
QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams


 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Work
2.1. Methods for Resolving Online Information Overloading
2.2. Online Spatial Data Sampling
2.3. QoS-Aware Big Data Management
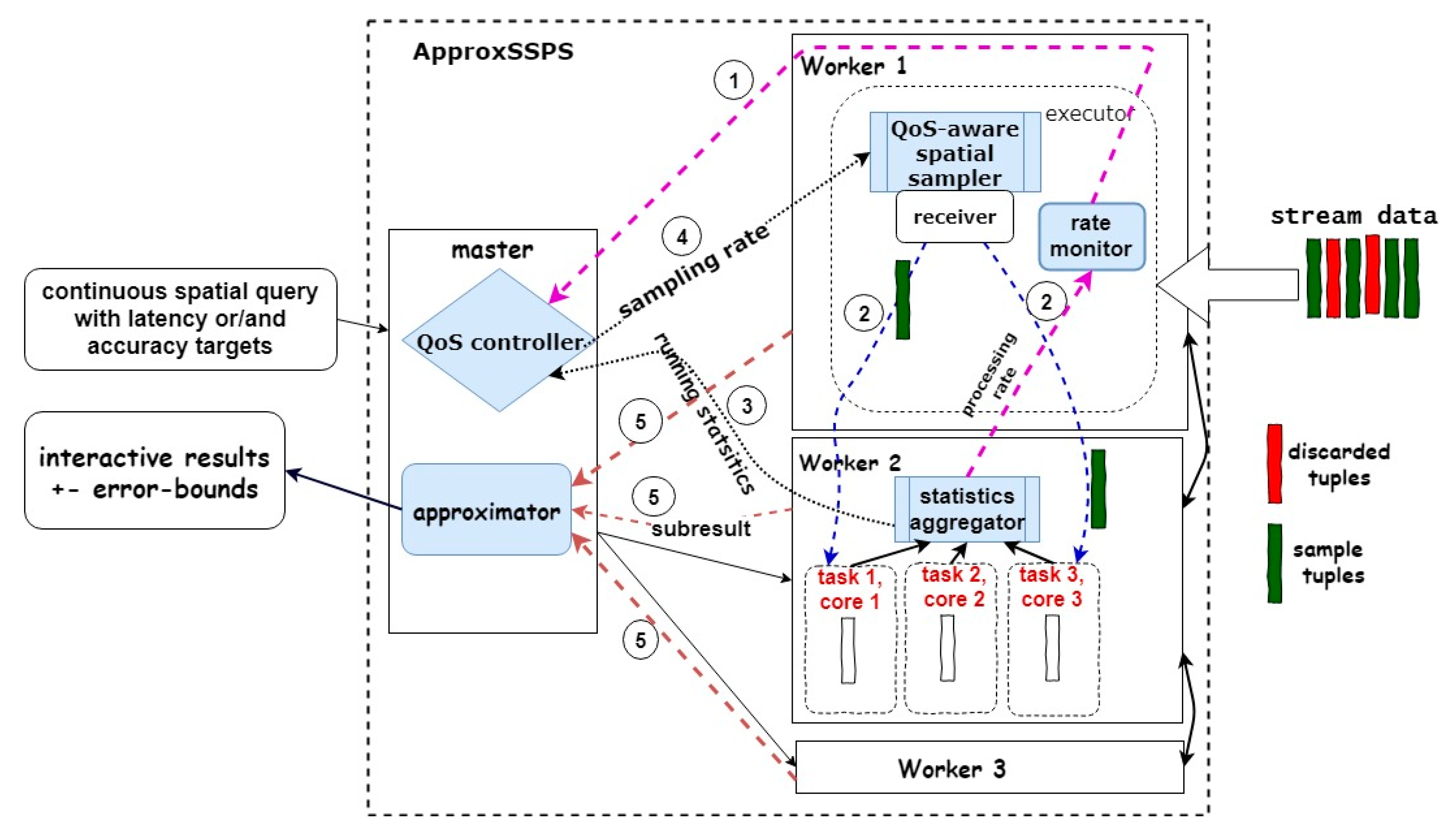
3. ApproxSSPS: Approximate Processing of Spatial Data Streams in Smart Cities
3.1. System Architecture and Features
3.2. QoS Controller Component of the System
3.2.1. Accuracy Controller
3.2.2. Latency Controller
4. Experimental Evaluation
4.1. Baseline System
4.1.1. Baseline System Architecture
4.1.2. Query Performance Metrics of the Baseline System
4.2. Experimental Environment Setup
4.3. Experimental Results
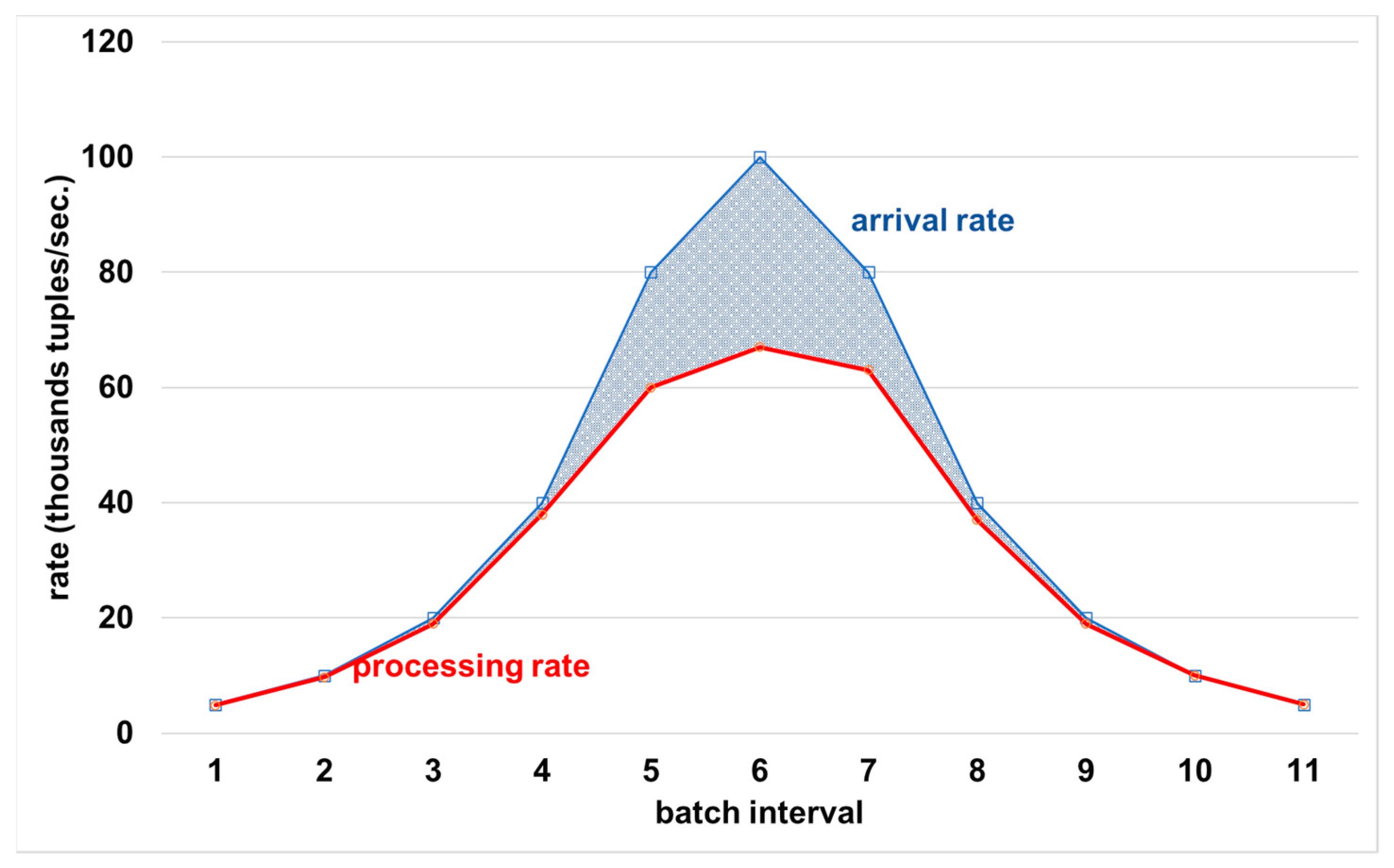
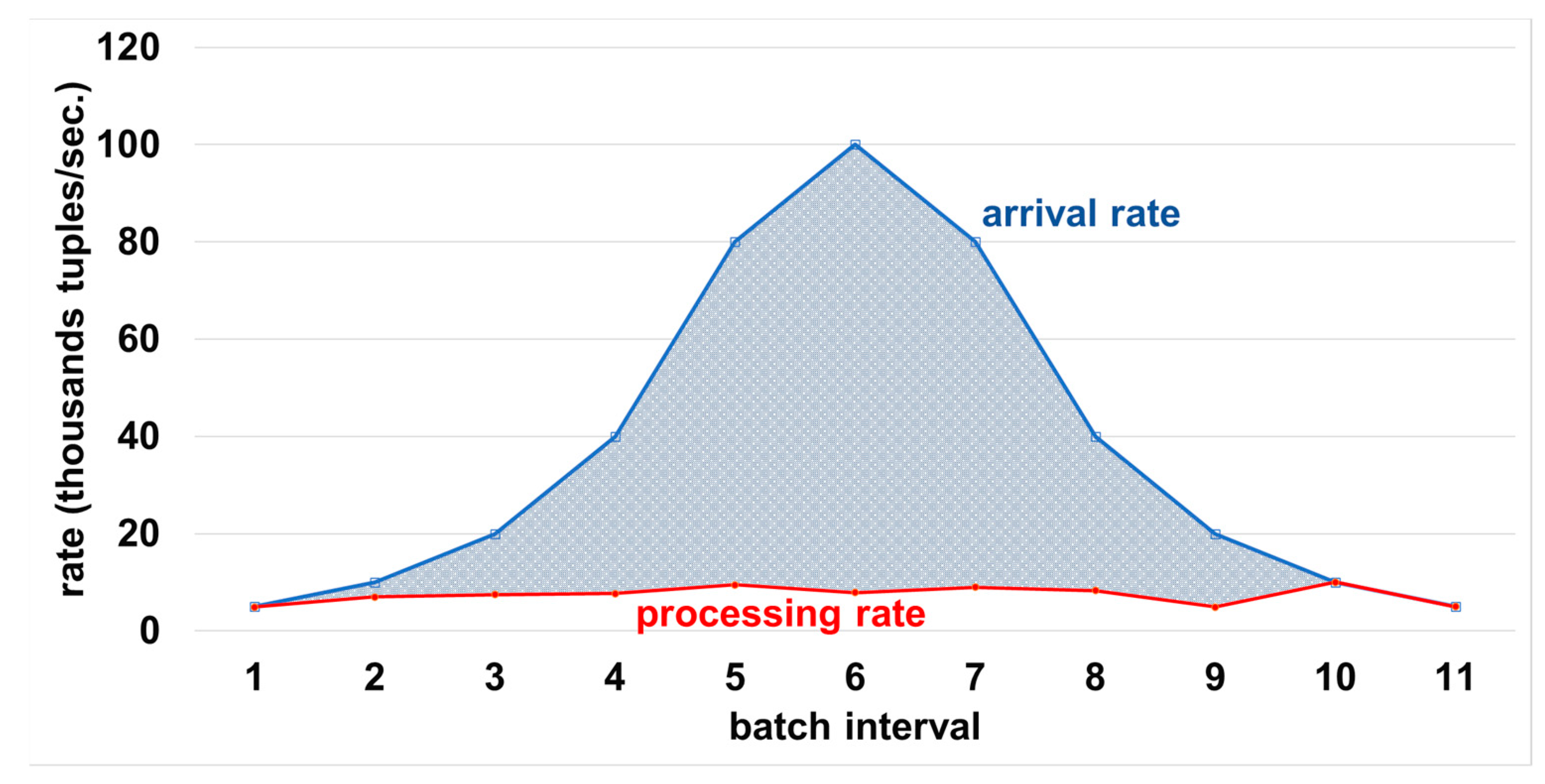
4.3.1. Latency Controller Ability to Maintain System Stability during Peak Times
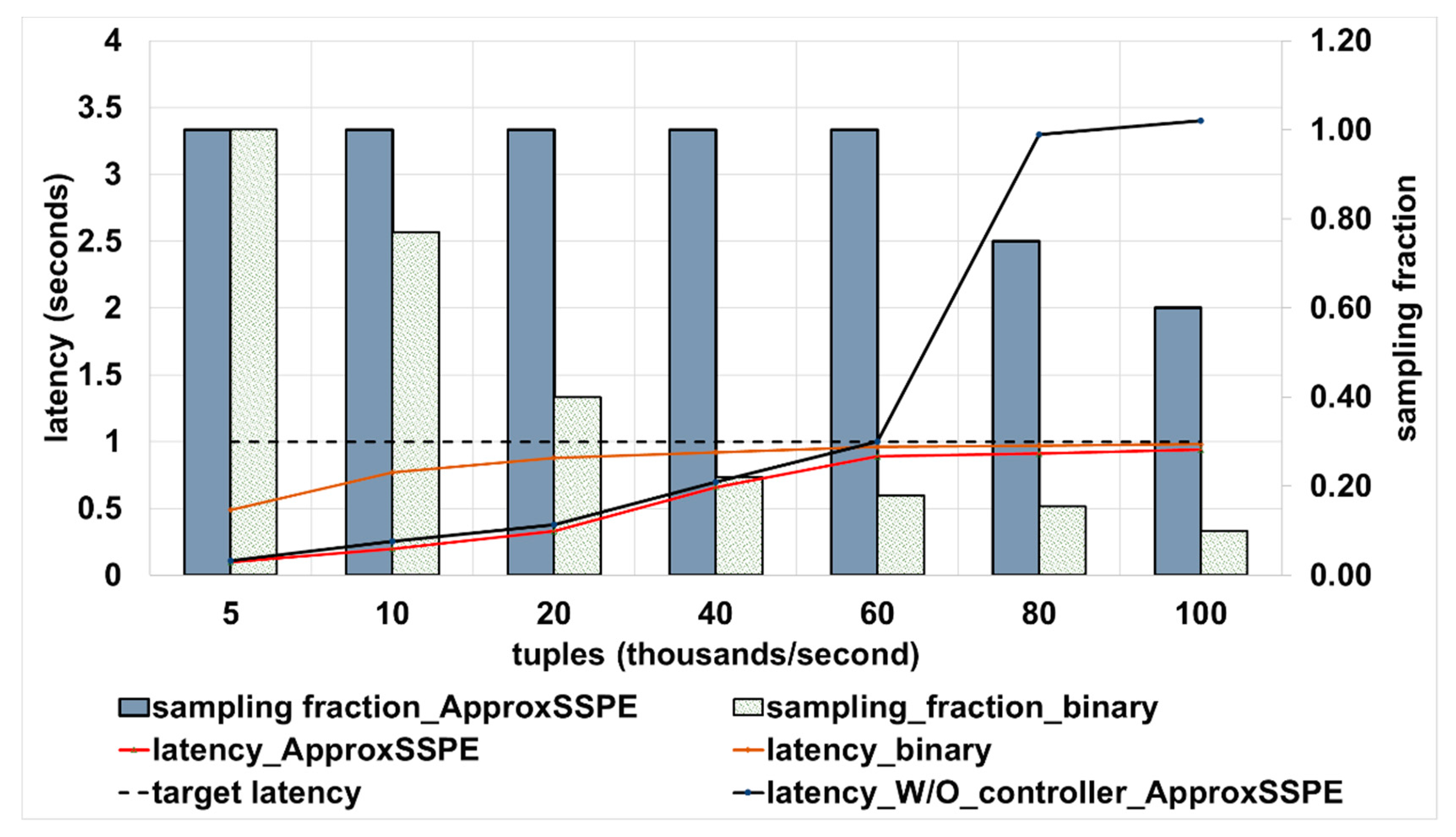
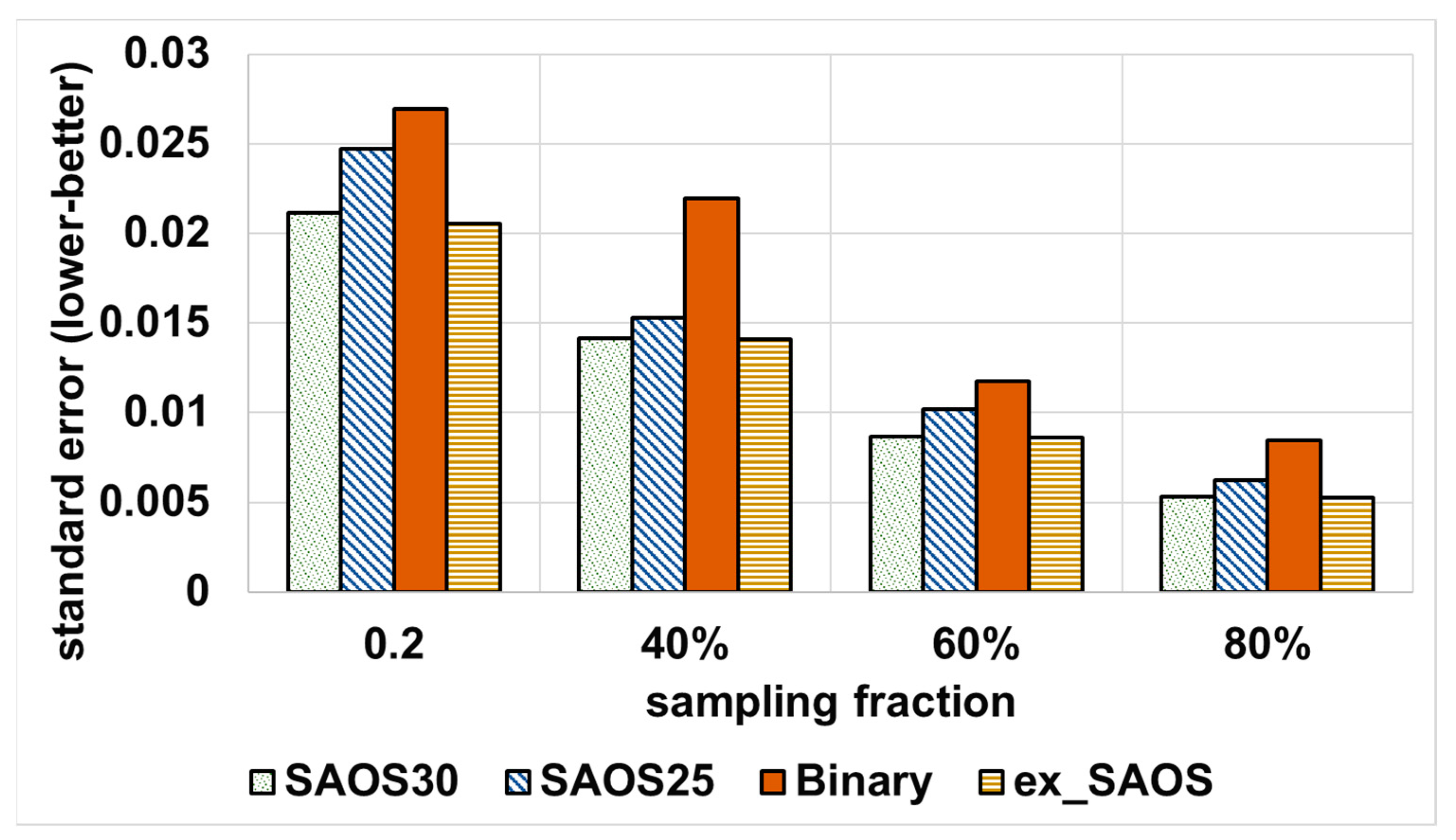
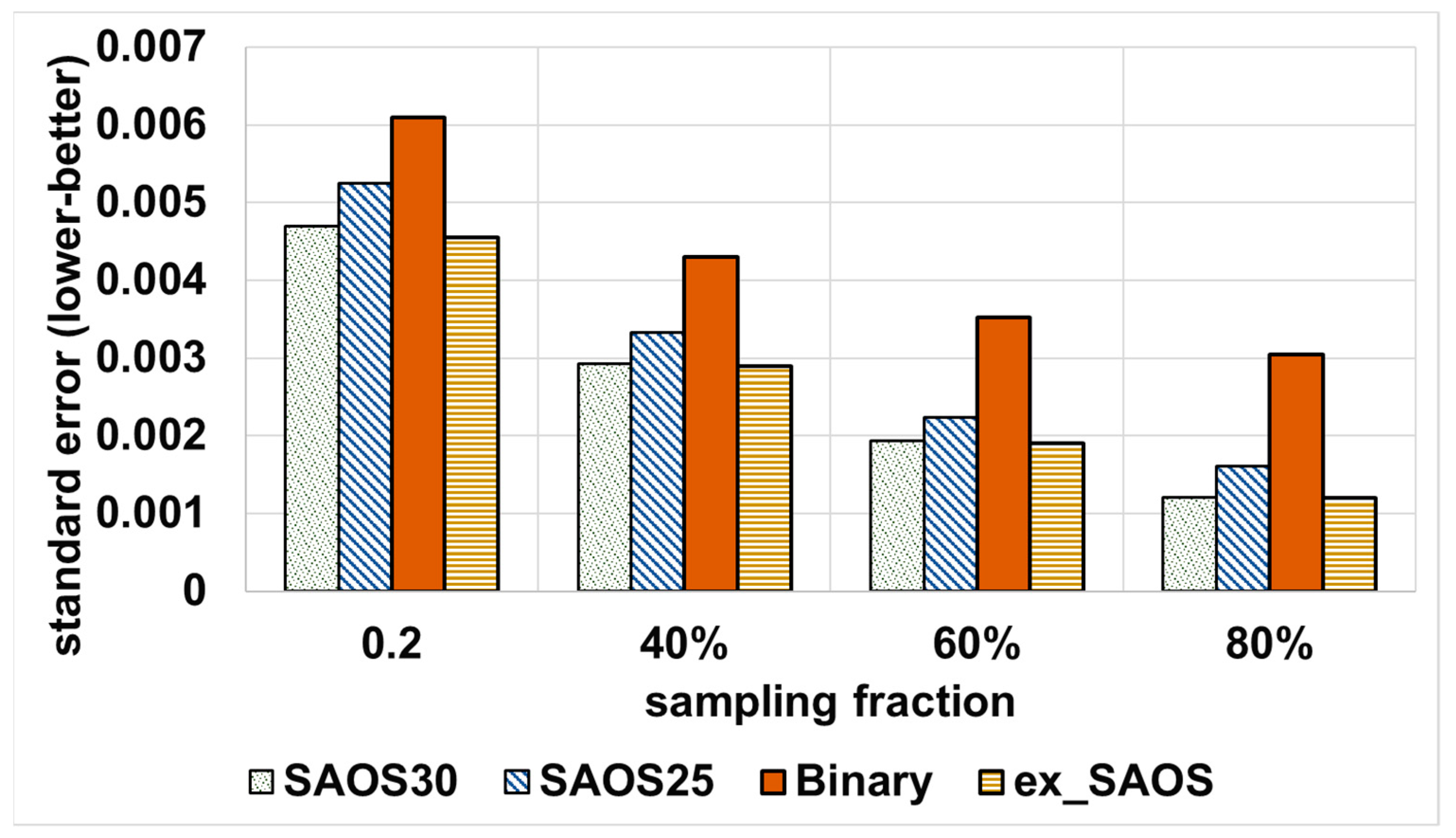
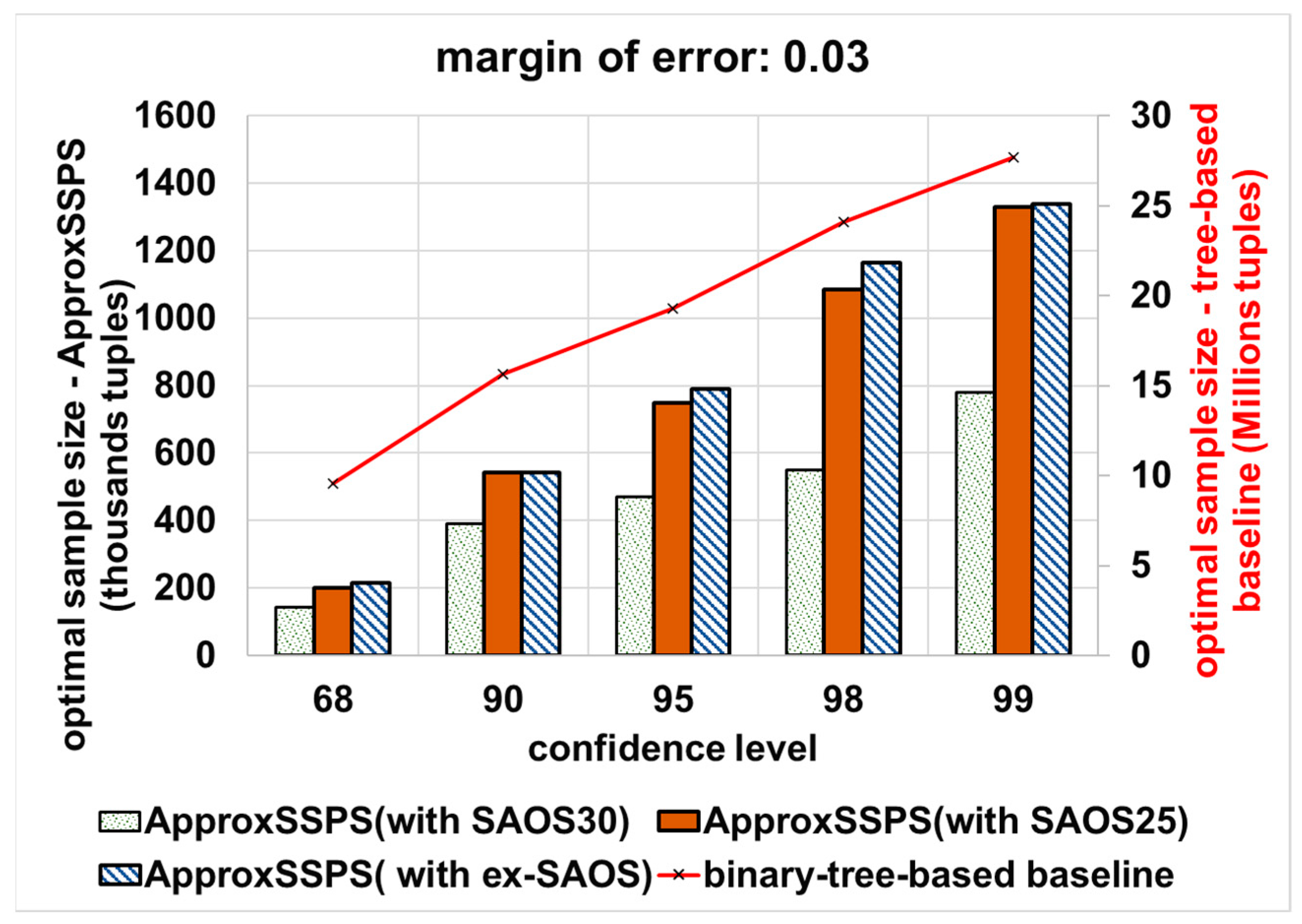
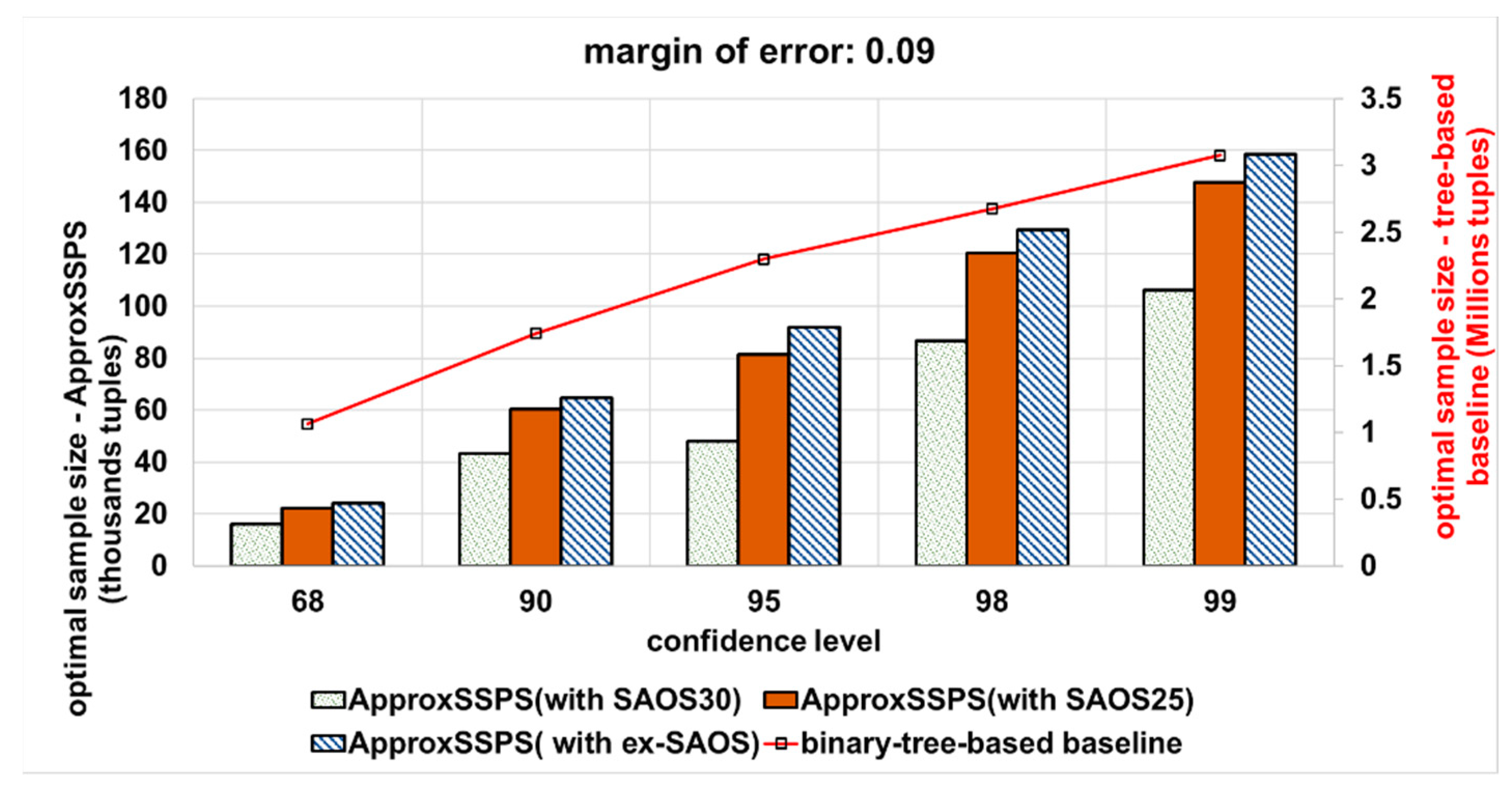
4.3.2. Accuracy Controller Ability in Trading off QoS Goals
4.4. Results Summary and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aljawarneh, I.M.; Bellavista, P.; De Rolt, C.R.; Foschini, L. Dynamic Identification of Participatory Mobile Health Communities. In Cloud Infrastructures, Services, and IoT Systems for Smart Cities; Springer: Cham, Switzerland, 2017; pp. 208–217. