HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter

Abstract
1. Introduction
- (1)
- We improve the Staple’s histogram score model and introduce it into our HKSiamFC tracker. Unlike the Staple, we don’t use the histogram score model to generate an integral image, but optimize it with Gaussian filter and use it to provide appearance information of the target.
- (2)
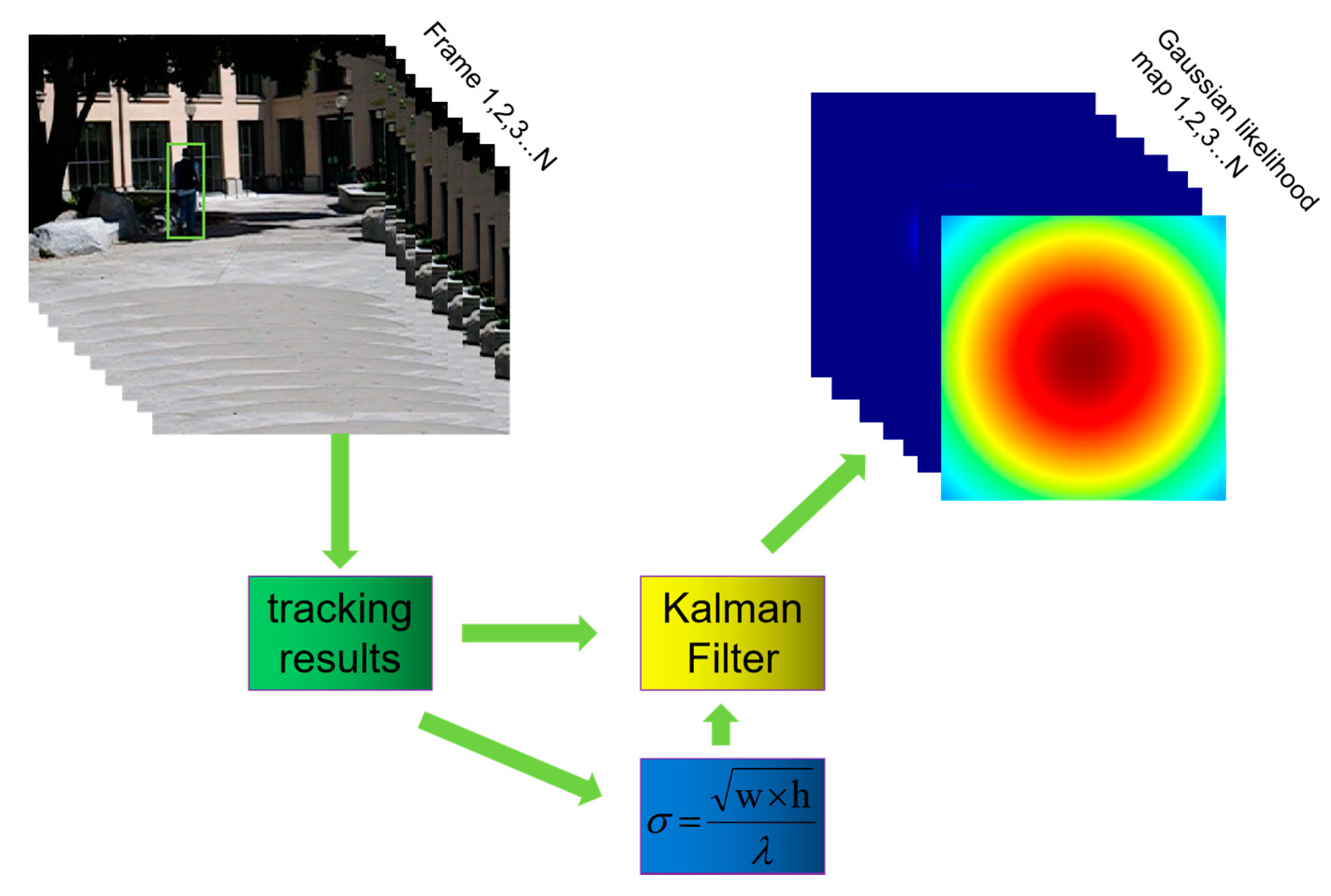
- We build a Gaussian likelihood map on the basis of a Kalman filter to describe the target’s trajectory information, and then use this Gaussian likelihood map and the histogram score map to process the SiamFC’s response score map by element-wise multiplication.
