Vision-Based Building Seismic Displacement Measurement by Stratification of Projective Rectification Using Lines


Abstract
:1. Introduction
- This study addresses the problem of extracting structural dynamic displacement information from a single, uncalibrated camera;
- There is no need for stationary cameras and cameras with any perspective view are allowed to be used during the measurement process;
- Line segments are natural and plentiful in man-made architectural buildings, which makes the proposed algorithm applicable in real-world applications;
- The proposed algorithm is especially useful for automatic perspective distortion removal and image rectification from video sequence.
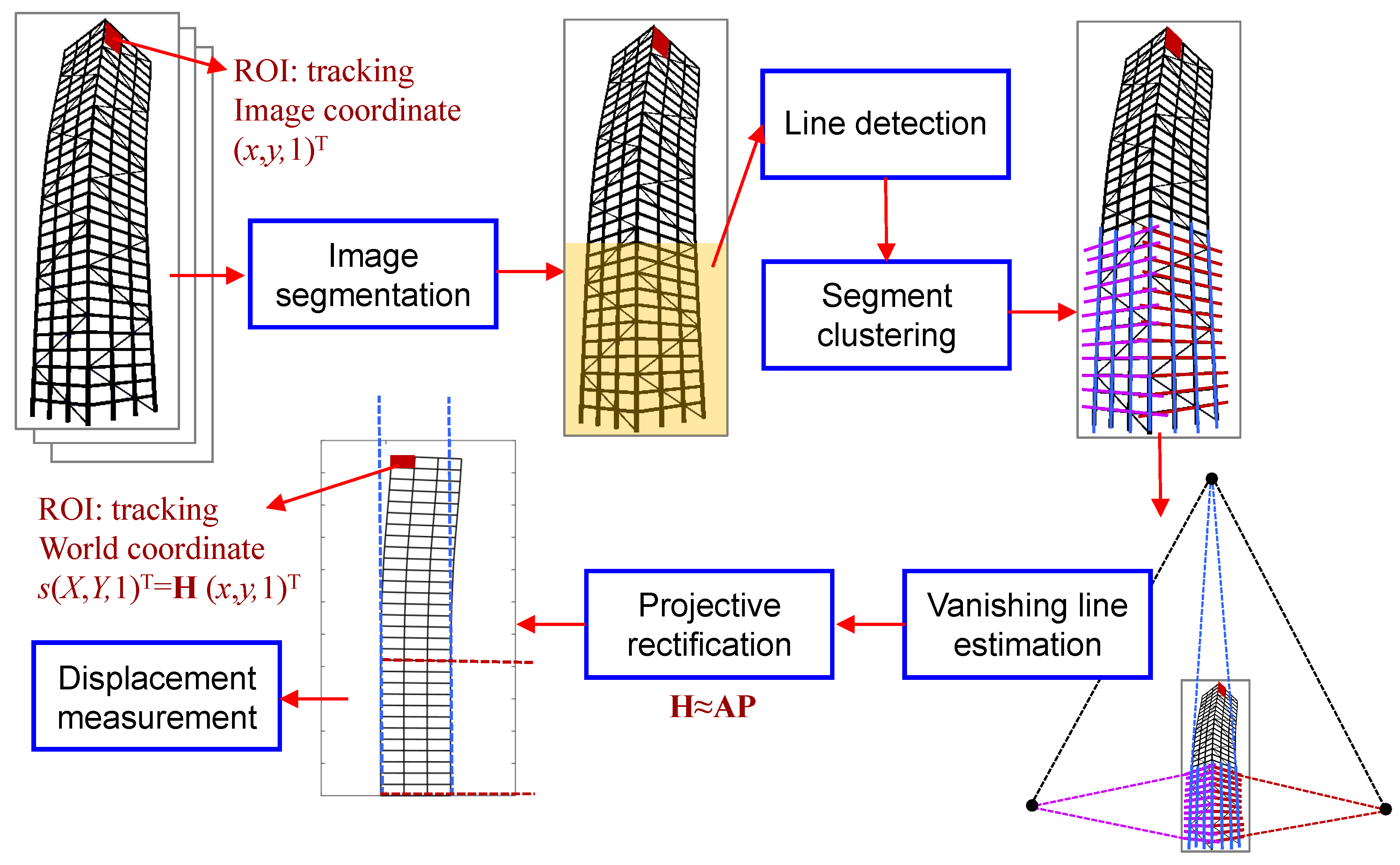
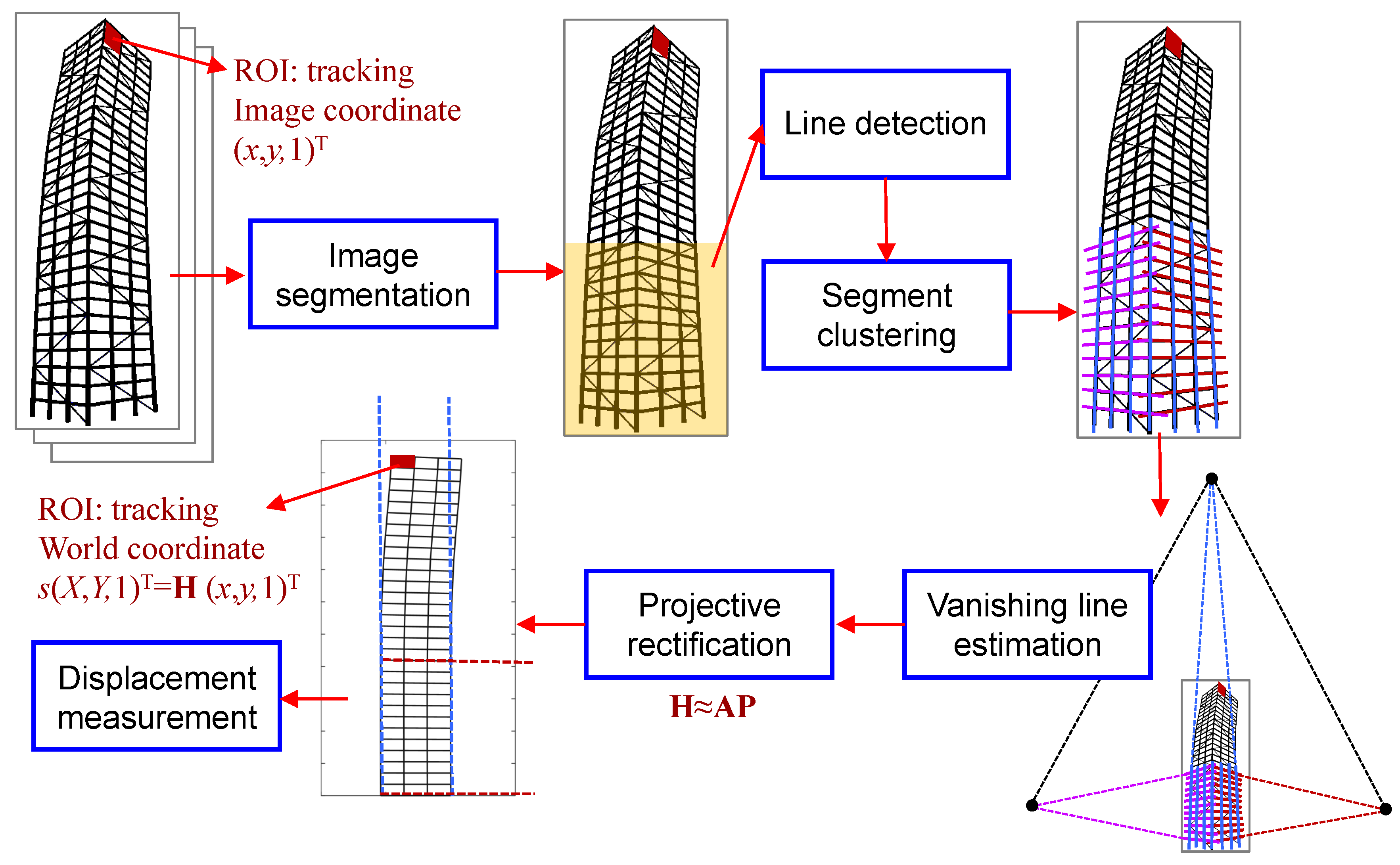
2. Methodology
2.1. Image Segmentation
2.2. Line Detection and Segment Clustering
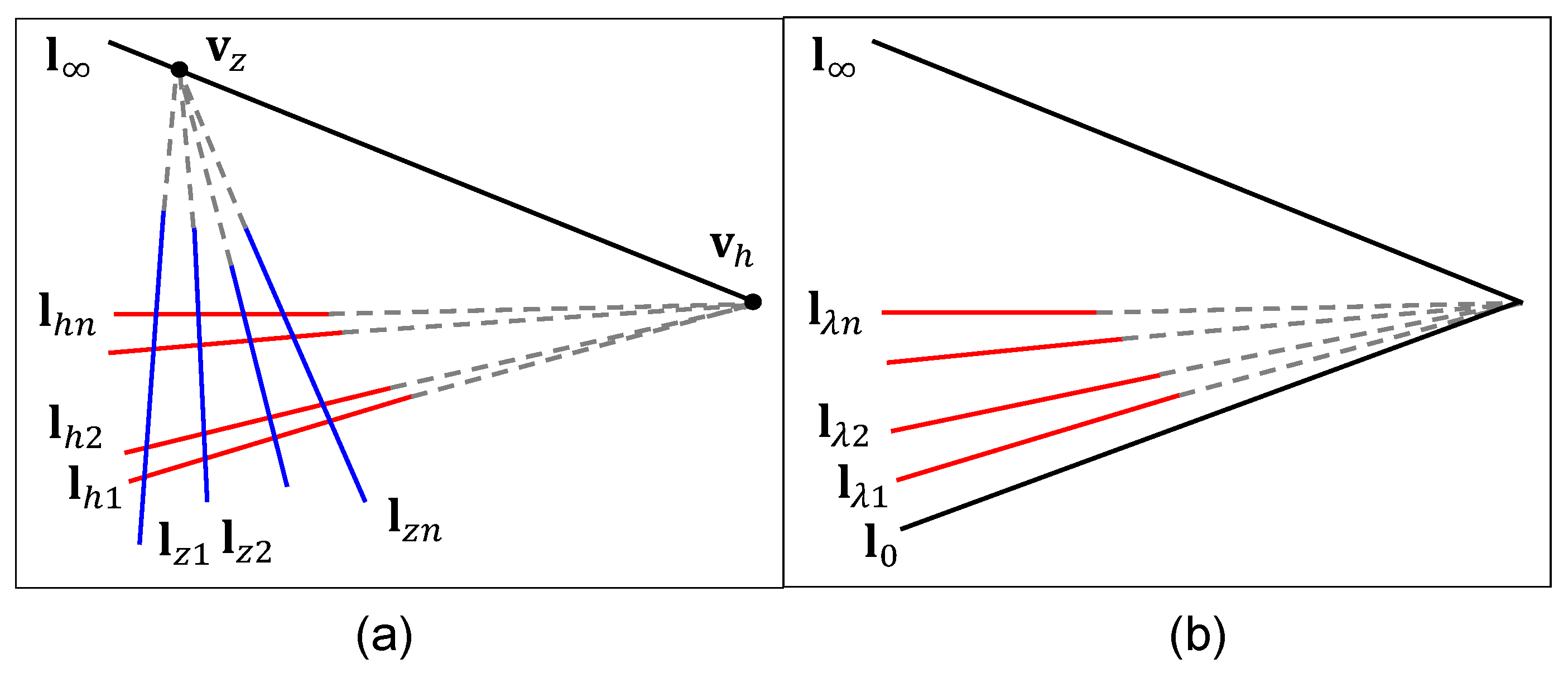
2.3. Vanishing Line Estimation
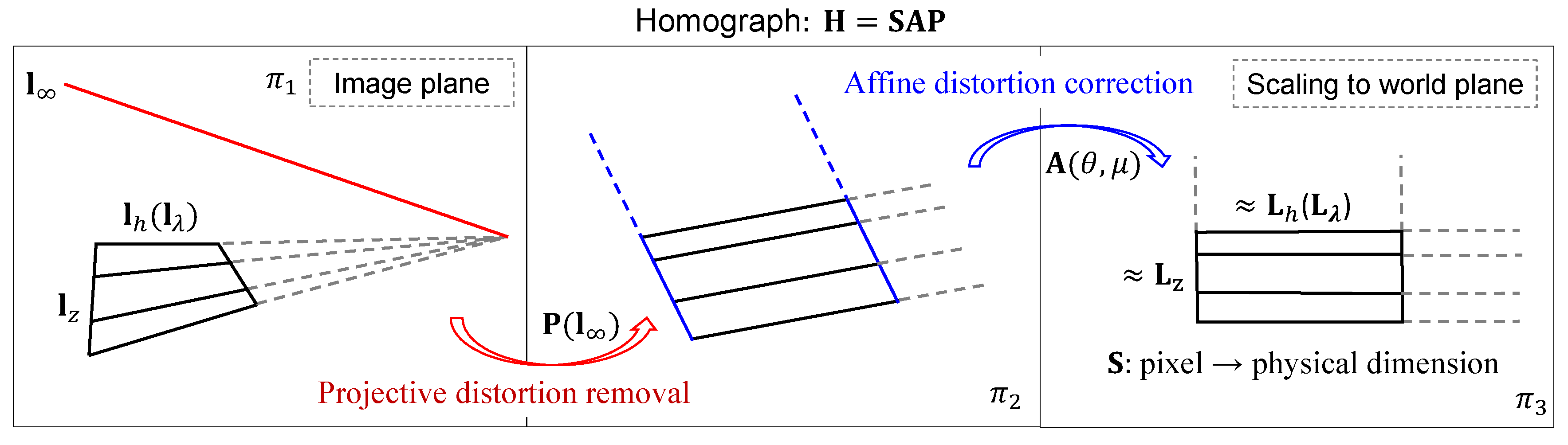
2.4. Stratification of Projective Rectification
2.4.1. Projective Distortion Removal
2.4.2. Affine Distortion Correction
3. Experimental Case Studies
3.1. Synthetic Experiments
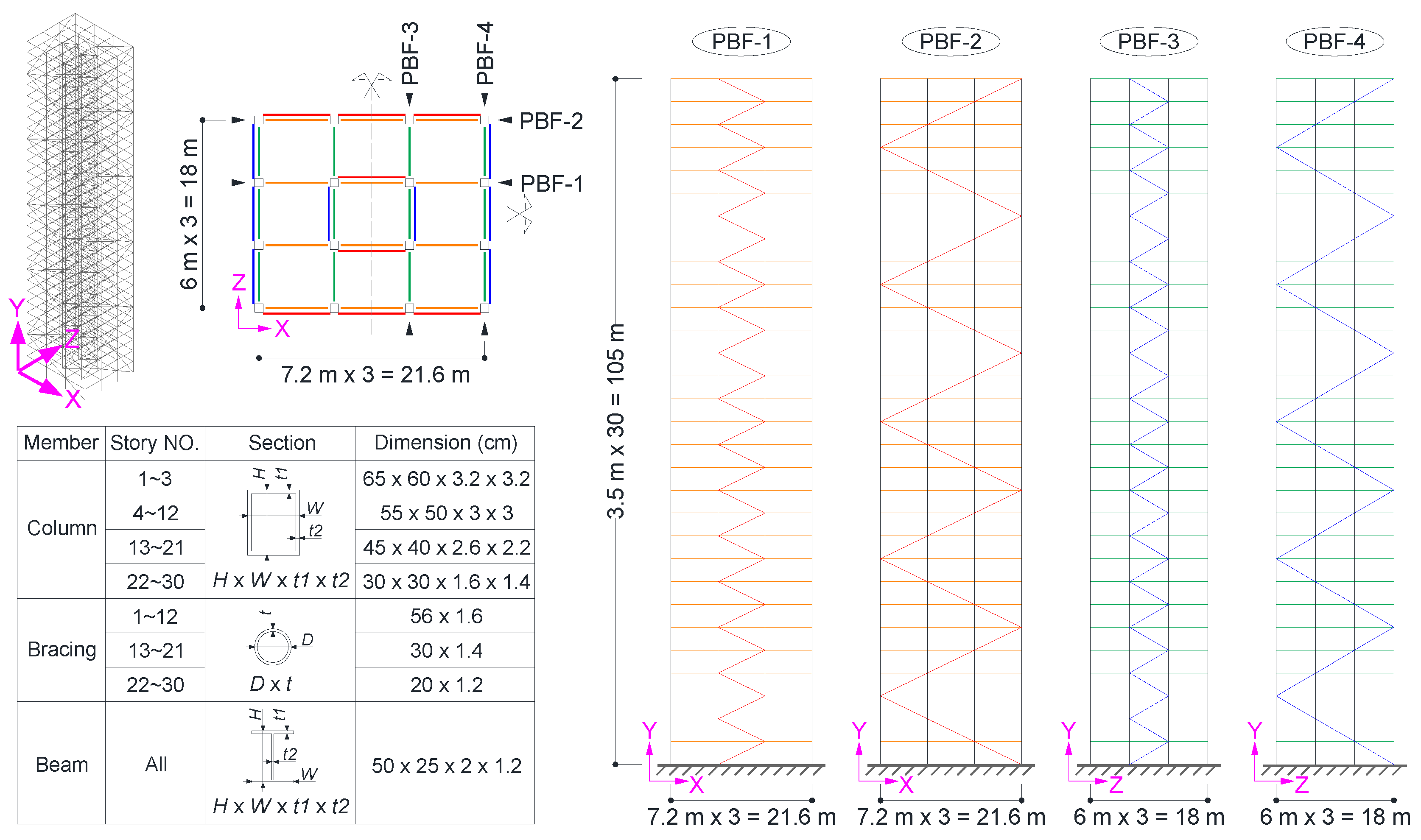
3.1.1. A 30-Story Building Model
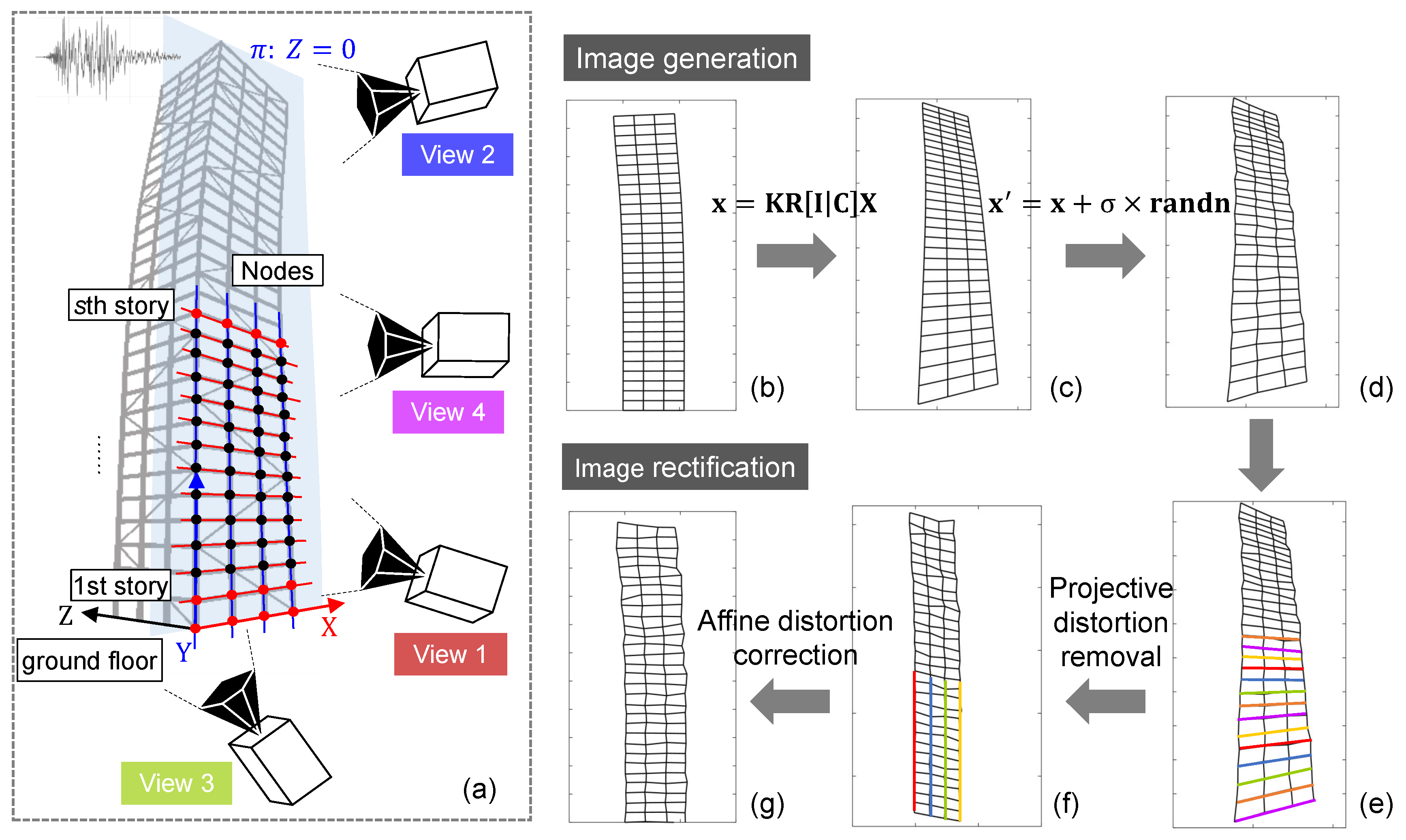
3.1.2. Image Generation
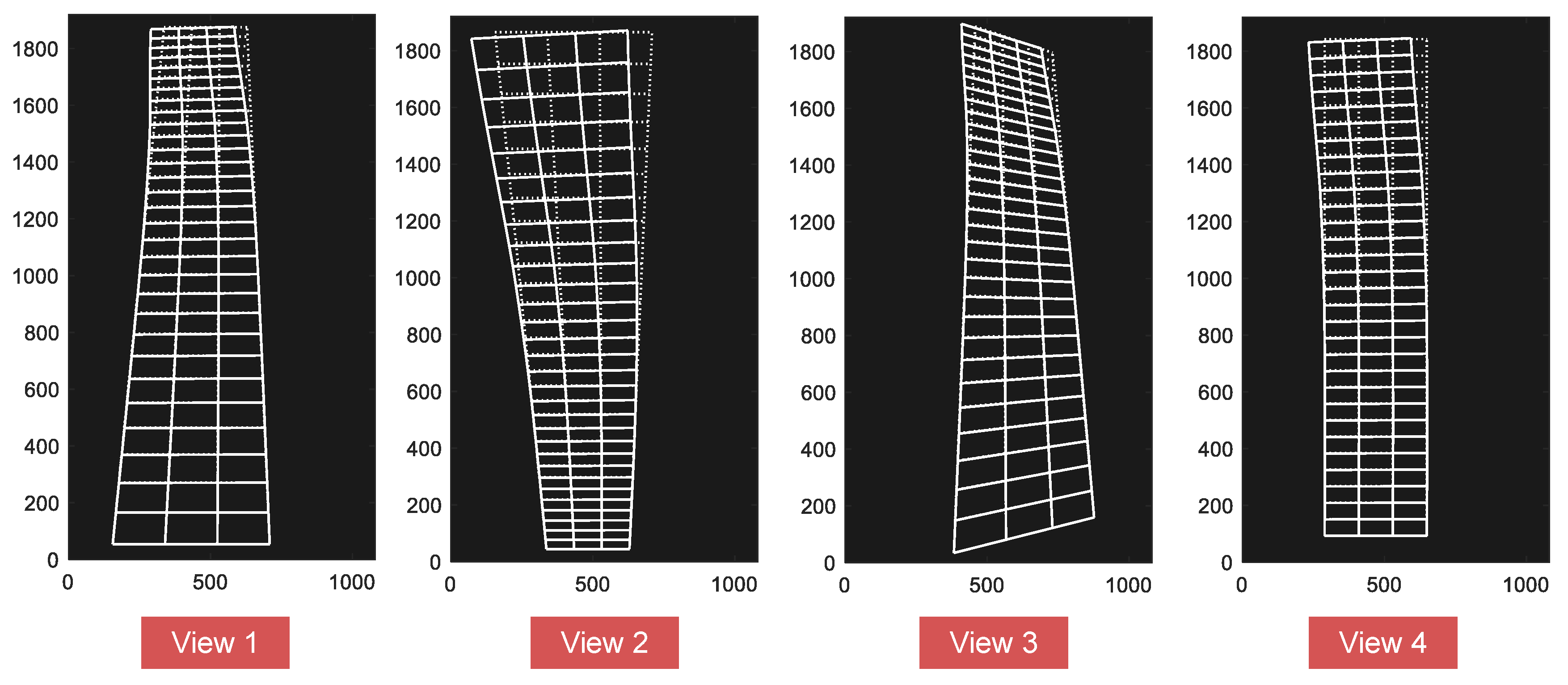
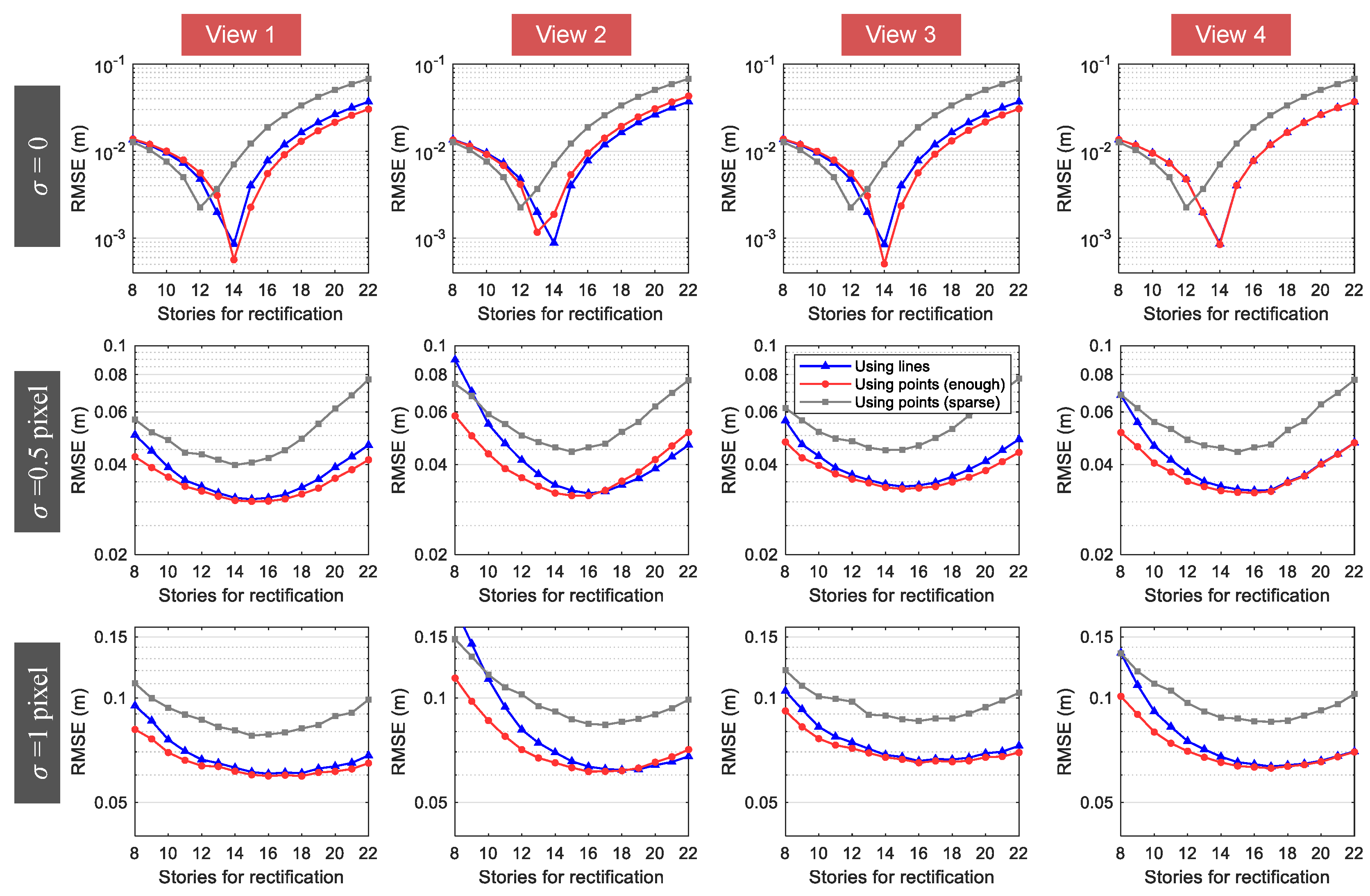
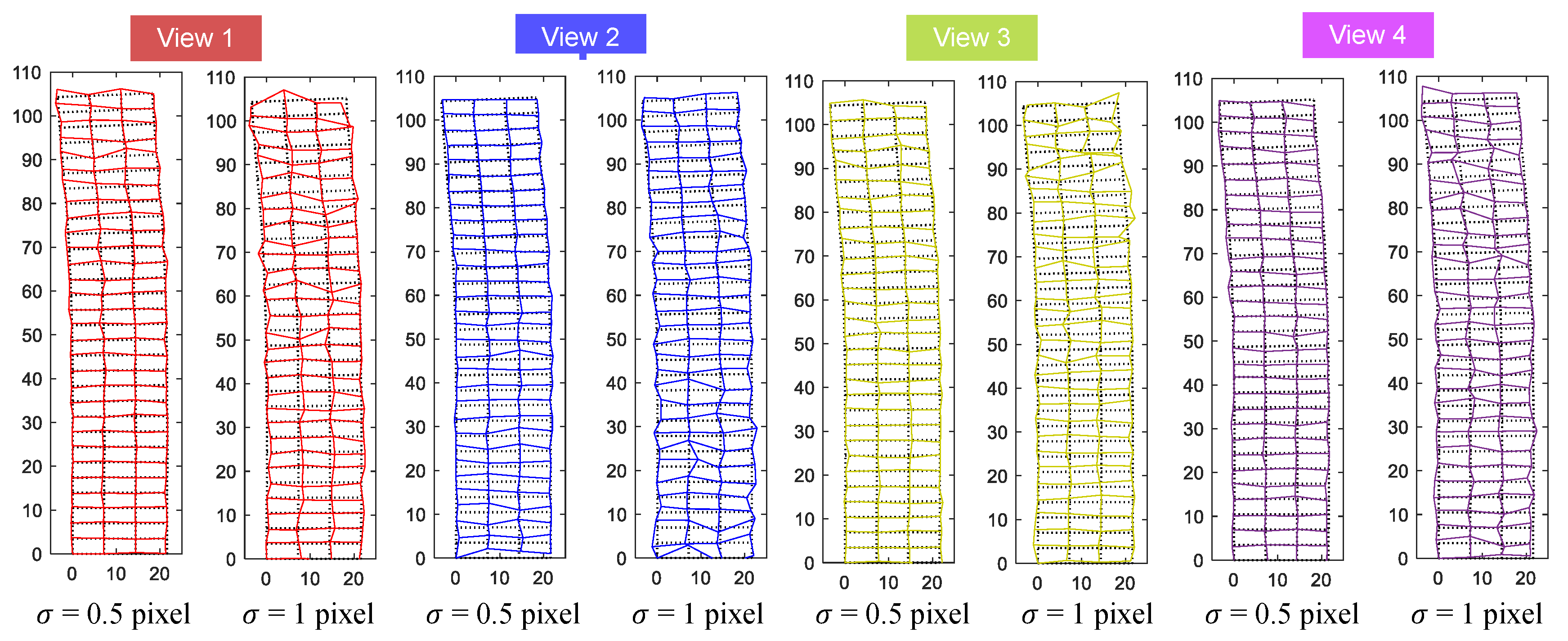
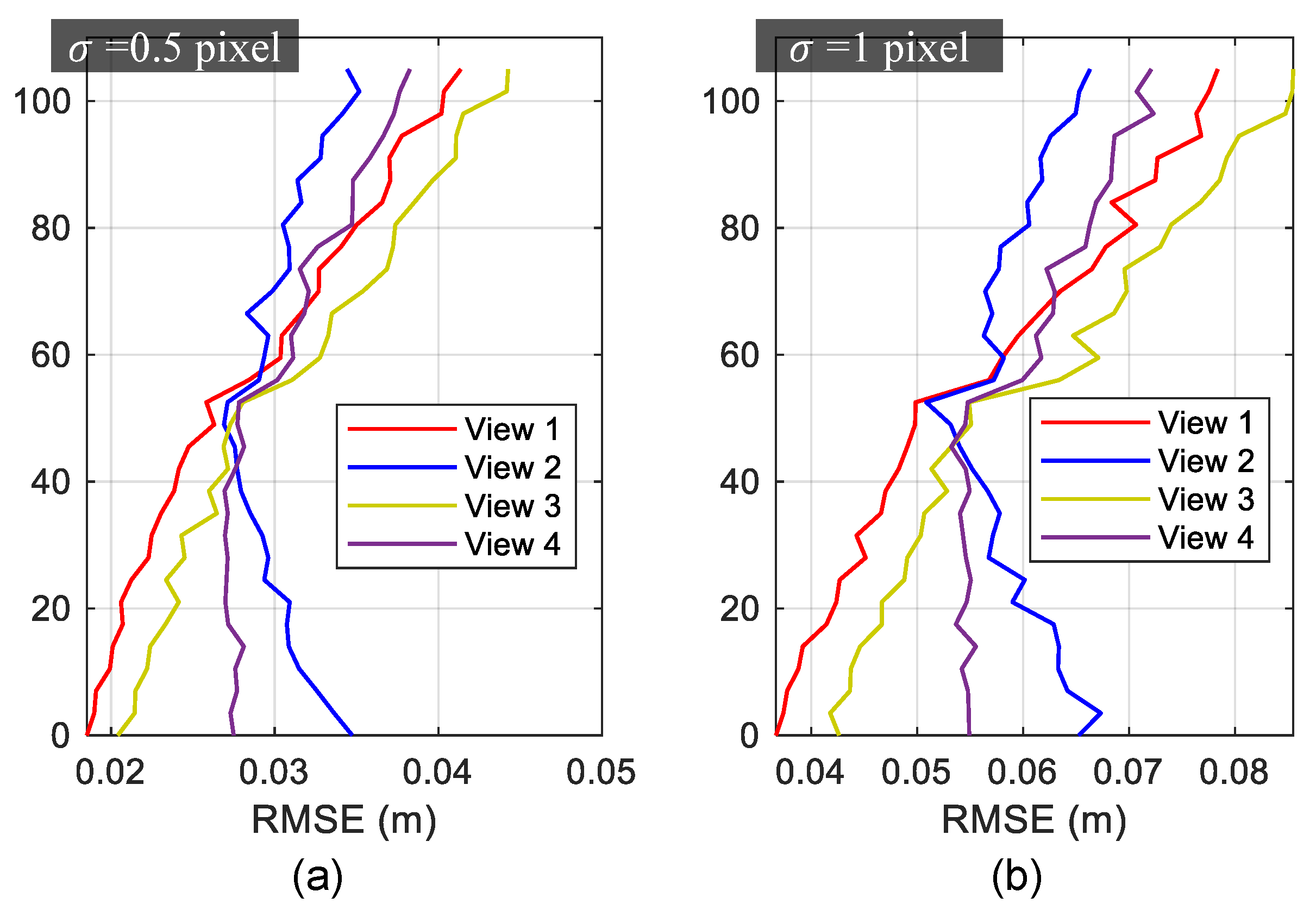
3.1.3. Measurement Results
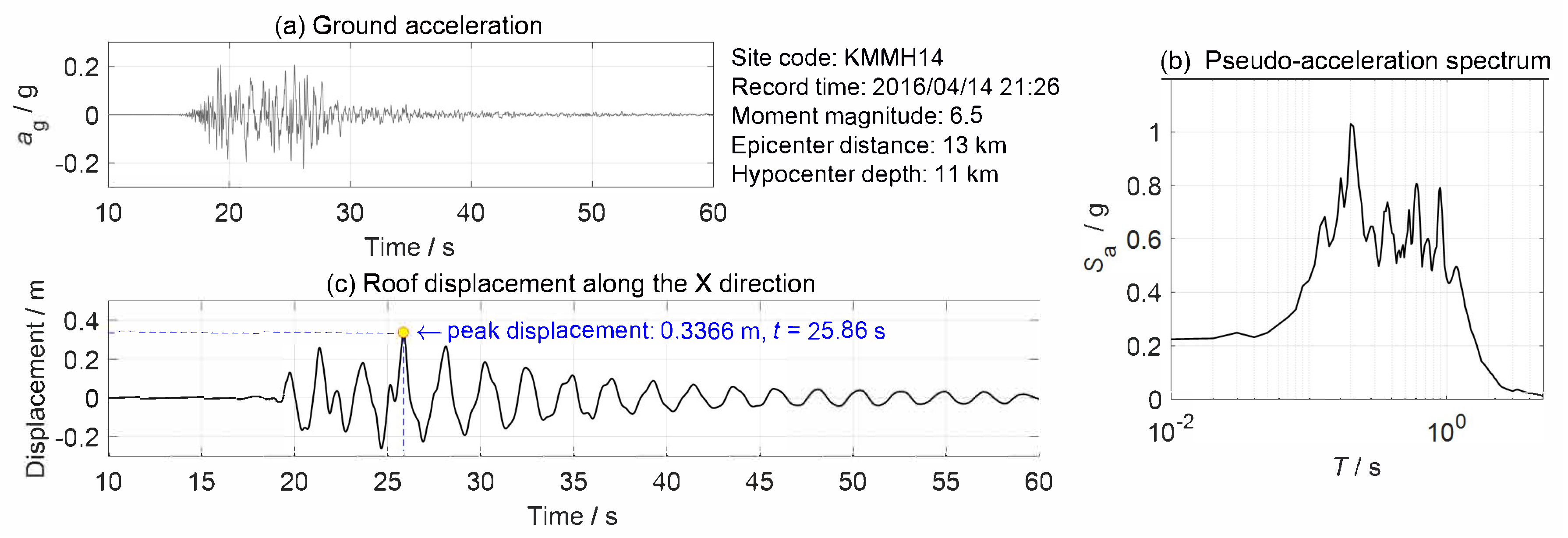
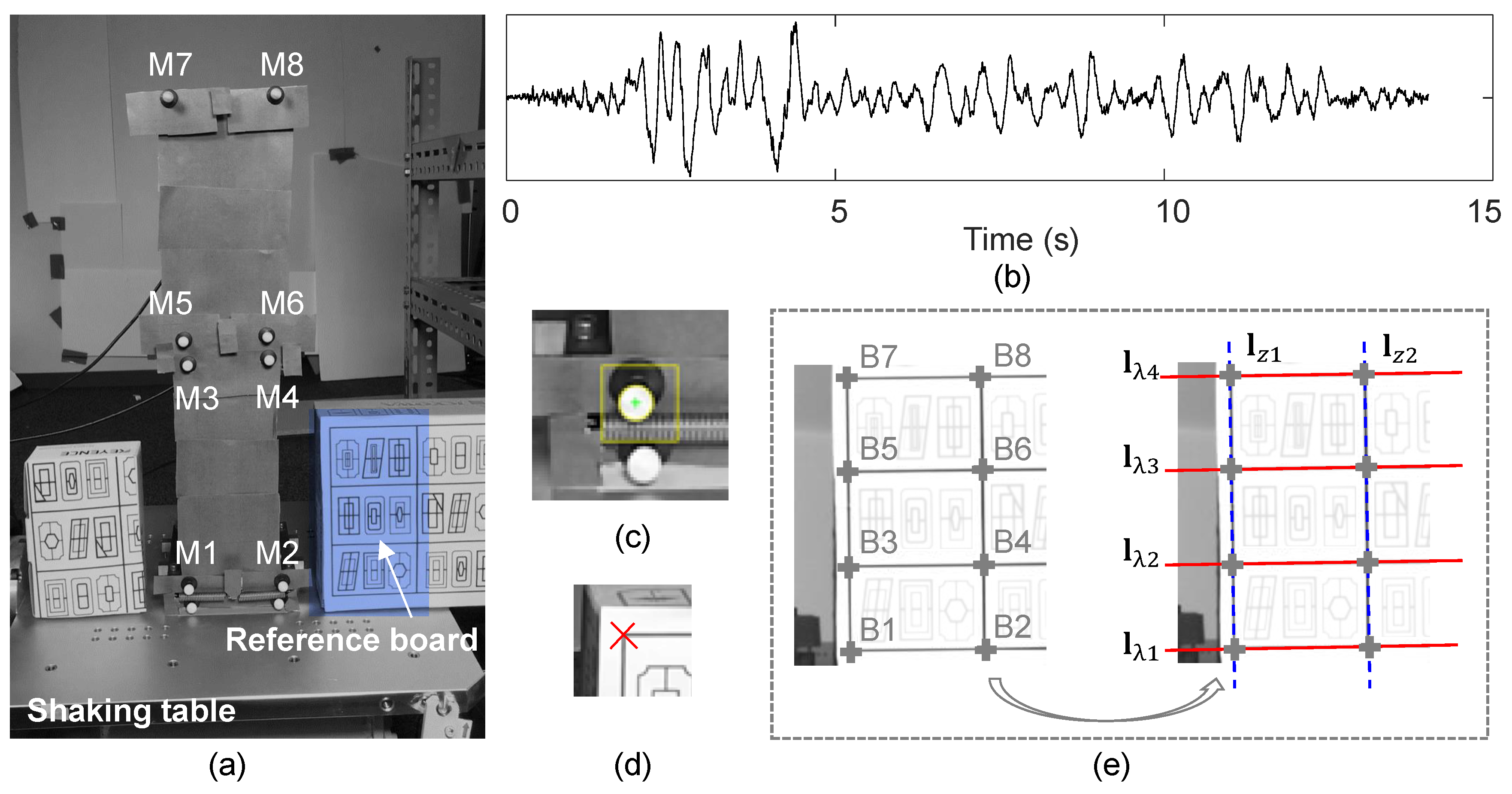
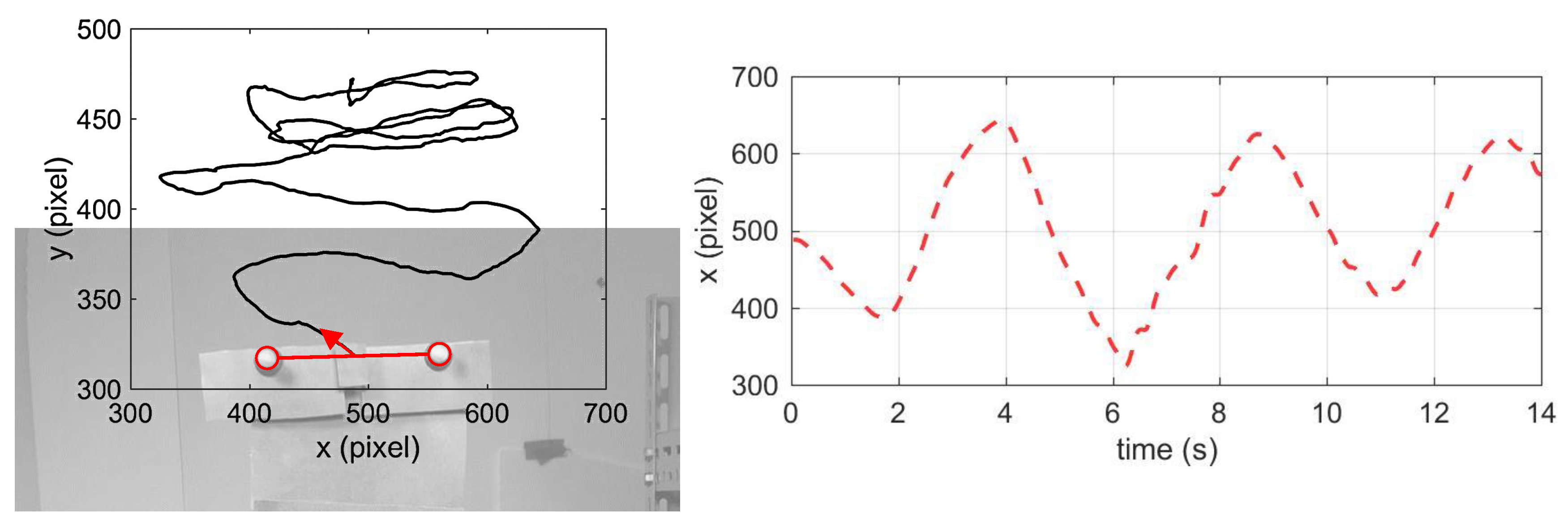
3.2. Experiments on Real Video Sequences
3.2.1. Experiment Test Setup
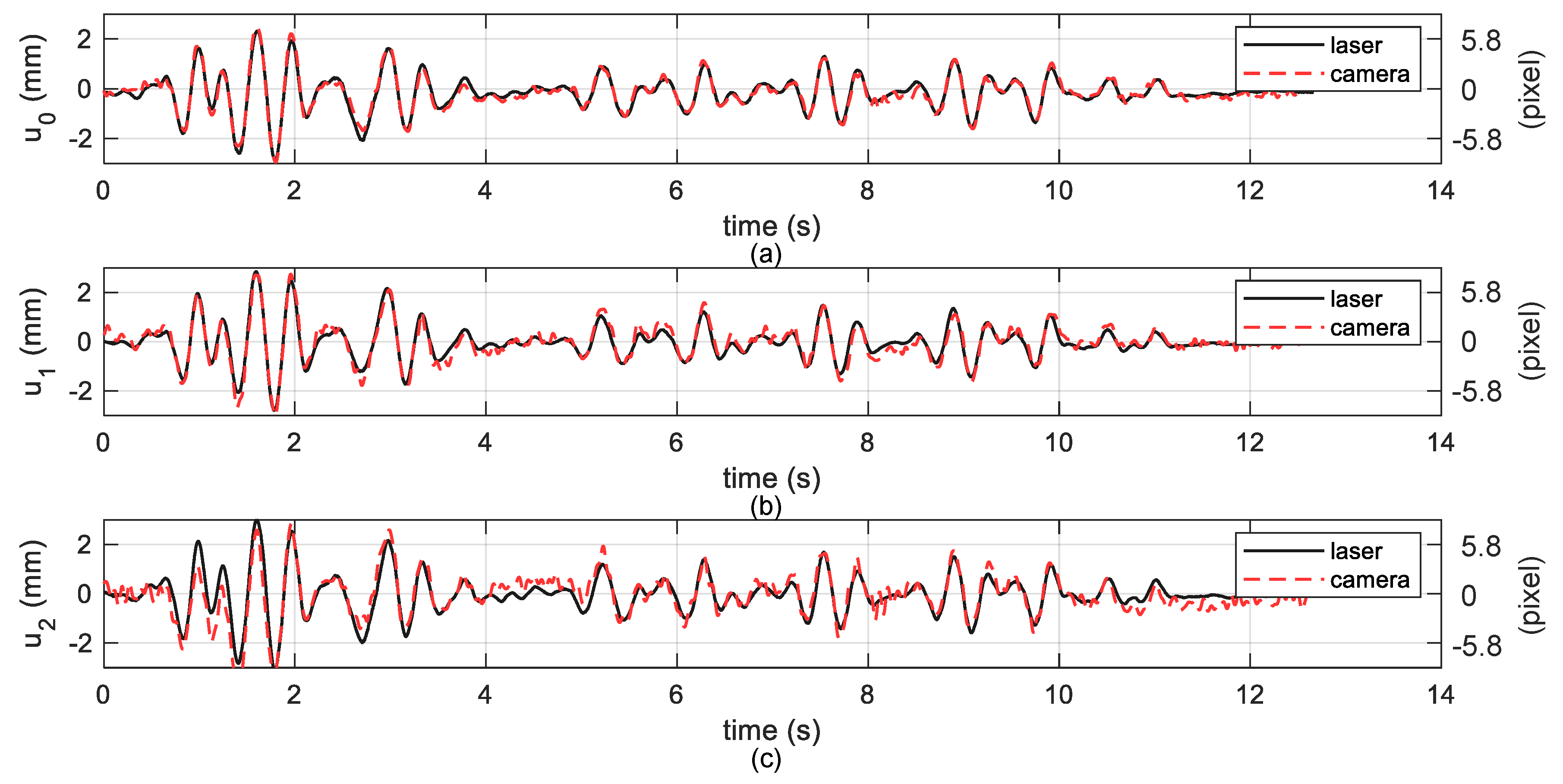
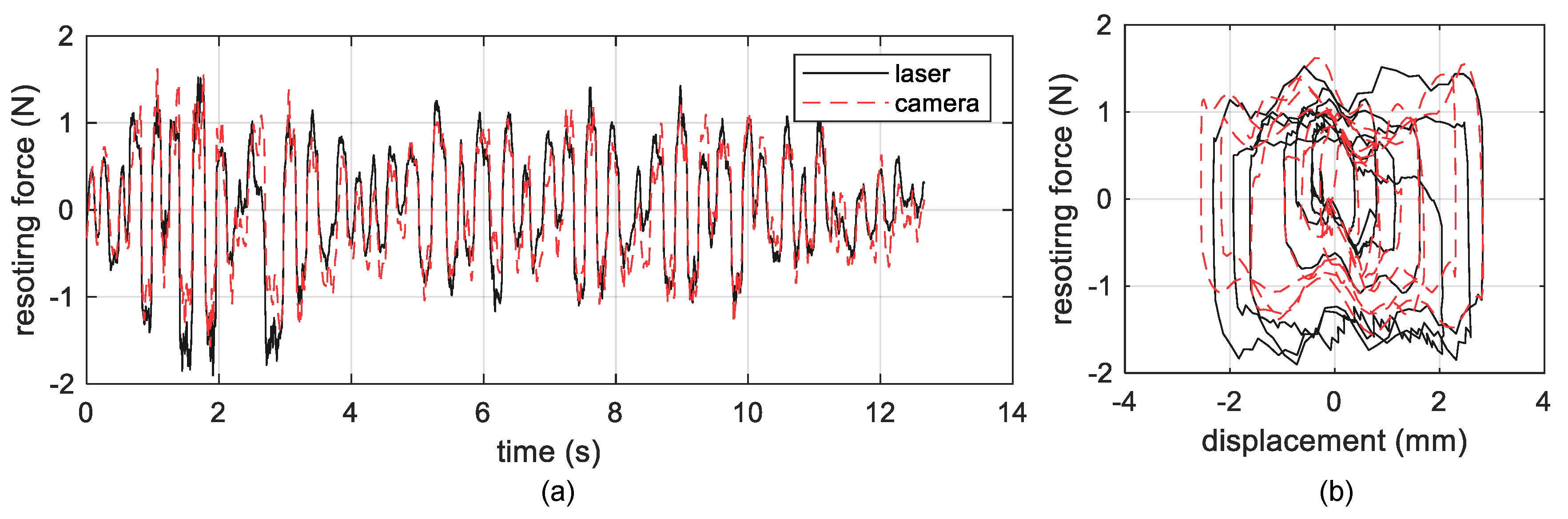
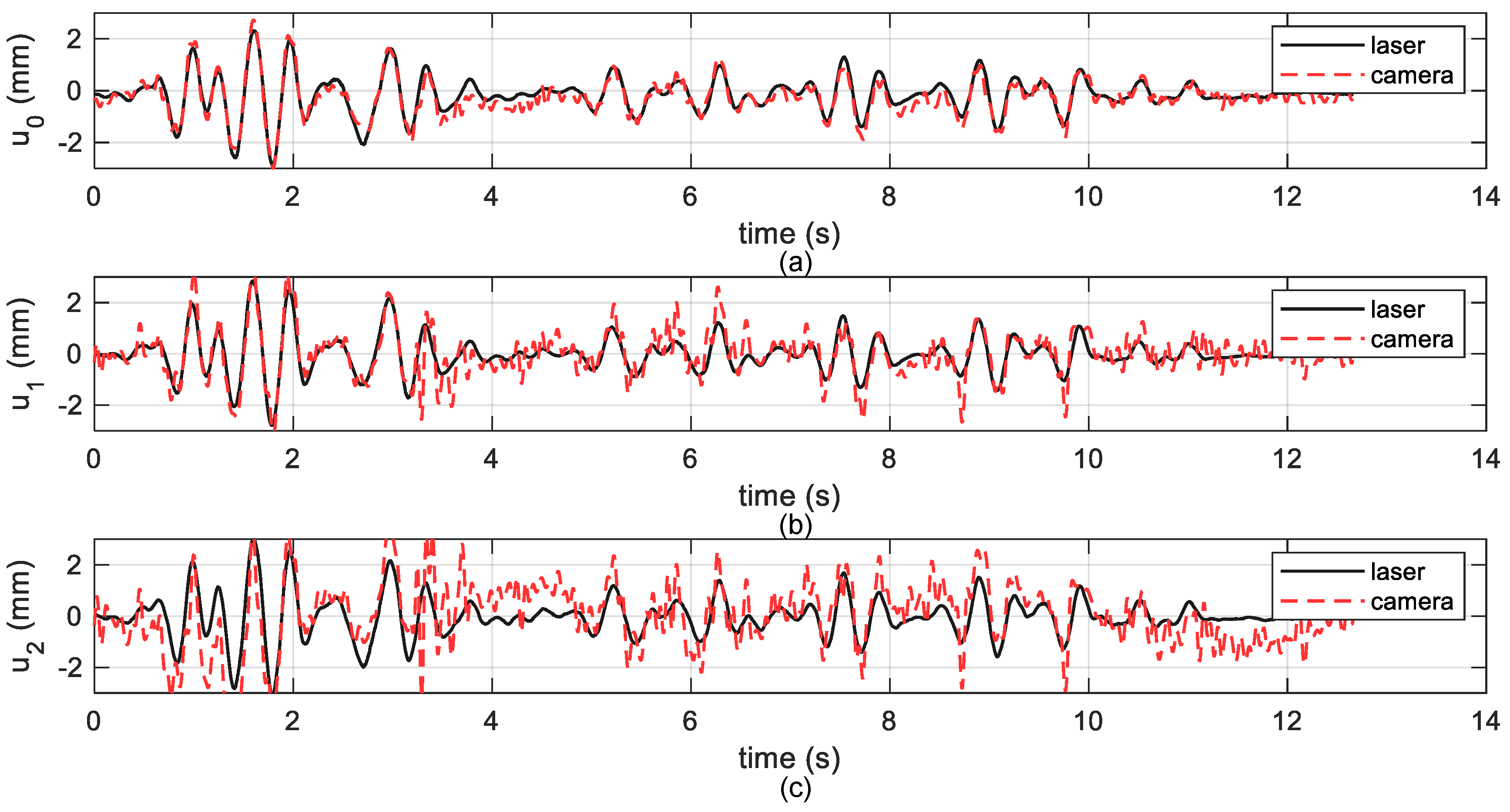
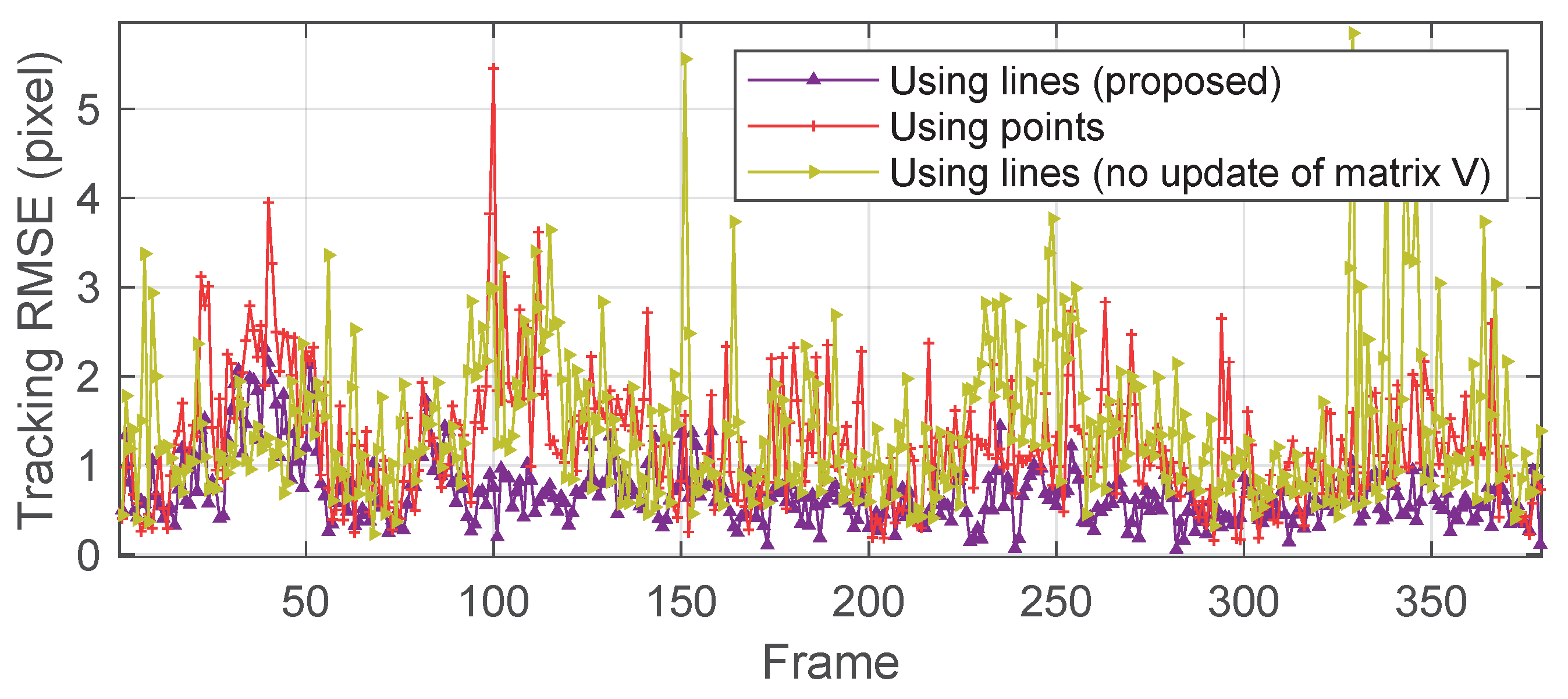
