
A Spatio-Temporal Ensemble Deep Learning Architecture for Real-Time Defect Detection during Laser Welding on Low Power Embedded Computing Boards

 ,
, 
Abstract
1. Introduction
- Development and evaluation of a unique ensemble deep learning architecture combining CNNs and GRUs with high performance classification algorithms (i.e., SVM, kNN) for real time detection of six different welding quality classes;
- Comparison of the proposed architecture with available deep learning architectures as well as classical machine learning methods based on manual feature extraction;
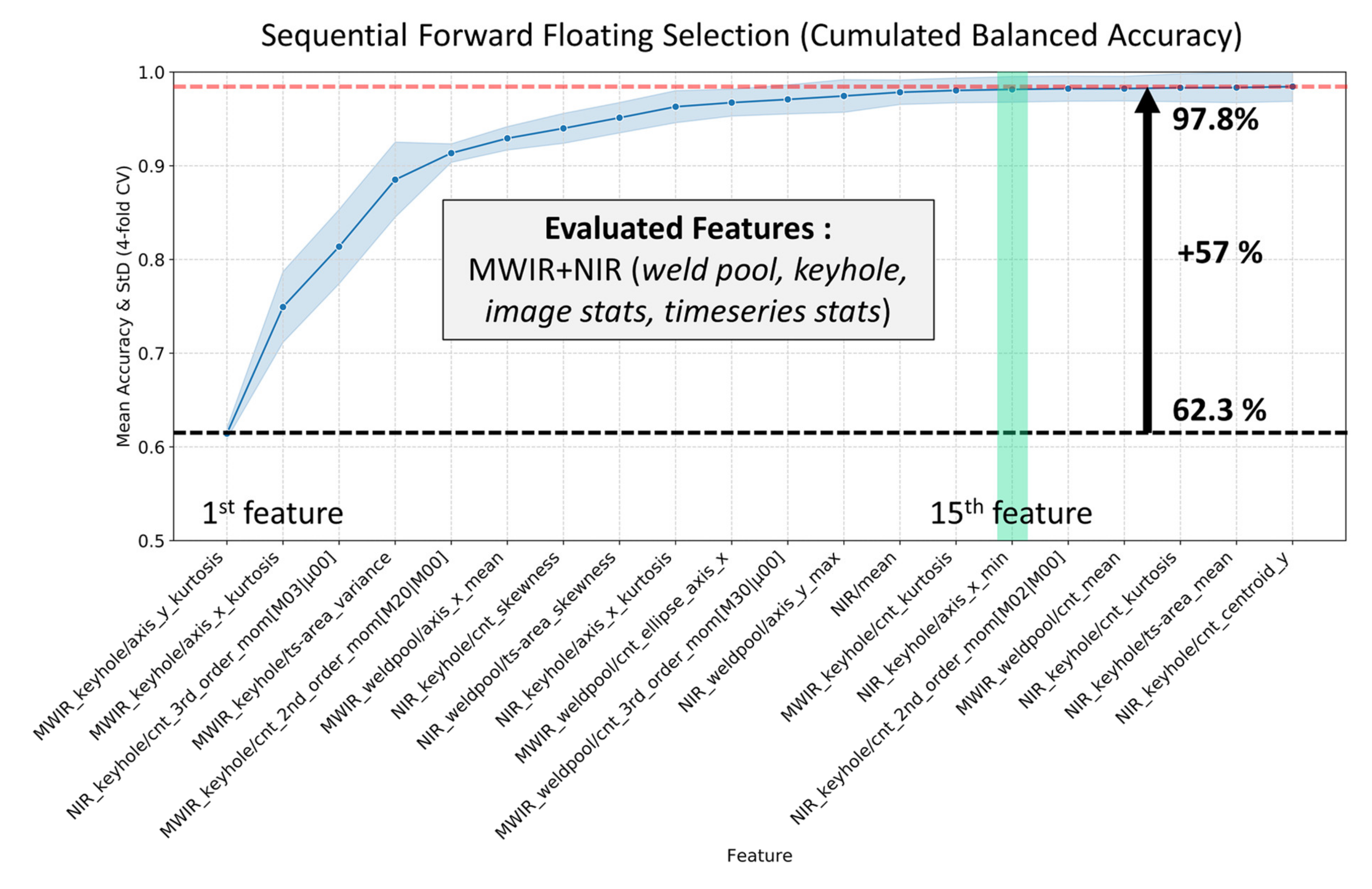
- Assessment of the significance of geometric and statistical features extracted from the keyhole and weld pool region of two different image data sources (i.e., MWIR and NIR) with respect to the ability to detect particular weld defects;
- Development and evaluation of a real-time inference pipeline for the proposed method operating on low-power embedded computing devices.
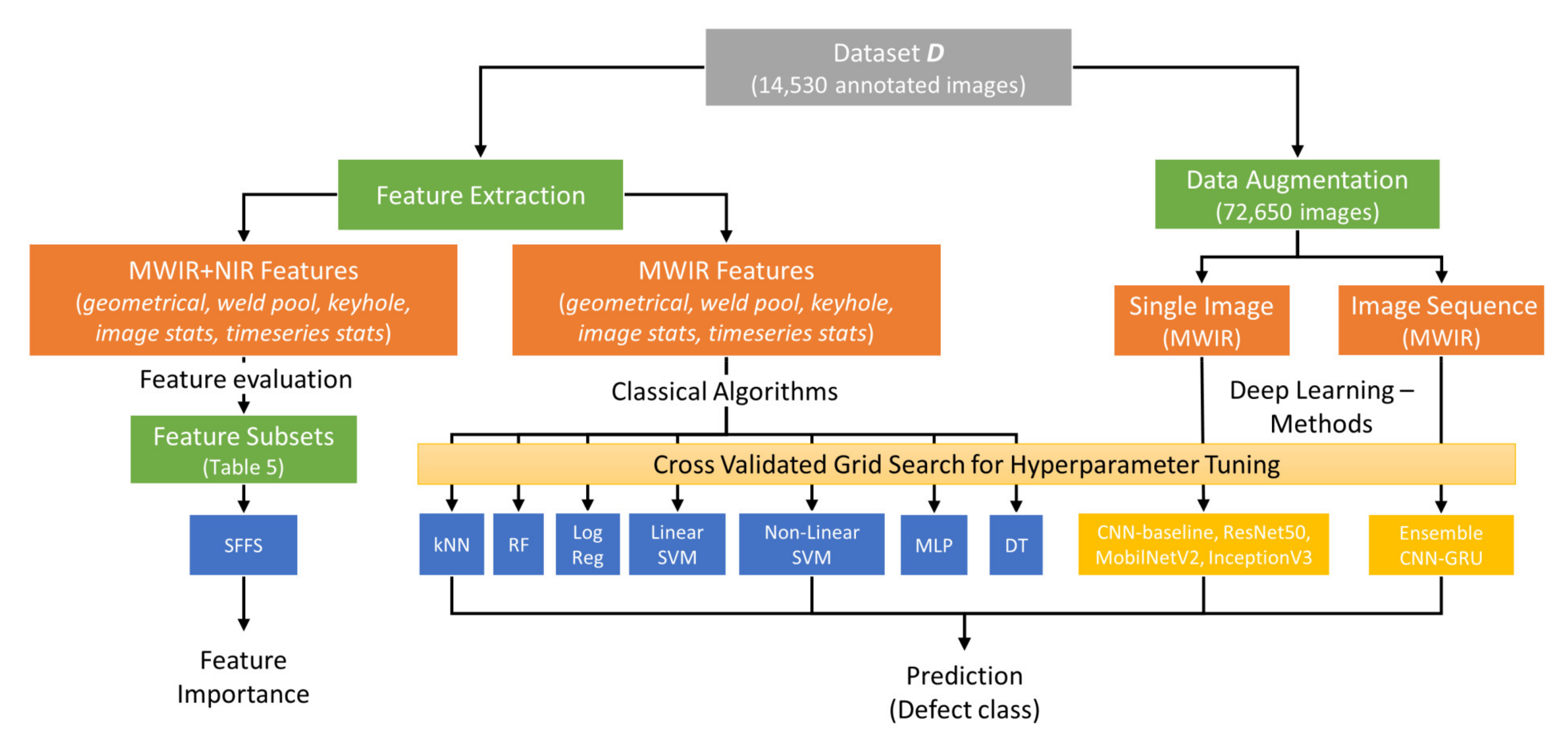
2. Methodology and Background Knowledge
- Decision tree (DT);
- K-nearest neighbors (kNN);
- Random forest (RF);
- Support vector machine (SVM);
- Logistic regression (LogReg);
- Artificial neural network (ANN).
