A Light-Weight Practical Framework for Feces Detection and Trait Recognition




Abstract
1. Introduction
- A novel research field for public health is proposed, in which the fecal image dataset is collected in a real hospital environment and labeled by professional doctors. This dataset has a high clinical value and a high medical value;
- A quick automatic accurate and robust diagnosis framework is proposed. The feces object is accurately detected with a well-designed threshold-based segmentation scheme on the selected color component to reduce the background disturbance. We find that the CNN does not resist the illumination variance well. In contrast, our framework has a strong tolerance for illumination variances, and the trait classification accuracy is satisfactory;
- Our light-weight framework is economical and meets the requirements of practical applications. The computational complexity is low and the number of parameters is small. It is feasible and convenient to fine-tune the structure with a common hardware source.
2. Related Works
3. Materials and Methods
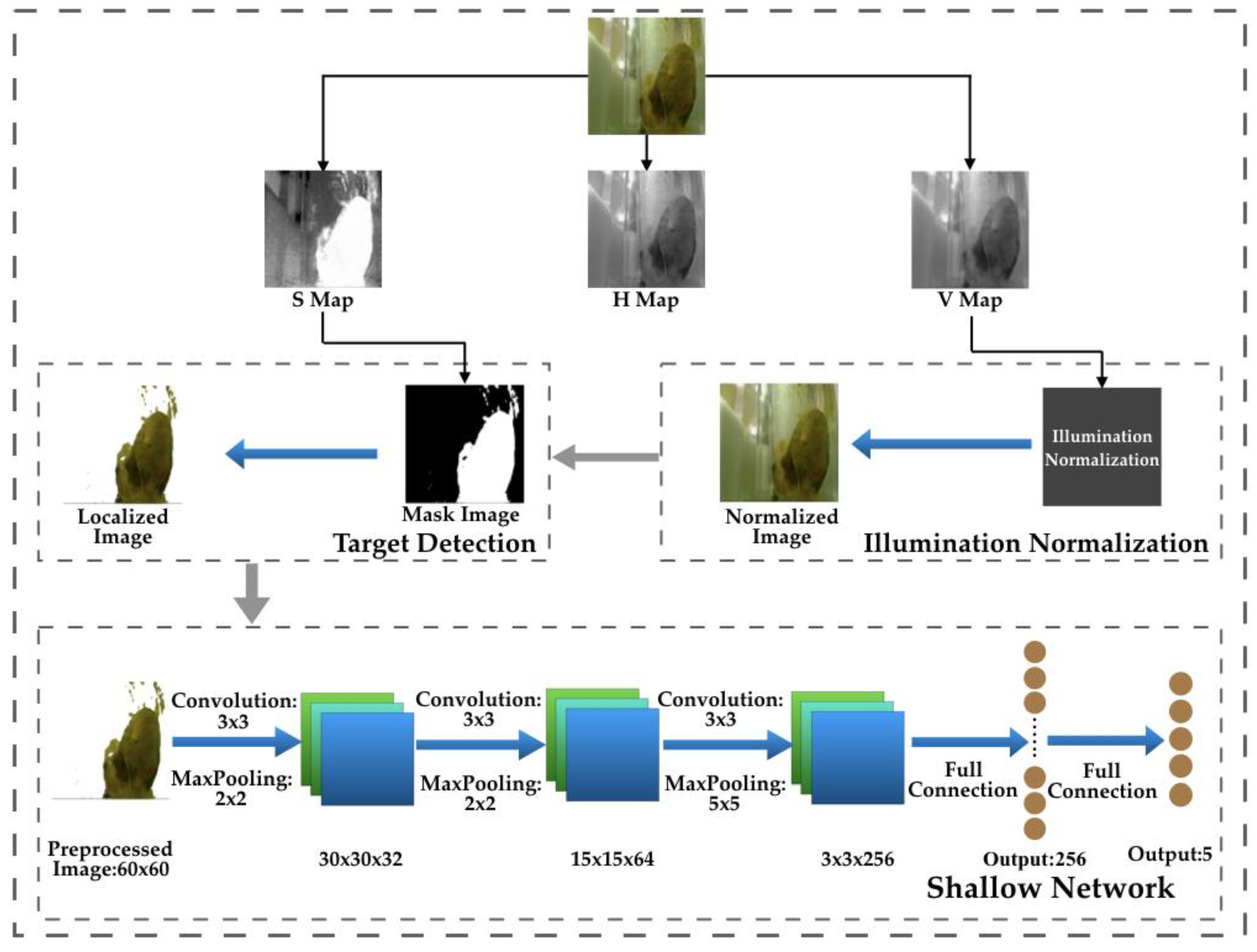
3.1. Overview of the Framework
3.2. Illumination Normalization
3.3. Object Detection
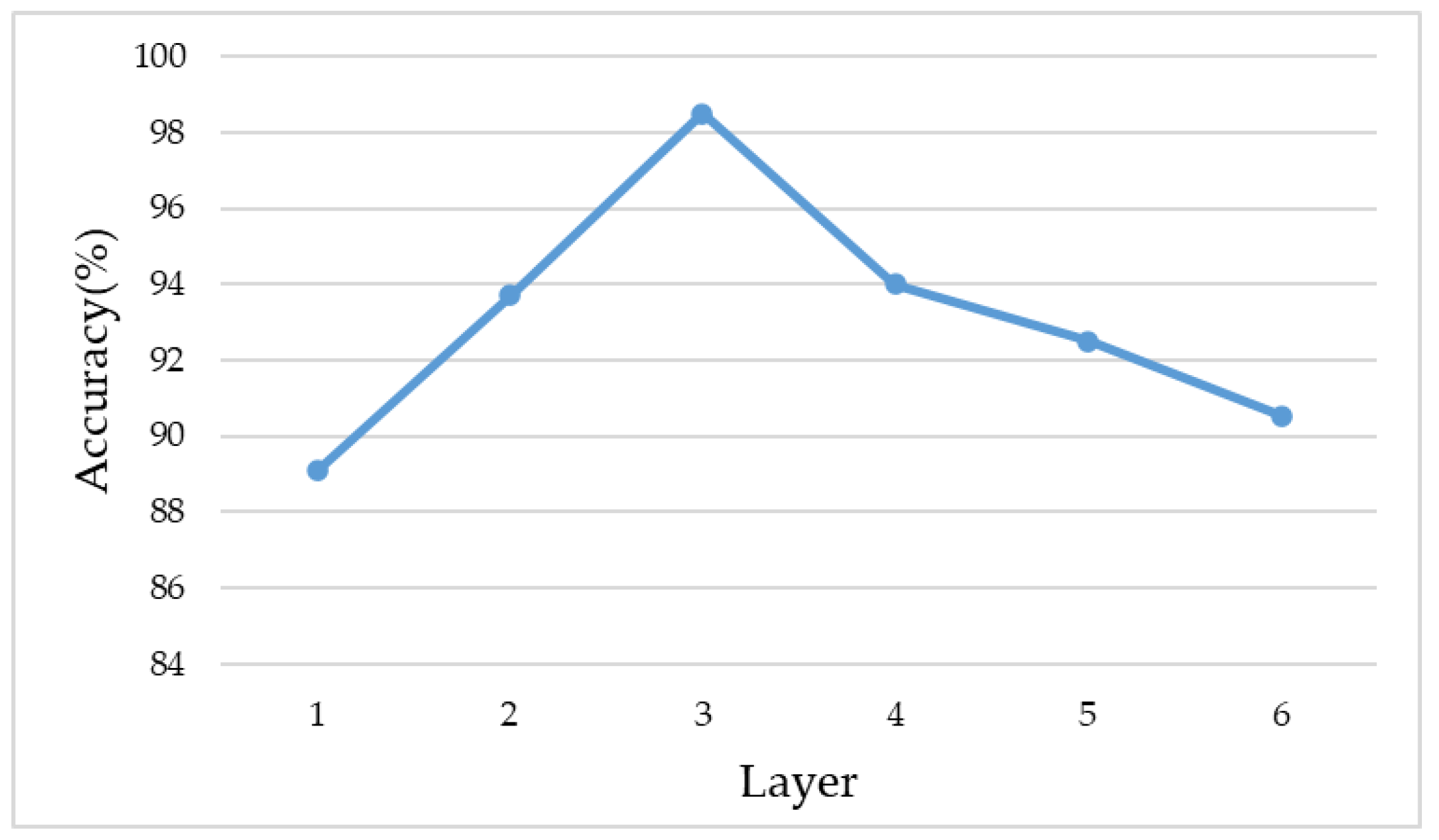
3.4. Shallow CNN
4. Experiments and Discussion
- The recognition tasks are different. In [44], the method is designed for fecal color recognition, but the main objective of this paper was to design a quick, automatic, accurate, and robust method to classify the traits of fecal images. Color recognition and trait recognition are both important for macroscopic examinations, but typically trait recognition is more difficult than color recognition;
- The method described in [44] cannot maintain its level of performance in the task presented in this paper, which is demonstrated by the experimental results. The developed novel method in this paper can work well in the trait classification task;