3.2.2. Measurement Results
4. Conclusions and Discussion
- Only step (3)–(5) in Section 2 were validated via experimental case studies in this study, since no real recorded video for seismic-induced motion measurement of building structures was available at the present time. A vision-based system with the newly released Canon EOS R5 camera (4 K at 120 fps) has already been incorporated into a structural health monitoring system of a high-rise building and the proposed method is expected to contribute to the further research;
- Although sub-pixel level accuracy was attained in this study, the real application of this image-processing technique might be inferior to the laboratory precision since, in the real world, there exists not only pixel noise, but also image distortion as well as line segment extraction error, which make the problem much more challenging;
- When using vanishing points to rectify the image, any horizontal/vertical parallel lines, coplanar or not, can be involved in the algorithm, while the method using equal spaced lines requires coplanar parallel lines;
- When structures are subjected to out-of-plane motion, the proposed method is still applicable. To measure in three dimensions, image rectifications with respect to two mutually orthogonal planes of the building, e.g., and in Figure 7a, should be employed from a single image. Therefore, three dimensional measurements may incur the trade-off problem between measurement resolution and the field of view. A higher resolution, such as 4 K (e.g., ), is suggested to be set for accurate measurement.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Takewaki, I.; Fujita, K.; Yoshitomi, S. Uncertainties in long-period ground motion and its impact on building structural design: case study of the 2011 Tohoku (Japan) earthquake. Eng. Struct. 2013, 49, 119–134. [Google Scholar] [CrossRef] [Green Version]
