
Detecting Facial Region and Landmarks at Once via Deep Network †

Abstract
:1. Introduction
2. Materials and Methods
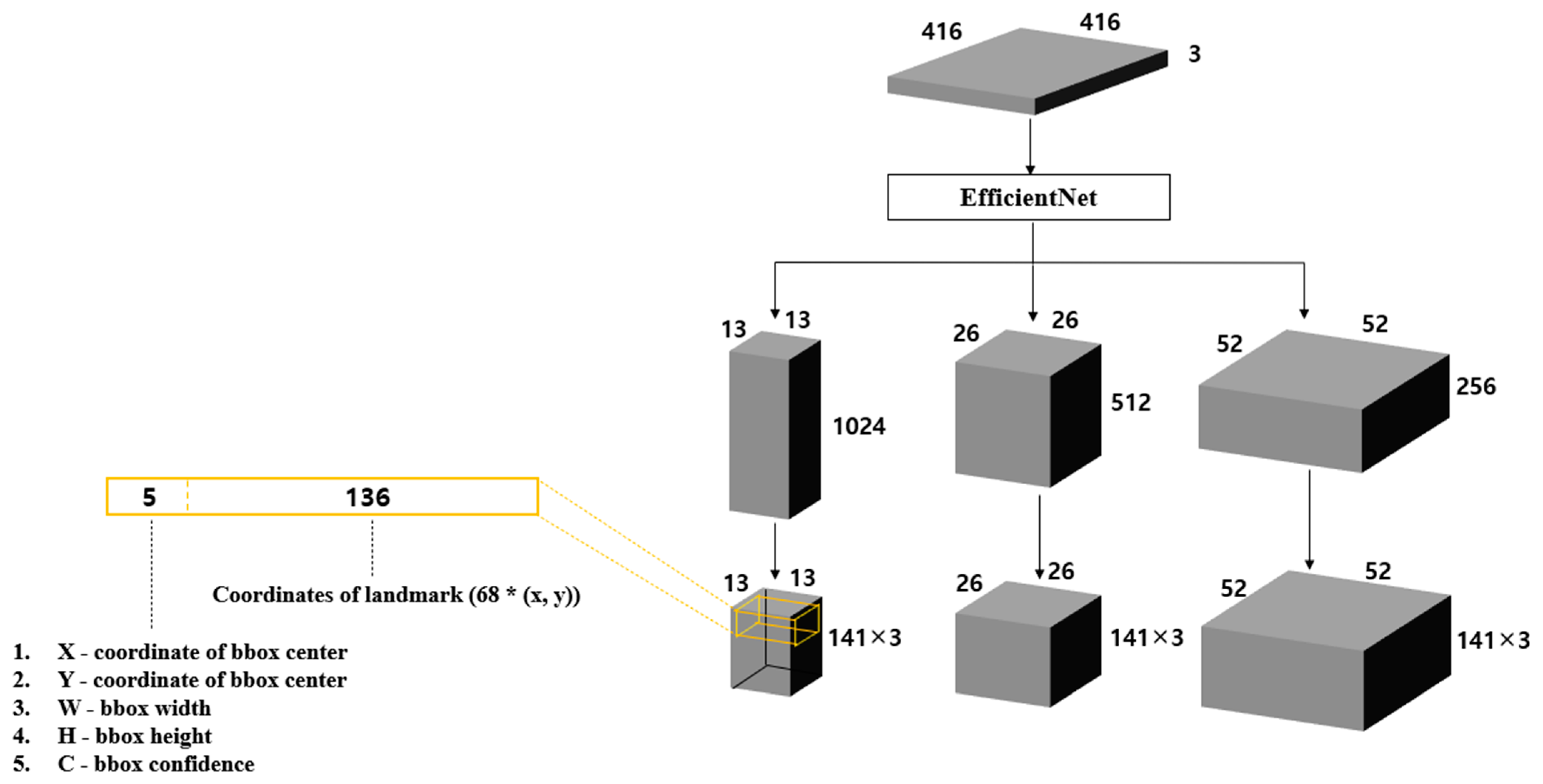
2.1. Architecture of the Proposed Model
2.2. Loss Function of the Proposed Model
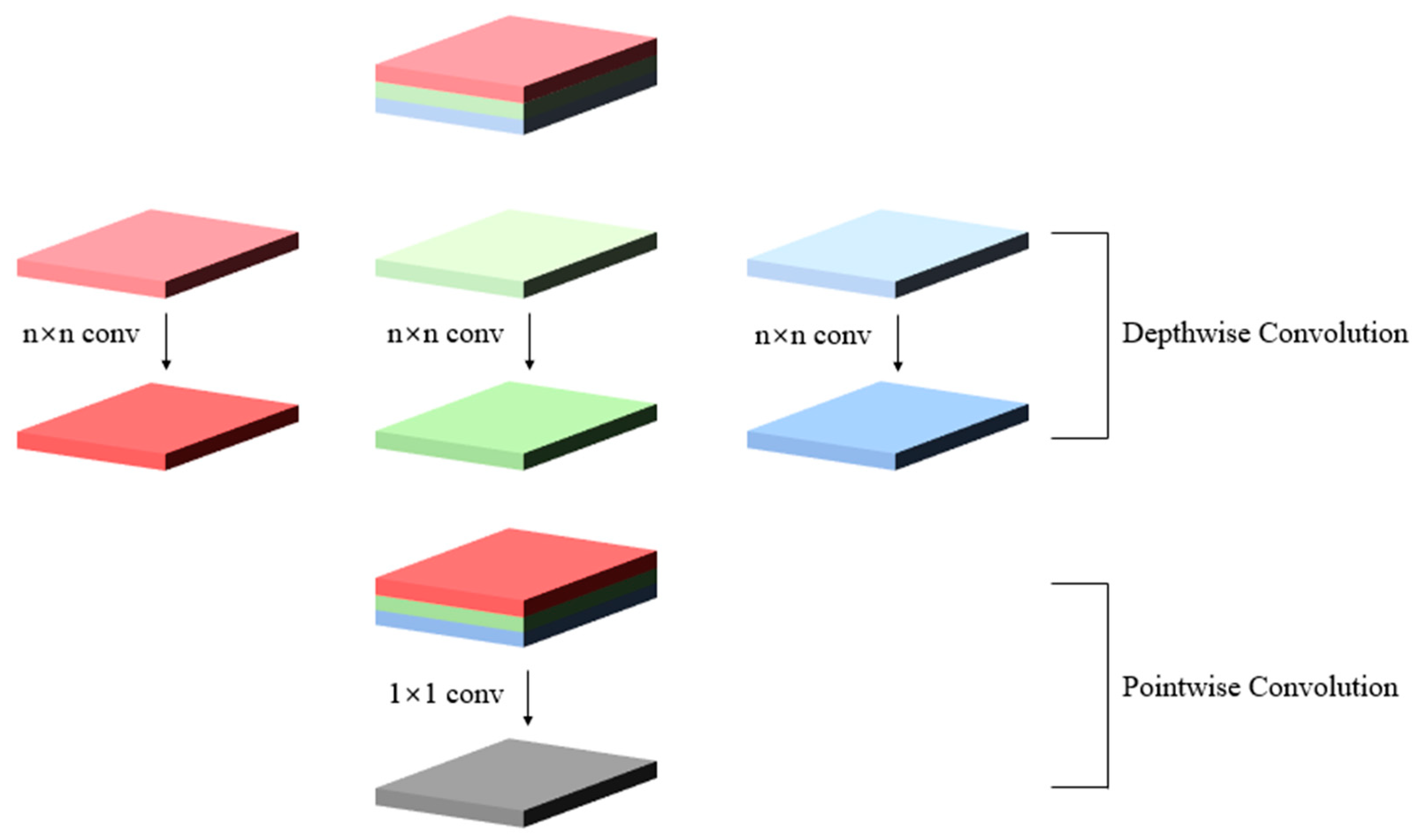
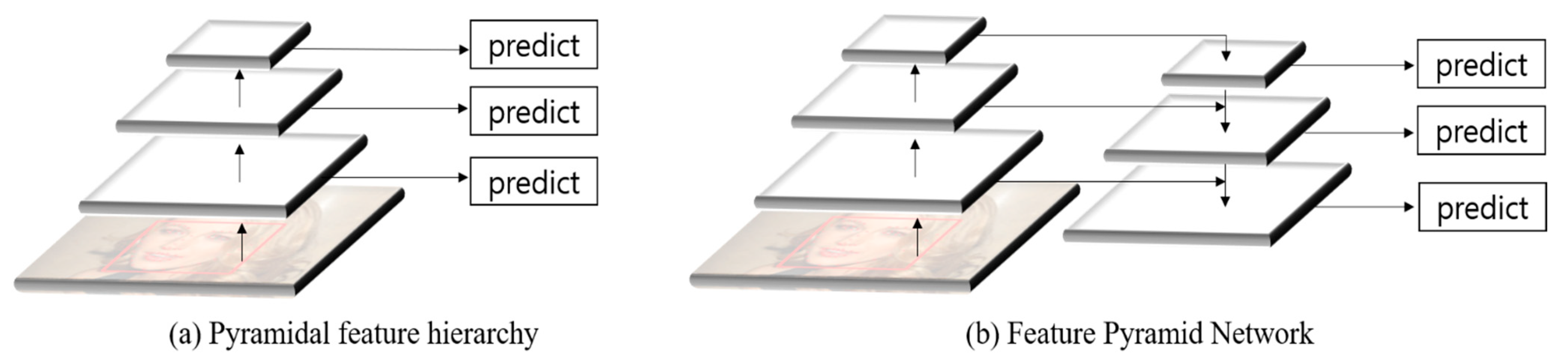
2.3. Backbone Network
2.4. Database for Model Training and Verification
2.5. Evaluation Metric
3. Results
3.1. Experimental Setup
3.2. Comparison Results of Backbone Network
3.3. Training Results
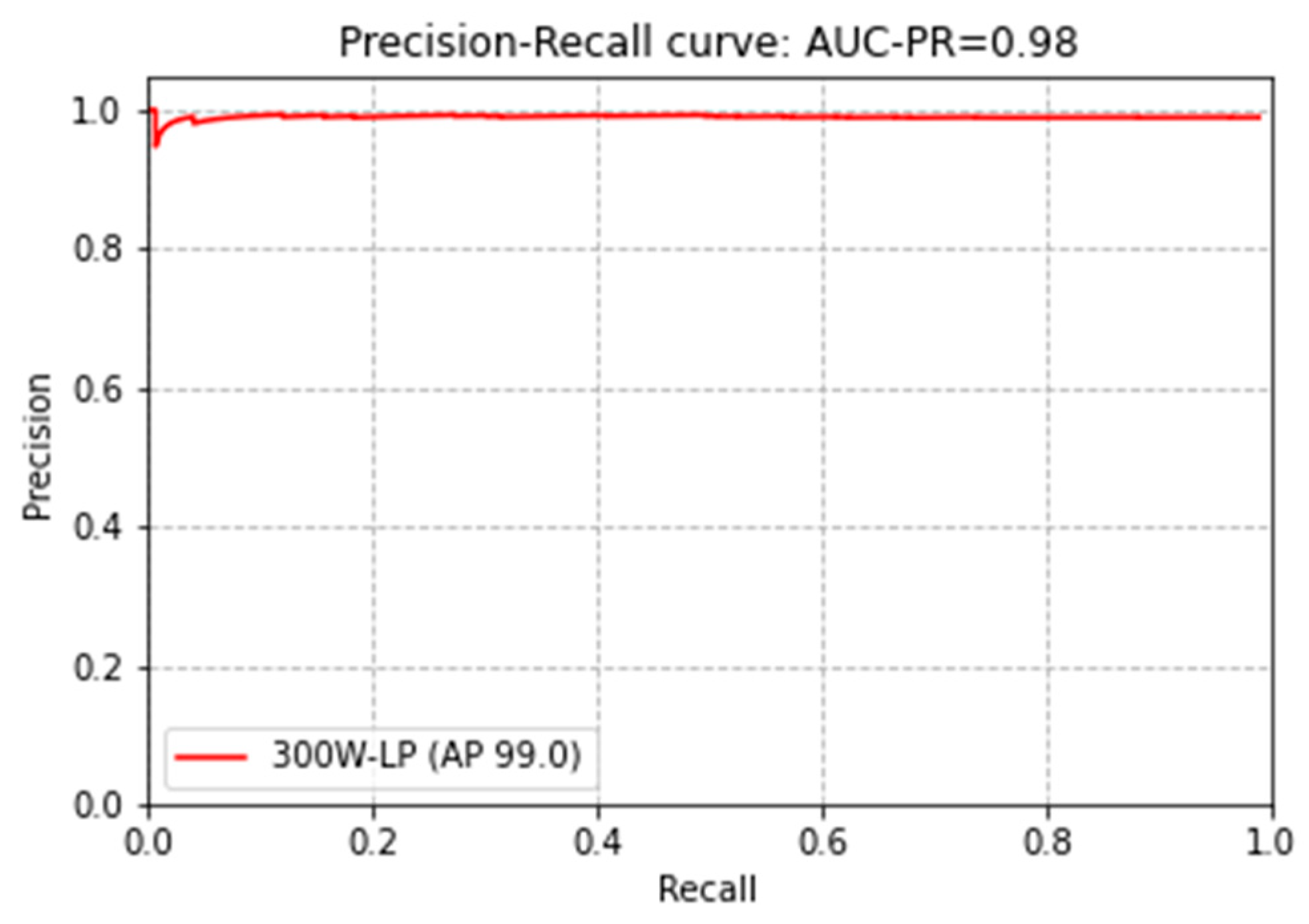
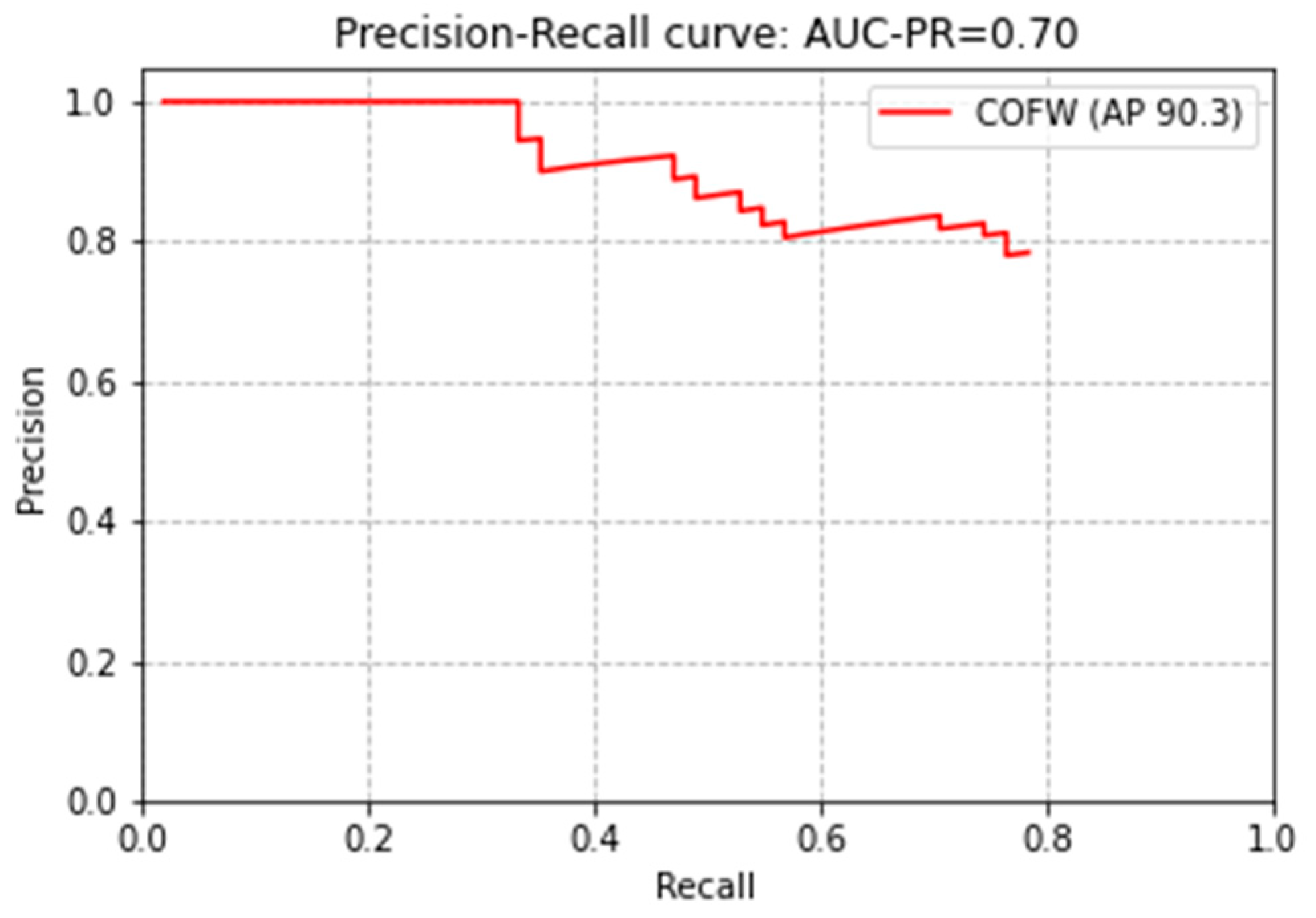
3.4. Verification Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, T.; Mok, J.W.; Lee, E.C. 1-Stage Face Landmark Detection using Deep Learning. In Proceedings of the 12th International Conference on Intelligent Human Computer Interaction, LNCS, Daegu, Korea, 24–26 November 2020; Volume 12616, pp. 239–247. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Kemelmacher-Shlizerman, I.; Basri, R. 3D face reconstruction from a single image using a single reference face shape. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 394–405. [Google Scholar] [CrossRef] [PubMed]