- The method described in [44] cannot work well at different illumination levels. In contrast, the illumination problem has been solved well in this paper.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nakarai, A.; Kato, J.; Hiraoka, S.; Takashima, S.; Takei, D.; Inokuchi, T.; Sugihara, Y.; Takahara, M.; Harada, M.; Okada, H. Ulcerative Colitis Patients in Clinical Remission Demonstrate Correlations between Fecal Immunochemical Examination Results, Mucosal Healing, and Risk of Relapse. World J. Gastroenterol. 2016, 22, 5079–5087. [Google Scholar] [CrossRef]
- Hachuel, D.; Jha, A.; Estrin, D.; Martinez, A.; Staller, K.; Velez, C. Augmenting Gastrointestinal Health: A Deep Learning Approach to Human Stool Recognition and Characterization in Macroscopic Images. arXiv 2019, arXiv:1903.10578. [Google Scholar] [CrossRef]
- Kopylov, U.; Yung, D.E.; Engel, T.; Avni, T.; Battat, R.; Ben-Horin, S.; Plevris, J.N.; Eliakim, R.; Koulaouzidis, A. Fecal Calprotectin for the Prediction of Small-Bowel Crohn’s Disease by Capsule Endoscopy: A Systematic Review and Meta-Analysis. Eur. J. Gastroenterol. Hepatol. 2016, 28, 1137–1144. [Google Scholar] [CrossRef]
- Costea, P.; Zeller, G.; Sunagawa, S.; Pelletier, E.; Alberti, A.; Levenez, F.; Tramontano, M.; Driessen, M.; Hercog, R.; Jung, F.E.; et al. Towards Standards for Human Fecal Sample Processing in Metagenomic Studies. Nat. Biotechnol. 2017, 35, 1069–1076. [Google Scholar] [CrossRef]
- Teimoori, S.; Arimatsu, Y.; Laha, T.; Kaewkes, S.; Sereerak, P.; Sripa, M.; Tangkawattana, S.; Brindley, P.J.; Spripa, B. Chicken IgY-based Coproantigen Capture ELISA for Diagnosis of Human Opisthorchiasis. Parasitol. Int. 2017, 66, 443–447. [Google Scholar] [CrossRef]
- Inpankaew, T.; Schär, F.; Khieu, V.; Muth, S.; Dalsgaard, A.; Marti, H.; Traub, R.J.; Odermatt, P. Simple Fecal Flotation is A Superior Alternative to Guadruple Kato Katz Smear Examination for the Detection of Hookworm Eggs in Human Stool. PLoS Negl. Trop. Dis. 2014, 8, e3313. [Google Scholar] [CrossRef]
- Cai, X.Q.; Yu, H.Q.; Bai, J.S.; Tang, J.D.; Hu, X.C.; Chen, D.H.; Zhang, R.L.; Chen, M.X.; Ai, L.; Zhu, X.Q. Development of A TaqMan based Real-Time PCR Assay for Detection of Clonorchis sinensis DNA in Human Stool Samples and Fishes. Parasitol. Int. 2016, 61, 183–186. [Google Scholar] [CrossRef]
- Jiang, Y.S.; Riedel, T.E.; Popoola, J.A.; Morrow, B.R.; Cai, S.; Ellington, A.D.; Bhadra, S. Portable Platform for Rapid In-Field Identification of Human Fecal Pollution in Water. Water Res. 2018, 131, 186–195. [Google Scholar] [CrossRef]
