
A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways


Abstract
:1. Introduction
On-Board Sensor Technologies for Obstacle Detection and Distance Estimation in Railways
2. Vision-Based On-Board Obstacle Detection in Railways
2.1. Traditional CV Methods
2.1.1. Rail Track Detection
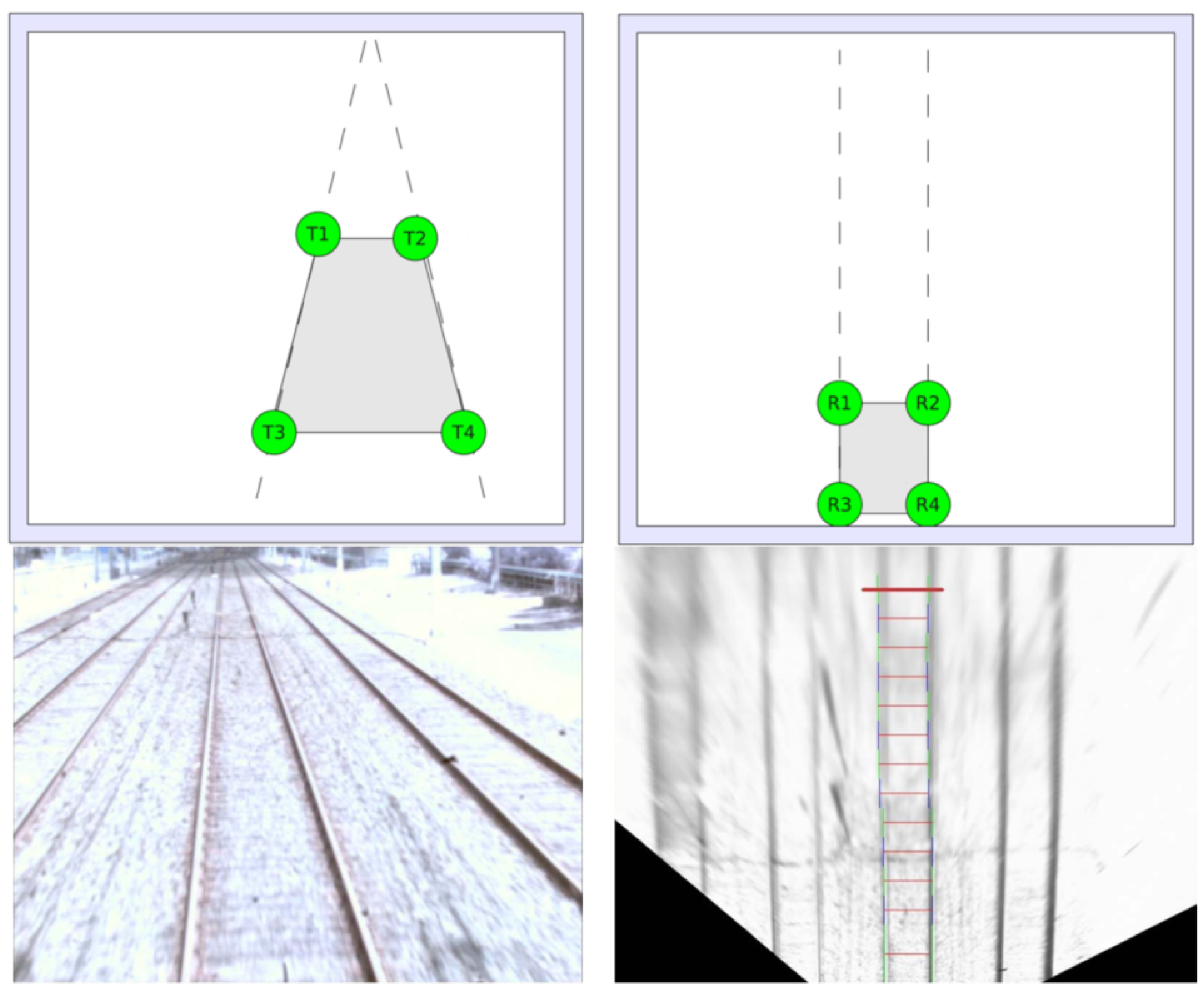
2.1.2. Detection of Obstacles on the Rail Tracks
2.1.3. Obstacle Distance Estimation
2.2. AI-Based Methods
2.2.1. Rail Track Detection
2.2.2. Obstacle Detection
2.2.3. Distance Estimation
3. Evaluation Tests
4. Discussion, Identifying Research Gaps and Future Research Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Rail Accident Fatalities in the EU. Available online: Https://ec.europa.eu/eurostat/statistics-explained/index.php/Rail_accident_fatalities_in_the_EU (accessed on 15 January 2021).
