Abstract
With the advent of unmanned aerial vehicles (UAVs), a major area of interest in the research field of UAVs has been vision-aided inertial navigation systems (V-INS). In the front-end of V-INS, image processing extracts information about the surrounding environment and determines features or points of interest. With the extracted vision data and inertial measurement unit (IMU) dead reckoning, the most widely used algorithm for estimating vehicle and feature states in the back-end of V-INS is an extended Kalman filter (EKF). An important assumption of the EKF is Gaussian white noise. In fact, measurement outliers that arise in various realistic conditions are often non-Gaussian. A lack of compensation for unknown noise parameters often leads to a serious impact on the reliability and robustness of these navigation systems. To compensate for uncertainties of the outliers, we require modified versions of the estimator or the incorporation of other techniques into the filter. The main purpose of this paper is to develop accurate and robust V-INS for UAVs, in particular, those for situations pertaining to such unknown outliers. Feature correspondence in image processing front-end rejects vision outliers, and then a statistic test in filtering back-end detects the remaining outliers of the vision data. For frequent outliers occurrence, variational approximation for Bayesian inference derives a way to compute the optimal noise precision matrices of the measurement outliers. The overall process of outlier removal and adaptation is referred to here as “outlier-adaptive filtering”. Even though almost all approaches of V-INS remove outliers by some method, few researchers have treated outlier adaptation in V-INS in much detail. Here, results from flight datasets validate the improved accuracy of V-INS employing the proposed outlier-adaptive filtering framework.
Keywords:
V-INS; UAV; EKF; IMU; camera vision; computer vision; image processing; outlier rejection; adaptive filtering; sensor fusion; navigation 1. Introduction
The most widely used algorithms for estimating the states of a dynamic system are a Kalman Filter [1,2] and its nonlinear versions such as an extended Kalman filter (EKF) [3,4]. After the NASA Ames Research Center implemented the Kalman filter into navigation computers to estimate the trajectory of the Apollo program, engineers have developed a myriad of applications of the Kalman filter in navigation system research areas [5]. For example, Magree and Johnson [6] developed a simultaneous localization and mapping (SLAM) architecture with improved numerical stability based on the UD factored EKF, and Song et al. [7] proposed a new EKF system that loosely fuses both absolute state measurements and relative state measurements. Furthermore, Mostafa et al. [8] integrated radar odometry and visual odometry via EKF to help overcome their limitations in navigation. Despite the development of numerous applications of the Kalman filter in various fields, it suffers from inaccurate estimation when required assumptions fail.
Estimation using a Kalman filter is optimal when process and measurement noise are Gaussian. However, sensor measurements are often corrupted by unmodeled non-Gaussian or heavy-tailed noise. An abnormal value relative to an overall pattern of the nominal Gaussian noise distribution is called an outlier. In other words, in statistics, an outlier is an observation that deviates so much from other observations as to arouse suspicion that it is generated by a different mechanism [9]. Such outliers have many anomalous causes. They arise due to unanticipated changes in system behavior (e.g., temporary sensor failure or transient environmental disturbance) or unmodeled factors (e.g., human errors or unknown characteristics of intrinsic noise). As an example of measurement outliers in many navigation systems, either computer vision data contaminated by outliers or sonar data corrupted by phase noise lead to erroneous measurements. Process outliers also occur by chance. Inertial measurement unit (IMU) dead reckoning and wheel odometry as a proxy often generate inaccurate dynamic models in visual-inertial odometry (VIO) and SLAM algorithms, respectively. Without accounting for outliers, the accuracy of the estimator significantly degrades, and control systems that rely on high-quality estimation can diverge.
1.1. Related Work
1.1.1. State Estimation for Measurements with Outliers
As the performance of the Kalman filter degrades at the presence of measurement outliers, many researchers have investigated other approaches to mitigate the impact of the outliers. Mehra [10] created adaptive filtering with the identification of noise covariance matrices and showed the asymptotic convergence of the estimates towards their true values. Maybeck [11] and Stengel [12] found other noise-adaptive filtering such as covariance matching. However, all of these filters performed only offline and required filter tuning. To estimate parameter values in unknown covariances without the need for manual parameter tuning, Ting et al. [13] used a variational expectation–maximization (EM) framework. That is, they introduced a scalar weight for each observed data sample and modeled the weights to be Gamma distributed random variables. However, it assumed that noise characteristics are homogeneous across all measurements even though sensors have distinct properties. Särkkä and Nummenmaa [14] provided the online learning of the parameters of the measurement noise variance, but to simultaneously track the system states and the levels of sensor noise, they additionally defined a heuristic transition model for the noise parameters. Piché et al. [15] developed Gaussian assumed density filtering and smoothing framework for nonlinear systems using the multivariate Student t-distribution, and Roth et al. [16] included an approximation step for heavy-tailed process noise, but these filters are not applicable in high dimensions. Next, Solin and Särkkä [17] found that the added flexibility of Student-t processes over Gaussian processes robustifies inference in outlier-contaminated noisy data, but they treated only analytic solutions enabled by the noise entanglement.
Recently, Agamennoni et al. developed the outlier-robust Kalman filter (ORKF) [18,19] to obtain the optimal precision matrices of measurement outliers by variational approximation for Bayesian inference [20]. However, this method requires iterations at every time, even when observed data contain no outliers. Graham et al. also established the -norm filter [21] for both types of sparse outliers. However, the filter might not work for nonlinear systems since they derived the constraint of -norm optimization based on only linear system equations. Similar to the ORKF, the -norm filter needs the constrained optimization at all times, even when no additional noise present as outliers. Therefore, these two approaches demand some extensive computational complexity for either iterations or optimization. As outliers do not always arise (i.e., are rare), we reduce such computation cost if a test detects the time when outliers occur. All of the above methods were not validated for complicated systems such as unmanned aerial vehicles or vision-aided inertial navigation [6,22,23] or with sequential measurement updates [24,25].
1.1.2. Outlier Rejection Techniques
One of the primary problems in vision-aided inertial navigation systems (V-INS) is incorrect vision data correspondence or association. Matched features between two different camera views are corrupted by outliers because of image noise, occlusions, and illumination changes that are not modeled by the feature matching techniques. To provide cleaned measurement data to the filter, outlier removal in image processing front-end is essential. One of standard outlier rejection techniques is RANdom SAmple Consensus (RANSAC) [26]. RANSAC is an iterative approach to estimate the parameters of a mathematical model from a set of observed data contaminated by outliers. An underlying assumption is that the data consist of inliers whose distribution is described by some set of the parameters of the model and outliers that do not fit the model. The generated parameters are then verified on the remaining subset of the data, and the model with the highest consensus is a selected solution. In particular, 2-point RANSAC [27,28] is an extended RANSAC-based method for two consecutive views of a camera rigidly mounted on a vehicle platform. Given gyroscopic data from IMU measurements, randomly selected two-feature correspondences hypothesize an ego-motion of the vehicle. This motion constraint discards wrong data associations in the feature matching processes.
