
SDN-Based Network Slicing Mechanism for a Scalable 4G/5G Core Network: A Kubernetes Approach †


 ,
,  ,
, 

Abstract
1. Introduction
- Enhanced mobile broadband (eMBB) will provide higher bandwidths and lower latency. It will be suitable for smart home applications, ultra-high-definition (UHD) television, or Cloud gaming services (for example, Google Stadia).
- Massive machine-type communications (mMTC) will improve the existing low-power wide-area networks (LPWANs). The purpose of this type of service is to pave the way for smart cities. The two LPWAN technologies used in 4G networks, NB-IoT and LTE-M, will still be used and will be important factors in meeting the requirements of the 5G standard for IoT.
- Ultra-reliable and low-latency communications (URLLC) is a special type of communications designed for mission-critical applications which require more bandwidth and lower latencies than mMTC. A specific case is illustrated in [8], where URLLC slices provide low latency for autonomous cars in an SDN-based core network (CN).
2. Related Work
3. Proposed System Architecture
- The first experiment is related to a containerized telemetry application for IoT devices. We aim to analyze and compare the resource consumption of this application in three different deployment scenarios for both cloud and edge: (1) using a balenaCloud environment, (2) using AWS EC2 instances, and (3) using the AWS IoT cloud service. We chose these cloud environments because they can be used in a wide variety of deployment scenarios for IoT and M2M systems. balenaCloud is suitable for building and deploying containerized applications on remote devices in the edge. In AWS, we implemented the same application to perform a comparison in terms of resource consumption between cloud and edge. Third, Amazon Web Services IoT is one of the five major solutions with the largest market share alongside equivalent IoT platforms from Microsoft, Cisco, Google, and IBM [39]. Moreover, AWS IoT can be further integrated with AWS Wavelength for 5G deployments.
- The second experiment focuses on implementing an end-to-end testbed in order to deliver different types of traffic, with different traffic requirements through specific network slices when network congestion is detected. Moreover, the Mobile Private Cloud (MPC) network components are deployed as CNFs and orchestrated with Kubernetes. The motivation for using Kubernetes was to be able to provide high availability, scalability based on latency, and lifecycle management for the CNFs. This scenario aims to prove the feasibility and efficiency of our proposed algorithm for scaling the UPF and load-balancing the network traffic to the least-load CNF.
