A Dynamic Plane Prediction Method Using the Extended Frame in Smart Dust IoT Environments


Abstract
1. Introduction
2. Related Works
2.1. DPDK (Dual Plane Development Kit)
2.2. A High-Performance Implementation of an IoT System Using DPDK
3. The Dynamic Plane Partition Algorithm
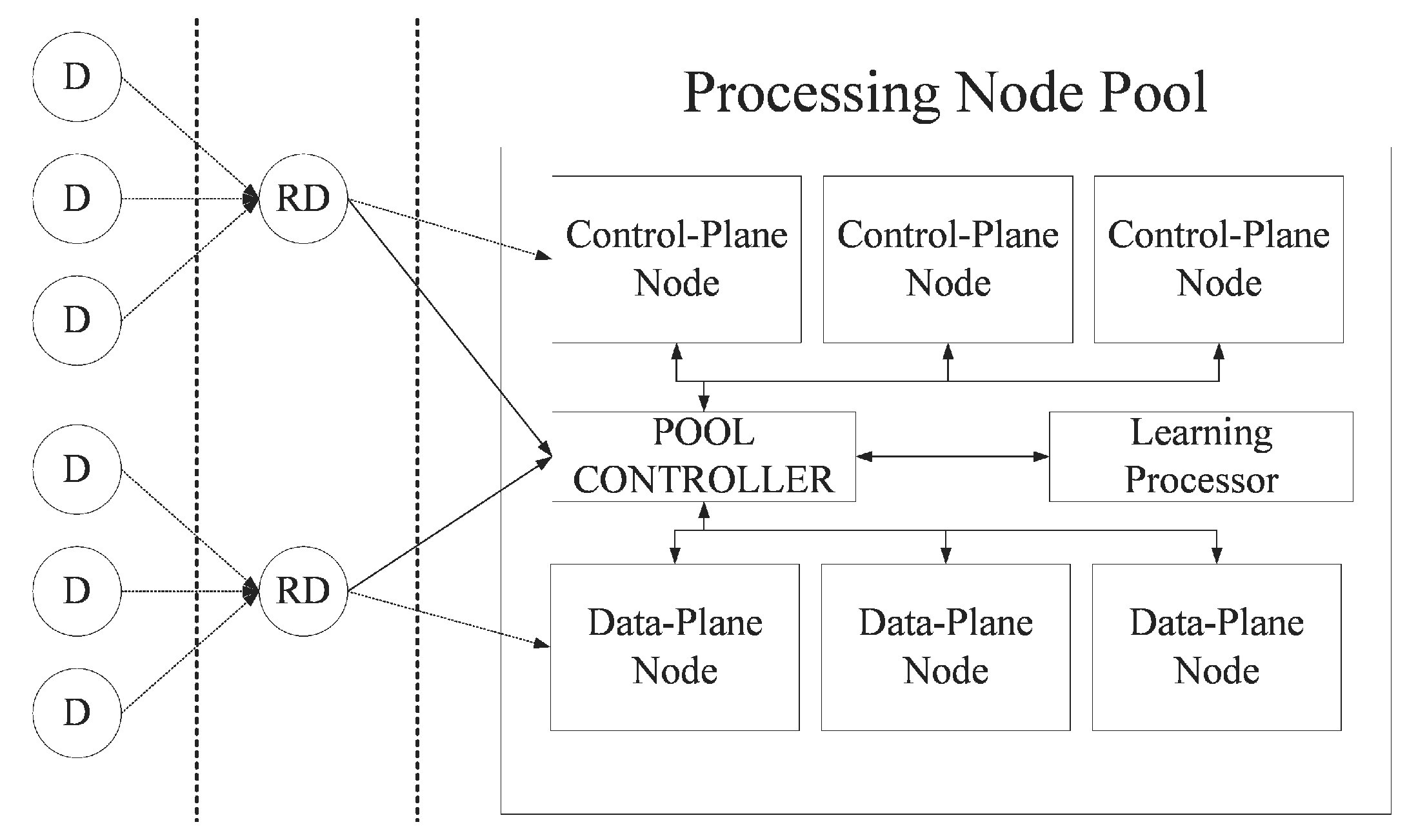
3.1. System Overview
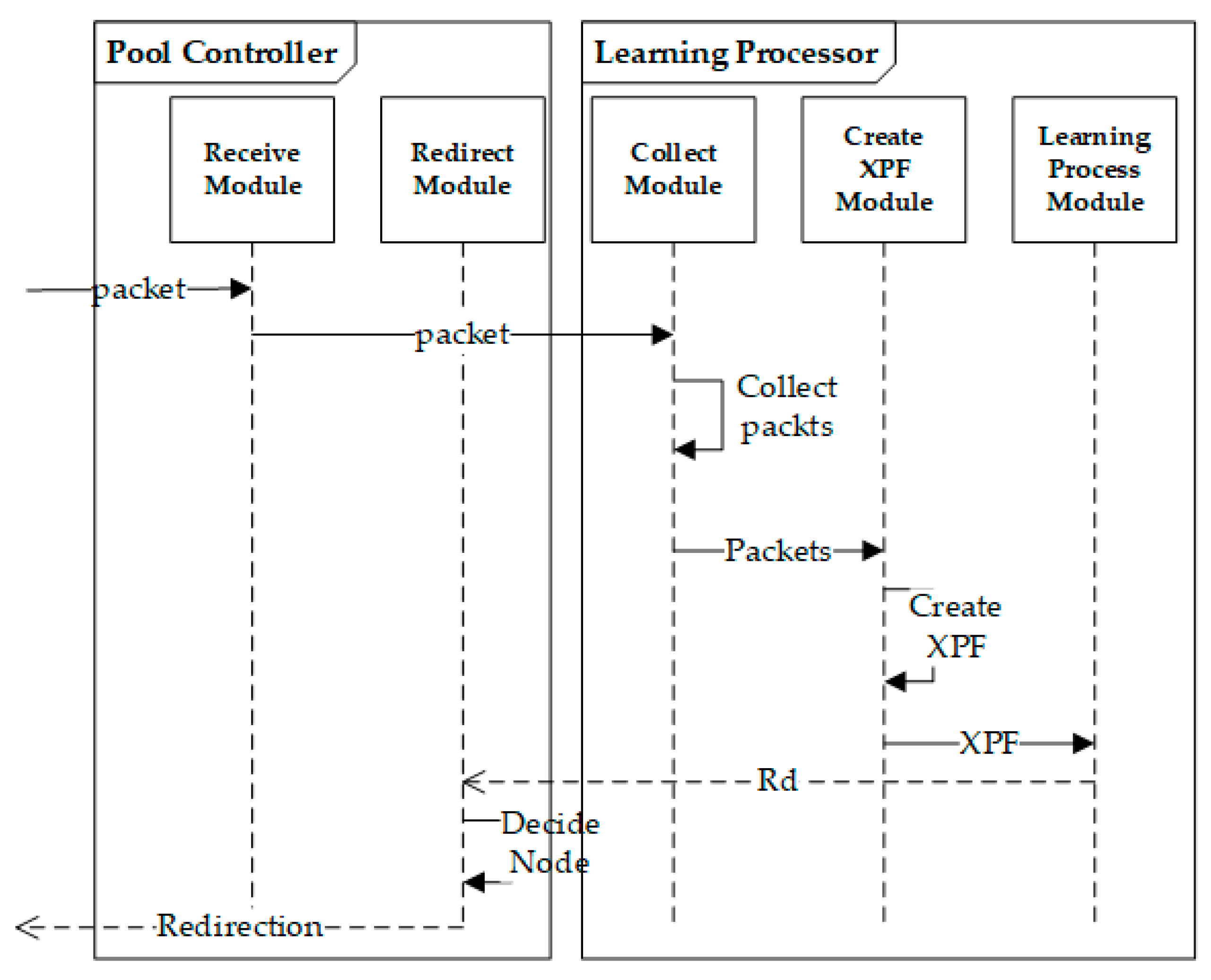
