Abstract
This work thoroughly compares the efficiency of Long Short-Term Memory Networks (LSTMs) and Gated Recurrent Unit (GRU) neural networks as models of the dynamical processes used in Model Predictive Control (MPC). Two simulated industrial processes were considered: a polymerisation reactor and a neutralisation (pH) process. First, MPC prediction equations for both types of models were derived. Next, the efficiency of the LSTM and GRU models was compared for a number of model configurations. The influence of the order of dynamics and the number of neurons on the model accuracy was analysed. Finally, the efficiency of the considered models when used in MPC was assessed. The influence of the model structure on different control quality indicators and the calculation time was discussed. It was found that the GRU network, although it had a lower number of parameters than the LSTM one, may be successfully used in MPC without any significant deterioration of control quality.
1. Introduction
In Model Predictive Control (MPC) [1,2], a dynamical model of the controlled process is used to predict its behaviour over a certain time horizon and to optimise the control policy. This problem formulation leads to very good control quality, much better than that in classical control methods. As a result, MPC methods have been used for a great variety of processes, e.g., chemical reactors [3], heating, ventilation and air conditioning systems [4], robotic manipulators [5], electromagnetic mills [6], servomotors [7], electromechanical systems [8] and stochastic systems [9]. It must be pointed out that satisfactory control is only possible if the model used is precise enough. Although there are numerous types of dynamical models, e.g., fuzzy systems, polynomials, and piecewise linear structures [10], neural networks of different kinds [11] are very popular due to their excellent accuracy and simple structure [12]. In particular, Recurrent Neural Networks (RNNs) [13,14,15,16] can serve as a model as they are able to give predictions over the required horizon.
In theory, RNNs can be extremely useful in various machine learning tasks in which the data are time-dependent such as modelling of time series, speech synthesis or video analysis. In contrast to the classical feedforward neural networks, RNNs can be used to create models and predictions from sequential data. However, in practice, their use is limited due to their one major drawback: the lack of long-term memory. RNNs have short-term memory capabilities; however, they tend to forget about the long-term input–output time dependencies during the backpropagation training. This problem is caused by the vanishing gradient phenomena, which was described in great detail in [17,18,19]. Many ways of limiting the vanishing gradient influence on the training process have been proposed, such as using different activation functions (such as ReLU) or branch normalisation. Another approach is to modify the network architecture in a way that improves the gradient flow during training. Residual Neural Networks (ResNets) proposed in [20] and the Long Short-Term Memory Network (LSTM) structure proposed first in [18] and its modification—the Gated Recurrent Unit (GRU) architecture proposed in [21]—can serve as examples.
The unique long-term memory properties of LSTM and GRU neural networks made them widely popular in a large variety of machine learning tasks. Example applications of the LSTM architecture are: data classification [22], speech recognition [23,24], handwriting recognition [25], speech synthesis [26], text coherence tests [27], biometric authentication and anomaly detection [28], detecting deception from gaze and speech [29] and anomaly detection [30]. Similarly, example applications of the GRU structure are: facial expression recognition [31], human activity recognition [32], cyberbullying detection [33], defect detection [34], human activity surveillance [35], automated classification of cognitive workload tasks [36] and speaker identification [37].
Recently, the LSTM networks have been also used to model dynamical processes. Examples are: a benchmark process [38], a pH reactor [39], a reverse osmosis plant [40], temperature control [41] or an autonomous mobility-on-demand system [42]. In all cited publications, it was shown that the LSTM models are able to approximate the properties of dynamical processes; the models have very good accuracy. Some of these models have been used for prediction in MPC [40,41,42]; very good control quality has been reported. Although GRU networks are similar to the LSTM ones and they have many successful applications in classification and detection tasks, as mentioned in the previous paragraph, they are very rarely used as models of dynamical processes, e.g., a tandem-wing quadplane drone model was discussed in [43]. Hence, two important questions should be formulated:
- (a)
- What is the accuracy of the dynamical models based on the GRU networks, and how do they compare to the LSTM ones?
- (b)
- How do the GRU dynamical models perform in MPC, and how do they compare to the LSTM-based MPC approach?
Both of these issues are worth considering since the GRU networks have a simpler architecture and a lower number of parameters than the LSTM ones.
This work has three objectives:
- (a)
- A thorough comparison of LSTM and GRU neural networks as models of two dynamical processes, polymerisation and neutralisation (pH) reactors, is considered. An important question is whether or not the GRU network, although it has a simpler structure as the LSTM one, offers satisfying modelling accuracy;
- (b)
- The derivation of MPC prediction equations for the LSTM and GRU models;
- (c)
- The development of MPC algorithms for the two aforementioned processes with different LSTM and GRU models used for prediction. An important question is whether or not the GRU network offers control quality comparable to that possible when the more complex LSTM structure is applied.
Unfortunately, to the best of the authors’ knowledge, the efficiency of LSTM and GRU networks as dynamical models and their performance in MPC have not been thoroughly compared in the literature; typically, the LSTM structures are used [40,41,42].
The article is organised in the following way. Section 2 describes the structures of the LSTM and GRU neural networks. Section 3 defines the MPC optimisation task algorithm and details how the two discussed types of neural models are used for prediction in MPC. Section 4 thoroughly compares the efficiency of LSTM and GRU neural networks used as models of the two dynamical systems. Moreover, the efficiency of both considered model classes is validated in MPC. Finally, Section 5 summarises the whole article.
2. LSTM and GRU Neural Networks
2.1. The LSTM Neural Network
The LSTM approach aims to create a model that has a long-term memory and, at the same time, is able to forget about unimportant information in the training data. To achieve this, three main differences in comparison to classical RNNs are introduced:
- Two types of activation functions;
- A cell state that serves as the long-term memory of the neuron;
- The neuron is called a cell and has a complex structure consisting of four gates that regulate the information flow.
2.1.1. Activation Functions
In the classical RRNs, the most commonly used activation function is the tanh type:
The output values of the hyperbolic tangent are in the range . This helps to regulate the data flow through the network and avoid the exploding gradient phenomena [17,44]. In the LSTM networks, the usage of tanh is kept; however, the sigmoid activation function is additionally implemented. This function is defined as:
The output values of the sigmoid function are in the range of . This allows the neural network to discard irrelevant information. If the output values are close to zero, they are not important and should be forgotten. If the values are close to one, they should be kept.
2.1.2. Hidden State and Cell State
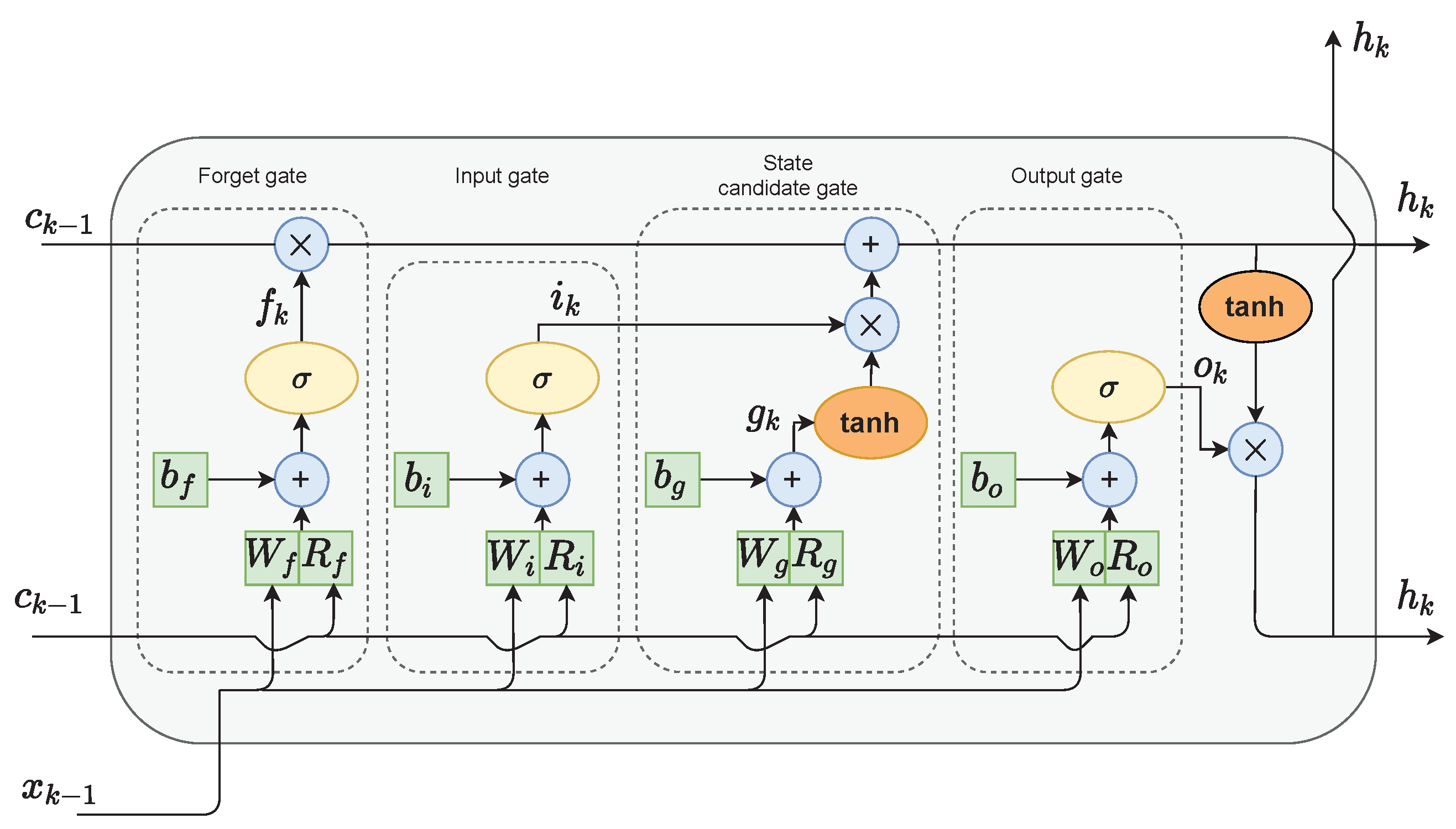
In the classical RNN architecture, the hidden state is used as a memory of the network and an output of the hidden layer of the network. The LSTM networks additionally implement a cell state. In their case, the hidden state serves as a short-term working memory. On the other hand, the cell state is used as a long-term memory to keep information about important data from the past. As depicted in Figure 1, only a few linear operations are performed on the cell state. Therefore, the gradient flow during the backpropagation training is relatively undisturbed. This helps to limit the occurrence of the vanishing gradient problem.
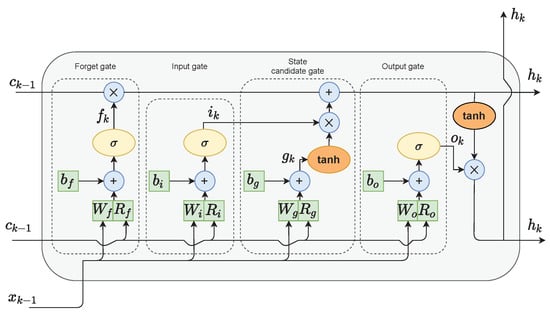
Figure 1.
The LSTM cell structure.
2.1.3. Gates
The LSTM network has the ability to modify the value of the cell state through a mechanism called gates. The LSTM cell shown in Figure 1 consists of four gates:
- The forget gate f decides which values of the previous cell state should be discarded and which should be kept;
- The input gate i selects values from the previous hidden state and the current input to update by passing them through the sigmoid function. The function product is then multiplied by the previous cell state;
- The cell state candidate gate g first regulates the information flow in the network by using the tanh function on the previous hidden state and the current input. The product of tanh is multiplied by the input gate output to calculate the candidate for the current cell state. The candidate is then added to the previous cell state;
- The output gate o first calculates the current hidden state by passing the previous hidden state and the current input through the sigmoid function to select which new information should be taken into account. Then, the current cell state value is passed through the tanh function. The products of both of those functions are finally multiplied.
2.1.4. LSTM Layer Architecture
The LSTM layer of a neural network is composed of neurons. The layer has input signals. For a network used as a dynamical model of the process represented by the general equation:
this parameter can be written as . The vector of the network’s input signals at the time instant k is then:
When considering the entire LSTM network layer consisting of cells, the gates can be represented as vectors , , , , each of dimensionality . The LSTM layer of the network contains also a number of weights. The symbol denotes the weights associated with the input signals ; the symbol denotes the so-called recursive weights, associated with the hidden state of the cell from the previous moment ; the symbol denotes the constant (bias) components. The subscripts f, g, i or o appear next to all the weights; they indicate to which gate the weights belong. Network weights can be therefore written in matrix form as:
The matrices , , and have dimensionality ; the matrices , , and have dimensionality ; the vectors , , and have dimensionality .
At the time instant k, the following calculations are performed sequentially in the LSTM layer of the network:
The new cell state at the time instant k is then determined:
Finally, the hidden state at the time instant k can be calculated:
The symbol ∘ denotes the Hadamard product of the vectors. In other words, the vectors are multiplied elementwise. In Equation (10), this operation is used twice. The cell state from the previous time instant is multiplied by the values output by the forget gate. If those values are close to zero, the Hadamard product is close to zero as well, and therefore, the past information stored in the cell state is discarded. If the forget gate values are close to one, the past information becomes mostly unchanged. Then, the output of the input gate and cell candidate gate is pointwise multiplied. The purpose of this operation is similar. If the input gate values are close to zero, no new information is added to the cell state. Otherwise, the previous cell state values are updated with the values from the cell state candidate gate. In Equation (11), the Hadamard product is close to zero when the output gate values are close to zero. In this situation, the hidden state from the previous time instant becomes mostly unchanged. Otherwise, the new hidden state is updated with the new values from the cell state.
