Prediction of Visual Memorability with EEG Signals: A Comparative Study †



Abstract
1. Introduction
2. Method
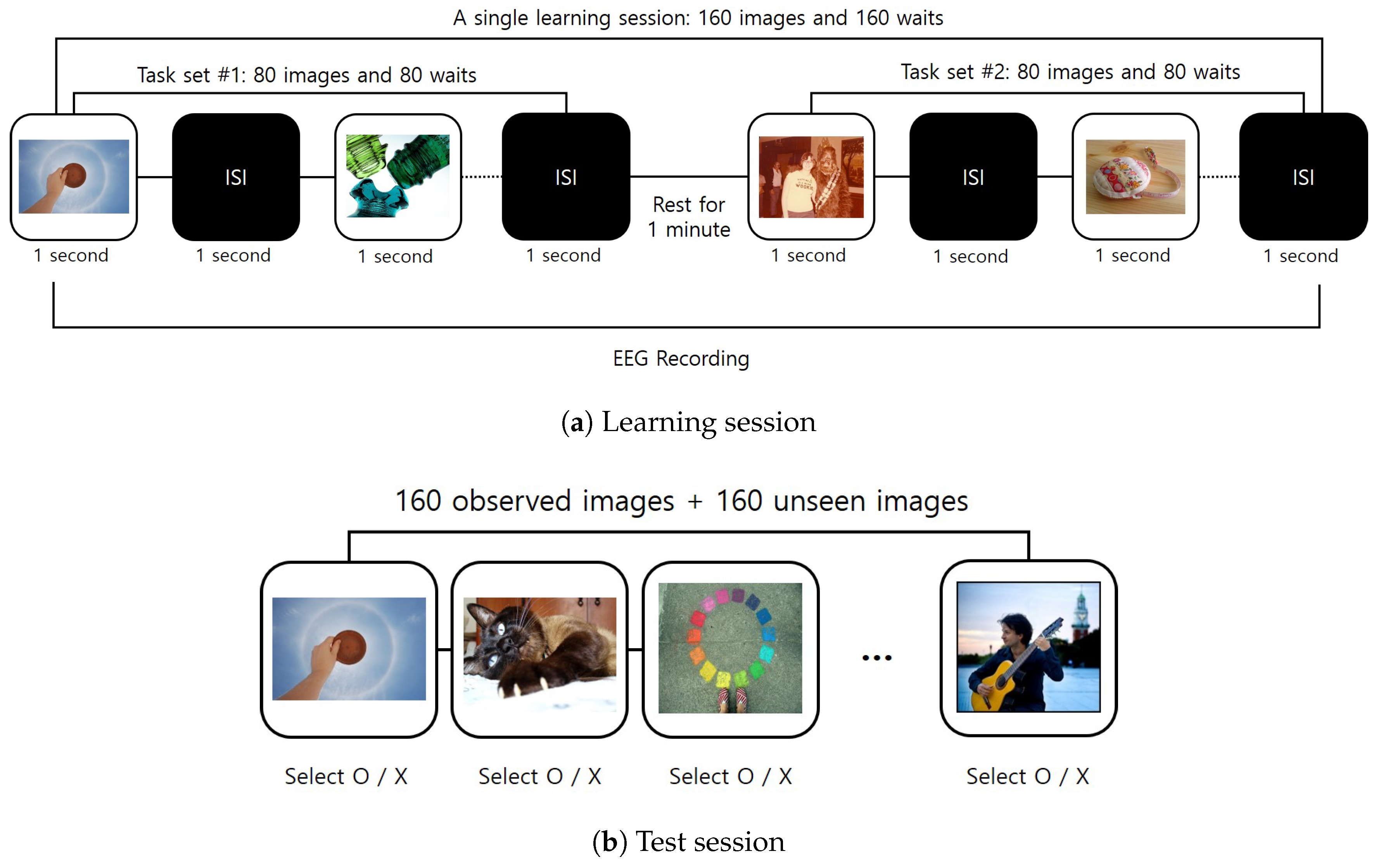
2.1. Experimental Paradigm Design
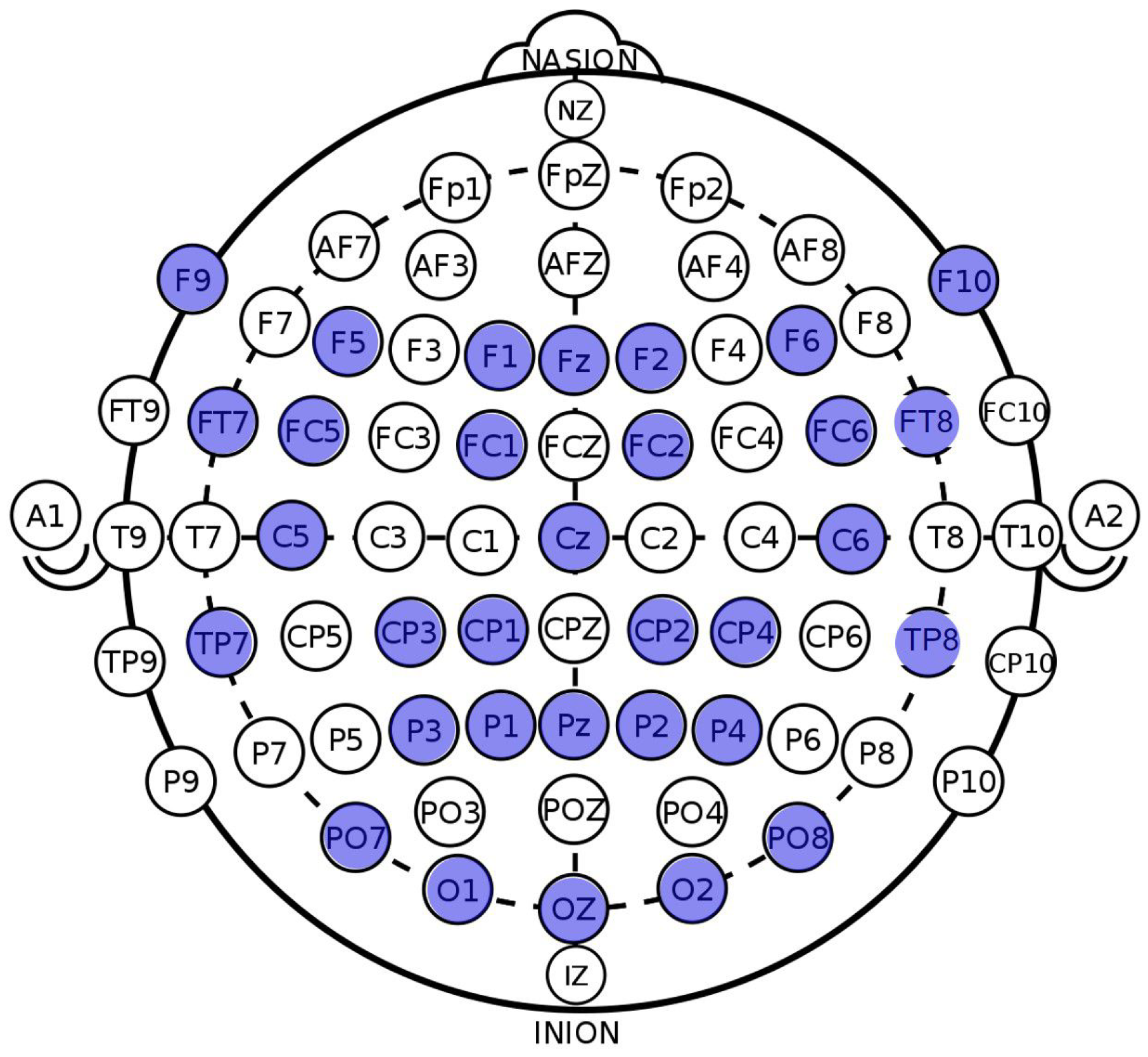
2.2. EEG Signal Pre-Processing
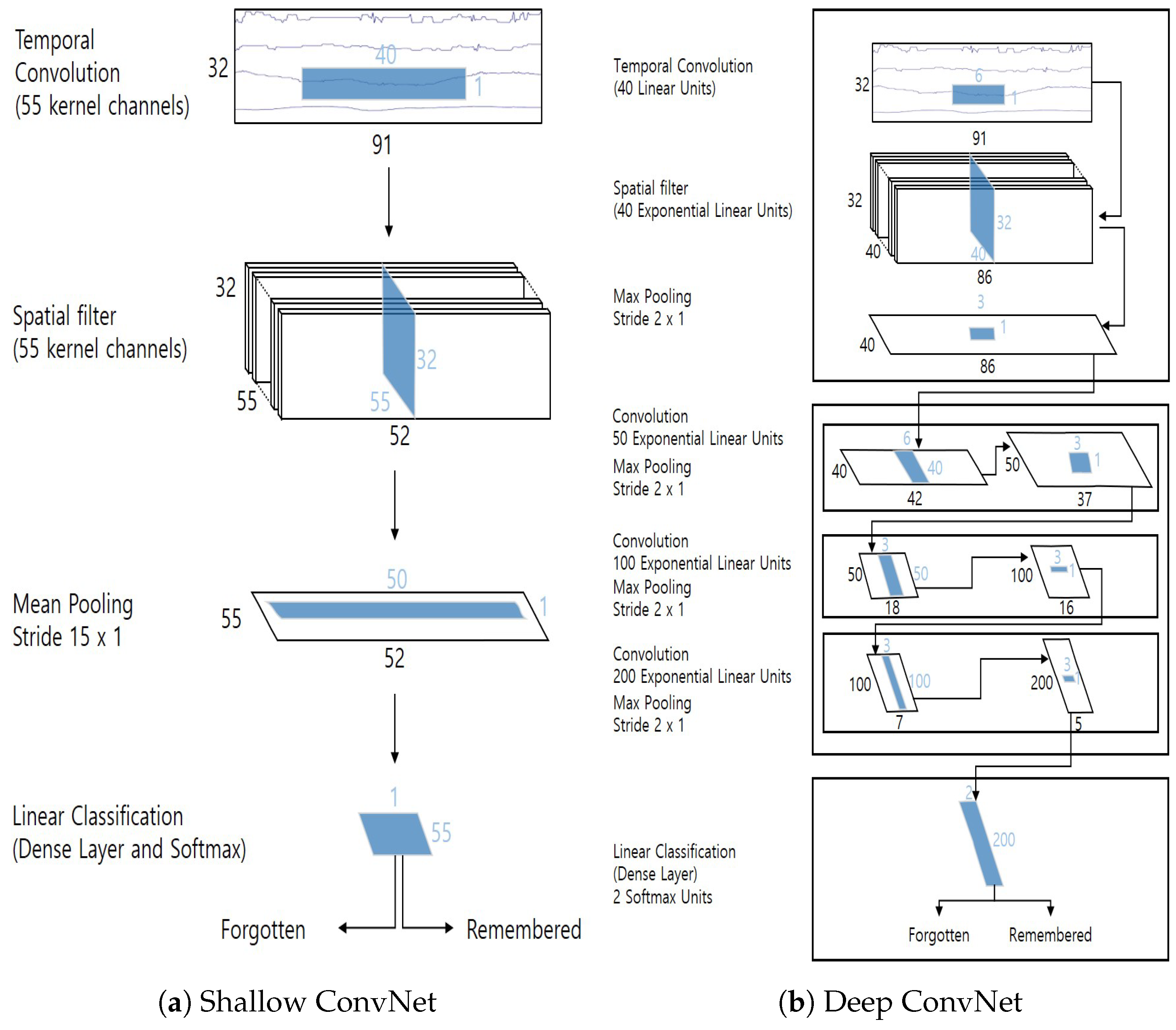
2.3. Classification Models
- (1)
- SVM is a supervised learning algorithm that tries to find a -dimensional hyperplane that can divide the n-dimensional feature space into two parts. It is well known that the best separation is achieved by the hyper-plane that has the largest distance to the nearest training data points of any class (support vectors). Generally, the larger the margin, the lower the generalization error of the classifier. In our experiment, an RBF-kernel SVM classifier with hyper-parameters and was used.
- (2)