3.1. First Experiment: Monitoring the Resource Consumption of an IoT Telemetry Application in balenaCloud, Amazon Web Services, and Amazon Web Services IoT
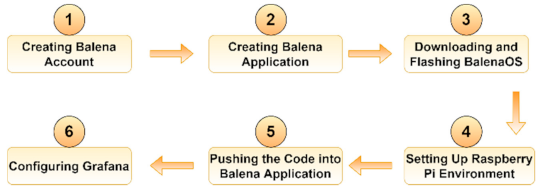
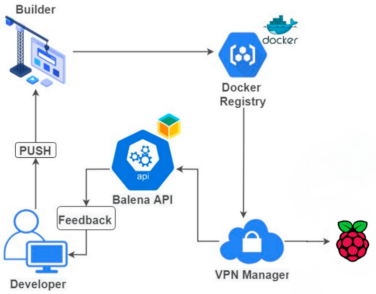
3.1.1. balenaCloud
3.1.2. Amazon Web Services
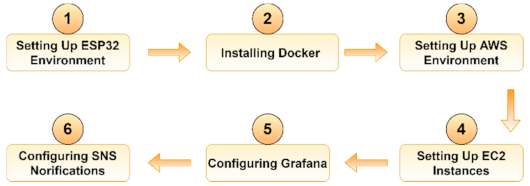
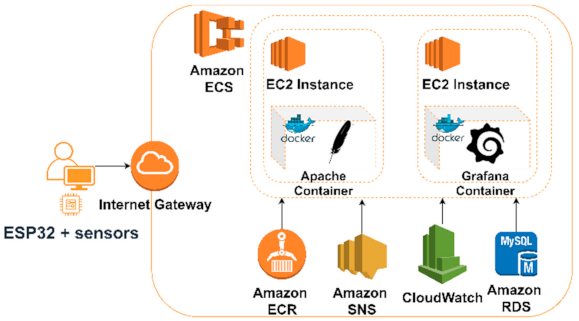
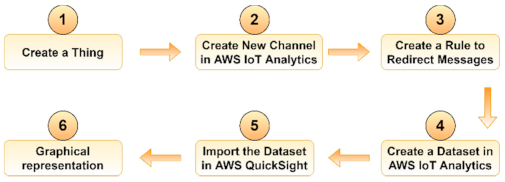
3.1.3. Amazon Web Services IoT
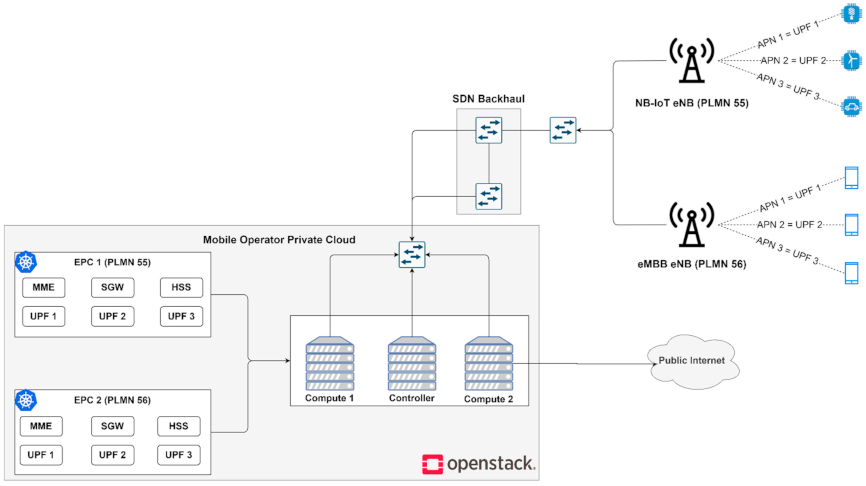
3.2. Second Experiment: Network Slice Scalability Managed with SDN and Kubernetes in a Private Cloud Orchestrated by OpenStack
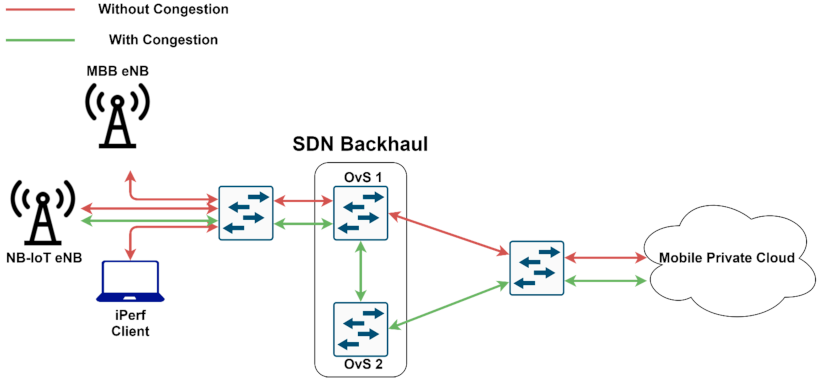
3.2.1. Testbed Description
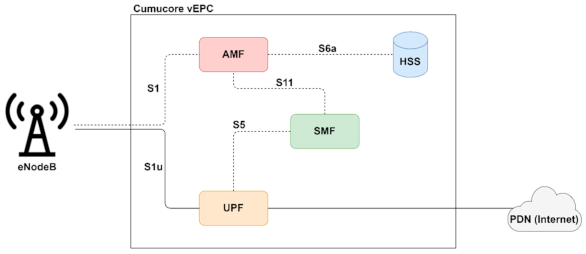
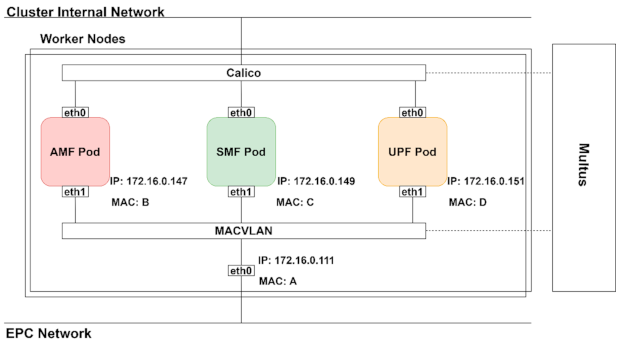
3.2.2. Migration to Cloud-Native Network Functions
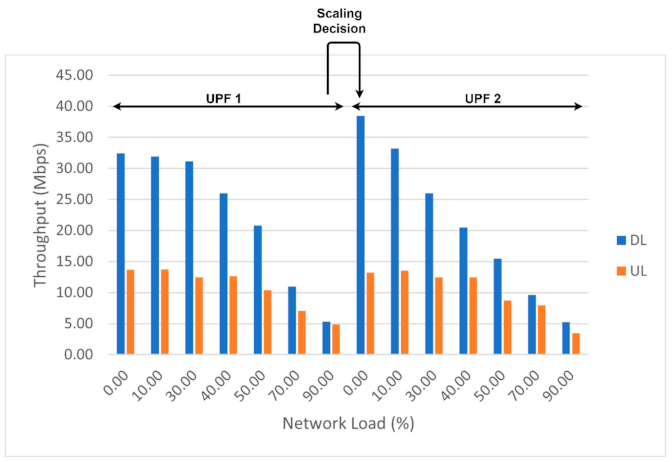
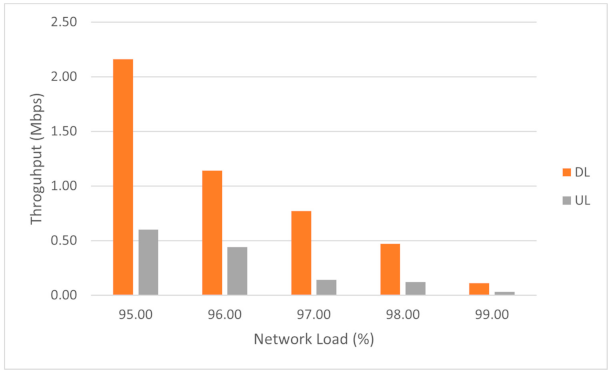
3.2.3. Scaling Algorithm for UPF
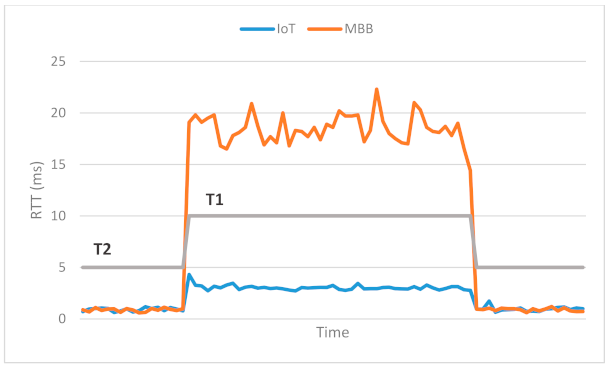
3.2.4. Network Slicing for Different Types of Network Traffic
4. Experimental Results
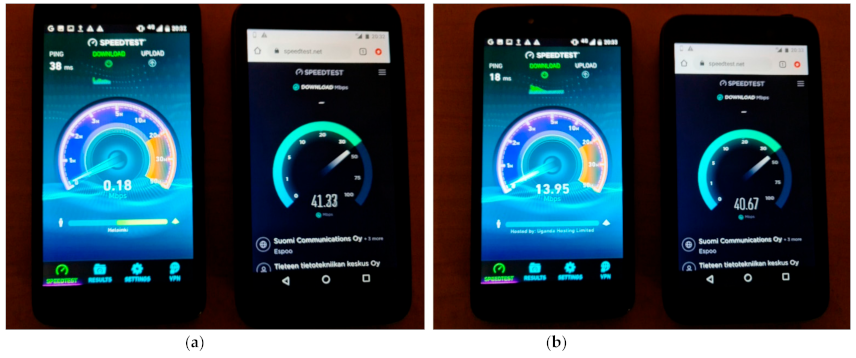
4.1. Experimental Results for the First Scenario
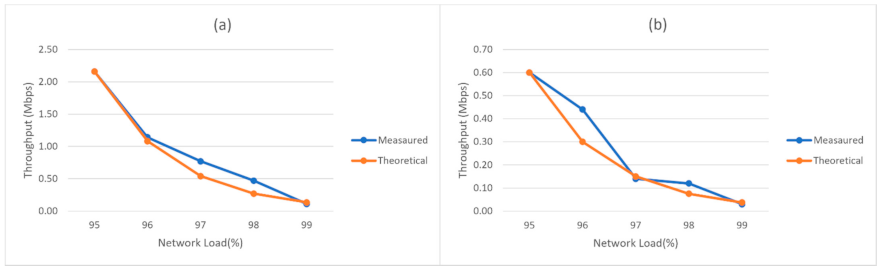
4.2. Experimental Results for the Second Scenario
5. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cisco Annual Internet Report (2018–2023) White Paper. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 25 March 2021).