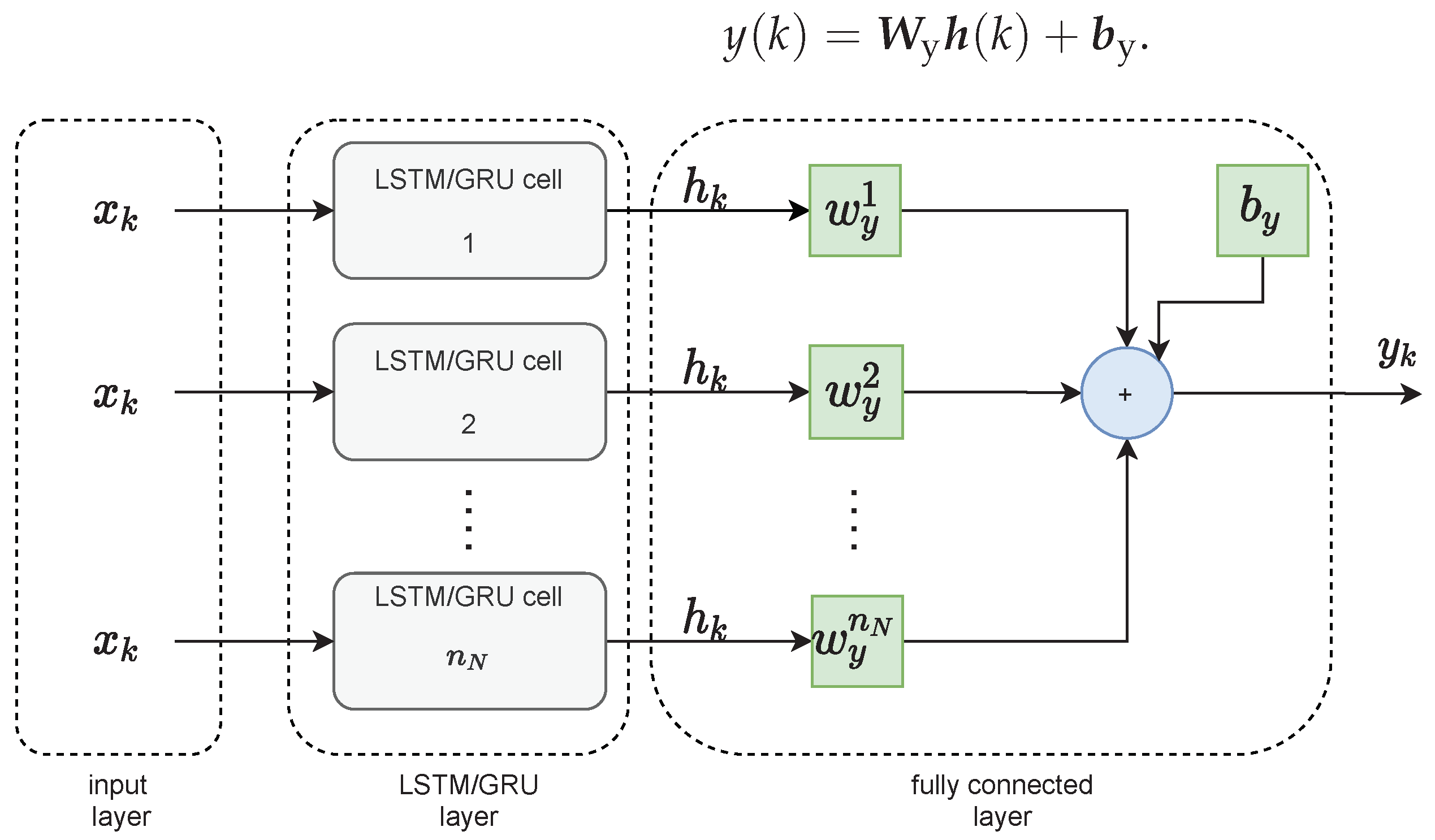
The LSTM layer of the neural network is then connected to the fully connected layer, as shown in Figure 2. It has its weight vector of dimensionality and bias . The output of the network at the time instant k is calculated as follows:
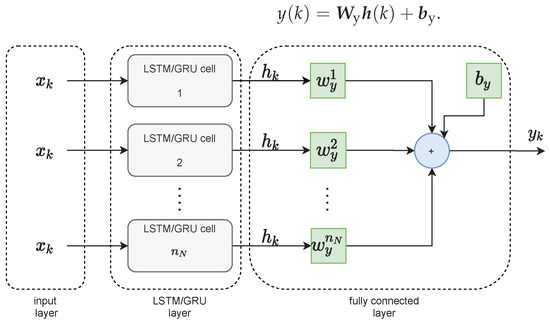
Figure 2.
The topology of the LSTM and GRU networks.
2.2. The GRU Neural Network
The GRU network is a modification of the LSTM concept, which aims to reduce to network’s computational cost. There are some differences between the architectures, mainly:
- The GRU cell lacks the output gate; therefore, it has fewer parameters;
- The usage of the cell state is discarded. The hidden state serves both as the working and long-term memory of the network.
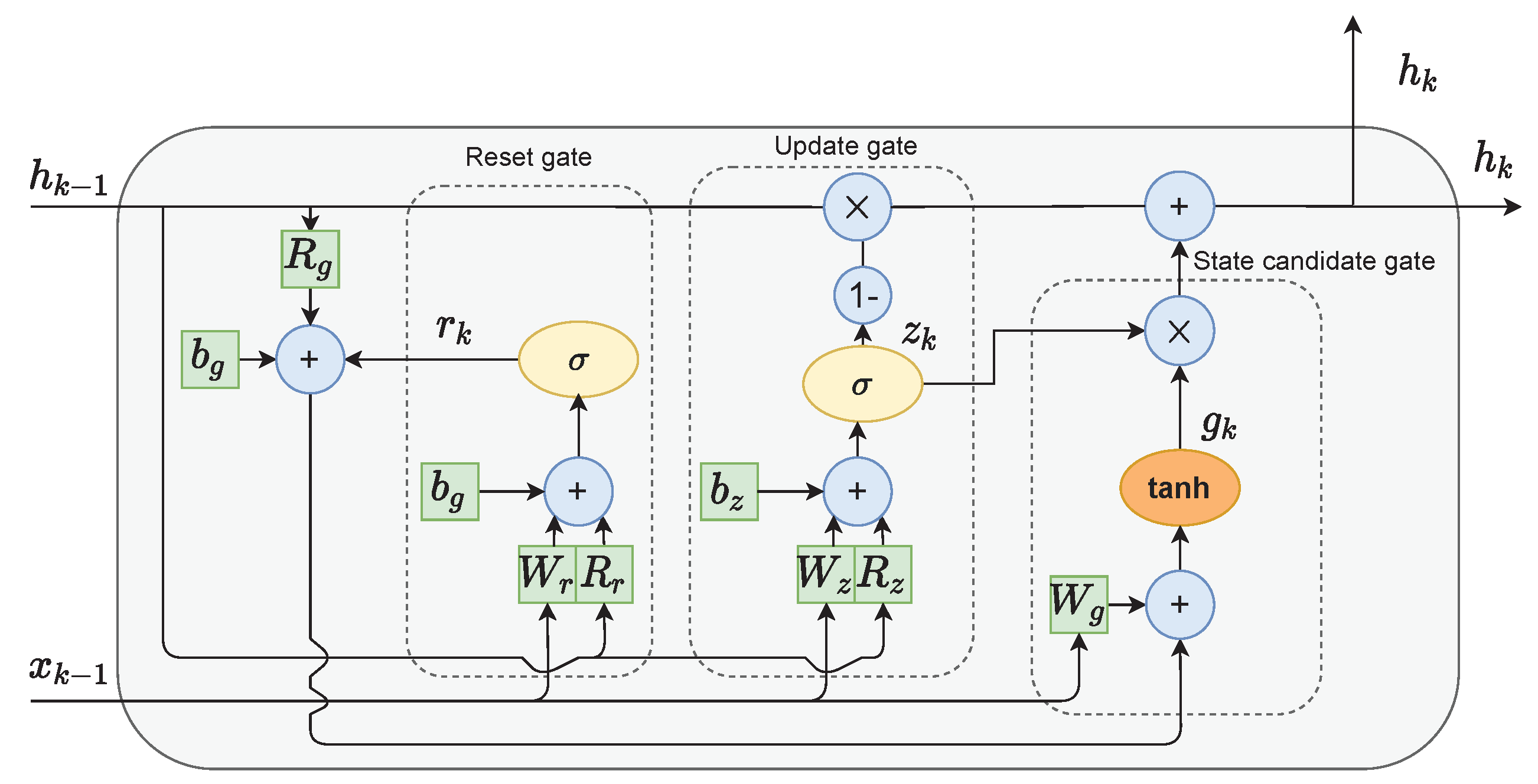
The single-GRU cell layout is presented in Figure 3. It consists of three gates:
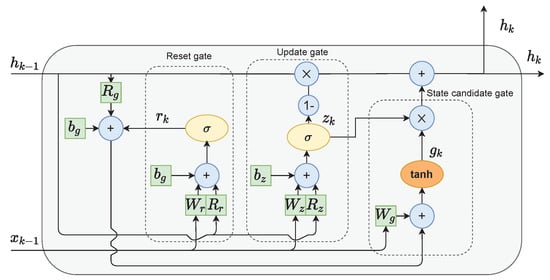
Figure 3.
The GRU cell structure.
- The reset gate r is used to select which information to discard from the previous hidden state and input values;
- The role of the update gate z is to select which information from the previous hidden state should be kept and passed along to the next steps;
- Candidate state gate g calculates the candidate for the future hidden state. This is done by firstly multiplying the previous state with the reset gate’s output. This step can be interpreted as forgetting unimportant information from the past. Next, new data form the input are added to the remaining information. Finally, the tanh function is applied to the data to regulate the information flow.
The current hidden state is calculated as follows. Firstly, the output from the update gate z is subtracted from one and then multiplied with the previous state . Then, the state candidate g is multiplied by the unchanged output from the update gate z. The results of both of those operations are finally added. This means that if the values output from update gate z are close to zero, more new information is added to the current state h. Alternatively, if the values output from update gate z are close to one, the current state is mostly kept as it was in the previous time iterations.
When considering the whole GRU layer of cells, the weight matrices , , have dimensions , matrices , , have dimensions , and vectors , , have dimensions . The matrices can be written as:
The following calculations are performed at the sampling time k:
Similar to the LSTM layer, the GRU layer of the neural network is then connected to the fully connected layer. It has its weight vector of dimensionality and a constant component . The output of the network at the time k is determined by the hidden state of all cells of the GRU layer multiplied by the weights of the fully connected layer, respectively, according to the following relation:
3. LSTM and GRU Neural Networks in Model Predictive Control
The manipulated variable, i.e., the input of the controlled process, is denoted by u, while the controlled one, i.e., the process output, is denoted by y. A good control algorithm is expected to calculate the value of the manipulated variable, which leads to fast control, i.e., the process output should follow the changes of the set-point. Moreover, since fast control usually requires abrupt changes of the manipulated variables, which may be dangerous for the actuator, such situations should be penalised. Finally, it is necessary to take some constraints; they are usually imposed on the magnitude and the rate of change of the manipulated variable. In some cases, constraints can also be imposed on the process output variable.
3.1. The MPC Problem
The vector of decision variables calculated online at each sampling instant of MPC is defined as the increments of the manipulated variable:
where the control horizon is denoted by . The general MPC optimisation problem is:
The cost function can be divided into two parts. The first part describes the control error, which is defined as the sum of the differences between the set-point value and the output prediction over the prediction horizon N. The notation should be interpreted as follows: the prediction of the moment in the future is calculated in the current moment k. The second part of the cost function consists of the change of the manipulated variables multiplied by the weighting coefficient . When the whole cost function is taken into account, one can observe that it minimises both control errors and the change of control signals. Weighting coefficient is used to fine-tune the procedure.
The constraints of the MPC optimisation problem are as follows:
- The magnitude constraints and are enforced on the manipulated variable over the control horizon ;
- The constraints and are imposed on the increments of the same variable over the control horizon ;
- The constraints put on the predicted output variable and over the prediction horizon N.
When the optimisation procedure calculates the decision vector (Equation (19)) from Equation (20), the first element of it is applied to the process. The most common way of this application is given by the following equation:
The whole computational scheme is then repeated at the next sampling instants.
In MPC [2], the general prediction equation for the sampling instant is:
where . The output of the model for the sampling instant calculated at the current instant k is , and the current estimation of the unmeasured disturbance acting on the process output is . Typically, it is assumed that the disturbance is constant over the whole prediction horizon, and its value is determined as the difference between the real (measured) value of the process output and the model output calculated using the process input and output signals up to the sampling instant :
3.2. The LSTM Neural Network in MPC
In the case of the LSTM model, to determine the predicted output, it is necessary to first calculate the prediction values of the cell state given by Equations (6)–(10) in the following way:
Using Equations (6)–(9) and Equation (11), one can then calculate the prediction of the hidden state:
Taking into account the input vector of the network (Equation (4)), for prediction over the prediction horizon, the vector of arguments of the network is:
3.3. The GRU Neural Network in MPC
There is no cell state in the GRU neural networks, and therefore, to calculate the predicted output signal values , only the prediction of hidden state h is necessary to evaluate first. This is performed based on Equations (14)–(17) in the following way:
where is an identity matrix with dimensions . The prediction of the output signal Equation (32), as well as the input vector Equation (35) are the same as in the LSTM neural network model.
The proposed MPC control procedure may be summarised as follows:
- The estimated disturbance is calculated from Equation (22):
- a.
- b.
- The MPC optimisation task is then performed. To calculate the output prediction, the cell and hidden state prediction must be calculated first:
- a.
- b.
- The first element of the calculated decision vector (Equation (19)) is applied to the process, i.e., .
4. Results of the Simulations
In order to compare the accuracy of the LSTM and GRU networks and their efficiency in MPC, we considered two dynamical systems: a polymerisation reactor and a neutralisation (pH) reactor.
4.1. Description of the Dynamical Systems
First, two considered processes are briefly described. Moreover, a short description of the data preparation procedure is given.
4.1.1. Benchmark 1: The Polymerisation Reactor
The first considered benchmark was a polymerisation reaction taking place in a jacketed continuous stirred-tank reactor. The reaction was the free-radical polymerisation of methyl methacrylate with azo-bis-isobutyronitrile as the initiator and toluene as the solvent. The process input was the inlet initiator flow rate (m h); the output was the value of Number Average Molecular Weight () of the product(kg kmol). The detailed fundamental model of the process was given in [45]. The process was nonlinear: in particular, its static gain depended on the operating point. The polymerisation reactor is frequently used to evaluate model identification algorithms and advanced nonlinear control methods, e.g., [12,45,46].
The fundamental model of the polymerisation process, comprising four nonlinear differential equations, was solved using the Runge–Kutta 45 method to obtain training and validation and test datasets, each of them having 2000 samples. After each 50 samples, there was a step change of the control signal. The magnitude of the control signal was chosen randomly. Next, since process input and output signals had different magnitudes, these signals were scaled in the following way:
where and 20,000 denote the values of the variables at the nominal operating point. The sampling time was 1.8 s.
4.1.2. Benchmark 2: The Neutralisation Reactor
The second considered benchmark was a neutralisation reactor. The process input was the base () streamflow-rate (mL/s); the output was the value of the pH of the product. The detailed fundamental model of the process was given in [47]. The process was nonlinear since its static and dynamic properties depended on the operating point. Hence, it is frequently used as a good benchmark to evaluate model identification algorithms and advanced nonlinear control methods, e.g., [46,47,48].
The fundamental model of the neutralisation process, comprising two nonlinear differential equations and a nonlinear algebraic equation, was solved using the Runge–Kutta 45 method to obtain training and validation and test datasets, each of them having 2000 samples. After each 50 samples, there was a step change of the control signal. The magnitude of the control signal was chosen randomly. The process signals were scaled in the following way:
where and denote the values of the variables at the nominal operating point. The sampling time was 10 s.
4.2. LSTM and GRU Neural Networks for Modelling of Polymerisation and Neutralisation Reactors
A number of LSTM and GRU models were trained for the two considered dynamic processes. All models were trained using the Adam optimisation algorithm. The maximum number of training epochs (iterations) was:
- 500 for the models with ;
- 750 for the models with ;
- 1000 for the models with .
