2.2. Classification and Segmentation Algorithm
Our aim is to detect individual object instances in the scene in order to have a system that is usable in real-world environments. Therefore, we need a classifier that is capable of detecting more than a single object instance for given frame, for example, having two cups and a toy plane on a table would require us to rebuild both of the cups and the toy plane models, respectively. Fortunately, some research has already been performed in the area of individual object instance classification [
44,
45,
46].
For this reason, to perform our classification task we use one of existing state-of-the-art classifiers as it has shown to produce some of the best results in classification tasks, i.e.
YOLOv3 [
47], which we have adapted to our needs to output an additional geometric segmentation mask (
Figure 1), while authors have mentioned to be unable to achieve object instance segmentation in their original paper. Additionally, we define the term geometric segmentation as extension to segmentation that allows to discriminate between nearby object instances. This is done by generating a heatmap glow that radiates from the origin of the object. While other more lightweight methods exist, such as
MobileNet [
48], in our paper we try to compare the classification results using three different methods: using only color information; using only depth information; using both color and depth information. Therefore, we have decided to use a slower, but more accurate algorithm to have the most representative results.
Just as the majority of the individual object instance classifying algorithms, YOLOv3 uses what is know as anchors for object detection. These anchors are used as jumping off bounding boxes when classifying objects, for example, a motor vehicle has a very different profile from a basketball. While the basketball in most cases has close to 1:1 aspect ratio bounding box, meaning that their width is the same, or very close when the image is distorted, to its height, while a motor vehicle like an automobile for the most part has height that is lower than its width. For this reason, one anchor could specialize in detecting automobiles, while the other can specialize in detecting basketballs. Additional feature, albeit a less useful one due to the way our training and testing dataset is generated, is the specification of bounding box scales by the authors of YOLOv3. These size specializations group bounding boxes into three groups: small, medium and large. For example small objects may include kitchen utensils, medium objects may include people, large objects may include vehicles. However, these bounding box groups are not exclusionary for these objects unlike anchors as these can vary a lot based on the camera distance from the object. Therefore, as our dataset is completely uniformly generating object scales this grouping loses some of its usefulness.
In our work, we have experimented with three types of inputs into the ANN: color space, front-to-back object depth field and the combination of both. In the case of color space, we use 3 channel inputs for representation of
red,
green,
blue colors; when using depth field, we use a single channel input containing only normalized depth field values and for the combination of both we use
RGBD channels in the same principle. Depth value normalization is performed by dividing each pixel