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Foschini, L.; Montanari, R. Spatial-Aware Approximate Big Data Stream Processing. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Sánchez-Corcuera, R.; Nuñez-Marcos, A.; Sesma-Solance, J.; Bilbao-Jayo, A.; Mulero, R.; Zulaika, U.; Azkune, G.; Almeida, A. Smart cities survey: Technologies, application domains and challenges for the cities of the future. Int. J. Distrib. Sensor Netw. 2019, 15, 1550147719853984. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and batch processing in a single engine. Bull. IEEE Comput. Soc. Tech. Committee Data Eng. 2015, 36, 28–38. [Google Scholar]
- Chen, X.; Vigfusson, Y.; Blough, D.M.; Zheng, F.; Wu, K.-L.; Hu, L. GOVERNOR: Smoother Stream Processing Through Smarter Backpressure. In Proceedings of the 2017 IEEE International Conference on Autonomic Computing (ICAC), Columbus, OH, USA, 17–21 July 2017; pp. 145–154. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Spatially Representative Online Big Data Sampling for Smart Cities. In Proceedings of the 2020 IEEE 25th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Virtual Conference, Pisa, Italy, 14–16 September 2020; pp. 1–6. [Google Scholar]
- Wei, X.; Liu, Y.; Wang, X.; Gao, S.; Chen, L. Online adaptive approximate stream processing with customized error control. IEEE Access 2019, 7, 25123–25137. [Google Scholar] [CrossRef]
