
Context-Aware Emotion Recognition in the Wild Using Spatio-Temporal and Temporal-Pyramid Models






Abstract
1. Introduction
2. Related Works
2.1. Image-Based Facial Expression Recognition
2.2. Video-Based Emotion Recognition
3. Proposed Idea
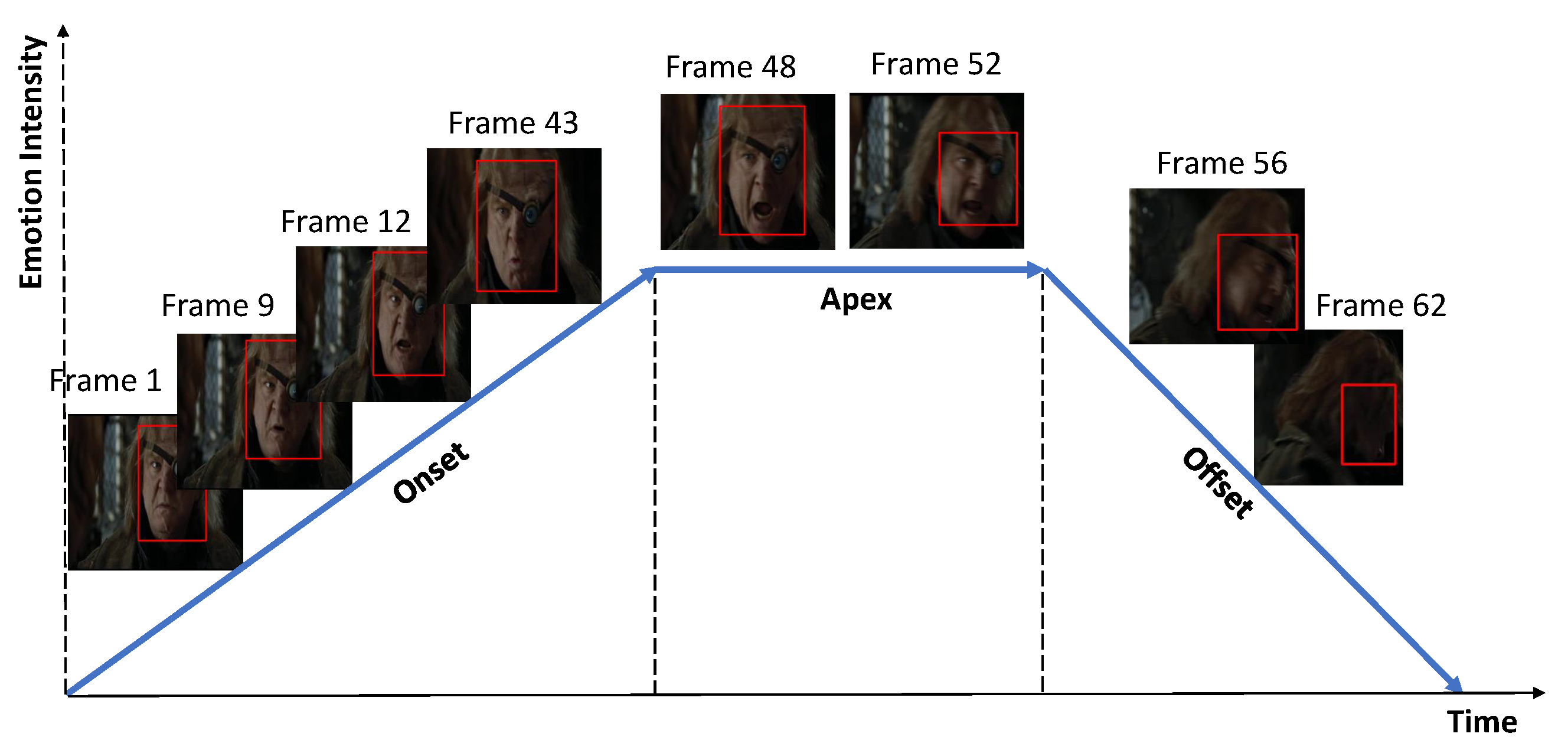
3.1. Problem Definition
3.2. Proposed System
3.3. Face and Person Tracking
3.3.1. Tracking Database of Tracked Faces and Persons
3.3.2. Face and Person Candidates
3.3.3. Face and Person Matching
3.3.4. Face and Person Update
3.4. Face Voting
3.5. Face and Context Feature Extraction
4. Network Architectures
4.1. Context Spatiotemporal LSTM-3DCNN Model
4.2. Context Temporal-Pyramid Model
5. Best Selection Ensemble
6. Experiments and Discussion
6.1. Datasets
6.1.1. Image-Based Emotion Recognition in the Wild
6.1.2. Video-Based Emotion Recognition in the Wild
6.2. Environmental Setup, Evaluation Metrics, and Experimental Setup
6.3. Experiments on Face and Context Feature Extraction Models
6.4. Experiments on Spatiotemporal Models
6.5. Experiments on Temporal-Pyramid Models
6.6. Experiments on Best Selection Ensemble
6.7. Discussion and Comparison with Related Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Corneanu, C.A.; Simon, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-Related Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef]
- Bänziger, T.; Grandjean, D.; Scherer, K.R. Emotion recognition from expressions in face, voice, and body: The Multimodal Emotion Recognition Test (MERT). Emotion 2009, 9, 691–704. [Google Scholar] [CrossRef]
- Martinez, B.; Valstar, M.F. Advances, Challenges, and Opportunities in Automatic Facial Expression Recognition. In Advances in Face Detection and Facial Image Analysis; Springer International Publishing: Cham, Switzerland, 2016; pp. 63–100. [Google Scholar] [CrossRef]
- Wieser, M.J.; Brosch, T. Faces in Context: A Review and Systematization of Contextual Influences on Affective Face Processing. Front. Psychol. 2012, 3. [Google Scholar] [CrossRef]
- Koelstra, S.; Pantic, M.; Patras, I. A Dynamic Texture-Based Approach to Recognition of Facial Actions and Their Temporal Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1940–1954. [Google Scholar] [CrossRef] [PubMed]
- Bernin, A.; Müller, L.; Ghose, S.; Grecos, C.; Wang, Q.; Jettke, R.; von Luck, K.; Vogt, F. Automatic Classification and Shift Detection of Facial Expressions in Event-Aware Smart Environments. In Proceedings of the 11th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018; pp. 194–201. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Kotsia, I.; Pitas, I. Facial Expression Recognition in Image Sequences Using Geometric Deformation Features and Support Vector Machines. IEEE Trans. Image Process. 2007, 16, 172–187. [Google Scholar] [CrossRef] [PubMed]
- Pantic, M.; Patras, I. Dynamics of facial expression: Recognition of facial actions and their temporal segments from face profile image sequences. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 433–449. [Google Scholar] [CrossRef]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on Local Binary Patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Liu, W.; Song, C.; Wang, Y.; Jia, L. Facial expression recognition based on Gabor features and sparse representation. In Proceedings of the 2012 12th International Conference on Control, Automation, Robotics and Vision, ICARCV 2012, Guangzhou, China, 5–7 December 2012; pp. 1402–1406. [Google Scholar] [CrossRef]
