Collaborative Multi-Expert Active Learning for Mobile Health Monitoring: Architecture, Algorithms, and Evaluation


Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- Architecture. We propose a novel architecture designed for multi-expert M-health systems. The key idea is to keep the system’s uncertainty below a pre-specified threshold while minimizing the overall cost of re-training the learning algorithm. The architecture also provides a closed-loop collaboration between experts.
- Formulation. The functionality of the architecture is formulated from a learning prospective and is divided according to the different aspects of the architecture. Firstly, the architecture uses training data from the most similar context in order to initialize the learner of the system (i.e., transfer learning). Secondly, an active learning process manages the source(s) of knowledge for each query.
- Algorithms. Correspondingly, two algorithms are designed to handle the two aspects of the architecture. The first algorithm is proposed to find the most relevant training samples. The second algorithm is a cost-sensitive active learning approach to minimize the overall cost.
- Evaluation. We evaluate the proposed architecture using two different human physical activity datasets as case studies. The first dataset is on daily activities (e.g., walking, sitting), and the second dataset is on workout activities (e.g., running on a treadmill). We show that using the architecture increases accuracy of activity recognition by up to for the daily activities and by up to for sport activities compared to the case where the architecture is not used. We also show that the number of queries from costly experts is reduced by .
2. Background and Related Work
2.1. Active Learning
2.2. Transfer Learning
3. Scenarios Driving Reconfiguration
3.1. Configuration Change
3.2. Context Change
3.3. User Need Change
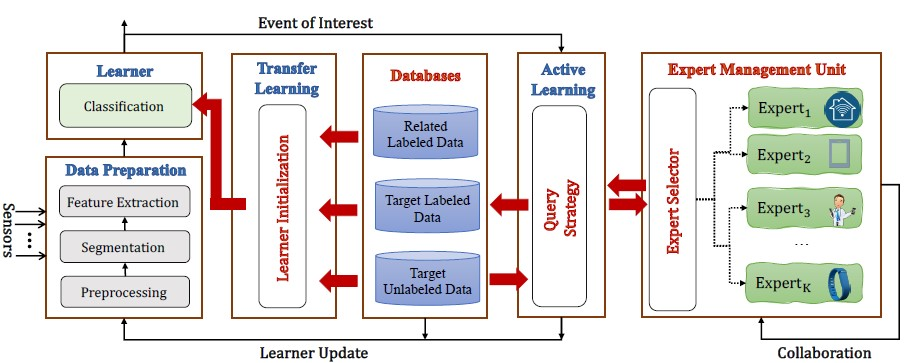
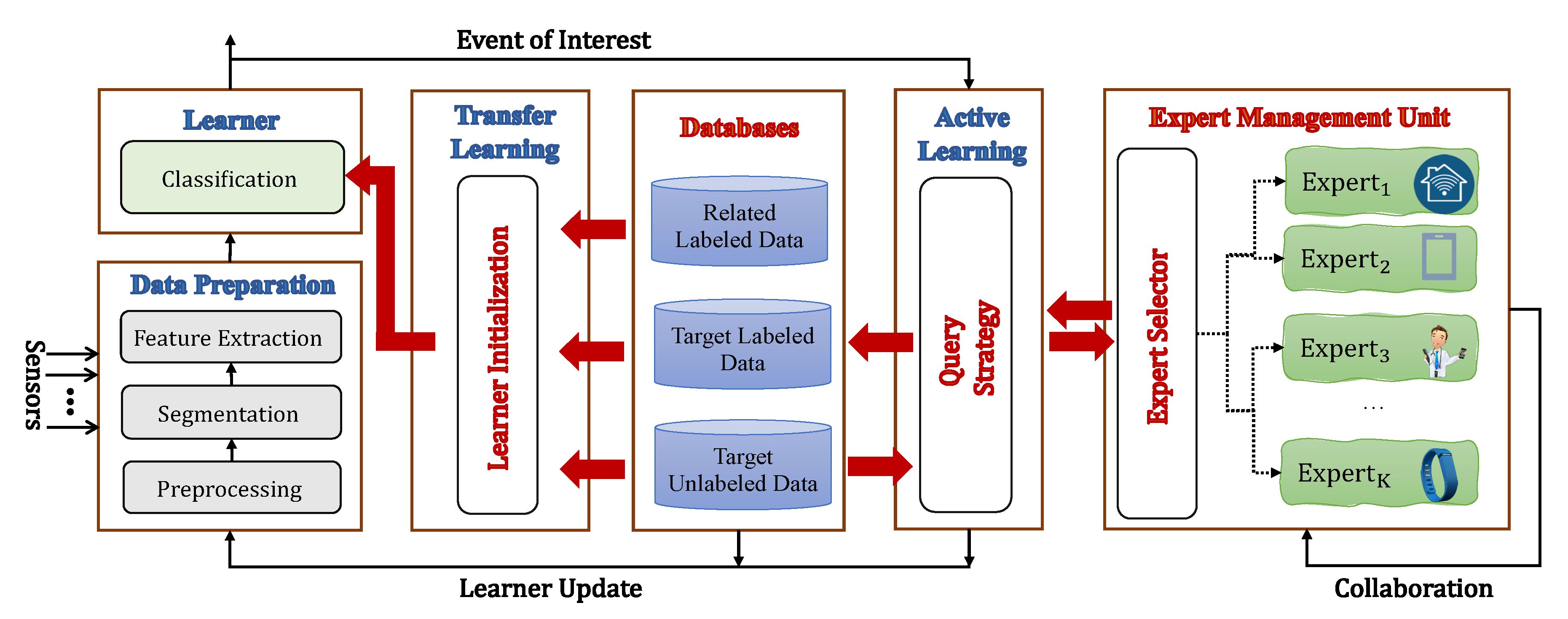
4. The Co-Meal Architecture
4.1. Learner Initialization
4.2. Query Strategy
4.3. The Databases (Dictionaries)
4.4. The Expert Management Unit
- The learning process relies on the collective intelligence of a group of experts.
