1. Introduction
Anomaly detection is a hot topic in various domains, such as manufacturing anomaly detection [
1,
2], cyber attack detection [
3,
4,
5,
6], and crowded scene video anomaly detection [
7,
8]. Cyber attacks detection typically detects three types of external attacks, i.e., false data injection attack, denial-of-service attack, and confidentiality attack. The crowded scene video anomaly detection seeks to detect abnormal human behaviors from the video source. This paper emphasizes on the anomaly detection of discrete manufacturing systems due to the surge of smart manufacturing and Industry 4.0. The smart manufacturing systems—equipped with mass sensors, fast networks, and sophisticated controllers—seek to make production efficient and reliable, which inevitably becomes increasingly complex. Such complexity makes it very difficult for even experts to fully understand the behaviors of the systems and identify anomalies in a timely and precise manner. On the other hand, smart devices (i.e., sensors, controllers) and wireless networks make the data collection and distribution to computers easier, thus promoting extensive researches on data-based anomaly detection algorithms. Based on the type of data, anomaly detection algorithms can deal with time-series data [
9,
10,
11], discrete data [
12,
13,
14,
15], or mixed types of data [
16].
This paper seeks to deal with anomaly detection for discrete event data that result from discrete manufacturing systems. Discrete manufacturing systems produce distinct items, such as auto mobiles, smart phones, and air planes, which can be easily identified and counted. Producing one item typically involves multiple operations by different machines. The sequential actions of machines, such as turning on a button and turning off the button, define a series of events, thus generating various discrete event data.
In the production process, there can be some abnormal activities, besides, the conditions of machines that are involved in the production process might also be abnormal. In this paper, we consider three types of abnormal behaviors: missing necessary events, wrong order of events, and false process injection. Discrete manufacturing systems usually consist of parallel processes to produce different parts of the product that will be assembled later.
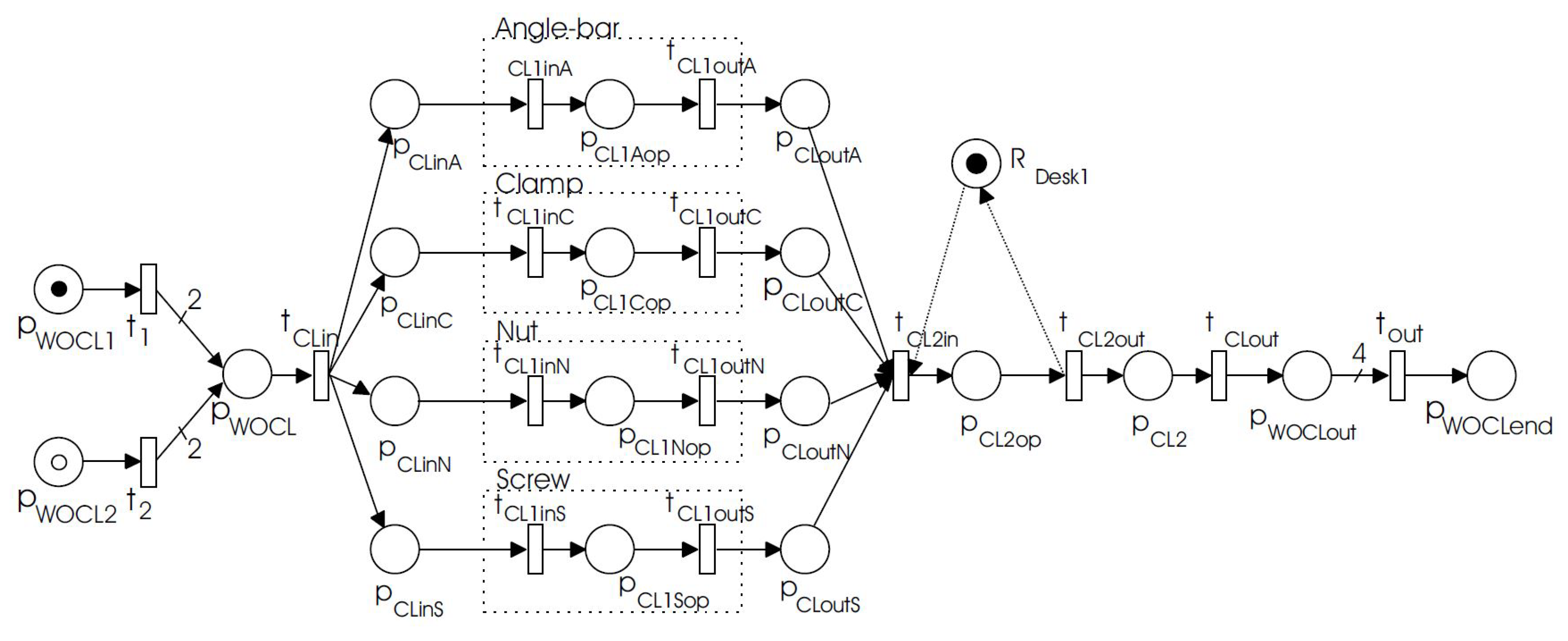
Figure 1 gives an example of producing an L-shaped corner clamp with four parallel processes, see details in [
17]. Besides, the whole process may also include loop processes, e.g., a material will be sent back to the same machine to process again when the material should be re-positioned and re-processed. This paper will take these two features into account when designing the anomaly detection algorithms, and such feature-based algorithms facilitate us to reach good performance at low costs: required small-sized data.
Chandola et. al. reviewed the classical anomaly detection methods in discrete sequences in [
12]. The authors summarized four approaches used in sequence-based anomaly detection problems, namely, kernel-based methods, window-based methods, Markovian methods, and Hidden Markov model (HMM)-based methods. Kernel-based methods are one of the similarity-based algorithms, which detect anomalies by comparing the similarity between the testing sequences and the training sequences. These algorithms are tolerant of false negatives, which may result in huge loss when considering the fact that customs may lose their money once ATM has a problem and manufacturing companies may suffer great losses once severe abnormal behaviors occur. Thus, in this paper, we set a strict bar to anomalous behaviors: as long as anomalous factor appears, the testing sequence will be considered to be abnormal. Window-based algorithms first cut the long sequence by windows of length
k and then compare the similarity of each window. The shortcoming of window-based algorithms is that it is sensitive to the selection of
k, cannot be optimized easily. The Markovian, HMM, or Automata (see [
15]) model-based algorithms focus on modeling the transition of states, which cannot reflect parallel processes, since parallel transitions may result in the same state changes as sequential processes. Recently, machine learning and deep learning based algorithms spring up, such as in [
10,
18]. It is essentially a model-based algorithm and the model can be described as a certain weighted structure of a network. This usually needs a larger data set to train a network.
The aforementioned algorithms mainly focus on the performance (usually measured by F-score), but pay little attention to how much data are required to reach such performance. Nowadays, although data collection is cheap, data cleaning and processing may also be labor extensive and time-consuming. This paper will evaluate both the algorithm performance and size of the data set required.
In this paper, we proposed a centralized pattern relation-based algorithm (Algorithm 1) and a parallel pattern relation-based algorithm (Algorithm 2) to detect anomalies in manufacturing systems, especially for parallel processes and loop processes. Algorithm 1 seeks to build a relation table between patterns—combinations of events that are meaningful in the models. Algorithm 2 seeks to build multiple relation tables for each pattern. Besides, developed algorithms provide two ways in searching for patterns that can describe the loop processes.
To test the proposed algorithms, we generated two artificial data sets due to the following reasons: (1) in reality, it is expensive or impossible to design an experiment to get large data sets with balanced data. (2) For new products or the products in the design stage, there are limited data. (3) Artificial data sets can easily provide more scenarios to test the robustness of the proposed algorithms. Data sets are generated through simulation techniques of Timed Petri Net that can model parallel and loop processes.
