
Graph Attention Feature Fusion Network for ALS Point Cloud Classification


Abstract
:1. Introduction
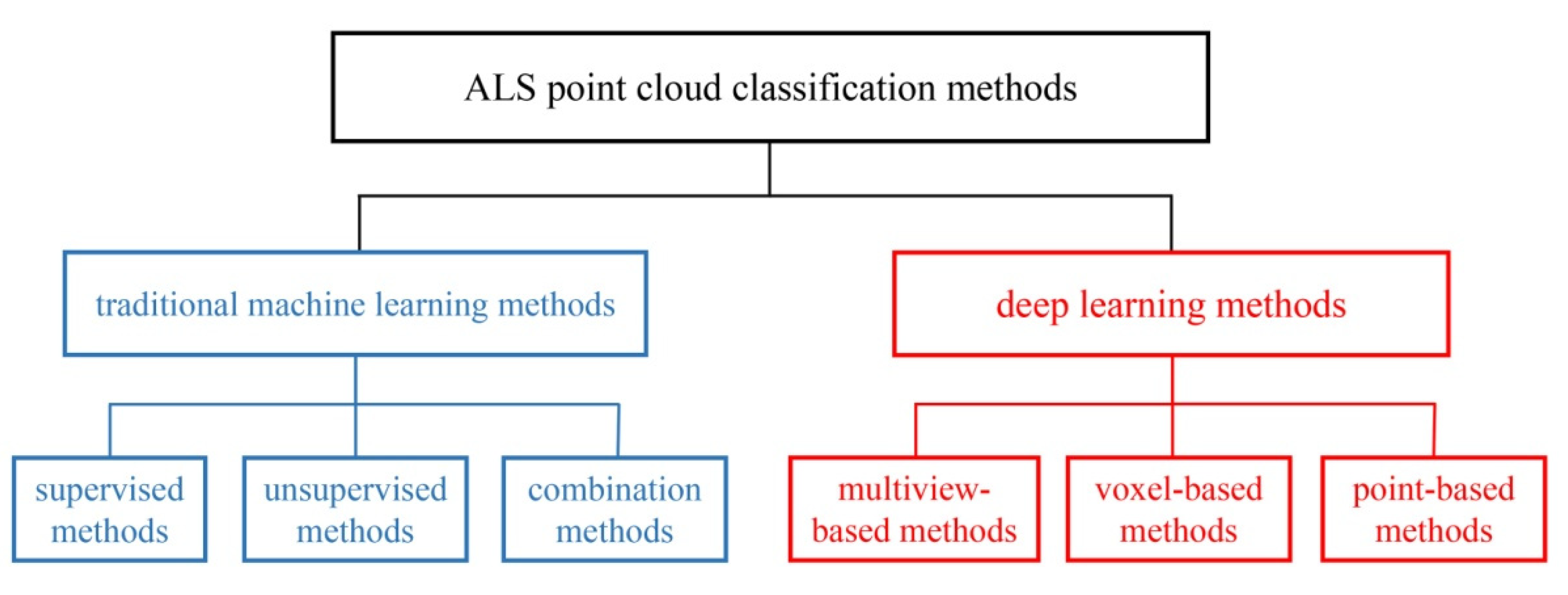
2. Related Work
3. Methodology
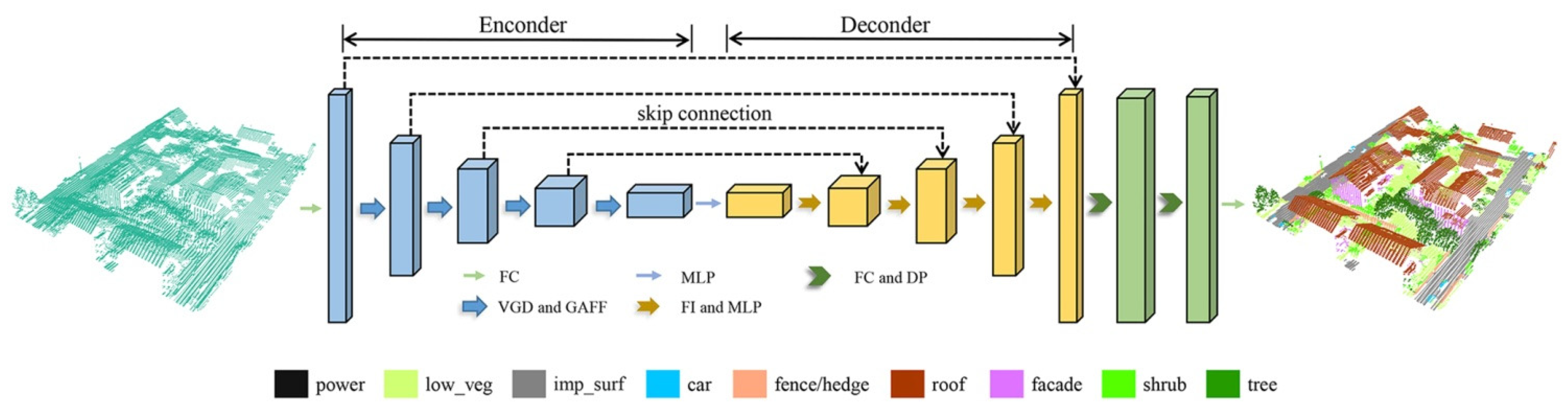
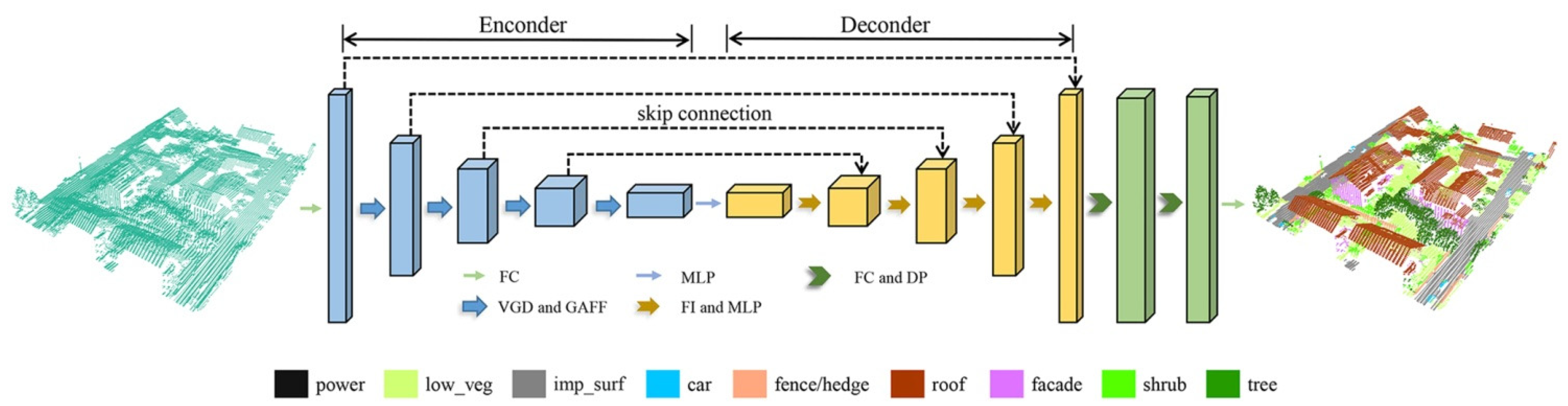
3.1. Overview
3.2. Graph Pyramid Construction
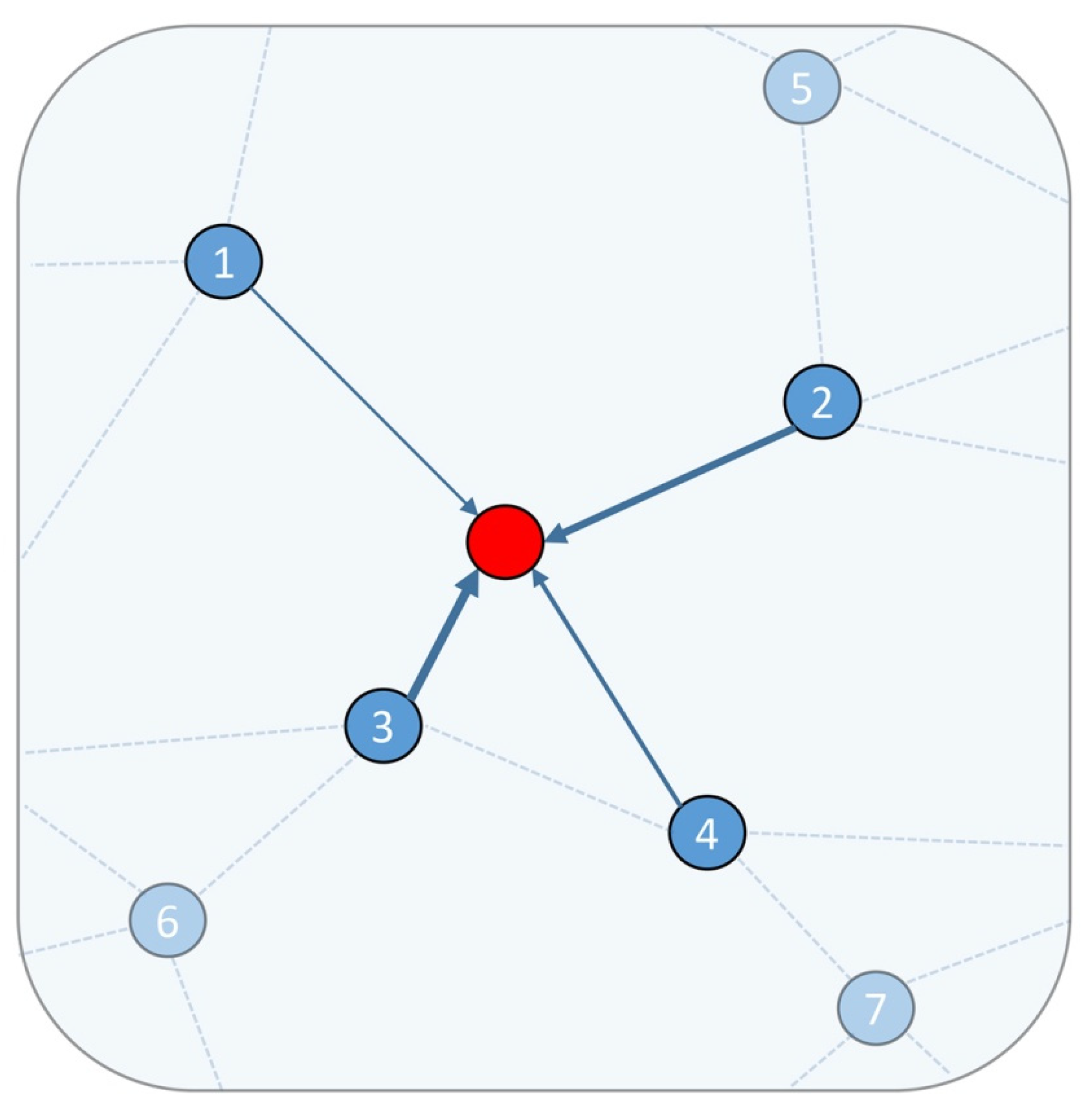
3.2.1. Graph Construction
3.2.2. Graph Coarsening
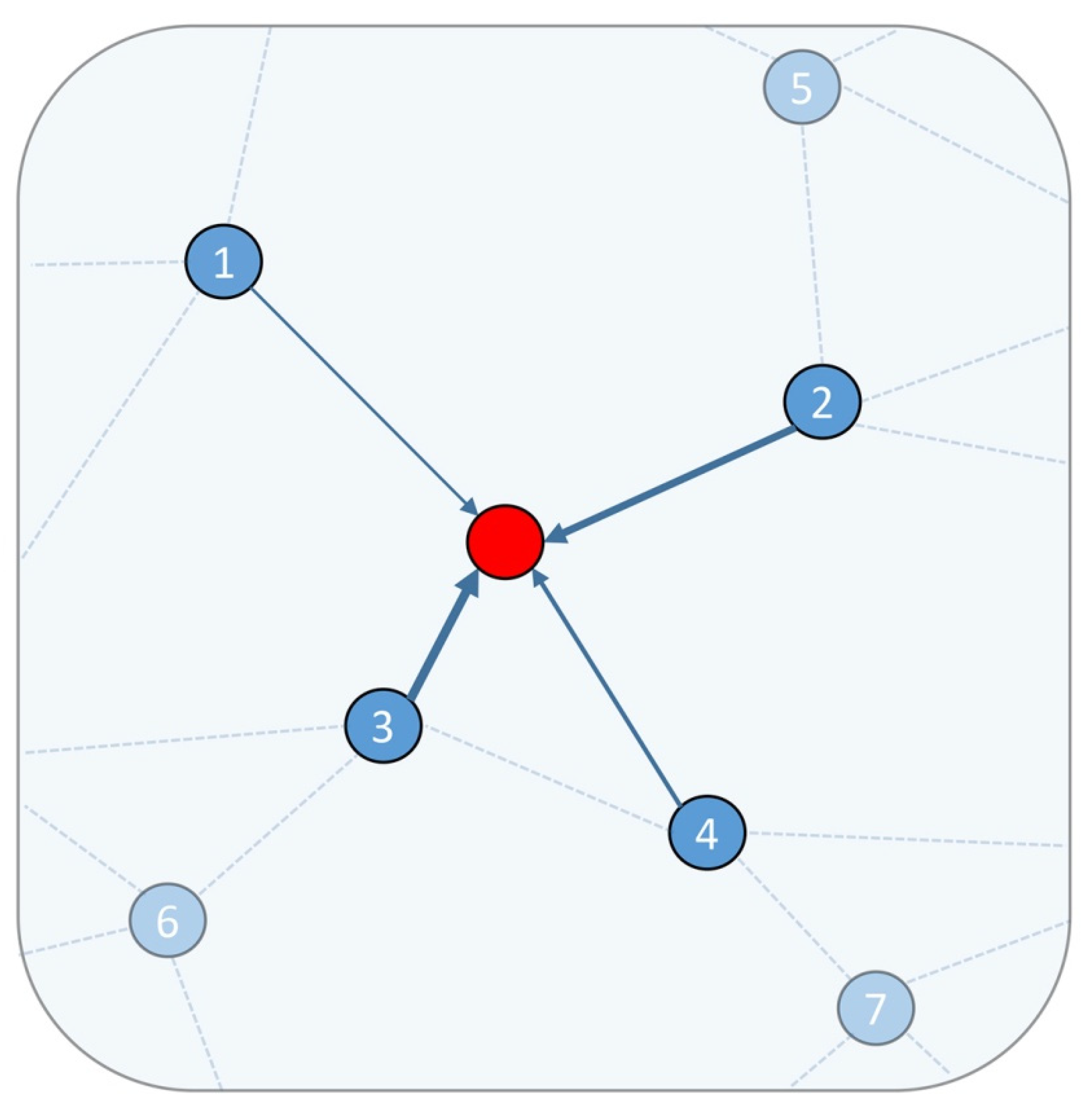
3.3. Graph Attention Feature Fusion Module
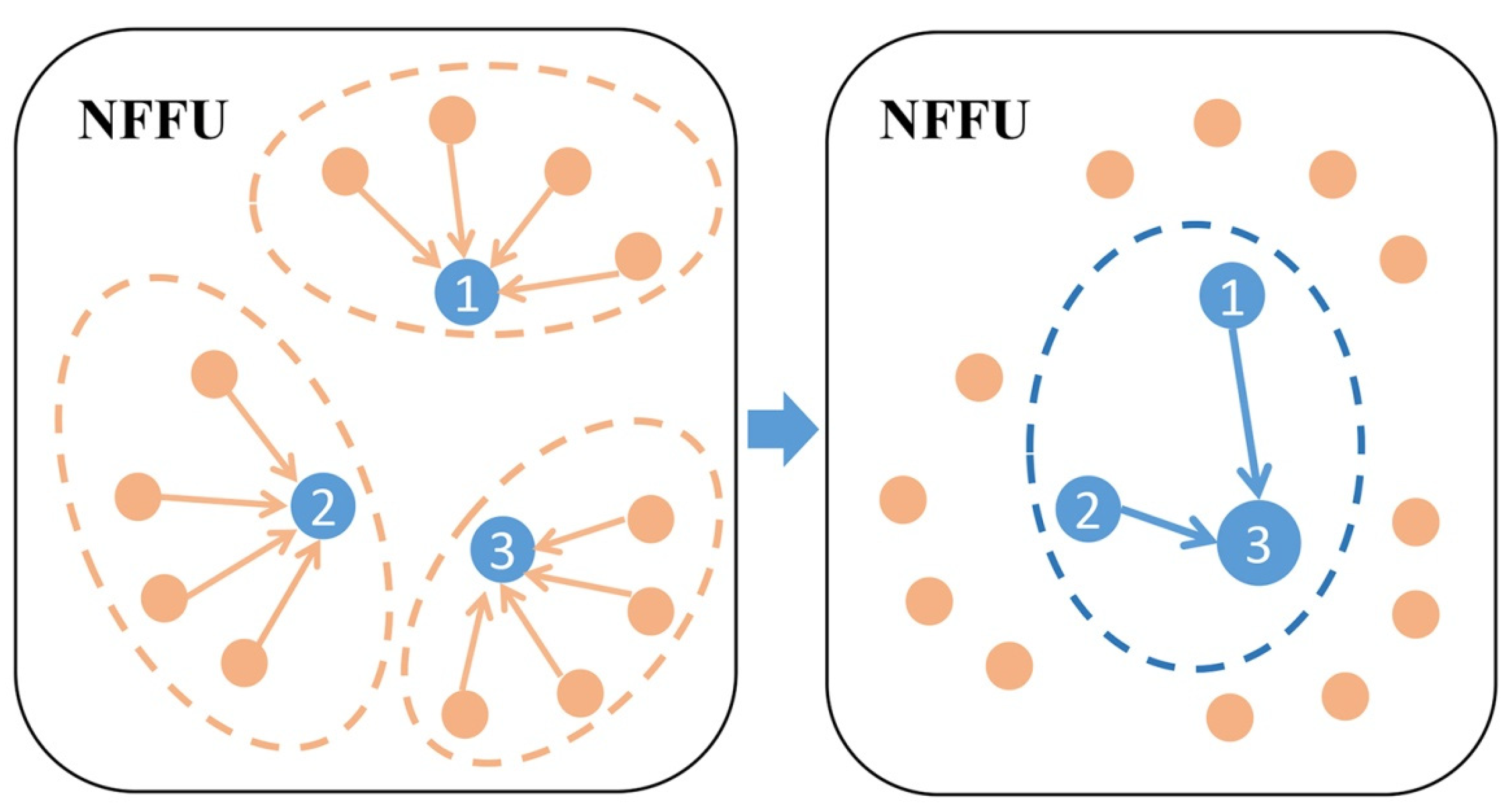
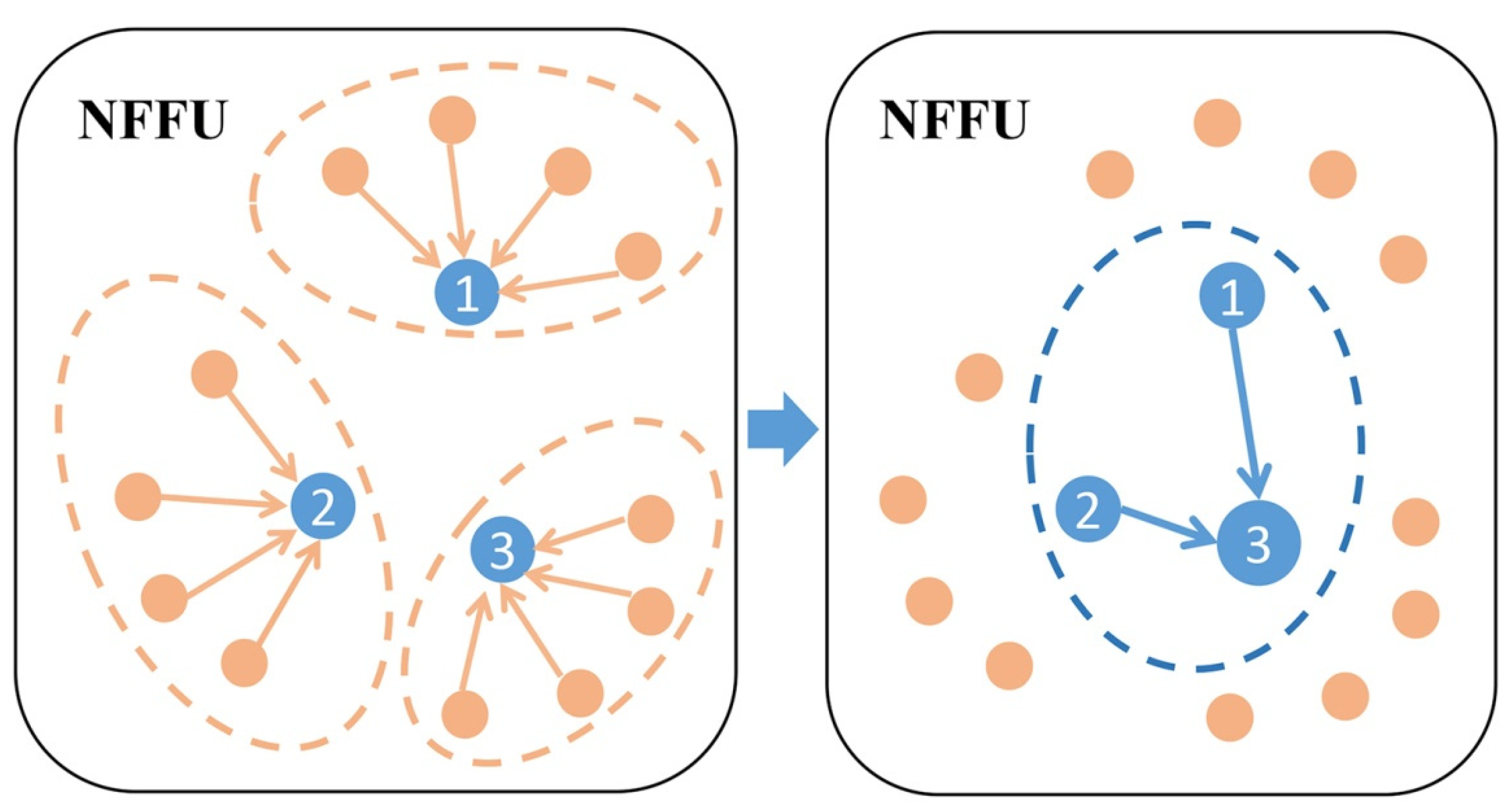
3.3.1. Neighborhood Feature Fusion Unit
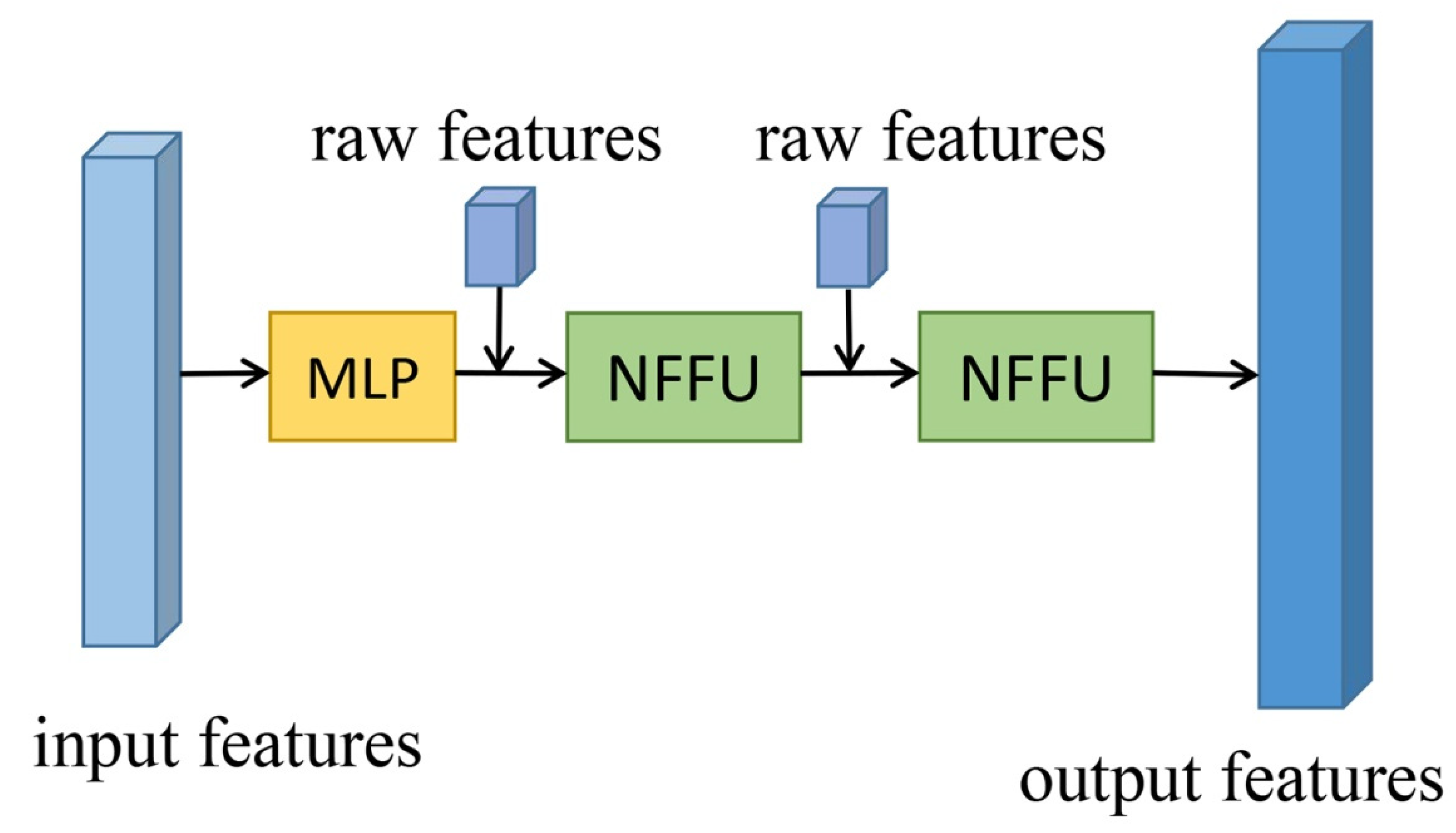
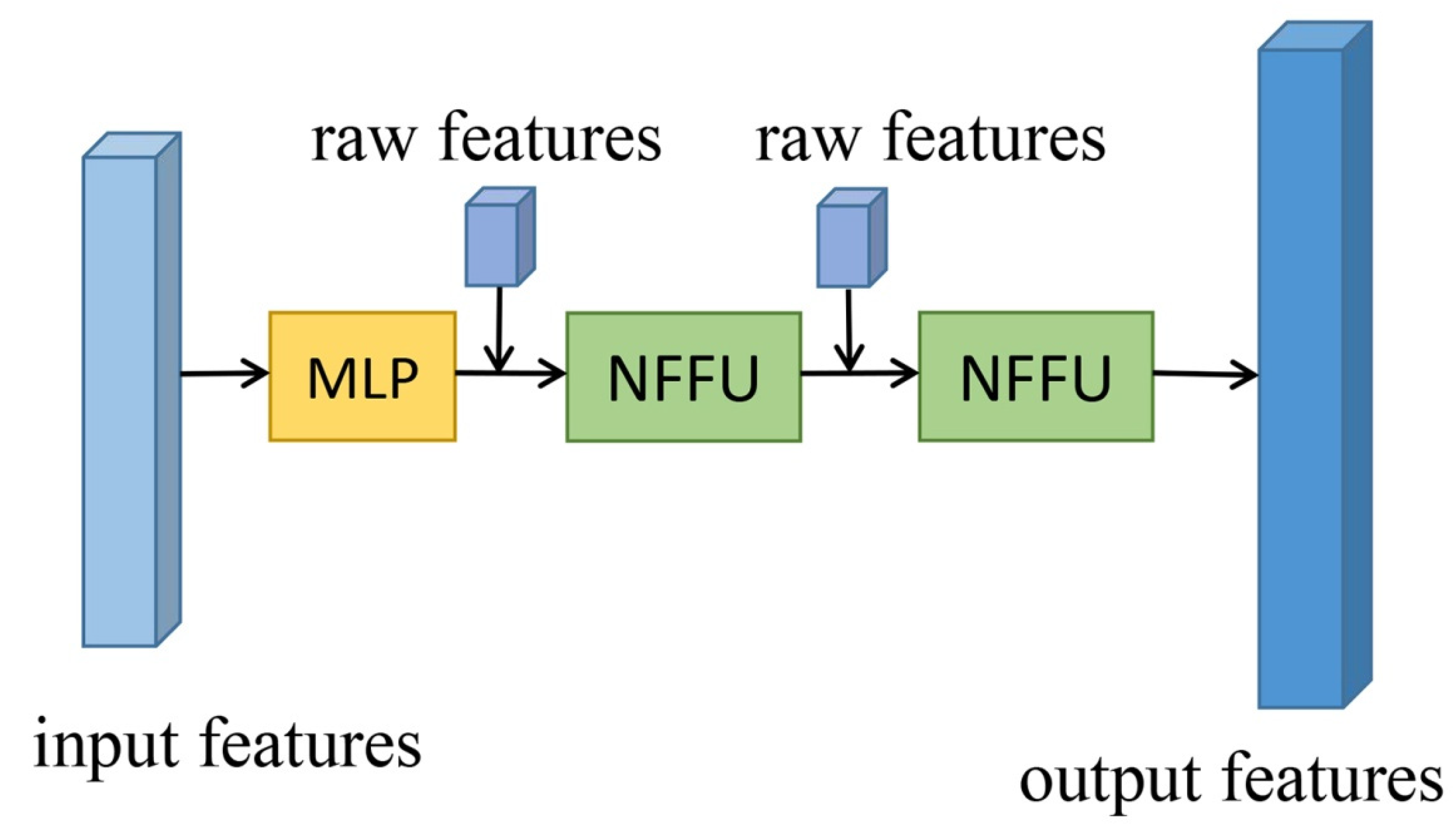
3.3.2. Extended Neighborhood Feature Fusion Block
3.4. Graph Attention Feature Fusion Network
4. Experiments
4.1. Data Description
4.2. Implementation Details
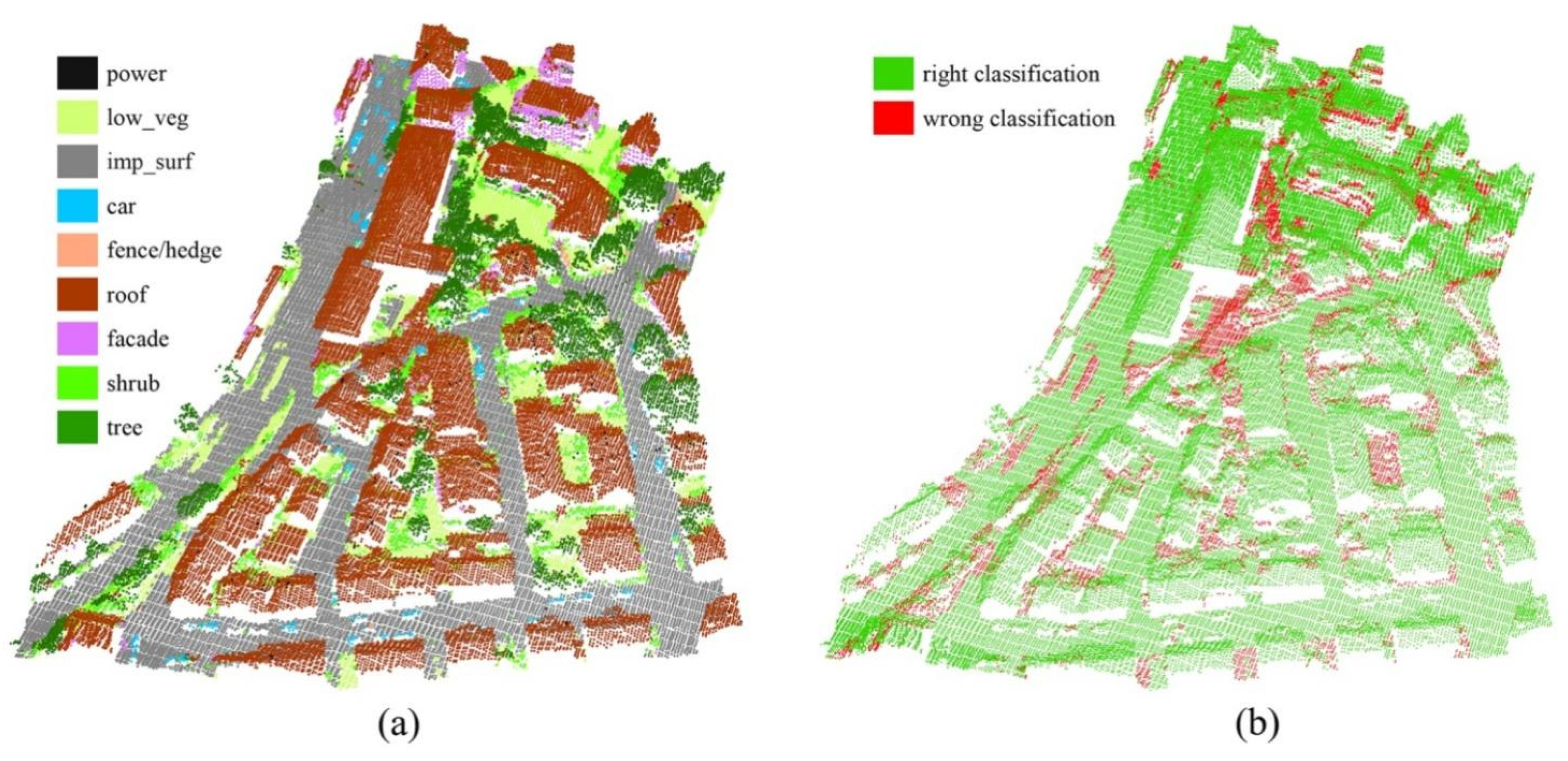
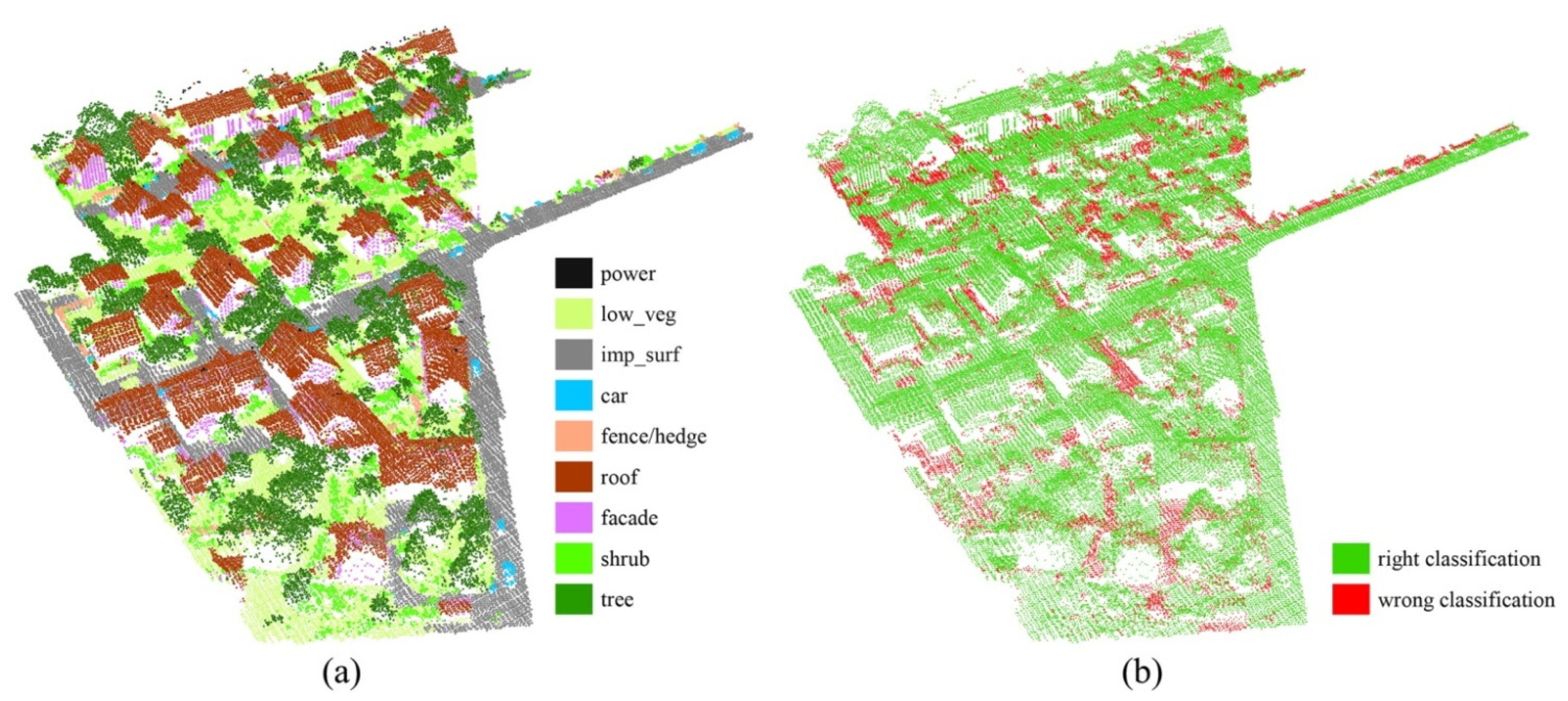
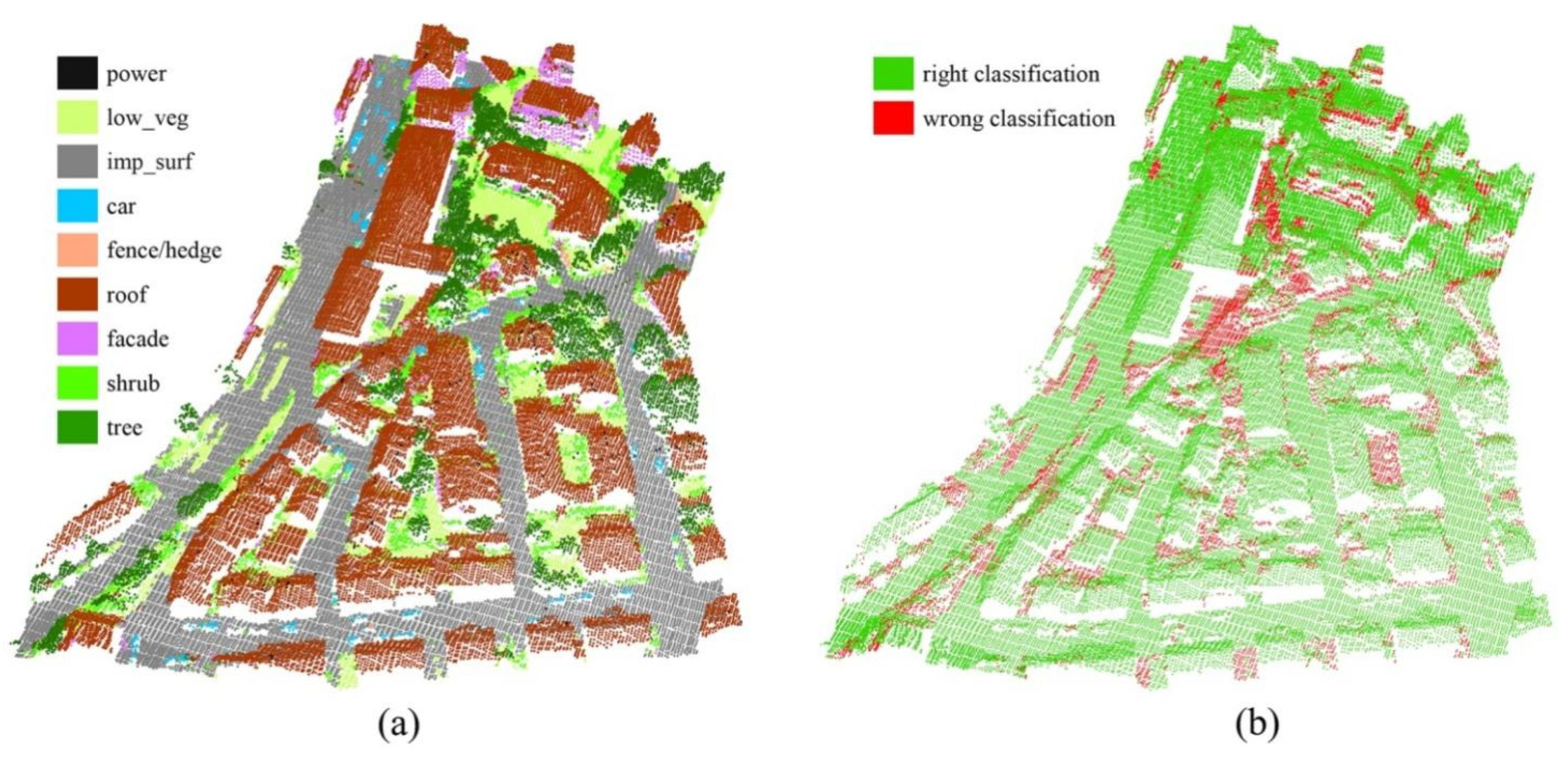
4.3. Experiment Results
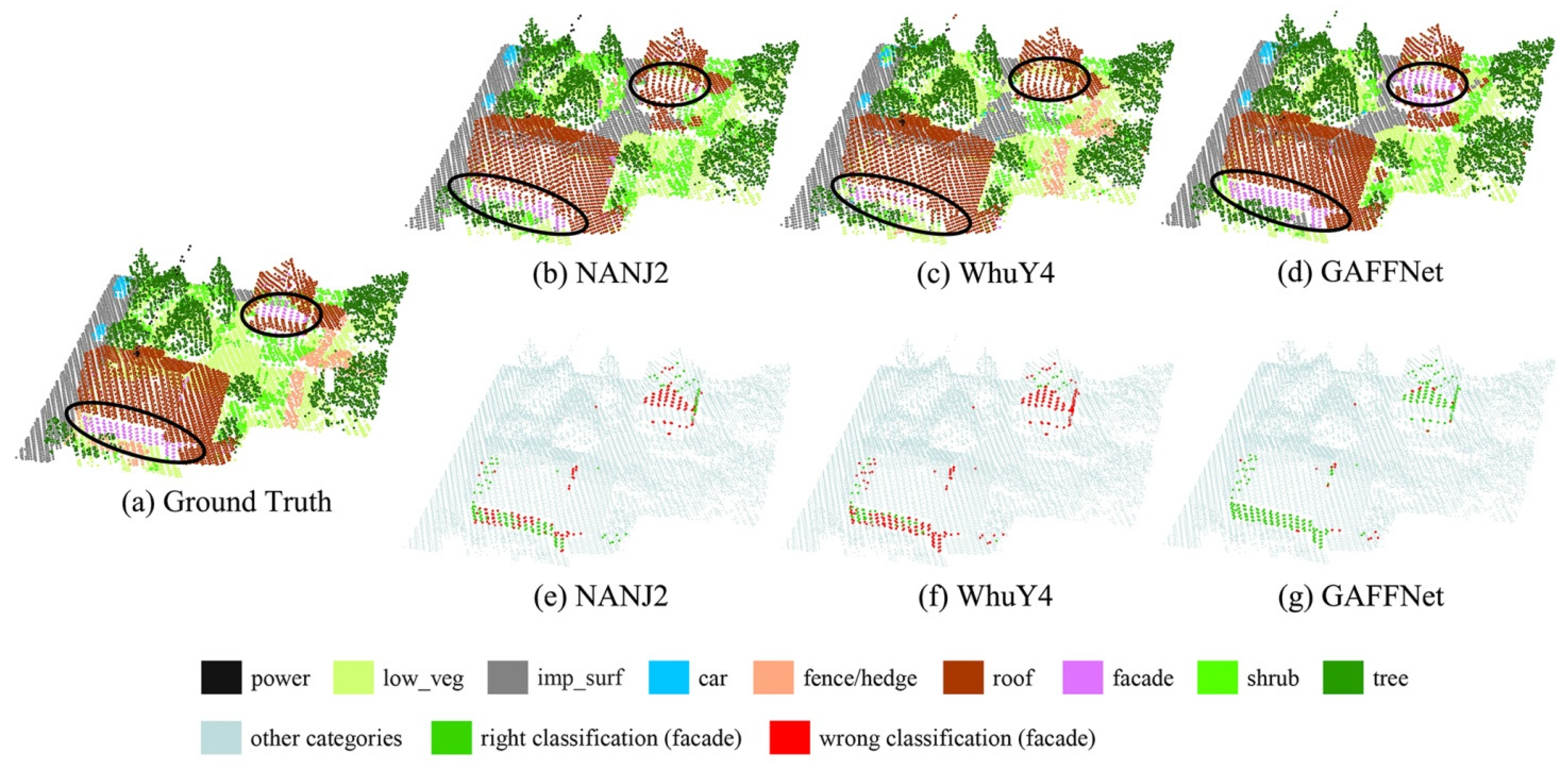
4.4. Comparison with Other Methods