For detecting remaining outliers that are not rejected in the image processing front-end, outlier detection tests are required in filtering back-end. Most of the statistical tests [29] that require access to the entire set of data samples for detecting outliers might not be a viable option in real-time applications. For example, the typicality and eccentricity data analysis [30,31] used in [32] is an inadequate measure in V-INS, as computing the means and the variances of each residual of sequential measurements is challenging. In V-INS, the tracking of some measured features is possibly lost due to out of sight, and new feature measurements are coming for initialization.
For the real-time outlier detection of sequential measurements in V-INS, the Mahalanobis gating test [33] is a useful measure based on the analysis of residual and covariance signals at each feature measurement. The approach builds upon each Mahalanobis distance [34] of residuals and compares each value against a threshold given by the quantile of the chi-squared distribution with a certain degree of freedom. The confidence level of the threshold is designated prior to examining the data. Most commonly, the 95% confidence level is used. This hypothesis testing, called goodness of fit, is a commonly used outlier detection method in practice. Because of such suitability of the Mahalanobis gating test to real-time detection in V-INS, this paper combines the test with the ORKF [18,32] to detect and handle measurement outliers in vision-aided estimation problems. Similar to the derivation of update steps for handling measurement outliers in the ORKF, for computing the optimal precision matrices of unmodeled outliers in V-INS, Section 4 will derive feasible update procedures by variational inference. In other words, whenever unexpected outliers appear, the outlier-adaptive filtering in this paper updates and marginalizes measurement outliers to improve the robustness of the navigation systems.
1.2. Summary of Contributions
This paper presents improving the use of outlier removal techniques in image processing front-end and the development of a robust and adaptive state estimation framework for V-INS when frequent outliers occur. For outlier removal in the image processing front-end of V-INS, feature correspondence constitutes the following three steps: tracking, stereo matching, and 2-point RANSAC. To estimate the states of V-INS in which vision measurements still contain remaining outliers, we propose a novel approach that combines a real-time outlier detection technique with an extended version of the ORKF in the filtering back-end of V-INS. Therefore, our approach does not restrict noise at either a constant or Gaussian level in filtering. The testing results of benchmark flight datasets show that our approach leads to greater improvement in accuracy and robustness under severe illumination environments.
Starting from the architecture of the existing vision-aided inertial navigation system, this paper more focuses on contributing to the development of red boxes in Figure 3.
1.3. A Guide to This Document
The remainder of this document contains the following sections. Section 2 introduces background for all of this study. To estimate the states of V-INS in which frequent outliers arise, Section 3 examines outlier rejection techniques in image processing front-end, and Section 4 and Section 5 formulate a novel implementation of robust outlier-adaptive filtering. Section 6 shows testing results of this study on benchmark flight datasets. The last section concludes and plans future work.
2. Preliminaries
2.1. The Extended Kalman Filter
The system equations with continuous-time dynamics and a discrete-time sensor are as follows,
where is the state and a measurement. and are the nonlinear dynamic and measurement functions, respectively. Let us assume that these functions are known based on each equation of motion and modeling. To clarify, t denotes continuous time, subscript k represents the k-th time step, and initial condition is given. Moreover, let us assume that both propagation and measurements are corrupted by additive zero-mean white Gaussian noise; that is, and .
2.1.1. Time Update
To estimate the state variables of the system, we design a hybrid EKF in the following steps. In the propagation step, state estimate and its error-covariance are integrated from time to time with respect to variable
where let . Hat “ ” denotes an estimate, and superscripts − and + represent a priori and a posteriori estimates, respectively. Here, for one numerical solution of the ordinary differential equation, we use the Heun’s method [35] that refers to the improved Euler’s method or a similar two-stage Runge–Kutta method. Jacobian A, B, and state transition matrix are defined by
where . Letting , the time update of error covariance is
2.1.2. Measurement Update
Using actual sensor measurements, the measurement update step of the EKF corrects state estimates and its corresponding error covariance after propagation. Letting , at every time k when is measured,
where K is called the Kalman gain and Jacobian C is defined as
Equation (7) is the Joseph’s form [36] of the covariance measurement update, so this form preserves its symmetry and positive definite. For more details such as optimality and derivation, see References [24,37].
2.1.3. Sequential Measurement Update
When myriad measurements are observed at one time, sequential Kalman filtering is useful. In fact, we obtain N measurements, , at time k; that is, we first measure , then , ⋯, and finally , shown in Figure 1.
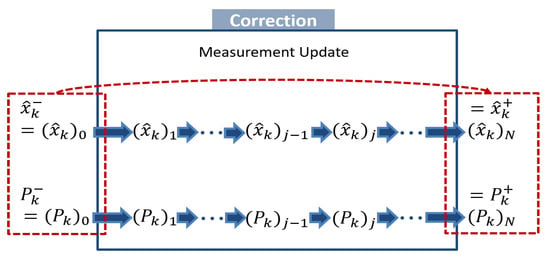
Figure 1.
A schematic of the sequential measurement update.
We first initialize a posteriori estimate and covariance after zero measurement is processed; that is, they are equal to the a priori estimate and covariance. For , perform the general measurement update using the i-th measurement. We lastly assign the a posteriori estimate and covariance as and . Based on Simon [24]’s proof that the sequential Kalman filtering is equivalent formulation of the standard EKF, the order of updates does not affect overall performance of estimation.
2.2. Models of Vision-Aided Inertial Navigation
2.2.1. Vehicle Model
The nonlinear dynamics of a vehicle is driven by raw micro-electromechanical system (MEMS) IMU sensor data including specific force and angular velocity inputs. The estimated vehicle state is given by
where , are the position and velocity of the vehicle with respect to the inertial frame, respectively. is the error quaternion of the attitude of the vehicle, and its more details are explained in [38,39,40]. and are the acceleration and gyroscope biases of the IMU, respectively. Left superscript i denotes a vector expressed in the inertial frame. The EKF propagates the vehicle state vector by dead reckoning with data from the IMU. Raw MEMS IMU sensor measurements and are corrupted by noise and bias as follows,
where and are the true acceleration and angular rate, respectively, and g is the gravitational acceleration in the inertial frame. and are zero-mean, white, Gaussian noise of the accelerometer and gyroscope measurement, and denotes the rotation matrix from the inertial frame to the body frame.
and in Equations (9) and (10) are the random walk rate of the acceleration and gyroscope biases. From the works in [40,41,42], the MEMS accelerometer and gyroscope are subject to flicker noise in the electronics and other components susceptible to random flickering. The flicker noise causes their biases to wander over time. Such bias fluctuations are usually modeled as a random walk. In other words, slow variations in the bias of the IMU sensor are modeled with a “Brownian motion” process, also termed a random walk in discrete-time. In practice, the biases are constrained to be within some range, and thus the random walk model is only a good approximation to the true process for short periods of time.