- Presad, R.; Rohokale, V. Internet of Things (IoT) and Machine to Machine (M2M) Communication. In Cyber Security: The Lifeline of Information and Communication Technology; Prasad, R., Jackson, O., Eds.; Springer: Cham, Switzerland, 2020; pp. 125–141. [Google Scholar] [CrossRef]
- Marjani, M.; Nasaruddin, F.; Gani, A.; Karim, A.; Hashem, I.A.T.; Siddiqa, A.; Yaqoob, I. Big IoT Data Analytics: Architecture, Opportunities, and Open Research Challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar] [CrossRef]
- Xiang, Z.; Gabriel, F.; Urbano, E.; Nguyen, G.T.; Reisslein, M.; Fitzek, F.H.P. Reducing Latency in Virtual Machines: Enabling Tactile Internet for Human-Machine Co-Working. IEEE J. Sel. Areas Commun. 2019, 37, 1098–1116. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, L.; Pu, C.; Dou, Q.; Wu, L.; Zhou, W. A Comparative Study of Containers and Virtual Machines in Big Data Environment. In Proceedings of the IEEE 11th International Conference on Cloud Comput. (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 178–185. [Google Scholar] [CrossRef]
- Mekki, K.; Bajic, E.; Chaxel, F.; Meyer, F. A comparative study of LPWAN technologies for large-scale IoT deployment. ICT Express 2019, 5, 1–7. [Google Scholar] [CrossRef]
- The Path to 5G: As Much Evolution as Revolution. Available online: https://www.3gpp.org/news-events/1774-5g_wiseharbour (accessed on 26 March 2021).
- Chekired, D.A.; Togou, M.A.; Khoukhi, L.; Ksentini, A. 5G-Slicing-Enabled Scalable SDN Core Network: Toward an Ultra-Low Latency of Autonomous Driving Service. IEEE J. Sel. Areas Commun. 2019, 37, 1769–1782. [Google Scholar] [CrossRef]
- Yu, H.; Lee, H.; Jeon, H. What is 5G? Emerging 5G Mobile Services and Network Requirements. Sustainability 2017, 9, 1848. [Google Scholar] [CrossRef]
- Basta, A.; Blenk, A.; Hoffmann, K.; Morper, H.J.; Hoffmann, M.; Kellerer, W. Towards a Cost Optimal Design for a 5G Mobile Core Network Based on SDN and NFV. IEEE Trans. Netw. Serv. Manag. 2017, 14, 1061–1075. [Google Scholar] [CrossRef]
- Cloud-Native Network Functions. Available online: https://www.cisco.com/c/en/us/solutions/service-provider/industry/cable/cloud-native-network-functions.html#~introduction (accessed on 26 March 2021).
- Botez, R.; Strautiu, V.; Ivanciu, I.-A.; Dobrota, V. Containerized Application for IoT Devices: Comparison between balenaCloud and Amazon Web Services Approaches. In Proceedings of the 2020 International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 5–6 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Bouras, C.; Ntarzanos, P.; Papazois, A. Cost modeling for SDN/NFV based mobile 5G networks. In Proceedings of the 8th International Congress on Ultra-Modern Telecommunications and Control Systems and Workshops (ICUMT), Lisbon, Portugal, 18–20 October 2016; pp. 56–61. [Google Scholar] [CrossRef]
- Enabling Next Generation Mobile Networks. Available online: https://cumucore.com/#products (accessed on 27 March 2021).