2.1. Convolutional Neural Network (CNN)
2.2. Recurrent Neural Networks and Gated Recurrent Units (GRU)
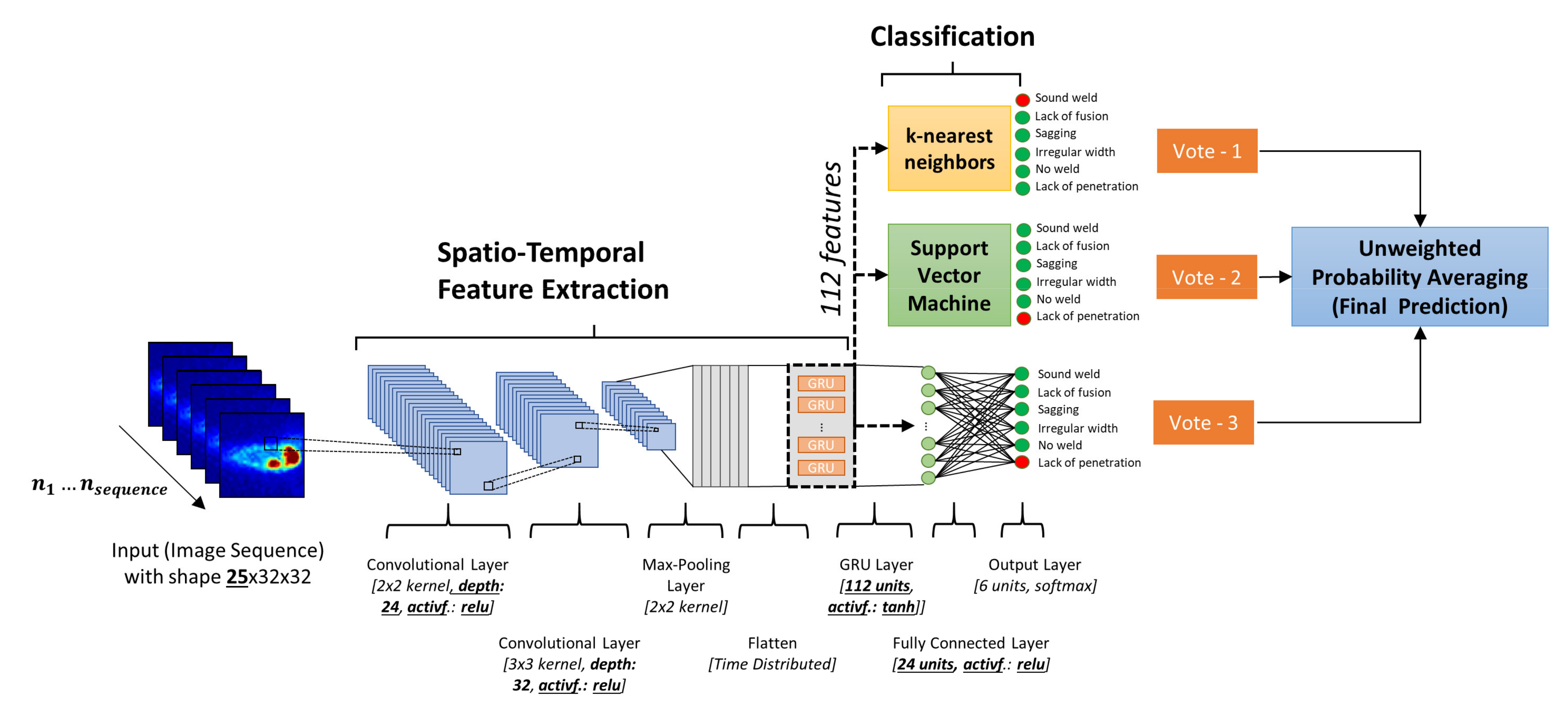
2.3. Ensemble Deep Learning
3. Experiment Setup and Data Preprocessing
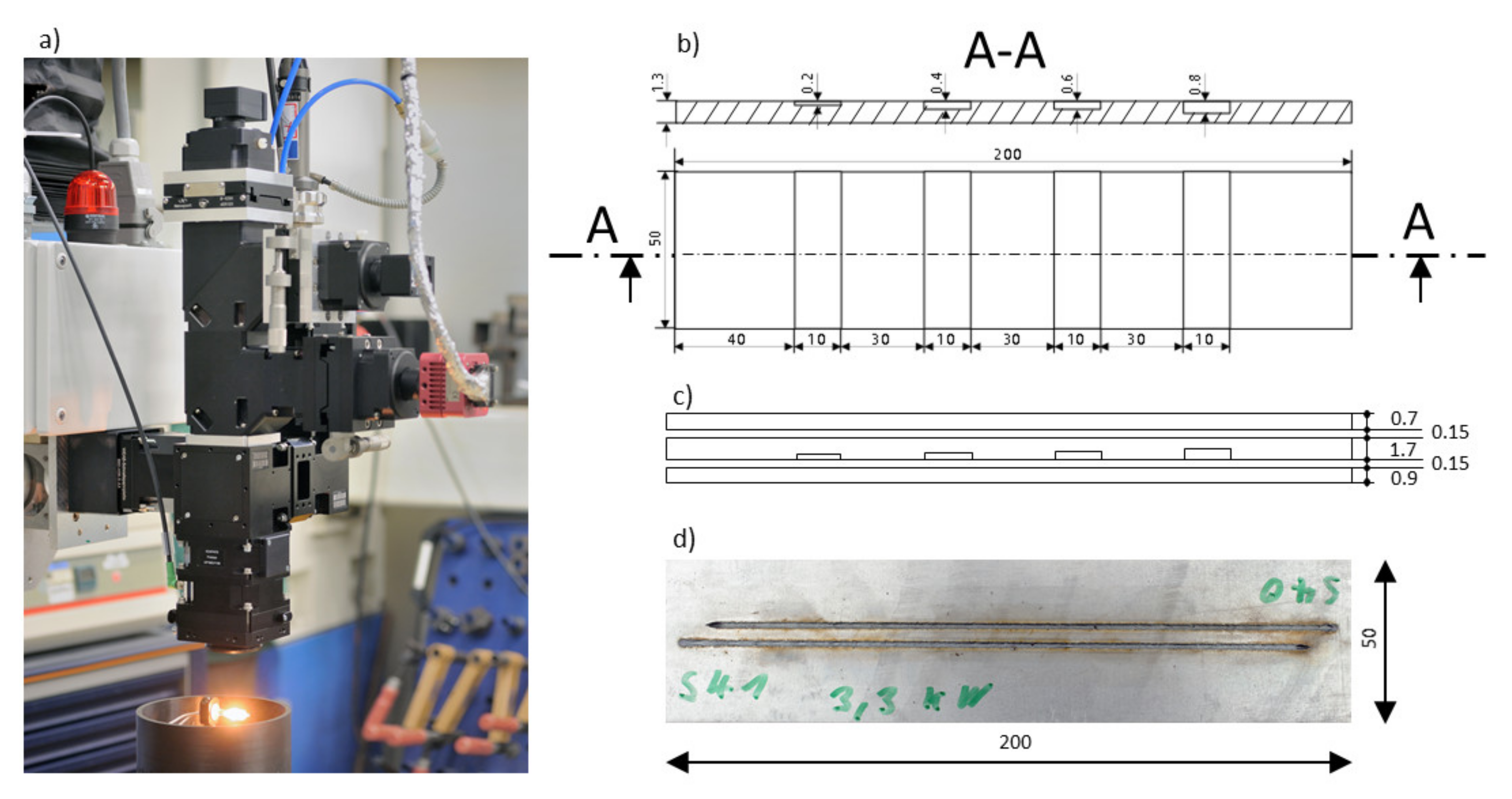
3.1. Multi-Camera Welding Setup
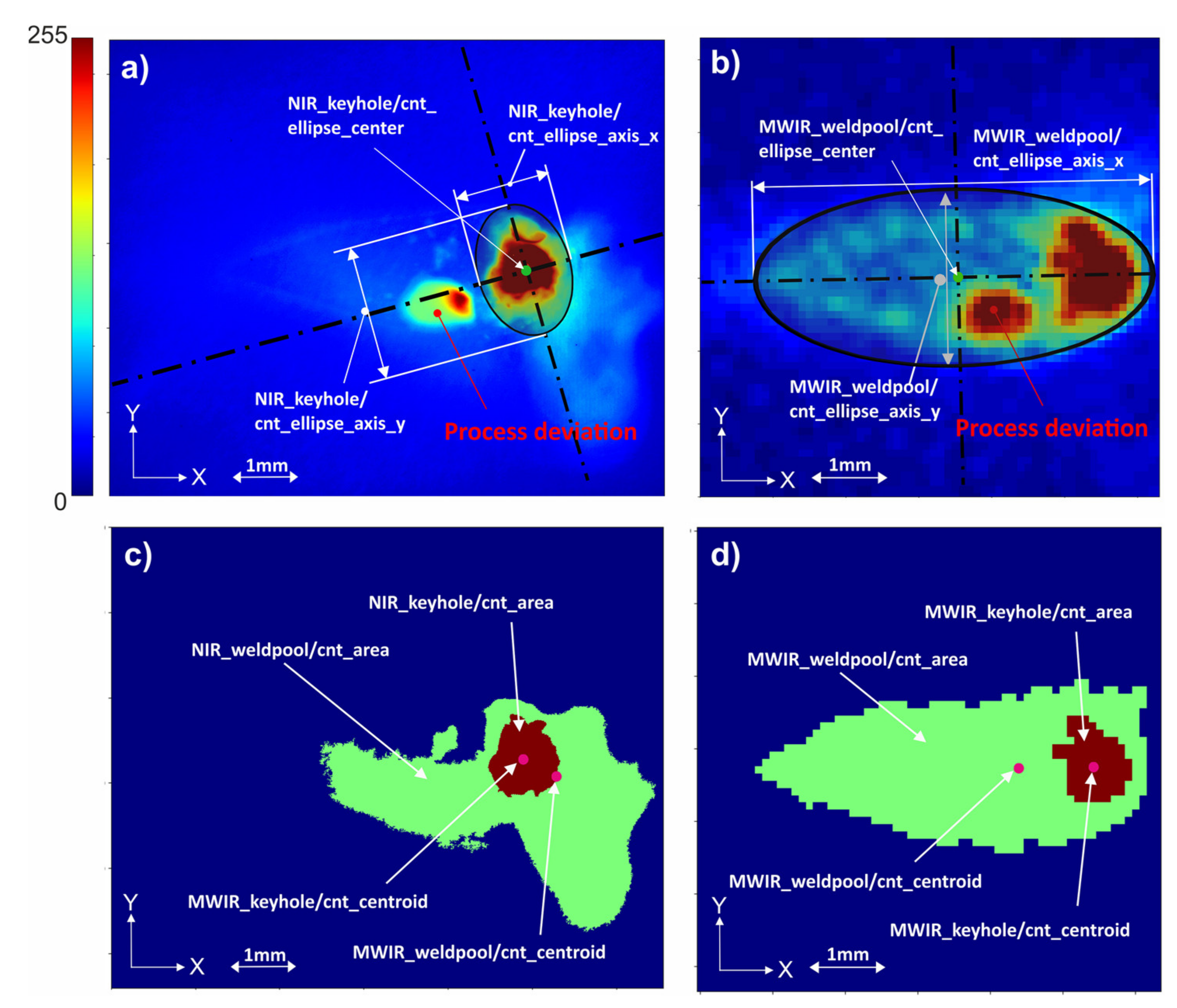
3.2. Feature Extraction for In Situ Weld Image Data
- Binarize image based on the target object threshold (keyhole threshold > weld pool threshold);
- Detect contour (connected boundary line of an object) using the algorithm of Suzuki et al. [59] and select largest contour from all contours found in image;
- Calculate contour properties such as centroids and other image moments Table A1);
- Fit an ellipse to the found contour;
- Obtain geometrical parameters of the ellipse (Table A1 in Appendix A);
- Calculate additional features such as statistical and sequence-based features (Table A2).