The vehicle dynamics is given by
where is a skew symmetric matrix, and function maps a 3 by 1 vector of the angular velocity into a 4 by 4 matrix [25]. The use of the 4 by 1 quaternion representation in state estimation causes the covariance matrix to become singular, so it requires considerable accounting for the quaternion constraints. To avoid these difficulties, engineers developed the error-state Kalman filter in which 3 by 1 infinitesimal error quaternion is used instead of 4 by 1 quaternion q in the state vector. In other words, we use attitude error quaternion to express the incremental difference between tracked reference body frame and actual body frame b for the vehicle. Jacobian matrix and are computed in Appendix A.
2.2.2. Camera Model
An intrinsically calibrated pinhole camera model [27,43] is given by
where x is the state vector including the vehicle state and the feature state, and measurement is the j-th feature 2D location on the image plane. and are the horizontal and vertical focal lengths, respectively, and and are additive, zero-mean, white, Gaussian noise of the measurement. Vectors , are the j-th feature 3D position with respect to the camera frame and the inertial frame, respectively. Extrinsic parameter and are known and constant. Jacobian matrix is computed in Appendix A. In addition, from Equation (19), if j-th measurement on an image is a new feature, then is unknown so need to be initialized. Details of feature initialization are explained in Appendix B.
3. Outlier Rejection in Image Processing Front-End
3.1. Feature Correspondence
In this study, a feature detector using the Features from Accelerated Segment Test (FAST) algorithm [44,45] maintains a minimum number of features in each image. For each new image, a feature extractor using the Kanade–Lucas–Tomasi (KLT) sparse optical flow algorithm [46] tracks the existing features. Even though Paul et al. [47] proved that descriptor-based methods for temporal feature tracking are more accurate than KLT-based methods, as Sun et al. [48] found that descriptor-based methods require much more computing resource with a small gain in accuracy, we employ the KLT optical flow algorithm in the image processing front-end of this study. Next, our stereo matching using a fixed baseline stereo configuration also applies to the KLT optical flow algorithm for saving computational loads compared to other stereo matching approaches. With the matched features, a 2-point RANSAC [26] is applied to remove remaining outliers by utilizing the RANSAC step in the fundamental matrix test [27]. In the scope of this study, we implement the 2-point RANSAC algorithm by simply running one of open source codes.
Similar to [48,49], our outlier rejection is composed of three steps, shown in Figure 2. We assume that features from previous and images are outlier-rejected points, where and are left and right camera frames of a stereo camera, respectively. The three steps form a closed loop of previous and current frames of left and right cameras. The first step is the stereo matching of tracked features on current image to image. The next steps are applying 2-point RANSAC between previous and current images of the left camera and another 2-point RANSAC between previous and current images of the right camera. For steps 2 and 3, stereo-matched features are directly used in each RANSAC.
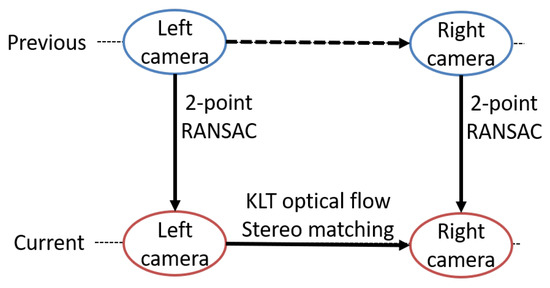
Figure 2.
Close loop steps of outlier rejection in image processing front-end.
3.2. Algorithm of Feature Correspondence
Algorithm 1 summarizes the feature correspondence for outlier rejection. For the scope of this paper, the OpenCV library [50] and open source codes of RANSAC are extremely useful and directly applied.
| Algorithm 1 Feature Correspondence for Outlier Rejection |
| Require: Pyramids and outlier-rejected points of previous , images |
|
In Algorithm 1, Pyramid is a type of multi-scale signal representation in which an image is subject to repeated smoothing and sub-sampling.
4. Outlier Adaptation in Filtering Back-End
Even though image processing front-end removes outliers by tracking, stereo matching, and 2-point RANSAC, some outlier features still survive and enter the filter as inputs. This section explains the outlier rejection procedure in filtering back-end.
4.1. Outlier Removal in Feature Initialization
If a measurement is a new feature, our system initializes its 3D position with respect to the inertial frame. In feature initialization, Gaussian–Newton least-squares minimization first estimates the depth of left camera. If either the estimated depth of the left or right camera is negative, then the solution of the minimization is invalid since features are always in front of both camera frames observing them. This process of removing features that has the invalid depth is referred to as outlier removal in feature initialization.
4.2. Outlier Detection by Chi-Squared Statistical Test
Before operating navigation systems, we initialize the chi-squared test table with a 95% confidence level. While the systems estimate the state variable, if j-th measurement at time k is the existing feature, then its residual and Jacobian are computed. Next, we proceed a Mahalanobis gating test [33] for residual to detect remaining outliers. In fact, Mahalanobis distance [34] is a measure of the distance between residual and covariance matrix
In the statistic test, we compare value against a threshold given by the 95-th percentile of the distribution with degree of freedom. Here, is the number of observations of the j-th feature minus one. If the feature passes the test, the EKF uses residual to process the measurement update.
4.3. Outlier-Adaptive Filtering
Unlike the extended ORKF (EORKF) [32], for a practical estimation approach in V-INS, this study investigates only measurement outliers due to the following reasons. As the measurement update is not the process performed at every time step, the outlier detection by each residual value cannot directly detect the outliers of IMU measurements. Furthermore, in the sequential measurement update, multiple residuals are computed to update at one IMU time stamp. In other words, as only rare observations among feature measurements from one image are corrupted by the remaining outliers, hypothesizing that the outliers come from the IMU may be faulty. Therefore, in the scope of this paper, we handle only measurement outliers.
4.3.1. Student’s t-Distribution
Despite the true system with outliers, the classical EKF assumes that each model in the filter is corrupted with additive white Gaussian noise. The levels of the noise are assumed to be constant and encoded by sensor covariance matrices Q and R (i.e., ). However, as outliers arise in the realistic system, now we do not restrict noise at either a constant or Gaussian level. Instead, their levels vary over time, or noise have heavier tails than the normal distribution as follows,
where denotes a Student’s t-distribution, and is degrees of freedom. Covariance matrix follows the inverse-Wishart distribution, denoted as . is precision matrix.
