Author Contributions
Conceptualization and study design, B.R.H., O.A.M., and W.-H.O.; Methodology, B.R.H., O.A.M., and W.-H.O.; Data curation, B.R.H. and J.W.F.S.; Writing—original draft preparation, B.R.H.; Writing—review and editing, B.R.H., O.A.M., and W.-H.O.; Supervision, O.A.M., W.-H.O., and J.W.F.S. All authors have read and agreed to the published version of the manuscript.
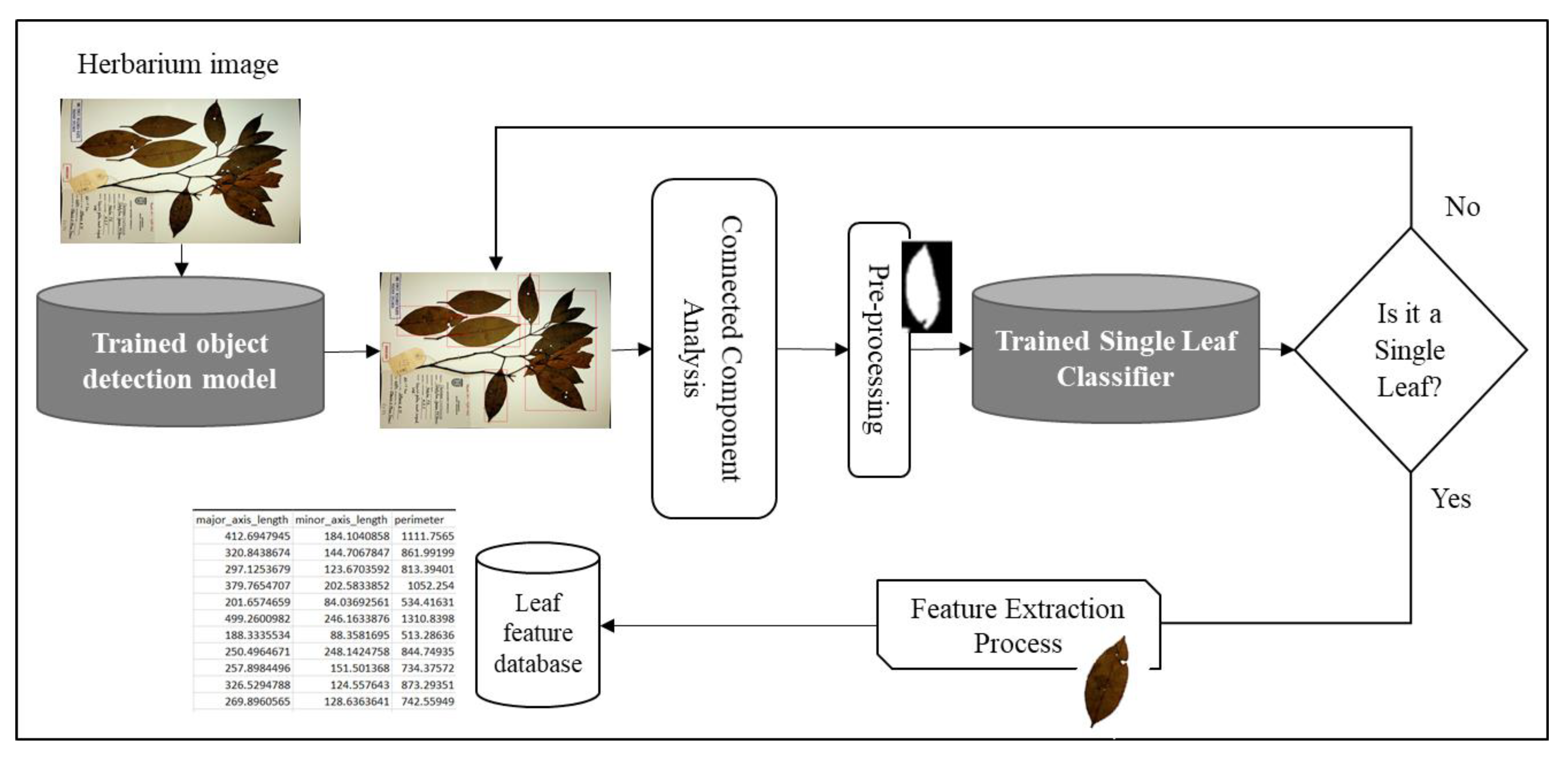
Figure 1.
