A Multi-Scale U-Shaped Convolution Auto-Encoder Based on Pyramid Pooling Module for Object Recognition in Synthetic Aperture Radar Images


Abstract
1. Introduction
- (1)
- Most of these models learn representations at a large single scale with the hierarchical structure. However, without using local and detailed discriminative information at multiple scales, the classification performance of the features learned by these methods is limited;
- (2)
- Most of the models are optimized according to the minimum reconstruction deviation criterion, importing useless information of speckle in the learned feature and diluting the discriminative features that could benefit classification and ATR tasks;
- (3)
- Small incomplete training benchmarks in SAR ATR limit the application of complicated and deeper DL model due to the large number of trainable parameters and overfitting arising therefrom.
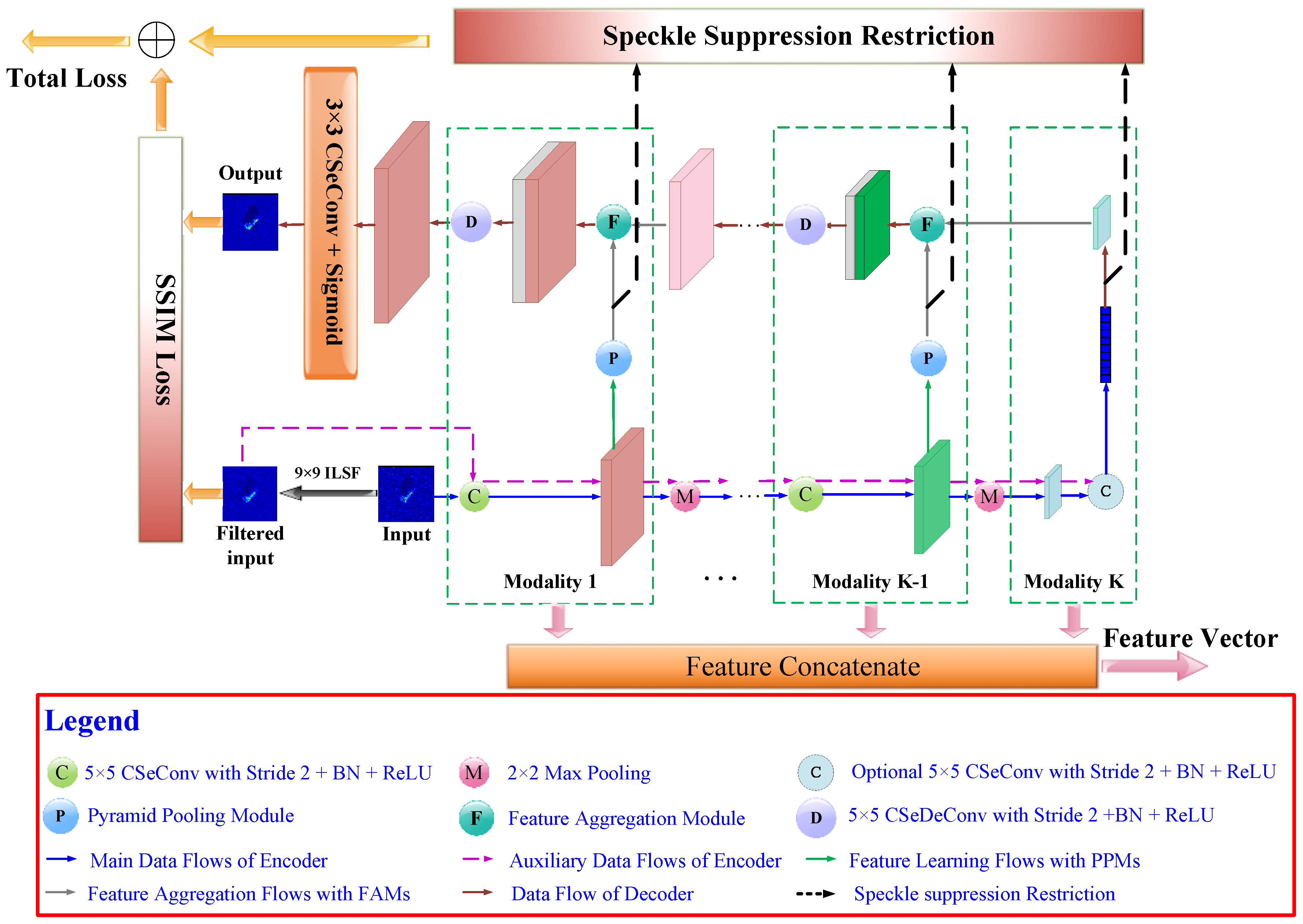
2. The Multi-Scale Convolution Auto-Encoder
2.1. Overall Structure of the MSCAE
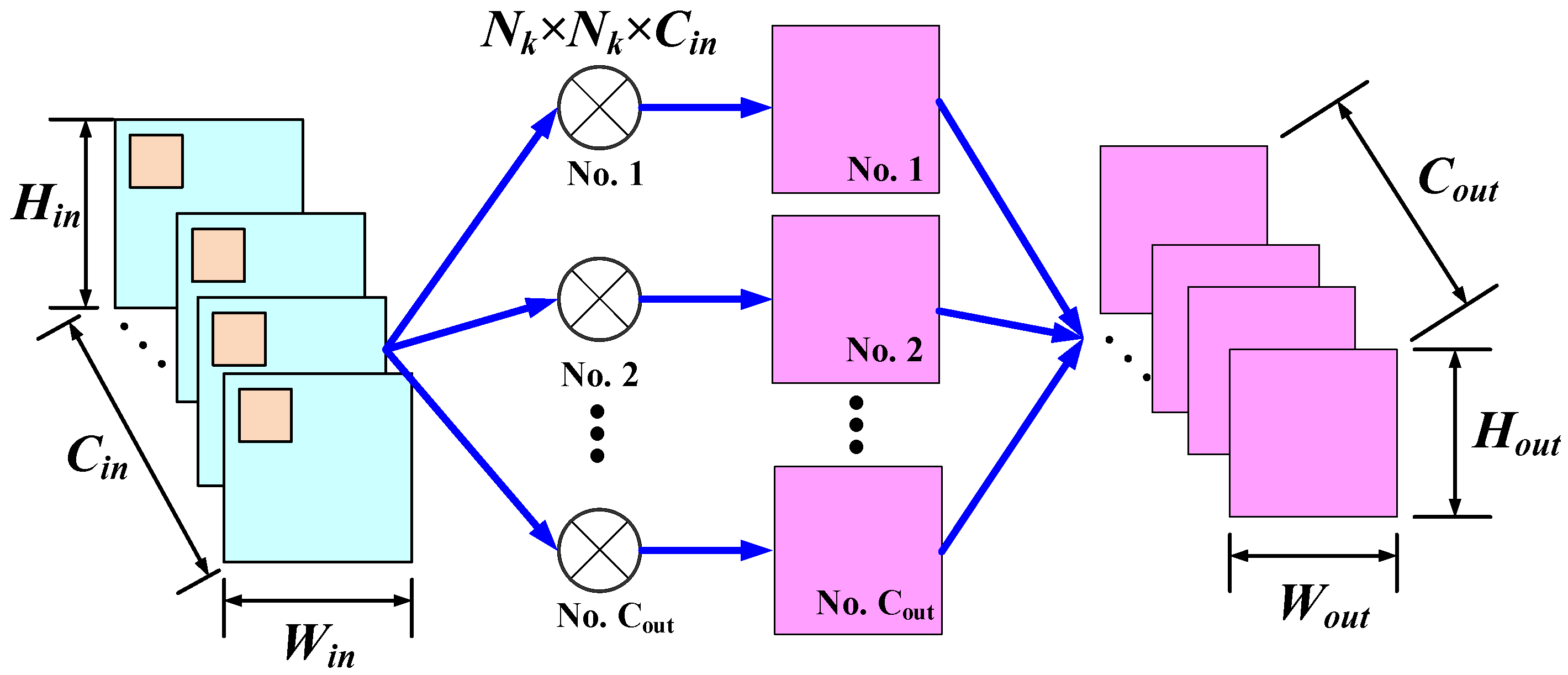
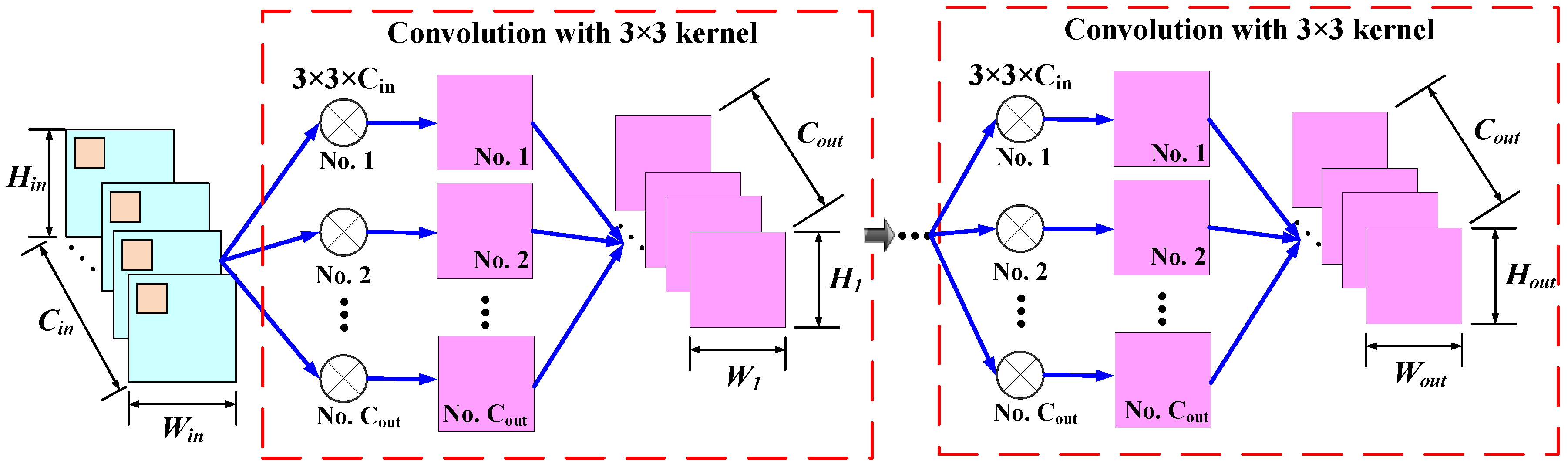
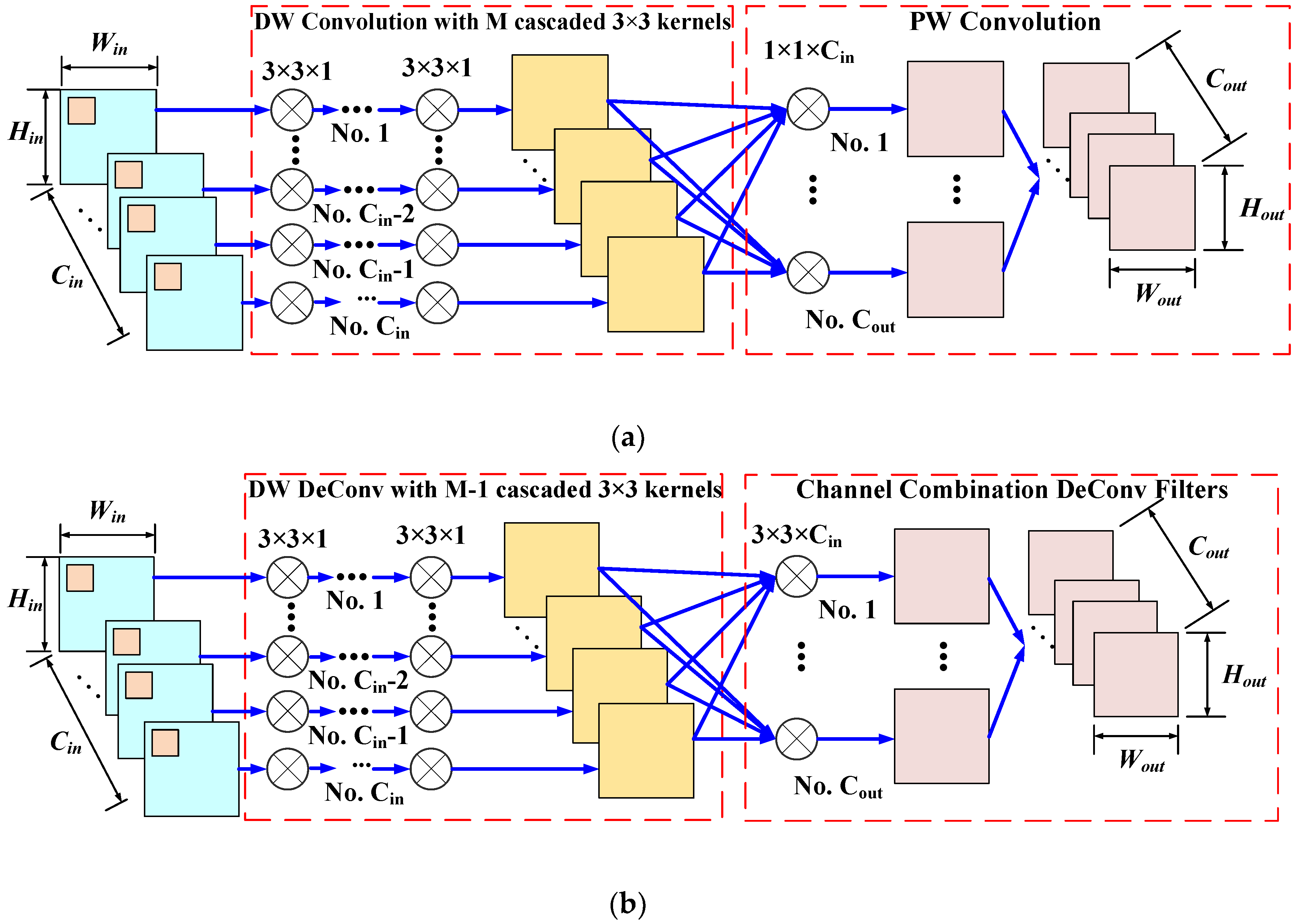
2.2. Compact Depth-Wise Separable Convolution and the Corresponding Deconvolution
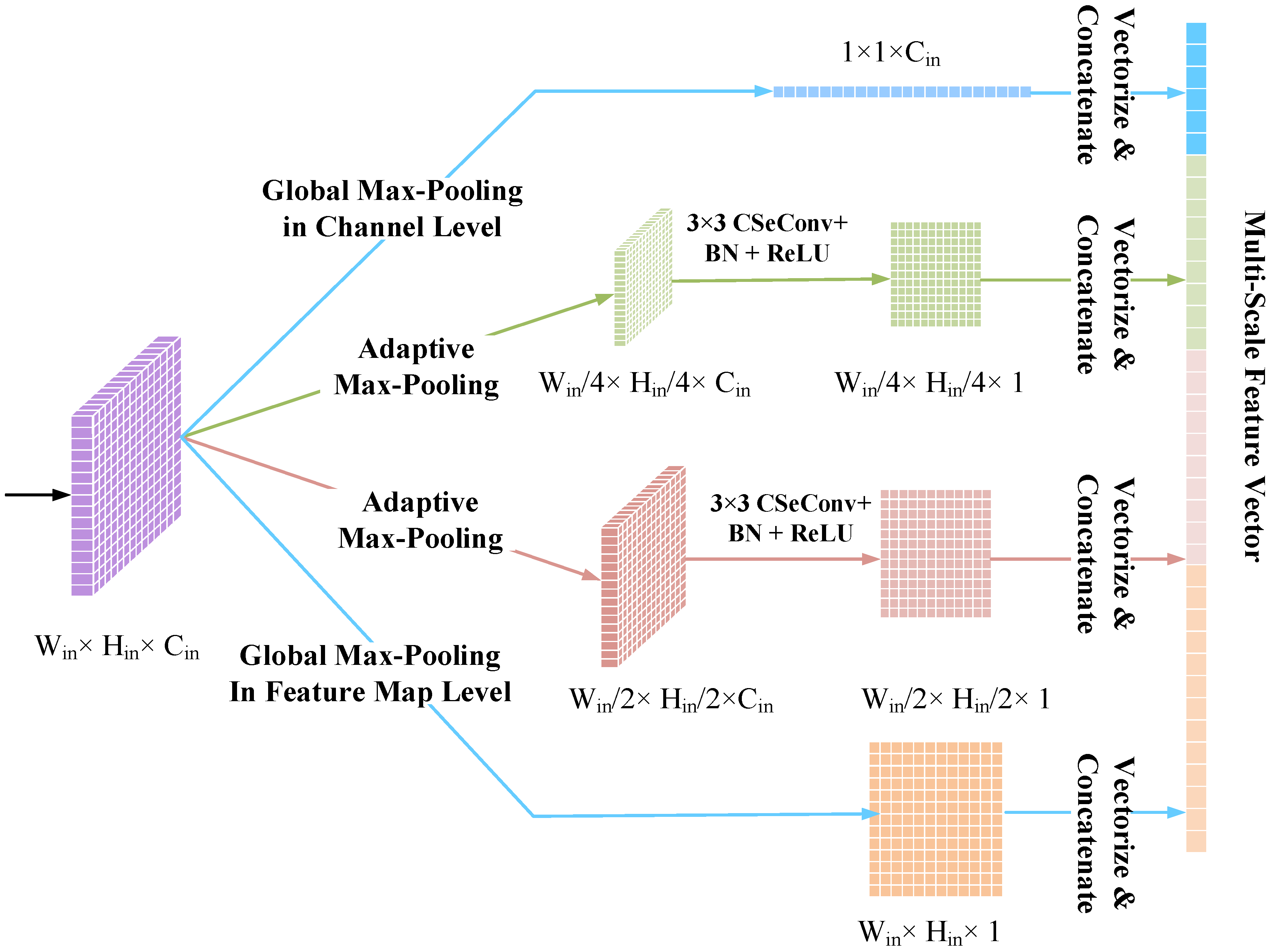
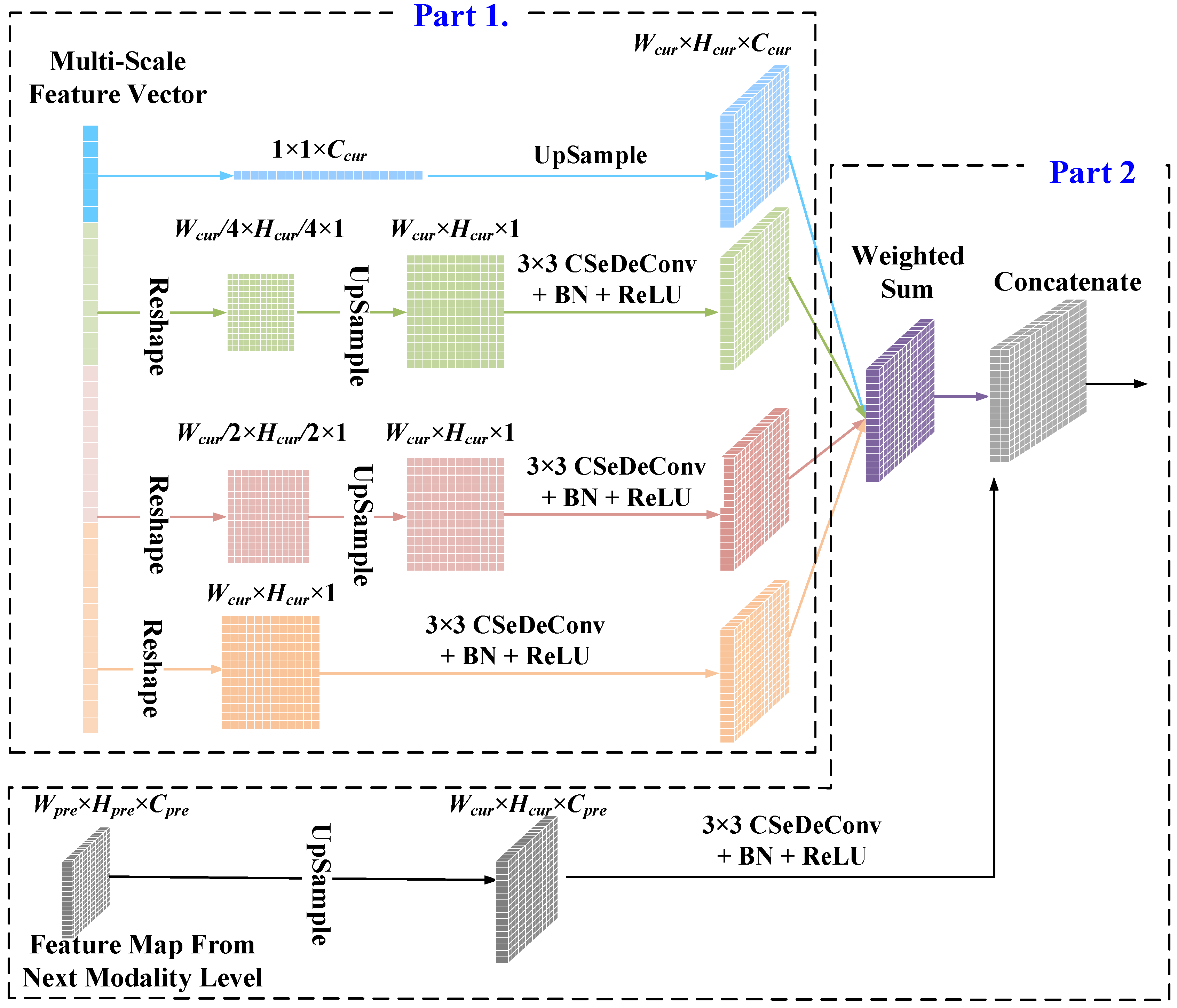
2.3. Multi-Scale Representation Learning with Pyramid Pooling Module and Feature Aggregation Module
2.3.1. Pyramid Pooling Module for Multi-Scale Feature Extraction
2.3.2. Feature Aggregation Module (FAM) for Feature Map Reconstruction
2.4. Loss Function Based on the Modified Reconstruction Loss and Speckle Filtering Restriction
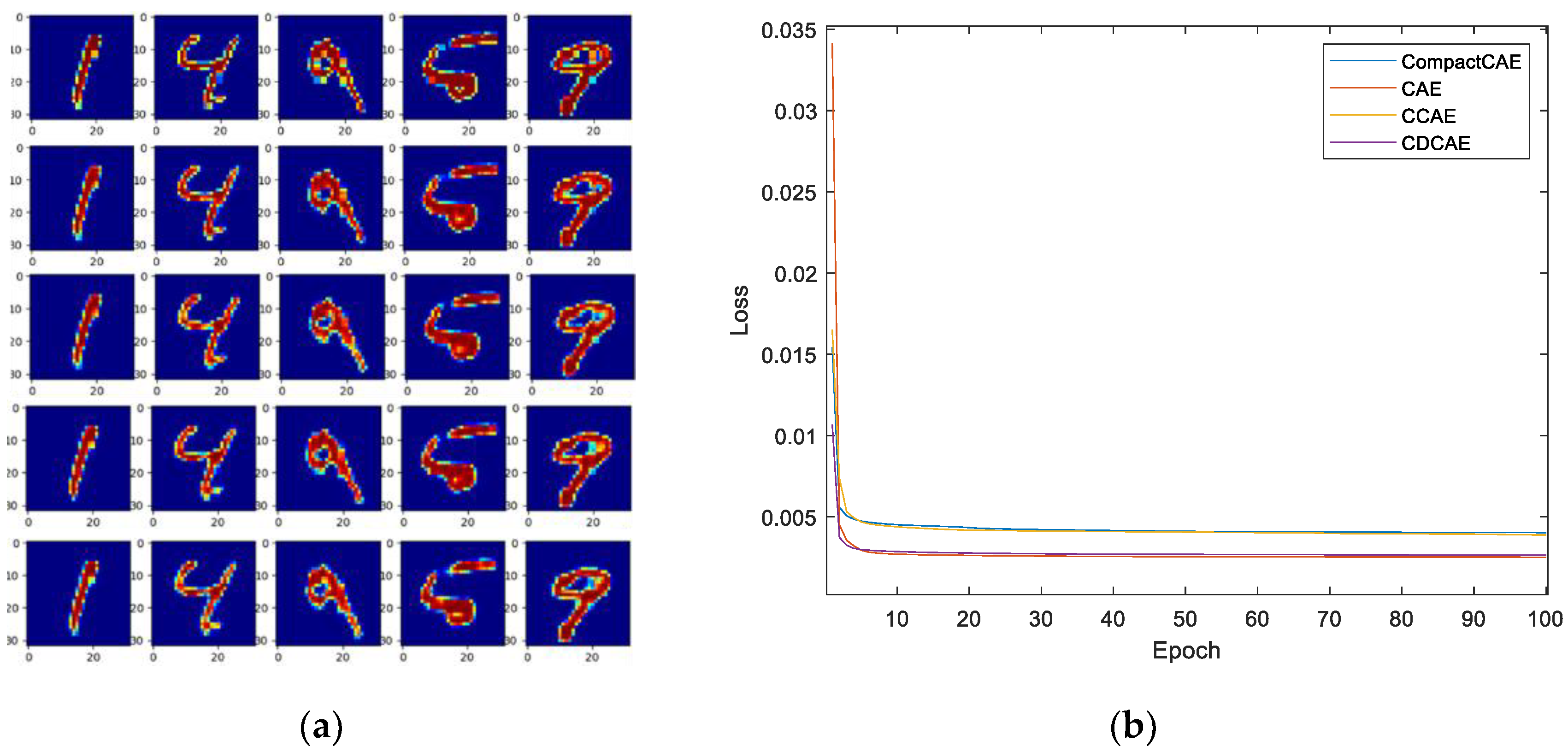
3. Experiments and Discussion
3.1. Experimental Data Sets
3.2. Experiment Configuration
3.2.1. Data Preprocessing
3.2.2. Model Configuration and Experiment Design
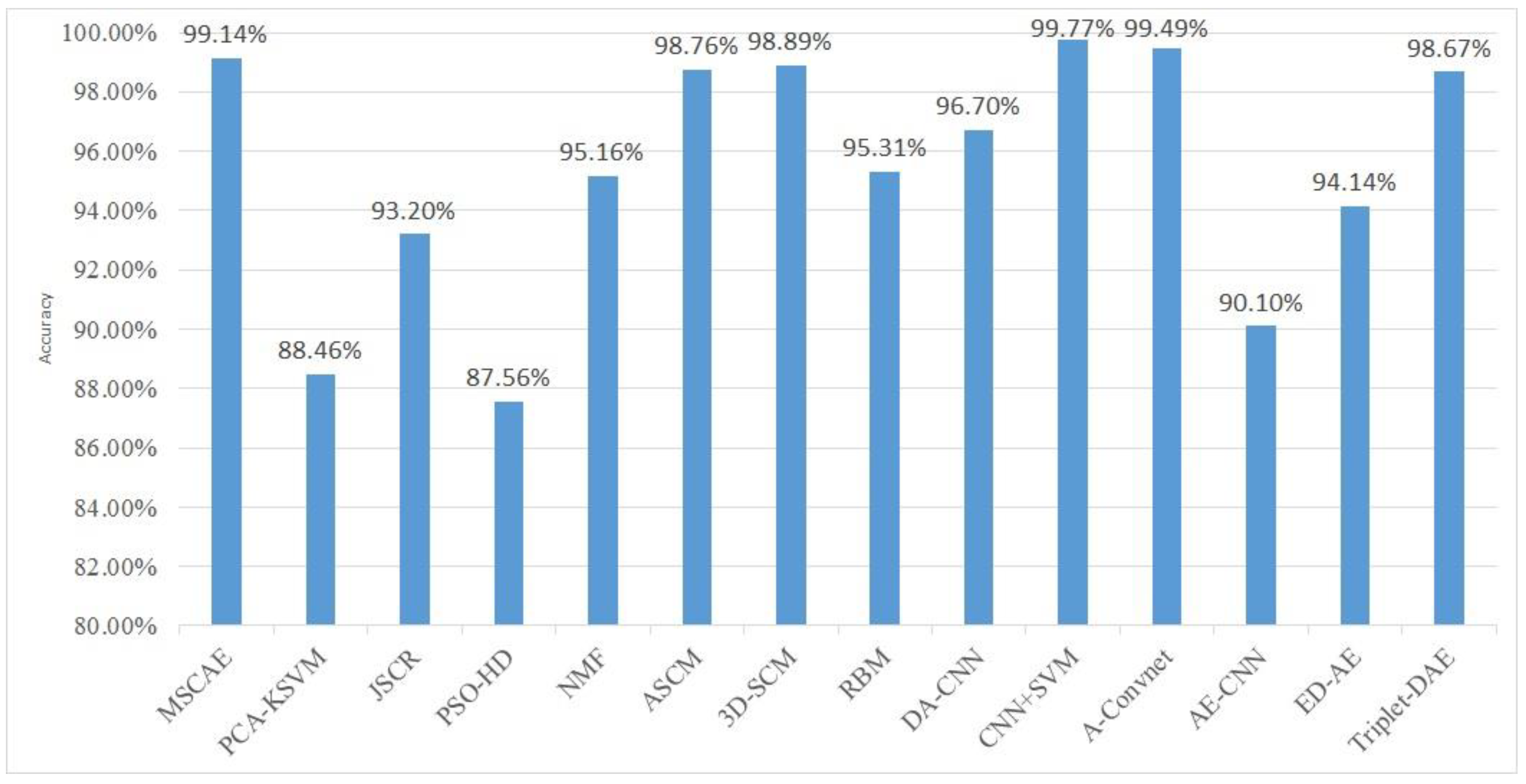
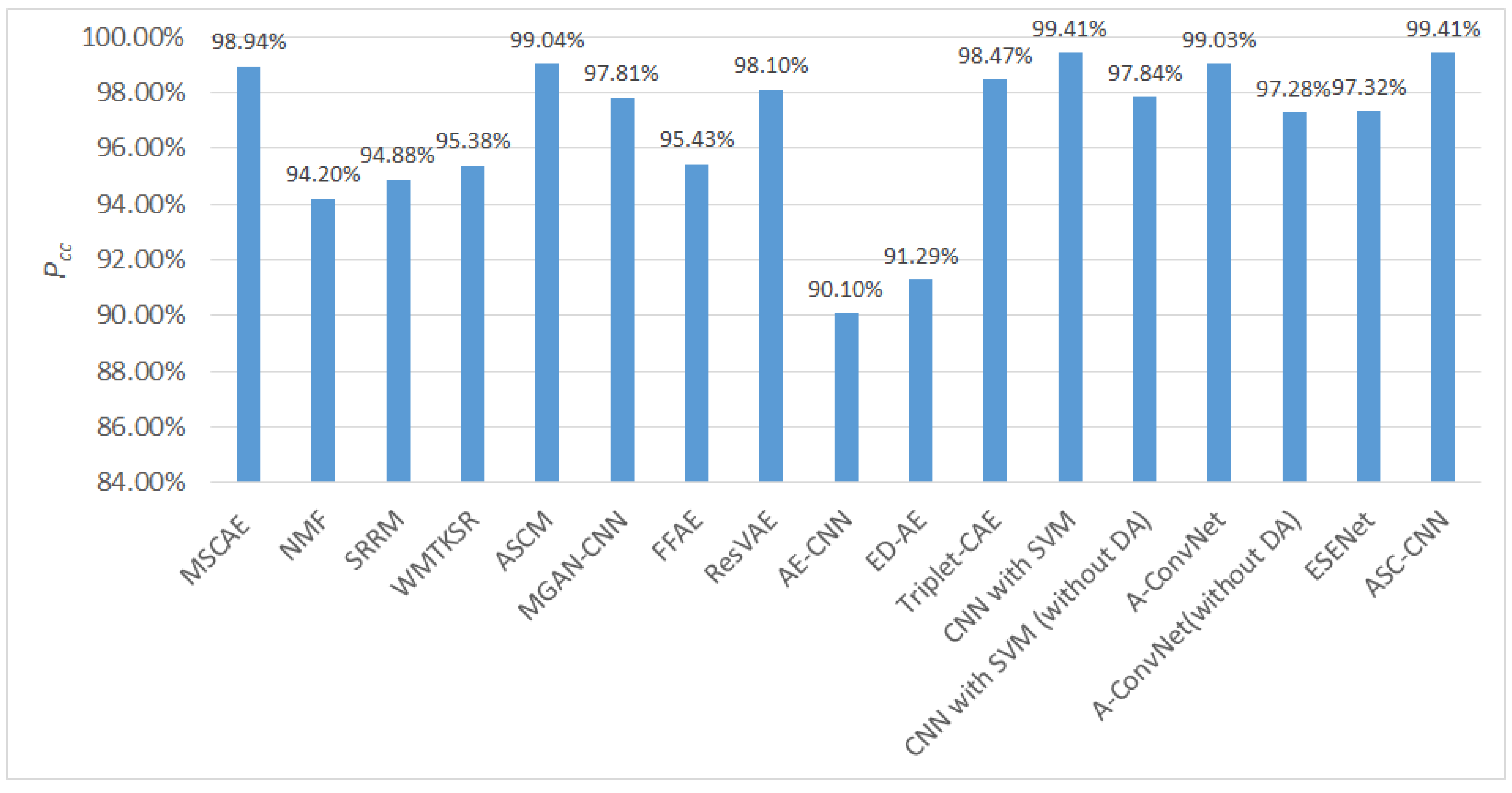
3.3. Evaluation on Three-target Classification
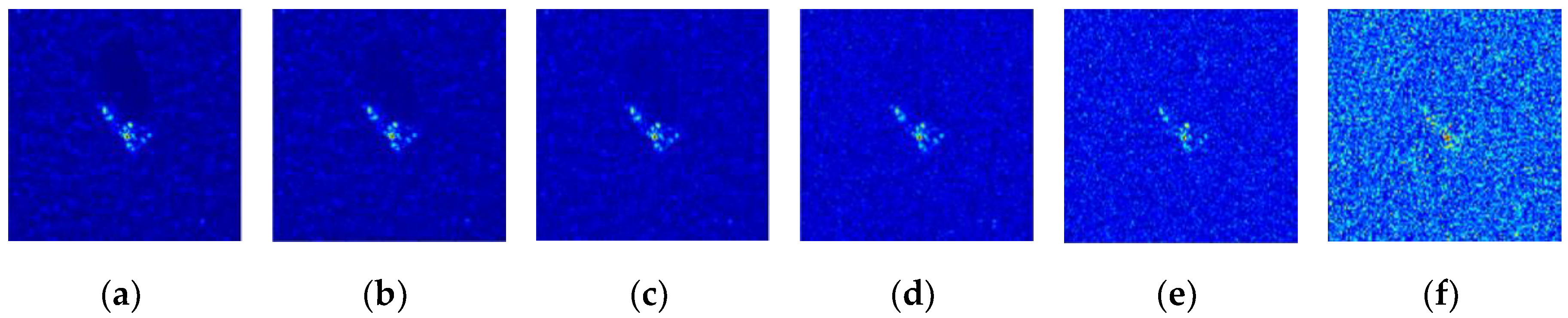
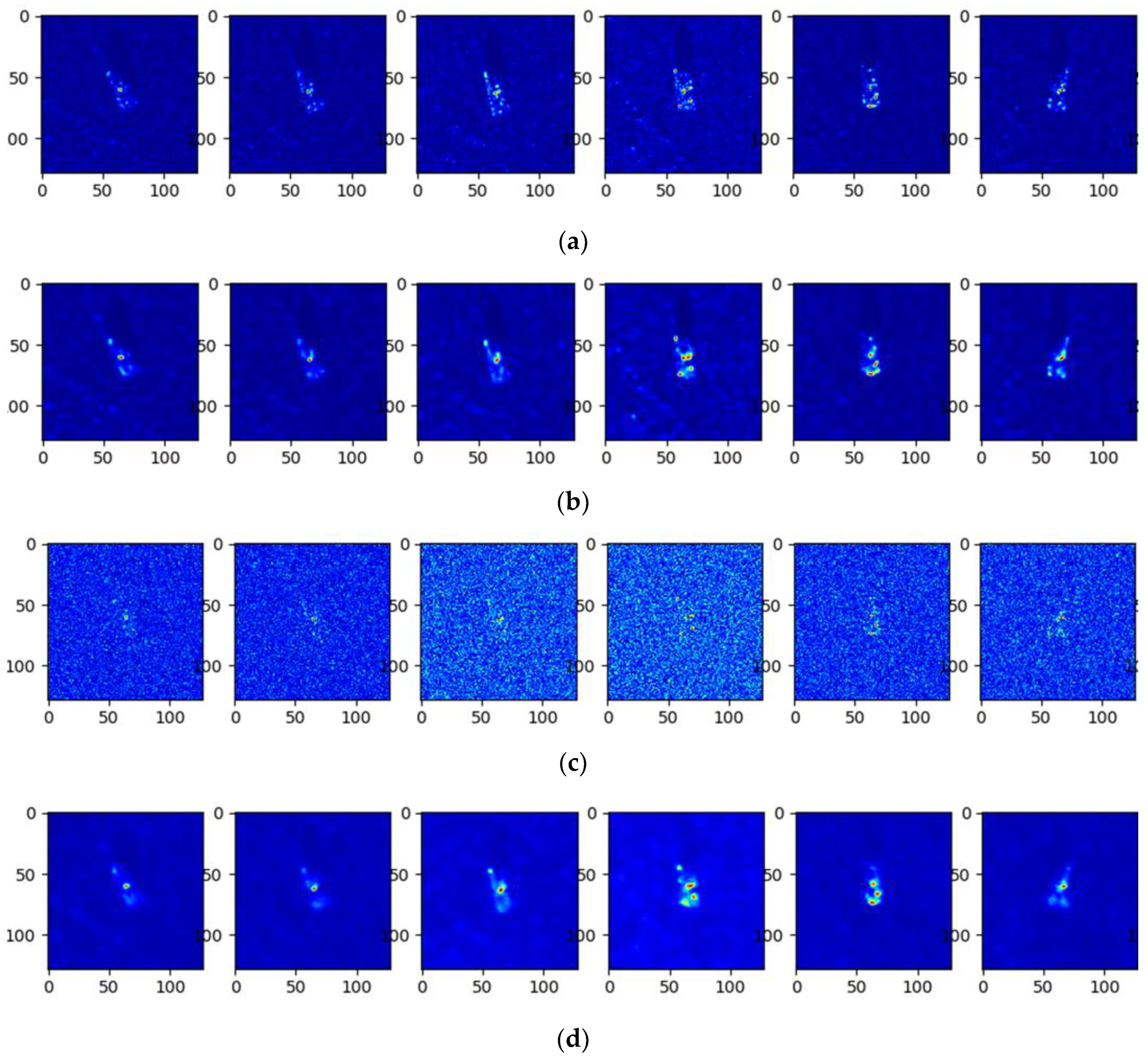
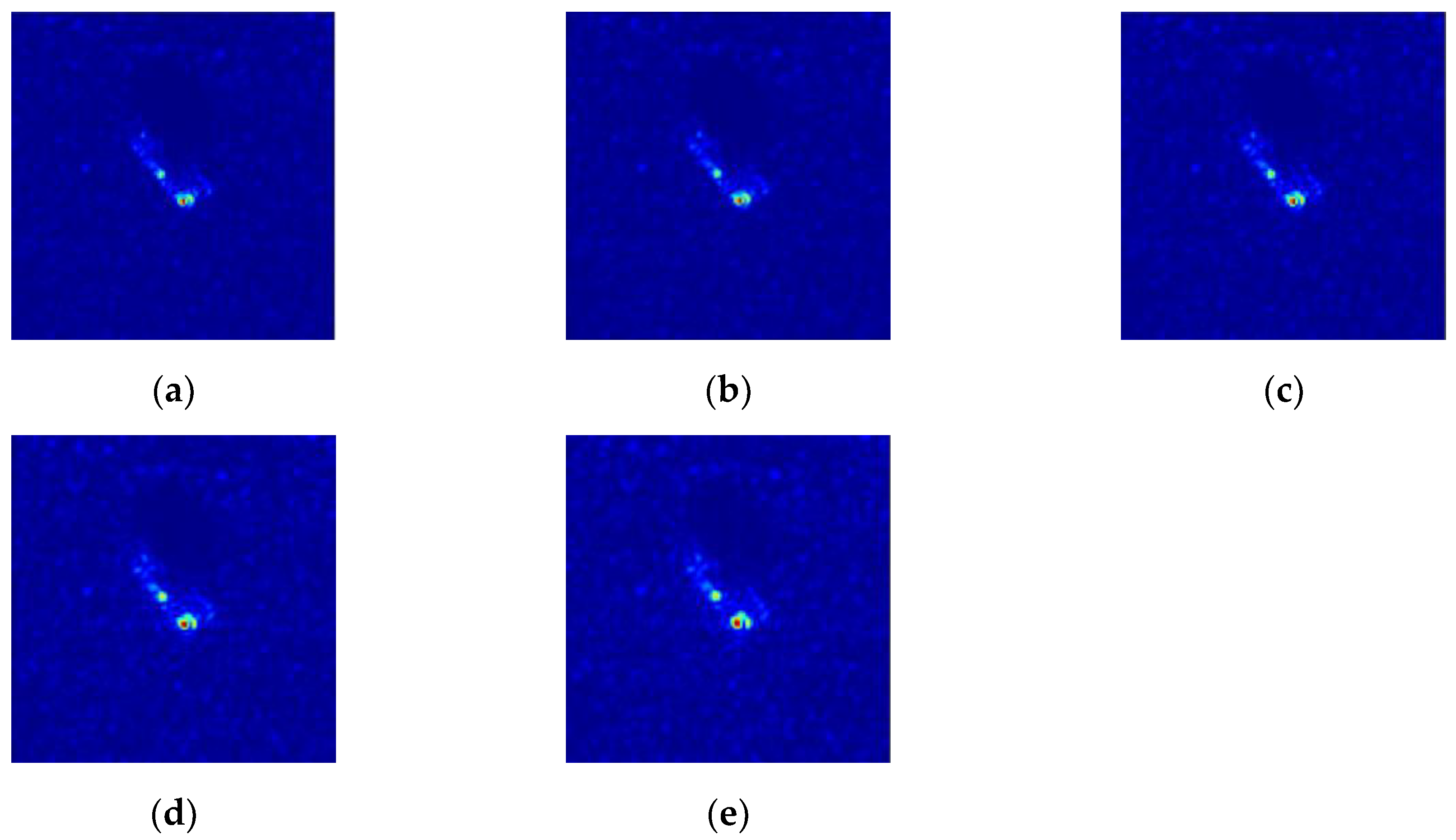
3.4. Validation of the Model Component
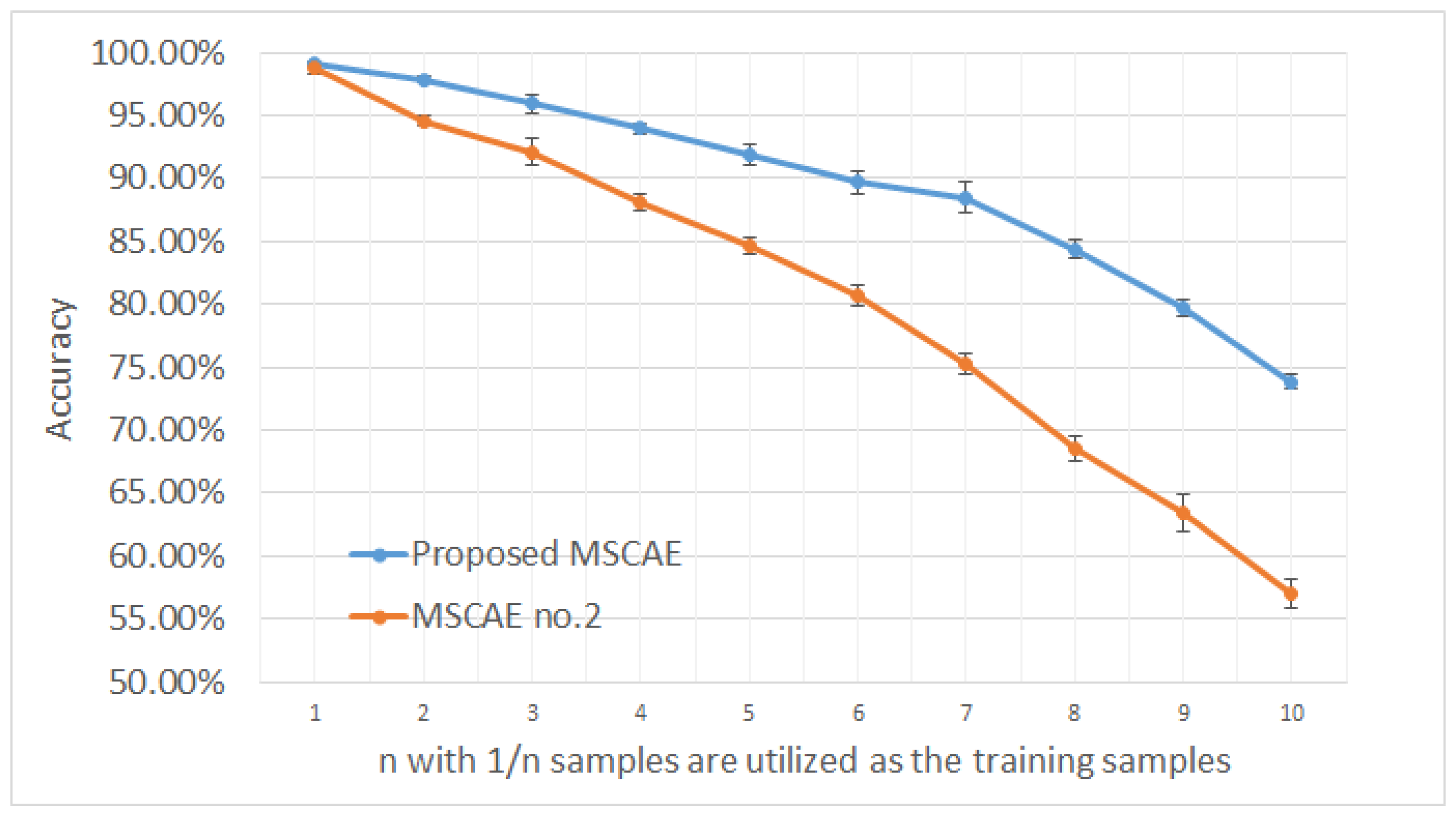
3.5. Evaluation on Ten-Target Classification
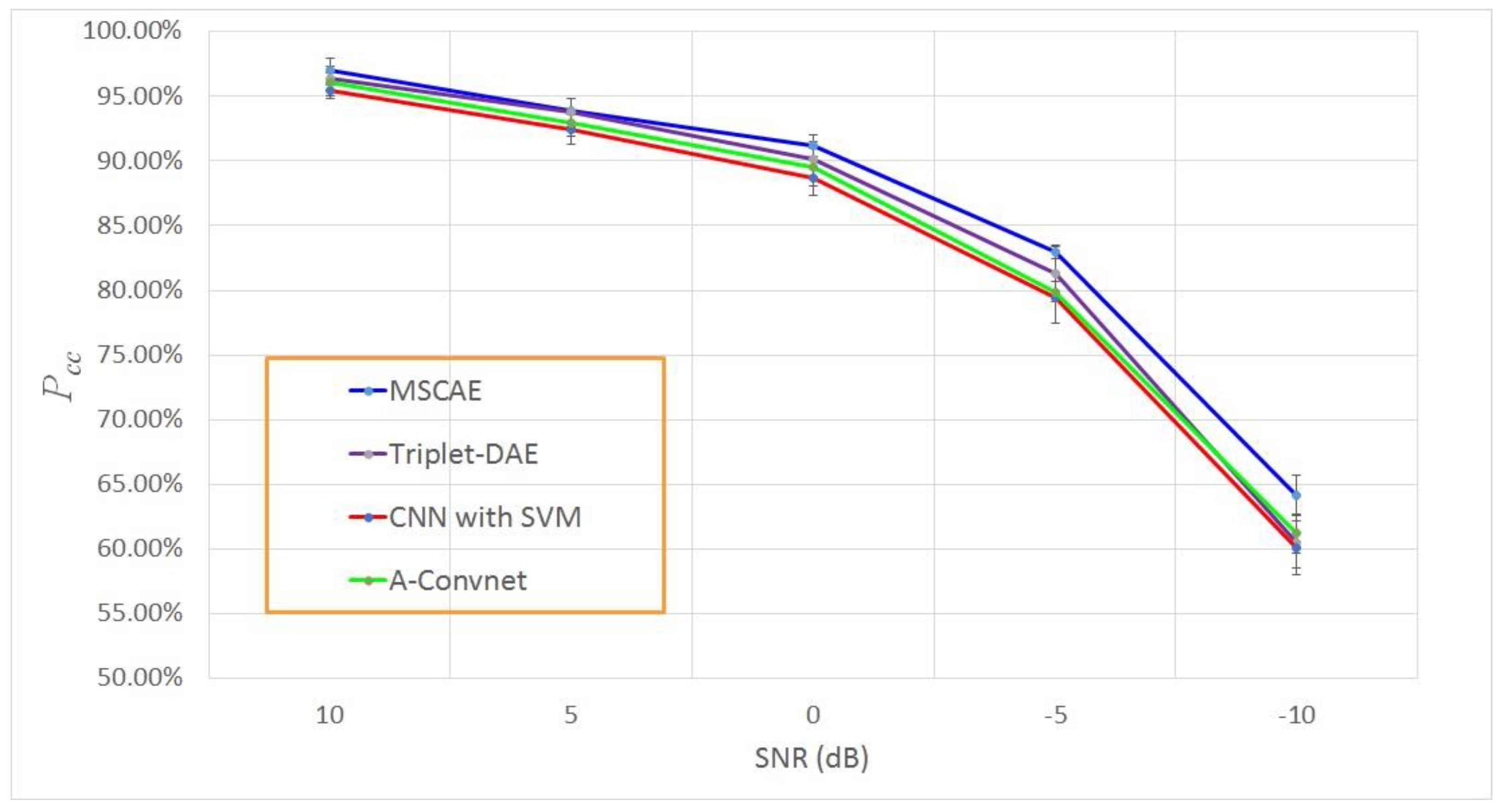
3.6. Classification Experiment with Noise Corruption
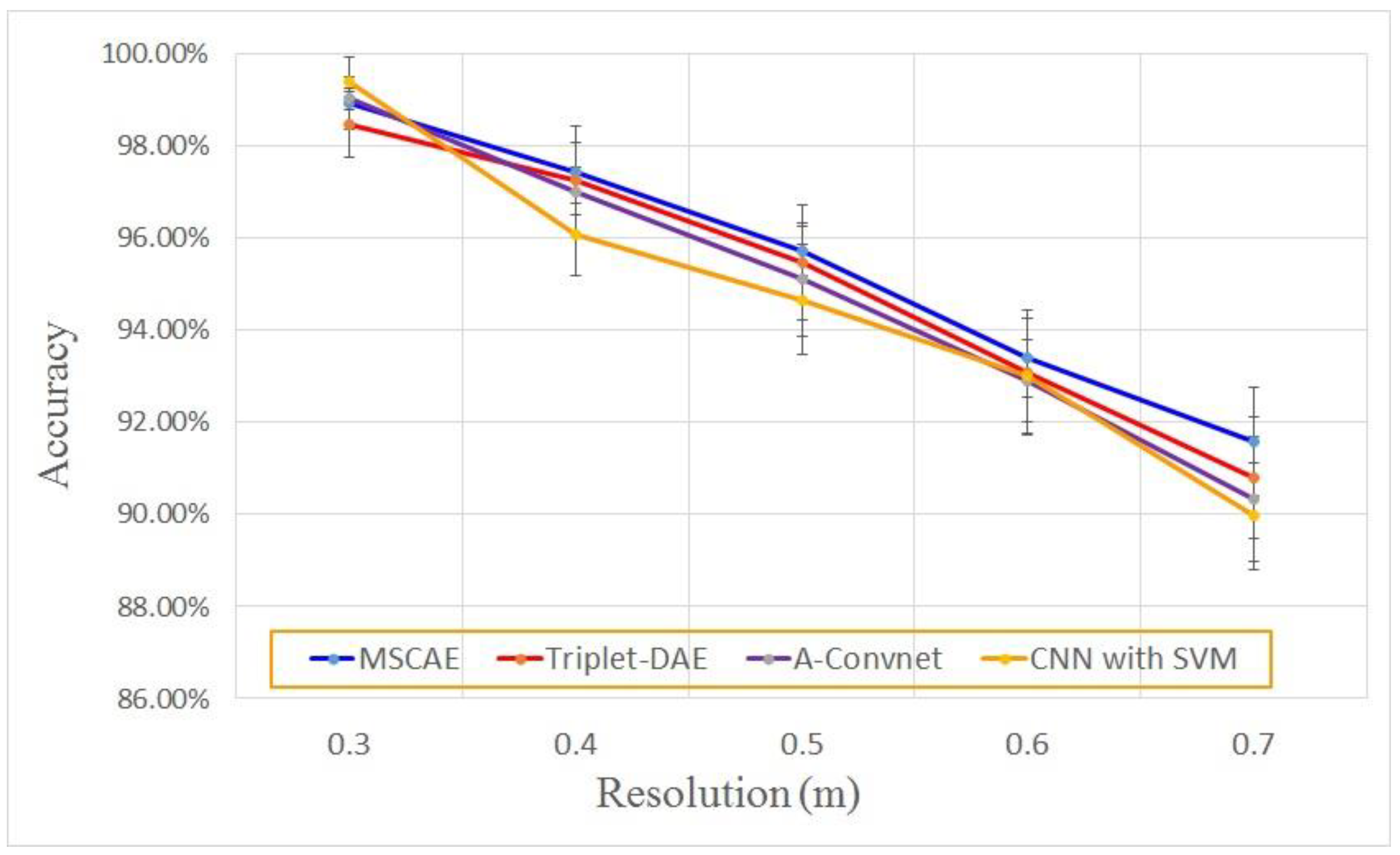
3.7. Classification Experiment with Resolution Variance
4. Conclusions and Future Work
