
Computationally Efficient Nonlinear Model Predictive Control Using the L1 Cost-Function



Abstract
:1. Introduction
- (a)
- Neural networks are most often used as black-box models of dynamical processes. Various structures are used: the classical MLP networks [29,32,33], Radial Basis Function (RBF) networks [34,35,36], Long Short-Term Memory (LSTM) [37,38,39] and Gated Recurrent Unit (GRU) [39] structures. Typically, the input–output neural models are used. The state–space neural models [29,40,41] are used when the state–space process description is necessary, although such an approach is significantly less popular.
- (b)
- (c)
- (d)
- Neural step response models [50]. In this approach, time-varying coefficients of the model are computed on-line by a neural network.
- (e)
- Neural multi-models [51,52]. In this approach, separate networks calculate the predictions for the consecutive sampling instants over the prediction horizon. As a result, the neural model is not used recurrently, which significantly simplifies training. Additionally, prediction errors are not propagated.
- (f)
- Hybrid neural models [53]. In this approach, neural networks are used to calculate the parameters of the first-principle models.
- (g)
- (a)
- (b)
- (c)
- (d)
2. Problem Formulation
3. Computationally Efficient Nonlinear MPC Using the L Cost-Function
- (a)
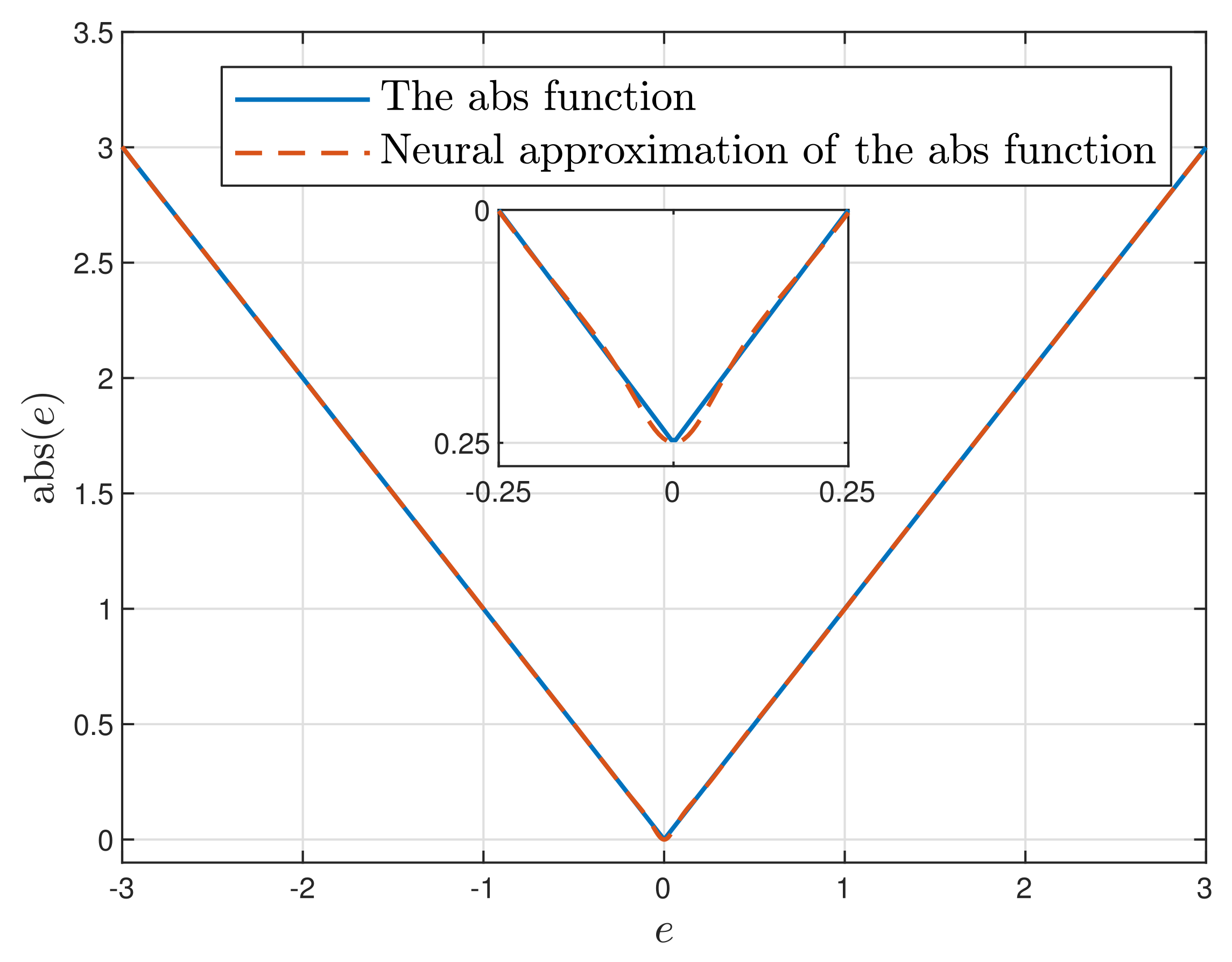
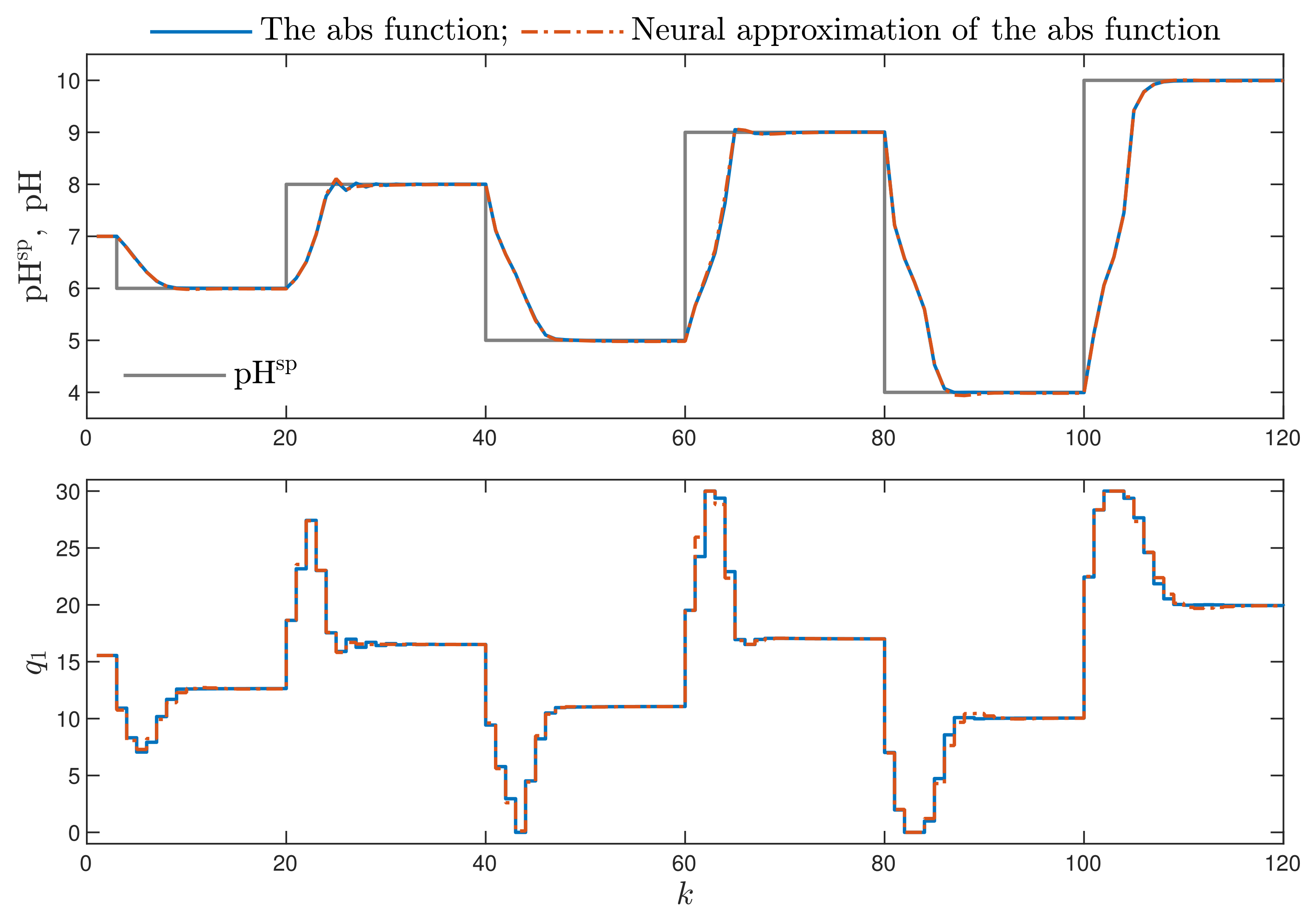
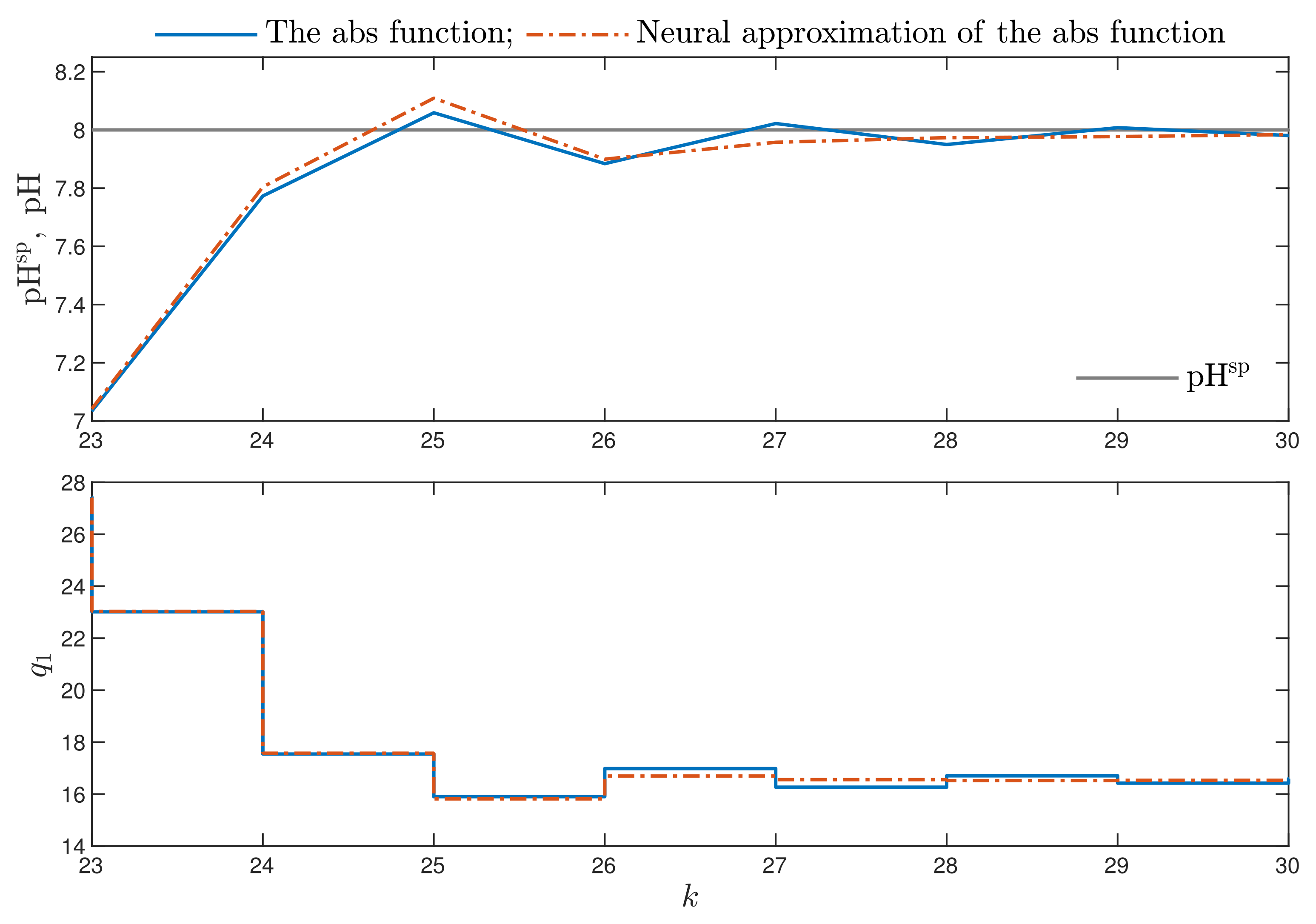
- The first part of the non-differentiable cost function (4) is replaced by its differentiable representation. For this purpose, a neural network approximation of the absolute value function is used.
