CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors



Abstract
1. Introduction
- (1)
- We propose a novel emotion recognition algorithm to classify the valence and arousal in finer granularity using wearable physiological sensors. The proposed algorithm is tested both on an indoor-desktop dataset (CASE [19]), and on an outdoor-mobile dataset (MERCA), which we collected using wearable physiological sensors while users watched short-form (<10 min) [38] mobile videos. Results show good performance for binary valence-arousal (V-A) classification on both datasets ( and of V-A on CASE; and for V-A on MERCA), respectively. Our results outperform other state-of-the-art baseline methods for emotion recognition, including classic ML-based support vector machines (SVMs) and sequential learning approaches such as Long Short-Term Memory (LSTM) networks.
- (2)
- We compare the performance of CorrNet through testing experiments with different parameters (e.g., different lengths of instances and different sampling rates) and discuss how they could affect the recognition results. The discussion provides insight into how to design a fine-grained emotion recognition algorithm using segmented physiological signals. Our discussion also shows high recognition accuracy can be achieved using wearable physiological signals with low sampling rate (≤64 Hz), which means lower power consumption and easier sensor deployment (e.g., do not need to stick electrodes on users’ skin) compared with laboratory-grade sensors with higher sampling rate (≥1000 Hz).
2. Related Work
2.1. Discrete vs. Dimensional Emotion Models
2.2. Wearable Physiological Sensing for Emotion Recognition
2.3. Emotion Recognition Algorithms Using Physiological Signals
2.4. Fine-Grained Emotion Recognition
3. Methodology
| Algorithm 1 CorrNet |
| Input: Training set with n instances in modality 1: and modality 2: Output: Fine-grained emotion labels (i.e., valence: and arousal )
|
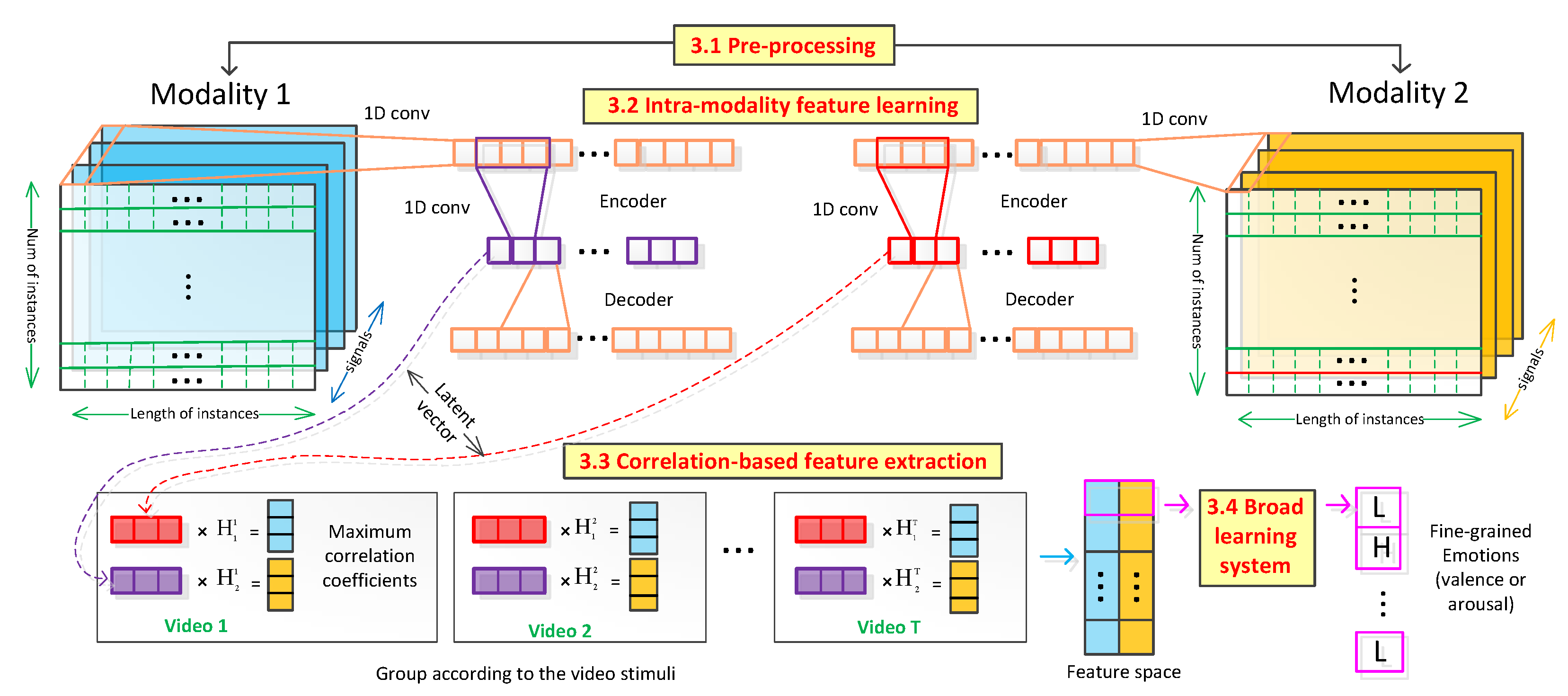
3.1. Pre-Processing
3.2. Intra-Modality Feature Learning
3.3. Correlation-Based Feature Extraction
3.4. Broad Learning System For Classification
4. Datasets
4.1. CASE Dataset
4.2. MERCA Dataset
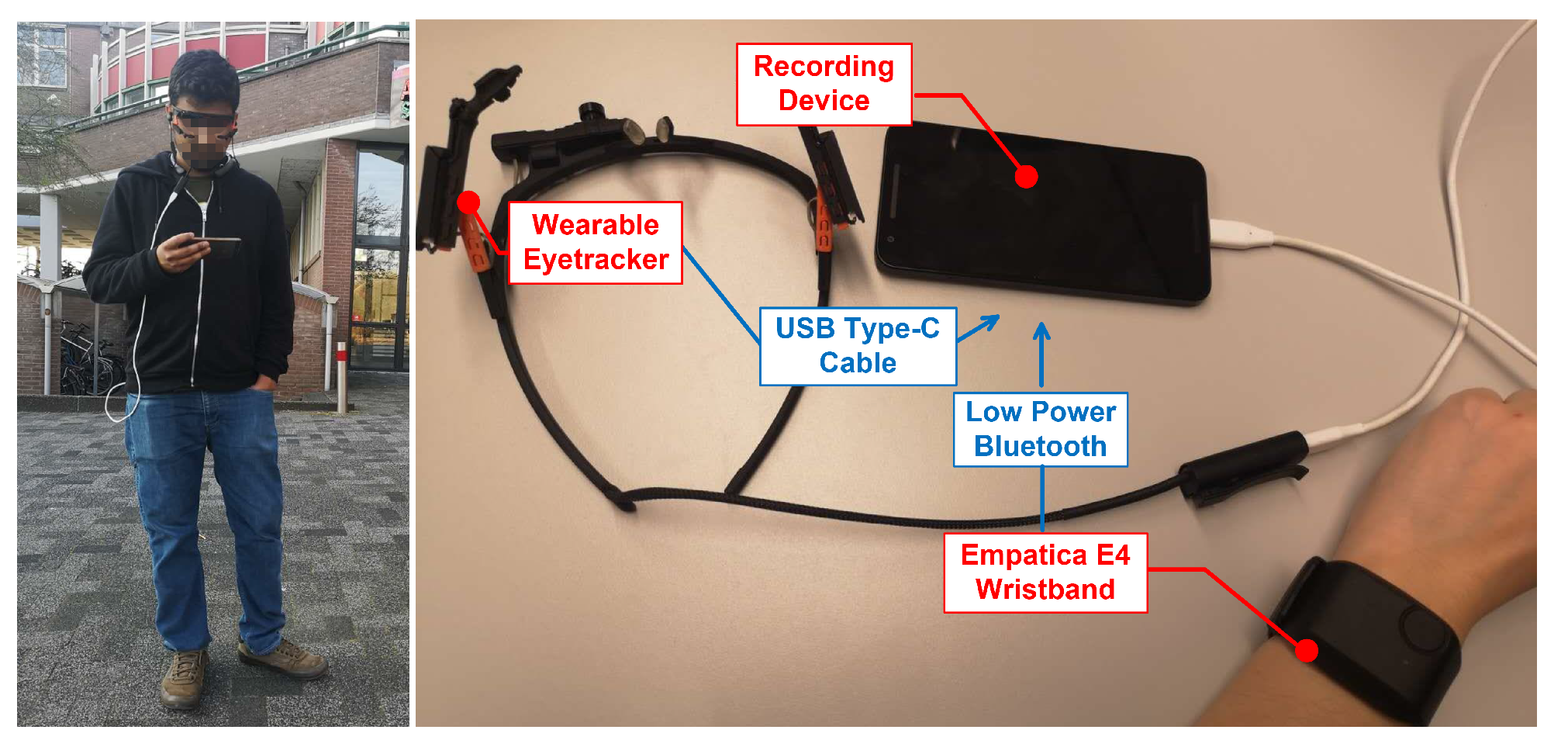
4.2.1. Experiment Setup
4.2.2. Video Stimuli
4.2.3. Software Setup
4.2.4. Data Collection
5. Experiment and Results
5.1. Implementation Details
5.2. Evaluation Protocol and Baselines
5.2.1. Classification Tasks
5.2.2. Evaluation Metrics
- Accuracy: the percentage of correct predictions;
- Confusion matrix: the square matrix that shows the type of error in a supervised paradigm [70];
- Weighted F1-score (W-F1): the harmonic mean of precision and recall for each label (weighted averaged by the number of true instances for each label) [111].