The training procedure was performed as follows:
- The order of the dynamics of the LSTM model was set to . The number of neurons in the hidden layer was set to . For the considered configuration, ten models were trained, and the best one was chosen;
- The number of neurons was increased to two. Ten models were trained, and the best was chosen. This procedure was repeated until the number of neurons reached ;
- The first two steps were repeated with the increased order of the dynamics , .
It is important to stress that setting the order of the dynamics to higher than did not result in any significant increase of the modelling quality. Therefore, further experiments with are not presented.
It is an interesting question if LSTM and GRU models without recurrent input signals can perform well in modelling tasks. In theory, the recurrent nature of hidden state h should be sufficient to ensure good model quality. To verify this expectation, an additional series of models was trained. The training procedure was similar to the one described above, the only difference being that now, the model order of the dynamics was first set to , , then increased to , and, finally, to , .
The quality of all trained models was then validated with the mean squared error chosen as the quality index. The models were validated in the nonrecurrent Autoregressive with eXogenous input (ARX) mode and the Output Error (OE) recurrent mode. The model input vectors for the two considered cases are:
It is important to stress that in the case of the models with , the ARX and OE modes were the same.
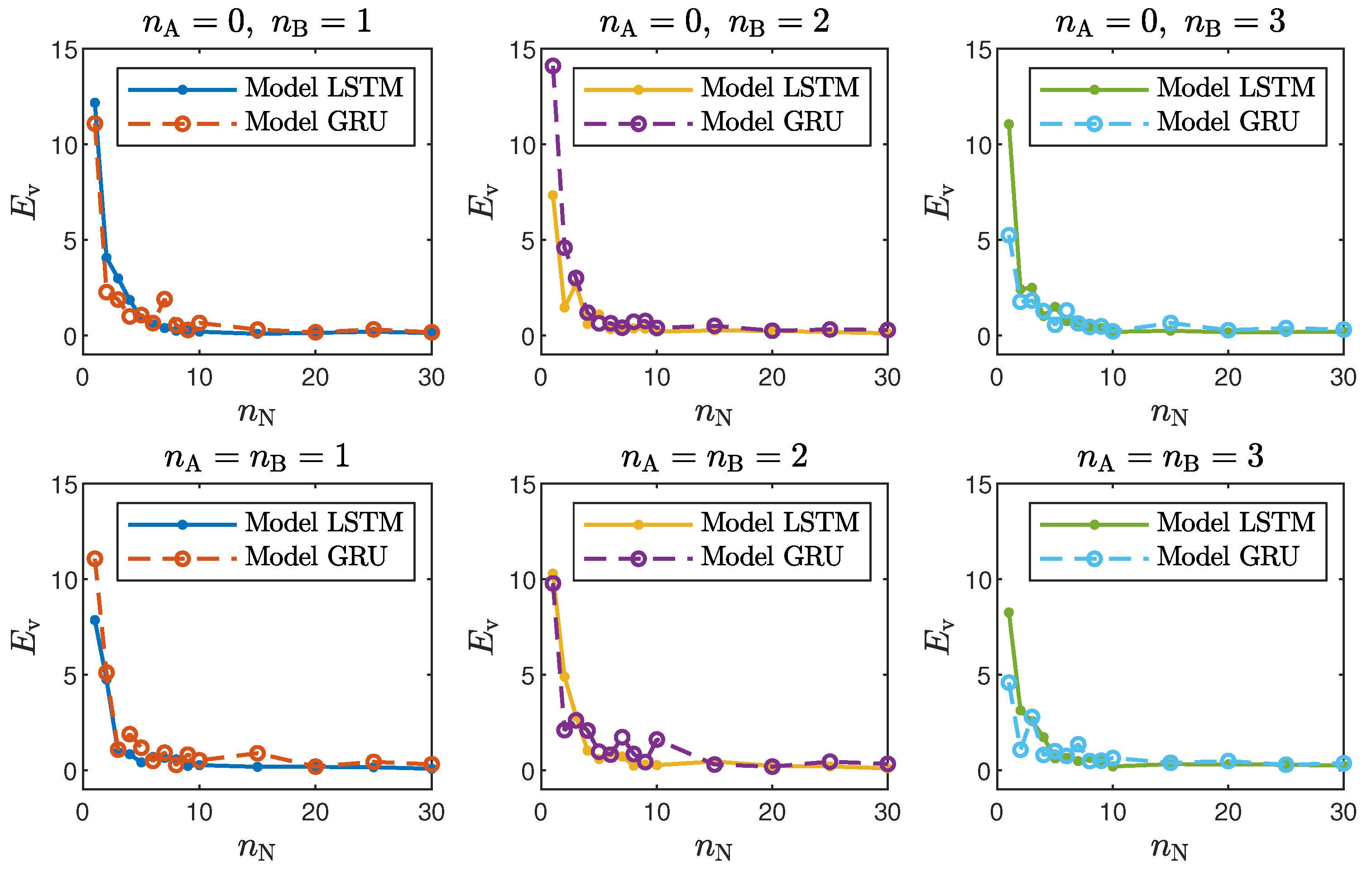
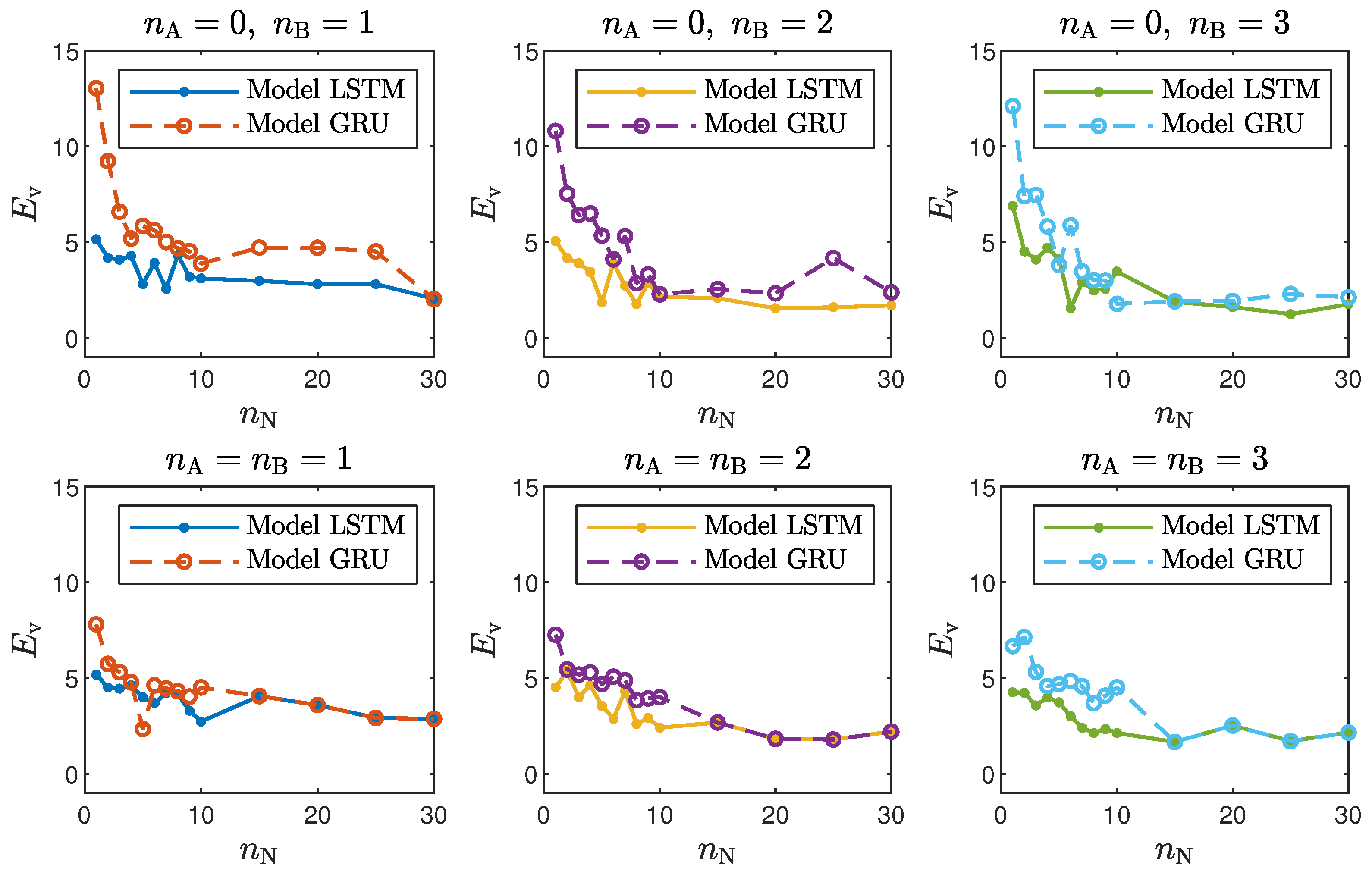
Taking into account the objective of this work, it is interesting to compare the accuracy of the LSTM and GRU models with different structures, defined by the number of neurons, , and the order of the model dynamics, determined by and . For the polymerisation reactor, the results for the chosen networks are given in Table 1 and Table 2, and Figure 4 depicts the model validation errors for all considered numbers of neurons. For the neutralisation reactor, the results for the chosen networks are given in Table 3 and Table 4, and Figure 5 depicts the model validation errors for all considered numbers of neurons. The following notation is used:

Table 1.
The polymerisation reactor: comparison of selected LSTM and GRU networks without the recurrent inputs () in terms of the training () and validation errors ().
Table 2.
The polymerisation reactor: comparison of selected LSTM and GRU networks with the recurrent inputs in terms of the training () and validation errors ().
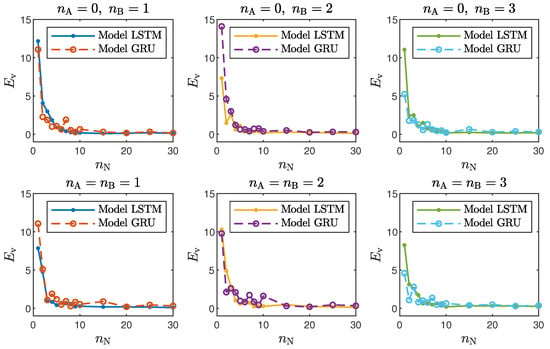
Figure 4.
The polymerisation reactor: LSTM and GRU model validation errors for different numbers of neurons .
Table 3.
The neutralisation reactor: comparison of selected LSTM and GRU networks without the recurrent inputs () in terms of the training () and validation errors ().
Table 4.
The neutralisation reactor: comparison of selected LSTM and GRU networks with the recurrent inputs in terms of the training () and validation errors ().
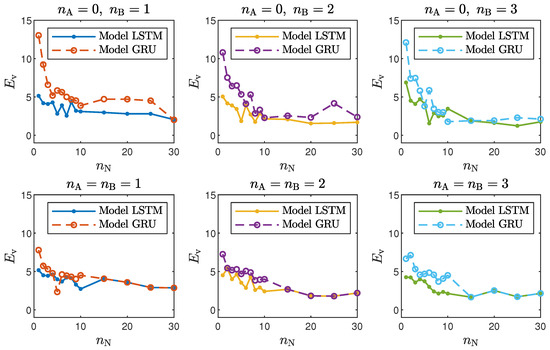
Figure 5.
The neutralisation reactor: LSTM and GRU model validation errors for different numbers of neurons .
- is the the mean squared error for the training dataset in ARX mode;
- is the the mean squared error for the validation dataset in ARX mode;
- is the the mean squared error for the training dataset in recurrent mode;
- is the the mean squared error for the validation dataset in recurrent mode.
The presented results can be summarised in the following way:
- In the case of the polymerisation reactor, the results achieved with the LSTM and GRU networks were comparable. As seen in Figure 4, the means squared errors were similar for every combination of , and ;
- In the case of the neutralisation reactor, the LSTM models ensured a better quality of modelling, especially for models with a low number of parameters. However, as seen in Figure 5, as the number of neurons increased, this difference became more and more negligible. This is again not surprising. GRU networks have less parameters than LSTM networks. Therefore, GRU models with a low number of neurons and a low order of the dynamics performed worse than their LSTM counterparts. As the models became bigger and more complex, the difference between their quality decreased.
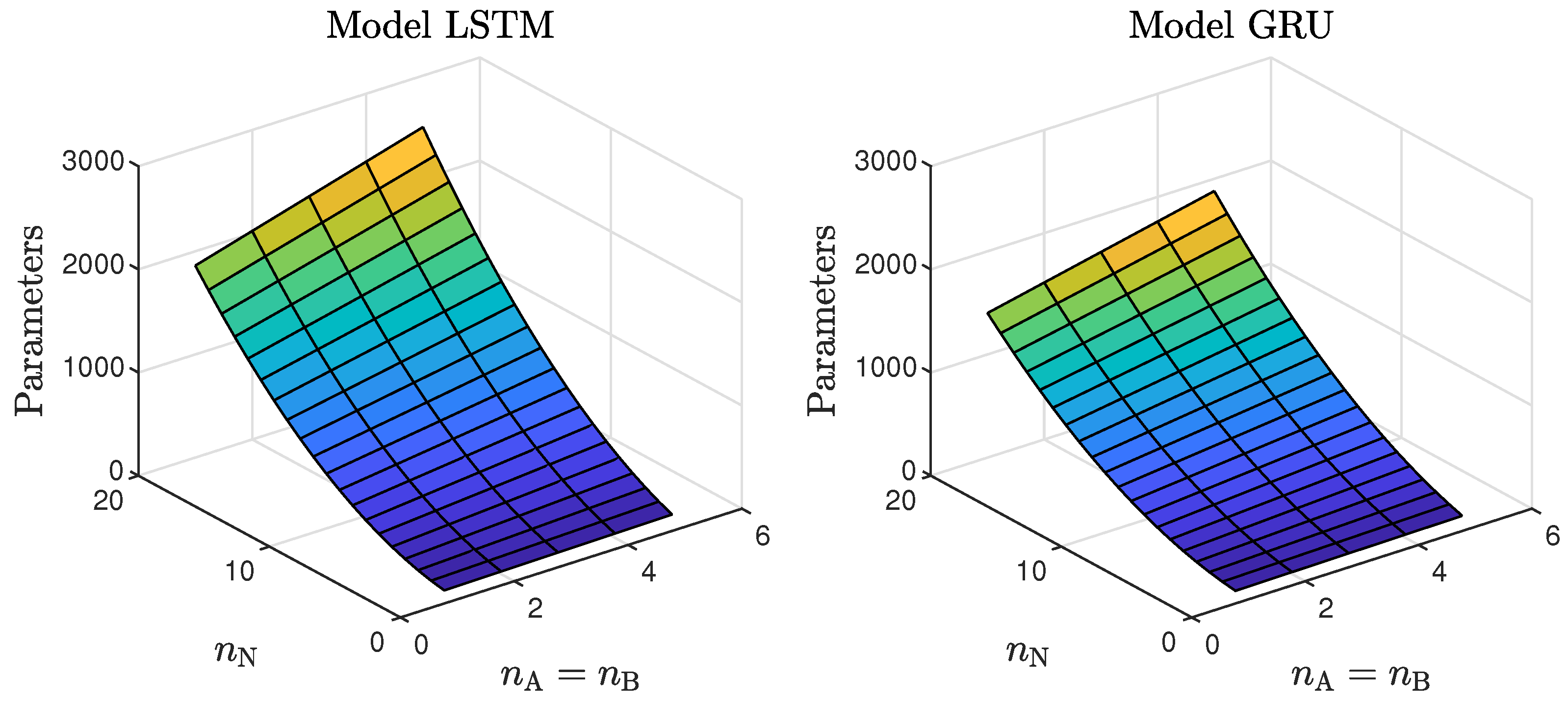
- Models with a higher numbers of neurons (15–30) ensured the best and most consistent modelling quality. This is not surprising, as the number of model parameters is directly proportional to the capacity to reproduce the behaviour of more complex processes. However, this can also be a main drawback of complex models, because of the enormous number of parameters, as shown in Figure 6 and Figure 7, increases their computational cost significantly;
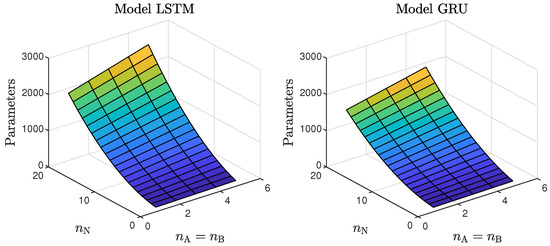 Figure 6. The number of the parameters of the LSTM and GRU models as a function of the number of neurons and the order of the dynamics determined by .