z value using
of the frame thus landing the depth in range of
. Our input layer is thereafter connected to
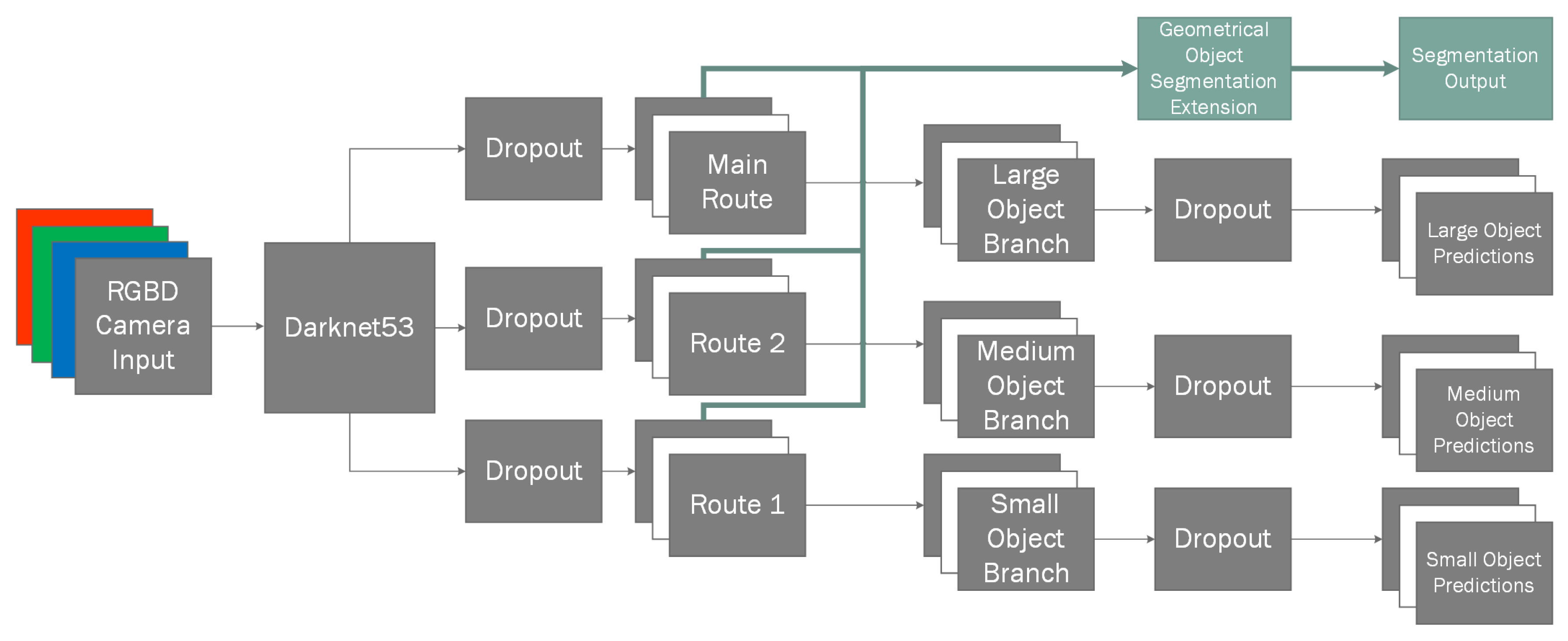
DarkNet53 network containing 53 convolutional layers as per specifications, which outputs three routes:
main route used generally used for larger objects,
route 2 used for medium sized objects and, finally,
route 1 for smaller objects. Due to testing set being uniformly randomly generated, and containing the same object in potentially all size categories, we lose some of the flexibility that is provided by this setup and it impacts classification performance minimally, if removed. However, to stay true to the original algorithm and have an as unbiased result as possible, we have decided to keep all of the branches used in the source material. Additionally, these three routes provide good jumping off points for shortcuts to be used in our segmentation extension (
Figure 2).
Due to each of the nearby routes being separated by the power-of-two scale, we use transposed convolutional layer [
49] to upscale them gradually and then and merge them into desired final shape matrix. We construct our classless geometric segmentation mask by firstly upscaling the
main route output and merging it with
route 2, and the resulting layer is then upscaled again and merged with the final
DarkNet output (
route 1) which provides us a layer containing latent information of all previous layers that are each specified in learning different sized objects.
Next, we branch out our resulting hidden nodes into four different layers. Each layer contains slightly different network configuration, allowing them to essentially vote on their influence in the final result by extracting different latent feature-maps from the previous layers (
Table 1). The first three branches (
A, B, C) are convolutional branches containing one, two and three convolutional layers, respectively. However, for our final branch (
D) instead of the convolutional layer, we use a max pool layer to extract the most prominent features. We have selected this parallel stacked approach, because we found it to be more efficient in extracting the object masks than linearly stacked layers when training the segmentation layers independently from the entirety of a model. This decoupling of the segmentation task from the classification task when training gives the additional benefit of allowing us to use transfer learning, which has shown to have very good practical results [
50].
Next, we run our concatenated branches through convolutional layers to extract the most viable features and normalize their output in the range of (0, 1) giving us the final segmentation image. In our case the final segmentation output is 80 × 60 due to it being more than sufficient to extract approximate depth masks as we do not require pixel perfect segment representations. Finally, we use cascading flood-fill (Algorithm 1) to classify the masks pixels-wise. This is done because we found the generated binary masks to be impervious to false positives and false negatives, unlike classification using bounding boxes which can have three types of errors: false positives, false negatives and misclassification. This allows us to remove false positive bounding box detections when they do not intersect the origin of the mask. In our testing set, best cascade parameters were
,
.