5.2.3. Evaluation Method
5.2.4. Baseline Comparison
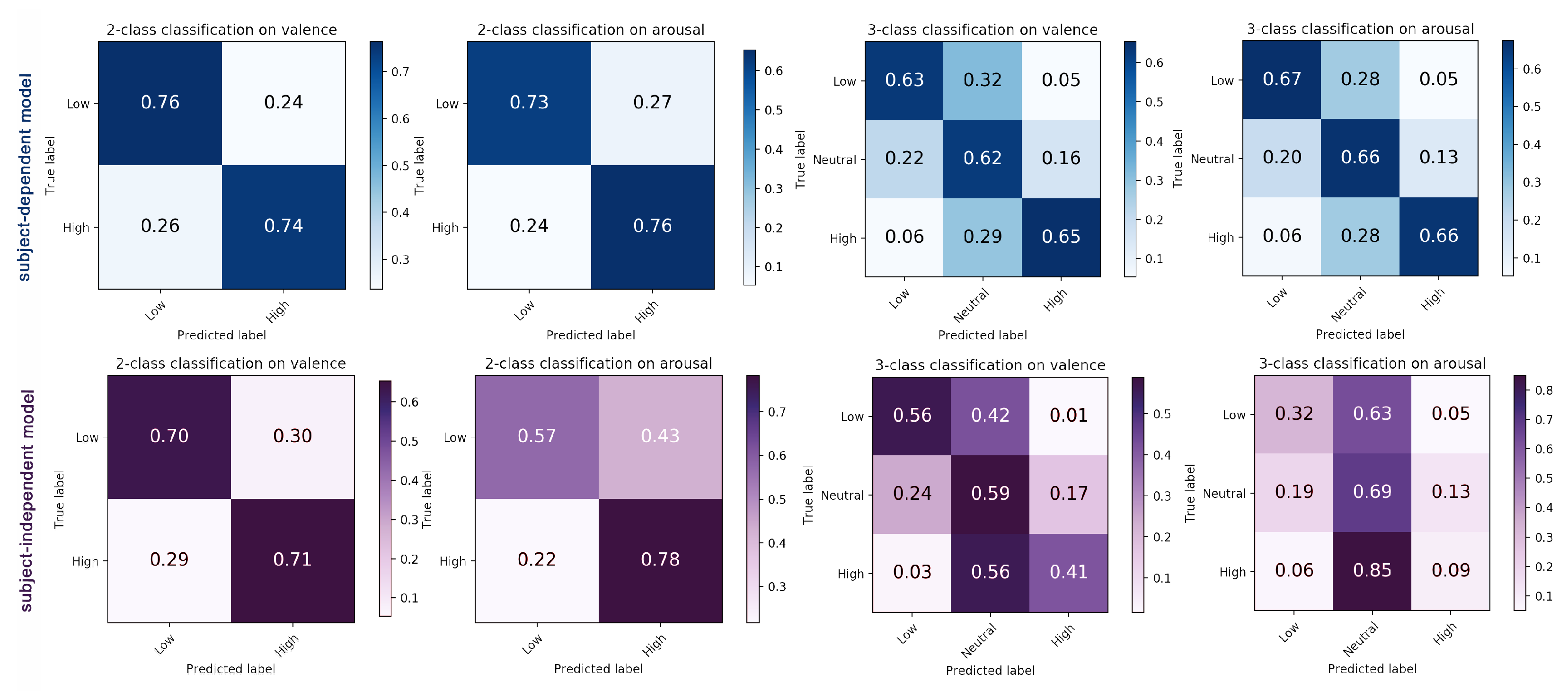
5.3. Experiment Results
5.4. Comparison with DL and ML Methods
5.5. Ablation Study
5.6. Computational Cost
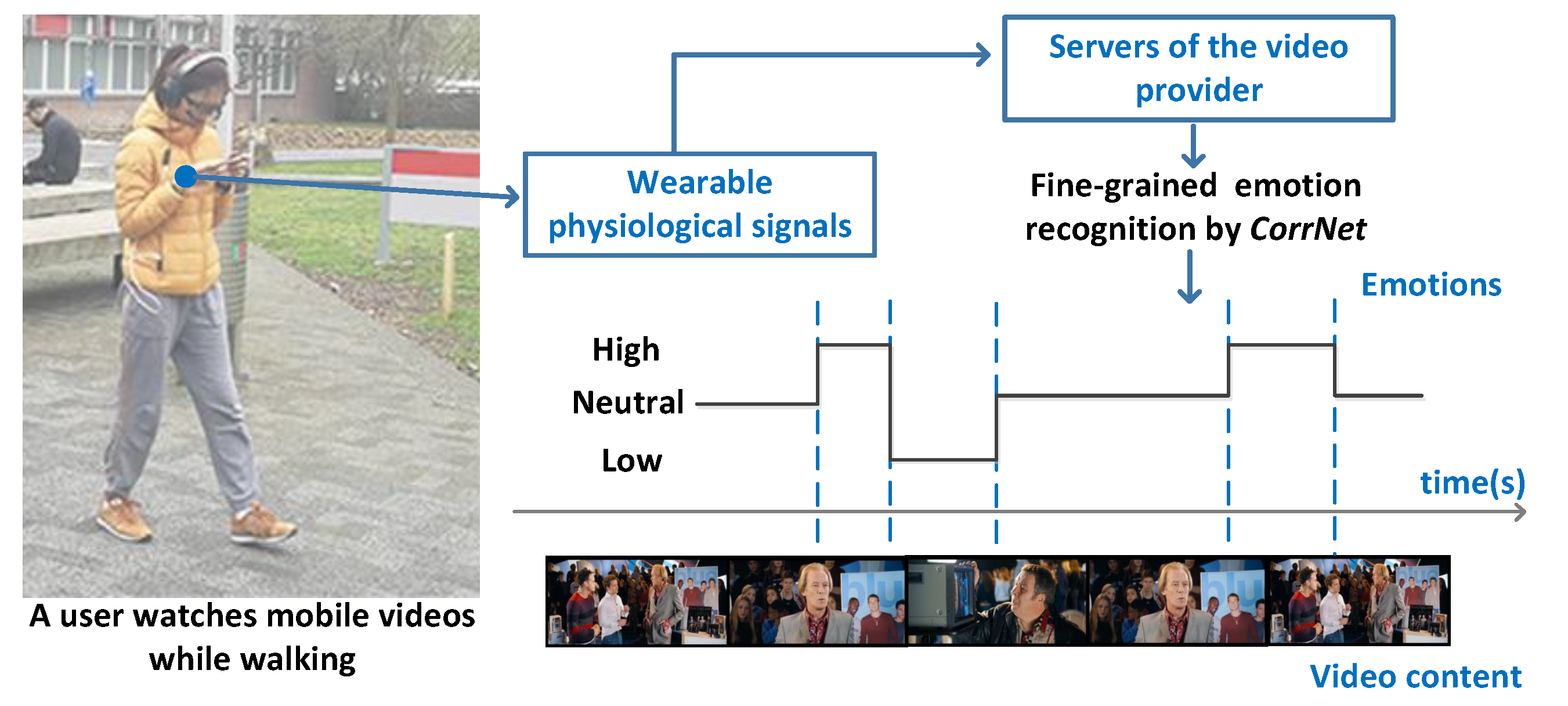
6. Discussion
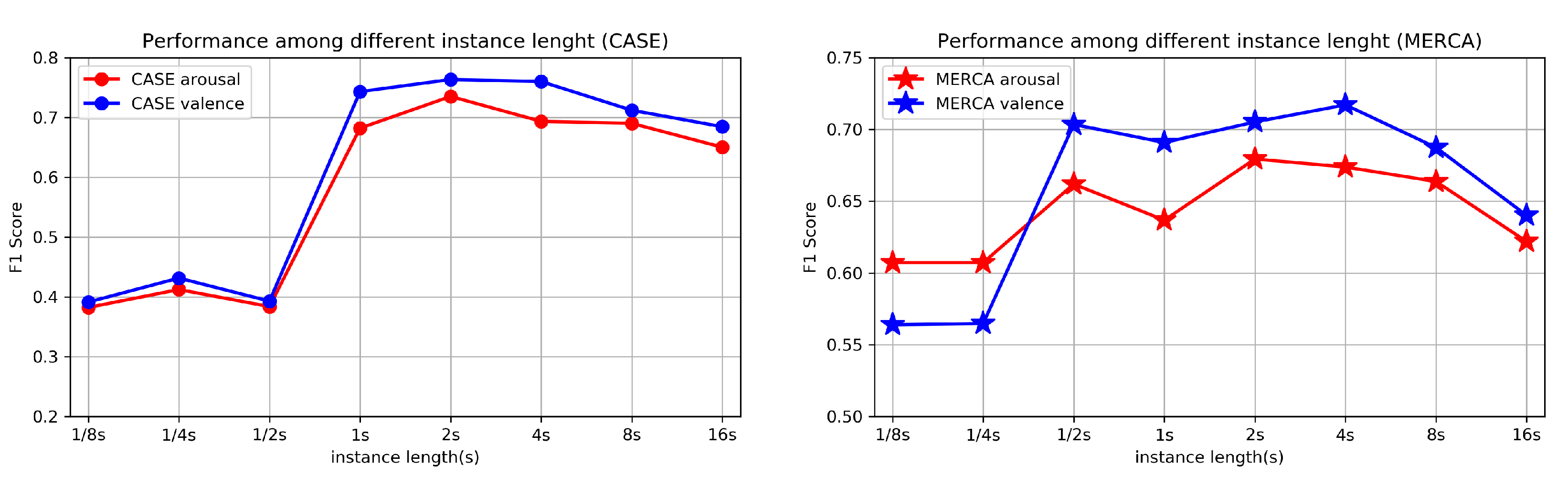
6.1. Towards More Precise Emotion Recognition: How Fine-Grained Should It Be?
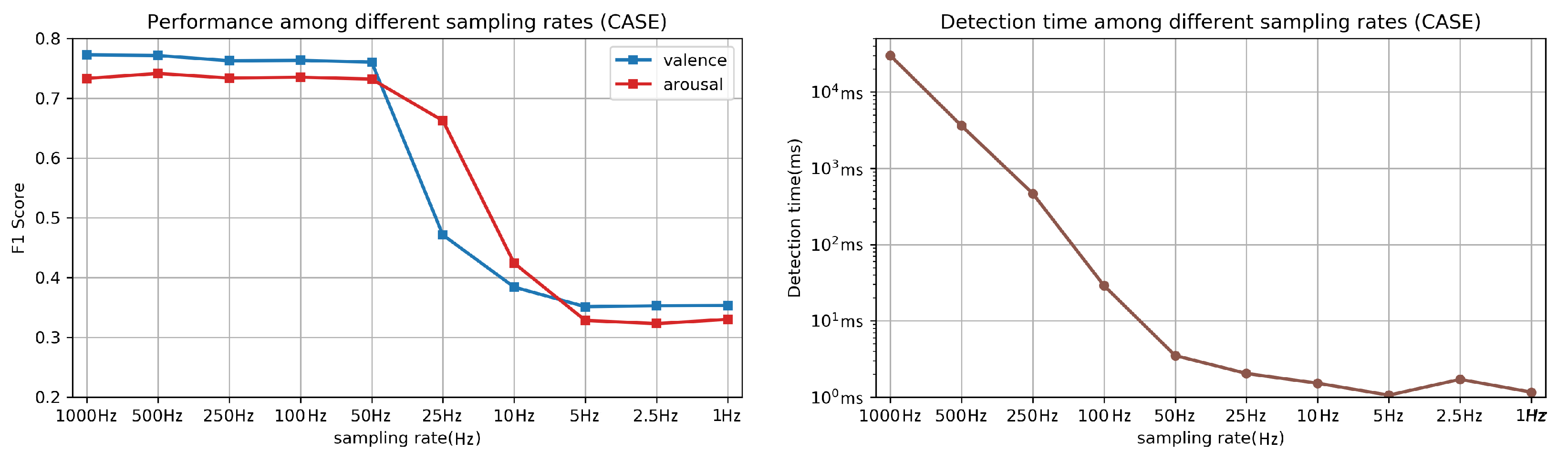
6.2. Emotion Recognition Using Wearable Physiological Sensing: Do Higher Sampling Rates Result in Higher Accuracies?
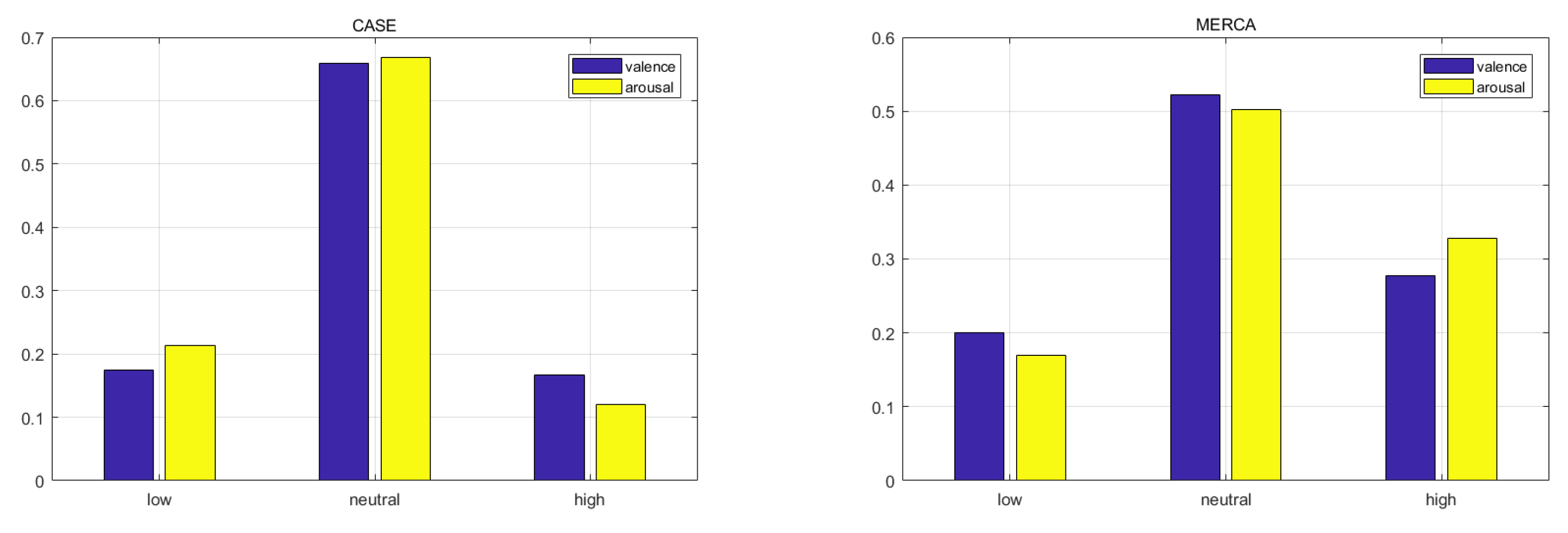
6.3. Data Imbalance and Overfitting in Fine-Grained Emotion Recognition
7. Limitations and Future Work
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal emotion recognition in response to videos. IEEE Trans. Affect. Comput. 2011, 3, 211–223. [Google Scholar] [CrossRef]
- Niu, J.; Zhao, X.; Zhu, L.; Li, H. Affivir: An affect-based Internet video recommendation system. Neurocomputing 2013, 120, 422–433. [Google Scholar] [CrossRef]
- Tripathi, A.; Ashwin, T.; Guddeti, R.M.R. EmoWare: A Context-Aware Framework for Personalized Video Recommendation Using Affective Video Sequences. IEEE Access 2019, 7, 51185–51200. [Google Scholar] [CrossRef]
- Yazdani, A.; Lee, J.S.; Vesin, J.M.; Ebrahimi, T. Affect recognition based on physiological changes during the watching of music videos. ACM Trans. Interact. Intell. Syst. (TiiS) 2012, 2, 1–26. [Google Scholar] [CrossRef]
- Ali, M.; Al Machot, F.; Haj Mosa, A.; Jdeed, M.; Al Machot, E.; Kyamakya, K. A globally generalized emotion recognition system involving different physiological signals. Sensors 2018, 18, 1905. [Google Scholar] [CrossRef] [PubMed]
- Shu, L.; Xie, J.; Yang, M.; Li, Z.; Li, Z.; Liao, D.; Xu, X.; Yang, X. A Review of Emotion Recognition Using Physiological Signals. Sensors 2018, 18, 2074. [Google Scholar] [CrossRef] [PubMed]
- Jerritta, S.; Murugappan, M.; Nagarajan, R.; Wan, K. Physiological signals based human emotion recognition: A review. In Proceedings of the 2011 IEEE 7th International Colloquium on Signal Processing and its Applications, Penang, Malaysia, 4–6 March 2011; pp. 410–415. [Google Scholar]
- Maria, E.; Matthias, L.; Sten, H. Emotion recognition from physiological signal analysis: A review. Electron. Notes Theor. Comput. Sci. 2019, 343, 35–55. [Google Scholar]
- Nagel, F.; Kopiez, R.; Grewe, O.; Altenmüller, E. EMuJoy: Software for continuous measurement of perceived emotions in music. Behav. Res. Methods 2007, 39, 283–290. [Google Scholar] [CrossRef]
- Soleymani, M.; Asghari-Esfeden, S.; Fu, Y.; Pantic, M. Analysis of EEG signals and facial expressions for continuous emotion detection. IEEE Trans. Affect. Comput. 2015, 7, 17–28. [Google Scholar] [CrossRef]
- Lang, P.J. The emotion probe: Studies of motivation and attention. Am. Psychol. 1995, 50, 372. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Paul, E. Emotions Revealed: Recognizing Faces and Feelings to Improve Communication and Emotional Life; OWL Books: New York, NY, USA, 2007. [Google Scholar]
- Levenson, R.W. Emotion and the autonomic nervous system: A prospectus for research on autonomic specificity. Soc. Psychophysiol. Theory Clin. Appl. 1988, 17–42. [Google Scholar]
- Domínguez-Jiménez, J.; Campo-Landines, K.; Martínez-Santos, J.; Delahoz, E.; Contreras-Ortiz, S. A machine learning model for emotion recognition from physiological signals. Biomed. Signal Process. Control 2020, 55, 101646. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Cowie, R.; Douglas-Cowie, E.; Savvidou, S.; McMahon, E.; Sawey, M.; Schröder, M. ’FEELTRACE’: An instrument for recording perceived emotion in real time. In Proceedings of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion, Newcastle, UK, 5–7 September 2000. [Google Scholar]
- Girard, J.M.; Wright, A.G. DARMA: Software for dual axis rating and media annotation. Behav. Res. Methods 2018, 50, 902–909. [Google Scholar] [CrossRef]
- Sharma, K.; Castellini, C.; van den Broek, E.L.; Albu-Schaeffer, A.; Schwenker, F. A dataset of continuous affect annotations and physiological signals for emotion analysis. Sci. Data 2019, 6, 1–13. [Google Scholar] [CrossRef]