- Aljawarneh, I.M.; Bellavista, P.; Corradi, A.; Montanari, R.; Foschini, L.; Zanotti, A. Efficient spark-based framework for big geospatial data query processing and analysis. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Crete, Greece, 3–6 July 2017; pp. 851–856. [Google Scholar]
- Herbst, N.R.; Kounev, S.; Reussner, R. Elasticity in cloud computing: What it is, and what it is not. In Proceedings of the 10th International Conference on Autonomic Computing (ICAC 13), San Jose, CA, USA, 26–28 June 2013; pp. 23–27. [Google Scholar]
- Lorido-Botran, T.; Miguel-Alonso, J.; Lozano, J.A. A Review of Auto-scaling Techniques for Elastic Applications in Cloud Environments. J. Grid Comput. 2014, 12, 559–592. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Casimiro, F.; Corradi, A.; Foschini, L. Cost-effective strategies for provisioning NoSQL storage services in support for industry 4.0. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; pp. 01227–01232. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Efficient QoS-Aware Spatial Join Processing for Scalable NoSQL Storage Frameworks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2437–2449. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Big Spatial Data Management for the Internet of Things: A Survey. J. Netw. Syst. Manag. 2020, 28, 990–1035. [Google Scholar] [CrossRef]
- Ordonez-Ante, L.; Van Seghbroeck, G.; Wauters, T.; Volckaert, B.; De Turck, F. EXPLORA: Interactive Querying of Multidimensional Data in the Context of Smart Cities. Sensors 2020, 20, 2737. [Google Scholar] [CrossRef] [PubMed]
- Ramnarayan, J.; Mozafari, B.; Wale, S.; Menon, S.; Kumar, N.; Bhanawat, H.; Chakraborty, S.; Mahajan, Y.; Mishra, R.; Bachhav, K. Snappydata: A hybrid transactional analytical store built on spark. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2153–2156. [Google Scholar]
- Olma, M.; Papapetrou, O.; Appuswamy, R.; Ailamaki, A. Taster: Self-tuning, elastic and online approximate query processing. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macau, China, 8–11 April 2019; pp. 482–493. [Google Scholar]
- Goiri, I.; Bianchini, R.; Nagarakatte, S.; Nguyen, T.D. Approxhadoop: Bringing approximations to mapreduce frameworks. In Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems, Istanbul, Turkey, 14–18 March 2015; pp. 383–397. [Google Scholar]
- Xie, D.; Li, F.; Yao, B.; Li, G.; Zhou, L.; Guo, M. Simba: Efficient in-memory spatial analytics. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1071–1085. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st international conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar]
- Armbrust, M.; Das, T.; Torres, J.; Yavuz, B.; Zhu, S.; Xin, R.; Ghodsi, A.; Stoica, I.; Zaharia, M. Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 601–613. [Google Scholar]
