1. Introduction
Conventional predictive Artificial Neural Network (ANN) models commonly operate with a feed-forward framework using deterministic weight matrices as the network weight parameters [
1,
2,
3]. Specifically, the estimation of ANNs is conducted with matrix operations between given samples and the trained network parameters with non-linear activation functions.
While outstanding progress has been made in ANNs in recent years [
4,
5] and ANNs are widely used for many practical applications [
6,
7,
8,
9,
10], conventional predictive ANN models have an obvious limitation since their estimation corresponds to a point estimate. Such a limitation causes the restrictions of using ANN for medical diagnosis, law problems, and portfolio management, where the risk of the predictions is also essential in practice. The conventional ANN models produce the same form of predictions even if the predictions are very uncertain, and such uncertain prediction results cannot be distinguished from confident and regular predictions.
In short, conventional ANN models cannot say ‘I don’t know’, and it corresponds to a type of overfitting since overfitting stands for failure to estimate untrained data precisely due to excessive precision for training data resulting from high flexibility of the model. For instance, the models attempt to make a confident prediction for an outlier or even complete noise data of which predictions are meaningless and impossible. In such a framework, it is not clear how much the models are sure on their predictions.
To handle such a problem, a probabilistic approach of ANNs, called Bayesian Neural Networks (BNNs), has been introduced [
11,
12,
13]. In BNNs, values of the network weight parameters are not fixed, and instead obtained by a sampling process from certain distributions. Therefore, the prediction of BNN for a given sample differs in each operation. Integrated with the Monte Carlo method in which many different predictions are made for a given sample, the prediction of BNNs also forms a distribution of which variance can represent the risk and uncertainty of the predictions.
However, the training of BNNs is not straightforward since the Monte Carlo method is employed for the training process as well [
11]. In the training process, the network parameters are sampled from posterior distributions of the network parameters, and gradients are calculated and back-propagated for the sampled parameters. Therefore, such randomness intrinsic in the training process hinders fast training and convergence of BNNs. Furthermore, the training of deep BNNs is also not straightforward due to such a problem.
As another probabilistic neural network model that can produce a form of distributions as its outputs, Generative Adversarial Networks (GANs) have shown superior performance for sample generation [
14,
15,
16,
17,
18]. Generally, GANs learn the sample distribution of a certain dataset in order to produce synthetic but realistic samples from input noises by mapping features intrinsic in the dataset onto the input noise space. While typical GAN models produce random samples, conditional variants of GANs (cGANs) have been introduced to generate the desired samples and have shown fine results to produce samples by using conditional inputs [
19,
20,
21,
22]. Moreover, by taking advantage of such a innovative framework of GAN, the modified GAN models have been introduced in many applications [
23,
24,
25,
26,
27,
28,
29].
Basically, this paper addresses the following question that has arisen from the characteristic of cGANs: Since cGANs can learn the probability distribution of samples, i.e., Pr, is it possible to learn the probability distribution of labels, i.e., Pr, by reversing the inputs and outputs of the cGANs? If it is possible, we can utilize cGANs as a predictive probabilistic neural network model, similar function to BNNs. Moreover, such a model can solve the problems in BNNs since deep architectures can be employed for GANs, and their training is relatively simple compared to BNNs. However, such an issue has not yet been studied extensively.
In this paper, we propose an adversarial learning framework for utilizing the generator in cGANs as a predictive deep learning model with uncertainty. Since the outputs of the proposed model are a form of distribution, the uncertainty of predictions can be represented as the variance of the distribution. Furthermore, in order to measure and quantify the uncertainty of estimations, we introduce the entropy and relative entropy for regression problems and classification problems, respectively.
3. Methods
3.1. Conditional Generative Adversarial Networks as a Prediction Model
In this paper, we proposed a new framework to use the generator in cGAN as a predictive model while the existing cGAN is routinely employed for sample generation. By simply reversing the output and the conditional input in cGAN and using the same form of network architectures, the model can successfully be used as a probabilistic predictive neural network model, which has the same function as BNNs:
where
is a feature network that extracts
u-dimensional features from samples. Therefore,
corresponds to one of the prediction results using cGAN; we can use the sample
instead of the feature network if the dimension of the sample space, i.e.,
p, is low. Such a modification simply changes the input and output in (
7).
By sampling different noise vectors
, a probability distribution of predictions can be obtained in a similar manner with BNNs as described in (
5). Such a sampling process is the same with that of ordinary GAN in (
6). Therefore, the inference process of the proposed model is similar to ordinary GAN using
. However, while each noise vector can produce a synthetic sample in the ordinary GAN, predictions using the proposed method are conducted with a bunch of noise vectors so that a form of distribution is constructed as follows.
In the training of GAN structures, the generator is trained in an adversarial manner to deceive the discriminator; therefore, the discriminator is required to be set in order to train
. In this paper, the projection discriminator [
19], which shows superior performance compared to simple concatenation, is employed for the training of the generator. The architecture of the projection discriminator is as follows:
where
denotes the projection discriminator,
is a weight matrix for the output layer of the discriminator,
, and
is an ANN structure with an output dimension of
u.
In order to solve a classification problem with the proposed framework, where the input of the discriminator is a one-hot vector, the can be replaced by a matrix as follows.
Proposition 1. The is equivalent to , where if is a one-hot vector.
Proof. For every one-hot vector , every possible output of , i.e., , is equivalent to since there exists a matrix that satisfies . □
Therefore, for classification problems, (
10) can be simplified as the following.
Hence, throughout the paper, we use (
10) and (
11) for regression problems and classification problems, respectively.
3.2. Entropy to Measure the Uncertainty of Predictions
We introduce entropy metrics to measure and quantify the uncertainty of predictions from cGANs. While the variance of estimated distribution can be used to represent uncertainty if the distribution follows a normal distribution, we employ the entropy in this paper since we cannot reject the possibility that the distribution does not follow a normal distribution. For regression problems, the regular entropy of the estimated distribution in (
9) is employed, which can be calculated as follows:
where
is the probability of
kth element of
. Notice that
, so that the entropy is calculated for each target variable.
On the other hand, for classification problems, the relative entropy, also known as the Kullback–Leibler divergence, is used instead of the ordinary entropy since the difference in distributions between the predicted class and the other classes can represent the certainty of the point prediction. If a prediction is certain, the distribution of predicted class has low variance, and its distance from the other distributions would be far; such variance and distance can be comprehensively represented by relative entropy. Let
be an index of the predicted class given a sample
, for example,
, if we use the average as the point estimation of each class. However, the relative entropy is asymmetric, which can hardly be used as a metric for uncertainty. Therefore, we use the sum of two relative entropy measures by using different orders of distributions in order to make the measure symmetric.
By employing these entropies, we can measure the uncertainty of predictions for regression problems and classification problems as follows.
Notice that is used to describe the uncertainty since the ordinary relative entropy represents the difference in class distributions; therefore, the minus relative entropy indicates similarity between the predicted class distribution and the other class distributions, which corresponds to uncertainty. In contrast, the ordinary entropy measures a type of variance of distributions; thereby, a high value of the entropy indicates the uncertainty of predictions.
For classification problems, however, ordinary ANN models have a sort of uncertainty measure of which the function is similar to the proposed uncertainty measure. The softmax function is commonly employed for the last layer of ANN classifiers, and the outputs of the function provide a kind of probability for each class. Therefore,
, the cross-entropy loss for the softmax function, can indicate the uncertainty of prediction. However, there exists overfitting in ordinary ANN models, as described in the previous section; therefore, this measure becomes imprecise. We will compare the performance between the proposed uncertainty measure and this existing method in
Section 4.