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Fernandez-Diaz, J.C.; Carter, W.E.; Shrestha, R.L.; Leisz, S.J.; Fisher, C.T.; Gonzalez, A.M.; Thompson, D.; Elkins, S. Archaeological prospection of north Eastern Honduras with airborne mapping LiDAR. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec, QC, Canada, 13–18 July 2014; pp. 902–905. [Google Scholar] [CrossRef]
- Soilán, M.; Riveiro, B.; Liñares, P.; Pérez-Rivas, A. Automatic Parametrization of Urban Areas Using ALS Data: The Case Study of Santiago de Compostela. ISPRS Int. J. Geo-Inf. 2018, 7, 439. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Ni-Meister, W. Forest Canopy Height and Gaps from Multiangular BRDF, Assessed with Airborne LiDAR Data (Short Title: Vegetation Structure from LiDAR and Multiangular Data). Remote Sens. 2019, 11, 2566. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Peng, Y.; Lang, M.; Yeo, I.-Y.; McCarty, G. Wetland inundation mapping and change monitoring using Landsat and airborne LiDAR data. Remote Sens. Environ. 2014, 141, 231–242. [Google Scholar] [CrossRef]
- Kim, H.; Sohn, G. 3D classification of power-line scene from airborne laser scanning data using random forests. Int. Arch. Photogramm. Remote Sens. 2010, 38, 126–132. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Conditional random fields for lidar point cloud classification in complex urban areas. