
Research on Network Security Situation Awareness Based on the LSTM-DT Model

Abstract
:1. Introduction
1.1. Main Contributions
- This paper proposes a new NSSA method, which perceives the network security state from three aspects: network situation factor extraction, network situation assessment, and network situation prediction.
- We propose the concept of “attack probability”, which changes the previous scholars’ limitation of situation awareness only being able to identify attack types, and makes the final situation value more accurate.
- We propose the concept of “the influence degree of each network attack” and evaluate it by various methods, which makes the identified attack types have a more objective expression.
- The model has good stability, and the prediction accuracy can reach 95% when describing the general network environment, while the accuracy can still remain above 80% when describing the complex network environment.
1.2. Structure of the Paper
2. Related Works
3. Related Model and Algorithms
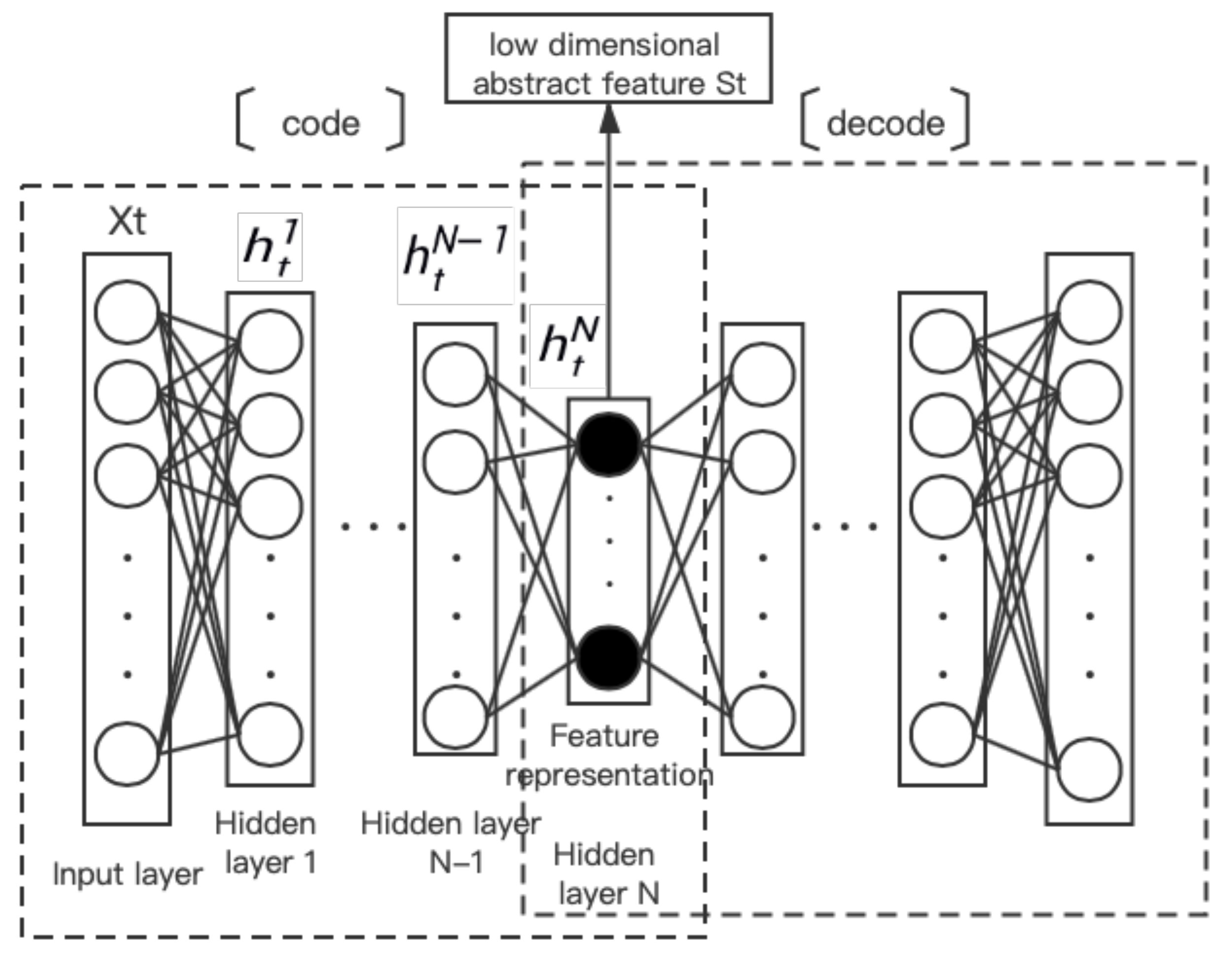
3.1. Stack Sparse Auto-Encoder
3.2. LSTM and DT
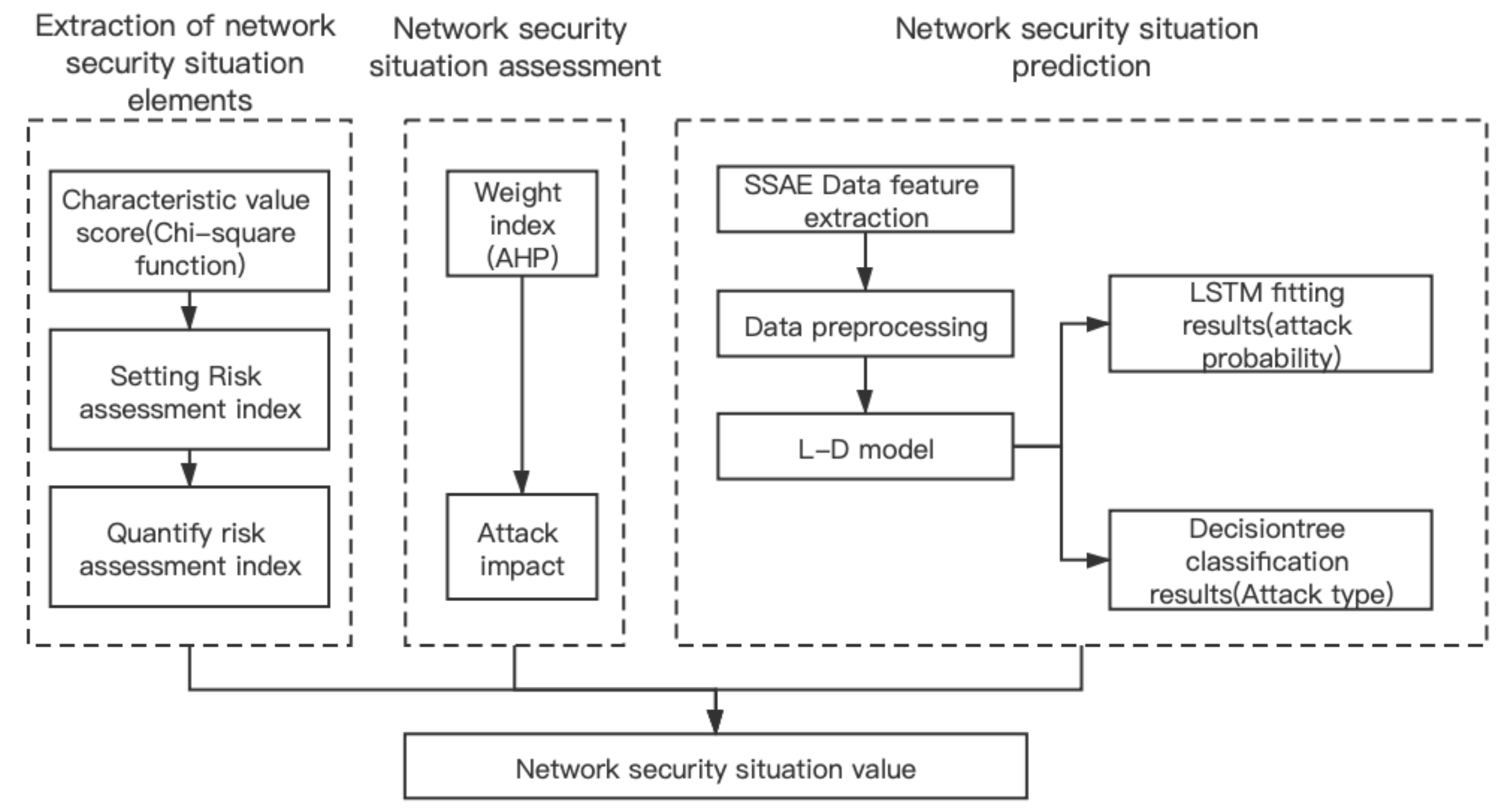
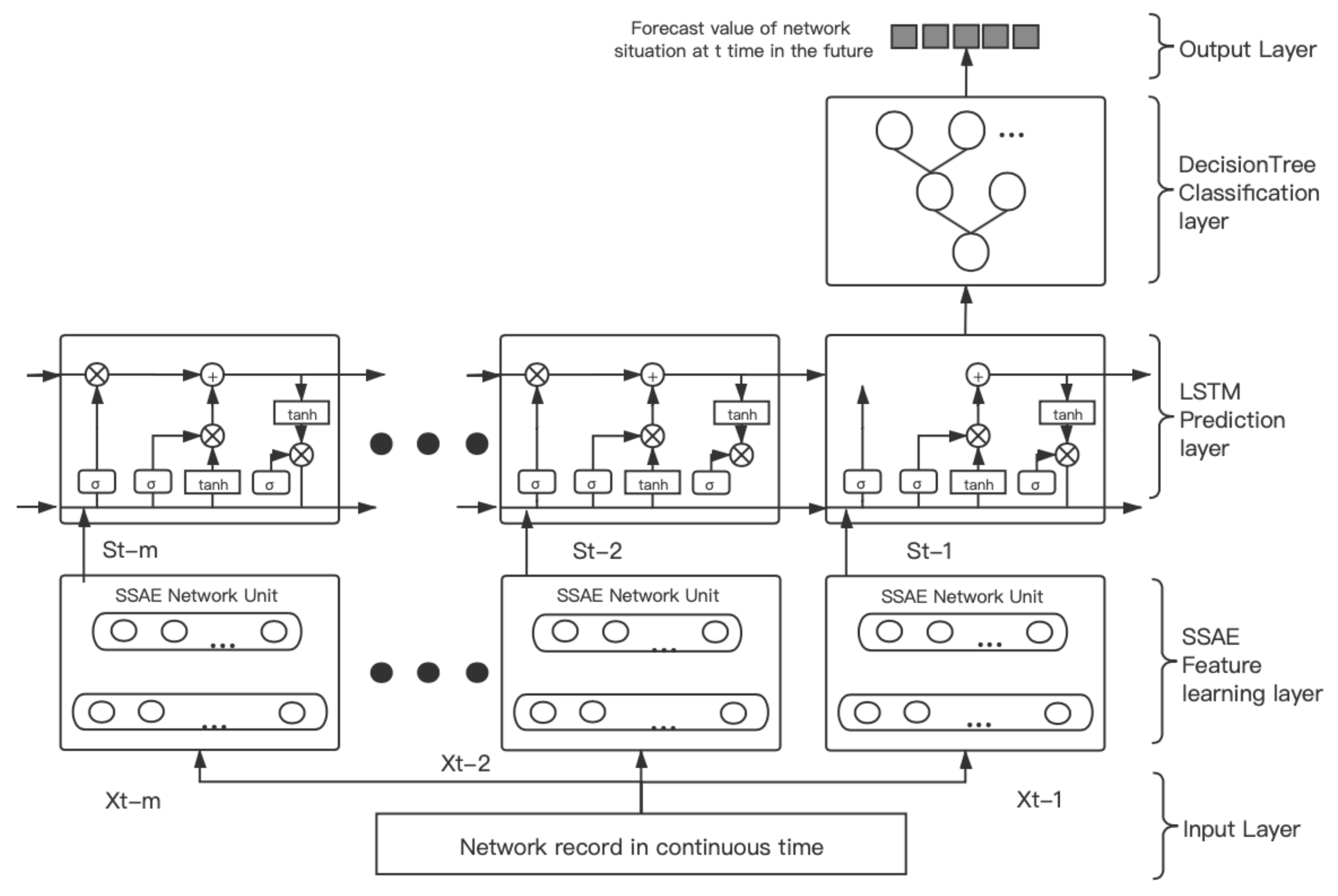
4. The Design of the LSTM-DT Hybrid Model
- Extraction of network security situation elementsWe evaluate the dataset by the chi-square function in order to set the network security situation elements and give the quantitative formula.
- Network security situation assessmentThe weight of the selected network security situation elements is calculated by the AHP method. At the same time, we give the attack influence degree of each attack mode.