3.3. Comparison to Related Works
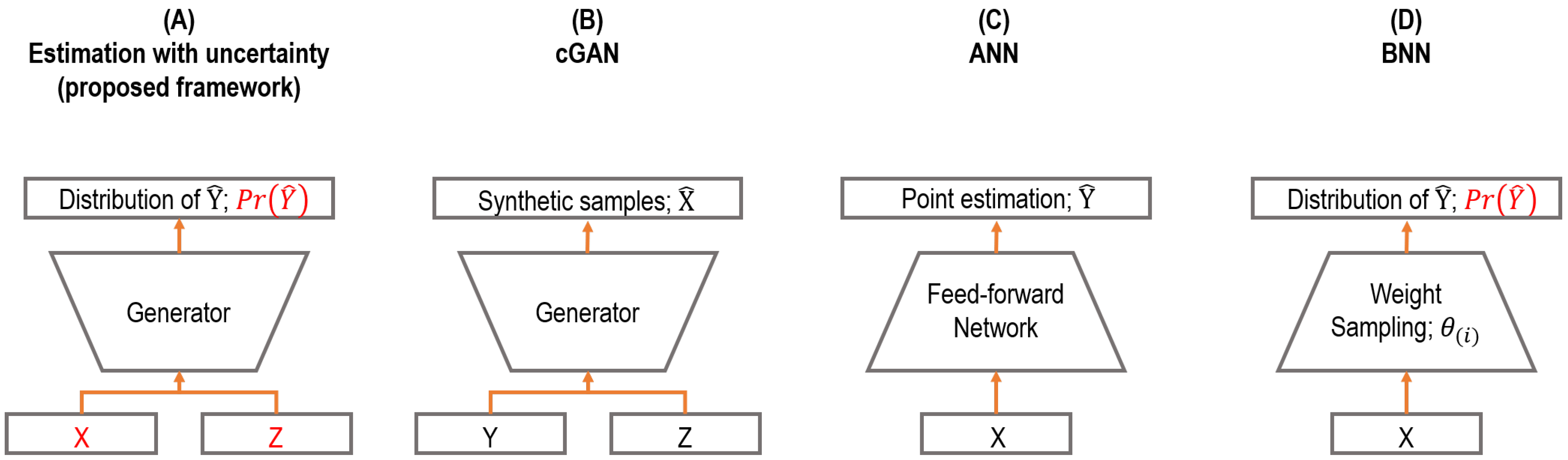
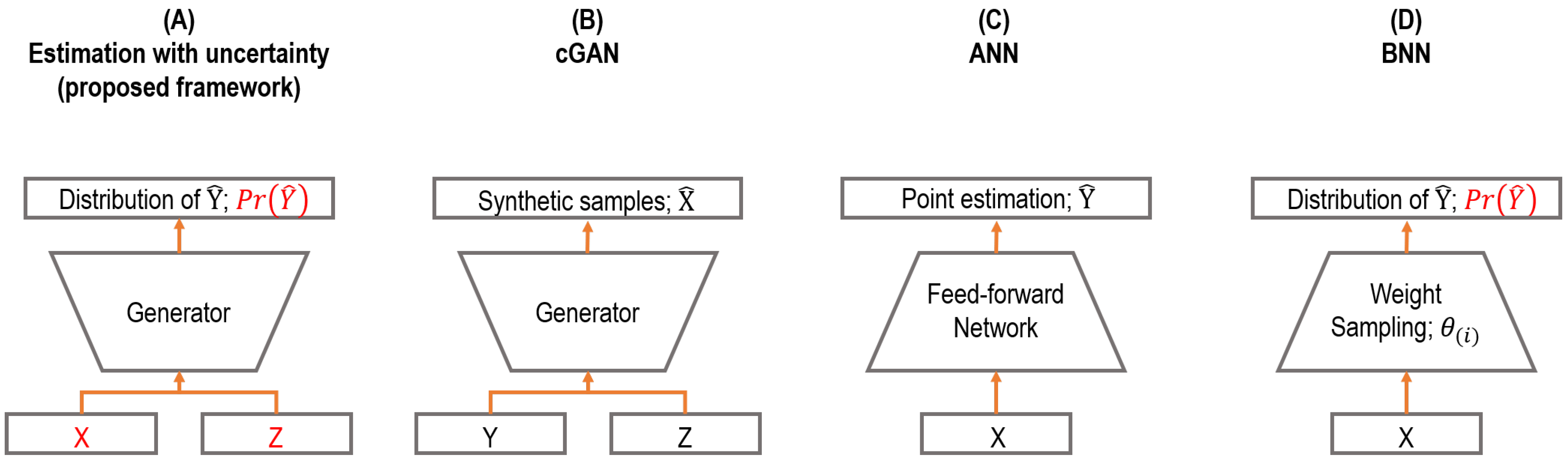
In this section, we compare the proposed framework with related prior works. The key differences are summarized and illustrated in
Figure 1.
Comparison to ordinary cGANs. The conventional generator in cGAN is used for synthetic sample generation [
19]. Ordinary cGAN learns the conditional sample distribution, i.e.,
, and then produces synthetic samples integrated with the Monte Carlo method over the noise vector
. In contrast, we used cGAN as a prediction model where the model learns the target distribution, i.e.,
, and performs predictions as a form of distributions, i.e.,
, with a stochastic input
given a sample
as the conditional input of cGAN. In short, the neural network architectures of cGANs in both studies are basically identical, while the proposed framework corresponds to reversing the input and output in the typical use of cGAN.
Comparison to ANNs and BNNs. ANN has a limitation to express the uncertainty of predictions, as described in the previous sections. The output of an ANN is a point estimate, while the output of the proposed framework is a distribution that can represent the uncertainty of predictions, which can handle such a limitation. Likewise, BNN also produces predictions as a form of distribution, which is similar to the proposed framework; however, BNN uses stochastic weights to perform such work, which generally hinders the convergence in training and construction of deep neural network architecture. In contrast, the proposed framework uses deterministic weights and stochastic inputs instead. In addition, the training process is also different, where an adversarial training manner with a discriminator is employed for the proposed framework, which can avoid overfitting resulting from the high complexity of neural network architectures.
4. Results
4.1. The Prediction of Stock Prices with the Uncertainty Measure of the Prediction
Stock market prediction is one of the most specific problems where the predictions of returns and the uncertainties of the prediction are comprehensively required in practice. In modern portfolio theory [
41,
42,
43,
44], both expected returns and risks of a portfolio must be calculated for the selection of a portfolio; the prediction of the expected returns and the risks exactly corresponds to the estimation with uncertainty, the aim of the proposed framework.
We apply the proposed framework to NASDAQ-100 Future Index data. The model is trained with returns of the past 30 days as the input and the 5 day return as the target. The 5 day return is the change in prices over 5 days, calculated by
, where
is the price at time
t. For the training set, the close price index from January 2001 to December 2015 are used; the data from January 2016 to April 2019 are employed for the test set. For the stability of the data, the price data are preprocessed to the returns. The preprocessing process for the price data is provided in
Section E in the Supplementary Materials.