3.2. Software Configuration of the System
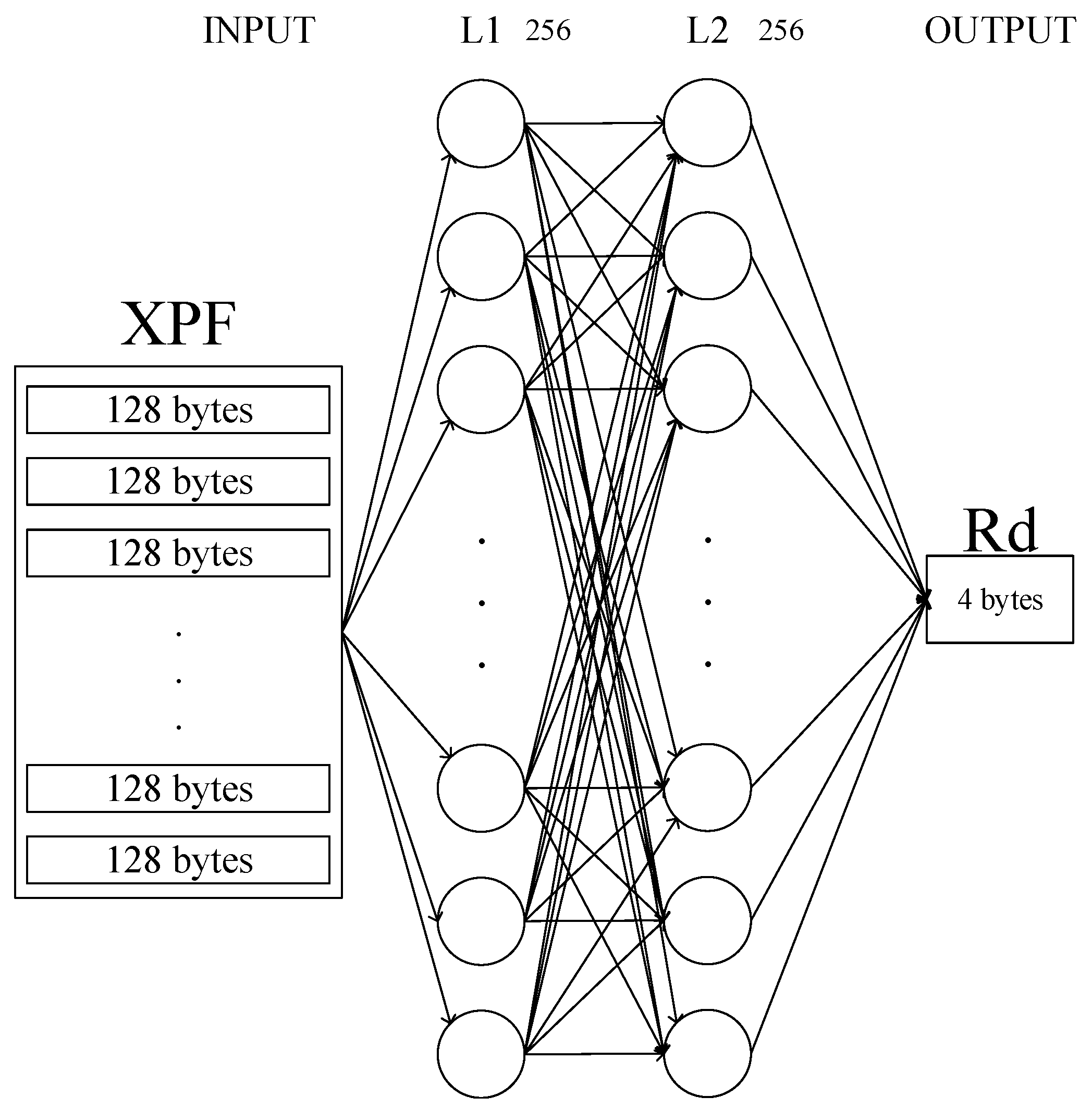
3.3. A Prediction Algorithm for the Dynamic Plane
- (1)
- Data of variable size must be fixed to pass through the ANN, resulting in overhead.
- (2)
- Data of a fixed size can distinguish the kind of packet by whether the specific byte is set without a full parsing of the packet.
- (3)
