
Deep-Framework: A Distributed, Scalable, and Edge-Oriented Framework for Real-Time Analysis of Video Streams


Abstract
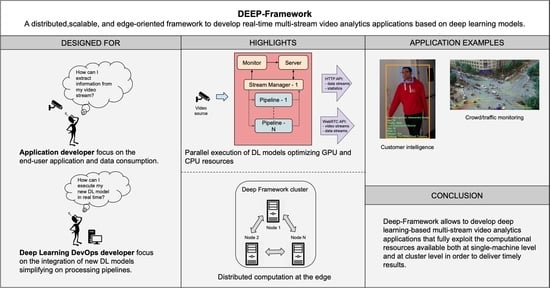
1. Introduction
- Distributed architecture for deploying the real-time analysis of video on a cluster of small cost-effective machines as well as on a single powerful machine;
- Resource allocation mechanism that automatically allocates every algorithm according to its deep learning framework, optimizing the use of GPU and CPU resources in the cluster;
- Modular organization of components that allows efficient scaling to a large number of video cameras with multiple processing pipelines per video stream;
- Frame-skipping policy, adopted for each component of the processing pipelines, that ensures a real-time behavior of the system;
- Python interfaces that allow researchers and developers to easily include and deploy new deep learning models using the most mature deep learning frameworks;
- Standard HTTP and WebRTC APIs for providing web-based video analytics services and allowing the integration of web-based client applications.
