
Gender and Age Estimation Methods Based on Speech Using Deep Neural Networks


Abstract
:1. Introduction
Related Works
2. Data
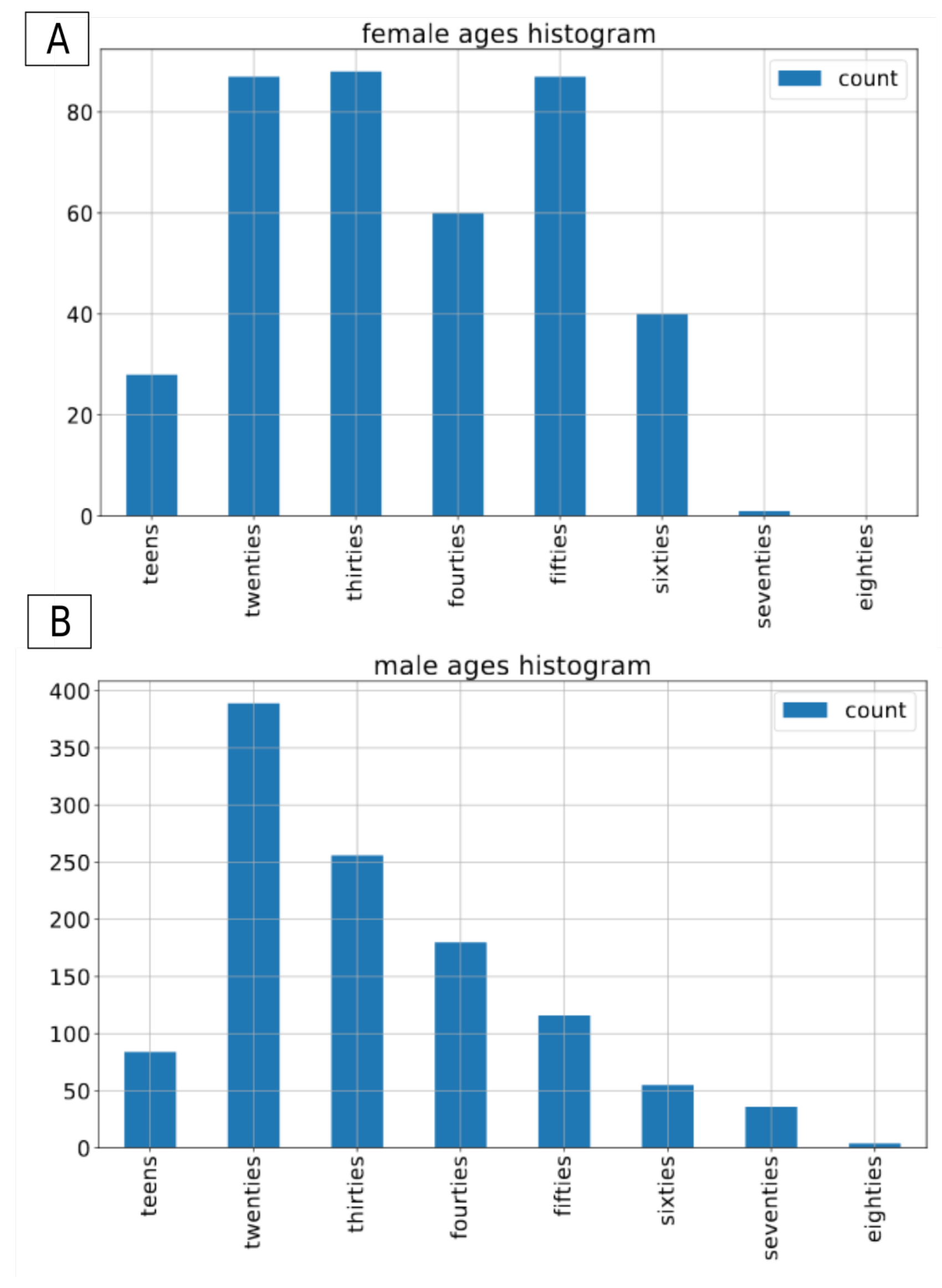