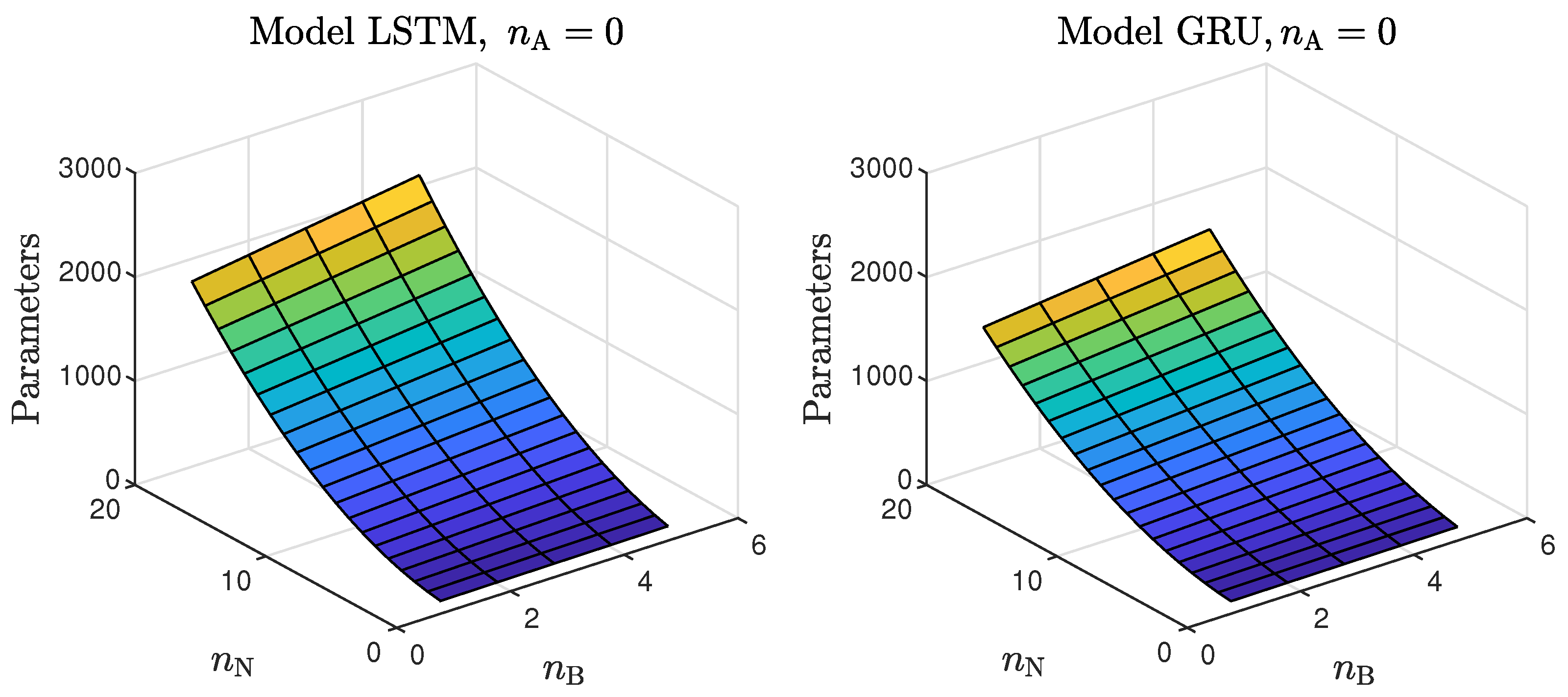
Figure 6. The number of the parameters of the LSTM and GRU models as a function of the number of neurons and the order of the dynamics determined by .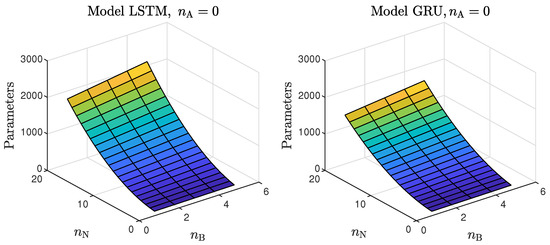 Figure 7. The number of parameters of the LSTM and GRU models as a function of the number of neurons and the order of the dynamics determined by ; .These models had too few parameters to accurately represent the behaviour of the processes under study;
Figure 7. The number of parameters of the LSTM and GRU models as a function of the number of neurons and the order of the dynamics determined by ; .These models had too few parameters to accurately represent the behaviour of the processes under study; - For the models with a medium number of neurons (3–10), the modelling quality was not consistent. In some cases, it was quite poor; in others, it even outperformed models with a huge number of neurons (an example can be found in Table 4, the GRU network with ). One can conclude that this group of models has a structure complex enough to represent the behaviour of the systems under investigation. The training procedure must be, however, performed many times, as training may sometimes not be successful. In other words, if the goal is to find the model with the minimum number of parameters and good quality, the medium-sized models are the best option;
- Models with a low (1–2) number of neurons did not ensure a good modelling quality regardless of the neural network type and the model order of the dynamics, as shown in Figure 8 and Figure 9.
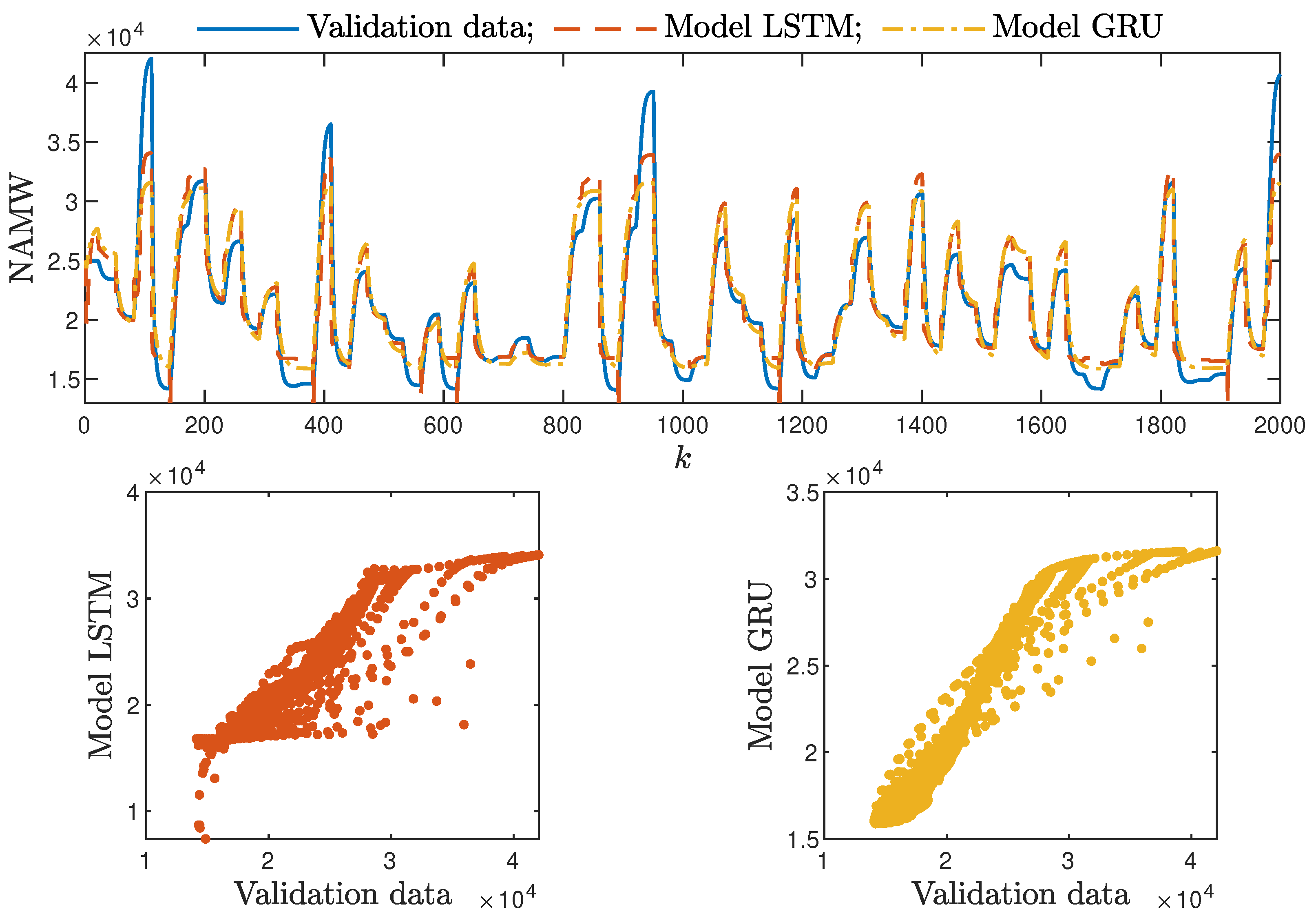
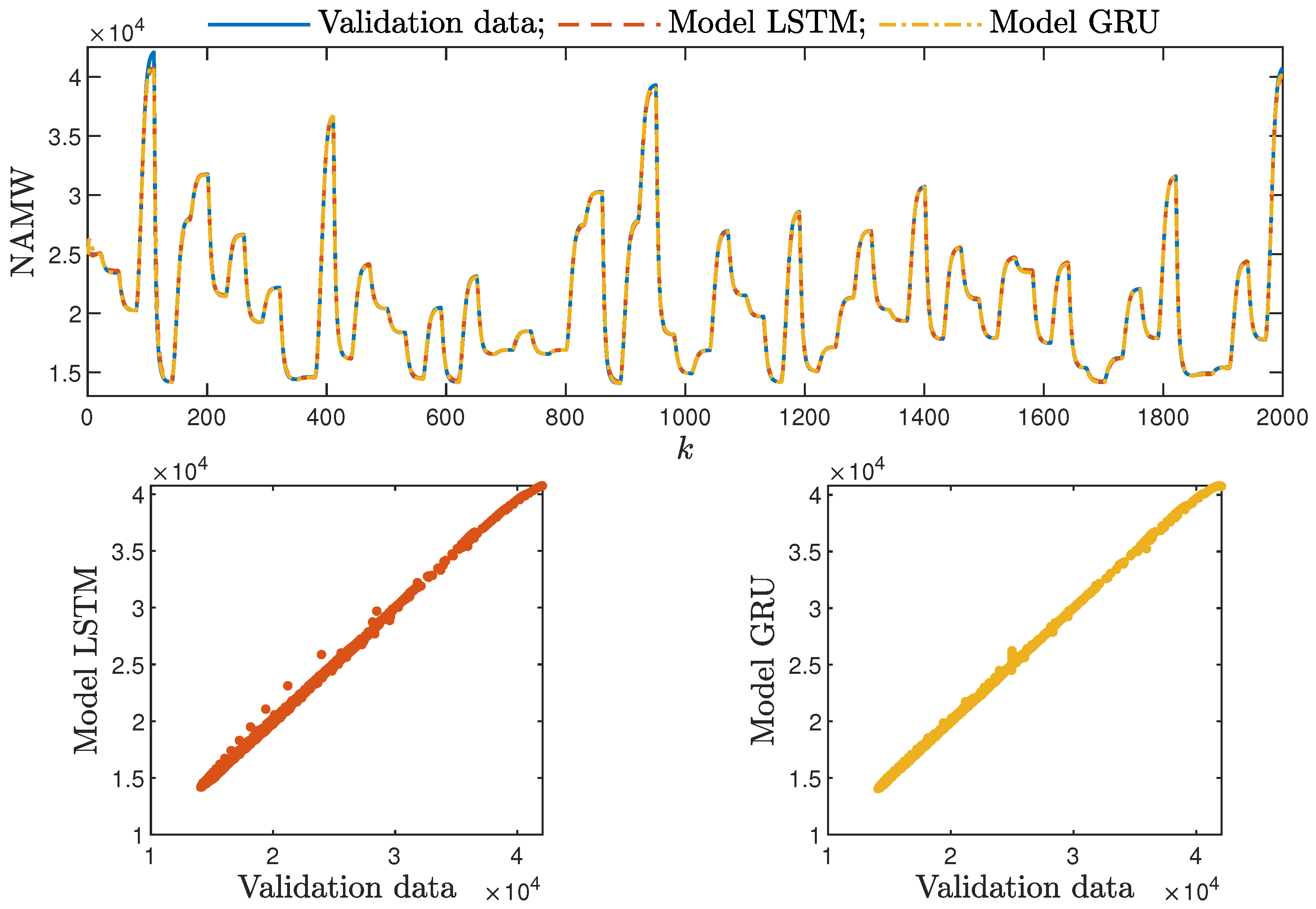
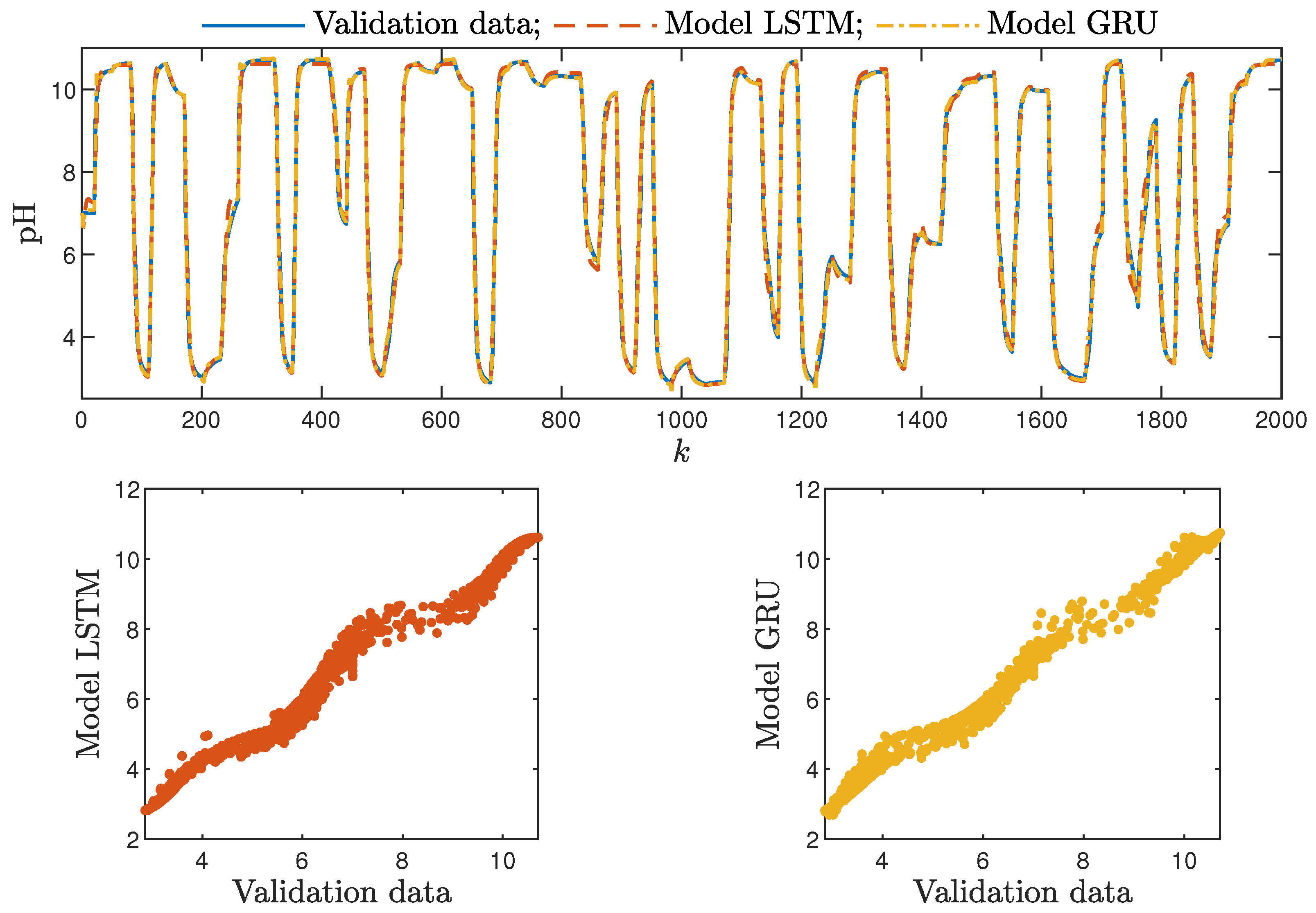
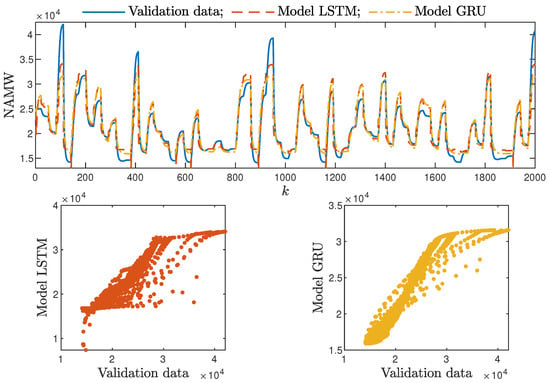 Figure 8. The polymerisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , .
Figure 8. The polymerisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , .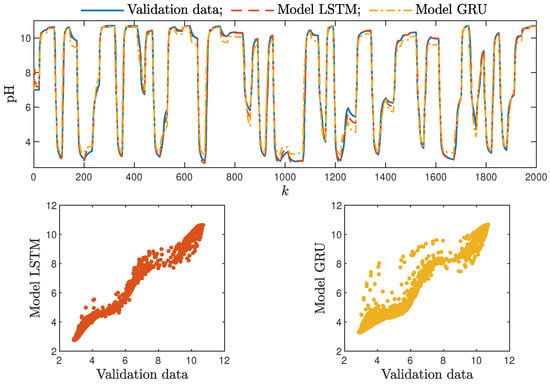 Figure 9. The neutralisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , .
Figure 9. The neutralisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , . - Interestingly enough, the order of the dynamics of the model seemed not to greatly impact the modelling quality. Models with higher order were most commonly only slightly better than those with . Only in the case of the neutralisation reactor with in Table 3 could a noticeable improvement be observed when was set to two. The unique long-term memory quality of the networks under study may be a cause of this phenomenon. The information about the important previous input and output signals from the past can be kept inside the hidden and cell states, and therefore, the networks can perform very well with only the most recent input values (i.e., , );
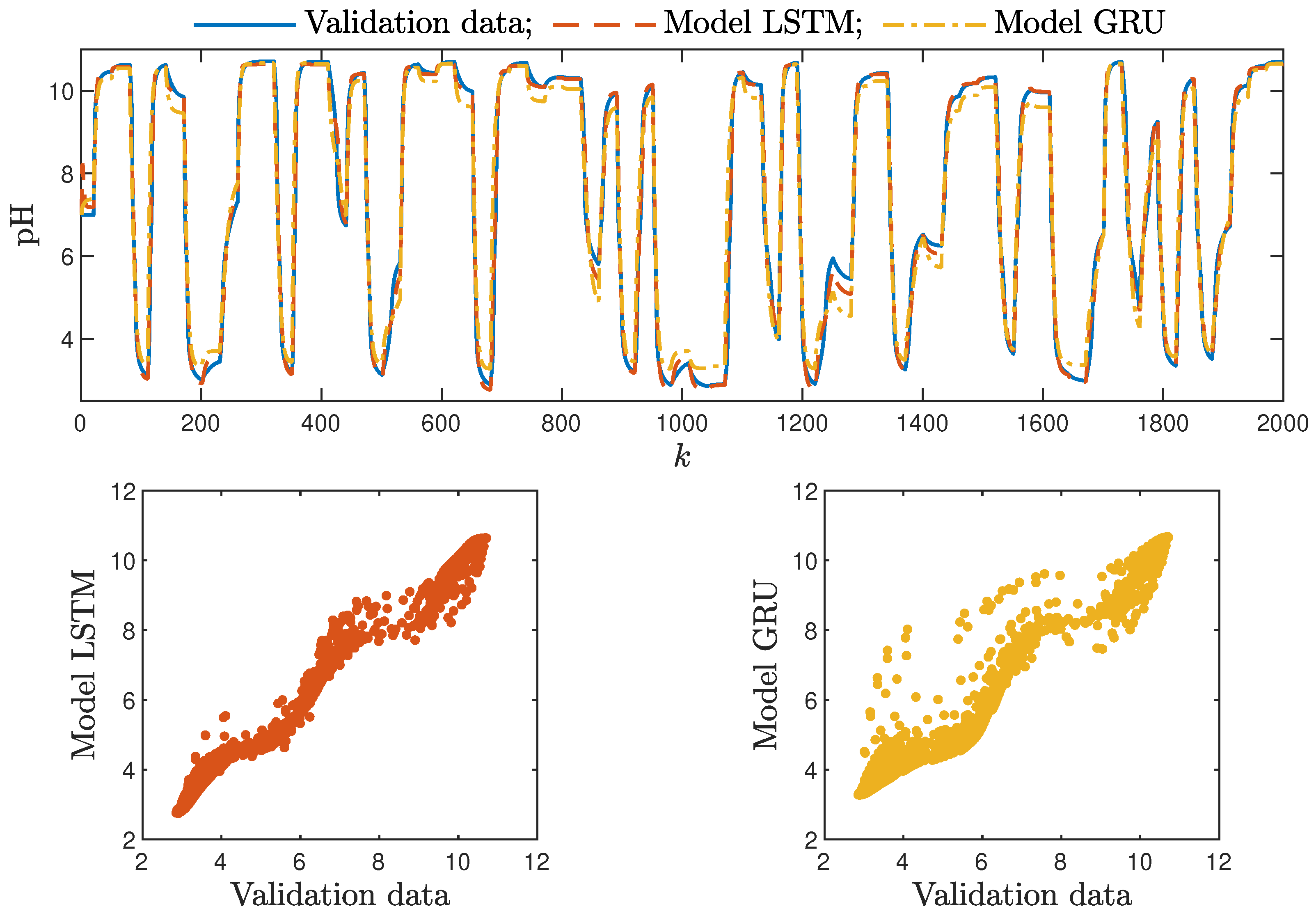
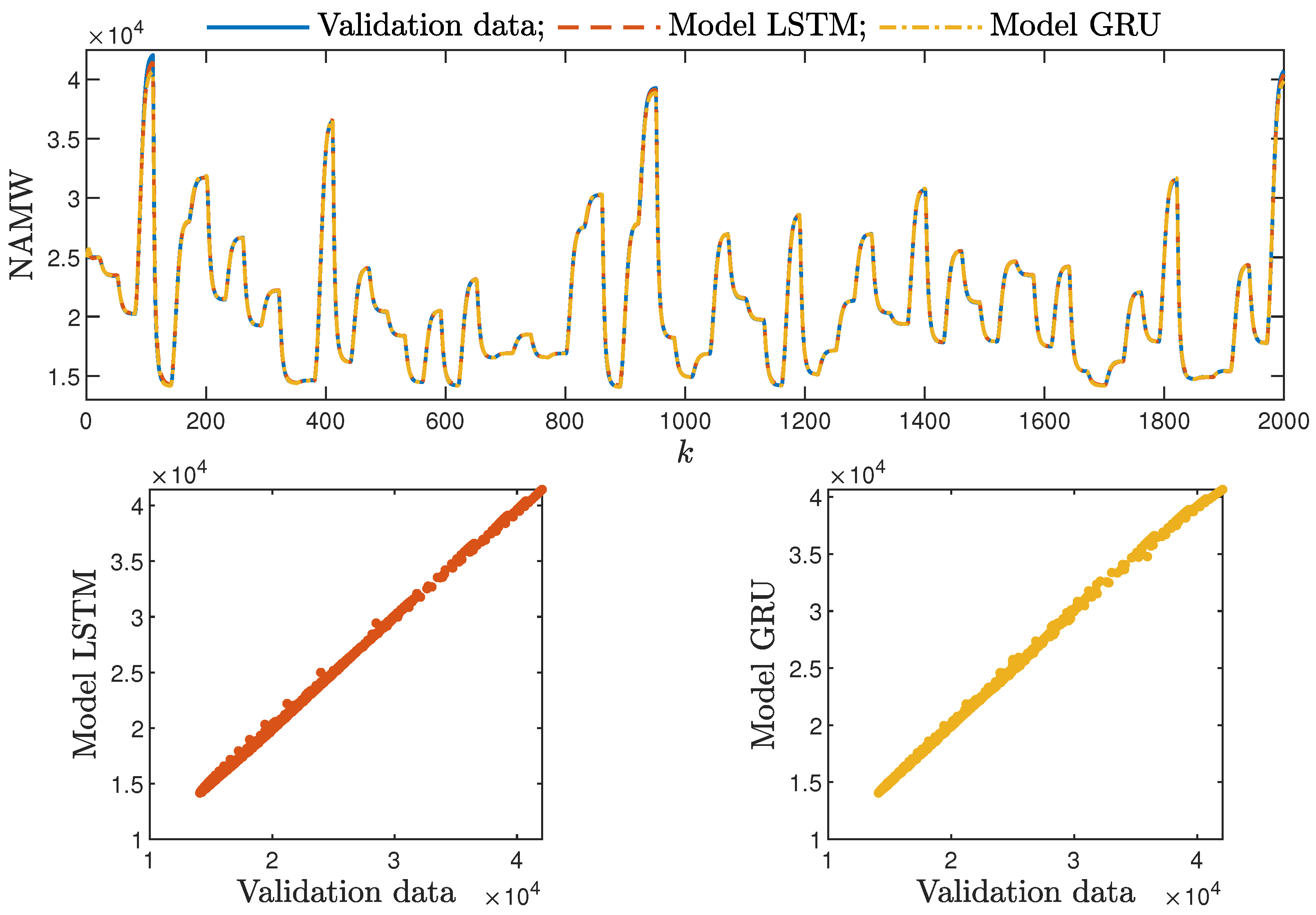
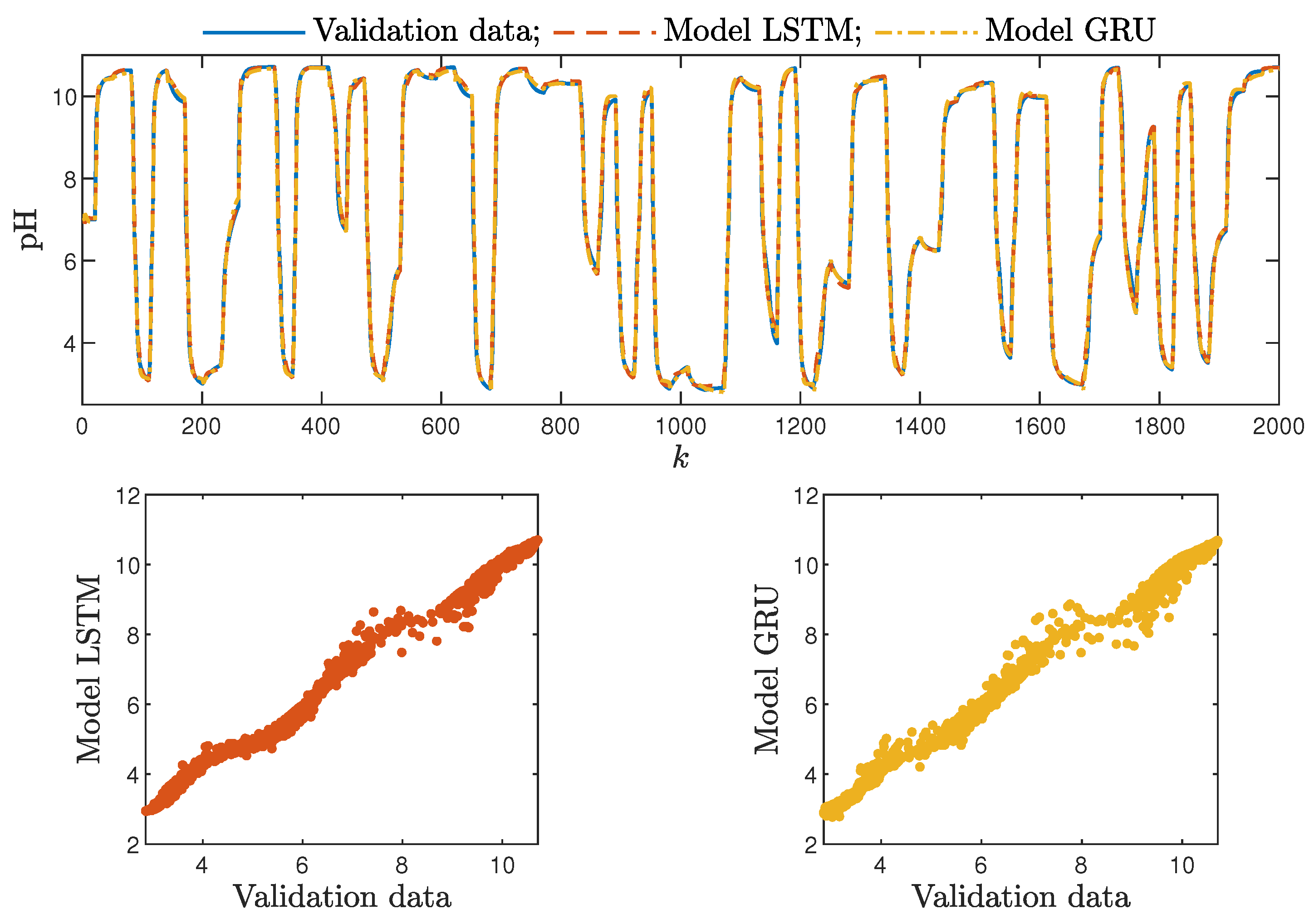
Based on the observations summarised above, it can be concluded that it is a good practice to train a model with a medium number of neurons and a low order of the dynamics. This approach may require many training trials, but as a result, the model has a relatively low number of parameters; therefore, a lower computational cost can be achieved. A direct comparison of the polymerisation reactor models can be seen in Figure 10 and Figure 11. Both models performed very well, and the modelling errors were minimal. A similar comparison for the pH reactor can be seen in Figure 12 and Figure 13. The modelling quality was again very satisfactory. Here, it is important to stress that in the case of the GRU model with , it was necessary to choose one with a higher order of the dynamics to achieve results similar to those ensured by the simpler LSTM models.