- (3)
- We evaluated HKSiamFC tracker on the dataset of online tracking benchmark (OTB) and Temple Color (TC128), and experiments showed that it achieved competitive performance when compared with baseline trackers and other state-of-the-art trackers.
2. Related Work
2.1. Correlation-Filter-Based Trackers
2.2. Deep-Learning-Based Trackers
3. Proposed Algorithm
3.1. SiamFC Tracker
3.2. Histogram Score Model from Tracker Staple
3.3. Optimize Histogram Score with Gaussian Filter
3.4. Gaussian Likelihood Map Based on Kalman Filter
3.5. Template Update
4. Experiments
4.1. Benchmark and Evaluation Metric
4.2. Ablation Experiment
4.2.1. Overall Performance
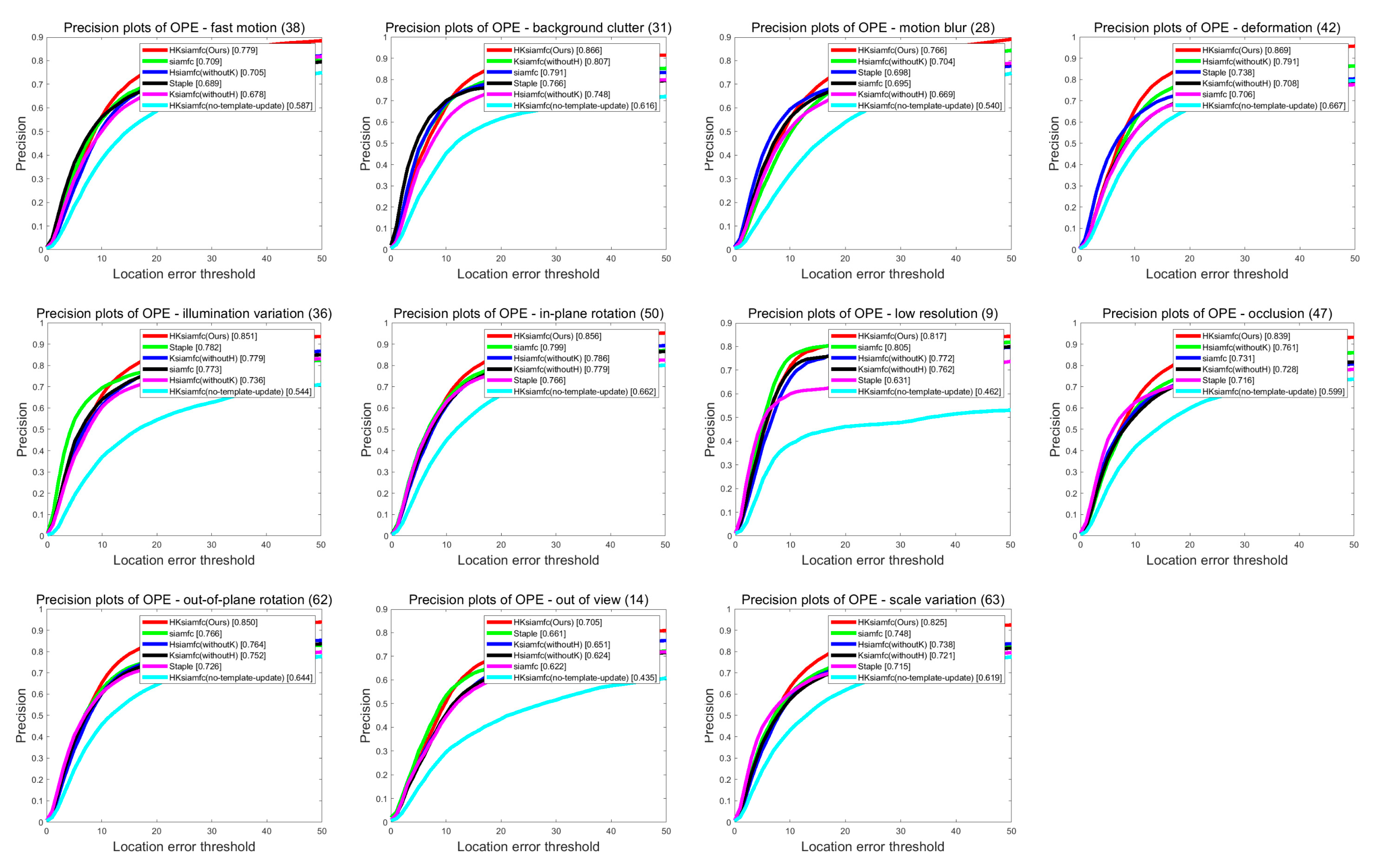
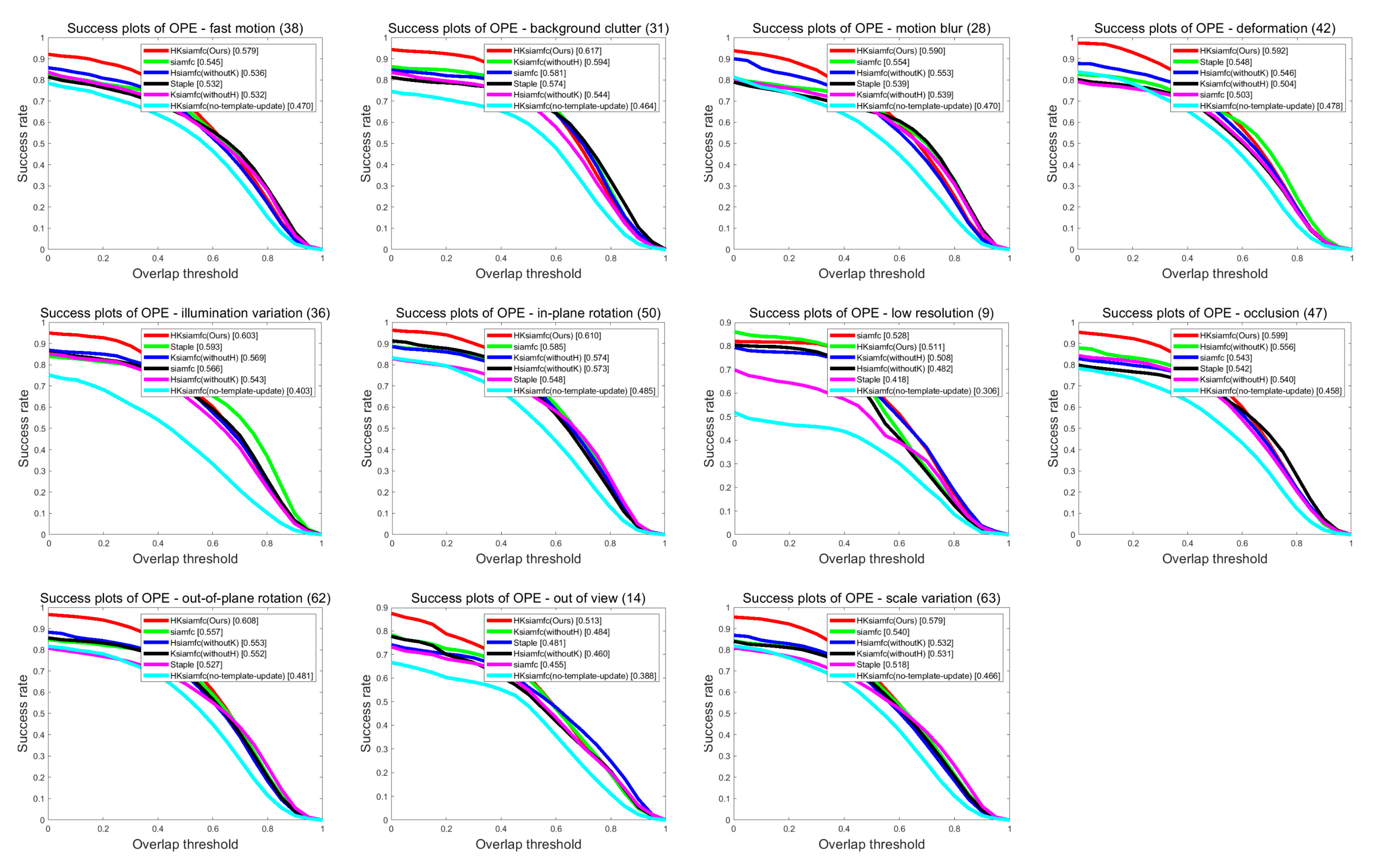
4.2.2. Scenario-Based Performance
4.3. Comparison with State-of-the-Art Trackers on OTB100
4.3.1. Overall Performance
4.3.2. Scenario-Based Performance on OTB100
4.4. Comparison with State-of-the-Art Trackers on TC128
4.5. Qualitative Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ward, J.; Antonucci, G.; Barter, E.; Brooks-Tyreman, F.; Connaughton, C.; Coughlan, M.; Kuhne, R.; Kaiser, M.; Wang, V. Evaluation of the Accuracy of a Computer-Vision Based Crowd Monitoring System; CrowdVision: London, UK, 2018. [Google Scholar]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Bouchrika, I.; Carter, J.N.; Nixon, M.S. Towards automated visual surveillance using gait for identity recognition and tracking across multiple non-intersecting cameras. Multimed. Tools Appl. 2016, 75, 1201–1221. [Google Scholar] [CrossRef]
- Tokekar, P.; Isler, V.; Franchi, A. Multi-target visual tracking with aerial robots. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3067–3072. [Google Scholar]
- Lien, J.; Olson, E.M.; Amihood, P.M.; Poupyrev, I. RF-Based Micro-Motion Tracking for Gesture Tracking and Recognition. U.S. Patent No.10,241.581, 26 March 2019. [Google Scholar]
- Wang, N.; Shi, J.; Yeung, D.-Y.; Jia, J. Understanding and diagnosing visual tracking systems. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 3101–3109. [Google Scholar]