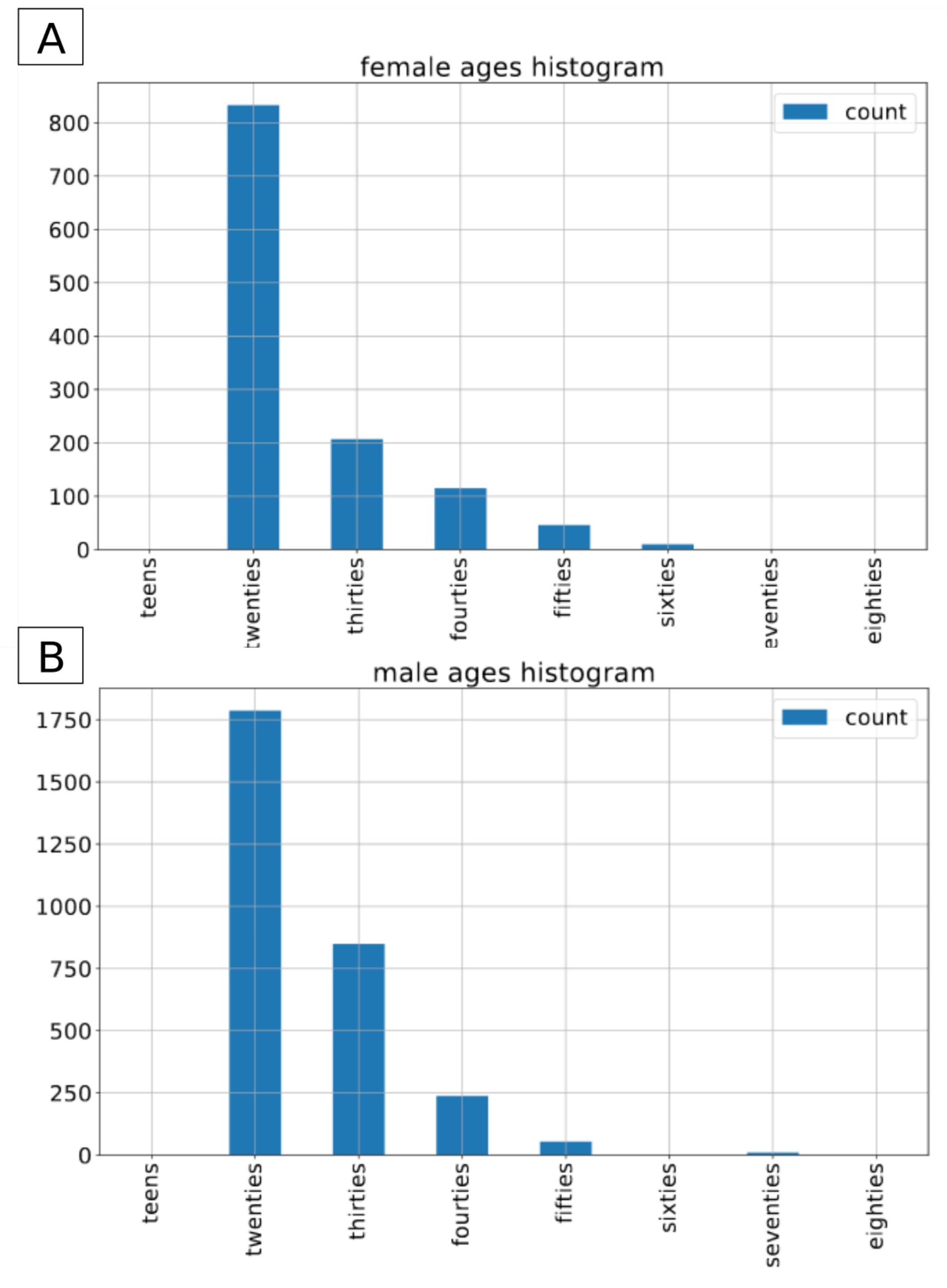
2.1. Voxceleb 1
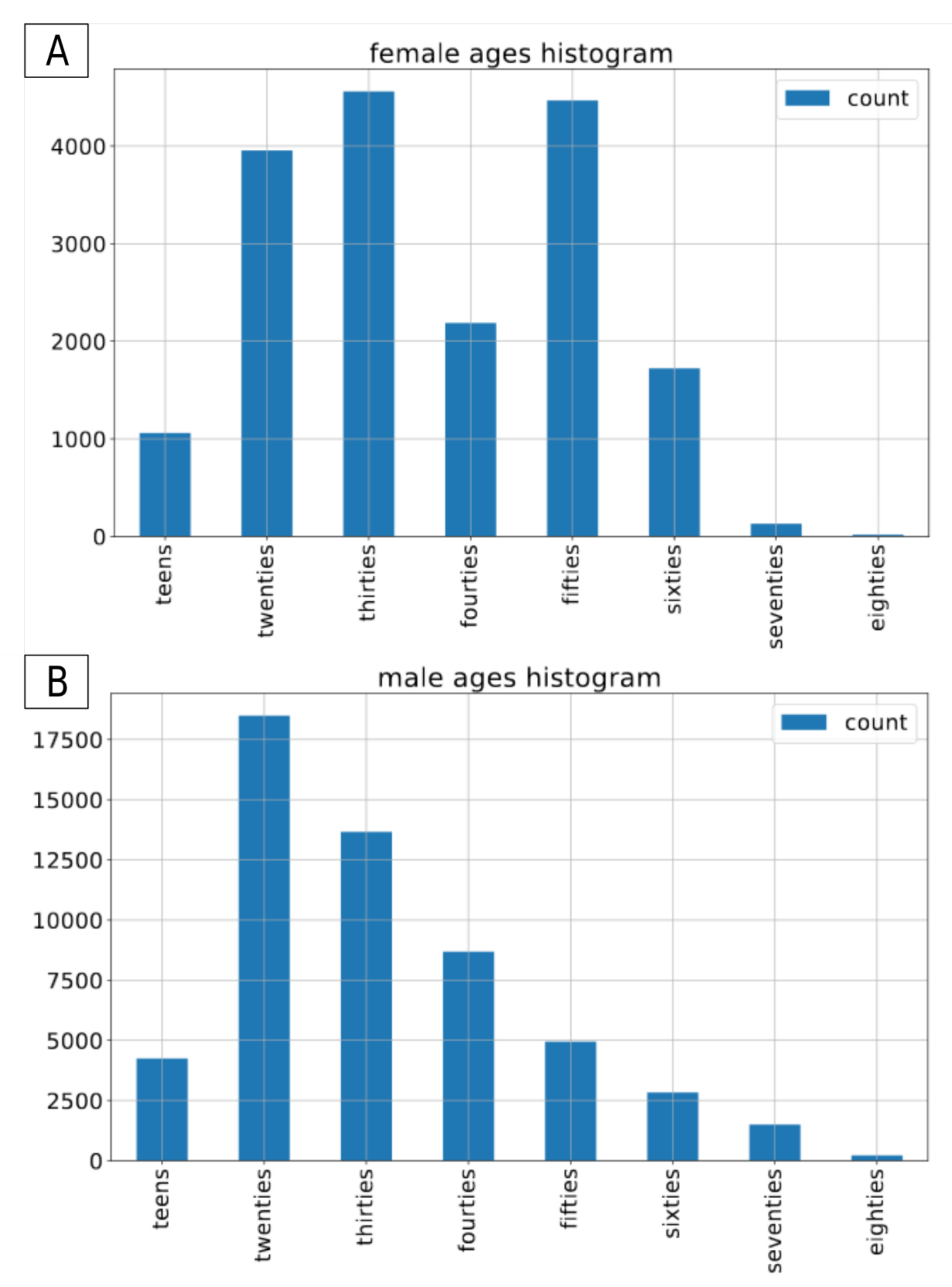
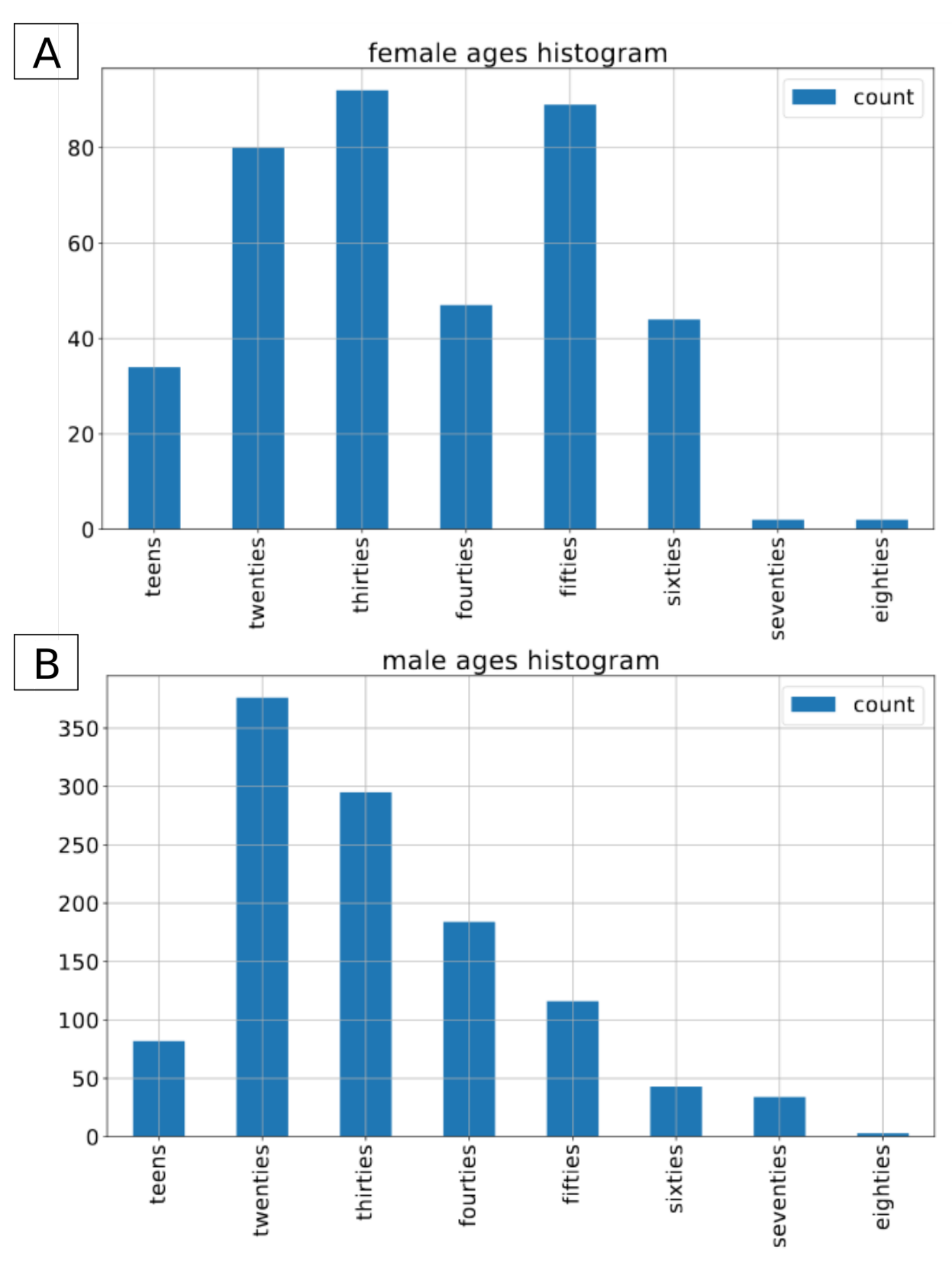
2.2. Common Voice