- Network security situation predictionFirst, the dataset is extracted through the SSAE network to obtain new low-dimensional abstract features. Then the processed network traffic data are input into the LSTM-DT model in batches for training. The model is divided into two parts: fitting and classification. The LSTM network is used to make the fitting results. The prediction value is regarded as the probability of attack occurrence, and the tag value in the dataset is updated to serve the classification results, defining the type of network attack. Finally, the network security situation value is obtained by the product of attack probability and impact degree in the current time. The model is shown in Figure 2.
5. Extraction and Evaluation of Network Security Situation Elements
- Determine the risk assessment indicators.
- Construct the pairwise comparison matrix for the evaluation indexes and obtain their respective weights by the AHP.
- Calculate the risk assessment index for each attack based on the eigenvalues of training sets.
- Obtain the impact of each attack through the attack risk assessment index and its corresponding weight.
5.1. Extraction of Network Security Situation Elements
5.1.1. Packet Loss Rate
5.1.2. Data Traffic Rate of Change
5.1.3. Data Throughput of the Network
5.2. Network Security Situation Assessment
5.2.1. Paired Comparison Matrix
5.2.2. Consistency Checking
6. Network Security Situation Prediction Algorithm
| Algorithm 1 Network security situation awareness algorithm based on LSTM-DT model. |
| Input: D, m,, seed, steps, , attribute A Output: Prediction value, loss value and sort results corresponding to test set 1. get , from D by m 2. = SSAE () 3. ’ = zscore () 4. create by 5. connect by 6. initialize by seed 7. for each step in 1:steps 8. P = (’) 9. 