- Kasai, K.; Pu, W.; Wada, A. Responses of controlled tall buildings in Tokyo subjected to the Great East Japan earthquake. In Proceedings of the International Symposium on Engineering Lessons Learned from the 2011 Great East Japan earthquake, Tokyo, Japan, 1–4 March 2012; pp. 1–4. [Google Scholar]
- Stiros, S.C. Errors in velocities and displacements deduced from accelerographs: An approach based on the theory of error propagation. Soil Dyn. Earthq. Eng. 2008, 28, 415–420. [Google Scholar] [CrossRef]
- Herring, T.; Gu, C.; Toksöz, M.N.; Parol, J.; Al-Enezi, A.; Al-Jeri, F.; Al-Qazweeni, J.; Kamal, H.; Büyüköztürk, O. GPS measured response of a tall building due to a distant Mw 7.3 earthquake. Seismol. Res. Lett. 2019, 90, 149–159. [Google Scholar] [CrossRef]
- Nickitopoulou, A.; Protopsalti, K.; Stiros, S. Monitoring dynamic and quasi-static deformations of large flexible engineering structures with GPS: Accuracy, limitations and promises. Eng. Struct. 2006, 28, 1471–1482. [Google Scholar] [CrossRef]
- Stanbridge, A.; Ewins, D. Modal testing using a scanning laser Doppler vibrometer. Mech. Syst. Signal Process. 1999, 13, 255–270. [Google Scholar] [CrossRef]
- Choi, I.; Kim, J.; Kim, D. A target-less vision-based displacement sensor based on image convex hull optimization for measuring the dynamic response of building structures. Sensors 2016, 16, 2085. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, D.; Guo, J.; Lei, X.; Zhu, C. A high-speed vision-based sensor for dynamic vibration analysis using fast motion extraction algorithms. Sensors 2016, 16, 572. [Google Scholar] [CrossRef]
- Feng, D.; Feng, M.Q.; Ozer, E.; Fukuda, Y. A vision-based sensor for noncontact structural displacement measurement. Sensors 2015, 15, 16557–16575. [Google Scholar] [CrossRef] [PubMed]