- Soleymani, M.; Asghari-Esfeden, S.; Pantic, M.; Fu, Y. Continuous emotion detection using EEG signals and facial expressions. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Haripriyadharshini, S.; Gnanasaravanan, S. EEG Based Human Facial Emotion Recognition System Using LSTMRNN. Asian J. Appl. Sci. Technol. (AJAST) 2018, 2, 264–269. [Google Scholar]
- Hasanzadeh, F.; Annabestani, M.; Moghimi, S. Continuous Emotion Recognition during Music Listening Using EEG Signals: A Fuzzy Parallel Cascades Model. arXiv 2019, arXiv:1910.10489. [Google Scholar]
- Wu, S.; Du, Z.; Li, W.; Huang, D.; Wang, Y. Continuous Emotion Recognition in Videos by Fusing Facial Expression, Head Pose and Eye Gaze. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 40–48. [Google Scholar]
- Zhao, S.; Yao, H.; Jiang, X. Predicting continuous probability distribution of image emotions in valence-arousal space. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 879–882. [Google Scholar]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef]
- Casson, A.J. Wearable EEG and beyond. Biomed. Eng. Lett. 2019, 9, 53–71. [Google Scholar] [CrossRef]
- Khamis, M.; Baier, A.; Henze, N.; Alt, F.; Bulling, A. Understanding Face and Eye Visibility in Front-Facing Cameras of Smartphones Used in the Wild. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ’18), Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Friedman, B.; Kahn, P.H., Jr.; Hagman, J.; Severson, R.L.; Gill, B. The watcher and the watched: Social judgments about privacy in a public place. Hum. Comput. Interact. 2006, 21, 235–272. [Google Scholar] [CrossRef]
- Stanko, T.L.; Beckman, C.M. Watching you watching me: Boundary control and capturing attention in the context of ubiquitous technology use. Acad. Manag. J. 2015, 58, 712–738. [Google Scholar] [CrossRef]
- Ragot, M.; Martin, N.; Em, S.; Pallamin, N.; Diverrez, J.M. Emotion recognition using physiological signals: Laboratory vs. wearable sensors. In International Conference on Applied Human Factors and Ergonomics; Springer: Berlin/Heidelberg, Germany, 2017; pp. 15–22. [Google Scholar]
- Gashi, S.; Di Lascio, E.; Stancu, B.; Swain, V.D.; Mishra, V.; Gjoreski, M.; Santini, S. Detection of Artifacts in Ambulatory Electrodermal Activity Data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–31. [Google Scholar] [CrossRef]
- Zhang, T.; El Ali, A.; Wang, C.; Hanjalic, A.; Cesar, P. RCEA: Real-Time, Continuous Emotion Annotation for Collecting Precise Mobile Video Ground Truth Labels. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI’20), Honolulu, HI, USA, 26 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Ma, J.; Tang, H.; Zheng, W.L.; Lu, B.L. Emotion Recognition using Multimodal Residual LSTM Network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 176–183. [Google Scholar]
- Zhong, S.H.; Fares, A.; Jiang, J. An Attentional-LSTM for Improved Classification of Brain Activities Evoked by Images. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1295–1303. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced lstm for natural language inference. arXiv 2016, arXiv:1609.06038. [Google Scholar]
- Bentley, F.; Lottridge, D. Understanding Mass-Market Mobile TV Behaviors in the Streaming Era. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI’19), Glasgow, UK, 4–9 May 2019; ACM: New York, NY, USA, 2019; pp. 261:1–261:11. [Google Scholar] [CrossRef]
- Zhang, X.; Li, W.; Chen, X.; Lu, S. Moodexplorer: Towards compound emotion detection via smartphone sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–30. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Taylor, B.; Dey, A.; Siewiorek, D.; Smailagic, A. Using physiological sensors to detect levels of user frustration induced by system delays. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 517–528. [Google Scholar]