A graphical summary of the single leaf extraction process. In the first phase, the herbarium image is passed through a trained deep learning semantic segmentation model. The generated mask is then enhanced through various image pre-processing techniques before passing the image to the connected component to extract all potential leaves. A trained deep learning classifier based on binary image is then used as a filter to filter out individual leaves from the rest of the detected potential leaves. Finally, phenotypic measurements are then extracted from the filtered individual intact leaves.
Figure 1.
A graphical summary of the single leaf extraction process. In the first phase, the herbarium image is passed through a trained deep learning semantic segmentation model. The generated mask is then enhanced through various image pre-processing techniques before passing the image to the connected component to extract all potential leaves. A trained deep learning classifier based on binary image is then used as a filter to filter out individual leaves from the rest of the detected potential leaves. Finally, phenotypic measurements are then extracted from the filtered individual intact leaves.
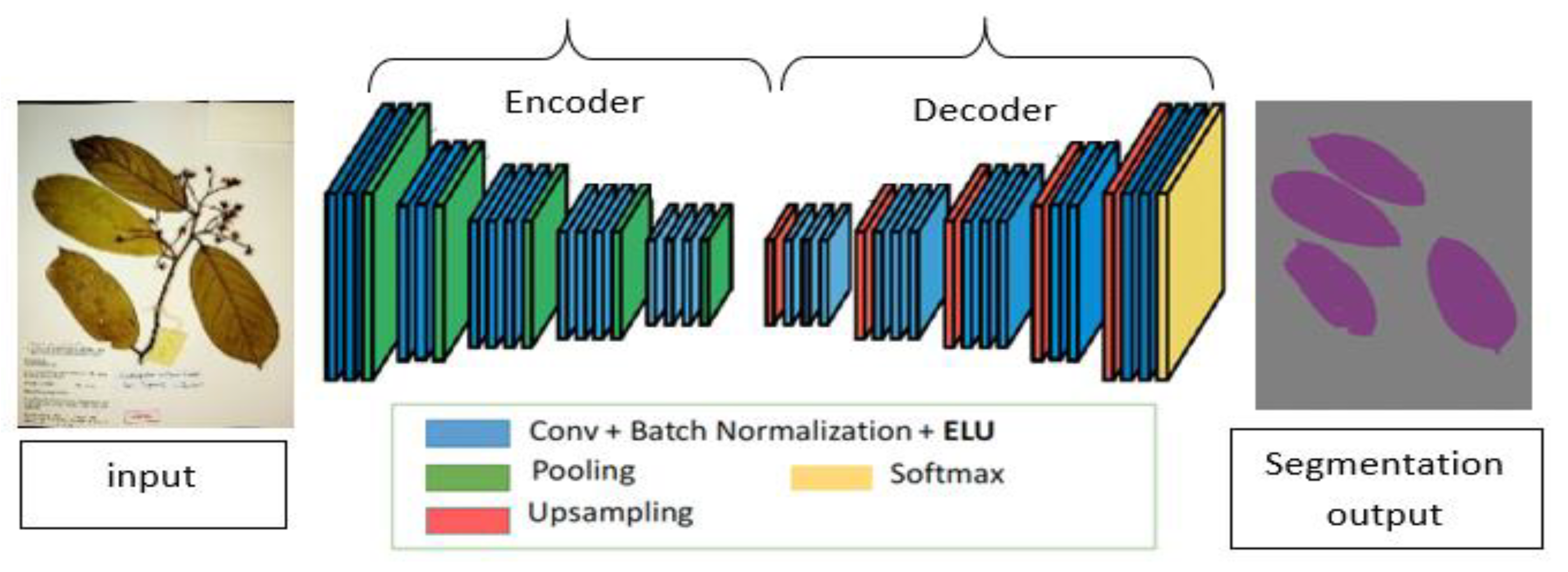
Figure 2.
