Exposing Digital Image Forgeries by Detecting Contextual Abnormality Using Convolutional Neural Networks



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
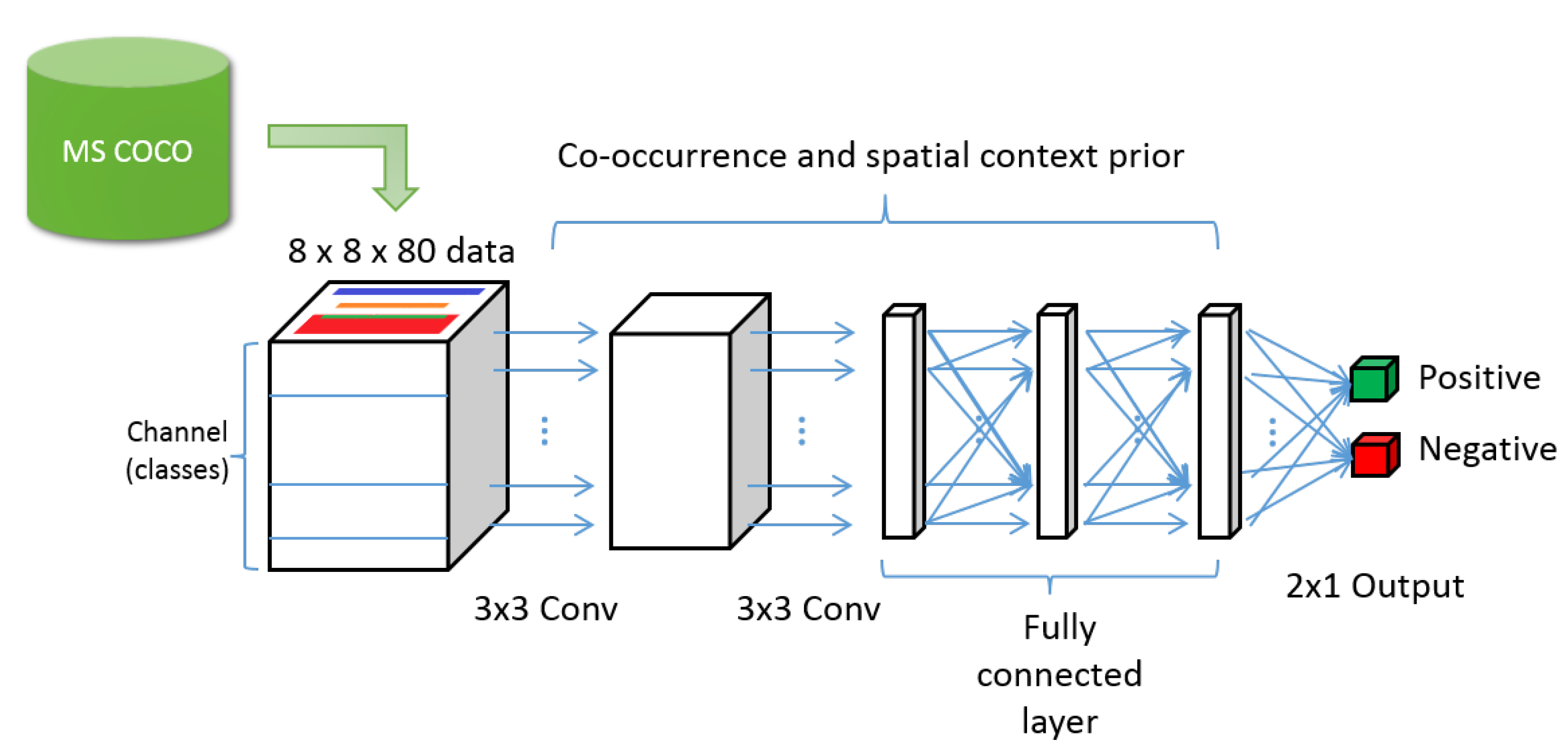
- We propose a CL-CNN that detects contextual abnormality in an image. The CL-CNN was trained using a large annotated image database (COCO 2014), and was then used to learn the spatial context that was not provided by the existing graph-based context models.
- In combination with a well-known object detector such as a region-based convolutional neural network (R-CNN), the proposed method can evaluate the contextual scores according to the combination of the objects in the image, and the spatial context among the objects. The proposed detector in combination with CL-CNN and the object detector can detect image forgeries based on contextual abnormality as long as the objects in the image can be identified by the R-CNN, in contrast to the family of low-level feature-based forgery detectors.
