
Attention-Based 3D Human Pose Sequence Refinement Network



Abstract
:1. Introduction
- We propose a novel method to refine a 3D human pose sequence consisting of 3D rotations of joints. The proposed method performs human pose refinement independently from existing 3D human pose estimation methods. It can be applied to the results of any existing method in a model-agnostic manner and is easy to use.
- The proposed method is based on a simple but effective weighted-averaging operation and generates interpretable affinity weights using a non-local attention mechanism.
- In accordance with our experimental results, the proposed method consistently improves the 3D pose estimation and mesh reconstruction performance (i.e., accuracy and smoothness of output sequences) of existing methods for various real datasets.
2. Related Work
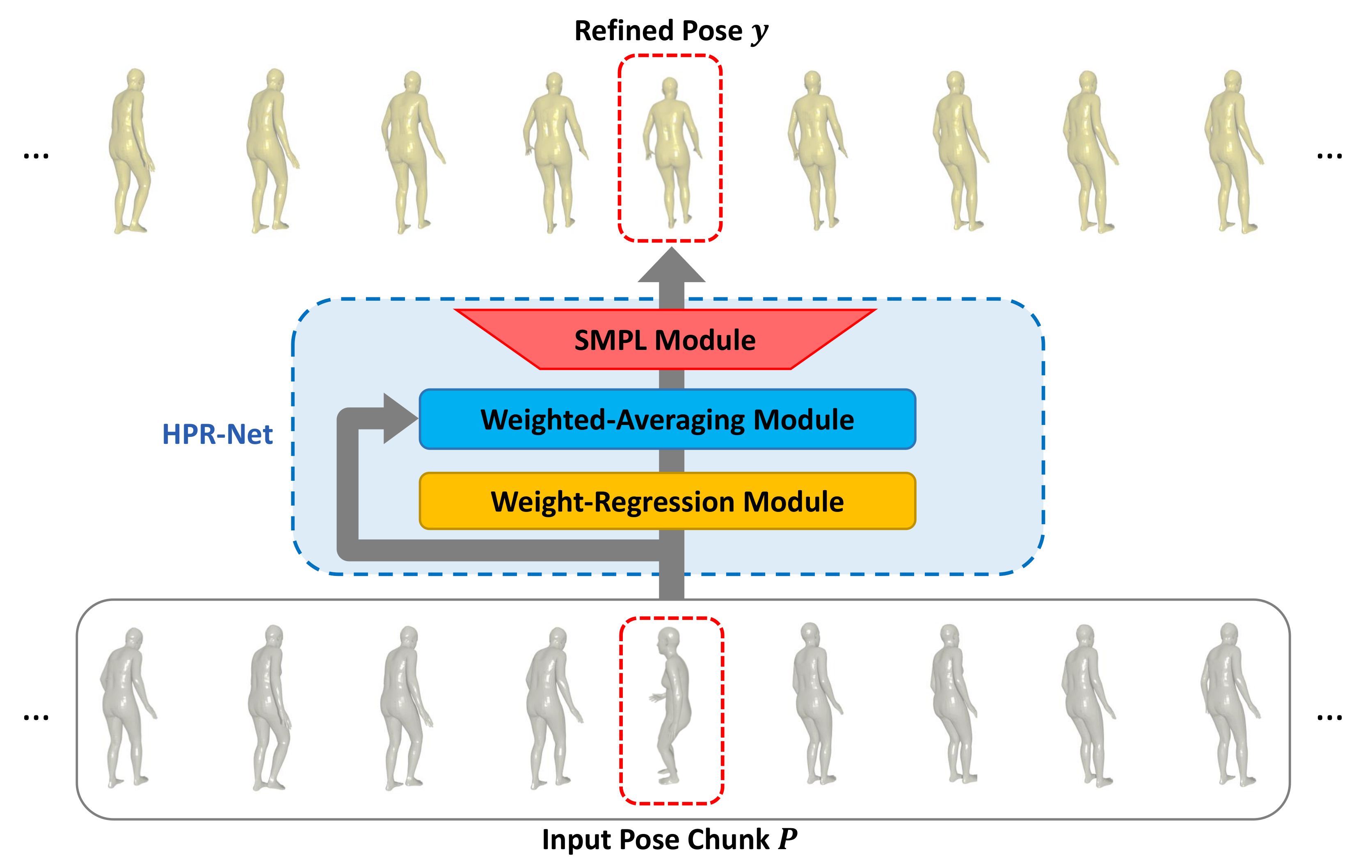
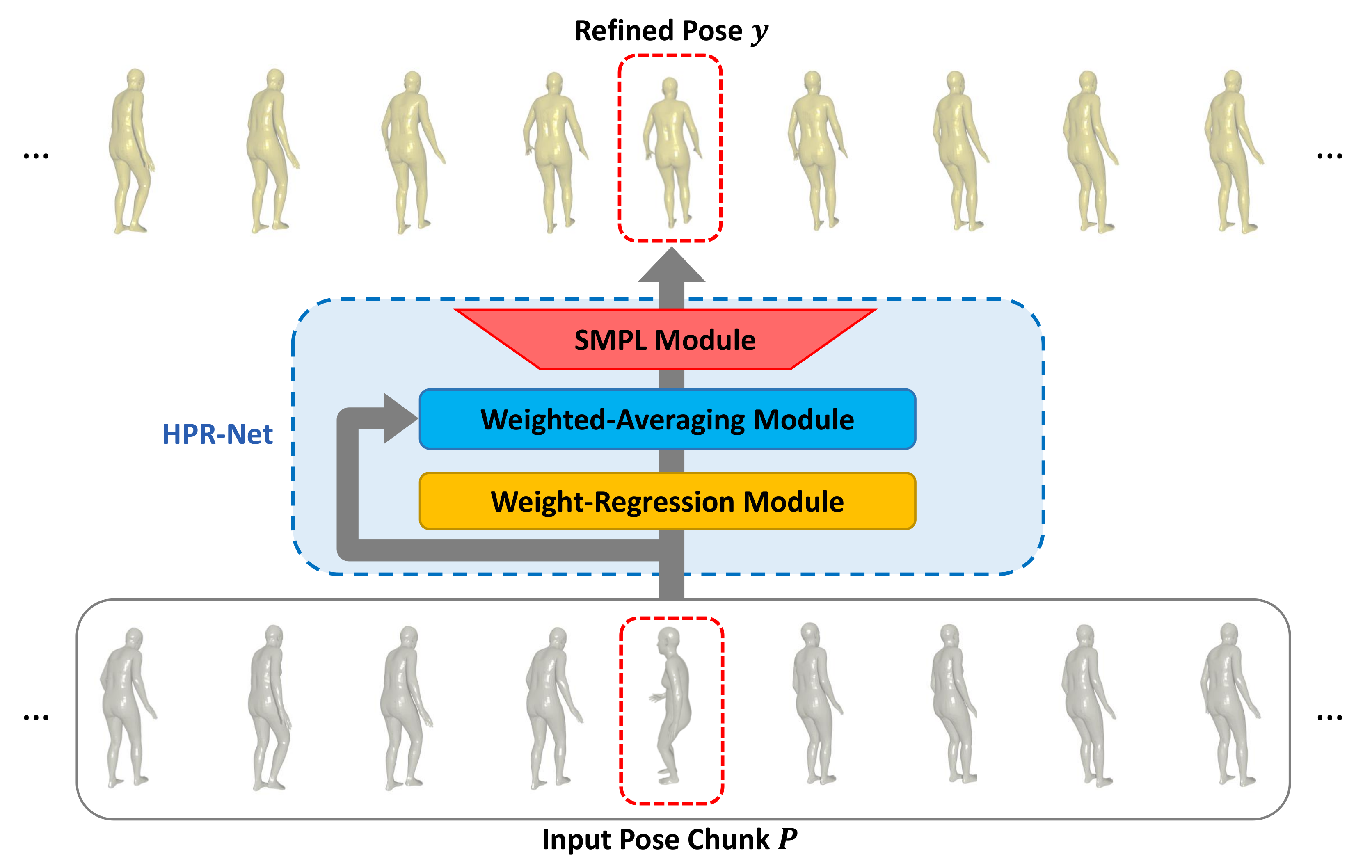
3. Proposed Method
3.1. SMPL Module
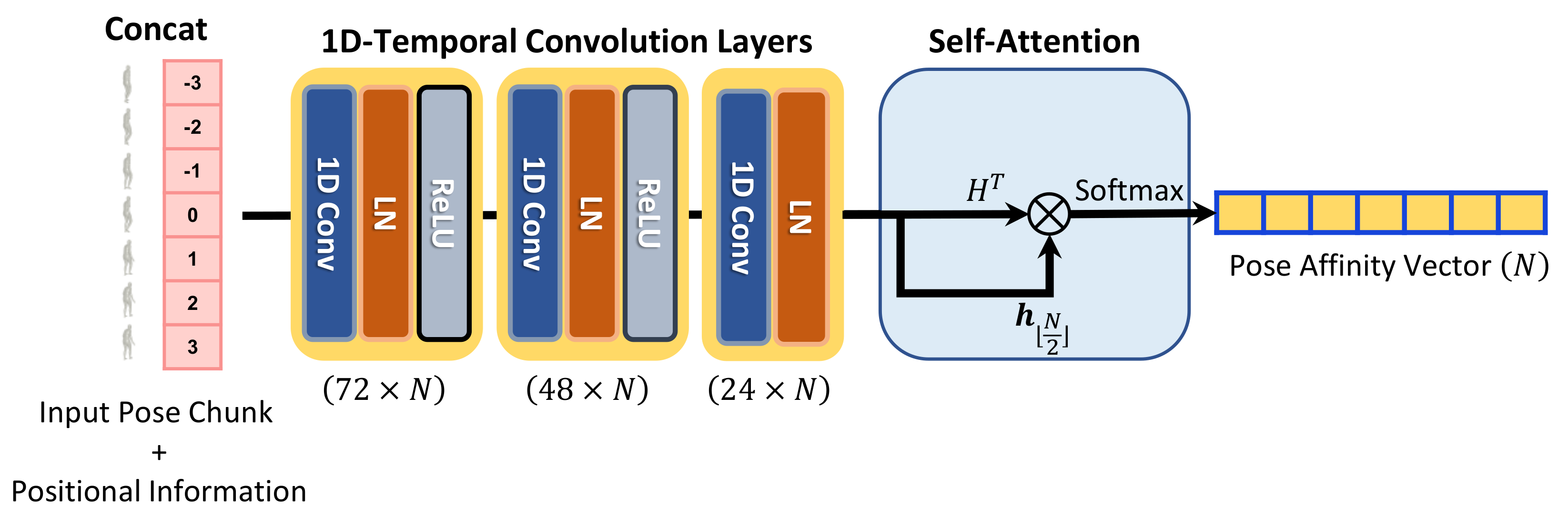
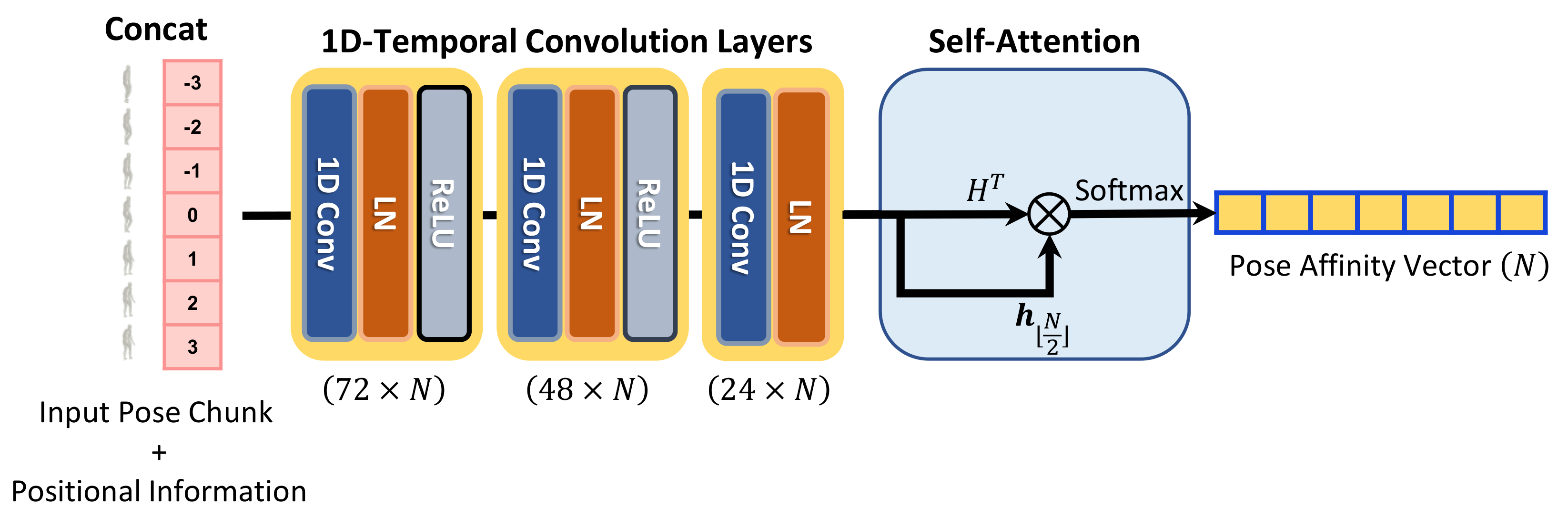
3.2. Weight-Regression Module
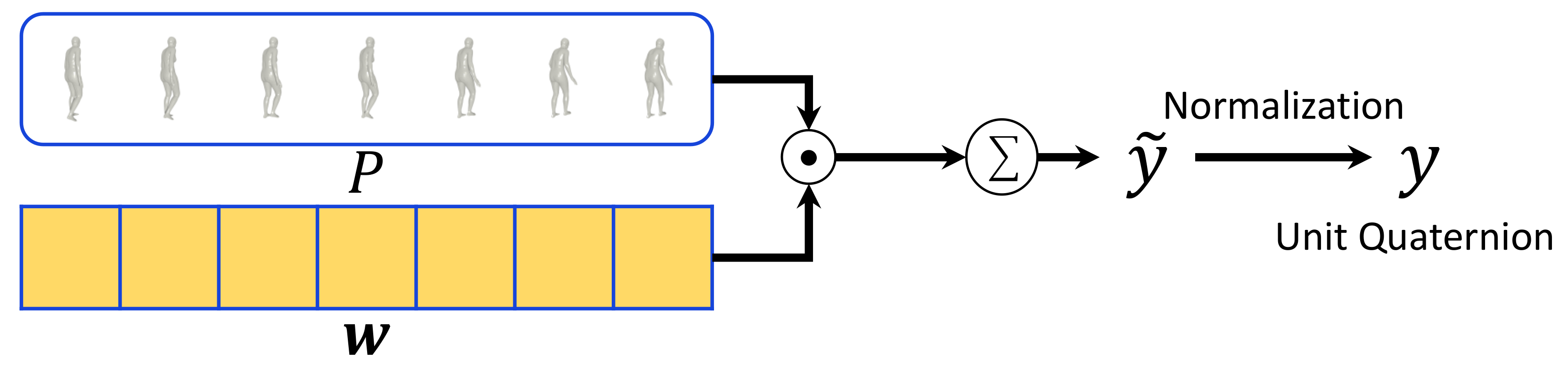
3.3. Weighted-Averaging Module
4. Experimental Results
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Study
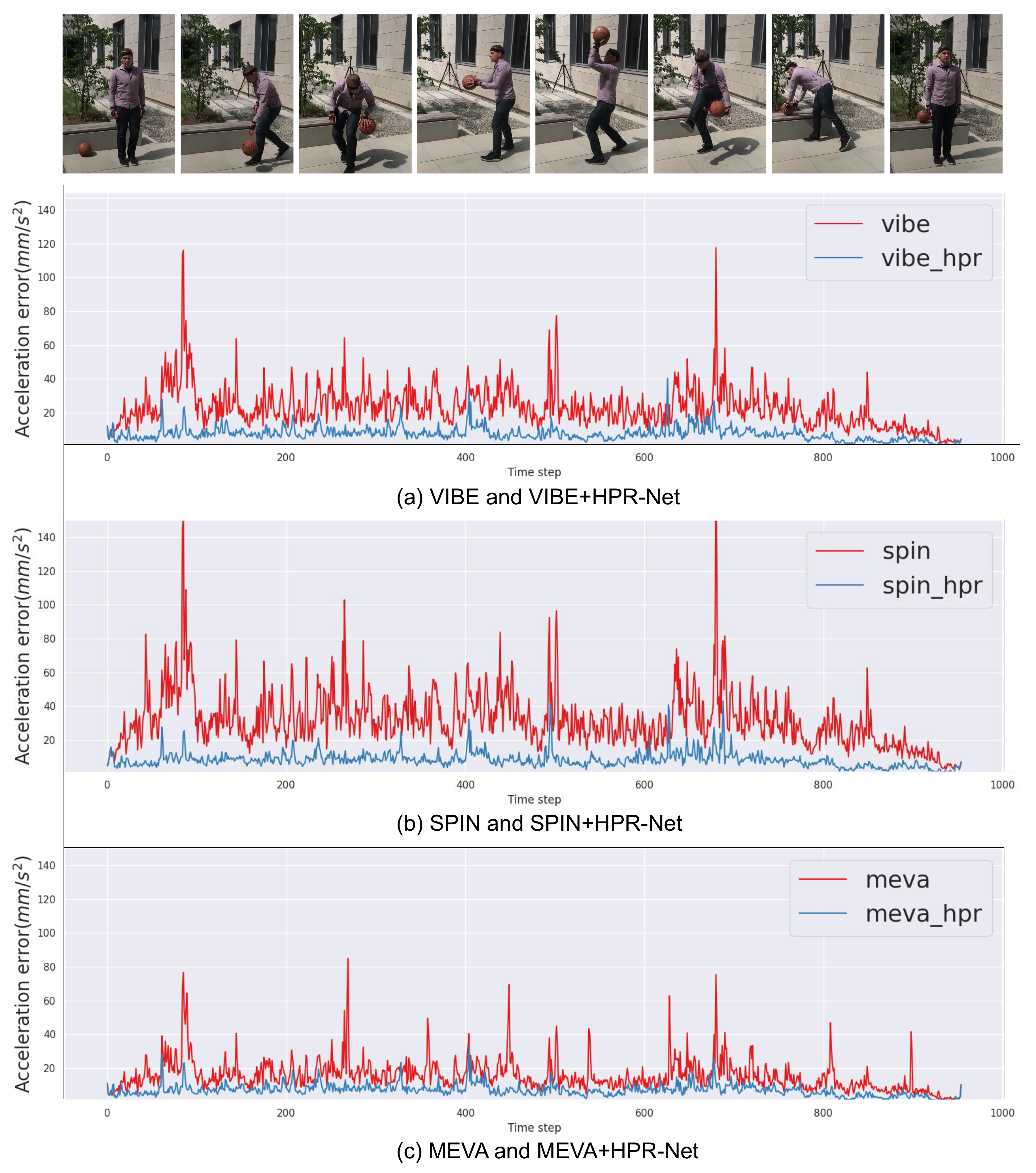
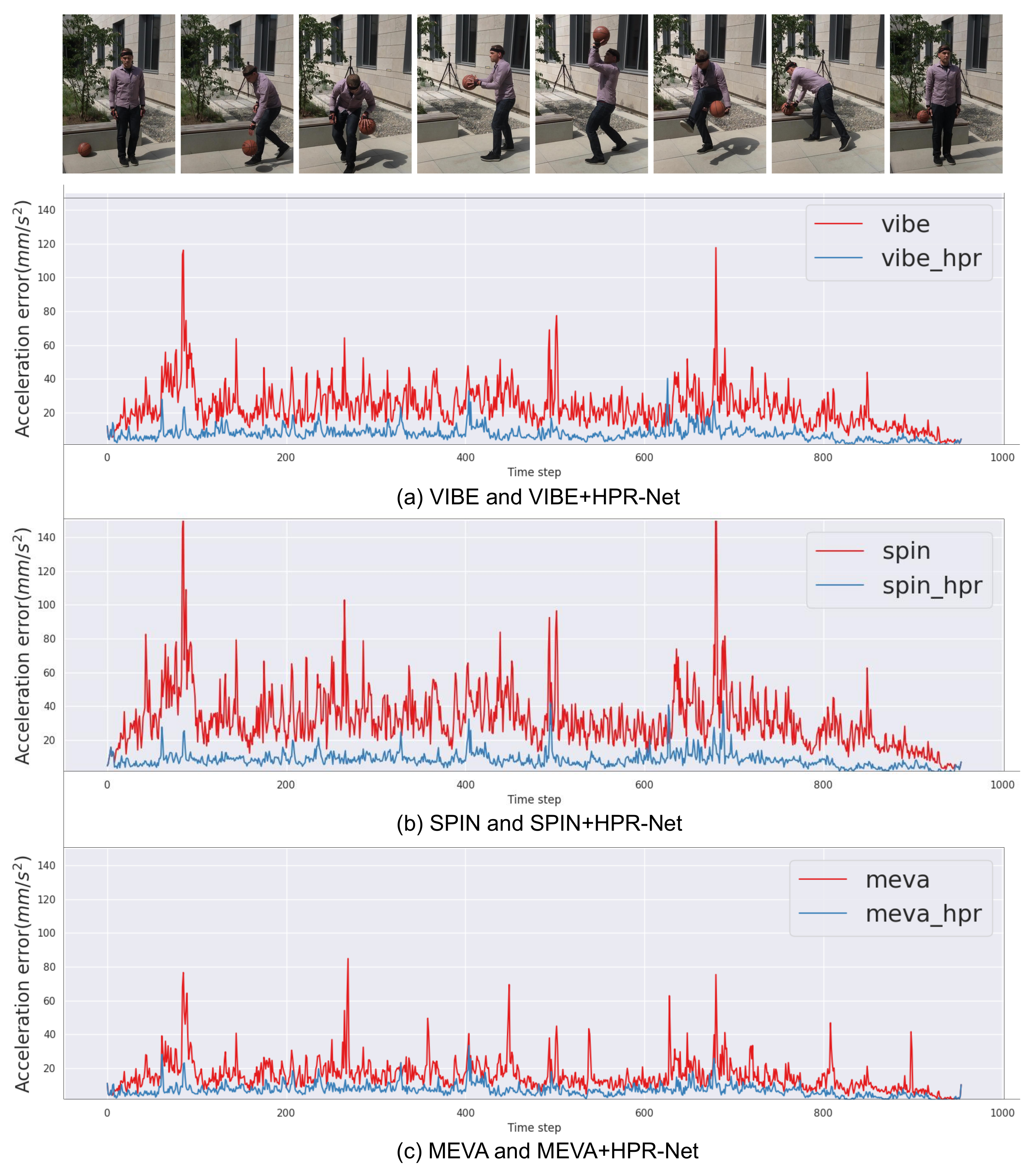
4.4. Refinement on State-of-the-Art Methods
4.5. Comparison with Other Pose Refinement Methods
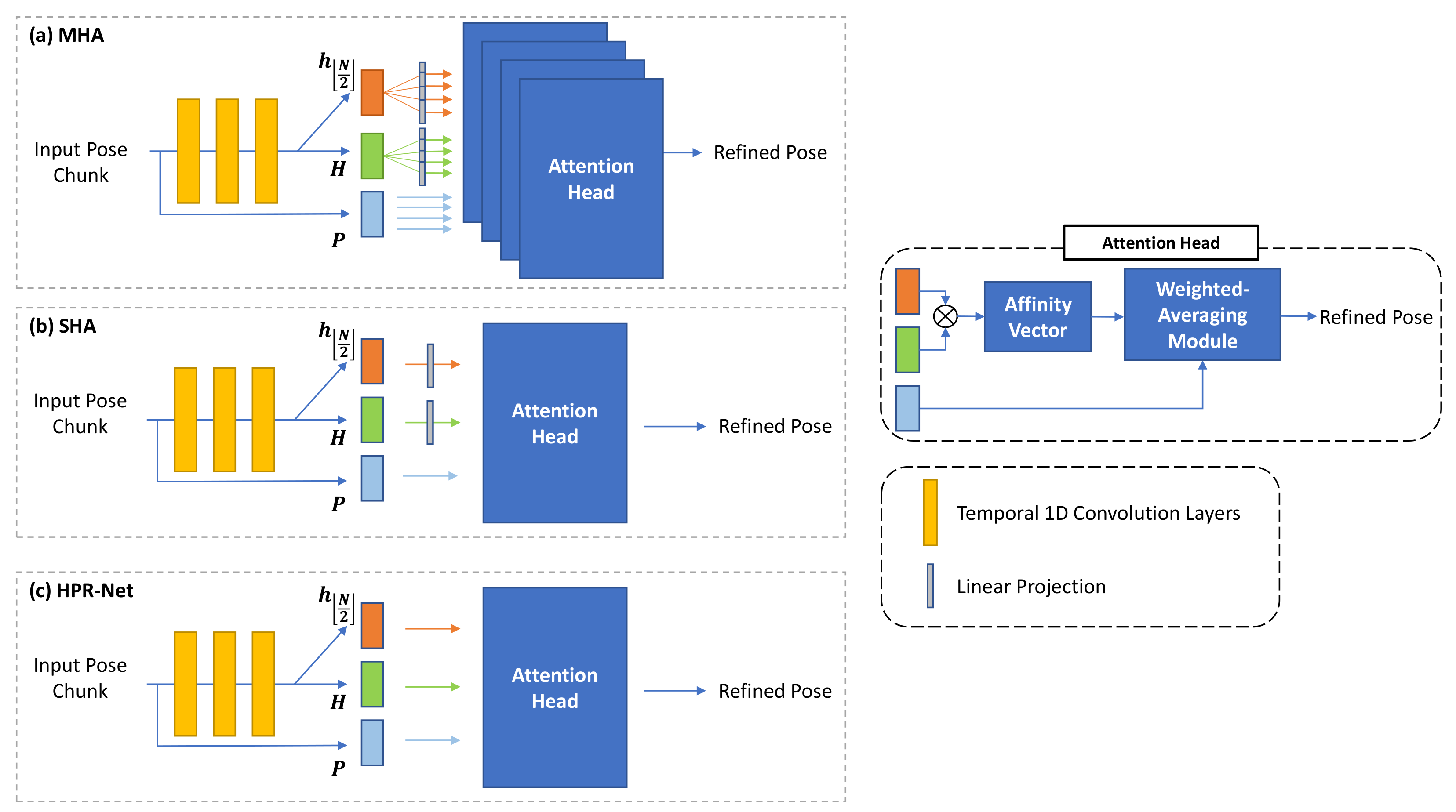
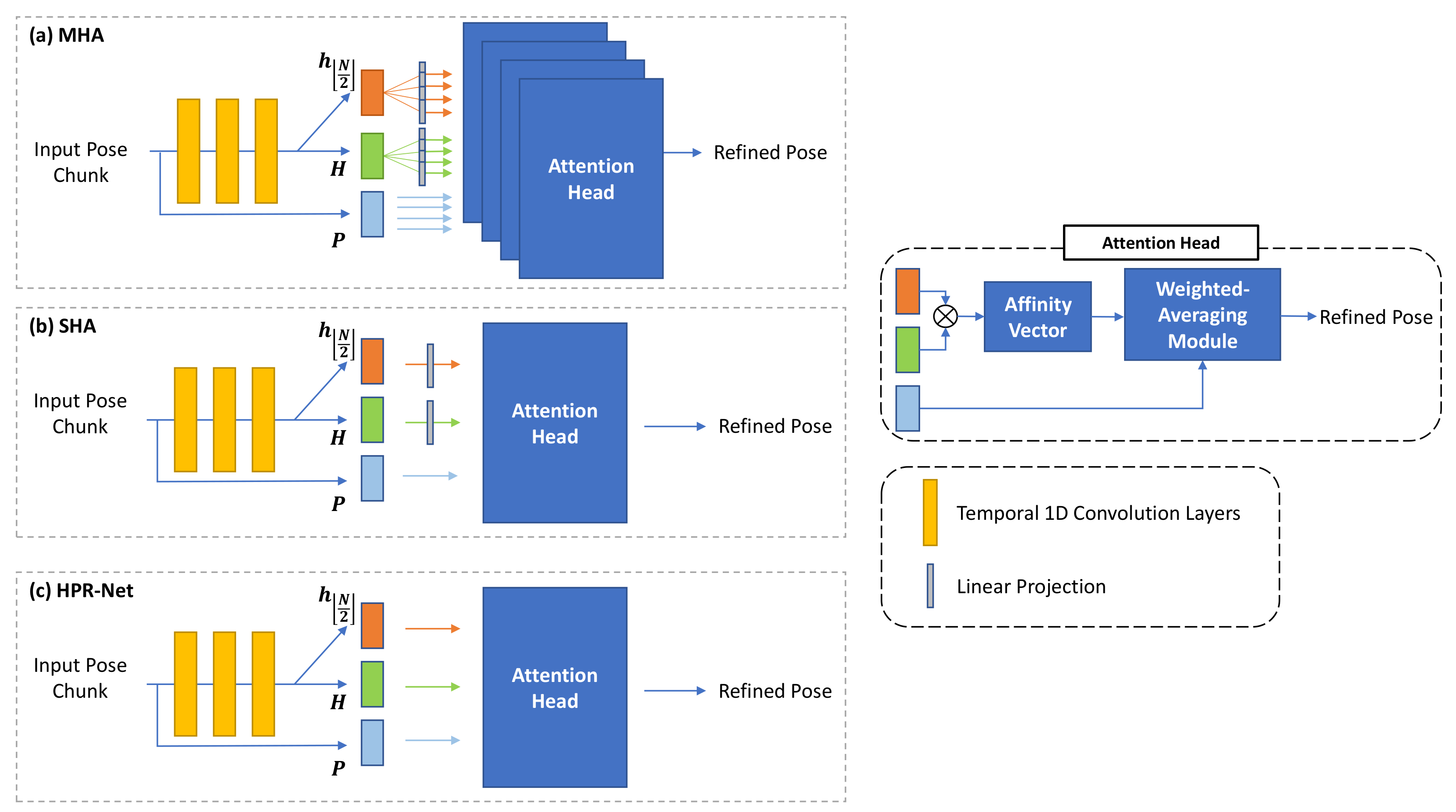
4.6. Network Design Based on Non-Local Attention
4.7. Qualitative Results