In Bayesian statistics, the inverse-Wishart distribution is used as the conjugate prior for the covariance matrix of a multivariate normal distribution [20]. The probability density function (pdf) of the inverse-Wishart is
where denotes the trace of a square matrix in linear algebra. Moreover, in probability and statistics, a Student’s t-distribution is any member of a family of continuous probability distributions that arises when estimating the mean of a normally distributed population in situations where the standard deviation of the population is unknown [51]. Whereas a normal distribution describes a full population, a t-distribution describes samples drawn from a full population; thus, the larger the sample, the more the distribution resembles a normal distribution. Indeed, as the degree of freedom goes to infinity, the t-distribution approaches the standard normal distribution. In other words, when the variance of a normally distributed random variable is unknown and a conjugate prior placed over it that follows an inverse-Wishart distribution, the resulting marginal distribution of the variable follows a Student’s t-distribution [52]. Then, the Student-t, a sub-exponential distribution with much heavier tails than the Gaussian, is more prone to producing outlying values that fall far from its mean.
4.3.2. Variational Inference
The purpose of filtering is generally to find the approximations of posterior distributions , where is the histories of sensor measurements obtained up to time k. For systems with the heavy-tailed noise, we also wish to produce another inference about covariance matrices whose priors follow the inverse-Wishart distribution. Hence, our goal in this section is to find both approximations for posterior distribution and model evidence . Compared to sampling methods, the variational Bayesian method performs approximate posterior inference at low computational cost for a wide range of models [20,52]. In the method, we decompose log marginal probability
where
p is the true distribution that is intractable for non-Gaussian noise models, and q is a tractable approximate distribution.
In probability theory, a measure of the difference between two probability distributions p and q is the Kullback–Leibler divergence, denoted as . If we allow any possible choice for q such as the Gaussian distribution, then lower bound is maximum when the KL divergence vanishes; that is, . To minimize the KL divergence, we seek the member of a restricted family of . Indeed, maximizing is equivalent to minimizing another new KL divergence [52], and thus the minimum occurs when factorized distributions and the following Equations (25) and (26) hold,
where represents the expectation with respect to . With assuming that initial state is Gaussian, the measurement update with varying noise covariance , which closely resemble the EKF updates, solve Equation (25). Algorithm 2 describes the details of the updates.
Now let us assume that the true priors are IID noise models as the case in this study; that is, follows distribution. Then, second term in the right-hand side of Equation (26) is computed using the pdf of the inverse-Wishart distribution in Equation (21) with its prior noise model.
As the term is conjugate prior for Equation (20), the approximations of have same mathematical forms as priors; that is, also follows distribution.
As ,
From Equations (26)–(29), to handle measurement outliers, similar to Agamennoni et al. [18,19]’s derivation, we derive how to compute precision matrix of approximate distribution of as follows,
where each feature from one image is independent and
Next, in Equation (30),
where estimation error and the Jacobian . In the sequential measurement update, and are corrected by Kalman gain that is a function of , so these update steps are coupled. Hence no a closed-form solution exists, and we can only solve iteratively. The purpose of the iteration seems to be similar to that of the online learning of unknown variances of each noise [10]. In addition, similar to Agamennoni et al.’s interpretation [19], the convergence and optimality of the derived update steps for outliers are guaranteed since the variational lower bound is convex with respect to , , and . In particular, as the j-th feature is observed countless times (i.e., →∞), converges to R in the limit of an infinitely precise noise distribution, so the iterative update steps reduce to the standard sequential measurement update of the EKF.
If true state is significantly different from its estimate , then statistics dominates, and becomes much larger than R. This is regarded as a measurement outlier at time k. As Kalman gain is a function of the inverse of precision matrix , the larger values, the smaller the Kalman gain. Therefore, to deal with situations where measurement outliers occur, the iteration for Equations (30) and (31) corrects the state estimates and its covariance with low weights.
5. Implementation
5.1. Marginalization of Feature States
If measurement outliers often occur, a few numbers of sequential updates in the EKF are proceeded to correct the state estimates. Without a sufficient number of measurement updates, the EKF is not robust and even diverges. Hence, outlier-adaptive filtering introduced in Section 4.3 performs the modified measurement update even when a residual is detected as an outlier. Indeed, to save computation resources, this study operates the outlier-adaptive filtering for only features detected frequently outliers. For implementation, we count how many numbers of features augmented in state variables are detected as outliers. Once updating feature outliers by the outlier-adaptive filtering approach, we prune the used feature states from the state vector (Figure 3). In addition, similar to that mentioned in Appendix B, to maintain a certain size of the state vector, after the feature initialization, we marginalize the features with the least number of observations among tracked features.
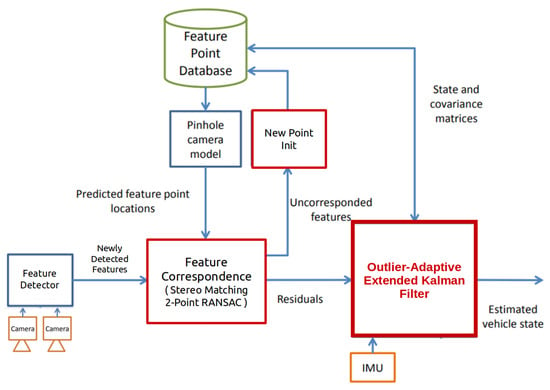
Figure 3.
A block diagram of the vision-aided inertial navigation system employing the outlier-adaptive filtering.
5.2. Summarized Algorithm
This section summarizes and describes an implementation of the proposed method. Figure 4 and Algorithm 2 illustrate a flow chart and the pseudocode of the overall process of the outlier-adaptive filtering approach for V-INS, respectively. For the robust outlier-adaptive filter presented in this paper, the blue boxes in Figure 4 are extended from the figure in [25].
| Algorithm 2 The Outlier-Adaptive Filtering |
| Require: |
|
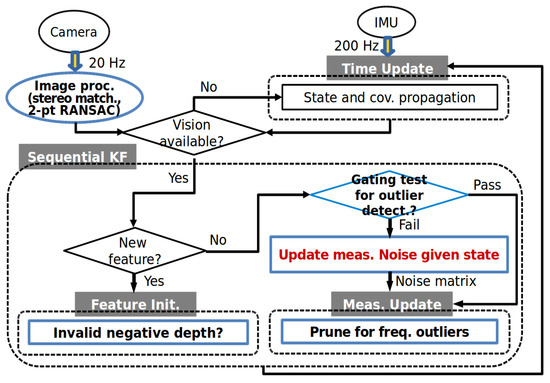
Figure 4.