- The architecture could also provide a learning opportunity for experts. In particular, our system allows for each expert to update their knowledge based on the feedback from other experts in each round of query.
- The expert selection submodule chooses the expert(s) in such a way that the query cost is minimized, while keeping the provided label for the queried instance accurate.
- The architecture leverages different points of view from the experts to provide a more comprehensive model through the system’s life time. For example, new class labels may arise during the life time, or a new sensor may be integrated into the mobile health system.
- An expert can be part of the data processing unit. For example, in a multi-node mobile system, one node shares the label with the DPU whenever the node is confident.
5. Problem Statement
6. Algorithms
6.1. Driver Algorithm: Collaborative Active Learning
| Algorithm 1 CAL-D |
| Input:, , , , K, , E Output: L
|
6.2. Learner Initialization: Transfer Learning
| Algorithm 2 IL |
| Input:, , Output:
|
6.3. Expert Management: Active Learning
- Perfect Expert: A perfect expert supplies correct labels for every query, but the cost of data labeling is high. Our goal is to minimize the number of queries from such experts. An experienced physician, a multi-sensor smart health facility center, a supervised data collection system are all examples of perfect experts.
- Imperfect Expert: An imperfect expert provides labels for each query, but the validity of a label is questionable. In other words, the expert is knowledgeable in only part of the data distribution and it may provide incorrect labels. Examples of imperfect experts are inexperienced doctors, the user, and sensory systems with limited capabilities (e.g., limited number of sensors). The cost of labeling by an imperfect expert is lower, but still we need to minimize the number of queries from such experts.
- On-demand Expert: An on-demand expert, in contrast to the other types of experts, provides labels with little or zero cost. However, their knowledge is limited (e.g., a subset of label set L) and they may not be able to reply to every query. Other wearable sensors with different configurations are examples of on-demand experts.