- Kyriakou, K.; Resch, B.; Sagl, G.; Petutschnig, A.; Werner, C.; Niederseer, D.; Liedlgruber, M.; Wilhelm, F.H.; Osborne, T.; Pykett, J. Detecting moments of stress from measurements of wearable physiological sensors. Sensors 2019, 19, 3805. [Google Scholar] [CrossRef]
- Sethi, K.; Ramya, T.; Singh, H.P.; Dutta, R. Stress detection and relief using wearable physiological sensors. Telkomnika 2019, 17, 1139–1146. [Google Scholar] [CrossRef]
- Salekin, A.; Eberle, J.W.; Glenn, J.J.; Teachman, B.A.; Stankovic, J.A. A weakly supervised learning framework for detecting social anxiety and depression. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Costa, A.; Rincon, J.A.; Carrascosa, C.; Julian, V.; Novais, P. Emotions detection on an ambient intelligent system using wearable devices. Future Gener. Comput. Syst. 2019, 92, 479–489. [Google Scholar] [CrossRef]
- Zenonos, A.; Khan, A.; Kalogridis, G.; Vatsikas, S.; Lewis, T.; Sooriyabandara, M. HealthyOffice: Mood recognition at work using smartphones and wearable sensors. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, Australia, 14–18 March 2016; pp. 1–6. [Google Scholar]
- Ayata, D.; Yaslan, Y.; Kamasak, M.E. Emotion based music recommendation system using wearable physiological sensors. IEEE Trans. Consum. Electron. 2018, 64, 196–203. [Google Scholar] [CrossRef]
- Yao, L.; Liu, Y.; Li, W.; Zhou, L.; Ge, Y.; Chai, J.; Sun, X. Using physiological measures to evaluate user experience of mobile applications. In International Conference on Engineering Psychology and Cognitive Ergonomics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 301–310. [Google Scholar]
- Gashi, S.; Di Lascio, E.; Santini, S. Using unobtrusive wearable sensors to measure the physiological synchrony between presenters and audience members. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–19. [Google Scholar] [CrossRef]
- Puke, S.; Suzuki, T.; Nakayama, K.; Tanaka, H.; Minami, S. Blood pressure estimation from pulse wave velocity measured on the chest. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 6107–6110. [Google Scholar]
- Huynh, S.; Kim, S.; Ko, J.; Balan, R.K.; Lee, Y. EngageMon: Multi-Modal Engagement Sensing for Mobile Games. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–27. [Google Scholar] [CrossRef]
- Di Lascio, E.; Gashi, S.; Santini, S. Unobtrusive assessment of students’ emotional engagement during lectures using electrodermal activity sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–21. [Google Scholar] [CrossRef]
- Yang, W.; Rifqi, M.; Marsala, C.; Pinna, A. Towards Better Understanding of Player’s Game Experience. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 442–449. [Google Scholar]
- Wioleta, S. Using physiological signals for emotion recognition. In Proceedings of the 2013 6th International Conference on Human System Interactions (HSI), Sopot, Poland, 6–8 June 2013; pp. 556–561. [Google Scholar]
- Niu, X.; Chen, L.; Xie, H.; Chen, Q.; Li, H. Emotion pattern recognition using physiological signals. Sens. Transducers 2014, 172, 147. [Google Scholar]
- Zecca, M.; Micera, S.; Carrozza, M.C.; Dario, P. Control of multifunctional prosthetic hands by processing the electromyographic signal. Crit. Rev. Biomed. Eng. 2002, 30, 459–485. [Google Scholar] [CrossRef]
- Calvo, R.A.; D’Mello, S. Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- He, C.; Yao, Y.J.; Ye, X.S. An emotion recognition system based on physiological signals obtained by wearable sensors. In Wearable Sensors and Robots; Springer: Berlin/Heidelberg, Germany, 2017; pp. 15–25. [Google Scholar]
- Chen, L.; Li, M.; Su, W.; Wu, M.; Hirota, K.; Pedrycz, W. Adaptive Feature Selection-Based AdaBoost-KNN With Direct Optimization for Dynamic Emotion Recognition in Human–Robot Interaction. IEEE Trans. Emerg. Top. Comput. Intell. 2019. [Google Scholar] [CrossRef]
- Rigas, G.; Katsis, C.D.; Ganiatsas, G.; Fotiadis, D.I. A user independent, biosignal based, emotion recognition method. In International Conference on User Modeling; Springer: Berlin/Heidelberg, Germany, 2007; pp. 314–318. [Google Scholar]