2. Related Work
3. Materials and Methods
- Initializes the components, builds the pipelines, and creates the related services;
- Creates the cluster of nodes in which the services will be executed;
- Allocates the services with DL models that require GPU to nodes with GPU capability, taking into account the number of nodes, the available memory, and the installed DL frameworks; the other services are scheduled on a different node whenever possible. In Algorithm 1, this procedure is explained in detail;
- Defines the connection with video sources.

| Algorithm 1: Allocation of algorithm services to nodes. |
 |
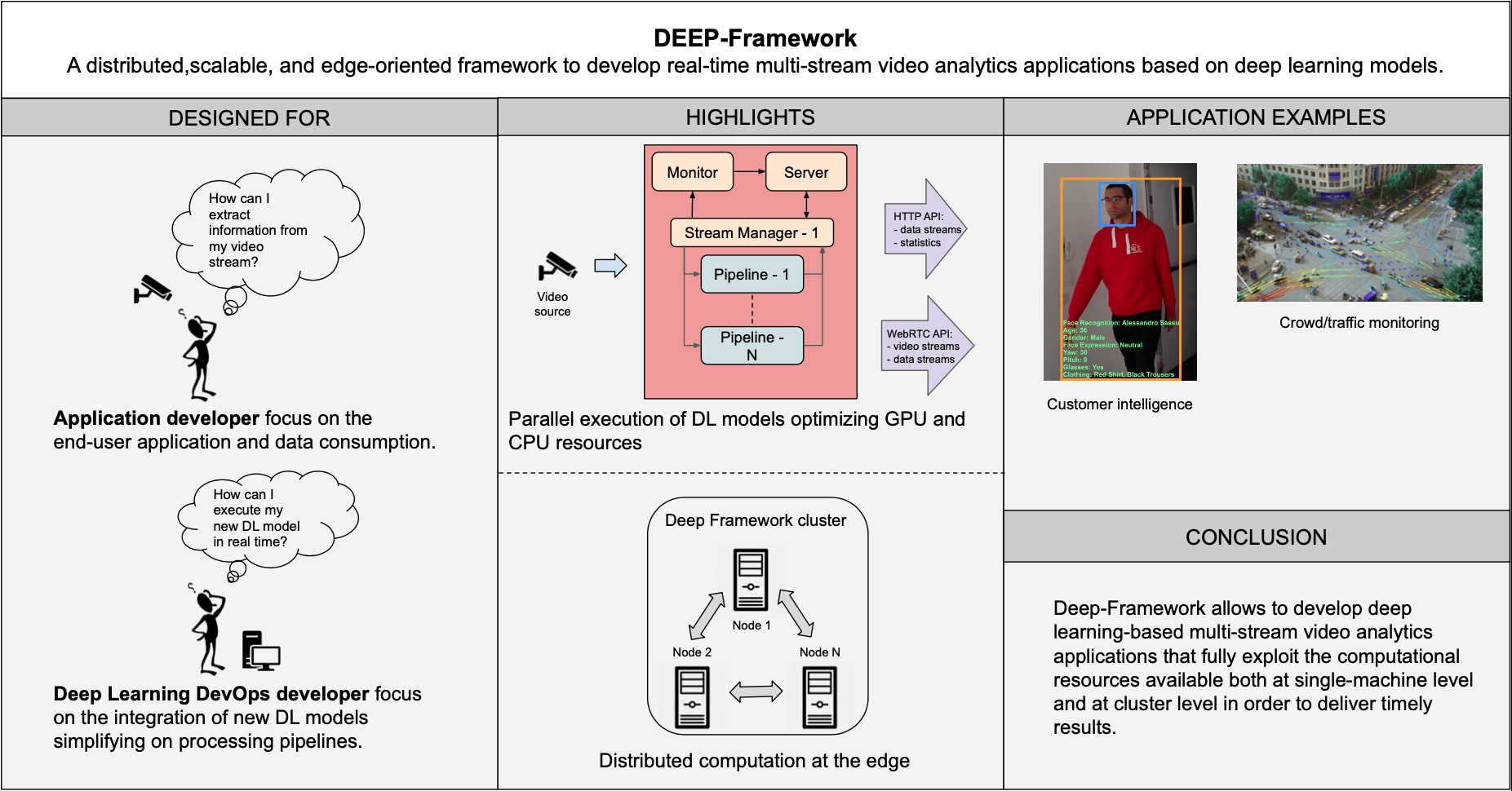
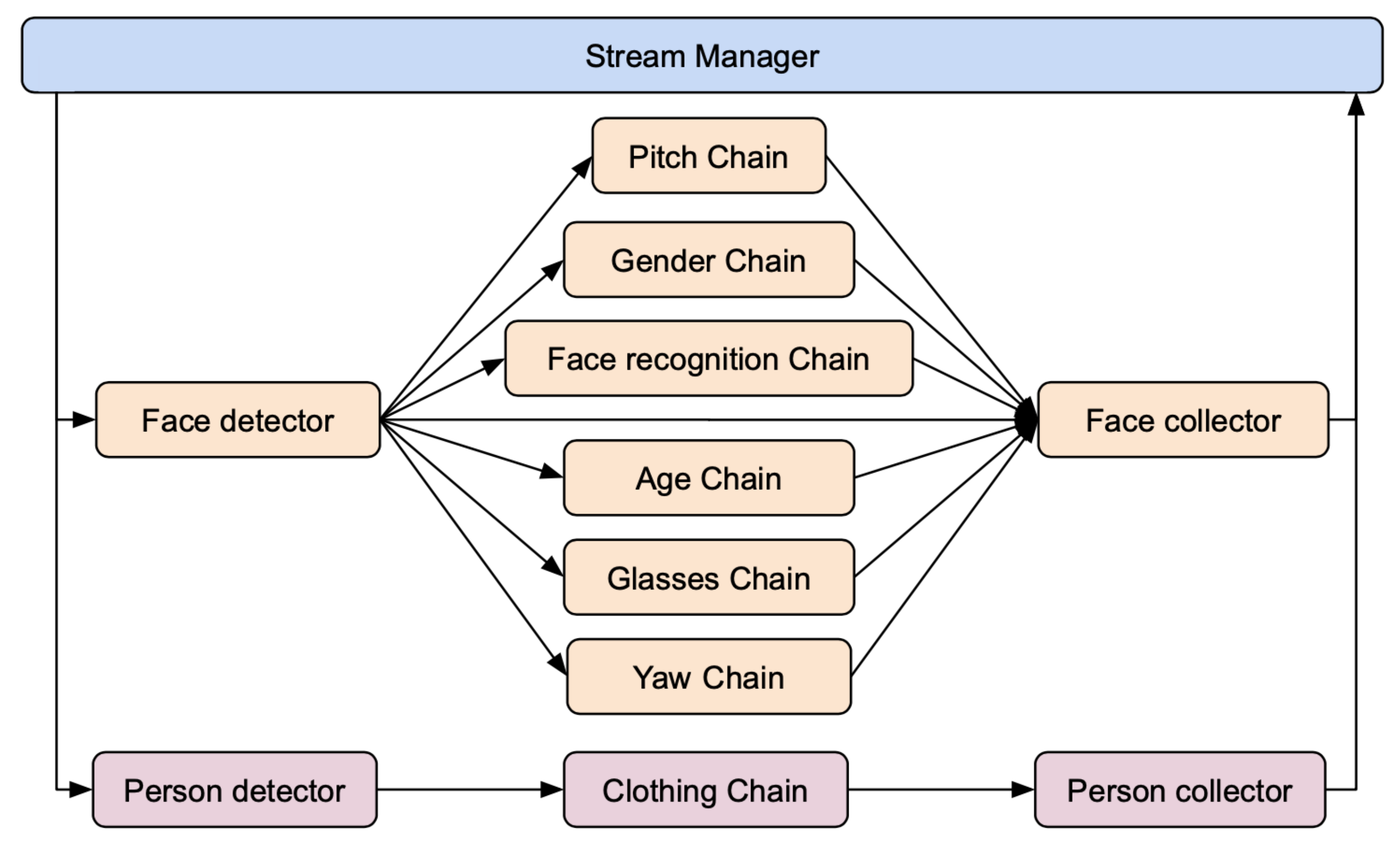
3.1. Architecture
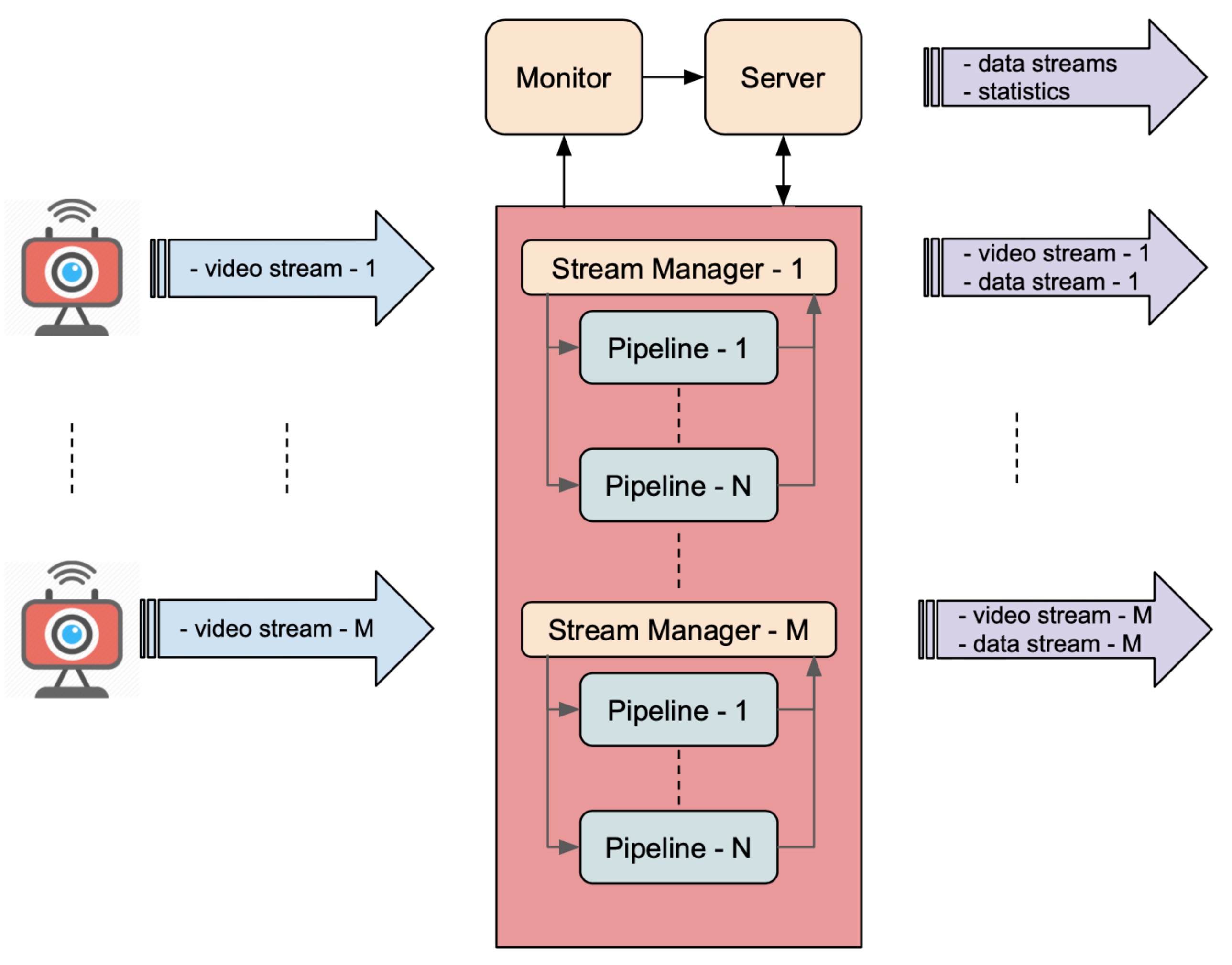
- Object detection: objects or areas of interest within an image are identified and tracked along subsequent images using detection and tracking methods. The component that performs this task is called Detector.