A schematic diagram of a fully convolution neural network for semantic segmentation. The network consists of an encoder part where the model extracts potential useful features and the decoder part, which up-samples the extracted feature map to produce the final segmentation results.
Figure 2.
A schematic diagram of a fully convolution neural network for semantic segmentation. The network consists of an encoder part where the model extracts potential useful features and the decoder part, which up-samples the extracted feature map to produce the final segmentation results.
Figure 3.
A sample of herbarium images (top row) and their corresponding annotation (bottom row) used for training the segmentation model from the UBDH dataset. This dataset consisted of 500 herbarium images together with their ground truth annotation for the training segmentation model.
Figure 3.
A sample of herbarium images (top row) and their corresponding annotation (bottom row) used for training the segmentation model from the UBDH dataset. This dataset consisted of 500 herbarium images together with their ground truth annotation for the training segmentation model.
Figure 4.
Negative samples manually extracted from the segmentation model results for training the single-leaf classifier. The dataset consisted of 881 intact individual leaves as positive training samples and 1015 negative samples.
Figure 4.
Negative samples manually extracted from the segmentation model results for training the single-leaf classifier. The dataset consisted of 881 intact individual leaves as positive training samples and 1015 negative samples.
Figure 5.
Mask post-processing step, (a) original image, (b) generated mask from segmentation model, (c) image b after thresholding, (d) new image after masking operation between image a and c, (e) new generated mask to be passed to phase 2.
Figure 5.
Mask post-processing step, (a) original image, (b) generated mask from segmentation model, (c) image b after thresholding, (d) new image after masking operation between image a and c, (e) new generated mask to be passed to phase 2.
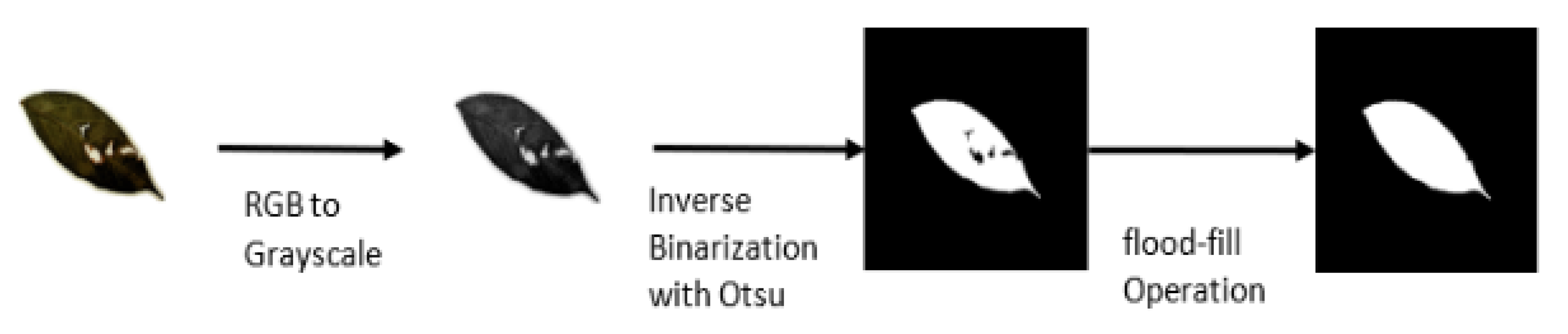
Figure 6.