- Li, K.; He, F.-Z.; Yu, H.-P. Robust visual tracking based on convolutional features with illumination and occlusion handing. J. Comput. Sci. Technol. 2018, 33, 223–236. [Google Scholar] [CrossRef]
- Du, X.; Clancy, N.; Arya, S.; Hanna, G.B.; Kelly, J.; Elson, D.S.; Stoyanov, D. Robust surface tracking combining features, intensity and illumination compensation. Int. J. Comput. Assist. Radiol. Surg. 2015, 10, 1915–1926. [Google Scholar] [CrossRef] [PubMed]
- Alismail, H.; Browning, B.; Lucey, S. Robust tracking in low light and sudden illumination changes. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 389–398. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1135–1143. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2019; pp. 1265–1274. [Google Scholar]
- Higgins, I.; Matthey, L.; Glorot, X.; Pal, A.; Uria, B.; Blundell, C.; Mohamed, S.; Lerchner, A. Early visual concept learning with unsupervised deep learning. arXiv 2016, preprint. arXiv:1606.05579. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 702–715. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Coloring channel representations for visual tracking. In Scandinavian Conference on Image Analysis; Springer: Copenhagen, Denmark, 2015; pp. 117–129. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.-H. Long-term correlation tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Huang, G.; Ji, H.; Zhang, W. Adaptive spatially regularized correlation filter tracking via level set segmentation. J. Electron. Imaging 2019, 28, 063013. [Google Scholar] [CrossRef]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.-H. Learning spatial-temporal regularized correlation filters for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4904–4913. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.-H. Hedged deep tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4303–4311. [Google Scholar]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Dong, X.; Shen, J. Triplet loss in siamese network for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2019; pp. 4591–4600. [Google Scholar]