- Yoon, H.; Shin, J.; Spencer Jr, B.F. Structural displacement measurement using an unmanned aerial system. Comput.-Aided Civil Infrastruct. Eng. 2018, 33, 183–192. [Google Scholar] [CrossRef]
- Yoneyama, S.; Ueda, H. Bridge deflection measurement using digital image correlation with camera movement correction. Mater. Trans. 2012, 53, 285–290. [Google Scholar] [CrossRef] [Green Version]
- Dworakowski, Z.; Kohut, P.; Gallina, A.; Holak, K.; Uhl, T. Vision-based algorithms for damage detection and localization in structural health monitoring. Struct. Control Health Monit. 2016, 23, 35–50. [Google Scholar] [CrossRef]
- Yoon, H.; Elanwar, H.; Choi, H.; Golparvar-Fard, M.; Spencer Jr, B.F. Target-free approach for vision-based structural system identification using consumer-grade cameras. Struct. Control Health Monit. 2016, 23, 1405–1416. [Google Scholar] [CrossRef]
- Chen, J.G.; Davis, A.; Wadhwa, N.; Durand, F.; Freeman, W.T.; Büyüköztürk, O. Video camera–based vibration measurement for civil infrastructure applications. J. Infrastruct. Syst. 2017, 23, B4016013. [Google Scholar] [CrossRef]
- Cheng, C.; Kawaguchi, K. A preliminary study on the response of steel structures using surveillance camera image with vision-based method during the Great East Japan Earthquake. Measurement 2015, 62, 142–148. [Google Scholar] [CrossRef]
- Kim, S.W.; Kim, N.S. Dynamic characteristics of suspension bridge hanger cables using digital image processing. NDT E Int. 2013, 59, 25–33. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Wildenauer, H.; Hanbury, A. Robust camera self-calibration from monocular images of Manhattan worlds. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, RI, USA, 16–21 June 2012; pp. 2831–2838. [Google Scholar]
