A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking


Abstract
:1. Introduction
- Reinforce well-known but unwritten facts of the aforementioned techniques.
- Provide new insights that should be considered by the reader when selecting a beamforming technique.
2. Materials and Methods
2.1. Evaluated Techniques
2.1.1. Delay-and-Sum (DAS)
2.1.2. Minimum Variance Distortion-Less Response (MVDR)
2.1.3. Linearly-Constrained Minimum Variance (LCMV)
- Minimize the energy of , except in the direction of .
- Cancel the energy in the direction of known interferences ().
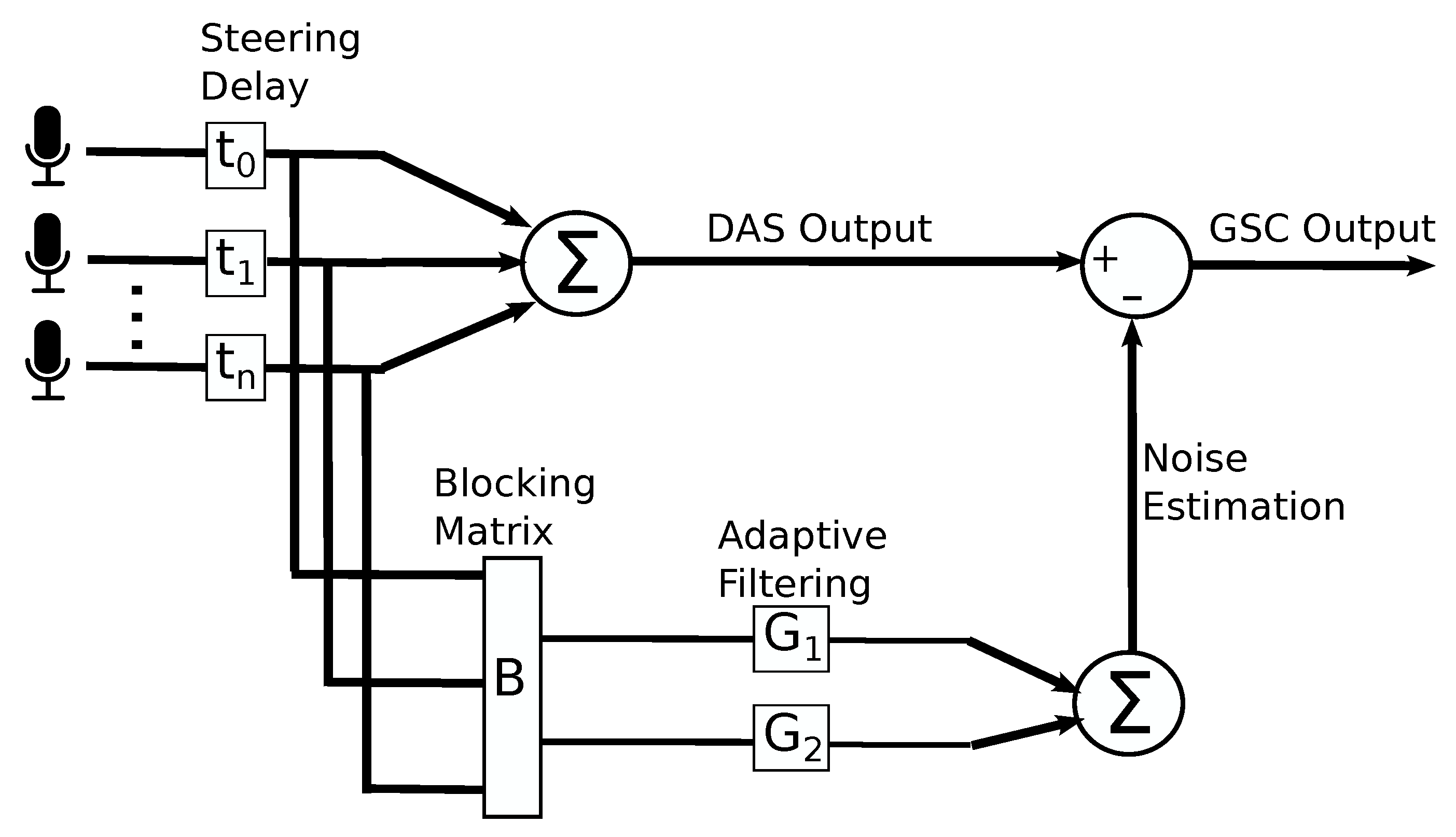
2.1.4. Generalized Sidelobe Canceller (GSC)
2.1.5. Geometric Source Separation (GSS)
- for each separated source.