Overall, the contributions of this paper are threefold. First, two novel approaches are proposed in order to perform the anomaly detection. Second, the proposed approaches are tested for two complex manufacturing systems, one is a parallel system with loop processes, and the other one is a parallel system with nested loop processes. Finally, we investigate the size of the data that are needed to achieve a certain level of performance. The simulation results showed that the AUC values of our proposed algorithms can reach up to 0.92 with as little as 50 training sequences and up to 1 with more sequences.
The paper is organized, as follows.
Section 2 formulates the anomaly detection problem and overviews two proposed relation-based anomaly detection approaches.
Section 3 describes Algorithm 1 and
Section 4 describes Algorithm 2 in detail, respectively. In
Section 5, we present the simulation results and conclude in
Section 6.
2. Pattern Relation-Based Anomaly Detection Approaches
2.1. Problem Formulation
The anomaly detection problem can be defined as
Given: a training data set D consists of N normal sequences, each of which contains a series of basic events (denoted by lower case English letters in the example, which can be extended to the Unicode set).
Task: for any new sequence , detect to see whether it is normal or abnormal.
Example: with the training data set , then for each sequence in , identify each as normal or abnormal. This data set will be used to illustrate the proposed algorithms steps-by-steps through the paper.
2.2. Overview of the Proposed Algorithms
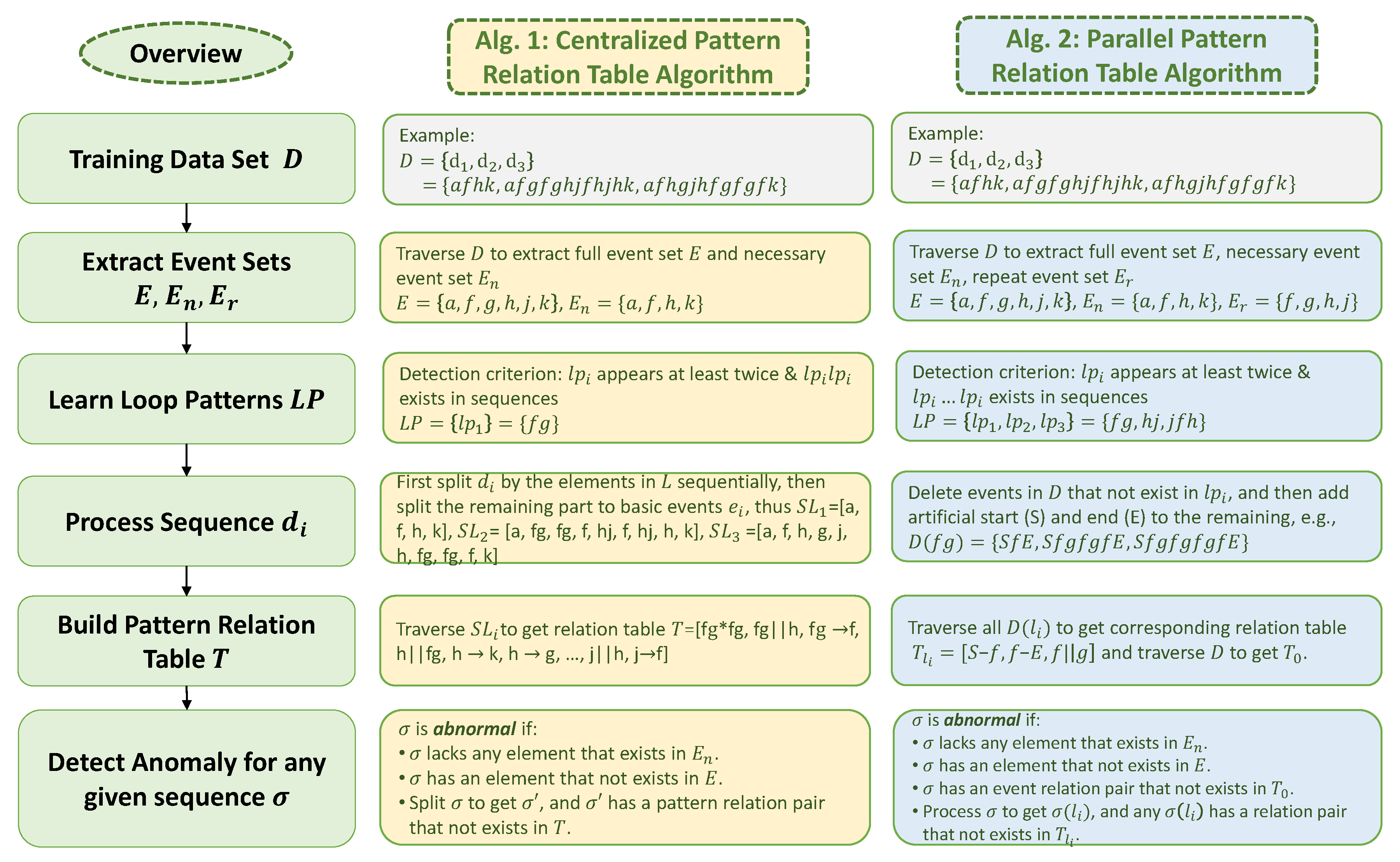
The main idea of the proposed relation-based anomaly detection algorithms follows such a pipeline: first, train a model with normal data sets, and then do the anomaly detection based on the model. The “core piece” of the model is so-called pattern relation tables, where the pattern is a combination of events that can represent a special relation of the events. The differences between the two algorithms proposed are the way of detecting patterns and building the relation tables.
We first define some common notations that are used in describing the models.
Let be the training data set, and is a sequence containing events occurred in order in a normal process (e.g., can be , where each letter represents an event).
Let be the event set of all the unique events existed in the data set, and K is the cardinality of set E (e.g., in the Example, , and ). Let be the necessary event set, which contains the events that appeared in every sequence (thus, in the Example, ). Let be the repeat event set, where the repeat event appeared at least twice in a sequence. In the Example, .
Let be the loop pattern set that contains repeatedly appeared sub-sequences with length varies in the range of in D. In the two proposed methods, s are different. Let be the pattern set and the pattern set should include the elements that can fully recover the training set D. Note that the choice of P is not unique. For example, the simplest one is and , and the most useless one is and which doesn’t provide any new information from the training set. How to extract a suitable P is the key to the proposed algorithms.
Let T be the pattern relation table whose row index and column index equal to elements in P (Algorithm 1) or elements in each (Algorithm 2). A table cell represents an order relation between the two elements in the sequences. The relation tables are also different in the two proposed algorithms: Algorithm 1 builds one table in a centralized way while Algorithm 2 builds tables in a parallel way. We will introduce them in detail in each subsection.
Now, we are ready to define the model
and we will introduce how we train
from
D for different algorithms. Both of the algorithms require four steps to learn
and the final step is to do the anomaly detection.
Figure 2 provides an overview of the approaches and summarizes the main idea of each step in Algorithms 1 and 2. Note that, not all elements in
will be used in each algorithm. Algorithm 1 needs
and Algorithm 2 needs
.
3. Algorithm 1: Centralized Pattern Relation Table Algorithm
Algorithm 1 summaries the five steps in the centralized pattern relation table algorithm and the following subsections elaborate each step.
| Algorithm 1 Centralized Pattern Relation Table Algorithm |
Input: Training data set D, test sequence Output: Detect if is normal or abnormal - 1:
Extract the event set E and the necessary event set . - 2:
Learn the loop pattern set by Subroutines 1 and 2. - 3:
Split by Subroutine 3. - 4:
Build the Pattern Relation Table T by Subroutine 4. - 5:
Detect if is normal or not by Subroutine 5.
|
3.1. Extract the Event Sets E and the Necessary Event Set
Traverse all sequences in the training data set D, extract the event set (the cardinality ) and the necessary event set . Subsequently, the event set E can be decoupled into two subsets: necessary event set and the unnecessary event set . In the Example, , , , and .
