1. Introduction
More than one-third of the adult population in the United States is obese and this is linked to certain factors, such as physical inactivity, improper diet, family history, and the environment [
1]. As reported by “The GBD 2015 Obesity Collaborators” in 2015, a total of 107.7 million children and 603.7 million adults were obese [
2]. After analyzing data from 68.5 million people from 195 countries between 1990 and 2015, the research team concluded that the burden of “obesity and overweight” is related to high body-mass index (BMI), age, and gender. With the number of obese people doubling in two decades (from 1.3 million people obese globally in 1980 to double in 2008), unhealthy habits (such as consumption of tobacco and alcoholic beverages), unhealthy diet (such as energy drinks, consumption of excess salt and sugar, intake of high saturated fat, and discretionary foods), and physical inactivity are the major pillars of “obesity and overweight”. In 2016, more than 1.9 billion adults (39%) aged eighteen years and older were overweight, and of these, over 650 million (13%) were obese. In 2016, more than 340 million children and teenagers aged five to nineteen were overweight or obese, and in 2018, 40 million children under the age of five were overweight or obese. The universal predominance of “obesity and overweight” nearly tripled between 1975 and 2016. Juvenile obesity is linked to a higher chance of obesity, untimely death, and infirmity in adulthood [
3,
4,
5,
6]. The chronic conditions associated with “obesity and overweight” are considered as health care and social burdens. According to the latest study conducted by the “National Health and Nutrition Examination Survey (NHANES, 2007–2012)” on aggregated data (2007–2008, 2009–2010, and 2011–2012) collected from 15,208 adults with an age >=25, excluding pregnancy (n = 125) and incorrect noisy data (n = 827), a significant correlation was observed between sex, age, race, or ethnicity with “obesity and overweight” [
1]. Potential risk factors related to obesity/overweight may vary in children under age five, adolescents, adults, older people, and pregnant women.
The consequences of “Obesity and overweight”, which continues to be the foremost public health anxiety, increases the risk of the other four primary lifestyle diseases, such as cardiovascular diseases (CVD), cancers, diabetes (type II), and chronic lung diseases (chronic obstructive pulmonary disease (COPD), asthma). The burden of these diseases is extremely high among lower-income countries and populations. A total of 63% (36 million) of global death occurred in 2008 due to lifestyle diseases or non-communicable diseases (NCDs). Additionally, 80% of the 36 million dead people belonged to low- and middle-income classes, 13% were from high-income classes, and 29% of the total NCD deaths occurred below the age of sixty years. An increase of 10 million deaths annually on average due to NCDs has been observed from selected literature study. In 2016, the number increased to 56.9 million (71%), and by 2030, it is predicted to achieve 75%, with 88.5% death in developed countries and 65% death in developing countries. The risk for the stated lifestyle diseases increases with “body mass index” (BMI) in direct proportion. BMI is a number calculated by “Weight/Height
2” and is used to assess body composition [
3,
4,
5,
6,
7]. However, BMI is rather a bad indicator of percent of body fat, as BMI does not capture information on the mass of fat in different body sites and is highly dependent on age [
8]. In 2012, as identified by the Institute of Medicine, population-based obesity prevention strategies, such as physical activity, healthy diet, models of healthy social rules, and context-based and tailored recommendations by setting have the potential to combat “obesity and overweight” [
9]. Thus, health behavior change should be given precedence to circumvent severe damages.
An electronic coaching (“eCoaching”) system can empower people to manage a healthy lifestyle with early risk predictions and appropriate individualized recommendations. To develop an intelligent eCoach system for automated, personalized, contextual, and behavioral recommendations to achieve personal wellness goals, addressing obesity as a study case, we propose to (a) identify associated health risk factors, (b) perform data collection from identified controlled trials, (c) analyze the data, and (d) perform a predictive analysis with machine learning algorithms for future health risk predictions and behavioral interventions [
10,
11].
In this tutorial of ML models to identify the risk factors of overweight and obesity, we reviewed the performance of different machine learning algorithms (regression and classification) on existing datasets available in “Kaggle” and “UCI” so that we could create a list of risk factors associated with obesity/overweight with an appropriate quantitative analysis. The obtained result at the end of the study helped us to decide which risk factors health and wellness data would be collected on for our future research work—“eCoach behavioral interventions for obesity and overweight”.
A comparative performance analysis of different classification algorithms helped to hypothesize which model to use under which circumstances, such as data volume, binary class, or multi-class classification. “Childhood and elderly obesity”, “obesity and genetic profiling”, “obesity and pregnancy”, “nutrition”, “recommendation generation and goal evaluation”, and “robotic interaction” are beyond the scope of this paper. Our primary focus was obesity/overweight in adults. In this paper, we used the term “eCoaching” [
10,
11], which is our future research focus for behavioral intervention for the promotion of a healthy lifestyle targeting “obesity and overweight” as a study case. “eCoaching” as such is also not in the scope of this paper.
The main contributions of this paper are as follows:
- (1)
Identifying a set of risk factors associated with obesity/overweight following different established statistical methods on health datasets available in “Kaggle” [
12] and “UCI” [
13];
- (2)
Understanding how the identified risk factors are correlated to weight change with regression analysis and data visualization techniques;
- (3)
Reviewing various machine learning (ML) models for the classification and regression of the same selected datasets.
The remainder of the paper is structured as follows. In
Section 2, we summarize the methodology for the study selection. In
Section 3, we describe the related works along with a brief elaboration on how we searched, selected, and reviewed scientific literature in this context.
Section 4 presents the methodology utilized related to the data selection, data analysis, statistical analysis, ML model training and testing, ML model evaluation, model reuse, and the assessment of body composition in adults. In
Section 5, we discuss our analysis and findings.
Section 6 ends with the conclusions of the paper. This study can be considered as a tutorial on using ML models to identify the risk factors of overweight and obesity, because there is no prior hypothesis on any specific risk factors. To reproduce the results as discussed in
Section 5, codebase has been uploaded in GitHub as mentioned in Section “
Supplementary Materials”.
3. Related Work
“Obesity and overweight” remains as a significant public health problem not only in the USA but also in other countries for the last ten to fifteen years. It has prevailed among pre-school students and childbearing-age women at a low rate but is increasing among school students rapidly and scores high in adults, mainly in the group of girls or women with less education or schooling. In developed countries, it occurs mostly in vulnerable groups of the economically weak population, and the opposite occurs in less developed societies as household nutrition transition and underweight can coexist with weight increase. Obesity tends to decline with increasing income. In developed countries, women are suffering almost double when compared to men in the lower socioeconomic group [
18]. Projects have been conducted by different research groups on “obesity-related risk predictions with machine learning and deep learning approaches” to generate useful regression and classification models.
Singh et al. [
19] evaluated different multivariate regression methods and multilayer perceptron (MLP) feed-forward neural network models on the dataset obtained from a millennium cohort study (MCS) with over 90% accuracy to predict teenager BMI from previous BMI values. Twenty neurons in the hidden layer resulted in the lowest mean absolute error (MAE), with a mean training time of 1.63 s and a regularization factor of 0.9.
Bassam et al. [
20] performed a study on data obtained from the Kuwait Health Network (KHN) to build prognostic models to predict the future risk of diabetes (type II) using machine learning algorithms (logistic regression, k-nearest neighbor (KNN), support vector machine (SVM)) with a five-fold cross-validation technique. The study included age, sex, body mass index (BMI), pre-existing hypertension, family history of hypertension, and diabetes (type II) as baseline non-invasive parameters. As a result, KNN outperformed the other models, with area under the ROC (receiver operating characteristic) curve (AUC)values of 0.83, 0.82, and 0.79 for 3-, 5-, and 7-year prediction limits.
Meghana et al. [
21] used “auto-sklearn”, an automatic machine learning (AutoML) library for developing classifiers of CVDs. They experimented on both the heart UCI dataset and a cardiovascular disease dataset consisting of 70,000 records of patients and, as a result, AutoML outperformed traditional machine learning classifiers.
Seyla et al. [
22] studied how to classify obesity from dietary and physical activity patterns using machine learning classification algorithms and, as a result, support vector machine (SVM) outperformed other classifiers.
Jindal et al. [
23] performed ensemble machine learning approaches for obesity prediction based on the key determinants—age, height, weight, and “BMI”. The ensemble model utilized Random Forest (RF), generalized linear model, and partial least square, with a prediction accuracy of 89.68%. Grabner at al. performed a study on “National Health and Nutrition Examination Survey (NHANES)”, “National Health Interview Survey (NHIS)”, and “Behavioral Risk Factor Surveillance System (BRFSS)” datasets from the 1970s to 2008 to analyze the trend of BMI in the USA over time and across race, gender, socioeconomic background, and status (SES). It was observed that SES–BMI gradients were steadily more significant for women than for men.
Zheng et al. [
24] used binary logistic regression, improved decision tree (IDT), weighted k-nearest neighbor (KNN), and artificial neural network (ANN) on nine health-related behaviors from the 2015 Youth Risk Behavior Surveillance System (YRBSS) for the state of Tennessee in their study to predict obesity in high school students by focusing on both risk and protective factors. The result showed that the IDT model achieved an 80.23% accuracy and 90.74% specificity, the weighted KNN model achieved an 88.82% accuracy and 93.44% specificity, and the ANN model achieved an 84.22% accuracy and 99.46% specificity in the classification problem.
Dunstan et al. [
25] used three non-linear machine learning algorithms—SVM, Random Forest (RF), and Extreme Gradient Boosting (XGB) to predict obesity incidence at the country level, based on countrywide sales of a small subset of food and beverage classes. The study predicted that baked goods and flours, followed by cheese and sweet carbonated drinks, were the most pertinent food categories to predict obesity.
DeGregory et al. [
26] suggested in their literature review of “machine learning in obesity” that smart wearable wireless sensors, electronic medical health records, smartphone apps, and insurance data are rich sources of obesity-related data and are quite promising to treat and prevent obesity/overweight. Machine learning algorithms do have the potential to describe, classify, and predict obesity-related risks and consequences. They reviewed various machine learning methods, such as linear and logistic regression, artificial neural networks, deep learning, decision tree analysis, cluster analysis, principal component analysis (PCA), network science, and topological data analysis with the strengths and limitations of each method on the National Health and Nutrition Examination Survey to demonstrate the methodology, utility, and outcomes.
Golino et al. [
27] used a machine learning technique, namely, a classification tree, to investigate the prediction of increased blood pressure by body mass index (BMI), waist (WC) and hip circumference (HC), and waist–hip ratio (WHR) on 400 college students from 16-63 years of age (56.3% women). The model outperformed the traditional logistic regression model in terms of predictive power. The model presented a sensitivity of 80.86% and specificity of 81.22% in the training set and, respectively, 45.65% and 65.15% in the test sample for women and a sensitivity of 72% and specificity of 86.25% in the training set and, respectively, 58.38% and 69.70% in the test set for men.
The relationship between body fat and anthropometry is quite popular in obesity calculation. In the following three different ways, anthropometric measurements can be conducted: (a) BMI, (b) waist circumference, and (c) hip circumference to body fat. Pleuss et al. [
28] conducted a machine learning-based study in 3D image processing to obtain hundreds of anthropometric measurements within seconds after analyzing the images obtained from a 3D scanner.
Maharana et al. [
29] used the convolutional neural network (CNN) approach on approximately 150,000 high-resolution satellite images from Google Static Maps application program interface (API) to check associations between the built environment and obesity; their developed regression model concluded that obesity varied across studies and geographical contexts. The cross-sectional study was conducted on 1695 census areas in six cities, and the data on adult obesity prevalence were obtained from the Centers for Disease Control and Prevention’s 500 Cities project.
Obesity/overweight is a consequence of an energy imbalance in our body. Therefore, a proper diet is also essential along with a physical activity to balance calories intake and consumption. Pouladzadeh et al. [
30] proposed a deep learning (CNN)-based solution with 10,000 high-resolution food images for system training that would run on the smartphones as an application and would have the capability to take a picture of the food and calculate the amount of calorie intake automatically.
Machine learning and deep learning are natural extensions to conventional statistical methods. It has become an essential tool for the modern healthcare system. Whether an algorithm is high or low on the machine learning or deep learning continuum, the best rational methods must be utilized to ensure that the result is robust and valid. It is true in healthcare because these algorithms can affect the lives of millions of people [
2]. From the related work, we identified a list of machine learning (ML) and deep learning (DL) models and risk factors related to obesity/overweight, as described in
Table 2. In
Section 4, we only executed machine learning models on the available sample health data in a public repository. Execution of the deep learning models will be performed in a future study.
