Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network



Abstract
1. Introduction
2. Methodology
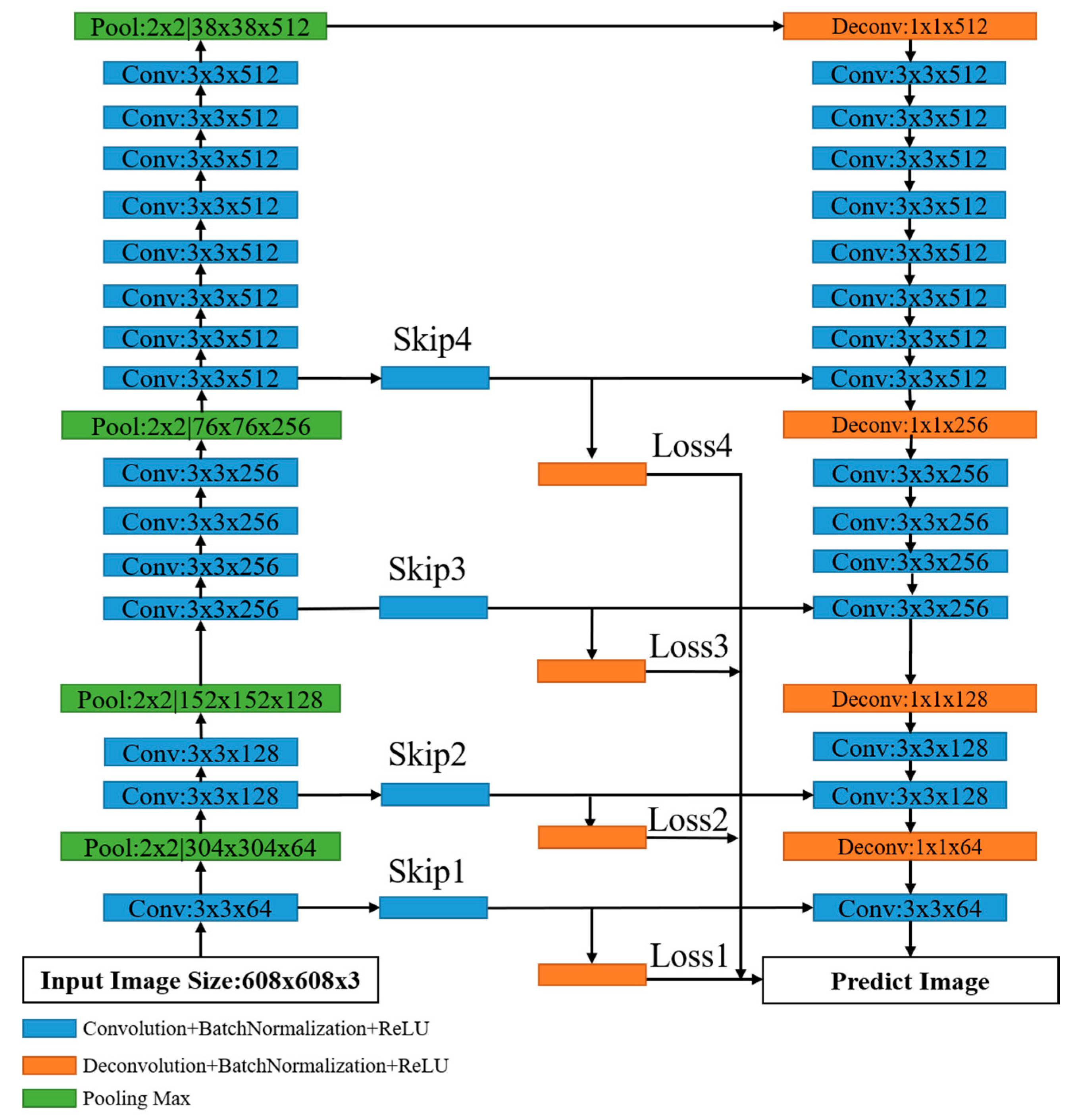
2.1. The Architecture of CDDS Network
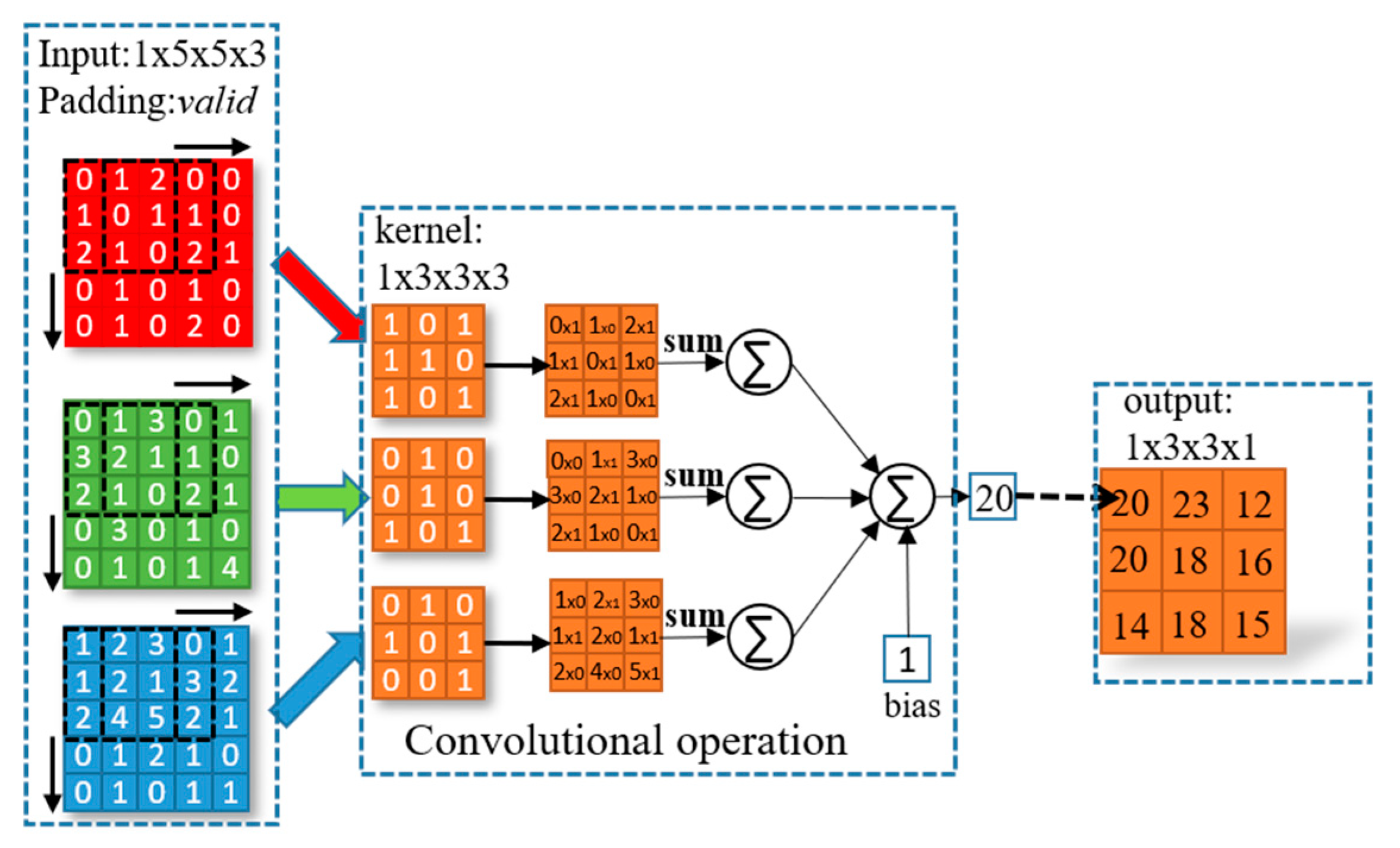
2.2. Convolutional Layer
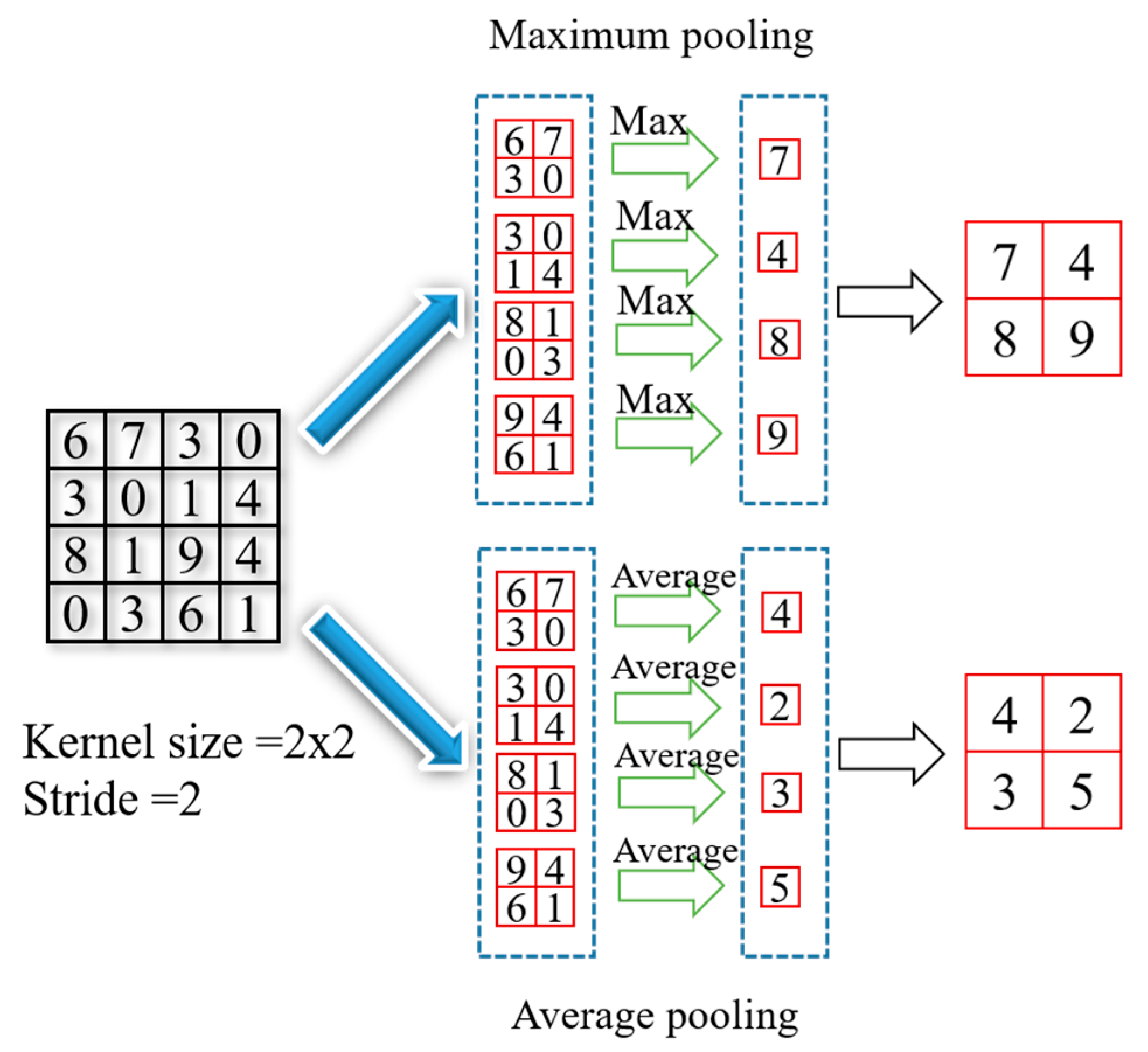
2.3. Pooling Layer
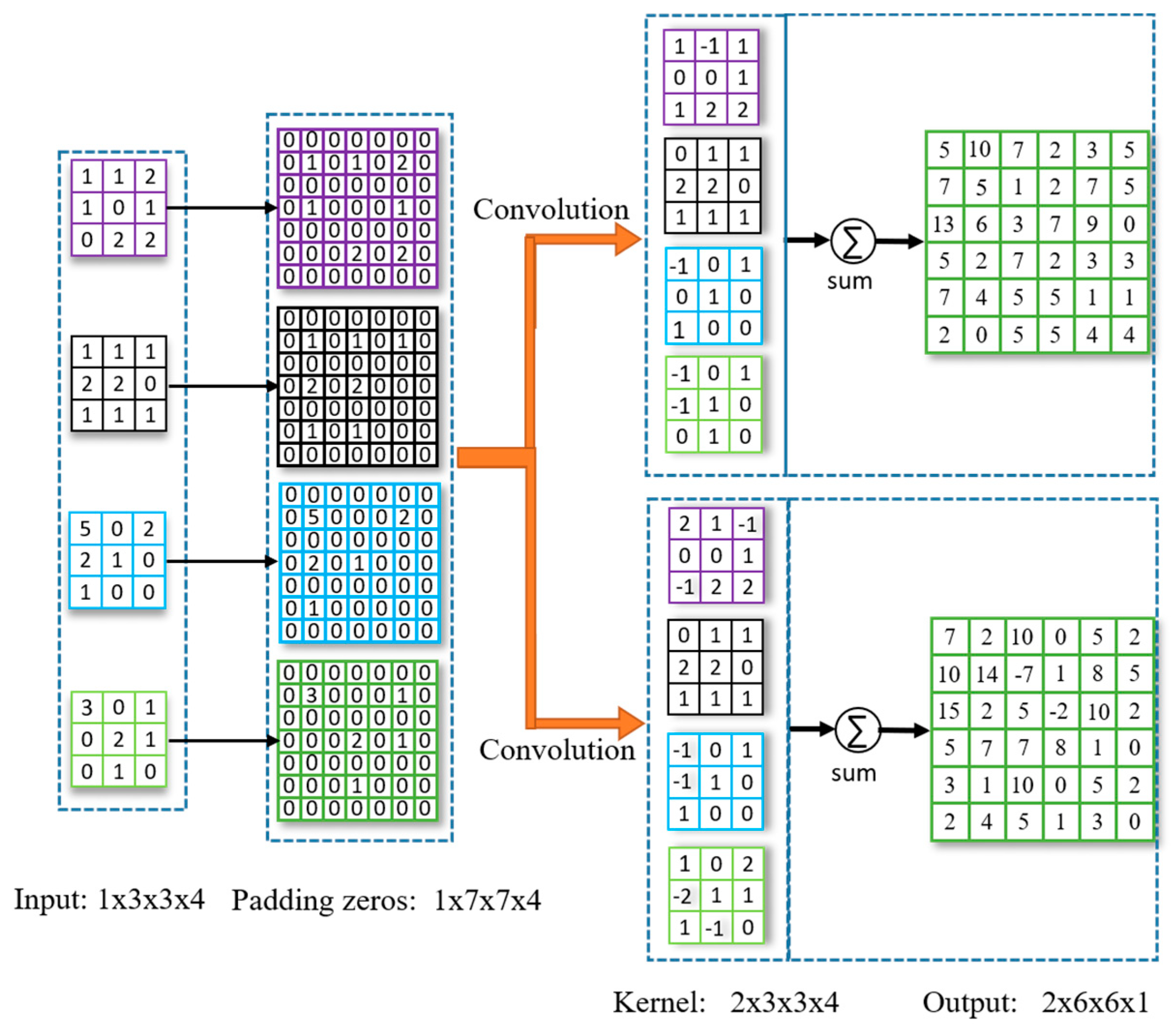
2.4. Deconvolutional Layer
3. Experiments
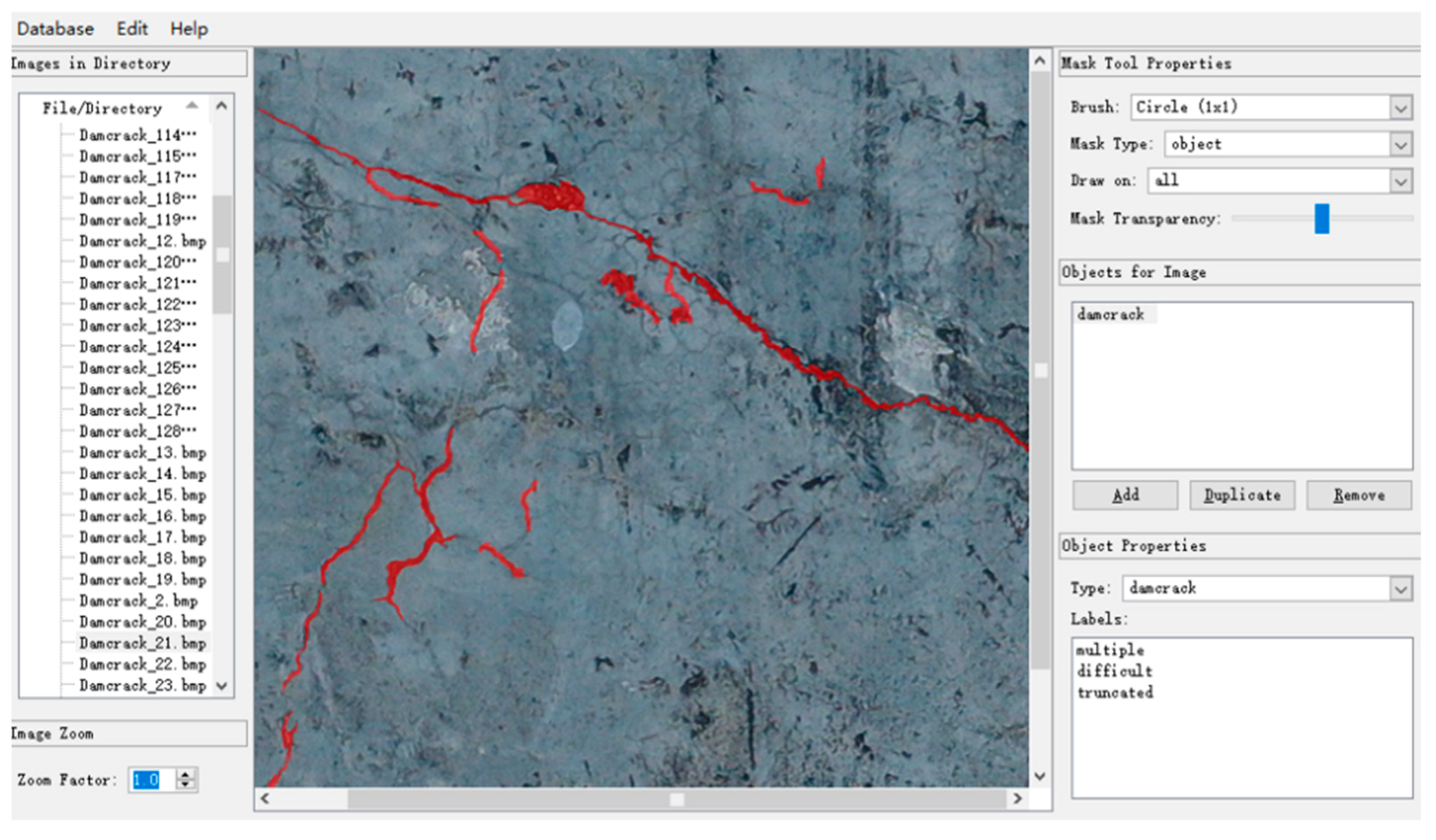
3.1. Crack Database of the Dam Surface
3.2. Experimental Settings
3.3. Evaluation Metrics of the Network
4. Results and Discussion
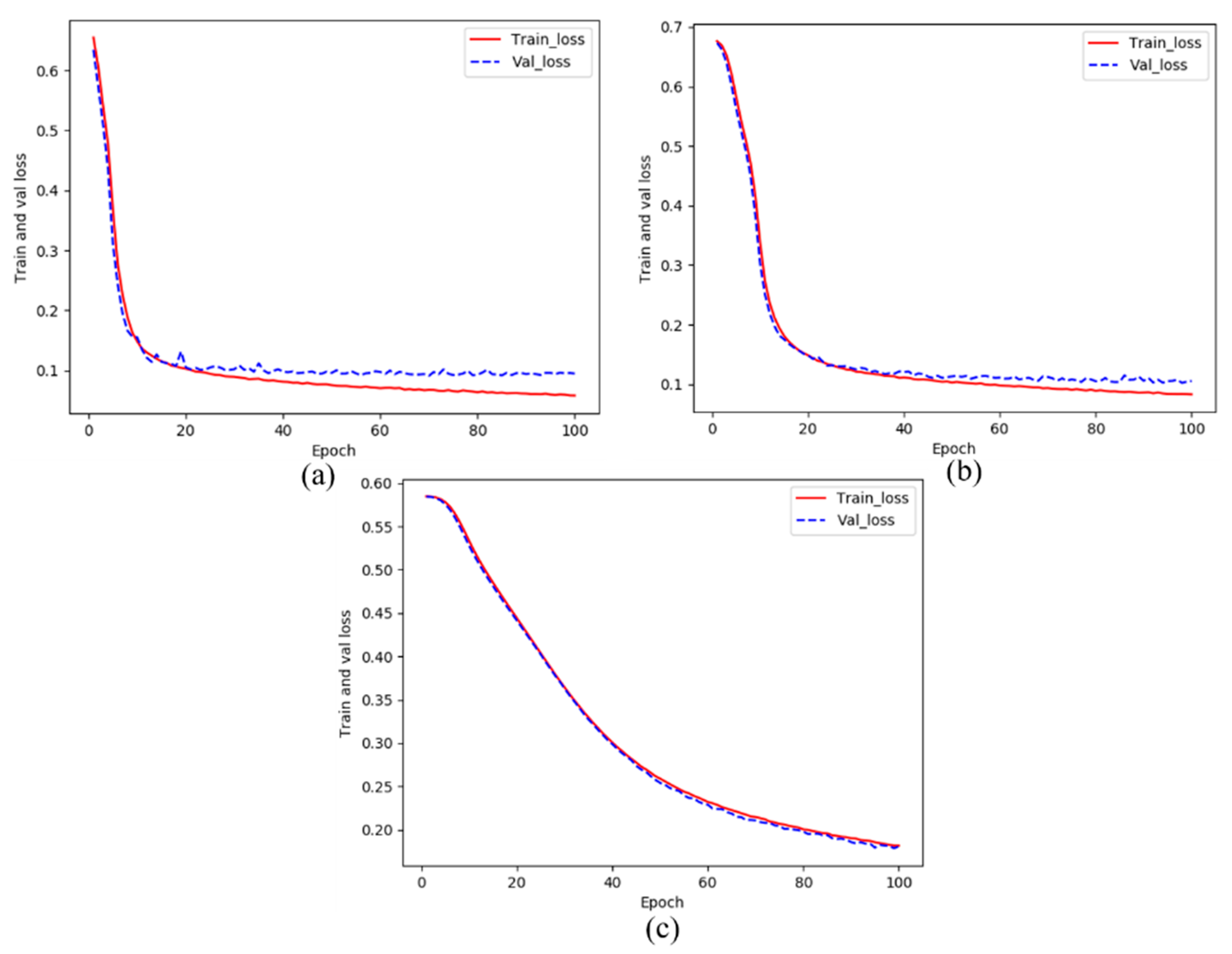
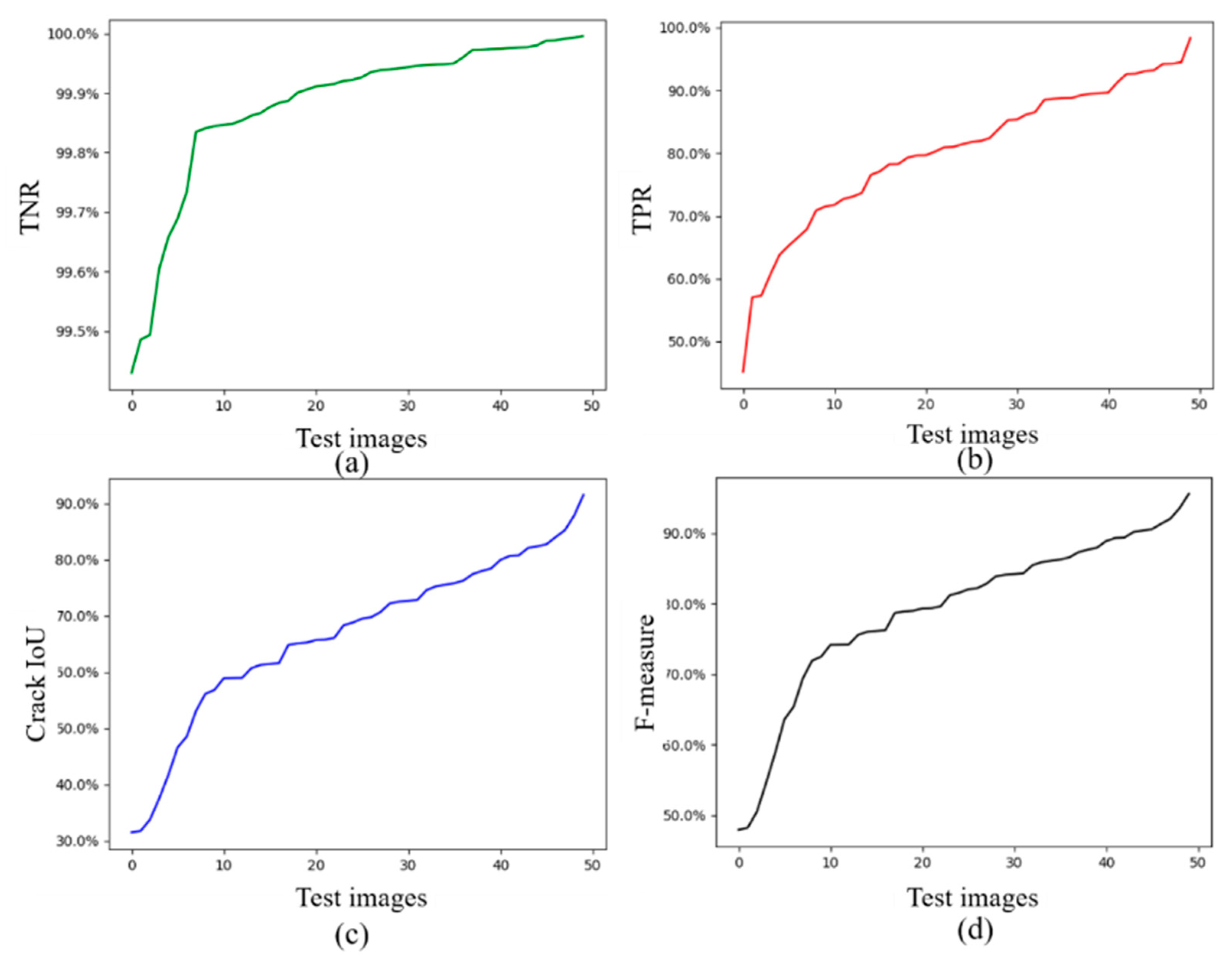
4.1. Results of CDDS Training
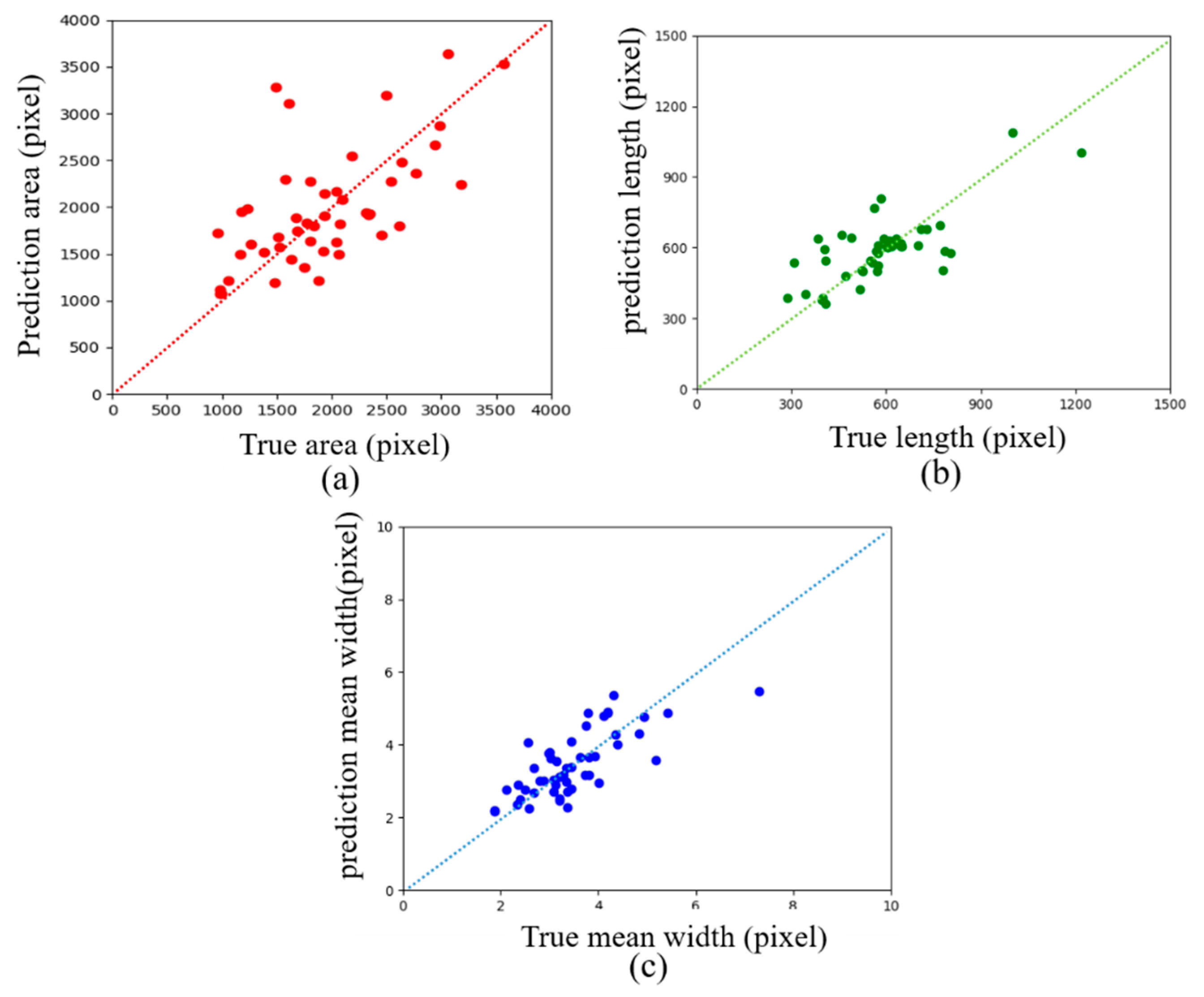
4.2. Calculation of Crack Size on the Dam Surface
5. Comparative Study
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rafiei, M.H.; Adeli, H. A novel machine learning-based algorithm to detect damage in high-rise building structures. Struct. Des. Tall Spec. Build. 2017, 26, e1400. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated crack detection on concrete bridges. IEEE Trans. Autom. Sci. Eng. 2014, 13, 591–599. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.H. Crack and noncrack classification from concrete surface images using machine learning. Struct. Health Monit. 2019, 18, 725–738. [Google Scholar] [CrossRef]
- Liu, Z.; Suandi, S.A.; Ohashi, T.; Ejima, T. Tunnel crack detection and classification system based on image processing. Mach. Vis. Appl. Ind. Insp. X Int. Soc. Opt. Photon. 2002, 4664, 145–152. [Google Scholar]
- Sinha, S.K.; Fieguth, P.W. Automated detection of cracks in buried concrete pipe images. Autom. Constr. 2006, 15, 58–72. [Google Scholar] [CrossRef]
- Takafumi, N.; Junji, Y.; Toshiyuki, S. Concrete crack detection by multiple sequential image filtering. Comput. Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar]
- Cha, Y.J.; You, K.; Choi, W. Vision-based detection of loosened bolts using the hough transform and support vector machines. Autom. Constr. 2016, 71, 181–188. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Zalama, E.; Gómez-García-Bermejo, J.; Medina, R.; Llamas, J. Road crack detection using visual features extracted by Gabor filters. Comput. Aided Civ. Infrastruct. Eng. 2014, 29, 342–358. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.; Du, K.; Ru, F.; Zhang, Y. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Nakamura, S.; Saegusa, R.; Hashimoto, S. Image-based crack detection for real concrete surfaces. IEEJ Trans. Electr. Electron. Eng. 2008, 3, 128–135. [Google Scholar] [CrossRef]
- Cho, H.; Yoon, H.J.; Jung, J.Y. Image-Based Crack Detection Using Crack Width Transform (CWT) Algorithm. IEEE Access 2018, 6, 60100–60114. [Google Scholar] [CrossRef]
- Ying, L.; Salari, E. Beamlet transform-based technique for pavement crack detection and classification. Comput. Aided Civ. Infrastruct. Eng. 2010, 25, 572–580. [Google Scholar] [CrossRef]
- Ito, A.; Aoki, Y.; Hashimoto, S. Accurate extraction and measurement of fine cracks from concrete block surface image. In Proceedings of the IEEE 2002 28th Annual Conference of the Industrial Electronics Society, Sevilla, Spain, 5–8 November 2002; Volume 3, pp. 2202–2207. [Google Scholar]
- Li, G.; He, S.; Ju, Y.; Du, K. Long-distance precision inspection method for bridge cracks with image processing. Autom. Constr. 2014, 41, 83–95. [Google Scholar] [CrossRef]
