Abstract
Previous knowledge of the possible spatial relationships between land cover types is one factor that makes remote sensing image classification “smarter”. In recent years, knowledge graphs, which are based on a graph data structure, have been studied in the community of remote sensing for their ability to build extensible relationships between geographic entities. This paper implements a classification scheme considering the neighborhood relationship of land cover by extracting information from a graph. First, a graph representing the spatial relationships of land cover types was built based on an existing land cover map. Empirical probability distributions of the spatial relationships were then extracted using this graph. Second, an image was classified based on an object-based fuzzy classifier. Finally, the membership of objects and the attributes of their neighborhood objects were joined to decide the final classes. Two experiments were implemented. Overall accuracy of the two experiments increased by 5.2% and 0.6%, showing that this method has the ability to correct misclassified patches using the spatial relationship between geo-entities. However, two issues must be considered when applying spatial relationships to image classification. The first is the “siphonic effect” produced by neighborhood patches. Second, the use of global spatial relationships derived from a pre-trained graph loses local spatial relationship in-formation to some degree.
1. Introduction
Machine learning has been widely used in remote sensing image classification. Some studies have experimented on small regions, reaching an overall accuracy of more than 90% [1,2,3,4,5]. The accuracy is high enough at the national level if the overall accuracy is more than 85% [6]. In reality, however, there is still a large amount of remote sensing image classification requiring human interpretation or modification [6]. Traditional machine learning focuses on classification based on isolated information such as spectral, shape, and texture information for the extraction of ground features. Many researchers have flocked into the field of deep learning to seek breakthroughs in remote sensing image classification methods, precisely because traditional machine learning methods have shown bottlenecks that are difficult to break through [7,8,9,10,11]. For example, most machine learning methods are developed to converge upon a fixed solution, however, an ideal learning method should capable of continual learning by incorporate some common-sense knowledge. Deep learning has higher requirements on the number of training images, although transfer learning enables the network to adjust parameters and reduce the number of training images. The diversity of remote sensing imagery and the ground it depicts, however, make classification an extremely complex process, especially with the constant emergence of new sensors. Training for each sensor’s data and each geographic scene for remote sensing image classification is an unusually tough job for deep learning applications [12]. The knowledge of spatial relations within and between objects can be used as important knowledge in classification [13], because although there are many variables regarding sensor characteristics such as band ranges, spatial resolution, and revisit cycles, the distribution of the ground features usually has a certain pattern.
Early in 1987, scholars designed an expert system for remote sensing [14], a knowledge representation structure, and the knowledge contained in the system. Later, expert knowledge based on fuzzy logic was used to describe knowledge on the basis of the probability or degree [15]. There are also expert systems designed for land cover classification [16]. Early expert system knowledge representation for remote sensing imagery was usually based on a tree-like structure, which is conducive to rule-based inference such as If-Then rules [17], Dempster’s combination rule [18], or decision trees [19]. These expert systems usually contain information on spatial relationships between land cover types. It was difficult to apply that knowledge to classification until the emergence of object-based image analysis [20]. Object-based image analysis can easily include contextual and neighborhood information into the classification process [21]. Mutual relations between image objects include the similarity/dissimilarity of spectra between neighborhood objects, while contextual information includes spectral relationships to sub- and super-objects and spatial relationships such as ‘existence of,’ ‘border to’, and ‘distance to’ [22,23,24]. Qiao et al. [25] proposed a maximum spatial adjacency and directional spatial adjacency method to extract certain land cover classes. A representative platform, eCognition Developer, provides tools to perform a hierarchical rule-based classification scheme where the relationship between objects can be manually defined [26]. The object-oriented classification method has provided a solution to understanding image semantics [27].
Two issues are usually considered for knowledge-based classification of remote sensing images. First is to build a knowledge base. The key issue in building an appropriate knowledge base is to identify an appropriate data structure and knowledge representation (knowledge acquisition, conceptualization, and formalization [28,29]). Second is the implementation of knowledge. The key issue in implementing knowledge is to effectively use prior knowledge for interpretation and “scene understanding” for image classification. There are many recent studies focusing on knowledge-based methods for remote sensing data classification. Forestier et al. used a knowledge base constructed by ontology for scene and concept matching [29]. Rejichi et al. [30] designed an expert knowledge scheme for SITS (satellite image timeseries) analysis using scene ontology and a tree-like organized data structure. To localize the knowledge base, they proposed to compare similarity between an extracted graph from a knowledge base with the user request. Belgiu et al. [31] used existing literature on evaluated building types to build an ontology based on If-Then rules, random forest was used to classify the building types by the features described in the ontology. Forestier et al. [32] also used an object-oriented method for the classification of coastal areas, and an ontology describing existing classes in the region was built. A hypothesis about the semantics of the region was made and knowledge on the type of region was used to check and modify the hypothesis. Belgiu et al. developed a method to automatically embed a formalized ontology into an object-based image analysis (OBIA) process [33]. Objects produced by image segmentation are usually used as the basic processing units in the knowledge-based classification methods [34,35]. That is, knowledge is extracted by relationships between image objects rather than pixels. Recent years, ontology-based data structure is usually used for geographic knowledge representation.
To extract the knowledge of spatial relationships, Dale et al. reviewed and analyzed the value of geo-spatial graphs [36]. The authors suggested that “future applications should include explicit spatial elements for landscape studies of ecological, genetic, and epidemiological phenomena”. Cheuang et al. [37] practiced a graph-based representation of landscape relationships where a graph-based structure was implemented to present landscape topology. Moreover, graph edit distance was leveraged to project the structural attributes of a landscape entity’s topology to vector dimensions. The graph-based data structure enables more analysis regarding spatial relationships between landscape entities such as subgraph mining and kernel analysis. Recently, Xu et al. [38] used graphs to explore the morphological changes between adjacent tidal flat objects. Aside from directly using graph-based spatial relationships in the process of classification, graph convolutional neural networks (GCN) have been implemented in remote sensing image classification. Ouyang and Li proposed a method to first extract features of objects and then constructed a graph containing the extracted features of objects for the implementation of a GCN classifier [39]. Li et al. proposed a scene classification scheme that first extracted scene features then segmented the feature map to construct a graph. Finally, the graph was classified by a graph attention network (GAT) [40]. Ma et al. proposed a sum of minimum distance parameter to determine graph adjacency relationships. The parameter was used for the classification of hyperspectral image (HSI) data [41]. Pu et al. reviewed the application of GCN on HSI classification and proposed a graph-based CNN (Convolutional Neural Network) classifier to classify HSI data [42]. Scholars in the remote sensing community usually leverage graphs to extract spatial relationships.
Motivated by the notion that the graph-based structure can learn adjacency information, we propose a method to make use of adjacency information by combining information at the decision level. The proposed method consists of three parts. First, the original image is segmented and classified by a fuzzy classifier to produce a membership, which represents the probability they belong to a class. In the second step, a graph based on an existing land cover map is produced to calculate the probability of adjacency between land cover types. In the final step, the two probabilities are assembled to produce the final class decision. The main contributions of this paper can be summarized as follows:
- We propose a method to extract the adjacency probability by using a graph.
- The adjacency probability derived from the graph is aggregated with pre-classification results at the decision level.
- Two experiments show that the method has some ability to correct misclassified objects with neighborhood information, but problems regarding global uncertainty and the “siphonic effect” need to be considered in future work.
2. Method
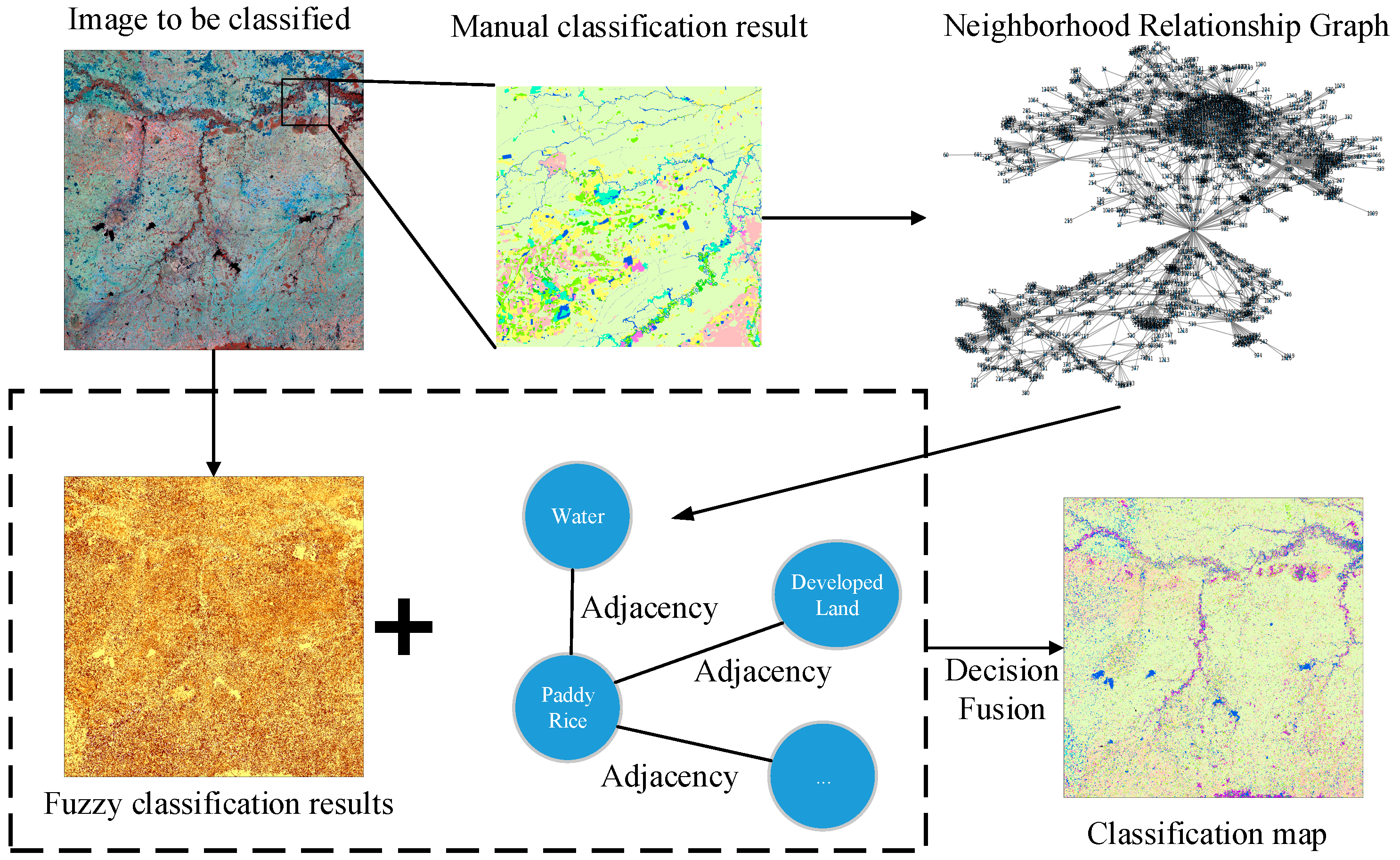
Our proposed framework is illustrated in Figure 1. Generally, we proposed a way to train previous knowledge of the distribution pattern of land cover types using graph theory and aggregated the trained distribution pattern with physical features of the land cover to the final decision module. Specifically, because manually interpreting and classifying small regions enabled us to get an accurate spatial distribution pattern of land cover types, we trained the previous knowledge by manually interpreting and classifying small regions as ROI (Region of Interests) of the region to be classified. Second, we built a graph of the land cover features of the ROI and calculated each node’s degree by land cover type. This degree represents the probability of the presence of neighboring land cover types. Third, fuzzy classification was conducted on the image to obtain the membership. Finally, we combined the probability of the presence of neighboring land cover types with membership to reach the final decision.
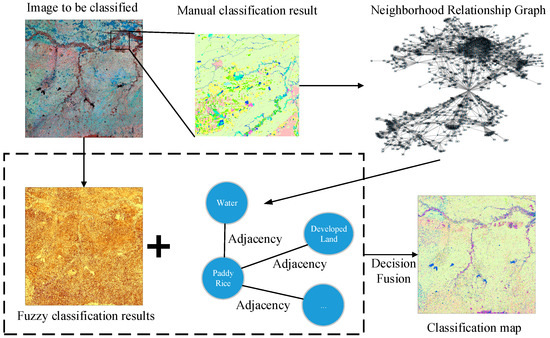
Figure 1.
Overview of the proposed framework.
2.1. Generating the Spatial Relationship Graph
To generate pre-trained knowledge on the relationships between classes, a simple graph-based method was used. First, a small region was chosen as an ROI within the area to be classified, and the area was manually interpreted and classified to produce a land cover map. Manual interpretation is usually used as reference map because of its accuracy This can also be done by classifying very-high resolution remote sensing images [43,44], but the classified land cover map must be processed using a generalization technique to guarantee the integration of converted features. Small features should be merged into neighboring polygons. Because of landscape may changes overtime hence effects adjacency possibility. We suggest that using images collected near the to-be-classified image dates for manually interpretation.
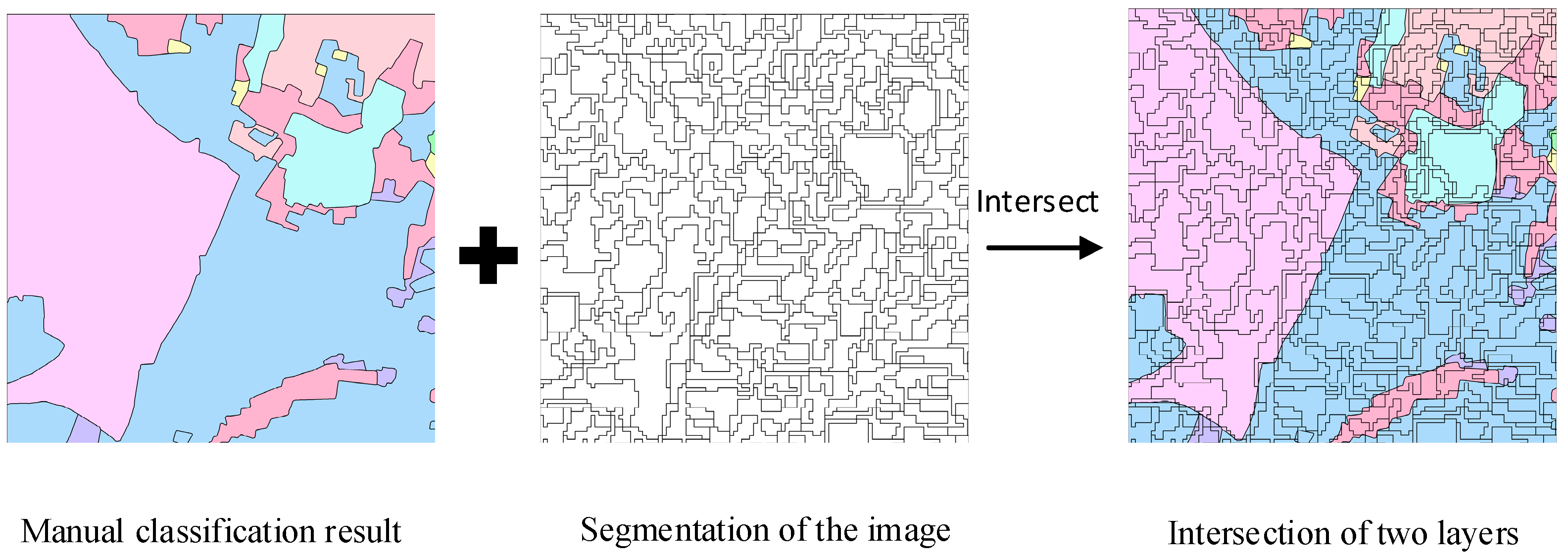
Second, the image was segmented using the same segmentation scales as the whole region. The segmented image was intersected with the manually classified land cover map to guarantee the object adjacent to each node had the same scale with the image to be classified. For example, in the manually classified land cover map, land cover areas of the same type are outlined as one feature, but when segmenting the image to be classified, adjacent land cover areas of the same type may be segmented as separate objects. The manually classified land cover map has few adjacent features with identical types, but the segmented map has many. Intersection of the segmented features with the land cover map can reflect an identical segment scale with the image to be classified, showing the probability of adjacent features. The process is shown in Figure 2.
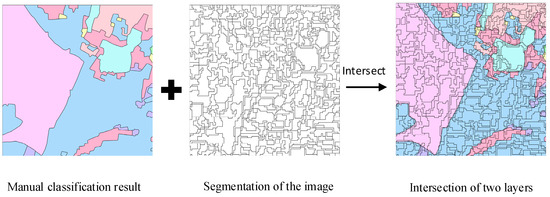
Figure 2.
Process to obtain the feature map for graph construction.
The polygons of the segmented manually classified land cover map are denoted as a set SMC. Assume there are polygons in , and }. Each polygon should have a class type . Assume there are types of land cover in the area.
Third, the graph was built using the manually classified land cover map. Set is a set of nodes in , which are polygons of the manually classified land cover map. Set is a set of edges in G, which have no direction nor weight and denote the adjacency relationship between polygons. The objective was to get the probability of each type adjacency to }. The probability of polygons with type adjacency to polygons with type were calculated via the graph using the degree of nodes . The calculation is shown in Equation (1):
where is the probability that type is adjacent to type ; is the degree of node ; is the degree of nodes , which have the attributes that belongs to type ; and is the number of edges that connect nodes , which have the attributes that belongs to type , and nodes which have the attributes that belongs to type .