Pre-processing steps for training a single-leaf classifier. For each training sample, the image is converted to grayscale and binarized using the Otsu algorithm. Finally, a flood-fill operation is applied to fill in the missing pixel in-side a binary leaf.
Figure 6.
Pre-processing steps for training a single-leaf classifier. For each training sample, the image is converted to grayscale and binarized using the Otsu algorithm. Finally, a flood-fill operation is applied to fill in the missing pixel in-side a binary leaf.
Figure 7.
Object detection-based approach for single leaf and feature extraction. The same setup was used as the proposed method except that the segmentation process was replaced by an object detection approach.
Figure 7.
Object detection-based approach for single leaf and feature extraction. The same setup was used as the proposed method except that the segmentation process was replaced by an object detection approach.
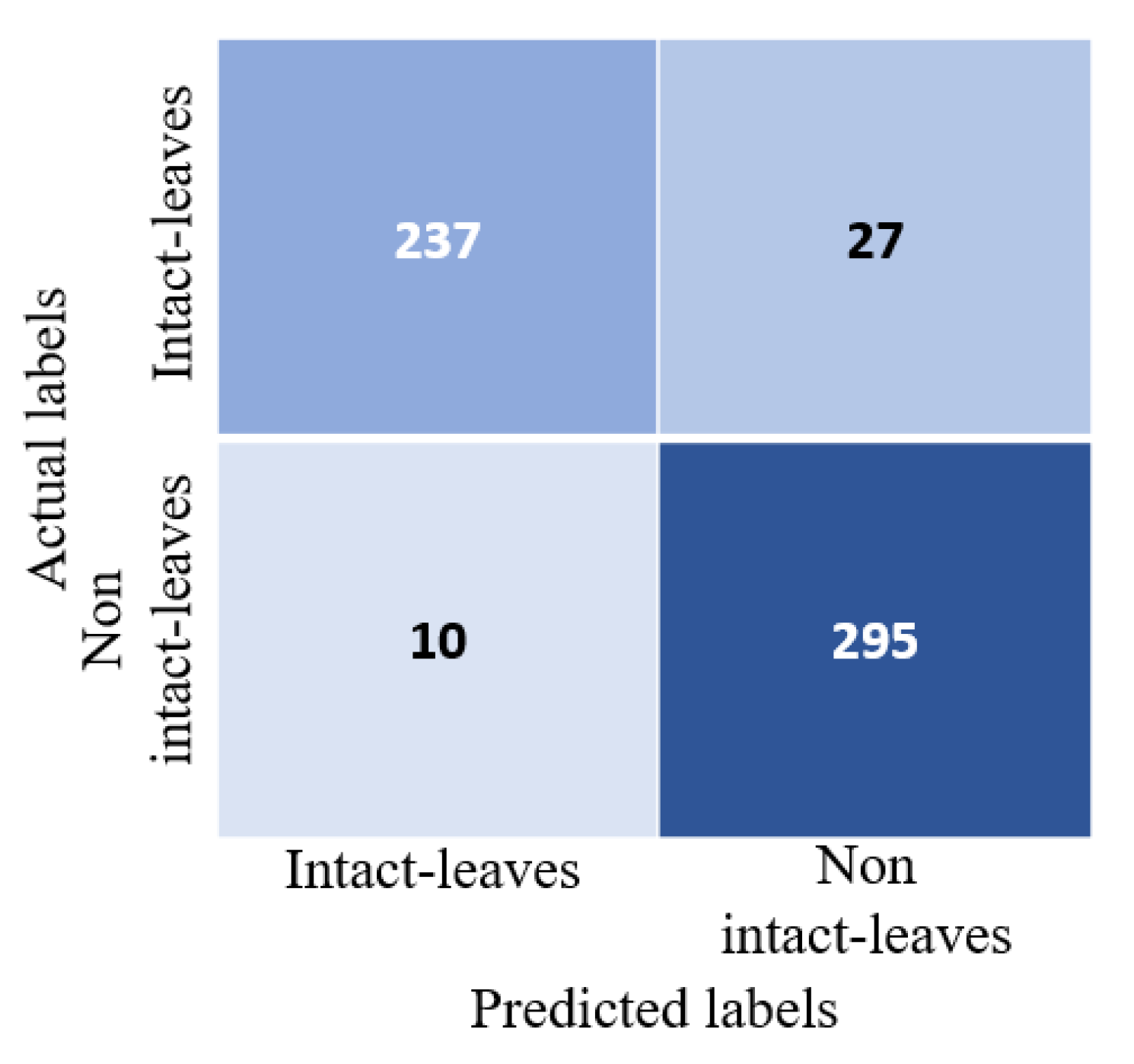
Figure 8.