2. Related Work
2.1. Image Forensics
2.2. Object Detection Based on Deep Learning
3. Context-Learning CNN
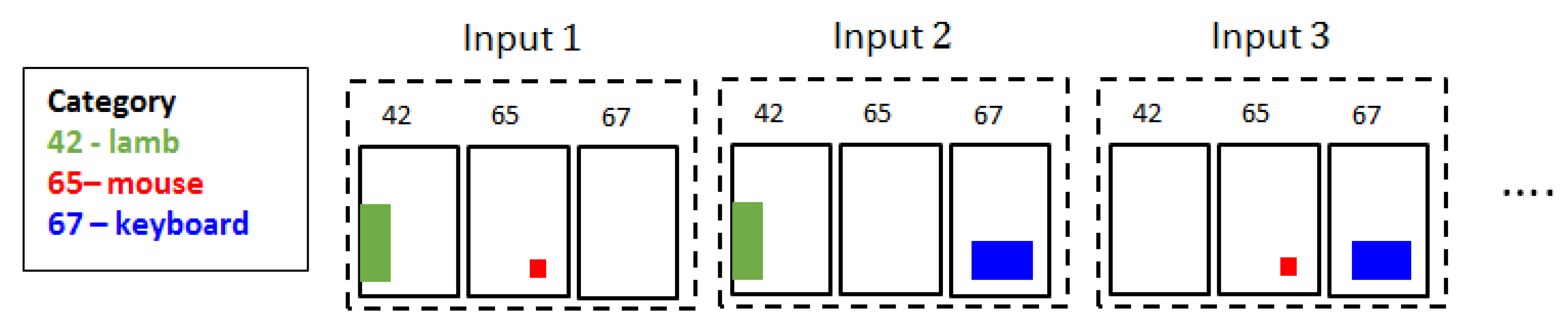
3.1. Input Data Structure
3.2. CL-CNN Structure
3.3. Dataset Generation
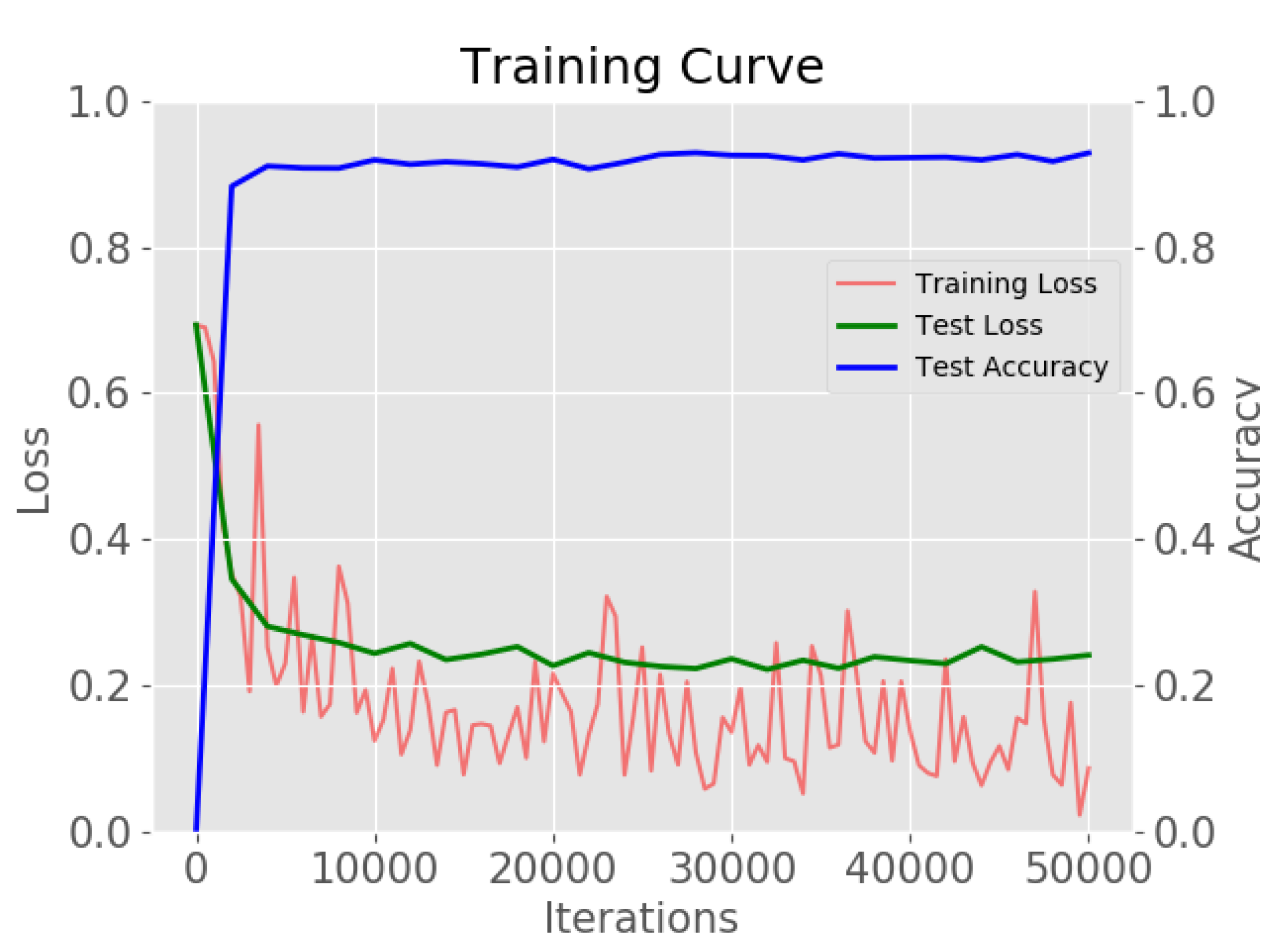
3.4. Network Training
4. Detection of Contextual Abnormality of Target Image
5. Experimental Results
5.1. Implementation Details
5.2. Detection Results
5.3. Detection Complement with Other Detectors
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems Conference, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Blitz, M.J. Lies, Line Drawing, and Deep Fake News. Okla. L. Rev. 2018, 71, 59. [Google Scholar]
- Farid, H. Image forgery detection. IEEE Signal Process. Mag. 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Sencar, H.T.; Memon, N. Algorithms, Architectures and Information Systems Security; World Scientific Press: Singapore, 2008; Volume 3, pp. 325–348. [Google Scholar]
- Lukas, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Chen, M.; Fridrich, J.; Goljan, M.; Lukas, J. Determining Image Origin and Integrity Using Sensor Noise. IEEE Trans. Inf. Forensics Secur. 2008, 3, 74–90. [Google Scholar] [CrossRef]
- Hou, J.U.; Jang, H.U.; Lee, H.K. Hue modification estimation using sensor pattern noise. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 30 October 2014; pp. 5287–5291. [Google Scholar] [CrossRef]
- Hou, J.U.; Lee, H.K. Detection of hue modification using photo response non-uniformity. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1826–1832. [Google Scholar] [CrossRef]
- Fridrich, A.J.; Soukal, B.D.; Lukáš, A.J. Detection of copy-move forgery in digital images. In Proceedings of the Digital Forensic Research Workshop, Cleveland, OH, USA, 6–8 August 2003. [Google Scholar]
- Huang, H.; Guo, W.; Zhang, Y. Detection of Copy-Move Forgery in Digital Images Using SIFT Algorithm. In Proceedings of the 2008 IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application, Wuhan, China, 19–20 December 2008; Volume 2, pp. 272–276. [Google Scholar] [CrossRef]
