Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns

 ,
,  and
and
Abstract
1. Introduction
2. Related Work
3. CSP-Based Approach
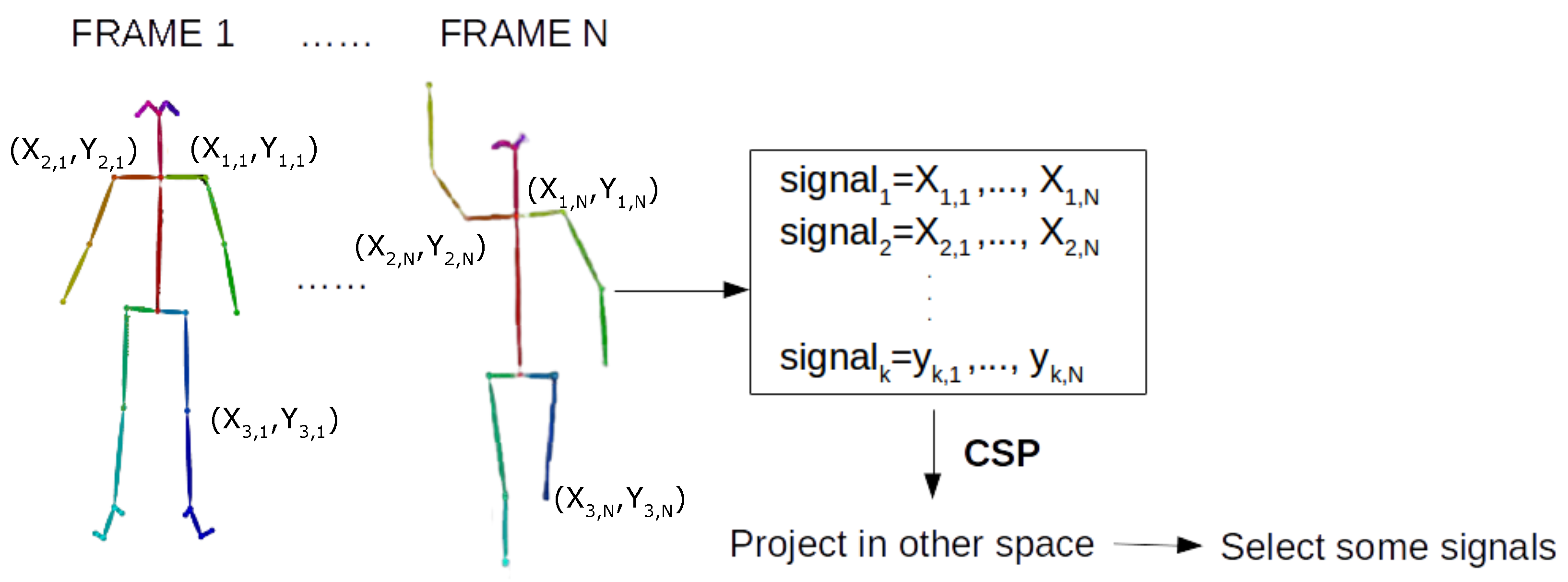
3.1. CSP
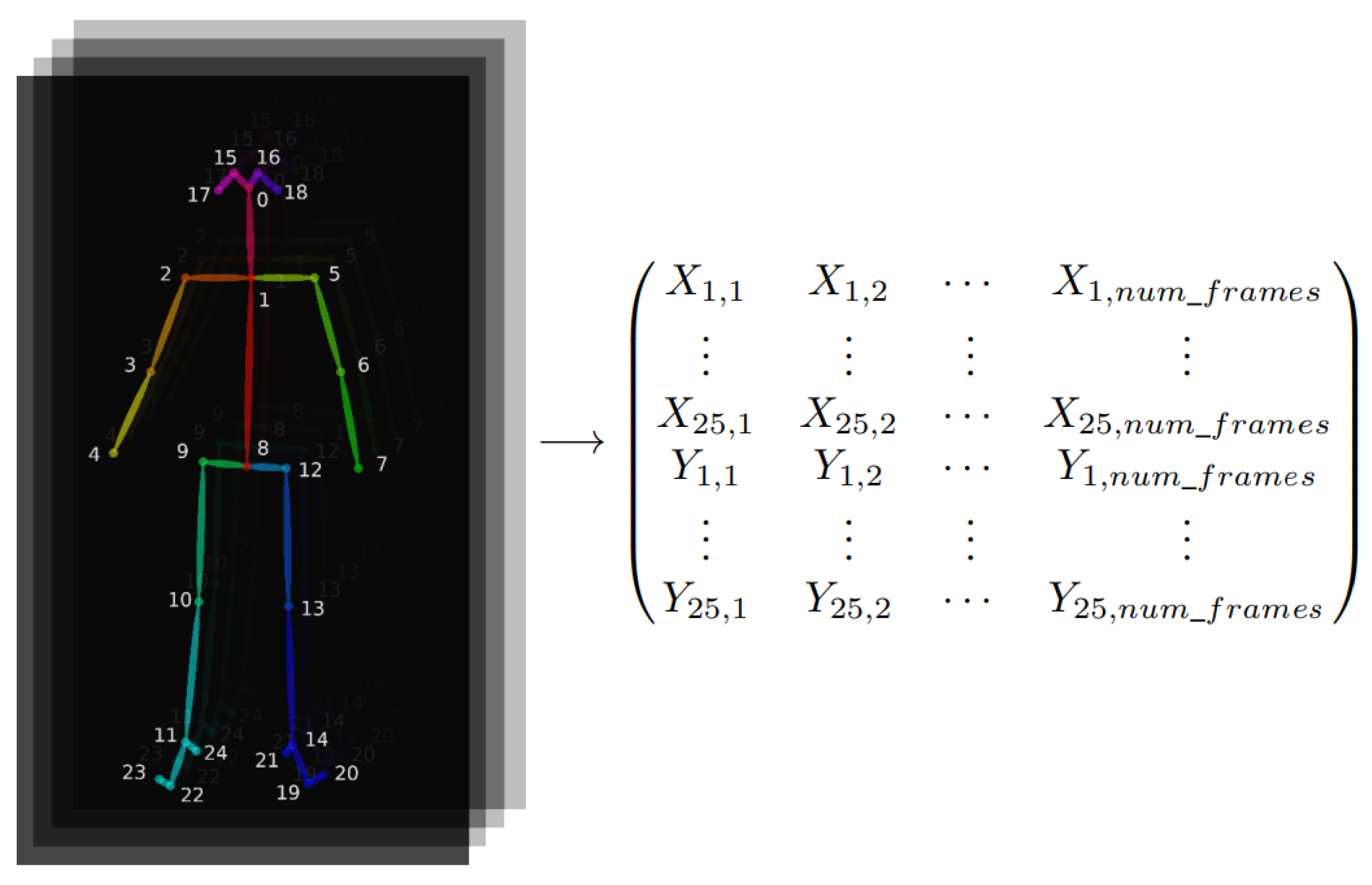
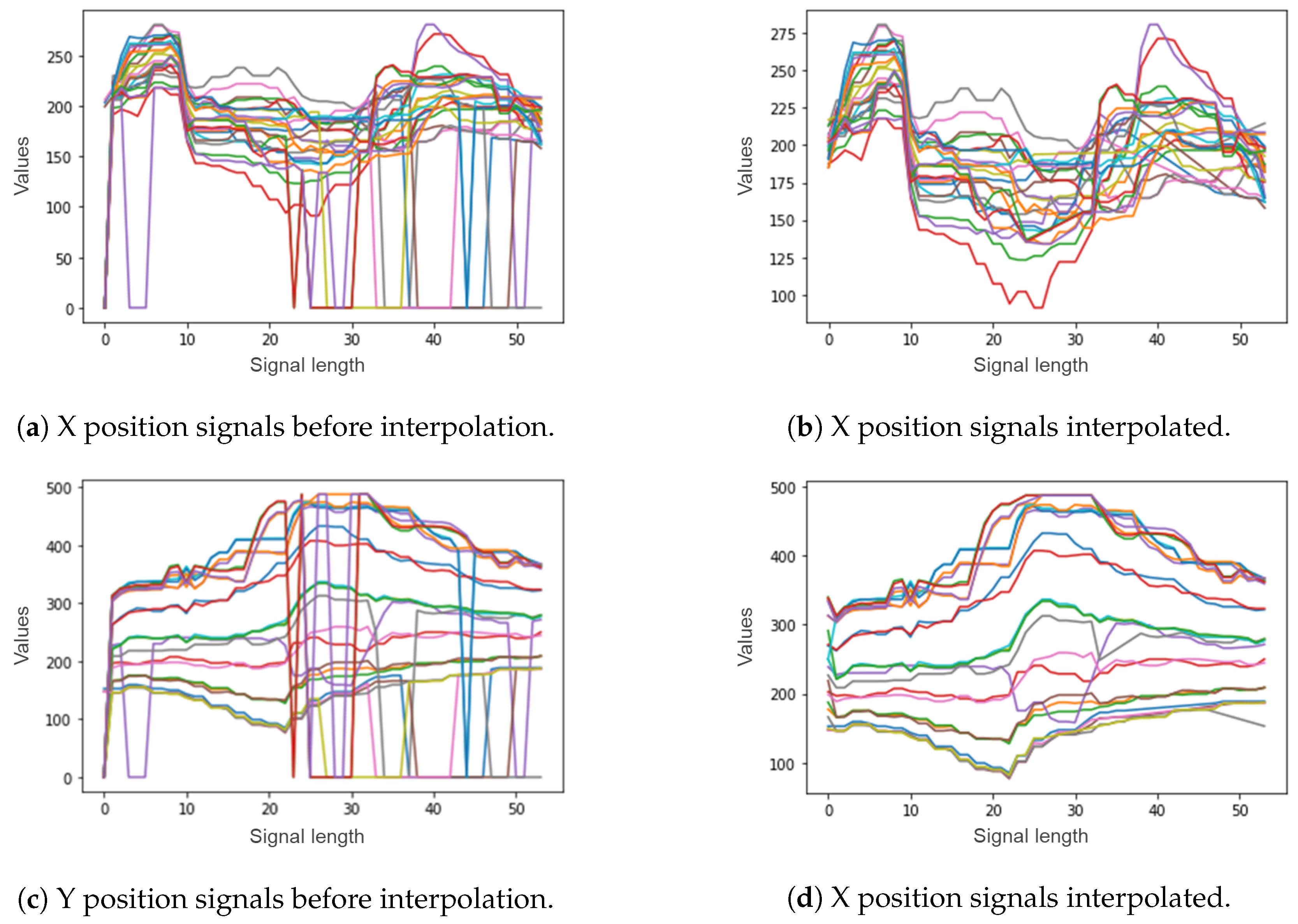
3.2. Proposed Approach
4. Experimental Results
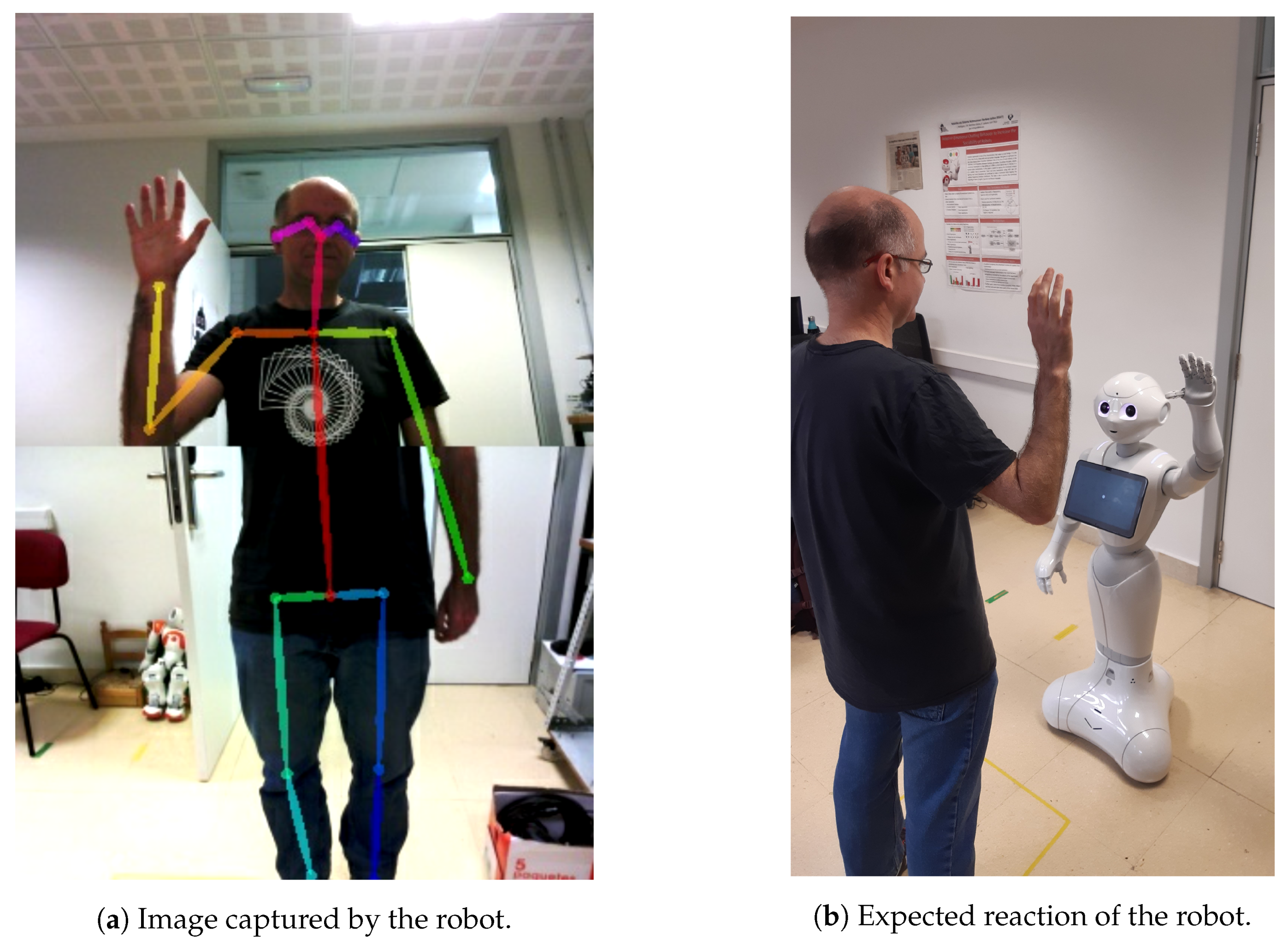
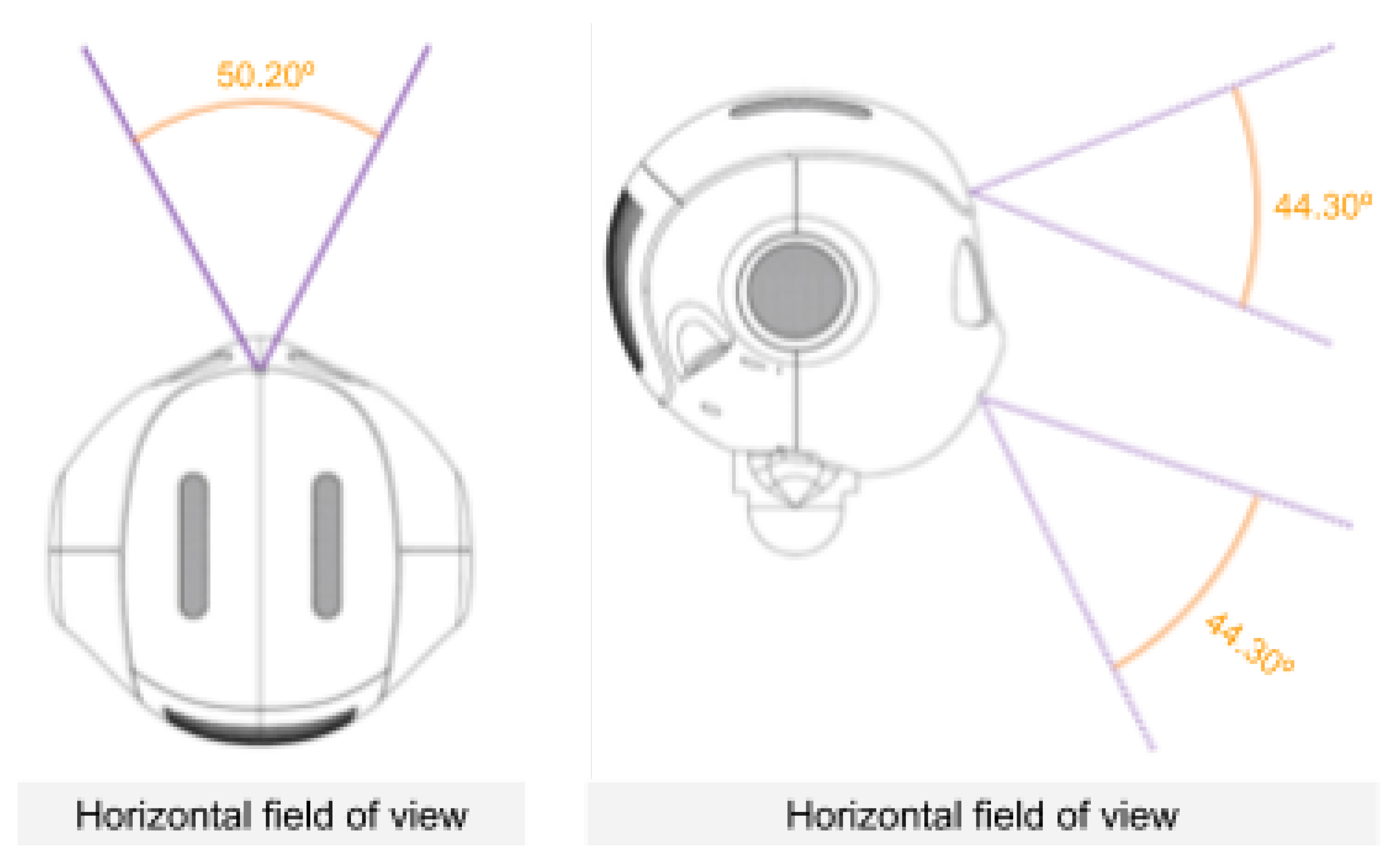
4.1. Robotic Platform and Human Pose Estimation
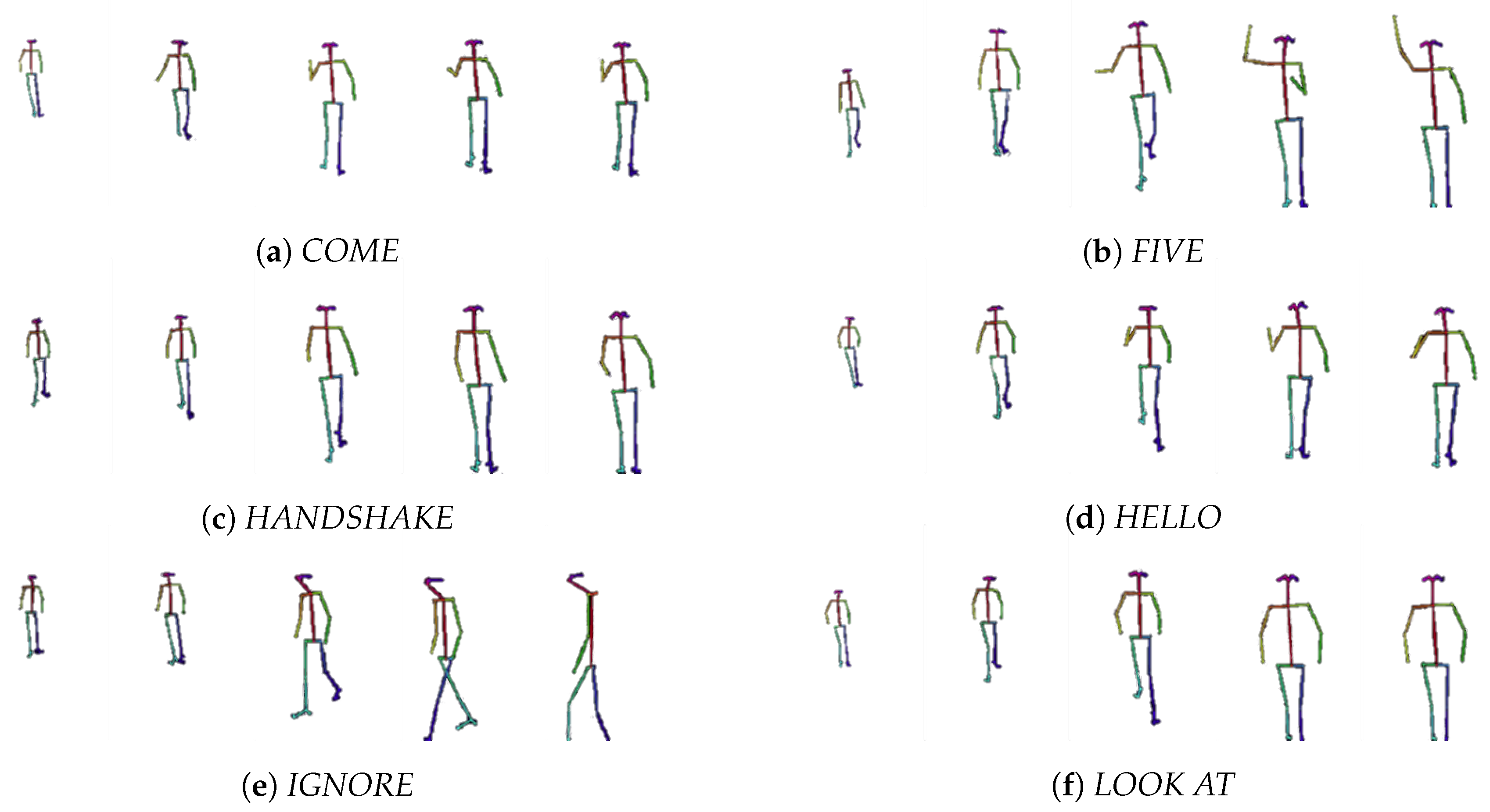
4.2. Dataset
- COME: gesture for telling the robot to come to you.
- FIVE: gesture of “high five”.