- Xu, C.; Zhang, L.; Cheng, L.; Koch, R. Pose estimation from line correspondences: A complete analysis and a series of solutions. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1209–1222. [Google Scholar] [CrossRef]
- Topal, C.; Akinlar, C. Edge drawing: A combined real-time edge and segment detector. J. Vis. Commun. Image Represent. 2012, 23, 862–872. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef]
- López, J.; Santos, R.; Fdez-Vidal, X.R.; Pardo, X.M. Two-view line matching algorithm based on context and appearance in low-textured images. Pattern Recognit. 2015, 48, 2164–2184. [Google Scholar] [CrossRef]
- Xu, Y.; Oh, S.; Hoogs, A. A minimum error vanishing point detection approach for uncalibrated monocular images of man-made environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 1376–1383. [Google Scholar]
- Wu, L.J.; Casciati, F.; Casciati, S. Dynamic testing of a laboratory model via vision-based sensing. Eng. Struct. 2014, 60, 113–125. [Google Scholar] [CrossRef]
- Guo, J.; Jiao, J.; Fujita, K.; Takewaki, I. Damage identification for frame structures using vision-based measurement. Eng. Struct. 2019, 199, 109634. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE T. Ssyt. Man. Cy.-S. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. arXiv 2020, arXiv:2001.05566. [Google Scholar]
- Teboul, O.; Simon, L.; Koutsourakis, P.; Paragios, N. Segmentation of building facades using procedural shape priors. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3105–3112. [Google Scholar]
- Hernández, J.; Marcotegui, B. Morphological segmentation of building façade images. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 4029–4032. [Google Scholar]
- Wendel, A.; Donoser, M.; Bischof, H. Unsupervised facade segmentation using repetitive patterns. In Joint Pattern Recognition Symposium; Springer: Berlin, Germany, 2010; pp. 51–60. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 679–698. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: a line segment detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef] [Green Version]