- Huang, Y.; Xu, B. Automatic inspection of pavement cracking distress. J. Electron. Imaging 2006, 15, 013017. [Google Scholar] [CrossRef]
- Subirats, P.; Dumoulin, J.; Legeay, V.; Barba, D. Automation of pavement surface crack detection using the continuous wavelet transform. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 3037–3040. [Google Scholar]
- Wu, L.; Mokhtari, S.; Nazef, A.; Nam, B.; Yun, H.B. Improvement of crack-detection accuracy using a novel crack defragmentation technique in image-based road assessment. J. Comput. Civ. Eng. 2014, 30, 04014118. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Liao, T.Y. On-line vehicle routing problems for carbon emissions reduction. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 1047–1063. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Li, L.; Zhang, H.; Pang, J.; Huang, J. Dam surface crack detection based on deep learning. In Proceedings of the 2019 International Conference on Robotics, Intelligent Control and Artificial Intelligence, Shanghai, China, 20–22 September 2019; pp. 738–743. [Google Scholar]
- Makantasis, K.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Loupos, C. Deep convolutional neural networks for efficient vision based tunnel inspection. In Proceedings of the 2015 IEEE International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 3–5 September 2015; pp. 335–342. [Google Scholar]
- Nhat-Duc, H.; Nguyen, Q.L.; Tran, V.D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Feng, C.; Liu, M.Y.; Kao, C.C.; Lee, T.Y. Deep active learning for civil infrastructure defect detection and classification. In Proceedings of the ASCE International Workshop on Computing in Civil Engineering, Seattle, WA, USA, 25–27 June 2017; pp. 298–306. [Google Scholar]
- Dorafshan, S.; Maguire, M. Bridge inspection: Human performance, unmanned aerial systems and automation. J. Civ. Struct. Health Monit. 2018, 8, 443–476. [Google Scholar] [CrossRef]
- Khaloo, A.; Lattanzi, D.; Jachimowicz, A.; Devaney, C. Utilizing UAV and 3D computer vision for visual inspection of a large gravity dam. Front. Built Environ. 2018, 4. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Coopmans, C.; Maguire, M. Deep learning neural networks for sUAS-assisted structural inspections: Feasibility and application. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 874–882. [Google Scholar]
- Kim, I.H.; Jeon, H.; Baek, S.C.; Hong, W.H.; Jung, H.J. Application of crack identification techniques for an aging concrete bridge inspection using an unmanned aerial vehicle. Sensors 2018, 18, 1881. [Google Scholar] [CrossRef] [PubMed]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Li, Y. A fast detection method via region-based fully convolutional neural networks for shield tunnel lining defects. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 638–654. [Google Scholar] [CrossRef]
- Li, R.; Yuan, Y.; Zhang, W.; Yuan, Y. Unified vision-based methodology for simultaneous concrete defect detection and geolocalization. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 527–544. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion. IEEE Trans. Ind. Electron. 2017, 65, 4392–4400. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X.; Zhou, G. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 405–420. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Zhang, T.Y.; Suen, C.Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware/Environmental | Specifications/Parameters |
|---|---|
| UAV | DJI MAVIC 2 |
| Sensor | 1’’CMOS; Effective Pixels: 20 million |
| Camera Lens | 35 mm Format Equivalent: 28 mm |
| Light Condition | 5000 Lux–20000 Lux |
| Wind Speed | 1 m/s–2 m/s |
| Total Collection Time | 18 h |
| Collection Distance | 3 m |
| Hardware/Software | Specifications/Parameters/Version |
|---|---|
| CPU | Inter®Xeon(R) CPU E5-2650 v4 @ 2.20 GHz × 48 |
| GPU | Quadro P4000/PCIe/SSE2/8 GB |
| RAM | 62.8 GB |
| CUDA | 9.1 |
| CUDNN | 7.1.5 |
| Python | 2.7.5 |
| Anaconda | 3–5.1.0 |
| TensorFlow | 1.10 |
| Ground Truth | Prediction Results | |
|---|---|---|
| Crack | Background | |
| Crack Background | TP | FN |
| FP | TN | |
| Methods | Recall (%) | Precision (%) | F-measure (%) | Crack IoU (%) | Background IoU (%) |
|---|---|---|---|---|---|
| ResNet152-based | 57.49 | 74.99 | 63.68 | 47.68 | 99.54 |
| FCN | 71.53 | 72.57 | 69.37 | 55.70 | 99.69 |
| UNet | 78.33 | 77.14 | 76.20 | 62.71 | 99.73 |