- Theriot, C.M.; Joshua, R.F. Human Fecal Metabolomic Profiling could Inform Clostridioides Difficile Infection Diagnosis and Treatment. J. Clin. Invest. 2019, 129, 3539–3541. [Google Scholar] [CrossRef]
- Carvalho Carvalho, A.O.F.; Silva, A.C.; Paiva, A.C.; Nunes, R.A.; Gattass, M. Lung-Nodule Classification Based on Computed Tomography Using Taxonomic Diversity Indexes and an SVM. J. Signal Process. Syst. 2017, 87, 179–196. [Google Scholar] [CrossRef]
- Soundararajan, K.; Sureshkumar, S.; Anusuya, C. Diagnostic Decision Support System for Tuberculosis using Fuzzy Logic. Int. J. Comput. Sci. Inform. Technol. Secur. 2012, 2, 684–689. [Google Scholar]
- Madeira, T.; Oliveira, M.; Dias, P. Enhancement of RGB-D Image Alignment Using Fiducial Markers. Sensors 2020, 20, 1497. [Google Scholar] [CrossRef]
- Zhang, Y.; Chu, J.; Leng, L.; Miao, J. Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation. Sensors 2020, 20, 1010. [Google Scholar] [CrossRef]
- Chu, J.; Tu, X.; Leng, L.; Miao, J. Double-Channel Object Tracking with Position Deviation Suppression. IEEE Access 2020, 8, 856–866. [Google Scholar] [CrossRef]
- Chu, J.; Guo, Z.; Leng, L. Object Detection based on Multi-Layer Convolution Feature Fusion and Online Hard Example Mining. IEEE Access 2018, 6, 19959–19967. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, B.-G.; Roy, P.P.; Jeong, D.M. Efficient Facial Expression Recognition Algorithm Based on Hierachical Deep Neural Network Sructure. IEEE Access 2019, 7, 41273–41285. [Google Scholar] [CrossRef]
- Kumar, P.; Mukerjee, S.; Saini, R.; Roy, P.P.; Dogra, D.P.; Kim, B.G. Plant Disease Identification Using Deep Neural Networks. J. Multimedia Inf. Syst. 2017, 4, 233–238. [Google Scholar]
- Jeong, D.; Kim, B.G.; Dong, S.Y. Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition. Sensors 2020, 20, 1936. [Google Scholar] [CrossRef]
- Baamonde, S.; de Moura, J.; Novo, J.; Charlón, P.; Ortega, M. Automatic Identification and Intuitive Map Representation of the Epiretinal Membrane Presence in 3D OCT Volumes. Sensors 2019, 19, 5269. [Google Scholar] [CrossRef]