| Algorithm 3 A |
| Input:x, E, semi-label , Output: label ℓ
|
6.4. Variants on the Driver Algorithm
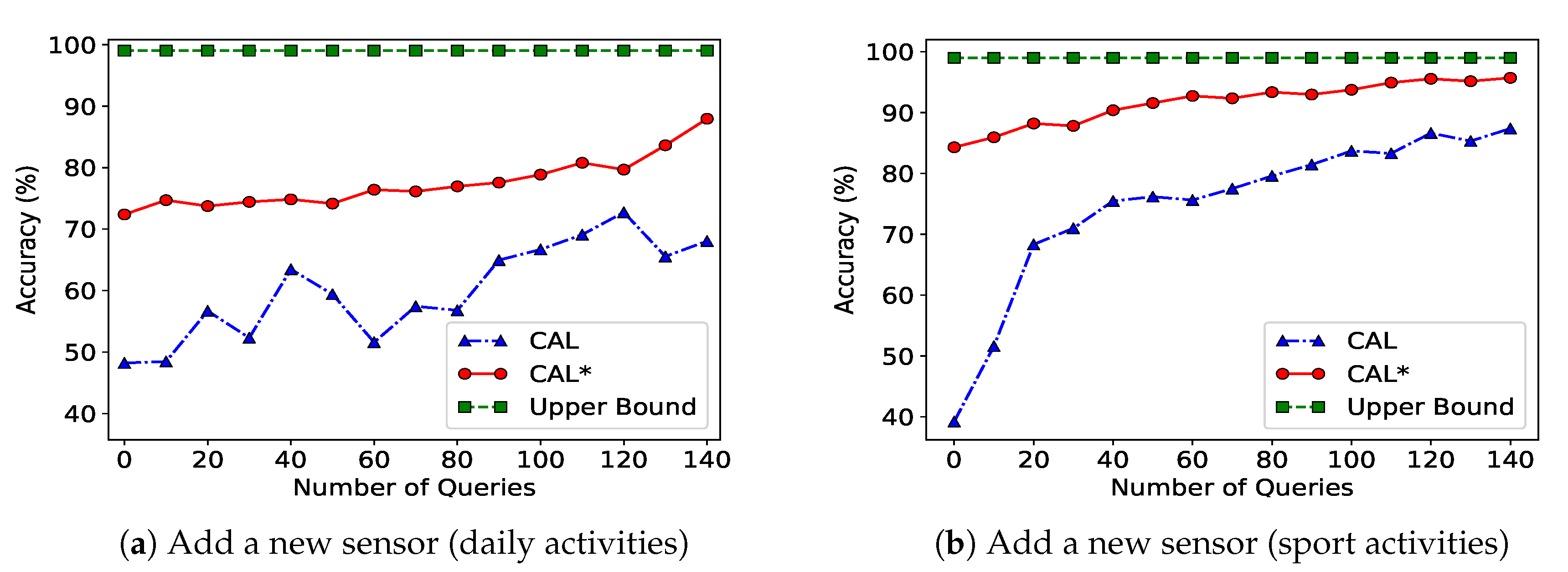
- CAL corresponds to the “normal” operation of the Co-MEAL architecture with both transfer learning and collaboration, but with no prior knowledge available. This is a variant of Algorithm 1 in which lines 2–6 are excluded.
- CAL* corresponds to the case where learner(s) have been in the system with less knowledge and the active learning phase is used to upgrade the system with changes such as adding a new sensor or new labels. CAL* is variant of Algorithm 1 in which the lines 2–6 are included.
- NCAL corresponds to the operation of the Co-MEAL architecture with transfer learning and without collaboration. NCAL is simply a variant of Algorithm 1 in which the lines 15 and 16 corresponding to collaboration between experts are excluded.
7. Experimental Setting
7.1. Datasets
7.2. Data Processing
7.3. Setting of Experts
- Perfect Expert. We used the ground truth label as the least uncertain (most confident) expert in the expert management unit. In a real-world scenario, this expert can be a highly confident physician or the user in the monitoring system. To be more realistic, we also allow for the possibility of error made by a perfect expert. We set the probability of error between to depending on the difficulty of detecting the specific label.
- Imperfect Expert. We model an imperfect expert using the sensors from other locations (as opposed to the learner’s location). However, in order to generate imperfect experts, we partly use the expert initialization data. For example, we only use of the expert initialization data for each label. If we need to decrease the uncertainty of an imperfect expert, we add more labeled data to build its classifier. We estimate the uncertainty score vector for each expert based on their prediction error on the evaluation data. We assume that, in real world scenarios, an expert is aware of its own knowledge.
- On-demand Expert. Each on-demand expert is trained in such a way that it is only confident over a subset of the label set . To simulate an on-demand expert, we use all the expert initialization data for to train the classifier, and a few instances for other labels.