- Fayyaz, M.A.B.; Johnson, C. Object Detection at Level Crossing Using Deep Learning. Micromachines 2020, 11, 1055. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art. Found. Trends Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Looking at Vehicles on the Road: A Survey of Vision-Based Vehicle Detection, Tracking, and Behavior Analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef] [Green Version]
- Rosique, F.; Navarro, P.J.; Fernández, C.; Padilla, A. A Systematic Review of Perception System and Simulators for Autonomous Vehicles Research. Sensors 2019, 19, 648. [Google Scholar] [CrossRef] [Green Version]
- Selver, A.M.; Ataç, E.; Belenlioglu, B.; Dogan, S.; Zoral, Y.E. Visual and LIDAR Data Processing and Fusion as an Element of Real Time Big Data Analysis for Rail Vehicle Driver Support Systems. In Innovative Applications of Big Data in the Railway Industry; Kohli, S., Senthil Kumar, A.V., Easton, J.M., Roberts, C., Eds.; IGI Global: Hershey, PA, USA, 2017; pp. 40–66. [Google Scholar]
- Gebauer, O.; Pree, W.; Stadlmann, B. Autonomously Driving Trains on Open Tracks—Concepts, System Architecture and Implementation Aspects. Inf. Technol. 2012, 54, 266–279. [Google Scholar] [CrossRef]
- Yamashita, H. Railway Obstacle Detection System; Mitsubishi Heavy Industries Ltd.: Tokyo, Japan, 1996; Volume 33. [Google Scholar]
- Ukai, M.; Tomoyuki, B.; Nozomi, N.N. Obstacle Detection on Railway Track by Fusing Radar and Image Sensor. In Proceedings of the 9th World Congress on Railway Research (WCRR), Lille, France, 22–26 May 2011; pp. 1–12. [Google Scholar]
- Kruse, F.; Milch, S.; Rohling, H. Multi Sensor System for Obstacle Detection in Train Applications. In Proceedings of the 2003 IEEE Intelligent Vehicles Symposium, Columbus, OH, USA, 9–11 June 2003; pp. 42–46. [Google Scholar]
- Rüder, M.; Mohler, N.; Ahmed, F. An obstacle detection system for automated trains. In Proceedings of the IEEE IV2003 Intelligent Vehicles Symposium, Columbus, OH, USA, 9–11 June 2003; pp. 180–185. [Google Scholar] [CrossRef]
- Weichselbaum, J.; Zinner, C.; Gebauer, O.; Pree, W. Accurate 3D-vision-based obstacle detection for an autonomous train. Comput. Ind. 2013, 64, 1209–1220. [Google Scholar] [CrossRef]
- Ye, T.; Wang, B.; Song, P.; Li, J. Automatic Railway Traffic Object Detection System Using Feature Fusion Refine Neural Network under Shunting Mode. Sensors 2018, 18, 1916. [Google Scholar] [CrossRef] [Green Version]
- Ye, T.; Wang, B.; Song, P.; Li, J. Railway Traffic Object Detection Using Differential Feature Fusion Convolution Neural Network. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Gleichauf, J.; Vollet, J.; Pfitzner, C.; Koch, P.; May, S. Sensor Fusion Approach for an Autonomous Shunting Locomotive. In Informatics in Control, Automation and Robotics; Gusikhin, O., Madani, K., Eds.; Publishing House: Cham, Switzerland, 2020; pp. 603–624. [Google Scholar] [CrossRef]
- Möckel, S.; Scherer, F.; Schuster, P.F. Multi-Sensor Obstacle Detection on Railway Tracks. In Proceedings of the IEEE IV2003 Intelligent Vehicles Symposium, Columbus, OH, USA, 9–11 June 2003; pp. 42–46. [Google Scholar] [CrossRef]
- Uribe, J.A.; Fonseca, L.; Vargas, J.F. Video Based System for Railroad Collision Warning. In Proceedings of the IEEE International Carnahan Conference on Security Technology (ICCST), Newton, MA, USA, 15–18 October 2012; pp. 280–285. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Hu, Y.H.; Qiu, J. RailNet: A Segmentation Network for Railroad Detection. IEEE Access 2019, 7, 143772–143779. [Google Scholar] [CrossRef]
- Ross, R. Vision-Based Track Estimation and Turnout Detection Using Recursive Estimation. In Proceedings of the Annual Conference on Intelligent Transportation System, Madeira Island, Portugal, 19–22 September 2010; pp. 1330–1335. [Google Scholar] [CrossRef]