2.2. Object-Oriented Fuzzy Classification
An object-oriented method for pre-classification was used to reduce the data processing time. More importantly, the object-oriented method better reflects relationships between classes. The degree to adjacent land cover is more robust and enables the built graph to be more applicable and extensible to larger regions [45]. This is because images with different resolutions will show different probabilities of adjacency. Images with a higher resolution will need more pixels to store real surface features, which will make the probability of adjacency smaller.
It is labor-intensive to produce a land cover map of a sample region, though reference land cover maps from high-resolution satellite imagery have a high accuracy of classification. To transform the high-resolution classification data, the strategy in this paper is to overlay the segmented polygons on the high-resolution land cover map and assign major land cover types within each polygon as the land cover map of the segmented polygon.
2.2.1. Image Segmentation
The eCognition platform uses five parameters to control multi-resolution segmentation (MRS), including the scale, shape, color, compactness, and smoothness parameters. The segmentation scale is the most critical parameter that controls the size of resultant polygons. A good segmentation will produce a balance between polygon size and the homogeneity within an object and heterogeneity between objects [46,47]. The shape and color parameters define the weight that the shape and color criteria should have when segmenting the image. The higher the value of the shape, the lower the influence of color on the segmentation process. For the compactness and smoothness criteria, the higher the weight value, the more compact image objects may be. Note that different test sites should have different segmentation parameter values.
2.2.2. Selected Fuzzy Classifier
- Nearest neighbor
Nearest neighbor (NN) classification first builds a feature space using spectrum, geometry, or texture of samples [48]. Then each object is classified by mapping its features to the feature space. Finally, the Euclidean distance between sample features is used with the object’s features for classification. The NN classification is based on the minimum distance in the NN feature space where the training data are constructed by spectral, shape, or texture feature values. The distance can also be seen as the reliability of the classification results. The distance function is shown in Equation (6) [49]:
where is the Euclidean distance of samples to be classified in the NN feature space. The data are more similar to the samples when the Euclidean distance is smaller. The Euclidean distances provide a chance to range the feature values into fuzzy membership values between 0 and 1.
After the segmentation, the objects were classified via sample points. The fuzzy classification process was also performed in eCognition. The object information, including the spectral, texture, shape, and difference with neighbor objects were input in the NN feature space for the training of samples. The distance was output as membership to use in the decision phase.
- Fuzzy SVM
SVM is another popular classification technique [50]. The principle of SVM can be briefly described as follows [51]. Given a set of instance-label pairs (), where and , the SVM requires the solution of the following optimization problem:
Here, training vectors are mapped into a higher (maybe infinite) dimensional space by the function . The SVM finds a linear separating hyperplane with the maximal margin in this higher dimensional space. is the penalty parameter of the error term. Furthermore, is called the kernel function. The most commonly used kernel function is the Gaussian radial basis function (RBF):
Fuzzy SVM means the output is a probabilistic prediction. Hong and Hwang [52] provided a strategy in training the SVM and mapping the outputs into probabilities. The probability is measured by Bayesian theory, and the kernel model is replaced by a Bayes formula:
where is the label and is the decision function:
where {} is a set of nonzero multipliers. For multiple classes, Equation (7) is used:
where is the probability that the sample belongs to class when considering only the two classes and so that the one-one classification is transferred into a one-all classification.
2.3. Aggregation of Graph and Membership
We obtained the membership of each object according to Section 2.2 as well as the probability of land cover adjacency. The membership of polygons can be treated as the probability that the polygon belongs to a land cover type. The classification is based on spectral, shape, or texture information of objects and does not contain neighborhood information of objects. The degree obtained from the neighborhood relationship graph contains the probability of land cover types that are adjacent to other types. We can combine the two probability values by a decision fusion scheme:
where is the classification result of the polygon; is the probability obtained by the fuzzy classification based on spectral, shape, and texture information of the object; and is the probability obtained by neighborhood information from the pre-trained graph.
More specifically, each node contains the fuzzy classification membership of each polygon. Also, we obtained the probability that the land cover is adjacent to others. Supposing that a polygon has adjacent polygons, the adjacent polygons of polygon Y were denoted as . Supposing there are types of land cover, the land cover types were denoted as
. The membership of polygons are given as and the probability of land cover adjacent to is . The fusion was conducted as the following equation:
where is the membership value of type in polygon Y; X is the adjacent polygons to polygon Y; is the membership value of type in polygon X; and is the probability of land cover adjacent to obtained by the built graph in Section 2.1.
The final decision of land cover type in polygon Y is max (. The aggregation equation is intended to consider the land cover types of the neighborhood of the polygon to be classified as well as the fuzzy classification result on its own.
3. Experiments
The purpose of using a graph is to make use of previous knowledge on the distribution of land cover types. Our scheme used a localized knowledge of the probability of land cover adjacency and a simple degree of the nodes. The information of this localized knowledge was used by the decision fusion of membership and the probability of land cover adjacency.
3.1. Study Area and Satellite Data
3.1.1. Brief Introduction to the Study Area
We used two satellite images to test on two test sites. One region is the Mun River Basin, the other is Kent County, Delaware, USA. The land cover of the Mun River Basin is mainly paddy rice, while Kent County consists of multiple land cover classes such as forest, agriculture, and cities.
- Mun River Basin
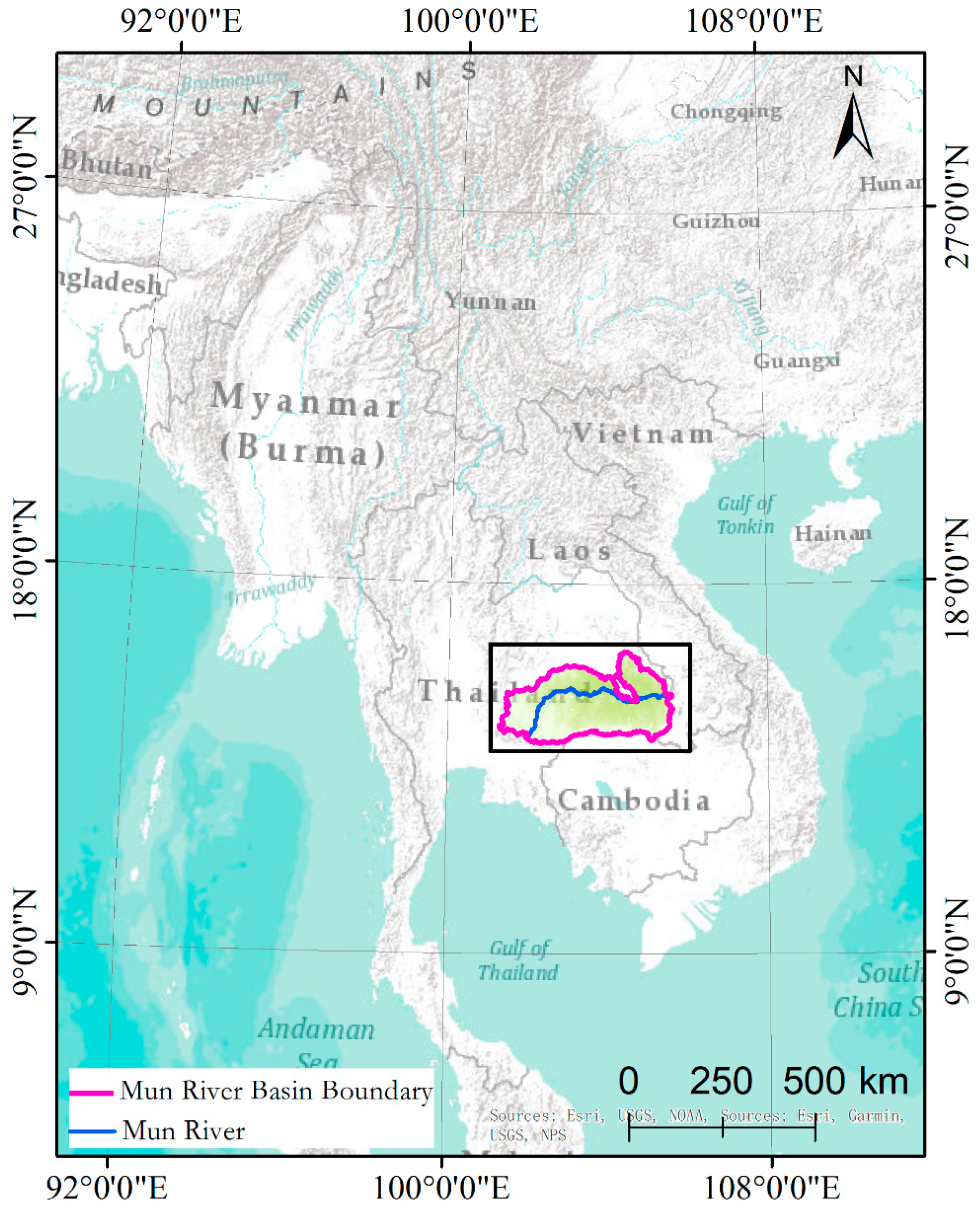
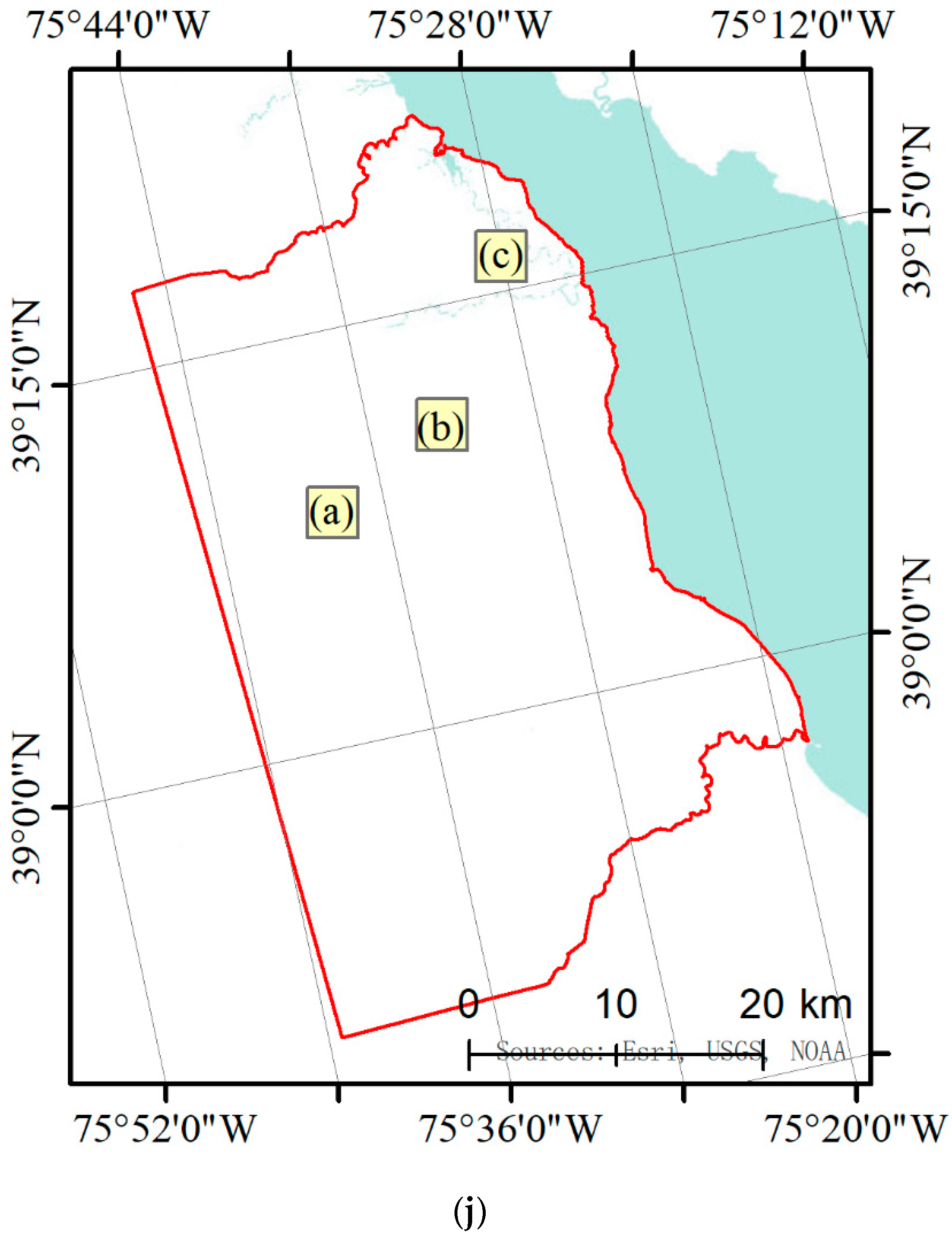
The Mun River Basin is located in northeastern Thailand bordering Laos to the east and Cambodia to the south, between 101°30′–105°30′ E and 14°–16° N. It is the largest river basin in Thailand, the largest river on the Khorat Plateau, and the second longest river in Thailand (the largest is the Chak River). It is also a major tributary of the Mekong River. The main stream of the Mun River is about 673 km long and the basin area is about 70,500 km2. Vegetation coverage in the Mun River Basin is large, about 12% natural vegetation and about 80% artificial vegetation, and the rest of the land cover types are water bodies and developed land. The location of the area is shown in Figure 3.
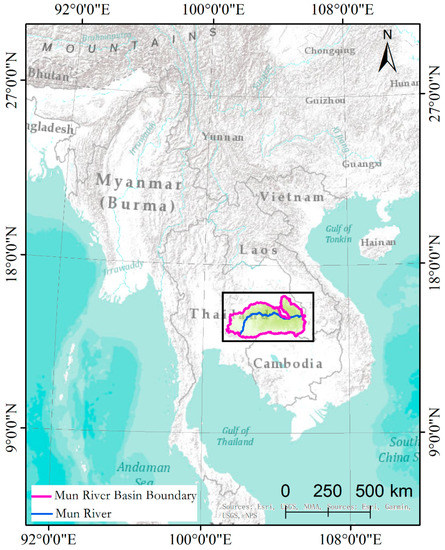
Figure 3.
Location of the Mun River Basin test site in northeastern Thailand.
- 2.
- Kent County, Delaware, USA
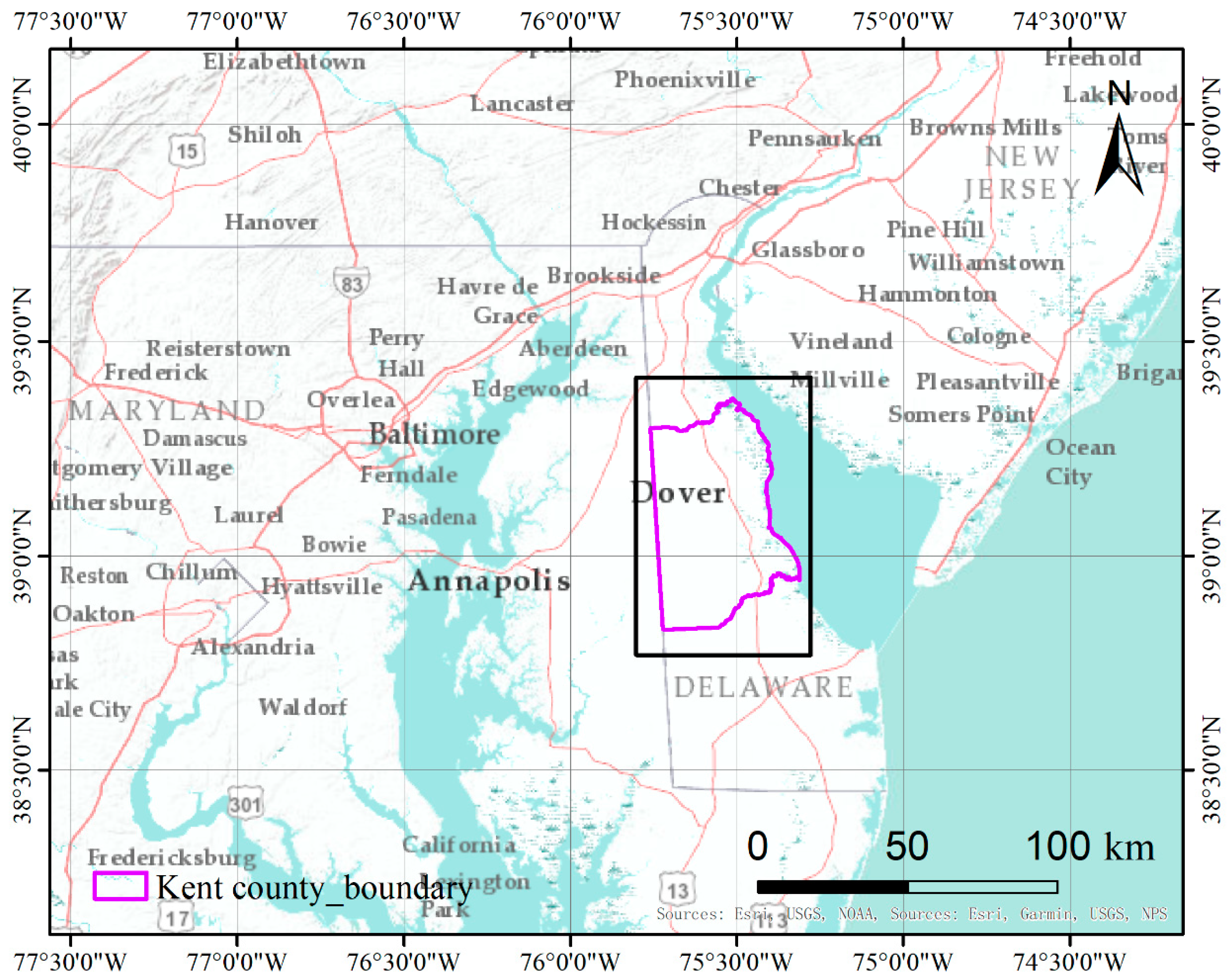
Kent County is located in the central part of the U.S. state of Delaware within the Chesapeake Bay area, the largest estuary in the United States [53]. Kent County has a humid subtropical climate according to the Köppen climate classification, while the Trewartha climate classification considers the climate oceanic because only seven months average >10° C (>50° F). All months average above freezing and Dover has three months averaging above 22° C (71.6° F.) The hardiness zone is mostly 7a with very small areas of 7b [54]. The location of the site is shown in Figure 4.