Confusion matrix for a single-leaf classifier on a separate test set. The test set consisted of 264 individual intact leaves (positive samples) and 305 non-intact individual leaves (negative samples).
Figure 8.
Confusion matrix for a single-leaf classifier on a separate test set. The test set consisted of 264 individual intact leaves (positive samples) and 305 non-intact individual leaves (negative samples).
Figure 9.
Samples from the UBDH and HCD evaluation datasets (top row) together with the predicted segmentation mask using the proposed method (middle row). The bottom row represents intact individual leaves that the proposed method was able to extract. The first three columns represent evaluation samples from UBDH (consisted of 54 image samples) and the last three columns represent evaluation samples from the HCD (consisting of 90 image samples).
Figure 9.
Samples from the UBDH and HCD evaluation datasets (top row) together with the predicted segmentation mask using the proposed method (middle row). The bottom row represents intact individual leaves that the proposed method was able to extract. The first three columns represent evaluation samples from UBDH (consisted of 54 image samples) and the last three columns represent evaluation samples from the HCD (consisting of 90 image samples).
Figure 10.
Comparison of precision, recall, and F1 score between the approaches on a separate test set. The UBDH dataset consisted of 54 images with a total of 190 individual intact leaves. The HCD dataset consisted of 90 images with a total of 260 individual leaves.
Figure 10.
Comparison of precision, recall, and F1 score between the approaches on a separate test set. The UBDH dataset consisted of 54 images with a total of 190 individual intact leaves. The HCD dataset consisted of 90 images with a total of 260 individual leaves.
Figure 11.
Samples of intact leaves extracted and used for feature extraction. First row represents the ground truth leaves that were manually segmented; the second row consists of leaves extracted using the proposed method; the third row represents leaves extracted based on the Faster R-CNN model; and the last row represents the leaves extracted when using the YOLOv5s model. The first three columns for object detection-based approaches showed some artifact encountered when using object detection-based approaches as opposed to segmentation. The last three column showed some failure cases even for the segmentation model with small artifacts at the boundary of the leaves and missing leaf apex.
Figure 11.
Samples of intact leaves extracted and used for feature extraction. First row represents the ground truth leaves that were manually segmented; the second row consists of leaves extracted using the proposed method; the third row represents leaves extracted based on the Faster R-CNN model; and the last row represents the leaves extracted when using the YOLOv5s model. The first three columns for object detection-based approaches showed some artifact encountered when using object detection-based approaches as opposed to segmentation. The last three column showed some failure cases even for the segmentation model with small artifacts at the boundary of the leaves and missing leaf apex.
Table 1.
Dataset summary used for training the single-leaf classifier.
Table 1.
Dataset summary used for training the single-leaf classifier.
| Datasets | Single Leaves (Positive Samples) | Non-Single Leaves (Negative Samples) |
|---|
| UBDH dataset | 798 | 1015 |
| Flavia dataset | 83 | 0 |
| Total | 881 | 1015 |
Table 2.
A summary of the hyperparameter used for training the deep learning models.
Table 2.