- Ross, R. Track and Turnout Detection in Video-Signals Using Probabilistic Spline Curves. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 294–299. [Google Scholar] [CrossRef]
- Qi, Z.; Tian, Y.; Shi, Y. Efficient railway tracks detection and turnouts recognition method using HOG features. Neural Comput. Appl. 2013, 23, 245–254. [Google Scholar] [CrossRef]
- Nakasone, R.; Nagamine, N.; Ukai, M.; Mukojima, H.; Deguchi, D.; Murase, H. Frontal Obstacle Detection Using Background Subtraction and Frame Registration. Q. Rep. RTRI 2017, 58, 298–302. [Google Scholar] [CrossRef] [Green Version]
- Wohlfeil, J. Vision based rail track and switch recognition for self-localization of trains in a rail network. In Proceedings of the Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 1025–1030. [Google Scholar] [CrossRef]
- Berg, A.; Öfjäll, K.; Ahlberg, J.; Felsberg, M. Detecting Rails and Obstacles Using a Train-Mounted Thermal Camera. In Image Analysis; Paulsen, R.R., Pedersen, K.S., Eds.; Springer: Cham, Switzerland, 2015; pp. 492–503. [Google Scholar] [CrossRef] [Green Version]
- Ye, T.; Zhang, Z.; Zhang, X.; Zhou, F. Autonomous Railway Traffic Object Detection Using Feature-Enhanced Single-Shot Detector. IEEE Access 2020, 8, 145182–145193. [Google Scholar] [CrossRef]
- Nassu, B.T.; Ukai, M. A Vision-Based Approach for Rail Extraction and its Application in a Camera Pan–Tilt Control System. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1763–1771. [Google Scholar] [CrossRef]
- Nassu, B.T.; Ukai, M. Rail extraction for driver support in railways. In Proceedings of the Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 83–88. [Google Scholar] [CrossRef]
- Athira, S. Image Processing based Real Time Obstacle Detection and Alert System for Trains. In Proceedings of the 3rd International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 12–14 June 2019; pp. 740–745. [Google Scholar] [CrossRef]
- Ukai, M. Obstacle detection with a sequence of ultra telephoto camera images. In Proceedings of the Computer in Railways IX, Dresden, Germany, 17–19 May 2004; pp. 1003–1012. [Google Scholar] [CrossRef]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. Non-Handcrafted Features for Computer Vision Classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Kudinov, I.A.; Kholopov, I.S. Perspective-2-Point Solution in the Problem of Indirectly Measuring the Distance to a Wagon. In Proceedings of the 9th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 8–11 June 2020; pp. 740–745. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, X.; Damiani, L.; Giribone, P.; Revetria, R.; Ronchetti, G. Transportation Safety Improvements Through Video Analysis: An Application of Obstacles and Collision Detection Applied to Railways and Roads. In Transactions on Engineering Technologies; Ao, S.I., Kim, H., Castillo, O., Chan, A.S., Katagiri, H., Eds.; Springer: Singapore, 2018; pp. 1–15. [Google Scholar] [CrossRef]
- Maire, F.; Bigdeli, A. Obstacle-free range determination for rail track maintenance vehicles. In Proceedings of the 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; pp. 2172–2178. [Google Scholar] [CrossRef] [Green Version]
- Kaleli, F.; Akgul, Y.S. Vision-based railroad track extraction using dynamic programming. In Proceedings of the 12th International IEEE Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 3–7 October 2009; pp. 42–47. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, X.; Yan, Y.; Jia, C.; Cai, B.; Huang, Z.; Wang, G.; Zhang, T. An inverse projective mapping-based approach for robust rail track extraction. In Proceedings of the 8th International Congress on Image and Signal Processing (CISP), Shenyang, China, 14–16 October 2015; pp. 888–893. [Google Scholar] [CrossRef]