10. update by Loss and 11. get * 12. for each j in 0:(n − m − 1) = *(P) append with [−1] 13. = de_zscore () 14. update by 15. get ’ 16. Tree = Create root node n 17. for all attribute A∈’ do Use compute information-theoretic criteria get 18. end for 19. Tree = Create node that tests in the root 20. get from ’ based on 21. for all do = C4.5() Attach to the corresponding branch of Tree 22. end for 23. return sort results(attack type) |
7. Datasets and Experiments
7.1. Data Sources
7.2. Extraction of Network Situation Elements and Analysis of Evaluation Results
7.2.1. Extraction Results of Network Situation Elements
7.2.2. Network Situation Assessment Results
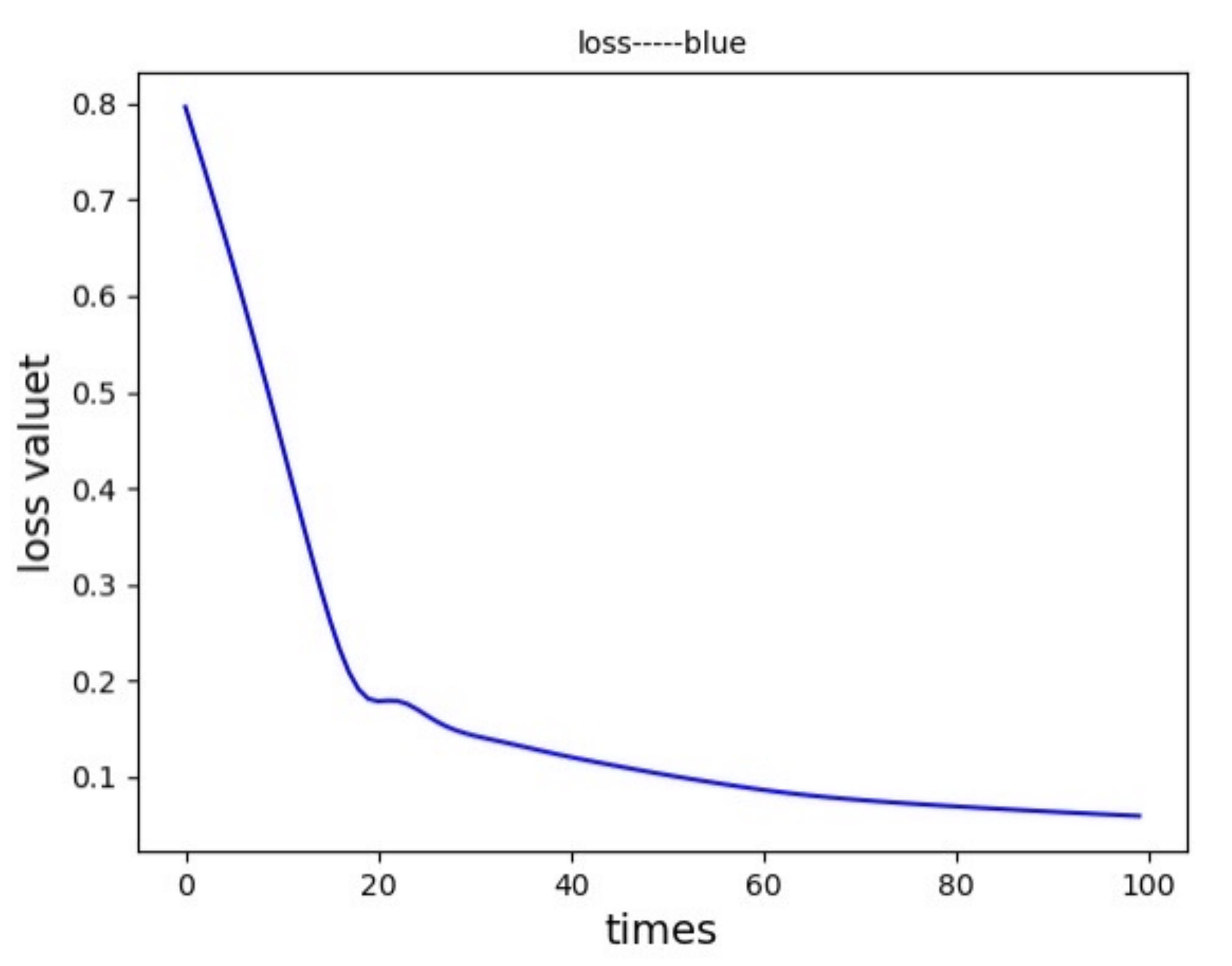
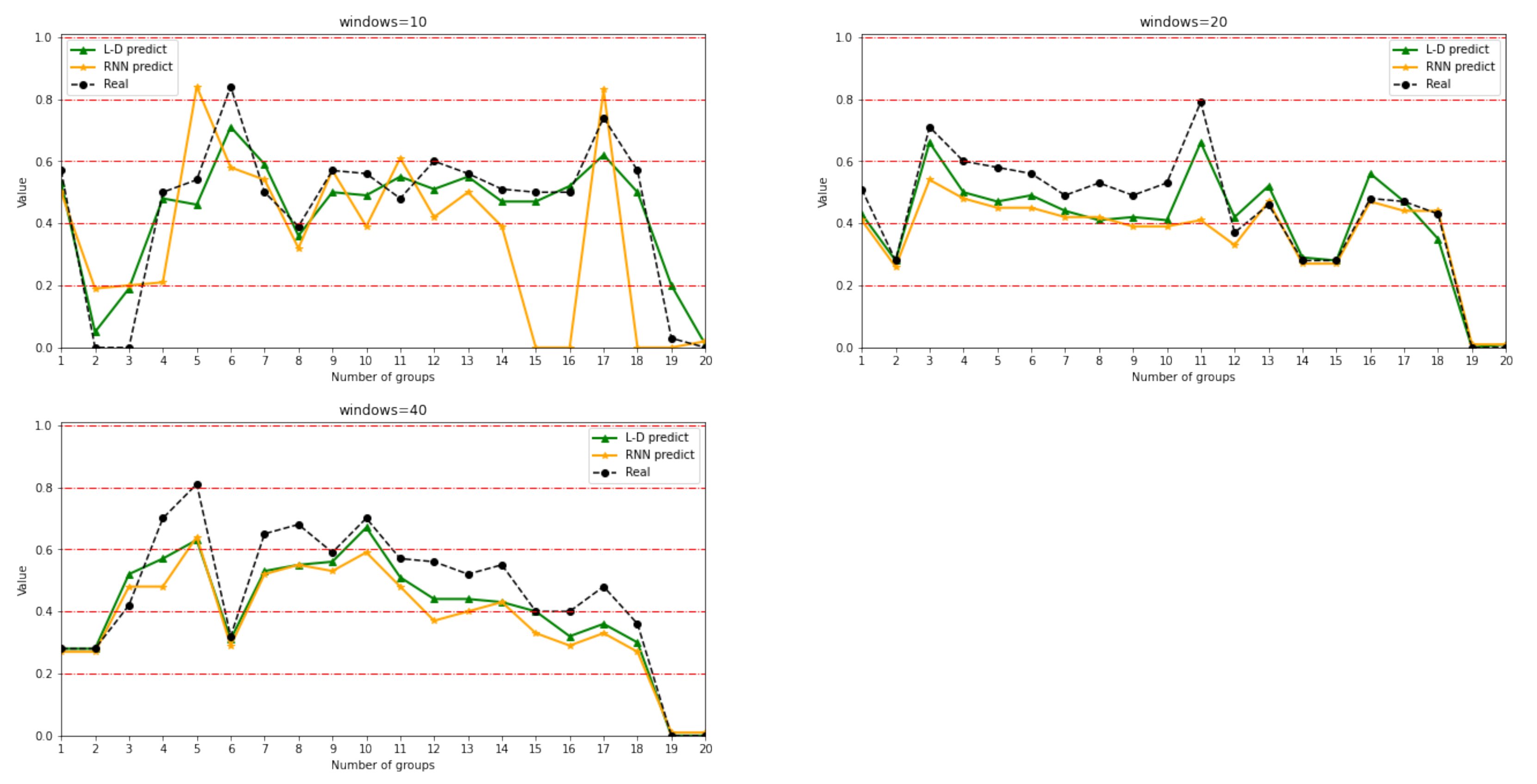
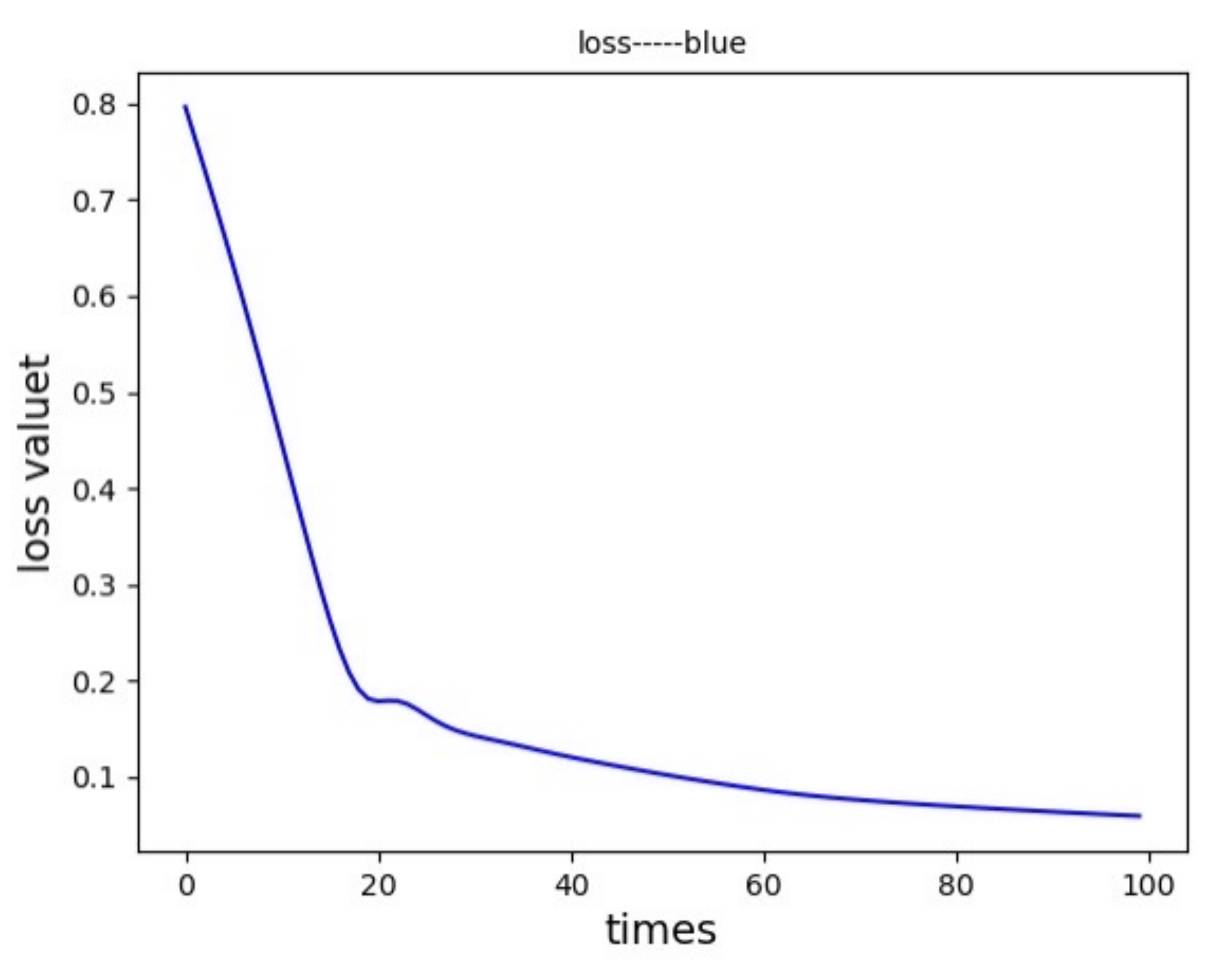
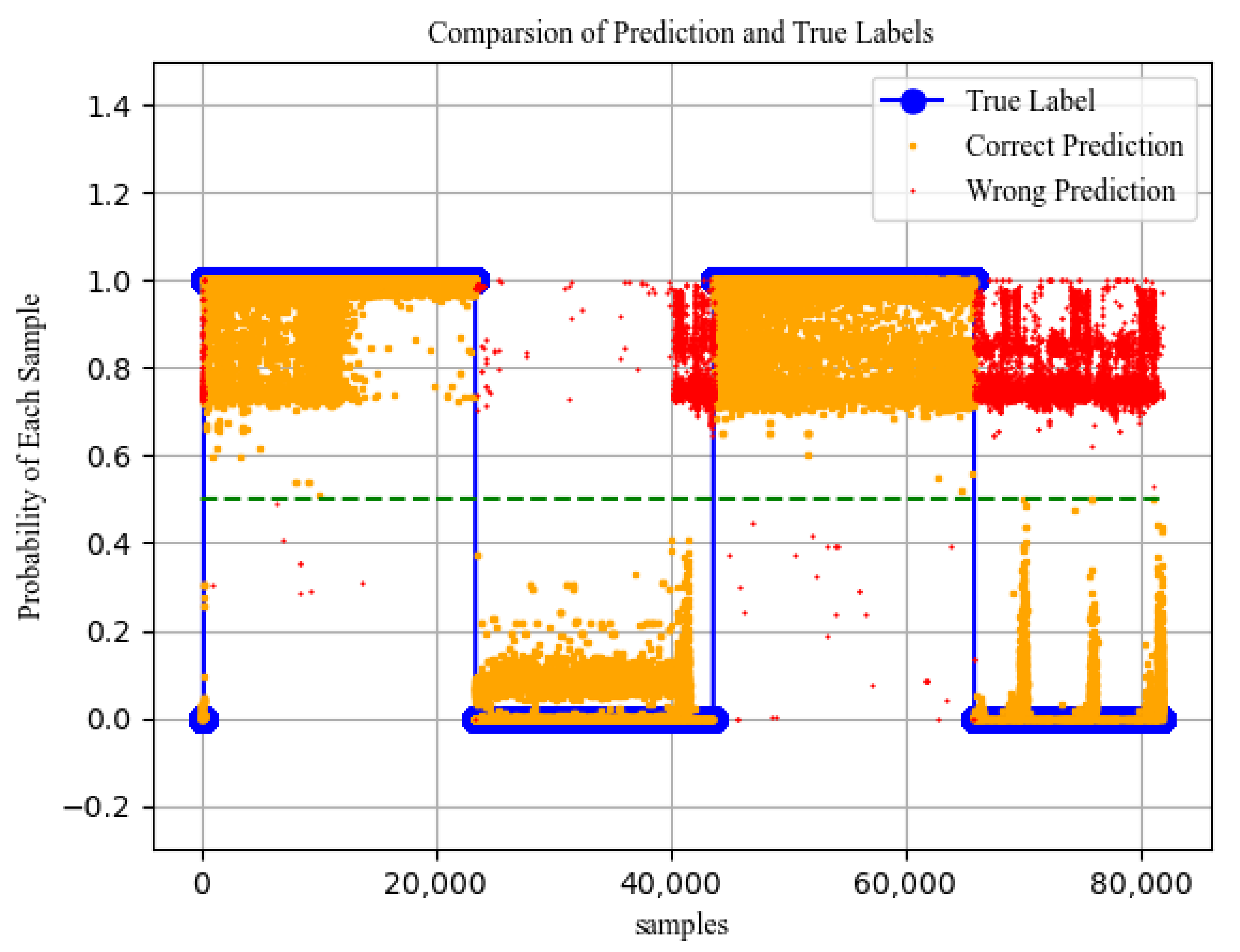
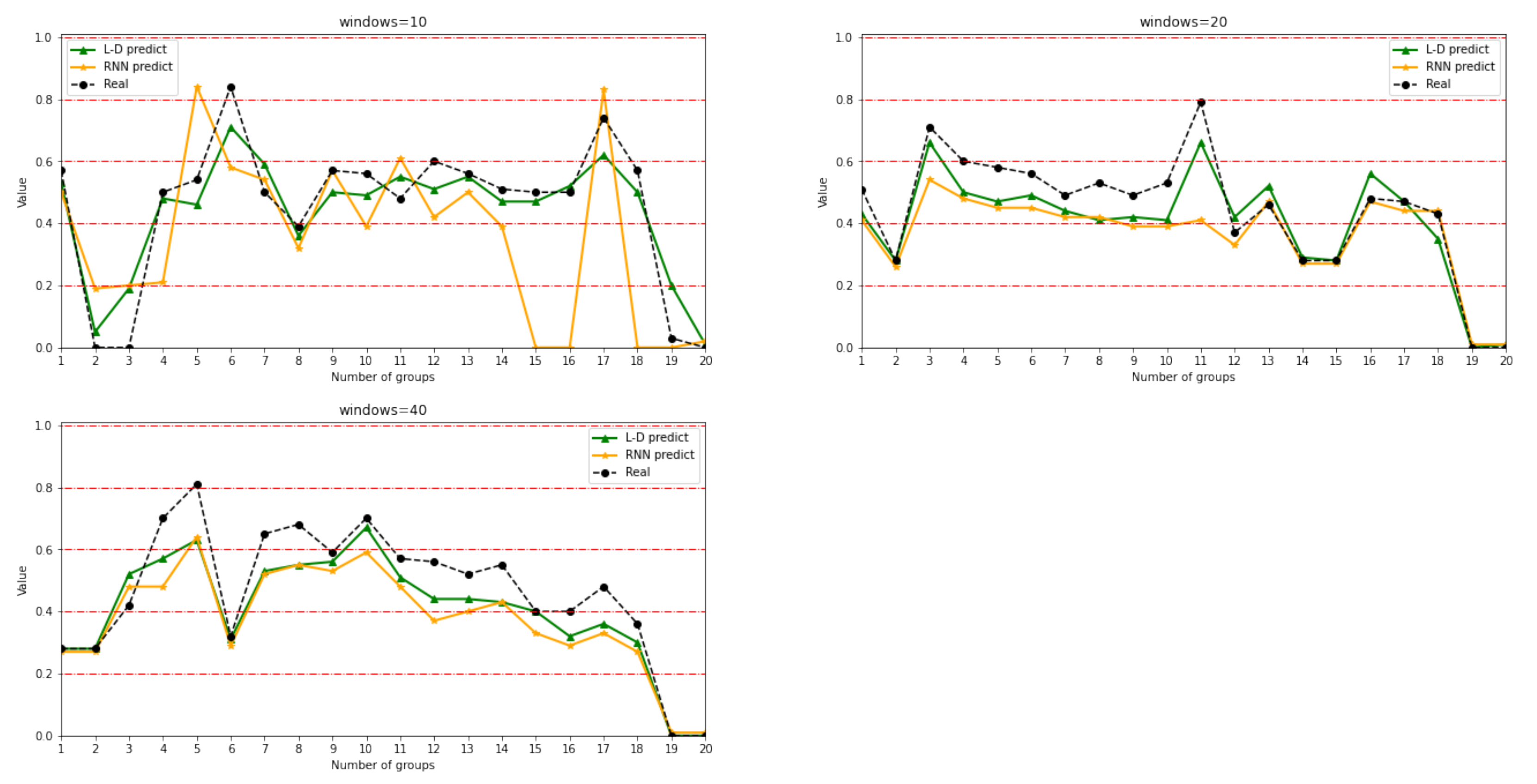
7.3. Analysis of Network Situation Prediction Results
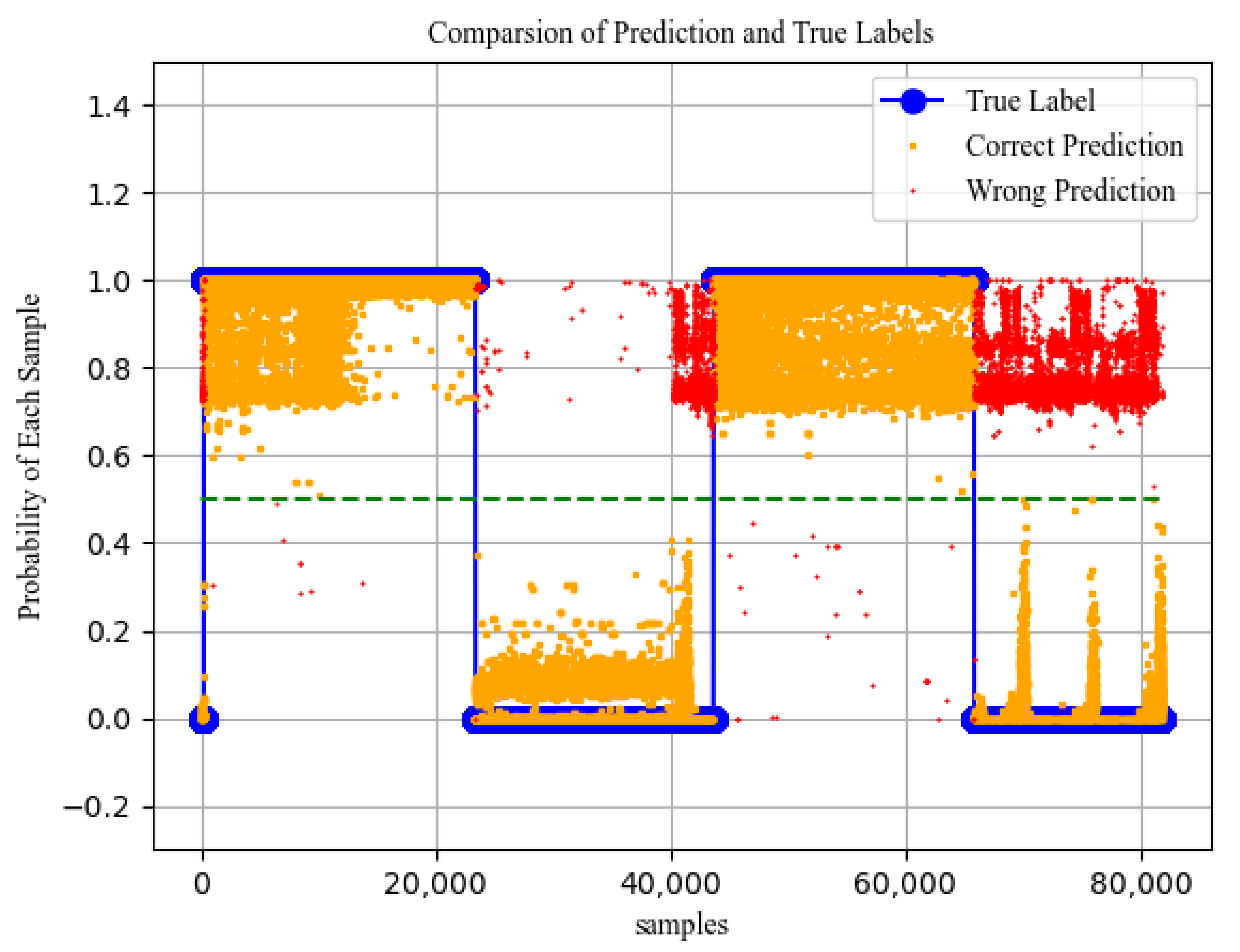
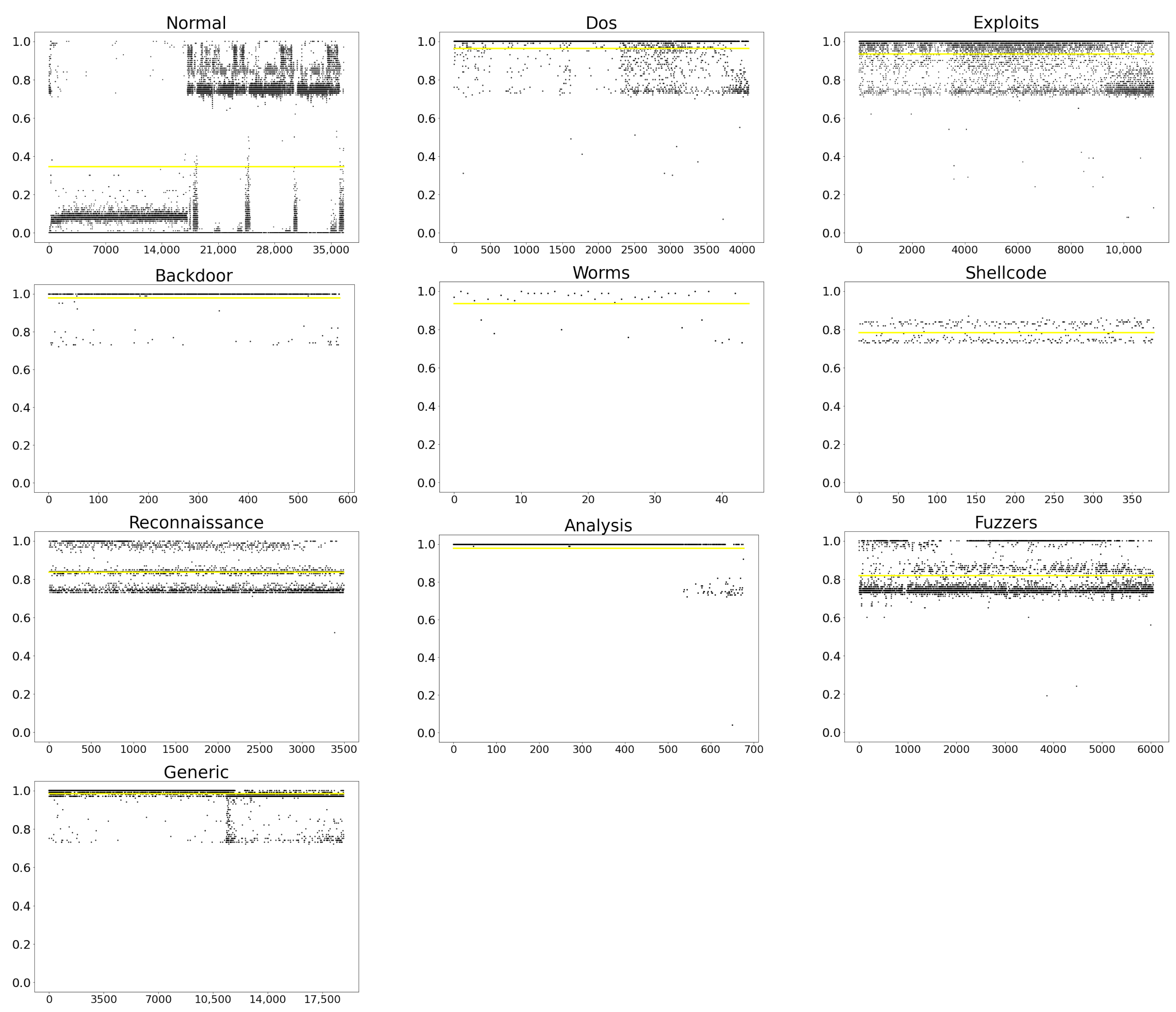
Network Attack Probability Analysis
8. Analysis and Comparison
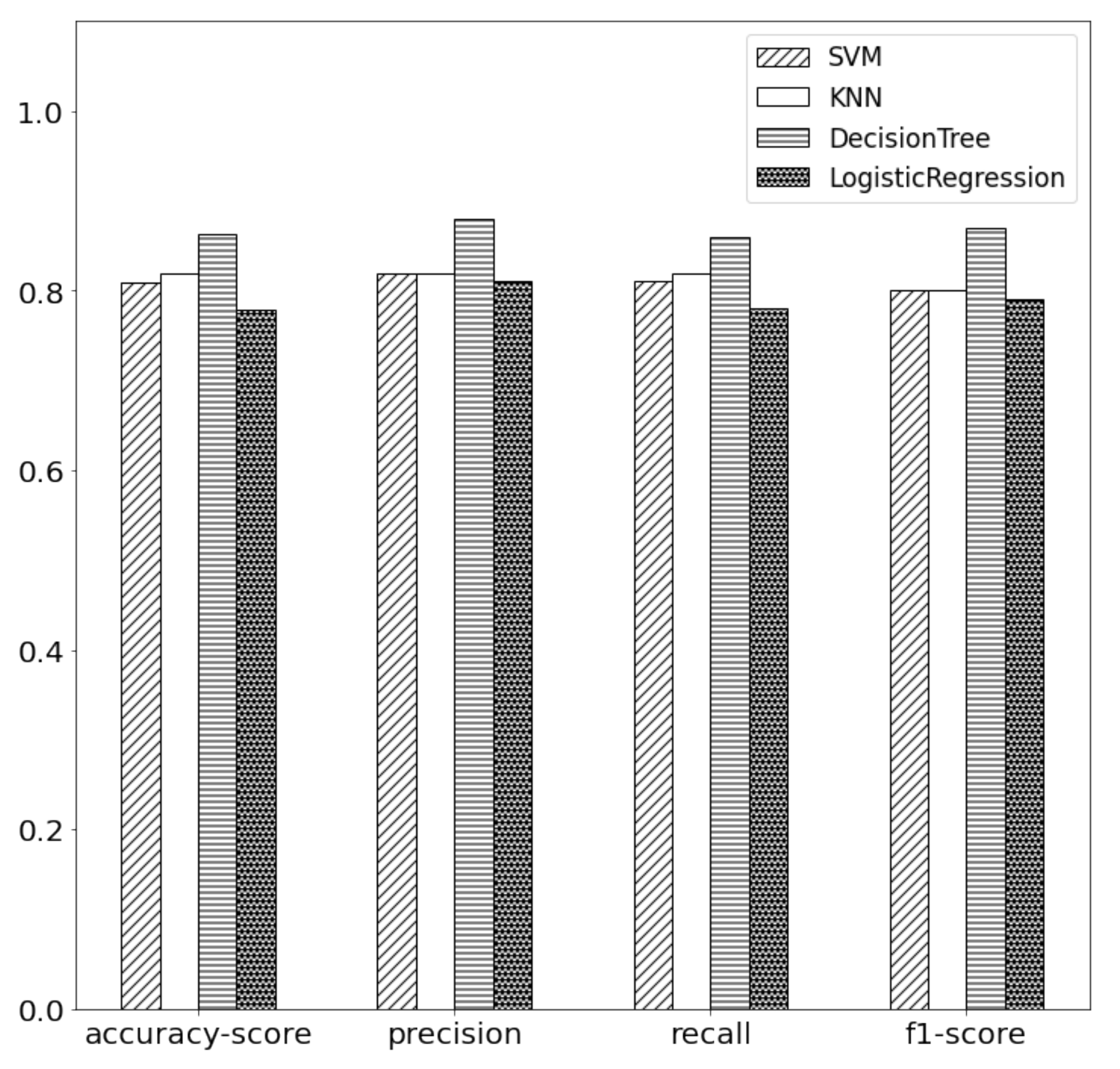
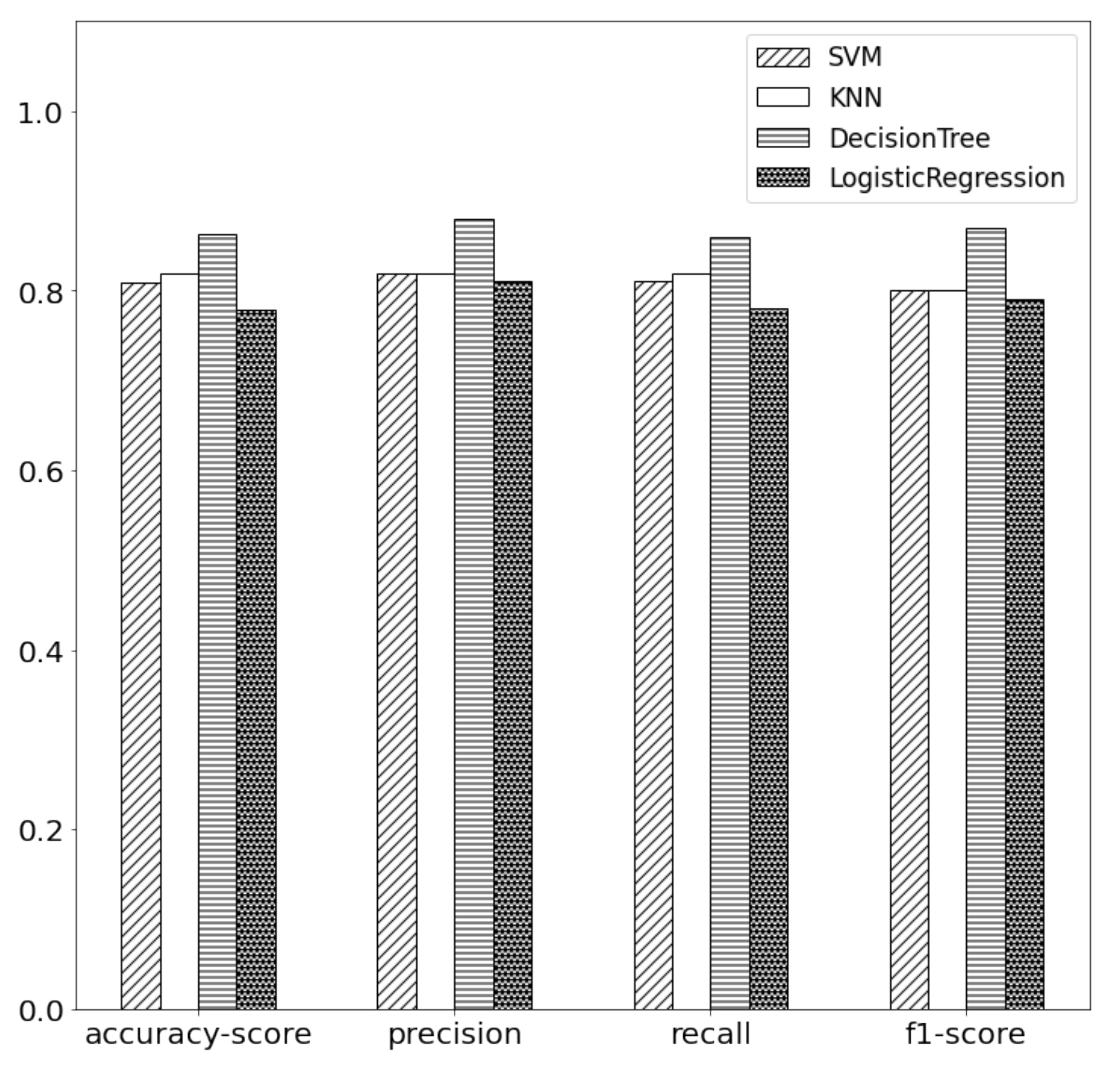
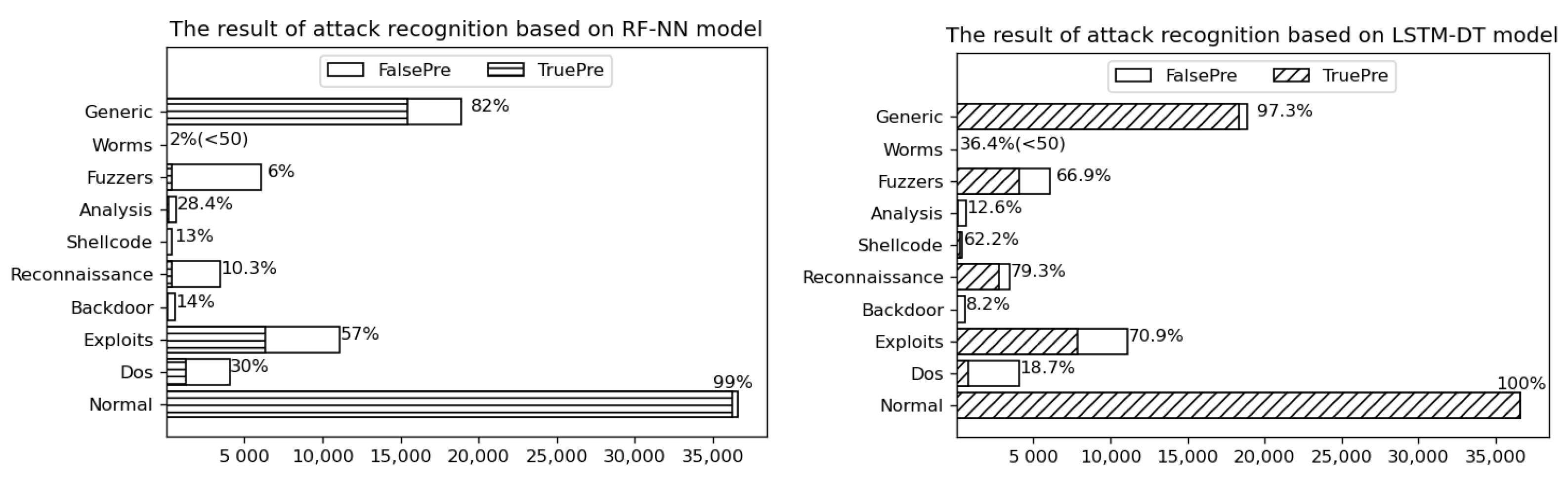
8.1. Analysis and Comparison of Classification Results
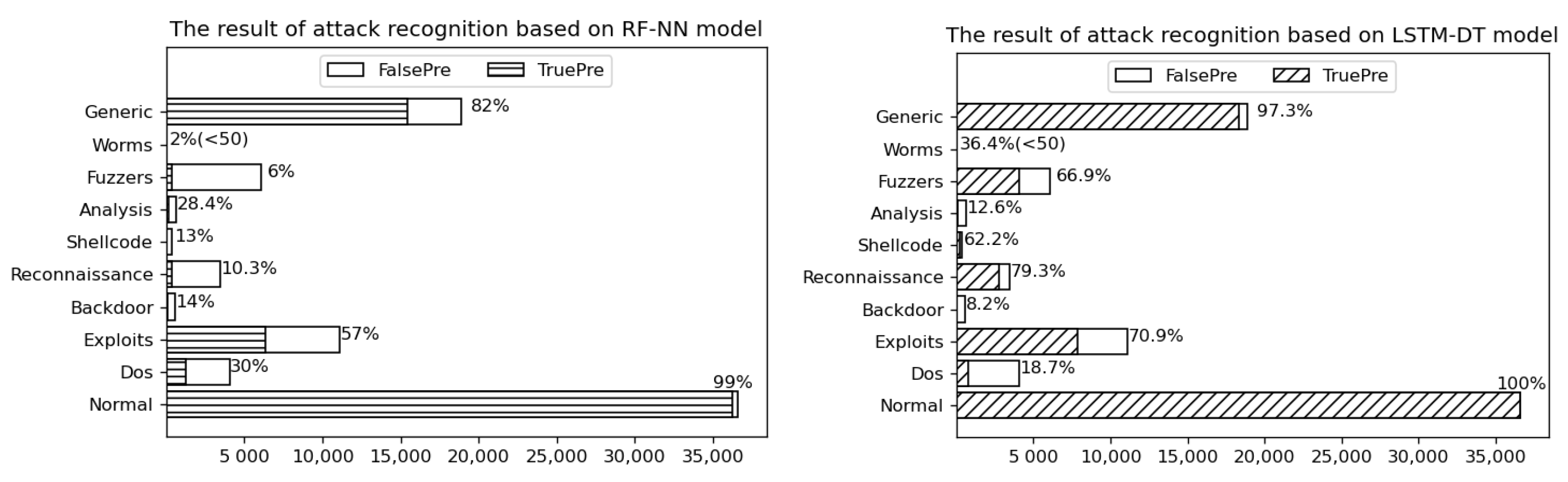
8.2. Analysis and Comparison of Network Security Situation Awareness
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Endsley, M.R. Design and evaluation for situation awareness enhancement. In Proceedings of the Human Factors Society Annual Meeting, Chicago, IL, USA, 5–9 October 1988; Sage Publications Sage CA: Los Angeles, CA, USA, 1988; Volume 32, pp. 97–101. [Google Scholar]
- Bass, T. Intrusion Detection Systems and Multisensor Data Fusion. Commun. ACM 2000, 43, 99–105. [Google Scholar] [CrossRef]