The hinge loss and Wasserstein distance are employed for fine training of cGAN, according to recent studies of cGAN [
19,
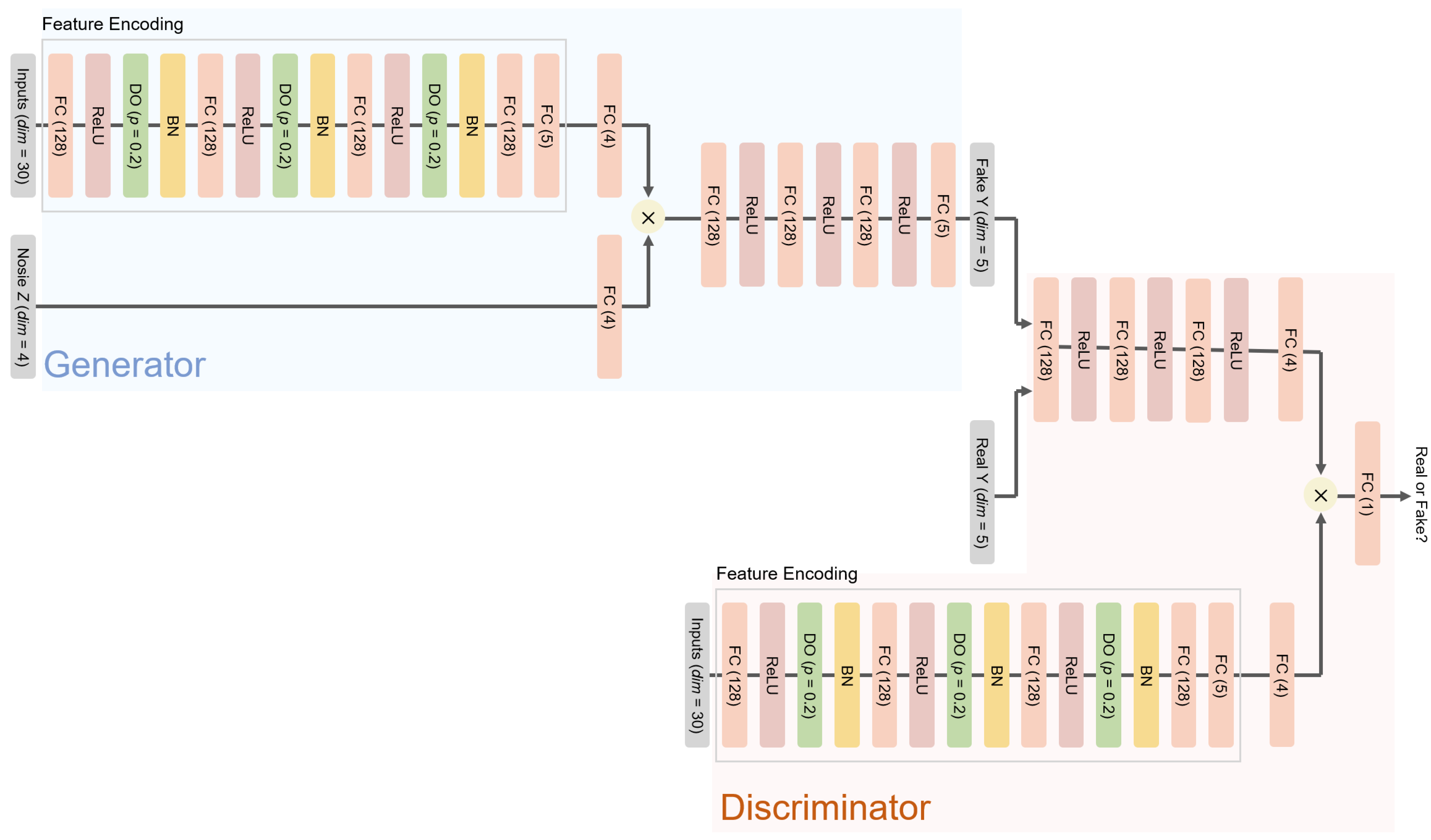
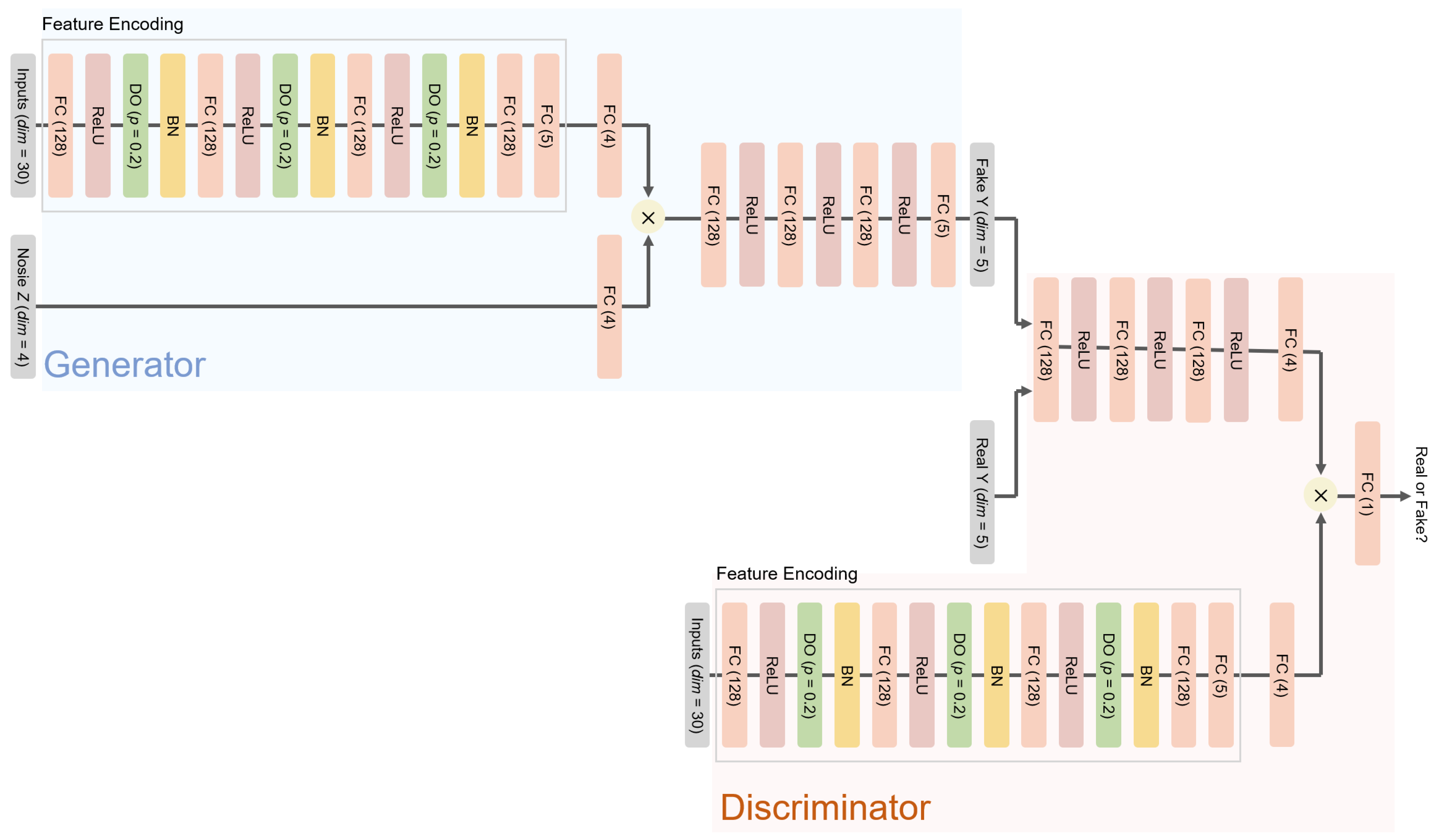
45]. For probabilistic models that produce a form of distributions as their output, the mode is employed for the point estimation. The ANN and cGAN-UC, that is cGAN for the prediction with uncertainty, i.e., the proposed framework, are trained over 2000 epochs; in contrast, BNN models are trained over 5000 epochs, but the 5 layer BNN fails to converge within the training process, which demonstrates the difficulty of the training of stochastic weights in BNNs, as described previously. The architectures of the models used in this experiment are provided in
Figure 2 and
Section C.1 and C.4 in the Supplementary Materials.
The models are comprehensively evaluated by the prediction performance of returns and whether the estimated uncertainty is actually correlated with prediction errors, which means the risk of predictions can properly be measured.