4. Methods
We utilized the established ML models in our research to perform a statistical analysis on available public datasets in “Kaggle”, [
12] and “UCI” [
13] to study the correlation between the identified risk factors and weight change. Subsequently, we evaluated the performance of different machine learning models for classification and regression. The overall process includes data collection, data pre-processing, statistical analysis and data visualization, algorithm selection for classification and feature predictions, model training and testing, model evaluation, and model reuse [
31,
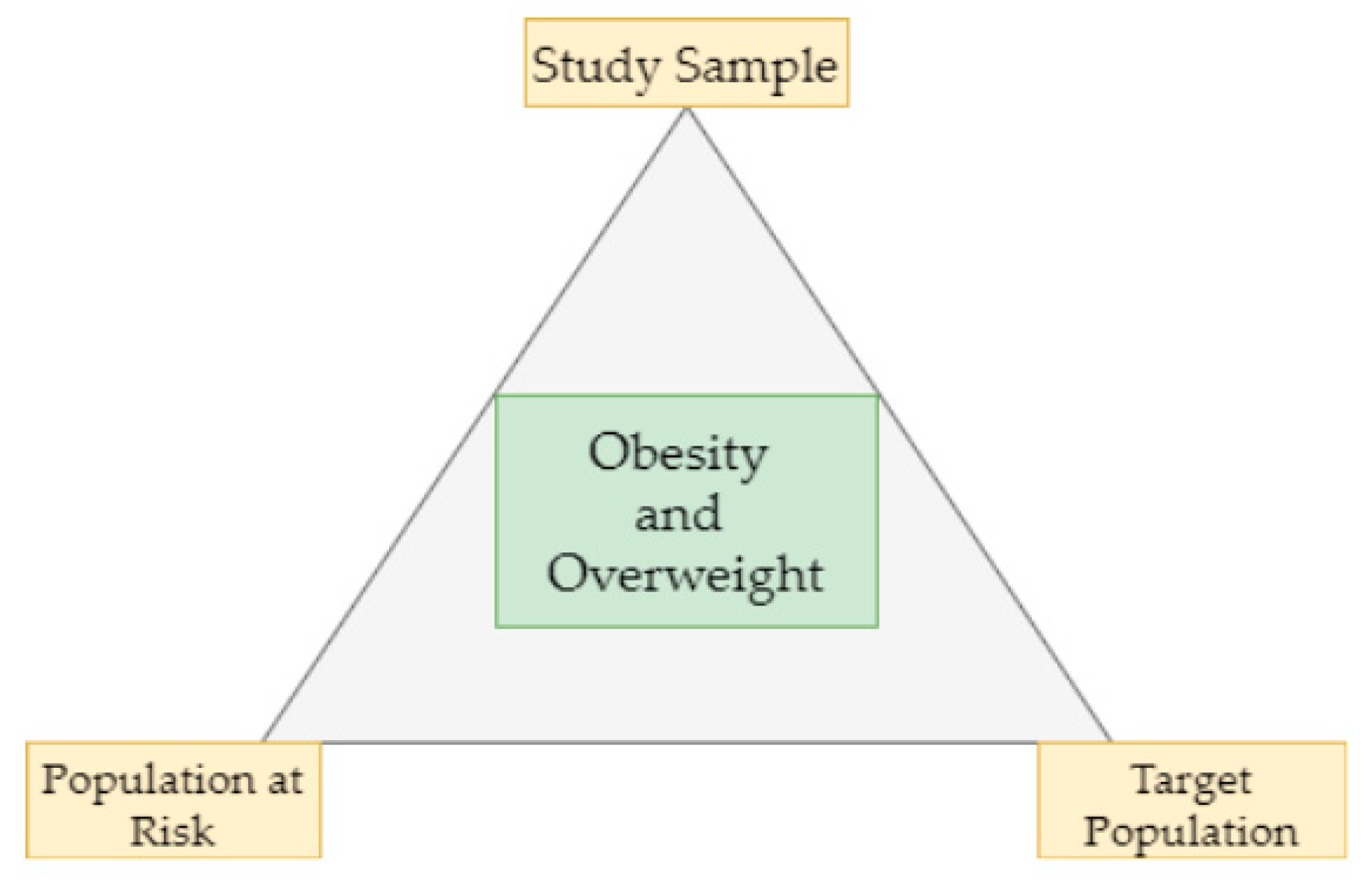
32]. In this study, we focused on three things—the population at risk, the study sample, and the target population (
Figure 2). We studied different samples of data and the corresponding target population, as described in
Section 4.1, on the population at risk in the age group of >20 and <60, excluding pregnancy and genetic factors. In this study, we have not predicted any brand-new risk factors.
4.1. Data Collection
We found in the selected literature study that BMI (height, weight); sex; age; environment; blood pressure; and behavioral risks, such as physical inactivity, improper diet, body energy imbalance, and habit are the foremost risk factors of obesity/overweight. Obesity/overweight gradually develops CVDs and diabetes type II in humans with deliberate economic decline. We hypothesize that obesity/overweight correlates with CVDs and diabetes and that some common risk factors exist, such as age, sex, cholesterol, lipid profile, sugar level, blood pressure, and family history.
In this study, we performed a regression analysis to visualize the trend of change in age, tobacco consumption, sweet beverages, economic condition, fast food, sleeping pattern, diet, blood pressure, blood glucose, lipid profile, adiposity, exercise, and family history in relation to obesity/overweight/weight change/CVDs/diabetes type II in the sample population, excluding genetic factors and pregnancy. Currently, we have no collected data that combine all the intended risk factors in a single dataset, eligible for this study. In our future research related to “behavioral interventions through eCoaching for obesity”, we have a plan to collect data related to identified risk factors from south Norway in both males and females with an age group of >20 and <60, excluding pregnancy and genetic factors. Thus, for our current study, we focused on existing health datasets. From the review, we identified three potential public reliable sources of data, namely “Kaggle” [
12], “UCI” [
13], and “Physio Net” [
34]. Our primary target was to find existing health-related data (obesity/overweight/CVDs/diabetes type II) from a reputed and reliable machine learning data repository; we found our required data in “Kaggle” and “UCI” with proper references. Most of the “UCI” data are available in “Kaggle”. After a proper background verification of the data, we selected 5 sets of data, as summarized in
Table 3. The explanation and source of the corresponding data are available in the “Kaggle” and “UCI” web portals.
The data obtained from both “Kaggle” and “UCI” are not from the same sources and the same target population. Their data volume is also different, but they contain most of the identified potential risk factors. Hence, combining the data into a single source is merely difficult. It might result in a very small single set of data after the removal of all unnecessary heterogeneous features, and the resulting dataset might be inappropriate for machine learning model training with cross-validation. That is the reason we processed the individual datasets separately with the identified risk-features obtained from the literature study. Our focused population age was >20 and <60, without pregnancy and genetic factors. A short description of the data is provided in
Table 4. The data from different sources have added a provision to find if there are any more risk factors associated with it. The selected data are classified into three categories—(a) obesity, (b) diabetes type II, and (c) CVDs. The identified key features, as described in
Table 4, were used for the machine learning model training for both regression and classification.
4.2. Data Processing
The collected data are categorized among two groups—continuous and categorical. The accumulated data in this research are labeled. We have used supervised machine learning models (classification and regression) for training and testing the accuracy. Several selected datasets are small, some are noisy, and the remaining contain a good volume of data to train the supervised machine learning model. Data mining was included to filter the data samples from each of the datasets and to discard samples containing outliers. Data mining involves pattern discovery, the calculation of feature association (and correlation), feature selection, classification, clustering, and outlier analysis.
During data cleaning, we removed data that were incomplete, beyond the age >20 and <60, and features such as pregnancy, having children/number of children. Data processing incorporates three steps, as stated below [
24,
25,
30,
31]:
Data preprocessing includes data integration, the removal of noisy data that are incomplete and inconsistent, data normalization and feature scaling, encoding of the categorical data, feature selection after correlation analysis, and split data for training and testing a machine learning model.
Training of a machine learning model and testing its accuracy with a k-fold cross validation.
Data postprocessing includes pattern evaluation, pattern selection, pattern interpretation, and pattern visualization.
In this experiment, we have used python 3.x language libraries for the data processing, as described in
Table 5. We set up a “Python” environment using an anaconda distribution and used spyder IDE for developing the python-based “data science” applications.
4.3. Statistical Analysis
Statistical analysis of the selected datasets involves the following methods, as stated in
Table 6. According to the central limit theorem, when a bunch of random numbers is added together, it produces a normal distribution. The normal distribution can be described entirely by the two parameters µ (mean) and σ (standard deviation). As always, the mean is the center of the distribution, and the standard deviation is the measure of the variation around the mean. Let random variable “X” follow the normal or gaussian distribution (bell curve) if the probability of the density function of “X” is presented by
and the area under the normal curve is 1% or 100%.
The probability of normal distribution can be calculated through the standard normal distribution “Z” (). The Z-score transformation is a linear transformation with µ = 0 and σ = 1, is used for feature scaling. A normality test is used to check whether a distribution is gaussian. The normal distribution is symmetric about µ. This leaves that the area to the left of µ is equal to the area to the right of µ.
Hypothesis testing is a statistical method that is used in achieving statistical decisions using trial data. A hypothesis test estimates two mutually exclusive statements about a population to ascertain which statement is supported by the trial data. The critical parameter of hypothesis testing is the null hypothesis (
H0) that tells us there is nothing different or significant about the data. On the contrary, the alternative hypothesis (
Ha) directly contradicts H
0. The confidence factor or value of significance (α) is used to decide whether to accept or reject an
H0. The value of α is usually kept as 0.05% or 5%, as 100% accuracy is impossible to achieve whether accepting or rejecting
H0. Popular widely used hypothesis testing methods, a short description, and the required sample size are demonstrated in
Table 7. A hypothesis test can be either a one-tailed test or a two-tailed test. For each of the testing methods, the resulting probability value (
P-value) is compared with “α” to accept or reject a null hypothesis. However, it may carry type-I error (false positive) or type-II error (false negative) [
31,
32,
39].
Example:
H0:
Sample looks “Gaussian”.
Ha:
Sample does not look like “Gaussian” and α = 5% or 0.05.
“Shapiro-Wil”k, “D” Agostino’s K^2, and “Anderson-Darling” test calculate the P-value to decide if a sample looks like gaussian (P-value > α = 0.05) or not (P-value < α = 0.05). Covariance (COV(x,y)) is a property of a function to retain its form when its variables are linearly transformed. It helps to measure the correlation (r
xy) that measures the strength of the linear relationship between two variables.
“Sign” shows the direction of the relationship among two variables x and y.
Table 8 shows the meaning of different |r| values. If two variables are strongly correlated, it is recommended to select any one of them during feature selection. Pearson’s correlation coefficient is used to summarize the strength of the linear relationship between two variables in normal distribution and Spearman’s correlation is used to calculate the non-linear relationship between two variables [
31,
32,
39].
A quantile analysis divides the distribution into four parts—min, Q1 (25%), median, Q3 (75%), and max. The interquartile range (IQR = Q3 − Q1) is a measure of data dispersion and used to check if data (X) are outliers or not. Data (X) are outliers if:
4.4. Model Training and Testing
In this study, we have selected machine learning algorithms for the classification and regression analysis, as described in
Table 9 and explained in
Section 5.
The steps used to train and test a machine learning model are described below:
Load data.
Data pre-processing:
- ⚬
remove missing values from the loaded data;
- ⚬
encode categorical features;
- ⚬
check distribution of data and features;
- ⚬
remove data from outliers;
- ⚬
remove data redundancy;
- ⚬
correlation analysis among features and feature scaling if required. We compared the correlation between features and removed one of two features that had a correlation higher than 0.9;
- ⚬
column/feature selection based on the p-value with the help of “regressor_OLS”;
- ⚬
visualize the distribution of selected features;
- ⚬
shuffle the data.
Split data for training and testing (80:20) with some random state.
Machine learning model selection, as described in
Table 6, based on regression or classification problem statement and building the model.
K-fold cross validation on data (in our study, K = 5).
Perform a prediction.
Evaluate the model performance with metrics, as described in
Section 4.5, following discrimination and calibration-based performance measures.
Perform model tuning with a “grid search” parameter optimization technique.
Note: a. Selection of learning rate (α): if too small then it slows the convergence in the gradient descent (GD), and if too large then it slows the convergence in GD or the GD may diverge.
b. Let “m” training samples have “n” features. If there are too many features (m <= n), then delete some features or use regularization with the regularization factor ‘λ’.
c. If ‘λ’ is too large then the algorithm fails to eliminate overfitting, or even sometimes underfits and the GD fails to converge. ‘λ’ (∞) increases to lead a high bias and decreases to lead a high variance.
d. Underfitting results in a high bias and overfitting leads to a high variance.
e. If a learning algorithm is suffering from a high bias, more training data will not help much. If a learning algorithm is suffering from high variance, more training data is likely to help.
f. C = (1/λ) = line separation effect in SVM: large “C” leads to a lower bias and high variance, small ‘C’ leads to a higher bias and low variance.
g. Gradient descent follows the convex optimization technique with upper bound (L) and lower bound (µ) on the curvature f:
4.5. Model Evaluation
The developed machine learning models for classification and regression are evaluated with the following metrics: [
28,
31,
32,
40]
Classification metrics: accuracy score, classification report, and confusion matrix.