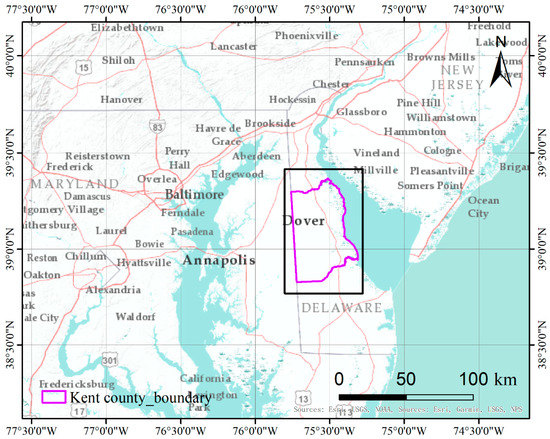
Figure 4.
Location of the Kent County test site in the Chesapeake Bay area.
3.1.2. Satellite Data and Pre-Processing
- Landsat 8 OLI
Landsat 8 data from the United States Geological Survey (USGS) website (https://earthexplorer.usgs.gov/, accessed on 15 August 2021) were used for the Mun River Basin, selecting high-quality images (cloud cover less than 10%) from 2015. The Landsat 8 satellite carries the Operational Land Imager (OLI) including nine bands, among which eight are multispectral bands with a resolution of 30 m and another 15 m panchromatic band. The imaging width is 185 km × 185 km. The Landsat 8 OLI image used is a Level 1T product. We conducted radiometric calibration and FLAASH model-based atmospheric correction with the ENVI 5.0 SP3 software. Then the Landsat 8 OLI data were resampled to 25 m with the nearest resampling technique.
To obtain an accurate land cover map by manual interpretation and classification, Google Earth imagery was downloaded and georeferenced using Landsat data and DEM images (Shuttle Radar Topography Mission, SRTM, 30 m data).
- 2.
- Sentinel-2
Sentinel-2 data were used in Kent County, Delaware, downloaded from the CREODIAS website (https://creodias.eu/, accessed on 15 August 2021). Sentinel-2 is a wide-swath, high-resolution, multi-spectral imaging mission, supporting Copernicus Land Monitoring studies, including the monitoring of vegetation, soil, and water cover, as well as observation of inland waterways and coastal areas. It uses a Multispectral Instrument (MSI) that samples thirteen spectral bands: four bands at 10 m, six bands at 20 m, and three bands at 60 m spatial resolution. The acquired data, mission coverage, and high revisit frequency provide for the generation of geoinformation at local, regional, national, and international scales. We used high-quality images (cloud free) from 2016. The downloaded level 1 data were processed with orthographic correction and geometric correction on a sub-pixel level. Atmospheric correction should be conducted in principle, but the quality of the data was good enough for classification and we did not conduct atmospheric correction. We only used four bands at 10 m for classification, including the Red, Green, Blue, and NIR bands.
3.2. Results of the Mun River Basin
We first built the pre-trained graph for spatial relationship extraction by selecting regions that contain all types of land cover to perform manual interpretation and classification.
3.2.1. Trained Graph in the Mun River Basin
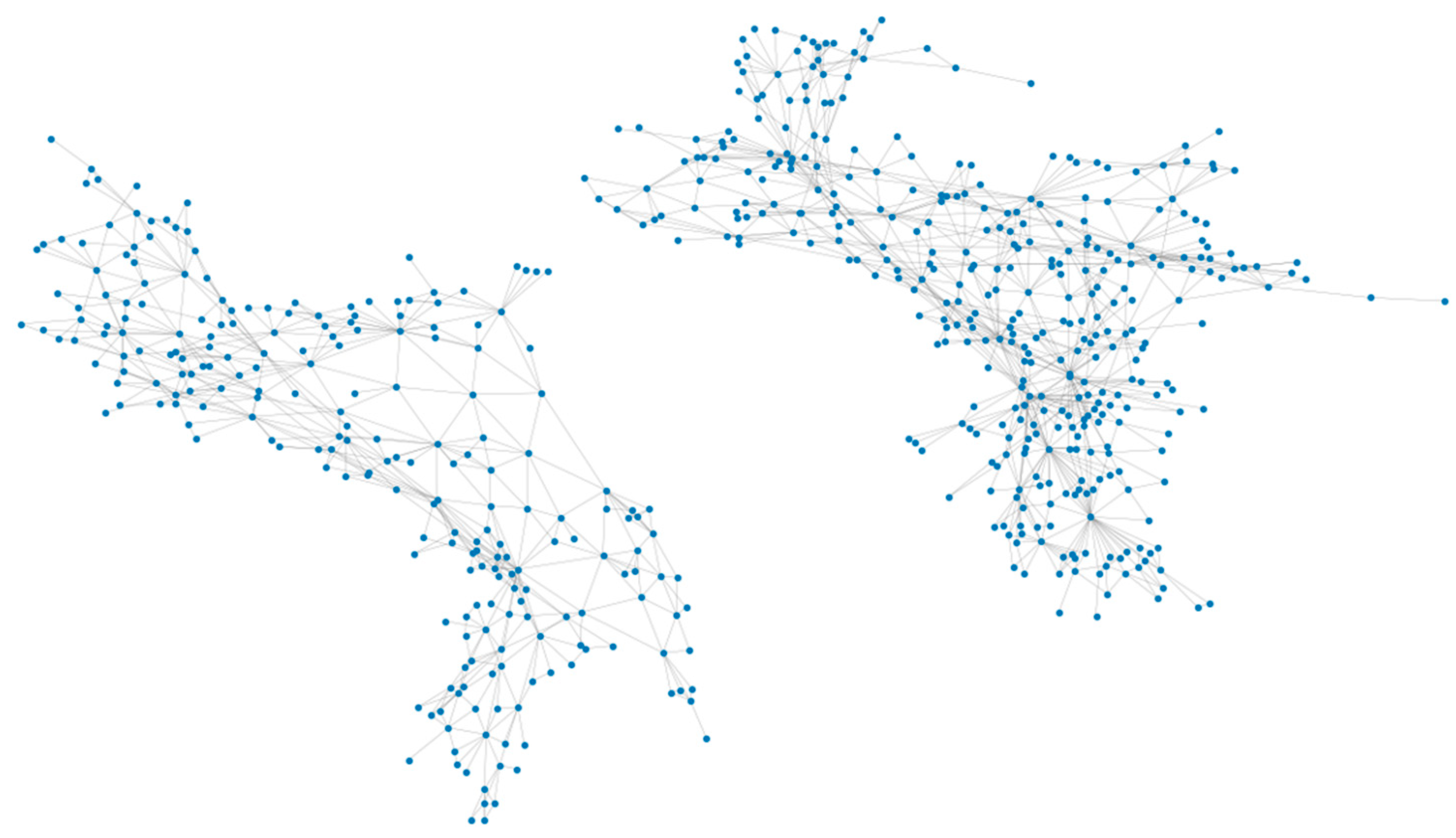
The sampling region’s area of 672 km2 comprised 3710 polygons in the manually classified land cover map. After the segmentation and intersection, 76,141 polygons were generated. For the graph, 498,908 edges were generated for the 76,141 nodes. The edges denote that the nodes are adjacent to each other. We visualized 9722 nodes and their 63,432 edges.
From the graph, statistics were calculated for each node’s degree with different labels according to Equation (1). For example, nodes labeled “artificial forest” have 4000 degrees. Among the edges connected to nodes labeled “artificial forest”, 200 nodes are labeled “wetland”. The probability of “artificial forest” being adjacent to “wetland” is 200/4000. Table 1 shows the probability of land cover adjacent to other land cover types. Using this probability, we can aggregate the fuzzy classification result with the adjacent probabilities.

Table 1.
Probability of land cover types being adjacent to each other in the Mun River Basin.
3.2.2. Pre-Fuzzy-Classification Results in the Mun River Basin
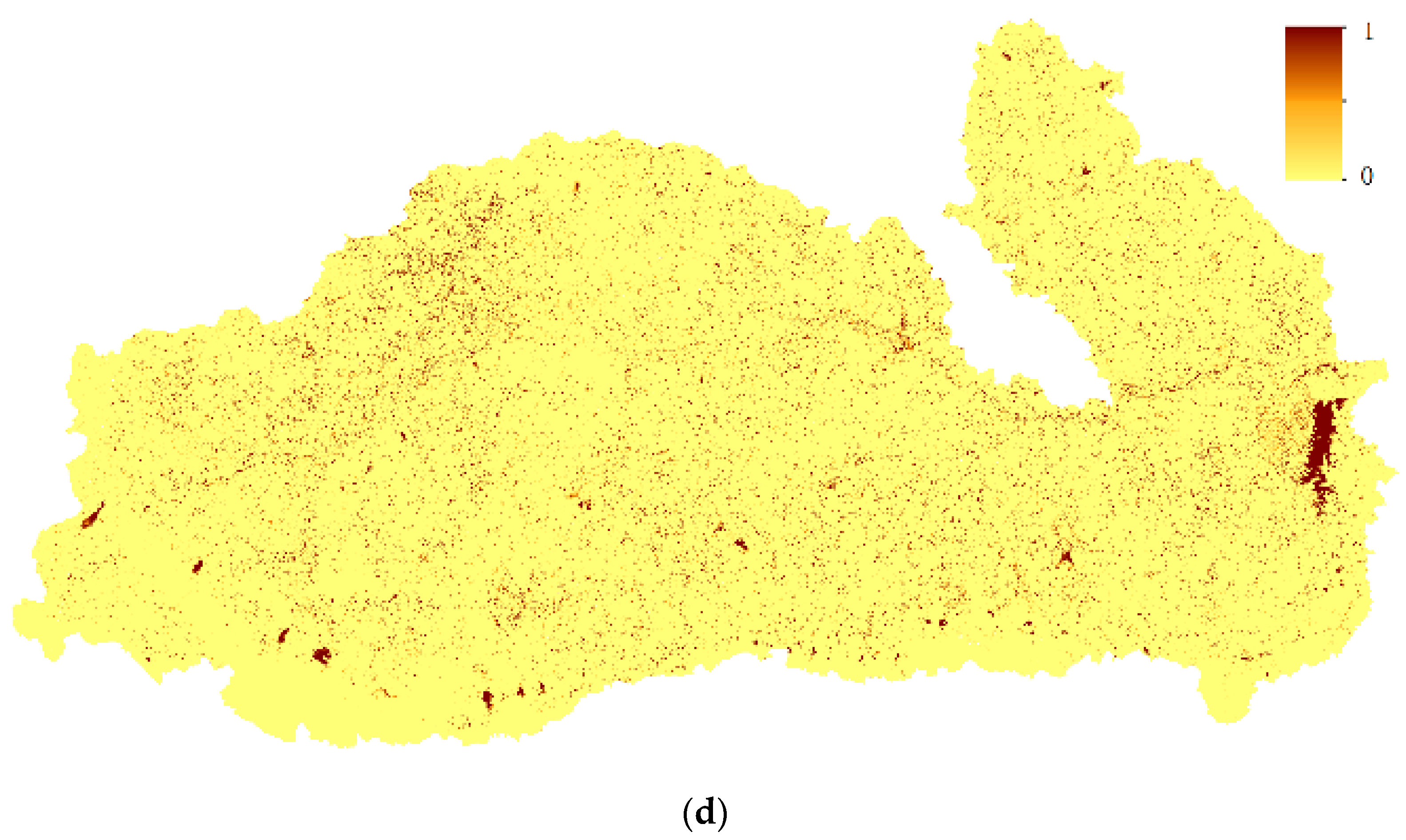
The nearest neighbor classifier used 6000 points for the classification of the Mun River Basin. We used a relatively large number of sample points for training to guarantee the accuracy of pre-classification results. Thus, the improvement in the fusion stage was not caused by the low accuracy of pre-classification results. Fuzzy classification using the nearest-neighbor classifier was implemented in eCognition with a scale parameter of 60 in the multi-resolution segmentation model, a shape criterion of 0.1, and a compactness of 0.5. All bands participated in the segmentation. In the classification process, we chose the mean value of each band, the NDVI value, and the width/length value to input into the nearest neighbor feature space. The result is shown in Figure 5a. Membership of selected land cover types including paddy rice, evergreen forest, and water is also shown in Figure 5.
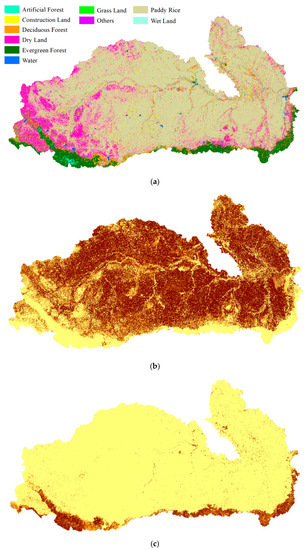
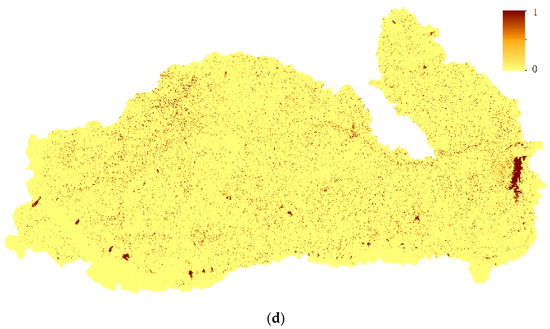
Figure 5.
Fuzzy classification results and membership of selected land cover types in the Mun River Basin: (a) classification result by nearest neighbor; (b) membership of paddy rice; (c) membership of evergreen forest; (d) membership of water.
3.2.3. Decision Fusion Map of the Mun River Basin
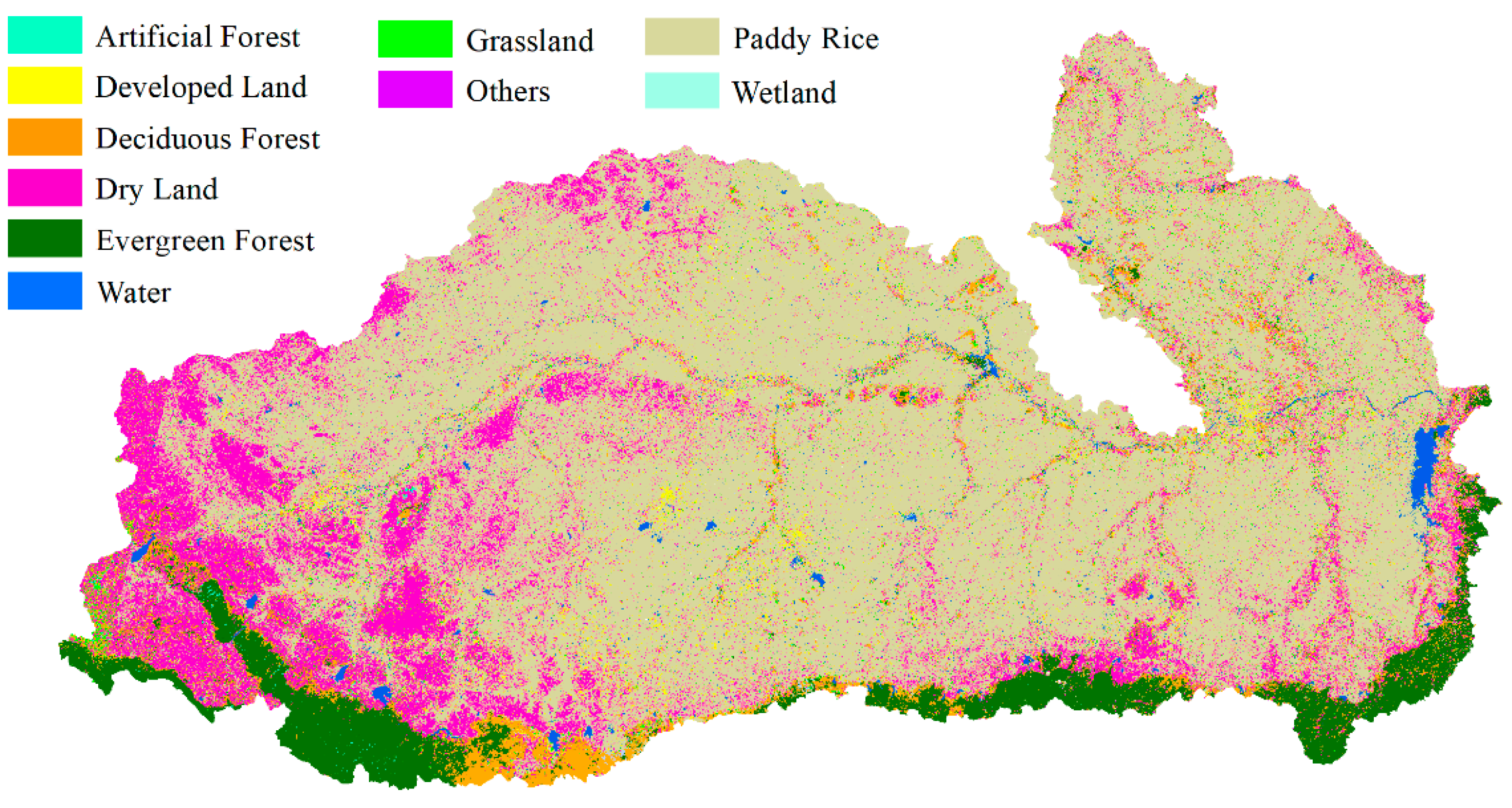
According to Equation (9), the fuzzy classification results were aggregated with neighborhood land cover probability. A decision fusion map of the Mun River Basin is shown in Figure 6.