- (1)
- A proposed unsupervised multi-scale representation learning framework for feature extraction in SAR ATR. The utilization of the U-shaped multi-scale architecture and the PPM blocks simultaneously obtained abstract features and local detailed characteristics of targets, boosting the representational power of the proposed model;
- (2)
- An objective function composed of a modified reconstruction loss and a speckle suppression restriction. The reconstruction loss based on SSIM and ILSF forces the MSCAE to learn adaptive speckle suppression capability, while the restriction guarantees that the speckle filtering procedure was implemented in the feature learning step;
- (3)
- The CSeConv and the CSeDeConv decreased the trainable parameters and calculation consumption, avoiding overfitting caused by insufficient samples. Moreover, they introduced more nonlinearity and slightly improved the performance of the MSCAE.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhu, J.-W.; Qiu, X.; Pan, Z.; Zhang, Y.-T.; Lei, B. An Improved Shape Contexts Based Ship Classification in SAR Images. Remote. Sens. 2017, 9, 145. [Google Scholar] [CrossRef]
- Mishra, A.K.; Motaung, T. Application of linear and nonlinear PCA to SAR ATR. In Proceedings of the 2015 25th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 21–22 April 2015; pp. 349–354. [Google Scholar]
- Yin, K.; Jin, L.; Zhang, C.; Guo, Y. A method for automatic target recognition using shadow contour of SAR image. IETE Tech. Rev. 2013, 30, 313. [Google Scholar] [CrossRef]
- Li, T.; Du, L. Target Discrimination for SAR ATR Based on Scattering Center Feature and K-center One-Class Classification. IEEE Sensors J. 2018, 18, 2453–2461. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G. Target Reconstruction Based on 3-D Scattering Center Model for Robust SAR ATR. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 3772–3785. [Google Scholar] [CrossRef]
- Li, Y.-B.; Zhou, C.; Wang, N. A survey on feature extraction of SAR Images. In Proceedings of the International Conference on Computer Application and System Modeling (ICCASM), Taiyuan, China, 22–24 October 2010. [Google Scholar]
- Ding, B.; Wen, G.; Huang, X.; Ma, C.; Yang, X. Target Recognition in Synthetic Aperture Radar Images via Matching of Attributed Scattering Centers. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 3334–3347. [Google Scholar] [CrossRef]