2.1.6. Phase-Based Binary Masking (PBM)
| Algorithm 1: Calculated the average phase difference in frequency f. |
 |
2.2. Implementation
- JACK Audio Connection Kit (JACK) [28]: It is an audio server that can provide connectivity between audio agents, while providing low latency. This library provides direct access, with near real-time response, to multi-channel synchronous input and output audio signals. In addition, it also provides a transparent manner to switch between evaluation mode (audio files are fed to the beamformers; detailed later) and live mode (the beamformers are connected to live hardware).
- Robot Operating System (ROS) [29]: It is a framework that provides a structured communication layer between software modules. This library provides an easy-to-implement mechanism to launch the beamformers and communicate with them while they are running. It substantially simplified the automation of the evaluation.
2.3. Evaluation Methodology
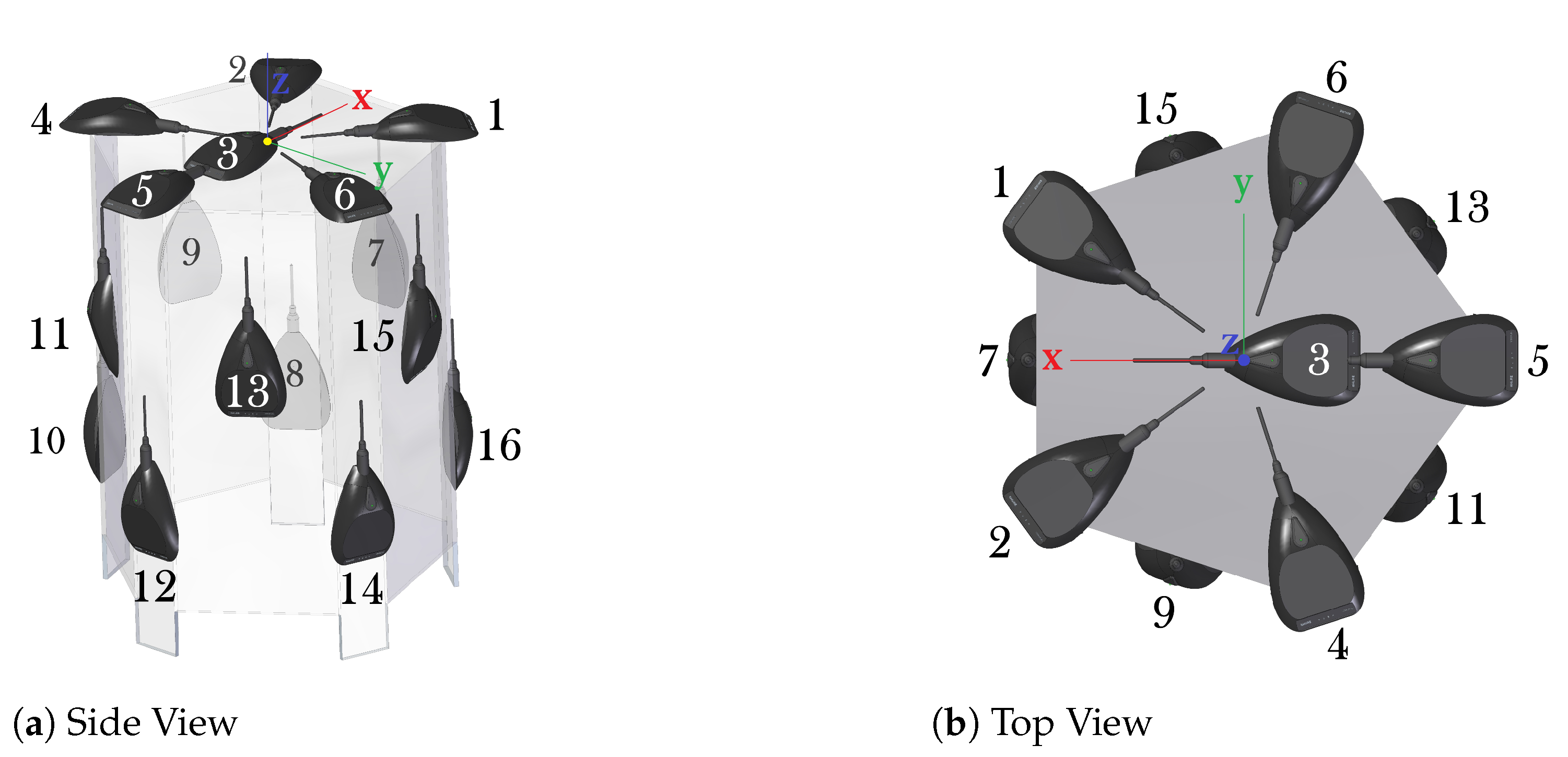
2.3.1. Acoustic Interactions for Robot Audition (AIRA)