Regression metrics: mean absolute error (MAE), mean squared error (MSE), and R2-score.
Calibration: Goodness-of-fit statistics with a Brier score metric for binary classification. The Brier score is a metric which is a combination of the calibration loss and refinement loss. Calibration loss is the mean squared deviation from the empirical probabilities derived from the slope of the ‘Receiver Operating Characteristic (ROC)’ segments. Refinement loss is the expected optimal loss as measured by the area under the optimal cost curve [
41].
The classification report includes precision, recall, and F1-score. A confusion matrix is a table with two dimensions, “actual” and “predicted”, and both the dimensions have “true positives (TP)”, “true negatives (TN)”, “false positives (FP)”, “false negatives (FN)”.
TP—both actual class and predicted class of data point is 1.
TN—both actual class and predicted class of data point is 0.
FP—actual class of data point is 0 and predicted class of data point is 1.
FN—actual class of data point is 1 and predicted class of data point is 0.
Formulas for calculating the classification metrics are stated as below:
Accuracy tells us how close a measured value is to the real one. Precision determines how close a measured value is to the real one. Recall or sensitivity defines the total number of positives (actual) returned by the machine learning model.
MAE is the easiest error metric used in the regression problem following the formula:
MSE squares the difference of actual and predicted output before adding them all instead of using the absolute value following the formula:
An R
2 regression metric has been used for an explanatory purpose to provide an indication of the fitness in the predicted output values to the actual output values. It is calculated with a formula with the numerator as the MSE and the denominator as the variance in Y values.
Calibration implies the measure of the agreement between observations and predictions. It is a post-processing technique to enhance the error distribution of a predictive ML model. It helps to understand how the resulting errors are distributed and how well the probability estimations are made. Though many ML techniques are good in overall results, they might have a bad evaluation of the distribution of error. To develop a calibrated classification model, we followed two steps—probability prediction, and prediction of calibration with a reliability diagram/calibration plot. A reliability diagram/calibration plot describes how well the forecast probabilities are calibrated with a comparative frequency of what was observed (Y-axis) versus the predicted probability frequency (X-axis). The better calibrated or more reliable a forecast, the closer the points might appear along the main diagonal from the bottom left to the top right of the plot. The position of the points or the curve relative to the diagonal might help to interpret the probabilities. For example, (a) below the diagonal, the model has over-forecast as the probabilities are too large; (b) above the diagonal, the model has under-forecast as the probabilities are too small. An “S-shaped” curve expresses pessimistic tendencies, over-forecasting low probabilities and under-forecasting high probabilities. There are two calibration techniques, as follows—sigmoid or Platt’s scaling, and isotonic scaling/regression [
40,
42,
43,
44]. We used the “Brier Score” [
41] for the binary class classification as a metric which indicates the smaller the Brier score, the better the calibration. To calibrate the binary scores/probabilities, we reduced the multiclass problems to a binary classification problem. Then, we compared the relativity curves of different classification problems and followed by choosing the best model based on the minimum Brier score for both the “sigmoid” and “isotonic” methods. A well-calibrated classifier is a probabilistic classifier for which the output of the “predict_proba” [
41] method can be directly inferred as a confidence level. Platte scaling is very efficient when the distortion/bias in the predicted probabilities is sigmoid (“S”) shaped, else, we can use isotonic regression. For large training sets, isotonic regression is useful.
where
f(
t) = the probability that was forecast and
o(
t) = the actual outcome of the event at instance
t.
Note: the logic to convert a multiclass problem to a binary classification problem is as follows: if (BMI ≤ 24.9) then the predicted class will be “class-0” or “class-1”.
4.6. Model Store and Reuse
We saved our final trained machine learning model in a file and restored it to use it again either by comparing the model with other models or by testing the model on new or updated data. The process of storing the model is called serialization, and restoring the model is called deserialization. It can be done in two ways, as described in
Table 10. The pickled model can be stored in the database for distributed access.
4.7. Assessment of Body Composition
The assessment of body composition is performed with two popular techniques—(a) BMI and (b) waist–hip ratio. A waist–hip ratio of > 0.85 and 1.00 are associated with a greater than average risk in women and men, respectively. Here, the BMI has been used to categorize different weight groups in adults of twenty years or older for both men and women [
26]:
Weak: BMI < 18.5.
Normal weight: BMI is 18.5 to 24.9.
Overweight: BMI is 25 to 29.9.
Obesity class I: BMI >= 30.0 and BMI <= 34.9.
Obesity class II: BMI >= 35.0 and BMI <= 39.9.
Obesity class III: BMI >= 40.0.
In this study, we considered “obesity class II” and “obesity class III” as extreme obesity. This study excluded pregnant women and genetic factors.
5. Results and Discussions
The “BMI” dataset has 500 records with four features—“gender”, “height”, “weight”, and “index”. The dataset has no missing or incomplete data. The “index” determines whether a person is extremely weak (0), weak (1), normal weight (2), overweight (3), obese (4), or extremely obese (5). We added the extra feature “BMI” (weight/height2) to the dataset in pre-processing, and later it was removed during the model training due to high correlation. The remaining features are chosen based on the hypothesis testing (p-value). The correlation in
Figure 3 exhibits a strong correlation between “BMI” and “index” (obesity-determining class), and it is appropriate in accordance with
Section 4.7. We used the dataset for a multiclass classification to group people according to their body composition. For the multiclass classification, we used “SVM” with linear and radial basis function (RBF) kernel, “Naïve Bayes” (gaussian and current), “Decision Tree (DT)” (gini and gain), “RF” (estimators 50 and 100), and “KNN” (neighbor 2 and 6) models, but “SVM” with linear kernel provided the best classification, with an accuracy = 0.95, MSE = 0.08, R
2 = 0.96, and MAE = 0.06 with the 5-fold cross-validation technique. The best parameters of SVM are {’C’: 0.01, ’gamma’: 0.001, ‘kernel’: linear}, with a score of 95% following the grid search method. The resultant performance metrics of “SVM” are depicted in
Figure 4.
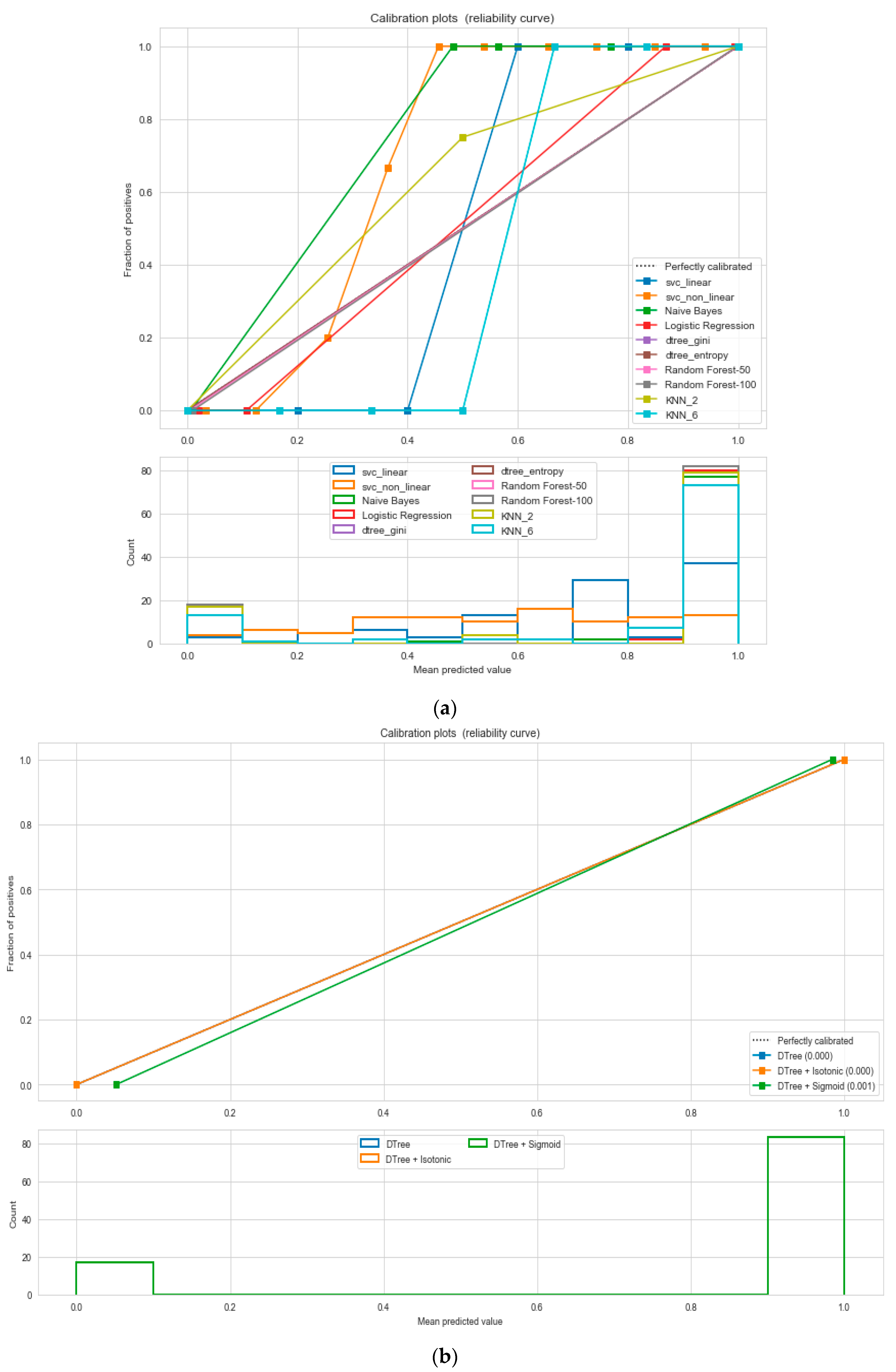
For the calibrated classification technique, we converted the multiclass “BMI” dataset to a binary classification problem by adding an extra prediction feature class “Risk” following the logic that if (extremely weak, weak, normal weight) then “Risk” = 0, else 1. Both the uncalibrated “SVM” and “Decision Tree” classifiers performed the best in binary classification. In contrast, the calibrated “Decision Tree” classifier performed the best, as depicted in the
Figure 5, following the “isotonic” calibration method with a Brier score = 0.000. It shows that the uncalibrated and calibrated “Decision Tree” classifiers give equal performance.