- Yoshua, B. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar]
- Dong, G.; Liao, G.; Liu, H.; Kuang, G. A Review of the Autoencoder and Its Variants: A Comparative Perspective from Target Recognition in Synthetic-Aperture Radar Images. IEEE Geosci. Remote. Sens. Mag. 2018, 6, 44–68. [Google Scholar] [CrossRef]
- Li, H.; Gong, M.; Wang, C.; Miao, Q. Self-paced stacked denoising autoencoders based on differential evolution for change detection. Appl. Soft Comput. 2018, 71, 698–714. [Google Scholar] [CrossRef]
- Gao, F.; Yang, Y.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. A Deep Convolutional Generative Adversarial Networks (DCGANs)-Based Semi-Supervised Method for Object Recognition in Synthetic Aperture Radar (SAR) Images. Remote. Sens. 2018, 10, 846. [Google Scholar] [CrossRef]
- Gao, F.; Liu, Q.; Sun, J.; Hussain, A.; Zhou, H. Integrated GANs: Semi-Supervised SAR Target Recognition. IEEE Access 2019, 7, 113999–114013. [Google Scholar] [CrossRef]
- Jia, C.N.; Yue, L.X. SAR automatic target recognition based on a visual cortical system. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; pp. 778–782. [Google Scholar]
- Geng, J.; Fan, J.; Wang, H.; Ma, X.; Li, B.; Chen, F. High-Resolution SAR Image Classification via Deep Convolutional Autoencoders. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 2351–2355. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Xing, X.; Zou, H. Synthetic Aperture Radar Target Recognition with Feature Fusion Based on a Stacked Autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef] [PubMed]
- Gleich, D.; Planinsic, P. SAR patch categorization using dual tree orientec wavelet transform and stacked autoencoder. In Proceedings of the 2017 International Conference on Systems, Signals and Image Processing (IWSSIP), Poznan, Poland, 22–24 May 2017; pp. 1–4. [Google Scholar]
- Zhang, L.; Ma, W.; Zhang, D. Stacked Sparse Autoencoder in PolSAR Data Classification Using Local Spatial Information. IEEE Geosci. Remote. Sens. Lett. 2016, 13, 1359–1363. [Google Scholar] [CrossRef]
- Zhang, L.; Jiao, L.; Ma, W.; Duan, Y.; Zhang, D. PolSAR image classification based on multi-scale stacked sparse autoencoder. Neurocomputing 2019, 351, 167–179. [Google Scholar] [CrossRef]
- Hou, B.; Kou, H.; Jiao, L. Classification of Polarimetric SAR Images Using Multilayer Autoencoders and Superpixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Chen, Y.; Jiao, L.; Li, Y.; Zhao, J. Multilayer Projective Dictionary Pair Learning and Sparse Autoencoder for PolSAR Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 6683–6694. [Google Scholar] [CrossRef]