- Anechoic Chamber: This environment is located inside the full-anechoic chamber [30] of the Instituto de Ciencias Aplicadas y Tecnologia (ICAT, formerly known as the Centro de Ciencias Aplicadas y Desarrollo Tecnologico, CCADET) of the Universidad Nacional Autonoma de Mexico (UNAM). It measures 5.3 m × 3.7 m × 2.8 m. It has a very low noise level (≈0.13 dB SPL) with an average reverberation time s. No other noise sources were present in this setting. Recordings have a SNR of ≈43 dB. The microphone pre-amplification was set at 0 dB, and the the speaker amplification was set at −30 dB to compensate for the maximum SPL difference between monitors.
- Cafeteria: This environment is a cafeteria located inside the UNAM campus and was used during a 5 h period of high customer presence. It has an approximate size of 20.7 m × 9.6 m × 3.63 m. It has a high noise level (71 dB SPL) with an average reverberation time of 0.27 s. Its ceilings and floor are made of concrete, and its walls are made of a mixture of concrete and glass. Noise sources around the array included: people talking, babies crying, tableware clanking, some furniture movement, and cooling fans of stoves. The recordings in this environment have a Signal-to-Noise Ratio (SNR) of ∼16 dB.
2.3.2. Evaluation Metrics
2.3.3. Evaluation Variables
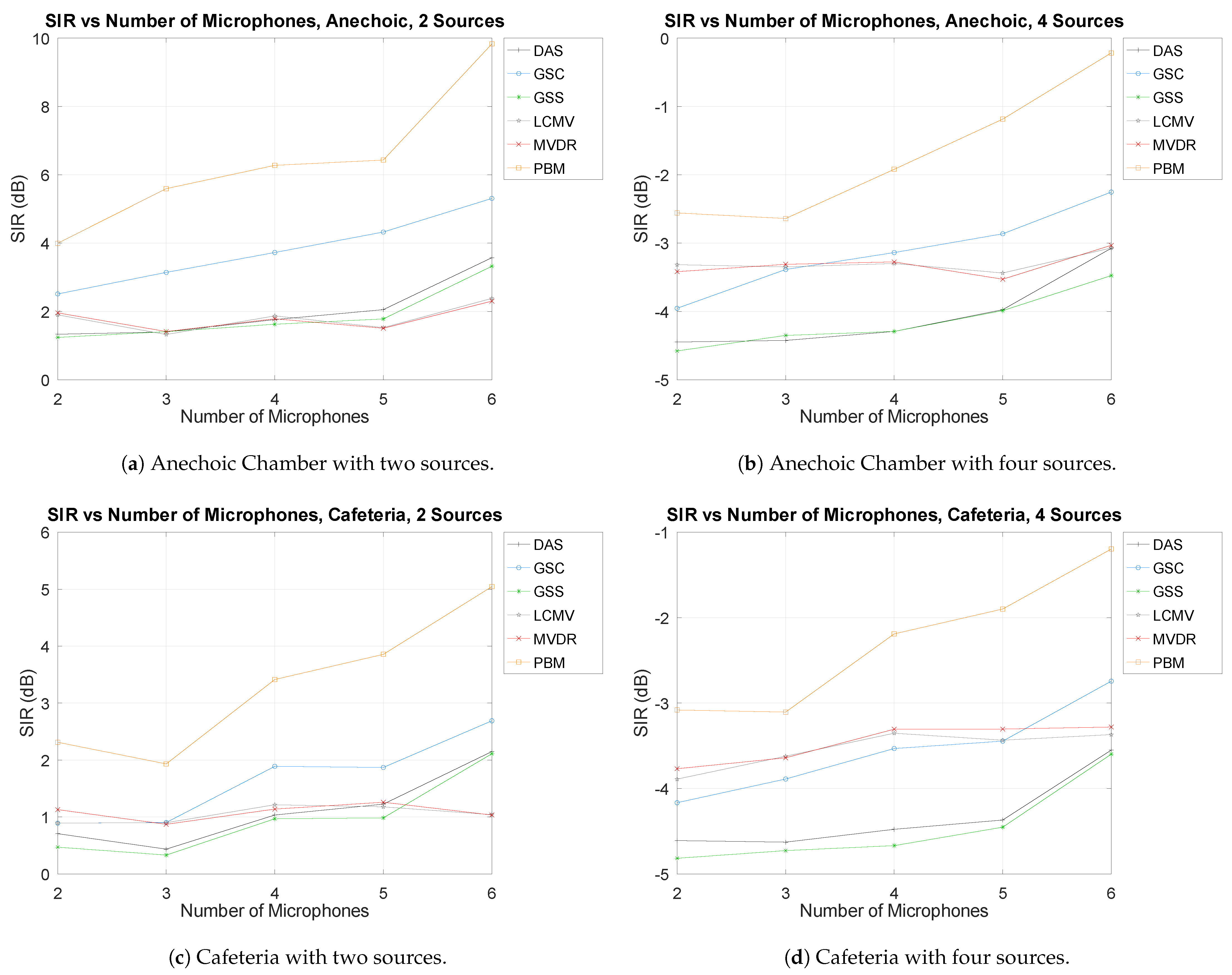
- Acoustic Environments. As mentioned above, two acoustic environments were used: a noise-less Anechoic Chamber and a noisy Cafeteria.
- Number of Interferences. Since AIRA has a maximum of 4 active sources, the SOI was considered one of those sources and the rest were interferences (ranging from 1 to 3). It is important to mention that, with each set of recordings, the technique was evaluated the same number of times as the number of sources, with each evaluation considering each active source as the SOI and the rest as interferences.
- Number of Microphones. As mentioned above, the six first microphone of the three-dimensional array were used since they do not break the free-field assumption. Thus, the number of microphones ranged from 2 to 6.