3.2. Learn the Loop Pattern Set
We observed that, in practical discrete manufacturing systems, the events that are involved in the loops must be repeated at least twice in the sequence. Accordingly, we define a loop pattern as some sequential events (at least two events) repeatedly appeared in any single sequence . The learning process of the loop pattern set is implemented by Subroutines 1 and 2.
Subroutine 1 illustrates the process of extracting a loop pattern candidate list C. Candidate is obtained by traversing all to find sub-strings of length 2 to K and appearance frequency . Besides, the elements in C is ordered by its importance value—defined by the length of multiply its appearance frequency—in the training data. We use the Example to show the details.
In the Example, there are no sub-strings with length
appeared for more than once in
, so no loop pattern candidate can be extracted. Then for
, we start with the length-of-2 sub-string
, and find its appearance frequency is only 1, so discard it; according to the running basis, we then come to
, and add it to
C since its frequency is 2; append
due to the same reason; go on until the end of
. And then come to traversing the length-of-3 sub-strings,
appears only once, so discard it, as well as
whose frequency is only 1; continue this process until the end. And no patterns with length
that appeared more than once. Perform the same process for
. So eventually, the
. Meanwhile, calculate the importance value for each element in
C and reorder
C by the importance (the importance values of elements in
C are
, respectively. Subsequently, the ordered
. It is worth noting that, although
has appeared in all three sequences
in
D, yet it does not appear twice or more in any single sequence, so it was not added into
C.
| Subroutine 1Candidate Patterns Extracting () |
Input: Data set D, event cardinality K Output: Ordered candidate pattern set C - 1:
- 2:
fordo - 3:
for sub-string of with do - 4:
frequency of w in - 5:
if then - 6:
.add(w,0) if - 7:
- 8:
end if - 9:
end for - 10:
end for - 11:
Order the based on in a descending order - 12:
return.keys()
|
Note that the candidate C may include redundant elements, since, if a longer sub-sequence repeated more than twice, then all of the sub-sequences will be repeated more than twice and become the candidates automatically. Therefore, we need a eliminate routine to select the most proper loop pattern elements among them. Moreover, a loop pattern element may exist in the form of in any sequence. Accordingly, the next step is to filter the candidates by Subroutine 2 in order to obtain the true loop pattern set . Steps 1–6 in Subroutine 2 is to eliminate latter candidates that can be represented by a former candidate together with some basic elements. Steps 7–14 are to eliminate candidate that never appeared with the form in any sequence .
Continued the above example, the candidate loop pattern set C has three elements . We then check the first one (i.e., ) to see whether it is a subset of any other pattern, if so, then the latter element will be marked as −1 and won’t be added into the loop pattern set (in the Example, is a subset of , so will be marked as −1); then, check the second one (), and do the same process, and if it is marked as −1, we will skip it and go on. Eventually, We add all of the candidate patterns not marked as −1 to the loop pattern . So far, the loop pattern candidate is . Subsequently, test whether there exists the form for the loop element in the split list obtained from splitting by the current with Subroutine 3.
In the Example,
, then if sequential
exists in
, then
will be retained; otherwise, it will be discarded. Here,
exists in
and
, but
doesn’t exist in any
, so, eventually,
.
| Subroutine 2Pattern Learning Subroutine (C) |
Input: Ordered candidate pattern set C Output: Loop pattern set - 1:
- 2:
for candidate !=-1 in C do - 3:
for in do - 4:
-1 if - 5:
end for - 6:
.append() if !=-1 - 7:
end for - 8:
for in D do - 9:
Sequence Processing Subroutine() - 10:
for in do - 11:
if no sequential in then - 12:
.remove() - 13:
end if - 14:
end for - 15:
end for - 16:
return
|
3.3. Sequence Processing Subroutine
The Sequence Processing Subroutine () (Subroutine 3) returns an ordered list by splitting any given sequence with a given ordered list S and the basic event set E. This subroutine will be applied in getting the loop pattern set and building the relation table T later.
This subroutine starts with splitting
by
in
S one by one (so
is of the highest priority, then
and so on) in Steps 1–5. For the remaining part that not match any
will be split by basic events
in
E, see Steps 6–12. Note that
is an ordered list and concatenate all the elements in
can obtain the original sequence
. In the Example, if
S is
, then the split of
will be
, since there is no sub-sequence includes any element in
,
will be
, and
will be
.
| Subroutine 3Sequence Processing Subroutine () |
Input: Any sequence , given ordered list S and event set E Output: A split-list obtained from splitting by S and E sequentially = for in S do replace by ’-’++’-’ in end for .replace(’–’,’-’) for each symbol in .split(’-’) do if in S then .append() else .append( split by basic events ) end if end for return |
3.4. Build a Relation Table
Define the pattern set as the union of the loop pattern set and the basic event set. Now, we are ready to build a pattern table T to describe the relationship between pattern events for a given data set D. There are three types of relations:
, meaning that pattern appears ahead of , but cannot be ahead of .
, meaning that and both exist in the normal data set.
, meaning that this pattern can repeat itself as many times as possible. We can infer that any loop pattern must have this relation.
Subroutine 4 provides more details of building such a relation table and
Table 1 shows the result for the data set
D in the Example.
| Subroutine 4Pattern Table Building Subroutine () |
Input: Loop Pattern , Event Set E, Training Data Set D Output: Pattern Table T Pattern set , Pattern table for sequence in D do = Sequence Splitting Routine(, , D) for () in do if equals to if is empty or →, and is empty if is empty or →, and end for end for return T |
3.5. Anomaly Detection Algorithm
Now, the model has been trained from the normal data set D. Accordingly, three rules are proposed to detect anomalous behaviors in a new sequence :
lacks any element in the necessary event set .
has any element that is not in the basic event set E.
Split by Subroutine 3 to obtain , check in T and the cell is empty.
The first rule is to ensure that the normal sequence should have the necessary events in D. The second rule is to ensure that there is no event out of the basic event set E. For the third one, we believe the normal orders between the pattern elements have existed in T. See the details in Subroutine 5.
The centralized algorithm shows all of the relations between pattern elements in one table
T. Consider that the systems may be complex and the dimension of
T is large, this algorithm will be time-consuming. Subsequently, we propose a parallel algorithm that allows for multiple such
Ts to be used simultaneously.
| Subroutine 5 Anomaly Detection of Any Sequence |
Input: Model , test sequence Output: Detect if is normal or abnormal - 1:
Extract the event set of . - 2:
if or then - 3:
return is abnormal. - 4:
end if - 5:
Sequence Splitting Routine() - 6:
for pattern pair () in do - 7:
if is ∅ then - 8:
return is abnormal. - 9:
end if - 10:
end for - 11:
return is normal.
|
4. Algorithm 2: Parallel Pattern Relation Table Algorithm
The parallel pattern relation table algorithm in Algorithm 2 has the same work flow as in Algorithm 1. However, in this algorithm, we take a different point of view of the loops in the data set, i.e., when the loop process happens, there must exist some events that will be repeated and the combinations of repeated events show the patterns of the loops. Therefore, a repeated event set needs to be learned. Besides, to extract multiple pattern relation tables in a parallel way, the subroutines to process a sequence and learn the loop pattern set will be changed accordingly. We will introduce the difference in the following subsections.