- Schaffalitzky, F.; Zisserman, A. Planar grouping for automatic detection of vanishing lines and points. Image Vis. Comput. 2000, 18, 647–658. [Google Scholar] [CrossRef]
- Lezama, J.; Grompone von Gioi, R.; Randall, G.; Morel, J.M. Finding vanishing points via point alignments in image primal and dual domains. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Ohio, OH, USA, 24–27 June 2014; pp. 509–515. [Google Scholar]
- Almansa, A.; Desolneux, A.; Vamech, S. Vanishing point detection without any a priori information. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 502–507. [Google Scholar] [CrossRef]
- Horn, R.A.; Horn, R.A.; Johnson, C.R. Topics in Matrix Analysis; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Liebowitz, D.; Zisserman, A. Metric rectification for perspective images of planes. In Proceedings of the 1998 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No. 98CB36231), Santa Barbara, CA, USA, 25 June 1998; pp. 482–488. [Google Scholar]
- Liebowitz, D.; Criminisi, A.; Zisserman, A. Creating Architectural Models from Images. Computer Graphics Forum; Blackwell Publishers Ltd.: Oxford, UK; Boston, MA, USA, 1999; Volume 18, pp. 39–50. Available online: https://doi.org/10.1111/1467-8659.00326 (accessed on 1 May 2020).
- Multiphysics; A Version 16.0; ANSYS, Inc.: Canonsburg, PA, USA, 2015.
- Satake, N.; Suda, K.i.; Arakawa, T.; Sasaki, A.; Tamura, Y. Damping evaluation using full-scale data of buildings in Japan. Int. J. Struct. Eng. 2003, 129, 470–477. [Google Scholar] [CrossRef]
- Tremblay, R. Fundamental periods of vibration of braced steel frames for seismic design. Earthq. Spectra. 2005, 21, 833–860. [Google Scholar] [CrossRef]