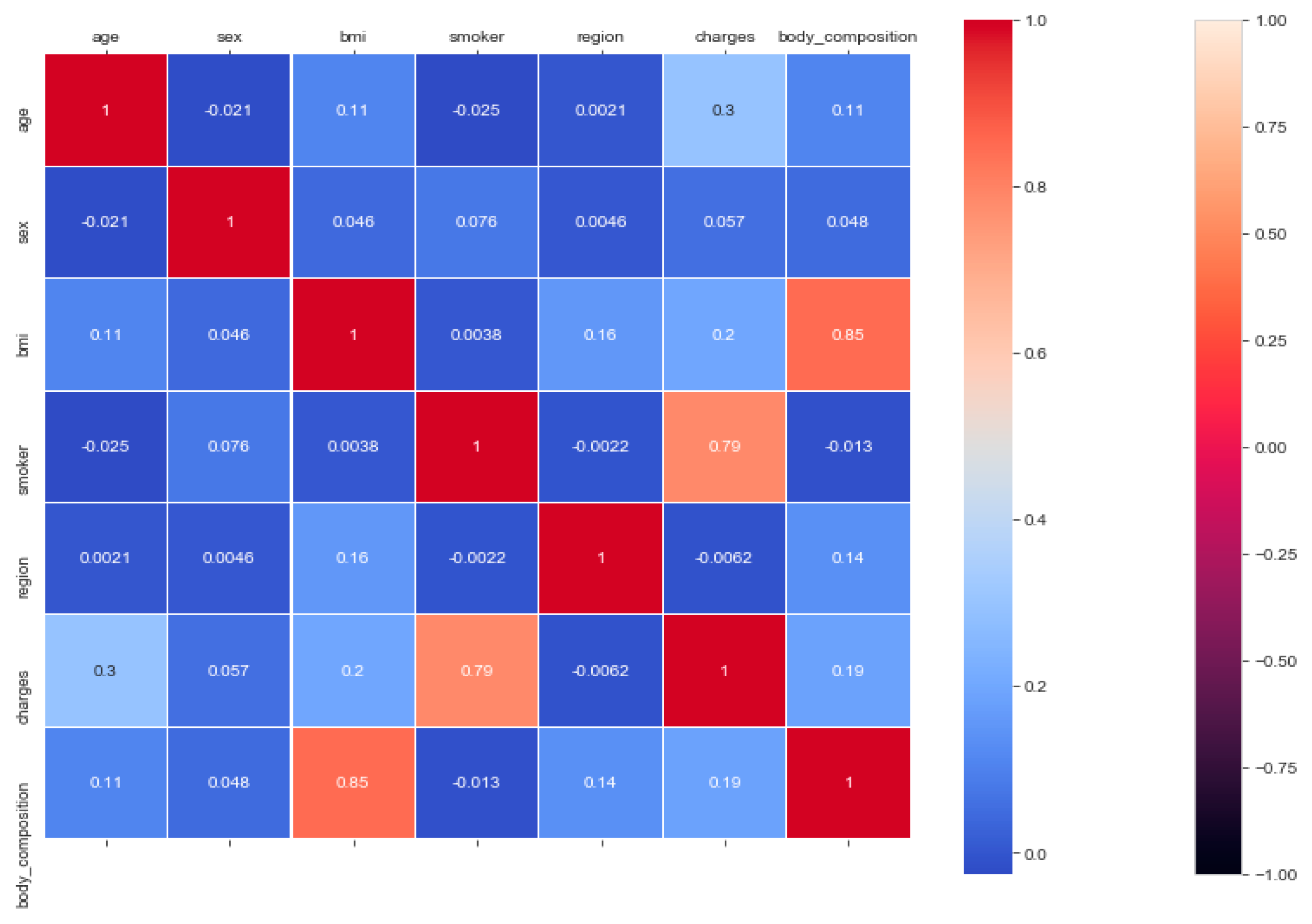
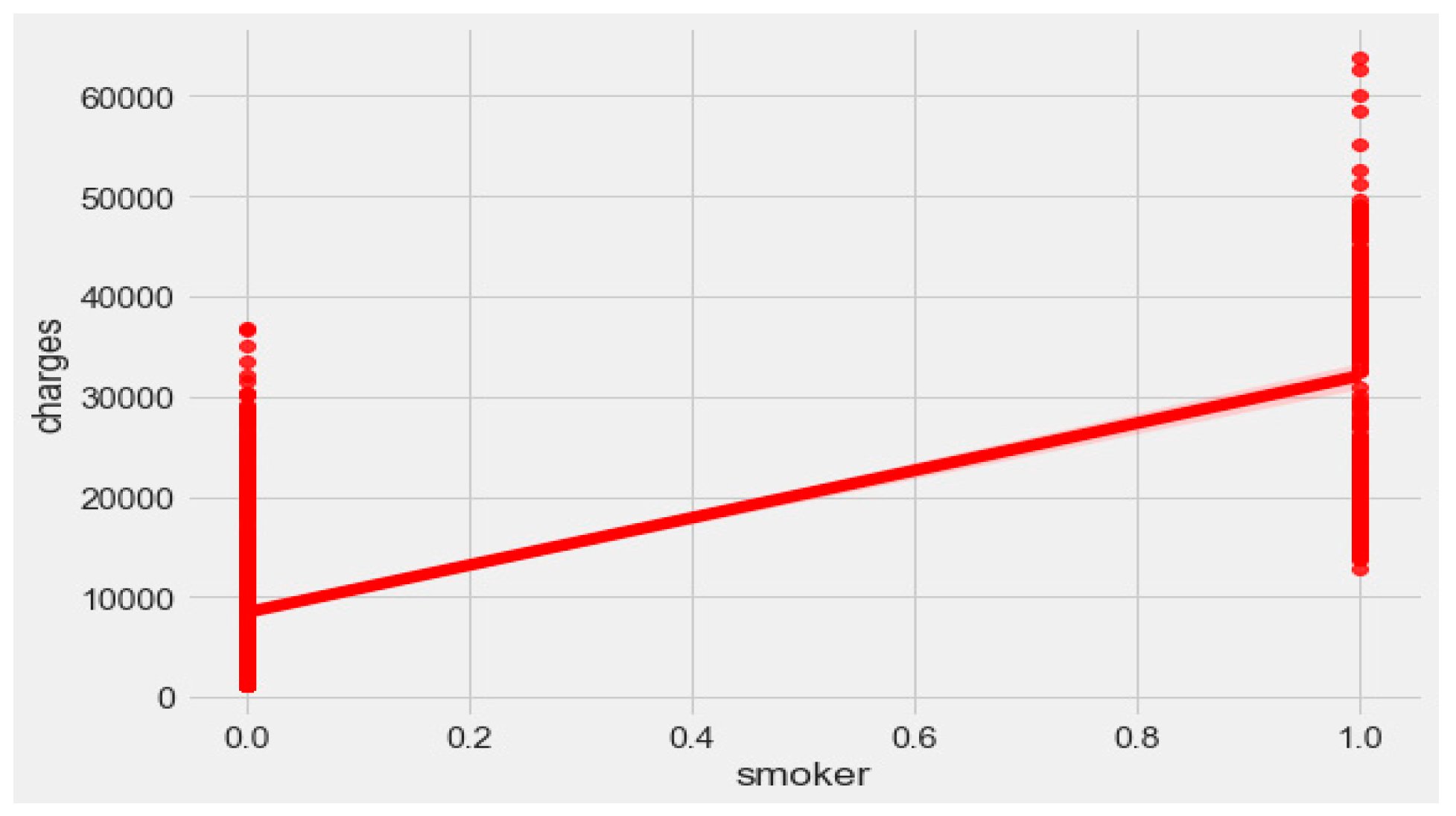
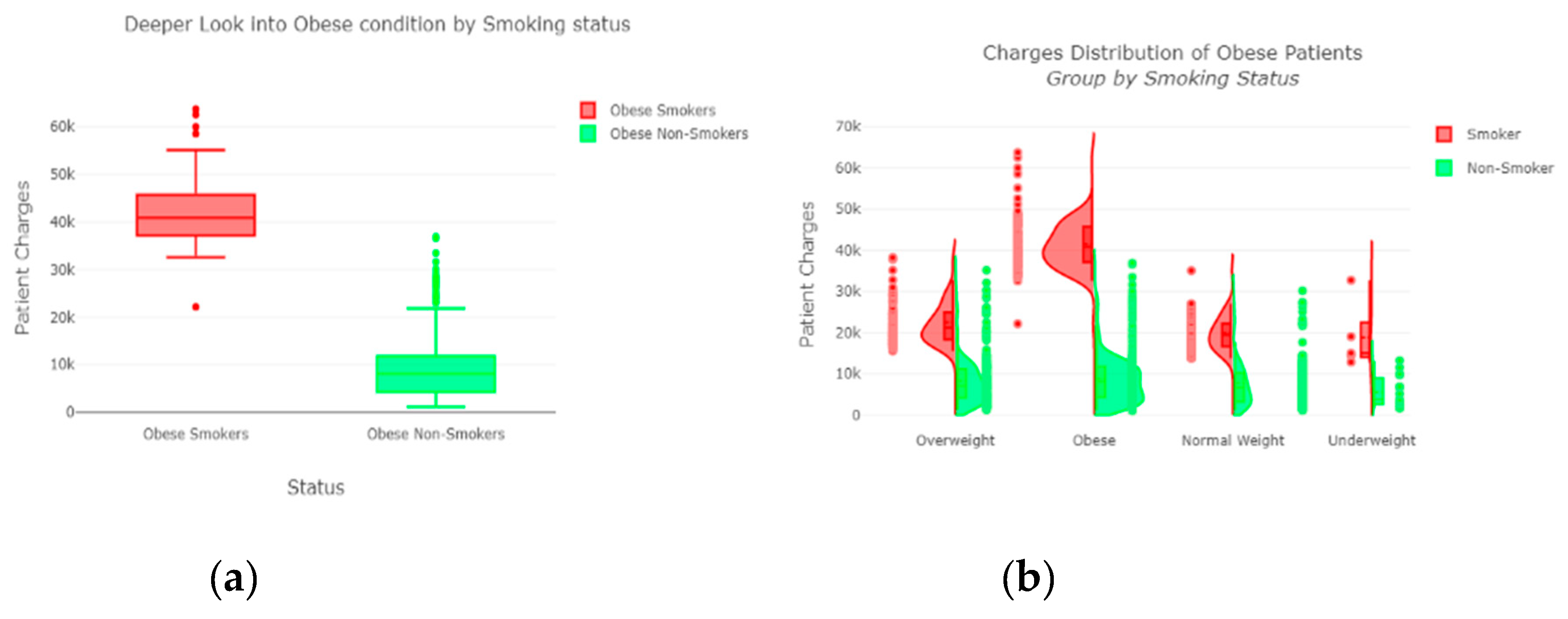
The “insurance” dataset has 1338 records and seven features—“age”, “sex”, “BMI”, “children”, “smoker”, “region”, and “charges”. During data pre-processing, we included records with an age >20 and <60 and excluded the feature “children”. It resulted in 1058 records. Then, we added the extra feature “body_composition” based on the “BMI” feature, and the feature classified the records among four classes—underweight (0), normal weight (1), overweight (2), and obese (3). We encoded the categorical features such as sex, smoker, and region. We found a strong correlation between “smoking” and “charge”, with |r| = 0.79, as depicted in
Figure 6 and
Figure 7. Smoking is one of the most frequently negative health behaviors in humans. Negative health behavior has a great impact on weight change, as found in the literature study. If the charge of the insurance increases, then it might lead to an adverse effect on personal or family financial planning, and it is one of the consequences of lifestyle diseases as predicted by WHO 4]. Thus, excess smoking does not only create a powerful negative impact on health but also creates a passive negative impact on economic position. We used insurance data for both the classification and regression analysis.
