A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition †





Abstract
1. Introduction
- A framework of combining short-term spatial and frequency domain feature extraction and long-term independently-recurrent-neural-network (IndRNN)-based recognition is proposed. The long-range temporal processing problem is divided into two problems to take advantage of the periodic characteristics of the sensor data.
- A dense IndRNN model is developed to capture the long-term temporal information. Due to the capability of IndRNN in constructing deep networks and processing long sequences, the dense IndRNN model can effectively process the short-term features to obtain long-term information.
2. Related Work
2.1. Conventional Handcrafted-Features-Based Methods
2.2. Deep Learning Based Methods
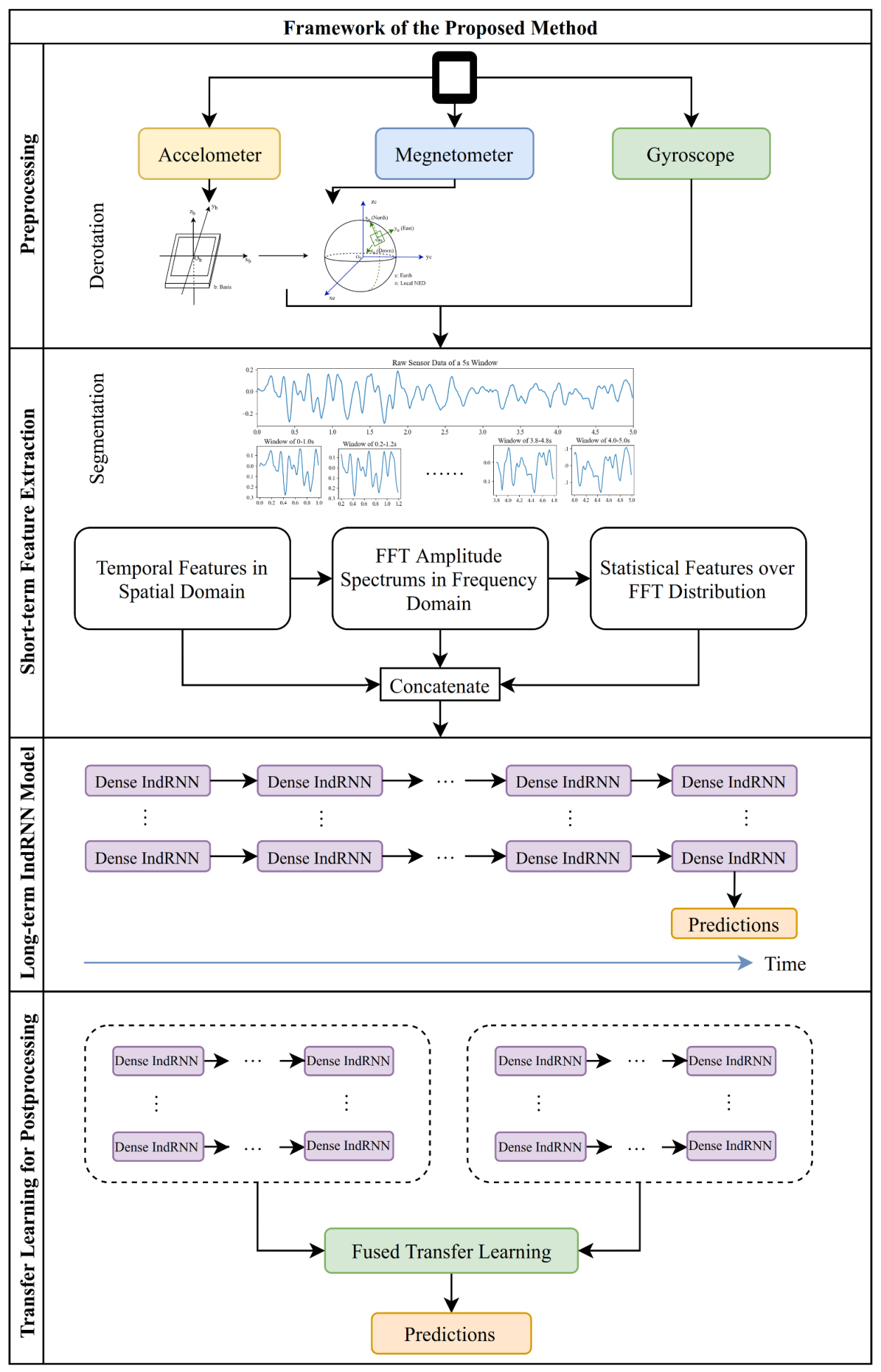
3. Proposed Method
3.1. Overall Framework
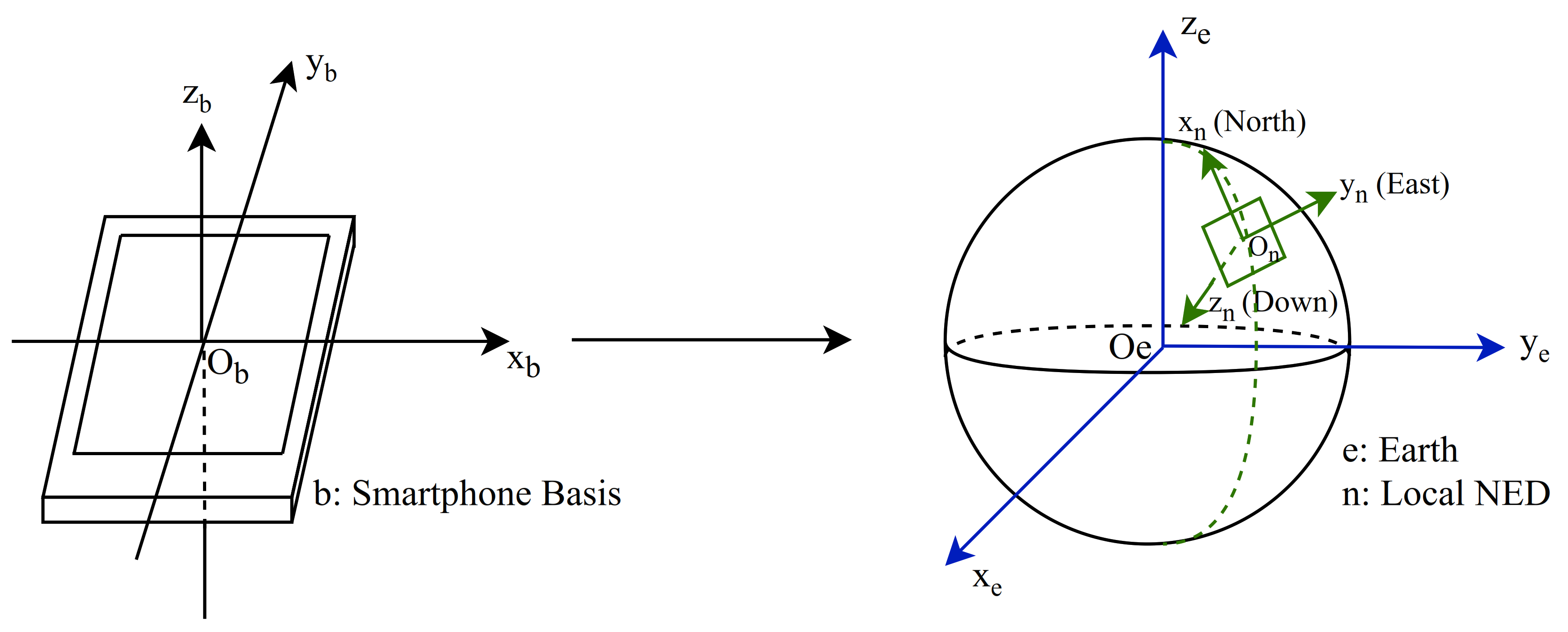
3.2. Preprocessing
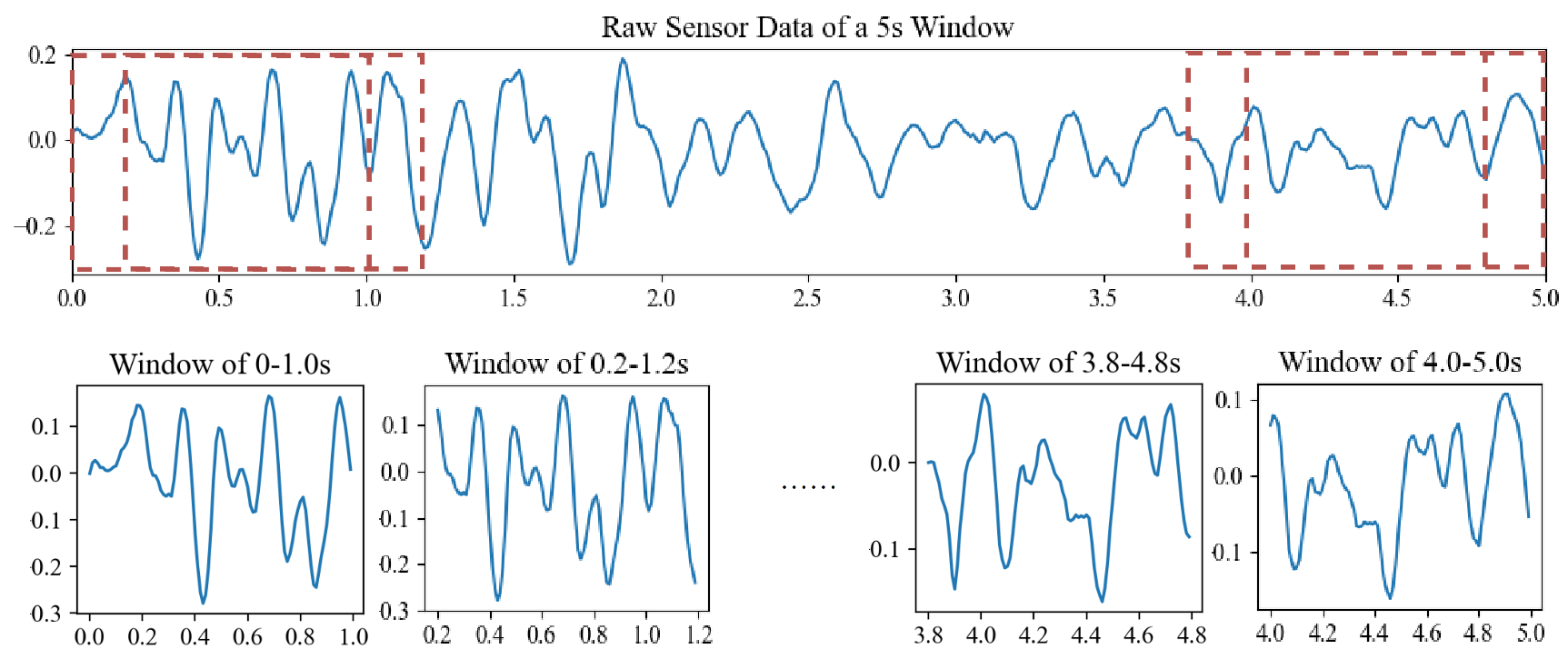
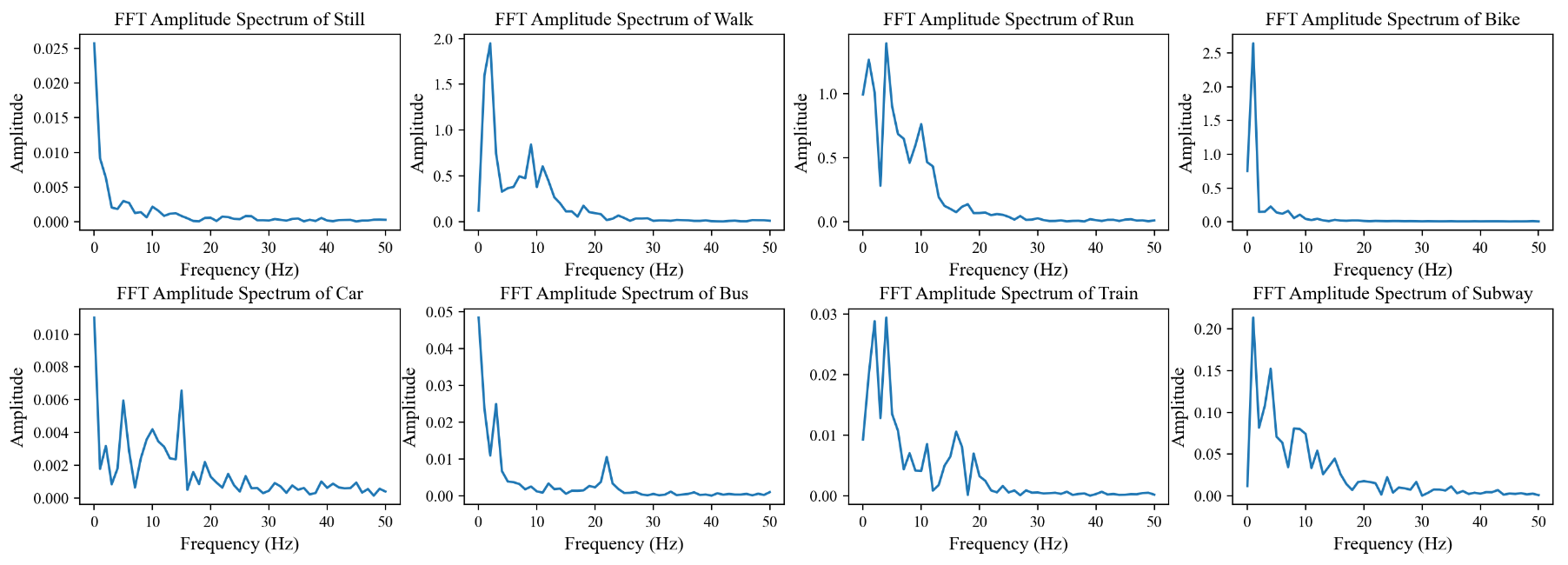
3.3. Short-Term Spatial and Frequency Domain Feature Extraction
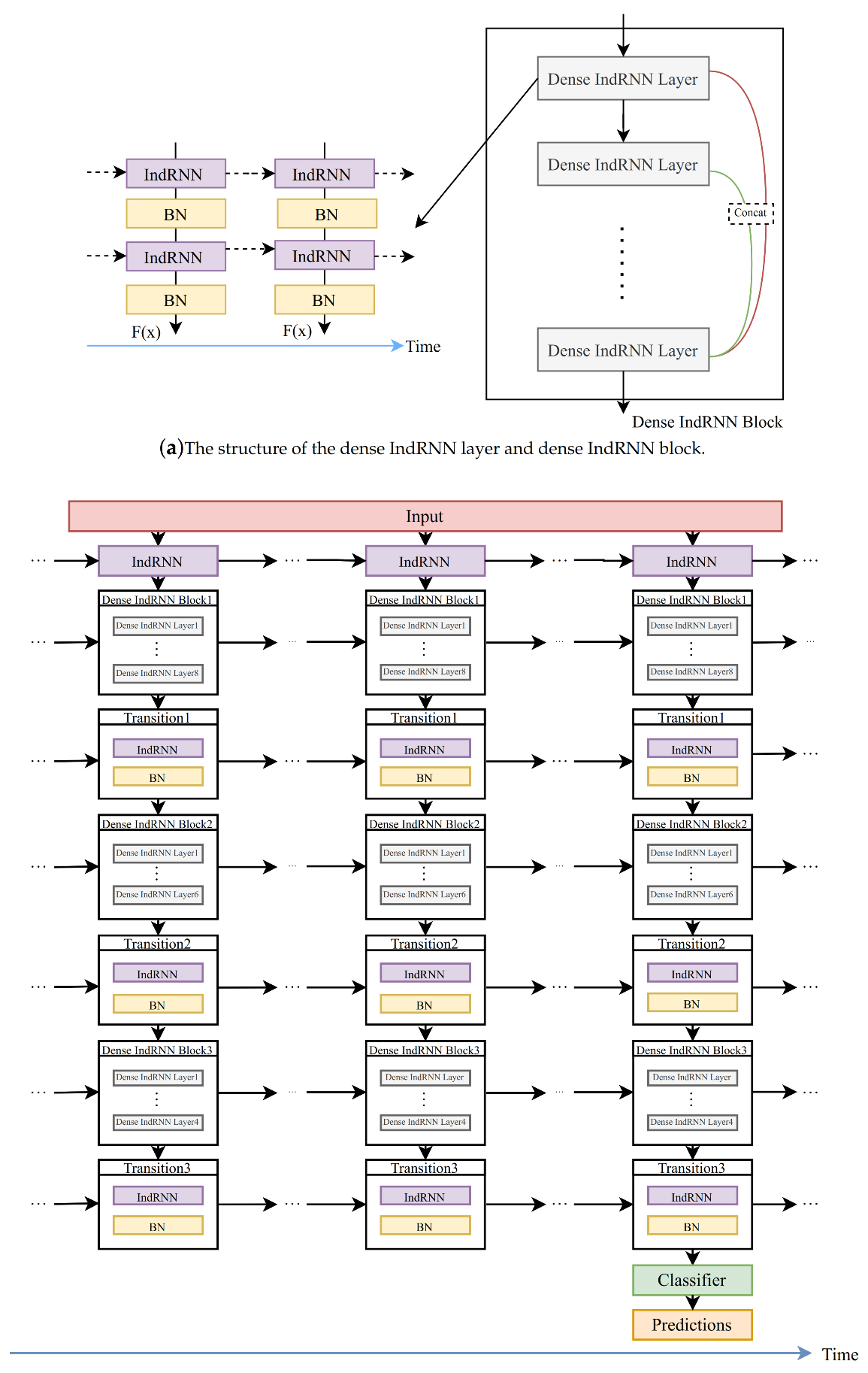