- Ali, M.; Al Machot, F.; Mosa, A.H.; Kyamakya, K. Cnn based subject-independent driver emotion recognition system involving physiological signals for adas. In Advanced Microsystems for Automotive Applications 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 125–138. [Google Scholar]
- Santamaria-Granados, L.; Munoz-Organero, M.; Ramirez-Gonzalez, G.; Abdulhay, E.; Arunkumar, N. Using deep convolutional neural network for emotion detection on a physiological signals dataset (AMIGOS). IEEE Access 2018, 7, 57–67. [Google Scholar] [CrossRef]
- Suhara, Y.; Xu, Y.; Pentland, A. Deepmood: Forecasting depressed mood based on self-reported histories via recurrent neural networks. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 715–724. [Google Scholar]
- Zhang, T. Multi-modal Fusion Methods for Robust Emotion Recognition using Body-worn Physiological Sensors in Mobile Environments. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 463–467. [Google Scholar]
- Tkalcic, M.; Odic, A.; Kosir, A.; Tasic, J. Affective labeling in a content-based recommender system for images. IEEE Trans. Multimed. 2012, 15, 391–400. [Google Scholar] [CrossRef]
- Chang, C.Y.; Zheng, J.Y.; Wang, C.J. Based on support vector regression for emotion recognition using physiological signals. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–7. [Google Scholar]
- Hassanien, A.E.; Kilany, M.; Houssein, E.H.; AlQaheri, H. Intelligent human emotion recognition based on elephant herding optimization tuned support vector regression. Biomed. Signal Process. Control 2018, 45, 182–191. [Google Scholar] [CrossRef]
- Wei, J.; Chen, T.; Liu, G.; Yang, J. Higher-order multivariable polynomial regression to estimate human affective states. Sci. Rep. 2016, 6, 23384. [Google Scholar] [CrossRef] [PubMed]
- Nicolaou, M.A.; Gunes, H.; Pantic, M. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. IEEE Trans. Affect. Comput. 2011, 2, 92–105. [Google Scholar] [CrossRef]
- Romeo, L.; Cavallo, A.; Pepa, L.; Berthouze, N.; Pontil, M. Multiple Instance Learning for Emotion Recognition using Physiological Signals. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Gibson, J.; Katsamanis, A.; Romero, F.; Xiao, B.; Georgiou, P.; Narayanan, S. Multiple instance learning for behavioral coding. IEEE Trans. Affect. Comput. 2015, 8, 81–94. [Google Scholar] [CrossRef]
- Lee, C.C.; Katsamanis, A.; Black, M.P.; Baucom, B.R.; Georgiou, P.G.; Narayanan, S.S. Affective state recognition in married couples’ interactions using PCA-based vocal entrainment measures with multiple instance learning. In International Conference on Affective Computing and Intelligent Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 31–41. [Google Scholar]
- Wu, B.; Zhong, E.; Horner, A.; Yang, Q. Music emotion recognition by multi-label multi-layer multi-instance multi-view learning. In Proceedings of the 22nd ACM International Conference on Multimedia, Mountain View, CA, USA, 18–19 June 2014; pp. 117–126. [Google Scholar]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. Adv. Neural Inf. Process. Syst. 1997, 10, 570–576. [Google Scholar]
- Fernandez, E.; Gangitano, C.; Del Fà, A.; Sangiacomo, C.O.; Talamonti, G.; Draicchio, F.; Sbriccoli, A. Oculomotor nerve regeneration in rats: Functional, histological, and neuroanatomical studies. J. Neurosurg. 1987, 67, 428–437. [Google Scholar] [CrossRef]
- Ibbotson, M.R.; Crowder, N.A.; Cloherty, S.L.; Price, N.S.; Mustari, M.J. Saccadic modulation of neural responses: Possible roles in saccadic suppression, enhancement, and time compression. J. Neurosci. 2008, 28, 10952–10960. [Google Scholar] [CrossRef]
- Picard, R.W. Future affective technology for autism and emotion communication. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3575–3584. [Google Scholar] [CrossRef] [PubMed]
- Greaney, J.L.; Kenney, W.L.; Alexander, L.M. Sympathetic regulation during thermal stress in human aging and disease. Auton. Neurosci. 2016, 196, 81–90. [Google Scholar] [CrossRef]
- Chen, M.; Shi, X.; Zhang, Y.; Wu, D.; Guizani, M. Deep features learning for medical image analysis with convolutional autoencoder neural network. IEEE Trans. Big Data 2017. [Google Scholar] [CrossRef]