8. Experimental Evaluation
8.1. Performance Evaluation Scenarios
8.1.1. Context Change (New Subject)
8.1.2. Configuration Change (Sensor Addition)
8.1.3. User Need Change (New Activity)
8.2. Query Cost Evaluation
8.2.1. Uncertainty Threshold, Imperfect Experts
8.2.2. Number of On-Demand Experts
8.2.3. Benefits of Collaborative Active Learning
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kay, M.; Santos, J.; Takane, M. mHealth: New horizons for health through mobile technologies. World Health Organ. 2011, 3, 66–71. [Google Scholar]
- Mosa, A.S.M.; Yoo, I.; Sheets, L. A systematic review of healthcare applications for smartphones. BMC Med. Inf. Decis. Mak. 2012, 12, 67. [Google Scholar] [CrossRef] [PubMed]
- Adams, Z.W.; McClure, E.A.; Gray, K.M.; Danielson, C.K.; Treiber, F.A.; Ruggiero, K.J. Mobile devices for the remote acquisition of physiological and behavioral biomarkers in psychiatric clinical research. J. Psychiatr. Res. 2017, 85, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Qiu, M.; Tsai, C.W.; Hassan, M.M.; Alamri, A. Health-CPS: Healthcare cyber-physical system assisted by cloud and big data. IEEE Syst. J. 2017, 11, 88–95. [Google Scholar] [CrossRef]
- Yoon, J.G.; Zarayeneh, N.; Suh, S.C. Interrelationship between the general characteristics of Korean stroke patients and the variables of the sexual functions: random forest and boosting algorithm. J. Phys. Ther. Sci. 2017, 29, 613–617. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Free, C.; Phillips, G.; Watson, L.; Galli, L.; Felix, L.; Edwards, P.; Patel, V.; Haines, A. The effectiveness of mobile-health technologies to improve health care service delivery processes: A systematic review and meta-analysis. PLoS Med. 2013, 10, e1001363. [Google Scholar] [CrossRef]
- Hayes, D.F.; Markus, H.S.; Leslie, R.D.; Topol, E.J. Personalized medicine: risk prediction, targeted therapies and mobile health technology. BMC Med. 2014, 12, 37. [Google Scholar] [CrossRef]
- Shahrokni, A.; Mahmoudzadeh, S.; Saeedi, R.; Ghasemzadeh, H. Older people with access to hand-held devices: Who are they? Telemed. e-Health 2015, 21, 550–556. [Google Scholar] [CrossRef]
- Marcelli, E.; Capucci, A.; Minardi, G.; Cercenelli, L. Multi-Sense CardioPatch: A Wearable Patch for Remote Monitoring of Electro-Mechanical Cardiac Activity. Asaio J. 2017, 63, 73–79. [Google Scholar] [CrossRef]
- Eggers, P.E.; Eggers, E.A.; Bailey, B.Z. Wearable Apparatus, System and Method for Detection of Cardiac Arrest and Alerting Emergency Response. US Patent 20,160,174,857, 23 June 2016. [Google Scholar]
- Birjandtalab, J.; Pouyan, M.B.; Cogan, D.; Nourani, M.; Harvey, J. Automated seizure detection using limited-channel EEG and non-linear dimension reduction. Comput. Biol. Med. 2017, 82, 49–58. [Google Scholar] [CrossRef]
- Zakim, D.; Schwab, M. Data collection as a barrier to personalized medicine. Trends Pharmacol. Sci. 2015, 36, 68–71. [Google Scholar] [CrossRef] [PubMed]
- Fallahzadeh, R.; Pedram, M.; Saeedi, R.; Sadeghi, B.; Ong, M.; Ghasemzadeh, H. Smart-cuff: A wearable bio-sensing platform with activity-sensitive information quality assessment for monitoring ankle edema. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), St. Louis, MI, USA, 23–27 March 2015; pp. 57–62. [Google Scholar]
- Di Tore, P.A. Situation awareness and complexity: The role of wearable technologies in sports science. J. Human Sport Exerc. 2015, 10, 500–506. [Google Scholar] [CrossRef]
- Lomasky, R.; Brodley, C.E.; Aernecke, M.; Walt, D.; Friedl, M. Active class selection. In European Conference on Machine Learning; Springer: New York, NY, USA, 2007; pp. 640–647. [Google Scholar]
- Settles, B.; Craven, M.; Friedland, L. Active learning with real annotation costs. In Proceedings of the NIPS Workshop on Cost-Sensitive Learning, Vancouver, BC, Canada, 13 December 2008; pp. 1–10. [Google Scholar]
- Sagha, H.; Millán, J.d.R.; Chavarriaga, R. A probabilistic approach to handle missing data for multi-sensory activity recognition. In Proceedings of theWorkshop on Context Awareness and Information Processing in Opportunistic Ubiquitous Systems at 12th ACM International Conference on Ubiquitous Computing, Copenhagen, Denmark, 26–29 September 2010. number EPFL-CONF-151974. [Google Scholar]
- Fallahzadeh, R.; Ghasemzadeh, H. Personalization without User Interruption: Boosting Activity Recognition in New Subjects Using Unlabeled Data (An Uninformed Cross-Subject Transfer Learning Algorithm). In Proceedings of the International Conference on Cyber-Physical Systems (ICCPS), Pittsburgh, PA, USA, 18–21 April 2017; pp. 293–302. [Google Scholar]
