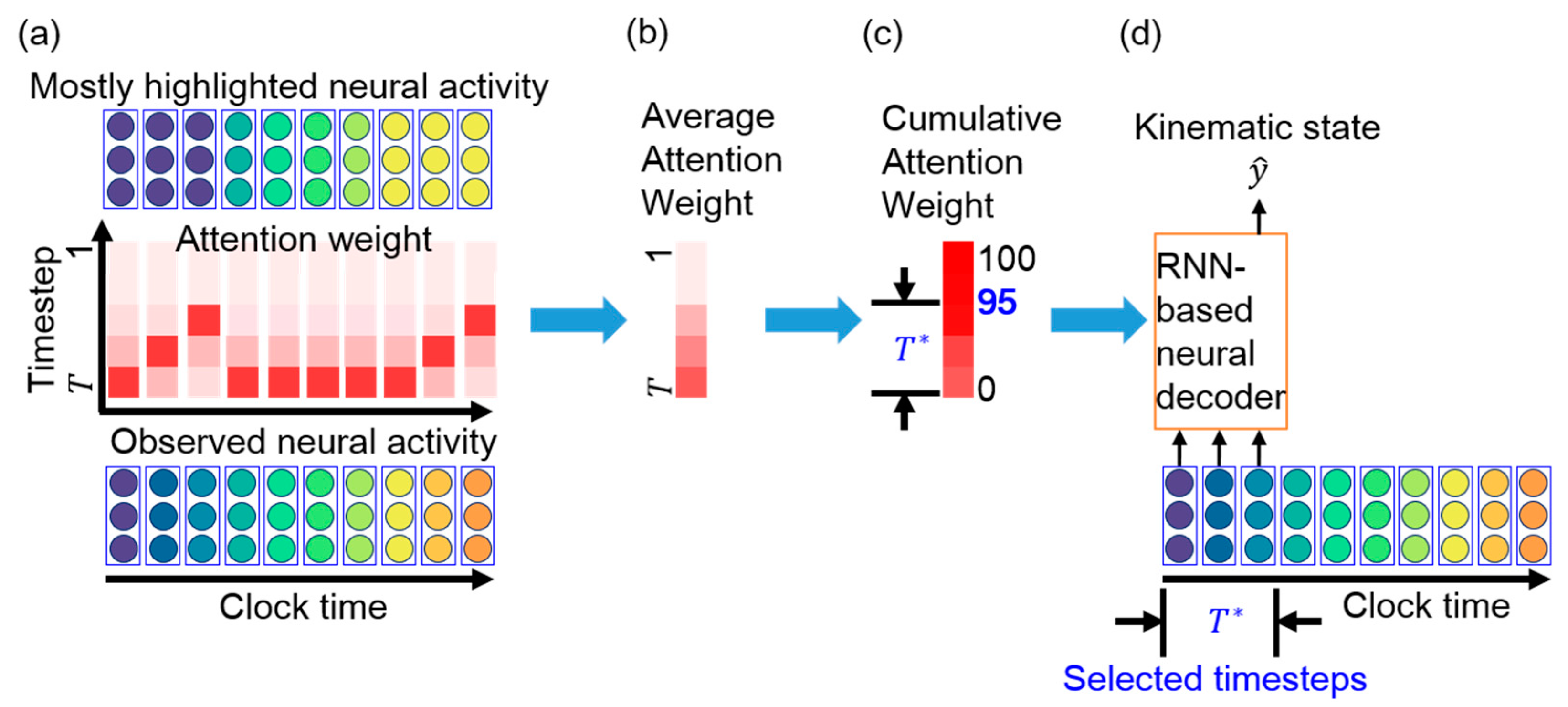
3.3. Essential Timestep Selection for Neural Decoding
3.4. Neural Decoder Retraining with Short Input Sequence
3.5. Optimization
3.6. Performance Evaluation and Statistical Evaluation
4. Experimental Results
4.1. Implementation Details
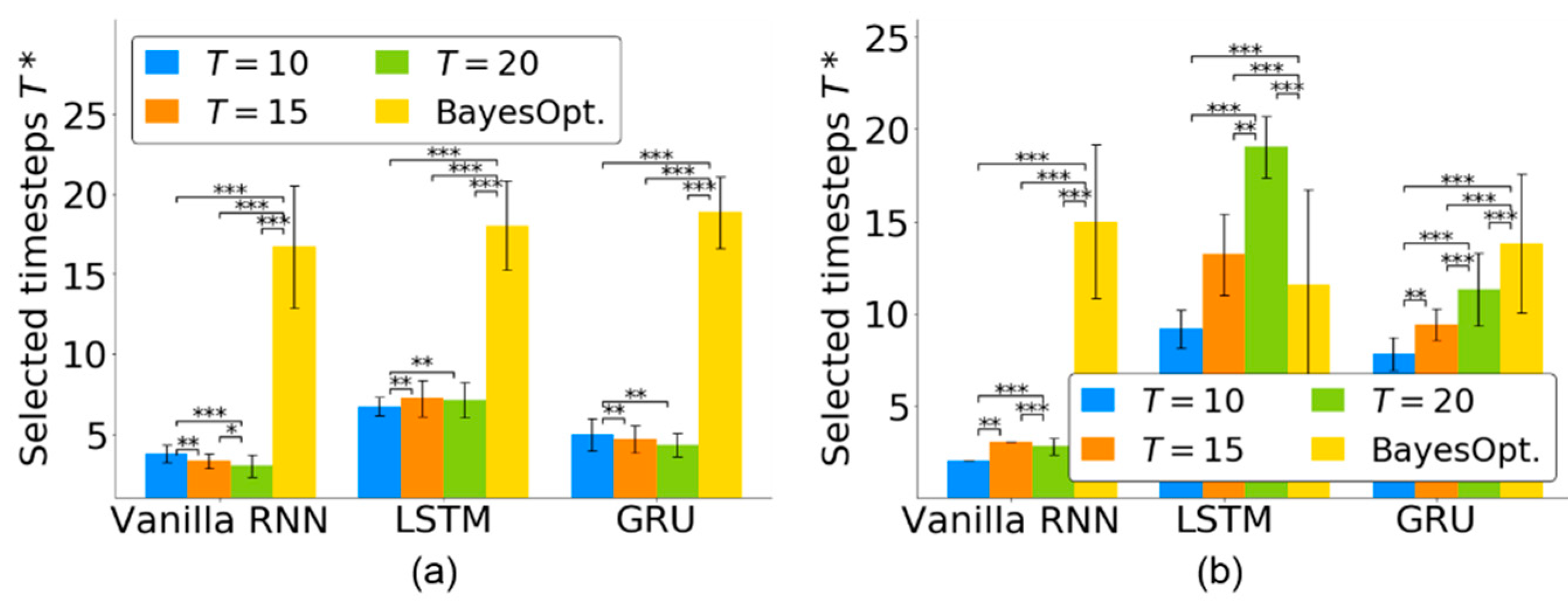
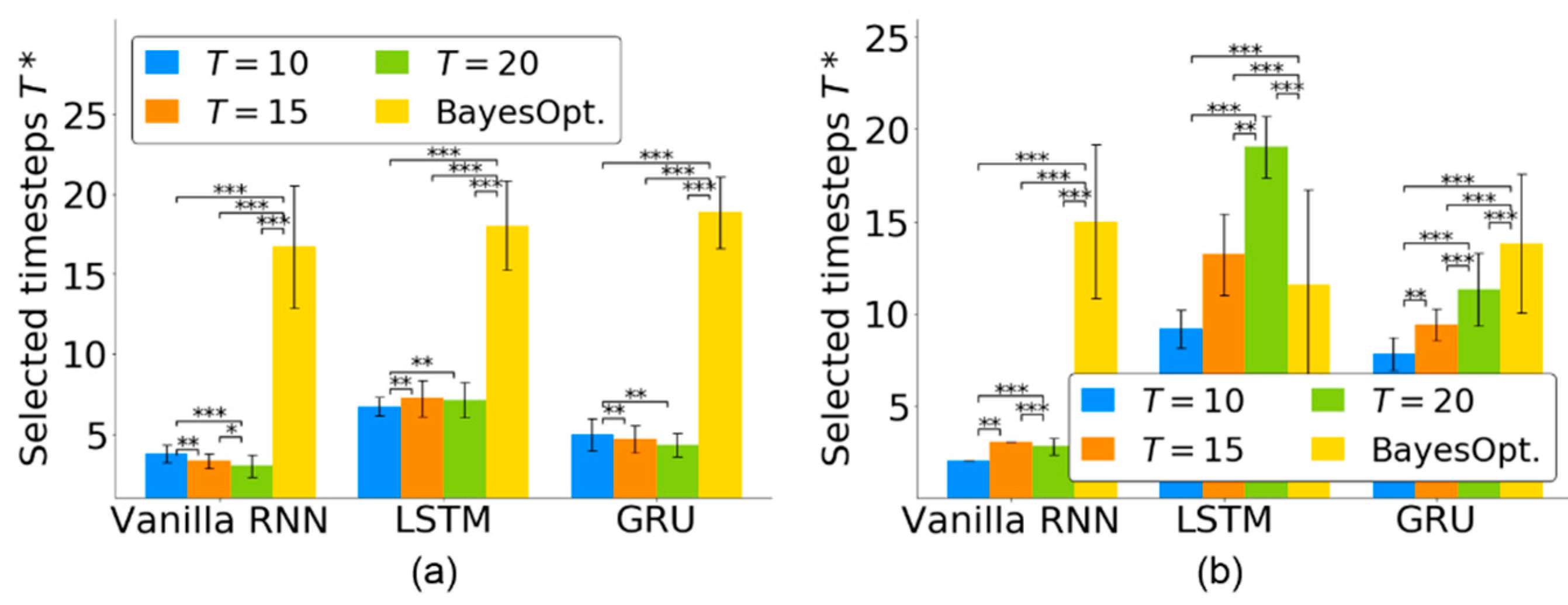
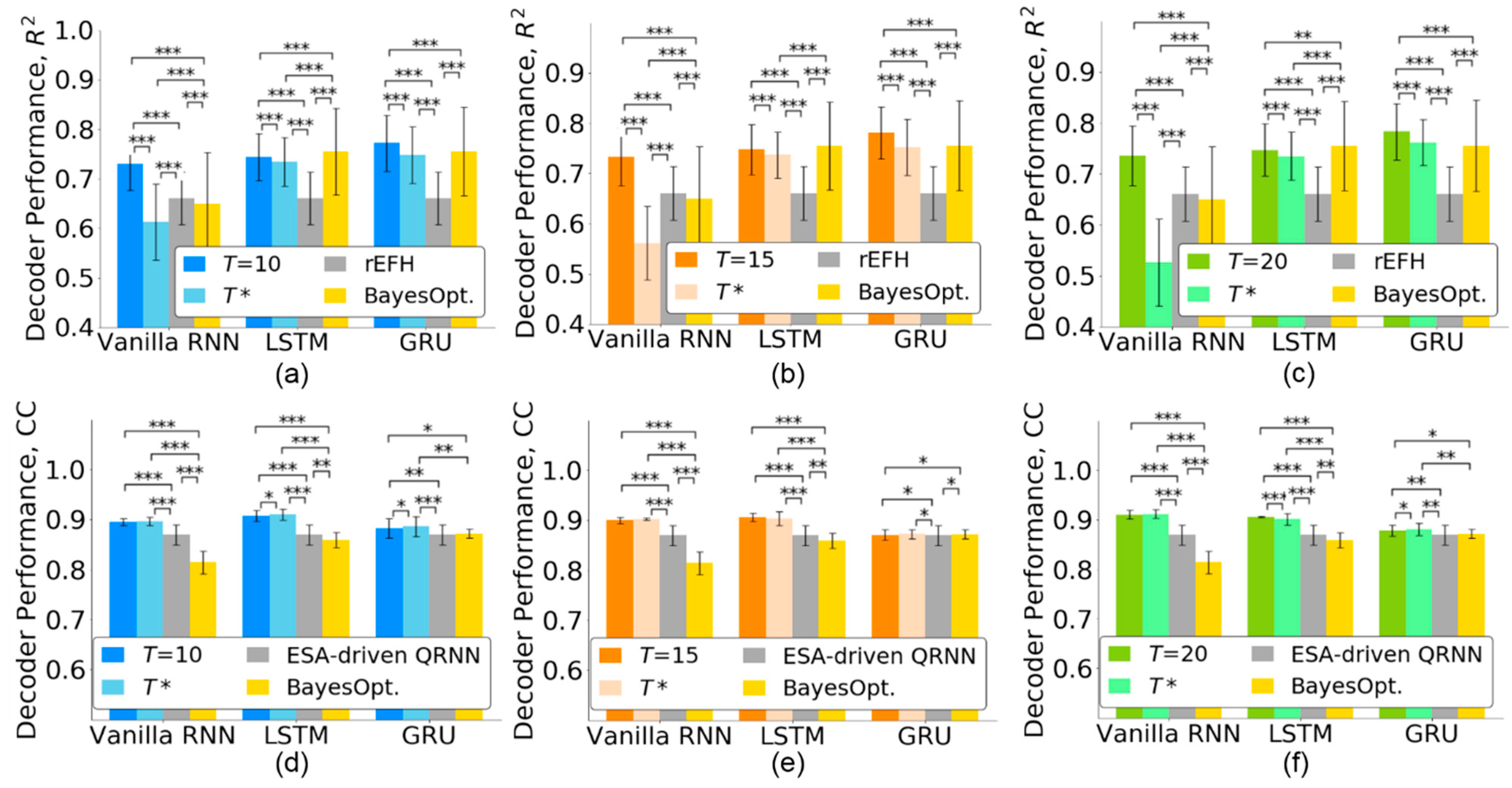
4.2. Timestep Selection for Neural Decoders
4.3. Timestep Selection across Multiple Sessions
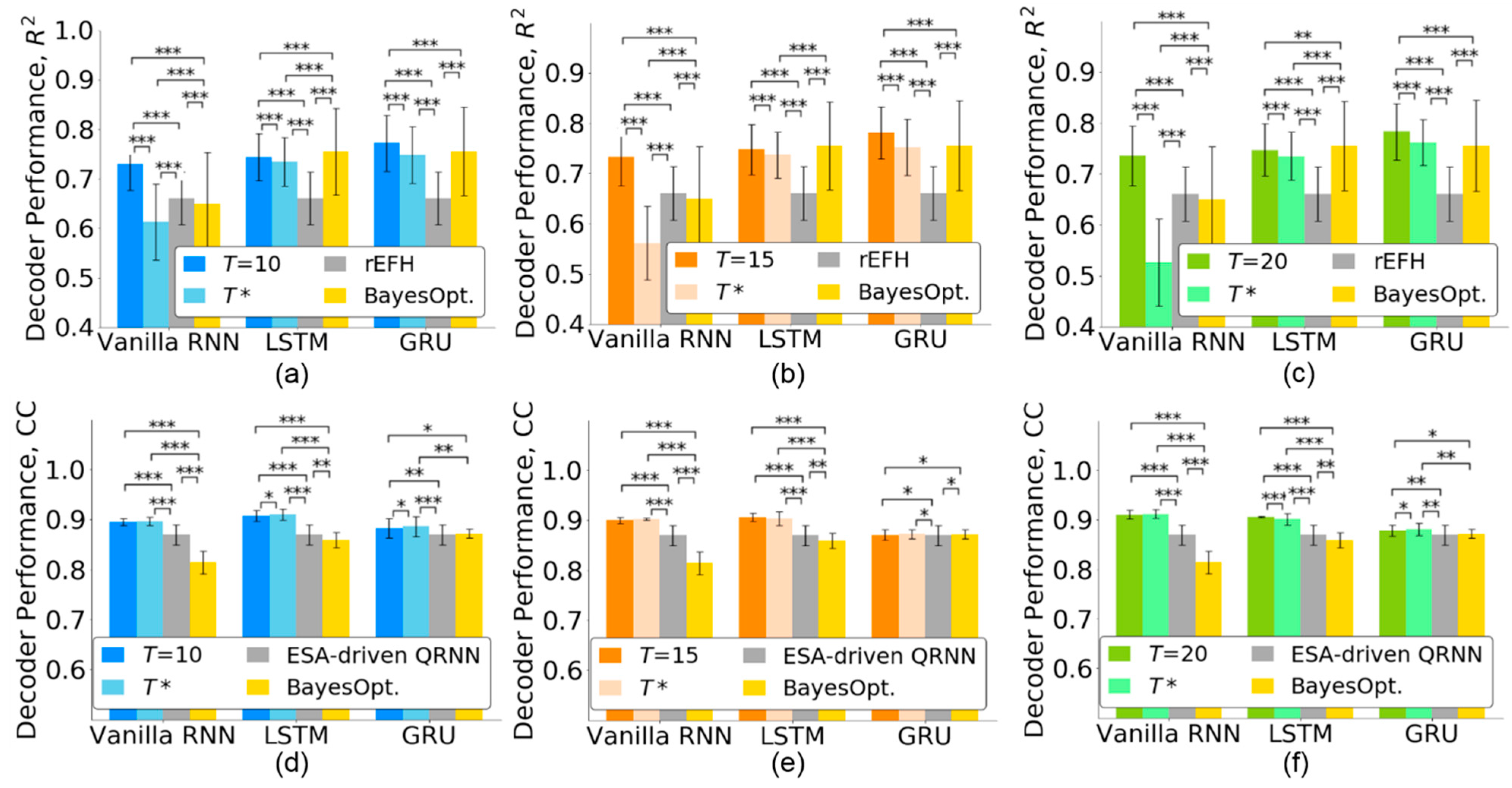
4.4. Comparison with State-of-the-Art Methods
4.5. Reduced Computation Time
4.6. Visualization of Attention Weights in TTS
5. Discussion
5.1. Timestep Selection for Varying Recording Conditions
5.2. Computational Efficiency and Comparable Decoding Performance
5.3. Interpretation of Attention Weights in TTS
5.4. Limitation of TTS
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shaikh, S.; So, R.; Sibindi, T.; Libedinsky, C.; Basu, A. Sparse Ensemble Machine Learning to improve robustness of long-term decoding in iBMIs. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 28, 380–389. [Google Scholar] [CrossRef]
- Zhang, P.; Li, W.; Ma, X.; He, J.; Huang, J.; Li, Q. Feature-Selection-Based Transfer Learning for Intracortical Brain–Machine Interface Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 29, 60–73. [Google Scholar] [CrossRef]