- Fan, H.; Ling, H. Siamese cascaded region proposal networks for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2019; pp. 7952–7961. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OH, USA, 23–28 June 2018; pp. 2411–2418. [Google Scholar]
- Liang, P.; Blasch, E.; Ling, H. Encoding color information for visual tracking: Algorithms and benchmark. IEEE Trans. Image Process. 2015, 24, 5630–5644. [Google Scholar] [CrossRef] [PubMed]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Choi, J.; Jin Chang, H.; Fischer, T.; Yun, S.; Lee, K.; Jeong, J.; Demiris, Y.; Young Choi, J. Context-aware deep feature compression for high-speed visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 479–488. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. Dcfnet: Discriminant correlation filters network for visual tracking. arXiv 2017, preprint. arXiv:1704.0405. [Google Scholar]
- Wang, M.; Liu, Y.; Huang, Z. Large margin object tracking with circulant feature maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4021–4029. [Google Scholar]
- Zhang, T.; Xu, C.; Yang, M.-H. Multi-task correlation particle filter for robust object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4335–4343. [Google Scholar]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.-H. Robust visual tracking via convolutional networks without training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Adaptive decontamination of the training set: A unified formulation for discriminative visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1430–1438. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional features for correlation filter based visual tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 58–66. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OCC | LR | IV | MB | OPR | OV | BC | DEF | FM | IPR | SV | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | HKSiamFC | 0.839 | 0.817 | 0.851 | 0.766 | 0.850 | 0.705 | 0.866 | 0.869 | 0. 779 | 0. 856 | 0.825 |
| SiamFC | 0.731 | 0.805 | 0.773 | 0.695 | 0.766 | 0.622 | 0.791 | 0. 706 | 0. 709 | 0. 799 | 0.748 | |
| Staple | 0.716 | 0.631 | 0.782 | 0.698 | 0.726 | 0.661 | 0.766 | 0. 783 | 0. 689 | 0. 766 | 0.715 | |