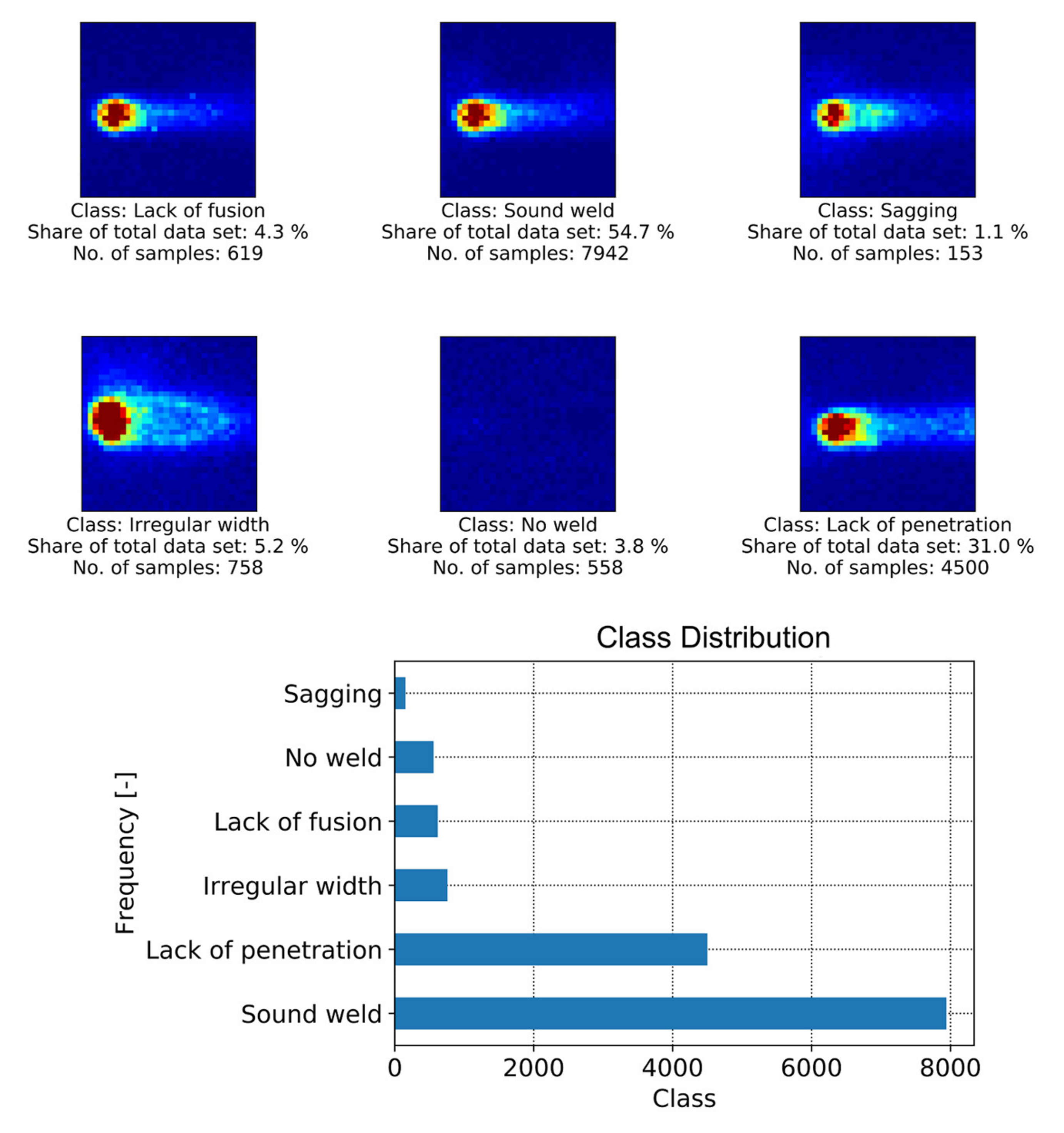
3.3. Welding Defects and Data Preparation
4. Results and Discussion
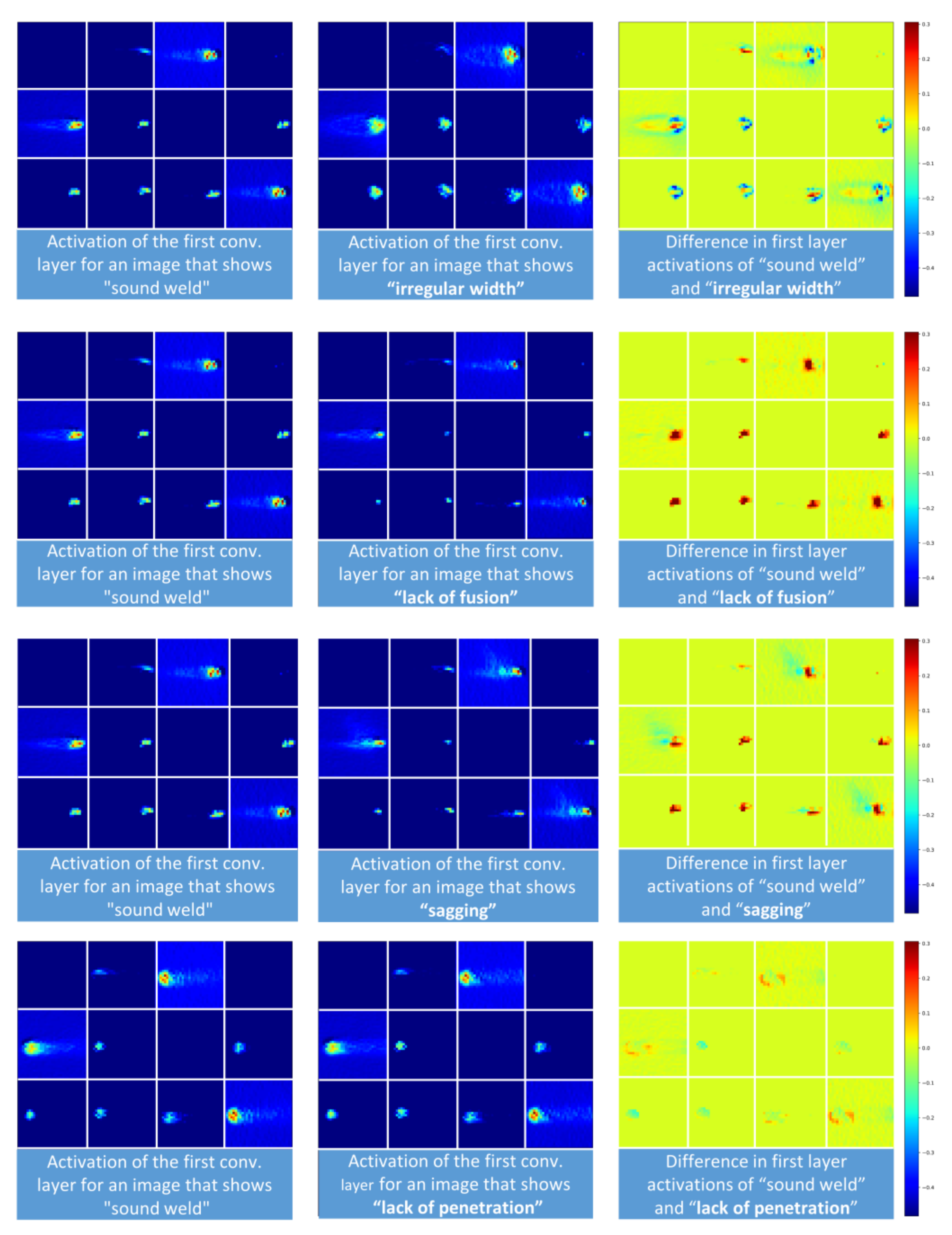
4.1. Assessment of Feature Importance
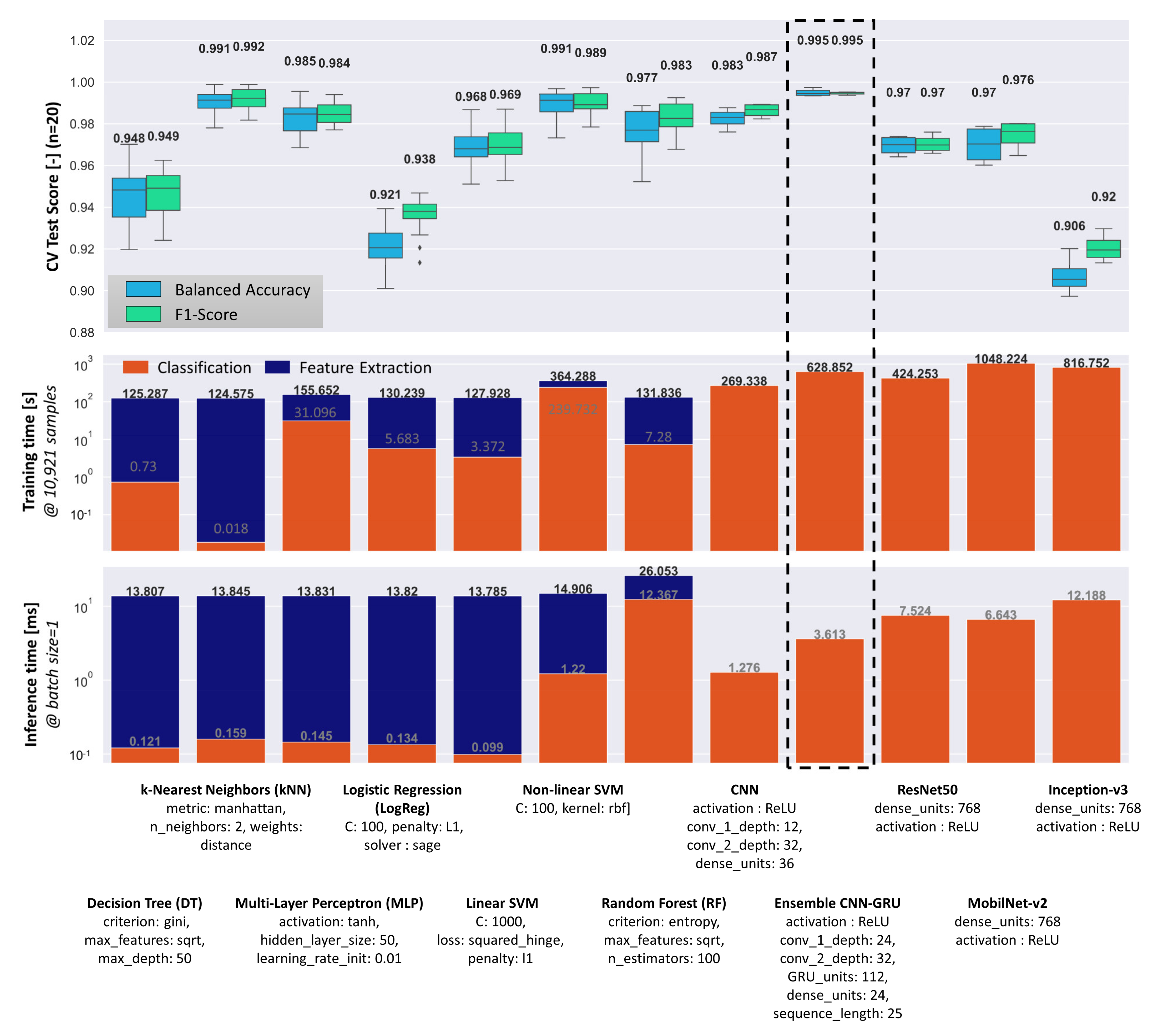
4.2. Model Comparison Based on Grid Search Results
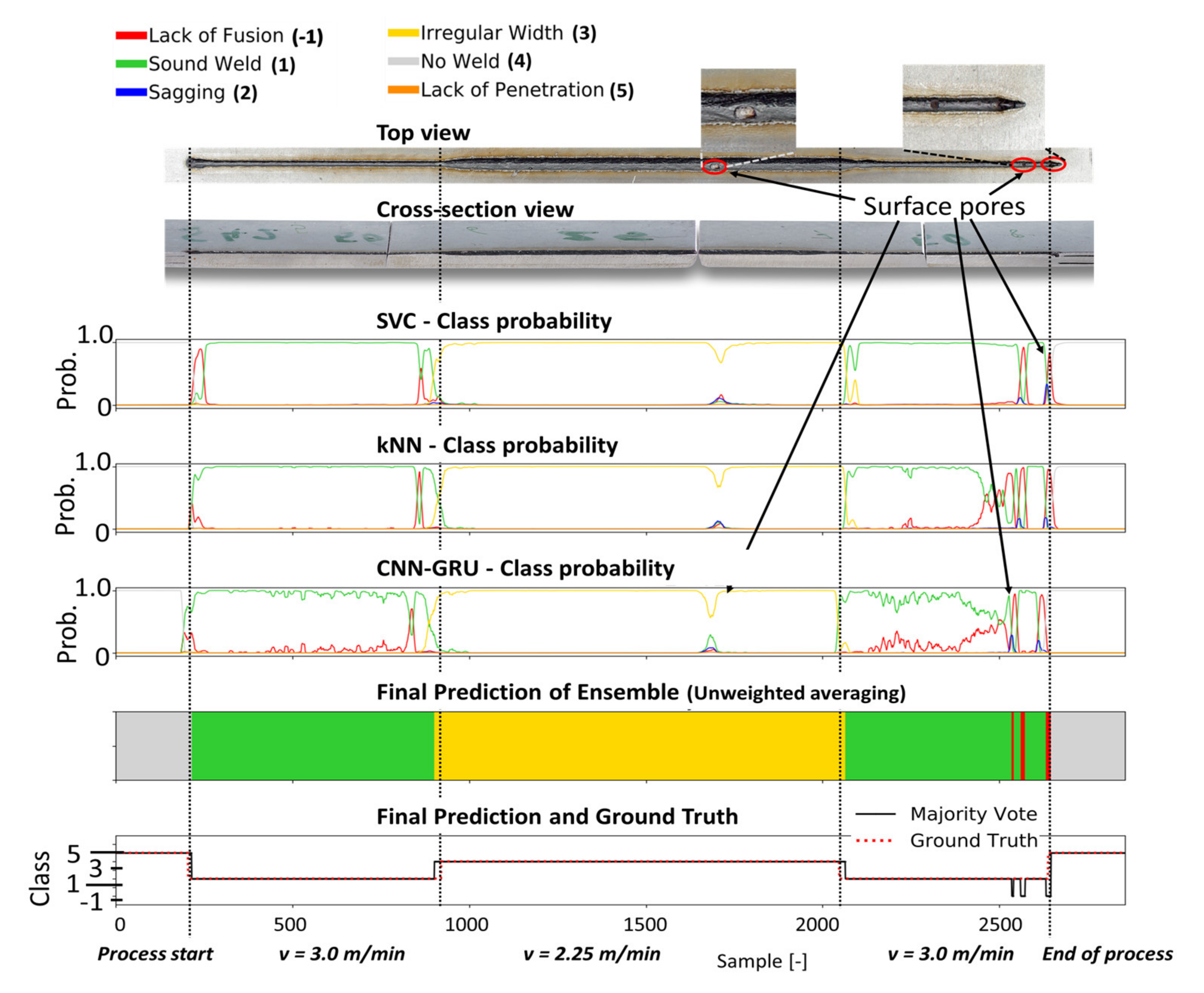
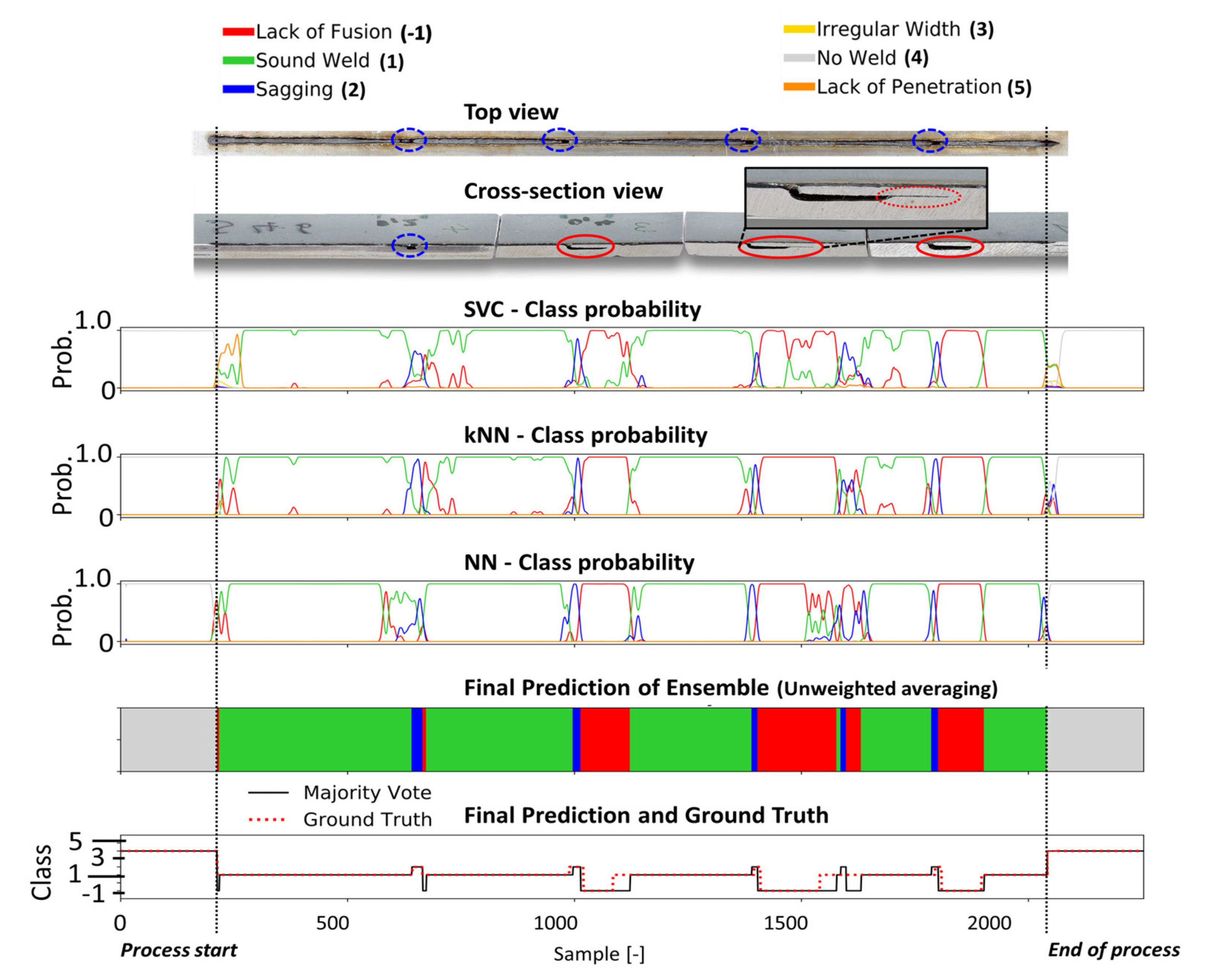
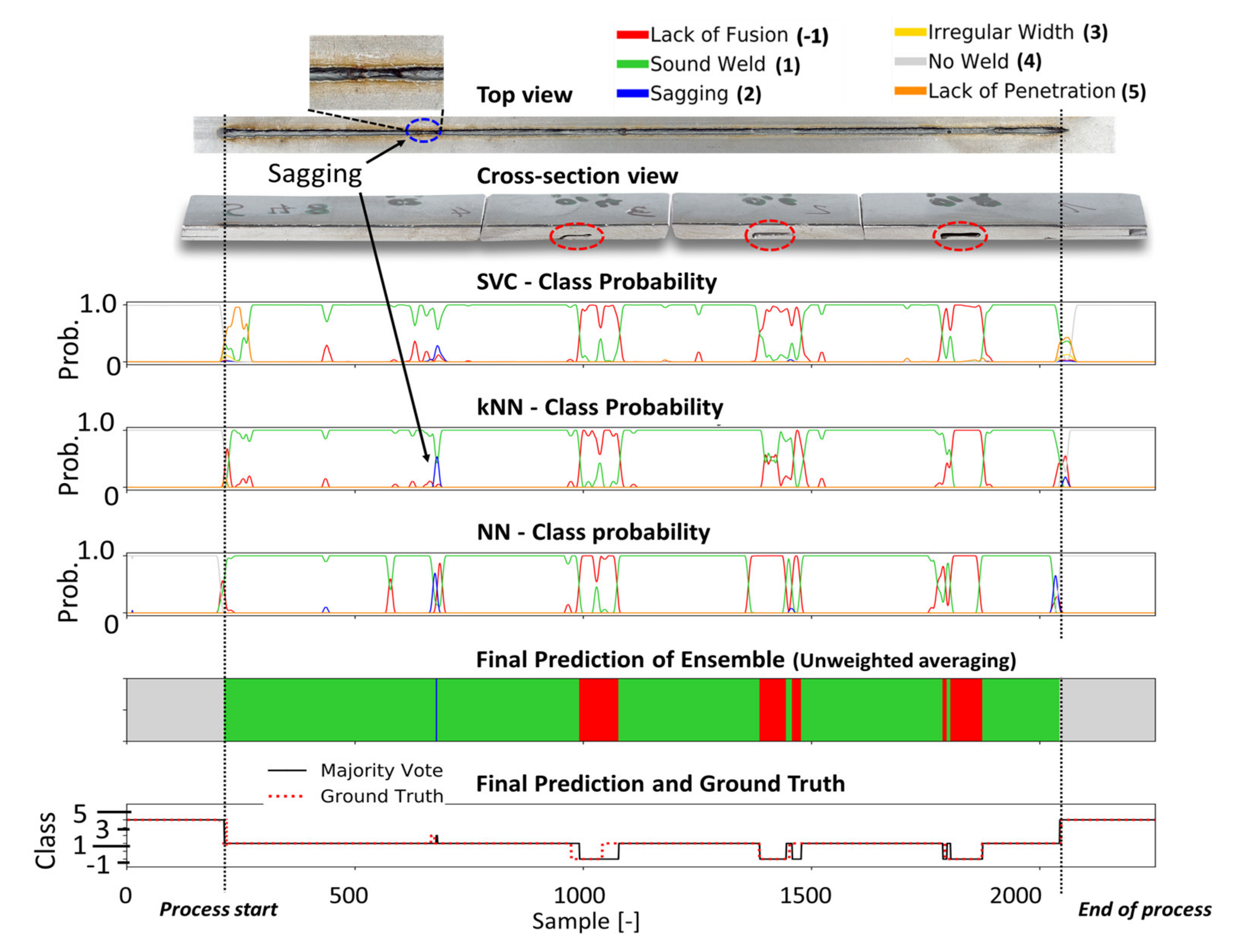
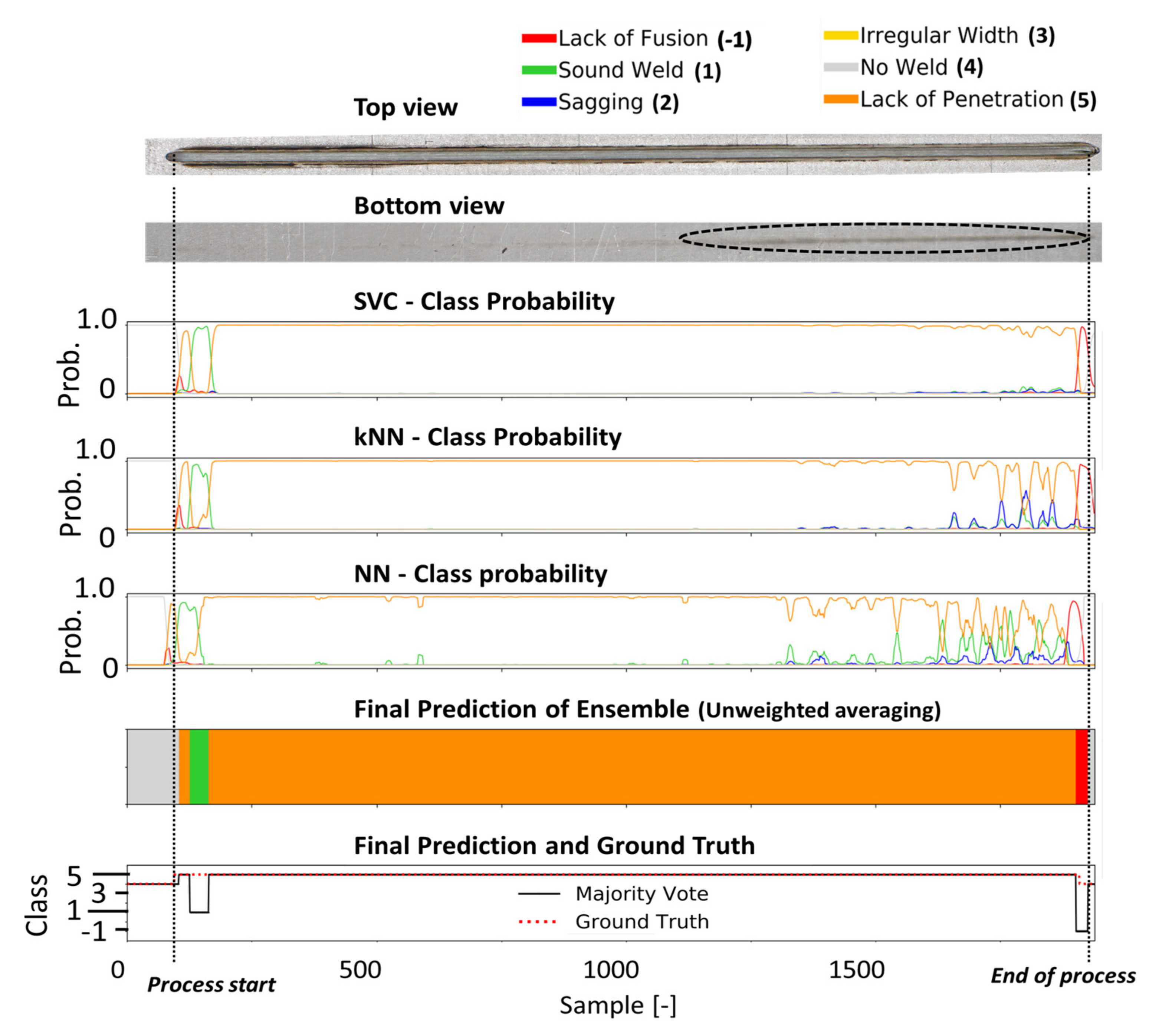
4.3. Experimental Evaluation
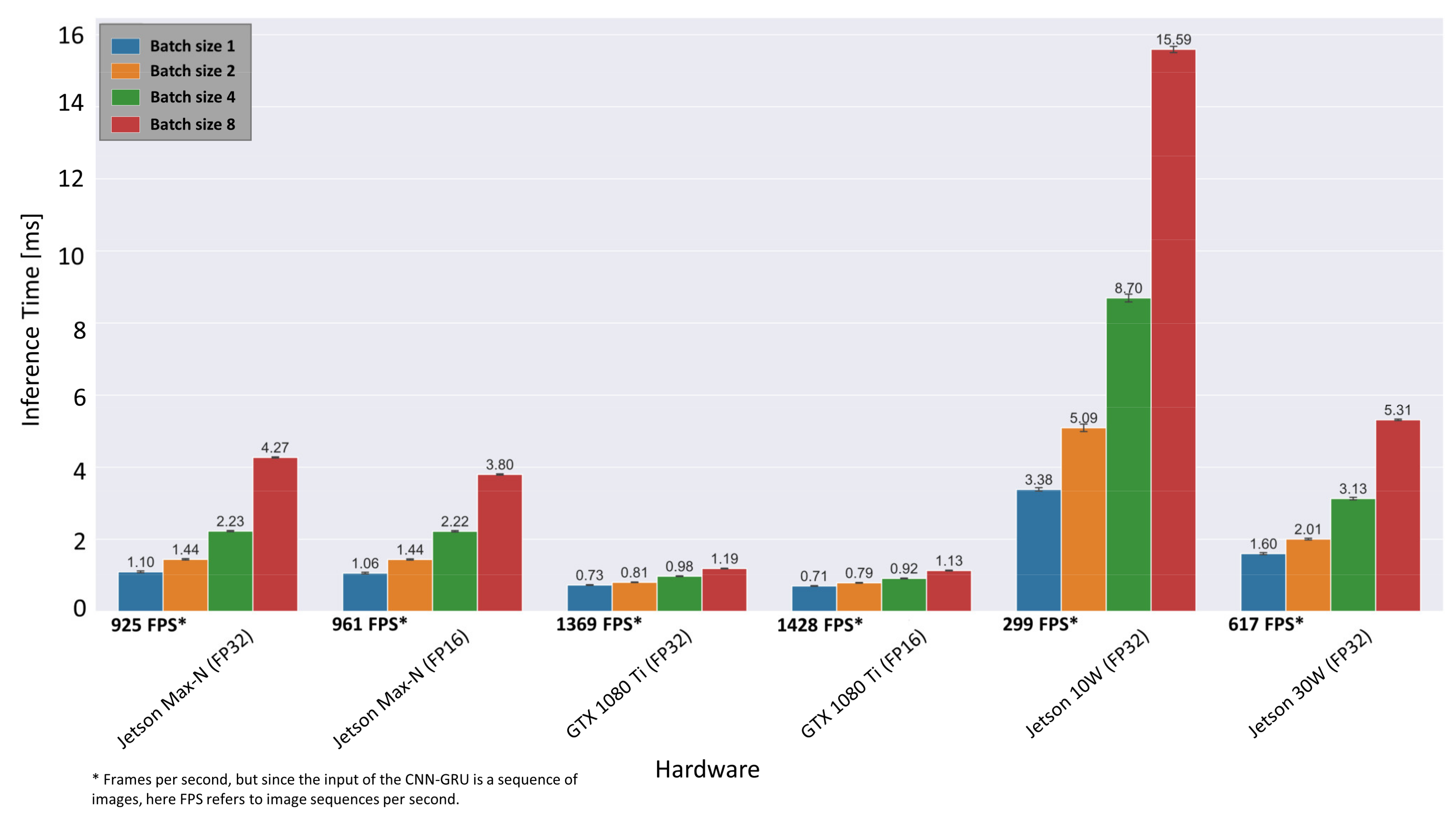
4.4. Real-Time Optimization and Inference Times on Embedded Systems
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Feature Expression | Feature Description |
|---|---|---|
| cnt_area | 0th-order moment which represents the area | |
| cnt_centroid_x/y | 1st-order moments: Center of gravity (COG) | |
| cnt_2nd_order_mom[Mxx|M00] | 2nd-order moments: distribution of contour pixel around COG normalized by | |
| cnt_3nd_order_mom[Mxx|M00] | 3rd-order image moments of the given contour normalized by | |
| cnt_ellipse_angle (Ellipse rotation angle ) | Calculates the ellipse that fits (in a least-squares sense) the given contour best of all | |
| cnt_ellipse_center_x/y ( coordinate of the center) | = 1 | The algebraic distance algorithm is used [70] |
| cnt_ellipse_axis_x/y (major semi-axis a/b) | Algorithm returns five ellipse parameters | |
| cnt_equi_diameter | Calculates the diameter of a circle based on the contour area | |
| cnt_aspect_ratio | Defines bounding rectangle of the contour in terms of height and width | |
| cnt_extent | Extent is defined as contour area divided by the area of the enclosing rectangle | |
| cnt_solidity | Ratio of contour area to the area of the convex hull. |
| Feature Name | Feature Expression | Feature Description |
|---|---|---|
| Prefix1_mean | Mean of the data depending on prefix | |
| Prefix1_variance | Variance of the data depending on prefix | |
| Prefix1_skewness | Skewness of the data depending on prefix | |
| Prefix1_kurtosis | Kurtosis of the data depending on prefix |
| Algorithm Name | Hyperparameter | Grid Values |
|---|---|---|
| Decision Tree Classifier (DT) | max_depth: Maximum depth of decision tree max_features: Number of unique features used to evaluate the best split criterion: Estimation of the split quality | [10,20,30,40,50] [sqrt(n_features)’, ‘log2(n_features))’] [‘gini’, ‘entropy’] |
| KNeighbors Classifier (kNN) | metric: Metric used to measure distance between two data points in an n-dimensional feature space weights: Function used to weight points in each neighborhood n_neighbours: number of neighbors to evaluate | [‘minkowski’, ‘euclidean’,‘manhattan’] [‘uniform’,‘distance’] [2–6] |
| Support Vector Classifier with non-linear kernel (SVM (non-linear)) | C: regularization strength (L2 penalty) while regularization is inversely proportional to C. Used for all kernels (sigmoid, rbf, polynomial) kernel: type of kernel used degree: Degree of the polynomial kernel function (poly) | [0.01,0.1,1,10,100,1000,10000] [‘rbf‘,‘poly‘,‘sigmoid‘] [3–6] |