- Zheng, V.W.; Hu, D.H.; Yang, Q. Cross-domain activity recognition. In Proceedings of the 11th International Conference on Ubiquitous Computing, Orlando, FL, USA, 12–16 September 2009; pp. 61–70. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Computer Science Technical Report 1648; University of Wisconsin: Madison, WI, USA, 2010; p. 67. [Google Scholar]
- Chu, W.; Zinkevich, M.; Li, L.; Thomas, A.; Tseng, B. Unbiased online active learning in data streams. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 22–27 August 2011; pp. 195–203. [Google Scholar]
- Wang, B.; Tsotsos, J. Dynamic label propagation for semi-supervised multi-class multi-label classification. Pattern Recognit. 2016, 52, 75–84. [Google Scholar] [CrossRef]
- Doukas, C.; Maglogiannis, I. Bringing IoT and cloud computing towards pervasive healthcare. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Palermo, Italy, 4–6 July 2012; pp. 922–926. [Google Scholar]
- Kumar, S.; Nilsen, W.; Pavel, M.; Srivastava, M. Mobile health: Revolutionizing healthcare through transdisciplinary research. Computer 2013, 46, 28–35. [Google Scholar] [CrossRef]
- Gatouillat, A.; Badr, Y.; Massot, B.; Sejdić, E. Internet of medical things: A review of recent contributions dealing with cyber-physical systems in medicine. IEEE Int. Things J. 2018, 5, 3810–3822. [Google Scholar] [CrossRef]
- Saeedi, R.; Sasani, K.; Gebremedhin, A.H. Co-MEAL: Cost-Optimal Multi-Expert Active Learning Architecture for Mobile Health Monitoring. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Boston, MA, USA, 20–23 August 2017; pp. 432–441. [Google Scholar]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Gadde, A.; Anis, A.; Ortega, A. Active semi-supervised learning using sampling theory for graph signals. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 492–501. [Google Scholar]
- Yang, Y.; Ma, Z.; Nie, F.; Chang, X.; Hauptmann, A.G. Multi-class active learning by uncertainty sampling with diversity maximization. Int. J. Comput. Vis. 2015, 113, 113–127. [Google Scholar] [CrossRef]
- Longstaff, B.; Reddy, S.; Estrin, D. Improving activity classification for health applications on mobile devices using active and semi-supervised learning. In Proceedings of the 2010 4th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Munchen, Germany, 22–25 March 2010; pp. 1–7. [Google Scholar]
- Rey, V.F.; Lukowicz, P. Label Propagation: An Unsupervised Similarity Based Method for Integrating New Sensors in Activity Recognition Systems. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 94. [Google Scholar] [CrossRef]
- Bagaveyev, S.; Cook, D.J. Designing and evaluating active learning methods for activity recognition. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; pp. 469–478. [Google Scholar]
- Hoque, E.; Stankovic, J. AALO: Activity recognition in smart homes using Active Learning in the presence of Overlapped activities. In Proceedings of the 2012 6th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), San Diego, CA, USA, 21–24 May 2012; pp. 139–146. [Google Scholar]
- Donmez, P.; Carbonell, J.G. Proactive learning: cost-sensitive active learning with multiple imperfect oracles. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 619–628. [Google Scholar]
- Arora, S.; Nyberg, E.; Rosé, C.P. Estimating annotation cost for active learning in a multi-annotator environment. In Proceedings of the NAACL HLT 2009 Workshop on Active Learning for Natural Language Processing. Association for Computational Linguistics, Boulder, CO, USA, 5 June 2009; pp. 18–26. [Google Scholar]
- Gorriz, M.; Carlier, A.; Faure, E.; Giro-i Nieto, X. Cost-Effective Active Learning for Melanoma Segmentation. arXiv 2017, arXiv:1711.09168. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef]
- Saeedi, R.; Ghasemzadeh, H.; Gebremedhin, A.H. Transfer learning algorithms for autonomous reconfiguration of wearable systems. In Proceedings of the 2016 IEEE International Conference on Big Data, Washington DC, USA, 5–8 December 2016; pp. 563–569. [Google Scholar]
- Saeedi, R.; Gebremedhin, A. A Signal-Level Transfer Learning Framework for Autonomous Reconfiguration of Wearable Systems. IEEE Trans. Mob. Comput. 2018. [Google Scholar] [CrossRef]
- Rokni, S.A.; Ghasemzadeh, H. Plug-n-learn: Automatic learning of computational algorithms in human-centered internet-of-things applications. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; p. 139. [Google Scholar]
- Jiang, J. A Literature Survey on Domain Adaptation of Statistical Classifiers. 2008. Available online: http://sifaka.cs.uiuc.edu/jiang4/domainadaptation/survey (accessed on 30 March 2020).