- Sun, W.; Zheng, B.; Wei, Q. Computer Aided Lung Cancer Diagnosis with Deep Learning Algorithms. SPIE Med. Imaging 2016, 9785, 97850Z. [Google Scholar]
- Arabasadi, Z.; Alizadehsani, R.; Roshanzamir, M.; Moosaei, H.; Yarifard, A.A. Computer Aided Decision Making for Heart Disease Detection using Hybrid Neural Network-Genetic Algorithm. Comput. Meth. Programs Biomed. 2017, 141, 19–26. [Google Scholar] [CrossRef]
- Oktay, O.; Ferrante, E.; Kamnitsas, K.; Heinrich, M.; Bai, W.; Caballero, J.; Cook, S.A.; De Marvao, A.; Dawes, T.; O’Regan, D.P.; et al. Anatomically Constrained Neural Networks (ACNNs): Application to Cardiac Image Enhancement and Segmentation. IEEE Trans. Med. Imaging 2018, 37, 384–395. [Google Scholar] [CrossRef]
- Leng, L.; Li, M.; Kim, C.; Bi, X. Dual-Source Discrimination Power Analysis for Multi-Instance Contactless Palmprint Recognition. Multimed. Tools Appl. 2017, 76, 333–354. [Google Scholar] [CrossRef]
- Leng, L.; Zhang, J.S. PalmHash Code vs. PalmPhasor Code. Neurocomputing 2013, 108, 1–12. [Google Scholar] [CrossRef]
- Leng, L.; Teoh, A.B.J.; Li, M.; Khan, M.K. A Remote Cancelable Palmprint Authentication Protocol based on Multi-Directional Two-Dimensional PalmPhasor-Fusion. Secur. Commun. Netw. 2014, 7, 1860–1871. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, H.; Wang, Z.; Ji, S. Global Pixel Transformers for Virtual Staining for Microscopy Images. IEEE Trans. Med. Imaging 2020. [Google Scholar] [CrossRef]
- Li, M.; Hsu, W.; Xie, X.; Cong, J.; Gao, W. SACNN: Self-Attention Convolutional Neural Network for Low-Dose CT Denoising with Self-supervised Perceptual Loss Network. IEEE Trans. Med. Imaging 2020. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Akay, B.N.; Argenziano, G.; Blum, A.; Braun, R.P.; Cabo, H.; Gourhant, J.Y.; Kreusch, J.; Lallas, A.; et al. Expert-Level Diagnosis of Nonpigmented Skin Cancer by Combined Convolutional Neural Netowrks. JAMA Dermatol. 2019, 155, 58–65. [Google Scholar] [CrossRef]
- Singhal, A.; Kumar, P.; Saini, R.; Roy, P.P.; Dogra, D.P.; Kim, B.G. Summarization of Videos by Analyzing Affective State of the User through Crowdsource. Cogn. Syst. Res. 2018, 52, 917–930. [Google Scholar] [CrossRef]