- Gilja, V.; Pandarinath, C.; Blabe, C.H.; Nuyujukian, P.; Simeral, J.D.; Sarma, A.A.; Sorice, B.L.; Perge, J.A.; Jarosiewicz, B.; Hochberg, L.R. Clinical translation of a high-performance neural prosthesis. Nat. Med. 2015, 21, 1142. [Google Scholar] [CrossRef] [Green Version]
- Schwemmer, M.A.; Skomrock, N.D.; Sederberg, P.B.; Ting, J.E.; Sharma, G.; Bockbrader, M.A.; Friedenberg, D.A. Meeting brain–computer interface user performance expectations using a deep neural network decoding framework. Nat. Med. 2018, 24, 1669–1676. [Google Scholar] [CrossRef]
- Pandarinath, C.; Ames, K.C.; Russo, A.A.; Farshchian, A.; Miller, L.E.; Dyer, E.L.; Kao, J.C. Latent factors and dynamics in motor cortex and their application to brain–machine interfaces. J. Neurosci. 2018, 38, 9390–9401. [Google Scholar] [CrossRef]
- Tseng, P.-H.; Urpi, N.A.; Lebedev, M.; Nicolelis, M. Decoding movements from cortical ensemble activity using a long short-term memory recurrent network. Neural Comput. 2019, 31, 1085–1113. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Ólafsdóttir, H.F.; Barry, C.; Vicente, R. Efficient neural decoding of self-location with a deep recurrent network. PLoS Comput. Biol. 2019, 15, e1006822. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, N.; Constandinou, T.G.; Bouganis, C.-S. Robust and accurate decoding of hand kinematics from entire spiking activity using deep learning. J. Neural Eng. 2021, 18, 026011. [Google Scholar] [CrossRef]
- Wang, Y.; Truccolo, W.; Borton, D.A. Decoding Hindlimb Kinematics from Primate Motor Cortex using Long Short-Term Memory Recurrent Neural Networks. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 1944–1947. [Google Scholar]