- (b)
- The cost function with a neural approximator is differentiable but nonlinear in terms of the computed control moves (1). To simplify the calculation scheme, an advanced trajectory linearisation method is used. As a result, a simple-to-solve quadratic optimisation task is obtained in place of the nonlinear one. Quadratic optimisation problems, for , have only one minimum, which is the global one.
3.1. Neural Approximation of the MPC-L Cost-Function
3.2. Advanced Trajectory Linearisation of the MPC-L Cost-Function
3.3. Formulation of the Computationally Simple MPC-L Quadratic Optimisation Task
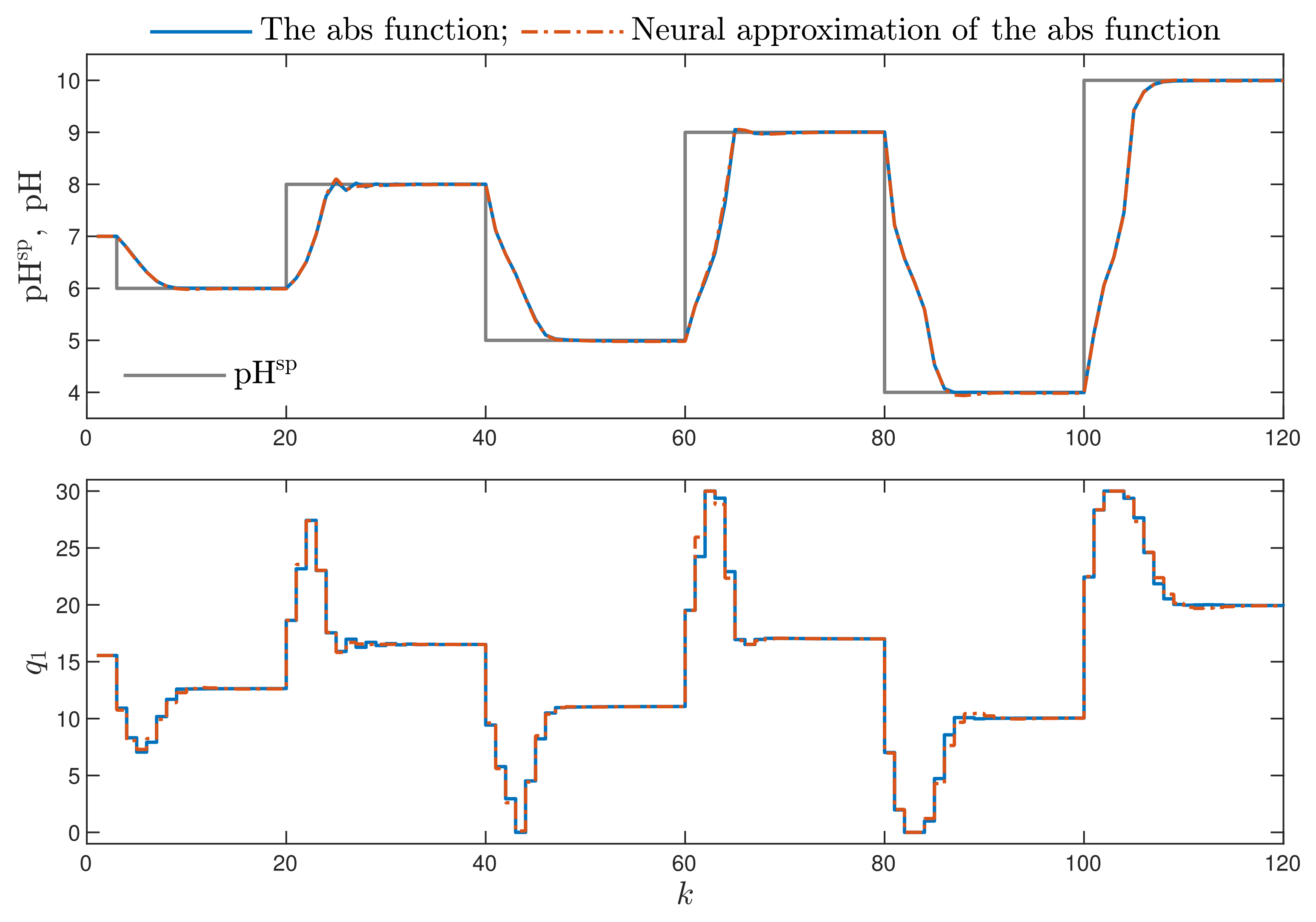
4. Simulations
4.1. The Neutralisation Reactor
4.2. Neutralisation Reactor Modelling for MPC
4.3. Calculation of the Predicted Trajectories for the Wiener Model of the Neutralisation Reactor
4.4. Calculation of the Matrices of Derivatives for the Wiener Model of the Neutralisation Reactor
4.5. Organisation of Calculations
- For the Wiener model, the disturbance estimate is calculated from Equation (42).
- The trajectory of the manipulated variable, , that defines the linearisation point (Equation (11)), is formed. Three possible choices are discussed in the next section.
- The quadratic optimisation task (25) is solved.
- In the case of the MPC-NPLT-L algorithm, the first element of the obtained decision vector, , is applied to the process, i.e., .
- In the case of the MPC-NPLPT-L algorithm, steps 2–5 are repeated a few times (in this work, maximally five times). The trajectory used for linearisation is defined as , where the matrix and the vector are defined by Equations (23) and (24), respectively, and denotes the optimal solution calculated in the previous internal iteration (for the current sampling instant k). When the internal iterations are terminated, the first element of the decision vector computed in the last internal iteration is applied to the process.