- Lv, N.; Chen, C.; Qiu, T.; Sangaiah, A.K. Deep Learning and Superpixel Feature Extraction Based on Contractive Autoencoder for Change Detection in SAR Images. IEEE Trans. Ind. Informatics 2018, 14, 5530–5538. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, G.; Wang, K.; Leung, H. SAR Target Recognition Based On Variational Autoencoder. In Proceedings of the 2019 IEEE MTT-S International Microwave Biomedical Conference (IMBioC), Nanjing, China, 6–8 May 2019; Volume 1, pp. 1–4. [Google Scholar]
- Song, Q.; Xu, F.; Jin, Y.-Q. SAR Image Representation Learning With Adversarial Autoencoder Networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9498–9501. [Google Scholar]
- Kim, H.; Hirose, A. Unsupervised Fine Land Classification Using Quaternion Autoencoder-Based Polarization Feature Extraction and Self-Organizing Mapping. IEEE Trans. Geosci. Remote. Sens. 2017, 56, 1839–1851. [Google Scholar] [CrossRef]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. Classification of fusing SAR and multispectral image via deep bimodal autoencoders. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 823–826. [Google Scholar]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote. Sens. 2017, 9, 907. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote. Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, L.; Wang, L. Stacked Sparse Autoencoder Modeling Using the Synergy of Airborne LiDAR and Satellite Optical and SAR Data to Map Forest Above-Ground Biomass. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 5569–5582. [Google Scholar] [CrossRef]
- De, S.; Bruzzone, L.; Bhattacharya, A.; Bovolo, F.; Chaudhuri, S. A Novel Technique Based on Deep Learning and a Synthetic Target Database for Classification of Urban Areas in PolSAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 154–170. [Google Scholar] [CrossRef]
- Deng, S.; Du, L.; Li, C.; Ding, J.; Liu, H. SAR Automatic Target Recognition Based on Euclidean Distance Restricted Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 3323–3333. [Google Scholar] [CrossRef]
- Tian, S.; Wang, C.; Zhang, H.; Bhanu, B. SAR object classification using the DAE with a modified triplet restriction. IET Radar Sonar Navig. 2019, 13, 1081–1091. [Google Scholar] [CrossRef]