- Li, S.; Li, J.; Li, Z. An improved unscented kalman filter based decoder for cortical brain-machine interfaces. Front. Neurosci. 2016, 10, 587. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Chao, L.; Chen, Y.; Ma, X.; Wang, W.; He, J.; Huang, J.; Li, Q. Reinforcement Learning Based Fast Self-Recalibrating Decoder for Intracortical Brain–Machine Interface. Sensors 2020, 20, 5528. [Google Scholar] [CrossRef]
- Williams, A.H.; Poole, B.; Maheswaranathan, N.; Dhawale, A.K.; Fisher, T.; Wilson, C.D.; Brann, D.H.; Trautmann, E.M.; Ryu, S.; Shusterman, R. Discovering precise temporal patterns in large-scale neural recordings through robust and interpretable time warping. Neuron 2020, 105, 246–259.e248. [Google Scholar] [CrossRef] [PubMed]
- Naufel, S.; Glaser, J.I.; Kording, K.P.; Perreault, E.J.; Miller, L.E. A muscle-activity-dependent gain between motor cortex and EMG. J. Neurophysiol. 2019, 121, 61–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mwata-Velu, T.y.; Ruiz-Pinales, J.; Rostro-Gonzalez, H.; Ibarra-Manzano, M.A.; Cruz-Duarte, J.M.; Avina-Cervantes, J.G. Motor Imagery Classification Based on a Recurrent-Convolutional Architecture to Control a Hexapod Robot. Mathematics 2021, 9, 606. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmadi, N.; Constandinou, T.G.; Bouganis, C.-S. Decoding Hand Kinematics from Local Field Potentials using Long Short-Term Memory (LSTM) Network. In Proceedings of the 9th International IEEE/EMBS Conference on Neural Engineering (NER), Shanghai, China, 2–6 April 2019; pp. 415–419. [Google Scholar]