3.4. Long-Term IndRNN (Independently Recurrent Neural Network) Model
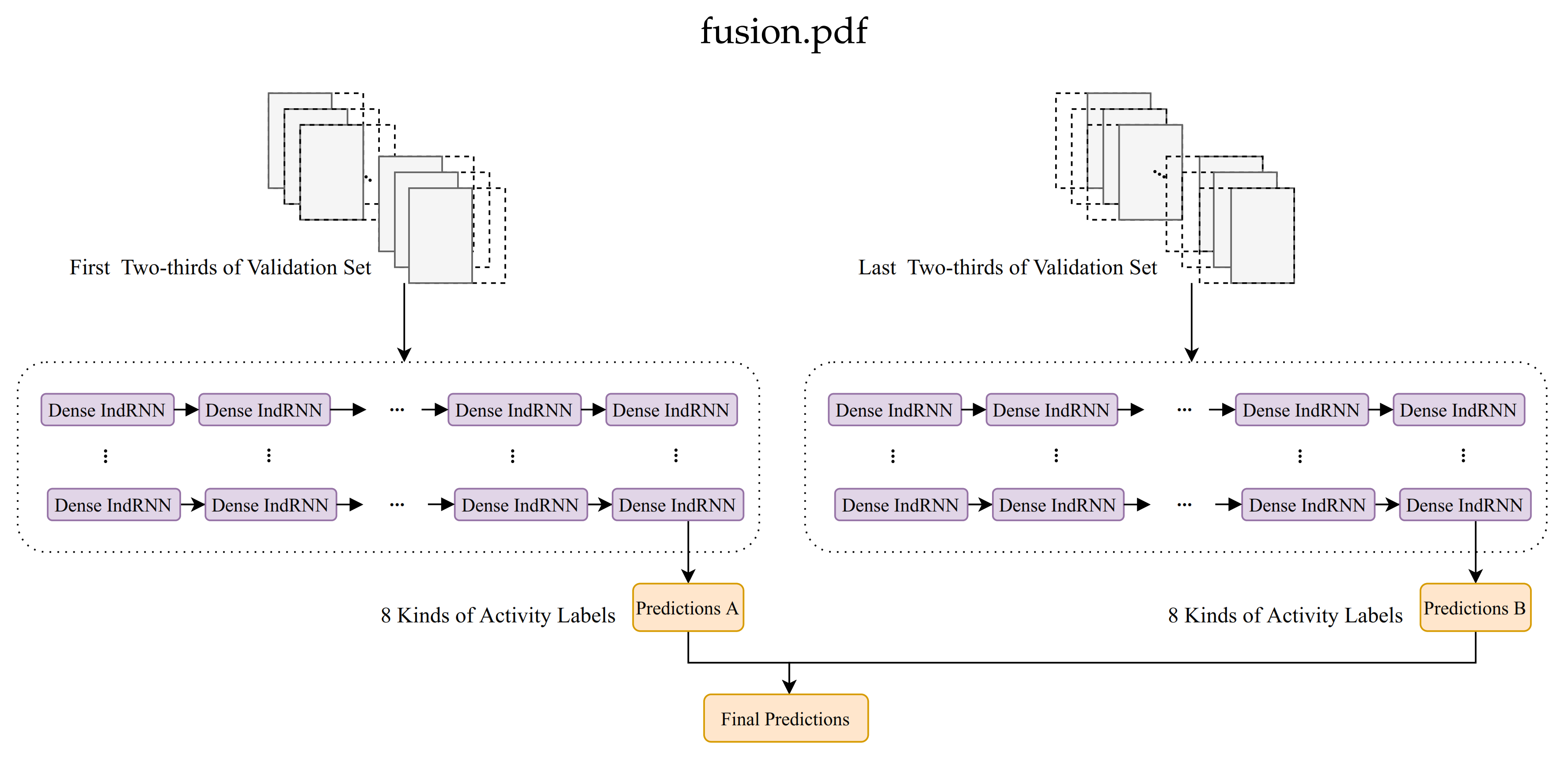
3.5. Transfer Learning for Postprocessing
4. Experimental Results
4.1. Dataset and Setup
4.1.1. SHL Dataset
4.1.2. Training Setup
4.1.3. Evaluation
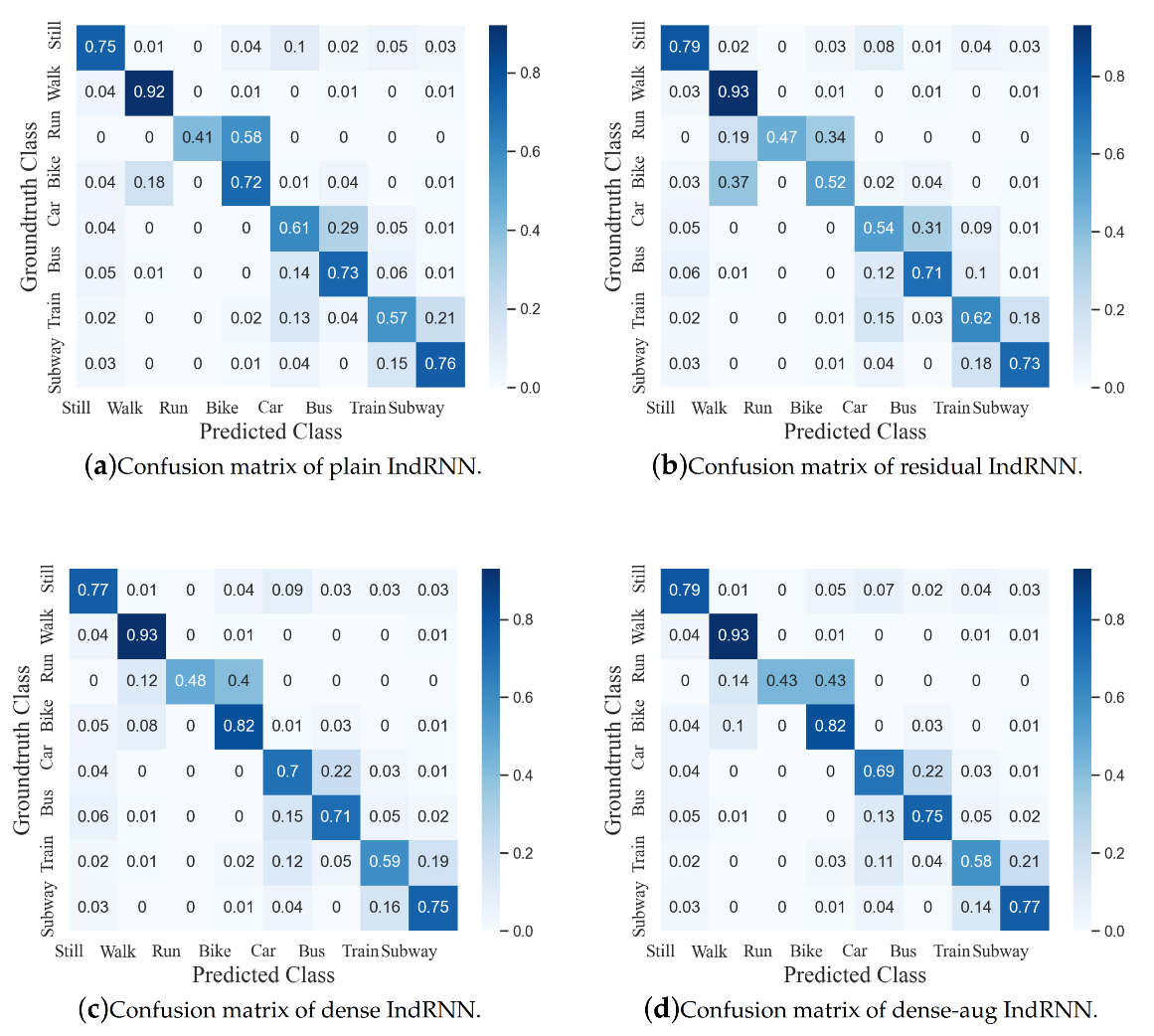
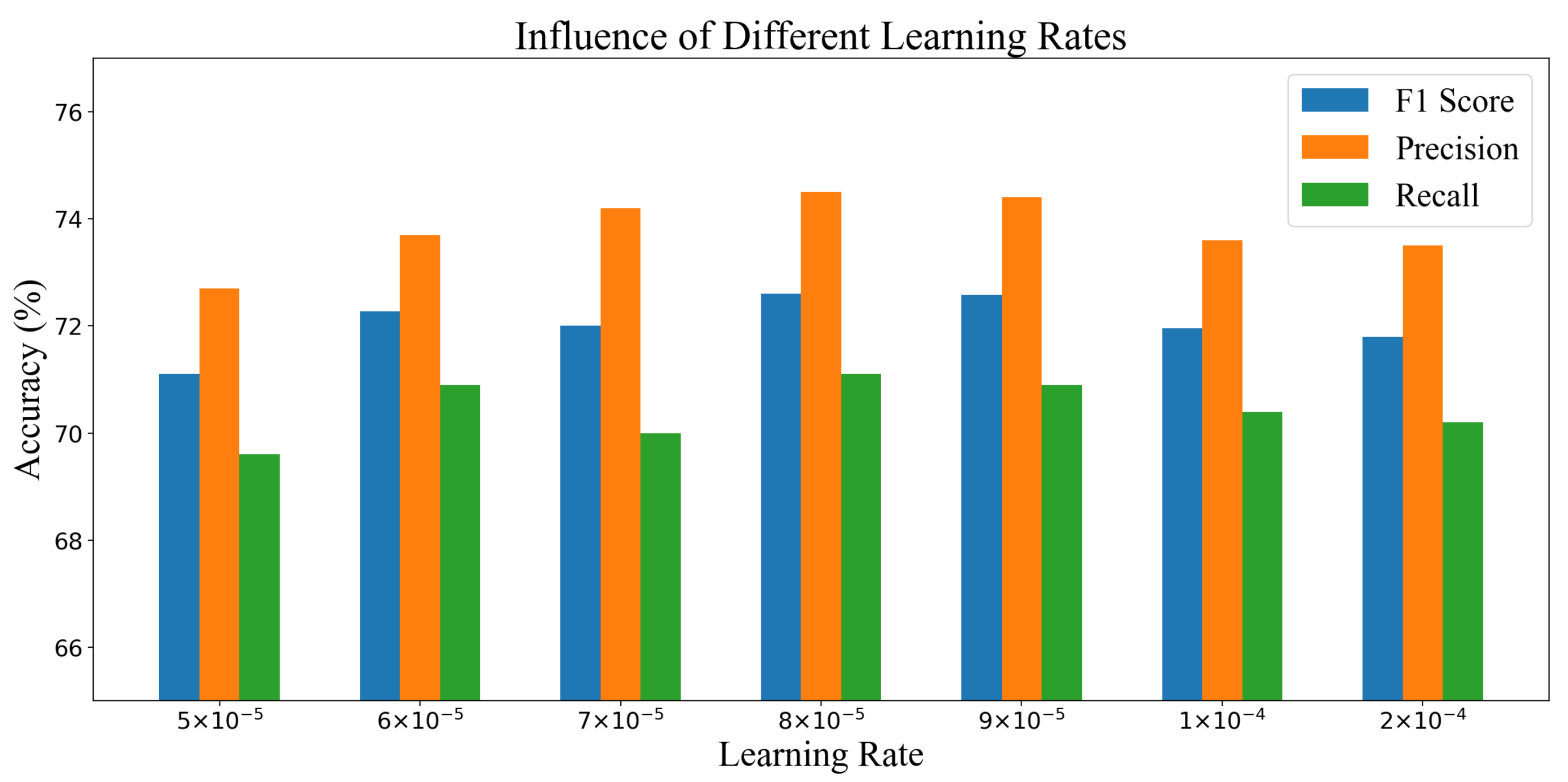
4.2. Ablation Studies on Models, Augmentation and Learning Rates
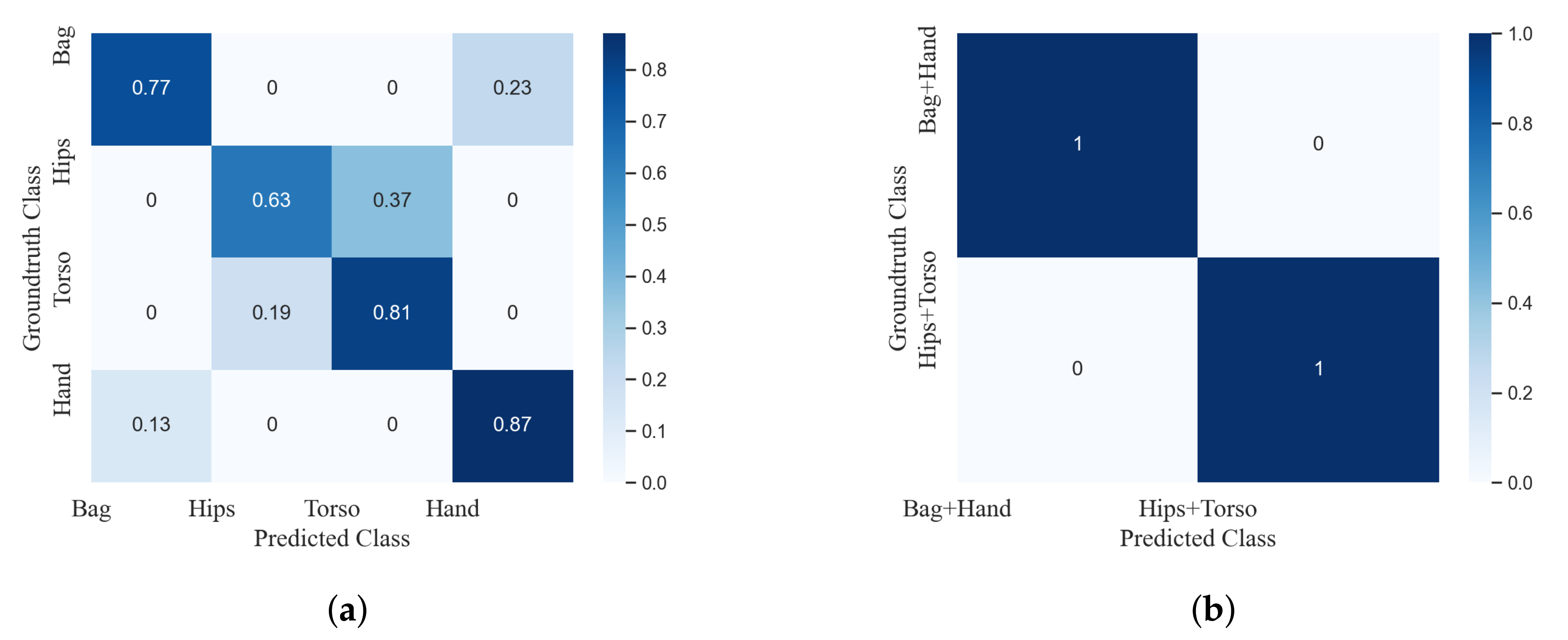
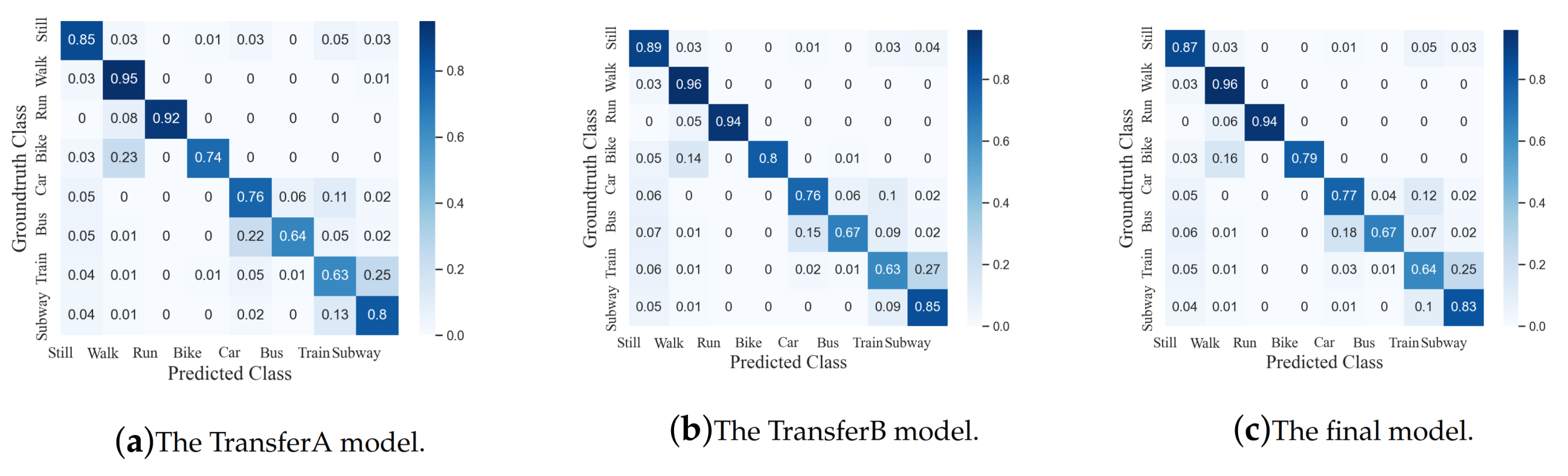
4.3. Transfer Learning
4.4. Comparison with State-of-the-Art Classification Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vishwakarma, S.; Agrawal, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Lin, W.; Sun, M.; Poovandran, R.; Zhang, Z. Human activity recognition for video surveillance. In Proceedings of the IEEE International Symposium on Circuits and Systems, Seattle, WA, USA, 18–21 May 2008; pp. 2737–2740. [Google Scholar]
- Niu, W.; Long, J.; Han, D.; Wang, Y. Human activity detection and recognition for video surveillance. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 719–722. [Google Scholar]