- Xie, W.; Jiao, L.; Hou, B.; Ma, W.; Zhao, J.; Zhang, S.; Liu, F. POLSAR Image Classification via Wishart-AE Model or Wishart-CAE Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Wang, J.; Hou, B.; Jiao, L.; Wang, S. POL-SAR Image Classification Based on Modified Stacked Autoencoder Network and Data Distribution. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 1678–1695. [Google Scholar] [CrossRef]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Wang, L.; Bai, X.; Zhou, F. SAR ATR of Ground Vehicles Based on ESENet. Remote. Sens. 2019, 11, 1316. [Google Scholar] [CrossRef]
- Shao, J.; Qu, C.; Li, J.; Peng, S. A Lightweight Convolutional Neural Network Based on Visual Attention for SAR Image Target Classification. Sensors 2018, 18, 3039. [Google Scholar] [CrossRef]
- Wagner, S. SAR ATR by a combination of convolutional neural network and support vector machines. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2861–2872. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Jiang, C.; Zhou, Y. Hierarchical Fusion of Convolutional Neural Networks and Attributed Scattering Centers with Application to Robust SAR ATR. Remote. Sens. 2018, 10, 819. [Google Scholar] [CrossRef]
- Lee, J.-S.; Wen, J.-H.; Ainsworth, T.L.; Chen, K.-S.; Chen, A. Improved Sigma Filter for Speckle Filtering of SAR Imagery. IEEE Trans. Geosci. Remote. Sens. 2008, 47, 202–213. [Google Scholar]
- Wissinger, J.; Ristroph, R.; Diemunsch, J.R.; Severson, W.E.; Fruedenthal, E. MSTAR’s extensible search engine and model-based inferencing toolkit. Proc. SPIE Int. Soc. Opt. Eng. 1999, 3721, 554–570. [Google Scholar]
- Ross, T.D.; Worrell, S.W.; Velten, V.J.; Mossing, J.C.; Bryant, M.L. Standard SAR ATR evaluation experiments using the MSTAR public release data set. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery V, Orlando, FL, USA, 14–17 April 1998. [Google Scholar]
- Dumoulin, V.; Visin, F. A Guide to Convolution Arithmetic for Deep Learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR 15), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Boureau, Y.L.; Ponce, J.; Lecun, Y. A Theoretical Analysis of Feature Pooling in Visual Recognition. In Proceedings of the International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image. Process 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Tian, S.; Yin, K.; Wang, C.; Zhang, H. An SAR ATR Method Based on Scattering Centre Feature and Bipartite Graph Matching. IETE Tech. Rev. 2015, 32, 1–12. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2014. [Google Scholar]