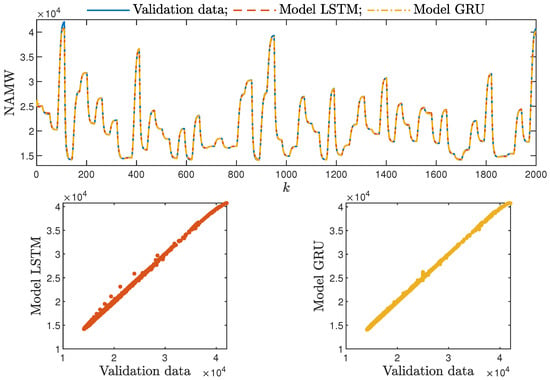
Figure 10.
The polymerisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , , .
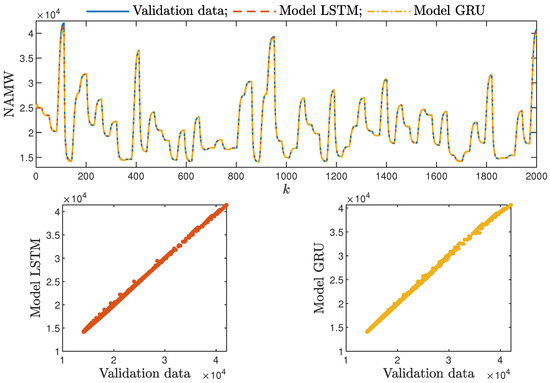
Figure 11.
The polymerisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , .
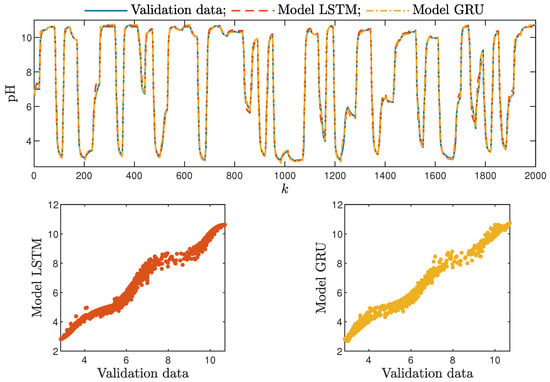
Figure 12.
The neutralisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , .
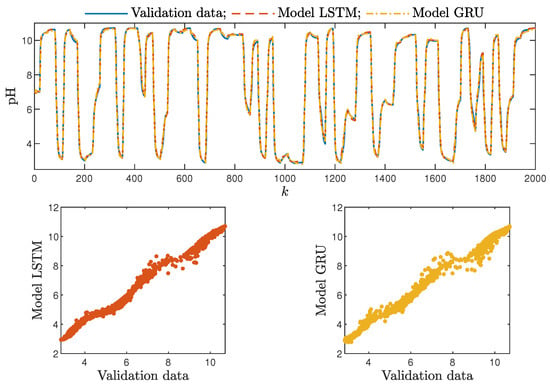
Figure 13.
The neutralisation reactor: the validation dataset vs. the output of the LSTM and GRU models for , , .
4.3. LSTM and GRU Neural Network for the MPC of Polymerisation and Neutralisation Reactors
A few of the best-performing models were been chosen with the aim of being applied in the MPC control scheme for prediction. First, let us describe the tuning procedure of the MPC controller. It starts with the selection of the prediction horizon. It should be long enough to cover the dynamic behaviour of the process. However, if the horizons are too long, the computation cost of the optimisation task increases. The control horizon cannot be too short since it gives insufficient control quality, while its lengthening also increases the computational burden. The process of tuning was therefore as follows:
- The constant weighting coefficient was assumed;
- The prediction horizon N and the control horizon were set to have the same, arbitrarily chosen lengths. If the controller was not working properly, both horizons were lengthened;
- The prediction horizon was gradually shortened, and its minimal possible length was chosen (with the condition );
- The effect of changing the length of the control horizon on the resulting control quality was then assessed experimentally (e.g., assuming successively ). The shortest possible control horizon was chosen;