- Logistic regression is a probabilistic classifier that makes use of supervised learning. Given a feature vector of a sample, a logistic regression method learns a vector of weights representing how important each input feature is for the classification decision. The probability of a sample is finally computed by a logistic (sigmoid) function. In our experiment, stochastic gradient descent (SGD) with 100 iterations was used as an optimizer, and L2 regularization was applied.
- (3)
- The decision tree observes a set of training samples and extracts a set of decision rules as a tree structure. Decision trees are simple to understand and to interpret; however, they can also generate overly complex trees that do not generalize well, which causes an over-fitting problem. In our experiment, we set the impurity measure for classification to the Gini criterion and the minimum number of samples required for split to 10.
- (4)
- The ensemble method is a technique to combine the predictions from a set of classification models to improve the generalizability or robustness over a single model. The ensemble method of decision trees, the so-called random forest, produces a final prediction value through majority voting for the prediction values from a set of decision trees. In our experiment, the RF classifier used an entropy criterion for the impurity measure, 500 individual trees to make a decision, and the square root of the number of original features as the number of features to consider when searching for the best split.
- (5)
- K-nearest neighbor (KNN) algorithm first finds a predefined number (i.e., k) of training samples closest in distance to the new sample. Then, the class of a sample is determined by the majority voting over the found nearest neighbors. The distance between the samples is typically measured by the Euclidean metric. In our experiment, the number of neighbors was set to 6.