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. Handb. Res. Mach. Learn. Appl. Trends: Algorithm. Methods Tech. 2009, 1, 242. [Google Scholar]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. inf. syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed]
- Dillon Feuz, K.; Cook, D.J. Heterogeneous transfer learning for activity recognition using heuristic search techniques. Int. J. Pervasive Comput. Commun. 2014, 10, 393–418. [Google Scholar] [CrossRef]
- Rokni, S.A.; Ghasemzadeh, H. Synchronous dynamic view learning: A framework for autonomous training of activity recognition models using wearable sensors. In Proceedings of the 16th ACM/IEEE International Conference on Information Processing in Sensor Networks; Association for Computing Machinery: New York, NY, USA, 2017; pp. 79–90. [Google Scholar]
- Calma, A.; Leimeister, J.M.; Lukowicz, P.; Oeste-Reiß, S.; Reitmaier, T.; Schmidt, A.; Sick, B.; Stumme, G.; Zweig, K.A. From active learning to dedicated collaborative interactive learning. In Proceedings of the ARCS 2016, Nuremberg, Germany, 4–7 April 2016; pp. 1–8. [Google Scholar]
- Zhang, Z.; Poslad, S. Improved use of foot force sensors and mobile phone GPS for mobility activity recognition. IEEE Sens. J. 2014, 14, 4340–4347. [Google Scholar] [CrossRef]
- Saeedi, R.; Amini, N.; Ghasemzadeh, H. Patient-centric on-body sensor localization in smart health systems. In Proceedings of the 2014 48th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 2–5 November 2014; pp. 2081–2085. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: an investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–18 March 2016; pp. 1–9. [Google Scholar]
- Chen, Y.; Shen, C. Performance Analysis of Smartphone-Sensor Behavior for Human Activity Recognition. IEEE Access 2017, 5, 3095–3110. [Google Scholar] [CrossRef]
- Barshan, B.; Yüksek, M.C. Recognizing daily and sports activities in two open source machine learning environments using body-worn sensor units. Comput. J. 2013, 57, 1649–1667. [Google Scholar] [CrossRef]
- Ghasemzadeh, H.; Guenterberg, E.; Jafari, R. Energy-Efficient Information-Driven Coverage for Physical Movement Monitoring in Body Sensor Networks. IEEE J. Sel. Areas Commun. 2009, 27, 58–69. [Google Scholar] [CrossRef]
- Ghasemzadeh, H.; Ostadabbas, S.; Guenterberg, E.; Pantelopoulos, A. Wireless medical-embedded systems: A review of signal-processing techniques for classification. IEEE Sens. J. 2013, 13, 423–437. [Google Scholar] [CrossRef]
- Zappi, P.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Troster, G. Activity recognition from on-body sensors by classifier fusion: sensor scalability and robustness. In Proceedings of the 3rd International Conference on Intelligent Sensors, Sensor Networks and Information, Melbourne, Australia, 3–6 December 2007; pp. 281–286. [Google Scholar]










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeedi, R.; Sasani, K.; Gebremedhin, A.H. Collaborative Multi-Expert Active Learning for Mobile Health Monitoring: Architecture, Algorithms, and Evaluation. Sensors 2020, 20, 1932. https://doi.org/10.3390/s20071932
Saeedi R, Sasani K, Gebremedhin AH. Collaborative Multi-Expert Active Learning for Mobile Health Monitoring: Architecture, Algorithms, and Evaluation. Sensors. 2020; 20(7):1932. https://doi.org/10.3390/s20071932
Chicago/Turabian StyleSaeedi, Ramyar, Keyvan Sasani, and Assefaw H. Gebremedhin. 2020. "Collaborative Multi-Expert Active Learning for Mobile Health Monitoring: Architecture, Algorithms, and Evaluation" Sensors 20, no. 7: 1932. https://doi.org/10.3390/s20071932
APA StyleSaeedi, R., Sasani, K., & Gebremedhin, A. H. (2020). Collaborative Multi-Expert Active Learning for Mobile Health Monitoring: Architecture, Algorithms, and Evaluation. Sensors, 20(7), 1932. https://doi.org/10.3390/s20071932