- Ruffieux, S.; Lalanne, D.; Mugellini, E. ChAirGest: A challenge for multimodal mid-air gesture recognition for close HCI. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction (ICMI ’13), Sydney, Australia, 9 December 2013; pp. 483–488. [Google Scholar]
- Biancat, J.; Brighenti, C.; Brighenti, A. Review of transportation mode detection techniques. EAI Endorsed Trans. Ambient Syst. 2014, 1, 1–10. [Google Scholar] [CrossRef][Green Version]
- Hassana, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Lo, B.; Yang, G. A Deep Learning Approach to on-Node Sensor Data Analytics for Mobile or Wearable Devices. IEEE J. Biomed. Health Inform. 2017, 21, 56–64. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Yang, J.; Li, Q. Smartphone-Based activity recognition for indoor localization using a convolutional neural network. Sensors 2019, 19, 621. [Google Scholar] [CrossRef] [PubMed]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Peng, B.; Lei, J.; Fu, H.; Shao, L.; Huang, Q. A Recursive Constrained Framework for Unsupervised Video Action Clustering. IEEE Trans. Ind. Inform. 2020, 16, 555–565. [Google Scholar] [CrossRef]
- Vito, J.; Rešçiç, N.; Mlakar, M.; Drobnič, V.; Gams, M.; Slapničar, G.; Gjoreski, M.; Bizjak, J.; Marinko, M.; Luštrek, M. A New Frontier for Activity Recognition: The Sussex-Huawei Locomotion Challenge. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers (UbiComp ’18), Singapore, 8 October 2018; pp. 1511–1520. [Google Scholar]
- Wang, L.; Gjoreski, H.; Ciliberto, M.; Lago, P.; Murao, K.; Okita, T.; Roggen, D. Summary of the Sussex-Huawei Locomotion-Transportation Recognition Challenge 2020. In Proceedings of the 2020 ACM International Joint Conference and 2020 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Virtual Event. Mexico, 10 September 2020; pp. 351–358. [Google Scholar]
- Wang, L.; Gjoreski, H.; Ciliberto, M.; Mekki, S.; Valentin, S.; Roggen, D. Enabling reproducible research in sensor-based transportation mode recognition with the Sussex-Huawei dataset. IEEE Access 2019, 7, 10870–10891. [Google Scholar] [CrossRef]
- Choi, J.; Lee, J. EmbraceNet for activity: A deep multimodal fusion architecture for activity recognition. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers (UbiComp/ISWC ’19 Adjunct), London, UK, 9 September 2019; pp. 693–698. [Google Scholar]