- Kim, B.G.; Shim, J.I.; Park, D.J. Fast Image Segmentation based on Multi-Resolution Analysis and Wavelets. Pattern Recognit. Lett. 2003, 24, 2995–3006. [Google Scholar] [CrossRef]
- Gong, C.; Tao, D.; Liu, W.; Maybank, S.J.; Fang, M.; Fu, K.; Yang, J. Saliency Propagation from Simple to Difficult. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2531–2539. [Google Scholar]
- Yang, F.; Li, W.; Hu, H.; Li, W.; Wang, P. Multi-Scale Feature Integrated Attention-Based Rotation Network for Object Detection in VHR Aerial Images. Sensors 2020, 20, 1686. [Google Scholar] [CrossRef]
- Pang, L.; Liu, H.; Chen, Y.; Miao, J. Real-time Concealed Object Detection from Passive Millimeter Wave Images Based on the YOLOv3 Algorithm. Sensors 2020, 20, 1678. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, Z.; Li, J.; Min, W.; Wang, Q. Real-Time Pre-Identification and Cascaded Detection for Tiny Faces. Appl. Sci. 2019, 9, 4344. [Google Scholar] [CrossRef]
- Yuan, Y.; Chu, J.; Leng, L.; Miao, J.; Kim, B.G. A Scale-Adaptive Object-Tracking Algorithm with Occlusion Detection. EURASIP J. Image Video Process. 2020, 1, 1–15. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Fu, K.; Zhao, Q.; Gu, I.Y.H.; Yang, J. Deepside: A General Deep Framework for Salient Object Detection. Neurocomputing 2019, 9, 4344. [Google Scholar] [CrossRef]
- Shallari, I.; O’Nils, M. From the Sensor to the Cloud: Intelligence Partitioning for Smart Camera Applications. Sensors 2019, 19, 5162. [Google Scholar] [CrossRef]
- Kim, J.H.; Hong, G.S.; Kim, B.G.; Dogra, D.P. DeepGesture: Deep Learning-based Gesture Recognition Scheme using Motion Sensors. Displays 2018, 55, 38–45. [Google Scholar] [CrossRef]
- Sadak, F.; Saadat, M.; Hajiyavand, A.M. Vision-Based Sensor for Three-Dimensional Vibrational Motion Detection in Biological Cell Injection. Sensors 2019, 19, 5074. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Nkamgang, O.T.; Tchiotsop, D.; Fotsin, H.B.; Talla, P.K.; Dorr, V.L.; Wolf, D. Automatic the Clinical Stools Exam using Image Processing Integrated in An Expert System. Inform. Med. Unlocked 2019, 15, 100165. [Google Scholar] [CrossRef]
- Yang, Z.; Leng, L.; Kim, B.G. StoolNet for Color Classification of Stool Medical Images. Electronics 2019, 8, 1464. [Google Scholar] [CrossRef]