- Evolve Your Core Network for 5G. Available online: https://www.ericsson.com/en/core-network/5g-core (accessed on 27 March 2021).
- 5G Core (5GC). Available online: https://www.nokia.com/networks/portfolio/5g-core/#5g-core-solution (accessed on 27 March 2021).
- Taleb, T.; Corici, M.; Parada, C.; Jamakovic, A.; Ruffino, S.; Karagiannis, G.; Magedanz, T. EASE: EPC as a service to ease mobile core network deployment over cloud. IEEE Netw. 2015, 78–88. [Google Scholar] [CrossRef]
- Amogh, P.C.; Veeramachaneni, G.; Rangisetti, A.K.; Tamma, B.R.; Franklin, A.A. A cloud native solution for dynamic auto scaling of MME in LTE. In Proceedings of the IEEE 28th Annual International Symposium on Personal Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Banerjee, A.; Mahindra, R.; Sundaresan, K.; Kasera, S.; Van der Merwe, K.; Rangarajan, S. Scaling the LTE control-plane for future mobile access. In Proceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies, Heidelberg, Germany, 1–4 December 2015; pp. 1–13. [Google Scholar] [CrossRef]
- Alawe, I.; Hadjadj-Aoul, Y.; Ksentini, A.; Bertin, P.; Darche, D. On the scalability of 5G core network: The AMF case. In Proceedings of the 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Hefele, A.; Costa-Requena, J. SDN managed Network Slicing in Mobile Backhaul. In Proceedings of the International Conference on Electronics Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Adem, A.; Costa-Requena, J.; Kantola, R. SDN Network Slicing for URLLC NB-IOT. In Proceedings of the International Conference on Electronics Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Yang, G.; Yu, B.-y.; Jin, H.; Yoo, C. Libera for Programmable Network Virtualization. IEEE Commun. Mag. 2020, 58, 38–44. [Google Scholar] [CrossRef]
- Open vSwitch. Available online: https://docs.openvswitch.org/en/latest (accessed on 20 April 2021).
- Firestone, D. VFP: A Virtual Switch Platform for Host SDN in the Public Cloud. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 27–29 March 2017; pp. 315–328. [Google Scholar]
- Ferguson, A.D.; Gribble, S.; Hong, C.Y.; Killian, C.; Mohsin, W.; Muehe, H.; Ong, J.; Poutievski, L.; Singh, A.; Vicisano, L.; et al. Orion: Google’s Software-Defined Networking Control Plane. In Proceedings of the 18th USENIX Symposium on Networked Systems Design and Implementation Virtual Conference, Boston, MA, USA, 12–14 April 2021; pp. 83–98. [Google Scholar]
- Costa-Requena, J.; Poutanen, A.; Vural, S.; Kamel, G.; Clark, C.; Roy, S.K. SDN-Based UPF for Mobile Backhaul Network Slicing. In Proceedings of the 2018 European Conference on Networks and Communications (EuCNC), Ljubljana, Slovenia, 18–21 June 2018; pp. 48–53. [Google Scholar] [CrossRef]
- Open Source MANO. Available online: https://osm.etsi.org (accessed on 20 April 2021).
- Open Network Automation Platform. Available online: https://www.onap.org (accessed on 20 April 2021).
- OPEN BATON. Available online: https://openbaton.github.io (accessed on 20 April 2021).
- Cloudify. Available online: https://cloudify.co/technologies/ (accessed on 20 April 2021).
- The 5G Infrastructure Public Private Partnership. Available online: https://5g-ppp.eu (accessed on 20 May 2021).
- SONATA. Available online: https://5g-ppp.eu/sonata/ (accessed on 20 May 2021).
- Soenen, T.; Van Rossem, S.; Tavernier, W.; Vicens, F.; Valocchi, D.; Trakadas, P.; Karkazis, P.; Xilouris, G.; Eardley, P.; Kolometsos, S.; et al. Insights from SONATA: Implementing and Integrating a Microservice-based NFV Service Platform with a DevOps Methodology. In Proceedings of the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Multus-CNI. Available online: https://github.com/k8snetworkplumbingwg/multus-cni (accessed on 21 May 2021).
- DANM. Available online: https://github.com/nokia/danm (accessed on 21 May 2021).