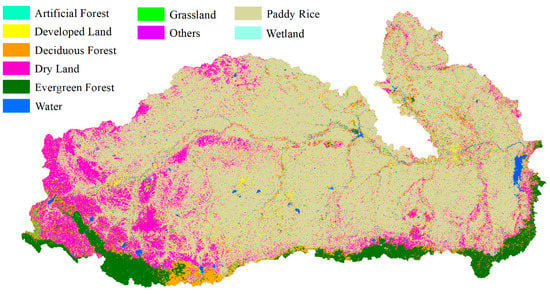
Figure 6.
Land cover map of the aggregated pre-trained neighborhood spatial relationship and fuzzy classification membership.
The major pattern of land cover distribution did not have many differences compared with the pre-classification map and true land cover classification map. The main land cover class is paddy rice. Dry land is mostly distributed in the west of the basin while water and developed land are distributed evenly. Forests, including deciduous and evergreen, are mostly distributed in the south.
3.2.4. Accuracy Assessment of the Mun River Basin
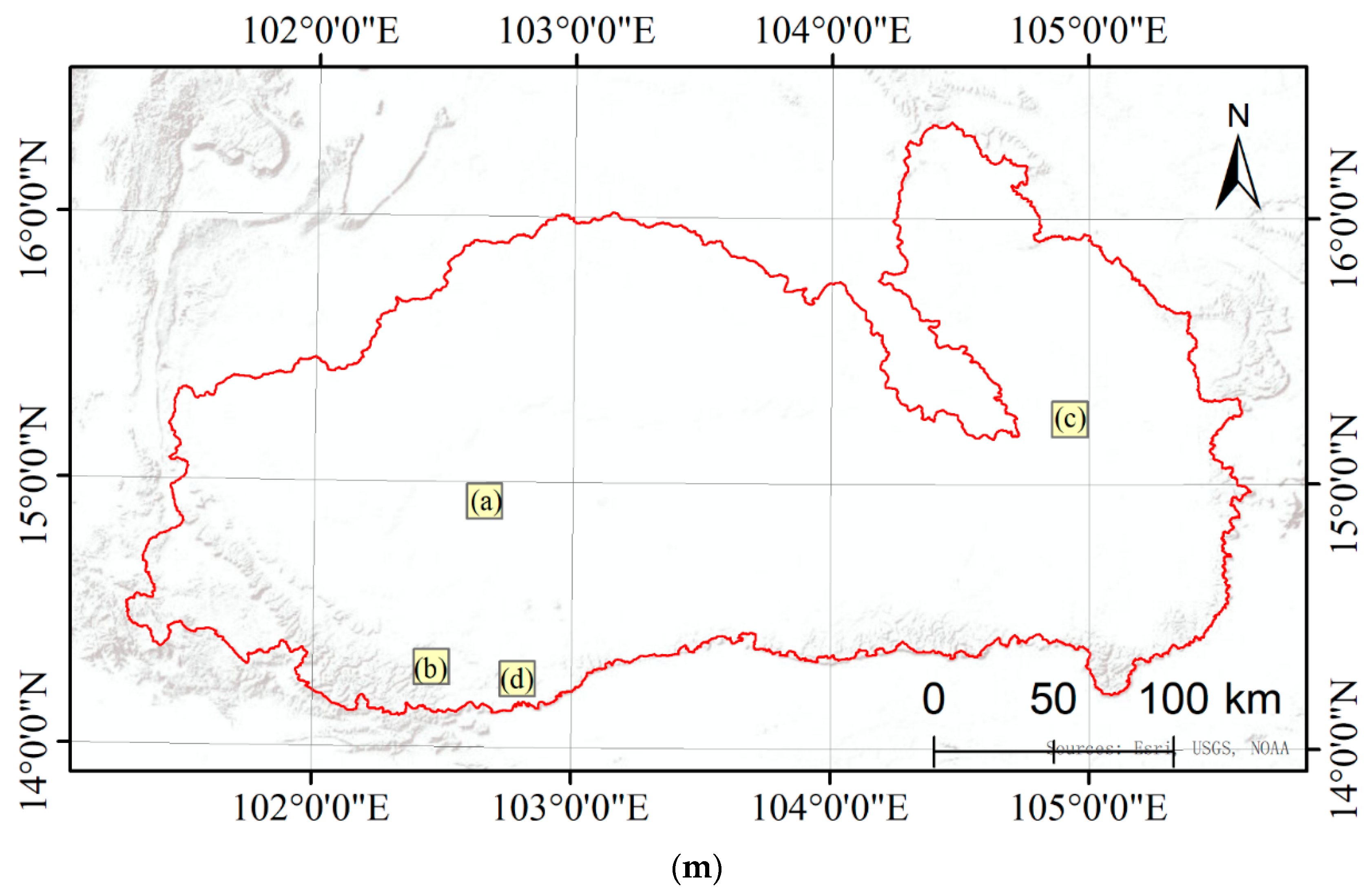
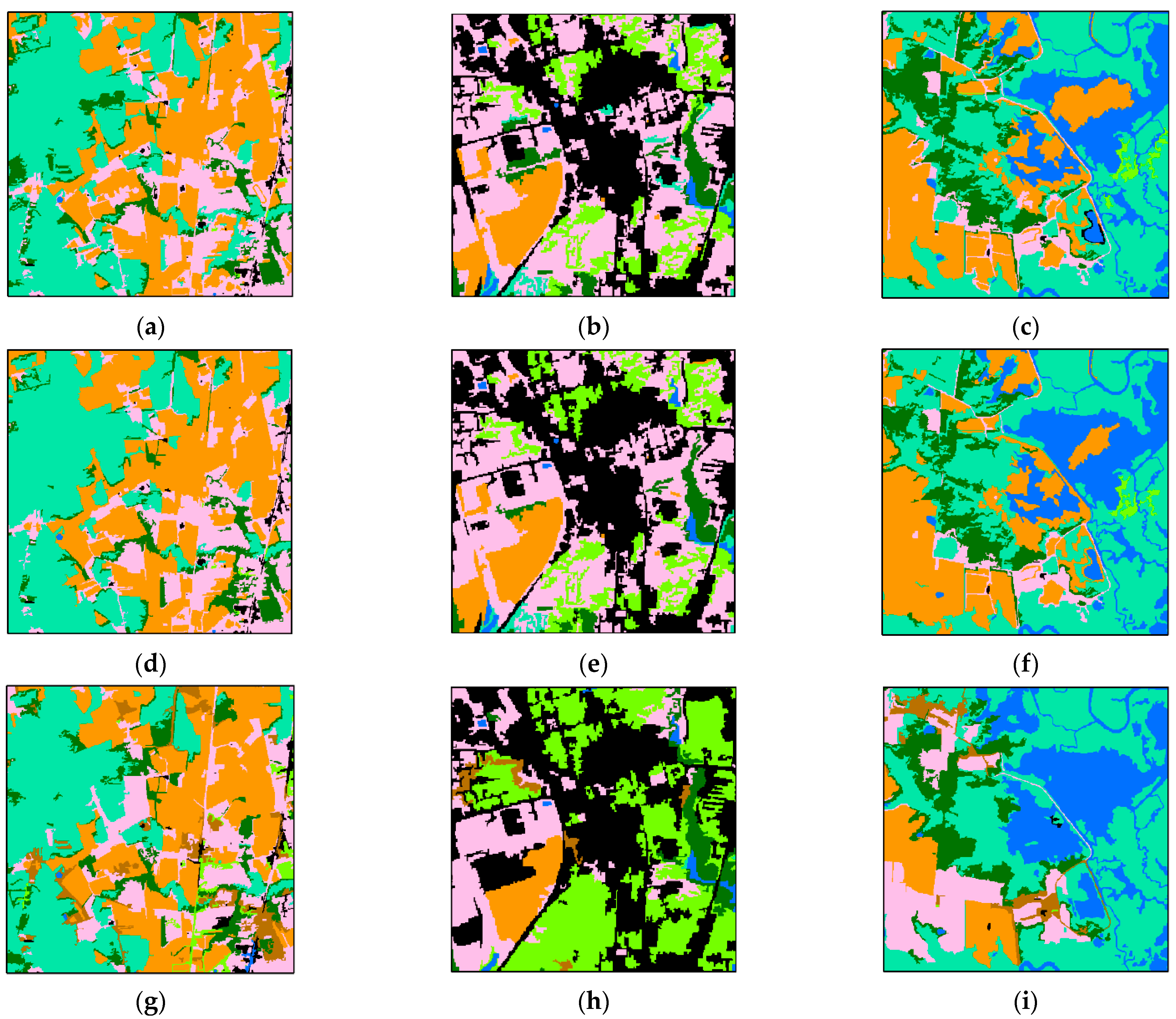
In order to compare the detailed differences between the pre-classification map, fusion map, and true land cover classification map, four regions were chosen and shown at a larger scale for demonstration. The main land cover types in each are, respectively, paddy rice, dry land, and developed land; dryland and forest; paddy rice, water, and developed land; and dryland and forest. Comparisons are shown in Figure 7.
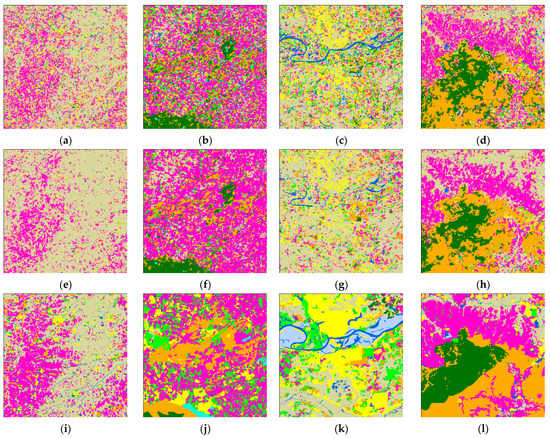
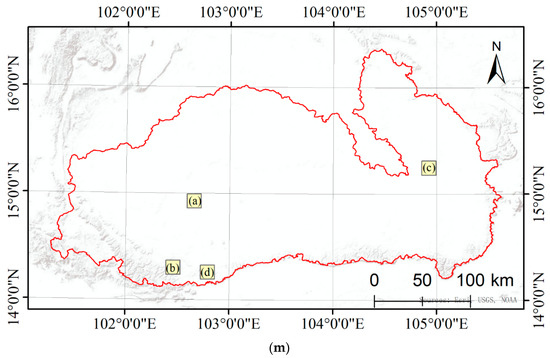
Figure 7.
Details of the pre-classification land cover map versus the decision fusion land cover map. Four locations mainly containing paddy rice, dryland, developed land, and forests are shown at a larger scale: (a) mainly paddy rice, dry land, and developed land; (b) mainly dryland and forest; (c) mainly paddy rice, water, and developed land; (d) mainly dryland and forest; (e–h) the same regions with decision fusion results; (i–l) the same regions with manually interpreted land cover. (m) is the location of the four regions.
As shown in Figure 7a,e,i, the pre-classification results preserved more details of dry land and developed land. Figure 7b,f,j show that the pre-classification map and decision map are not very similar to the true land cover map. On the fusion map, more patches are classified as dry land. The evergreen forest in the bottom left is more intact on the decision map than the pre-classification map. More dry land is classified in the fusion map compared with the pre-classification map. In Figure 7c,g,k, the most obvious difference in the decision fusion map and pre-classification map is that the decision fusion map failed to correctly classify the water in the middle of the river. In Figure 7d,h,l, the distribution of land cover does not have much of a difference with the pre-classification map. However, the decision fusion map captured more intact patches compared with the pre-classification map. These results demonstrate that fusion after aggregation loses details in the land cover map. Patches are more intact compared with the pre-classification map of the nearest neighbor classifier.
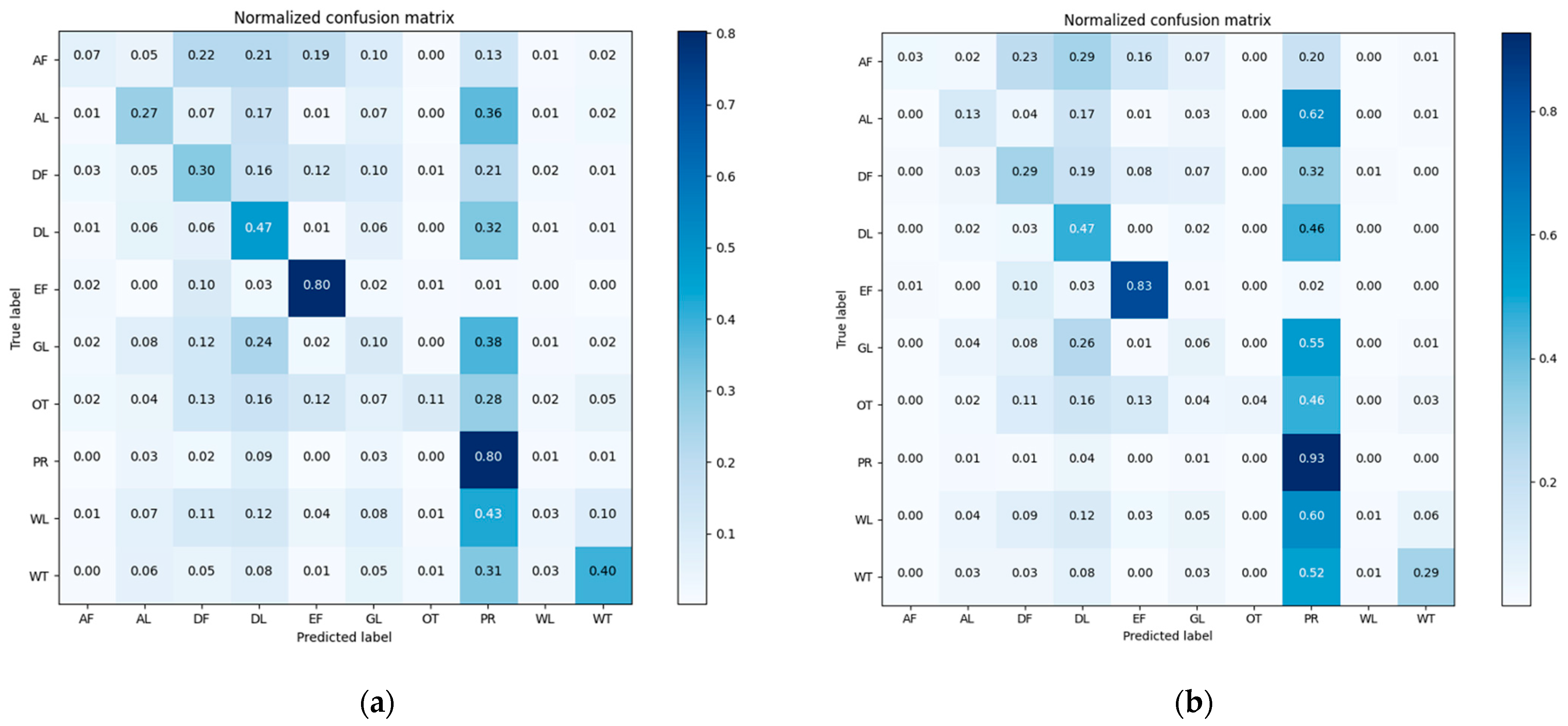
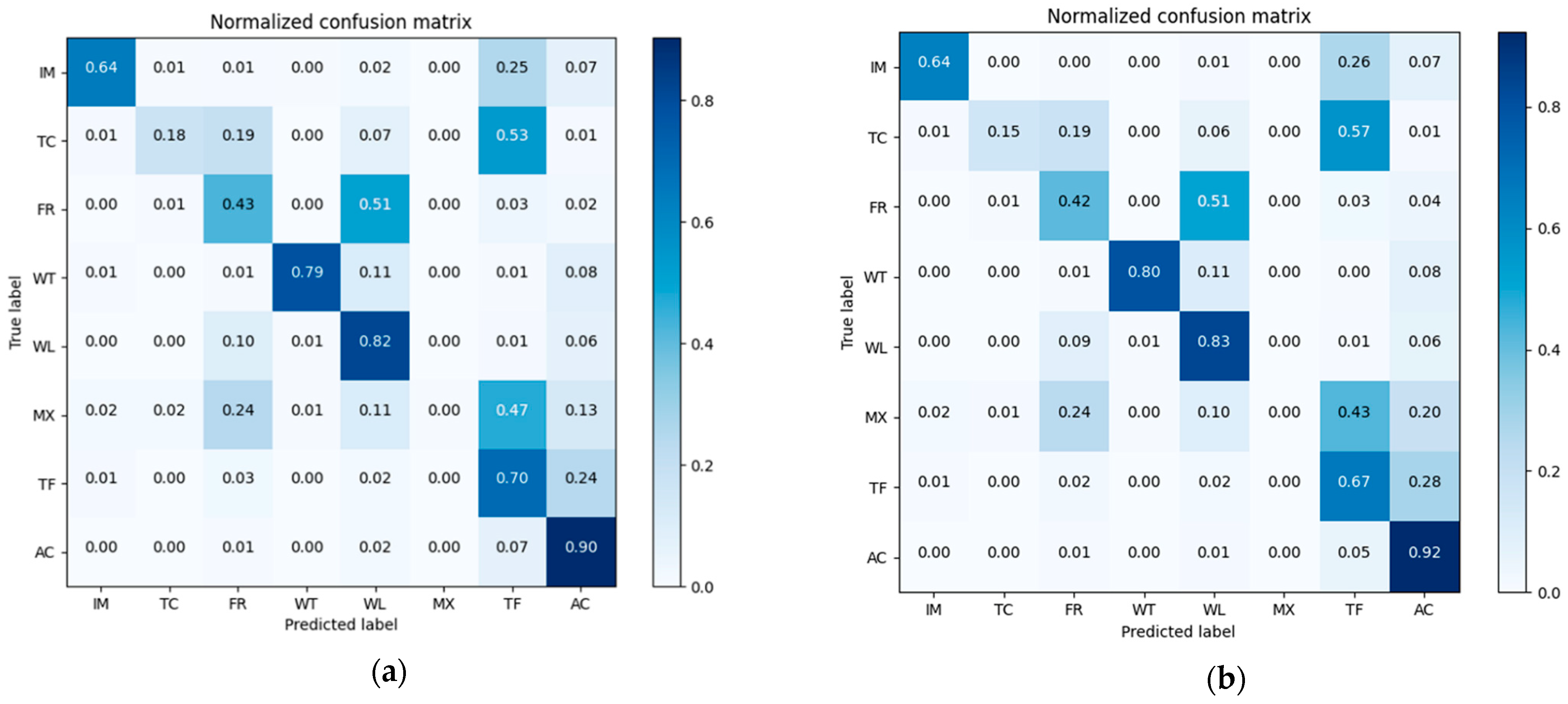
Confusion matrixes of the classification results of pre-classification and after-fusion are shown in Figure 8. We normalized the confusion matrix [55] for visual comparison.