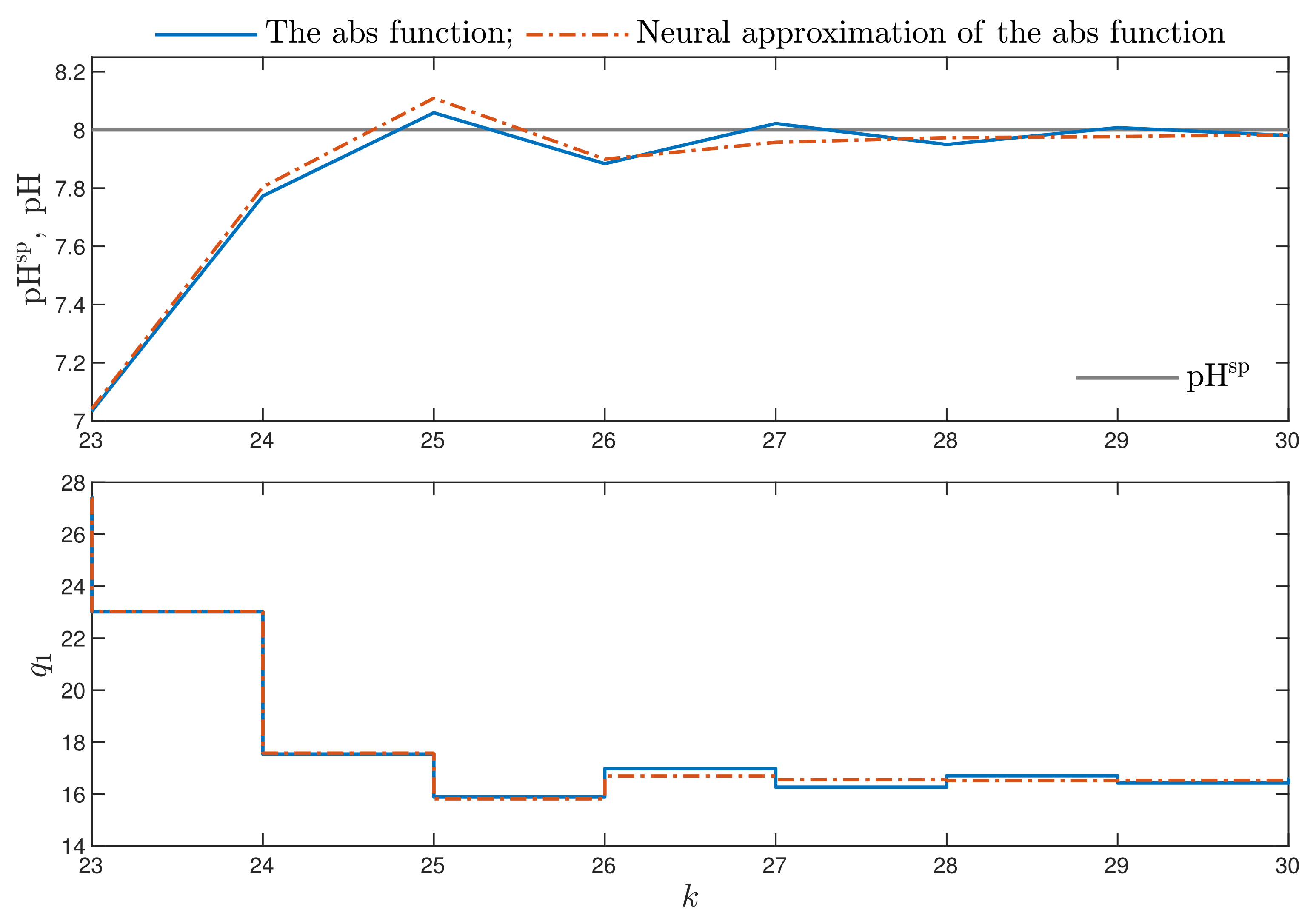
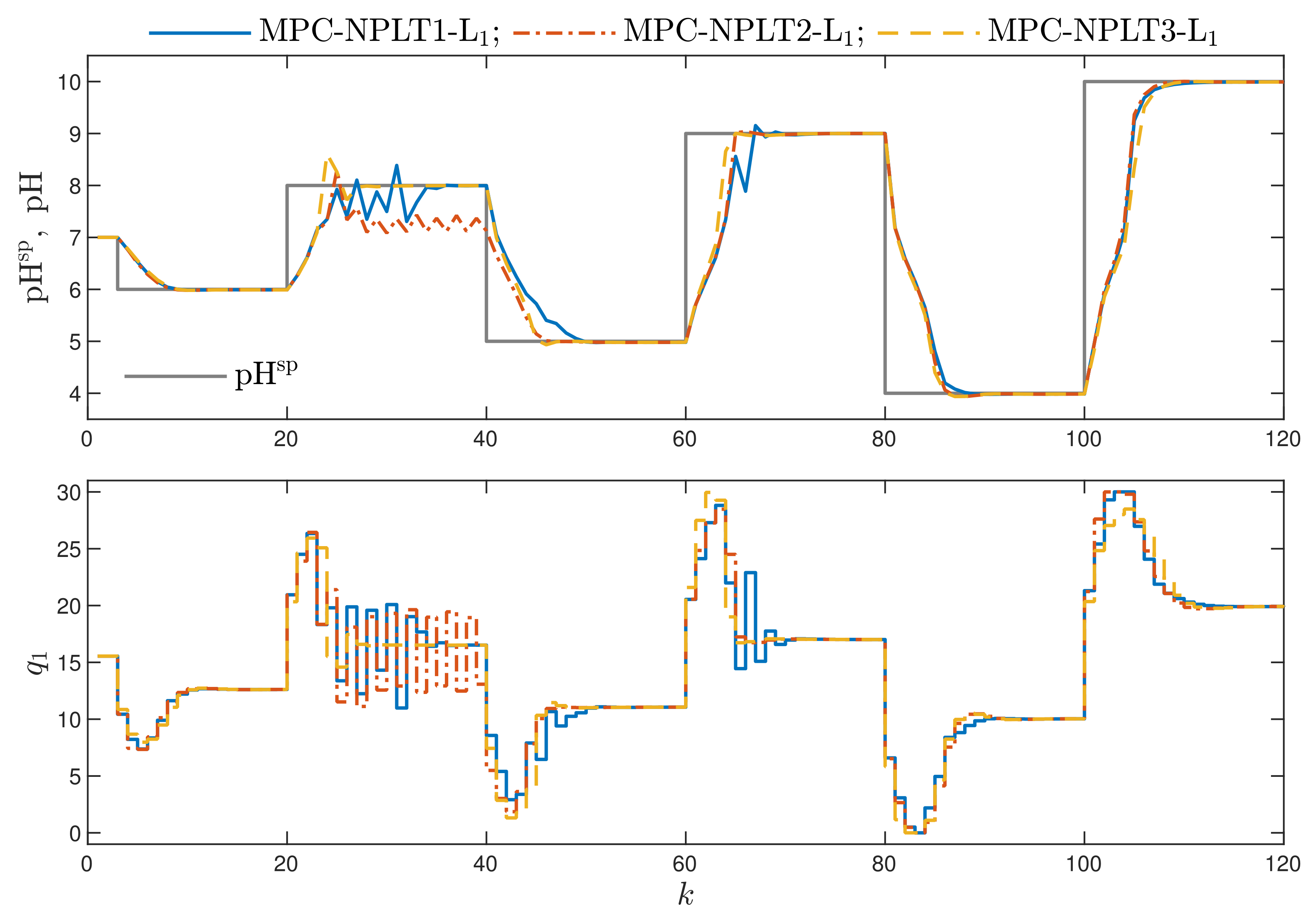
4.6. Comparison of MPC-L and MPC-L Algorithms for the Neutralisation Reactor
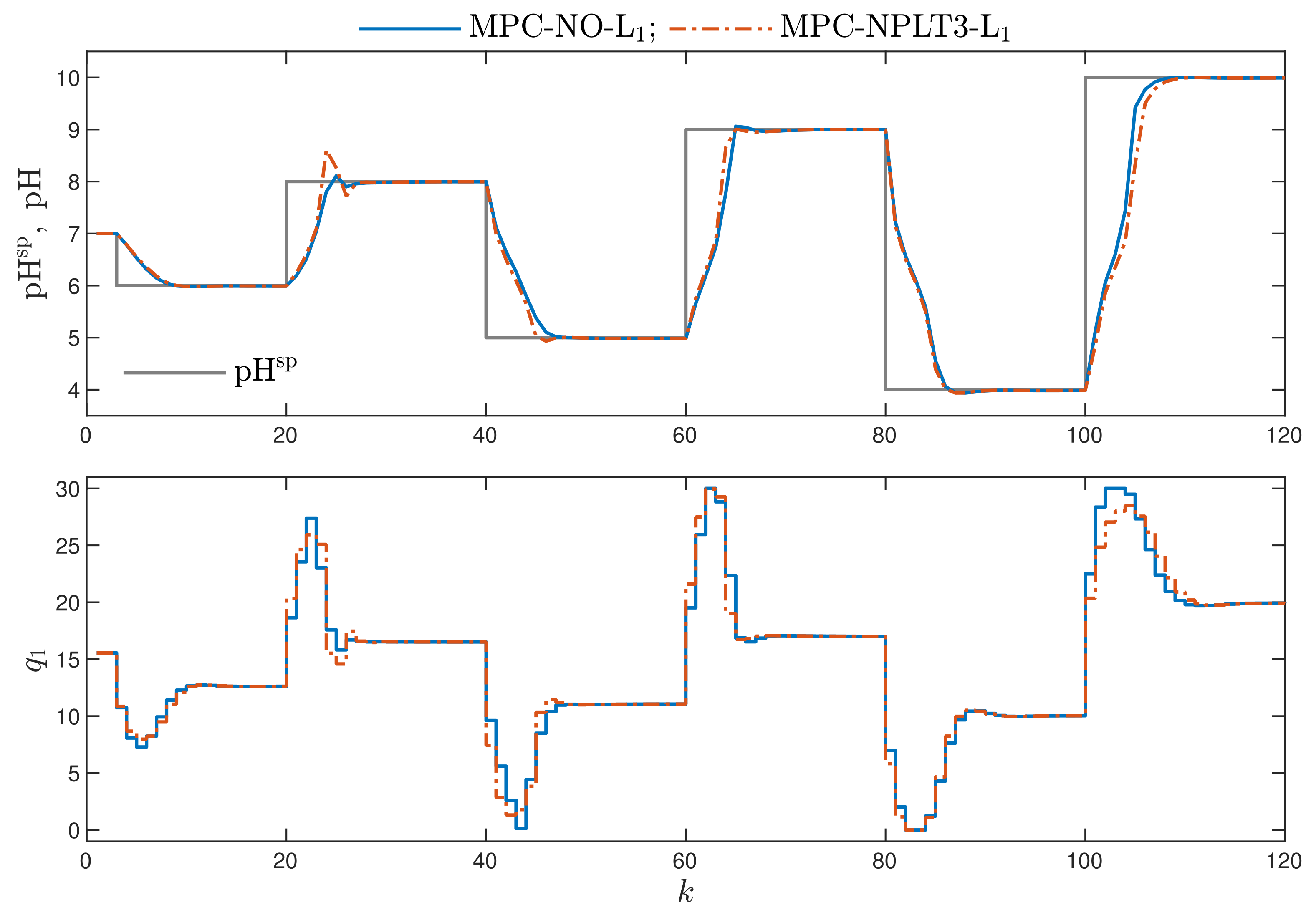
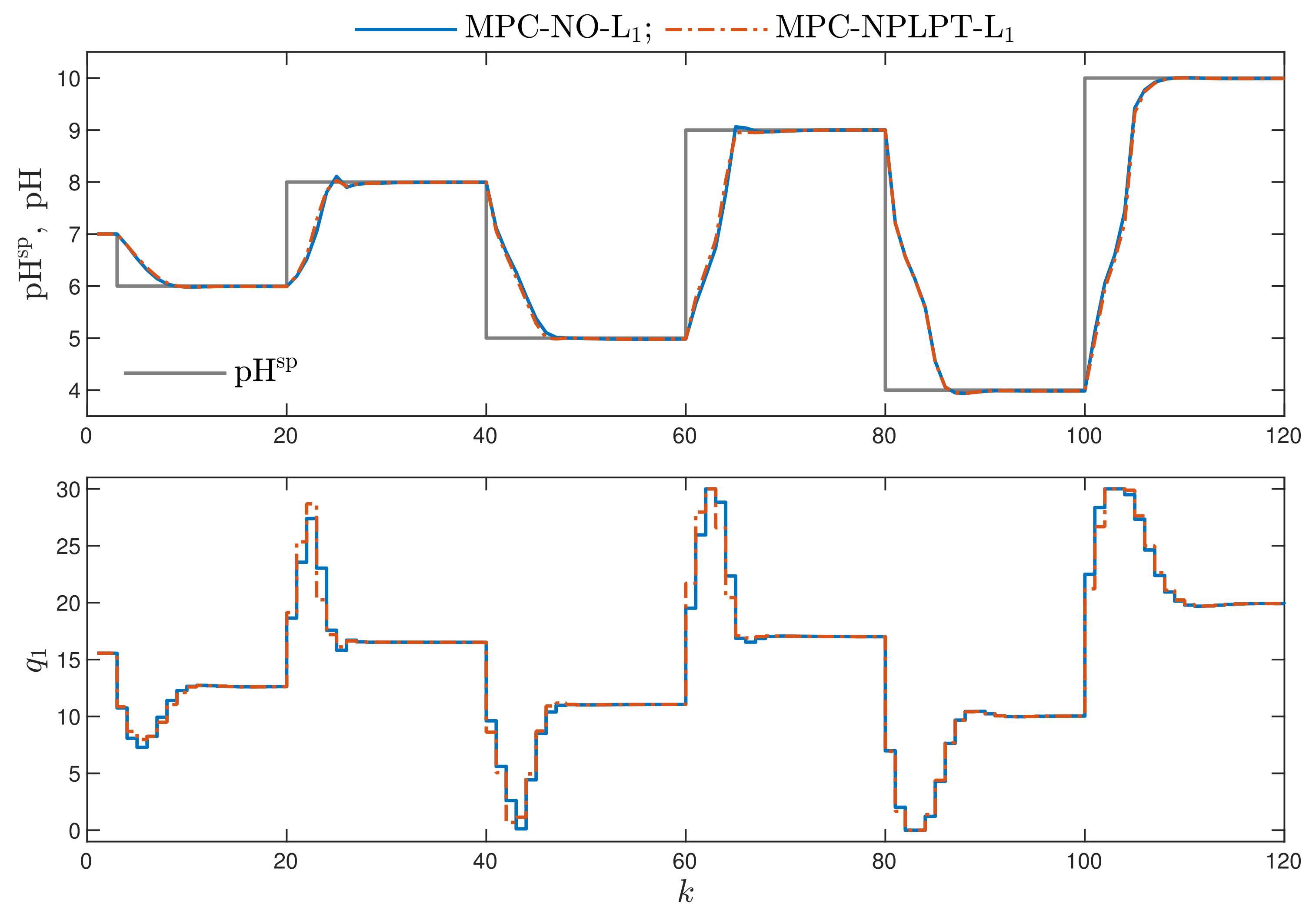
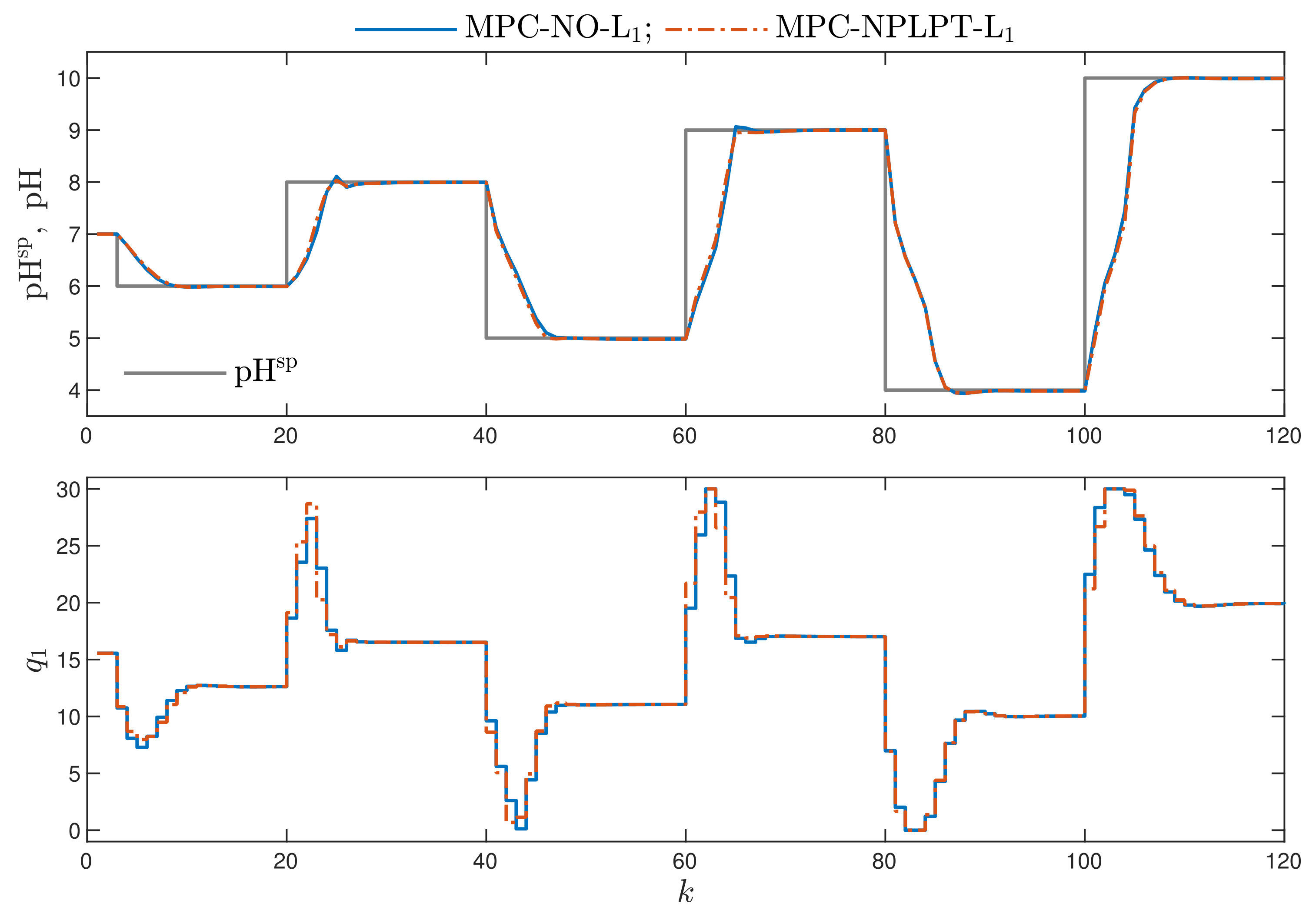
- MPC-NO-L: the MPC algorithm with nonlinear optimisation with the L norm used in the first part of the minimised cost function defined by Equation (4). The resulting nonlinear optimisation task is given by Equation (5). Two versions of the MPC-NO-L are considered: the non-differentiable absolute value function or its differentiable neural approximation may be used.
- MPC-NPLT1-L: the discussed MPC algorithm with nonlinear prediction and linearisation along the trajectory. The neural network is used to approximate the non-differentiable absolute value function. Moreover, a linear approximation of the nonlinear trajectory of the predicted control errors over the prediction horizon is used in the cost function. The resulting quadratic optimisation task is given by Equation (25). The trajectory used for linearisation, i.e., (Equation (11)) is constant; all its elements are equal to the value of the manipulated variable calculated at the previous sampling instant, i.e., , and applied to the process.