- Batching multiple pieces of data together rather than processing a single piece of data has an overall processing speed advantage.
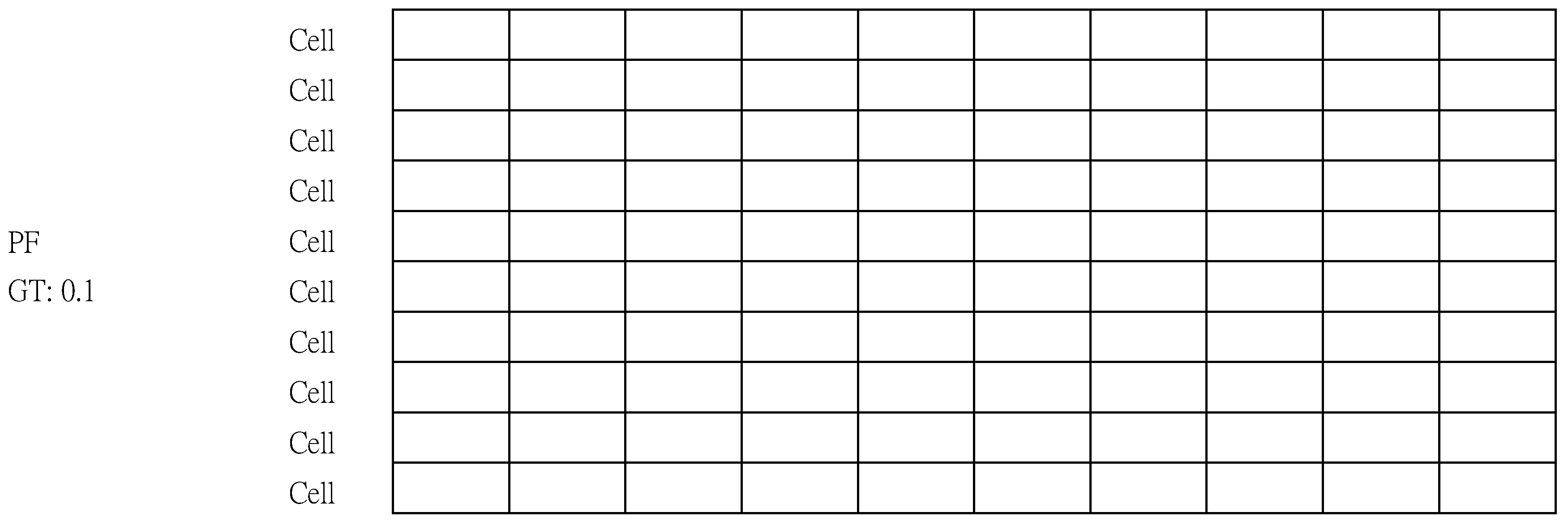
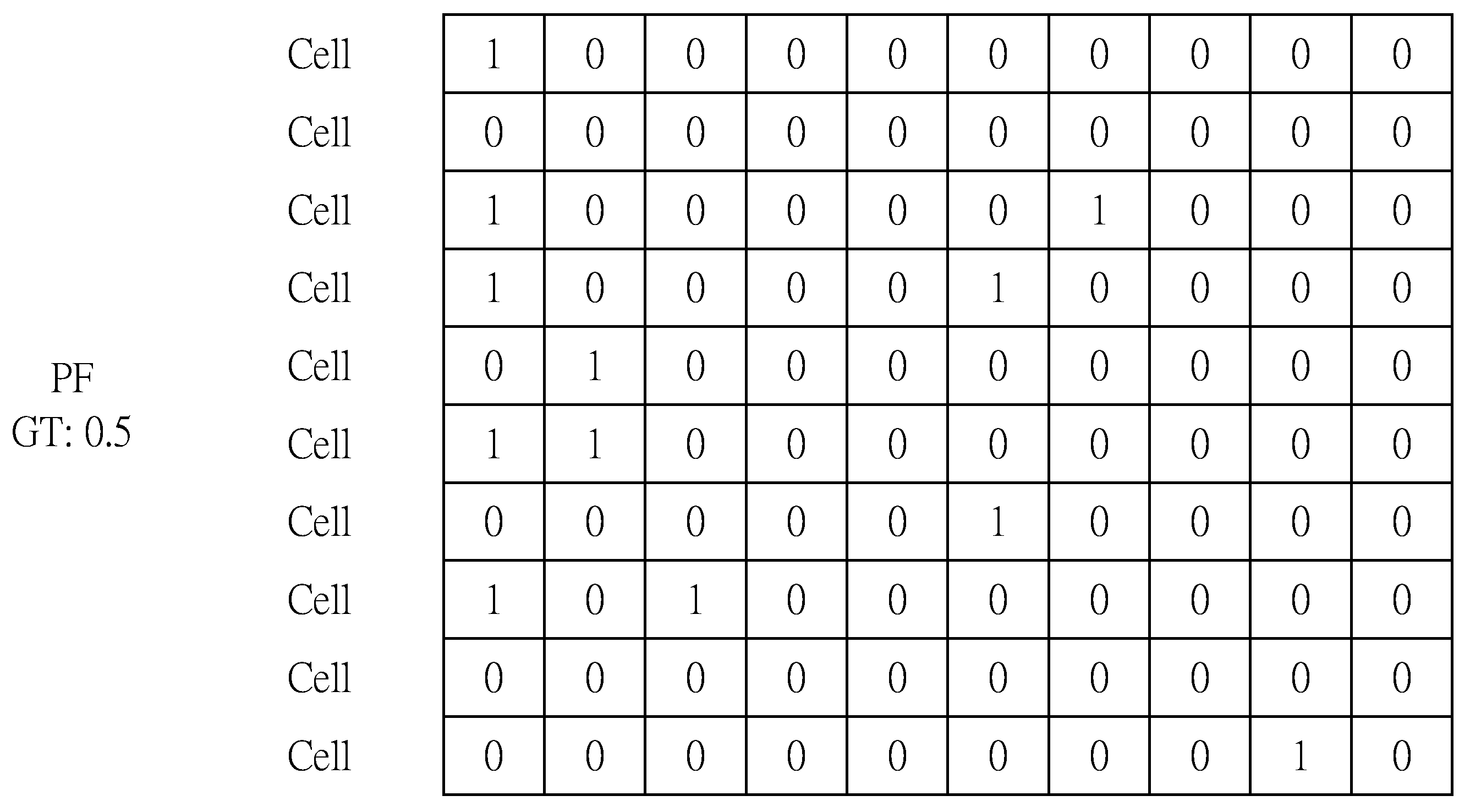
- The Cell is the minimum space to hold a packet.
- The Permuted Frame (PF) is a set of Cells with a Ground Truth (GT).
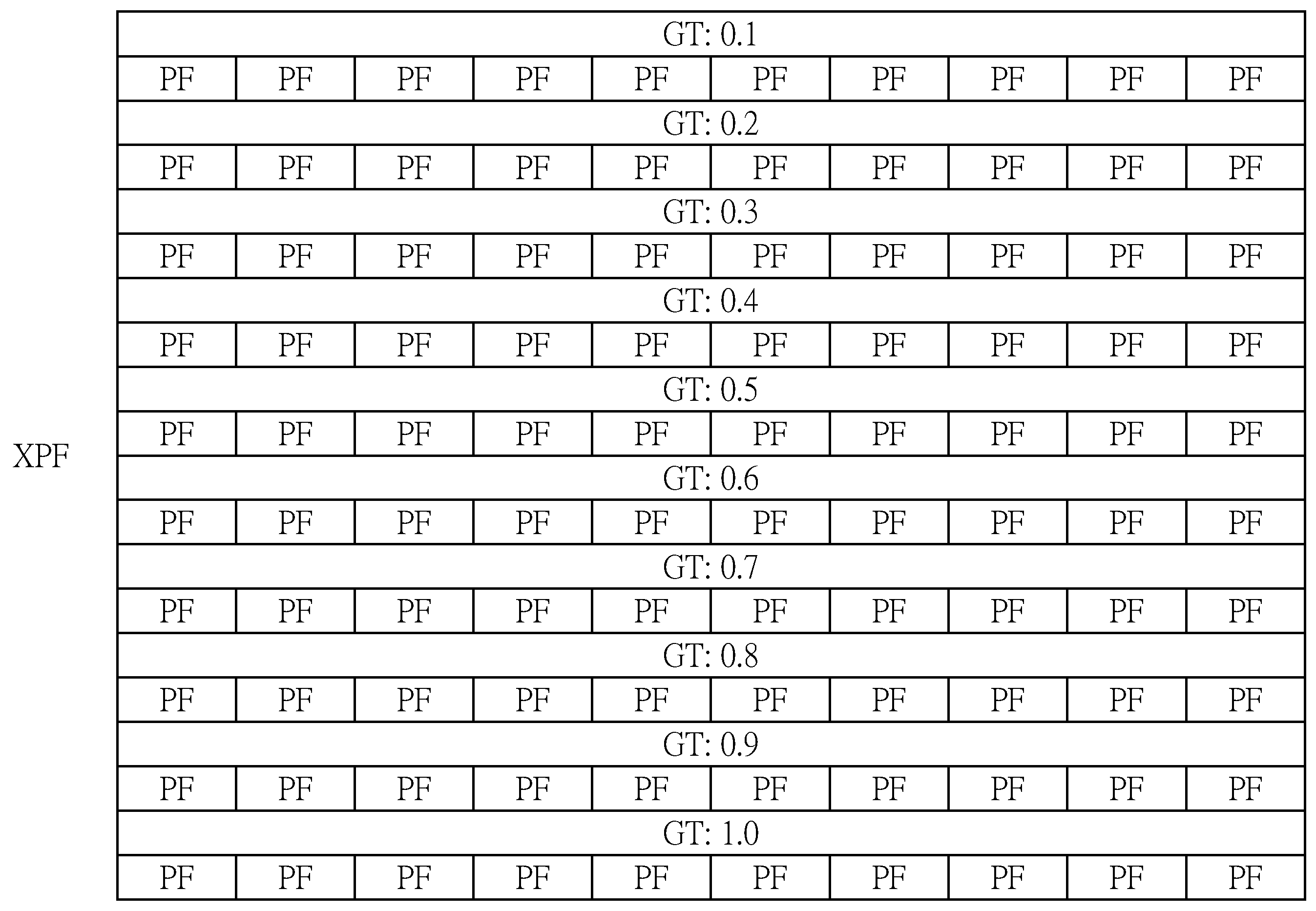
- The eXtended Permuted Frame (XPF) is a set of PFs to contain multiple PF patterns.