3. Experiment
3.1. Experimental Setting
3.2. User Responses
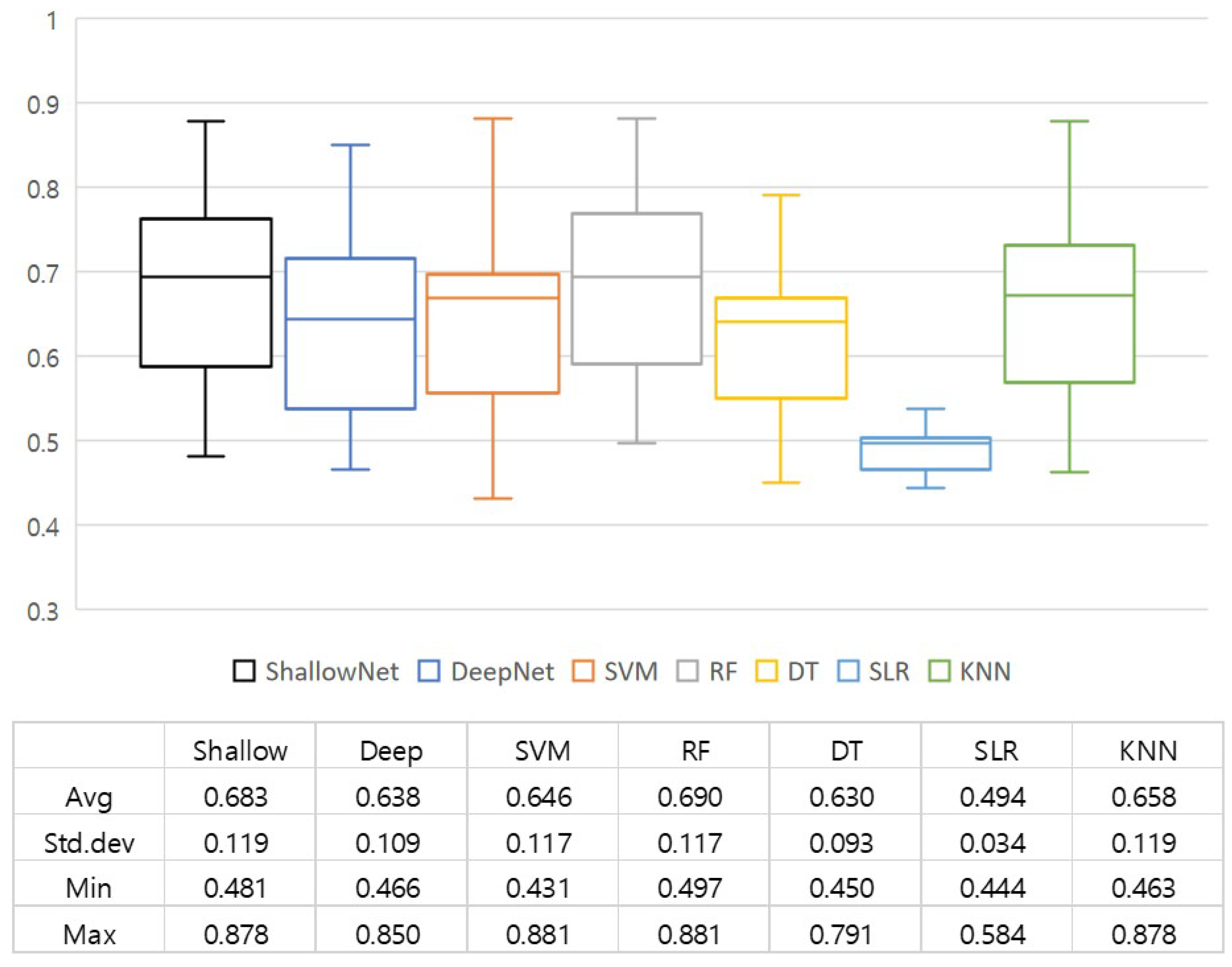
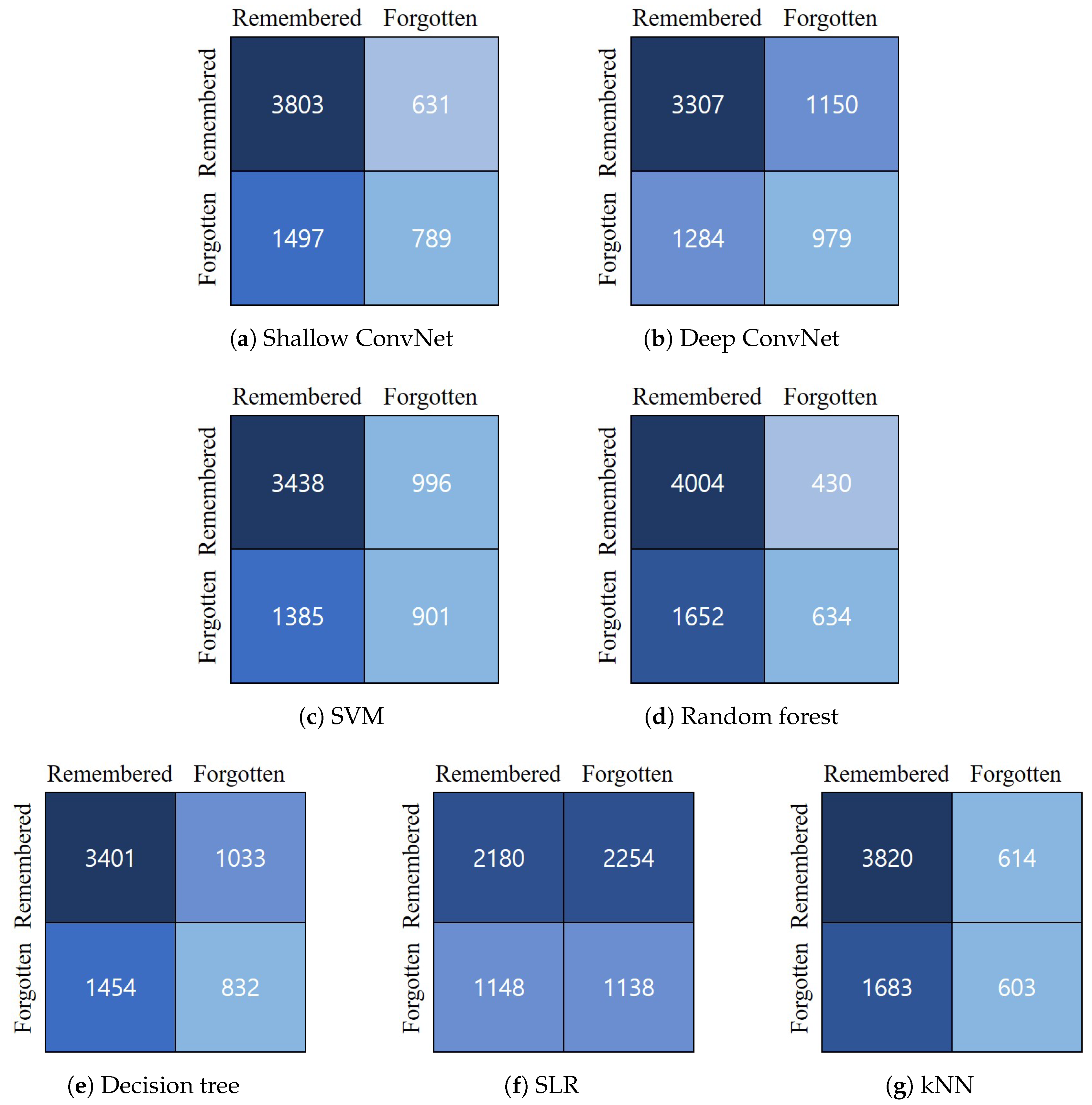
3.3. Quantitative Results
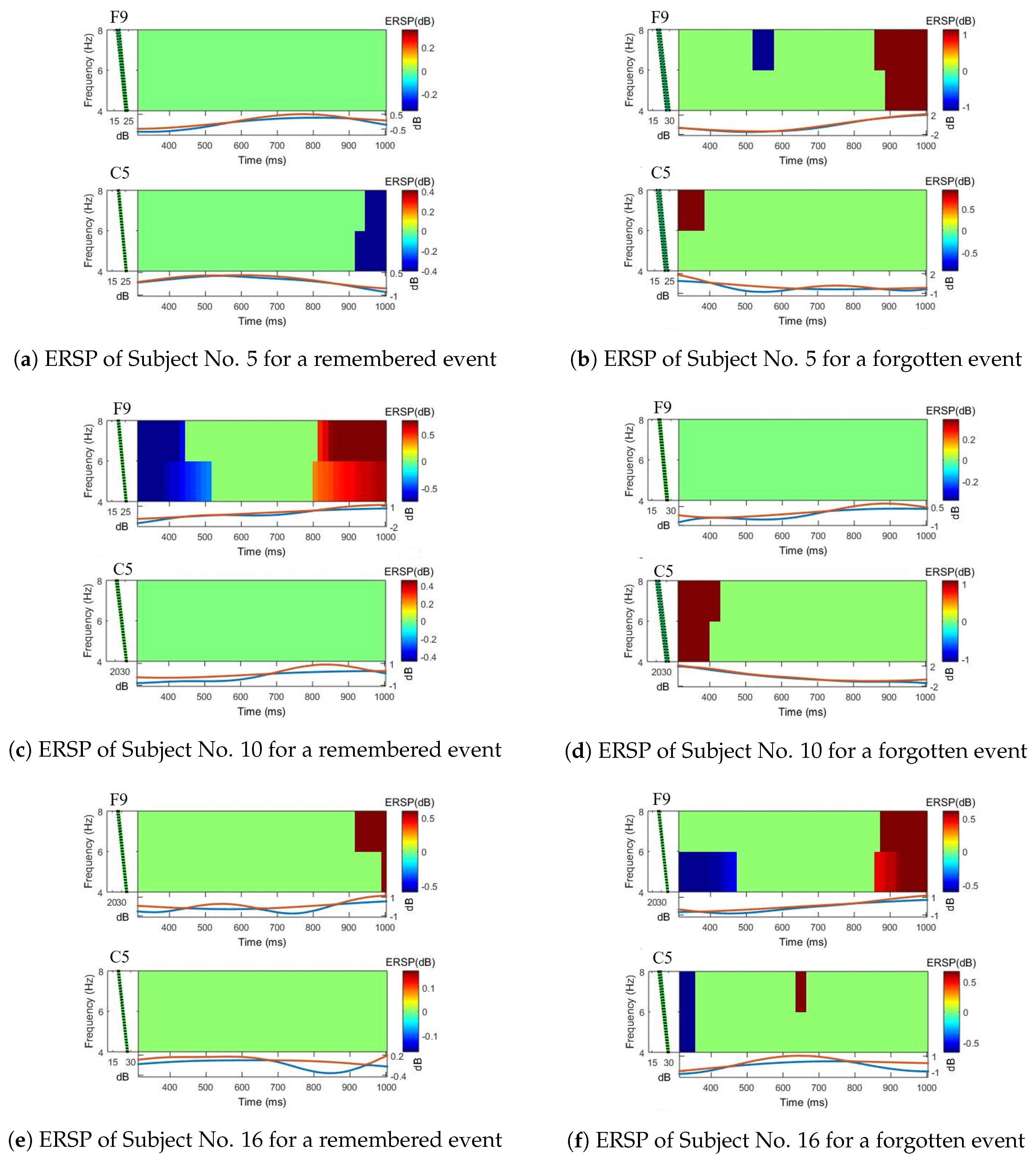
3.4. Qualitative Analysis
4. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A. Comparison of Accuracy

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shallow ConvNet | Deep ConvNet | SVM | RF | DT | SLR | KNN | |
|---|---|---|---|---|---|---|---|
| Subject 1 | 0.69 | 0.65 | 0.69 | 0.69 | 0.68 | 0.49 | 0.67 |
| Subject 2 | 0.78 | 0.77 | 0.67 | 0.79 | 0.77 | 0.70 | 0.76 |
| Subject 3 | 0.55 | 0.53 | 0.43 | 0.59 | 0.58 | 0.50 | 0.46 |
| Subject 4 | 0.62 | 0.61 | 0.61 | 0.62 | 0.65 | 0.54 | 0.57 |
| Subject 5 | 0.86 | 0.73 | 0.86 | 0.86 | 0.70 | 0.46 | 0.85 |
| Subject 6 | 0.70 | 0.65 | 0.70 | 0.69 | 0.65 | 0.58 | 0.66 |
| Subject 7 | 0.73 | 0.65 | 0.72 | 0.75 | 0.66 | 0.50 | 0.73 |
| Subject 8 | 0.64 | 0.64 | 0.69 | 0.68 | 0.62 | 0.47 | 0.67 |
| Subject 9 | 0.75 | 0.68 | 0.67 | 0.75 | 0.63 | 0.46 | 0.70 |
| Subject 10 | 0.76 | 0.61 | 0.71 | 0.75 | 0.64 | 0.44 | 0.71 |
| Subject 11 | 0.59 | 0.58 | 0.56 | 0.58 | 0.55 | 0.46 | 0.60 |
| Subject 12 | 0.89 | 0.85 | 0.75 | 0.88 | 0.77 | 0.45 | 0.88 |
| Subject 13 | 0.48 | 0.50 | 0.48 | 0.51 | 0.55 | 0.47 | 0.53 |
| Subject 14 | 0.63 | 0.60 | 0.69 | 0.69 | 0.55 | 0.51 | 0.66 |
| Subject 15 | 0.54 | 0.52 | 0.57 | 0.56 | 0.51 | 0.5 | 0.47 |
| Subject 16 | 0.56 | 0.54 | 0.57 | 0.50 | 0.53 | 0.49 | 0.51 |
| Subject 17 | 0.77 | 0.76 | 0.53 | 0.77 | 0.67 | 0.53 | 0.73 |
| Subject 18 | 0.88 | 0.84 | 0.67 | 0.88 | 0.79 | 0.54 | 0.78 |
| Subject 19 | 0.52 | 0.53 | 0.88 | 0.53 | 0.45 | 0.49 | 0.55 |
| Subject 20 | 0.65 | 0.47 | 0.5 | 0.64 | 0.56 | 0.50 | 0.57 |
| Subject 21 | 0.76 | 0.72 | 0.51 | 0.78 | 0.75 | 0.50 | 0.77 |