- MPC-NPLT2-L: the trajectory used for linearisation is defined by the last elements of the optimal solution computed at the previous sampling instant. Only the first element of this sequence is actually used for control.
- MPC-NPLT3-L: the trajectory used for linearisation is constant, all its elements are equal to the value of the process input corresponding to the current output set-point. For this purpose, the inverse static model of the process is used: . In this work, a neural network of the MLP type with two layers serves as the inverse model (the first nonlinear layer contains 10 hidden nodes of the tanh type).
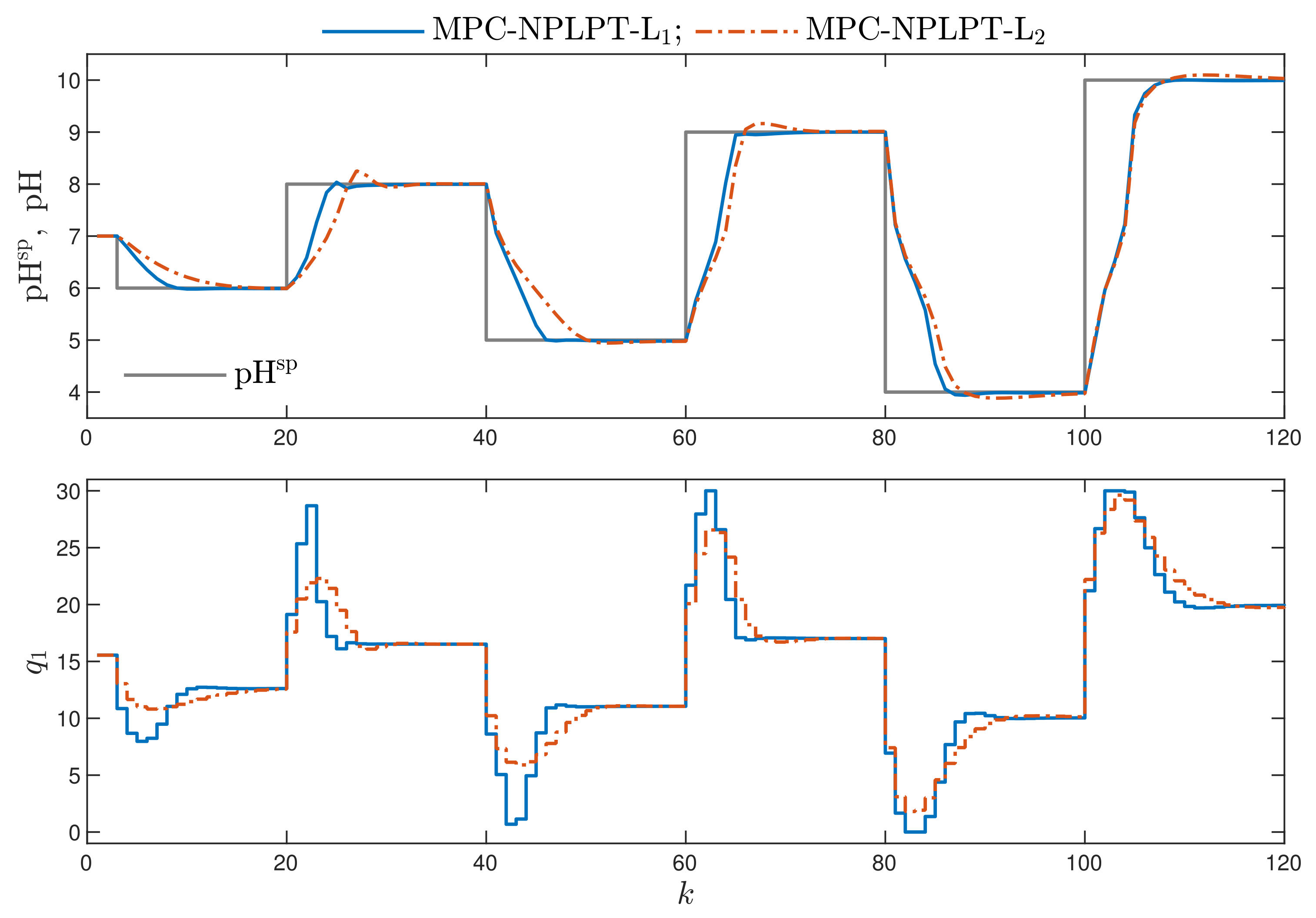
- MPC-NPLPT-L: the discussed MPC algorithm with nonlinear prediction and linearisation along the predicted trajectory. In this case, trajectory linearisation and quadratic optimisation are repeated maximally five times at each sampling instant. The trajectory used for linearisation is taken from the previous internal iteration of the algorithm. In the first internal iteration, for linearisation, the trajectory obtained from the inverse static model for the current set-point is used, exactly as it is done in the MPC-NPLT3-L scheme.