A summary of the hyperparameter used for training the deep learning models.
| | Segmentation Model | Single-Leaf Classifier |
|---|
| Input dimension | 512 × 512 | 300 × 300 |
| Batch size | 3 | 32 |
| Learning rate | 1 × 10−4 | 1 × 10−4 |
| Optimizer | Adam optimizer | Adam optimizer |
| Loss function | binary cross-entropy | binary cross-entropy |
| Epochs | 100 | 100 |
| Pre-trained network | ResNet101-DeepLabv3+ | Modified-VGG16 |
Table 3.
Performance of semantic segmentation model.
Table 3.
Performance of semantic segmentation model.
| Performance Metric | Validation Results | Testing Results |
|---|
| Leaf Acc | 92.87% | 92.21% |
| Background Acc | 99.71% | 98.98% |
| MIoU | 94.17% | 93.71% |
Table 4.
Performance comparison of all models on the test set.
Table 4.
Performance comparison of all models on the test set.
| Model | mAP | Precision | Recall |
|---|
| DeepLabv3+ | 95.6 | 98.9 | 98.3 |
| YOLOv5s | 99.8 | 100.0 | 100.0 |
| Faster R-CNN | 88.2 | 88.2 | 90.9 |
Table 5.
Performance of the proposed method for single leaf extraction.
Table 5.
Performance of the proposed method for single leaf extraction.
| Dataset | No of Images | TP | FP | FN | Total Expected | Total Extracted | Undetected Leaf |
|---|
| UBDH | 54 | 168 | 7 | 7 | 190 | 175 | 15 |
| HCD | 90 | 232 | 10 | 24 | 260 | 256 | 4 |
Table 6.
Performance of Faster R-CNN for single leaf extraction.
Table 6.
Performance of Faster R-CNN for single leaf extraction.
| Dataset | No of Images | TP | FP | FN | Total Expected | Total Extracted | Undetected |
|---|
| UBDH | 54 | 161 | 0 | 19 | 190 | 180 | 10 |
| HCD | 90 | 206 | 4 | 45 | 260 | 251 | 9 |
Table 7.
Performance of the YOLOv5s approach for single leaf extraction.
Table 7.
Performance of the YOLOv5s approach for single leaf extraction.
| Dataset | No of Images | TP | FP | FN | Total Expected | Total Extracted | Undetected |
|---|
| UBDH | 54 | 157 | 1 | 19 | 190 | 176 | 14 |
| HCD | 90 | 201 | 2 | 41 | 260 | 242 | 18 |
Table 8.
Summary comparison between the proposed method (based on semantic segmentation) vs. object detection-based approaches. ↑ indicates that a higher value reflects better performance, ↓ indicates that lower values reflect better.
Table 8.
Summary comparison between the proposed method (based on semantic segmentation) vs. object detection-based approaches. ↑ indicates that a higher value reflects better performance, ↓ indicates that lower values reflect better.
| | UBDH | HCD |
|---|
| Metrics | Proposed Method | Faster R-CNN | YOLOv5s | Proposed Method | Faster R-CNN | YOLOv5s |
|---|
| TP ↑ | 168 | 161 | 157 | 232 | 206 | 201 |
| FP ↓ | 7 | 0 | 1 | 10 | 4 | 2 |
| FN ↓ | 7 | 19 | 19 | 24 | 45 | 41 |
| Total extracted ↑ | 175 | 180 | 176 | 256 | 251 | 242 |
| Undetected leaf ↓ | 15 | 10 | 14 | 4 | 9 | 18 |
Table 9.
Comparison of leaf measurement differences against the ground truth for 76 manually collected leaves. For all metrics, lower values indicate better results.
Table 9.