| Support Vector Classifier with linear kernel (SVM linear) | C: Regularization strength while regularization is inversely proportional to C loss: Specifies the loss function penalty: Application of Lasso (L1) or Ridge (L2) regularization | [0.01,0.1,1,10,100,1000,10000] [‘hinge’, ‘squared_hinge’] [l2, l1] |
| Random Forest (RF) | n_estimators: Number of overall decision trees max_features: Number of unique features used to evaluate the best split criterion: Estimation of the split quality | [5,10,100,500] [sqrt(n_features)’,‘log2(n_features))’] [‘gini’, ‘entropy’] |
| Multi-Layer Perceptron (MLP) | learning_rate_init: Learning rate at start that manages the weight update rate. Activation: The hidden layer’s activation function hidden_layer_sizes: Number of nodes the hidden layer consists of | [0.01, 0.05, 0.1, 0.5, 1.0] [‘logistic, ‘relu’, ‘tanh’] [25,50,100] |
| Logistic Regression (LogReg) | C: Regularization strength while regularization is inversely proportional to C solver: Algorithm to solve the optimization problem penalty: Application of Lasso (L1) or Ridge (L2) regularization | [0.01,0.1,1,10,100,1000,10000] [’liblinear’, ’saga] [l2, l1] |
| Convolutional Neural Network (CNN-baseline) | Activation: the activation function for convolution and fully connected layer conv_1_depth: the number of output filters in the first convolutional layer conv_2_depth: the number of output filters in the 2nd convolutional layer Dense_units: number of units in the hidden layer | [ReLU, tanh] [24,32,48] [36,50,64] [24,36,48] |
| Convolutional Neural Network + Gated Recurrent Units (CNN-GRU) | Activation: The activation function for convolution and fully connected layer conv_1_depth: The number of output filters in the first convolutional layer conv_2_depth: The number of output filters in the 2nd convolutional layer GRU_units: Number of units in the Gated Recurrent Unit layer Dense_units: Number of nodes in the hidden layer nsequence: Length of the input image sequence to be classified | [ReLU, tanh] [12,20,32] [8,16,24,32] [48,64,96,112,128] [8,10,12,24,32] [3,9,15,25,35] |
References
- You, D.Y.; Gao, X.D.; Katayama, S. Review of laser welding monitoring. Sci. Technol. Weld. Join. 2013, 19, 181–201. [Google Scholar] [CrossRef]
- Shao, J.; Yan, Y. Review of techniques for on-line monitoring and inspection of laser welding. J. Phys. Conf. Ser. 2005, 15, 101–107. [Google Scholar] [CrossRef]
- Stavridis, J.; Papacharalampopoulos, A.; Stavropoulos, P. Quality assessment in laser welding: A critical review. Int. J. Adv. Manuf. Technol. 2017, 94, 1825–1847. [Google Scholar] [CrossRef]
- Kim, C.; Ahn, D.-C. Coaxial monitoring of keyhole during Yb:YAG laser welding. Opt. Laser Technol. 2012, 44, 1874–1880. [Google Scholar] [CrossRef]