- MPC-NO-L: the MPC algorithm with nonlinear optimisation with the L norm used in two parts of the minimised cost function. The resulting nonlinear optimisation task is given by Equation (2).
- MPC-NPLT1-L, MPC-NPLT2-L and MPC-NPLT3-L: the MPC algorithm with nonlinear prediction and linearisation along the trajectory [29]. Trajectory linearisation and quadratic optimisation are performed once at each sampling instant.
- MPC-NPLPT-L: the MPC algorithm with Nonlinear Prediction and Linearisation along the Predicted Trajectory [29]. Trajectory linearisation and quadratic optimisation are repeated maximally five times at each sampling instant.
- The sum of absolute values of control errors for the whole simulation horizon defined as:where denotes the real value of the process output obtained in simulation.
- The sum of absolute values of differences between the output of the process when it is controlled by the “ideal” MPC-NO-L algorithm () and the output of the process when it is controlled by a compared MPC scheme (). These differences are considered for the whole simulation horizon:
- The sum of squared control errors for the whole simulation horizon defined as:
- The sum of squared differences between the output of the process when it is controlled by the “ideal” MPC-NO-L algorithm and the output of the process when it is controlled by a compared MPC scheme. These differences are considered for the whole simulation horizon:
- Comparing the MPC algorithms with the norm L, in which one trajectory linearisation and quadratic optimisation are executed at each sampling instant, the best results are obtained in the MPC-NPLT3-L scheme, in which the trajectory linearisation is performed using an inverse static model of the process. That algorithm gives the lowest values of the performance indices and . It confirms the comparison given in Figure 3.
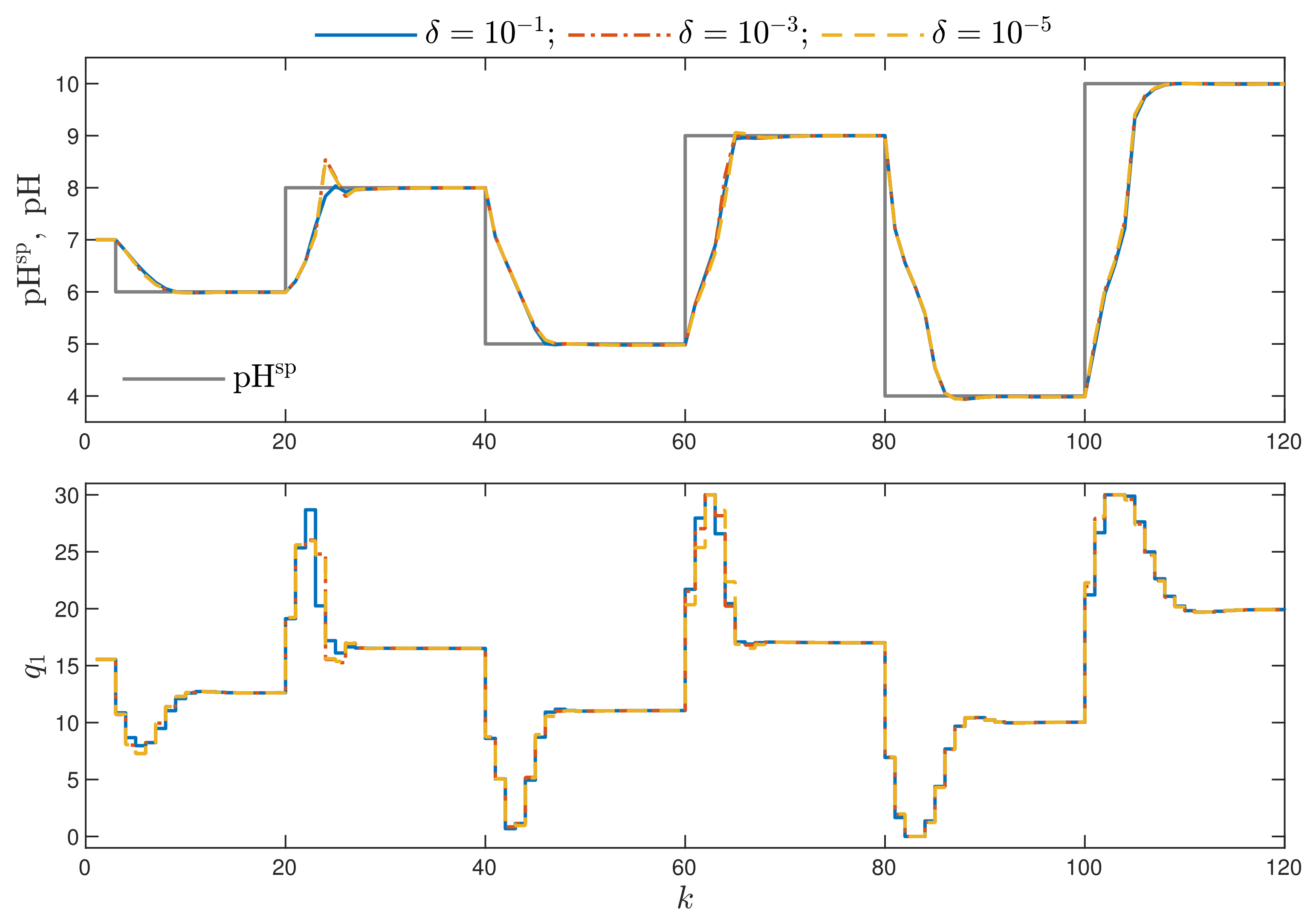
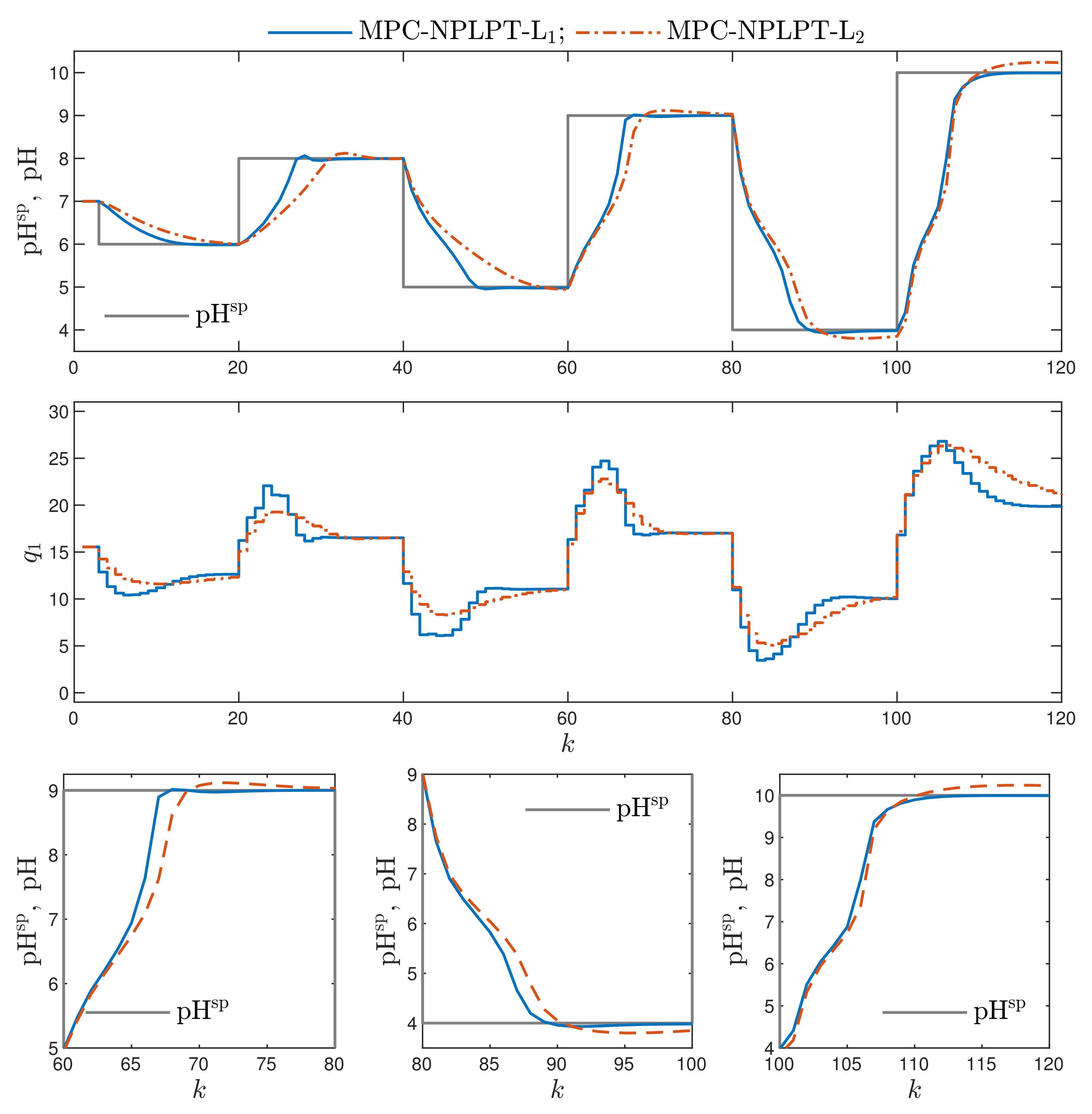
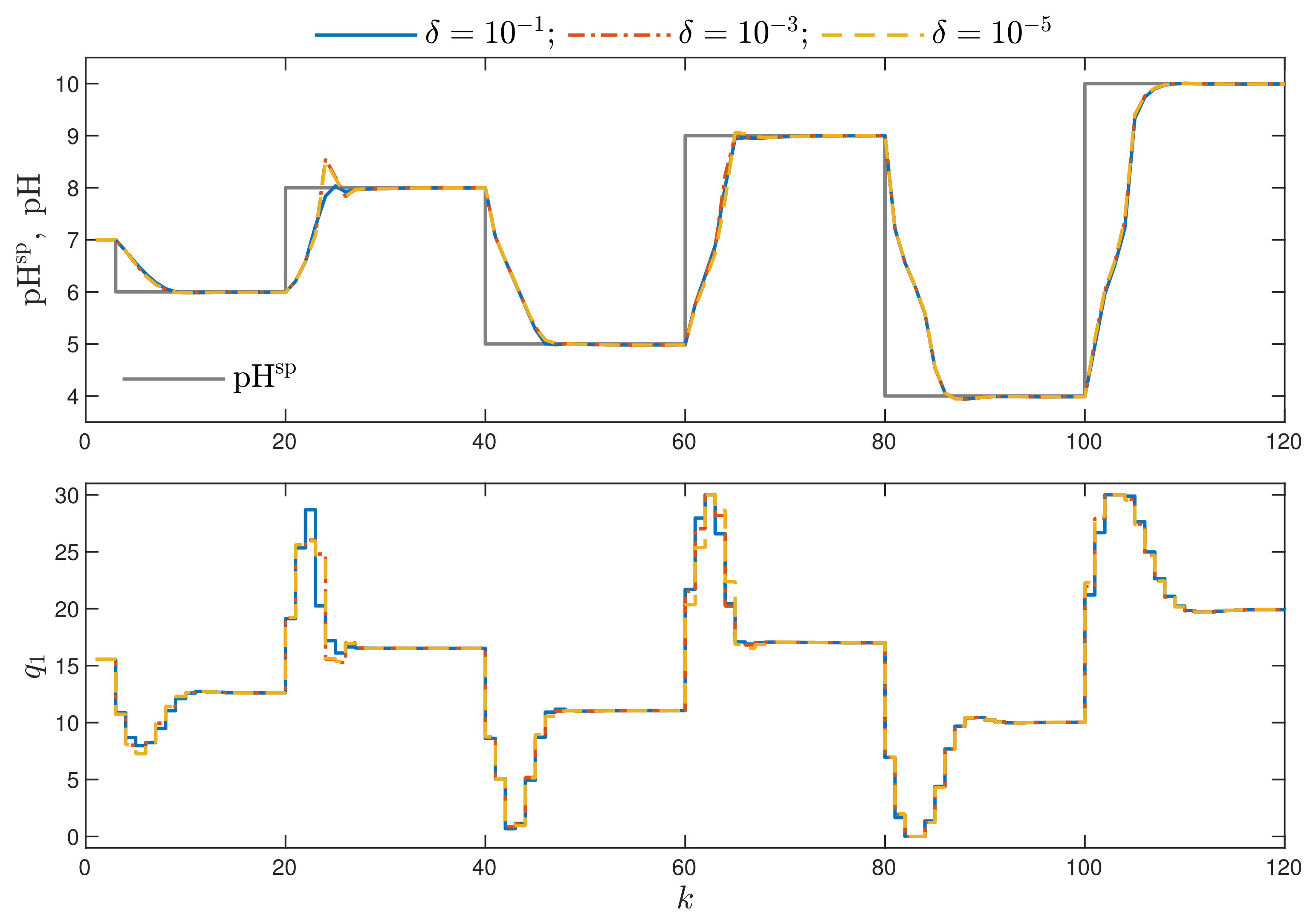
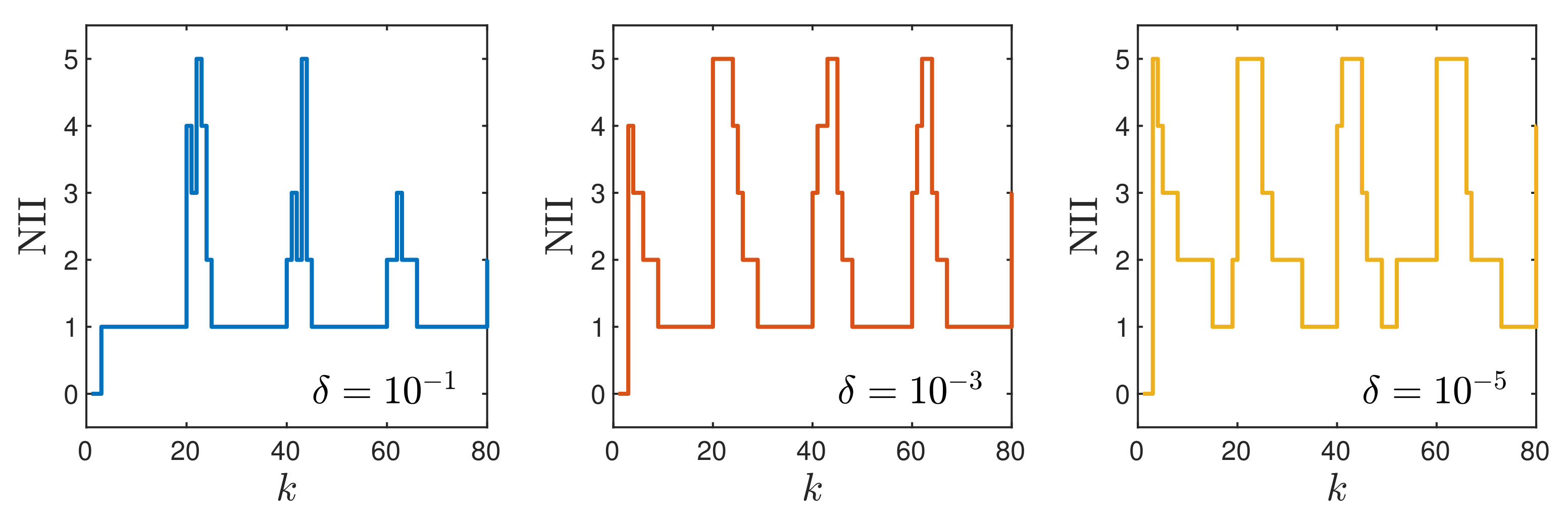
- Better results are possible when a few repetitions of trajectory linearisation and quadratic optimisation are possible at each sampling instant in the MPC-NPLPT-L scheme. The obtained value of the indices and are lower. It confirms the comparison given in Figure 7. Moreover, the lower the parameter , the more similar the obtained trajectory is to that possible in the reference MPC-NO-L scheme.
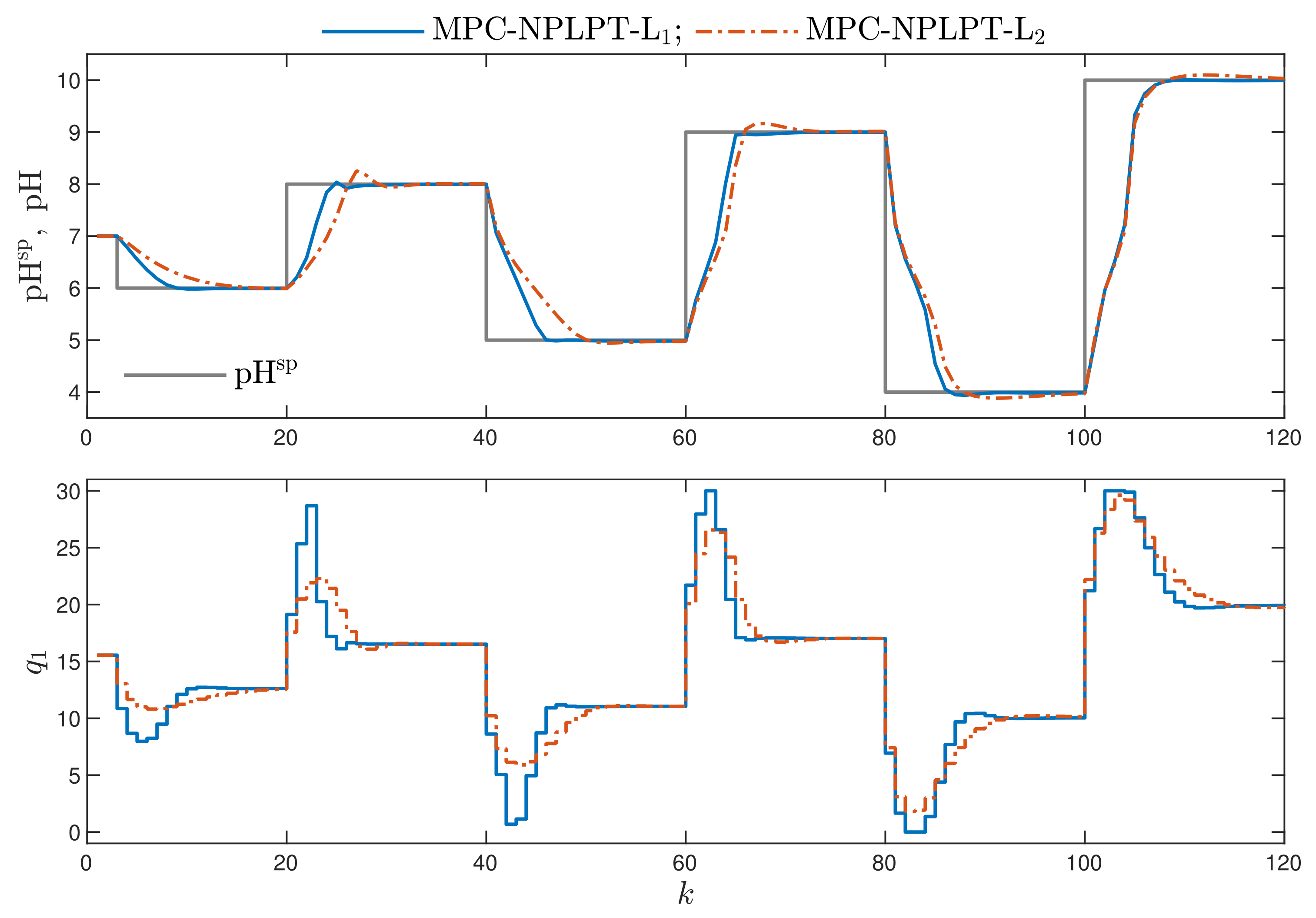
- Bearing in mind our expectations and objectives, the classical MPC algorithms that use the L norm give a worse performance. This confirms the comparison given in Figure 8. For the corresponding algorithms, the values of both and performance indices are better (i.e., lower) when the norm L is used; the norm L gives worse results. This effect is best visible when we consider the performance index. For example, comparing the MPC-NPLPT-L and MPC-NPLPT-L algorithms with , that index is in the first case approximately 11 times lower.