- Lee, W.H.; Lee, R. Implicit sensor-based authentication of smartphone users with smartwatch. In Proceedings of the Hardware and Architectural Support for Security and Privacy, Seoul, Korea, 18 June 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Wang, T.; Song, Z.; Ma, J.; Xiong, Y.; Jie, Y. An anti-fake iris authentication mechanism for smart glasses. In Proceedings of the 2013 3rd International Conference on Consumer Electronics, Communications and Networks, Xianning, China, 20–22 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 84–87. [Google Scholar]
- Hwang, J.I. Mobile augmented reality research trends and prospects. Korea Inst. Inf. Technol. Mag. 2013, 11, 85–90. [Google Scholar]
- Song, M.Y.; Kim, Y.S. Development of virtual makeup tool based on mobile augmented reality. J. Korea Soc. Comput. Inf. 2021, 26, 127–133. [Google Scholar]
- Kim, D.J. Implementation of multi-channel network platform based augmented reality facial emotion sticker using deep learning. J. Digit. Contents Soc. 2018, 19, 1349–1355. [Google Scholar] [CrossRef]
- Firmanda, M.R.; Dewantara, B.S.B.; Sigit, R. Implementation of illumination invariant face recognition for accessing user record in healthcare Kiosk. In Proceedings of the 2020 International Electronics Symposium (IES), Delft, The Netherlands, 17–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 371–376. [Google Scholar]
- Min-Jae, K.; Tae-Won, K.; Hyo-Jin, L.; Il-Hyun, J.; Woongsup, K. Kiosk system development using eye tracking and face-recognition technology. Korea Inf. Process. Soc. 2020, 27, 486–489. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2879–2886. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map flitting with constrained local models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, VCPR, Portland, OR, USA, 23–28 June 2013; pp. 3444–3451. [Google Scholar]
- Tzimiropoulos, G.; Pantic, M. Gauss-newton deformable part models for face alignment in-the-wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Columbus, OH, USA, 23–28 June 2014; pp. 1851–1858. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef] [PubMed]
- Burgos-Artizzu, X.P.; Perona, P.; Dollar, P. Robust face landmark estimation under occlusion. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Sydney, Australia, 1–8 December 2013; pp. 1513–1520. [Google Scholar]