- Zhu, Y.; Zhao, F.; Chen, R. Applying 1D sensor DenseNet to Sussex-Huawei locomotion-transportation recognition challenge. In Proceedings of the Adjunct Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers (UbiComp/ISWC ’19 Adjunct), London, UK, 9 September 2019; pp. 873–877. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Li, S.; Gao, Y. IndRNN based long-term temporal recognition in the spatial and frequency domain. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 368–372. [Google Scholar]
- Inoue, S.; Ueda, N.; Nohara, Y.; Nakashima, N. Mobile activity recognition for a whole day: Recognizing real nursing activities with big dataset. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp ’15), Osaka, Japan, 7 September 2015; pp. 1269–1280. [Google Scholar]
- Zhuo, S.; Sherlock, L.; Dobbie, G.; Koh, Y.S.; Russello, G.; Lottridge, D. Real-time smartphone activity classification using inertial sensors—recognition of scrolling, typing, and watching videos while sitting or walking. Sensors 2020, 20, 655. [Google Scholar] [CrossRef] [PubMed]
- Zdravevski, E.; Lameski, P.; Trajkovik, V.; Kulakov, A.; Chorbev, I.; Goleva, R.; Pombo, N.; Garcia, N. Improving Activity Recognition Accuracy in Ambient-Assisted Living Systems by Automated Feature Engineering. IEEE Access 2017, 5, 5262–5280. [Google Scholar] [CrossRef]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh – A Python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Parkka, J.; Ermes, M.; Korpipaa, P.; Mantyjarvi, J.; Peltola, J.; Korhonen, I. Activity classification using realistic data from wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 119–128. [Google Scholar] [CrossRef] [PubMed]
- Ustev, Y.E.; Incel, O.D.; Ersoy, C. User, device and orientation independent human activity recognition on mobile phones: Challenges and a proposal. In Proceedings of the 2013 ACM conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8 September 2013; pp. 1427–1436. [Google Scholar]
- Kim, Y.; Kang, B.; Kim, D. Hidden Markov Model Ensemble for Activity Recognition Using Tri-Axis Accelerometer. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015; pp. 3036–3041. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Fleury, A.; Vacher, M.; Noury, N. SVM-Based Multimodal Classification of Activities of Daily Living in Health Smart Homes: Sensors, Algorithms, and First Experimental Results. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 274–283. [Google Scholar] [CrossRef] [PubMed]
- Janko, V.; Gjoreski, M.; De Masi, C.M.; Reščič, N.; Luštrek, M.; Gams, M. Cross-location transfer learning for the sussex-huawei locomotion recognition challenge. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers (UbiComp/ISWC ’19 Adjunct), London, UK, 9 September 2019; pp. 730–735. [Google Scholar]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sen- sors. Proceedings of International Conference on Mobile Computing, Applications and Services (MobiCASE), Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. Web-Age Inf. Tion Manag. 2014, 8485, 298–310. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Pradhan, S.; Longpre, S. Exploring the Depths of Recurrent Neural Networks with Stochastic Residual Learning. Available online: https://cs224d.stanford.edu/reports/PradhanLongpre.pdf (accessed on 7 December 2020).