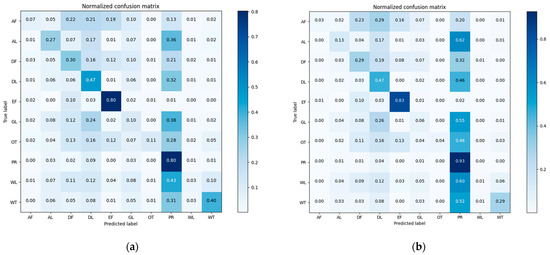
Figure 8.
Confusion matrixes of the Mun River Basin for (a) pre-classification results and (b) neighborhood spatial relationship and fuzzy classification fusion results.
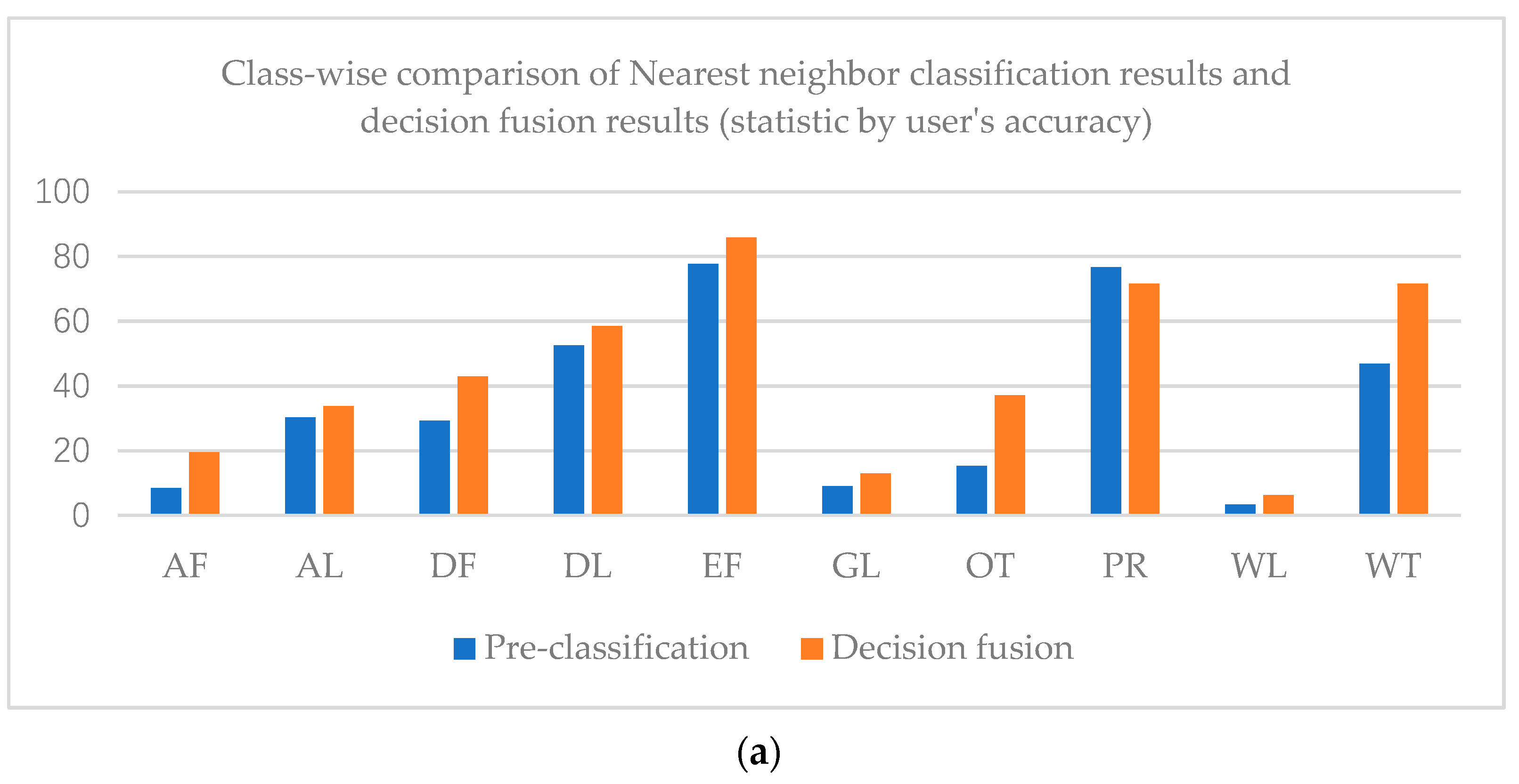
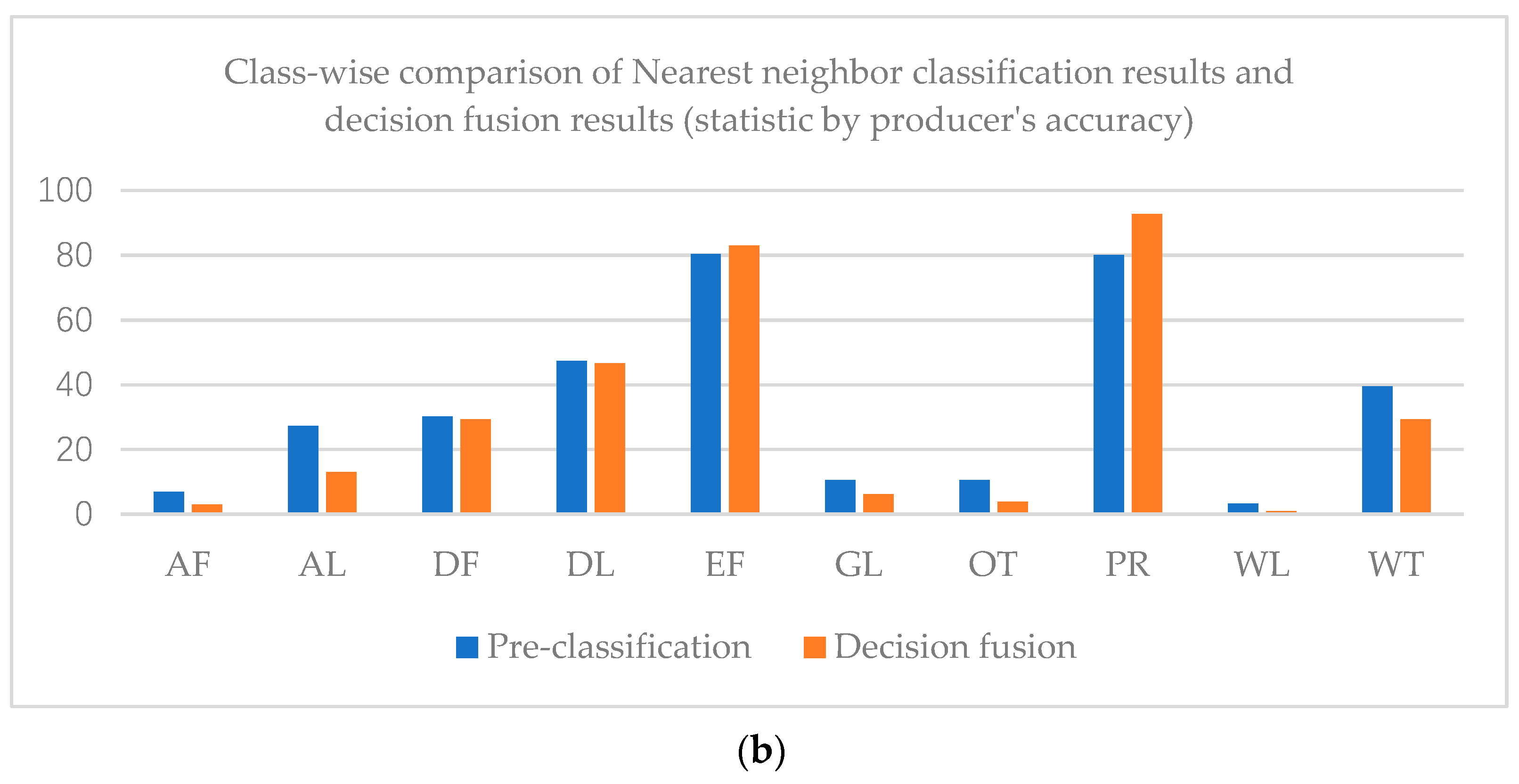
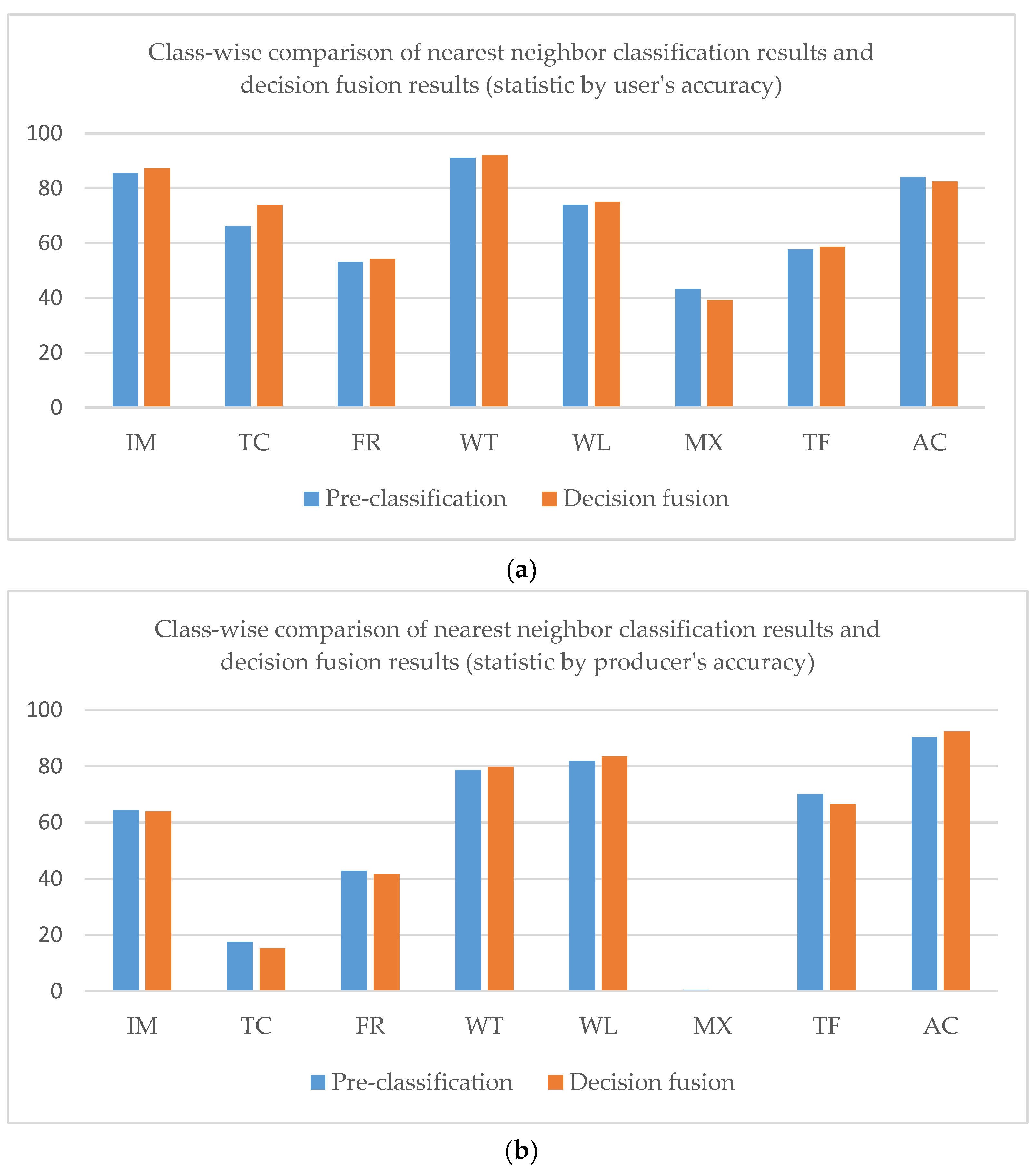
The overall accuracy of the nearest neighbor classification result is 61.71%, while that of the decision fusion result is 66.95%. As to the Kappa coefficient, the nearest neighbor classification kappa coefficient is 0.42 and the decision fusion result is 0.43. Paddy rice’s predicted label increased in the decision map, as did evergreen forest, while other classes decreased. Class-wise comparison of the nearest neighbor classification results and decision fusion results are shown in Figure 9.
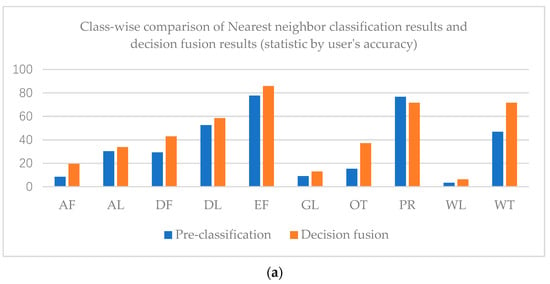
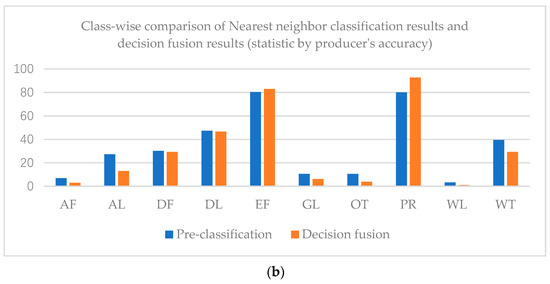
Figure 9.
Class-wise comparison of nearest neighbor classification results and decision fusion results (statistic by user’s accuracy (a) and producer’s accuracy (b)) in the Mun River Basin.
As shown in Figure 9, user’s accuracies of all classes in the decision fusion results are higher than the pre-classification results. However, only the evergreen forest and paddy rice producer’s accuracies of decision fusion results are higher than the pre-classification results.
3.3. Results for Kent County
Following the method above, we also conducted the experiment for Kent County.
3.3.1. Trained Graph in Kent County
Unlike the Mun River Basin’s true land cover map, which was obtained by manually interpreting and classifying land cover, the “true” land cover map was obtained by a 1 m computer classification. To achieve a better effect on the scale issue we introduced in 2.2, the segmentation polygon was overlaid on the 1 m land cover map. Segmentation polygon is obtained by multi-resolution segmentation of the sentinel-2 image on the eCognition development platform. Segmentation scale is set as 80. And a shape criterion of 0.1, and a compactness of 0.5.