A flow chart of the overall process of the outlier-adaptive filtering.
6. Flight Datasets Test Results
To examine the influence of outliers in V-INS and validate the reliability and robustness of the proposed outlier-adaptive approach for navigation systems with outliers, we test one of benchmark flight datasets, the so-called “EuRoC MAV datasets” [53]. The visual-inertial sequences of the datasets were recorded onboard a micro aerial vehicle (MAV) while a pilot manually flew around the indoor motion capture environment. For more details, see Appendix C. To articulate the significance of outliers, we select two datasets of the bright scene, called “EuRoC V1 Easy”, and motion blur, called “EuRoC V1 Difficult.” As the images in the difficult dataset are dark scene or motion blur, we hypothesize that outliers occur more frequently in the difficult dataset.
The EKF estimates the relative location and orientation from a starting point. As we do not know the exact absolute location of the origin of given datasets, to compare with ground-truth data given in the datasets, we require certain evaluation error metrics such as so-call “absolute trajectory error [54]”. For more details, see Appendix D. The absolute trajectory error as an evaluation error metric yields the following various comparison plots. Figure 5 illustrates the top-down view of the estimated flight trajectory of the difficult dataset.
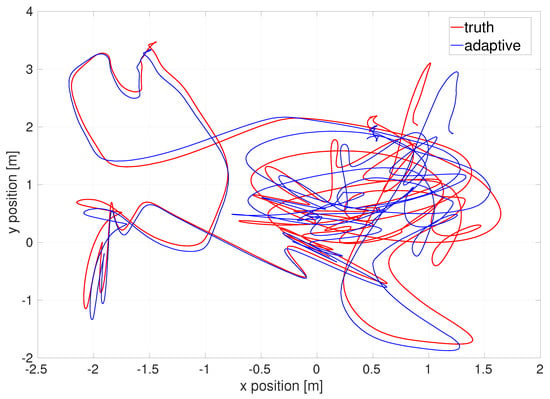
Figure 5.
Top-down view of flight trajectory of the EuRoC V1 difficult dataset by the outlier-adaptive filter.
Figure 6 depict the estimated x, y, z position and their respective estimation errors. All the estimation errors are bounded within each standard deviation envelope, so the proposed approach is reliable vision-aided inertial navigation under even poor illumination environments. Conceptually, the position error gets locked in, and it tends to increase with the length of the trajectory until new features are being mapped.
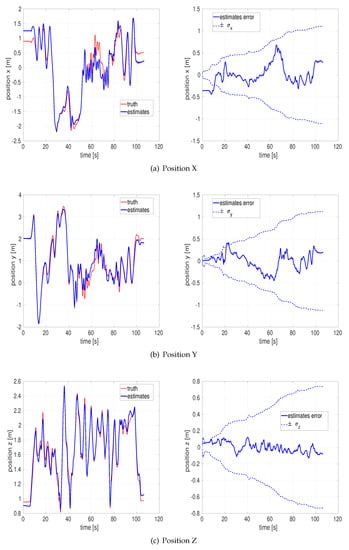
Figure 6.
Position and estimation error of the EuRoC V1 difficult dataset by the outlier-adaptive filter.
Similar to the analysis presented in [25], the adaptive filter is a well-tuned estimator since the performance of doing runs with ×3 or ×10 ( /3 or /10) multiplier on the R matrix used in the filter is worse for all of those, shown in Table 1. That is, the fact that using the multipliers reveals larger root mean square (RMS) estimation errors indicates that our filter is well-tuned.

Table 1.
Indication that the outlier-adaptive filter is well-tuned for the EuRoC V1 difficult dataset.
Figure 7 shows the advantages of the addition of the outlier adaptation proposed in this paper by comparing it with a baseline, the standard EKF in V-INS.
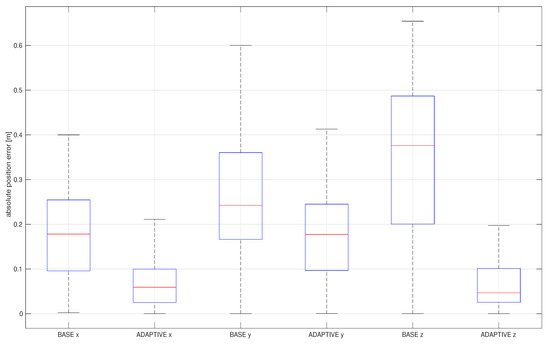
Figure 7.
Box plot of absolute estimation error of the position of the EuRoC V1 difficult dataset by the outlier-adaptive filter.
As Lee [25] and other researchers showed that the standard EKF is a basic filter in V-INS, we choose the method as a baseline here. The baseline only rejects outliers whenever the chi-squared test fails, whereas the outlier-adaptive filtering follows all proposed adaptive approaches in Algorithm 2. Although the iteration in the outlier-adaptive filtering might increase computational resources, it significantly improves the accuracy of estimation. Fortunately, the “while” loop iteration in Algorithm 2 rapidly converges to the optimal noise covariance by twice or three times iterations. For sensitivity analysis, RMS position errors resulting from the baseline and the outlier-adaptive filtering are compiled in Table 2.
Table 2.
Sensitivity analysis in RMS position error [m] of the outlier-adaptive filtering.
Motion blur datasets are more sensitive to outliers as the improvement is larger when applied to those datasets. Although the outlier-adaptive filtering is the best choice for motion blur datasets, we can select an adequate mode depending on computation margin and cost.
Although a number of researchers have investigated V-INS of the EuRoC datasets [55], only a few of them thoroughly has focused on vision measurements with outliers. Table 3 reveals that the proposed estimator, the outlier-adaptive filter, outperforms other state-of-the-art V-INS techniques, called “SVO+MSF [56,57]” and “S-MSCKF [48,58] ” in which stereo is available. As SVO+MSF is loosely coupled, its algorithm actually gets diverged.
Table 3.
Comparison with other methods in RMS position error [m] of the outlier-adaptive filtering.
7. Discussion
This paper has presented practical outlier-adaptive filtering for a vision-aided inertial navigation systems (V-INS) and evaluated its performance with flight datasets testing. In other words, this study develops a robust and adaptive state estimation framework for V-INS under frequent outliers occurrence. In the image processing front-end of the framework, we propose the improved utilization of outlier removal techniques. In filtering back-end, for estimating the states of V-INS with measurement outliers, we implement a novel approach of the outlier-robust extended Kalman filter (EKF) to V-INS, for which we derive iterative update steps for computing the precision noise matrices of vision outliers when the Mahalanobis gating test detects remaining outliers.