4.8. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. (TOG) 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Kanazawa, A.; Zhang, J.Y.; Felsen, P.; Malik, J. Learning 3D human dynamics from video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5614–5623. [Google Scholar]
- Kocabas, M.; Athanasiou, N.; Black, M.J. VIBE: Video inference for human body pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5253–5263. [Google Scholar]
- Luo, Z.; Golestaneh, S.A.; Kitani, K.M. 3D human motion estimation via motion compression and refinement. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Hartley, R.; Trumpf, J.; Dai, Y.; Li, H. Rotation averaging. Int. J. Comput. Vis. 2013, 103, 267–305. [Google Scholar] [CrossRef]
- Gramkow, C. On averaging rotations. J. Math. Imaging Vis. 2001, 15, 7–16. [Google Scholar] [CrossRef]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heisenberg, Germany, 2016; pp. 561–578. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3D hands, face, and body from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7122–7131. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Black, M.J.; Daniilidis, K. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2252–2261. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heisenberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. arXiv 2020, arXiv:2012.00364. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heisenberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Ruggero Ronchi, M.; Perona, P. Benchmarking and error diagnosis in multi-instance pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 369–378. [Google Scholar]
- Mall, U.; Lal, G.R.; Chaudhuri, S.; Chaudhuri, P. A deep recurrent framework for cleaning motion capture data. arXiv 2017, arXiv:1712.03380. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3D human pose in the wild using imus and a moving camera. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 601–617. [Google Scholar]
- Gower, J.C. Generalized procrustes analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Length | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| 9 | 82.14 | 51.82 | 98.25 | 7.31 |
| 17 | 81.10 | 51.26 | 97.13 | 6.94 |
| 33 | 82.11 | 51.63 | 98.26 | 18.36 |
| 65 | 81.23 | 50.97 | 97.24 | 8.19 |
| 129 | 81.81 | 51.35 | 97.89 | 11.69 |
| MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ | |||
|---|---|---|---|---|---|---|
| ✓ | 85.60 | 55.03 | 102.07 | 12.39 | ||