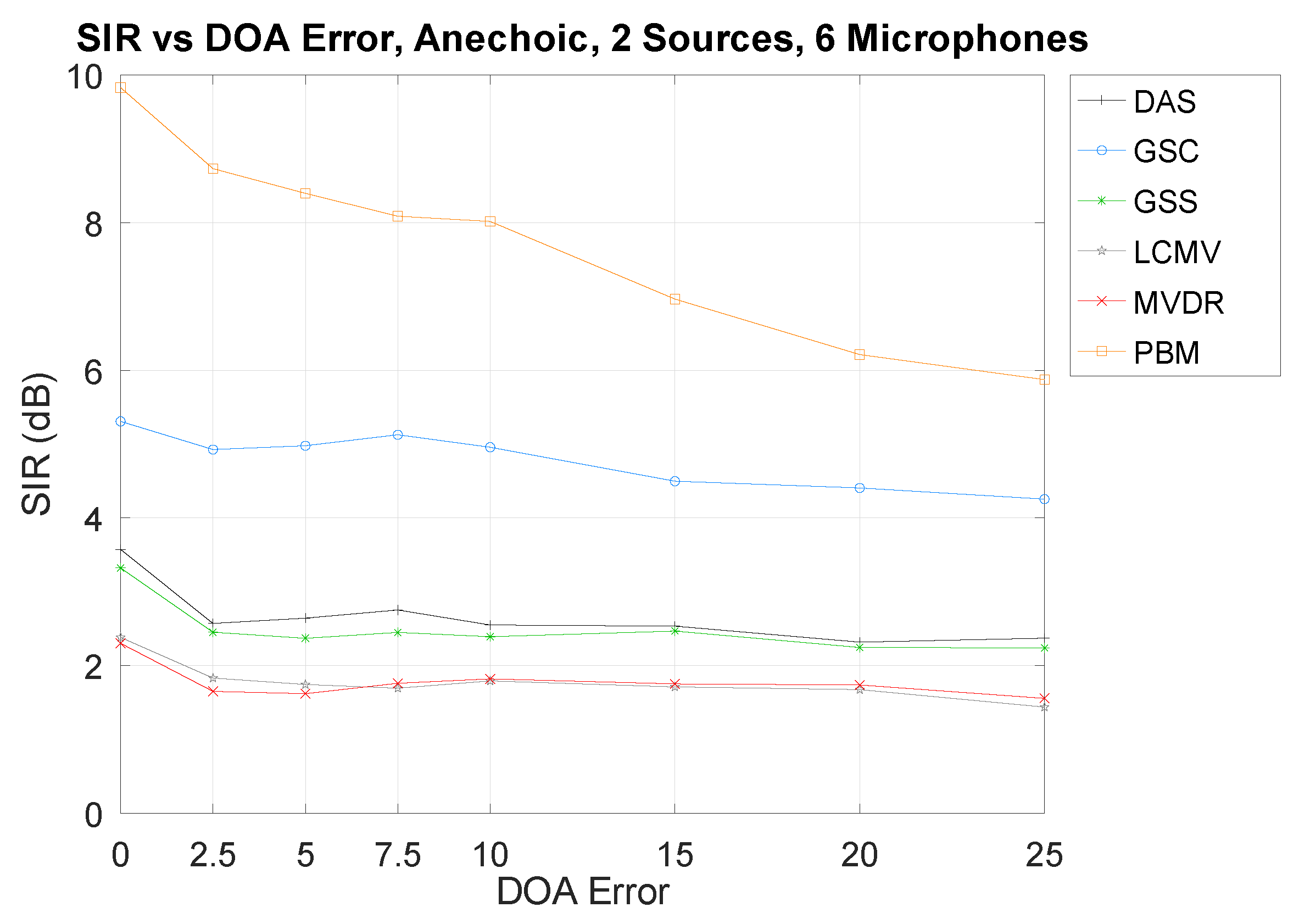
- Direction-of-Arrival Error. To evaluate the robustness of the techniques against an erroneous DOA of the SOI, an error was artificially introduced ranging from 0 to 25.
2.3.4. Technique Parameters during Evaluation
- DAS. No parameters were required to be set.
- MVDR and LCMV. Ten windows were used to calculate , and only frequencies between 100 and 16,000 Hz and that have a normalized amplitude above 0.001 were analyzed.
- GSC. was set at 0.001, was set at 0.1, and the filter length (K) was set at 128.
- GSS. One window was used to calculate , only frequencies between 100 and 16,000 Hz and that have a normalized amplitude above 0.001 were analyzed, and was set at 0.001.
- PBM. Only frequencies that have a normalized amplitude above 0.001 were analyzed, and the upper phase difference threshold () was set at 20.