| SegNet | 79.15 | 77.85 | 77.22 | 64.37 | 99.74 |
| CDDS | 80.45 | 80.31 | 79.16 | 66.76 | 99.76 |
| Methods | Training Time | Testing Time (for Per Image) |
|---|---|---|
| ResNet152-based | 3 h and 12 min | 0.13 s |
| FCN | 6 h and 4 min | 0.17 s |
| UNet | 9 h and 17 min | 0.20 s |
| SegNet | 6 h and 2 min | 0.21 s |
| CDDS | 9 h and 24 min | 0.26 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, C.; Zhang, H.; Wang, H.; Wang, S.; Li, Y. Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors 2020, 20, 2069. https://doi.org/10.3390/s20072069
Feng C, Zhang H, Wang H, Wang S, Li Y. Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors. 2020; 20(7):2069. https://doi.org/10.3390/s20072069
Chicago/Turabian StyleFeng, Chuncheng, Hua Zhang, Haoran Wang, Shuang Wang, and Yonglong Li. 2020. "Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network" Sensors 20, no. 7: 2069. https://doi.org/10.3390/s20072069
APA StyleFeng, C., Zhang, H., Wang, H., Wang, S., & Li, Y. (2020). Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors, 20(7), 2069. https://doi.org/10.3390/s20072069