| Algorithm 2 Parallel Pattern Relation Table Algorithm |
Input: Training data set D, test sequence Output: Detect if is normal or abnormal - 1:
Extract the event set E and the necessary event set . - 2:
Extract the repeated event set by Subroutine 6. - 3:
Learn the loop pattern set introduced in Section 4.2. - 4:
Process the sequence in parallel introduced in Section 4.3. - 5:
Build multiple relation tables in parallel introduced in Section 4.4. - 6:
Detect if is normal or not by Subroutine 7.
|
4.1. Extract the Repeated Event
Similar to Algorithm 1, this algorithm also needs to extract the event set
E and the necessary event set
from the normal training data set
D. Subsequently, a repeated event set
whose elements appear at least twice in a single sequence is extracted. Subroutine 6 provides a way to extract the
. In the Example,
.
| Subroutine 6Repeated Events Extracting Subroutine () |
Input: Training data set D, Event set E Output: Repeated event set - 1:
- 2:
for sequence in D do - 3:
for event in E do - 4:
if pattern in and then - 5:
.add() - 6:
end if - 7:
end for - 8:
end for - 9:
return
|
4.2. Learn the Loop Pattern Set
In this step, first, process the data set D get a modified data set by traversing over D and removing all events not in while keeping the original order. Subsequently, the remaining process can be done in a parallel way. For each element in , extract the candidate loop pattern set from , where each element in is started and ended with the same single event . Then sort according to the length of the elements therein and the shortest one in is the pattern of . In the Example, , , , , , so far the loop pattern set is . However, for each pattern element, the order of the events is not necessary, just keep the event set of the pattern elements and remove the redundant ones and get the final loop pattern set. Continue the Example, , so is identified as redundant and it will be removed from , eventually, .
4.3. Sequence Processing Subroutine
The third step is to define a subroutine to process any given sequence based on each element in and obtain a corresponding new sequence . It is still a removal process that is based on -for each remove all elements not in , and keep the order of remaining elements. Subsequently, apply it to every sequence in the training data D and obtain , and add artificial start (S) and end(E) symbols to every at its two ends. For example, , then , , and .
4.4. Build Multiple Relation Tables
Afterwards, the fourth step is to build multiple relation tables
based on
(then the number of
equals to
). In addition, we also build a basic event relation table
(see
Table 2) based on consecutive event relation in the original training data set
D. The process of building the relation table is the same, as shown in Subroutine 4, based on the
D. Accordingly, for
, the corresponding relation table
has indices of
(see
Table 3); for
and
, the corresponding
and
are shown in
Table 4 and
Table 5, respectively.
4.5. Parallel Anomaly Detection Algorithm
In the parallel algorithm, the anomaly detection is based on relation tables . Only when all of the relation pairs obtained from processing are shown to be normal, the sequence will be a normal one; otherwise, it is abnormal. Subroutine 7 summarizes this process.
It is worth noting that after extracting the loop pattern set
, the algorithm can be run in parallel based on the element in
to speed up the algorithm. That’s why we called it “Parallel Anomaly Detection Algorithm”.
| Subroutine 7 Parallel Relation Table Anomaly Detection Algorithm |
Input: Model , test sequence Output: Detect if is normal or not - 1:
Extract the event set of . - 2:
iforthen - 3:
return is abnormal. - 4:
end if - 5:
for event pair () in do - 6:
if is ∅ then - 7:
return is abnormal. - 8:
end if - 9:
end for - 10:
for Loop pattern in do - 11:
= Sequence processing() - 12:
for event pair () in do - 13:
if is ∅ then - 14:
return is abnormal. - 15:
end if - 16:
end for - 17:
end for - 18:
return is normal.
|
5. Simulation
In this section, we test the proposed algorithms with two artificial data sets. The data sets are generated by a discrete event model Timed Petri Nets and we begin with briefly introduce the definitions and mechanisms of the Timed Petri Net. A detailed introduction can be found in the book [
18].
5.1. Timed Petri Net
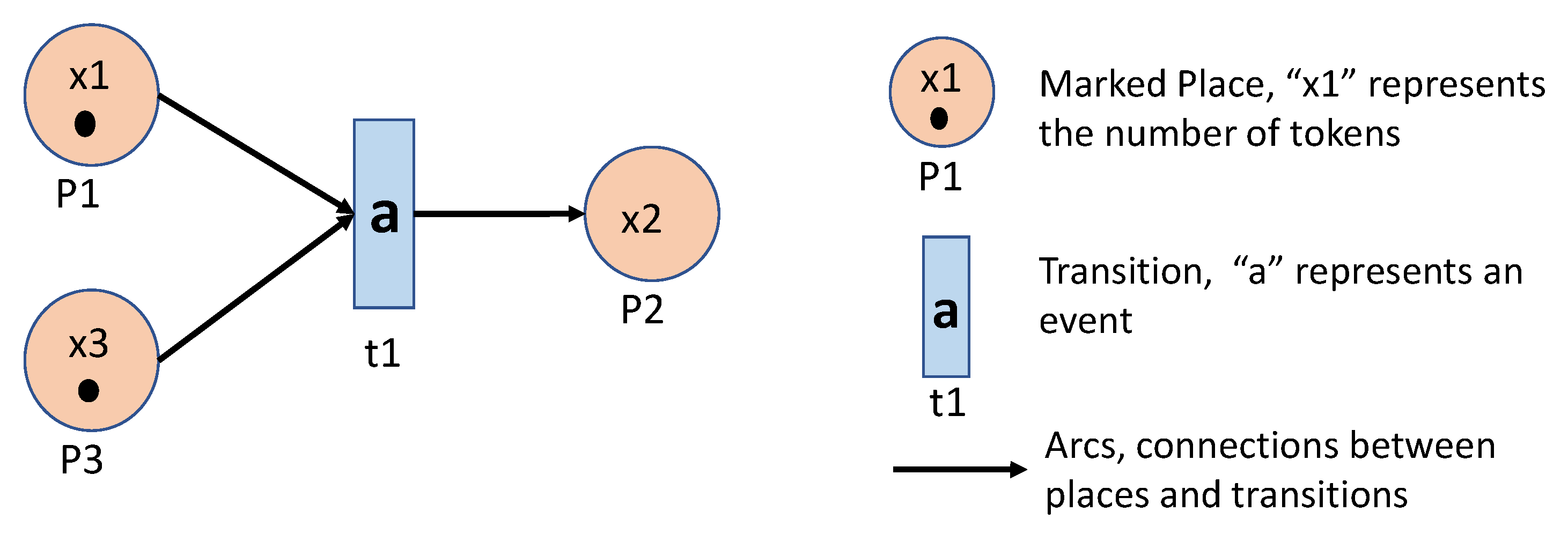
Petri Net is a classical model of Discrete Event Systems. When compared with Automata, it is more straightforward to demonstrate discrete manufacturing systems, such as parallel processes and loop processes.
A Timed Petri Net is a six-tuple , where
P is a set of places, that is conditions required to enable transitions.
T is a set of transitions.
contains all arcs from places to transitions and from transitions to places.
is the weight function on the arcs.
x is the marking function of the Petri Net, where a marking represents the number of tokens in each place in the net.
is a clock structure and the clock sequence is associated with a transition .
The clock structure means that, if the th fired time of the transition is t, then the next fired time could be .
A Petri net graph can visualize a Petri net.
Figure 3 shows a Petri net with
,
,
,
,
,
. The marking function
. A possible clock structure is
.
A transition
is defined as enabled or feasible if
for all
, where
contains the input places to transition
. In other words, transition
is enabled when the number of tokens in
is at least as large as the weight of the arc connecting
to
, for all places
that are inputs to transition
. A transition
is fired if it happened at some time and then moved tokens to the next places. For example, in
Figure 3, we can say
is enabled during the period
, and fired at
.
