A Methodology for Network Analysis to Improve the Cyber-Physicals Communications in Next-Generation Networks



Abstract
1. Introduction
- A methodology is presented to analyze real network data sets, extract the comportment of each analyzed area and acquire the knowledge of the network users’ behavior.
- Two data sets are analyzed in order to prove the methodology introduced in [15]. These real data sets are provided by Telecom Italia and cover different areas of Italy. One is located in the Trento province in Italy, which is a mainly rural area and covers a larger zone than the other analyzed data set. The second one is located in the city of Milan, which covers a metropolitan zone; the area is smaller and the number of connected devices is bigger.
- A new technique is developed to compare the comportments obtained in both analyses, grouping them in a single cluster set and reducing those that are similar, making more accurate the methodology presented in this work.
2. Proposed Methodology
| Algorithm 1 Pseudocode of Orthogonal Subspace Projection algorithm. |
|
3. Experimental Results
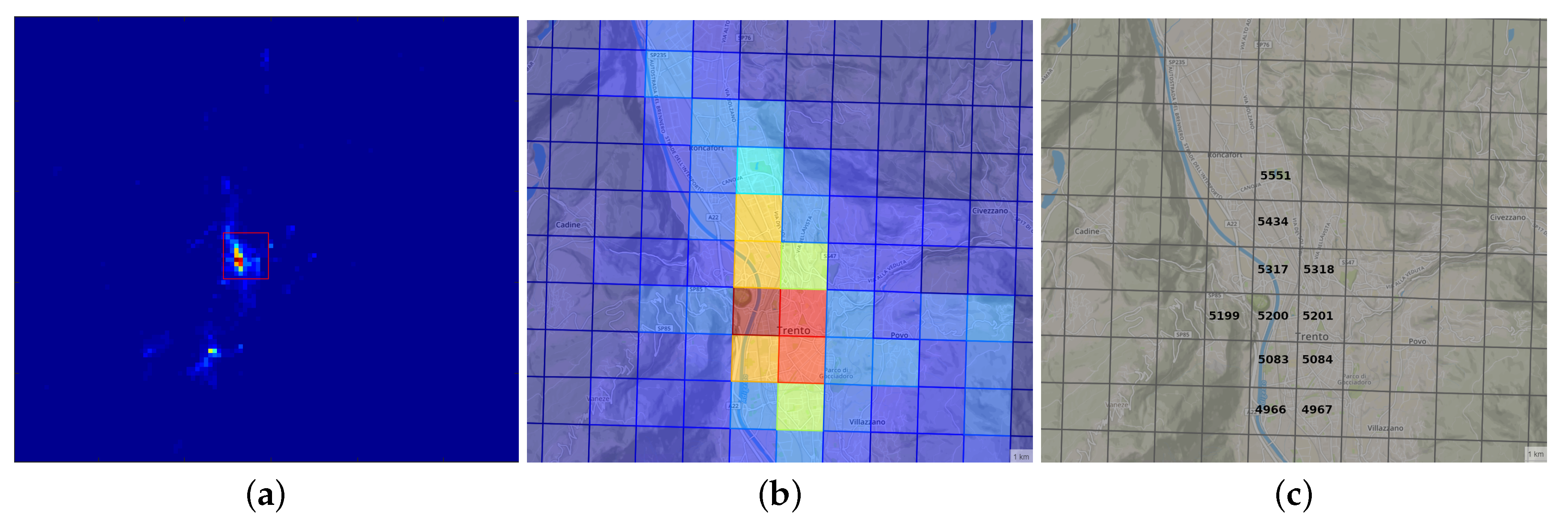
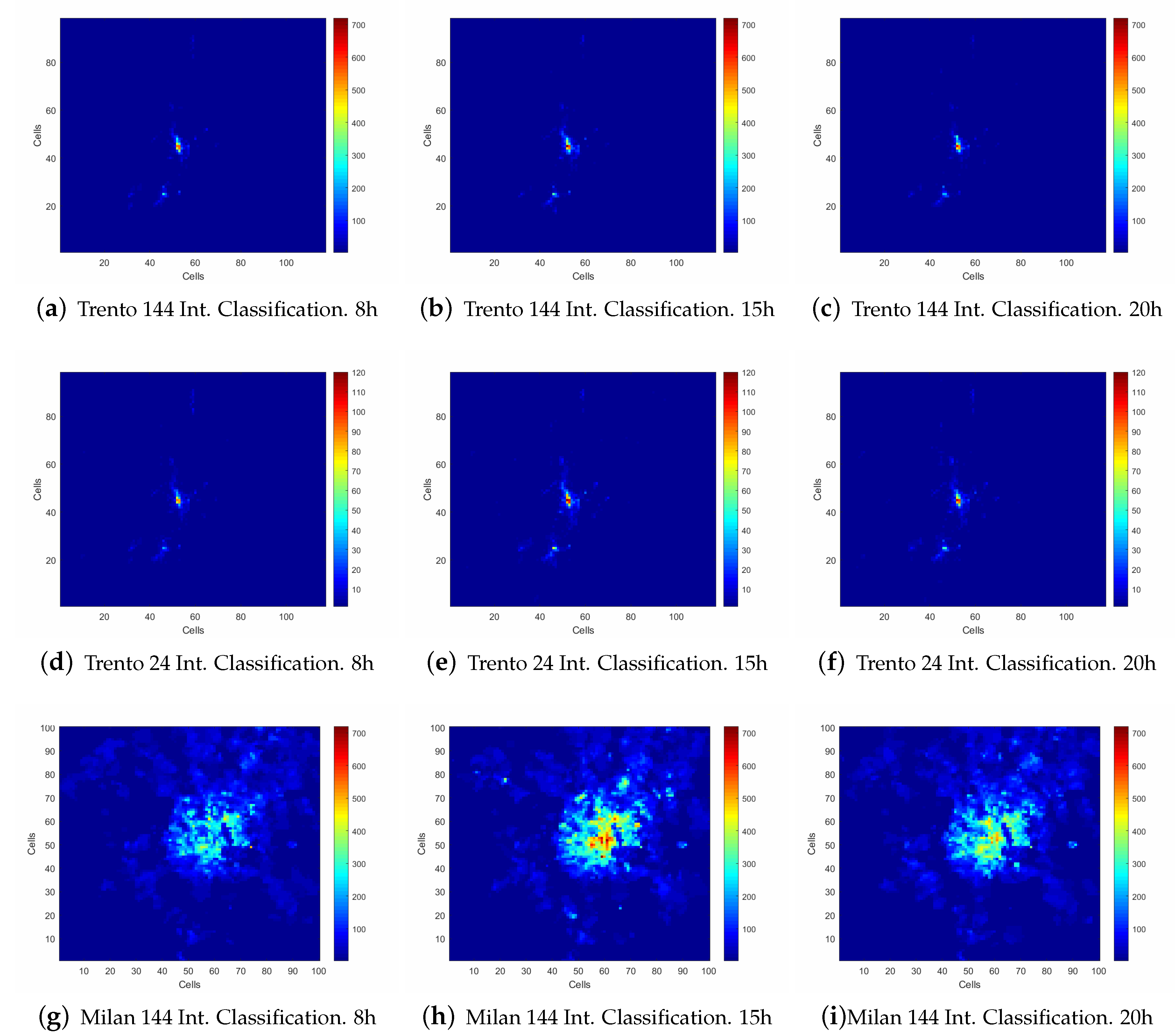
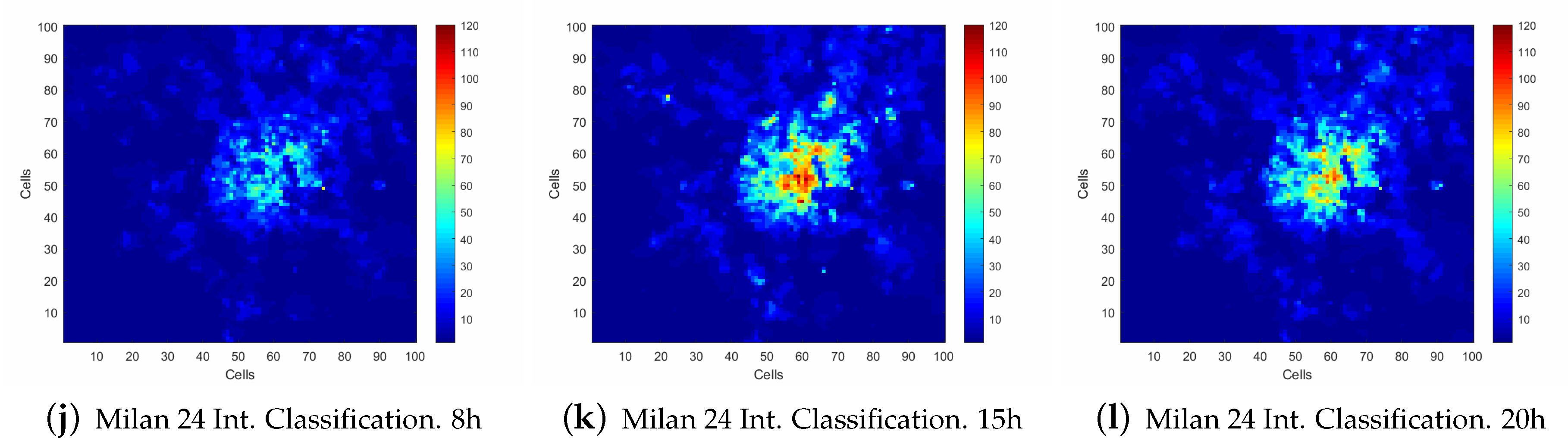
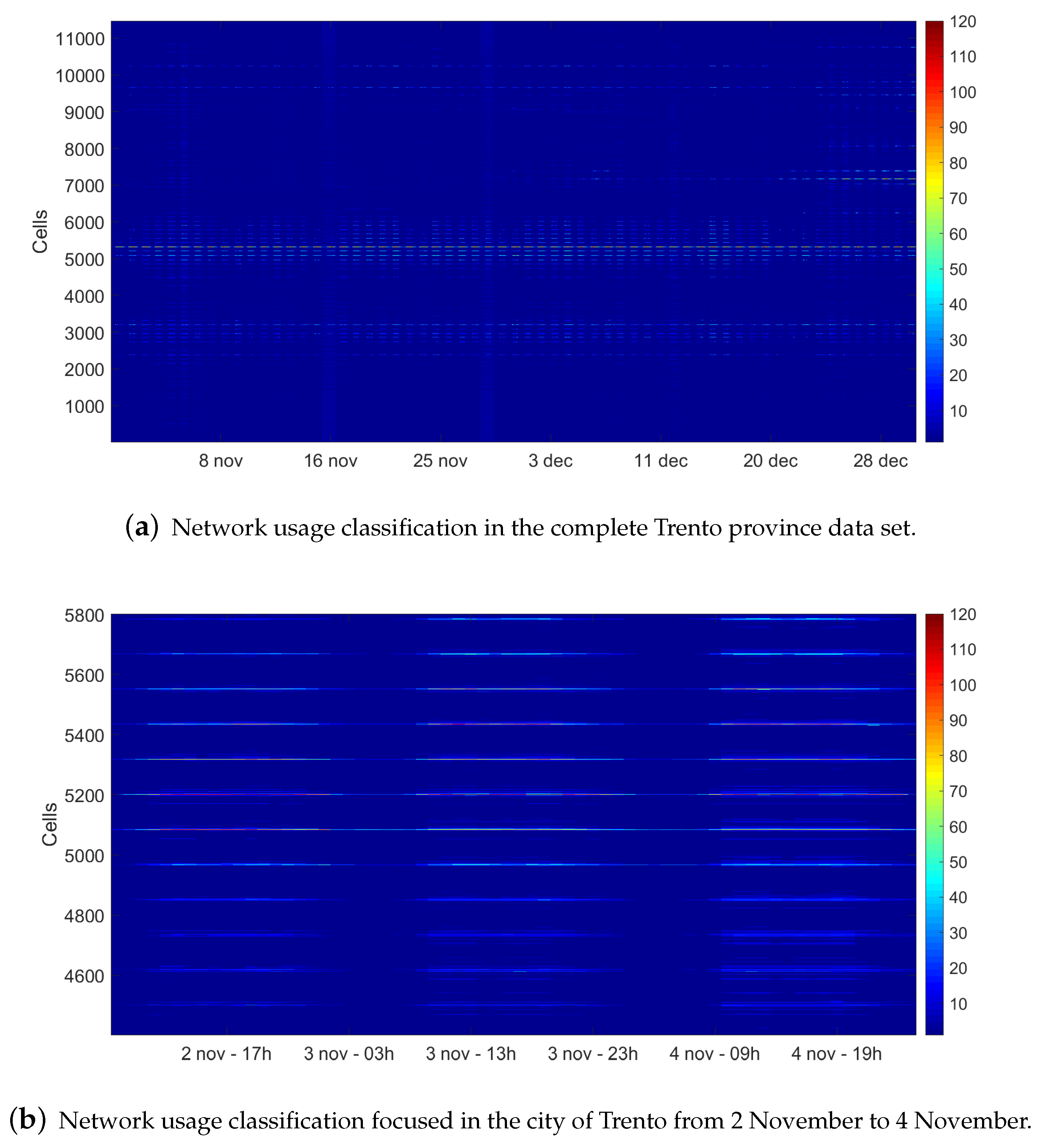
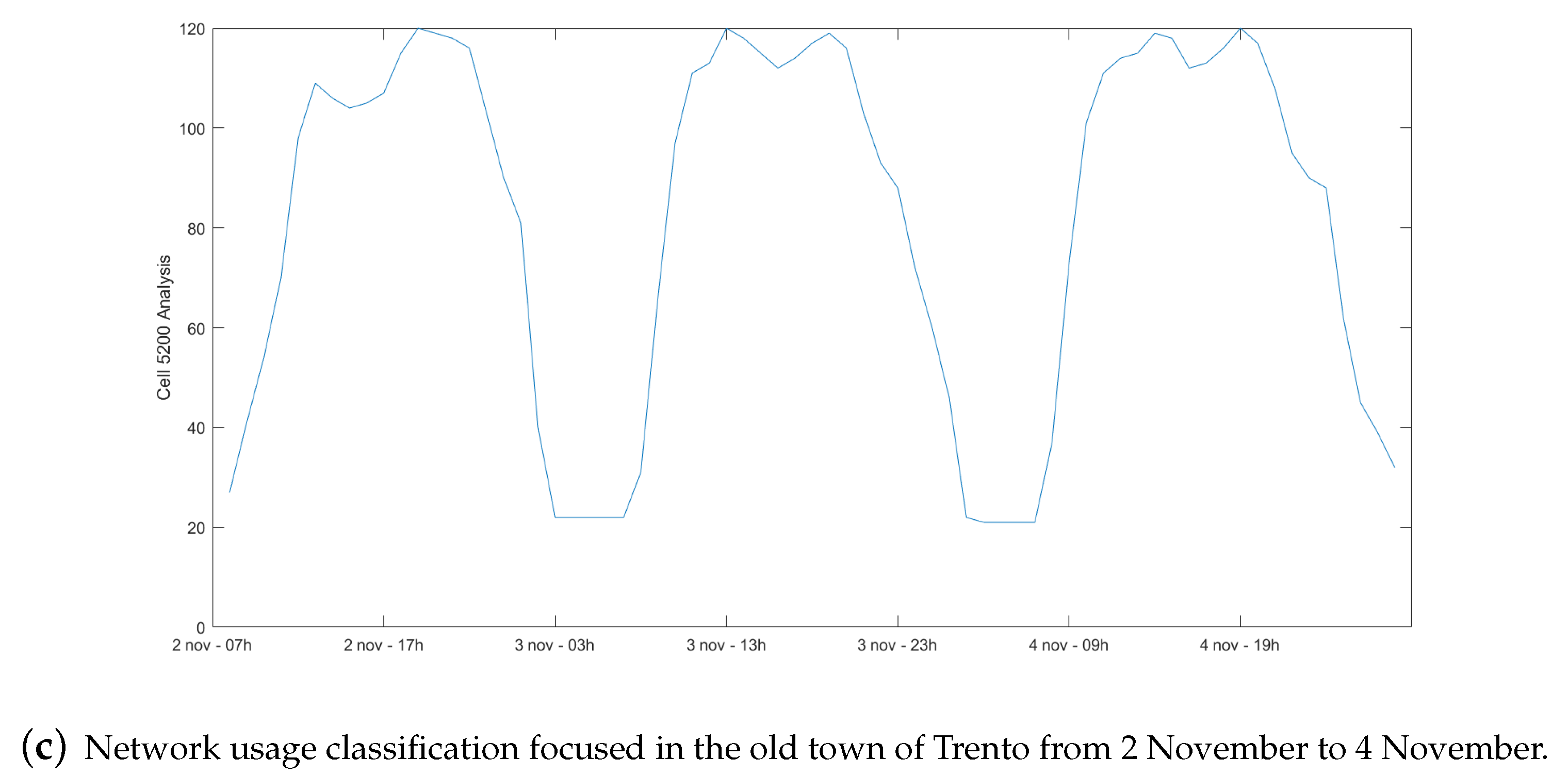
3.1. Description of the Used Data Sets
3.2. Analysis Conducted of the Data Set
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco Systems, Inc. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2017–2022. July 2019. Available online: www.cisco.com (accessed on 15 April 2020).
- Lee, J.; Bagheri, B.; Kao, H. A Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Atat, R.; Liu, L.; Wu, J.; Ashdown, J.; Yi, Y. Green Massive Traffic Offloading for Cyber-Physical Systems over Heterogeneous Cellular Networks. Mob. Netw. Appl. 2019, 24, 1364–1372. [Google Scholar] [CrossRef]