| Min | 0.48 | 0.47 | 0.43 | 0.50 | 0.45 | 0.44 | 0.46 |
| Max | 0.88 | 0.85 | 0.88 | 0.88 | 0.79 | 0.58 | 0.88 |
| Avg | 0.68 | 0.64 | 0.65 | 0.69 | 0.63 | 0.49 | 0.66 |
| Std. Dev. | 0.12 | 0.11 | 0.12 | 0.12 | 0.09 | 0.03 | 0.12 |
References
- Borkin, M.A.; Vo, A.A.; Bylinskii, Z.; Isola, P.; Sunkavalli, S.; Oliva, A.; Pfister, H. What Makes a Visualization Memorable? IEEE Trans. Vis. Comput. Graph. 2013, 19, 2306–2315. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Xu, M.; Yang, R.; Wang, Z. Understanding and Predicting the Memorability of Natural Scene Images. arXiv 2018, arXiv:1810.06679. [Google Scholar]
- Squalli-Houssaini, H.; Duong, N.Q.K.; Gwenaelle, M.; Demarty, C. Deep Learning for Predicting Image Memorability. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2371–2375. [Google Scholar] [CrossRef]
- Khosla, A.; Raju, A.S.; Torralba, A.; Oliva, A. Understanding and Predicting Image Memorability at a Large Scale. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2390–2398. [Google Scholar] [CrossRef]
- Isola, P.; Xiao, J.; Parikh, D.; Torralba, A.; Oliva, A. What Makes a Photograph Memorable? IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1469–1482. [Google Scholar] [CrossRef] [PubMed]
- Osipova, D.; Takashima, A.; Oostenveld, R.; Fernández, G.; Maris, E.; Jensen, O. Theta and Gamma Oscillations Predict Encoding and Retrieval of Declarative Memory. J. Neurosci. 2006, 26, 7523–7531. [Google Scholar] [CrossRef] [PubMed]
- Kang, T.; Chen, Y.; Kim, D.; Fazli, S. EEG-based decoding of declarative memory formation. In Proceedings of the 2016 4th International Winter Conference on Brain-Computer Interface (BCI), Yongpyong, Korea, 22–24 February 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Kang, T.; Chen, Y.; Fazli, S.; Wallraven, C. Decoding of human memory