- Finally, after determining the horizon’s lengths, the weighting coefficient was adjusted.
After applying the tuning procedure on both processes under study, the following settings were determined:
- , , for the polymerisation process;
- , , for the neutralisation process.
Simulations of the MPC algorithms were performed with MATLAB. For optimisation, the fmincon() function was used with the following settings:
- Optimisation algorithm—Sequential Quadratic Programming (SQP);
- Finite differences type—centred.
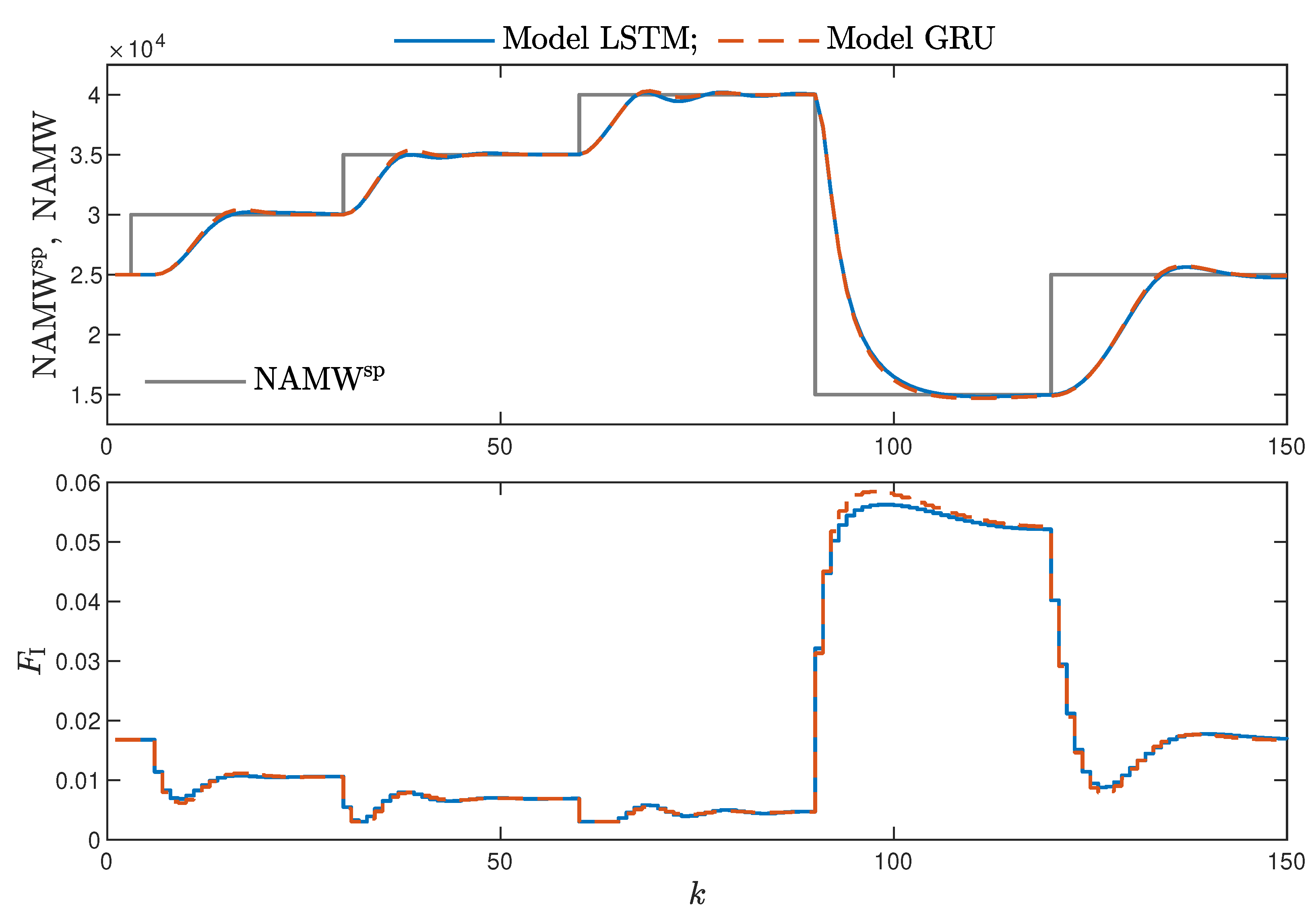
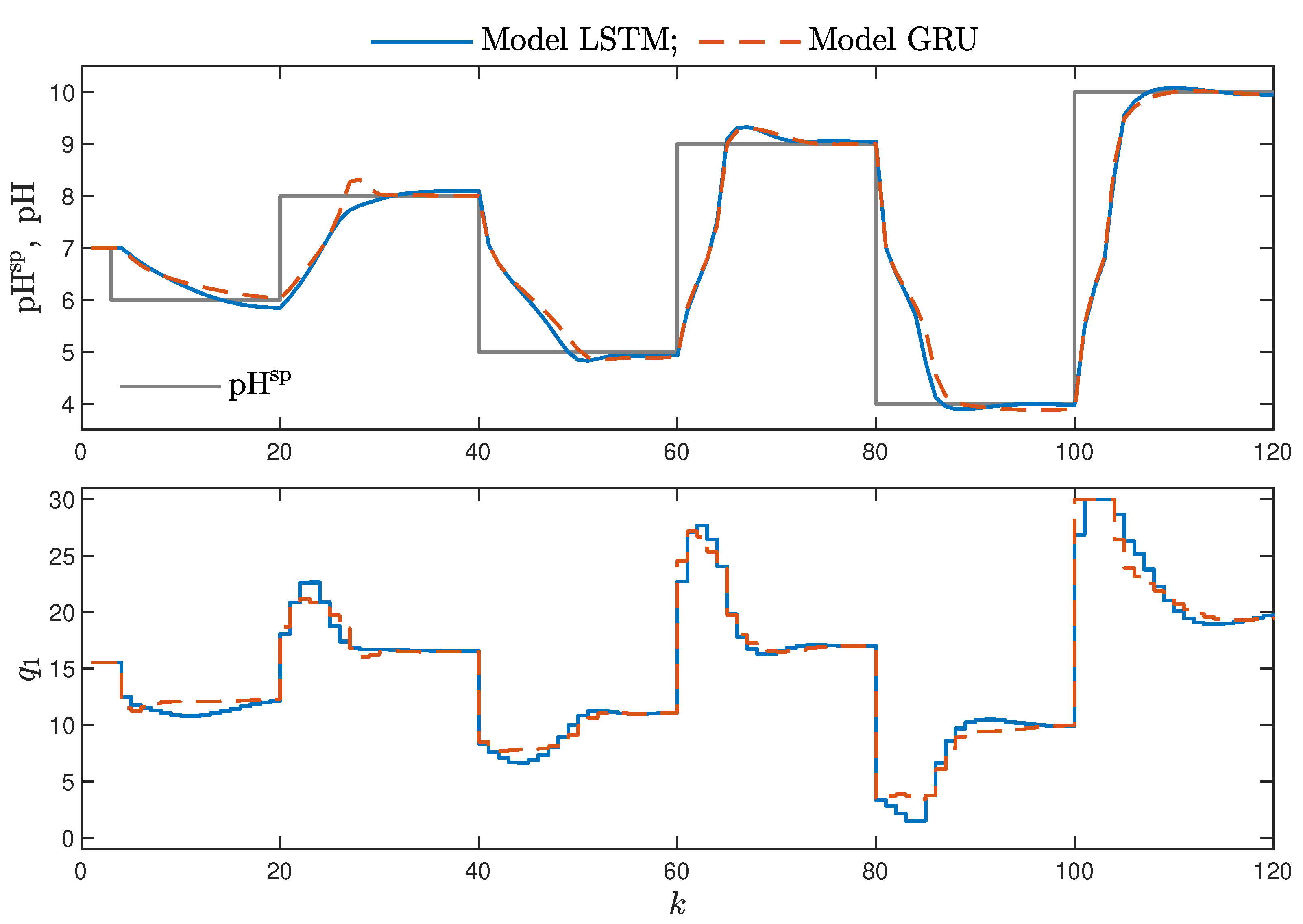
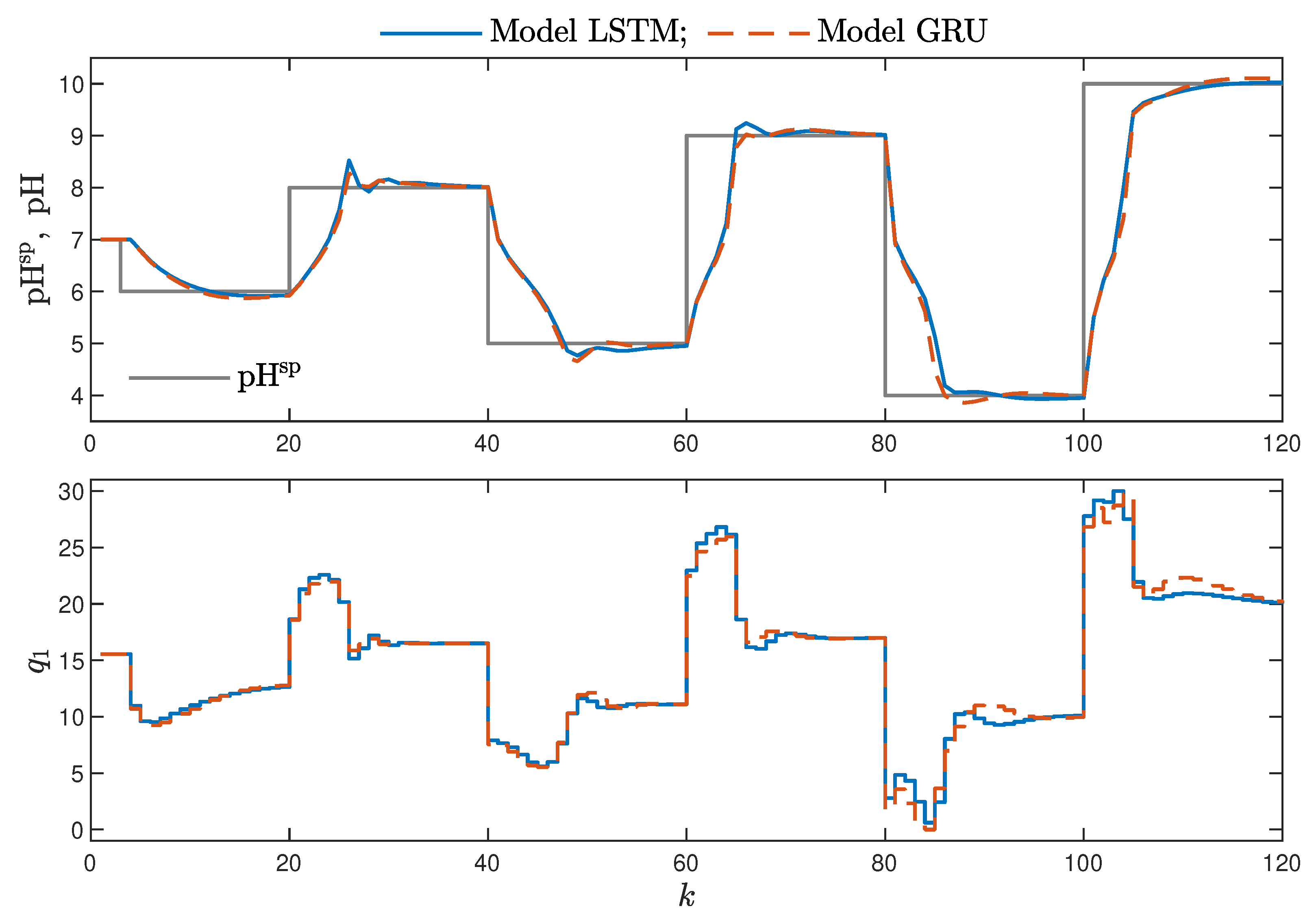
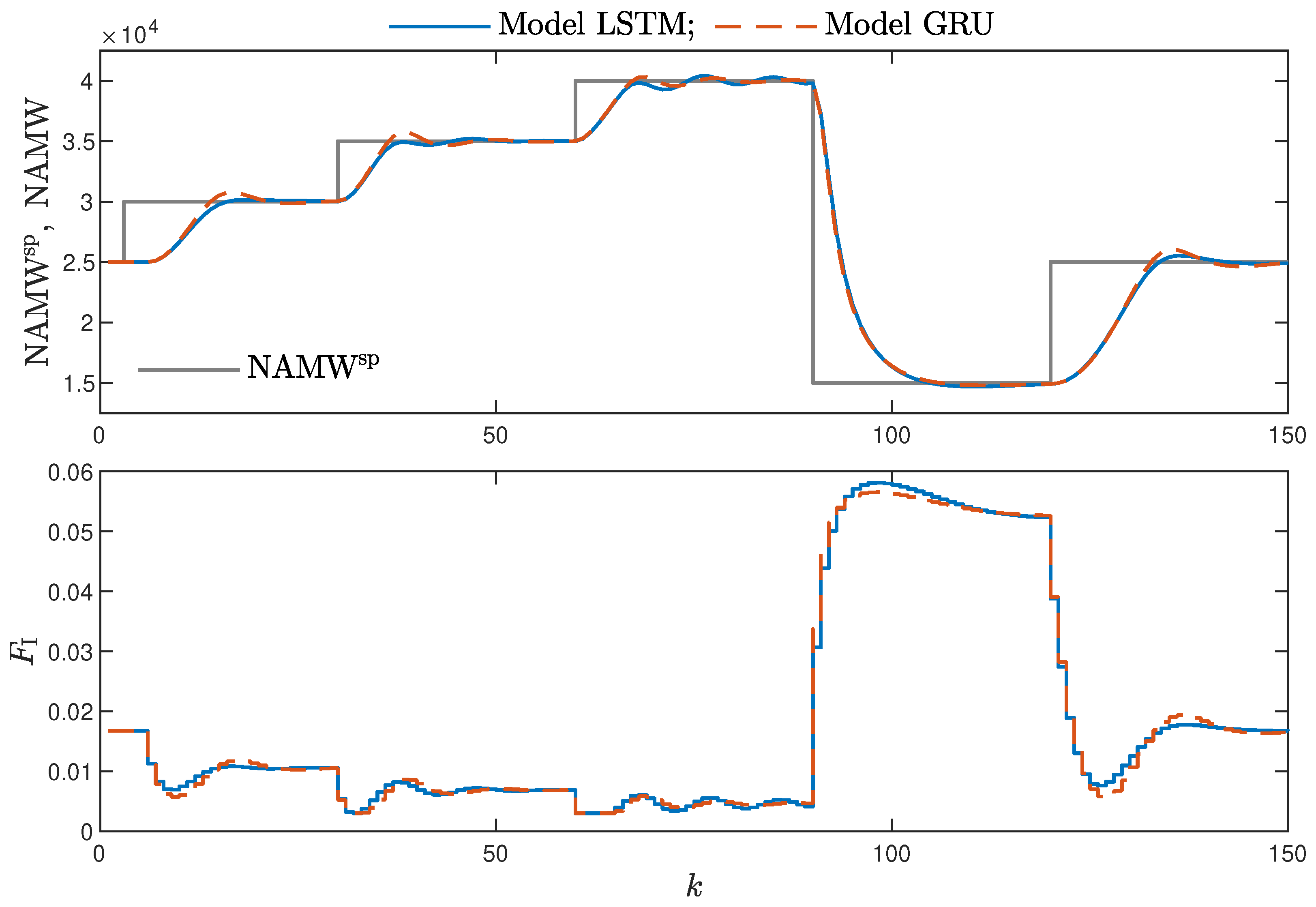
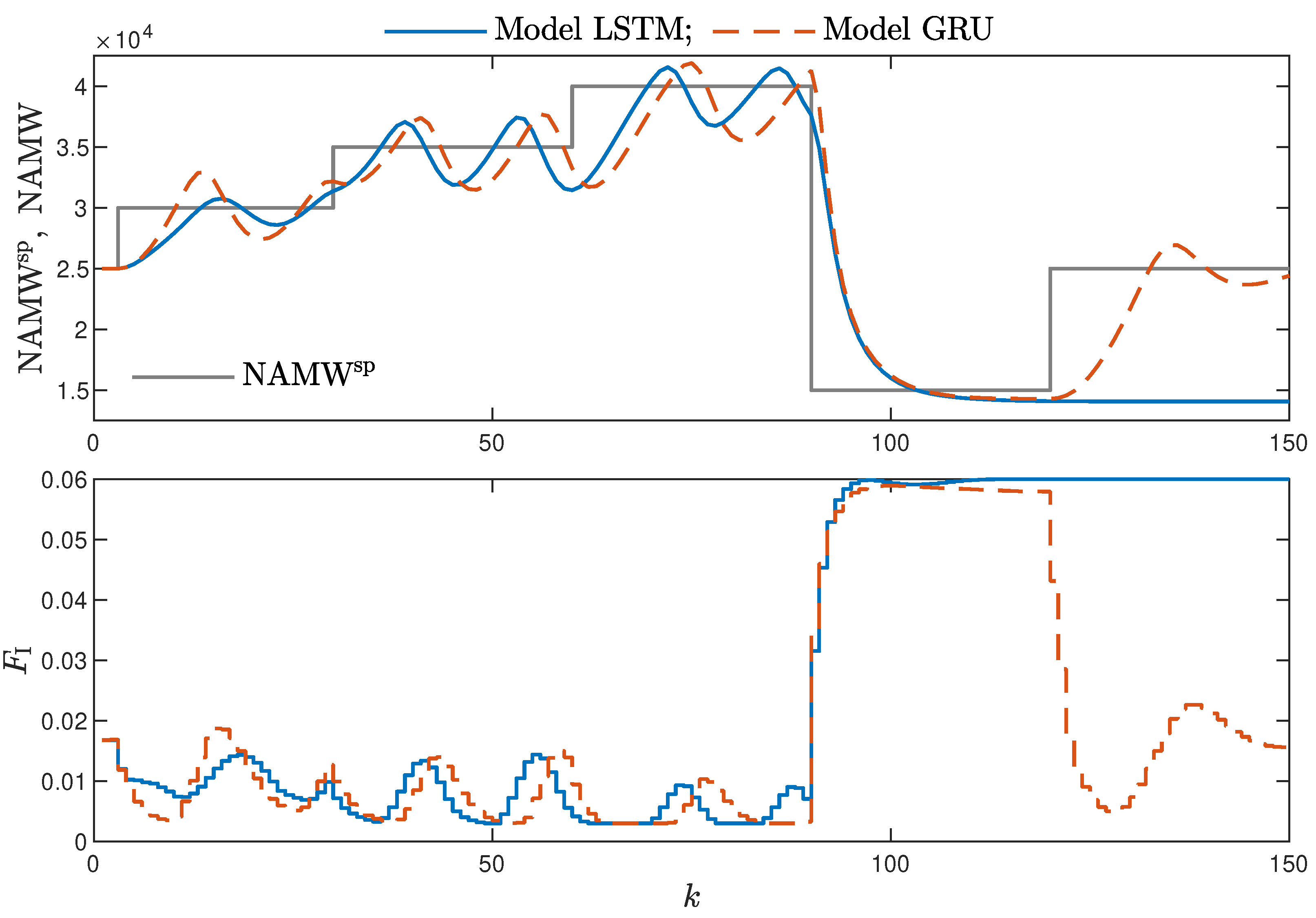
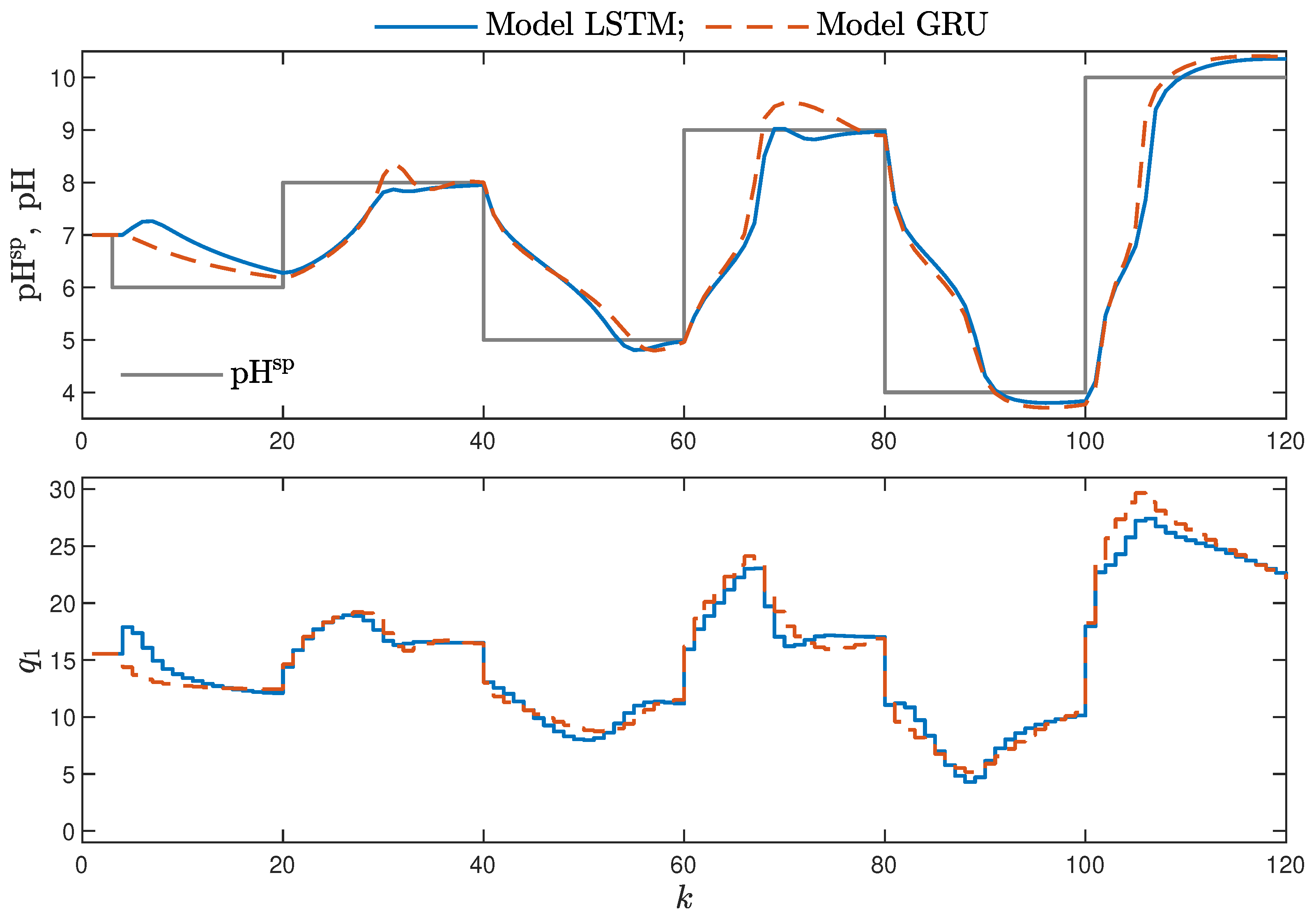
MPC performance using the models without the recursive input signals () proved to be very satisfactory. In the case of the polymerisation reactor, in Figure 14, minimal overshoot and a short settling time can be observed. Similar control quality was achieved for the neutralisation reactor system as depicted in Figure 15. Interestingly enough, for MPC with more complex models (), the results were comparable, as demonstrated in Figure 16. In the case of the polymerisation system and the LSTM model, small oscillations around the set-point could be observed, as shown in Figure 17, and the overall control quality was slightly worse. Table 5 and Table 6 compare the simulation results of the MPC algorithms based on the LSTM and GRU models, for the polymerisation and neutralisation processes, respectively. The following indicators used in process control performance assessment were considered [49]:
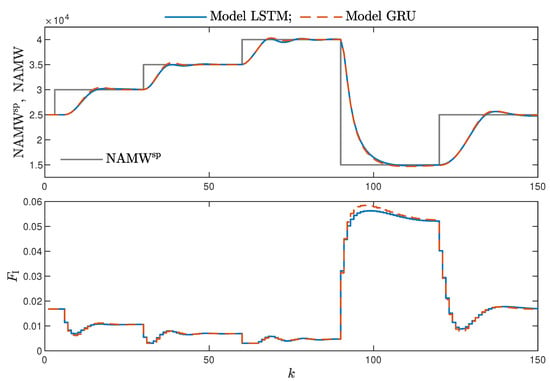
Figure 14.
The polymerisation reactor: MPC results with the LSTM and GRU models , , .