- Atat, R.; Liu, L.; Chen, H.; Wu, J.; Li, H.; Yi, Y. Enabling cyber-physical communication in 5G cellular networks: Challenges, spatial spectrum sensing, and cyber-security. IET Cyber-Phys. Syst. Theory Appl. 2017, 2, 49–54. [Google Scholar] [CrossRef]
- Varga, P.; Peto, J.; Franko, A.; Balla, D.; Haja, D.; Janky, F.; Soos, G.; Ficzere, D.; Maliosz, M.; Toka, L. 5G support for Industrial IoT Applications—Challenges, Solutions, and Research gaps. Sensors 2020, 20, 828. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Jha, R.K. A Survey of 5G Network: Architecture and Emerging Technologies. IEEE Access 2015, 3, 1206–1232. [Google Scholar] [CrossRef]
- Siddiqi, M.A.; Yu, H.; Joung, J. 5G Ultra-Reliable Low-Latency Communication Implementation Challenges and Operational Issues with IoT Devices. Electronics 2019, 8, 981. [Google Scholar] [CrossRef]
- Qiao, Y.; Xing, Z.; Fadlullah, Z.M.; Yang, J.; Kato, N. Characterizing Flow, Application, and User Behavior in Mobile Networks: A Framework for Mobile Big Data. IEEE Wirel. Commun. 2018, 25, 40–49. [Google Scholar] [CrossRef]