- Zhong, S.H.; Huang, H.J.; Chen, A. An Effective Intrusion Detection Model Based on Random Forest and Neural Networks. Adv. Mater. Res. 2011, 267, 308–313. [Google Scholar] [CrossRef]
- Qian, Z.K. Network Security Situation Awareness Framework and Random Forest Assessment Model. J. Southwest China Norm. Univ. 2019, 44, 118–123. [Google Scholar]
- Yu, Q.; Ren, J.; Zhang, J.; Liu, S.; Zhang, W. An Immunology-Inspired Network Security Architecture. IEEE Wirel. Commun. 2020, 27, 1–6. [Google Scholar] [CrossRef]
- Zhu, B.; Chen, Y.; Cai, Y. Three Kinds of Network Security Situation Awareness Model Based on Big Data. Int. J. Netw. Secur. 2019, 21, 115–121. [Google Scholar]
- Zhao, D.; Song, H.; Li, H. Fuzzy integrated rough set theory situation feature extraction of network security. J. Intell. Fuzzy Syst. 2021, 40, 1–12. [Google Scholar]
- Kou, G.; Wang, S.; Zhang, D. Recognition of Network Security Situation Elements Based on Depth Stack Encoder and Back Propagation Algorithm. J. Electron. Inf. Technol. 2019, 41, 154–159. [Google Scholar]
- Duan, Y.; Li, X.; Yang, X.; Yang, L. Network Security Situation Factor Extraction Based on Random Forest of Information Gain. In Proceedings of the 2019 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 194–197. [Google Scholar] [CrossRef]
- Ji, F.Z.; Zhou, Y.T.; Tang, Q.J.; Hu, F.X.; Ma, S.F. Network Security Situation Assessment Based on FAHP. In Proceedings of the 2015 International Conference on Automation, Mechanical Control and Computational Engineering, Ji’nan, China, 24–26 April 2015; Atlantis Press: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Zhi, W.W.; Zhou, X.X.; Yang, L. Application of Fuzzy Comprehensive Method and Analytic Hierarchy Process in the Evaluation of Network Security Level Protection Research. J. Phys. Conf. Ser. 2021, 1820, 012187. [Google Scholar] [CrossRef]