- Ryu, S.J.; Kirchner, M.; Lee, M.J.; Lee, H.K. Rotation Invariant Localization of Duplicated Image Regions Based on Zernike Moments. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1355–1370. [Google Scholar] [CrossRef]
- Chen, J.; Kang, X.; Liu, Y.; Wang, Z.J. Median filtering forensics based on convolutional neural networks. IEEE Signal Process. Lett. 2015, 22, 1849–1853. [Google Scholar] [CrossRef]
- Verdoliva, L. Deep Learning in Multimedia Forensics. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 3–4. [Google Scholar]
- Toor, A.S.; Wechsler, H. Biometrics and forensics integration using deep multi-modal semantic alignment and joint embedding. Pattern Recogn. Lett. 2018, 113, 29–37. [Google Scholar] [CrossRef]
- Deng, C.; Li, Z.; Gao, X.; Tao, D. Deep Multi-scale Discriminative Networks for Double JPEG Compression Forensics. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–20. [Google Scholar] [CrossRef]
- Zhu, X.; Qian, Y.; Zhao, X.; Sun, B.; Sun, Y. A deep learning approach to patch-based image inpainting forensics. Signal Process. Image Commun. 2018, 67, 90–99. [Google Scholar] [CrossRef]
- Hou, J.U.; Jang, H.U.; Park, J.S.; Lee, H.K. Exposing Digital Forgeries by Detecting a Contextual Violation Using Deep Neural Networks. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 24–26 August 2017; pp. 16–24. [Google Scholar]
- Wu, T.F.; Xia, G.S.; Zhu, S.C. Compositional boosting for computing hierarchical image structures. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Choi, M.J.; Lim, J.J.; Torralba, A.; Willsky, A.S. Exploiting hierarchical context on a large database of object categories. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 129–136. [Google Scholar]
- Zhu, Y.; Urtasun, R.; Salakhutdinov, R.; Fidler, S. Segdeepm: Exploiting segmentation and context in deep neural networks for object detection. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4703–4711.