- Von Mörner, M. Application of Call Detail Records—Chances and Obstacles. Transp. Res. Proced. 2017, 25, 2233–2241. [Google Scholar] [CrossRef]
- Naboulsi, D.; Fiore, M.; Ribot, S.; Stanica, R. Large-Scale Mobile Traffic Analysis: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 124–161. [Google Scholar] [CrossRef]
- Cheng, X.; Chen, C.; Zhang, W.; Yang, Y. 5G-Enabled Cooperative Intelligent Vehicular (5GenCIV) Framework: When Benz Meets Marconi. IEEE Intell. Syst. 2017, 32, 53–59. [Google Scholar] [CrossRef]
- Barlacchi, G.; Nadai, M.D.; Larcher, R.; Casella, A.; Chitic, C.; Torrisi, G.; Antonelli, F.; Vespignani, A.; Pentland, A.; Lepri, B. A multi-source dataset of urban life in the city of Milan and the Province of Trentino. Sci. Data Nat. 2015, 2, 150055. [Google Scholar] [CrossRef] [PubMed]
- Roman, S.; Axler, S.; Gehring, F.W. Advanced Linear Algebra; Springer: New York, NY, USA, 2005; Volume 3. [Google Scholar]
- Khalil, H.K. Nonlinear Systems; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Cortés-Polo, D.; Jimenez, L.I.; Calle-Cancho, J.; González-Sánchez, J.L. A novel methodology based on orthogonal projections for a mobile network data set analysis. IEEE Access 2019, 7, 158007–158015. [Google Scholar] [CrossRef]
- Andrews, J.G.; Buzzi, S.; Choi, W.; Hanly, S.V.; Lozano, A.; Soong, A.C.; Zhang, J.C. What will 5G be? IEEE J. Select. Areas Commun. 2014, 32, 1065–1082. [Google Scholar] [CrossRef]
- Thompson, K.; Miller, G.J.; Wilder, R. Wide-area Internet traffic patterns and characteristics. IEEE Netw. 1997, 11, 10–23. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | 0.016 | 0.052 | 0.116 | 0.295 | 0.439 |
| Number of Classes Decreased | 61 (25.42%) | 127 (52.92%) | 176 (73.33%) | 190 (79.17%) | 213 (88.75%) |
| Number of Classes Extracted | |||||
| from the Milan Data Set | 93 (51.95%) | 59 (52.21%) | 31 (48.44%) | 28 (56%) | 12 (59.26%) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cortés-Polo, D.; Jimenez Gil, L.I.; González-Sánchez, J.-L.; Calle-Cancho, J. A Methodology for Network Analysis to Improve the Cyber-Physicals Communications in Next-Generation Networks. Sensors 2020, 20, 2247. https://doi.org/10.3390/s20082247
Cortés-Polo D, Jimenez Gil LI, González-Sánchez J-L, Calle-Cancho J. A Methodology for Network Analysis to Improve the Cyber-Physicals Communications in Next-Generation Networks. Sensors. 2020; 20(8):2247. https://doi.org/10.3390/s20082247
Chicago/Turabian StyleCortés-Polo, David, Luis Ignacio Jimenez Gil, José-Luis González-Sánchez, and Jesús Calle-Cancho. 2020. "A Methodology for Network Analysis to Improve the Cyber-Physicals Communications in Next-Generation Networks" Sensors 20, no. 8: 2247. https://doi.org/10.3390/s20082247
APA StyleCortés-Polo, D., Jimenez Gil, L. I., González-Sánchez, J.-L., & Calle-Cancho, J. (2020). A Methodology for Network Analysis to Improve the Cyber-Physicals Communications in Next-Generation Networks. Sensors, 20(8), 2247. https://doi.org/10.3390/s20082247