- Dhall, A.; Asthana, A.; Goecke, R.; Gedeon, T. Emotion recognition using PHOG and LPQ features. In Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, FG 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 878–883. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a Deep Face Recognition Net for Expression Recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017. [Google Scholar] [CrossRef]
- Klaeser, A.; Marszalek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the British Machine Vision Conference 2008, Leeds, UK, 1–4 September 2008; pp. 99.1–99.10. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikäinen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007. [Google Scholar] [CrossRef] [PubMed]
- Sikka, K.; Wu, T.; Susskind, J.; Bartlett, M. Exploring bag of words architectures in the facial expression domain. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar] [CrossRef]
- Jain, S.; Hu, C.; Aggarwal, J.K. Facial expression recognition with temporal modeling of shapes. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1642–1649. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Ji, Q. Capturing Complex Spatio-temporal Relations among Facial Muscles for Facial Expression Recognition. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3422–3429. [Google Scholar] [CrossRef]
- Lu, C.; Zheng, W.; Li, C.; Tang, C.; Liu, S.; Yan, S.; Zong, Y. Multiple Spatio-temporal Feature Learning for Video-based Emotion Recognition in the Wild. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA, 2018; Volume III, pp. 646–652. [Google Scholar] [CrossRef]
- Liu, C.; Tang, T.; Lv, K.; Wang, M. Multi-Feature Based Emotion Recognition for Video Clips. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA, 2018; pp. 630–634. [Google Scholar] [CrossRef]
- Kim, D.H.; Lee, M.K.; Choi, D.Y.; Song, B.C. Multi-modal emotion recognition using semi-supervised learning and multiple neural networks in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction—ICMI 2017, Glasgow, UK, 13–17 November 2017; ACM Press: New York, New York, USA, 2017; pp. 529–535. [Google Scholar] [CrossRef]
- Knyazev, B.; Shvetsov, R.; Efremova, N.; Kuharenko, A. Leveraging Large Face Recognition Data for Emotion Classification. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 692–696. [Google Scholar] [CrossRef]
- Bargal, S.A.; Barsoum, E.; Ferrer, C.C.; Zhang, C. Emotion recognition in the wild from videos using images. In Proceedings of the 18th ACM International Conference on Multimodal Interaction—ICMI 2016, Tokyo Japan, 12–16 November 2016; ACM Press: New York, NY, USA, 2016; pp. 433–436. [Google Scholar] [CrossRef]
- Zhu, X.; Ye, S.; Zhao, L.; Dai, Z. Hybrid attention cascade network for facial expression recognition. Sensors 2021, 21, 2003. [Google Scholar] [CrossRef]