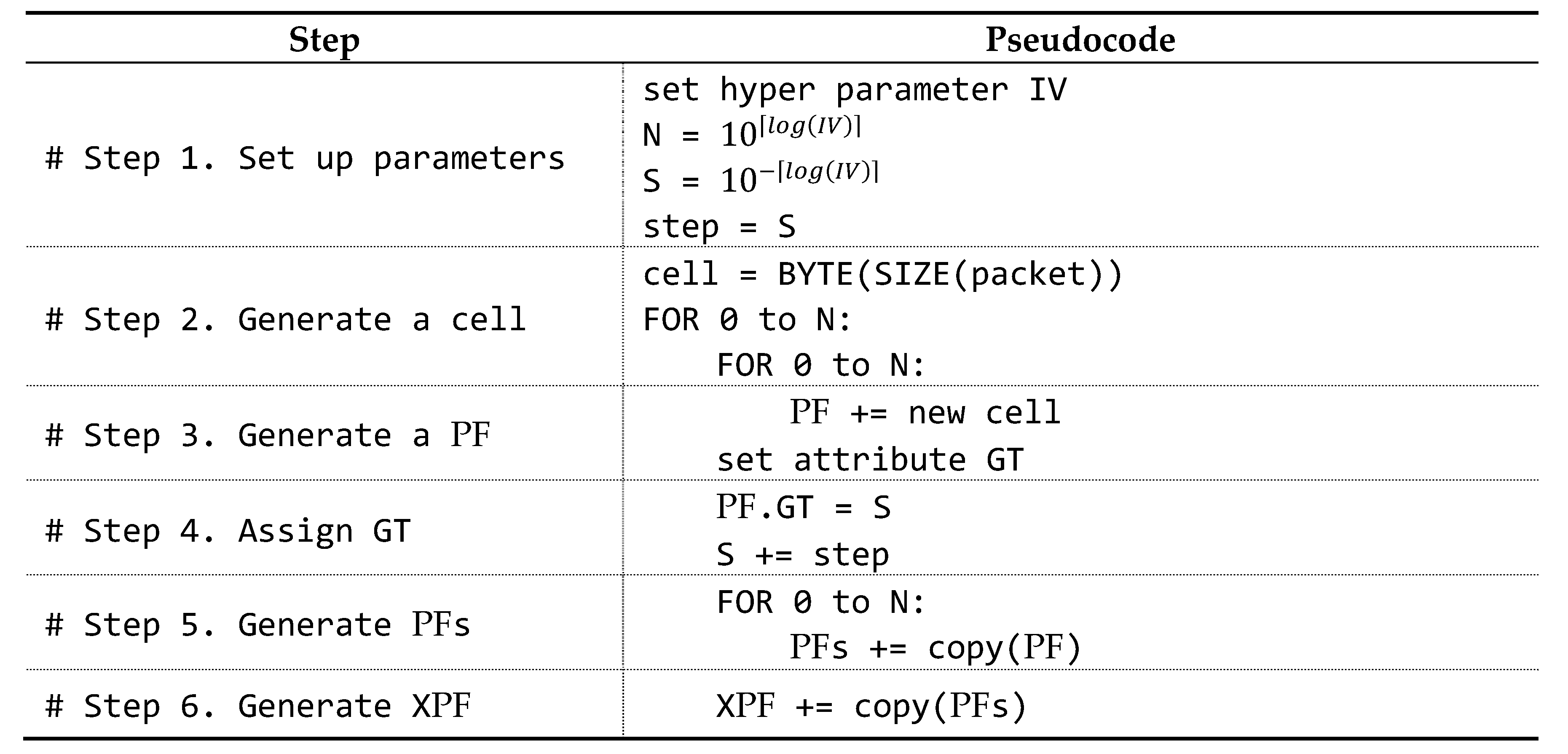
Example of XPF Generation Process
4. Experiment
4.1. Experimental Materials
4.2. Environments
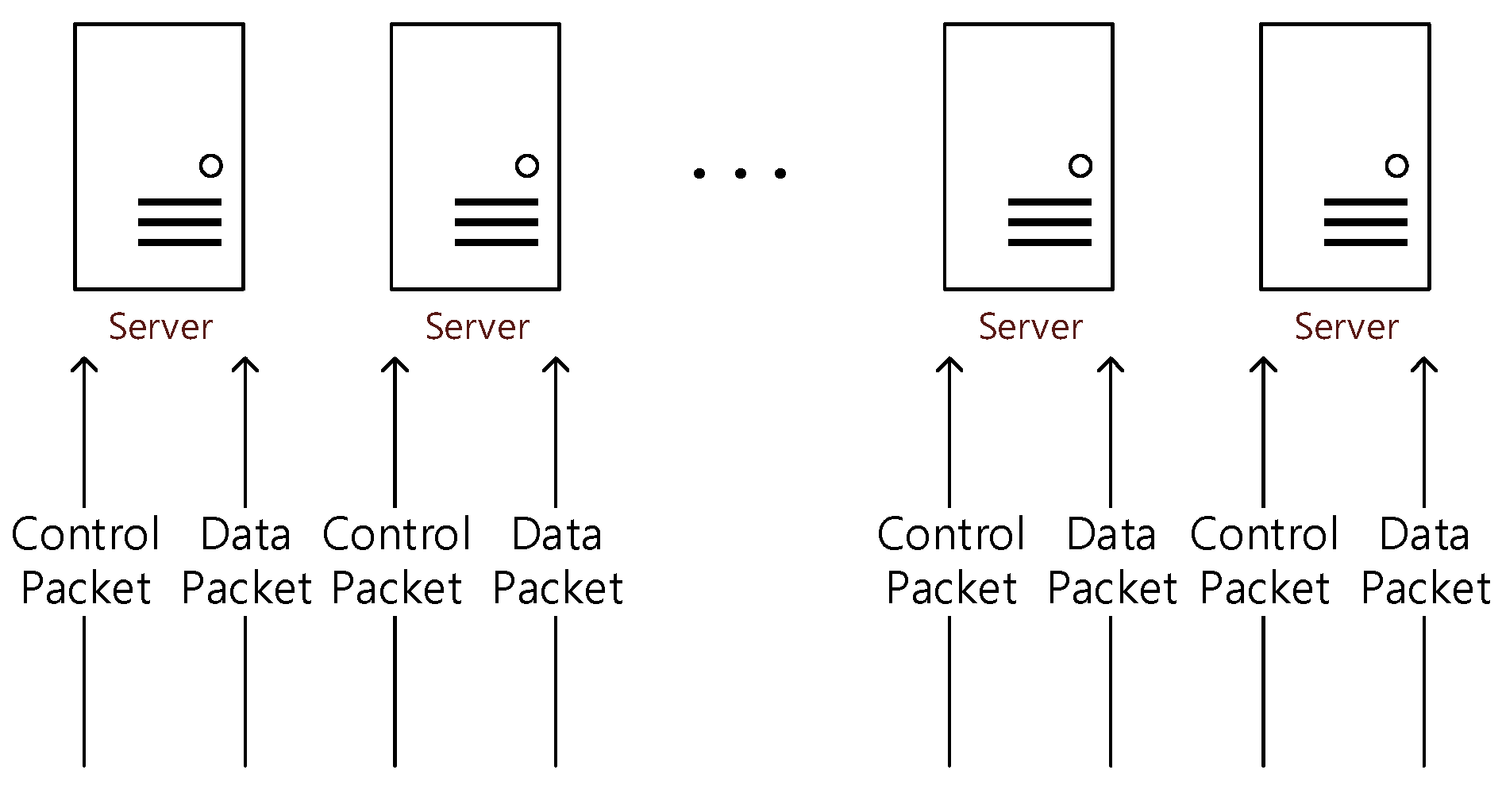
- A dual environment that has both data and control plane on one processing node
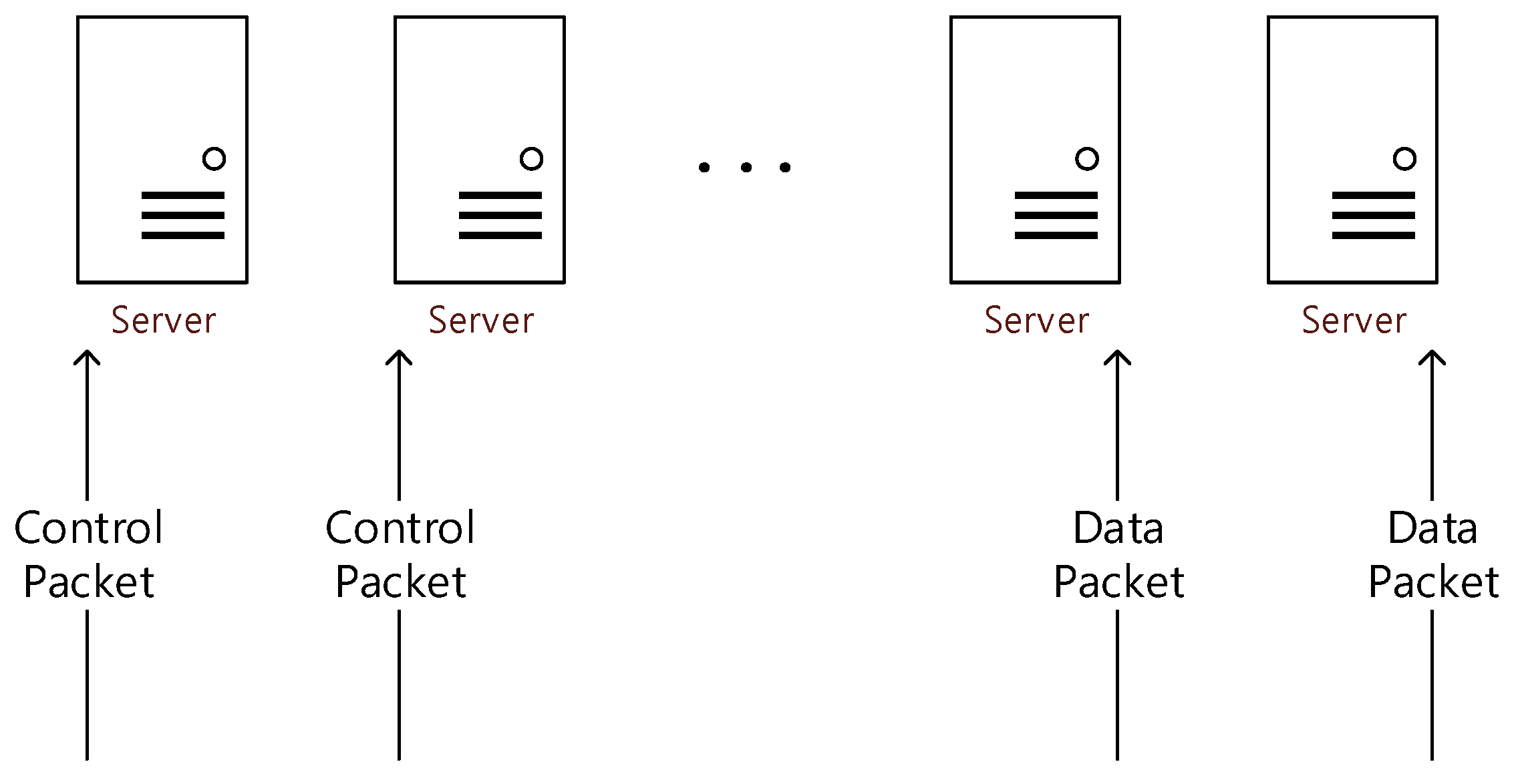