We assumed that there was only one type of land cover within an object. Land cover types were accounted for within the segmented polygon of the land cover map and the land cover type with the highest count was treated as the land cover of the object. The comparison of the land cover maps is shown in Figure 10.
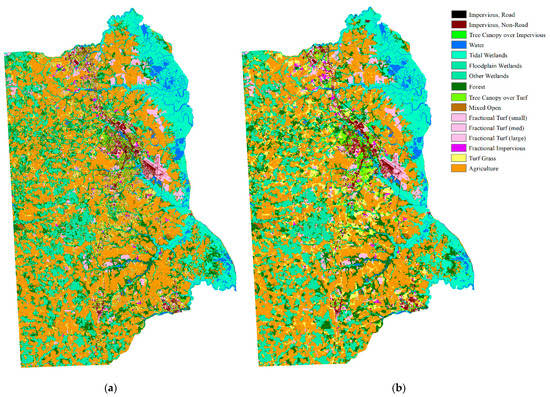
Figure 10.
Comparison of 1 m land cover map and the overlaid segmentation map: (a) 1 m land cover map; (b) overlaid segmentation map.
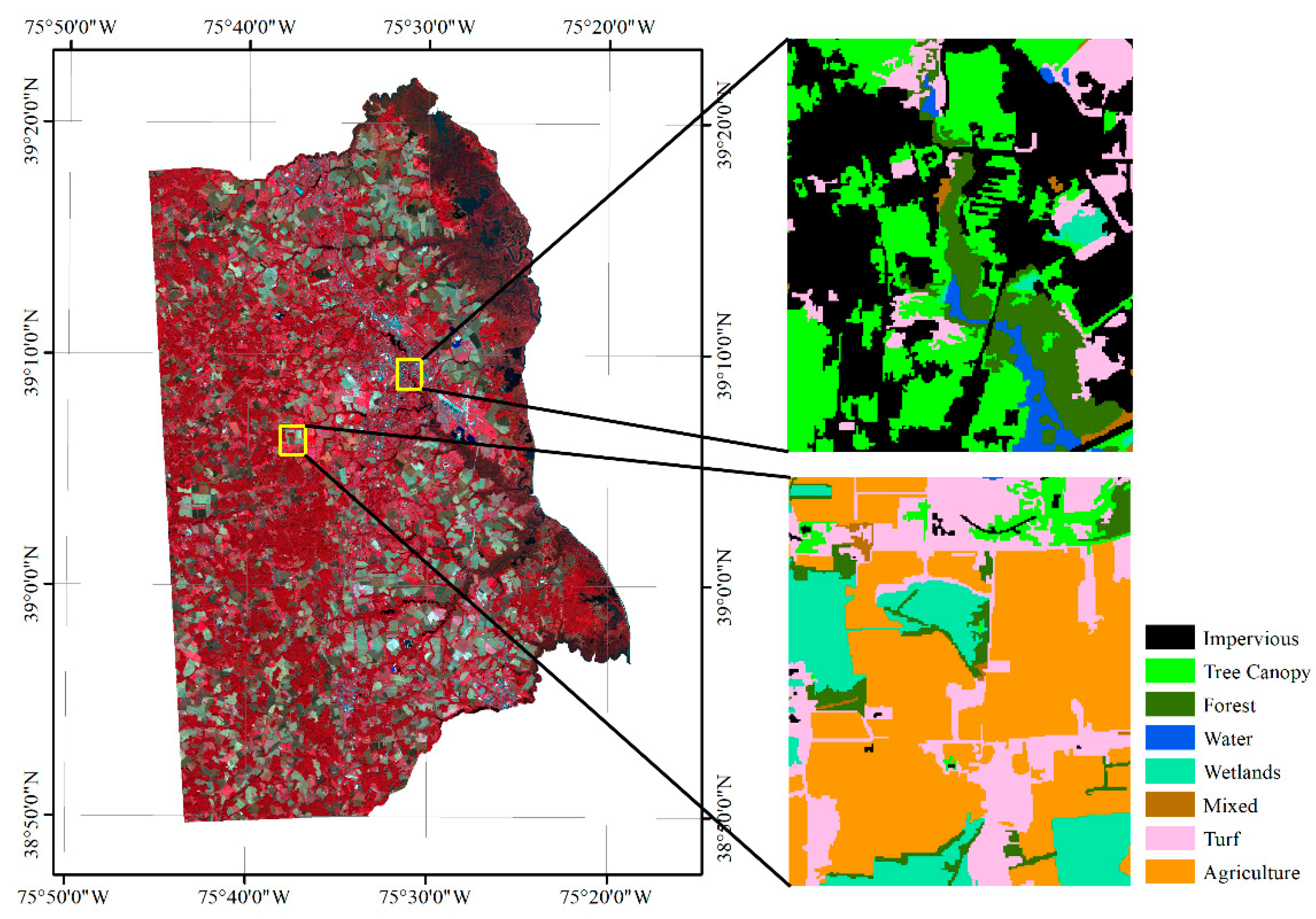
Unlike the homogeneous landscape of the Mun River Basin, Kent County can roughly be divided into urban and suburban landscapes. Two small regions were selected to represent the urban region and suburban region to build the graph. The overlaid segmentation map is coarser and loses some details in the 1 m image classification map, but the overall land cover types are identical. In a real application, it is not necessary to transfer the entire high-resolution land cover map to the object level. Only sample regions that are used for graph building are needed (Figure 11).
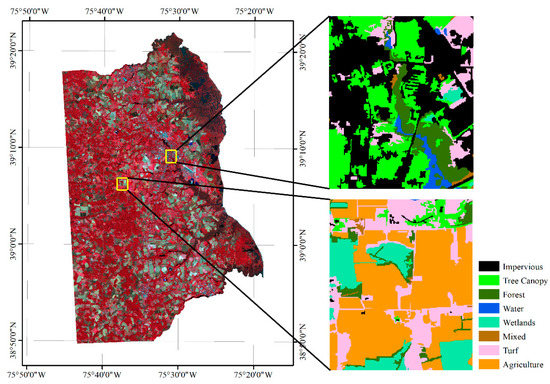
Figure 11.
Location of the sample region for building the graph of Kent County.
Because of the spectral similarity and the definition homogeneity, we combined some of the classes. The final classification scheme has eight types of land cover: impervious, tree canopy, water, wetlands, forest, mixed land, turf, and agriculture. In total, 2662 edges were generated for the 603 nodes for graph building. The edges denote that the nodes are adjacent to each other. We visualized the built graph of the two sample regions in Figure 12.
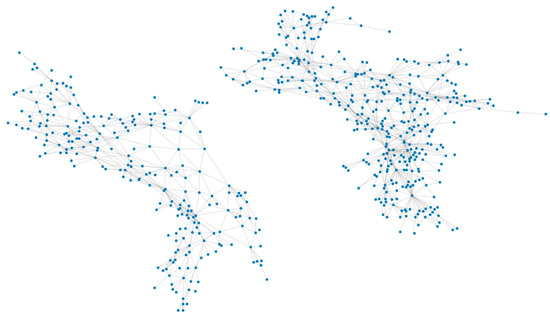
Figure 12.
Visualized graph for the pre-trained spatial relationship of Kent County.
From the graph, the statistics of each node’s degree with different labels according to Equation (1) were calculated. The calculation of the probability of land cover types being adjacent to each other in Kent County were the same as the Mun River Basin. Table 2 shows the probability of land cover types being adjacent to other types. Using this probability, we can aggregate the fuzzy classification result with the adjacent probabilities.
Table 2.
Probability of land cover types being adjacent to each other in Kent County.
3.3.2. Pre-Fuzzy-Classification Results in Kent County
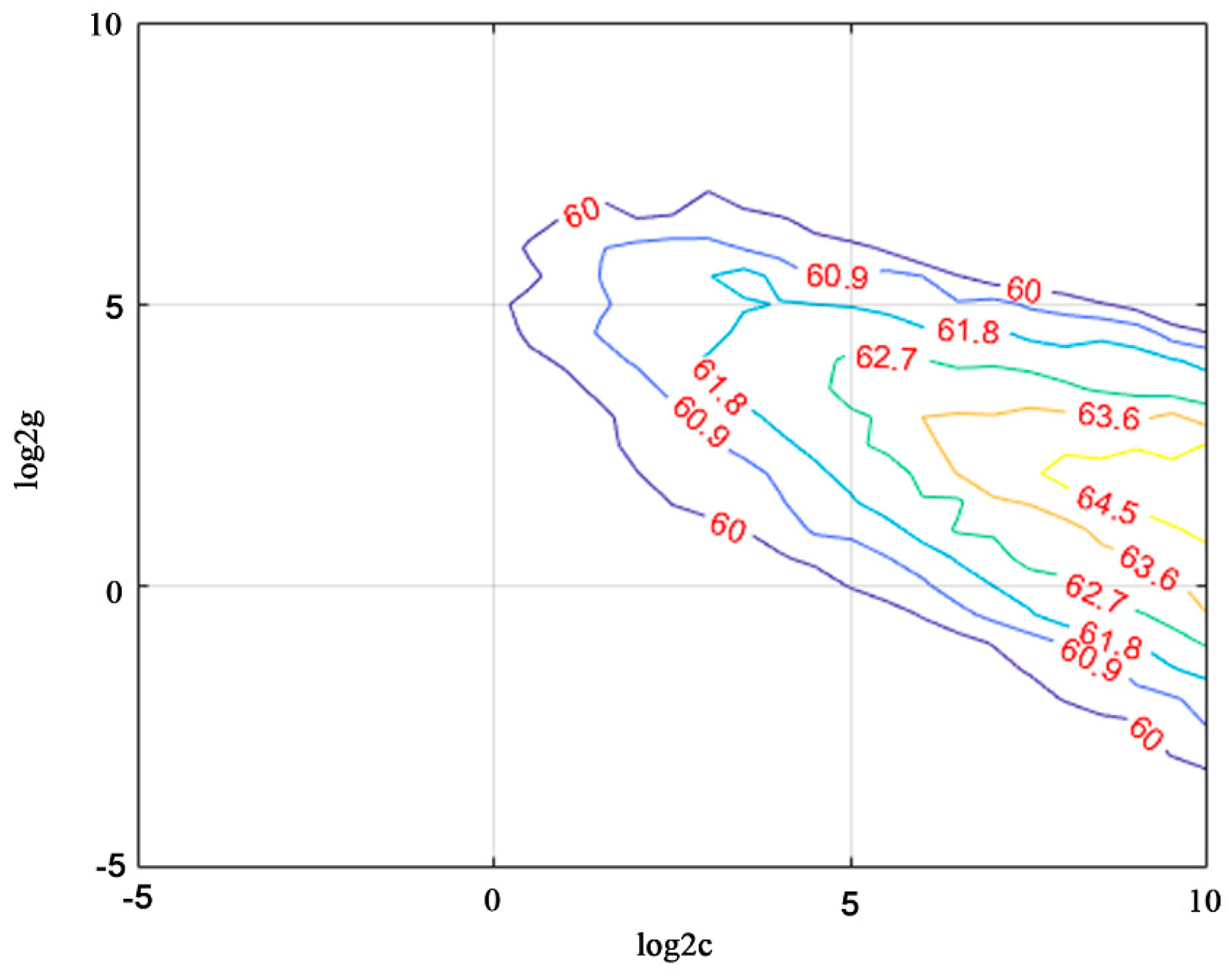
LIBSVM 3.2.4 was implemented for pre-classification in Kent County [56]. C-SVC was implemented for the SVM model and RBF was run as the SVM kernel. Parameter values were trained on 1500 samples and five folds of cross-validation accuracy was 43.35%. The best c value is 724.0773 and the best g value is 2.8284, as shown in Figure 13. However, testing 6000 samples yielded an accuracy of 65.55% (statistics of object numbers rather than area). Therefore, we decided to use this parameter for SVM model training.
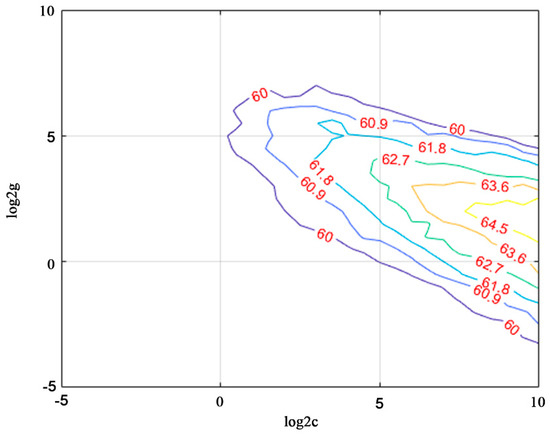
Figure 13.
Training for c and g values for the RBF kernel of the SVM classifier.
LIBSVM uses an All-versus-All strategy to achieve multi-label classification. We directly used the multi-classification solution for our classification. The pre-classification result in Kent County is as shown in Figure 14a. Membership in the selected land cover types including impervious, forest, and agriculture is also shown in Figure 14.

Figure 14.
Fuzzy classification results and selected land cover type membership in Kent County: (a) classification result by SVM; (b) membership in agriculture; (c) membership in forest; (d) membership in impervious.
3.3.3. Decision Fusion Maps in Kent County
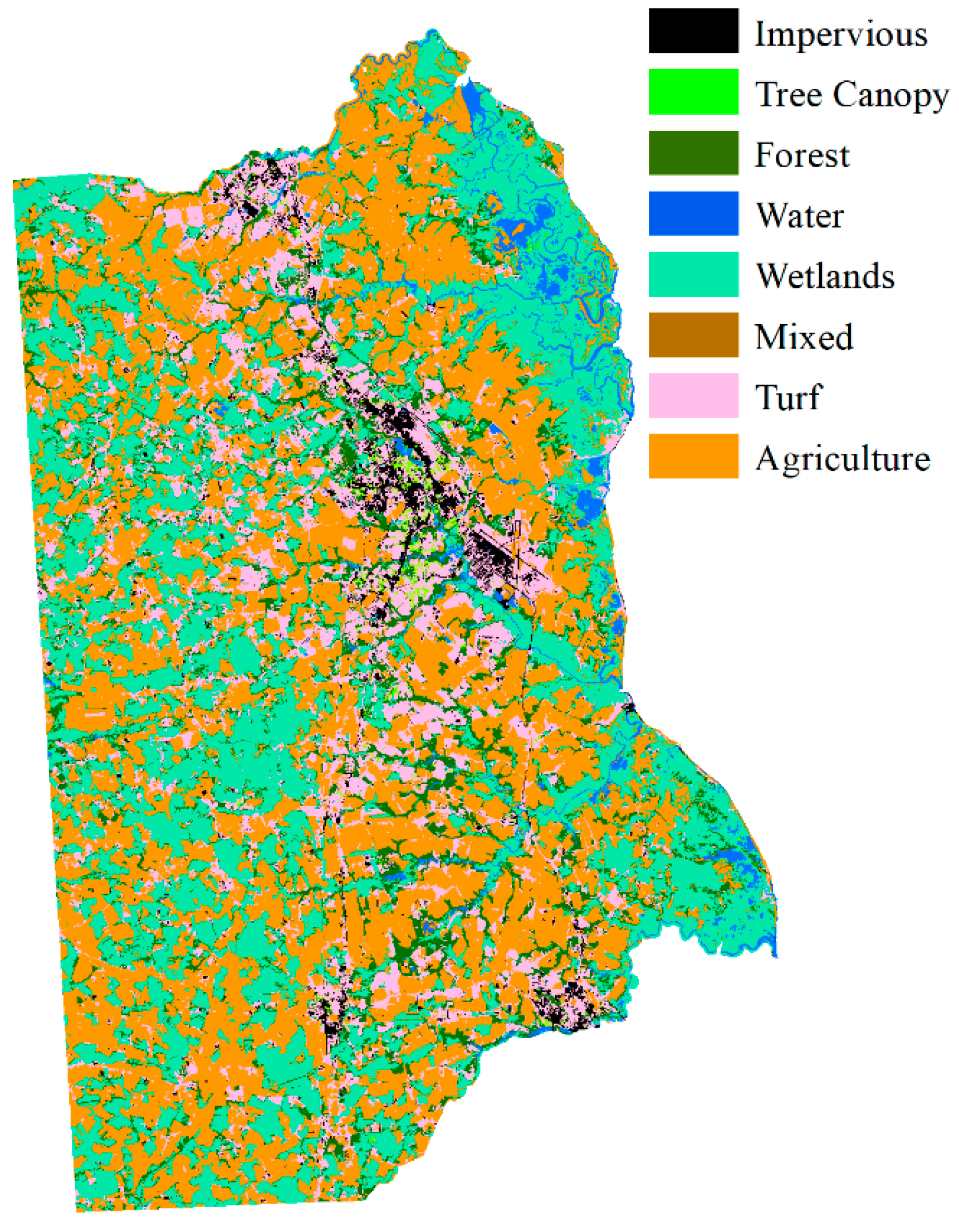
According to Equation (9), the fuzzy classification results were aggregated with neighborhood land cover probability. The decision fusion map of Kent County is shown in Figure 15.