- Wang, Y.; Han, P.; Lu, X.; Wu, R.; Huang, J. The Performance Comparison of Adaboost and SVM Applied to SAR ATR. In Proceedings of the 2006 CIE International Conference on Radar, Shanghai, China, 16–19 October 2006; pp. 1–4. [Google Scholar]
- Zhang, H.; Nasrabadi, N.M.; Zhang, Y.; Huang, T. Multi-View Automatic Target Recognition using Joint Sparse Representation. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 2481–2497. [Google Scholar] [CrossRef]
- Dungan, K.E. Feature-Based Vehicle Classification in Wide-Angle Synthetic Aperture Radar. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2010. [Google Scholar]
- Cui, Z.; Feng, J.; Cao, Z.; Ren, H.; Yang, J. Target recognition in synthetic aperture radar images via non-negative matrix factorisation. IET Radar Sonar Navig. 2015, 9, 1376–1385. [Google Scholar] [CrossRef]
- Cui, Z.; Cao, Z.; Yang, J.; Ren, H. Hierarchical Recognition System for Target Recognition from Sparse Representations. Math. Probl. Eng. 2015, 2015, 1–6. [Google Scholar] [CrossRef]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional Neural Network With Data Augmentation for SAR Target Recognition. IEEE Geosci. Remote. Sens. Lett. 2016, 13, 1–5. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H. SAR target recognition based on deep learning. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; pp. 541–547. [Google Scholar]
- Dong, G.; Kuang, G. Target Recognition in SAR Images via Classification on Riemannian Manifolds. IEEE Geosci. Remote. Sens. Lett. 2014, 12, 199–203. [Google Scholar] [CrossRef]
- Ning, C.; Liu, W.; Zhang, G.; Wang, X. Synthetic Aperture Radar Target Recognition Using Weighted Multi-Task Kernel Sparse Representation. IEEE Access 2019, 7, 181202–181212. [Google Scholar] [CrossRef]
- Zheng, C.; Jiang, X.; Liu, X. Semi-Supervised SAR ATR via Multi-Discriminator Generative Adversarial Network. IEEE Sens. J. 2019, 19, 7525–7533. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | In | Out | Kernel Size | |||||
|---|---|---|---|---|---|---|---|---|
| Ordinary | DW | PW | ||||||
| Standard | / | / | 1 | |||||
| DW SeConv | / | |||||||
| DeCConv | 1st: ; Other: | / | / | |||||
| CSeConv | / | |||||||
| CSeDeConv | / | |||||||
| Type | Serial Number | Number of Samples | |
|---|---|---|---|
| 17° Depression | 15° Depression | ||