- Wang, Z.; Cai, B.; Chunxiao, J.; Tao, C.; Zhang, Z.; Wang, Y.; Li, S.; Huang, F.; Fu, S.; Zhang, F. Geometry constraints-based visual rail track extraction. In Proceedings of the 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 993–998. [Google Scholar] [CrossRef]
- Gschwandtner, M.; Pree, W.; Uhl, A. Track Detection for Autonomous Trains. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Pavlidis, I., Feris, R., McGraw, T., Elendt, M., Kopper, R., Ragan, E., et al., Eds.; Springer: Berlin, Germany, 2018; pp. 19–28. [Google Scholar] [CrossRef]
- Selver, M.A.; Er, E.; Belenlioglu, B.; Soyaslan, Y. Camera based driver support system for rail extraction using 2D Gabor wavelet decompositions and morphological analysis. In Proceedings of the IEEE International Conference on Intelligent Rail Transportation (ICIRT), Birmingham, UK, 23–25 August 2016; pp. 270–275. [Google Scholar] [CrossRef]
- Selver, M.A.; Zoral, E.Y.; Belenlioglu, B.; Dogan, S. Predictive modeling for monocular vision based rail track extraction. In Proceedings of the 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Fioretti, F.; Ruffaldi, E.; Avizzano, C.A. A single camera inspection system to detect and localize obstacles on railways based on manifold Kalman filtering. In Proceedings of the IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Torino, Italy, 4–7 September 2018; pp. 768–775. [Google Scholar] [CrossRef]
- Fonseca Rodriguez, L.A.; Uribe, J.A.; Vargas Bonilla, J.F. Obstacle Detection over Rails Using Hough Transform. In Proceedings of the XVII Symposium of Image, Signal Processing, and Artificial Vision (STSIVA), Medellin, Antioquia, Colombia, 12–14 September 2012; pp. 317–322. [Google Scholar] [CrossRef]
- Mukojima, H.; Deguchi, D.; Kawanishi, Y.; Ide, I.; Murase, H.; Ukai, M.; Nagamine, N.; Nakasone, R. Moving camera background-subtraction for obstacle detection on railway tracks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3967–3971. [Google Scholar] [CrossRef]
- Vazquez, J.; Mazo, M.; Lizaro, J.L.; Luna, C.A.; Urena, J.; Garcia, J.J.; Cabello, J.; Hierrezuelo, L. Detection of moving objects in railway using vision. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 872–875. [Google Scholar] [CrossRef]
- Barney, D.; Haley, D.; Nikandros, G. Calculating Train Braking Distance. In Safety Critical Systems and Software 2001, Sixth Australian Workshop on Safety-Related Programmable Systems, (SCS2001), St Lucia, Queensland, Australia, 6 July 2001; Lindsay, P.A., Ed.; Australian Computer Society: Darlinghurst, Australia, 2001; pp. 23–30. [Google Scholar]
- Gavrilova, N.M.; Dailid, I.A.; Molodyakov, S.A.; Boltenkova, E.O.; Korolev, I.N.; Popov, P.A. Application of computer vision algorithms in the problem of coupling of the locomotive with railcars. In Proceedings of the International Symposium on Consumer Technologies (ISCT), St-Petersburg, Russia, 11–12 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Zendel, O.; Murschitz, M.; Zeilinger, M.; Steininger, D.; Abbasi, S.; Beleznai, C. RailSem19: A Dataset for Semantic Rail Scene Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1221–1229. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, X.; Yu, G.; Li, M. Efficient Rail Area Detection Using Convolutional Neural Network. IEEE Access 2018, 6, 77656–77664. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv 2015. Available online: Https://arxiv.org/pdf/1505.07293.pdf (accessed on 25 March 2021).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Wedberg, M. Detecting Rails in Images from a Train-Mounted Thermal Camera Using a Convolutional Neural Network. Master’s Thesis, Linköping University, Linköping, Sweden, June 2017. [Google Scholar]