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 263–268. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhang, L.; Zhang, L.; Li, R.; Zheng, Y.; Zhu, Z. A deep neural network with spatial pooling (DNNSP) for 3-D point cloud classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4594–4604. [Google Scholar] [CrossRef]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z.; Seker, D.Z. Machine Learning-Based Supervised Classification of Point Clouds Using Multiscale Geometric Features. ISPRS Int. J. Geo-Inf. 2021, 10, 187. [Google Scholar] [CrossRef]
- Niemeyer, J.; Wegner, J.D.; Mallet, C.; Rottensteiner, F.; Soergel, U. Conditional random fields for urban scene classification with full waveform LiDAR data. In Proceedings of the ISPRS Conference on Photogrammetric Image Analysis, Munich, Germany, 5–7 October 2011; pp. 233–244. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-based classification of segmented airborne LiDAR point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef] [Green Version]
- Pang, G.; Neumann, U. Training-based object recognition in cluttered 3d point clouds. In Proceedings of the 2013 International Conference on 3D Vision-3DV 2013, Seattle, WA, USA, 29 June–1 July 2013; pp. 87–94. [Google Scholar] [CrossRef] [Green Version]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10296–10305. [Google Scholar] [CrossRef]
- Wen, C.; Li, X.; Yao, X.; Peng, L.; Chi, T. Airborne LiDAR point cloud classification with global-local graph attention convolution neural network. ISPRS J. Photogramm. Remote Sens. 2021, 173, 181–194. [Google Scholar] [CrossRef]
- Meng, X.; Wang, L.; Silván-Cárdenas, J.L.; Currit, N. A multi-directional ground filtering algorithm for airborne LIDAR. ISPRS J. Photogramm. Remote Sens. 2009, 64, 117–124. [Google Scholar] [CrossRef] [Green Version]
- Matikainen, L.; Hyyppä, J.; Kaartinen, H. Comparison between first pulse and last pulse laser scanner data in the automatic detection of buildings. Photogramm. Eng. Remote Sens. 2009, 75, 133–146. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on X-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Te, G.; Hu, W.; Zheng, A.; Guo, Z. Rgcnn: Regularized graph cnn for point cloud segmentation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 746–754. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Engelmann, F.; Kontogianni, T.; Leibe, B. Dilated point convolutions: On the receptive field size of point convolutions on 3D point clouds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Virtual, 31 May–31 August 2020; pp. 9463–9469. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-Test on Digital Airborne Camera Evaluation—Overview and Test Design. Photogramm.-Fernerkund.-Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Horvat, D.; Žalik, B.; Mongus, D. Context-dependent detection of non-linearly distributed points for vegetation classification in airborne LiDAR. ISPRS J. Photogramm. Remote Sens. 2016, 116, 1–14. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. ISPRS-Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, XLI-B3, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32, 960–979. [Google Scholar] [CrossRef]
- Yang, Z.; Tan, B.; Pei, H.; Jiang, W. Segmentation and multi-scale convolutional neural network-based classification of airborne laser scanner data. Sensors 2018, 18, 3347. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Power | Low_Veg | Imp_Surf | Car | Fence/Hedge | Roof | Facade | Shrub | Tree |
|---|---|---|---|---|---|---|---|---|---|
| Training Set | 546 | 180,850 | 193,723 | 4614 | 12,070 | 152,045 | 27,250 | 47,605 | 135,173 |
| Test Set | 600 | 98,690 | 101,986 | 3708 | 7422 | 109,048 | 11,224 | 24,818 | 54,226 |
| Dataset | Power | Low_Veg | Imp_Surf | Car | Fence/Hedge | Roof | Facade | Shrub | Tree |
|---|---|---|---|---|---|---|---|---|---|
| Training Set | 0.07 | 23.99 | 25.70 | 0.61 | 1.60 | 20.17 | 3.61 | 6.31 | 17.93 |
| Test Set | 0.15 | 23.97 | 24.77 | 0.90 | 1.80 | 26.49 | 2.73 | 6.03 | 13.17 |
| Metrics | Power | Low_Veg | Imp_Surf | Car | Fence/Hedge | Roof | Facade | Shrub | Tree |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.768 | 0.850 | 0.894 | 0.883 | 0.678 | 0.939 | 0.632 | 0.441 | 0.770 |
| Recall | 0.475 | 0.789 | 0.940 | 0.691 | 0.234 | 0.942 | 0.578 | 0.454 | 0.879 |
| F1 | 0.587 | 0.818 | 0.916 | 0.775 | 0.348 | 0.941 | 0.603 | 0.447 | 0.821 |
| Methods | Power | Low_Veg | Imp_Surf | Car | Fence/Hedge | Roof | Facade | Shrub | Tree | OA | Macro Avg F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| UM | 0.461 | 0.790 | 0.891 | 0.477 | 0.052 | 0.920 | 0.527 | 0.409 | 0.779 | 0.808 | 0.590 |
| LUH | 0.596 | 0.775 | 0.911 | 0.731 | 0.340 | 0.942 | 0.563 | 0.466 | 0.831 | 0.816 | 0.684 |
| BIJ_W | 0.138 | 0.785 | 0.905 | 0.564 | 0.363 | 0.922 | 0.532 | 0.433 | 0.784 | 0.815 | 0.603 |