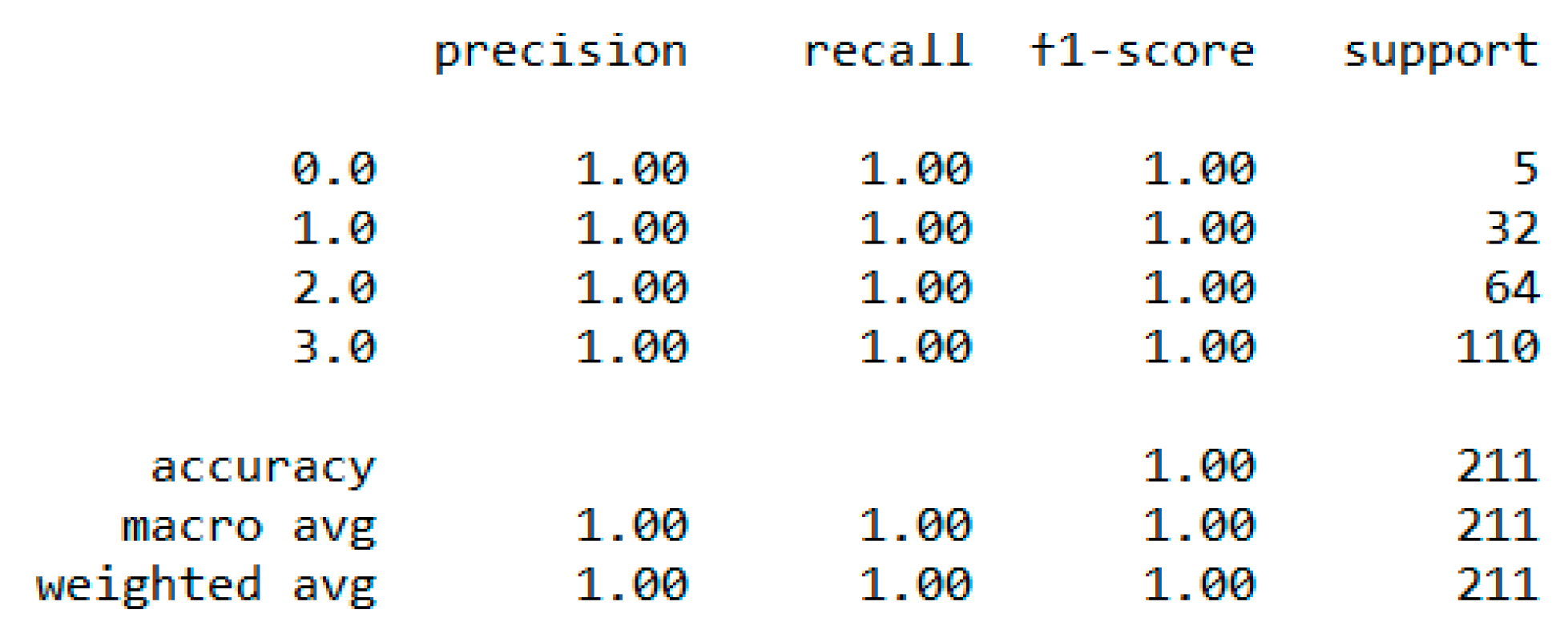
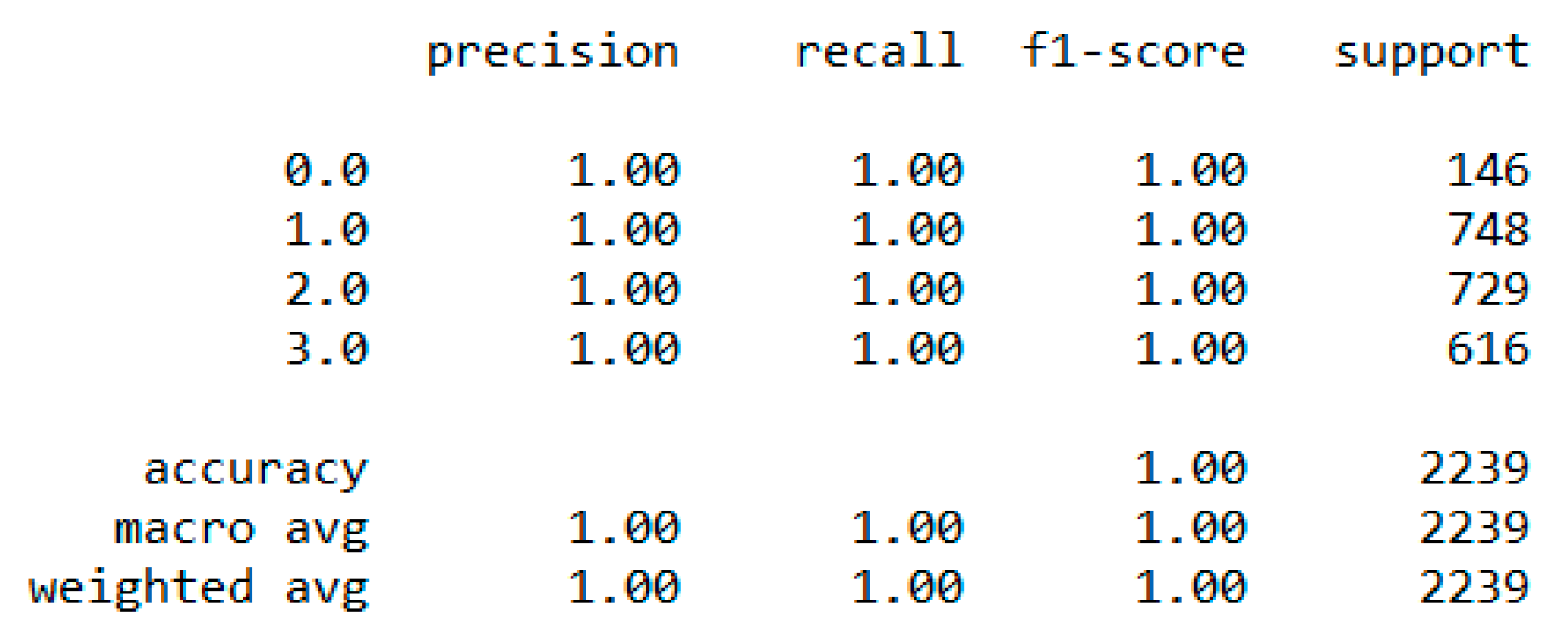
In classification, we used “body_composition” as a predicted feature, and the “Decision Tree” model performed the best with a 99.64% accuracy as depicted in
Figure 8.
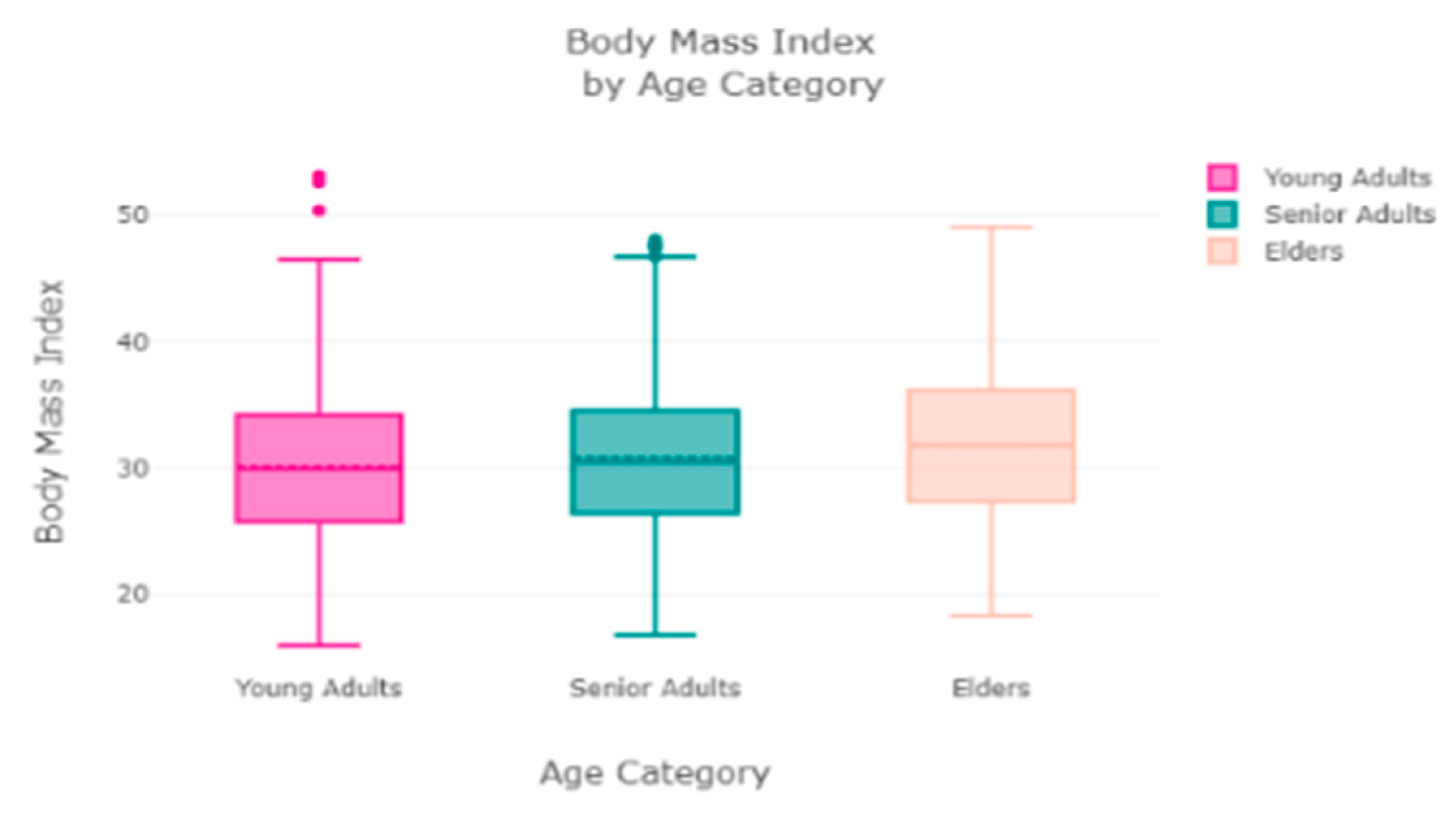
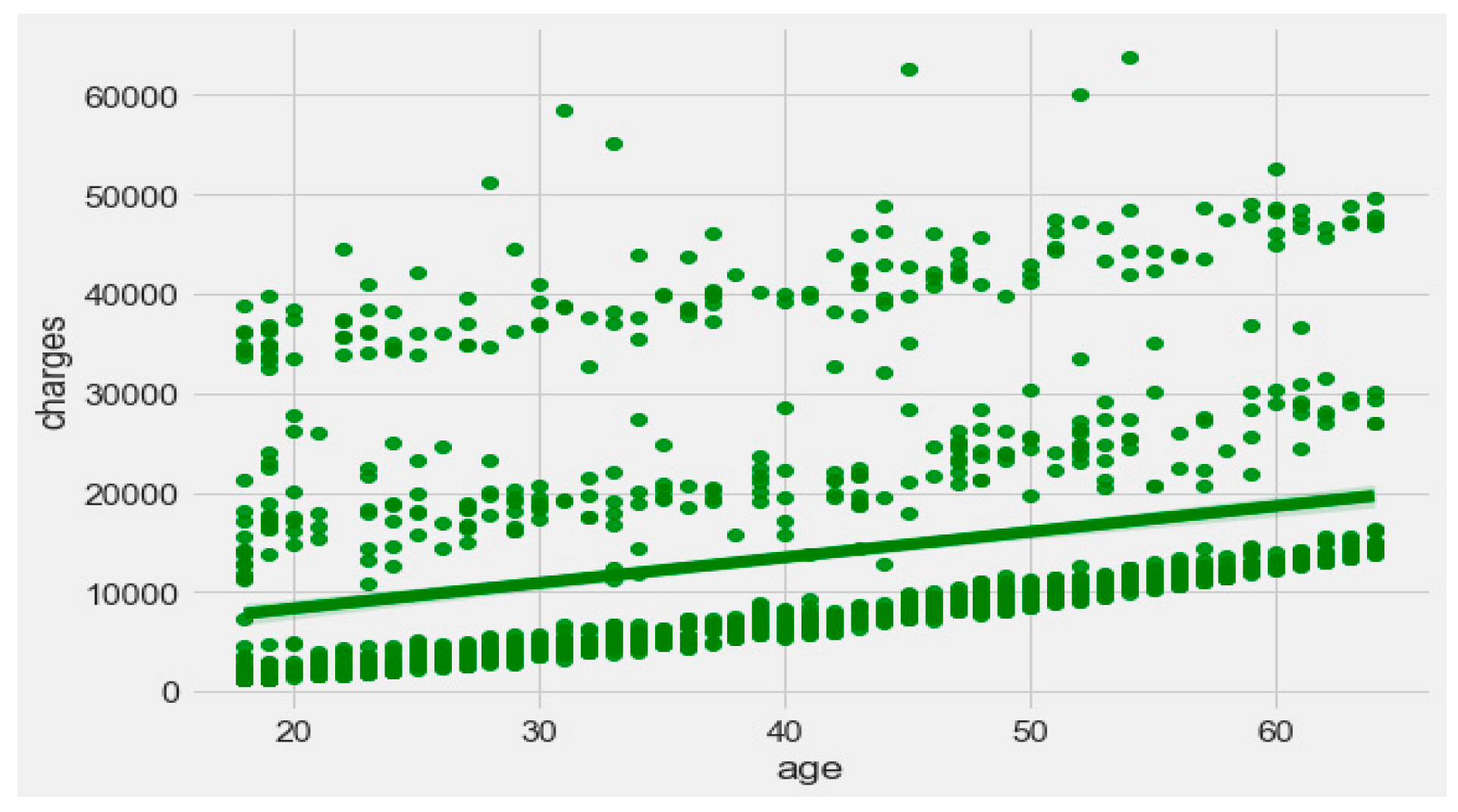
The finest parameters of the “Decision Tree” classifier are {best criterion: entropy, best max_depth: 24, best number of components: 6, min_samples_leaf=1, min_samples_split=2, and splitter=’best’}, following the grid search method. For the regression, we used “charges” as a predicted feature and performed the hypothesis testing with “ANOVA” results to retain Ha= {a significant change between the three age categories (young adults, senior adults, elders) with “BMI”}, with a P-value of 0.001, 0.060, and 0.000, respectively. The boxplot analysis in
Figure 9 exhibits that “BMI” increases with “age”, and average “BMI”s for each of the groups are in the obesity range, which is a risk. Therefore, the body composition changes with increasing age both in males and females, and this is a risk to humans. The pattern of the data demonstrates that the charge of the insurance increases with increasing age, as depicted in
Figure 10. From
Figure 9, it is evident that BMI increases with age. Hence, with a transitive relation, it is evident that the charge of the insurance increases with increasing BMI. The change in insurance charge with smoking condition and age is depicted in
Figure 11.