- Xiong, X.; De la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Zhang, J.; Shan, S.; Kan, M.; Chen, X. Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 1–16. [Google Scholar]
- Zhu, S.; Li, C.; Change Loy, C.; Tang, X. Face alignment by coarse-to-fine shape searching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Boston, MA, USA, 7–12 June 2015; pp. 4998–5006. [Google Scholar]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: Database and results. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 94–108. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, Hawaii, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.; Huang, T.S. Interactive facial feature localization. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 679–692. [Google Scholar]
- Wu, Y.; Ji, Q. Facial landmark detection: A literature survey. Int. J. Comput. Vis. 2019, 127, 115–142. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EfficientNet-B0 | MobileNetv1 | ResNet50 | |
|---|---|---|---|
| Training loss | 0.0017 | 0.0039 | 0.0030 |
| Validation loss | 0.1041 | 0.0847 | 0.2054 |
| Normalized error | 2.32 | 3.54 | 3.69 |
| HELEN | LFPW | ||
|---|---|---|---|
| Method | Normalized Error | Method | Normalized Error |
| FPLL [13] | 8.16 | FPLL [13] | 8.29 |
| DRMF [14] | 6.70 | DRMF [14] | 6.57 |
| RCPR [17] | 5.93 | RCPR [17] | 6.56 |
| Gaussian–Newton DPM [15] | 5.69 | Gaussian–Newton DPM [15] | 5.92 |
| SDM [18] | 5.53 | SDM [18] | 5.67 |
| CFAN [19] | 5.50 | CFAN [19] | 5.44 |
| CFSS [20] | 4.63 | CFSS [20] | 4.87 |
| Proposed method | 2.36 | Proposed method | 2.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Mok, J.; Lee, E. Detecting Facial Region and Landmarks at Once via Deep Network. Sensors 2021, 21, 5360. https://doi.org/10.3390/s21165360
Kim T, Mok J, Lee E. Detecting Facial Region and Landmarks at Once via Deep Network. Sensors. 2021; 21(16):5360. https://doi.org/10.3390/s21165360
Chicago/Turabian StyleKim, Taehyung, Jiwon Mok, and Euichul Lee. 2021. "Detecting Facial Region and Landmarks at Once via Deep Network" Sensors 21, no. 16: 5360. https://doi.org/10.3390/s21165360
APA StyleKim, T., Mok, J., & Lee, E. (2021). Detecting Facial Region and Landmarks at Once via Deep Network. Sensors, 21(16), 5360. https://doi.org/10.3390/s21165360