- Park, J.; Kim, S.-P. Estimation of Speed and Direction of Arm Movements from M1 Activity Using a Nonlinear Neural Decoder. In Proceedings of the 7th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Korea, 18–20 February 2019; pp. 1–4. [Google Scholar]
- Pei, W.; Baltrusaitis, T.; Tax, D.M.; Morency, L.-P. Temporal Attention-Gated Model for Robust Sequence Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6730–6739. [Google Scholar]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1243–1251. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, P.; Hu, V.T.; Mettes, P.; Snoek, C.G. Localizing the Common Action Among a Few Videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 505–521. [Google Scholar]
- Liu, D.; Jiang, T.; Wang, Y. Completeness Modeling and Context Separation for Weakly Supervised Temporal Action Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1298–1307. [Google Scholar]
- O’Doherty, J.E.; Cardoso, M.; Makin, J.; Sabes, P. Nonhuman Primate Reaching with Multichannel Sensorimotor Cortex Electrophysiology. 2017. Available online: https://zenodo.org/record/583331 (accessed on 1 September 2020).
- Brochier, T.; Zehl, L.; Hao, Y.; Duret, M.; Sprenger, J.; Denker, M.; Grün, S.; Riehle, A. Massively parallel recordings in macaque motor cortex during an instructed delayed reach-to-grasp task. Sci. Data 2018, 5, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Makin, J.G.; O’Doherty, J.E.; Cardoso, M.M.; Sabes, P.N. Superior arm-movement decoding from cortex with a new, unsupervised-learning algorithm. J. Neural Eng. 2018, 15, 026010. [Google Scholar] [CrossRef]