- Creswell, A.; Arulkumaran, K.; Bharath, A.A. On denoising autoencoders trained to minimise binary cross-entropy. arXiv 2017, arXiv:1708.08487. [Google Scholar]
- Ap, S.C.; Lauly, S.; Larochelle, H.; Khapra, M.; Ravindran, B.; Raykar, V.C.; Saha, A. An autoencoder approach to learning bilingual word representations. Adv. Neural Inf. Process. Syst. 2014, 27, 1853–1861. [Google Scholar]
- Zhang, T.; El Ali, A.; Wang, C.; Zhu, X.; Cesar, P. CorrFeat: Correlation-based Feature Extraction Algorithm using Skin Conductance and Pupil Diameter for Emotion Recognition. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 404–408. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1247–1255. [Google Scholar]
- Chen, C.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 10–24. [Google Scholar] [CrossRef]
- Movahedi, F.; Coyle, J.L.; Sejdić, E. Deep belief networks for electroencephalography: A review of recent contributions and future outlooks. IEEE J. Biomed. Health Inform. 2018, 22, 642–652. [Google Scholar] [CrossRef]
- Liu, C.; Tang, T.; Lv, K.; Wang, M. Multi-Feature Based Emotion Recognition for Video Clips. In Proceedings of the ACM 2018 on International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 630–634. [Google Scholar]
- Chen, H.; Jiang, B.; Ding, S.X. A Broad Learning Aided Data-Driven Framework of Fast Fault Diagnosis for High-Speed Trains. IEEE Intell. Transp. Syst. Mag. 2020. [Google Scholar] [CrossRef]
- Jain, A.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef]
- Hewig, J.; Hagemann, D.; Seifert, J.; Gollwitzer, M.; Naumann, E.; Bartussek, D. A revised film set for the induction of basic emotions. Cogn. Emot. 2005, 19, 1095. [Google Scholar] [CrossRef]
- Bartolini, E.E. Eliciting Emotion with Film: Development of a Stimulus Set; Wesleyan University: Middletown, CT, USA, 2011. [Google Scholar]
- Park, C.Y.; Cha, N.; Kang, S.; Kim, A.; Khandoker, A.H.; Hadjileontiadis, L.; Oh, A.; Jeong, Y.; Lee, U. K-EmoCon, a multimodal sensor dataset for continuous emotion recognition in naturalistic conversations. arXiv 2020, arXiv:2005.04120. [Google Scholar] [CrossRef]
- Abadi, M.K.; Subramanian, R.; Kia, S.M.; Avesani, P.; Patras, I.; Sebe, N. DECAF: MEG-based multimodal database for decoding affective physiological responses. IEEE Trans. Affect. Comput. 2015, 6, 209–222. [Google Scholar] [CrossRef]
- Lin, T.T.; Chiu, C. Investigating adopter categories and determinants affecting the adoption of mobile television in China. China Media Res. 2014, 10, 74–87. [Google Scholar]
- McNally, J.; Harrington, B. How Millennials and Teens Consume Mobile Video. In Proceedings of the 2017 ACM International Conference on Interactive Experiences for TV and Online Video (TVX ’17), Hilversum, The Netherlands, 14–16 June 2017; ACM: New York, NY, USA, 2017; pp. 31–39. [Google Scholar] [CrossRef]
- O’Hara, K.; Mitchell, A.S.; Vorbau, A. Consuming Video on Mobile Devices. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’07), San Jose, CA, USA, 28 April–3 May 2007; ACM: New York, NY, USA, 2007; pp. 857–866. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Ferdinando, H.; Seppänen, T.; Alasaarela, E. Enhancing Emotion Recognition from ECG Signals using Supervised Dimensionality Reduction. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017; pp. 112–118. [Google Scholar]
- Gui, D.; Zhong, S.H.; Ming, Z. Implicit Affective Video Tagging Using Pupillary Response. In International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2018; pp. 165–176. [Google Scholar]
- Olson, D.H.; Russell, C.S.; Sprenkle, D.H. Circumplex Model: Systemic Assessment and Treatment of Families; Psychology Press: Hove, UK, 1989. [Google Scholar]
- Itten, J. Mein Vorkurs am Bauhaus; Otto Maier Verlag: Ravensburg, Germany, 1963. [Google Scholar]
- Schmidt, P.; Reiss, A.; Dürichen, R.; Van Laerhoven, K. Labelling Affective States “in the Wild” Practical Guidelines and Lessons Learned. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 654–659. [Google Scholar]