- Courtois, M.; Carin, M.; Le Masson, P.; Gaied, S.; Balabane, M. A complete model of keyhole and melt pool dynamics to analyze instabilities and collapse during laser welding. J. Laser Appl. 2014, 26, 042001. [Google Scholar] [CrossRef]
- Saeed, G.; Zhang, Y.M. Weld pool surface depth measurement using a calibrated camera and structured light. Meas. Sci. Technol. 2007, 18, 2570–2578. [Google Scholar] [CrossRef]
- Bertrand, P.; Smurov, I.; Grevey, D. Application of near infrared pyrometry for continuous Nd:YAG laser welding of stainless steel. Appl. Surf. Sci. 2000, 168, 182–185. [Google Scholar] [CrossRef]
- Kong, F.; Ma, J.; Carlson, B.; Kovacevic, R. Real-time monitoring of laser welding of galvanized high strength steel in lap joint configuration. Opt. Laser Technol. 2012, 44, 2186–2196. [Google Scholar] [CrossRef]
- Purtonen, T.; Kalliosaari, A.; Salminen, A. Monitoring and Adaptive Control of Laser Processes. Phys. Proc. 2014, 56, 1218–1231. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, C.; Tan, L.; Li, S. Coaxial monitoring of the fibre laser lap welding of Zn-coated steel sheets using an auxiliary illuminant. Opt. Laser Technol. 2013, 50, 167–175. [Google Scholar] [CrossRef]
- Knaak, C.; Kolter, G.; Schulze, F.; Kröger, M.; Abels, P. Deep learning-based semantic segmentation for in-process monitoring in laser welding applications. Appl. Mach. Learn. 2019, 11139, 1113905. [Google Scholar] [CrossRef]
- Tenner, F.; Riegel, D.; Mayer, E.; Schmidt, M. Analytical model of the laser welding of zinc-coated steel sheets by the aid of videography. J. Laser Appl. 2017, 29, 22411. [Google Scholar] [CrossRef]
- Schmidt, M.; Otto, A.; Kägeler, C. Analysis of YAG laser lap-welding of zinc coated steel sheets. CIRP Ann. 2008, 57, 213–216. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.-D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Xing, B.; Xiao, Y.; Qin, Q.H.; Cui, H. Quality assessment of resistance spot welding process based on dynamic resistance signal and random forest based. Int. J. Adv. Manuf. Technol. 2017, 94, 327–339. [Google Scholar] [CrossRef]
- Knaak, C.; Thombansen, U.; Abels, P.; Kröger, M. Machine learning as a comparative tool to determine the relevance of signal features in laser welding. Procedia CIRP 2018, 74, 623–627. [Google Scholar] [CrossRef]
- Jager, M.; Hamprecht, F. Principal Component Imagery for the Quality Monitoring of Dynamic Laser Welding Processes. IEEE Trans. Ind. Electron. 2008, 56, 1307–1313. [Google Scholar] [CrossRef]