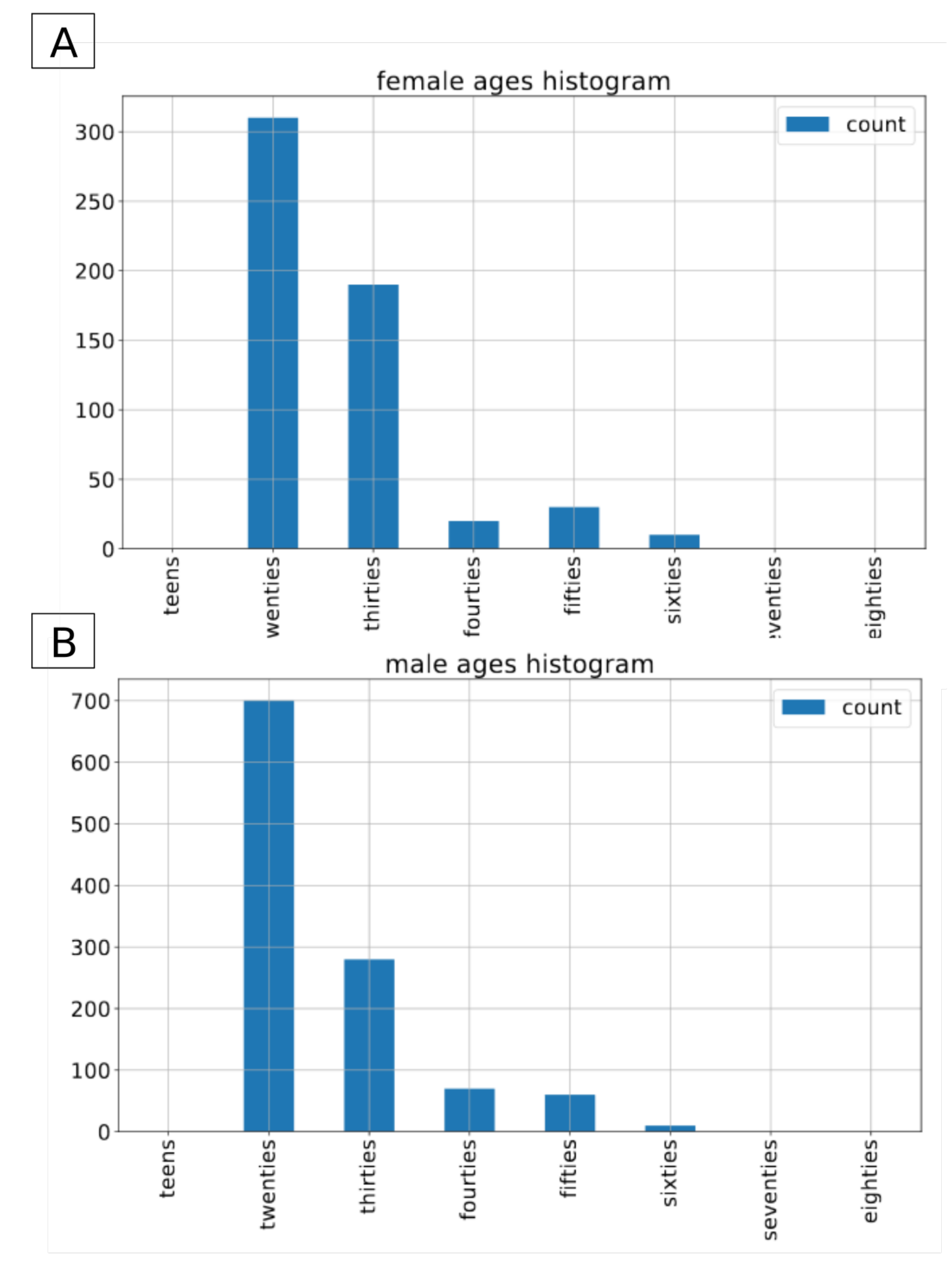
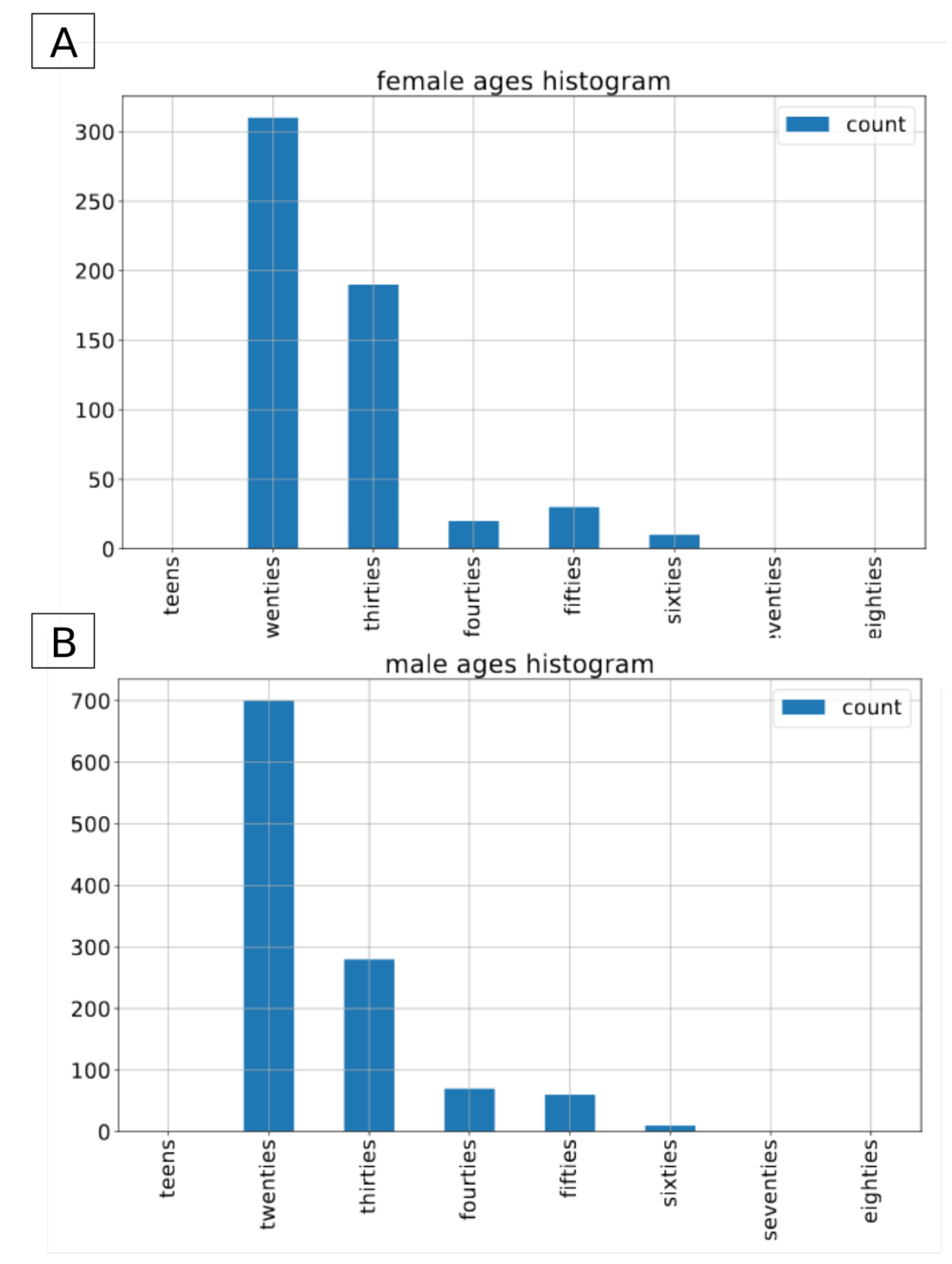
2.3. Timit
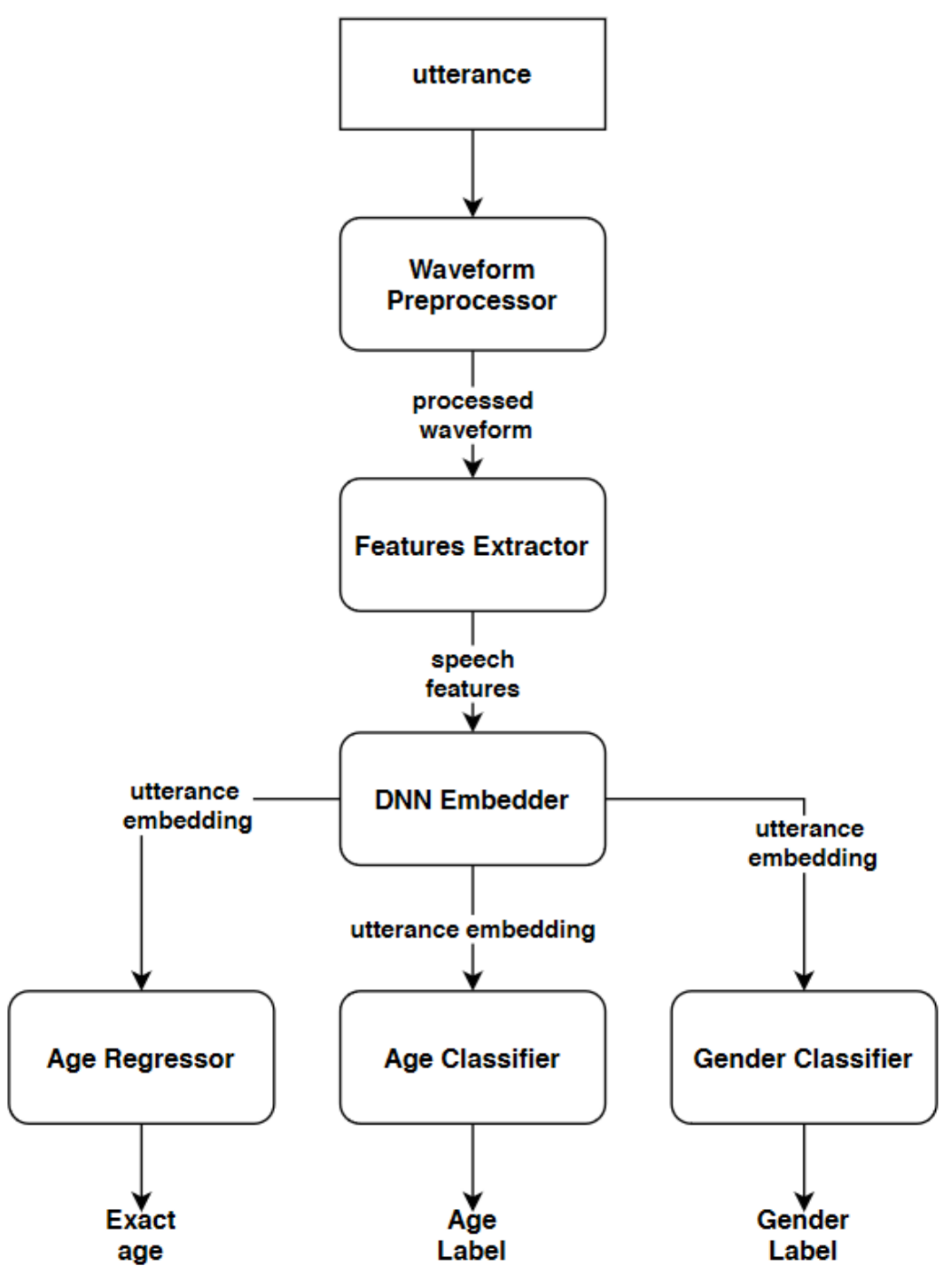
3. Methods
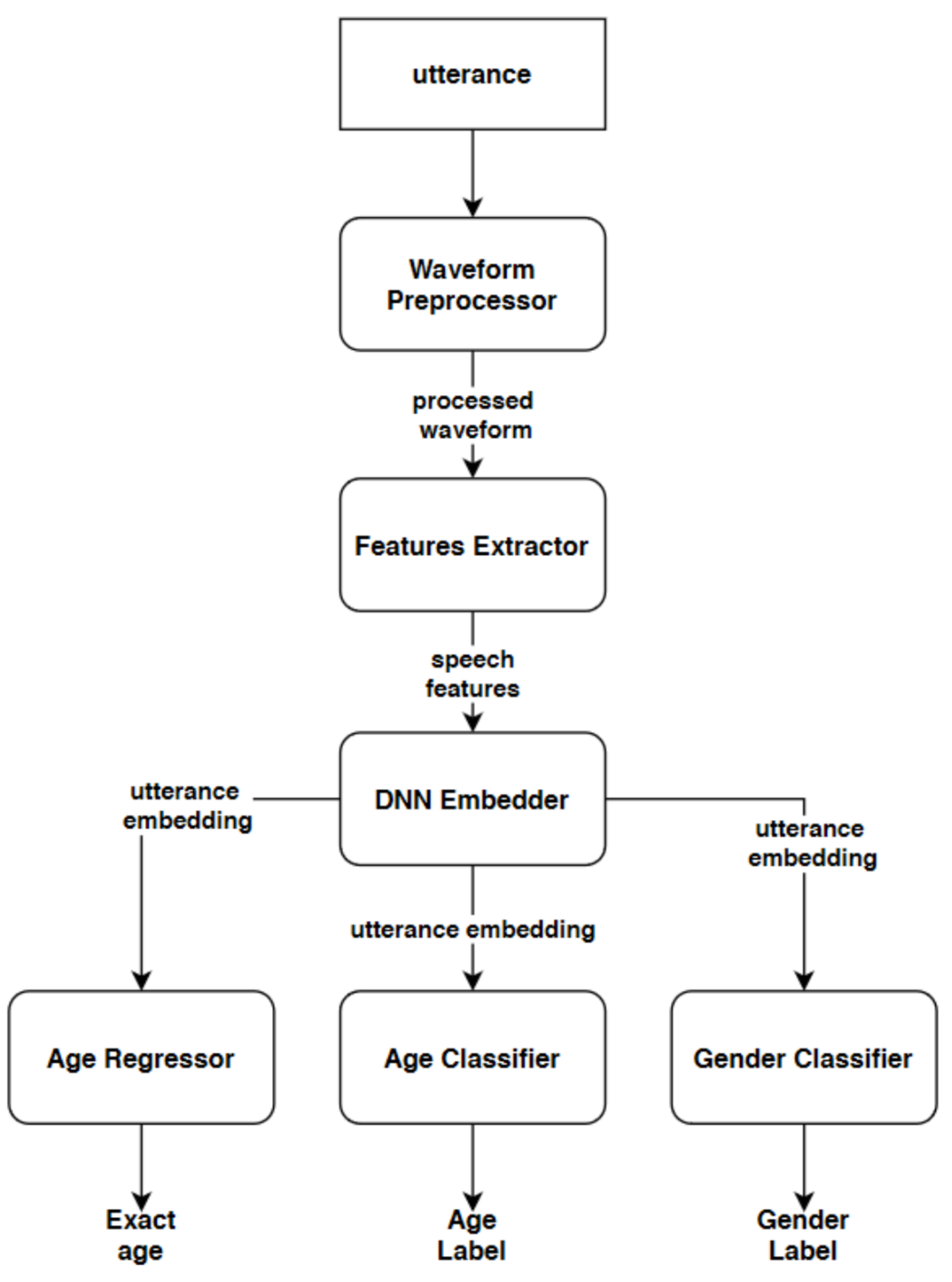
3.1. Embedder Architectures
3.1.1. Time Delay Neural Network Based X-Vector Embedder
3.1.2. Quartznet X-Vector Embedder
3.1.3. D-Vector Embedder
3.2. Front-End Modules
4. Results
- only on the TIMIT train dataset,
- only on the Common Voice train dataset, or
- pretrained on the Common Voice train dataset and then fine-tuned on the TIMIT train dataset.