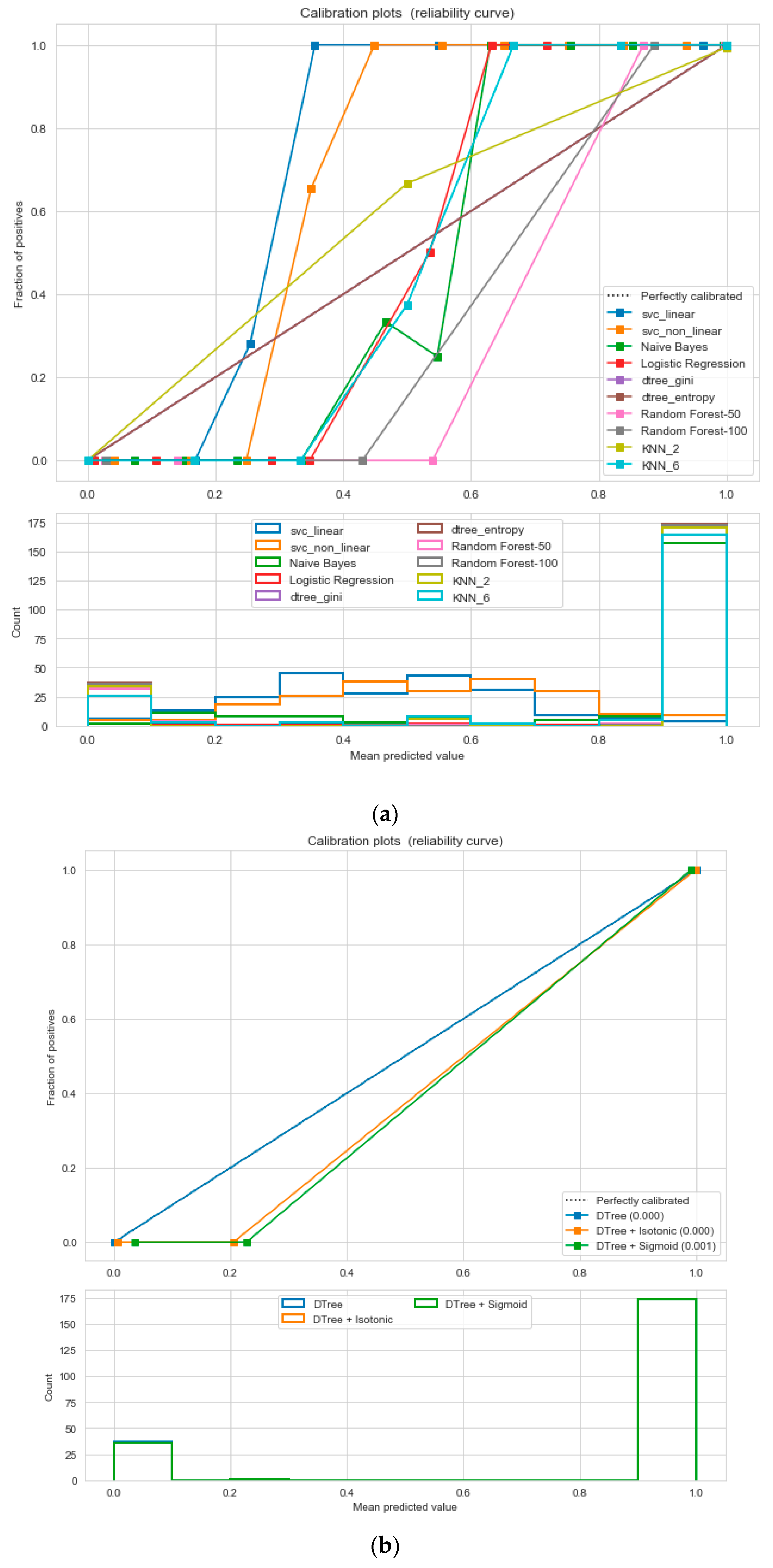
For the calibrated classification, we converted the multiclass “insurance” dataset to a binary classification problem following the logic that if (underweight, normal weight) then “body_composition” = 0, else 1. The uncalibrated “SVM”, “Decision Tree”, and “Random Forest” classifiers performed the best in the binary classification. On the contrary, the calibrated “DecisionTree” classifier outperformed the other classifiers, as depicted in
Figure 12, following the “isotonic” calibration method with a Brier score = 0.000, where the Brier scores for “SVM”, and “RF” were 0.216 and 0.001, respectively. It demonstrates that the uncalibrated and calibrated “Decision Tree” classifiers give a similar performance. After a performance comparison of the regression algorithms, we found that “Random Forest” performed the best, with an 81% accuracy. The finest parameters for the “Random Forest” regressor were {’bootstrap’: True, ’max_depth’: 50, ’max_features’: 5, ’min_samples_leaf’: 6, ’min_samples_split’: 8, ’n_estimators’: 100} following the grid search method.
The “Eating-health-module” dataset has 11,212 records and many features, but we included the following important features after the correlation study—“erbmi”, “eusoda”, “eusnap”, “euincome2”, “eugenhth”, “erincome”, “eudietsoda”, “euffyday”, “eufdsit”, “eufastfdfrq”, “ertseat”, “eudrink2, “eueat”, “euexfreq”, “euexercise”, “eufastfd”, “eumeat”, “eumilk”, “eustores”, “eustreason”, “euwic”. During the data pre-processing, we included records with a value > 1 and excluded features such as “erincome” due to high correlation [
37]. It resulted in 11,192 records and 21 columns. Then, we added an extra feature, “body_composition”, based on the “erbmi” feature, and the feature classified the records among four classes—underweight (0), normal weight (1), overweight (2), and obese (3). We processed the data with ML classification algorithms to classify the records based on the “body_composition” feature, and the “Decision Tree” classifier performed the best with a 99.7% accuracy, as depicted in
Figure 13. The finest parameters of the “Decision Tree” classifier were {best criterion: entropy, best max_depth: 36, best number of components: 13, min_samples_leaf=1, min_samples_split=2, and splitter=’best’} following the grid search method. The regression analysis of the selected feature revealed that sweet beverages, economic condition, fast food, sleeping, meat and milk consumption, a drinking habit, and exercise have a sharp impact on growing obesity in humans.
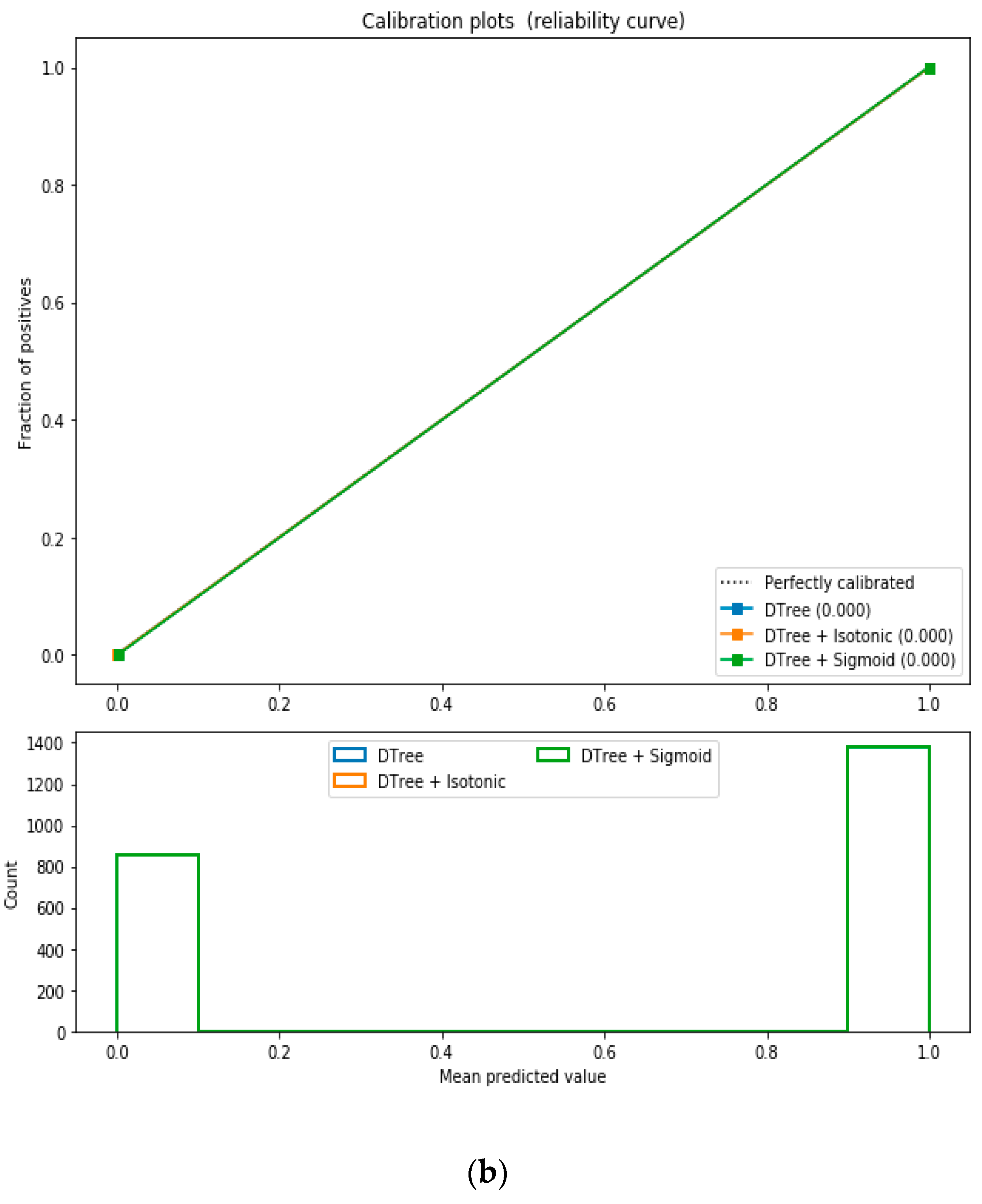
For calibration-based classification, we converted the multiclass “Eating-health-module” dataset to a binary classification problem following the logic that if (underweight, normal weight) then “body_composition” = 0, else 1. The uncalibrated “SVM”, “Decision Tree”, and “Random Forest” classifiers performed the best in the binary classification. On the contrary, the calibrated “DecisionTree” classifier outperformed the other classifiers, as depicted in
Figure 14, following the “isotonic” and “sigmoid” calibration methods with a Brier score = 0.000. It illustrates that both the calibrated and uncalibrated “Decision Tree” classifiers give same performance.