| ✓ | 81.29 | 51.04 | 97.33 | 7.72 | ||
| ✓ | 81.10 | 51.26 | 97.13 | 6.94 | ||
| ✓ | ✓ | 84.37 | 54.12 | 100.76 | 10.38 | |
| ✓ | ✓ | 81.46 | 51.16 | 97.48 | 9.79 | |
| ✓ | ✓ | 85.64 | 55.20 | 102.12 | 12.11 | |
| ✓ | ✓ | ✓ | 83.76 | 53.39 | 100.06 | 14.12 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| None | 81.63 | 52.00 | 97.72 | 6.97 |
| Sinusoidal | 81.53 | 51.15 | 97.58 | 8.42 |
| Ours | 81.10 | 51.26 | 97.13 | 6.94 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| None | 82.12 | 51.84 | 98.17 | 7.76 |
| BatchNorm | 82.66 | 52.07 | 98.81 | 12.93 |
| LayerNorm | 81.10 | 51.26 | 97.13 | 6.94 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| VIBE | 82.28 | 51.72 | 98.42 | 20.69 |
| VIBE + HPR-Net | 81.10 | 51.26 | 97.13 | 6.94 |
| SPIN | 102.46 | 60.05 | 129.22 | 29.78 |
| SPIN + HPR-Net | 100.95 | 59.30 | 127.58 | 8.19 |
| MEVA | 85.81 | 53.54 | 102.18 | 14.37 |
| MEVA + HPR-Net | 85.43 | 53.50 | 101.79 | 6.63 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | Accel-Error ↓ |
|---|---|---|---|
| VIBE | 78.35 | 53.58 | 9.76 |
| VIBE + HPR-Net | 77.77 | 53.17 | 2.13 |
| SPIN | 68.22 | 46.16 | 14.21 |
| SPIN + HPR-Net | 67.35 | 45.53 | 2.74 |
| MEVA | 73.64 | 48.48 | 7.22 |
| MEVA + HPR-Net | 73.06 | 48.06 | 1.83 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| SLERP | 82.72 | 52.13 | 99.88 | 12.38 |
| HPR-Gaussian | 82.15 | 51.58 | 98.30 | 18.04 |
| HPR-DR | 183.01 | 102.79 | 223.20 | 14.28 |
| HPR-Net | 81.10 | 51.26 | 97.13 | 6.94 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | MPVE ↓ | Accel-Error ↓ |
|---|---|---|---|---|
| MHA | 84.00 | 53.20 | 99.94 | 7.71 |
| SHA | 84.13 | 53.52 | 100.44 | 7.49 |
| HPR-Net | 81.10 | 51.26 | 97.13 | 6.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.-Y.; Chang, J.-Y. Attention-Based 3D Human Pose Sequence Refinement Network. Sensors 2021, 21, 4572. https://doi.org/10.3390/s21134572
Kim D-Y, Chang J-Y. Attention-Based 3D Human Pose Sequence Refinement Network. Sensors. 2021; 21(13):4572. https://doi.org/10.3390/s21134572
Chicago/Turabian StyleKim, Do-Yeop, and Ju-Yong Chang. 2021. "Attention-Based 3D Human Pose Sequence Refinement Network" Sensors 21, no. 13: 4572. https://doi.org/10.3390/s21134572
APA StyleKim, D.-Y., & Chang, J.-Y. (2021). Attention-Based 3D Human Pose Sequence Refinement Network. Sensors, 21(13), 4572. https://doi.org/10.3390/s21134572