- Zaharia, M.; Das, T.; Li, H.; Hunter, T.; Shenker, S.; Stoica, I. Discretized streams: Fault-tolerant streaming computation at scale. In Proceedings of the twenty-fourth ACM Symposium on Operating Systems Principles, Farmington, PA, USA, 3–6 November 2013; pp. 423–438. [Google Scholar]
- Lohr, S.L. Sampling: Design and Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R.; Zanotti, A. In-memory spatial-aware framework for processing proximity-alike queries in big spatial data. In Proceedings of the 2018 IEEE 23rd International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Barcelona, Spain, 17–19 September 2018; pp. 1–6. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Locality-Preserving Spatial Partitioning for Geo Big Data Analytics in Main Memory Frameworks. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference (Virtual Conference), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. In The Collected Works of Wassily Hoeffding; Springer: New York, NY, USA, 1994; pp. 409–426. [Google Scholar]
- Wang, G.; Chen, X.; Zhang, F.; Wang, Y.; Zhang, D. Experience: Understanding long-term evolving patterns of shared electric vehicle networks. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–21 October 2019; pp. 1–12. [Google Scholar]
- Allen, S.T.; Jankowski, M.; Pathirana, P. Storm Applied: Strategies for Real-Time Event Processing; Manning Publications Co.: New York, NY, USA, 2015. [Google Scholar]