3. Results
3.1. Number of Interferences
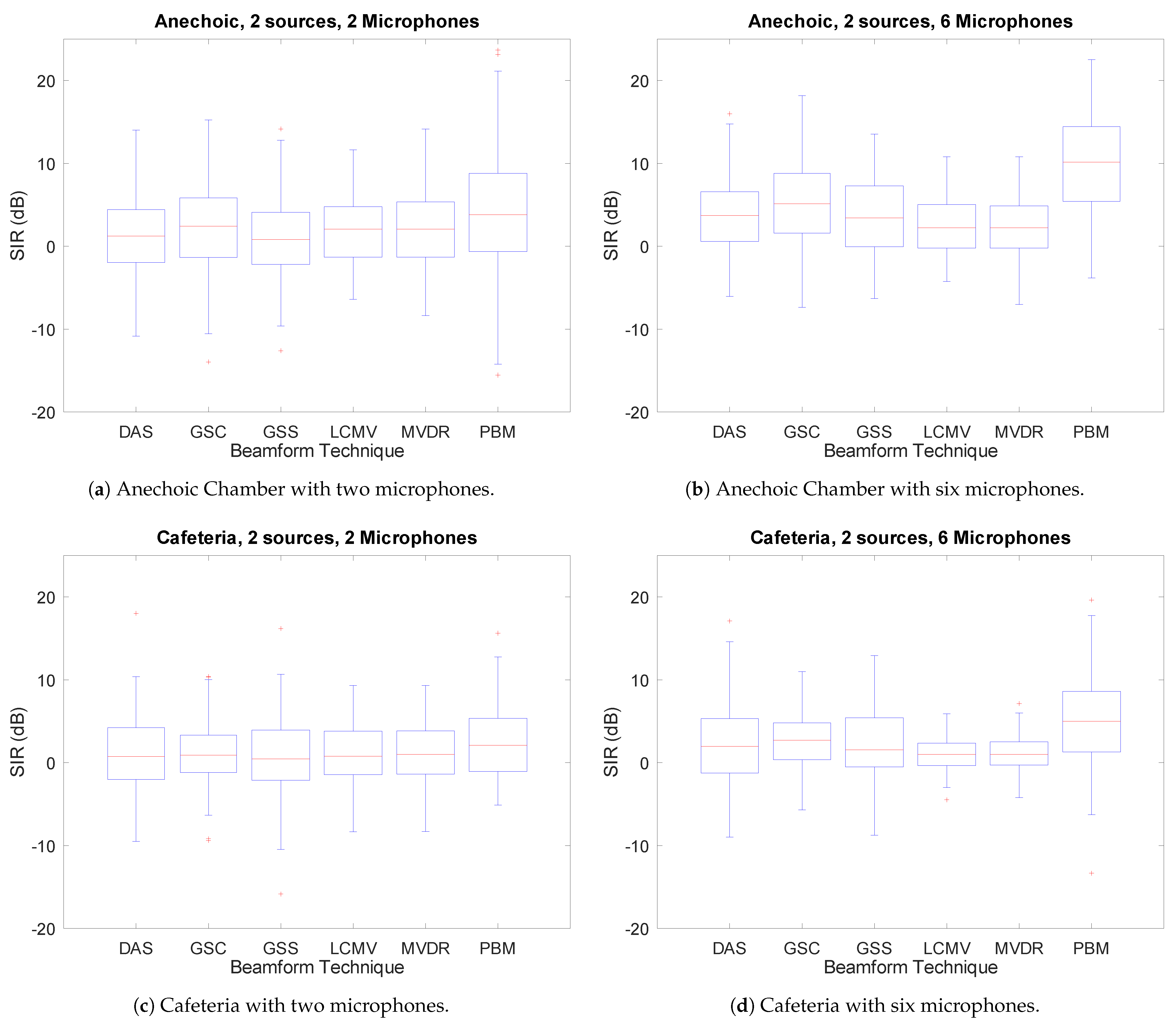
3.2. Number of Microphones
3.3. Direction-of-Arrival Error
3.4. Overall Results Variation
3.5. Number of Overruns
4. Discussion
5. Conclusions
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rascon, C.; Meza, I. Localization of sound sources in robotics: A review. Robot. Auton. Syst. 2017, 96, 184–210. [Google Scholar] [CrossRef]
- Grondin, F.; Létourneau, D.; Ferland, F.; Rousseau, V.; Michaud, F. The ManyEars open framework. Auton. Robot. 2013, 34, 217–232. [Google Scholar] [CrossRef]
- Valin, J.M.; Rouat, J.; Michaud, F. Enhanced robot audition based on microphone array source separation with post-filter. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2123–2128. [Google Scholar]
- Nakadai, K.; Nakajima, H.; Hasegawa, Y.; Tsujino, H. Sound source separation of moving speakers for robot audition. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3685–3688. [Google Scholar] [CrossRef]
- Wang, D. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: Boston, MA, USA, 2005; pp. 181–197. [Google Scholar]
- Rascon, C.; Meza, I.; Millan-Gonzalez, A.; Velez, I.; Fuentes, G.; Mendoza, D.; Ruiz-Espitia, O. Acoustic interactions for robot audition: A corpus of real auditory scenes. J. Acoust. Soc. Am. 2018, 144, EL399–EL403. [Google Scholar] [CrossRef] [PubMed]
- Maldonado, A.; Rascon, C.; Velez, I. Lightweight Online Separation of the Sound Source of Interest through BLSTM-Based Binary Masking. Comput. Sist. 2020, 24. [Google Scholar] [CrossRef]
- Vincent, E.; Gribonval, R.; Févotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]
- Volakis, J.L. Antenna Engineering Handbook; McGraw-Hill Education: New York, NY, USA, 2007. [Google Scholar]
- Mailloux, R.J. Phased Array Antenna Handbook; Artech House: Norwood, MA, USA, 2017. [Google Scholar]
- Friis, H.T.; Feldman, C.B. A multiple unit steerable antenna for short-wave reception. Proc. Inst. Radio Eng. 1937, 25, 841–917. [Google Scholar]
- Perrot, V.; Polichetti, M.; Varray, F.; Garcia, D. So you think you can DAS? A viewpoint on delay-and-sum beamforming. Ultrasonics 2021, 111, 106309. [Google Scholar] [CrossRef] [PubMed]
- Levin, M. Maximum-likelihood array processing. In Seismic Discrimination Semi-Annual Technical Summary Report; Lincoln Laboratory, Massachusetts Institute of Technology: Cambridge, MA, USA, 1964; Volume 21. [Google Scholar]