Table 1 shows correlation coefficients in the test set. The deterministic models show similar prediction performances, whereas cGAN-UCs show superior performance compared to the deterministic models as well as BNNs. The 5-layer cGAN-UC demonstrates the best prediction performance, while the uncertainty estimation is more precise in the 7-layer model. Such a resulting difference between cGAN-UG-5 and cGAN-UG-7 is from the number of layers in each model, which can differ by the hyper-parameter optimization. Moreover, we conjecture that the performance gain of the proposed model results from the adversarial learning process of GAN that can assist in learning the true distribution of noisy data and avoiding the overfitting inherent in the complex neural network architectures, which should be studied further for future work.
Moreover, it is demonstrated that the estimated uncertainty and prediction errors are correlated, which signifies that the predictions with high uncertainty have a high possibility of being wrong. While the predictions of returns by both the deterministic models and the probabilistic models are not very successful, where the correlation coefficients are below 0.1 due to the chaotic nature of the stock market, the proposed framework demonstrates that the uncertainty of the predictions can be measured. Such a result indicates a possibility to utilize the proposed uncertainty measure for risk management of portfolios using stock market predictions.
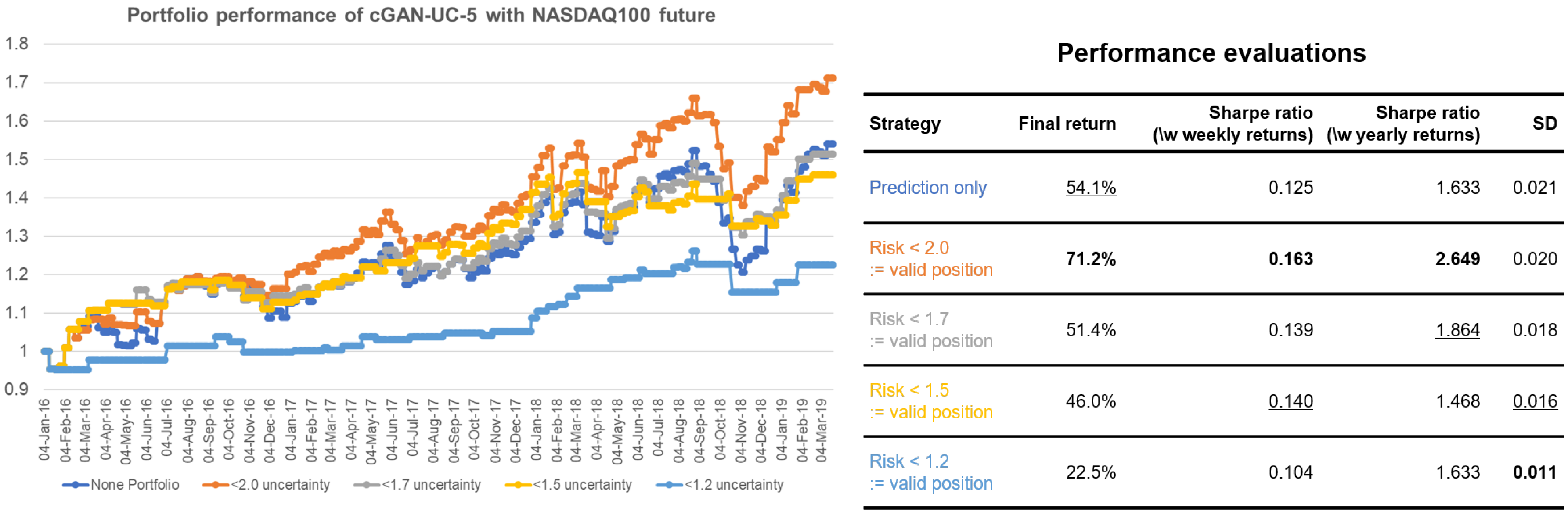
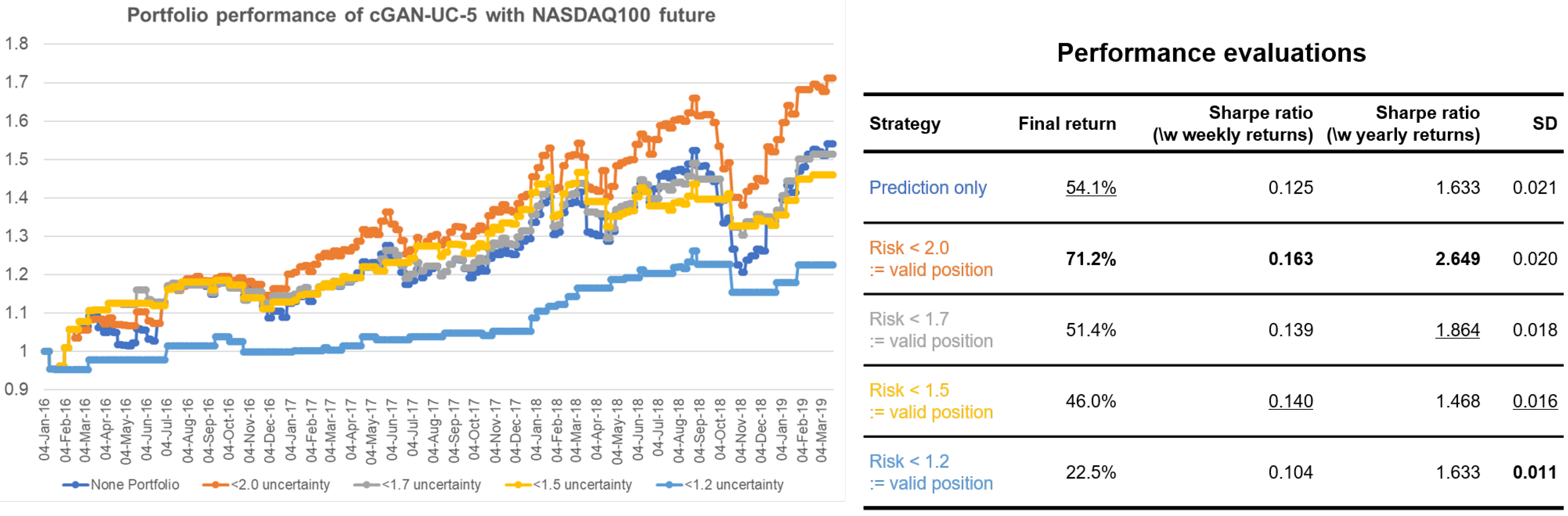
Figure 3 is an example of using the estimated uncertainty for portfolio management. For evaluation metrics, final returns and Sharpe ratio of strategies are used. While the final return of strategy can measure performance, low volatility of strategy is also crucial for a financial portfolio. The Sharpe ratio can measure both returns and volatility of a strategy, which is calculated as follows:
where
represents the Sharpe ratio of strategy A,
indicates the standard deviation,
is the return of a risk-free portfolio which is generally a national bond interest rate, and
is the return over a specific period of time, which is calculated as follows:
where
is the price of an asset
a at time t,
U is the investable universe,
k is the period of time, and
represents weights on the asset
a in the strategy A such that
.
When only the predictions of returns are given, the simplest strategy that uses the predictions is taking a long position if the prediction is positive and taking a short position when it is otherwise. The portfolio performance of the simplest strategy using only the prediction results of cGAN-UC is represented with dark blue in
Figure 3. We can further enhance the performance by using the estimated uncertainty (risk), along with the predictions. The other strategies employ the uncertainty by introducing a neutral position if the uncertainty is above certain thresholds; such an approach signifies that we do not take a risk for uncertain predictions. The orange strategy in the figure considers predictions with >2.0 uncertainty as invalid predictions; thus, we take neutral position in such cases. By using the strategy, the final return increases by 17.1% points, and the standard deviation of the portfolio simultaneously decreases, compared to the conventional strategy. Furthermore, interestingly, the standard deviation of the strategy with <1.7 uncertainty (gray) considerably decreases while the final returns of the strategies are similar to that of conventional strategy. Such a possibility of performance enhancement is another strong evidence that the estimated uncertainty is effective.