formation with EEG signals using convolutional networks. In Proceedings of the 2018 6th International Conference on Brain-Computer Interface (BCI), GangWon, Korea, 15–17 January 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Sun, X.; Qian, C.; Chen, Z.; Wu, Z.; Luo, B.; Pan, G. Remembered or Forgotten?—An EEG-Based Computational Prediction Approach. PLoS ONE 2016, 11, e0167497. [Google Scholar] [CrossRef] [PubMed]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed]
- Huiskes, M.J.; Lew, M.S. The MIR Flickr Retrieval Evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; ACM: New York, NY, USA, 2008; pp. 39–43. [Google Scholar] [CrossRef]
- Machajdik, J.; Hanbury, A. Affective Image Classification Using Features Inspired by Psychology and Art Theory. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; ACM: New York, NY, USA, 2010; pp. 83–92. [Google Scholar] [CrossRef]
- Khosla, A.; Das Sarma, A.; Hamid, R. What Makes an Image Popular? In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014; pp. 867–876. [Google Scholar] [CrossRef]
- Jurcak, V.; Tsuzuki, D.; Dan, I. 10/20, 10/10, and 10/5 systems revisited: Their validity as relative head-surface-based positioning systems. NeuroImage 2007, 34, 1600–1611. [Google Scholar] [CrossRef] [PubMed]
- Ieracitano, C.; Mammone, N.; Hussain, A.; Morabito, F.C. A novel multi-modal machine learning based approach for automatic classification of EEG recordings in dementia. Neural Netw. 2020, 123, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 2012. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; v. d. Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 3856–3866. [Google Scholar]
- Nik Aznan, N.K.; Bonner, S.; Connolly, J.; Al Moubayed, N.; Breckon, T. On the Classification of SSVEP-Based Dry-EEG Signals via Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 3726–3731. [Google Scholar] [CrossRef]