- Hu, J.; Ma, D.; Liu, C.; Shi, Z.; Hu, C. Network security situation prediction based on MR-SVM. IEEE Access 2019, 7, 130937–130945. [Google Scholar] [CrossRef]
- Hu, J.; Guo, S.; Kuang, X.; Meng, F.; Shi, Z. I-HMM-Based Multidimensional Network Security Risk Assessment. IEEE Access 2019, 8, 1431–1442. [Google Scholar] [CrossRef]
- Lv, Y.; Ren, H.; Gao, X.; Sun, T.; Guo, X. Multi-Scale Risk Assessment Model of Network Security Based on LSTM; Verification and Evaluation of Computer and Communication Systems; Springer International Publishing: New York, NY, USA, 2020. [Google Scholar]
- Wang, G. Comparative study on different neural networks for network security situation prediction. Secur. Priv. 2020, 4, e138. [Google Scholar] [CrossRef]
- Dong, Z.; Su, X.; Sun, L.; Xu, K. Network security situation prediction method based on strengthened LSTM neural network. J. Phys. Conf. Ser. 2021, 1856, 012056. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Wen, L.; Gao, L.; Li, X. A New Deep Transfer Learning Based on Sparse Auto-Encoder for Fault Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 136–144. [Google Scholar] [CrossRef]
- Li, D.; Deng, L.; Cai, Z.; Yao, X. Notice of Retraction: Intelligent Transportation System in Macao Based on Deep Self-Coding Learning. IEEE Trans. Ind. Inform. 2018, 14, 3253–3260. [Google Scholar] [CrossRef]
- Jia, W.; Muhammad, K.; Wang, S.; Zhang, Y. Five-category classification of pathological brain images based on deep stacked sparse autoencoder. Multimed. Tools Appl. 2019, 78, 4045–4064. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sathyadevan, S.; Nair, R.R. Comparative Analysis of Decision Tree Algorithms: ID3, C4.5 and Random Forest; Springer: New Delhi, India, 2015. [Google Scholar] [CrossRef]