4.1. Baseline Tdnn X-Vector System
4.2. Quartznet-Based X-Vector System
4.3. D-Vector Embedder-Based System
4.4. Pre-Training X-Vector Embedder on Voxceleb 1
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; MüLler, C.; Narayanan, S. Paralinguistics in speech and language—State-of-the-art and the challenge. Comput. Speech Lang. 2013, 27, 4–39. [Google Scholar] [CrossRef]
- Panek, D.; Skalski, A.; Gajda, J.; Tadeusiewicz, R. Acoustic analysis assessment in speech pathology detection. Int. J. Appl. Math. Comput. Sci. 2015, 25, 631–643. [Google Scholar] [CrossRef] [Green Version]
- Techmo. Available online: https://www.techmo.pl (accessed on 12 February 2021).
- Zazo, R.; Sankar Nidadavolu, P.; Chen, N.; Gonzalez-Rodriguez, J.; Dehak, N. Age Estimation in Short Speech Utterances Based on LSTM Recurrent Neural Networks. IEEE Access 2018, 6, 22524–22530. [Google Scholar] [CrossRef]
- Mahmoodi, D.; Marvi, H.; Taghizadeh, M.; Soleimani, A.; Razzazi, F.; Mahmoodi, M. Age Estimation Based on Speech Features and Support Vector Machine. In Proceedings of the 2011 3rd Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 13–14 July 2011; pp. 60–64. [Google Scholar]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-End Factor Analysis for Speaker Verification. IEEE Trans. Audio Speech Lang. 2011, 19, 788–798. [Google Scholar] [CrossRef]
- Villalba, J.; Chen, N.; Snyder, D.; Garcia-Romero, D.; McCree, A.; Sell, G.; Borgstrom, J.; Richardson, F.; Shon, S.; Grondin, F.; et al. State-of-the-Art Speaker Recognition for Telephone and Video Speech: The JHU-MIT Submission for NIST SRE18. In Proceedings of the INTERSPEECH 2019, Graz, Austria, 15–19 September 2019; pp. 1488–1492. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- McLaren, M.; Lawson, A.; Ferrer, L.; Castan, D.; Graciarena, M. The speakers in the wild speaker recognition challenge plan. In Proceedings of the Interspeech 2016 Special Session, San Francisco, CA, USA, 8–12 September 2015. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Jasuja, L.; Rasool, A.; Hajela, G. Voice Gender Recognizer Recognition of Gender from Voice using Deep Neural Networks. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 319–324. [Google Scholar]
- Djemili, R.; Bourouba, H.; Korba, M.C.A. A speech signal based gender identification system using four classifiers. In Proceedings of the 2012 International Conference on Multimedia Computing and Systems, Tangiers, Morocco, 10–12 May 2012; pp. 184–187. [Google Scholar]
- Buyukyilmaz, M.; Cibikdiken, A.O. Voice gender recognition using deep learning. In Proceedings of the 2016 International Conference on Modeling, Simulation and Optimization Technologies and Applications, Xiamen, China, 18–19 December 2016; pp. 409–411. [Google Scholar]
- Alhussein, M.; Ali, Z.; Imran, M.; Abdul, W. Automatic gender detection based on characteristics of vocal folds for mobile healthcare system. Mob. Inf. Syst. 2016, 2016. [Google Scholar] [CrossRef] [Green Version]
- Uddin, M.A.; Hossain, M.S.; Pathan, R.K.; Biswas, M. Gender Recognition from Human Voice using Multi-Layer Architecture. In Proceedings of the 2020 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Novi Sad, Serbia, 24–26 August 2020; pp. 1–7. [Google Scholar]
- Ertam, F. An effective gender recognition approach using voice data via deeper LSTM networks. Appl. Acoust. 2019, 156, 351–358. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. Gender recognition by voice using an improved self-labeled algorithm. Mach. Learn. Knowl. Extr. 2019, 1, 492–503. [Google Scholar] [CrossRef] [Green Version]
- Pribil, J.; Pribilova, A.; Matousek, J. GMM-based speaker age and gender classification in Czech and Slovak. J. Electr. Eng. 2017, 68, 3. [Google Scholar]
- Maka, T.; Dziurzanski, P. An analysis of the influence of acoustical adverse conditions on speaker gender identification. In Proceedings of the XXII Annual Pacific Voice Conference (PVC), Krakow, Poland, 11–13 April 2014; pp. 1–4. [Google Scholar]
- Craig, G.; Alvin, M.; David, G.; Linda, B.; Kevin, W. 2010 NIST Speaker Recognition Evaluation Test Set. Available online: https://catalog.ldc.upenn.edu/LDC2017S06 (accessed on 29 August 2020).