- Shi, J.; Liu, C.; Ishi, C.T.; Ishiguro, H. Skeleton-based emotion recognition based on two-stream self-attention enhanced spatial-temporal graph convolutional network. Sensors 2021, 21, 205. [Google Scholar] [CrossRef] [PubMed]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-net: A lightweight cnn-based speech emotion recognition system using deep frequency features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef] [PubMed]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef]
- Dhall, A.; Roland Goecke, S.G.; Gedeon, T. EmotiW 2019: Automatic Emotion, Engagement and Cohesion Prediction Tasks. In Proceedings of the ACM International Conference on Mutimodal Interaction, Suzhou, China, 14–18 October 2019. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 4489–4497. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. In 50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Pérez, P.; Hue, C.; Vermaak, J.; Gangnet, M. Color-Based Probabilistic Tracking. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 661–675. [Google Scholar] [CrossRef]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar] [CrossRef]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Leibe, B., Matas, J., Welling, M., Sebe, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 2011–2023. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble Methods for Classifiers. In Data Mining and Knowledge Discovery Handbook; Springer: New York, NY, USA, 2005; pp. 957–980. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Schaul, T.; Zhang, S.; LeCun, Y. No more pesky learning rates. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Barrett, L.F.; Mesquita, B.; Gendron, M. Context in emotion perception. Curr. Dir. Psychol. Sci. 2011. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; ACM: New York, NY, USA, 2016; pp. 445–450. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, W.; Cui, Z.; Tang, C.; Zhang, T.; Zong, Y.; Sun, N. Multi-clue fusion for emotion recognition in the wild. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; ACM: New York, NY, USA, 2016; pp. 458–463. [Google Scholar] [CrossRef]
- Vielzeuf, V.; Pateux, S.; Jurie, F. Temporal multimodal fusion for video emotion classification in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 569–576. [Google Scholar] [CrossRef]
- Hu, P.; Cai, D.; Wang, S.; Yao, A.; Chen, Y. Learning supervised scoring ensemble for emotion recognition in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; ACM: New York, NY, USA, 2017; pp. 553–560. [Google Scholar] [CrossRef]
- Kaya, H.; Gürpınar, F.; Salah, A.A. Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Vielzeuf, V.; Kervadec, C.; Pateux, S.; Lechervy, A.; Jurie, F. An Occam’s Razor View on Learning Audiovisual Emotion Recognition with Small Training Sets. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA, 2018; pp. 589–593. [Google Scholar] [CrossRef]
- Fan, Y.; Lam, J.C.K.; Li, V.O.K. Video-based Emotion Recognition Using Deeply-Supervised Neural Networks. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA, 2018; pp. 584–588. [Google Scholar] [CrossRef]
- Nguyen, D.H.; Kim, S.; Lee, G.S.; Yang, H.J.; Na, I.S.; Kim, S.H. Facial Expression Recognition Using a Temporal Ensemble of Multi-level Convolutional Neural Networks. IEEE Trans. Affect. Comput. 2019, 33, 1. [Google Scholar] [CrossRef]