- Jafarpour, H.; Desai, R.; Guy, D. KSQL: Streaming SQL Engine for Apache Kafka. In Proceedings of the 22nd International Conference on Extending Database Technology (EDBT), Lisbon, Portugal, 26–29 March 2019; pp. 524–533. [Google Scholar]
- Arasu, A.; Babcock, B.; Babu, S.; Cieslewicz, J.; Datar, M.; Ito, K.; Motwani, R.; Srivastava, U.; Widom, J. Stream: The stanford data stream management system. In Data Stream Management; Springer: Berlin/Heidelberg, Germany, 2016; pp. 317–336. [Google Scholar]
Short Biography of Authors
 | Isam Mashhour Al Jawarneh received a PhD degree in computer science and engineering from the University of Bologna, Italy, in 2020. He is now a postdoctoral researcher at the University of Bologna. His research interests cover many aspects of big data management and data science for highly dynamic applications in smart cities and urban informatics. He has authored/co-authored several articles and papers for flagship journals and conferences. He has more than 13 years of research and teaching experience at a higher education level. |
 | Paolo Bellavista received his MSc and PhD degrees in computer science engineering from the University of Bologna, Italy, where he is now a full professor of distributed and mobile systems. His research activities span from pervasive wireless computing to location/context-aware services, from edge cloud computing to middleware for Industry 4.0 applications. He is currently the scientific coordinator