- Capon, J. High-resolution frequency-wavenumber spectrum analysis. Proc. IEEE 1969, 57, 1408–1418. [Google Scholar] [CrossRef] [Green Version]
- Habets, E.A.P.; Benesty, J.; Cohen, I.; Gannot, S.; Dmochowski, J. New insights into the MVDR beamformer in room acoustics. IEEE Trans. Audio Speech Lang. Process. 2009, 18, 158–170. [Google Scholar] [CrossRef]
- Frost, O.L. An algorithm for linearly constrained adaptive array processing. Proc. IEEE 1972, 60, 926–935. [Google Scholar] [CrossRef]
- Schwartz, O.; Gannot, S.; Habets, E.A. Multispeaker LCMV beamformer and postfilter for source separation and noise reduction. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 940–951. [Google Scholar] [CrossRef]
- Griffiths, L.; Jim, C. An alternative approach to linearly constrained adaptive beamforming. IEEE Trans. Antennas Propag. 1982, 30, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Gannot, S.; Cohen, I. Speech enhancement based on the general transfer function GSC and postfiltering. IEEE Trans. Speech Audio Process. 2004, 12, 561–571. [Google Scholar] [CrossRef]
- Breed, B.R.; Strauss, J. A short proof of the equivalence of LCMV and GSC beamforming. IEEE Signal Process. Lett. 2002, 9, 168–169. [Google Scholar] [CrossRef]
- Bourgeois, J.; Minker, W. Time-Domain Beamforming and Blind Source Separation: Speech Input in the Car Environment. In Lecture Notes in Electrical Engineering; Springer: Boston, MA, USA, 2009; Volume 3. [Google Scholar]
- Parra, L.C.; Alvino, C.V. Geometric source separation: Merging convolutive source separation with geometric beamforming. IEEE Trans. Speech Audio Process. 2002, 10, 352–362. [Google Scholar] [CrossRef] [Green Version]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Brutti, A.; Tsiami, A.; Katsamanis, A.; Maragos, P. A Phase-Based Time-Frequency Masking for Multi-Channel Speech Enhancement in Domestic Environments. In Interspeech 2016; International Speech Communication Association: Grenoble, France, 2016; pp. 2875–2879. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Zhou, Y.; Liu, H. Phase Time-Frequency Masking Based Speech Enhancement Algorithm Using Circular Microphone Array. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 808–813. [Google Scholar] [CrossRef]
- Davis, P. JACK Audio Connection Kit. 2002. Available online: http://jackaudio.org (accessed on 22 June 2021).