- It is very interesting that the use of the L norm in place of the classical L one leads to not only better (lower) values of the indices and , which is natural, but also makes it possible to reduce the indices and . For all pairs of algorithms (with L and L norms), the index is slightly lower when the L norm is used. This difference is even more clear when we consider the index. It confirms the comparison given in Figure 8.
- In general, all MPC algorithms with the norm L are more computationally demanding than their counterparts that use the norm L. This is because, in the first case, in all calculations, i.e., in prediction, linearisation and optimisation, the neural approximator determines the absolute values of the control errors over the prediction horizon whereas, in the second case, no approximator is used, the predictions and control errors are used directly in all calculations.
- All MPC algorithms with linearisation and quadratic optimisation are less computationally demanding than the reference “ideal” MPC-NO algorithm.
- The more complicated the trajectory linearisation, the longer the calculation time. The lowest calculation time is observed in the MPC-NPLT1, MPC-NPLT2 and MPC-NPLT3 algorithms, with one repetition of linearisation and quadratic optimisation at each sampling instant. The calculation time becomes longer in the MPC-NPLPT scheme, with a few repetitions of linearisation and optimisation at each instant; the lower the parameter , the longer the calculation time.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tatjewski, P. Advanced Control of Industrial Processes, Structures and Algorithms; Springer: London, UK, 2007. [Google Scholar]
- Maciejowski, J. Predictive Control with Constraints; Prentice Hall: Harlow, UK, 2002. [Google Scholar]
- Nebeluk, R.; Marusak, P.M. Efficient MPC algorithms with variable trajectories of parameters weighting predicted control errors. Arch. Control Sci. 2020, 30, 325–363. [Google Scholar]
- Huyck, B.; De Brabanter, J.; De Moor, B.; Van Impe, J.F.; Logist, F. Online model predictive control of industrial processes using low level control hardware: A pilot-scale distillation column case study. Control Eng. Pract. 2014, 28, 34–48. [Google Scholar] [CrossRef] [Green Version]
- Ogonowski, S.; Bismor, D.; Ogonowski, Z. Control of complex dynamic nonlinear loading process for electromagnetic mill. Arch. Control Sci. 2020, 30, 471–500. [Google Scholar]
- Zarzycki, K.; Ławryńczuk, M. Fast real-time model predictive control for a ball-on-plate process. Sensors 2021, 21, 3959. [Google Scholar] [CrossRef]
- Horla, D. Experimental Results on Actuator/Sensor Failures in Adaptive GPC Position Control. Actuators 2021, 10, 43. [Google Scholar] [CrossRef]
- Eskandarpour, A.; Sharf, I. A constrained error-based MPC for path following of quadrotor with stability analysis. Nonlinear Dyn. 2020, 98, 899–918. [Google Scholar] [CrossRef]
- Ducajú, S.; Salt Llobregat, J.J.; Cuenca, Á.; Tomizuka, M. Autonomous Ground Vehicle Lane-Keeping LPV Model-Based Control: Dual-Rate State Estimation and Comparison of Different Real-Time Control Strategies. Sensors 2021, 21, 1531. [Google Scholar]
- Liang, Y.; Yin, Z.; Nie, L. Shared Steering Control for Lane Keeping and Obstacle Avoidance Based on Multi-Objective MPC. Sensors 2021, 21, 4671. [Google Scholar] [CrossRef] [PubMed]
- Patria, D.; Rossi, C.; Fernandez, R.A.S.; Dominguez, S. Nonlinear control strategies for an autonomous wing-in-ground-effect vehicle. Sensors 2021, 21, 4193. [Google Scholar] [CrossRef] [PubMed]
- Bassolillo, S.R.; D’Amato, E.; Notaro, I.; Blasi, L.; Mattei, M. Decentralized Mesh-Based Model Predictive Control for Swarms of UAVs. Sensors 2020, 20, 4324. [Google Scholar] [CrossRef]
- Bania, P. An information based approach to stochastic control problems. Int. J. Appl. Math. Comput. Sci. 2020, 30, 47–59. [Google Scholar]
- Ding, Z.; Sun, C.; Zhou, M.; Liu, Z.; Wu, C. Intersection Vehicle Turning Control for Fully Autonomous Driving Scenarios. Sensors 2021, 21, 3995. [Google Scholar] [CrossRef]
- Xiong, L.; Fu, Z.; Zeng, D.; Leng, B. An Optimized Trajectory Planner and Motion Controller Framework for Autonomous Driving in Unstructured Environments. Sensors 2021, 21, 4409. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H∞, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bououden, S.; Boulkaibet, I.; Chadli, M.; Abboudi, A. A Robust Fault-Tolerant Predictive Control for Discrete-Time Linear Systems Subject to Sensor and Actuator Faults. Sensors 2021, 21, 2307. [Google Scholar] [CrossRef]
- Karimshoushtari, M.; Novara, C.; Tango, F. How Imitation Learning and Human Factors Can Be Combined in a Model Predictive Control Algorithm for Adaptive Motion Planning and Control. Sensors 2021, 21, 4012. [Google Scholar] [CrossRef] [PubMed]
- Miller, A.; Rybczak, M.; Rak, A. Towards the Autonomy: Control Systems for the Ship in Confined and Open Waters. Sensors 2021, 21, 2286. [Google Scholar] [CrossRef] [PubMed]
- Yao, F.; Yang, C.; Liu, X.; Zhang, M. Experimental Evaluation on Depth Control Using Improved Model Predictive Control for Autonomous Underwater Vehicle (AUVs). Sensors 2018, 18, 2321. [Google Scholar] [CrossRef] [Green Version]
- Bacci di Capaci, R.; Vaccari, M.; Pannocchia, G. Model predictive control design for multivariable processes in the presence of valve stiction. J. Process Control 2018, 71, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Dötlinger, A.; Kennel, R.M. Near time-optimal model predictive control using an L1-norm based cost functional. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, Pittsburgh, PA, USA, 14–18 September 2014; pp. 3504–3511. [Google Scholar]
- Domański, P.; Ławryńczuk, M. Impact of MPC embedded performance index on control quality. IEEE Access 2021, 9, 24787–24795. [Google Scholar] [CrossRef]
- Fehér, M.; Straka, O.; Šmídl, V. Model predictive control of electric drive system with L1-norm. Eur. J. Control 2020, 56, 242–253. [Google Scholar] [CrossRef]
- Karamanakos, P.; Geyer, T.; Kennel, R. On the choice of norm in finite control set model predictive control. IEEE Trans. Power Electron. 2018, 33, 7105–7117. [Google Scholar] [CrossRef]
- Müller, M.; Worthmann, K. Quadratic costs do not always work in MPC. Automatica 2017, 82, 269–277. [Google Scholar] [CrossRef]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Boiroux, D.; Jørgensen, J.B. Sequential ℓ1 quadratic programming for nonlinear model predictive control. IFAC-PapersOnLine 2019, 52, 474–479. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Computationally Efficient Model Predictive Control Algorithms: A Neural Network Approach. In Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2014; Volume 3. [Google Scholar]
- Wu, X.; Shen, J.; Li, Y.; Wang, M.; Lawal, A. Flexible operation of post-combustion solvent-based carbon capture for coal-fired power plants using multi-model predictive control: A simulation study. Fuel 2018, 220, 931–941. [Google Scholar] [CrossRef] [Green Version]
- Marusak, P.M. A numerically efficient fuzzy MPC algorithm with fast generation of the control signal. Int. J. Appl. Math. Comput. Sci. 2021, 31, 59–71. [Google Scholar]
- Kittisupakorn, P.; Thitiyasook, P.; Hussain, M.A.; Daosud, W. Neural network based model predictive control for a steel pickling process. J. Process Control 2009, 19, 579–590. [Google Scholar] [CrossRef]
- Reynolds, J.; Rezgui, Y.; Kwan, A.; Piriou, S. A zone-level, building energy optimisation combining an artificial neural network, a genetic algorithm, and model predictive control. Energy 2018, 151, 729–739. [Google Scholar] [CrossRef]
- Ardabili, S.F.; Mahmoudi, A.; Gundoshmian, T.M. Modeling and simulation controlling system of HVAC using fuzzy and predictive (radial basis function, RBF) controllers. J. Build. Eng. 2016, 6, 301–308. [Google Scholar] [CrossRef]
- Han, H.G.; Qiao, J.F.; Chen, Q.L. Model predictive control of dissolved oxygen concentration based on a self-organizing RBF neural network. Control Eng. Pract. 2012, 20, 465–476. [Google Scholar] [CrossRef]
- Huang, C.; Li, L.; Wang, X. Extended Model Predictive Control Based on Multi-Structure RBF Networks: Design and Application to Clutch Control. IFAC-PapersOnLine 2018, 51, 653–658. [Google Scholar] [CrossRef]
- Jeon, B.K.; Kim, E.J. LSTM-based model predictive control for optimal temperature set-point planning. Sustainability 2021, 13, 894. [Google Scholar] [CrossRef]
- Karimanzira, D.; Rauschenbach, T. Deep learning based model predictive control for a reverse osmosis desalination plant. J. Appl. Math. Phys. 2020, 8, 2713–2731. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. LSTM and GRU neural networks as models of dynamical processes used in predictive control: A comparison of models developed for two chemical reactors. Sensors 2021, 21, 5625. [Google Scholar] [CrossRef]