- Nogales, B.; Vidal, I.; Lopez, D.R.; Rodriguez, J.; Garcia-Reinoso, J.; Azcorra, A. Design and Deployment of an Open Management and Orchestration Platform for Multi-Site NFV Experimentation. IEEE Commun. Mag. 2019, 57, 20–27. [Google Scholar] [CrossRef]
- Trakadas, P.; Karkazis, P.; Leligou, H.C.; Zahariadis, T.; Vicens, F.; Zurita, A.; Alemany, P.; Soenen, T.; Parada, C.; Bonnet, J.; et al. Comparison of Management and Orchestration Solutions for the 5G Era. J. Sens. Actuator Netw. 2020, 9, 4. [Google Scholar] [CrossRef]
- Making Sense of IoT Platforms: AWS vs. Azure vs. Google vs. IBM vs. Cisco. Available online: https://www.altexsoft.com/blog/iot-platforms/ (accessed on 22 May 2021).
- AWS Documentation. Available online: https://docs.aws.amazon.com (accessed on 19 April 2021).
- Kube Metrics Adapter. Available online: https://github.com/zalando-incubator/kube-metrics-adapter (accessed on 22 May 2021).
- Van Adrichem, N.L.M.; Doerr, C.; Kuipers, F.A. OpenNetMon: Network monitoring in OpenFlow Software-Defined Networks. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Speedtest. Available online: https://www.speedtest.net (accessed on 20 April 2021).
- Rutherford, E. A radio-active substance emitted from thorium compounds. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 49, 1–14. [Google Scholar] [CrossRef]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| M2M | IoT |
|---|---|
| Point-to-point communications | Connectivity via IP networks |
| Hardware-based technology | Suitable for both hardware and software |
| Not dependent on the Internet | Relies on Internet connectivity |
| Device-based communications | Interface devices with gateways or data systems |
| Limited scalability | Scalability is a key requirement |
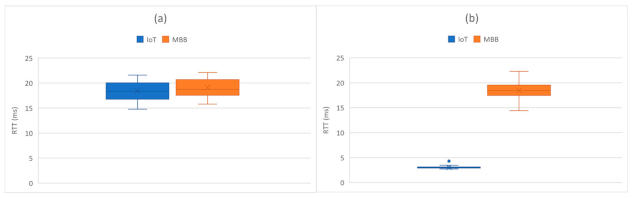
| Scope | LTE Band | Duplex Scheme | UL Carrier Frequency | DL Carrier Frequency | Channel Bandwidth | Carrier Power | MAC Address |
|---|---|---|---|---|---|---|---|
| IoT | 3 | FDD | 1720 MHz | 1815 MHz | 10 MHz | 24 dBm | D6:EF:CD:89:53:0B |
| MBB | 38 | TDD | 2610 MHz | 2610 MHz | 20 MHz | 24 dBm | D6:EF:CD:88:EF:E4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Botez, R.; Costa-Requena, J.; Ivanciu, I.-A.; Strautiu, V.; Dobrota, V. SDN-Based Network Slicing Mechanism for a Scalable 4G/5G Core Network: A Kubernetes Approach. Sensors 2021, 21, 3773. https://doi.org/10.3390/s21113773
Botez R, Costa-Requena J, Ivanciu I-A, Strautiu V, Dobrota V. SDN-Based Network Slicing Mechanism for a Scalable 4G/5G Core Network: A Kubernetes Approach. Sensors. 2021; 21(11):3773. https://doi.org/10.3390/s21113773
Chicago/Turabian StyleBotez, Robert, Jose Costa-Requena, Iustin-Alexandru Ivanciu, Vlad Strautiu, and Virgil Dobrota. 2021. "SDN-Based Network Slicing Mechanism for a Scalable 4G/5G Core Network: A Kubernetes Approach" Sensors 21, no. 11: 3773. https://doi.org/10.3390/s21113773
APA StyleBotez, R., Costa-Requena, J., Ivanciu, I.-A., Strautiu, V., & Dobrota, V. (2021). SDN-Based Network Slicing Mechanism for a Scalable 4G/5G Core Network: A Kubernetes Approach. Sensors, 21(11), 3773. https://doi.org/10.3390/s21113773