- You, D.; Gao, X.; Katayama, S. WPD-PCA-Based Laser Welding Process Monitoring and Defects Diagnosis by Using FNN and SVM. IEEE Trans. Ind. Electron. 2015, 62, 628–636. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Kruger, N.; Janssen, P.; Kalkan, S.; Lappe, M.; Leonardis, A.; Piater, J.; Rodriguez-Sanchez, A.J.; Wiskott, L. Deep Hierarchies in the Primate Visual Cortex: What Can We Learn for Computer Vision? IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1847–1871. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, A.-R.; Sainath, T.N.; Dahl, G.E.; Ramabhadran, B.; Hinton, G.E.; Picheny, M.A. Deep Belief Networks using discriminative features for phone recognition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5060–5063. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: http://tensorflow.org/ (accessed on 12 May 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F.D., Fox, E., Garnett, R., Eds.; Curran Associates Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. 2014. Available online: http://arxiv.org/pdf/1408.5093v1 (accessed on 10 May 2021).
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Knaak, C.; Masseling, L.; Duong, E.; Abels, P.; Gillner, A. Improving Build Quality in Laser Powder Bed Fusion Using High Dynamic Range Imaging and Model-Based Reinforcement Learning. IEEE Access 2021, 9, 55214–55231. [Google Scholar] [CrossRef]
- Xue, B.; Chang, B.; Du, D. Multi-Output Monitoring of High-Speed Laser Welding State Based on Deep Learning. Sensors 2021, 21, 1626. [Google Scholar] [CrossRef] [PubMed]
- Božič, A.; Kos, M.; Jezeršek, M. Power Control during Remote Laser Welding Using a Convolutional Neural Network. Sensors 2020, 20, 6658. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Li, B.; Zhang, W.; Lu, R.; Wada, S.; Zhang, Y. Real-time penetration state monitoring using convolutional neural network for laser welding of tailor rolled blanks. J. Manuf. Syst. 2020, 54, 348–360. [Google Scholar] [CrossRef]
- Günther, J.; Pilarski, P.M.; Helfrich, G.; Shen, H.; Diepold, K. First Steps towards an Intelligent Laser Welding Architecture Using Deep Neural Networks and Reinforcement Learning. Procedia Technol. 2014, 15, 474–483. [Google Scholar] [CrossRef]
- Gonzalez-Val, C.; Pallas, A.; Panadeiro, V.; Rodriguez, A. A convolutional approach to quality monitoring for laser manufacturing. J. Intell. Manuf. 2019, 31, 789–795. [Google Scholar] [CrossRef]
- Liu, T.; Bao, J.; Wang, J.; Zhang, Y. A Hybrid CNN–LSTM Algorithm for Online Defect Recognition of CO2 Welding. Sensors 2018, 18, 4369. [Google Scholar] [CrossRef]
- Ouyang, X.; Xu, S.; Zhang, C.; Zhou, P.; Yang, Y.; Liu, G.; Li, X. A 3D-CNN and LSTM Based Multi-Task Learning Architecture for Action Recognition. IEEE Access 2019, 7, 40757–40770. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Valiente, R.; Zaman, M.; Ozer, S.; Fallah, Y.P. Controlling Steering Angle for Cooperative Self-driving Vehicles utilizing CNN and LSTM-based Deep Networks. In Proceedings of the 30th IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 2423–2428. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative Study of CNN and RNN for Natural Language Processing. 2017. Available online: http://arxiv.org/pdf/1702.01923v1 (accessed on 12 May 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. 2016. Available online: https://arxiv.org/pdf/1603.05027 (accessed on 12 May 2021).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. 2015. Available online: https://arxiv.org/pdf/1512.00567 (accessed on 11 May 2021).