- Kwon, O.S.; Kim, E.S. Evaluation of building period formulas for seismic design. Earthq. Eng. Struct. Dyn. 2010, 39, 1569–1583. [Google Scholar] [CrossRef]
- Bartoli, A.; Sturm, P. Structure-from-motion using lines: Representation, triangulation, and bundle adjustment. Comput. Vis. Image Underst. 2005, 100, 416–441. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Li, B. Homography-based ground detection for a mobile robot platform using a single camera. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; pp. 4100–4105. [Google Scholar]
- Liu, C.; Kim, K.; Gu, J.; Furukawa, Y.; Kautz, J. Planercnn: 3D plane detection and reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4450–4459. [Google Scholar]
- Aoi, S.; Kunugi, T.; Fujiwara, H. Strong-motion seismograph network operated by NIED: K-NET and KiK-net. J. Jpn. Assoc. Earthq. Eng. 2004, 4, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Zeng, H.; Deng, X.; Hu, Z. A new normalized method on line-based homography estimation. Pattern Recognit. Lett. 2008, 29, 1236–1244. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: Video frame i is available to read | |
| Image segmentation to identify the target building facade ← Section 2.1 | |
| Line detection and segment clustering: in Part I of ← Section 2.2 | |
| Method using equally spaced parallel lines: | Method using vanishing points: |
| Part 1: Projective distortion removal | Projective distortion removal |
| 1. Group from ← Section 2.3 | 1. Obtain vanishing points from ← Section 2.2 |
| 2. in Section 2.3 | 2. |
| 3. in Section 2.4.1 | 3. in Section 2.4.1 |
| 4. in , , | 4. in , , |
| Part 2: Affine distortion correction | Affine distortion correction |
| 1. in Section 2.4.2 | 1. in Section 2.4.2 |
| 2. Rectangular structures | 2. Rectangular structures |
| 3. (with global scale factor) | 3. (with global scale factor) |