- Popescu, A.; Farid, H. Exposing digital forgeries by detecting traces of resampling. IEEE Trans. Signal Process. 2005, 53, 758–767. [Google Scholar] [CrossRef]
- Choi, C.H.; Lee, H.Y.; Lee, H.K. Estimation of color modification in digital images by CFA pattern change. Forensic Sci. Int. 2013, 226, 94–105. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Wang, R.; Tang, X.; Shum, H.Y. Detecting doctored images using camera response normality and consistency. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 1087–1092. [Google Scholar] [CrossRef]
- Hsu, Y.F.; Chang, S.-F. Camera response functions for image forensics: An automatic algorithm for splicing detection. IEEE Trans. Inf. Forensics Secur. 2010, 5, 816–825. [Google Scholar] [CrossRef]
- Farid, H. Exposing Digital Forgeries from JPEG Ghosts. IEEE Trans. Inf. Forensics Secur. 2009, 4, 154–160. [Google Scholar] [CrossRef]
- Johnson, M.K.; Farid, H. Exposing digital forgeries in complex lighting environments. IEEE Trans. Inf. Forensics Secur. 2007, 2, 450–461. [Google Scholar] [CrossRef]
- Peng, F.; Wang, L.X. Digital Image Forgery Forensics by Using Blur Estimation and Abnormal Hue Detection. In Proceedings of the 2010 Symposium on Photonics and Optoelectronic (SOPO), Chengdu, China, 19–21 June 2010; pp. 1–4. [Google Scholar] [CrossRef]
- O’Brien, J.F.; Farid, H. Exposing photo manipulation with inconsistent reflections. ACM Trans. Graph. 2012, 31, 4–15. [Google Scholar] [CrossRef]
- Kee, E.; O’brien, J.F.; Farid, H. Exposing Photo Manipulation from Shading and Shadows. ACM Trans. Graph. 2014, 33, 165–186. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 22–18 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–13 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollar, P. Microsoft coco: Common objects in context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Krawetz, N.; Solutions, H.F. A picture’s worth. Hacker Factor Solut. 2007, 6, 2. [Google Scholar]
- Lin, D.; Lu, C.; Liao, R.; Jia, J. Learning important spatial pooling regions for scene classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 24–27 June 2014; pp. 3726–3733. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]














© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, H.; Hou, J.-U. Exposing Digital Image Forgeries by Detecting Contextual Abnormality Using Convolutional Neural Networks. Sensors 2020, 20, 2262. https://doi.org/10.3390/s20082262
Jang H, Hou J-U. Exposing Digital Image Forgeries by Detecting Contextual Abnormality Using Convolutional Neural Networks. Sensors. 2020; 20(8):2262. https://doi.org/10.3390/s20082262
Chicago/Turabian StyleJang, Haneol, and Jong-Uk Hou. 2020. "Exposing Digital Image Forgeries by Detecting Contextual Abnormality Using Convolutional Neural Networks" Sensors 20, no. 8: 2262. https://doi.org/10.3390/s20082262
APA StyleJang, H., & Hou, J.-U. (2020). Exposing Digital Image Forgeries by Detecting Contextual Abnormality Using Convolutional Neural Networks. Sensors, 20(8), 2262. https://doi.org/10.3390/s20082262