- Bishop, C.M. Pattern recognition and machine learning. In Information Science and Statistics; Springer: New York, NY, USA, 2006; pp. 21–24. ISBN 9780387310732. [Google Scholar]
- Nixon, M.S.; Aguado, A.S. (Eds.) Feature Extraction & Image Processing for Computer Vision, 3rd ed.; Academic Press: Oxford, UK, 2012; ISBN 9780123965493. [Google Scholar]
- Runkler, T.A. Data Analytics: Models and Algorithms for Intelligent Data Analysis; Vieweg+Teubner Verlag: Wiesbaden, Germany, 2012; ISBN 9783834825889. [Google Scholar]
- Raschka, S. Python Machine Learning: Unlock Deeper Insights into Machine Learning with this Vital Guide to Cutting-Edge Predictive Analytics; Packt Publishing Open Source: Birmingham, UK, 2016; ISBN 9781783555130. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Duchesnay, E. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lee, K.B.; Cheon, S.; Kim, C.O. A Convolutional Neural Network for Fault Classification and Diagnosis in Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2017, 30, 135–142. [Google Scholar] [CrossRef]
- Arif, S.; Wang, J.; Hassan, T.U.; Fei, Z. 3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition. Future Internet 2019, 11, 42. [Google Scholar] [CrossRef]
- Kim, D.; Cho, H.; Shin, H.; Lim, S.-C.; Hwang, W. An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video. Sensors 2019, 19, 3579. [Google Scholar] [CrossRef] [PubMed]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J. Multimodal Gesture Recognition Using 3-D Convolution and Convolutional LSTM. IEEE Access 2017, 5, 4517–4524. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features. IEEE Access 2018, 6, 1155–1166. [Google Scholar] [CrossRef]
- Rana, R. Gated Recurrent Unit (GRU) for Emotion Classification from Noisy Speech. 2016. Available online: http://arxiv.org/pdf/1612.07778v1 (accessed on 11 May 2021).
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. 2014. Available online: http://arxiv.org/pdf/1406.1078v3 (accessed on 11 May 2021).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Tanveer, M.; Suganthan, P.N. Ensemble Deep Learning: A Review. 2021. Available online: https://arxiv.org/pdf/2104.02395 (accessed on 11 May 2021).
- DeWitt, D.P.; Nutter, G.D. Theory and Practice of Radiation Thermometry; John Wiley and Sons: New York, NY, USA, 1988. [Google Scholar]
- Suzuki, S.; Be, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- ISO 13919-1: Welding—Electron and Laser-Beam Welded Joints—Guidance on Quality Levels for Imperfections—Part 1: Steel, Nickel, Titanium and Their Alloys. International Standard ISO 13919-1:2018. 2018. Available online: https://www.iso.org/obp/ui/#iso:std:iso:13919:-1:ed-2:v1:en (accessed on 5 June 2021).