- Temporal Attention-Aware Timestep Selection. Available online: https://github.com/nclab-me-ncku/Temporal_Attention_LSTM (accessed on 8 September 2021).
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. Royal Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Razali, N.M.; Wah, Y.B. Power comparisons of shapiro-wilk, kolmogorov-smirnov, lilliefors and anderson-darling tests. J. Stat. Modeling Anal. 2011, 2, 21–33. [Google Scholar]
- Hertel, P.; Fagerquist, M.V.; Svensson, T.H. Enhanced cortical dopamine output and antipsychotic-like effects of raclopride by α2 adrenoceptor blockade. Science 1999, 286, 105–107. [Google Scholar] [CrossRef] [PubMed]
- Glaser, J.I.; Benjamin, A.S.; Chowdhury, R.H.; Perich, M.G.; Miller, L.E.; Kording, K.P. Machine learning for neural decoding. Eneuro 2020, 7, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Merrill, D.R.; Tresco, P.A. Impedance characterization of microarray recording electrodes in vitro. IEEE Trans. Biomed. Eng. 2005, 52, 1960–1965. [Google Scholar] [CrossRef]
- Hennequin, G.; Vogels, T.P.; Gerstner, W. Optimal control of transient dynamics in balanced networks supports generation of complex movements. Neuron 2014, 82, 1394–1406. [Google Scholar] [CrossRef] [Green Version]