- Leng, L.; Zhang, J.S.; Khan, M.K.; Chen, X.; Alghathbar, K. Dynamic Weighted Discrimination Power Analysis: A Novel Approach for Face and Palmprint Recognition in DCT Domain. Int. J. Phys. Sci. 2010, 5, 2543–2554. [Google Scholar]
- Leng, L.; Zhang, J.S.; Xu, J.; Khan, M.K.; Alghathbar, K. Dynamic Weighted Discrimination Power Analysis in DCT Domain for Face and Palmprint Recognition. In Proceedings of the International Conference on Information and Communication Technology Convergence, Jeju Island, Korea, 17–19 November 2010; pp. 467–471. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1125. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Abadi, M. Tensorflow: Learning Functions at Scale. ACM Sigplan Not. 2016, 51, 1. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Illumination Scale | Tar | Paste | Mucus | Watery | Loose |
|---|---|---|---|---|---|
| 0.5 | 0.0033 | 0.0047 | 0.0046 | 0.0053 | 0.0045 |
| 0.6 | 0.0028 | 0.0047 | 0.0039 | 0.0039 | 0.0039 |
| 0.7 | 0.0025 | 0.0038 | 0.0034 | 0.0029 | 0.0037 |
| 0.8 | 0.0022 | 0.0020 | 0.0034 | 0.0029 | 0.0028 |
| 0.9 | 0.0026 | 0.0024 | 0.0033 | 0.0021 | 0.0025 |
| 1.1 | 0.0058 | 0.0038 | 0.0041 | 0.0042 | 0.0060 |
| 1.2 | 0.0118 | 0.0056 | 0.0100 | 0.0060 | 0.0105 |
| 1.3 | 0.0281 | 0.0165 | 0.0128 | 0.0145 | 0.0191 |
| 1.4 | 0.0350 | 0.0282 | 0.0239 | 0.0203 | 0.0235 |
| 1.5 | 0.0417 | 0.0486 | 0.0380 | 0.0379 | 0.0282 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leng, L.; Yang, Z.; Kim, C.; Zhang, Y. A Light-Weight Practical Framework for Feces Detection and Trait Recognition. Sensors 2020, 20, 2644. https://doi.org/10.3390/s20092644
Leng L, Yang Z, Kim C, Zhang Y. A Light-Weight Practical Framework for Feces Detection and Trait Recognition. Sensors. 2020; 20(9):2644. https://doi.org/10.3390/s20092644
Chicago/Turabian StyleLeng, Lu, Ziyuan Yang, Cheonshik Kim, and Yue Zhang. 2020. "A Light-Weight Practical Framework for Feces Detection and Trait Recognition" Sensors 20, no. 9: 2644. https://doi.org/10.3390/s20092644
APA StyleLeng, L., Yang, Z., Kim, C., & Zhang, Y. (2020). A Light-Weight Practical Framework for Feces Detection and Trait Recognition. Sensors, 20(9), 2644. https://doi.org/10.3390/s20092644