- Zhao, B.; Wang, Z.; Yu, Z.; Guo, B. EmotionSense: Emotion recognition based on wearable wristband. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 346–355. [Google Scholar]
- Meijering, E. A chronology of interpolation: From ancient astronomy to modern signal and image processing. Proc. IEEE 2002, 90, 319–342. [Google Scholar] [CrossRef]
- Daniels, R.W. Approximation Methods for Electronic Filter Design: With Applications to Passive, Active, and Digital Networks; McGraw-Hill: New York, NY, USA, 1974. [Google Scholar]
- Fleureau, J.; Guillotel, P.; Orlac, I. Affective benchmarking of movies based on the physiological responses of a real audience. In Proceedings of the IEEE 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 73–78. [Google Scholar]
- Chu, Y.; Zhao, X.; Han, J.; Su, Y. Physiological signal-based method for measurement of pain intensity. Front. Neurosci. 2017, 11, 279. [Google Scholar] [CrossRef] [PubMed]
- Karthikeyan, P.; Murugappan, M.; Yaacob, S. Descriptive analysis of skin temperature variability of sympathetic nervous system activity in stress. J. Phys. Ther. Sci. 2012, 24, 1341–1344. [Google Scholar] [CrossRef]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Chinchor, N. MUC-3 evaluation metrics. In Proceedings of the 3rd Conference on Message Understanding; Association for Computational Linguistics: Stroudsburg, PA, USA, 1991; pp. 17–24. [Google Scholar]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schlögl, A.; Birch, G.E. Comparison of evaluation metrics in classification applications with imbalanced datasets. In Proceedings of the IEEE 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 777–782. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Wickramasuriya, D.S.; Faghih, R.T. Online and offline anger detection via electromyography analysis. In Proceedings of the 2017 IEEE Healthcare Innovations and Point of Care Technologies (HI-POCT), Bethesda, MD, USA, 6–8 November 2017; pp. 52–55. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Kukolja, D.; Popović, S.; Horvat, M.; Kovač, B.; Ćosić, K. Comparative analysis of emotion estimation methods based on physiological measurements for real-time applications. Int. J. Hum. Comput. Stud. 2014, 72, 717–727. [Google Scholar] [CrossRef]
- Critchley, H.D.; Garfinkel, S.N. Interoception and emotion. Curr. Opin. Psychol. 2017, 17, 7–14. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Ed-doughmi, Y.; Idrissi, N. Driver fatigue detection using recurrent neural networks. In Proceedings of the 2nd International Conference on Networking, Information Systems & Security, Sochi, Russia, 12–15 September 2019; pp. 1–6. [Google Scholar]
- Lou, J.; Wang, Y.; Nduka, C.; Hamedi, M.; Mavridou, I.; Wang, F.Y.; Yu, H. Realistic facial expression reconstruction for VR HMD users. IEEE Trans. Multimed. 2019, 22, 730–743. [Google Scholar] [CrossRef]
- Genç, Ç.; Colley, A.; Löchtefeld, M.; Häkkilä, J. Face mask design to mitigate facial expression occlusion. In Proceedings of the 2020 International Symposium on Wearable Computers, Cancun, Mexico, 14–17 September 2020; pp. 40–44. [Google Scholar]
- Oulefki, A.; Aouache, M.; Bengherabi, M. Low-Light Face Image Enhancement Based on Dynamic Face Part Selection. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Berlin/Heidelberg, Germany, 2019; pp. 86–97. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Signals | Sensor | Sampling Rate | Physiological System |
|---|---|---|---|---|
| CASE | ECG | SA9306 | 1000 Hz | Autonomic Nervous System |
| BVP | SA9308M | 1000 Hz | ||
| EDA | SA9309M | 1000 Hz | ||
| RESP | SA9311M | 1000 Hz | ||
| TEMP | SA9310M | 1000 Hz | ||
| EMG | SA9401M-50 | 1000 Hz | Facial Nerve System | |
| MERCA | HR | Empatica E4 | 1 Hz | Autonomic Nervous System |
| BVP | Empatica E4 | 64 Hz | ||
| EDA | Empatica E4 | 4 Hz | ||
| TEMP | Empatica E4 | 4 Hz | ||
| Pupil dilation | Pupil Core | 10 Hz | Oculomotor Nerve System | |
| Saccadic amplitude | Pupil Core | 10 Hz | ||
| Saccadic velocity | Pupil Core | 10 Hz |
| Hyper-Parameter | Meaning | Value | |