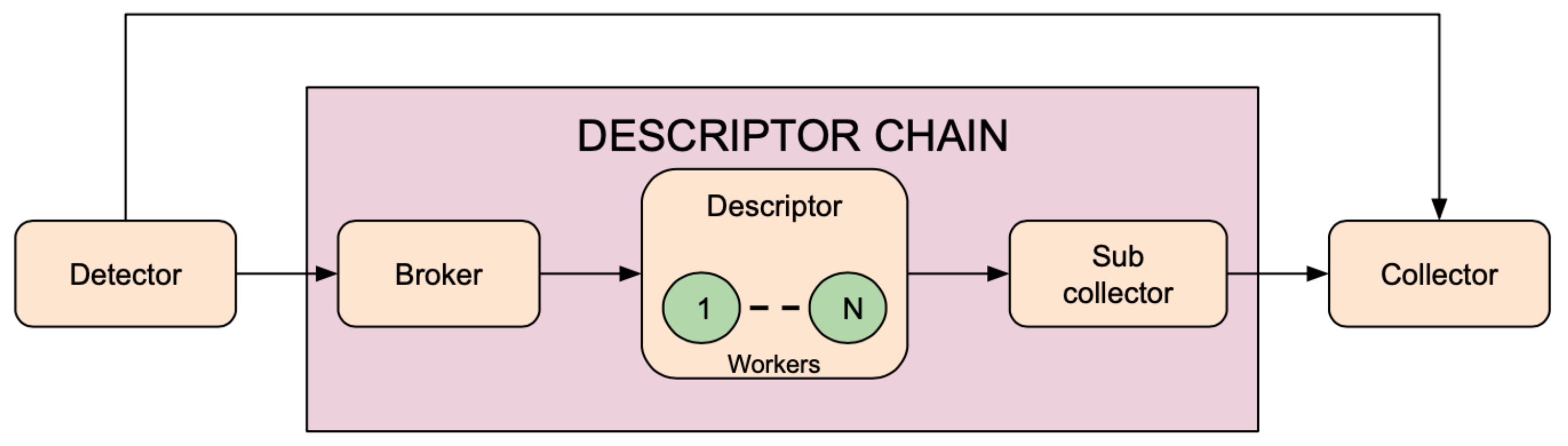
- Object description: objects are classified, characterized, or described using classification models, feature extractors, or generic analytical models. These tasks are performed by three components: Broker, Descriptor, Sub Collector. These components form a Descriptor Chain. Several Descriptor Chains may operate in parallel, each one dedicated to the extraction of a specific feature.
- Results collection: results are collected and aggregated to produce the output data stream. The component that performs this action is called Collector.
3.1.1. Processing Pipeline
Detector
- It instantiates the desired Detector;
- It receives images and enforces the frame skipping mechanism (as described below in this section);
- It creates a list of objects, each composed of an identifier, the coordinates of the bounding box, and and/or a list of keypoints, if available, and sends them to the Collector component;
- It sends the list of objects and their ROIs to the connected descriptors, using a publish–subscribe messaging pattern.
Descriptor
- It instantiates the desired Descriptor;
- It receives images and enforces the frame skipping mechanism;
- It extracts feature from ROIs and performs an average of the results obtained on N successive images in which the object is tracked.
Broker
Sub Collector
Collector
| Algorithm 2: Collector data aggregation and output message creation algorithm. |
 |
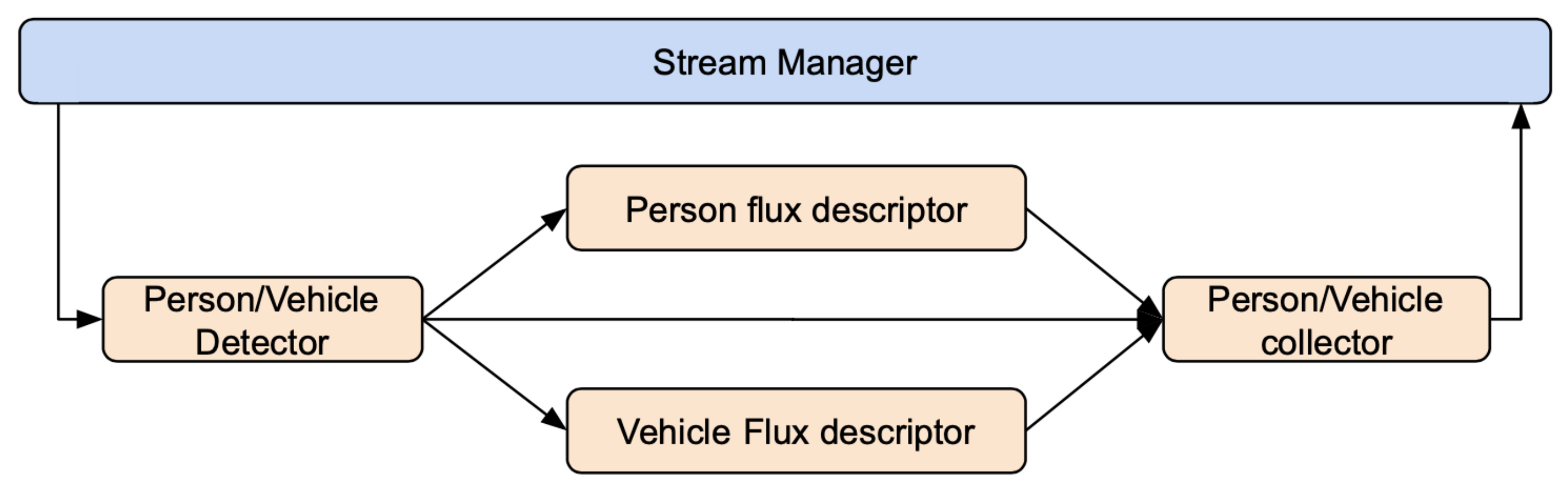
3.1.2. Stream Manager
3.1.3. Server
3.1.4. Monitor
3.2. Using Deep-Framework
- Cluster data (number of nodes and their type, IP addresses, user credentials);
- Frequency for generating statistics;
- Video sources and their types (video file, IP stream, WebRTC stream);
- Detectors to use (among those available) for each video source along with their computation mode (CPU/GPU).