- Sussillo, D.; Churchland, M.M.; Kaufman, M.T.; Shenoy, K.V. A neural network that finds a naturalistic solution for the production of muscle activity. Nature Neurosci. 2015, 18, 1025–1033. [Google Scholar] [CrossRef]
- Kaufman, M.T.; Seely, J.S.; Sussillo, D.; Ryu, S.I.; Shenoy, K.V.; Churchland, M.M. The largest response component in the motor cortex reflects movement timing but not movement type. Eneuro 2016, 3. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Decoded Kinematics | Neural Modality | Neural Decoder | #L | #H | #T | DR |
|---|---|---|---|---|---|---|---|---|
| Naufel et al. [13] | 2018 | Wrist electromyography | Spikes | LSTM | 1 | – | 10 (500 ms) | 0.25 |
| Wang et al. [9] | 2018 | Hindlimb kinematics | Spikes | LSTM | – | 200 | 3 (130 ms) | 0.2 |
| Tseng et al. [6] | 2019 | Hindlimb kinematics | Spikes | LSTM | 2 | 128 | 30 (1500 ms) | 0.2 |
| Ahmadi et al. [16] | 2019 | Velocity | Spikes, local field potentials | LSTM | 1 | 100 | 2 (256 ms) | 0.2 |
| Park et al. [17] | 2019 | Velocity | Spikes | LSTM | – | – | 3 (150 ms) | – |
| Shaikh et al. [1] | 2020 | Actions | Spikes | LSTM | 1 | 75–200 | 1–4 (600–900 ms) | 0 |
| Ahmadi et al. [8] | 2021 | Velocity | Spikes | Quasi-RNN | 1 | 400 | 2 (256 ms) | 0.4 |
| Parameter | RNN | LSTM | GRU |
|---|---|---|---|
| Number of hidden layers | 2 | 2 | 2 |
| Number of hidden states | 128 | 256 | 128 |
| Processing | Bidirectional | ||
| Mini-batch size | 32 | 256 | 64 |
| Learning rate | 1 × 10−4 | ||
| Number of weights | 0.42 M | 1.56 M | 1.19 M |
| Training | Testing | Training | Testing | |||
|---|---|---|---|---|---|---|