To validate the accuracy of the proposed approach and compare it with other state-of-the-art V-INS algorithms, we test the performance of V-INS employing the outlier-adaptive filtering algorithm in the realistic benchmark flight datasets. In particular, to show more improvements of our method over the others’ approaches, we use the fast motion and motion blur flight datasets. Results from the flight datasets testing show that the novel navigation approach in this study improves the accuracy and reliability of state estimation in V-INS with frequent outliers. Using the outlier-adaptive filtering reduces the root mean square (RMS) error of the estimates and accelerates the robustness of the estimates, especially for the motion blur datasets.
The primary goals of future work are listed as follows. Since an inertial measurement unit (IMU) is also a sensor, it could generate outliers in V-INS. With accounting for the process outliers, the accuracy and robustness of the estimator would be improved. If we distinguish process outliers from IMU sensors with measurement outliers from vision data, the extended outlier-robust EKF [32] may be an impressive and innovate approach for this case. Furthermore, the investigation of color noise in V-INS is another possible future work. One of the required assumptions of the Kalman filter is the whiteness of measurement noise. As an illustration, during sampling and transmission in image processing, color noise that may be originated from a multiplicity of sources could degrade the quality of images [59]. The vibrational effects of camera sensors might also produce colored measurement noise [60]. That is, if the residuals of vision data are correlated with themselves at different timestamp, then colored measurement noise occurs in V-INS. Therefore, the images with color noise would be filtered for ensuring the accuracy of locating landmarks. As modeling noise without additional prior knowledge of the noise statistics is typically difficult, the machine learning techniques-based state estimator for colored noise [61,62] may handle the unknown correlations in V-INS.
This study showcases the approaches using stereo cameras but is also suitable for monocular V-INS and employable to other filter-based V-INS frameworks. We test benchmark flight datasets to validate the reliability and robustness of this study, but additional validating with other flight datasets or real-time flight tests would help to prove its more robustness. In addition, we can operate unmanned aerial vehicles (UAVs) stacked the navigation algorithms in this study and a controller-in-the-loop. The use of the controller-in-the-loop could be a more important validation criteria due to the potential for navigation-controller coupling. The research objectives and contributions presented here will remarkably advance the state-of-the-art techniques of vision-aided inertial navigation for UAVs.
Author Contributions
Conceptualization, K.L. and E.N.J.; Data curation, Formal analysis, Investigation, Methodology, Resources, and Software, K.L.; Supervision, E.N.J.; Validation, Visualization, and Writing-original draft, K.L.; Writing-review & editing, K.L. and E.N.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| V-INS | Vision-aided Inertial Navigation Systems |
| VIO | Visual-Inertial Odometry |
| IMU | Inertial Measurement Unit |
| MEMS | Micro-ElectroMechanical System |
| EKF | Extended Kalman Filter |
| UAV | Unmanned Aerial Vehicle |
| RANSAC | RANdom SAmple Consensus |
| FAST | Features from Accelerated Segment Test |
| KLT | Kanade–Lucas–Tomasi |
| ST | Student’s t-distribution |
| ROS | Robot Operating System |
Nomenclature
| x | state | y | measurement |
| k | discrete time | j | index of measurements |
| Q | process noise covariance | R | measurement noise covariance |
| P | error state covariance | r | residual |
Appendix A. Jacobians of Models
From Section 2.2.1 and Section 2.2.2, Jacobian A,B, and C are
where for more detailed derivations, see reference [25,63].
Appendix B. Feature Initialization
In the first step of the measurement update, we employ Gauss–Newton least-squares minimization [58,64] to estimate feature 3D position . To avoid local minima, we apply the inverse depth parameterization of the feature position [65] that is numerically more stable than the Cartesian parameterization.
We assume that the intrinsic and extrinsic parameters of a stereo camera are known and constant values. , frames are the left and right camera frame of the stereo, respectively. Since the baseline of the stereo is fixed, rotation and translation between both cameras are constant and known values. Feature coordinates with respect to both cameras are
Simplifying Equation (A8),
where , , and are scalar functions of given j-th measurement and constant extrinsic rotation matrix. Based on Equation (17), as the measurement equations from the stereo camera are
right camera measurements are expressed in form.
where let
Therefore, the Gauss–Newton least-squares minimization estimates depth of left camera using the pseudo-inverse of A is
If either estimated depth or is negative, the solution of the minimization is invalid since the feature is always in front of both camera frames observing it. By substituting estimated into Equation (A8),
where is not related to the pose of the vehicle. Likewise, if a monocular camera is used instead, is the camera frame in which the feature was observed at the first time, and is the camera frame at a different time instance.
The j-th feature 3D position with respect to the inertial frame is
The new feature is initialized using only one image in which the feature is first observed. Although the new feature is initialized, as it still entails uncertainty, the EKF recursively estimates and updates its 3D position by augmenting into the state vector.
where is the estimated vehicle state vector defined in Equation (8). The overall initialization includes the initial value of the feature state and its error covariance assignment. The error covariance of the new feature are initialized using state augmentation with Jacobian J.
where Jacobian is computed as follows,
is the number of all features and is the initial uncertainty of the initialized new feature. The error pertains to measurement noise and the error of the least-squares minimization and so on. In fact, since Montiel et al. [65] validate that the initial uncertainty is coded as Gaussian, the EKF including the feature initialization still holds optimality.
Once initialized, the EKF processes the feature state in the prediction-update loop. In the time update of the EKF, we propagate P by Equation (4).
where state transition matrix . , is the error covariance of all features, and represents vehicle-feature correlations. In addition, we assume that surrounding is static, so the dynamics of features . In the measurement update of the EKF, only tracked features are used for the update. For the efficient management of the map database, if the size of the state vector exceeds than the maximum limit, then the feature with the least number of observations is pruned and marginalized.
Appendix C. Experimental Equipment and Environments
Burri et al. [53] provide the benchmark datasets of UAV flying, and Table A1 illustrates the specifications of the sensors used in the datasets.
Table A1.
Sensors of EuRoC Datasets.
Table A1.
Sensors of EuRoC Datasets.
| Sensor | Rate | Characteristics |
|---|---|---|
| Stereo Images (Aptina MT9V034) | 2 × 20 FPS | Global Shutter, WVGA Monochrome |
| MEMS IMU (ADIS16448) | 200 Hz | Instrumentally Calibrated |
They obtain the noise model parameters from the IMU at rest and provide them; that is, , , , and are known. The intrinsic and extrinsic parameters of both cameras are also given; that is, , , , and are known. The visual-inertial sensor unit is calibrated with Kalibr [66] prior to dataset collection. Furthermore, IMU and cameras are hardware time-synchronized such that the middle of the exposure aligned with the IMU measurements.