- Li, S.; Zheng, W.; Zong, Y.; Lu, C.; Tang, C.; Jiang, X.; Liu, J.; Xia, W. Bi-modality Fusion for Emotion Recognition in the Wild. In Proceedings of the 2019 International Conference on Multimodal Interaction, Jiangsu, China, 14–18 October 2019; ACM: New York, NY, USA, 2019; pp. 589–594. [Google Scholar] [CrossRef]
- Meng, D.; Peng, X.; Wang, K.; Qiao, Y. Frame Attention Networks for Facial Expression Recognition in Videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3866–3870. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Kim, S.; Park, J.; Sohn, K. Context-aware emotion recognition networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10142–10151. [Google Scholar] [CrossRef]
- Kumar, V.; Rao, S.; Yu, L. Noisy Student Training Using Body Language Dataset Improves Facial Expression Recognition. In Computer Vision—ECCV 2020 Workshops; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 756–773. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | AffectNet [16] | RAF-DB [15] | AFEW [33] | |||
|---|---|---|---|---|---|---|
| Training | Validation | Training | Validation | Training | Validation | |
| Angry | 24,882 | 500 | 705 | 162 | 133 | 64 |
| Disgust | 3803 | 500 | 717 | 160 | 74 | 40 |
| Fear | 6378 | 500 | 281 | 74 | 81 | 46 |
| Happy | 134,415 | 500 | 4772 | 1185 | 150 | 63 |
| Neutral | 74,874 | 500 | 2524 | 680 | 144 | 63 |
| Sad | 25,459 | 500 | 1982 | 478 | 117 | 61 |
| Surprise | 14,090 | 500 | 1290 | 329 | 74 | 46 |
| Total | 283,901 | 3500 | 12,271 | 3068 | 773 | 383 |
| No | Model | Pre-Train Weight | Affectnet [16] | RAF-DB [15] | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | ResNet 50 [18] | VGGFace2 [41] | 61.57% | 61.46% | 87.22% | 87.38% | 82.45% ± 09.20% | |
| 2 | Senet 50 [44] | VGGFace 1 [49] | 61.51% | 61.50% | 83.64% | 83.81% | ||
| 3 | Nasnet mobile [46] | ImageNet [50] | 59.20% | 58.88% | 80.74% | 81.01% | ||
| 4 | Densenet 201 [47] | ImageNet [50] | 59.31% | 58.91% | 83.08% | 83.23% | ||
| 5 | Inception Resnet [48] | Scratch | 62.51% | 62.41% | 81.23% | 81.79% | ||
| 6 | Xception [45] | Scratch | 56.26% | 56.38% | 80.90% | 81.03% | ||
| No | Method | Context | Feature | |||
|---|---|---|---|---|---|---|
| 1 | Spatiotemporal Model + Fix-Feature | Fix | 51.70% | 46.17% | ||
| 2 | Spatiotemporal Model + Nonfix-Feature | Nonfix | 52.22% | 48.26% | ||
| 3 | Spatiotemporal Model + Nonfix-Feature + Context | ✔ | Nonfix | 54.05% | 50.78% | 48.98% ± 32.28% |
| No | Method | Context | Level | |||
|---|---|---|---|---|---|---|
| 4 | Temporal-Pyramid Model + Level 3 | 3 | 55.87% | 52.76% | ||
| 5 | Temporal-Pyramid Model + Level 4 | 4 | 55.87% | 52.51% | ||
| 6 | Temporal-Pyramid Model + Level 0,1,2,3 | 0,1,2,3 | 55.87% | 54.06% | 51.85% ± 25.98% | |
| 7 | Temporal-Pyramid Model + Level 3 + Context | ✔ | 3 | 56.14% | 54.61% | |
| 8 | Temporal-Pyramid Model + Level 4 + Context | ✔ | 4 | 56.40% | 53.99% | |
| 9 | Temporal-Pyramid Model + Level 0,1,2,3 + Context | ✔ | 0,1,2,3 | 56.66% | 56.50% | 54.25% ± 16.63% |
| No | Method | |||
|---|---|---|---|---|
| 10 | Average Fusion | 57.70% | 55.00% | |
| 11 | Multi-modal Joint Late-Fusion [10] | 58.49% | 57.40% | |
| 12 | Best Selection Ensemble | 59.79% | 58.48% | 56.24% ± 23.26% |
| Authors | Method | Approach | Modality | Year | Accuracy |
|---|---|---|---|---|---|
| Fan et al. [55] | CNN + LSTM | Spatiotemporal (2D + T) | Visual | 2016 | 45.43% |