- HANDSHAKE: gesture of handshaking with the robot.
- HELLO: gesture for indicating hello to the robot.
- IGNORE: ignore the robot, pass by.
- LOOK AT: stare at the robot in front of it.
4.3. Long Short-Term Memory (LSTM) Neural Networks
- : input vector at time step t.
- : hidden state at time step t. W and U are weight matrices applied to the current input and to the previous hidden state, respectively. is an activation function, typically sigmoid (), tanh, or ReLU.
- : output vector at time step t. V is a weight matrix.
- : input vector at time step t.
- : activation vector of the forget gate at time step t.
- : activation vector of the input gate at time step t.
- : activation vector of the output gate at time step t.
- : cell state vector at time step t.
- : hidden state at time step t.
4.4. Results
| varianceq = 5 | varianceq = 10 | var, max, min, IQRq = 5 | varianceq = 15 | LSTM | ||||
| 0.8691 | > | 0.8622 | > | 0.8586 | > | 0.8506 | > | 0.8505 |
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Breazeal, C. Designing Sociable Robots; Intelligent Robotics and Autonomous Agents, MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Ke, S.R.; Thuc, H.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Vishwakarma, S.; Agrawal, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Chen, C.C.; Aggarwal, J. Recognizing human action from a far field of view. In Proceedings of the 2009 Workshop on Motion and Video Computing (WMVC), Snowbird, UT, USA, 8–9 December 2009; pp. 1–7. [Google Scholar]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1932–1939. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Robust 3D action recognition through sampling local appearances and global distributions. IEEE Trans. Multimed. 2018, 20, 1932–1947. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2014; pp. 568–576. [Google Scholar]
- Astigarraga, A.; Arruti, A.; Muguerza, J.; Santana, R.; Martin, J.I.; Sierra, B. User adapted motor-imaginary brain-computer interface by means of EEG channel selection based on estimation of distributed algorithms. Math. Probl. Eng. 2016, 2016, 1435321. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. arXiv 2018, arXiv:1812.08008. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 24 April 2020).