- Ghahremani, P.; Nidadavolu, P.S.; Chen, N.; Villalba, J.; Povey, D.; Khudanpur, S.; Dehak, N. End-to-end Deep Neural Network Age Estimation. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 277–281. [Google Scholar]
- Kalluri, S.B.; Vijayasenan, D.; Ganapathy, S. A Deep Neural Network Based End to End Model for Joint Height and Age Estimation from Short Duration Speech. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6580–6584. [Google Scholar]
- Garofolo, J.; Lamel, L.; Fisher, W.; Fiscus, J.; Pallett, D.; Dahlgren, N.; Zue, V. TIMIT Acoustic-phonetic Continuous Speech Corpus. Linguist. Data Consort. 1992. [Google Scholar]
- Kalluri, S.B.; Vijayasenan, D.; Ganapathy, S. Automatic speaker profiling from short duration speech data. Speech Commun. 2020, 121, 16–28. [Google Scholar] [CrossRef]
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Common Voice Database. Available online: https://www.kaggle.com/mozillaorg/common-voice (accessed on 30 December 2020).
- DARPA-TIMIT dataset. Available online: https://www.kaggle.com/mfekadu/darpa-timit-acousticphonetic-continuous-speech (accessed on 30 December 2020).
- Resemblyryzer. Available online: https://github.com/resemble-ai/Resemblyzer (accessed on 5 September 2020).
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September2015. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar]
- Sak, H.; Senior, A.W.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Lee, S.W.; Kim, J.H.; Jun, J.; Ha, J.W.; Zhang, B.T. Overcoming catastrophic forgetting by incremental moment matching. In Proceedings of the Advances in neural information processing systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4652–4662. [Google Scholar]
- Baevski, A.; Zhou, H.; rahman Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. arXiv 2020, arXiv:2012.03411. [Google Scholar]
- VoxCeleb1. Available online: https://www.robots.ox.ac.uk/~vgg/data/voxceleb/index.html#portfolio (accessed on 30 December 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Layer Context | Size |
|---|---|---|
| TDNN1 | 400 | |
| TDNN2 | 400 | |
| TDNN3 | 400 | |
| TDNN4 | 400 | |
| Stats pooling (Mean + STD) | 1500 + 1500 | |
| Dense + ReLu | T | 400 |
| Block Name | Kernel Length | Repeats | Residual | Size |
|---|---|---|---|---|
| Input | 3 | 1 | True | 512 |
| 5 | 2 | True | 512 | |
| 7 | 2 | True | 512 | |
| 9 | 2 | True | 512 | |
| Final | 1 | 1 | False | 512 |
| pooling (Mean + STD) | − | 1 | False | 1500 + 1500 |
| Dense + BatchNorm + ReLu | − | 1 | False | 512 |
| Dense + BatchNorm + ReLu | − | 1 | False | 512 |
| Layer | Layer Size |
|---|---|
| LSTM_1 | 256 |
| LSTM_2 | 256 |
| LSTM_3 | 256 |
| Dense + ReLu | 256 |
| Binary Classifier Network for Gender Classification | ||
| Layer | Input Size | Output Size |
| Dense + ReLu + BatchNorm | embedding size | embedding size |
| Dense + Sigmoid | embedding size | 1 |
| Multi Classifier Network for Age Group Classification or Speaker Identification | ||
| Layer | Input Size | Output Size |
| Dense + ReLu + BatchNorm | embedding size | embedding size |
| Dense + Logits | embedding size | number of classes |
| Regressor Network for Age Estimation | ||
| Layer | Input Size | Output Size |
| Dense + ReLu + BatchNorm | embedding size | embedding size |
| Dense + Logits | embedding size | 1 |
| System | Waveform Processing | ||
|---|---|---|---|
| VAD | Random Crop | dBFS Normalisation | |
| Baseline | TRUE | 5 s | - |
| Proposed with Quartznet | TRUE | 5 s | dBFS |
| System | Features Extraction | |||||||
|---|---|---|---|---|---|---|---|---|
| Type | No of Features | Low Cut-off Frequency | High Cut-off Frequency | Window Size | Window Step | Window | Post-Processing | |
| Baseline | MFCC | 23 | 40 Hz | 8000 Hz | 25 ms | 10 ms | Hamming | Cepstral Mean Normalization, 3 s window |
| Proposed with Quartznet | MFCC | 30 | 40 Hz | 8000 Hz | 25 ms | 10 ms | Hamming | - |
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results | |
|---|---|---|---|---|---|
| TIMIT train | - | Accuracy | MAE | RMSE | |
| All | 98.30% | 5.73 | 8.12 | ||
| Female | 95.70% | 5.84 | 8.44 | ||
| Male | 99.60% | 5.67 | 7.96 | ||
| Common Voice Train | - | Accuracy | MAE | RMSE | |
| All | 98.80% | 7.43 | 10.23 | ||
| Female | 96.80% | 7.65 | 10.46 | ||
| Male | 99.80% | 7.32 | 10.11 | ||
| Common Voice Train | TIMIT train | Accuracy | MAE | RMSE | |
| All | 98.80% | 5.72 | 8.25 | ||
| Female | 96.80% | 5.64 | 8.42 | ||
| Male | 99.80% | 5.77 | 8.16 | ||
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results |
|---|---|---|---|---|
| TIMIT train | - | Accuracy | Weighted_F1 | |
| All | 91.10% | 24% | ||
| Female | 75.40% | 23% | ||
| Male | 96.60% | 24% | ||
| Common Voice Train | - | Accuracy | Weighted_F1 | |
| All | 98.00% | 68% | ||
| Female | 95.40% | 71% | ||
| Male | 98.90% | 66% | ||
| Common Voice Train | TIMIT train | Accuracy | Weighted_F1 | |
| All | 94.20% | 31% | ||