When a transition is fired, then we can say an event occurred. To obtain a sequence of events, we need the dynamics of the Petri Net, i.e., the way of moving tokens from places to places. It is defined by and one can easily identify it through a Petri Net graph.
Given an initial state
and a Timed Petri Net, a sequence of fired events can be obtained by repeating the following steps: check the enabled transitions, fired the transition that is of the minimal scheduled time, and changes of states. This is the main idea of generating an event sequence, and a detailed description can be found in Chapter 10 of Ref. [
18].
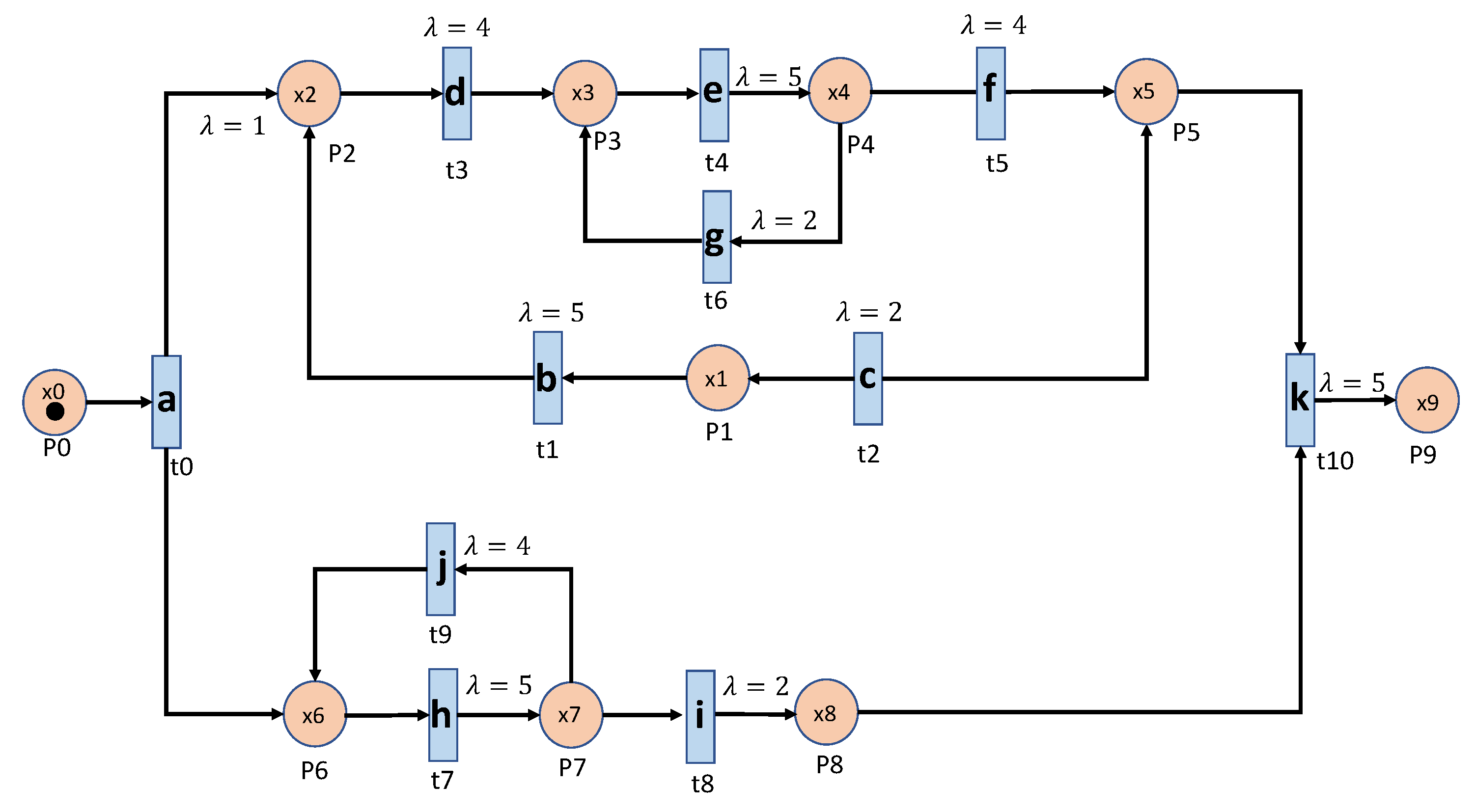
5.2. Experimental Systems
As we mentioned, we are interested in detecting any anomaly that exists in parallel processes, loop processes, and even nested loops and combinations of all these factors in more complex systems. Besides, the operation time (the interval time between two events) of a machine might be stochastic.
Figure 4 and
Figure 5 show the Petri Net graphs of two such manufacturing systems.
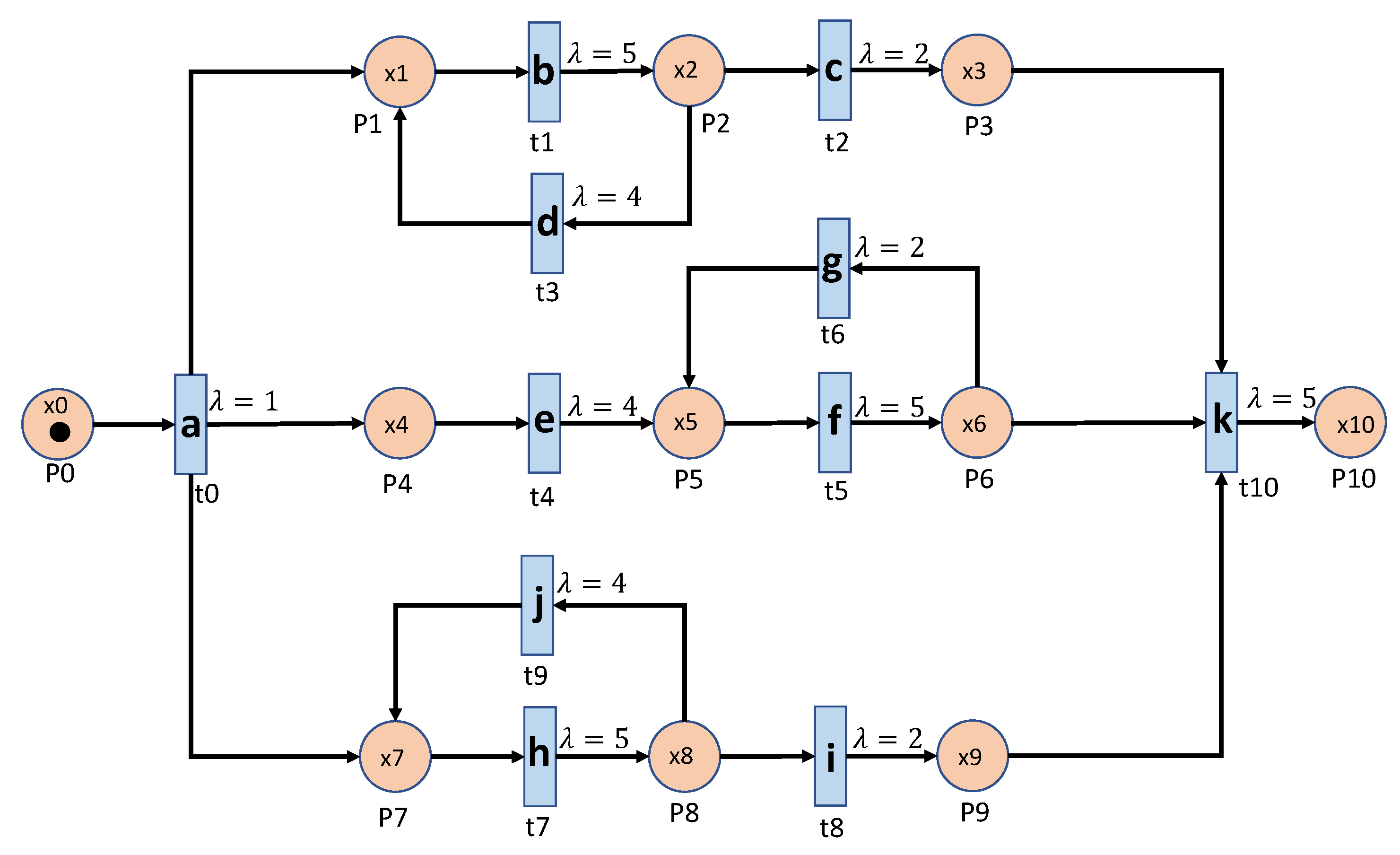
Figure 4 represents a system that consists of three parallel processes and each process has a loop process, which is the system used in [
14] for comparison purposes.