- Descriptors to use (among those available) for each detector (pipeline) along with their computation mode (CPU/GPU) and number of instances (workers).
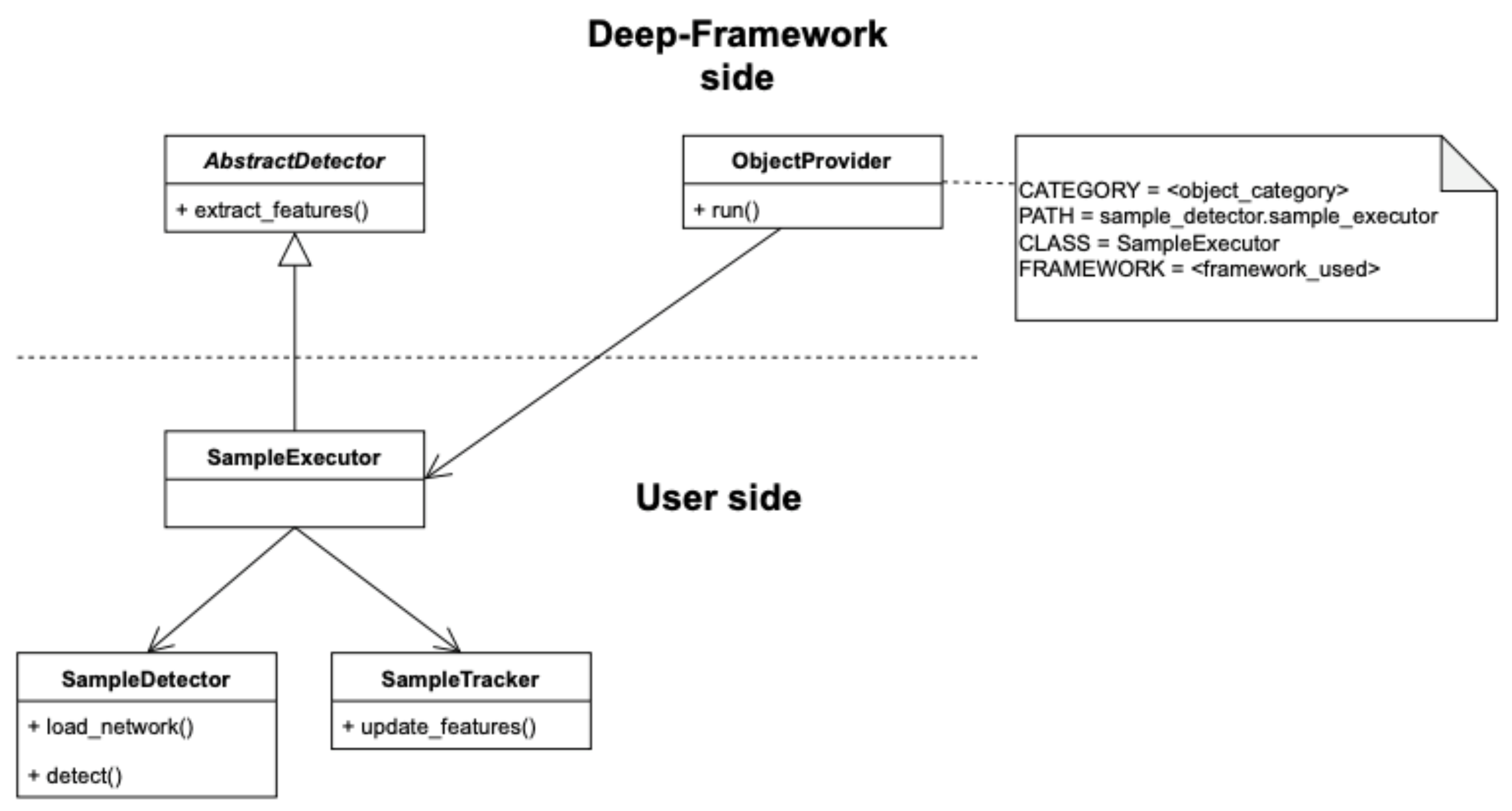
3.2.1. Integrating a Custom Detector
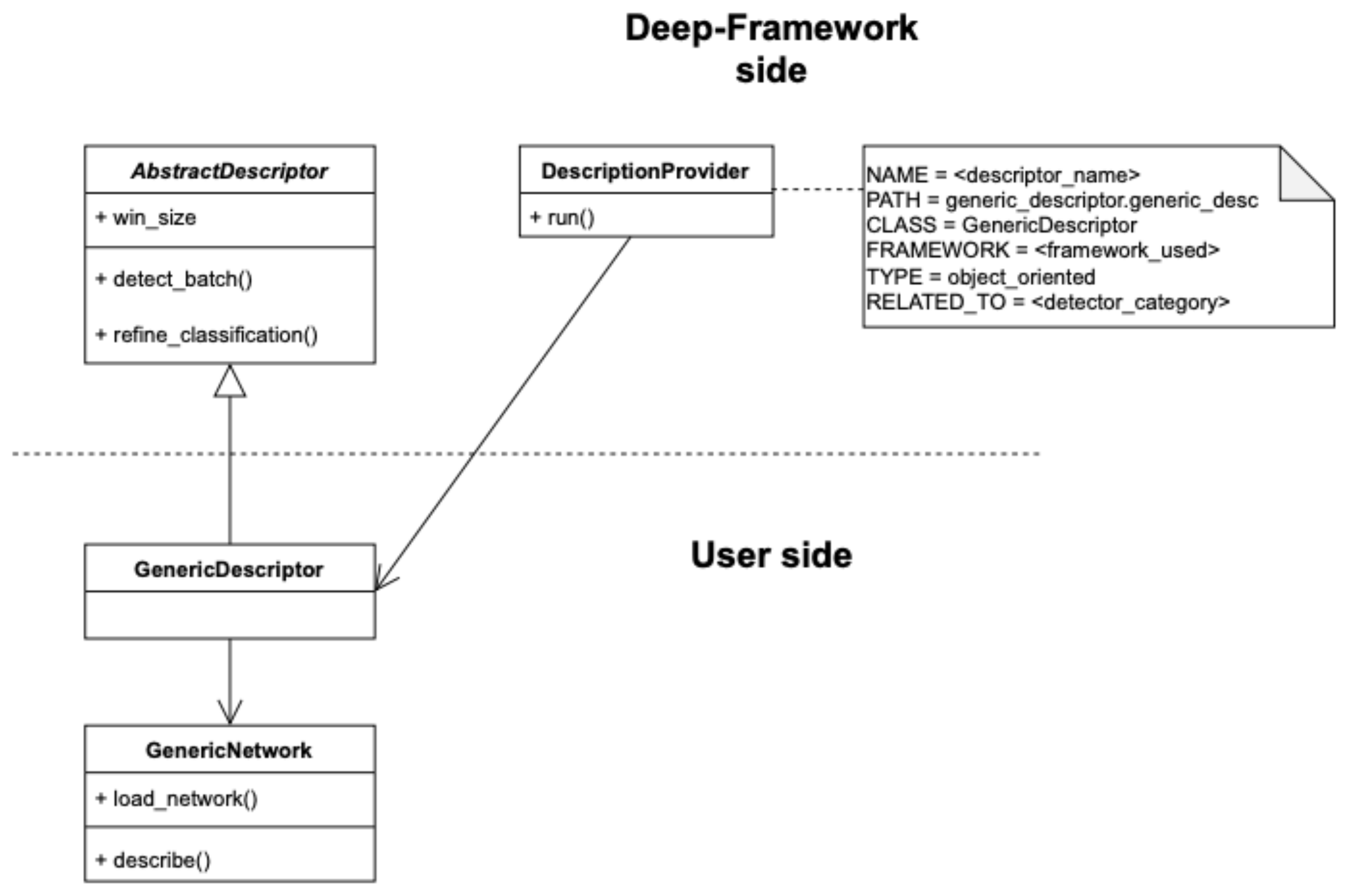