Comparison of leaf measurement differences against the ground truth for 76 manually collected leaves. For all metrics, lower values indicate better results.
| | MAE | MSE | RMSE |
|---|
| | Proposed Method | Faster R-CNN | YOLOv5s | Proposed Method | Faster R-CNN | YOLOv5s | Proposed Method | Faster R-CNN | YOLOv5s |
|---|
| eccentricity | 0.0030 | 0.0044 | 0.0038 | 0.0000 | 0.0001 | 0.0001 | 0.0049 | 0.0093 | 0.0073 |
| area | 342.6184 | 455.3947 | 1289.6842 | 162,057.5526 | 369,695.8158 | 26,847,791.5395 | 402.5637 | 608.0262 | 5181.4855 |
| bbox_area | 691.2632 | 1093.0789 | 2700.8289 | 1,193,423.7632 | 2,783,964.2368 | 60,037,639.8816 | 1092.4394 | 1668.5216 | 7748.3960 |
| convex_area | 361.5132 | 628.8816 | 1511.9474 | 230,122.8816 | 1,131,211.3289 | 29,410,001.1579 | 479.7112 | 1063.5842 | 5423.0989 |
| equivalent_diameter | 1.2161 | 1.6611 | 3.9151 | 1.9709 | 5.7467 | 206.0384 | 1.4039 | 2.3972 | 14.3540 |
| extent | 0.0099 | 0.0123 | 0.0174 | 0.0002 | 0.0003 | 0.0005 | 0.0143 | 0.0185 | 0.0225 |
| filled_area | 343.9474 | 461.2895 | 1300.0921 | 164,526.7895 | 383,162.7632 | 27,113,134.6711 | 405.6190 | 619.0014 | 5207.0274 |
| major_axis_length | 1.6697 | 2.8865 | 5.6320 | 6.1220 | 40.6365 | 349.0719 | 2.4743 | 6.3747 | 18.6835 |