Figure 5 contains parallel processes and nested loop processes that make the systems more complex. We will show that the proposed algorithms are also capable of dealing with such a system. In both systems, the stochastic operation time is modeled by a Poisson process with parameter
.
5.3. Data Generation
With these two systems and the data generation approaches, we can generate normal data sets. However, in order to test our algorithms, we also need to generate abnormal data sets. We introduce three types of abnormal behaviors, as follows:
Introduce an erroneous event transition to a normal sequence.
Remove a necessary event from a normal sequence.
Introduce some unrecorded/unknown events in a normal sequence.
Each type of anomalies accounts for 1/3 of sequences in the abnormal data set. Assume that the number of sequences in the training data set is N, in the testing data set, half of them are normal sequences, and the other half are abnormal ones.
5.4. Compared Approaches
We will compare our algorithms with the prefix tree algorithms and the basic event table algorithm, as introduced in [
14].
The prefix tree algorithm strictly compares the difference between the normal sequences and test sequence. When the testing sequence differs from any of the normal sequences, it is abnormal. In order to record the normal sequences in less space and to loop them up at high speed, the “prefix tree” data structure is used, hence its name.
The basic event table-based algorithm builds an event relation table between any two consecutive events in a normal sequence. When a testing sequence is given, if any two consecutive events within it do not exist in the relation table, then it is identified as abnormal.
5.5. Performance Metrics
Anomaly detection problems can also be viewed as a binary classification problem. Typical metrics for evaluating a classification algorithm include accuracy, sensitivity, precision, F-1 score, and AUC (area under curve). In reality, manufacturing systems can generate much more normal data than the abnormal one, so the data set will be highly unbalanced. We choose the F-1 score and AUC score as the performance metrics, as the accuracy does not work well under such circumstances. The F-1 score is calculated from the precision and recall, namely
where the precision is defined as
and the recall is defined as
The AUC is the area under the ROC (Receiver Operating Characteristic) curve, where an ROC curve plots the true positive rate vs. false positive rate at different classification thresholds. AUC represents the probability that a random positive example is positioned to the right of a random negative example. When , the classification result is better than a random classification method.