3.2.2. Integrating a Custom Descriptor
4. Results
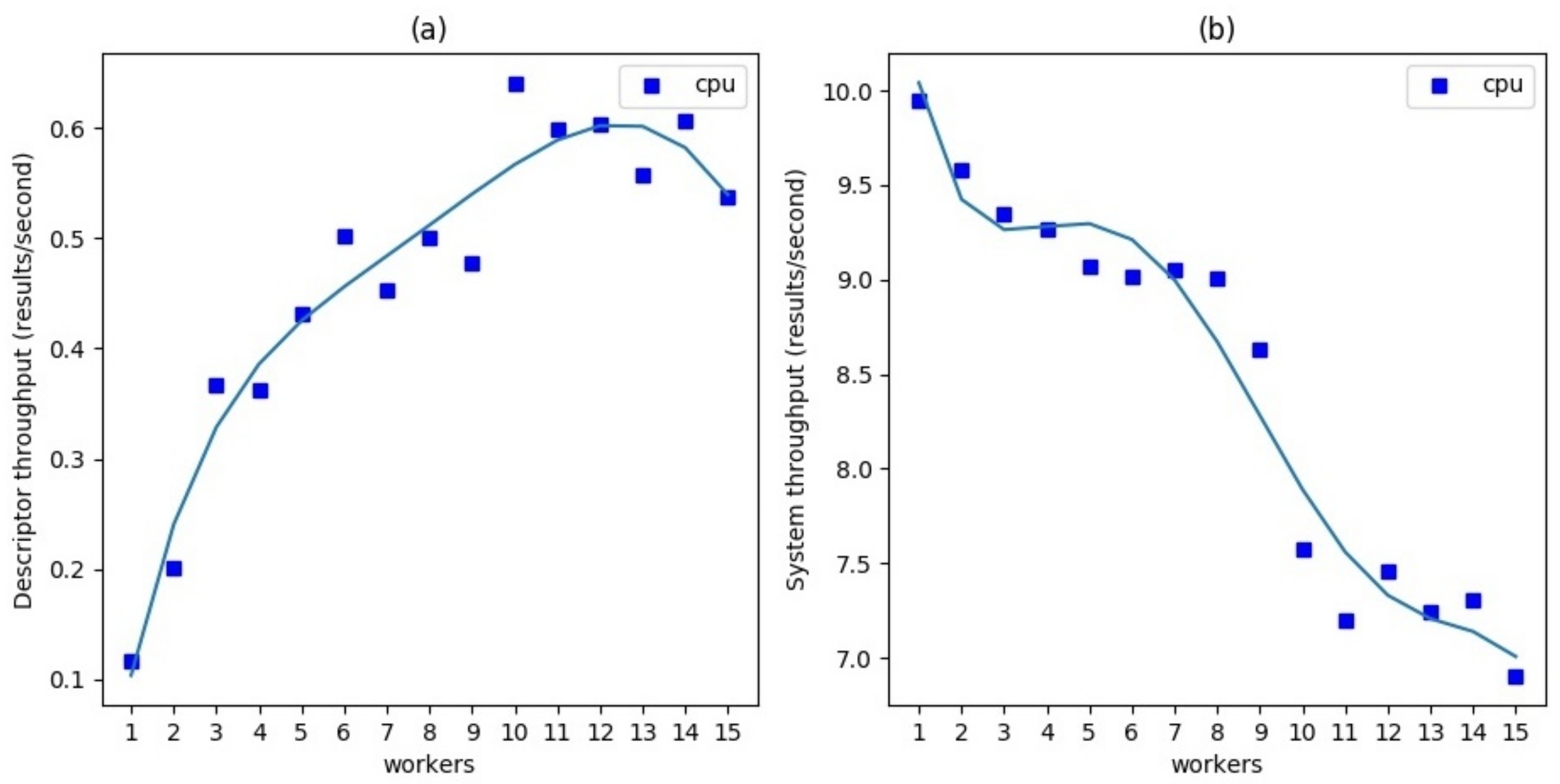
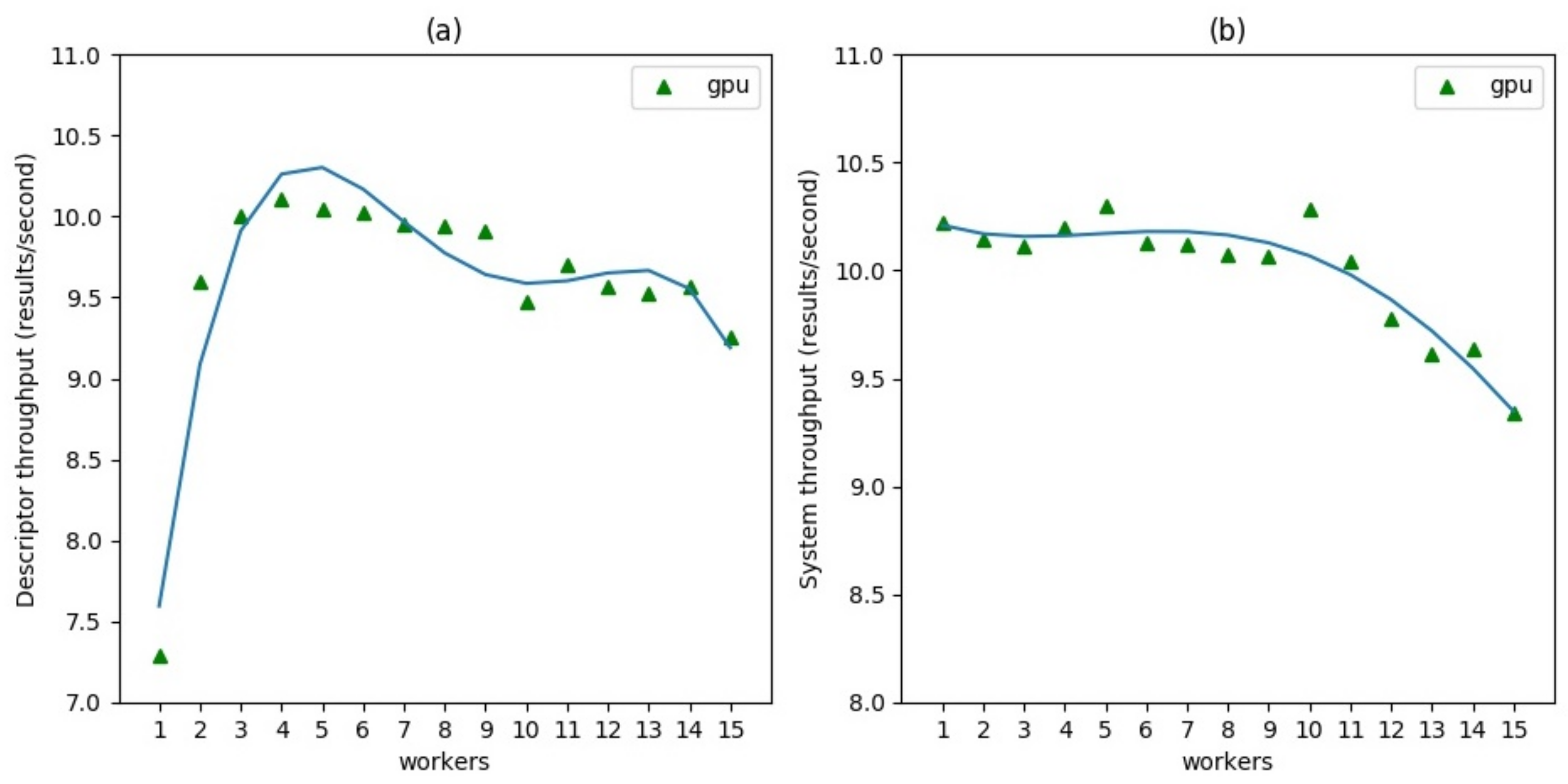
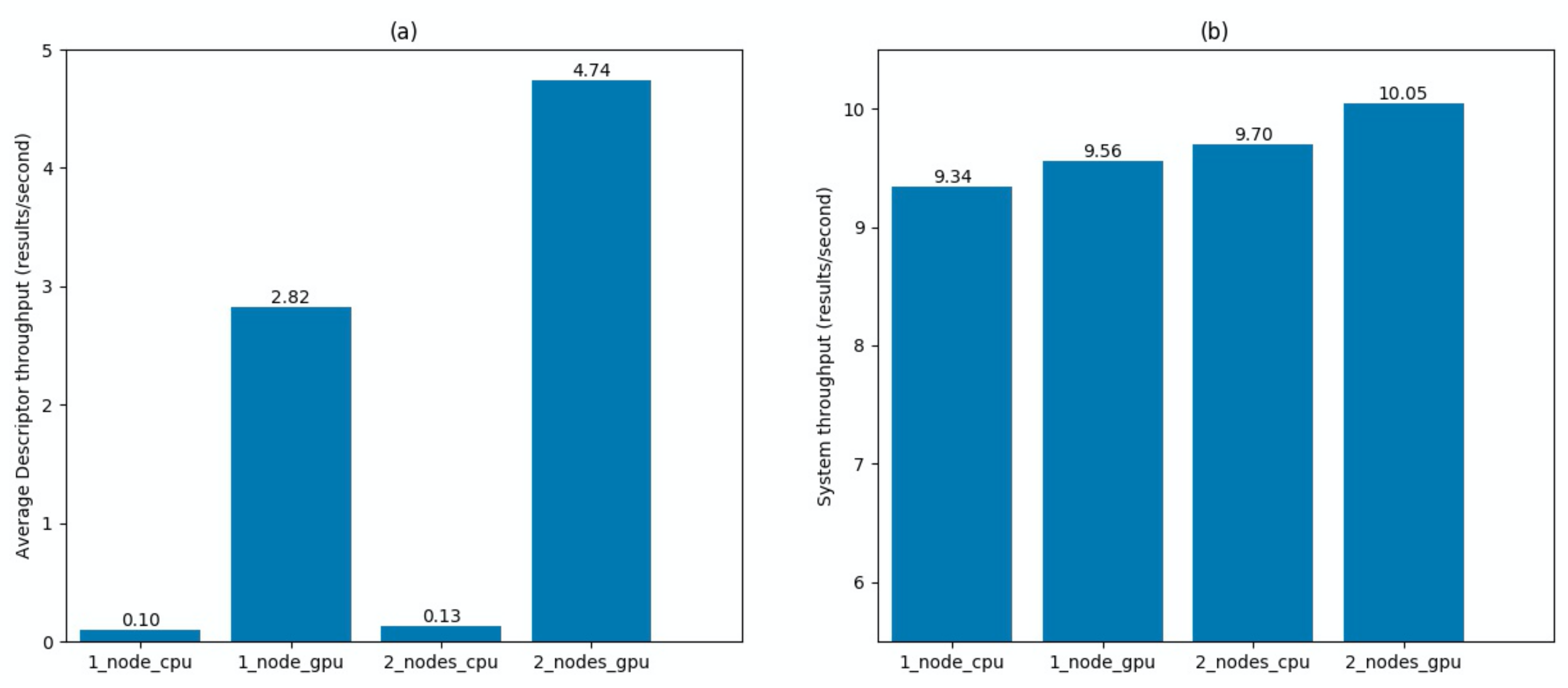
4.1. Experimental Results
- PC1: OS Ubuntu 16.04 LTS, processor Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20 GHz with 20 cores, 64 GB RAM, NVIDIA GeForce GTX 1080 Ti;
- PC2: OS Ubuntu 20.04 LTS, processor Intel(R) Core(TM) i9-9900K CPU @ 3.60 GHz with 16 cores, 32 GB RAM, NVIDIA GeForce RTX 2080 Ti.