| RIT_1 | 0.375 | 0.779 | 0.915 | 0.734 | 0.180 | 0.940 | 0.493 | 0.459 | 0.825 | 0.816 | 0.633 |
| NANJ2 | 0.620 | 0.888 | 0.912 | 0.667 | 0.407 | 0.936 | 0.426 | 0.559 | 0.826 | 0.852 | 0.693 |
| WhuY4 | 0.425 | 0.827 | 0.914 | 0.747 | 0.537 | 0.943 | 0.531 | 0.479 | 0.828 | 0.849 | 0.692 |
| GAFFNet | 0.587 | 0.818 | 0.916 | 0.775 | 0.348 | 0.941 | 0.603 | 0.447 | 0.821 | 0.841 | 0.695 |
| Methods | Power | Low_Veg | Imp_Surf | Car | Fence/Hedge | Roof | Facade | Shrub | Tree | OA | Macro Avg F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GAT-voxel | 0.380 | 0.752 | 0.892 | 0.656 | 0.305 | 0.880 | 0.324 | 0.409 | 0.773 | 0.785 | 0.597 |
| GACNN | 0.760 | 0.818 | 0.930 | 0.777 | 0.378 | 0.931 | 0.589 | 0.467 | 0.789 | 0.832 | 0.715 |
| GACNet | 0.628 | 0.819 | 0.908 | 0.698 | 0.252 | 0.914 | 0.562 | 0.395 | 0.763 | 0.817 | 0.660 |
| GACNet-voxel | 0.444 | 0.794 | 0.903 | 0.704 | 0.355 | 0.918 | 0.480 | 0.475 | 0.812 | 0.820 | 0.654 |
| DGCNN | 0.676 | 0.804 | 0.906 | 0.545 | 0.268 | 0.898 | 0.488 | 0.415 | 0.773 | 0.810 | 0.641 |
| DGCNN-voxel | 0.577 | 0.788 | 0.901 | 0.733 | 0.250 | 0.913 | 0.425 | 0.430 | 0.792 | 0.813 | 0.645 |