| HSiamFC | 0.761 | 0.772 | 0.736 | 0.704 | 0.764 | 0.624 | 0.748 | 0. 791 | 0. 705 | 0. 786 | 0.738 | |
| KSiamFC | 0.728 | 0.762 | 0.779 | 0.669 | 0.752 | 0.651 | 0.807 | 0. 708 | 0. 678 | 0. 779 | 0.721 | |
| HKSiamFC (No-Template-Update) | 0.599 | 0.462 | 0.544 | 0.540 | 0.644 | 0.435 | 0.616 | 0. 667 | 0. 587 | 0. 662 | 0.691 | |
| AUC | HKSiamFC | 0.599 | 0.511 | 0.603 | 0.590 | 0.608 | 0.513 | 0.617 | 0.592 | 0.579 | 0.610 | 0.579 |
| SiamFC | 0.543 | 0.528 | 0.566 | 0.554 | 0.557 | 0.455 | 0.581 | 0.503 | 0.545 | 0.585 | 0.540 | |
| Staple | 0.542 | 0.418 | 0.593 | 0.539 | 0.527 | 0.481 | 0.574 | 0.548 | 0.532 | 0.548 | 0.518 | |
| HSiamFC | 0.556 | 0.482 | 0.543 | 0.553 | 0.553 | 0.460 | 0.544 | 0.546 | 0.536 | 0.573 | 0.532 | |
| KSiamFC | 0.540 | 0.508 | 0.569 | 0.539 | 0.552 | 0.484 | 0.594 | 0.504 | 0.532 | 0.574 | 0.531 | |
| HKSiamFC (No-Template-Update) | 0.458 | 0.306 | 0.403 | 0.470 | 0.481 | 0.385 | 0.464 | 0.478 | 0.470 | 0.485 | 0.466 | |
| FM | BC | MB | DEF | IV | IPR | LR | OCC | OPR | OV | SV | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision Ranking | 6 | 2 | 5 | 2 | 3 | 2 | 5 | 2 | 2 | 8 | 2 |
| HKSiamFC | MCPF | SRDCF | Deep SRDCF | Staple | BACF | SRDCFdecon | HDT | CNT | |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 77.8 | 76.9 | 69.6 | 74.0 | 66.8 | 66.0 | 72.9 | 68.6 | 44.9 |
| AUC | 55.1 | 55.2 | 51.6 | 54.1 | 50.9 | 49.6 | 54.3 | 48.0 | 33.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Xing, Q.; Ma, Z. HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter. Sensors 2020, 20, 2137. https://doi.org/10.3390/s20072137
Li C, Xing Q, Ma Z. HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter. Sensors. 2020; 20(7):2137. https://doi.org/10.3390/s20072137
Chicago/Turabian StyleLi, Chenpu, Qianjian Xing, and Zhenguo Ma. 2020. "HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter" Sensors 20, no. 7: 2137. https://doi.org/10.3390/s20072137
APA StyleLi, C., Xing, Q., & Ma, Z. (2020). HKSiamFC: Visual-Tracking Framework Using Prior Information Provided by Staple and Kalman Filter. Sensors, 20(7), 2137. https://doi.org/10.3390/s20072137