| 2S1 | b01 | 299 | 274 |
| BMP-2 | 9563 | 233 | 195 |
| 9566 | 232 | 196 | |
| c21 | 233 | 196 | |
| BRDM-2 | E-71 | 298 | 274 |
| BTR-60 | K10yt7532 | 256 | 195 |
| BTR-70 | c71 | 233 | 196 |
| D7 | 92v13015 | 299 | 274 |
| T-62 | A51 | 299 | 273 |
| T-72 | 132 | 232 | 196 |
| 812 | 231 | 195 | |
| s7 | 233 | 191 | |
| ZIL-131 | E12 | 299 | 274 |
| ZSU-234 | d08 | 299 | 274 |
| Stage | Level | Input Size | Processes | Output Size | Feature Size |
|---|---|---|---|---|---|
| Encoder | 1 | ||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| Decoder | 4 | - | |||
| 3 | - | ||||
| 2 | - | ||||
| 1 | - |
| Scheme | BMP-2 | BTR-70 | T-72 | Without Variants | Variants Only | Average |
|---|---|---|---|---|---|---|
| L 1 | 89.05% | 99.39% | 99.79% | 96.15% | 94.34% | 95.12% |
| L 2 | 87.01% | 98.88% | 96.02% | 95.13% | 92.28% | 92.56% |
| L 3 | 82.35% | 98.06% | 96.01% | 93.08% | 90.37% | 90.44% |
| L 4 | 77.92% | 93.88% | 96.80% | 90.23% | 86.78% | 88.26% |
| L 1+2 | 95.33% | 99.39% | 99.14% | 98.47% | 97.35% | 97.54% |
| L 1+3 | 94.52% | 98.98% | 99.38% | 98.30% | 96.95% | 97.24% |
| L 1+4 | 93.94% | 99.39% | 99.62% | 98.26% | 96.92% | 97.14% |
| L 2+3 | 96.13% | 97.76% | 96.70% | 97.55% | 96.27% | 96.61% |
| L 2+4 | 93.52% | 98.98% | 99.48% | 97.75% | 96.74% | 96.85% |
| L 3+4 | 92.22% | 98.67% | 99.48% | 97.38% | 96.05% | 96.25% |
| L 1+2+3 | 96.70% | 99.39% | 99.90% | 99.25% | 98.15% | 98.45% |
| L 1+2+4 | 95.57% | 99.39% | 99.79% | 98.91% | 97.62% | 97.92% |
| L 1+3+4 | 95.30% | 99.39% | 99.90% | 98.26% | 97.53% | 97.85% |
| L 2+3+4 | 95.06% | 99.18% | 99.90% | 98.50% | 97.54% | 97.71% |
| All | 99.05% | 99.69% | 99.04% | 99.73% | 98.69% | 99.14% |
| Model | Description | BMP-2 | BTR-70 | T-72 | |
|---|---|---|---|---|---|
| No. 1 | No PPM and FAM | 93.41% | 98.81% | 99.66% | 96.85% |
| No. 2 | No CSeConv and CSeDeConv | 97.33% | 99.66% | 99.83% | 98.73% |
| No. 3 | MSE Measurement | 93.98% | 99.83% | 99.83% | 97.31% |
| No. 4 | No ILSF | 95.17% | 99.15% | 99.71% | 97.68% |
| No. 5 | No Speckle Suppression Restriction | 96.15% | 99.49% | 99.60% | 98.10% |
| Baseline | The proposed MSCAE | 99.05% | 99.69% | 99.04% | 99.14% |
| Scheme | 2S1 | BMP-2 | BRDM-2 | BTR-60 | BTR-70 | D7 | T-62 | T-72 | ZIL-131 | ZSU-234 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| L. 1 | 95.3% | 89.8% | 93.1% | 96.9% | 99.0% | 98.2% | 95.6% | 99.8% | 98.5% | 99.3% | 96.1% |