| Algorithm 1 Cascading flood-fill |
| 1: procedure GET_SEED() | ▹ Seeds initial values. |
| 2: | ▹ Get center for . |
| 3: ∅ | |
| 4: | ▹ Find closest max pixel within bounds. |
| 5: if then | |
| 6: | ▹ Set seed to box |
| 7: return | ▹ Return seed if value greater than |
| 8: end if | |
| 9: return ∅ | ▹ No valid seed was found. |
| 10: end procedure | |
| 11: procedure FILL_NEIGHBOURS() | ▹ Recursively fill free neightbours with same or lower values. |
| 12: for each do | ▹ For every neighboring mask pixel. |
| 13: if then | |
| 14: | ▹ Set neighbor to same as . |
| 15: | ▹ Call recursively. |
| 16: end if | |
| 17: end for | |
| 18: end procedure | |
| 19: | ▹ Sort bounding boxes by confidence. |
| 20: for each do | ▹ For each bounding box b |
| 21: | |
| 22: if ∅ then | |
| 23: | |
| 24: end if | |
| 25: end for | |
Additionally, we have also modified
YOLOv3 network for we had issues with the network being unable to train by consistently falling into local minima during gradient descent and getting perpetually stuck in them. To solve this issue we introduced periodic hyper parameters [
51] during model learning. Specifically, we had changed the learning rate to alternate in specified range of
,
.
This periodical learning rate (Equation (
1)) has vastly improved our models ability to learn the underlying relationships of input date by alternating between low and high training rates, therefore jumping out of potential local minima that it might start orbiting around during stochastic gradient descent. Our function has two stages, the first stage that consists of two training iterations, where
, and the second stage of 4 iterations, where
where
s is the number of steps per batch. We selected the two state learning function because having high learning rates initially may cause the model to diverge. Therefore, during the first stage we linearly increase the learning rate. Once in the second stage we use the cosine function and the modulus operator for the model to alternate between two values. The shape of the alternating function also can have influence in model convergence as some models require to be in different extremum points for different amounts of times. Therefore, having a different dataset may require more fine-tuning of parameters of this equation for different slope shapes, while still maintaining the benefits of having alternating learning rates.
Additionally, as we are training the NN from scratch, we have noticed that our network, despite being able to find better convergence results due to periodical learning rate jumping out of local minima, had a high bias rate. A high bias rate is an indicator that our model is over-fitting on our data set. To solve this additional issue, we modified the YOLOv3 network by adding additional dropout layers with the dropout rate of after each branch of DarkNet53 and before each of the final layers predicting the bounding boxes.
Furthermore, we had issues of model overfitting to the training set, to solve this we additionally modified the neural network by adding two additional dropout layers. We trained our model 6 times, each with 50 iterations using mini-batch of size 8 for comparison, because after about 50 iterations the standard YOLOv3 model starts to overfit and loose precision with our validation dataset. Therefore, for most objective comparison we trained our modified network for same number of epochs. Note that even though our method also starts to overfit, unlike the YOLOv3 network model, the accuracy of our modified model when overfitting remains roughly at the same value from which we can deduce that the changes make the model more stable.
Figure 3 shows the differences in loss function when trained using the RGB, RGB-D and Depth data as input. For the unmodified
YOLOv3 we are using
as the midpoint between our minimum and maximum learning rates in the periodic learning rate function. As we can see from the graph, the loss function using static learning rate on the RGB and RGB-D datasets reaches a local minimum causing the model to slow down its ability to learn new features, unlike our periodic learning rate which seems to temporarily force the model to overshoot its target which sometimes causes it to fall into a better local minimum. This effect can be seen in the distinct peaks and valleys in the graphs. The outlier in these graphs are depth-only data points. While in both cases the loss function seems lower and has a better downwards trajectory in stochastic descent, however, we have noticed that despite seemingly lower loss when compared to RGB and RGB-D, the actual model accuracy is very unstable on epoch-per-epoch basis. We assert that this is the case due to depth alone providing very unstable data that’s very hard to interpret. We make this assumption due to the fact that even when taken an expert to evaluate the depth maps alone, it is usually very hard to discern what type of object it is without knowing its texture; it is only possible to tell that there is in fact an object in the frame. Finally, we can see that the RGB-D data is a clear winner when training in both cases, which means that depth data can indeed help in model generalization.