Visual and inertial data is logged and timestamped onboard the MAV while ground truth is logged in the Vicon 6D motion capture system on the base station. The accuracy of the synchronization between the ground truth and the sensor data is limited by the fact that both sources are recorded on different machines and that the timestamps of the devices are unavailable for the ground-truth system. A maximum likelihood (ML) estimator [11] aligns the data temporally and calibrates the position of the ground-truth coordinate with respect to the body sensor unit. In fact, the ML estimator synchronizes the time-varying temporal offset between the ground truth and the body sensor system. Moreover, it determines the unknown transform between the ground-truth reference frame and the body frame. To obtain the full ML solution, they employ a batch estimator in an offline procedure. Finally, as ground truth, they provide the ML solutions instead of raw data.
Appendix D. Evaluation Error Metric
Sturm et al. [54] provide a set of tools used to preprocess the datasets and evaluate the tracking results. To validate estimation results, we need to evaluate the errors in the estimated trajectory by comparing it with the ground truth. Among various error metrics, two prominent methods are the absolute trajectory error (ATE) and the relative pose error (RPE). In this paper, to evaluate the overall performance of V-INS employing the outlier-adaptive filtering, the ATE measure is selected.
Appendix Absolute Trajectory Error (ATE)
The absolute trajectory error directly measures the difference between points of the true and the estimated trajectory. As a preprocessing step, we associate the estimated poses with ground-truth poses using the recorded timestamps. Based on this association, we align the true and the estimated trajectory using the Horn et al. [67]’s closed-form method based on singular value decomposition (SVD). Finally, we compute the differences between each pair of poses and output the mean, median, and standard deviation of these differences.
References
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kalman, R.E.; Bucy, R.S. New Results in Linear Filtering and Prediction Theory. J. Basic Eng. 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Anderson, B.D.; Moore, J.B. Optimal Filtering; Prentice Hall: Englewood Cliffs, NJ, USA, 1979; Chapters 2–4. [Google Scholar]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory Algorithms and Software; John Wiley & Sons: Hoboken, NJ, USA, 2004; Chapters 2–9. [Google Scholar]
- Schmidt, S.F. The Kalman Filter: Its Recognition and Development for Aerospace Applications. J. Guid. Control Dyn. 1981, 4, 4–7. [Google Scholar] [CrossRef]
- Magree, D.; Johnson, E.N. Factored Extended Kalman Filter for Monocular Vision-Aided Inertial Navigation. J. Aerosp. Inf. Syst. 2016, 13, 475–490. [Google Scholar] [CrossRef]
- Song, Y.; Nuske, S.; Scherer, S. A Multi-Sensor Fusion MAV State Estimation from Long-Range Stereo, IMU, GPS and Barometric Sensors. Sensors 2017, 17, 11. [Google Scholar] [CrossRef]
- Mostafa, M.; Zahran, S.; Moussa, A.; El-Sheimy, N.; Sesay, A. Radar and Visual Odometry Integrated System Aided Navigation for UAVS in GNSS Denied Environment. Sensors 2018, 18, 2776. [Google Scholar] [CrossRef] [Green Version]
- Hawkins, D.M. Identification of Outliers; Springer: Berlin/Heidelberg, Germany, 1980; Chapters 2–5. [Google Scholar]
- Mehra, R.K. On the Identification of Variances and Adaptive Kalman Filtering. IEEE Trans. Autom. Control 1970, 15, 175–184. [Google Scholar] [CrossRef]
- Maybeck, P.S. Stochastic Models, Estimation, and Control; Academic Press: Cambridge, MA, USA, 1982; Chapter 10; pp. 68–158. [Google Scholar]
- Stengel, R.F. Optimal Control and Estimation; Courier Corporation: Chelmsford, MA, USA, 2012; Chapter 4. [Google Scholar]
- Ting, J.A.; Theodorou, E.; Schaal, S. A Kalman Filter for Robust Outlier Detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Diego, CA, USA, 29 October–2 November 2007; pp. 1514–1519. [Google Scholar] [CrossRef]
- Särkkä, S.; Nummenmaa, A. Recursive Noise Adaptive Kalman Filtering by Variational Bayesian Approximations. IEEE Trans. Autom. Control 2009, 54, 596–600. [Google Scholar] [CrossRef]
- Piché, R.; Särkkä, S.; Hartikainen, J. Recursive Outlier-Robust Filtering and Smoothing for Nonlinear Systems Using the Multivariate Student-t Distribution. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Santander, Spain, 23–26 September 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Roth, M.; Özkan, E.; Gustafsson, F. A Student’s t Filter for Heavy Tailed Process and Measurement Noise. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 5770–5774. [Google Scholar] [CrossRef] [Green Version]
- Solin, A.; Särkkä, S. State Space Methods for Efficient Inference in Student-t Process Regression. In Proceedings of the International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 885–893. [Google Scholar]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. An Outlier-Robust Kalman Filter. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1551–1558. [Google Scholar] [CrossRef]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. Approximate Inference in State-Space Models with Heavy-Tailed Noise. IEEE Trans. Signal Process. 2012, 60, 5024–5037. [Google Scholar] [CrossRef]
- Beal, M.J. Variational Algorithms for Approximate Bayesian Inference. Ph.D. Thesis, University of London, London, UK, 2003. [Google Scholar]
- Graham, M.C.; How, J.P.; Gustafson, D.E. Robust State Estimation with Sparse Outliers. J. Guid. Control Dyn. 2015, 38, 1229–1240. [Google Scholar] [CrossRef] [Green Version]
- Wu, A.D.; Johnson, E.N.; Kaess, M.; Dellaert, F.; Chowdhary, G. Autonomous Flight in GPS-Denied Environments Using Monocular Vision and Inertial Sensors. J. Aerosp. Inf. Syst. 2013, 10, 172–186. [Google Scholar] [CrossRef]
- Nakamura, T.; Haviland, S.T.; Bershadsky, D.; Johnson, E.N. Vision Sensor Fusion for Autonomous Landing. In Proceedings of the AIAA Information Systems-AIAA Infotech@ Aerospace, Grapevine, TX, USA, 9–13 January 2017; p. 0674. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006; Chapters 2–13. [Google Scholar]
- Lee, K. Adaptive Filtering for Vision-Aided Inertial Navigation. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2018. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003; pp. 22–236. [Google Scholar]