- Damanik, I.S.; Windarto, A.P.; Wanto, A.; Poningsih; Andani, S.R.; Saputra, W. Decision Tree Optimization in C4.5 Algorithm Using Genetic Algorithm. J. Phys. Conf. Ser. 2019, 1255, 012012. [Google Scholar] [CrossRef] [Green Version]
- Ou, X.; Singhal, A. The Common Vulnerability Scoring System (CVSS); Quantitative Security Risk Assessment of Enterprise Networks; Springer: New York, NY, USA, 2012. [Google Scholar]
- Saaty, T.L. What is the Analytic Hierarchy Process? In Mathematical Models for Decision Support; Mitra, G., Greenberg, H.J., Lootsma, F.A., Rijkaert, M.J., Zimmermann, H.J., Eds.; Springer: Berlin/Heidelberg, Germany, 1988; pp. 109–121. [Google Scholar]
- Deloach, S.A.; Wood, M.F.; Sparkman, C.H. Multiagent Systems Engineering. Int. J. Softw. Eng. Knowl. Eng. 2008, 11, 231–258. [Google Scholar] [CrossRef]
- Alaoui, S.S.; Farhaoui, Y.; Aksasse, B. A Comparative Study of the Four Well-Known Classification Algorithms in Data Mining. In Proceedings of the International Conference on Advanced Information Technology, Services and Systems, Tangier, Morocco, 14–15 April 2017; Springer: Cham, Switzerland, 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Indicators | Risk Level |
|---|---|
| Loss > 0.002 | The first rank |
| Loss > 0.001 | The second rank |
| Loss > 0 | The third rank |
| Loss = 0 | The fourth rank |
| Risk Indicators | Risk Level |
|---|---|
| Rate (<10000) | The first rank |
| Rate (10,000–50,000) | The second rank |
| Rate (50,000–100,000) | The third rank |
| Rate (>100,000) | The fourth rank |
| Risk Indicators | Risk Level |
|---|---|