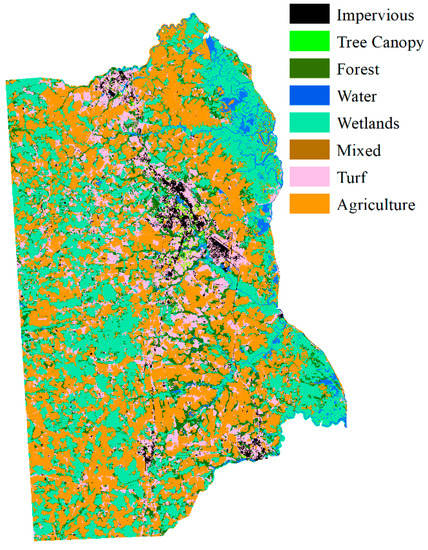
Figure 15.
Land cover map of the aggregated pre-trained neighborhood spatial relationship and fuzzy classification membership result.
3.3.4. Accuracy Assessment of Kent County
In order to compare the detailed difference between the pre-classification map, fusion map, and true land cover classification map, three small regions were randomly picked to show the detailed difference between pre-classification results and decision fusion results. The three small regions mainly contained wetland and agriculture; impervious and tree canopy; and water and wetlands.
As shown in Figure 16a,d,g, the decision fusion result corrected some wetland regions that were misclassified as forest in the pre-classification process. In Figure 16b,e,h the pre-classification map and decision map are similar. Most tree canopy was misclassified as turf and the decision fusion method failed to correct them. Some turf patches misclassified as forest in the pre-classification were corrected in the decision map. In Figure 16c,f,i, the decision fusion method also failed to correct the large area of turf that was misclassified as agriculture in the pre-classification map. Moreover, the decision fusion method connected the areas of agriculture, which led to misclassification of a small region of wetland. The decision fusion method succeeded in correcting a small water area that was misclassified as agriculture in the pre-classification map. This experiment demonstrated that the decision fusion method tends to connect large patches that belong to the same class. This conforms to the first law of geography [57] but may also lead to misclassification.
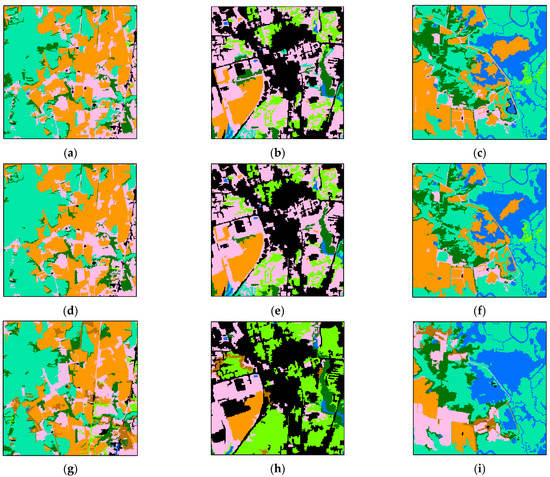
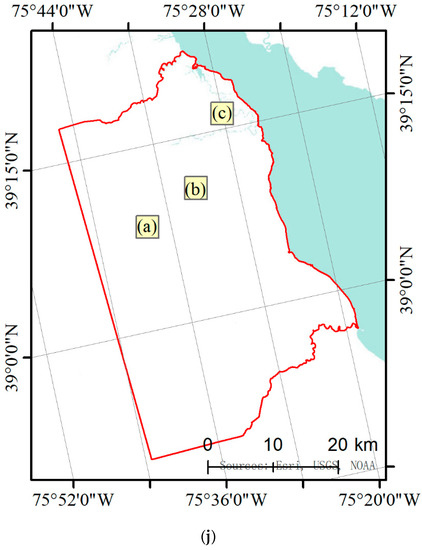
Figure 16.
Details of the pre-classification land cover map versus the decision fusion land cover map. The three locations, shown at a larger scale, respectively contain (a) wetland and agriculture, (b) impervious and tree canopy, and (c) water and wetland, while (d–f) are the same regions with decision fusion results and (g–i) are the same regions with manually interpreted land cover. (j) is the location of the sample regions.
Normalized Confusion matrixes of classification results in Kent County is shown in Figure 17. The overall accuracy of the nearest neighbor classification result is 73.64%, while that for the decision fusion result is 74.26%. As to the Kappa coefficient, the nearest neighbor classification kappa coefficient is 0.648 and the decision fusion result is 0.653. Impervious surfaces misclassified as water were corrected in the decision result. As shown in Figure 17, tree canopy decreased in the decision result and more tree canopy was misclassified as turf in the decision result. Some forest cover was corrected from misclassification as turf, wetland, and impervious surfaces in the pre-classification but some of the forest patches were misclassified as agriculture in the decision fusion. Some misclassified mixed land in pre-classification was corrected to water in the decision fusion, and some misclassified mixed land in pre-classification was corrected to wetland in the decision fusion. No mixed land was corrected by the decision fusion process. Some turf that was correctly classified in pre-classification was then mis-labeled as tree canopy in the decision fusion result. A comparison of class-wise fuzzy SVM classification and decision fusion is shown in Figure 18.
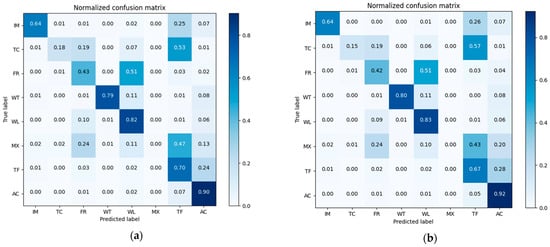
Figure 17.
Confusion matrixes in Kent County for (a) pre-classification results and (b) the neighborhood spatial relationship and fuzzy classification fusion results.
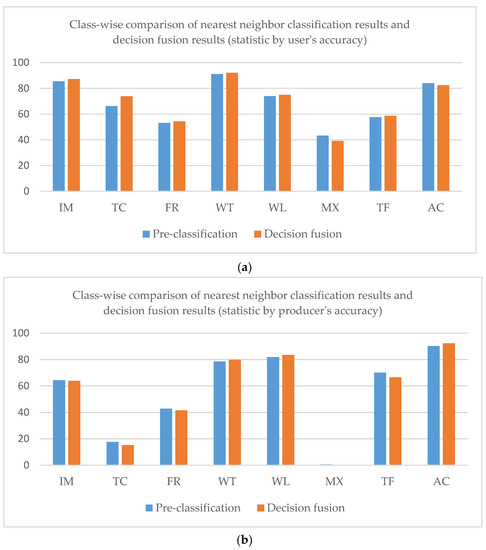
Figure 18.
Class-wise comparison of fuzzy SVM classification results and decision fusion results (statistic by user’s accuracy (a) and producer’s accuracy (b)) in Kent County.
As shown in Figure 18, the decision fusion user’s accuracy and producer’s accuracy did not change much compared with the fuzzy SVM classification result. We will analyze the reason for this result in the following section.
4. Discussion
4.1. Experiments Analysis
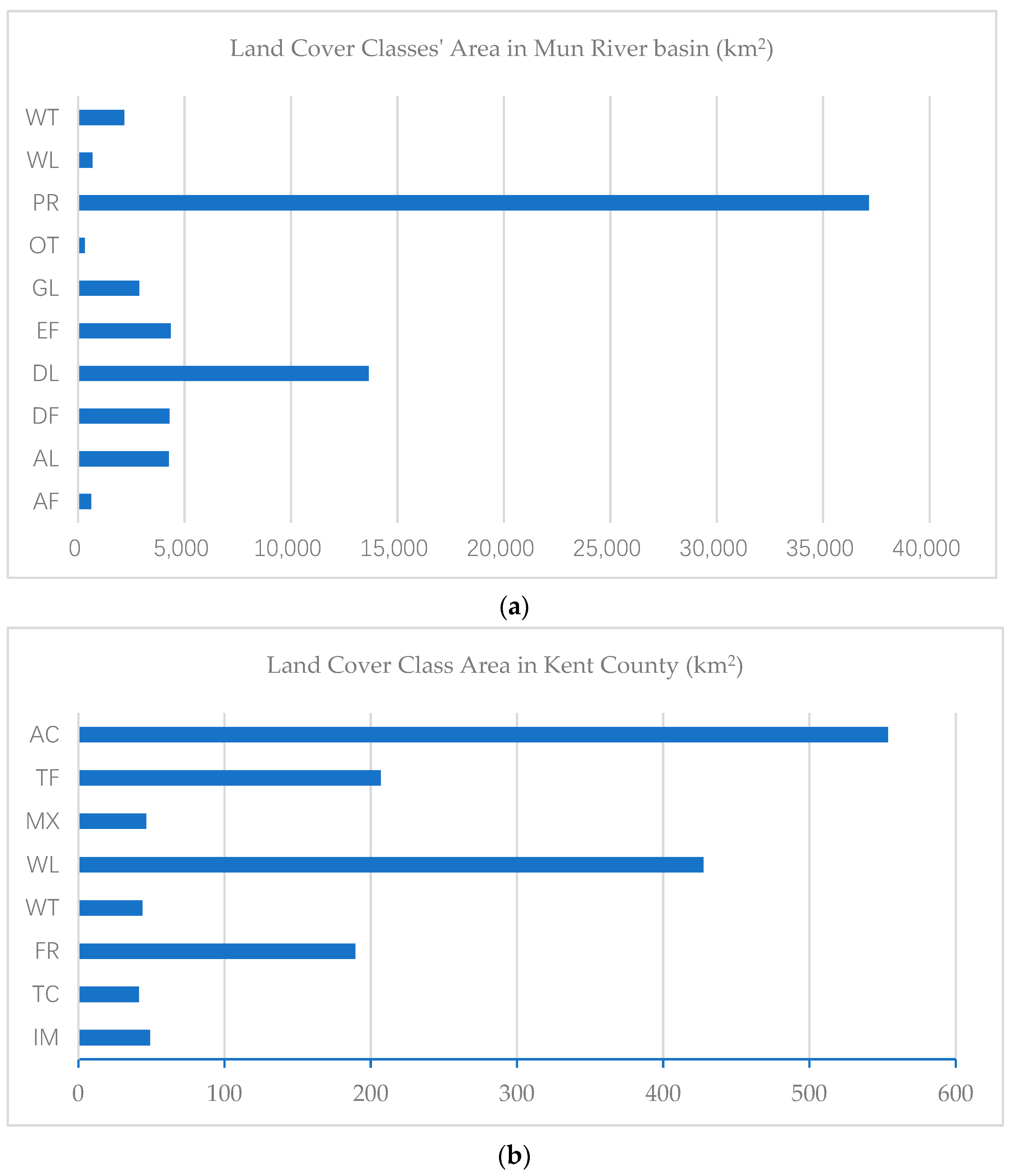
The first experiment’s overall accuracy improved 5.24%, whereas the second experiment’s overall accuracy only improved 0.62%. The main difference between the two regions is the distribution pattern of land cover classes. In the first region, the land cover distribution is imbalanced. As shown in Figure 19, the standard deviation of land cover classes in the Mun River Basin is 10,685.1, whereas the standard deviation of land cover classes in Kent County is 184.6.
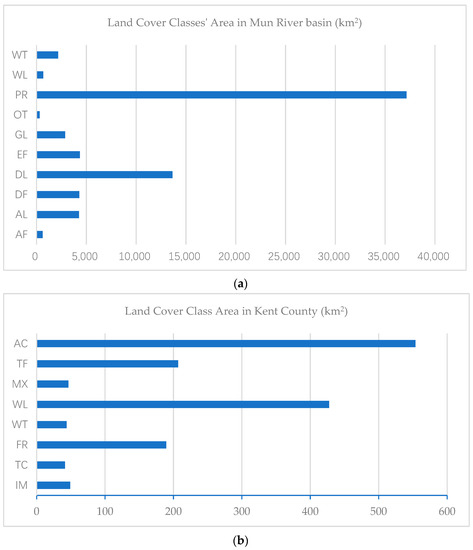
Figure 19.
Area of land cover classes in the Mun River Basin (a) and Kent County (b). The area distribution of classes in the Mun River Basin is imbalanced compared with Kent County.
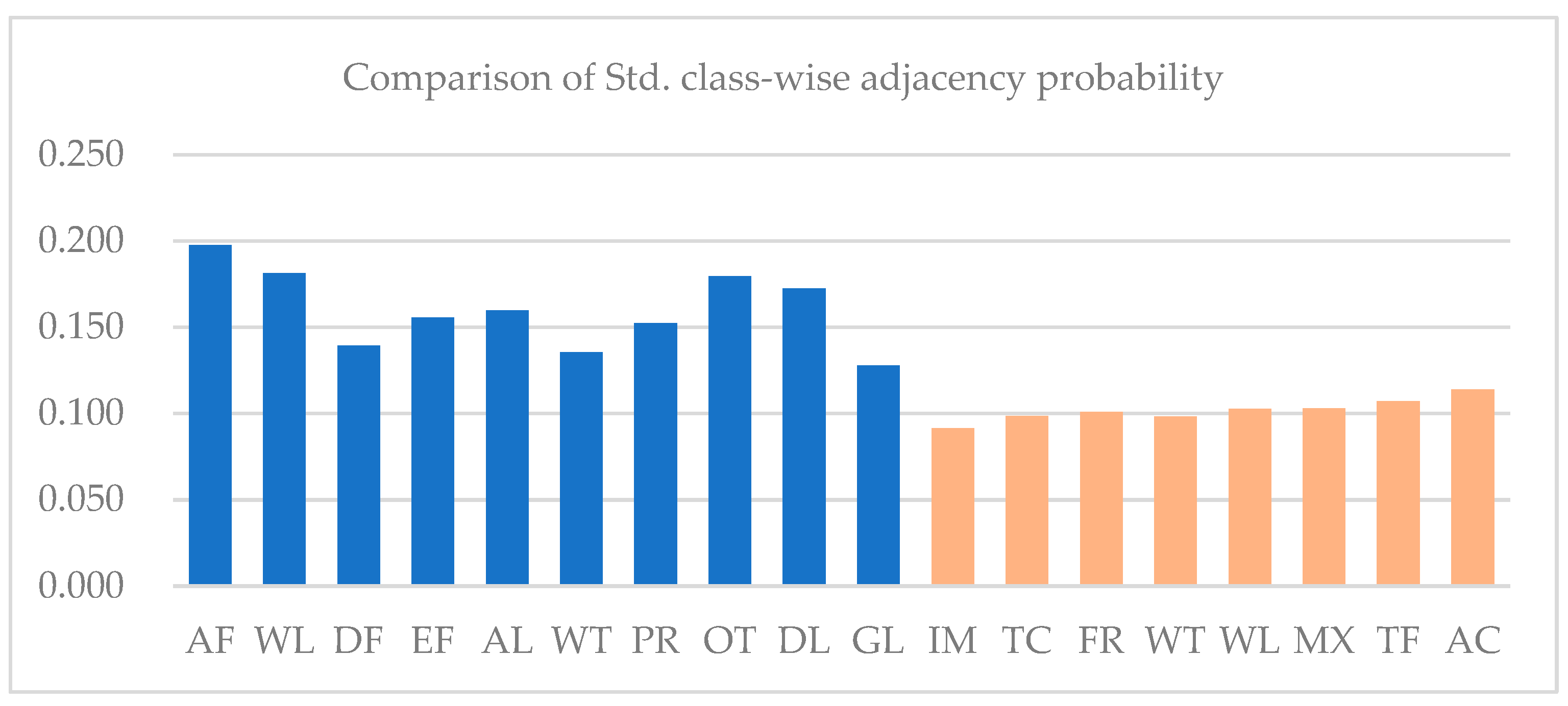
The imbalance of the distribution of land cover types is also inferred from Table 1 and Table 2, the probability of land cover types being adjacent to each other in sample regions. As shown in Figure 20, class-wise standard deviations of the probability of adjacency in the Mun River Basin are all higher than Kent County, caused by the extensive distribution of paddy rice in the former leading to a high probability of other land cover adjacency to paddy rice. In contrast, land cover class distribution in Kent County is relatively balanced.
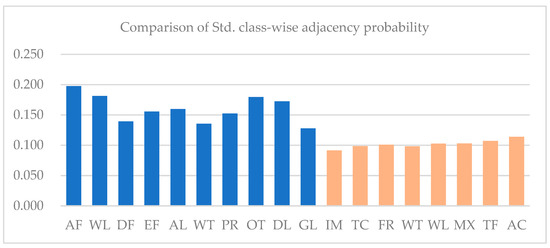
Figure 20.
Comparison of standard deviation of class-wise adjacency probability in Kent County and the Mun River Basin.
The imbalanced distribution of land cover classes meant a higher probability that classes with larger areas would have higher weights in the decision fusion process. This was also proved by the confusion matrix. More patches were misclassified as paddy rice in the decision fusion result. The problem was mainly caused by the single use of adjacency probability derived from the graph, which represents the global probability of adjacency rather than the local probability. Therefore, extracting the local probability of adjacency through more knowledge and spatial patterns is a worthwhile direction of study.
Kent County’s land cover distribution is relatively balanced. However, overall accuracy only improved 0.62%. There were 1632 among 52,719 objects that the decision fusion process successfully corrected from misclassification in pre-classification. The class membership of the corrected objects that were wrongly classified was close to the corrected class membership. The performance of pre-classification is vital in the performance of decision fusion.
There were 1395 among 52,719 objects that the pre-classification correctly classified but the decision fusion result misclassified. Focusing on these 1395 objects, two situations that led to incorrect classification were found, as shown in Table 3.