- Troiani, C.; Martinelli, A.; Laugier, C.; Scaramuzza, D. 2-Point-Based Outlier Rejection for Camera-IMU Systems with Applications to Micro Aerial Vehicles. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5530–5536. [Google Scholar] [CrossRef] [Green Version]
- Kriegel, H.P.; Kröger, P.; Zimek, A. Outlier Detection Techniques. Tutor. KDD 2010, 10, 1–76. [Google Scholar]
- Angelov, P. Anomaly Detection Based on Eccentricity Analysis. In Proceedings of the IEEE Symposium on Evolving and Autonomous Learning Systems (EALS), Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Costa, B.S.J.; Bezerra, C.G.; Guedes, L.A.; Angelov, P.P. Online Fault Detection Based on Typicality and Eccentricity Data Analytics. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Johnson, E.N. Robust State Estimation and Online Outlier Detection Using Eccentricity Analysis. In Proceedings of the IEEE Conference on Control Technology and Applications (CCTA), Mauna Lani, HI, USA, 27–30 August 2017; pp. 1350–1355. [Google Scholar] [CrossRef]
- Chang, G. Robust Kalman Filtering Based on Mahalanobis Distance as Outlier Judging Criterion. J. Geod. 2014, 88, 391–401. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the Generalized Distance in Statistics; National Institute of Science of India: Brahmapur, India, 1936. [Google Scholar]
- Atkinson, K.E. An Introduction to Numerical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2008; Chapters 5–6. [Google Scholar]
- Gelb, A. Applied Optimal Estimation; MIT Press: Cambridge, MA, USA, 1974; Chapters 4, 6; pp. 102–155, 180–228. [Google Scholar]
- Crassidis, J.L.; Junkins, J.L. Optimal Estimation of Dynamic Systems; CRC Press: Boca Raton, FL, USA, 2011; Chapters 3–4. [Google Scholar]
- Stevens, B.L.; Lewis, F.L.; Johnson, E.N. Aircraft Control and Simulation: Dynamics, Controls Design, and Autonomous Systems; John Wiley & Sons: Hoboken, NJ, USA, 2015; Chapters 1–2. [Google Scholar]
- Markley, F.L. Attitude Error Representations for Kalman Filtering. J. Guid. Control Dyn. 2003, 26, 311–317. [Google Scholar] [CrossRef]
- Sola, J. Quaternion Kinematics for the Error-State Kalman Filter. arXiv 2017, arXiv:1711.02508. [Google Scholar]
- Woodman, O.J. An Introduction to Inertial Navigation; Technical Report; University of Cambridge, Computer Laboratory: Cambridge, UK, 2007. [Google Scholar]
- Titterton, D.; Weston, J.L.; Weston, J. Strapdown Inertial Navigation Technology; The Institution of Engineering and Technology (IET): London, UK, 2004; Volume 17, Chapters 4–7. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 2002; Chapters 4–5. [Google Scholar]
- Trajković, M.; Hedley, M. Fast Corner Detection. Image Vis. Comput. 1998, 16, 75–87. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Morgan Kaufmann Publishers Inc.: Bullington, MA, USA, 1981; Volume 2, pp. 674–679. [Google Scholar]
- Paul, M.K.; Wu, K.; Hesch, J.A.; Nerurkar, E.D.; Roumeliotis, S.I. A Comparative Analysis of Tightly-Coupled Monocular, Binocular, and Stereo Vins. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 165–172. [Google Scholar] [CrossRef]
- Sun, K.; Mohta, K.; Pfrommer, B.; Watterson, M.; Liu, S.; Mulgaonkar, Y.; Taylor, C.J.; Kumar, V. Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight. IEEE Robot. Autom. Lett. 2018, 3, 965–972. [Google Scholar] [CrossRef] [Green Version]
- Kitt, B.; Geiger, A.; Lategahn, H. Visual Odometry Based on Stereo Image Sequences with Ransac-Based Outlier Rejection Scheme. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), San Diego, CA, USA, 21–24 June 2010; pp. 486–492. [Google Scholar] [CrossRef] [Green Version]
- Open CV. 2019. Available online: https://opencv.org/ (accessed on 8 November 2019).
- Devore, J.L. Probability and Statistics for Engineering and the Sciences; Cengage Learning: Boston, MA, USA, 2015; Chapter 7; pp. 267–299. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Chapter 10; pp. 461–522. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC Micro Aerial Vehicle Datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef] [Green Version]
- Delmerico, J.; Scaramuzza, D. A Benchmark Comparison of Monocular Visual-Inertial Odometry Algorithms for Flying Robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. number CONF. [Google Scholar] [CrossRef]
- Faessler, M.; Fontana, F.; Forster, C.; Mueggler, E.; Pizzoli, M.; Scaramuzza, D. Autonomous, Vision-Based Flight and Live Dense 3D Mapping with a Quadrotor Micro Aerial Vehicle. J. Field Robot. 2016, 33, 431–450. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-Aided Inertial Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar] [CrossRef]
- Xiong, S.; Zhou, Z.; Zhong, L.; Xu, C.; Zhang, W. Adaptive Filtering of Color Noise Using the Kalman Filter Algorithm. In Proceedings of the 17th IEEE Instrumentation and Measurement Technology Conference (IMTC), Baltimore, MD, USA, 1–4 May 2000; Volume 2, pp. 1009–1012. [Google Scholar] [CrossRef]
- Kumar, A.; Crassidis, J.L. Colored-Noise Kalman Filter for Vibration Mitigation of Position/Attitude Estimation Systems. In Proceedings of the AIAA Guidance, Navigation and Control Conference and Exhibit, Hilton Head, SC, USA, 20–23 August 2007; p. 6516. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Johnson, E.N. State Estimation Using Gaussian Process Regression for Colored Noise Systems. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Lee, K.; Choi, Y.; Johnson, E.N. Kernel Embedding-Based State Estimation for Colored Noise Systems. In Proceedings of the IEEE/AIAA 36th Digital Avionics Systems Conference (DASC), St. Petersburg, FL, USA, 17–21 September 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, A.D. Vision-Based Navigation and Mapping for Flight in GPS-Denied Environments. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2010. [Google Scholar]
- Bjorck, A. Numerical Methods for Least Squares Problems; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 1996; Volume 51, Chapters 2–9. [Google Scholar]
- Montiel, J.M.; Civera, J.; Davison, A.J. Unified Inverse Depth Parametrization for Monocular SLAM. In Proceedings of the Robotics: Science and Systems, Philadelphia, PA, USA, 16–19 August 2006. [Google Scholar] [CrossRef]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified Temporal and Spatial Calibration for Multi-Sensor Systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar] [CrossRef]
- Horn, B.K.; Hilden, H.M.; Negahdaripour, S. Closed-Form Solution of Absolute Orientation Using Orthonormal Matrices. J. Opt. Soc. Am. A 1988, 5, 1127–1135. [Google Scholar] [CrossRef] [Green Version]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).