- Sabzevari, S.; Heydari, R.; Mohiti, M.; Savaghebi, M.; Rodriguez, J. Model-free neural network-based predictive control for robust operation of power converters. Energies 2021, 14, 2325. [Google Scholar] [CrossRef]
- Zamarreno, J.; Vega, P.; Garcia, L.D.; Francisco, M. State-space neural network for modelling, prediction and control. Control Eng. Pract. 2000, 8, 1063–1075. [Google Scholar] [CrossRef]
- Cervantes-Bobadilla, M.; Escobar-Jimenez, R.F.; Gomez-Aguilar, J.F.; Garcia-Morales, J.; Olivares-Peregrino, V.H. Experimental study on the performance of controllers for the hydrogen gas production demanded by an internal combustion engine. Energies 2018, 11, 2157. [Google Scholar] [CrossRef] [Green Version]
- Huo, H.B.; Zhu, X.J.; Hu, W.Q.; Tu, H.Y.; Li, J.; Yang, J. Nonlinear model predictive control of SOFC based on a Hammerstein model. J. Power Sources 2008, 185, 338–344. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Suboptimal nonlinear predictive control based on multivariable neural Hammerstein models. Appl. Intell. 2016, 32, 173–192. [Google Scholar] [CrossRef]
- Arefi, M.A.; Montazeri, A.; Poshtan, J.; Jahed-Motlagh, M.R. Wiener-neural identification and predictive control of a more realistic plug-flow tubular reactor. Chem. Eng. J. 2008, 138, 274–282. [Google Scholar] [CrossRef]
- Li, S.; Li, Y. Model predictive control of an intensified continuous reactor using a neural network Wiener model. Neurocomputing 2016, 185, 93–104. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Nonlinear Predictive Control Using Wiener Models: Computationally Efficient Approaches for Polynomial and Neural Structures. In Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2022; Volume 389. [Google Scholar]
- Peng, H.; Wu, J.; Inoussa, G.; Deng, Q.; Nakano, K. Nonlinear system modeling and predictive control using the RBF nets-based quasi-linear ARX model. Control Eng. Pract. 2009, 17, 59–66. [Google Scholar] [CrossRef]
- Peng, H.; Ozaki, T.; Toyoda, Y.; Shioya, H.; Nakano, K.; Haggan-Ozaki, V.; Mori, M. RBF-ARX model-based nonlinear system modeling and predictive control with application to a NOx decomposition process. Control Eng. Pract. 2004, 12, 191–203. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Neural Dynamic Matrix Control algorithm with disturbance compensation. In Proceedings of the 23th International Conference on Industrial, Engineering & Other Applications of Applied Intelligent Systems (IEA-AIE 2010), Cordoba, Spain, 1–4 June 2010; García Pedrajas, N., Herrera, F., Fyfe, C., Benítez, J.M., Ali, M., Eds.; Lecture Notes in Artificial Intelligence. Springer: Berlin, Germany, 2010; Volume 6098, pp. 52–61. [Google Scholar]
- Doncevic, D.T.; Schweidtmann, A.M.; Vaupel, Y.; Schäfer, P.; Caspari, A.; Mitsos, A. Deterministic global nonlinear model predictive control with recurrent neural networks embedded. IFAC-PapersOnLine 2020, 53, 5273–5278. [Google Scholar] [CrossRef]
- Ławryńczuk, M.; Tatjewski, P. Nonlinear predictive control based on neural multi-models. Int. J. Appl. Math. Comput. Sci. 2010, 20, 7–21. [Google Scholar] [CrossRef] [Green Version]
- Hosen, M.A.; Hussain, M.A.; Mjalli, F.S. Control of polystyrene batch reactors using neural network based model predictive control (NNMPC): An experimental investigation. Control Eng. Pract. 2011, 19, 454–467. [Google Scholar] [CrossRef]
- Aggelogiannaki, E.; Sarimveis, H. Nonlinear model predictive control for distributed parameter systems using data driven artificial neural network models. Comput. Chem. Eng. 2008, 32, 1225–1237. [Google Scholar] [CrossRef]
- Aggelogiannaki, E.; Sarimveis, H.; Koubogiannis, D. Model predictive temperature control in long ducts by means of a neural network approximation tool. Appl. Therm. Eng. 2007, 27, 2363–2369. [Google Scholar] [CrossRef]
- Xie, W.; Bonis, I.; Theodoropoulos, C. Data-driven model reduction-based nonlinear MPC for large-scale distributed parameter systems. J. Process Control 2015, 35, 50–58. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Han, Z.; Liu, F.; Guan, X. Identification and control of nonlinear system based on Laguerre-ELM Wiener model. Commun. Nonlinear Sci. Numer. Simul. 2016, 38, 192–205. [Google Scholar] [CrossRef]
- Stogiannos, M.; Alexandridis, A.; Sarimveis, H. Model predictive control for systems with fast dynamics using inverse neural models. ISA Trans. 2018, 72, 161–177. [Google Scholar] [CrossRef] [PubMed]
- Vaupel, Y.; Hamacher, N.C.; Caspari, A.; Mhamdi, A.; Kevrekidis, I.G.; Mitsos, A. Accelerating nonlinear model predictive control through machine learning. J. Process Control 2020, 92, 261–270. [Google Scholar] [CrossRef]
- Bonzanini, A.D.; Paulson, J.A.; Makrygiorgos, G.; Mesbah, A. Fast approximate learning-based multistage nonlinear model predictive control using Gaussian processes and deep neural networks. Comput. Chem. Eng. 2021, 145, 107174. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Explicit nonlinear predictive control algorithms with neural approximation. Neurocomputing 2014, 129, 570–584. [Google Scholar] [CrossRef]
- Maddalena, E.T.; da S. Moraes, C.G.; Waltrich, G.; Jones, C.N. A neural network architecture to learn explicit MPC controllers from data. IFAC-PapersOnLine 2020, 53, 11362–11367. [Google Scholar] [CrossRef]
- Pan, Y.; Wang, J. Two neural network approaches to model predictive control. In Proceedings of the American Control Conference (ACC2008 ), Seattle, WA, USA, 11–13 June 2008; pp. 1685–1690. [Google Scholar]
- Xu, J.; Li, C.; He, X.; Huang, T. Recurrent neural network for solving model predictive control problem in application of four-tank benchmark. Neurocomputing 2016, 190, 172–178. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines; Pearson Education: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Gómez, J.C.; Jutan, A.; Baeyens, E. Wiener model identification and predictive control of a pH neutralisation process. IEE Proc. Control Theory Appl. 2004, 151, 329–338. [Google Scholar] [CrossRef] [Green Version]
- Janczak, A.; Korbicz, J. Two-stage instrumental variables identification of polynomial Wiener systems with invertible nonlinearities. Int. J. Appl. Math. Comput. Sci. 2019, 29, 571–580. [Google Scholar] [CrossRef] [Green Version]
- Ławryńczuk, M. Practical nonlinear predictive control algorithms for neural Wiener models. J. Process Control 2013, 23, 696–714. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Modelling and predictive control of a neutralisation reactor using sparse Support Vector Machine Wiener models. Neurocomputing 2016, 205, 311–328. [Google Scholar] [CrossRef]
- Domański, P. Control Performance Assessment: Theoretical Analyses and Industrial Practice. In Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2020; Volume 245. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Calculation Time | ||||
|---|---|---|---|---|---|
| MPC-NPLT1-L | 7.8818 × 101 | 1.0431 × 101 | 2.2752 × 102 | 4.4144 | 34.00% |
| MPC-NPLT2-L | 7.8897 × 101 | 1.5057 × 101 | 2.1985 × 102 | 9.3569 | 33.7% |
| MPC-NPLT3-L | 7.1167 × 101 | 7.4706 | 2.2197 × 102 | 3.6258 | 33.6% |
| MPC-NPLPT-L, | 6.9590 × 101 | 2.7467 | 2.1626 × 102 | 3.3734 × 10−1 | 40.3% |
| MPC-NPLPT-L, | 6.9768 × 101 | 2.6469 | 2.1435 × 102 | 8.7502 × 10−1 | 49.3% |
| MPC-NPLPT-L, | 7.0350 × 101 | 1.5524 | 2.1573 × 102 | 5.4643 × 10−1 | 60.8% |
| MPC-NO-L | 7.0371 × 101 | – | 2.1631 × 102 | – | 100.0% |
| MPC-NPLT1-L | 8.6977 × 101 | 1.8184 × 101 | 2.3746 × 102 | 8.9869 | 21.0% |
| MPC-NPLT2-L | 8.3845 × 101 | 1.6043 × 101 | 2.2758 × 102 | 5.8777 | 20.8% |
| MPC-NPLT3-L | 8.3647 × 101 | 1.5071 × 101 | 2.3459 × 102 | 6.2455 | 21.0% |
| MPC-NPLPT-L, | 8.3784 × 101 | 1.4916 × 101 | 2.3559 × 102 | 5.5591 | 23.6% |
| MPC-NPLPT-L, | 8.4162 × 101 | 1.6693 × 101 | 2.2885 × 102 | 6.6640 | 30.9% |
| MPC-NPLPT-L, | 8.4795 × 101 | 1.7317 × 101 | 2.2976 × 102 | 7.2166 | 35.6% |
| MPC-NO-L | 8.5089 × 101 | 1.7708 × 101 | 2.3033 × 102 | 7.6448 | 73.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ławryńczuk, M.; Nebeluk, R. Computationally Efficient Nonlinear Model Predictive Control Using the L1 Cost-Function. Sensors 2021, 21, 5835. https://doi.org/10.3390/s21175835
Ławryńczuk M, Nebeluk R. Computationally Efficient Nonlinear Model Predictive Control Using the L1 Cost-Function. Sensors. 2021; 21(17):5835. https://doi.org/10.3390/s21175835
Chicago/Turabian StyleŁawryńczuk, Maciej, and Robert Nebeluk. 2021. "Computationally Efficient Nonlinear Model Predictive Control Using the L1 Cost-Function" Sensors 21, no. 17: 5835. https://doi.org/10.3390/s21175835
APA StyleŁawryńczuk, M., & Nebeluk, R. (2021). Computationally Efficient Nonlinear Model Predictive Control Using the L1 Cost-Function. Sensors, 21(17), 5835. https://doi.org/10.3390/s21175835