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Bobick, A.; Davis, J. An appearance-based representation of action. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–19 August 1996; Volume 1, pp. 307–312. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Niebles, J.C.; Fei-Fei, L. A hierarchical model of shape and appearance for human action classification. In Proceedings of the Computer Vision and Pattern Recognition, CVPR’07, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Bosch, A.; Zisserman, A.; Munoz, X. Representing shape with a spatial pyramid kernel. In Proceedings of the 6th ACM International Conference on Image And Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 401–408. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Marszałek, M.; Schmid, C.; Harzallah, H.; Van De Weijer, J. Learning object representations for visual object class recognition. In Proceedings of the Visual Recognition Challange Workshop, in Conjunction with ICCV, Rio de Janeiro, Brazil, 14–20 October 2007. [Google Scholar]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local features and kernels for classification of texture and object categories: A comprehensive study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef]
- Efros, A.A.; Berg, A.C.; Mori, G.; Malik, J. Recognizing action at a distance. In Proceedings of the Ninth International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 726–733. [Google Scholar]
- Tran, D.; Sorokin, A. Human activity recognition with metric learning. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 548–561. [Google Scholar]
- Ercis, F. Comparison of Histogram of Oriented Optical Flow Based Action Recognition Methods. Ph.D. Thesis, Middle East Technical University, Ankara, Turkey, 2012. [Google Scholar]
- Lertniphonphan, K.; Aramvith, S.; Chalidabhongse, T.H. Human action recognition using direction histograms of optical flow. In Proceedings of the Communications and Information Technologies (ISCIT), 2011 11th International Symposium on Communications & Information Technologies (ISCIT 2011), Hangzhou, China, 12–14 October 2011; pp. 574–579. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique With an Application To Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Akpinar, S.; Alpaslan, F.N. Video action recognition using an optical flow based representation. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV), Las Vegas, NV, USA, 21–24 September 2014; p. 1. [Google Scholar]
- Satyamurthi, S.; Tian, J.; Chua, M.C.H. Action recognition using multi-directional projected depth motion maps. J. Ambient. Intell. Humaniz. Comput. 2018, 9, 1–7. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Choutas, V.; Weinzaepfel, P.; Revaud, J.; Schmid, C. PoTion: Pose MoTion Representation for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ren, J.; Reyes, N.H.; Barczak, A.; Scogings, C.; Liu, M. An Investigation of Skeleton-Based Optical Flow-Guided Features for 3D Action Recognition Using a Multi-Stream CNN Model. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 199–203. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream ConvNets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1933–1941. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features. IEEE Access 2018, 6, 1155–1166. [Google Scholar] [CrossRef]
- Fukunaga, K.; Koontz, W.L. Application of the Karhunen-Loève Expansion to Feature Selection and Ordering. IEEE Trans. Comput. 1970, 100, 311–318. [Google Scholar] [CrossRef]