| GAFFNet | 0.587 | 0.818 | 0.916 | 0.775 | 0.348 | 0.941 | 0.603 | 0.447 | 0.821 | 0.841 | 0.695 |
| Ablation Studies | OA | Macro Avg F1 |
|---|---|---|
| (1) max pooling | 0.834 | 0.693 |
| (2) sum pooling | 0.833 | 0.689 |
| (3) mean pooling | 0.827 | 0.680 |
| (4) GAFFNet-RS | 0.812 | 0.633 |
| (5) one NFFU | 0.815 | 0.662 |
| (6) three NFFUs | 0.832 | 0.685 |
| (7) no height above DTM | 0.835 | 0.699 |
| (8) no statistical features | 0.836 | 0.672 |
| GAFFNet | 0.841 | 0.695 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Zhang, X.; Huang, Y. Graph Attention Feature Fusion Network for ALS Point Cloud Classification. Sensors 2021, 21, 6193. https://doi.org/10.3390/s21186193
Yang J, Zhang X, Huang Y. Graph Attention Feature Fusion Network for ALS Point Cloud Classification. Sensors. 2021; 21(18):6193. https://doi.org/10.3390/s21186193
Chicago/Turabian StyleYang, Jie, Xinchang Zhang, and Yun Huang. 2021. "Graph Attention Feature Fusion Network for ALS Point Cloud Classification" Sensors 21, no. 18: 6193. https://doi.org/10.3390/s21186193
APA StyleYang, J., Zhang, X., & Huang, Y. (2021). Graph Attention Feature Fusion Network for ALS Point Cloud Classification. Sensors, 21(18), 6193. https://doi.org/10.3390/s21186193