- A static partition environment in which one processing node has only one plane (data or control plane) at a moment
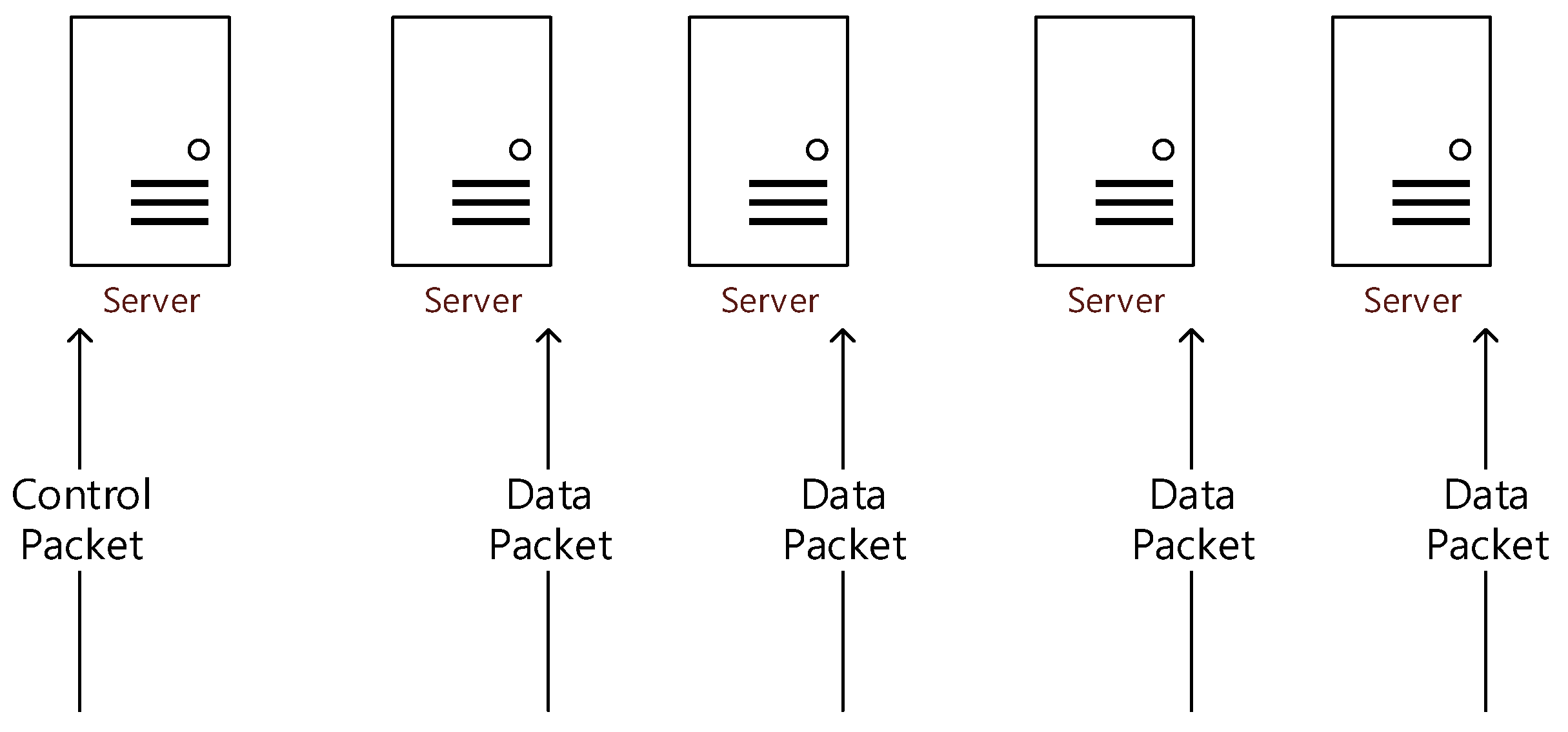
- A rated static partition environment that has only one plane (data or control plane) at a moment and the ratio of planes at the same rate as the packets being generated in the system.