- Yu, M.; Yang, P.; Wei, S. Railway obstacle detection algorithm using neural network. AIP Conf. Proc. 2018, 1967, 0400171–0400176. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kapoor, R.; Goel, R.; Sharma, A. Deep Learning Based Object and Railway Track Recognition Using Train Mounted Thermal Imaging System. J. Comput. Theor. Nanosci. 2018, 17, 5062–5071. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5936–5944. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhou, F.; Ye, T. Real-world railway traffic detection based on faster better network. IEEE Access 2018, 6, 68730–68739. [Google Scholar] [CrossRef]
- Xu, Y.; Gao, C.; Yuan, L.; Tang, S.; Wei, G. Real-time Obstacle Detection Over Rails Using Deep Convolutional Neural Network. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1007–1012. [Google Scholar] [CrossRef]
- Haseeb, M.A.; Guan, J.; Ristić-Durrant, D.; Gräser, A. A Novel Method for Distance Estimation from Monocular Camera. In Proceedings of the 10th Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), IROS, Madrid, Spain, 1 October 2018; Volume 10.
- Ristić-Durrant, D.; Haseeb, M.A.; Franke, M.; Banić, M.; Simonović, M.; Stamenković, D. Artificial Intelligence for Obstacle Detection in Railways: Project SMART and Beyond. In Dependable Computing – EDCC 2020 Workshops; Bernardi, S., Flammini, F., Marrone, S., Schneider, D., Nostro, N., Di Salle, A., Vittorini, V., Nardone, R., Adler, R., Schleiß, P., et al., Eds.; Springer: Cham, Switzerland, 2020; pp. 44–55. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2019. Available online: Https://arxiv.org/pdf/1804.02767.pdf (accessed on 25 March 2021).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in ContextN. In Computer Vision—ECCV 2014, Part V; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2020; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Chernov, A.; Butakova, M.; Guda, A.; Shevchuk, P. Development of Intelligent Obstacle Detection System on Railway Tracks for Yard Locomotives Using CNN. In Dependable Computing—EDCC 2020 Workshops; Bernardi, S., Vittorini, V., Flammini, F., Nardone, R., Marrone, S., Adler, R., Schneider, D., Schleiss, P., Nostro, N., Løvenstein Olsen, R., et al., Eds.; Springer: Cham, Switzerland, 2020; pp. 32–43. [Google Scholar] [CrossRef]
- Fel, L.; Zinner, C.; Kadiofsky, T.; Pointner, W.; Weichselbaum, J.; Reisner, C. An Anti-Collision Assistance System for Light Rail Vehicles and Further Development. In Proceedings of the 7th Transport Research Arena, Vienna, Austria, 16–19 April 2018. [Google Scholar] [CrossRef]
- Saika, S.; Takahashi, S.; Takeuchi, M.; Katto, J. Accuracy Improvement in Human Detection Using HOG Features on Train-Mounted Camera. In Proceedings of the IEEE 5th Global Conference on Consumer Electronics (GCCE), Kyoto, Japan, 11–14 October 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Haseeb, M.A.; Ristić-Durrant, D.; Gräser, A. Long-range Obstacle Detection from a Monocular Camera. In Proceedings of the ACM Computer Science in Cars Symposium (CSCS), Munich, Germany, 13–14 September 2018. [Google Scholar]
- Haseeb, M.A.; Ristić-Durrant, D.; Gräser, A.; Banić, M.; Stamenković, D. Multi-DisNet: Machine Learning-based Object Distance Estimation from Multiple Cameras. In Computer Vision Systems—Lecture Notes in Computer Science; Tzovaras, D., Giakoumis, D., Vincze, M., Argyros, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 457–469. [Google Scholar] [CrossRef]