Besides, we plot the relationship between the number of sequences (N) in the training data set and the AUC and the F-1 score in order to investigate the efficiency of the proposed algorithm.
5.6. Simulation Results and Discussion
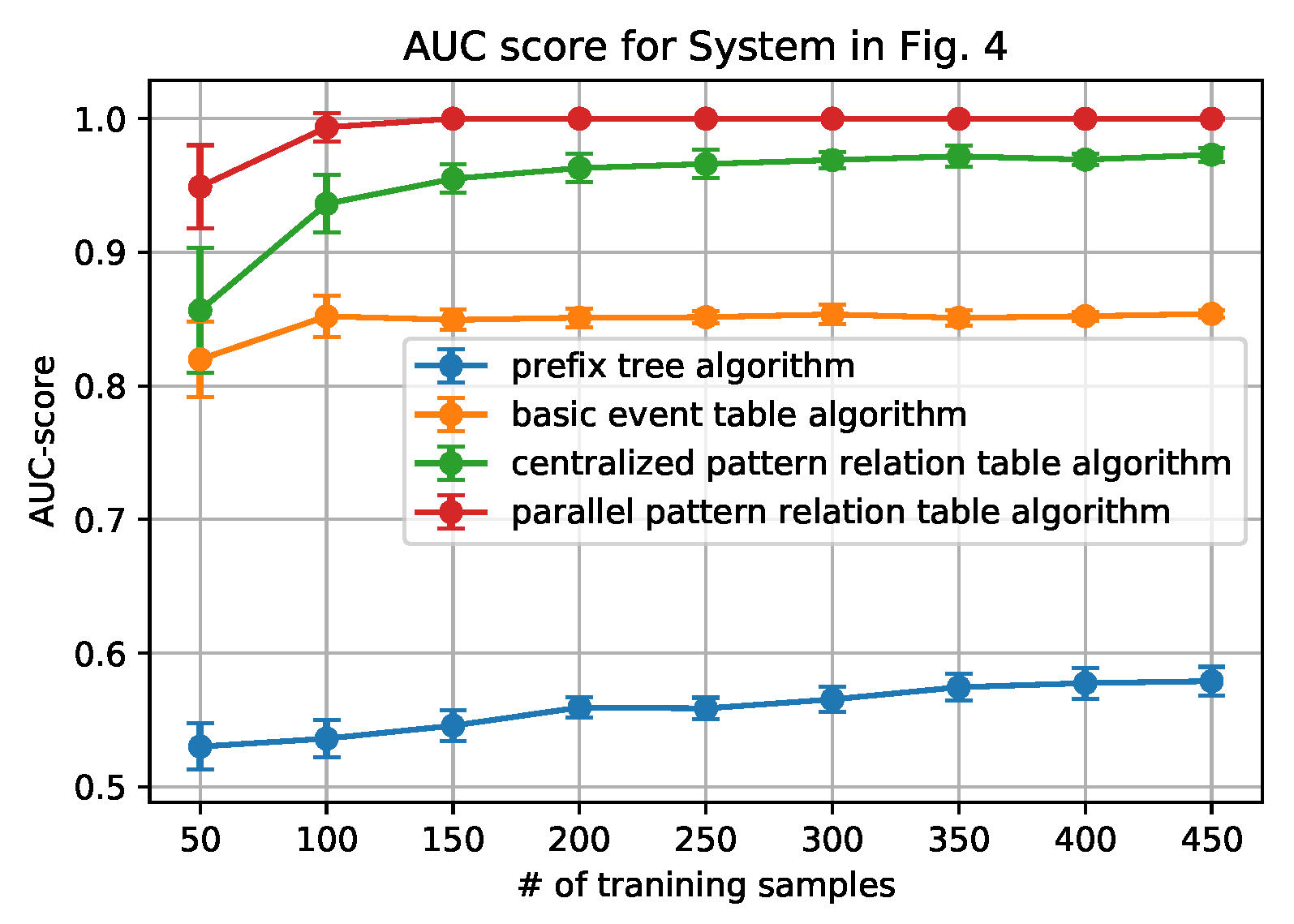
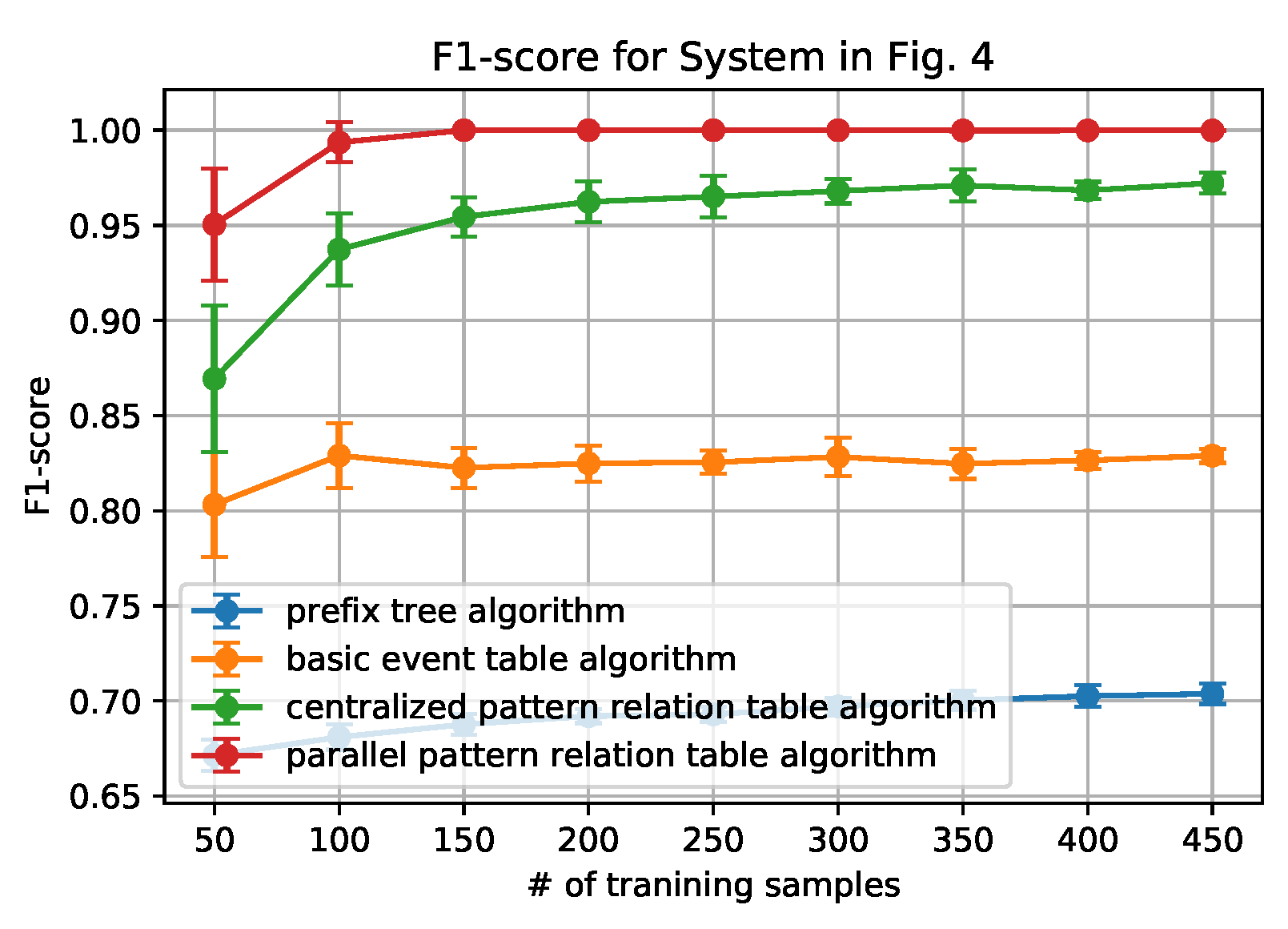
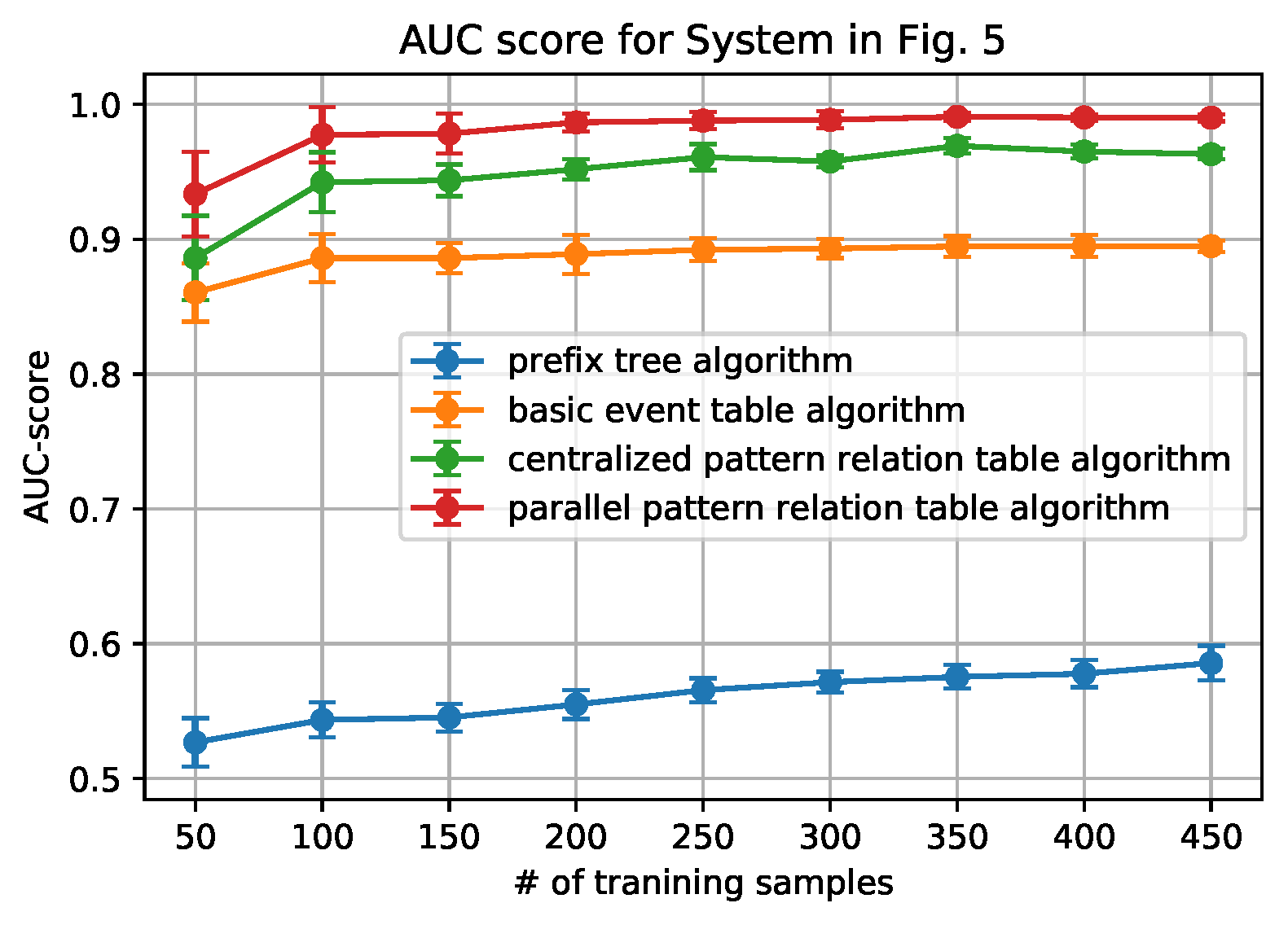
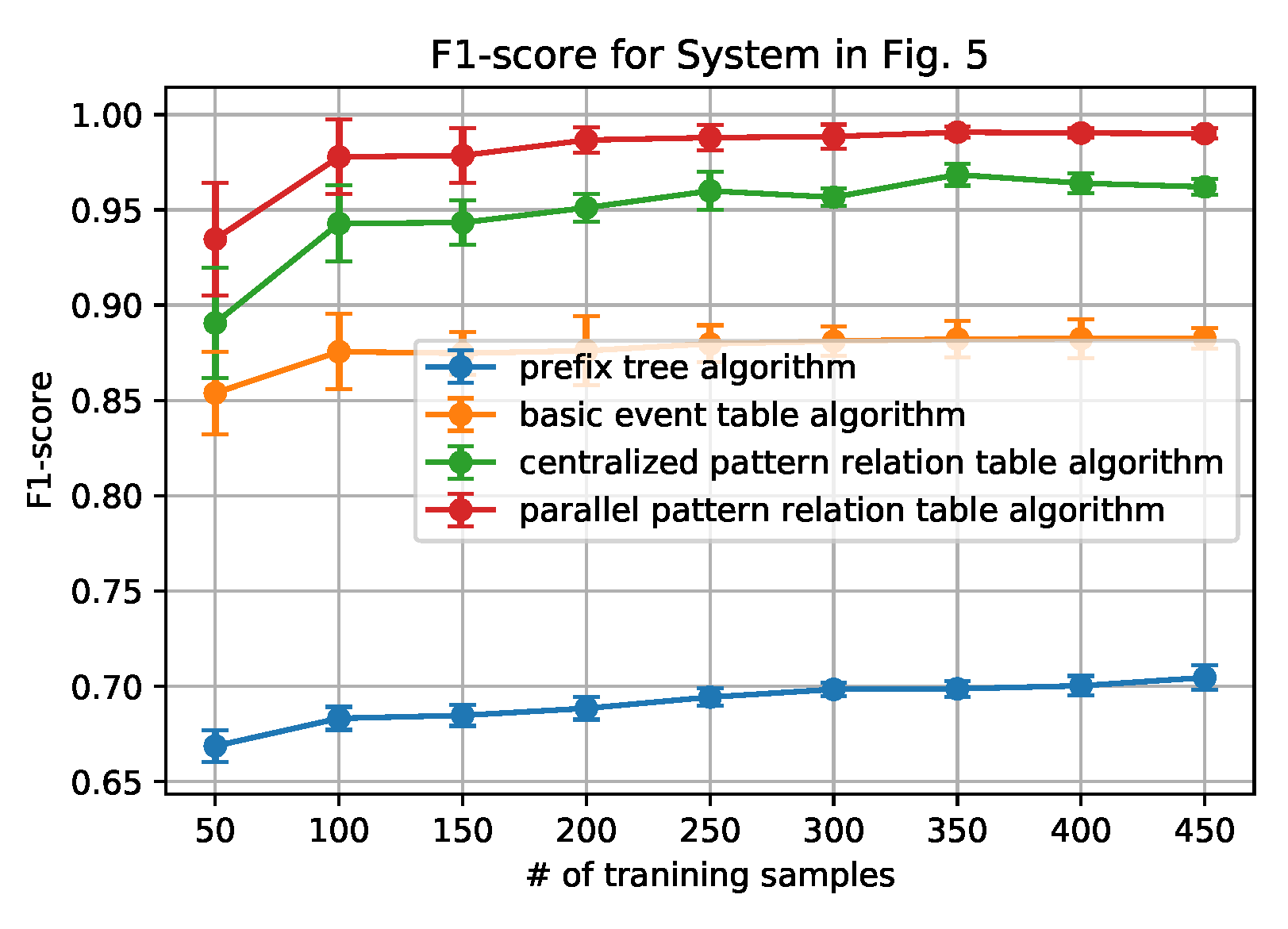
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show how the AUC and F-1 score vary with the number of sequences
N in the training data sets, where the dots represent the average values, and the upper and lower bars represent the standard deviations. These figures are obtained by the following steps: (1) for each
N, we ran the data generation routine for 10 times to get 10 data sets, which contain
N sequences of each set; (2) performed the anomaly detection algorithms; (3) calculated AUC and F-1 Score on each data set, and obtained the average and standard deviation; and, (4) draw the figures.
From the figures, we can conclude that the newly proposed algorithms-parallel pattern relation table algorithm and the centralized one-outperform the prefix tree algorithm and the basic event table algorithm. This is because there are inherent shortages in the latter two algorithms. In the prefix tree algorithm, the criterion of being detected as normal is strict that only the sequences that existed in the training data set can be identified. However, because there are loop processes, the number of normal sequences is unlimited. Therefore given a small size of training data, some actual normal cases (especially the loop ones) cannot be identified, thus making the F1-score and the AUC-score low. With the size of the normal data set grows, the performance will be better, but will not be able to achieve 1.
In the basic event table algorithm, it only considers the event relationship between the consecutive events in a sequence. This might misidentify the cases where some necessary events are missing as normal. Taking the case that is shown in
Figure 4 as an example, the sequence ‘abhcefgfk’ and ‘abhcefgik’ are mistakenly identified as normal, since there exist all of the consecutive events, yet ‘abhcefgfk’ misses ‘i’ and ‘abhcefgik’ misses ‘f’ between ‘fg’ and ‘k’.
In the centralized pattern relation table algorithm and the parallel pattern relation algorithm, they are designed to capture the loop patterns by focusing on the loop patterns or the repeated events. In the centralized algorithm, it overcomes the shortage of the basic event table algorithm by checking if all of the necessary events are included in the tested sequence. However, it still fails to detect the cases ‘abhcefgik’, since ‘fg’ is also normal to be followed by ‘i’. To address this issue, the parallel algorithm only focuses on the relationship between the events within the loop patterns by the deletion process of the sequences (sequence processing subroutine); moreover, it also builds the relationship with an artificial start (S) and end (E). For instance, only ‘f’ can be connected to ‘S’ and ‘E’ while ‘g’ cannot, as shown in