- Saha, P.; Fels, S. Hierarchical Deep Feature Learning For Decoding Imagined Speech From EEG. Proc. AAAI Conf. Artif. Intell. 2019, 33, 10019–10020. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, C.; Gong, X. Deep convolutional neural network for decoding motor imagery based brain computer interface. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xiamen, China, 22–25 October 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Golmohammadi, M.; Ziyabari, S.; Shah, V.; Obeid, I.; Picone, J. Deep Architectures for Spatio-Temporal Modeling: Automated Seizure Detection in Scalp EEGs. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2018; pp. 745–750. [Google Scholar] [CrossRef]
- Ha, K.W.; Jeong, J.W. Motor Imagery EEG Classification Using Capsule Networks. Sensors 2019, 19, 2854. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Chin, Z.Y.; Zhang, H.; Guan, C. Filter Bank Common Spatial Pattern (FBCSP) in Brain-Computer Interface. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 2390–2397. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Clevert, D.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lahrache, S.; El Ouazzani, R.; El Qadi, A. Rules of photography for image memorabilityanalysis. IET Image Process. 2018, 12, 1228–1236. [Google Scholar] [CrossRef]
- Kwak, Y.; Song, W.; Kim, S. Classification of Working Memory Performance from EEG with Deep Artificial Neural Networks. In Proceedings of the 2019 7th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Korea, 18–20 February 2019; pp. 1–3. [Google Scholar] [CrossRef]











| Seen Image | Unseen Image | |
|---|---|---|
| User response as “O” | 4457 | 450 |
| User response as “X” | 2263 | 6270 |