4.2. Application Examples
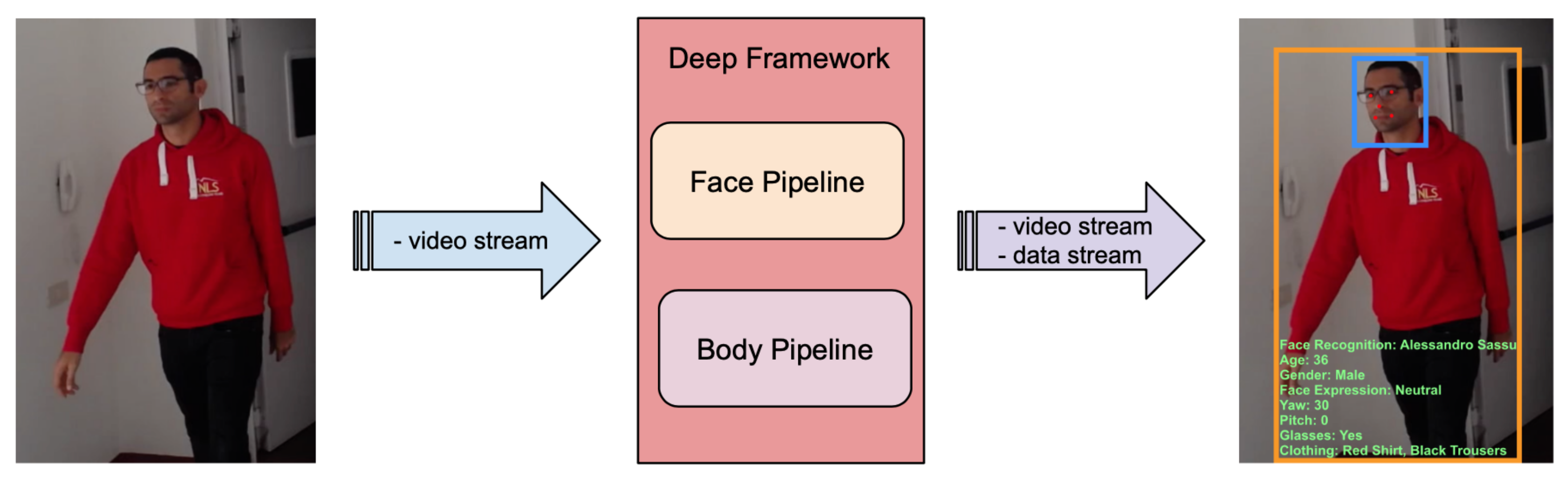
4.2.1. Customer Intelligence Application
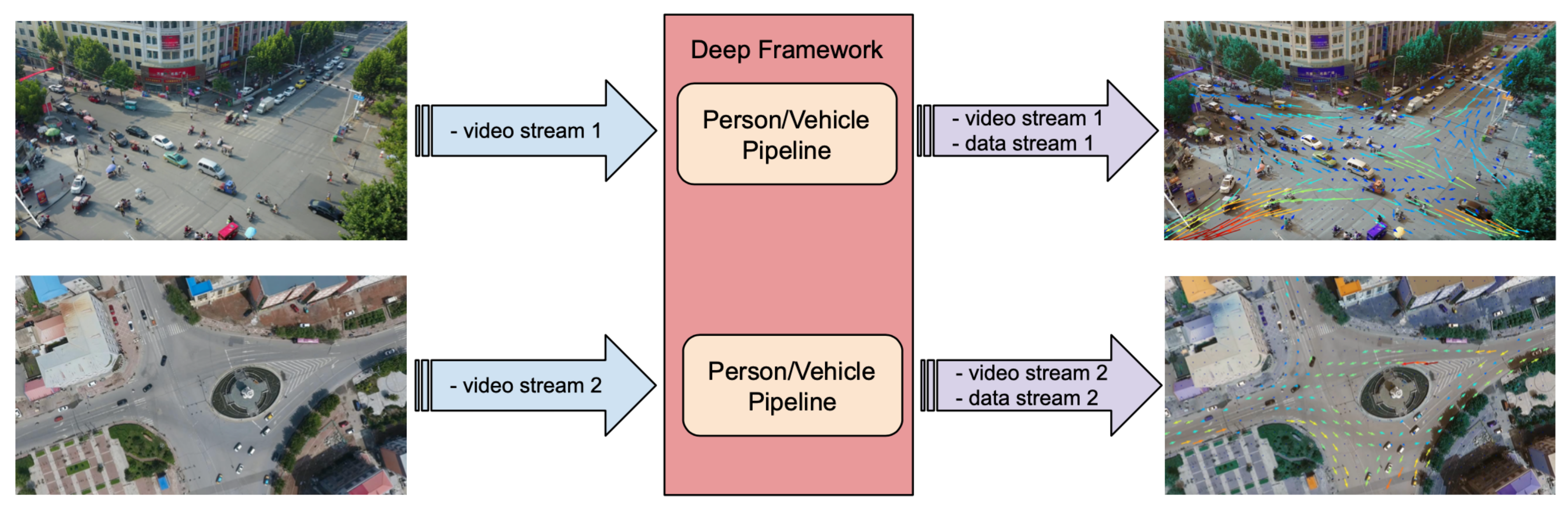
4.2.2. Crowd/Traffic Monitoring Application
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Integrating a Custom Detector
Appendix A.2. Integrating a Custom Descriptor
References
- Shan, C.; Porikli, F.; Xiang, T.; Gong, S. Video Analytics for Business Intelligence; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Ananthanarayanan, G.; Bahl, P.; Bodík, P.; Chintalapudi, K.; Philipose, M.; Ravindranath, L.; Sinha, S. Real-Time Video Analytics: The Killer App for Edge Computing. Computer 2017, 50, 58–67. [Google Scholar] [CrossRef]
- Cob-Parro, A.C.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Gardel-Vicente, A.; Bravo-Muñoz, I. Smart Video Surveillance System Based on Edge Computing. Sensors 2021, 21, 2958. [Google Scholar] [CrossRef] [PubMed]
- Barthélemy, J.; Verstaevel, N.; Forehead, H.; Perez, P. Edge-Computing Video Analytics for Real-Time Traffic Monitoring in a Smart City. Sensors 2019, 19, 2048. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Xie, Y.; Hu, Y.; Liu, Y.; Shou, G. Design and Implementation of Video Analytics System Based on Edge Computing. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 130–1307. [Google Scholar] [CrossRef]
- Bailas, C.; Marsden, M.; Zhang, D.; O’Connor, N.E.; Little, S. Performance of video processing at the edge for crowd-monitoring applications. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 482–487. [Google Scholar] [CrossRef]
- Wang, J.; Feng, Z.; Chen, Z.; George, S.; Bala, M.; Pillai, P.; Yang, S.W.; Satyanarayanan, M. Bandwidth-efficient live video analytics for drones via edge computing. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 159–173. [Google Scholar]
- Ran, X.; Chen, H.; Zhu, X.; Liu, Z.; Chen, J. Deepdecision: A mobile deep learning framework for edge video analytics. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1421–1429. [Google Scholar]
- Canel, C.; Kim, T.; Zhou, G.; Li, C.; Lim, H.; Andersen, D.G.; Kaminsky, M.; Dulloor, S.R. Scaling video analytics on constrained edge nodes. arXiv 2019, arXiv:1905.13536. [Google Scholar]
- Ananthanarayanan, G.; Bahl, V.; Cox, L.; Crown, A.; Nogbahi, S.; Shu, Y. Video analytics-killer app for edge computing. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Korea, 17–21 June 2019; pp. 695–696. [Google Scholar]
- Nazare, A.C., Jr.; Schwartz, W.R. A scalable and flexible framework for smart video surveillance. Comput. Vis. Image Underst. 2016, 144, 258–275. [Google Scholar] [CrossRef]
- Ali, M.; Anjum, A.; Yaseen, M.U.; Zamani, A.R.; Balouek-Thomert, D.; Rana, O.; Parashar, M. Edge enhanced deep learning system for large-scale video stream analytics. In Proceedings of the 2018 IEEE 2nd International Conference on Fog and Edge Computing (ICFEC), Washington, DC, USA, 1–3 May 2018; pp. 1–10. [Google Scholar]
- Liu, P.; Qi, B.; Banerjee, S. Edgeeye: An edge service framework for real-time intelligent video analytics. In Proceedings of the 1st International Workshop on Edge Systems, Analytics and Networking, Munich, Germany, 8–15 June 2018; pp. 1–6. [Google Scholar]