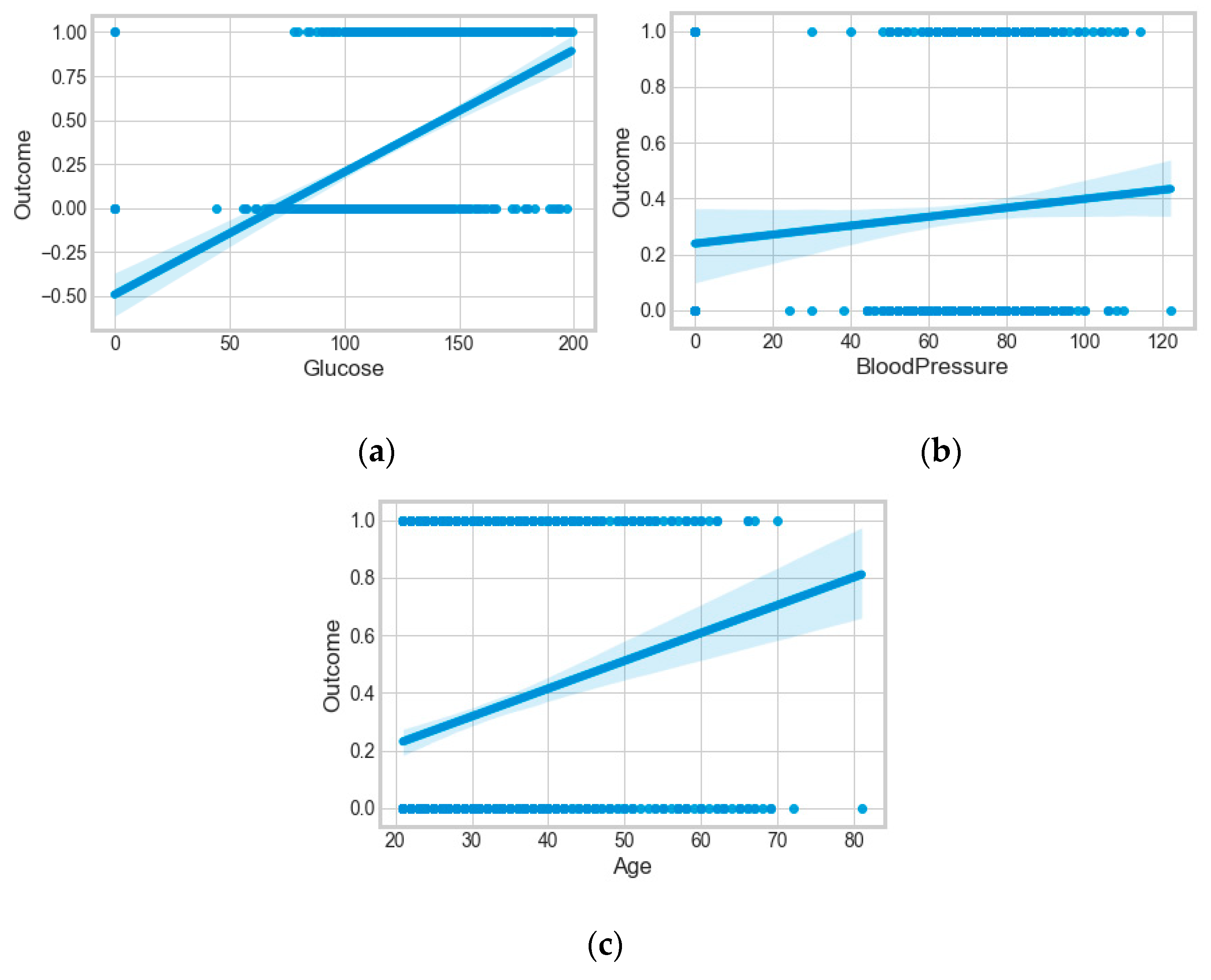
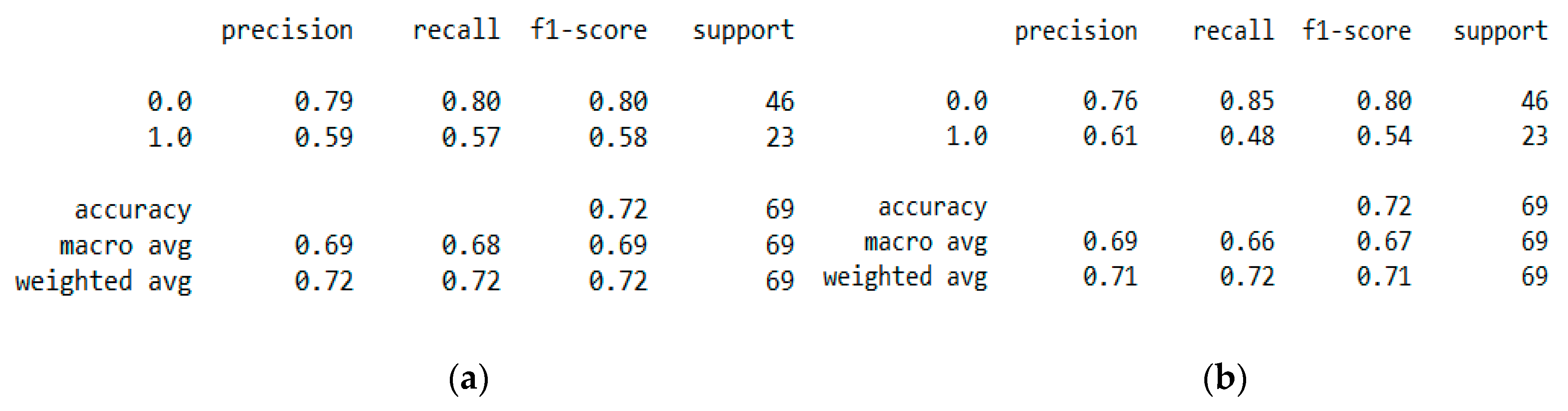
The “Pima-Indians-diabetes-database” dataset has 768 records and nine features: “pregnancies”, “glucose”, “blood pressure”, “skin thickness”, “insulin”, “BMI”, “diabetes pedigree function”, “age”, and “outcome”. During the data pre-processing, we included records with age >20 and <60 and excluded features such as “pregnancies”, “insulin”, and “skin thickness”.
It resulted in 736 records. The regression analysis of the dataset resulted in a positive dependency in
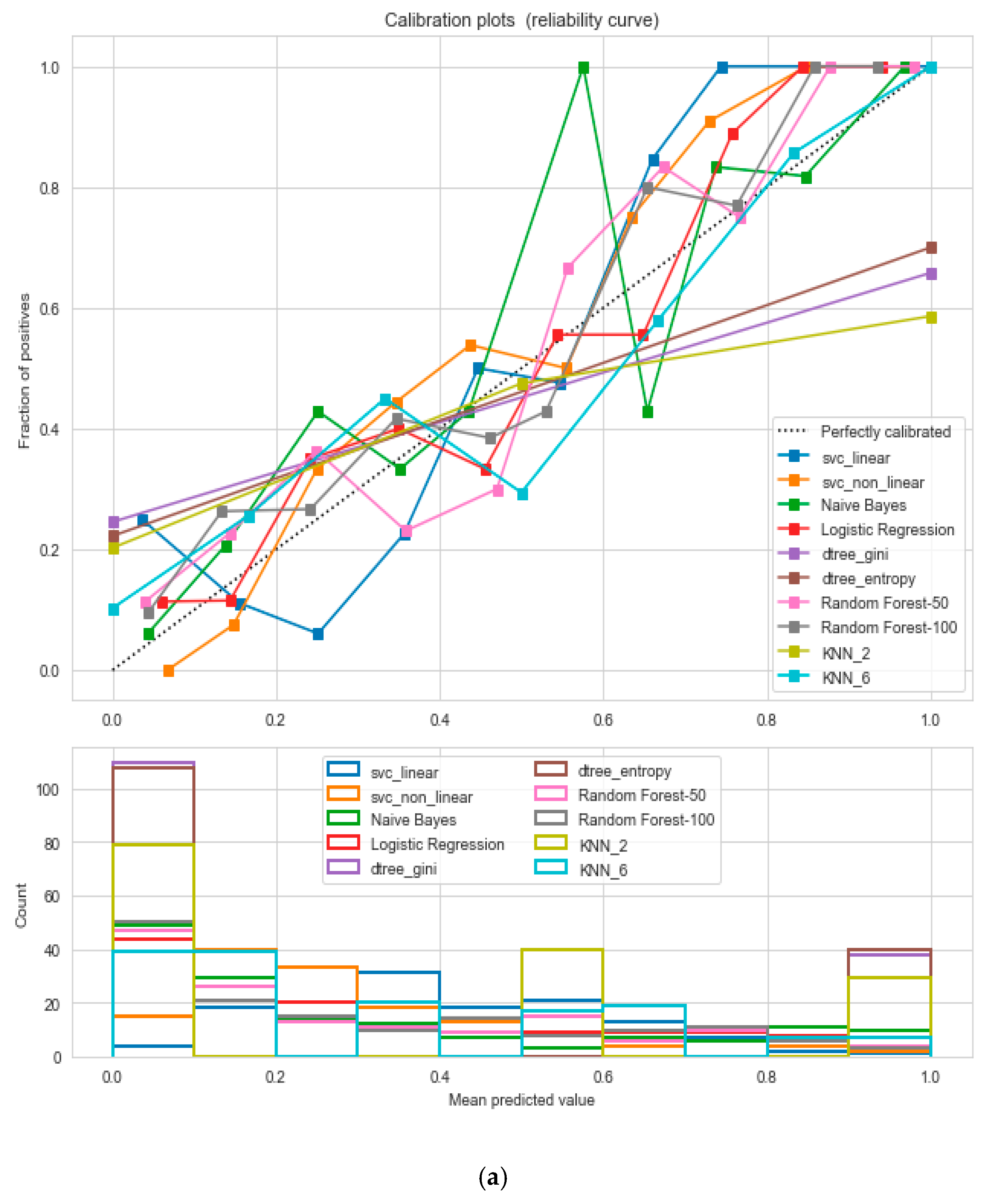
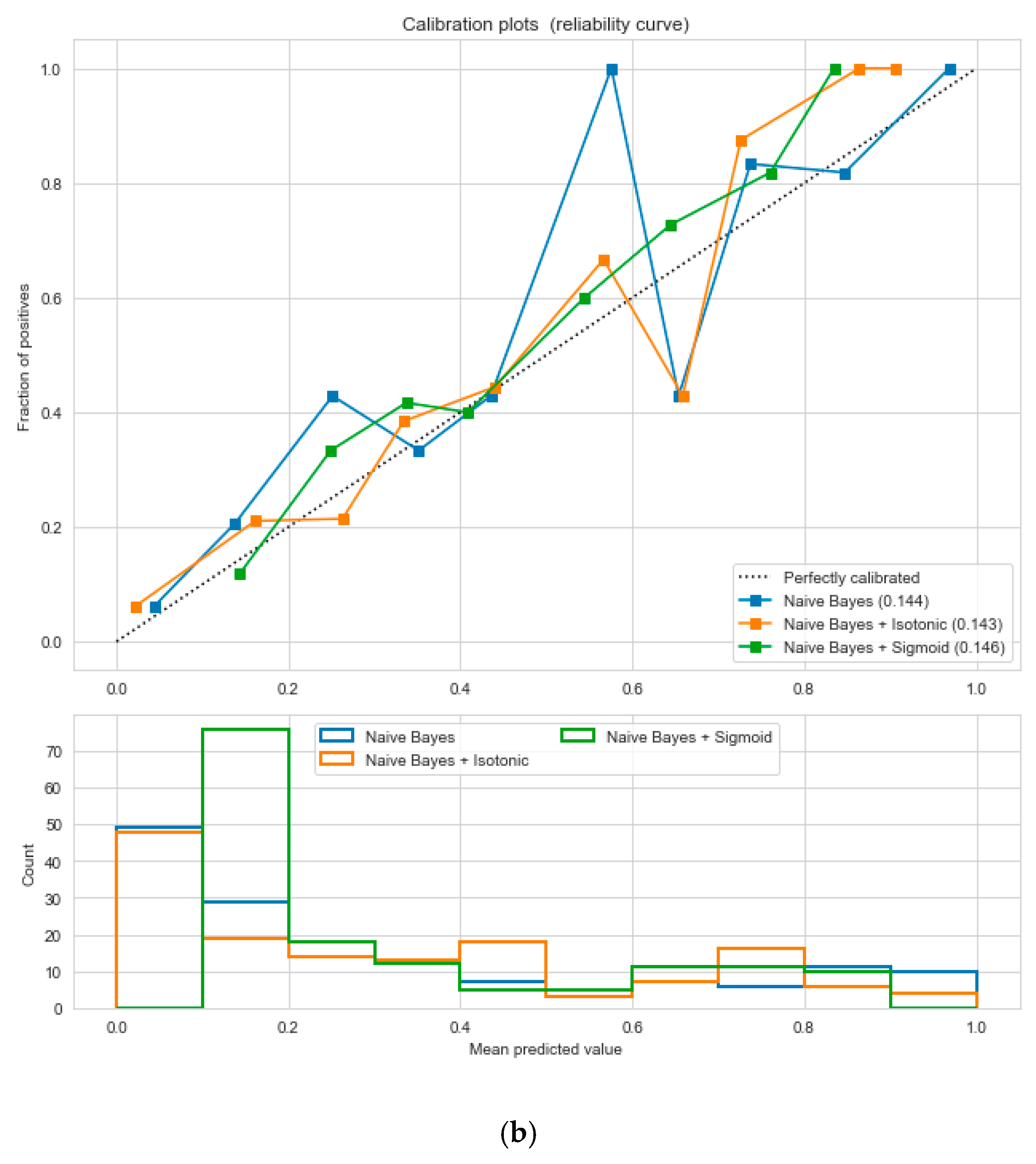
Figure 15, respectively. We used ML classification algorithms to classify the records among two classes, obese (0) and non-obese (1), under the feature column “outcome”. “GaussianNB”, “SVM”, and “Logistic Regression (LR)” outperformed the other classifiers, with a 5-fold cross-validation and 78% accuracy. The best parameters of “SVM” and “LR” were {‘C’: 10, ‘gamma’: 0.001, ‘kernel’: linear} and {’C’: 0.1, ’penalty’: ’l2’}, with a score of 0.78 following the grid search method. This analysis shows a relationship between obesity and diabetes. The logistic regression performed the best under the probability calibration method following the Brier score metric, as depicted in
Figure 16.