| minor_axis_length | 1.1301 | 1.4556 | 3.3250 | 1.5845 | 6.0962 | 130.0219 | 1.2588 | 2.4690 | 11.4027 |
| perimeter | 10.0381 | 21.1247 | 33.1226 | 258.5453 | 1608.1119 | 4932.9094 | 16.0793 | 40.1013 | 70.2347 |
| solidity | 0.0049 | 0.0077 | 0.0081 | 0.0000 | 0.0005 | 0.0004 | 0.0068 | 0.0227 | 0.0204 |
| diameter | 1.2207 | 1.6507 | 3.9047 | 1.9746 | 5.6350 | 205.8782 | 1.4052 | 2.3738 | 14.3485 |
| aspect_ratio | 0.0189 | 0.0330 | 0.0288 | 0.0008 | 0.0080 | 0.0042 | 0.0288 | 0.0894 | 0.0645 |
| rectangularity | 0.0019 | 0.0035 | 0.0046 | 0.0000 | 0.0002 | 0.0002 | 0.0030 | 0.0145 | 0.0128 |
| compactness | 0.5694 | 1.0373 | 1.2096 | 0.6377 | 5.2750 | 4.9619 | 0.7985 | 2.2967 | 2.2275 |
| circularity | 0.0184 | 0.0289 | 0.0352 | 0.0007 | 0.0025 | 0.0027 | 0.0258 | 0.0499 | 0.0523 |
| narrow_factor | 0.0035 | 0.0049 | 0.0045 | 0.0000 | 0.0001 | 0.0001 | 0.0052 | 0.0112 | 0.0078 |
| per_dia_ratio | 0.0564 | 0.0986 | 0.1163 | 0.0062 | 0.0410 | 0.0402 | 0.0787 | 0.2024 | 0.2004 |
| per_length_ratio | 0.0319 | 0.0637 | 0.0768 | 0.0021 | 0.0212 | 0.0218 | 0.0463 | 0.1455 | 0.1476 |
| per_length_width_ratio | 0.0232 | 0.0415 | 0.0507 | 0.0011 | 0.0075 | 0.0078 | 0.0330 | 0.0865 | 0.0884 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
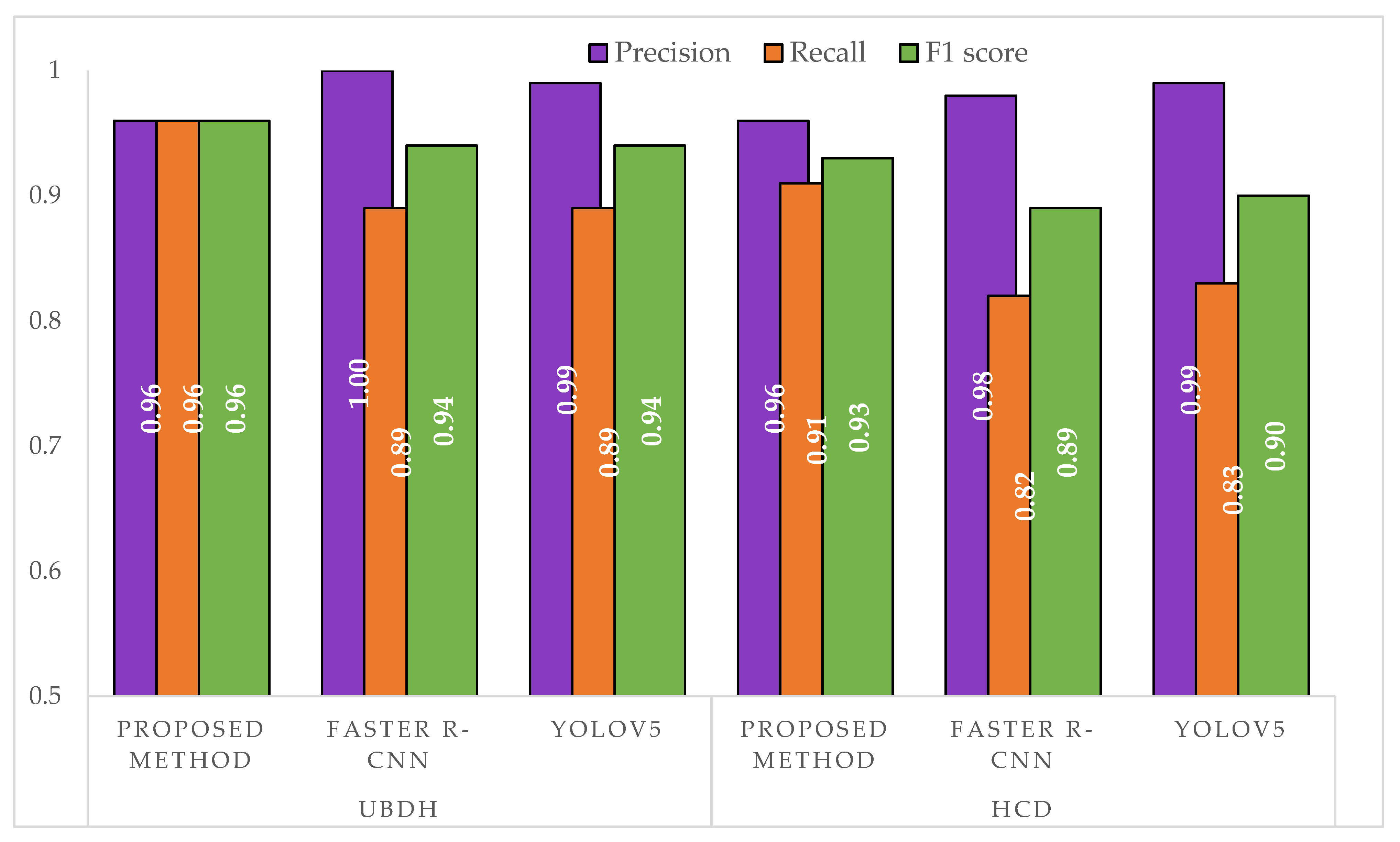{kind=link}
{kind=link}