4.3. Experimental Results
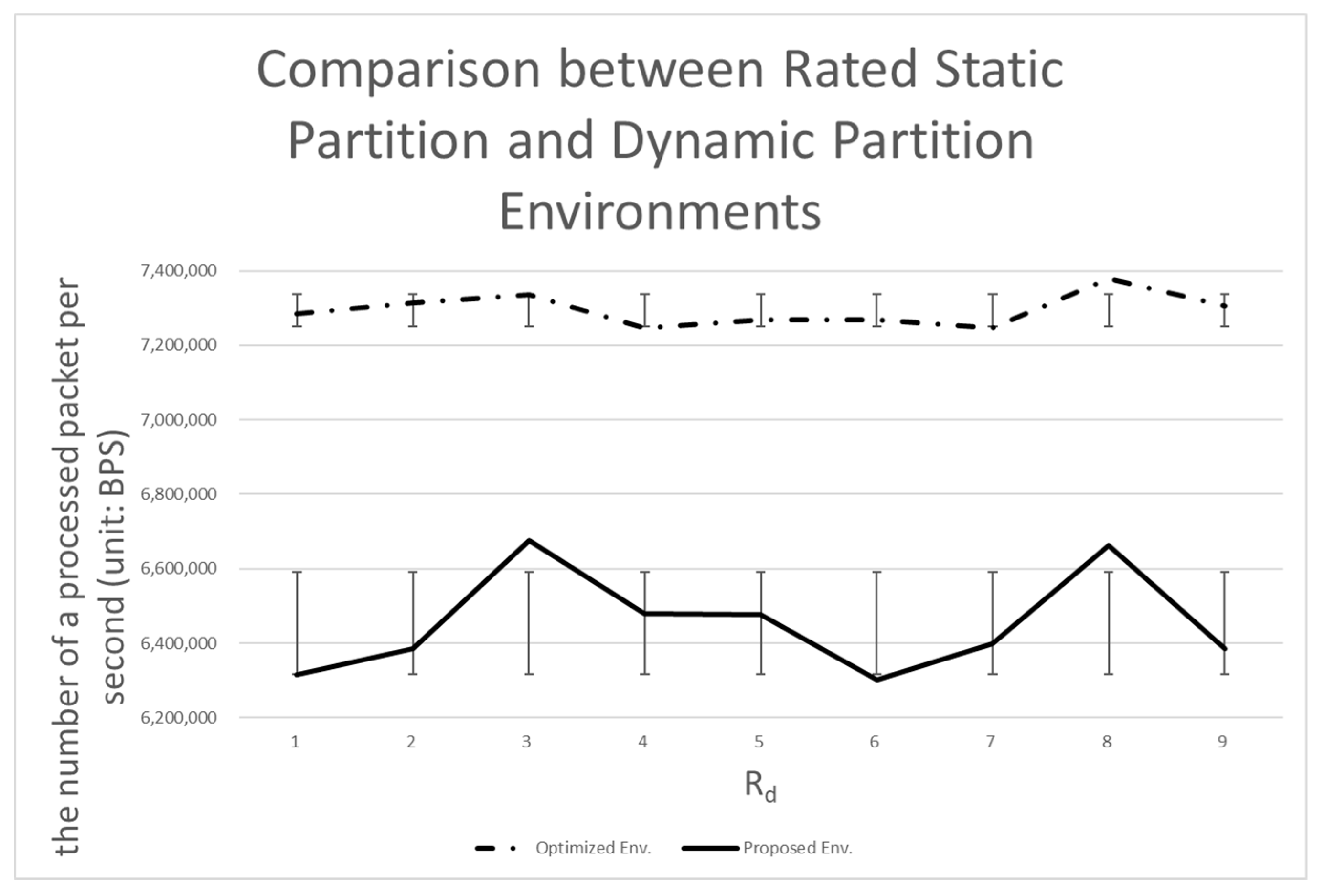
- (1)
- The dynamic partition environment shows about 88% the performance of the rated static partition environment (12% lower than the rated static partition environment).
- (2)
- The dynamic partition environment shows about 16% higher performance compared to the static partition environment.
- (3)
- The dynamic partition environment shows about 72% higher performance compared to the dual environment.
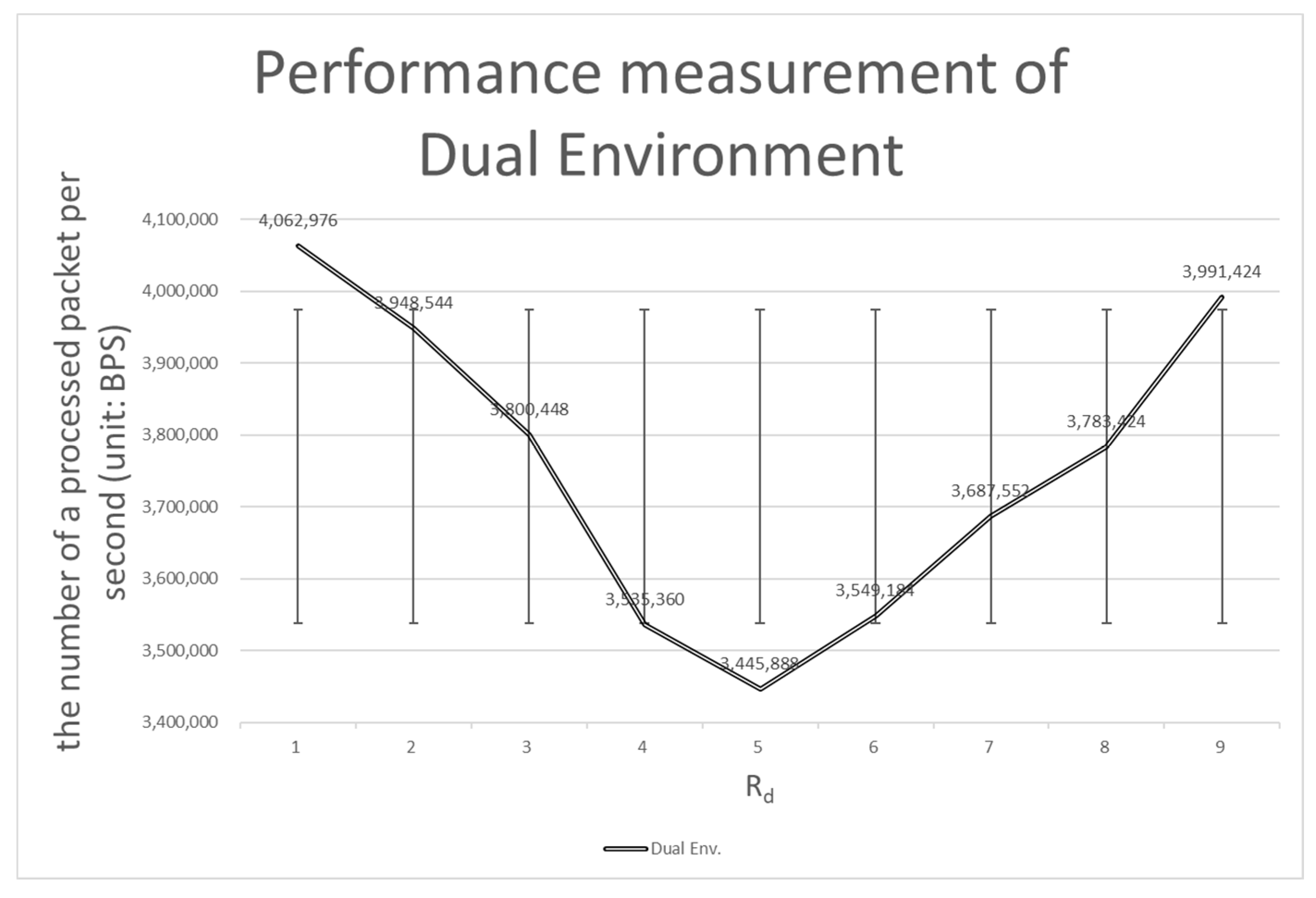
4.3.1. Comparison with the Dual Environment
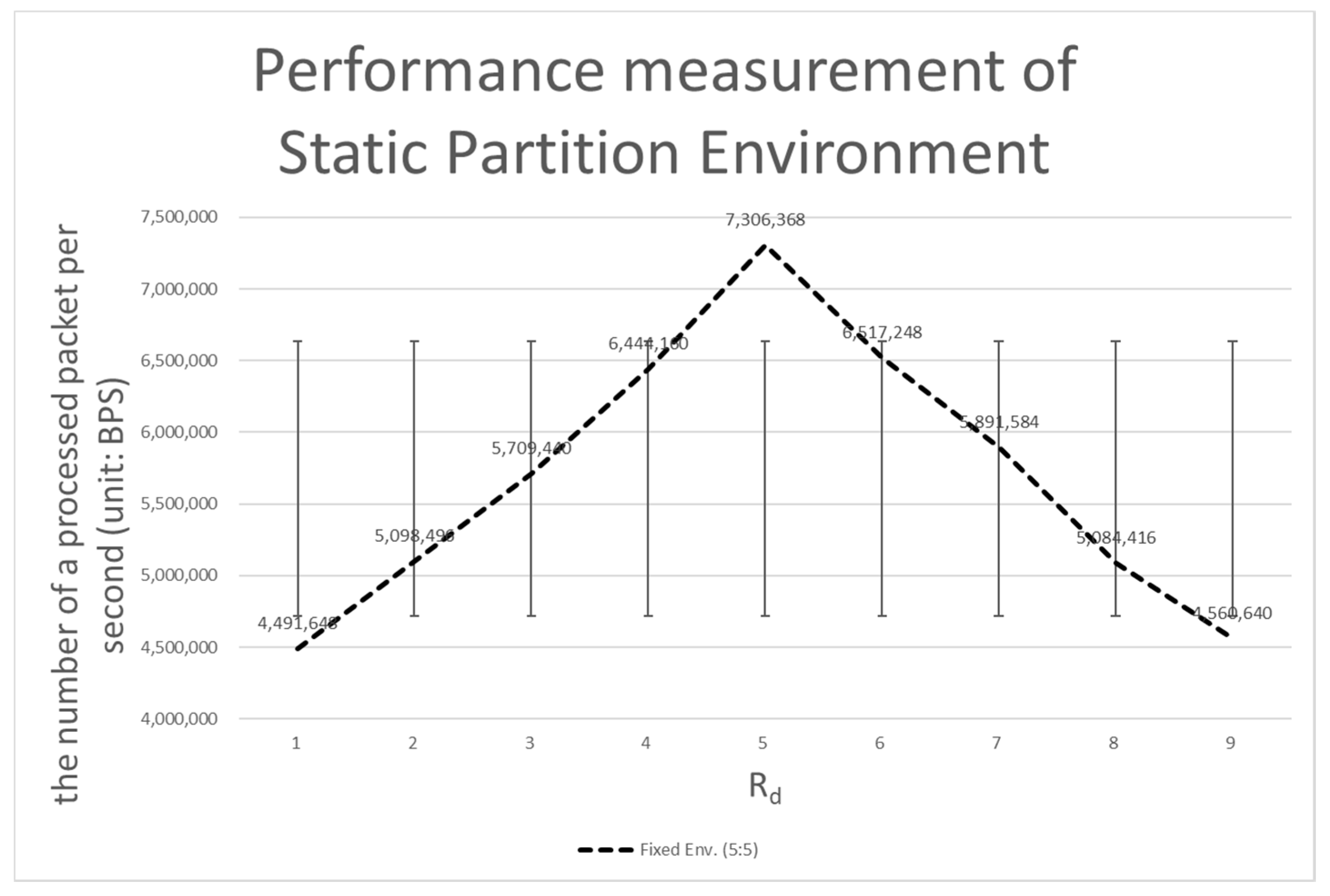
4.3.2. Comparison with the Static Partition Environment
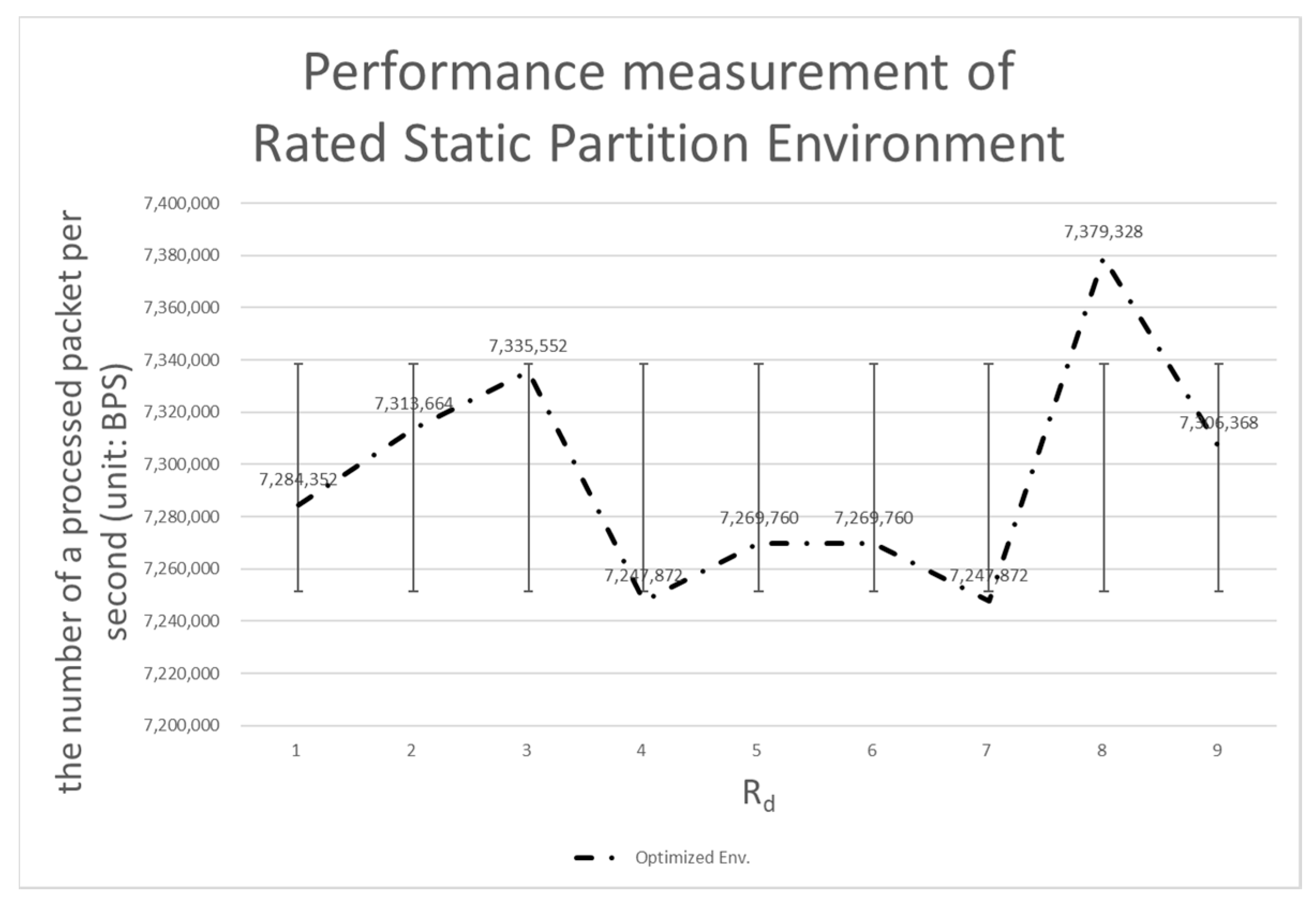
4.3.3. Comparison with the Rated Static Partition Environment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Luigi, A.; Iera, A.; Morabito, G. The Internet of Things: A Survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar]
- Gonzalez, G.R.; Organero, M.M.; Kloos, C.D. Early Infrastructure of an Internet of Things in Spaces for Learning. In Proceedings of the 2008 Eighth IEEE International Conference on Advanced Learning Technologies, Cantabria, Spain, 1–5 July 2008. [Google Scholar]
- Park, J.; Park, K. A Dynamic Plane Partition Method for DPDK in Smart Dust Environment. In Proceedings of the 2019 IEEE 10th Annual Information Technology, Electronics and Mobile Communication Conference, Vancouver, BC, Canada, 10–12 October 2019. [Google Scholar]
- Ray, P.P. A Survey on Internet of Things Architectures. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 291–319. [Google Scholar]
- Sterling, B. Shaping Things; Mediawork Pamphlet Series; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Jayavardhana, G.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (Iot): A Vision, Architectural Elements, and Future Directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar]
- Daniele, M.; Sicari, S.; de Pellegrini, F.; Chlamtac, I. Internet of Things: Vision, Applications and Research Challenges. Ad. Hoc. Netw. 2012, 10, 1497–1516. [Google Scholar]