|---|---|---|---|
| CASE | MERCA | ||
| L | Length of each instance | 2 s (100) | 2 s (64) |
| Dimension of latent space | L (200) | 2 × L (128) | |
| c | Size of conv-kernel | L/4 (25) | L/4 (16) |
| K | Dimension of corr features | L/2 (50) | L/2 (32) |
| Class | V-A Ratings (Binary) | V-A Ratings (3-Class) |
|---|---|---|
| Low | [1, 5) | [1, 3) |
| Neutral | - | [3, 6) |
| High | [5, 9] | [6, 9] |
| 4-Class | valence ratings | arousal ratings |
| High-High (HH) | [9, 5) | [9, 5) |
| High-Low (HL) | [9, 5) | [5, 1) |
| Low-Low (LL) | [5, 1) | [5, 1) |
| Low-High (LH) | [5, 1) | [9, 5) |
| 10-Fold (SD) | LOSOCV (SI) | |||||||
|---|---|---|---|---|---|---|---|---|
| CASE | MERCA | CASE | MERCA | |||||
| acc | f1 | acc | f1 | acc | f1 | acc | f1 | |
| valence-2 | 77.01% | 0.74 | 75.88% | 0.75 | 76.37% | 0.76 | 70.29% | 0.70 |
| arousal-2 | 80.11% | 0.79 | 74.98% | 0.74 | 74.03% | 0.72 | 68.15% | 0.67 |
| valence-3 | 61.83% | 0.61 | 63.89% | 0.63 | 60.15% | 0.53 | 53.88% | 0.53 |
| arousal-3 | 62.03% | 0.61 | 66.04% | 0.65 | 58.22% | 0.55 | 46.21% | 0.42 |
| 4-class | 69.36% | 0.67 | 72.16% | 0.70 | 55.08% | 0.53 | 51.51% | 0.50 |
| Deep Learning Methods | |||||
| 1D-CNN-2 | 1D-CNN-4 | LSTM | BiLSTM | CorrNet | |
| valence-2 | 58.26% (0.53) | 58.00% (0.52) | 48.58% (0.40) | 48.81% (0.41) | 76.37% (0.76) |
| arousal-2 | 51.38% (0.44) | 56.04% (0.48) | 51.29% (0.38) | 54.19% (0.42) | 74.03% (0.72) |
| valence-3 | 50.51% (0.38) | 49.31% (0.35) | 50.44% (0.35) | 51.58% (0.36) | 60.15% (0.53) |
| arousal-3 | 45.89% (0.31) | 47.11% (0.31) | 40.52% (0.31) | 42.12% (0.33) | 58.22% (0.55) |
| valence-2 | 58.13% (0.49) | 56.98% (0.48) | 56.01% (0.46) | 59.21% (0.46) | 70.29% (0.70) |
| arousal-2 | 58.11% (0.54) | 56.79% (0.53) | 51.37% (0.49) | 51.90% (0.50) | 68.15% (0.67) |
| valence-3 | 45.23% (0.32) | 43.50% (0.32) | 46.62% (0.31) | 46.56% (0.31) | 53.88% (0.53) |
| arousal-3 | 45.41% (0.32) | 46.56% (0.33) | 47.75% (0.32) | 47.70% (0.32) | 46.21% (0.42) |
| Classic Machine Learning Methods | |||||
| SVM | KNN | RF | GaussianNB | CorrNet | |
| valence-2 | 49.02% (0.42) | 50.76% (0.50) | 48.83% (0.48) | 50.99% (0.39) | 76.37% (0.76) |
| arousal-2 | 51.22% (0.42) | 51.13% (0.51) | 50.46% (0.49) | 52.08% (0.41) | 74.03% (0.72) |
| valence-3 | 42.52% (0.30) | 38.95% (0.37) | 37.62% (0.35) | 43.26% (0.31) | 60.15% (0.53) |
| arousal-3 | 50.18% (0.35) | 43.38% (0.40) | 42.29% (0.39) | 27.98% (0.15) | 58.22% (0.55) |
| valence-2 | 50.92% (0.39) | 51.27% (0.51) | 50.78% (0.50) | 48.34% (0.38) | 70.29% (0.70) |
| arousal-2 | 57.16% (0.45) | 51.34% (0.51) | 49.85% (0.49) | 52.59% (0.42) | 68.15% (0.67) |
| valence-3 | 44.89% (0.30) | 37.89% (0.36) | 38.48% (0.37) | 24.91% (0.15) | 53.88% (0.53) |
| arousal-3 | 44.49% (0.32) | 37.52% (0.37) | 38.44% (0.37) | 34.68% (0.24) | 46.21% (0.42) |
| CASE | MERCA | |||
|---|---|---|---|---|
| Valence | Arousal | Valence | Arousal | |
| BLS | 52.68% (0.50) | 56.53% (0.56) | 57.26% (0.57) | 57.88% (0.49) |
| IFL + BLS | 53.79% (0.46) | 57.80% (0.57) | 57.96% (0.56) | 58.78% (0.45) |
| CFE + BLS | 69.80% (0.68) | 66.41% (0.63) | 65.43% (0.65) | 63.82% (0.63) |
| IFL + CFE + BLS | 76.37% (0.76) | 74.03% (0.72) | 70.29% (0.70) | 68.15% (0.67) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; El Ali, A.; Wang, C.; Hanjalic, A.; Cesar, P. CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors. Sensors 2021, 21, 52. https://doi.org/10.3390/s21010052
Zhang T, El Ali A, Wang C, Hanjalic A, Cesar P. CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors. Sensors. 2021; 21(1):52. https://doi.org/10.3390/s21010052
Chicago/Turabian StyleZhang, Tianyi, Abdallah El Ali, Chen Wang, Alan Hanjalic, and Pablo Cesar. 2021. "CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors" Sensors 21, no. 1: 52. https://doi.org/10.3390/s21010052
APA StyleZhang, T., El Ali, A., Wang, C., Hanjalic, A., & Cesar, P. (2021). CorrNet: Fine-Grained Emotion Recognition for Video Watching Using Wearable Physiological Sensors. Sensors, 21(1), 52. https://doi.org/10.3390/s21010052