| L. 2 | 88.7% | 86.2% | 88.3% | 93.3% | 94.4% | 93.8% | 89.7% | 97.8% | 98.2% | 98.9% | 92.7% |
| L. 3 | 83.2% | 91.8% | 87.6% | 88.2% | 93.4% | 94.2% | 85.7% | 95.4% | 94.9% | 96.7% | 91.6% |
| L. 4 | 75.5% | 85.2% | 81.8% | 81.5% | 91.8% | 94.5% | 83.2% | 92.8% | 79.9% | 97.8% | 86.9% |
| L. 1+2 | 94.9% | 95.7% | 93.8% | 97.9% | 98.5% | 99.3% | 96.3% | 99.8% | 99.3% | 100.0% | 97.6% |
| L. 1+3 | 96.7% | 95.9% | 94.2% | 99.5% | 99.5% | 99.6% | 95.6% | 99.8% | 98.5% | 99.6% | 97.8% |
| L. 1+4 | 97.1% | 93.9% | 94.2% | 97.9% | 99.0% | 100.0% | 97.4% | 99.8% | 98.5% | 99.6% | 97.5% |
| L. 2+3 | 92.7% | 91.8% | 97.4% | 97.4% | 99.5% | 98.2% | 93.4% | 98.8% | 98.2% | 99.3% | 95.7% |
| L. 2+4 | 90.9% | 92.3% | 90.9% | 95.9% | 98.5% | 97.8% | 94.1% | 97.8% | 97.8% | 98.9% | 95.3% |
| L. 3+4 | 86.5% | 93.9% | 92.3% | 92.3% | 96.9% | 97.8% | 89.7% | 96.9% | 94.5% | 97.1% | 94.1% |
| L. 1+2+3 | 96.7% | 97.6% | 96.4% | 99.0% | 99.5% | 99.6% | 97.1% | 99.8% | 98.9% | 100.0% | 98.5% |
| L. 1+2+4 | 96.7% | 97.4% | 95.3% | 97.9% | 99.5% | 99.6% | 97.4% | 99.7% | 99.3% | 100.0% | 98.3% |
| L. 1+3+4 | 96.7% | 98.0% | 96.0% | 98.5% | 99.5% | 99.6% | 96.7% | 99.8% | 98.5% | 99.6% | 98.4% |
| L. 2+3+4 | 94.2% | 93.4% | 98.5% | 99.5% | 99.5% | 98.5% | 93.0% | 98.3% | 97.8% | 99.3% | 96.2% |
| ALL | 99.3% | 98.3% | 98.5% | 99.0% | 99.5% | 99.6% | 98.5% | 99.8% | 99.3% | 100.0% | 98.9% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Lin, Y.; Gao, W.; Zhang, H.; Wang, C. A Multi-Scale U-Shaped Convolution Auto-Encoder Based on Pyramid Pooling Module for Object Recognition in Synthetic Aperture Radar Images. Sensors 2020, 20, 1533. https://doi.org/10.3390/s20051533
Tian S, Lin Y, Gao W, Zhang H, Wang C. A Multi-Scale U-Shaped Convolution Auto-Encoder Based on Pyramid Pooling Module for Object Recognition in Synthetic Aperture Radar Images. Sensors. 2020; 20(5):1533. https://doi.org/10.3390/s20051533
Chicago/Turabian StyleTian, Sirui, Yiyu Lin, Wenyun Gao, Hong Zhang, and Chao Wang. 2020. "A Multi-Scale U-Shaped Convolution Auto-Encoder Based on Pyramid Pooling Module for Object Recognition in Synthetic Aperture Radar Images" Sensors 20, no. 5: 1533. https://doi.org/10.3390/s20051533
APA StyleTian, S., Lin, Y., Gao, W., Zhang, H., & Wang, C. (2020). A Multi-Scale U-Shaped Convolution Auto-Encoder Based on Pyramid Pooling Module for Object Recognition in Synthetic Aperture Radar Images. Sensors, 20(5), 1533. https://doi.org/10.3390/s20051533