4.2. Image Classification with Uncertainty
In this section, the proposed framework is applied to an image classification task with the CIFAR-10 dataset. The CIFAR-10 dataset consists of dimensional images, which contain 50,000 training samples and 10,000 test samples in 10 different categories. Unlike regression tasks, for classification tasks, deterministic models can estimate the uncertainty of predictions by using the probability of point estimates as the certainty of predictions since a softmax function is used for the last layer of the network in general. For instance, if a prediction of a deterministic model is ‘Car’ with a 98% probability, the uncertainty can be estimated by 2%. In this manner, for the uncertainty measure of deterministic models, the log of the probability of point estimates, i.e., the cross-entropy classification loss, is employed as a conventional method.
For the comparison between a deterministic model and cGAN-UC, densely the connected convolutional network (DenseNet), which generally shows fine performances for image classification tasks [
46,
47], is used for the feature network of cGAN-UC as well as the deterministic model. The architectures of cGAN-UC and DenseNet used in this experiment are provided in
Section C.2 and C.3 in the Supplementary Materials. As a result, the estimation accuracy of the two models is marginally different, where the test set prediction accuracy of cGAN-UC and ordinary DenseNet is 94.4% and 94.1%, respectively, which corresponds to a 0.3% point of enhancement, by using cGAN-UC.
Moreover, it is demonstrated that there exists a significant performance difference in the uncertainty measures of the models. In short, the conventional method to estimate the uncertainty does not perform well in general. Specifically, there is a sort of overfitting in the deterministic model where the model has a high certainty for wrong answers. For instance, in the test set of CIFAR-10, the median softmax output of DenseNet for the wrong answers is 0.968 (96.8%), which means that the deterministic classifier is overconfident to the estimations that are actually wrong.
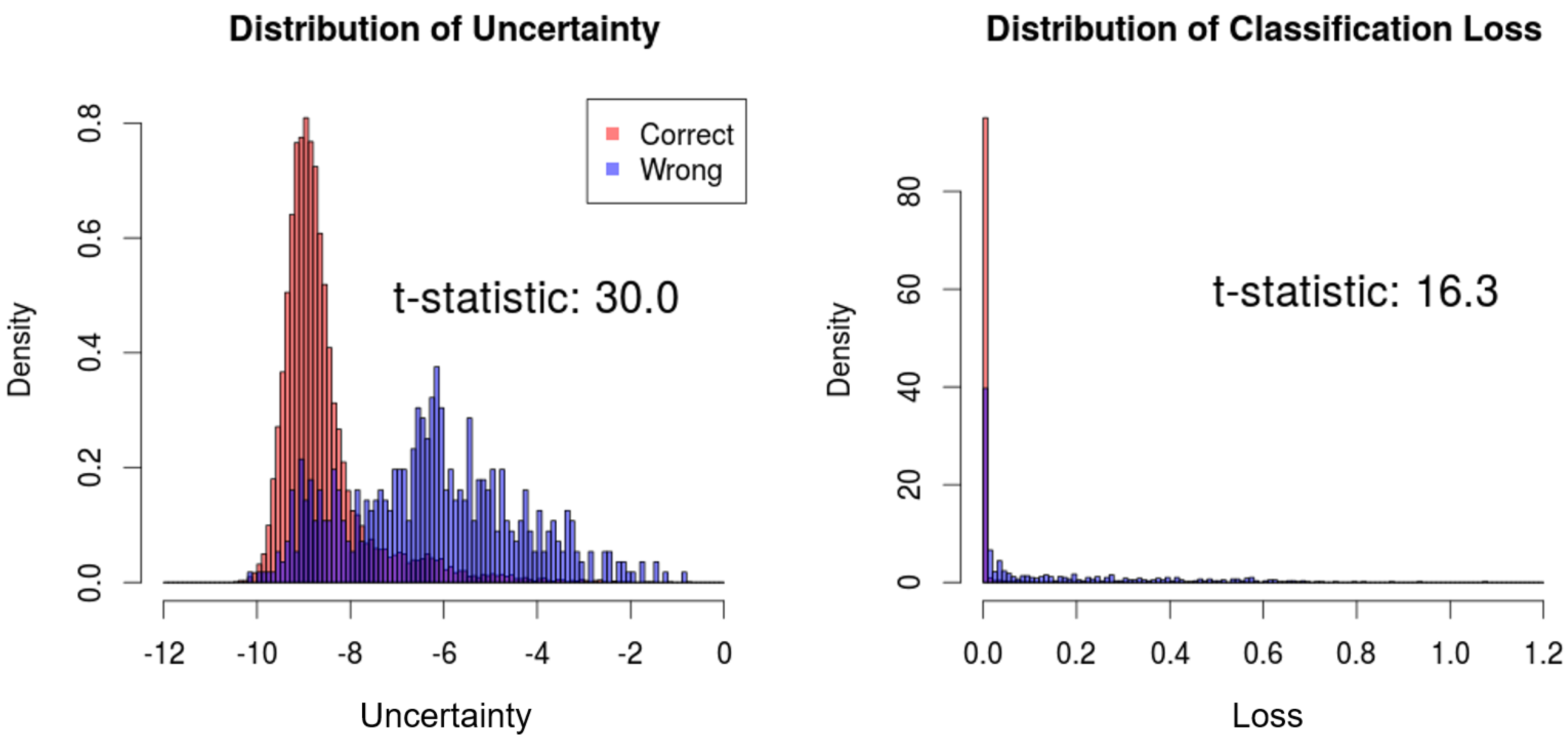
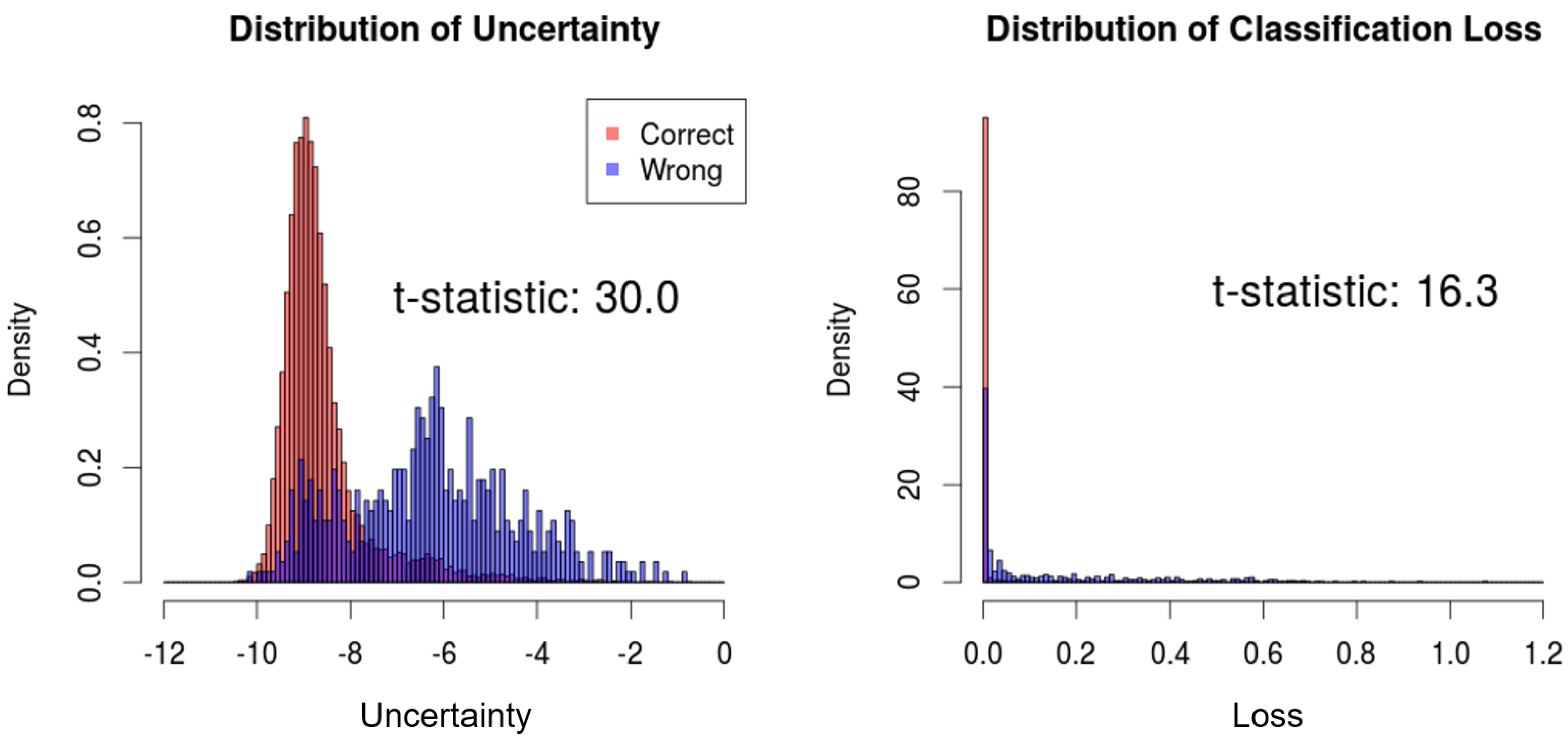
We compare the distributions of the proposed uncertainty measure and the conventional uncertainty measure with respect to correct and wrong predictions. Then, the
t-test is performed to measure the difference between the two distributions, which can indicate the correlation between the estimated uncertainty and actual prediction results. As a result, the t-statistics of the proposed uncertainty measure and the classification loss are 30.0 and 16.3, respectively, which signifies superior performance to estimate the uncertainty of predictions (
Figure 4).