Table 3. Applying the sequence processing subroutine, ‘abhcefgik’ will be ‘SfgE’ and it is detected as abnormal. That is why it can correctly identify the ‘abhcefgik’ case.
In addition, it is worth noting that the parallel algorithm can achieve higher performance with a smaller size of the data set. This is also owing to the sequence processing subroutine. In the parallel algorithm, as long as repeated events appear, the relationship between the repeated events can be built in the relation table. However, in the centralized algorithm, the repeated events should be first detected as a pattern and then appear repeatedly. Because the latter case is a subset of the former case, the parallel algorithm will be easier to capture the loop patterns that are based on a smaller sized data set.
Finally, we also note that the relation table based algorithms have their own limitations: the performance converges no matter how the number of the training data set grows. The reason is that, if the number of patterns or the number of the repeated event is fixed, the number of the relationship in the pattern relation tables is limited. As long as all of the relationships appear, the table is fully built.
6. Conclusions
We investigated anomaly detection problems in complex discrete manufacturing systems and proposed two effective methods for detecting anomalies of wrong orders, missing events, and unrecorded/unknown events. By fully taking the system structure (not the entire model) into account, our algorithms work well, even with quite small-sized training data sets. This implies that our methods can apply to the fields, where only limited data can be obtained and partial structure information is given, such as in the test of prototypes of intelligent sensor/control devices. In reality, such structure information is usually easier to be observed.
Note that, although our proposed algorithms seek to be applied in discrete manufacturing systems, they can also be used to other fields if parallel processes and loop processes exist, such as ATM fraud detection. Besides, the idea of searching for patterns in the centralized pattern relation algorithm may be applied to the natural language learning fields to learn the frequent words and grammar between the words.
Future work could be extended to several directions: (1) anomaly detection for totally unlabeled data, which includes both normal data and abnormal data; and, (2) event duration anomaly detection with normal data or unlabeled data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}