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In ICRA Workshop on Open Source Software; IEEE: Kobe, Japan, 2009; Volume 3.2, p. 5. [Google Scholar]
- Boullosa, R.R.; López, A.P. Some acoustical properties of the anechoic chamber at the Centro de Instrumentos, Universidad Nacional Autonoma de Mexico. Appl. Acoust. 1999, 56, 199–207. [Google Scholar] [CrossRef]
- Behringer. Behringer X32 User Guide. 2016. Available online: https://media.music-group.com/media/PLM/data/docs/P0ASF/X32_M_EN.pdf (accessed on 22 June 2021).
- Shure. Shure MX393 User Guide. 2015. Available online: https://pubs.shure.com/view/guide/MX39x/en-US.pdf (accessed on 22 June 2021).
- Liu, Y.; Wang, D. Causal Deep CASA for Monaural Talker-Independent Speaker Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2109–2118. [Google Scholar] [CrossRef] [PubMed]
- van de Sande, J. Real-time Beamforming and Sound Classification Parameter Generation in Public Environments. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2012. [Google Scholar]
- Liu, Y.; Delfarah, M.; Wang, D. Deep CASA for talker-independent monaural speech separation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6354–6358. [Google Scholar]
- Nakadai, K.; Takahashi, T.; Okuno, H.G.; Nakajima, H.; Hasegawa, Y.; Tsujino, H. Design and Implementation of Robot Audition System HARK - Open Source Software for Listening to Three Simultaneous Speakers. Adv. Robot. 2010, 24, 739–761. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mic. | x | y |
|---|---|---|
| 1 | 0.158 | 0.115 |
| 2 | 0.158 | −0.115 |
| 3 | −0.045 | 0.000 |
| 4 | −0.050 | −0.188 |
| 5 | −0.195 | 0.000 |
| 6 | −0.057 | 0.186 |
| Environment | DAS | GSC | GSS | LCMV | MVDR | PBM | |
|---|---|---|---|---|---|---|---|
| Anechoic | Avg. | 0.054 | 0.035 | 0.043 | 5.516 | 4.469 | 0.016 |
| Std. | 0.432 | 0.215 | 0.289 | 12.642 | 10.954 | 0.145 | |
| Cafeteria | Avg. | 0.021 | 0.027 | 0.044 | 113.077 | 106.160 | 0.020 |
| Std. | 0.245 | 0.205 | 0.248 | 169.970 | 167.322 | 0.163 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rascon, C. A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking. Sensors 2021, 21, 5005. https://doi.org/10.3390/s21155005
Rascon C. A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking. Sensors. 2021; 21(15):5005. https://doi.org/10.3390/s21155005
Chicago/Turabian StyleRascon, Caleb. 2021. "A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking" Sensors 21, no. 15: 5005. https://doi.org/10.3390/s21155005
APA StyleRascon, C. (2021). A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking. Sensors, 21(15), 5005. https://doi.org/10.3390/s21155005