- Uddin, M.A.; Alam, A.; Tu, N.A.; Islam, M.S.; Lee, Y.K. SIAT: A distributed video analytics framework for intelligent video surveillance. Symmetry 2019, 11, 911. [Google Scholar] [CrossRef]
- Rouhani, B.D.; Mirhoseini, A.; Koushanfar, F. Rise: An automated framework for real-time intelligent video surveillance on fpga. ACM Trans. Embed. Comput. Syst. (TECS) 2017, 16, 1–18. [Google Scholar] [CrossRef]
- Soppelsa, F.; Kaewkasi, C. Native Docker Clustering with Swarm; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Hintjens, P. ZeroMQ: Messaging for Many Applications; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Gougeaud, S.; Zertal, S.; Lafoucriere, J.C.; Deniel, P. Using ZeroMQ as communication/synchronization mechanisms for IO requests simulation. In Proceedings of the 2017 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), Seattle, WA, USA, 9–12 July 2017; pp. 1–8. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Van Gool, L. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Patacchiola, M.; Cangelosi, A. Head pose estimation in the wild using Convolutional Neural Networks and adaptive gradient methods. Pattern Recognit. 2017, 71, 132–143. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Morabito, R.; Beijar, N. Enabling Data Processing at the Network Edge through Lightweight Virtualization Technologies. In Proceedings of the 2016 IEEE International Conference on Sensing, Communication and Networking (SECON Workshops), London, UK, 27–30 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Mendki, P. Docker container based analytics at IoT edge Video analytics usecase. In Proceedings of the 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU), Bhimtal, India, 23–24 February 2018; pp. 1–4. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptor Name | Throughput (Results/second) |
|---|---|
| yaw | 13.18 |
| face recognition | 13.22 |
| glasses | 13.48 |
| age | 12.5 |
| gender | 12.3 |
| emotion | 12.95 |
| pitch | 13.47 |
| clothing | 22.57 |
| Pipeline Name | Throughput (Results/second) |
| Person | 22.63 |
| Face | 13.55 |
| Descriptor Name | Throughput (Results/second) |
|---|---|
| vehicle flux analysis | 3.05 |
| person flux analysis | 3.05 |
| System throughput | 3.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sassu, A.; Saenz-Cogollo, J.F.; Agelli, M. Deep-Framework: A Distributed, Scalable, and Edge-Oriented Framework for Real-Time Analysis of Video Streams. Sensors 2021, 21, 4045. https://doi.org/10.3390/s21124045
Sassu A, Saenz-Cogollo JF, Agelli M. Deep-Framework: A Distributed, Scalable, and Edge-Oriented Framework for Real-Time Analysis of Video Streams. Sensors. 2021; 21(12):4045. https://doi.org/10.3390/s21124045
Chicago/Turabian StyleSassu, Alessandro, Jose Francisco Saenz-Cogollo, and Maurizio Agelli. 2021. "Deep-Framework: A Distributed, Scalable, and Edge-Oriented Framework for Real-Time Analysis of Video Streams" Sensors 21, no. 12: 4045. https://doi.org/10.3390/s21124045
APA StyleSassu, A., Saenz-Cogollo, J. F., & Agelli, M. (2021). Deep-Framework: A Distributed, Scalable, and Edge-Oriented Framework for Real-Time Analysis of Video Streams. Sensors, 21(12), 4045. https://doi.org/10.3390/s21124045