- Guo, B.; Geng, G.; Zhu, L.; Shi, H.; Yu, Z. High-Speed Railway Intruding Object Image Generating with Generative Adversarial Networks. Sensors 2019, 19, 3075. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning Deep Semantic Segmentation Network under Multiple Weakly-Supervised Constraints for Cross-Domain Remote Sensing Image Semantic Segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Type of Vision System | Rail Track Detection | Obstacle Detection | Distance Estimation | Evaluation Tests—Comments |
|---|---|---|---|---|---|
| Fel et al., 2018 [65] | Stereo-vision system consisting of 3 RGB cameras | ✓ | ✓ | Short-range obstacle detection using stereo cameras with a small stereo baseline (0.25 m) and long range depth estimation with a larger baseline (0.8 m) | The evaluation from dedicated automatic detection analysis tools and the drivers’ feedbacks over three years and thousands of accumulated kilometres |
| Fioretti et al., 2018 [40] | Monocular RGB on-board cameras | ✓ | ✓ | 3D reconstruction of rails and of objects such as kilometres’ signs; distance (z-coordinate) range up to 200 m | Evaluation on image data of a single track railway recorded for 8 min and 20 s for 9 km at train speed of about 72 km/h. |
| Fonseca Rodriguez et al., 2012 [41] | — | ✓ | ✓ | — | Evaluation on several modified videos from the Internet; digital objects artificially added to video frames |
| Gavrilova et al., 2018 [45] | Standard RGB on-board camera | ✓ | ✓ | Using the image coordinates of the last point on detected obstacle-free rail tracks as wagon point coordinates, to calculate actual distance to wagon; up to 100 m | Evaluation on real-world images; 100 images with the object (wagon) on the rail tracks and 300 images without the object |
| Gebauer et al., 2012 [7] | Stereo-cameras + thermal camera | ✓ | ✓ | Using stereo-vision and laser scanner; up to 80 m | Evaluation on real-world images recorded on 15 km long railway in Austria on which a prototype train operates |
| Gschwandtner et al., 2010 [37] | Grayscale camera | ✓ | — | — | Evaluation on a dataset acquired in winter on the track length of approx. 15 km and the train driving at 40 km/h. |
| Kaleli et al., 2009 [34] | Standard RGB camera | ✓ | — | — | Evaluation on several video sequences taken from the on-board camera while the train was moving at high speeds |
| Kudinov et al., 2020 [31] | Grayscale camera | ✓ | ✓ | Short-range distances to wagons up to 50 m (absolute error no more than 1.2 m) | Evaluation on real-world images of the shunting track of the Ryazan-1 railway station recorded in cloudy weather |
| Maire et al., 2010 [33] | Grayscale camera | ✓ | — | Detection of obstacle-free rail tracks zone of about 100 m but no individual object distance estimation | Evaluation on real-world images of rather poor quality |
| Möckel et al., 2003 [16] | Multi-focal camera system, one short-range and two long-range cameras | ✓ | ✓ | Using LiDAR with an up to 400 m look-ahead range but no individual object distance estimation | Evaluation on images from real-world field tests on a public rail track near Munich used as test track; simulated obstacles |
| Mukojima et al., 2016 [42] | Standard RGB camera | — | ✓ | — | Evaluation on train frontal view images captured on a test line in the premises of the Railway Technical Research Institute, Japan. |
| Nakasone et al., 2017 [22] | Standard RGB camera | — | ✓ | The farthest obstacle at 235 m as the test track was straight at a length of about 250 m leading to the obstacle | Images from four train runs without obstacles used as reference. Evaluation on 5000 frames with obstacles captured in 17 train runs |