Table 3.
Two situations demonstrate the objects misclassified by decision fusion. Problems causing the misclassification are marked in underline.
The first situation that caused misclassification is similar to the Mun River Basin. When the membership of two classes was close, so was that of the adjacent object. The probability of adjacency of the false class was higher, shown in Table 3 Situation 1, and the decision tended to classify them as classes with higher adjacency probability like B-B. The second situation was caused by the “siphonic effect”. Although membership of the two classes was not very close, the high membership of adjacent objects like Class B caused misclassification as well.
To sum up, two problems were found to cause misclassification in the decision process. First, the single use of global probability of adjacency caused the tendency of classification to those classes with larger areas. Second, the “siphonic effect” led to misclassification caused by high membership probability of neighborhood objects.
4.2. Segmentation Effects
The adjacency estimation will ulteriorly influence the fusion results. So that the results of the graph-based neighborhood adjacency estimation are depending on the seg-mentation result. The segmentation scale will influence adjacency estimation as shown in Figure 21.
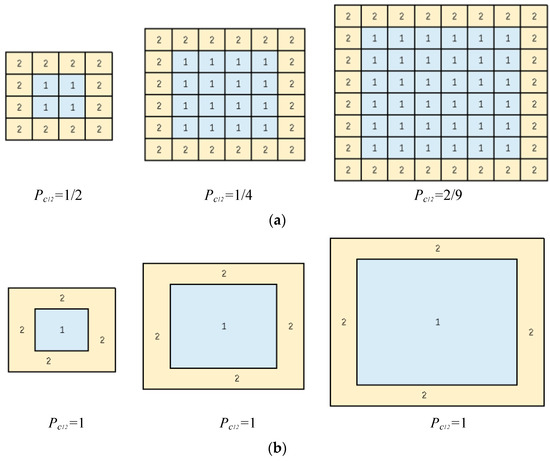
Figure 21.
The object-oriented method for pre-classification was chosen based on whether the model uses (a) pixels for pre-classification or (b) objects for pre-classification. The object model is more robust compared to the pixel model, which makes the built graph more applicable to it.
In the experiment, we segmented the image used multi-resolution segmentation with a self-defined segment scale in the eCognition software. In the experiment, we set a proper segmentation scale as 60 in the first experiment and 80 in the second experiment. The adjacency possibility is calculated by the segmented polygons in the two-study case. However, the second experiment indicate that fusion result doesn’t improve much even when the adjacency possibility is calculated in the same scale with the object-oriented classification process. In The second experiment, pre-classification overall accuracy is 73.64%. Much improvement is hardly achievable by incorporating adjacency possibilities. These results indicate that the fusion results are hardly affected by segmentation scale provided that proper segmentation scale is set in the object-oriented classification process.
5. Conclusions
In this paper, we presented a method to extract the probability of adjacency between classes using graph theory. In order to utilize adjacency probability in the decision fusion process, the pre-fuzzy-classification results and the adjacency probability were combined at the decision level. Two experiments exhibited improvement in the overall accuracy. Al though the overall accuracies are not significantly improved. As for the class-wise accuracy, the user’s accuracies are obviously improved in term of most of the classes.
In the first study case, Landsat data are used for pre-classification and the overall accuracy is 61.71%. It is likely to achieve more improvement in the fusion result compared with the second study case, which pre-classification overall accuracy is 73.64%. And indeed, the first study case achieved the 5.2% overall accuracy improvement and the second study case only improved by 0.6%. Another reason may lead to the limited improvement of the overall accuracy in the second study is that we are using a simulated “true” map rather than a manually interpreted map as in the first study case. It causes inaccuracy of adjacency possibility in the second study case. Although the overall accuracy of the decision fusion result is unsatisfactory in the second study case, user’s accuracy is obviously improved. We only used the 1th order adjacency degree to dig the adjacency information. Future work that explores more information from the graph is needed for overall accuracy improvement.
We analyzed the results and found two major problems in the proposed method. First, using adjacency probability derived from the samples of the regions to be classified resulted in imbalanced classification. Second, directly multiplying the adjacency probability and membership caused neighborhood objects to experience the “siphonic effect”.
There are improvements feasible to further digging the adjacency knowledge using graph theory. In this paper, we simply used the first order adjacent degree in the sampled graph to inference the adjacency probability. There was second order and even third order adjacency in the graph theory. Also, graph embedding theory and graph neural network theory were employed to extract spatial relationships between classes.
Researchers have used knowledge to inference land cover classes. The general scheme is to first match the scene knowledge, then use that knowledge to classify the im-age again. This is a practical effort. In our research, we found that using neighborhood adjacency probability caused problems. A practical improvement might be to use scene knowledge, inferencing adjacency probability from the scene knowledge rather than statistics from the whole map. Another direction is to embed the knowledge into the classifier. Some researchers have already used a GNN (Graph Neural Network) model to classify remote sensing imagery [39,40]. These studies have proved that the spatial relationship introduced by GCN boosts the performance and robustness of the classification model. Application of graph theory in extracting spatial relationship information and the use of prior knowledge in remote sensing image classification is worth further research in the future.
Author Contributions
Conceptualization, X.G.; methodology, C.H.; software, X.G.; validation, C.H. and A.L.; formal analysis, C.H.; investigation, X.G.; resources, C.H.; data curation, J.Y.; writing—original draft preparation, X.G.; writing—review and editing, C.H.; visualization, X.G.; supervision, A.L.; project administration, A.L.; funding acquisition, C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Science Foundation of China under grant 41901309, 41701433 and 42090015, the CAS “Light of West China” Program, the Youth Talent Team Program of the Institute of Mountain Hazards and Environment, CAS under grant SDSQB-2020000032, Y8R2230230, Sichuan Science and Technology Program under grant 2020JDJQ0003 and the Second Tibetan Plateau Scientific Expedition and Research Program under grant 2019QZKK0308.
Data Availability Statement
The data presented in this study are openly available in [Mendeley Data] at [DOI:10.17632/2sgkcpfh65.2], accessed on 13 August 2021.
Acknowledgments
We want to thank Lei Zou (Department of Geography, Texas A&M University) who talked about Google’s development of knowledge graph with me in November 2019, which enlightened our work. And Guangbin Lei (Research Center for Digital Mountain and Remote Sensing Application, Institute of Mountain Hazards and Environment, Chinese Academy of Sciences) for his helping with funding acquisition with this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, Y.; Liu, C.; Zhao, W.; Huang, Y. Multi-spectral remote sensing images feature coverage classification based on improved convolutional neural network. Math. Biosci. Eng. 2020, 17, 4443–4456. [Google Scholar] [CrossRef] [PubMed]
- Luo, B.; Zhang, L. Robust Autodual Morphological Profiles for the Classification of High-Resolution Satellite Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1451–1462. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, G.; Liu, J. A modified object-oriented classification algorithm and its application in high-resolution remote-sensing imagery. Int. J. Remote Sens. 2012, 33, 3048–3062. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land-Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.X.; Han, J.W.; Guo, L.; Xia, G.S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Gu, Y.T.; Wang, Y.T.; Li, Y.S. A Survey on Deep Learning-Driven Remote Sensing Image Scene Understanding: Scene Classification, Scene Retrieval and Scene-Guided Object Detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.H.; Du, B.; Zhang, L.P. Assessing the Threat of Adversarial Examples on Deep Neural Networks for Remote Sensing Scene Classification: Attacks and Defenses. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1604–1617. [Google Scholar] [CrossRef]
- Zhao, L.J.; Zhang, W.; Tang, P. Analysis of the inter-dataset representation ability of deep features for high spatial resolution remote sensing image scene classification. Multimed. Tools Appl. 2019, 78, 9667–9689. [Google Scholar] [CrossRef]
- Pacifici, F.; Chini, M.; Emery, W.J. A neural network approach using multi-scale textural metrics from very high-resolution panchromatic imagery for urban land-use classification. Remote Sens. Environ. 2009, 113, 1276–1292. [Google Scholar] [CrossRef]
- Zhang, L.P.; Zhang, L.F.; Du, B. Deep Learning for Remote Sensing Data A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Guo, Q.; Kelly, M.; Gong, P.; Liu, D. An Object-Based Classification Approach in Mapping Tree Mortality Using High Spatial Resolution Imagery. Giscience Remote Sens. 2007, 44, 24–47. [Google Scholar] [CrossRef]
- Goodenough, D.G.; Goldberg, M.; Plunkett, G.; Zelek, J. An expert system for remote sensing. IEEE Trans. Geosci. Remote Sens. 1987, 25, 349–359. [Google Scholar] [CrossRef]
- Metternicht, G. Assessing temporal and spatial changes of salinity using fuzzy logic, remote sensing and gis. Foundations of an expert system. Ecol. Model. 2001, 144, 163–179. [Google Scholar] [CrossRef]
- Kartikeyan, B.; Majumder, K.L.; Dasgupta, A.R. An expert system for land cover classification. IEEE Trans. Geosci. Remote Sens. 1995, 33, 58–66. [Google Scholar] [CrossRef]
- Murai, H.; Omatu, S. Remote sensing image analysis using a neural network and knowledge-based processing. Int. J. Remote Sens. 1997, 18, 811–828. [Google Scholar] [CrossRef]
- Sarma, L.; Sarma, V. A prototype expert system for interpretation of remote sensing image data. Sadhana 1994, 19, 93–111. [Google Scholar] [CrossRef] [Green Version]
- Dobson, M.C.; Pierce, L.E.; Ulaby, F.T. Knowledge-based land-cover classification using ERS-1/JERS-1 SAR composites. IEEE Trans. Geosci. Remote Sens. 1996, 34, 83–99. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Benz, U.C.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens. 2004, 58, 239–258. [Google Scholar] [CrossRef]
- Masjedi, A.; Zoej, M.J.V.; Maghsoudi, Y. Classification of polarimetric sar images based on modeling contextual information and using texture features. IEEE Trans. Geosci. Remote Sens. 2016, 54, 932–943. [Google Scholar] [CrossRef]
- Dianat, R.; Kasaei, S. Change Detection in Optical Remote Sensing Images Using Difference-Based Methods and Spatial Information. IEEE Geosci. Remote. Sens. Lett. 2010, 7, 215–219. [Google Scholar] [CrossRef]
- Cui, W.; Wang, F.; He, X.; Zhang, D.Y.; Xu, X.X.; Yao, M.; Wang, Z.W.; Huang, J.J. Multi-Scale Semantic Segmentation and Spatial Relationship Recognition of Remote Sensing Images Based on an Attention Model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef] [Green Version]
- Qiao, C.; Wang, J.; Shang, J.; Daneshfar, B. Spatial relationship-assisted classification from high-resolution remote sensing imagery. Int. J. Digital Earth 2015, 8, 710–726. [Google Scholar] [CrossRef]
- Bouziani, M.; Goita, K.; He, D.-C. Rule-Based Classification of a Very High Resolution Image in an Urban Environment Using Multispectral Segmentation Guided by Cartographic Data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3198–3211. [Google Scholar] [CrossRef]
- Benz, U.; Pottier, E. Object based analysis of polarimetric SAR data in alpha-entropy-anisotropy decomposition using fuzzy classification by eCognition. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. Proceedings. IEEE 2001 International Geoscience and Remote Sensing Symposium, Sydney, Australia, 9–13 July 2001; pp. 1427–1429. [Google Scholar]
- Guarino, N. Formal Ontology in Information Systems. In Proceedings of the 1st International Conference on Formal Ontology in Information Systems, Trento, Italy, 6–8 June 1998; pp. 3–15. [Google Scholar]
- Forestier, G.; Puissant, A.; Wemmert, C.; Gan Ca Rski, P. Knowledge-based region labeling for remote sensing image interpretation. Comput. Environ. Urban Syst. 2012, 36, 470–480. [Google Scholar] [CrossRef] [Green Version]
- Rejichi, S.; Chaabane, F.; Tupin, F. Expert Knowledge-Based Method for Satellite Image Time Series Analysis and Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2138–2150. [Google Scholar] [CrossRef]
- Mariana, B.; Ivan, T.; Thomas, L.; Thomas, B.; Bernhard, H. Ontology-Based Classification of Building Types Detected from Airborne Laser Scanning Data. Remote Sens. 2014, 6, 1347–1366. [Google Scholar] [CrossRef] [Green Version]
- Forestier, G.; Wemmert, C.; Puissant, A. Coastal image interpretation using background knowledge and semantics. Comput. Geosci. 2013, 54, 88–96. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Hofer, B.; Hofmann, P. Coupling formalized knowledge bases with object-based image analysis. Remote Sens. Lett. 2014, 5, 530–538. [Google Scholar] [CrossRef]
- Witharana, C.; Bhuiyan, M.A.E.; Liljedahl, A.K.; Kanevskiy, M.; Jorgenson, T.; Jones, B.M.; Daanen, R.; Epstein, H.E.; Griffin, C.G.; Kent, K.; et al. An object-based approach for mapping tundra ice-wedge polygon troughs from very high spatial resolution optical satellite imagery. Remote Sens. 2021, 13, 558. [Google Scholar] [CrossRef]
- Visser, F.; Buis, K.; Verschoren, V.; Schoelynck, J. Mapping of submerged aquatic vegetation in rivers from very high-resolution image data, using object-based image analysis combined with expert knowledge. Hydrobiologia 2018, 812, 157–175. [Google Scholar] [CrossRef] [Green Version]
- Dale, M.R.T.; Fortin, M.J. From Graphs to Spatial Graphs. Annu. Rev. Ecol. Evol. Syst. 2010, 41, 21–38. [Google Scholar] [CrossRef]
- Cheung, A.K.L.; O’Sullivan, D.; Brierley, G. Graph-assisted landscape monitoring. Int. J. Geogr. Inf. Sci. 2015, 29, 580–605. [Google Scholar] [CrossRef]
- Xu, C.; Liu, W. Integrating a Three-Level GIS Framework and a Graph Model to Track, Represent, and Analyze the Dynamic Activities of Tidal Flats. ISPRS Int. J. Geoinf. 2021, 10, 61. [Google Scholar] [CrossRef]
- Ouyang, S.; Li, Y. Combining Deep Semantic Segmentation Network and Graph Convolutional Neural Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2021, 13, 119. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R.; Zhang, Y.; Zhang, M.; Chen, L. Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sens. 2020, 12, 4003. [Google Scholar] [CrossRef]
- Ma, L.; Ma, A.D.; Ju, C.; Li, X.M. Graph-based semi-supervised learning for spectral-spatial hyperspectral image classification. Pattern Recognit. Lett. 2016, 83, 133–142. [Google Scholar] [CrossRef]
- Pu, S.; Wu, Y.; Sun, X.; Sun, X. Hyperspectral Image Classification with Localized Graph Convolutional Filtering. Remote Sens. 2021, 13, 526. [Google Scholar] [CrossRef]
- Jabari, S.; Zhang, Y. Building detection in very high resolution satellite image using HIS model. In Proceedings of the ASPRS 2014 Annual Conference, Louisville, KY, USA, 23–28 March 2014. [Google Scholar]
- Sebari, I.; He, D.-C. Automatic fuzzy object-based analysis of VHSR images for urban objects extraction. ISPRS J. Photogramm. Remote Sens. 2013, 79, 171–184. [Google Scholar] [CrossRef]
- Jabari, S.; Zhang, Y. Very high resolution satellite image classification using fuzzy rule-based systems. Algorithms 2013, 6, 762–781. [Google Scholar] [CrossRef]
- Pu, S.; Vosselman, G. Knowledge based reconstruction of building models from terrestrial laser scanning data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 575–584. [Google Scholar] [CrossRef]
- Zhao, M.; Wu, Y.; Pan, S.; Zhou, F.; An, B.; Kaup, A. Automatic registration of images with inconsistent content through line-support region segmentation and geometrical outlier removal. IEEE Trans. Img. Proc. 2018, 27, 2731–2746. [Google Scholar] [CrossRef] [PubMed]
- Chin-Liang, C. Finding Prototypes for Nearest Neighbor Classifiers. IEEE Trans. Comput. 1974, 23, 1179–1184. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar] [CrossRef]
- Batuwita, R.; Palade, V. FSVM-CIL: Fuzzy Support Vector Machines for Class Imbalance Learning. IEEE Trans. Fuzzy Syst. 2010, 18, 558–571. [Google Scholar] [CrossRef]
- Fan, R.-E.; Chen, P.-H.; Lin, C.-J. Working set selection using second order information for training SVM. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Hong, D.H.; Hwang, C.H. Support vector fuzzy regression machines. Fuzzy Sets Syst. 2003, 138, 271–281. [Google Scholar] [CrossRef] [Green Version]
- Chesapeake Bay. Available online: http://en.volupedia.org/wiki/Chesapeake_Bay (accessed on 17 March 2021).
- Kent County, Delaware. Available online: https://en.wikipedia.org/wiki/Kent_County,_Delaware (accessed on 17 March 2021).
- Libsvm. Available online: https://www.csie.ntu.edu.tw/~cjlin/libsvm/ (accessed on 7 April 2021).
- Hardin, P.J.; Shumway, J.M. Statistical significance and normalized confusion matrices. Photogramm. Eng. Remote Sens. 1997, 63, 735–740. [Google Scholar]
- Tobler, W. On the First Law of Geography: A Reply. Ann Assoc Am Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).