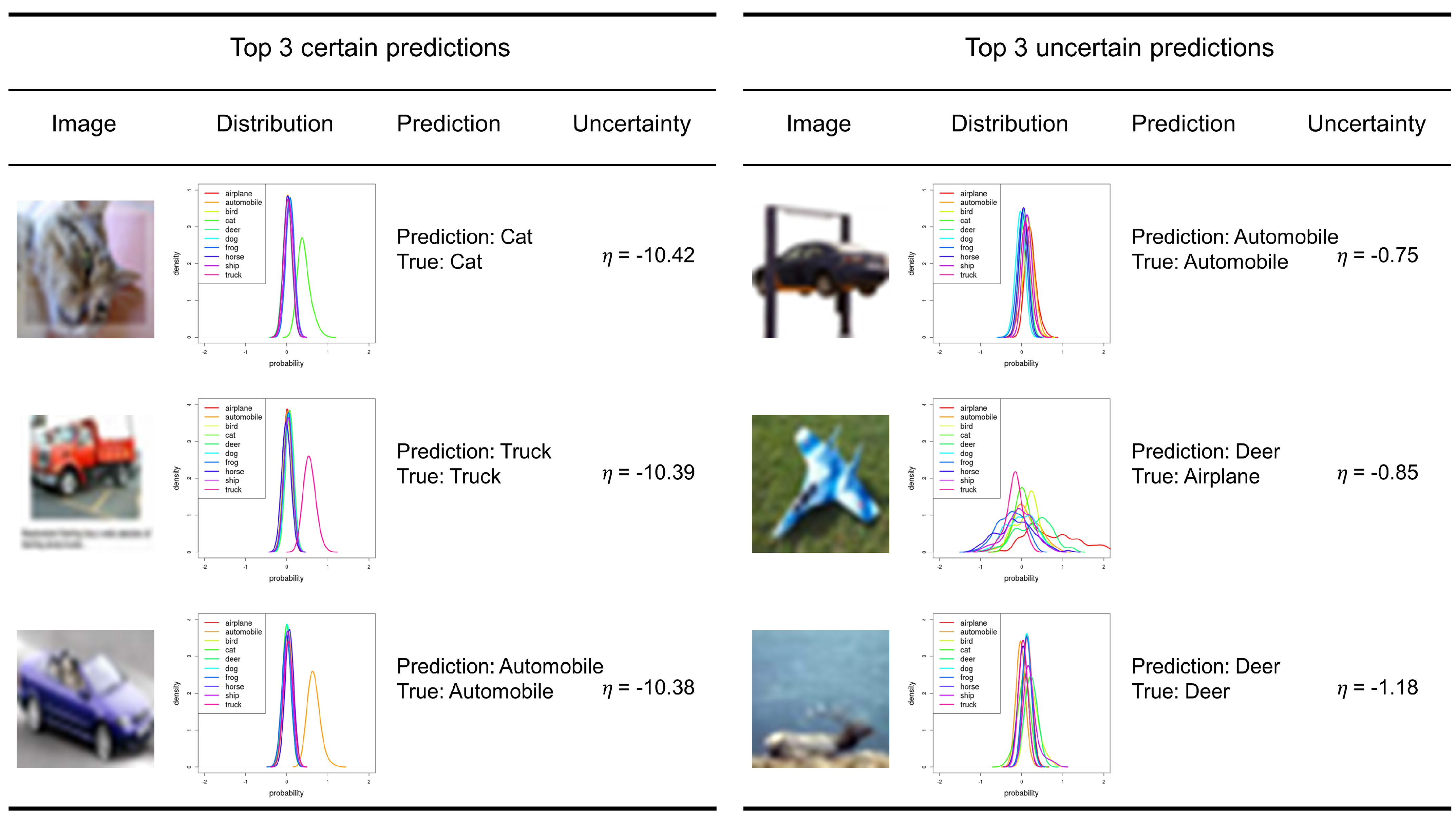
We preform a qualitative analysis for the most certain predictions and the most uncertain predictions of cGAN-UC (
Figure 5). We take the top three certain/uncertain predictions for the analysis. As a result, while the image samples of the certain predictions are obvious samples, those of the uncertain predictions correspond to a sort of outlier, i.e., an automobile in the air with a door, a toy airplane on the grass, and a deer that is hard to recognize. Moreover, the airplane is incorrectly classified as ‘Deer’. The overall results indicate that the proposed framework not only shows superior prediction performance but also can properly measure the uncertainty of the predictions.
4.3. Noisy Image Classification with Uncertainty
In this section, we further evaluate the proposed framework with noisy image data since we conjecture that the proposed framework shows robust performance against noise because the adversarial learning process is employed for the training of cGAN-UC. In the adversarial learning process, noisy results that are produced by ordinary samples are rejected by the discriminator; thus, cGAN-UC learns from the rejections, which makes cGAN-UC robust against noise. The proposed framework is evaluated with noisy CIFAR-10 image data, which are obtained by the following:
where
a indicates a parameter for noise, and
denotes a noisy sample. In short, in each experiment, we take different
a and then evaluate and compare the classification accuracy of the models. The neural network architectures and the other conditions are the same as those of the previous experiment.