- Kahn, M.J.; Katz, R.H.; Pister, K.S.J. Next Century Challenges: Mobile Networking for Smart Dust. In Proceedings of the 5th annual ACM/IEEE International Conference on Mobile Computing and Networking, Settle, WA, USA, 17–19 August 1999. [Google Scholar]
- Brett, W.; Last, M.; Liebowitz, B.; Pister, K.S.J. Smart Dust: Communicating with a Cubic-Millimeter Computer. Computer 2001, 34, 44–51. [Google Scholar]
- Kahn, M.J.; Katz, R.H.; Pister, K.S.J. Emerging Challenges: Mobile Networking for” Smart Dust. J. Commun. Netw. 2000, 2, 188–196. [Google Scholar] [CrossRef]
- Intel. Data Plane Development Kit. Available online: https://www.dpdk.org/ (accessed on 8 November 2019).
- Intel. Programmer’s Guide—Data Plane Development Kit. Available online: https://doc.dpdk.org/guides/prog_guide/index.html (accessed on 8 November 2019).
- Pak, J.G.; Park, K.H. A High-Performance Implementation of an Iot System Using DPDK. Appl. Sci. 2018, 8, 550. [Google Scholar] [CrossRef]
- Park, J.; Park, K. A Study on System Architecture Design for Plane Dynamic Scaling in Smart Dust Environments. In Proceedings of the 2019 Korea Information Processing Society Conference in Spring, Seoul, Korea, 10–11 May 2019. [Google Scholar]
- Park, K.; Kim, I.; Park, J. A High Speed Data Transmission method for DPDK-based IoT Systems (in Korean). In Proceedings of the International Conference on Future Information & Communication Engineering, Singapore, 23 April 2018; pp. 325–327. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. “Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Frid-Adar, M.; Maayan, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Kingma, P.D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Korea Meteorological Administration. Korea Meteorological Administration. Available online: http://www.kma.go.kr/ (accessed on 8 November 2019).
- Open Data Portal. Korea Public Open Data Portal. Available online: https://www.data.go.kr/ (accessed on 8 November 2019).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