| Nassu et al., 2011 [27] | Standard RGB camera | ✓ | — | Rail extraction in the long distance was performed in addition to rail extraction in the short distance; however, the long distance range was not defined | Three sets of videos captured in real operating conditions in several Japanese railways. The 1st set has 10 videos, with 3549 frames, the 2nd has 27 videos, with 14,474 frames and the 3rd has 12 videos, with 5879 frames with rails are mostly visible in the long distance |
| Nassu et al., 2012 [26] | RGB camera with zoom lens mounted on a pan–tilt unit | ✓ | — | Different rail exraction methods for short distances and long distances; no specification on distance range | Evaluation on 12 video sequences captured under real operating conditions in several Japanese railways, with 459,733 frames (4:15 h of recording). |
| Qi et al., 2013 [21] | RGB camera | ✓ | — | — | Evaluation on six real-world video datasets recorded in different illumination. The test data were collected in Hefei City, Anhui Province of China. The length of the rails approx. 10 km. The train speed of about 60 km/h. |
| Ross 2010 [19] | Grayscale camera | ✓ | — | — | Evaluation on on-board camera images taken near Karlsruhe, Germany. Dataset included images of single track situations and of turnout situations |
| Saika et al., 2016 [66] | Standard RGB camera | — | ✓ | — | Evaluation on a train driver’s view video, of scene of train approaching a platform, available on the Internet. The test video sequences of 12 frames |
| Selver et al., 2016 [38] | — | ✓ | — | — | Evaluation data set was a collection of publicly available in Internet cabin view videos (different weather conditions); 389 frames |
| Ukai, 2004 [29] | Ultra telephoto lens camera | ✓ | ✓ | Used camera allows for monitoring the rail tracks ahead up 600 m but no individual object distance estimation | The image sequence of 557 frames (18.56 s) recorded from a train was collected for evaluation |
| Uribe et al., 2012 [17] | — | ✓ | ✓ | — | Evaluation on images from Internet with artificially added obstacles |
| Vazquez et al., 2004 [43] | RGB camera | — | ✓ | — | Evaluation on real images captured in railway environment and in varied illumination and weather conditions (some images in very adverse conditions as images with fog) |
| Wang et al., 2017 [32] | Standard RGB on-board camera | ✓ | ✓ | — | Evaluation dataset is an open source video captured by on-board camera from Malmo to Angelholm, Sweden; videos were modified adding digital obstacles of different nature and shape |
| Wang et al., 2015 [35] | Grayscale camera | ✓ | — | — | Test images were taken at Fengtai west railway station freight yard, Beijing |
| Wang et al., 2016 [36] | Grayscale camera | ✓ | — | — | Test images were taken at Fengtai west railway station freight yard, Beijing |
| Weichselbaum et al., 2013 [12] | Stereo-vision | ✓ | ✓ | Obstacle distance from 10 m up to 80 m ahead | Evaluation on two representative real-world test sequences with various numbers of frames, situations and obstacles |
| Wohlfeil, 2011 [23] | Grayscale camera | ✓ | — | — | Evaluation test images from six different test rides in three different places at German railway tests sites; various challenging lightning conditions |
| Yamashita et al., 1996 [8] | Mono thermal camera with a telephoto lens | ✓ | ✓ | Using laser range finder, up to 1 km | Real-world tests; the system on-board test train of the East Japan Railway |
| Paper | Type of Vision System | Rail Track Detection | Obstacle Detection | Distance Estimation | Evaluation Tests—Comments |
|---|---|---|---|---|---|