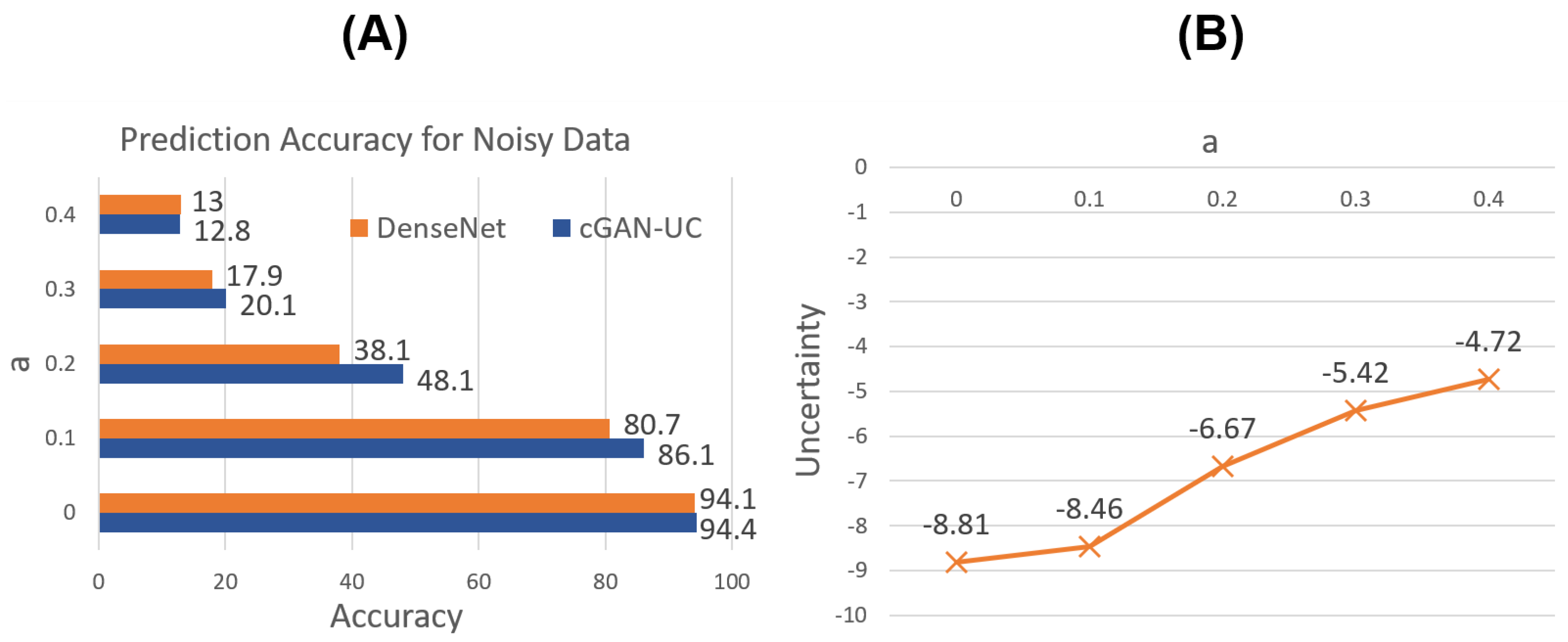
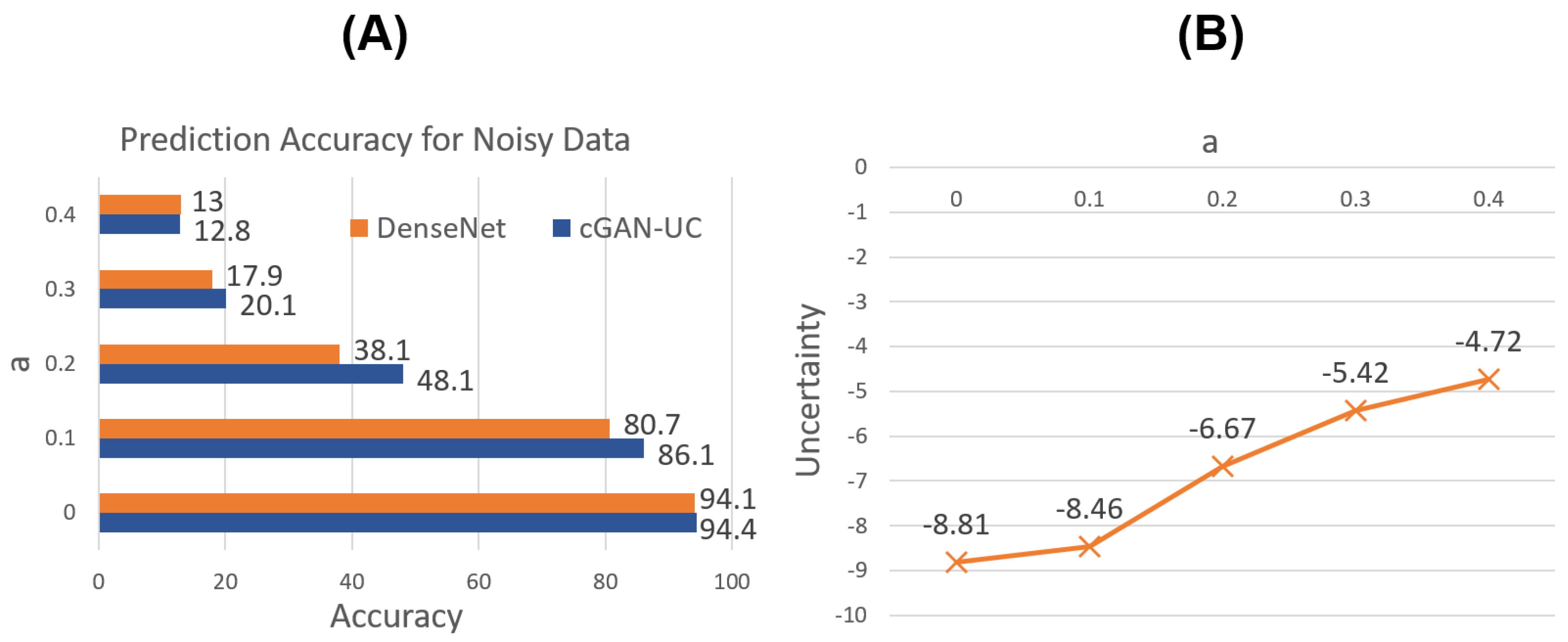
Figure 6A shows the prediction results for the noisy data. As expected, for not only the original image data but also the noisy data, it is demonstrated that cGAN-UC outperforms the ordinary DenseNet; moreover, the performance difference is more significant in the noisy data. Specifically, with
, the performance difference is 10.0% point where the accuracy of cGAN-UC and DenseNet is 48.1% and 38.1%, respectively.
In addition, the median of the proposed uncertainty measure is compared with regard to
a. As shown in
Figure 6B, the uncertainty increases as the proportion of noises increases. Such a result also strongly supports the claim that the proposed uncertainty measure actually represents the unsureness of predictions.
Furthermore, in this experiment, the proposed framework is evaluated with complete noise samples, i.e.,
, in order to demonstrate that the proposed method can properly discriminate the meaningless predictions with noises (
Figure 7). The deterministic model, DenseNet, however, shows a high certainty for the noises. Specifically, the median softmax output of DenseNet for the noises is 0.875 (87.5%), which reflects the limitation of deterministic models that cannot describe ‘I don’t know’, as aforementioned.