| C3D | Spatiotemporal (3D) | Visual | 39.69% | ||
| Yan et al. [56] | Trajectory Features + SVM | Geometry | Geometry | 2016 | 37.37% |
| CNN Features + Bi-directional RNN | Spatiotemporal (2D+T) | Visual | 44.46% | ||
| Fusion | Fusion | Visual + Geometry | 49.22% | ||
| Vielzeuf et al. [57] | VGG-LSTM | Spatiotemporal (2D+T) | Visual | 2017 | 48.60% |
| LSTM C3D | Spatiotemporal (3D) | Visual | 43.20% | ||
| ModDrop Fusion | Fusion | Visual | 52.20% | ||
| Hu et al. [58] | Face Features + Supervised Scoring Ensemble | Frame-Level | Visual | 2017 | 44.67% |
| Knyazev et al. [28] | Face Features + STAT (min,std,mean) + SVM | Frame-Level | Visual | 2017 | 53.00% |
| Weighted Average Score | Fusion | Visual | 55.10% | ||
| Kaya et al. [59] | CNN-FUN Features + Kernel ELMPLS | Spatiotemporal (3D) | Visual | 2017 | 51.60% |
| Lu et al. [25] | VGG-Face + BLSTM | Spatiotemporal (2D+T) | Visual | 2018 | 53.91% |
| C3D | Spatiotemporal (3D) | Visual | 39.36% | ||
| Weighted Average Fusion | Fusion | Visual | 56.05% | ||
| Liu et al. [26] | VGG16 FER2013 + LSTM | Spatiotemporal (2D+T) | Visual | 2018 | 46.21% |
| Face Features + STAT (min,std,mean) + SVM | Frame-Level | Visual | 51.44% | ||
| Landmark Euclidean Distance | Geometry | Geometry | 39.95% | ||
| Weighted Average Fusion | Fusion | Visual + Geometry | 56.13% | ||
| Vielzeuf et al. [60] | Max Score Selection + Temporal Pooling | Frame-Level | Visual | 2018 | 52.20% |
| Fan et al. [61] | Deeply-Supervised CNN (DSN) | Frame-Level | Visual | 2018 | 48.04% |
| Weighted Average Fusion | Fusion | Visual | 57.43% | ||
| Duong et al. [62] | CNN Features + LSTM | Spatiotemporal (2D+T) | Visual | 2019 | 49.30% |
| Li et al [63] | VGG-Face Features + Bi LSTM | Spatiotemporal (2D+T) | Visual | 2019 | 53.91% |
| Meng et al. [64] | Frame Attention Networks (FAN) | Frame-Level | Visual | 2019 | 51.18% |
| Lee et al. [65] | CAER-Net | Spatiotemporal (2D+T) | Visual | 2019 | 51.68% |
| Kumar et al. [66] | Noisy Student Training + Multi-level attention | Frame-Level | Visual | 2020 | 55.17% |
| Our method | Spatiotemporal model | Spatiotemporal (2D+T) | Visual | 54.05% | |
| Temporal-pyramid model | Frame-Level | Visual | 56.66% | ||
| Best Selection Ensemble | Fusion | Visual | 59.79% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do, N.-T.; Kim, S.-H.; Yang, H.-J.; Lee, G.-S.; Yeom, S. Context-Aware Emotion Recognition in the Wild Using Spatio-Temporal and Temporal-Pyramid Models. Sensors 2021, 21, 2344. https://doi.org/10.3390/s21072344
Do N-T, Kim S-H, Yang H-J, Lee G-S, Yeom S. Context-Aware Emotion Recognition in the Wild Using Spatio-Temporal and Temporal-Pyramid Models. Sensors. 2021; 21(7):2344. https://doi.org/10.3390/s21072344
Chicago/Turabian StyleDo, Nhu-Tai, Soo-Hyung Kim, Hyung-Jeong Yang, Guee-Sang Lee, and Soonja Yeom. 2021. "Context-Aware Emotion Recognition in the Wild Using Spatio-Temporal and Temporal-Pyramid Models" Sensors 21, no. 7: 2344. https://doi.org/10.3390/s21072344
APA StyleDo, N.-T., Kim, S.-H., Yang, H.-J., Lee, G.-S., & Yeom, S. (2021). Context-Aware Emotion Recognition in the Wild Using Spatio-Temporal and Temporal-Pyramid Models. Sensors, 21(7), 2344. https://doi.org/10.3390/s21072344