| Output: Displacements , then go to the next video frame | |
| Order | Type | Period/s | Mode 1 | Mode 3 | Mode 5 | Mode 2 | Mode 4 | Mode 6 |
|---|---|---|---|---|---|---|---|---|
| 1 | Translational-Y | 2.470 |  |  |  |  |  |  |
| 2 | Translational-X | 2.251 | ||||||
| 3 | Translational-Y | 0.736 | ||||||
| 4 | Translational-X | 0.709 | ||||||
| 5 | Translational-Y | 0.392 | ||||||
| 6 | Translational-X | 0.387 |
| View | Extrinsic Parameters | Intrinsic Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Camera Position | Camera Rotation | Focal Length | Principal Point Coordinate | ||||||
| (m) | (rad) | (pixel) | (pixel) | ||||||
| 1 | 15 | 30 | –30 | –0.2 | 0 | 0 | 600 | 539.5 | 959.5 |
| 2 | 15 | 75 | –30 | 0.2 | 0 | 0 | 600 | 539.5 | 959.5 |
| 3 | 0 | 30 | –30 | –0.2 | 0.2 | 0 | 600 | 539.5 | 959.5 |
| 4 | 15 | 52 | –30 | 0 | 0 | 0 | 500 | 539.5 | 959.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Xiang, Y.; Fujita, K.; Takewaki, I. Vision-Based Building Seismic Displacement Measurement by Stratification of Projective Rectification Using Lines. Sensors 2020, 20, 5775. https://doi.org/10.3390/s20205775
Guo J, Xiang Y, Fujita K, Takewaki I. Vision-Based Building Seismic Displacement Measurement by Stratification of Projective Rectification Using Lines. Sensors. 2020; 20(20):5775. https://doi.org/10.3390/s20205775
Chicago/Turabian StyleGuo, Jia, Yang Xiang, Kohei Fujita, and Izuru Takewaki. 2020. "Vision-Based Building Seismic Displacement Measurement by Stratification of Projective Rectification Using Lines" Sensors 20, no. 20: 5775. https://doi.org/10.3390/s20205775
APA StyleGuo, J., Xiang, Y., Fujita, K., & Takewaki, I. (2020). Vision-Based Building Seismic Displacement Measurement by Stratification of Projective Rectification Using Lines. Sensors, 20(20), 5775. https://doi.org/10.3390/s20205775