| Shallow ConvNet | Deep ConvNet | SVM | RF | DT | SLR | KNN | |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.68 | 0.64 | 0.65 | 0.69 | 0.63 | 0.49 | 0.66 |
| Sensitivity | 0.86 | 0.74 | 0.78 | 0.90 | 0.77 | 0.49 | 0.86 |
| Specificity | 0.35 | 0.43 | 0.39 | 0.28 | 0.36 | 0.50 | 0.26 |
| Behavioral Memorability Score | LaMem Memorability Score | |
|---|---|---|
| ShallowNet pseudo-memorability score | 0.71 | 0.41 |
| DeepNet pseudo-memorability score | 0.40 | 0.20 |
| Behavioral memorability score | - | 0.54 |
| Work | Domain | Feature | Target | Evaluation | Result |
|---|---|---|---|---|---|
| [2] | Image | Memorability score | SRCC | 0.58 | |
| [4] | Visual features | 0.64 | |||
| [5] | 0.31 | ||||
| [3] | CNN feature + caption | 0.72 | |||
| [33] | Image | Visual features | Memorability score | SRCC | 0.65 |
| Memorability classification | Accuracy | 82.9 | |||
| [7] | Text | EEG | Memorability classification | Accuracy | 51.18 |
| [8] | 61.9 | ||||
| [9] | 72.0 | ||||
| Ours | Image | EEG | Memorability score | SRCC | 0.71 |
| Memorability classification | Accuracy | 69.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, S.-Y.; Jeong, J.-W. Prediction of Visual Memorability with EEG Signals: A Comparative Study. Sensors 2020, 20, 2694. https://doi.org/10.3390/s20092694
Jo S-Y, Jeong J-W. Prediction of Visual Memorability with EEG Signals: A Comparative Study. Sensors. 2020; 20(9):2694. https://doi.org/10.3390/s20092694
Chicago/Turabian StyleJo, Sang-Yeong, and Jin-Woo Jeong. 2020. "Prediction of Visual Memorability with EEG Signals: A Comparative Study" Sensors 20, no. 9: 2694. https://doi.org/10.3390/s20092694
APA StyleJo, S.-Y., & Jeong, J.-W. (2020). Prediction of Visual Memorability with EEG Signals: A Comparative Study. Sensors, 20(9), 2694. https://doi.org/10.3390/s20092694