| Throughput (<500) | The first rank |
| Throughput (500–5000) | The second rank |
| Throughput (5000–10,000) | The third rank |
| Throughput (>10,000) | The fourth rank |
| Scale | Meaning |
|---|---|
| 1 | The two indicators have the same importance |
| 3 | The former is slightly more important than the latter |
| 5 | The former is a bit more important than the latter |
| 7 | The former is more important than the latter |
| 9 | The former is much more important than the latter |
| 2,4,6,8 | The median value of the above adjacent judgment |
| reciprocal | If is compared with to obtain , then is compared with to obtain 1/ |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|
| 0.00 | 0.00 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 |
| NORM | Generic | RCN | Exploits | Fuzzers | Dos | ANLS | Worms | Backdoors | Shellcode |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00057 | 0.00184 | 0.00102 | 0.00319 | 0.00084 | 0 | 0.00187 | 0.00125 | 0.00206 |
| 4 | 3 | 2 | 2 | 1 | 3 | 4 | 2 | 2 | 1 |
| NORM | Generic | RCN | Exploits | Fuzzers | Dos | ANLS | Worms | Backdoors | Shellcode |
|---|---|---|---|---|---|---|---|---|---|
| 121,829 | 195,836 | 43,363 | 50,718 | 39 | 14,305 | 137,064 | 36,705 | 55,580 | 45,423 |
| 4 | 4 | 2 | 3 | 1 | 2 | 4 | 2 | 3 | 2 |
| NORM | Generic | RCN | Exploits | Fuzzers | Dos | ANLS | Worms | Backdoors | Shellcode |
|---|---|---|---|---|---|---|---|---|---|
| 36,974 | 5581 | 1821 | 1896 | 2 | 487 | 6753 | 9008 | 2656 | 3238 |
| 4 | 4 | 2 | 2 | 1 | 1 | 3 | 3 | 2 | 2 |
| Attack Mode | Loss | Rate | Throughput | Attack Impact |
|---|---|---|---|---|
| Normal | 4 | 4 | 4 | 0.25 |
| Generic | 3 | 4 | 4 | 0.30 |
| Reconnaissance | 2 | 2 | 2 | 0.5 |
| Exploits | 2 | 3 | 2 | 0.473 |