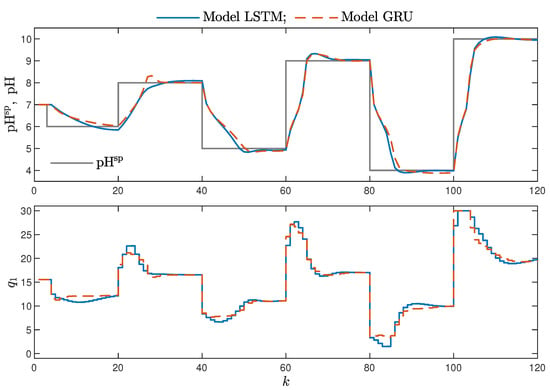
Figure 15.
The neutralisation reactor: MPC results with the LSTM and GRU models for , , .
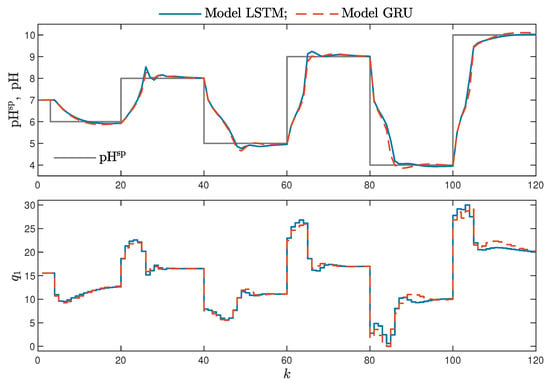
Figure 16.
The neutralisation reactor: MPC results with the LSTM and GRU models for , .
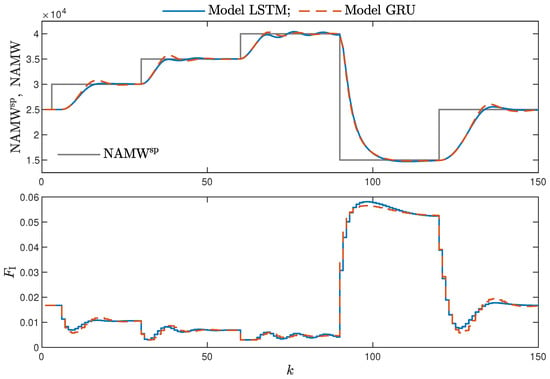
Figure 17.
The polymerisation reactor: MPC results with the LSTM and GRU models for , .
Table 5.
The polymerisation reactor: quality indexes and average time of calculation comparison.
Table 6.
The neutralisation reactor: quality indexes and average time of calculation comparison.
- The sum of squared errors (E);
- The Huber standard deviation () of the control error;
- The rational entropy () of the control error.
Additionally, the average time of calculation (t) during the whole simulation horizon (in seconds) was specified.
From the performed experiments, we were able to draw the following conclusions:
- Both types of neural networks allowed for a successful application of the MPC control scheme. All control performance indicators, i.e., E, and , showed that GRU network models, when applied for prediction in MPC, lead to very similar control quality when the rudimentary LSTM networks are used. What is more, as GRU models have fewer internal parameters, their computation cost and, therefore, the time of calculations are lower, as shown in Table 5 and Table 6;
- It is advisable to choose models with a relatively simple structure and a low number of parameters to implement in the MPC scheme. More complex models often provide comparable or even worse quality of control, and the computation cost rises with the number of parameters of the model;
- Minor model imperfections are reduced with great success by feedback in MPC. An example of this phenomenon can be observed in the bottom plots in Figure 12, where the model outputs differ slightly from the validation data in some areas. However, when the models are implemented in the MPC scheme, as shown in Figure 16, the quality of control is very satisfactory. However, the negative feedback is not sufficient to ensure satisfactory control if the model itself has poor quality. Example simulation results for the polymerisation process are presented in Figure 18. As a result of a very bad model, the MPC algorithm leads to unacceptable control quality, i.e., the set-point is never achieved, and strong oscillations are observed. Example simulations results when an inaccurate model is used in MPC for the neutralisation process are presented in Figure 19. In this case, the overshoot is larger and the setting time is longer when compared with the MPC algorithm based on a good model, e.g., as shown in Figure 15.
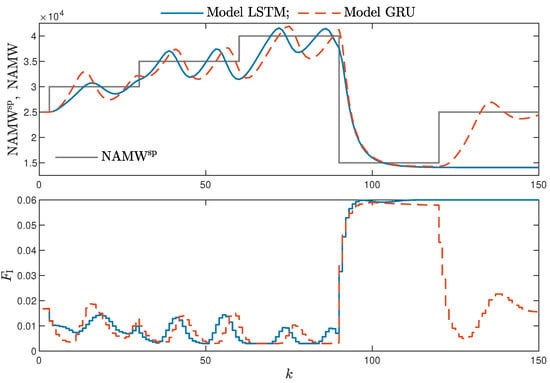 Figure 18. The polymerisation reactor: MPC results with the LSTM and GRU models for , .
Figure 18. The polymerisation reactor: MPC results with the LSTM and GRU models for , .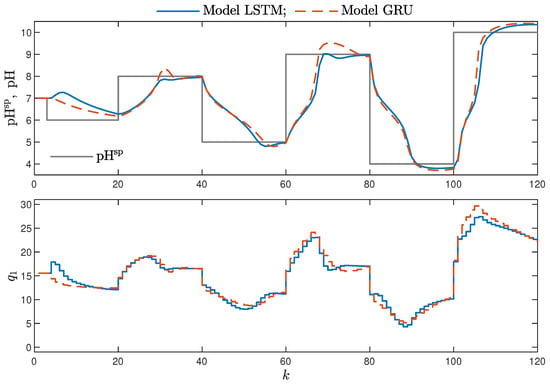 Figure 19. The neutralisation reactor: MPC results with the LSTM and GRU models for , .
Figure 19. The neutralisation reactor: MPC results with the LSTM and GRU models for , .
It is important to stress that the above observations are true for the two considered processes.
5. Conclusions
Having performed numerous experiments with different structures of LSTM and GRU neural networks as models of dynamical systems used in the MPC of two chemical reactors, we found that the GRU network gives very good results. Firstly, it approximates the properties of the dynamical systems with good accuracy, comparable with that possible when the rudimentary LSTM model is used. Secondly, it gives very good results when used for prediction in MPC, very similar to those observed in the case of the LSTM models. It is necessary to point out that the number of model parameters is lower in the case of the GRU network. Hence, the use of the GRU network is recommended for modelling of dynamical processes and MPC.
Future work is planned to develop more computationally efficient MPC control schemes based on the GRU structure and for Multiple-Input Multiple-Output (MIMO) processes. Moreover, it is planned to develop GRU models and use them in MPC applied to the ball-on-plate laboratory process [8].
Author Contributions
Conceptualisation, K.Z. and M.Ł.; methodology, K.Z.; software, K.Z.; validation, K.Z. and M.Ł.; formal analysis, K.Z.; investigation, K.Z.; writing—original draft preparation, M.Ł.; writing—review and editing, K.Z. and M.Ł.; visualisation, K.Z. and M.Ł.; supervision, M.Ł. Both authors read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Maciejowski, J. Predictive Control with Constraints; Prentice Hall: Harlow, UK, 2002. [Google Scholar]
- Tatjewski, P. Advanced Control of Industrial Processes, Structures and Algorithms; Springer: London, UK, 2007. [Google Scholar]
- Nebeluk, R.; Marusak, P. Efficient MPC algorithms with variable trajectories of parameters weighting predicted control errors. Arch. Control Sci. 2020, 30, 325–363. [Google Scholar]
- Carli, R.; Cavone, G.; Ben Othman, S.; Dotoli, M. IoT Based Architecture for Model Predictive Control of HVAC Systems in Smart Buildings. Sensors 2020, 20, 781. [Google Scholar] [CrossRef] [Green Version]
- Rybus, T.; Seweryn, K.; Sąsiadek, J.Z. Application of predictive control for manipulator mounted on a satellite. Arch. Control Sci. 2018, 28, 105–118. [Google Scholar]
- Ogonowski, S.; Bismor, D.; Ogonowski, Z. Control of complex dynamic nonlinear loading process for electromagnetic mill. Arch. Control Sci. 2020, 30, 471–500. [Google Scholar]
- Horla, D. Experimental Results on Actuator/Sensor Failures in Adaptive GPC Position Control. Actuators 2021, 10, 43. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. Fast real-time model predictive control for a ball-on-plate process. Sensors 2021, 21, 3959. [Google Scholar] [CrossRef]
- Bania, P. An information based approach to stochastic control problems. Int. J. Appl. Math. Comput. Sci. 2020, 30, 47–59. [Google Scholar]
- Nelles, O. Nonlinear System Identification: From Classical Approaches to Neural Networks and Fuzzy Models; Springer: Berlin, Germany, 2001. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines; Pearson Education: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Ławryńczuk, M. Computationally Efficient Model Predictive Control Algorithms: A Neural Network Approach; Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2014; Volume 3. [Google Scholar]
- Bianchi, F.M.; Maiorino, E.; Kampffmeyer, M.C.; Rizzi, A.; Jenssen, R. Recurrent Neural Networks for Short-Term Load Forecasting: An Overview and Comparative Analysis; Springer Briefs in Computer Science; Springer: Berlin, Germany, 2017. [Google Scholar]
- Hammer, B. Learning with Recurrent Neural Networks; Lecture Notes in Control and Information Sciences; Springer: Berlin, Germany, 2000; Volume 254. [Google Scholar]
- Mandic, D.P.; Chambers, J.A. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; Wiley: Chichester, UK, 2001. [Google Scholar]
- Rovithakis, G.A.; Christodoulou, M.A. Adaptive Control with Recurrent High-Order Neural Networks; Springer: Berlin, Germany, 2000. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. Untersuchungen zu Dynamischen Neuronalen Netzen. Master’s Thesis, Technical University Munich, Munich, Germany, 1991. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Islam, A.; Chang, K.H. Real-time AI-based informational decision-making support system utilizing dynamic text sources. Appl. Sci. 2021, 11, 6237. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Offline handwriting recognition with multidimensional recurrent neural networks. In Advances in Neural Information Processing Systems; Koller, D., Schuurmans, D., Bengio, Y., Bottou, L., Eds.; Curran Associates, Inc.: La Jolla, CA, USA, 2009; Volume 21, pp. 1–8. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech 2014, Singapore, 14–18 September 2014; pp. 338–342. [Google Scholar]
- Graves, A.; Abdel-Rahman, M.; Geoffrey, H. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Capes, T.; Coles, P.; Conkie, A.; Golipour, L.; Hadjitarkhani, A.; Hu, Q.; Huddleston, N.; Hunt, M.; Li, J.; Neeracher, M.; et al. Siri on-device deep learning-guided unit selection text-to-speech system. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 4011–4015. [Google Scholar]
- Telenyk, S.; Pogorilyy, S.; Kramov, A. Evaluation of the coherence of Polish texts using neural network models. Appl. Sci. 2021, 11, 3210. [Google Scholar] [CrossRef]
- Ackerson, J.M.; Dave, R.; Seliya, N. Applications of recurrent neural network for biometric authentication & anomaly detection. Information 2021, 12, 272. [Google Scholar]
- Gallardo-Antolín, A.; Montero, J.M. Detecting deception from gaze and speech using a multimodal attention LSTM-based framework. Appl. Sci. 2021, 11, 6393. [Google Scholar] [CrossRef]
- Kulanuwat, L.; Chantrapornchai, C.; Maleewong, M.; Wongchaisuwat, P.; Wimala, S.; Sarinnapakorn, K.; Boonya-Aroonnet, S. Anomaly detection using a sliding window technique and data imputation with machine learning for hydrological time series. Water 2021, 13, 1862. [Google Scholar] [CrossRef]
- Bursic, S.; Boccignone, G.; Ferrara, A.; D’Amelio, A.; Lanzarotti, R. Improving the accuracy of automatic facial expression recognition in speaking subjects with deep learning. Appl. Sci. 2020, 10, 4002. [Google Scholar] [CrossRef]
- Chen, J.; Huang, X.; Jiang, H.; Miao, X. Low-cost and device-free human activity recognition based on hierarchical learning model. Sensors 2021, 21, 2359. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Yang, S.; Zhao, B.; Huang, C. Cyberbullying detection in social networks using Bi-GRU with self-attention mechanism. Information 2021, 12, 171. [Google Scholar] [CrossRef]
- Knaak, C.; von Eßen, J.; Kröger, M.; Schulze, F.; Abels, P.; Gillner, A. A spatio-temporal ensemble deep learning architecture for real-time defect detection during laser welding on low power embedded computing boards. Sensors 2021, 21, 4205. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Varshney, A.; Ghosh, S.K.; Padhy, S.; Tripathy, R.K.; Acharya, U.R. Automated classification of mental arithmetic tasks using recurrent neural network and entropy features obtained from multi-channel EEG signals. Electronics 2021, 10, 1079. [Google Scholar] [CrossRef]
- Ye, F.; Yang, J. A Deep Neural Network Model for Speaker Identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Gonzalez, J.; Yu, W. Non-linear system modeling using LSTM neural networks. IFAC-PapersOnLine 2018, 51, 485–489. [Google Scholar] [CrossRef]
- Schwedersky, B.B.; Flesch, R.C.C.; Dangui, H.A.S. Practical nonlinear model predictive control algorithm for long short-term memory networks. IFAC-PapersOnLine 2019, 52, 468–473. [Google Scholar] [CrossRef]
- Karimanzira, D.; Rauschenbach, T. Deep learning based model predictive control for a reverse osmosis desalination plant. J. Appl. Math. Phys. 2020, 8, 2713–2731. [Google Scholar] [CrossRef]
- Jeon, B.K.; Kim, E.J. LSTM-based model predictive control for optimal temperature set-point planning. Sustainability 2021, 13, 894. [Google Scholar] [CrossRef]
- Iglesias, R.; Rossi, F.; Wang, K.; Hallac, D.; Leskovec, J.; Pavone, M. Data-driven model predictive control of autonomous mobility-on-demand systems. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6019–6025. [Google Scholar]
- Okulski, M.; Ławryńczuk, M. A novel neural network model applied to modeling of a tandem-wing quadplane drone. IEEE Access 2021, 9, 14159–14178. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 1310–1318. [Google Scholar]
- Doyle, F.J.; Ogunnaike, B.A.; Pearson, R. Nonlinear model-based control using second-order Volterra models. Automatica 1995, 31, 697–714. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Practical nonlinear predictive control algorithms for neural Wiener models. J. Process Control 2013, 23, 696–714. [Google Scholar] [CrossRef]
- Gómez, J.C.; Jutan, A.; Baeyens, E. Wiener model identification and predictive control of a pH neutralisation process. Proc. IEEE Part D Control Theory Appl. 2004, 151, 329–338. [Google Scholar] [CrossRef] [Green Version]
- Ławryńczuk, M. Modelling and predictive control of a neutralisation reactor using sparse Support Vector Machine Wiener models. Neurocomputing 2016, 205, 311–328. [Google Scholar] [CrossRef]
- Domański, P. Control Performance Assessment: Theoretical Analyses and Industrial Practice; Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2020; Volume 245. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).