- Ramoser, H.; Muller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gao, S.; Gao, X. Common spatial pattern method for channel selection in motor imagery based brain-computer interface. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 5392–5395. [Google Scholar]
- Novi, Q.; Guan, C.; Dat, T.H.; Xue, P. Sub-band common spatial pattern (SBCSP) for brain-computer interface. In Proceedings of the 2007 3rd International IEEE/EMBS Conference on Neural Engineering, Kohala Coast, HI, USA, 2–5 May 2007; pp. 204–207. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd international conference on document analysis and recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient flow in recurrent nets: The difficulty of learning long-term dependencies. In A Field Guide to Dynamical Recurrent Neural Networks; Kremer, S.C., Kolen, J.F., Eds.; IEEE Press: Piscataway, NJ, USA, 2001. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Talathi, S.S.; Vartak, A. Improving performance of recurrent neural network with relu nonlinearity. arXiv 2015, arXiv:1511.03771. [Google Scholar]
- Mendialdua, I.; Martínez-Otzeta, J.M.; Rodriguez-Rodriguez, I.; Ruiz-Vazquez, T.; Sierra, B. Dynamic selection of the best base classifier in one versus one. Knowl.-Based Syst. 2015, 85, 298–306. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | #Video | Resolution | FPS |
|---|---|---|---|
| COME | 46 | 320 × 480 | 10 |
| FIVE | 45 | 320× 480 | 10 |
| HANDSHAKE | 45 | 320 × 480 | 10 |
| HELLO | 44 | 320 × 480 | 10 |
| IGNORE | 46 | 320 × 480 | 10 |
| LOOK AT | 46 | 320 × 480 | 10 |
| Variance | Variance, Max, Min, IQR | |||||
|---|---|---|---|---|---|---|
| Pair of Categories | ||||||
| COME-FIVE | 0.7579 ± 0.13 | 0.8124 ± 0.12 | 0.7667 ± 0.17 | 0.7578 ± 0.12 | 0.8344 ± 0.14 | 0.7667 ± 0.16 |
| COME-HANDSHAKE | 0.8668 ± 0.10 | 0.8019 ± 0.12 | 0.6910 ± 0.17 | 0.8667 ± 0.13 | 0.7900 ± 0.12 | 0.6567 ± 0.16 |
| COME-HELLO | 0.5334 ± 0.16 | 0.5000 ± 0.09 | 0.5000 ± 0.14 | 0.4778 ± 0.16 | 0.4444 ± 0.09 | 0.4778 ± 0.15 |
| COME-IGNORE | 0.9779 ± 0.05 | 0.9667 ± 0.05 | 0.9667 ± 0.05 | 0.9667 ± 0.05 | 0.9667 ± 0.05 | 0.9444 ± 0.06 |
| COME-LOOK_AT | 0.8678 ± 0.09 | 0.8900 ± 0.09 | 0.8789 ± 0.11 | 0.8678 ± 0.10 | 0.8356 ± 0.14 | 0.8033 ± 0.14 |
| FIVE-HAND | 0.9557 ± 0.06 | 0.9333 ± 0.06 | 0.9223 ± 0.05 | 0.9333 ± 0.11 | 0.9000 ± 0.11 | 0.9000 ± 0.08 |
| FIVE-HELLO | 0.8208 ± 0.14 | 0.7986 ± 0.15 | 0.7764 ± 0.17 | 0.7750 ± 0.18 | 0.7528 ± 0.18 | 0.7319 ± 0.21 |
| FIVE-IGNORE | 0.9668 ± 0.07 | 0.9668 ± 0.07 | 0.9556 ± 0.11 | 0.9667 ± 0.07 | 0.9556 ± 0.11 | 0.9556 ± 0.11 |
| FIVE-LOOK_AT | 0.9667 ± 0.05 | 0.9556 ± 0.06 | 0.9556 ± 0.06 | 0.9556 ± 0.08 | 0.9556 ± 0.08 | 0.9011 ± 0.17 |
| HANDSHAKE-HELLO | 0.7431 ± 0.19 | 0.7861 ± 0.14 | 0.8097 ± 0.10 | 0.7111 ± 0.24 | 0.7889 ± 0.21 | 0.8000 ± 0.10 |
| HANDSHAKE-IGNORE | 0.9889 ± 0.04 | 1.0000 ± 0.00 | 1.0000 ± 0.00 | 1.0000 ± 0.00 | 0.9889 ± 0.04 | 0.9889 ± 0.04 |
| HANDSHAKE-LOOK_AT | 0.8235 ± 0.18 | 0.7789 ± 0.16 | 0.7567 ± 0.12 | 0.8122 ± 0.17 | 0.7467 ± 0.17 | 0.7456 ± 0.12 |
| HELLO-IGNORE | 0.9333 ± 0.14 | 0.9221 ± 0.14 | 0.9333 ± 0.11 | 0.9556 ± 0.14 | 0.9444 ± 0.14 | 0.9444 ± 0.11 |
| HELLO-LOOK_AT | 0.8445 ± 0.11 | 0.8334 ± 0.12 | 0.8556 ± 0.14 | 0.8556 ± 0.09 | 0.8000 ± 0.10 | 0.8667 ± 0.10 |
| IGNORE-LOOK_AT | 0.9889 ± 0.04 | 0.9889 ± 0.04 | 0.9889 ± 0.04 | 0.9778 ± 0.05 | 0.9678 ± 0.05 | 0.9678 ± 0.05 |
| MEAN | 0.8691 | 0.8623 | 0.8506 | 0.8586 | 0.8448 | 0.8301 |
| Variance | Variance, Max, Min, IQR | |||||
|---|---|---|---|---|---|---|
| Pair of Categories | ||||||