of a large H2020 big data innovation action called IoTwins (delivers distributed digital twins for the manufacturing industry). He serves on the editorial boards of IEEE Communications Surveys and Tutorials, ACM Computing Surveys, IEEE Transactions on Network and Service Management, Elsevier Pervasive Mobile Computing, and the Elsevier Journal of Network and Computing Applications, among the others. |
 | Antonio Corradi graduated from University of Bologna, Italy, and received his MS in electrical engineering from Cornell University, USA. He is a full professor of computer engineering at the University of Bologna. His research interests include distributed systems, middleware for pervasive and heterogeneous computing, infrastructure for services, and network management. |
 | Luca Foschini graduated from the University of Bologna, Italy, where he received a PhD in computer science engineering in 2007. He is currently an associate professor of computer engineering at the University of Bologna. His interests include integrated management of distributed systems and services, wireless pervasive computing, scalable context data distribution infrastructures, and context-aware services. He is currently working on mobile crowdsensing/crowdsourcing and management of cloud systems for Smart City environments. |
 | Rebecca Montanari graduated from the University of Bologna, where she received a PhD degree in computer science engineering in 2001. She is currently an associate professor of computer engineering at the University of Bologna. Her research primarily focuses on semantic-based middleware support for service provision, context-aware services, security solutions for pervasive environments, policy-based service management, and adaptive and scalable middleware solutions for system and service management. |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
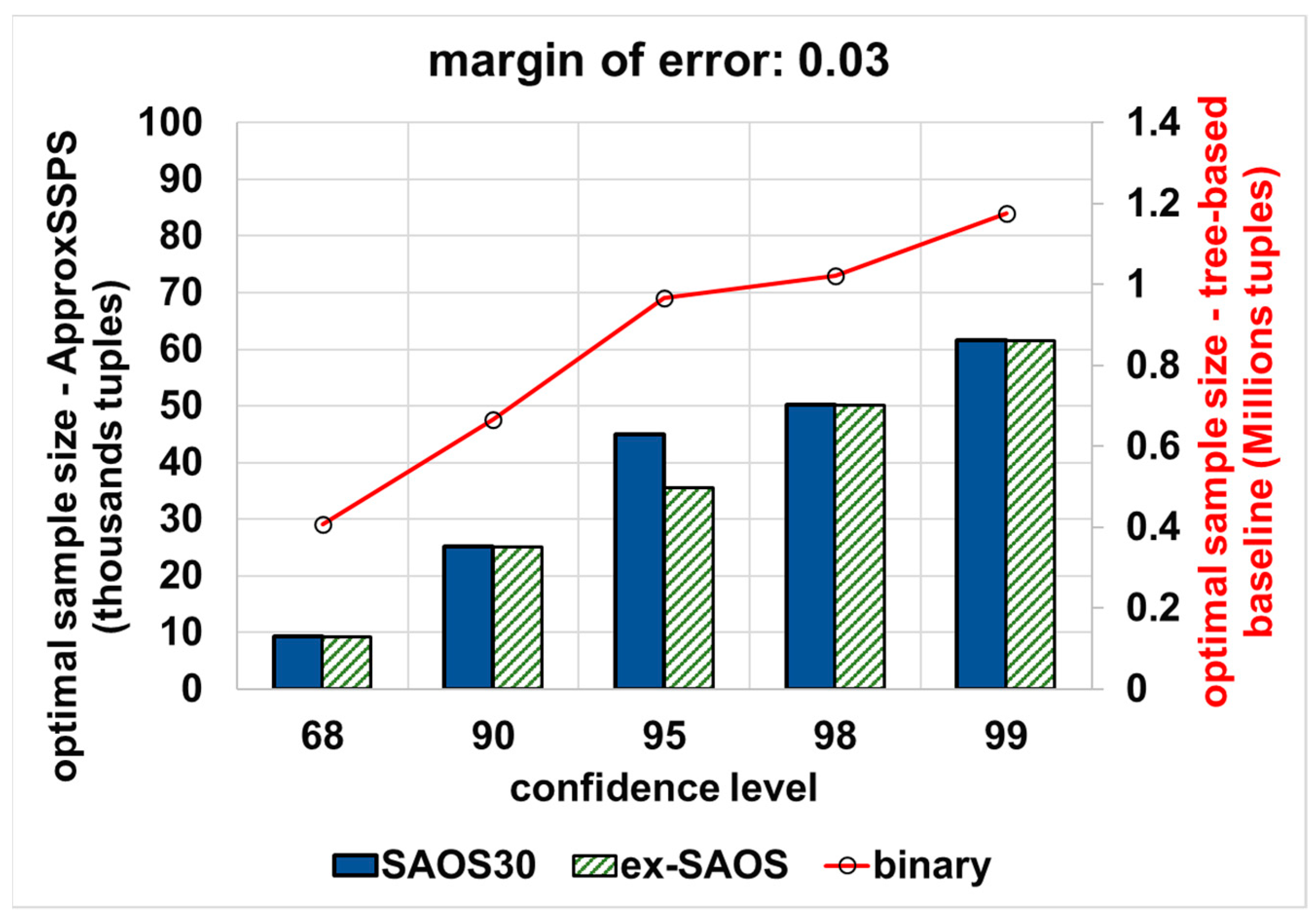{kind=link}
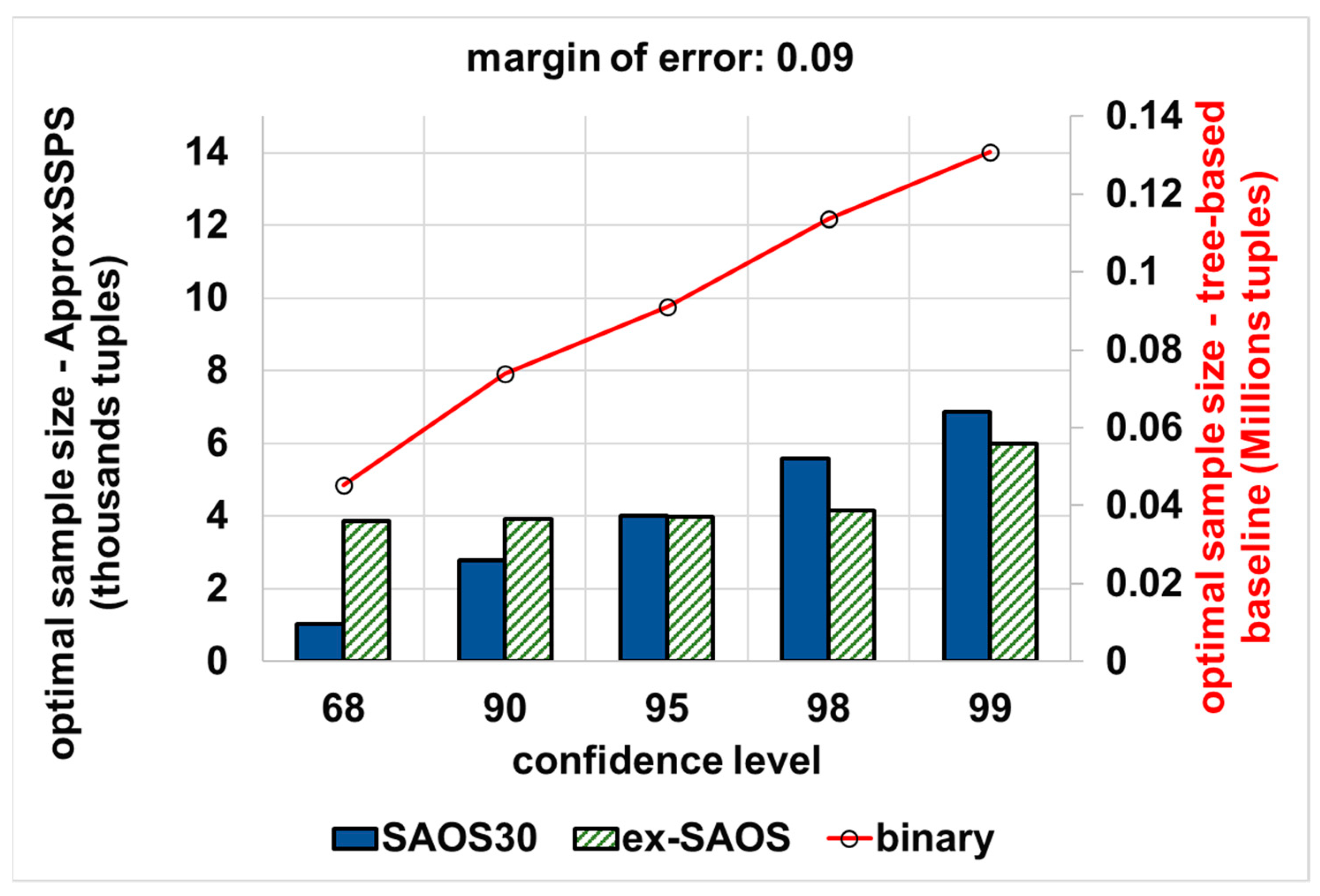{kind=link}
| Confidence Level | zα/2 |
|---|---|
| 68% | 1 |
| 90% | 1.645 |
| 95% | 1.96 |
| 98% | 2.326 |
| 99% | 2.576 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams. Sensors 2021, 21, 4160. https://doi.org/10.3390/s21124160
Al Jawarneh IM, Bellavista P, Corradi A, Foschini L, Montanari R. QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams. Sensors. 2021; 21(12):4160. https://doi.org/10.3390/s21124160
Chicago/Turabian StyleAl Jawarneh, Isam Mashhour, Paolo Bellavista, Antonio Corradi, Luca Foschini, and Rebecca Montanari. 2021. "QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams" Sensors 21, no. 12: 4160. https://doi.org/10.3390/s21124160
APA StyleAl Jawarneh, I. M., Bellavista, P., Corradi, A., Foschini, L., & Montanari, R. (2021). QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams. Sensors, 21(12), 4160. https://doi.org/10.3390/s21124160