| Haseeb et al., 2018 [60,67]; Haseeb et al., 2019 [68]; Ristić-Durrant et al., 2020 [61] | RGB cameras + thermal camera + night vision camera | — | ✓ | Feedforward neural network (NN)-based distance estimation. NN estimates object distance based on the features of the object Bounding Box (BB) extracted by the DL-based object detector. Mid-range (80–200 m) and long-range (up to 1000 m) distance estimation | Real-world tests; on-board multi-camera system mounted on the operational locomotive owned by Serbia Cargo and running on Serbian part of pan-European Corridor X in length of 120 km in different illumination and weather conditions |
| Wang et al., 2019 [18] | Standard RGB on-board camera | ✓ | — | — | Evaluation on 300 images recorded in operational environment of low-speed autonomous trains in China |
| Wang et al., 2018 [48] | Standard RGB on-board camera | ✓ | — | — | Evaluation on 1123 images recorded on the Beijing metro Yanfang line and Shanghai metro line 6 including tunnels and open lines |
| Wedberg, 2017 [53] | Thermal on-board camera | — | ✓ | Detecting rails at long-range; no details of distance range | The evaluation dataset consisted of on-board thermal infrared video sequences. The data were collected in northern Sweden in April 2015 |
| Xu et al., 2019 [59] | Standard RGB HD camera | — | ✓ | — | Evaluation on 1277 images recorded on the Hongkong MTR Tsuen Wan Line, Beijing Metro Yanfang line and Shanghai metro line 6 in different conditions, in daytime and night, sunny and rainy days |
| Ye et al., 2018 [13] | Standard RGB camera | ✓ | ✓ | Using millimeter-wave radar; no details on object distance measurement | Evaluation of custom dataset recorded in real-world railway shunting scenarios |
| Ye et al., 2020 [14] | Standard RGB camera | ✓ | ✓ | Using millimeter-wave radar; no details on object distance measurement | Evaluation of custom dataset recorded in real-world railway shunting scenarios |
| Ye et al., 2020 [25] | Standard RGB camera and a near infrared laser, supplementing the illumination of the camera | ✓ | ✓ | — | Evaluation of custom dataset recorded in real-world railway shunting scenarios |
| Yu et al., 2018 [54] | — | — | ✓ | — | Evaluation on 5000 images of outdoor railway scenes, which were collected from the Internet |
| Paper | Type of Vision System | Rail Track Detection | Obstacle Detection | Distance Estimation | Evaluation Tests—Comments |
|---|---|---|---|---|---|
| Chernov et al., 2020 [64] | Stereo RGB cameras | ✓ | ✓ | Stereo-vision system enables determining the safe distance from the yard locomotive to the car coupling device; no details on distance estimation | Evaluation on real-world test images recorded by stereo cameras mounted on yard locomotives |
| Kapoor et al., 2020 [56] | Thermal camera | ✓ | ✓ | Used cameras range up to 1500 m; Detection of objects within the rail tracks portions visible in the image but no individual object distance estimation | Evaluation on 749 images recorded with on-board thermal camera; no details of evaluation tests |
| Selver et al., 2017 [39] | Standard RGB camera | ✓ | — | — | Evaluation on 2185 manually delineated frames. These are obtained from 29 left and 24 right turns belonging acquired during common public journeys. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ristić-Durrant, D.; Franke, M.; Michels, K. A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors 2021, 21, 3452. https://doi.org/10.3390/s21103452
Ristić-Durrant D, Franke M, Michels K. A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors. 2021; 21(10):3452. https://doi.org/10.3390/s21103452
Chicago/Turabian StyleRistić-Durrant, Danijela, Marten Franke, and Kai Michels. 2021. "A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways" Sensors 21, no. 10: 3452. https://doi.org/10.3390/s21103452
APA StyleRistić-Durrant, D., Franke, M., & Michels, K. (2021). A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors, 21(10), 3452. https://doi.org/10.3390/s21103452