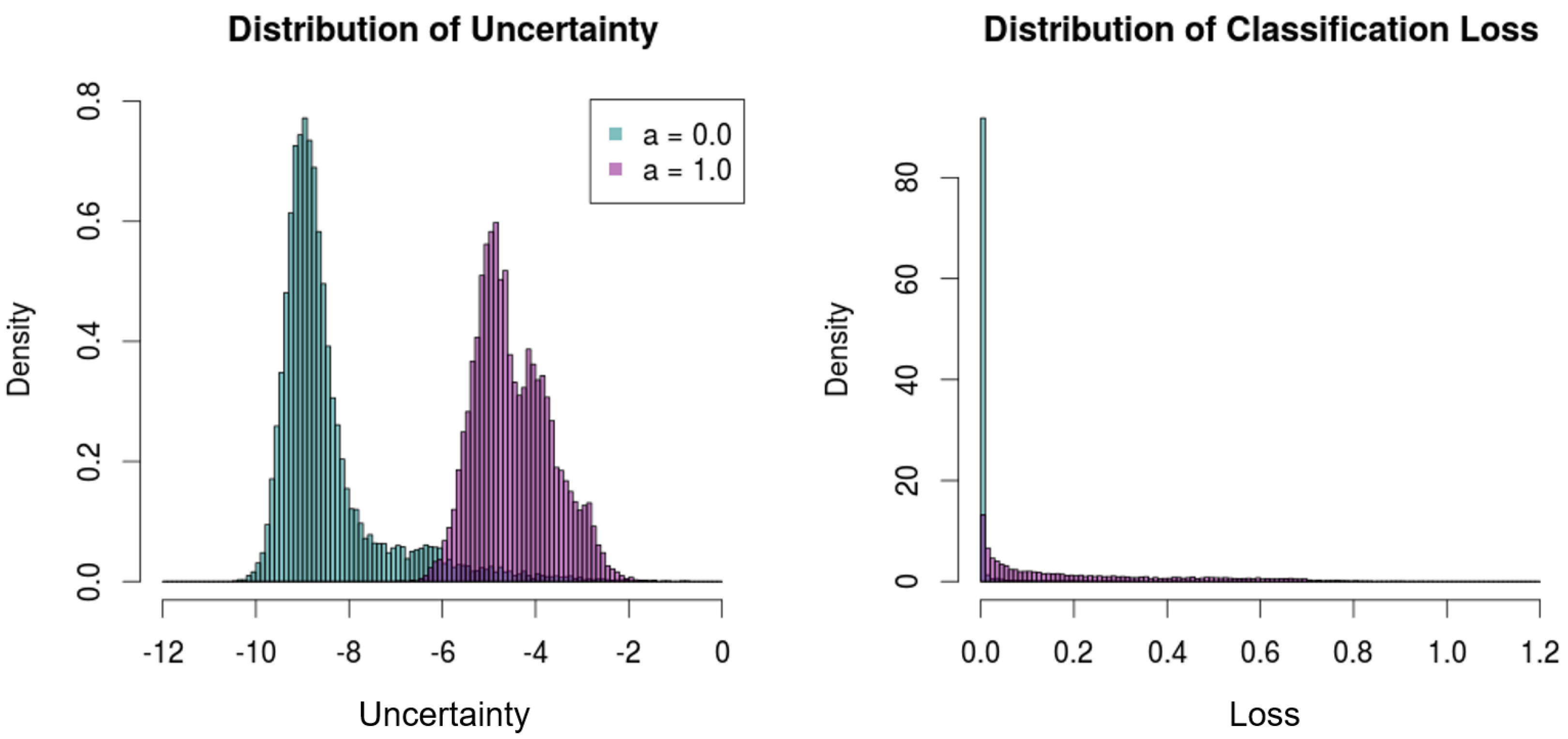
By contrast, the proposed framework shows low certainty/high uncertainty for noises compared to the results with the test set of CIFAR-10.
Figure 7 illustrates the uncertainty distributions of the original test set and the noises. The two distributions are significantly distinct from each other, where the median uncertainty measures of the test set and the noises are −8.81 and −4.63, respectively.
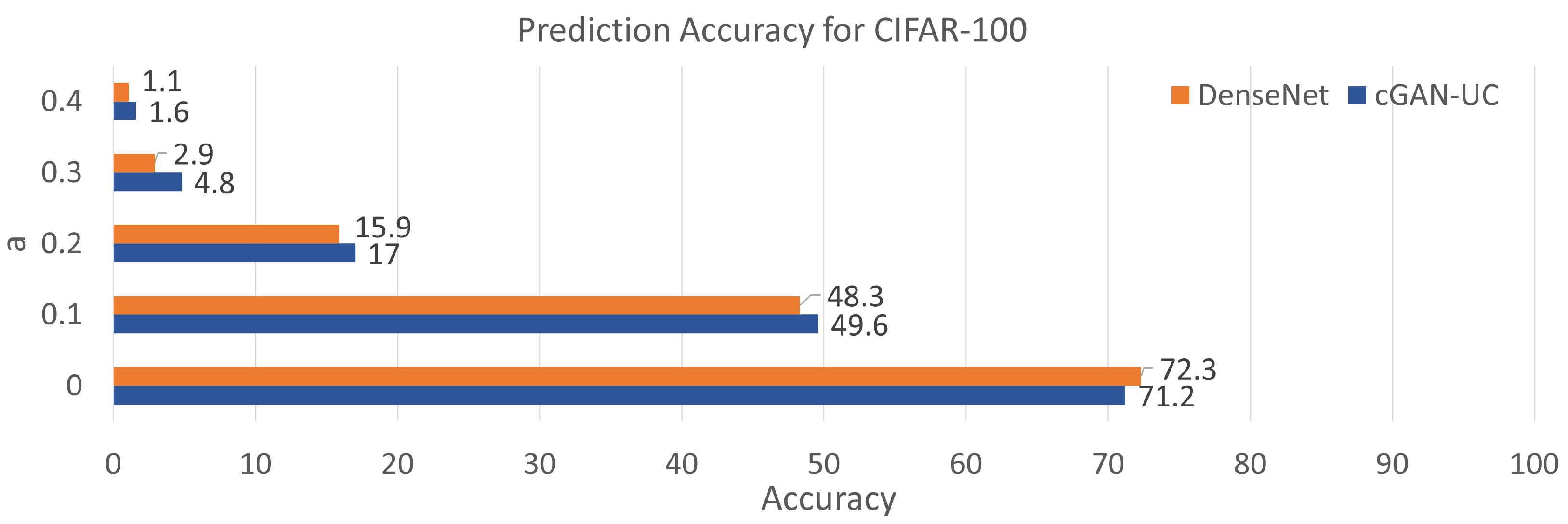
Additionally, it is also demonstrated that the proposed framework can be applied to other datasets (
Figure 8). In this experiment, We evaluate the proposed framework with another image dataset called CIFAR-100, which contains 50,000 image samples with 100 different categories in the training set. The image sizes and the number of test samples are the same with CIFAR-10. In the evaluation with CIFAR-100, although the prediction accuracy of the proposed model is slightly inferior to the deterministic model when the models are evaluated with complete data, cGAN-UC outperforms DenseNet with all the scenarios using noisy data, similar to the results of CIFAR-10. Such a result also indicates the noise-resistant feature and generality of the proposed framework. While the proposed model demonstrates a lower performance than DenseNet, we believe that such a performance can be enhanced by increasing the number of sampling process to make the distributions of predictions precise. Since there are 100 categories in CIFAR-100, it is expected that the increase in sampling process can enhance the prediction performance. Such a relationship between number of sampling and performance should be studied further in future work.
5. Conclusions
We proposed a predictive probabilistic neural network framework, which corresponds to a different manner of using the generator in cGAN that is initially introduced for sample generation. While cGAN has commonly been employed for conditional sample generation, with extensive experiments in this paper, it is demonstrated that the model also can be used as a predictive model. In addition, we introduced the uncertainty measures for prediction results of the proposed framework. The uncertainty of prediction is calculated by the entropy and relative entropy for regression problems and classification problems, respectively. The proposed framework was evaluated with stock market data and an image classification task. As a result, the proposed framework demonstrates superior prediction performance and successfully estimates the uncertainty of predictions.
Moreover, interestingly, the proposed framework showed robust performances for noisy data, compared to the deterministic model. We conjecture that these results are due to the adversarial learning process of the proposed framework, where noisy outcomes are rejected by the discriminator, and then the generator learns from the failures. For noisy data, since the performance gain by using the proposed framework is significant, such properties should be investigated further for future work.
In addition, for additional experiments, the proposed framework is evaluated with interpolations and other conditions with different degree of noises and shows superior performance as well. The full results for these additional experiments are provided in
Section A and B in the Supplementary Materials. We expect that the proposed framework can be a significant breakthrough in predictive neural network model since the proposed framework can predict the uncertainty of estimation that the conventional neural networks can hardly perform and has a possibility to produce superior performance for prediction tasks. Moreover, due to the recent developments in GAN training, the proposed framework, compared to BNNs, has advantages in adopting deep architectures and convergence in training process, which have been constant issues in using probabilistic neural networks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}