| Fuzzers | 1 | 1 | 1 | 1 |
| Dos | 3 | 2 | 1 | 0.56 |
| Analysis | 4 | 4 | 3 | 0.275 |
| Worms | 2 | 2 | 3 | 0.45 |
| Backdoors | 2 | 3 | 2 | 0.473 |
| Shellcode | 1 | 2 | 2 | 0.77 |
| Attack Probability | Attack Type | Attack Impact | Network Security Situation Value |
|---|---|---|---|
| 1.00 | Exploits | 0.473333333 | 0.473 |
| 1.00 | Exploits | 0.473333333 | 0.473 |
| 1.00 | Dos | 0.56 | 0.560 |
| 1.00 | Exploits | 0.473333333 | 0.473 |
| 0.97 | Exploits | 0.473333333 | 0.459 |
| 0.96 | Exploits | 0.473333333 | 0.454 |
| 1.00 | Exploits | 0.473333333 | 0.473 |
| 1.00 | Exploits | 0.473333333 | 0.473 |
| 1.00 | Fuzzers | 1 | 0.740 |
| 0.74 | Exploits | 0.473333333 | 0.473 |
| Windows | Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 10 | L-D | 0.95 | 1 | 0.95 | 0.97 |
| RNN | 0.80 | 0.73 | 0.80 | 0.76 | |
| 20 | L-D | 0.90 | 0.90 | 0.90 | 0.90 |
| RNN | 0.65 | 0.72 | 0.65 | 0.61 | |
| 40 | L-D | 0.80 | 0.84 | 0.80 | 0.78 |
| RNN | 0.50 | 0.67 | 0.50 | 0.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Kang, C.; Xiao, Y. Research on Network Security Situation Awareness Based on the LSTM-DT Model. Sensors 2021, 21, 4788. https://doi.org/10.3390/s21144788
Zhang H, Kang C, Xiao Y. Research on Network Security Situation Awareness Based on the LSTM-DT Model. Sensors. 2021; 21(14):4788. https://doi.org/10.3390/s21144788
Chicago/Turabian StyleZhang, Haofang, Chunying Kang, and Yao Xiao. 2021. "Research on Network Security Situation Awareness Based on the LSTM-DT Model" Sensors 21, no. 14: 4788. https://doi.org/10.3390/s21144788
APA StyleZhang, H., Kang, C., & Xiao, Y. (2021). Research on Network Security Situation Awareness Based on the LSTM-DT Model. Sensors, 21(14), 4788. https://doi.org/10.3390/s21144788