| COME-FIVE | 0.6800 ± 0.29 | 0.6022 ± 0.24 | 0.5811 ± 0.19 | 0.7133 ± 0.21 | 0.6244 ± 0.23 | 0.5922 ± 0.21 |
| COME-HANDSHAKE | 0.7000 ± 0.20 | 0.6900 ± 0.29 | 0.6344 ± 0.29 | 0.7556 ± 0.16 | 0.6678 ± 0.32 | 0.6344 ± 0.32 |
| COME-HELLO | 0.5111 ± 0.22 | 0.3889 ± 0.21 | 0.4222 ± 0.17 | 0.4889 ± 0.22 | 0.4222 ± 0.20 | 0.3889 ± 0.20 |
| COME-IGNORE | 0.9233 ± 0.12 | 0.8900 ± 0.17 | 0.8800 ± 0.18 | 0.9233 ± 0.12 | 0.8911 ± 0.15 | 0.8578 ± 0.20 |
| COME-LOOK_AT | 0.8133 ± 0.23 | 0.7800 ± 0.20 | 0.7456 ± 0.25 | 0.8122 ± 0.23 | 0.8122 ± 0.24 | 0.7789 ± 0.24 |
| FIVE-HANDSHAKE | 0.8889 ± 0.17 | 0.7778 ± 0.15 | 0.6444 ± 0.17 | 0.8444 ± 0.17 | 0.7667 ± 0.12 | 0.6667 ± 0.17 |
| FIVE-HELLO | 0.6264 ± 0.22 | 0.5500 ± 0.22 | 0.5028 ± 0.23 | 0.6264 ± 0.22 | 0.5361 ± 0.23 | 0.5236 ± 0.24 |
| FIVE-IGNORE | 0.9444 ± 0.14 | 0.9344 ± 0.14 | 0.9344 ± 0.14 | 0.9556 ± 0.11 | 0.9456 ± 0.11 | 0.9233 ± 0.14 |
| FIVE-LOOK_AT | 0.9000 ± 0.19 | 0.8889 ± 0.21 | 0.8233 ± 0.23 | 0.9111 ± 0.21 | 0.9000 ± 0.21 | 0.8556 ± 0.25 |
| HANDSHAKE-HELLO | 0.6875 ± 0.18 | 0.5708 ± 0.14 | 0.6111 ± 0.20 | 0.6889 ± 0.19 | 0.5819 ± 0.16 | 0.6556 ± 0.15 |
| HANDSHAKE-IGNORE | 0.9789 ± 0.04 | 0.9578 ± 0.07 | 0.9133 ± 0.12 | 0.9789 ± 0.04 | 0.9578 ± 0.07 | 0.9244 ± 0.11 |
| HANDSHAKE-LOOK_AT | 0.7344 ± 0.26 | 0.7556 ± 0.29 | 0.6789 ± 0.29 | 0.7456 ± 0.26 | 0.7456 ± 0.28 | 0.6678 ± 0.25 |
| HELLO-IGNORE | 0.9000 ± 0.14 | 0.8889 ± 0.17 | 0.8667 ± 0.21 | 0.9111 ± 0.15 | 0.8889 ± 0.17 | 0.8667 ± 0.21 |
| HELLO-LOOK_AT | 0.7667 ± 0.22 | 0.6556 ± 0.32 | 0.6556 ± 0.35 | 0.7889 ± 0.23 | 0.7556 ± 0.29 | 0.7333 ± 0.28 |
| IGNORE-LOOK_AT | 0.9222 ± 0.12 | 0.9333 ± 0.14 | 0.9222 ± 0.14 | 0.9333 ± 0.09 | 0.9111 ± 0.15 | 0.9333 ± 0.14 |
| MEAN | 0.7985 | 0.7509 | 0.7211 | 0.8052 | 0.7605 | 0.7335 |
| Pair of Categories | CSP (Variance and ) + LDA | LSTM |
|---|---|---|
| COME-FIVE | 0.7579 ± 0.13 | 0.8628 ± 0.11 |
| COME-HANDSHAKE | 0.8668 ± 0.10 | 0.7739 ± 0.16 |
| COME-HELLO | 0.5334 ± 0.16 | 0.7336 ± 0.17 |
| COME-IGNORE | 0.9779 ± 0.05 | 0.9575 ± 0.06 |
| COME-LOOK_AT | 0.8678 ± 0.09 | 0.7849 ± 0.10 |
| FIVE-HANDSHAKE | 0.9557 ± 0.06 | 0.8125 ± 0.14 |
| FIVE-HELLO | 0.8208 ± 0.14 | 0.9125 ± 0.07 |
| FIVE-IGNORE | 0.9668 ± 0.07 | 0.9789 ± 0.04 |
| FIVE-LOOK_AT | 0.9667 ± 0.05 | 0.8889 ± 0.11 |
| HANDSHAKE-HELLO | 0.7431 ± 0.19 | 0.7108 ± 0.21 |
| HANDSHAKE-IGNORE | 0.9889 ± 0.04 | 0.9764 ± 0.05 |
| HANDSHAKE-LOOK_AT | 0.8235 ± 0.18 | 0.8350 ± 0.12 |
| HELLO-IGNORE | 0.9333 ± 0.14 | 0.9789 ± 0.04 |
| HELLO-LOOK_AT | 0.8445 ± 0.11 | 0.5733 ± 0.18 |
| IGNORE-LOOK_AT | 0.9889 ± 0.04 | 0.9775 ± 0.05 |
| MEAN | 0.8691 | 0.8505 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Goienetxea, I.; Rodriguez-Rodriguez, I.; Sierra, B. Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns. Sensors 2020, 20, 2436. https://doi.org/10.3390/s20082436
Rodríguez-Moreno I, Martínez-Otzeta JM, Goienetxea I, Rodriguez-Rodriguez I, Sierra B. Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns. Sensors. 2020; 20(8):2436. https://doi.org/10.3390/s20082436
Chicago/Turabian StyleRodríguez-Moreno, Itsaso, José María Martínez-Otzeta, Izaro Goienetxea, Igor Rodriguez-Rodriguez, and Basilio Sierra. 2020. "Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns" Sensors 20, no. 8: 2436. https://doi.org/10.3390/s20082436
APA StyleRodríguez-Moreno, I., Martínez-Otzeta, J. M., Goienetxea, I., Rodriguez-Rodriguez, I., & Sierra, B. (2020). Shedding Light on People Action Recognition in Social Robotics by Means of Common Spatial Patterns. Sensors, 20(8), 2436. https://doi.org/10.3390/s20082436