| Vanilla RNN | 890.43 ± 5.21 | 1.08 ± 0.02 | 827.73 ± 6.76 (−7.04%) | 0.88 ± 0.02 (−18.52%) | 253.54 ± 32.24 | 45.66 ± 3.05 (−81.99%) |
| LSTM | 219.87 ± 51.22 | 1.51 ± 0.08 | 191.85 ± 44.08 (−12.74%) | 1.26 ± 0.07 (−16.56%) | 244.88 ± 12.43 | 81.41 ± 2.74 (−66.76%) |
| GRU | 1006.02 ± 6.18 | 1.20 ± 0.02 | 948.67 ± 13.77 (−5.70%) | 1.00 ± 0.03 (−16.67%) | 211.67 ± 7.38 | 108.61 ± 2.76 (−48.69%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.-H.; Huang, J.-W.; Huang, C.-J.; Chiu, P.-H.; Lai, H.-Y.; Chen, Y.-Y. Selection of Essential Neural Activity Timesteps for Intracortical Brain–Computer Interface Based on Recurrent Neural Network. Sensors 2021, 21, 6372. https://doi.org/10.3390/s21196372
Yang S-H, Huang J-W, Huang C-J, Chiu P-H, Lai H-Y, Chen Y-Y. Selection of Essential Neural Activity Timesteps for Intracortical Brain–Computer Interface Based on Recurrent Neural Network. Sensors. 2021; 21(19):6372. https://doi.org/10.3390/s21196372
Chicago/Turabian StyleYang, Shih-Hung, Jyun-We Huang, Chun-Jui Huang, Po-Hsiung Chiu, Hsin-Yi Lai, and You-Yin Chen. 2021. "Selection of Essential Neural Activity Timesteps for Intracortical Brain–Computer Interface Based on Recurrent Neural Network" Sensors 21, no. 19: 6372. https://doi.org/10.3390/s21196372
APA StyleYang, S.-H., Huang, J.-W., Huang, C.-J., Chiu, P.-H., Lai, H.-Y., & Chen, Y.-Y. (2021). Selection of Essential Neural Activity Timesteps for Intracortical Brain–Computer Interface Based on Recurrent Neural Network. Sensors, 21(19), 6372. https://doi.org/10.3390/s21196372