2.3. Reconstruction Algorithm
The proposed algorithm for 3D object reconstruction consists of two subsystems: voxel cloud reconstruction and post-processing (
Figure 4). In reconstruction step we take the outputs of the 3D classifier mask for the object and in conjunction with the original depth map which we feed into our reconstruction ANN (
Figure 5) that performs the object reconstruction task for the given masked input frame. Unlike the classification algorithm we only use the underlying depth input from the classifier as it provides enough information for the specific object reconstruction. This is due to fact that we already know the class of the object, which is required for classification because different objects can have very similar depth representations. However, during reconstruction this is not an issue because our ANN is designed in such a way that each branch is responsible for reconstructing similar object representations.
Once the classifier-segmentation branch has finished its task, for each object instance the appropriately trained reconstruction branch is selected. In our case all the branches are highly specialized on a single type of object that it can reconstruct, which is why object classification is required. However, we believe that there is no roadblock to having more generic object reconstruction branches for example all similar objects may be grouped to a single reconstruction task. This could potentially allow some simplifications in the classification-segmentation as it would no longer be required to classify highly specific object instances thus reducing failure rate caused by object similarities. For example, a cup and a basket can be very similar objects and be misclassified. Additionally, the hybridization allows for fine tuning of the reconstruction branches without having to retrain the entire neural network model potentially losing already existing gradients via on-line training skewing the results towards new data posed. This in turn reduces re-training time if new data points are provided for a specific object as we no longer need to touch the established branches due to modularity.
Inside our reconstruction network branch (
Figure 2) for given depth input we use convolutional layers to reduce the dimensionality of the input image during the encoding phase (see
Table 2). For a given input, we create a bottleneck convolution layer which extracts 96 features, afterwards we use a spatial 2D dropout [
53] layer before each with
to improve generalization. We use spatial dropout as it is shown to improve generalization during training as it reduces the effect of nearby pixels being strongly correlated within the feature maps. Afterwards, we add an additional inception [
54] layer (
Figure 6) which we will use as a residual block [
55] followed by another spatial dropout. Afterwards, we add two additional bottleneck residual layers, each followed by additional dropouts. With final convolution giving us final 256 features with the resolution of 20 × 15. Our final encoder layer is connected using a fully-connected layer to a variational autoencoder [
56] containing 2 latent dimensions, as variational autoencoders have shown great capabilities in generative tasks. Finally, the sampling layer is connected to full-connected layer which is then unpacked into a 4 × 4 × 4 matrix. We use the transposed three-dimensional convolutional layers in order to perform up-sampling. This is done twice, giving us 4 feature maps in 32 × 32 × 32 voxel space. Up to this point we have used Linear Rectified Units [
57] (ReLUs) for our activation function, however, for our final 3D convolutional layer we use a softmax function in order to normalize its outputs where each voxel contains two neurons. One neuron indicating the confidence of it being toggled on, the other neuron showing the confidence of the neuron being off. This switches the task from a regression task to a classification task, allowing us to use categorical cross entropy to measure the loss between the predicted value and our ground truth.
2.5. Dataset
As our method entails the requirement of a priori information for the captured object reconstruction, there is a need for a large well labeled element dataset. However, unlike for object recognition which has multiple datasets, e.g.,
COCO [
58] dataset,
Pascal VOC [
59]; there seems to be a lack of any public datasets that provide RGB-D scene representation in addition to it’s fully scanned point cloud information viable for our approach. While datasets like
ScanNet [
60] exist, they are missing finer object details due to focusing their scan on full room experience that we are trying to preserve. Therefore, our training data consists exclusively out of synthetically generated datasets, which use the
ShapeNetCore, a subset of
ShapeNet dataset that provides 3D object models spanning 55 categories (see an example of a coffee cup model in
Figure 8). In addition, we use real-life data acquired by the
Intel Realsense ZR300 and
Intel Realsense D435i (Intel Corp., Santa Clara, CA, USA) devices for visual validation as it is impossible to measure it objectively without having a 3D artist recreating a 1:1 replica of said objects, which is unfortunately unfeasible option. However, using real world samples as a validation set is not subject to training bias because they are never being use in the training process.