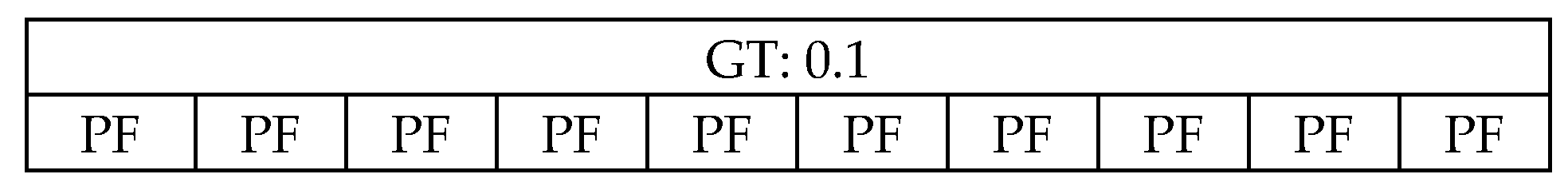{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation Point | Time | Temperature (°C) | Humidity (%) | Vapor Pressure (hPa) | Dew Point Temperature (°C) | Sunshine (h) | Solar Radiation (MJ/m2) | Ground Temperature (°C) |
|---|---|---|---|---|---|---|---|---|
| Daegu(143) | 25 January 2020 8:00 | 6 | 77 | 7.2 | 2.2 | 0 | 0.03 | 3.9 |
| Component | Item |
|---|---|
| CPU | i7-4770 3.4GHz |
| Main memory | 16.0 Gb |
| GPU | NVIDIA GeForce GTX 1050 3Gb X 2 |
| OS | Ubuntu 16.04 |
| Component | Item |
|---|---|
| CPU | i7-4770 3.4GHz |
| Main memory | 32.0 Gb |
| GPU | NVIDIA GeForce GTX 1050 3Gb |
| OS | VM Ware (Ubuntu 16.04) |
| Docker(Ubuntu 16.04) |
| Rd (%) | Dual Env. | A Static Partitioning Env. (5:5) | A Rated Static Partitioning Env. | A Dynamic Partitioning Env. |
|---|---|---|---|---|
| 10 | 4,062,976 | 4,491,648 | 7,284,352 | 6,315,520 |
| 20 | 3,948,544 | 5,098,496 | 7,313,664 | 6,384,768 |
| 30 | 3,800,448 | 5,709,440 | 7,335,552 | 6,675,328 |
| 40 | 3,535,360 | 6,444,160 | 7,247,872 | 6,479,488 |
| 50 | 3,445,888 | 7,306,368 | 7,269,760 | 6,477,312 |
| 60 | 3,549,184 | 6,517,248 | 7,269,760 | 6,302,848 |
| 70 | 3,687,552 | 5,891,584 | 7,247,872 | 6,399,744 |
| 80 | 3,783,424 | 5,084,416 | 7,379,328 | 6,663,424 |
| 90 | 3,991,424 | 4,560,640 | 7,306,368 | 6,385,664 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Park, K. A Dynamic Plane Prediction Method Using the Extended Frame in Smart Dust IoT Environments. Sensors 2020, 20, 1364. https://doi.org/10.3390/s20051364
Park J, Park K. A Dynamic Plane Prediction Method Using the Extended Frame in Smart Dust IoT Environments. Sensors. 2020; 20(5):1364. https://doi.org/10.3390/s20051364
Chicago/Turabian StylePark, Joonsuu, and KeeHyun Park. 2020. "A Dynamic Plane Prediction Method Using the Extended Frame in Smart Dust IoT Environments" Sensors 20, no. 5: 1364. https://doi.org/10.3390/s20051364
APA StylePark, J., & Park, K. (2020). A Dynamic Plane Prediction Method Using the Extended Frame in Smart Dust IoT Environments. Sensors, 20(5), 1364. https://doi.org/10.3390/s20051364