- ISO 6520-1: Classification of Geometric Imperfections in Metallic Materials—Part 1: Fusion welding. International Standard ISO 6520-1:2007. 2007. Available online: https://www.iso.org/obp/ui/#iso:std:iso:6520:-1:ed-2:v1:en (accessed on 5 June 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Zongker, D.; Jain, A. Algorithms for feature selection: An evaluation. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 29 August 1996; Volume 2, pp. 18–22. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2005, 30, 25–36. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bifet, A.; Gavaldà, R. Learning from Time-Changing Data with Adaptive Windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under Concept Drift: A Review. IEEE Trans. Knowl. Data Eng. 2018. [Google Scholar] [CrossRef]
- NVIDIA Corporation. NVIDIA TensorRT: SDK for High-Performance Deep Learning Inference. Available online: https://developer.nvidia.com/tensorrt (accessed on 5 June 2021).
- Fitzgibbon, A.W.; Fisher, R.B. A Buyer’s Guide to Conic Fitting. In Proceedings of the 6th British Machine Vision Conference, Birmingham, UK, 11–14 September 1995; Volume 51, pp. 1–10. [Google Scholar]














| Type of Camera | Sensor Material/ Sensitivity Range | Resolution | Acquisition Rate | Field of View | Bandpass Filter (CWL/FWHM) | Interface |
|---|---|---|---|---|---|---|
| Photonfocus D1312IE-160-CL (NIR) | Si/0.4–0.9 µm | 1312 × 1080 | 100 Hz | 11.6 × 5 mm2 | 840 nm/40 nm | CameraLink |
| NIT Tachyon μCore 1024 (MWIR) | PbSe/1–5 µm | 32 × 32 | 500 Hz | 9 × 9 mm2 | 1690 nm/82 nm | USB2.0 |
| Feature Sub-Group (Short Name) | Expression | Description |
|---|---|---|
| Geometrical features (geometrical) | Only geometrical features according to Table A1 based on the weld pool and keyhole region | |
| Overall image statistics (image stats) | Overall image statistics according to Table A2 | |
| Times series statistics (timeseries stats) | Time series statistics according to Table A2 based on weld pool area | |
| Weld pool features (weld pool) | Geometrical and statistical features according to Table A1 and Table A2 derived from the weld pool region | |
| Keyhole features (keyhole) | Geometrical and statistical features according to Table A1 and Table A2 derived from the keyhole region |
| Feature Subset | Cross-Validated F1-Score | ||||||
|---|---|---|---|---|---|---|---|
| Name | No. of Feat. | Lack of Fusion | Sound Weld | Sagging | Irregular Width | Lack of Penetration | Avg |
| MWIR+NIR (weld pool, keyhole, image stats, timeseries stats) | 172 | 0.983 | 0.998 | 0.913 | 1.0 | 0.999 | 0.978 |
| MWIR+NIR (geometrical) | 64 | 0.89 | 0.989 | 0.976 | 1.0 | 0.998 | 0.970 |
| MWIR+NIR (image stats) | 12 | 0.743 | 0.908 | 0.091 | 0.999 | 0.951 | 0.738 |
| MWIR+NIR (timeseries stats) | 12 | 0.701 | 0.867 | 0.000 | 1.0 | 0.914 | 0.694 |
| MWIR+NIR (weld pool) | 74 | 0.953 | 0.995 | 0.901 | 1.0 | 0.999 | 0.969 |
| MWIR+NIR (keyhole) | 74 | 0.948 | 0.995 | 0.829 | 1.0 | 0.999 | 0.954 |
| MWIR (weld pool, keyhole, image stats, timeseries stats) | 86 | 0.945 | 0.993 | 0.93 | 1.0 | 0.998 | 0.973 |
| MWIR (geometrical) | 32 | 0.834 | 0.96 | 0.864 | 1.0 | 0.98 | 0.928 |
| MWIR (image stats) | 6 | 0.688 | 0.74 | 0.000 | 1.0 | 0.862 | 0.658 |
| MWIR (timeseries stats) | 6 | 0.569 | 0.669 | 0.000 | 1.0 | 0.801 | 0.607 |
| MWIR (weld pool) | 37 | 0.896 | 0.987 | 0.951 | 1.0 | 0.997 | 0.966 |
| MWIR (keyhole) | 37 | 0.851 | 0.983 | 0.833 | 1.0 | 0.997 | 0.933 |
| NIR (weld pool, keyhole, image stats, timeseries stats) | 86 | 0.904 | 0.986 | 0.956 | 1.0 | 0.996 | 0.968 |
| NIR (geometrical) | 32 | 0.56 | 0.907 | 0.780 | 0.923 | 0.961 | 0.826 |
| NIR (image stats) | 6 | 0.403 | 0.862 | 0.000 | 0.922 | 0.937 | 0.625 |
| NIR (timeseries stats) | 6 | 0.544 | 0.808 | 0.000 | 0.989 | 0.855 | 0.639 |
| NIR (weld pool) | 37 | 0.787 | 0.941 | 0.902 | 0.993 | 0.971 | 0.918 |
| NIR (keyhole) | 37 | 0.791 | 0.955 | 0.863 | 0.995 | 0.978 | 0.916 |
| Welding Parameters | Weld 42 | Weld 46 | Weld 48 | Weld 216 |
|---|---|---|---|---|
| Laser power (kW) | 3.3 | 3.3 | 3.3 | 2.7 |
| Beam focus offset (mm) | 0 | 0 | 0 | −2 |
| Welding speed (mm/s) | 50; 37.5 | 50 | 50 | 50 |
| Shielding gas (L/min) | 60 | 60 | 60 | 60 |
| Sheet configuration | Three sheets; No slots | Three sheets; Slots point upwards | Three sheets; Slots point downwards | Two sheets; No middle sheet |
| Method | Weld 42 (2856 Samples) | Weld 46 (2255 Samples) | Weld 48 (2254 Samples) | Weld 216 (3140 Samples) | Avg. Accuracy | Avg. F1-Score |
|---|---|---|---|---|---|---|
| Decision Tree | 0.893 | 0.861 | 0.914 | 0.729 | 0.849 | 0.893 |
| kNN | 0.977 | 0.885 | 0.921 | 0.94 | 0.931 | 0.939 |
| MLP | 0.962 | 0.882 | 0.916 | 0.831 | 0.898 | 0.924 |
| LogReg | 0.944 | 0.873 | 0.911 | 0.782 | 0.878 | 0.892 |
| Linear SVM- | 0.93 | 0.815 | 0.906 | 0.75 | 0.85 | 0.867 |
| Non-Linear SVM * | 0.958 | 0.892 | 0.917 | 0.888 | 0.914 | 0.926 |
| RF | 0.97 | 0.921 | 0.927 | 0.796 | 0.904 | 0.923 |
| CNN-baseline | 0.822 | 0.895 | 0.916 | 0.933 | 0.892 | 0.897 |
| ResNet50 | 0.91 | 0.823 | 0.894 | 0.9174 | 0.887 | 0.902 |
| MobileNetV2 | 0.9488 | 0.869 | 0.9041 | 0.965 | 0.922 | 0.922 |
| InceptionV3 | 0.967 | 0.898 | 0.919 | 0.821 | 0.908 | 0.905 |
| Ensemble CNN-GRU * | 0.973 | 0.923 | 0.944 | 0.963 | 0.951 | 0.952 |
| Hardware | NVIDIA GeForce GTX 1080 Ti | NVIDIA JETSON AGX XAVIER |
|---|---|---|
| Type | Desktop GPU | Embedded GPU SoC |
| Power Consumption (TDP) | 250 Watt | 10W/15W/30W/Max-N * profiles |
| Cuda Cores | 3584 | 512 |
| Memory | 11GB (dedicated) | 16GB (Shared) |
| Clock Speed (Base/Boost)) | 1.48 GHz/1.58 GHz | 0.85 GHz/1.37GHz |
| Memory Bandwidth | 484.4 GB/s | 137 GB/s |
| Size | 267 mm × 112 mm (card only) | 87 mm × 100 mm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Knaak, C.; von Eßen, J.; Kröger, M.; Schulze, F.; Abels, P.; Gillner, A. A Spatio-Temporal Ensemble Deep Learning Architecture for Real-Time Defect Detection during Laser Welding on Low Power Embedded Computing Boards. Sensors 2021, 21, 4205. https://doi.org/10.3390/s21124205
Knaak C, von Eßen J, Kröger M, Schulze F, Abels P, Gillner A. A Spatio-Temporal Ensemble Deep Learning Architecture for Real-Time Defect Detection during Laser Welding on Low Power Embedded Computing Boards. Sensors. 2021; 21(12):4205. https://doi.org/10.3390/s21124205
Chicago/Turabian StyleKnaak, Christian, Jakob von Eßen, Moritz Kröger, Frederic Schulze, Peter Abels, and Arnold Gillner. 2021. "A Spatio-Temporal Ensemble Deep Learning Architecture for Real-Time Defect Detection during Laser Welding on Low Power Embedded Computing Boards" Sensors 21, no. 12: 4205. https://doi.org/10.3390/s21124205
APA StyleKnaak, C., von Eßen, J., Kröger, M., Schulze, F., Abels, P., & Gillner, A. (2021). A Spatio-Temporal Ensemble Deep Learning Architecture for Real-Time Defect Detection during Laser Welding on Low Power Embedded Computing Boards. Sensors, 21(12), 4205. https://doi.org/10.3390/s21124205