As mentioned, for the training of the black-box model we are using the
ShapeNetCore dataset that we prepare using
Blender [
61] in order to create the appropriate datasets. Due to the fact that we are training a hybrid neural network, we need two separate training and testing sets, one for each task.
2.5.1. Classification Dataset
To create this subset of data we create random scenes by performing the following procedure. Firstly, we randomly decide how many objects we want to have in the scene in the range of
and pick that many random objects from
ShapeNetCore dataset to populate the scene. Before applying any external transformations we transform the object geometry so that all objects are of uniform scale and have the same pivot point. To perform the required transformations firstly we calculate the geometry extents. Once we know the object extents we can move all the objects on
Up axis (in our case this is
z) and scale down all vertices by the largest axis (Algorithm 2). This gives us a uniformly scaled normalized geometry that we can freely use.
| Algorithm 2 Normalize geometry |
| 1: procedure Extents(G) | ▹ Calculates extents for geometry G |
| 2: | ▹ Initialize vector |
| 3: | ▹ Initialize vector |
| 4: for each do | ▹ For each vertex v |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: end for | |
| 12: return | |
| 13: end procedure | |
| 14: | |
| 15: | |
| 16: | |
| 17: for each do | ▹ For each vertex v |
| 18: | |
| 19: | |
| 20: | ▹ Offset the vertex on up axis before normalizing bounds |
| 21: end for | |
We place the selected objects with random transformation matrices in the scene, making sure sure that the objects would never overlap in space. To generate random local transformation matrix (
L) (Equation (
3)) we need three of it’s components: Scale (
S), Rotation (
) and with random value; use either capital or lower-case s in both places in the range of
; Rotation (
), where rotation is random value in the range of
, we perform rotation only on
z axis to ensure that randomly generated scenes are realistic and do not require artist intervention; Translation (
T), where
x and
y values are non-intersecting values in the range of
and
(Equation (
2)).
Once the selection objects are placed we need to apply lighting in order to have real-life like environments. To do this, we use the Lambertian shading model and directional lights. We randomly generate lights in the scene. We pick a random light rotation, we ignore translation as it does not matter in directional lights; we generate a random color in the range of , we selected the minimum bound of 0.7 to avoid unrealistic real-world lightning; and random intensity . This light acts as our key light. To avoid hard shadows being created, which wouldn’t be the case unless using spotlight in real world, for each key light we create a backlight which is pointing the opposite direction of key light with half the intensity and identical color to the key light.
Once the scene setup is complete, we render the scene in three modes: color, depth and mask. Color mode gives us the scene representation from a regular light spectrum camera. As we are not putting any background objects into the scene the generated background is black. However, later on we use augmentation during training to switch the backgrounds to improve recall rates. Once the color frame is extracted we extract the mask, in order to extract the mask we assign each object an incremental ID starting at 1, this allows us to differentiate between objects in the frame. Finally, we render the depth representation of the scene. Before rendering depth we place a plane on the ground that acts as our ground place, this allows for more realistic depth representations because the objects are no longer floating in space. The depth is rendered front-to-back, meaning the closer the object is to the camera the closer to zero depth value is, the front-to-back model was chosen because this is the same as Intel Realsense model.
Each of the scenes is rendered in
320 × 240 resolution
times by placing it in random locations (Algorithm 3) and pointing it at the center of the scene, where
,
,
.
| Algorithm 3 Camera location |
- 1:
- 2:
for i < n do - 3:
▹ Random float in the range of [i, i+1] - 4:
- 5:
- 6:
- 7:
end for
|
We save the perspectives as
OpenEXR format [
62] instead of traditional image formats instead of, for example,
PNG, as
OpenEXR file format is linear, allowing for retention of all depth range without any loss of information as it is not limited to 32 bits per pixel. The final
EXR file has these channels in it
R,
G,
B containing red, green and blue color information respectively;
id channel contains the information about the mask for specific pixel;
Z information containing the linear depth data.