| Female | 90.50% | 28% | ||
| Male | 95.50% | 32% |
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results | |
|---|---|---|---|---|---|
| TIMIT train | - | Accuracy | MAE | RMSE | |
| All | 98.30% | 5.98 | 8.47 | ||
| Female | 97.00% | 6.28 | 9.42 | ||
| Male | 98.90% | 5.83 | 7.96 | ||
| Common Voice Train | - | Accuracy | MAE | RMSE | |
| All | 97.70% | 7.97 | 10.32 | ||
| Female | 95.50% | 7.06 | 9.77 | ||
| Male | 98.80% | 8.42 | 10.59 | ||
| Common Voice Train | TIMIT train | Accuracy | MAE | RMSE | |
| All | 98.90% | 5.31 | 7.55 | ||
| Female | 97.10% | 5.2 | 7.91 | ||
| Male | 99.80% | 5.37 | 7.37 | ||
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results | |
|---|---|---|---|---|---|
| TIMIT train | - | Accuracy | MAE | RMSE | |
| All | 99.60% | 5.93 | 8.08 | ||
| Female | 99.50% | 6.15 | 8.81 | ||
| Male | 99.60% | 5.83 | 7.68 | ||
| Common Voice Train | - | Accuracy | MAE | RMSE | |
| All | 99.40% | 10.5 | 13.48 | ||
| Female | 99.10% | 12.17 | 14.97 | ||
| Male | 99.60% | 9.67 | 12.67 | ||
| Common Voice Train | TIMIT train | Accuracy | MAE | RMSE | |
| All | 99.60% | 5.46 | 7.52 | ||
| Female | 99.50% | 5.75 | 8.2 | ||
| Male | 99.60% | 5.32 | 7.16 | ||
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results |
|---|---|---|---|---|
| TIMIT train | - | Accuracy | Weighted_F1 | |
| All | 96.80% | 27% | ||
| Female | 93.80% | 19% | ||
| Male | 97.80% | 29% | ||
| Common Voice Train | - | Accuracy | Weighted_F1 | |
| All | 98.20% | 65% | ||
| Female | 96.70% | 66% | ||
| Male | 98.60% | 64% | ||
| Common Voice Train | TIMIT train | Accuracy | Weighted_F1 | |
| All | 96.90% | 35% | ||
| Female | 93.30% | 29% | ||
| Male | 98.20% | 37% |
| Group | Pretrained on 1 | Fine-Tuned on 1 | Fine-Tuned on 2 | Gender Results | Age Results | |
|---|---|---|---|---|---|---|
| VoxCeleb1 | TIMIT train | - | Accuracy | MAE | RMSE | |
| All | 98.50% | 5.37 | 7.74 | |||
| Female | 96.40% | 5.65 | 8.53 | |||
| Male | 99.50% | 5.23 | 7.31 | |||
| VoxCeleb1 | Common Voice train | - | Accuracy | MAE | RMSE | |
| All | 98.50% | 7.76 | 10.05 | |||
| Female | 97.00% | 8,01 | 10.58 | |||
| Male | 99.30% | 7.64 | 9.77 | |||
| VoxCeleb1 | Common Voice train | TIMIT train | Accuracy | MAE | RMSE | |
| All | 99.60% | 5.18 | 7.54 | |||
| Female | 98.80% | 5.29 | 8.12 | |||
| Male | 100.00% | 5.12 | 7.24 | |||
| Group | Trained on | Fine-Tuned on | Gender Results | Age Results |
|---|---|---|---|---|
| TIMIT train | - | Accuracy | Weighted_F1 | |
| All | 88.00% | 19% | ||
| Female | 57.90% | 19% | ||
| Male | 98.30% | 20% | ||
| Common Voice Train | - | Accuracy | Weighted_F1 | |
| All | 99.60% | 93% | ||
| Female | 99.00% | 94% | ||
| Male | 99.80% | 93% | ||
| Common Voice Train | TIMIT train | Accuracy | Weighted_F1 | |
| All | 87.30% | 25% | ||
| Female | 51.80% | 28% | ||
| Male | 99.50% | 25% |
| Published | Methods | Age Estimation (MAE) | Age Estimation (RMSE) | DataSet |
|---|---|---|---|---|
| [21] | x-vectors | 4.92 | - | NIST SRE 2010 |
| [21] | x-vectors with baseline i-vector system | 5.82 | - | NIST SRE 2010 |
| [22] | DNN initialization sheme | - | 7.60 for male; 8.63 female | TIMIT |
| [24] | feature-engineering based support vector regression system | 5.20 for male; 5.60 for female | - | TIMIT |
| (This paper) 1 | x-vector with QuartzNet embedder and 2-stage transfer learning | 5.12 for male; 5.29 for female | 7.24 for male; 8.12 for female | TIMIT |
| (This paper) 2 | d-vector feature extractor with frontend modules pretraining on Common Voice | 5.32 for male; 5.75 for female | 7.16 for male; 8.20 for female | TIMIT |
| Published | Methods | Gender Recognition (Accuracy) |
|---|---|---|
| [11] | MLP | 96.00% |
| [12] | MLP, GMM, vector quantization, learning vector quantization | 96.40% |
| [13] | MLP | 96.74% |
| [15] | k-NN, MLP | 96.80% |
| [17] | GMM | 97.50% |
| [14] | SVM | 98.27% |
| [16] | LSTM | 98.40% |
| [17] | iCST-Voting | 98.42% |
| [19] | SVM | 99.40% |
| (This paper) 1 | x-vector with QuartzNet embedder and 2-stage transfer learning | 99.60% |
| (This paper) 2 | d-vector feature extractor with frontend modules pretraining on Common Voice | 99.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwasny, D.; Hemmerling, D. Gender and Age Estimation Methods Based on Speech Using Deep Neural Networks. Sensors 2021, 21, 4785. https://doi.org/10.3390/s21144785
Kwasny D, Hemmerling D. Gender and Age Estimation Methods Based on Speech Using Deep Neural Networks. Sensors. 2021; 21(14):4785. https://doi.org/10.3390/s21144785
Chicago/Turabian StyleKwasny, Damian, and Daria Hemmerling. 2021. "Gender and Age Estimation Methods Based on Speech Using Deep Neural Networks" Sensors 21, no. 14: 4785. https://doi.org/10.3390/s21144785
APA StyleKwasny, D., & Hemmerling, D. (2021). Gender and Age Estimation Methods Based on Speech Using Deep Neural Networks. Sensors, 21(14), 4785. https://doi.org/10.3390/s21144785