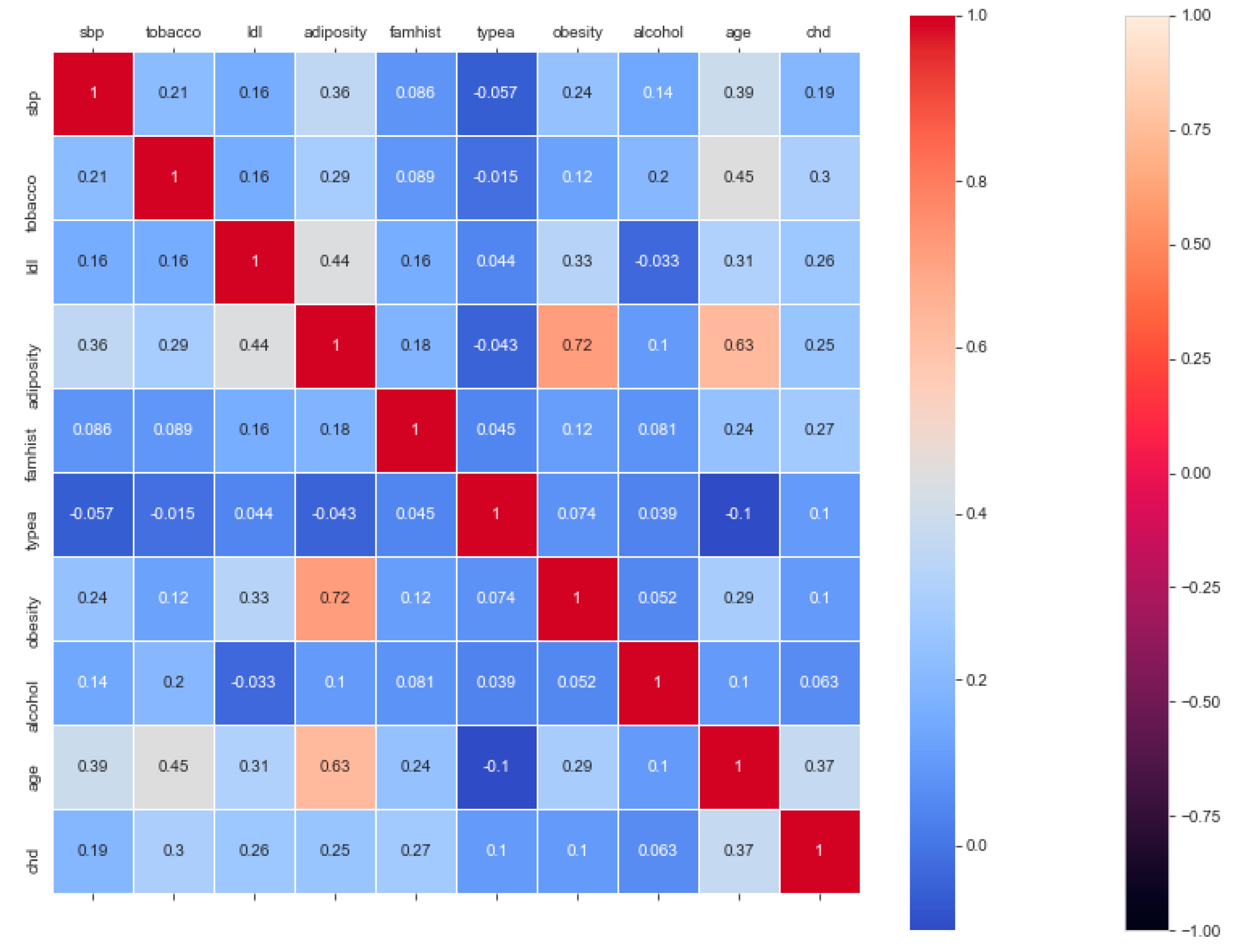
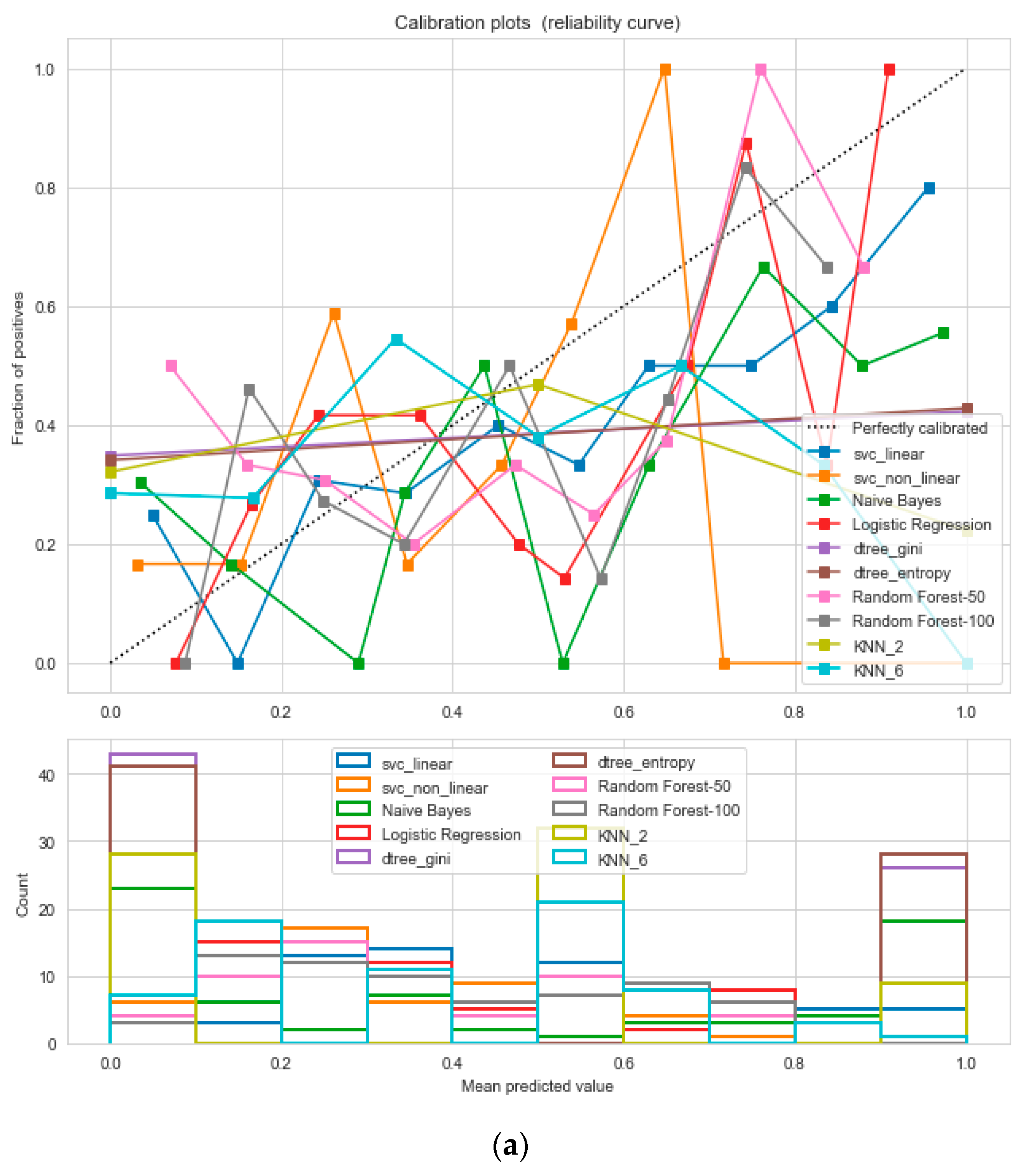
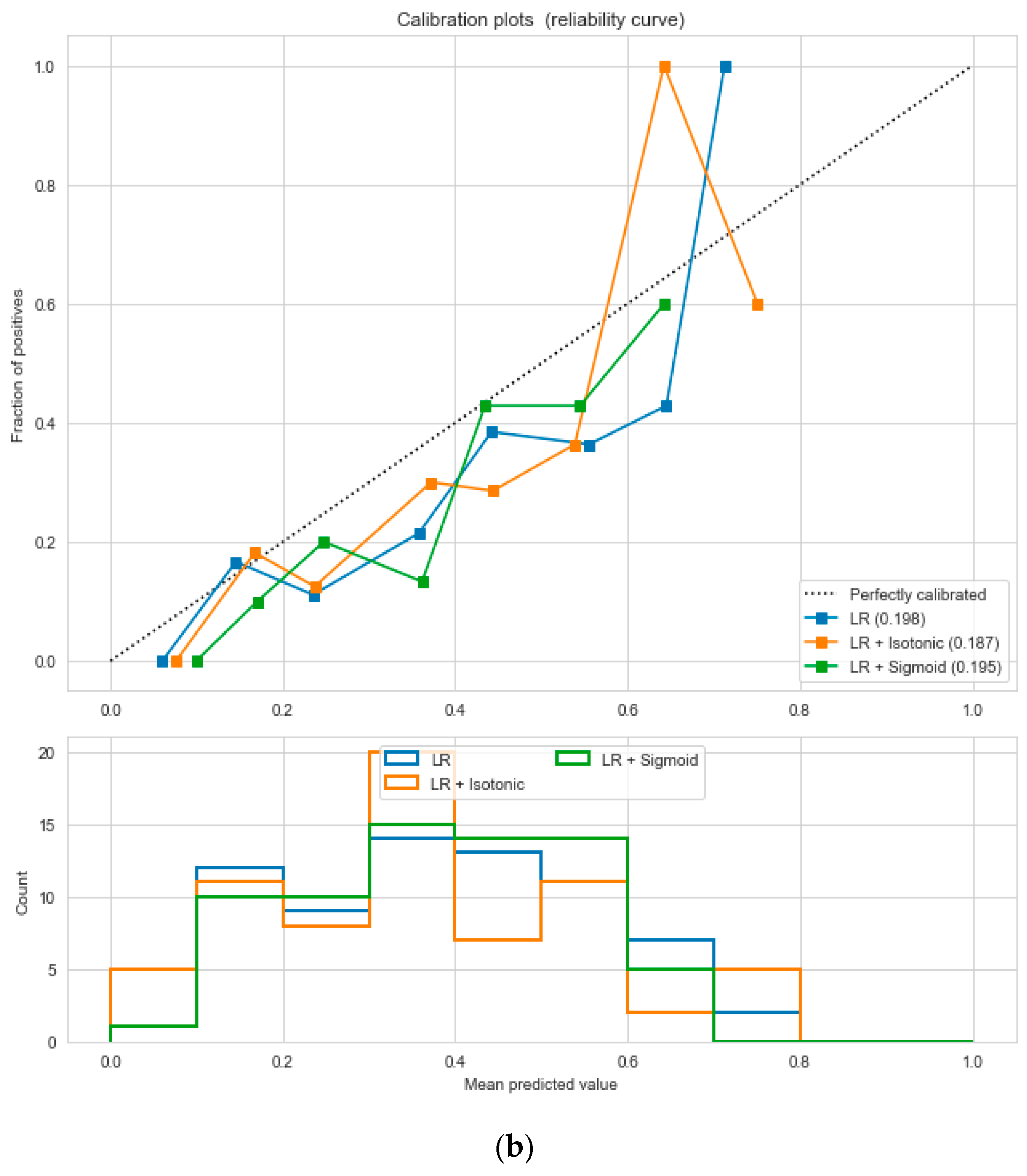
The “cardiovascular-disease” dataset has 462 records and 22 features: “ind” (index), “sbp” (blood pressure), “tobacco”, “ldl” (lipid profile), “adiposity”, “famhist” (family history), “typea”, “obesity”, “alcohol”, “age”, and “chd” (cardiac disease). During the data pre-processing, we included records with age >20 and <60 and excluded features such as “ind” (index).
This resulted in 342 records. The feature “chd” determines if a person has heart disease (1) or not (0). The regression analysis of the dataset revealed that blood pressure, tobacco consumption, lipid profile, adiposity, family history, obesity, drinking habit, and age has a strong connection with CVDs. In binary classification problems on the used heart dataset, SVM and logistic regression outperformed the other classifiers, with a 5-fold cross-validation and 72% accuracy. There is a a strong correlation between (a) “adiposity” and “obese” and (b) “age” and “adiposity”, with |r| = 0.72 and |r| = 0.63, respectively, as depicted in
Figure 17. The SVM and logistic regression estimated the best parameters as {’C’: 10, ’gamma’: 0.001, ‘kernel’: linear} and {’C’: 7.74, ’penalty’: L2}, respectively, under grid search method; the corresponding performance metrics are as depicted in
Figure 18.
The logistic regression performed the best under the probability calibration method following the Brier score metric, as depicted in
Figure 19.
The synopsis of the above analyses has been outlined in
Table 11 and
Table 12. From the above data analyses, it is observed that with limited dataset SVM (linear kernel) and “Decision Tree” classifiers outperformed the other classifiers. The logistic regression returns well-calibrated predictions for the binary class classification problem, as it directly optimizes the log loss. The identified risk factors from the above analysis related to “obesity and overweight” can be summarized as: (a) BMI, (b) age, (c) tobacco consumption, (d) sweet beverages, (e) economic condition, (f) fast food, (g) sleeping pattern, (h) diet, (i) blood pressure, (j) blood glucose, (k) lipid profile, (l) adiposity, (m) exercise, and (n) family history. In brief, the identified core risk factors for obesity/overweight are nutritional conditions or curbing, education, socioeconomic conditions, dietary changes, and physical inactivity. The analyses have established our assumed hypothesis that obesity/overweight has a sharp relation with CVDs and diabetes type II, and some common risk factors are age, sex, cholesterol, lipid profile, sugar level, blood pressure, and family history.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}