Once we create the input image, we additionally label the data and extract the segmentation mask that will be used as output when training the artificial neural net. We perform this step after the scene is rendered in order to account for any kind of occlusion that may occur when objects are in front of each other causing them to overlap. We extract the object bounding boxes by finding the most top-left and bottom-right pixel of the mask. The binary mask is extracted based on the pixel square distance from the center of the bounding box. This means that the center pixels for the bounding box are completely white and the closer to the edges it is the darker it gets. We use non-flat segmentation to be able to extrapolate individual object instances in the mask when they overlap, and this is done by interpolating the pixel intensity from the bounding box edge to bounding box center. The mask is then scaled down to 80 × 60 resolution as it is generally sufficient and reduces the required resources.
2.5.2. Anchor Selection
The existing anchors that are being used with
COCO,
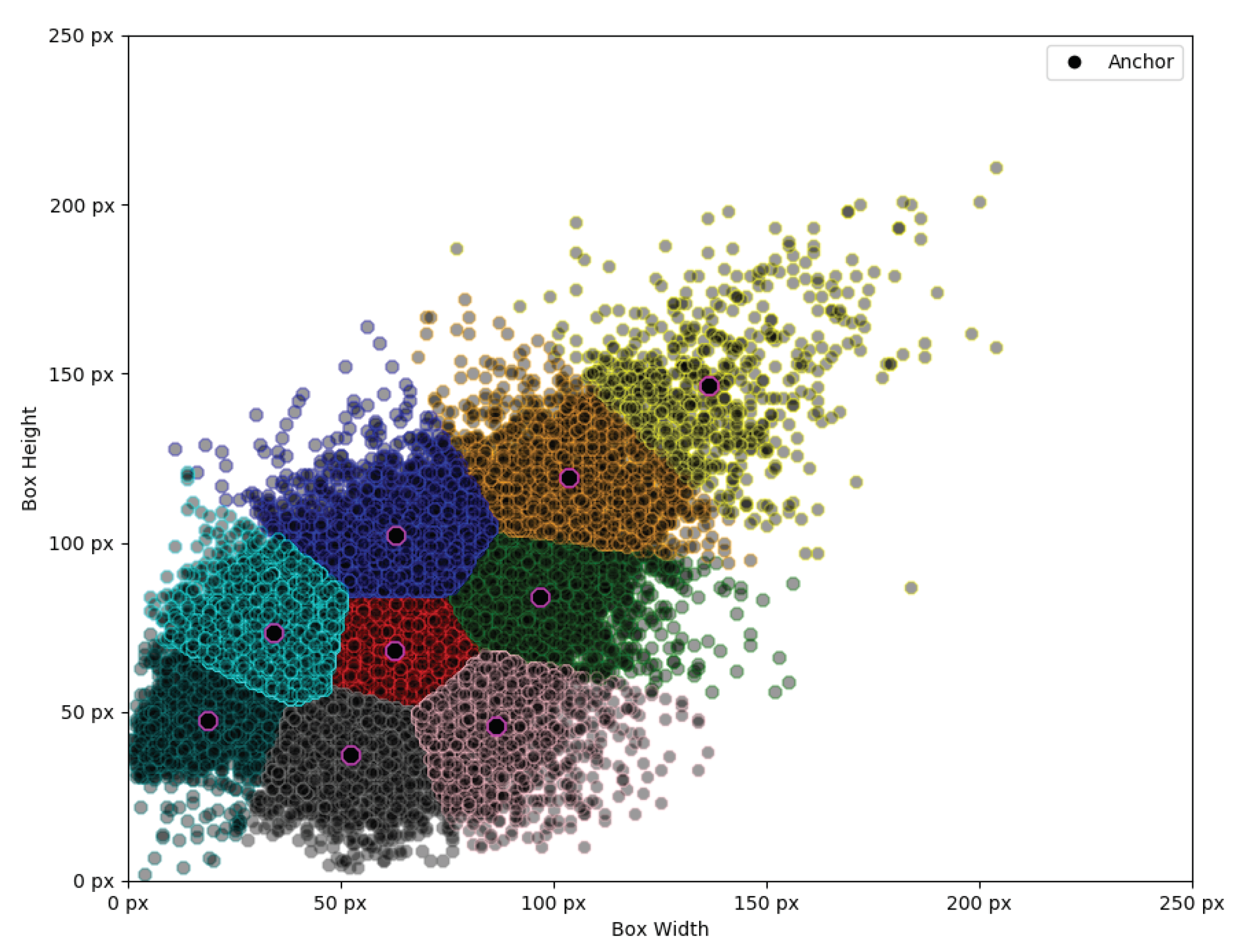
Pascal VOC and other datasets are not suitable for our dataset, rarely fitting into them. Therefore, we performed class data analysis and selected three most fitting anchors per classifier branch scale. As we can see from
Figure 9, our classes generally tend to be biased towards 1:1 aspect ratio due to data set being randomly generated unlike in real world applications.