- Xi, R.; Li, M.; Hou, M.; Fu, M.; Qu, M.; Liu, D.; Haruna, C.R. Deep Dilation on Multimodality Time Series for Human Activity Recognition. IEEE Accesss 2018, 6, 53381–53396. [Google Scholar] [CrossRef]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5457–5466. [Google Scholar]
- Li, S.; Li, W.; Cook, C.; Gao, Y. Deep Independently Recurrent Neural Network (IndRNN). arXiv 2019, arXiv:1910.06251. [Google Scholar]
- Li, S.; Li, C.; Li, W.; Hou, Y.; Cook, C. Smartphone-sensors Based Activity Recognition Using IndRNN. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers (UbiComp ’18), Singapore, 8 October 2018; pp. 1541–1547. [Google Scholar]
- Zheng, L.; Li, S.; Zhu, C.; Gao, Y. Application of IndRNN for human activity recognition: The Sussex-Huawei locomotion-transportation challenge. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers (UbiComp/ISWC ’19 Adjunct), London, UK, 9 September 2019; pp. 869–872. [Google Scholar]
- Gjoreski, H.; Ciliberto, M.; Wang, L.; Morales, F.J.O.; Mekki, S.; Valentin, S.; Roggen, D. The University of Sussex-Huawei locomotion and transportation dataset for multimodal analytics with mobile devices. IEEE Access 2018, 42592–42604. [Google Scholar] [CrossRef]
- Diederik, K.; Jimmy, B.; Adam, A. Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, J.; Li, W.; Ogunbona, P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1859–1867. [Google Scholar]
- Zhu, Y.; Luo, H.; Chen, R.; Zhao, F.; Su, L. DenseNetX and GRU for the sussex-huawei locomotion-transportation recognition challenge. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 373–377. [Google Scholar]
- Kalabakov, S.; Stankoski, S.; Reščič, N.; Kiprijanovska, I.; Andova, A.; Picard, C.; Janko, V.; Gjoreski, M.; Luštrek, M. Tackling the SHL challenge 2020 with person-specific classifiers and semi-supervised learning. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 323–328. [Google Scholar]
- Yaguchi, K.; Ikarigawa, K.; Kawasaki, R.; Miyazaki, W.; Morikawa, Y.; Ito, C.; Shuzo, M.; Maeda, E. Human activity recognition using multi-input CNN model with FFT spectrograms. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 364–367. [Google Scholar]
- Naseeb, C.; Saeedi, B.A. Activity recognition for locomotion and transportation dataset using deep learning. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 329–334. [Google Scholar]
- Siraj, M.S.; Faisal, M.A.A.; Shahid, O.; Abir, F.F.; Hossain, T.; Inoue, S.; Ahad, M.A.R. UPIC: User and position independent classical approach for locomotion and transportation modes recognition. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 340–345. [Google Scholar]
- Brajesh, S.; Ray, I. Ensemble approach for sensor-based human activity recognition. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 296–300. [Google Scholar]
- Widhalm, P.; Merz, P.; Coconu, L.; Brändle, N. Tackling the SHL recognition challenge with phone position detection and nearest neighbour smoothing. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 359–363. [Google Scholar]
- Sekiguchi, R.; Abe, K.; Yokoyama, T.; Kumano, M.; Kawakatsu, M. Ensemble learning for human activity recognition. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 335–339. [Google Scholar]
- Tseng, Y.; Lin, H.; Lin, Y.; Chen, J. Hierarchical classification using ML/DL for sussex-huawei locomotion-transportation (SHL) recognition challenge. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 346–350. [Google Scholar]
- Friedrich, B.; Lübbe, C.; Hein, A. Combining LSTM and CNN for mode of transportation classification from smartphone sensors. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 305–310. [Google Scholar]
- Hamidi, M.; Osmani, A.; Alizadeh, P. A multi-view architecture for the SHL challenge. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 317–322. [Google Scholar]
- Gunthermann, L.; Simpson, I.; Roggen, D. Smartphone location identification and transport mode recognition using an ensemble of generative adversarial networks. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers (UbiComp-ISWC ’20), Virtual Event. Mexico, 10 September 2020; pp. 311–316. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Domain Features | Description |
|---|---|
| Mean | The average value of the data for each axis in the window |
| Numbers above Mean | The numbers of values above the mean of the window |
| Numbers below Mean | The numbers of values below the mean of the window |
| Standard Deviation | Standard deviation of each axis in the window |
| Minimum Value | The minimum value of the data for each axis in the window |
| Maximum Value | The maximum value of the data for each axis in the window |
| Per Sample Normalized Pressure | The normalized pressure of each sample |
| Model | Presicion | Recall | F1 Score |
|---|---|---|---|
| Plain IndRNN | 71.70% | 67.40% | 69.48% |
| Residual IndRNN | 70.17% | 65.93% | 67.98% |
| Dense IndRNN | 74.37% | 69.41% | 71.80% |
| Dense-IndRNN-aug | 76.25% | 72.00% | 74.06% |
| Method | Performance | Final Performance |
|---|---|---|
| TransferA | 78.11% | 80.72% |
| TransferB | 80.97% |
| Method | Performance |
|---|---|
| XGBoost [48] | 55.0% |
| Nearest neighbor smoothing [46] | 61.2% |
| Random forest (without location estimation) [45] | 62.6% |
| Random forest (with location estimation) [44] | 69.1% |
| XGBoost (semisupervised) [41] | 77.9% |
| GAN [51] | 34.4% |
| Multiview CNN [50] | 37.3% |
| Logistic regression [47] | 55.7% |
| InceptionTime [43] | 69.4% |
| Three-layer CNN [42] | 76.4% |
| CNN + LSTM [49] | 52.8% |
| DenseNetX + GRU (Model Fusion based) [40] | 88.5% |
| Dense-IndRNN-aug | 80.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, B.; Li, S.; Gao, Y.; Li, C.; Li, W. A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition. Sensors 2020, 20, 6984. https://doi.org/10.3390/s20236984
Zhao B, Li S, Gao Y, Li C, Li W. A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition. Sensors. 2020; 20(23):6984. https://doi.org/10.3390/s20236984
Chicago/Turabian StyleZhao, Beidi, Shuai Li, Yanbo Gao, Chuankun Li, and Wanqing Li. 2020. "A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition" Sensors 20, no. 23: 6984. https://doi.org/10.3390/s20236984
APA StyleZhao, B., Li, S., Gao, Y., Li, C., & Li, W. (2020). A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition. Sensors, 20(23), 6984. https://doi.org/10.3390/s20236984