However, while the classes tend to be biased towards 1:1 for the most part, the assertion that all individual object instances would neatly fit into this aspect ratio would be incorrect as they still retain certain bias. According to previous Single Shot Detection (SSD) research [
63], selecting inadequate base anchor boxes can negatively affect the training process and cause the network to overfit. Therefore, we chose to have 3 anchors per anchor size as this seems to sufficiently cover the entire bounding box scale spread by including tall, wide and rectangle objects. We select the anchor points using
K-Means to split data into 9 distinct groups (
Figure 10).
Once we have our cluster points for bounding box detections, we sort them in order to group into small, medium and large anchor sets. Giving us three different anchors, each having the most popular aspect ratios per that scale detection branch as it can be seen in
Table 3.
The neural network architecture described in
Section 2.2 was trained in three separate modes in order to infer how much the additional depth information improves the classification results. These three modes consist of RGB, RGB-D and Depth training modes. Where RGB mode implies we train using only the color information that was generated from the dataset, the RGB-D mode uses both depth and color information and finally Depth mode trains the network using only depth information. We do not use any additional data augmentation when training in both RGB and RGB-D modes. We do however, add additional augmentation when training in the RGB-D mode. When training in the RGB-D mode there is a small chance that either RGB or Depth channel will not be included in the testing sample. We perform this augmentation because both RGB camera and Depth sensors may potentially have invalid frames. Therefore, we assert that both of these data points are equally necessary for the classification task, and that they must be generalized separately from each other and should provide equal contributions to the classification task. This is decided randomly when preparing the mini-batch to be sent to the artificial neural network for training. There is
chance that the input specific data point will be picked for additional augmentation. If the data point is picked for augmentation then there is equal probability that either RGB or Depth Data will be erased from the input and replaced with zeros. We decided on this augmentation approach because both RGB and Depth frames using real sensors are prone to errors. For example, the RGB camera may fail in bad lighting or even be unavailable when the room is pitch black. Likewise, the depth frames are also prone to errors due to inconsistencies in generating depth map which causes the sensor to create speckling effect in the depth information, additionally cameras being too close to object may be completely unable to extract proper depth information. Therefore, we chose this augmentation approach as it allows for the sensors to work in tandem when both are available, but fill in the gaps, when one of them is failing to provide an accurate information.
2.5.3. Reconstruction Dataset
For the reconstruction training set, we use the same
ShapeNetCore dataset to generate the corresponding depth images and ground truths for the individual objects voxel cloud. We used
Blender to generate the training data. However, the generated input data is different. We assert that the object material does not influence the objects shape, therefore we no longer generate the color map unlike when generating classification data. Therefore, we only render the depth information for each object. We render individual objects by placing the cameras in such a way that the specific object would be visible from all angles from 45° to 90° at a distance from 1 to 1.5 m, excluding the bottom. As a result we have 48 perspectives for each of the object models. Once again we save the models as
OpenEXR file in order to preserve the depth values in this lossless format. Finally, we generate the voxel-cloud representation [
64]. Voxelization is performed by partitioning into the equally sized cells, where the cell size is selected based on the largest object dimension axis. Following the space partitioning, we repeat over each of the cells and compute whether the specific cell should be filled by ray-polygon intersection [
65].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























































