Latent 3D Volume for Joint Depth Estimation and Semantic Segmentation from a Single Image


Abstract
:1. Introduction
- How to build a latent 3D volume;
- How to use the latent 3D volume for depth estimation and semantic segmentation; and
- How to learn the latent 3D volume efficiently.
- A novel 3D representation that aggregates geometric and semantic information in a latent space;
- A two-branch projection module that projects a latent 3D volume onto a 2D plane and decomposes it into geometric and semantic features;
- A training strategy to effectively learn a latent 3D volume by using a large-scale synthetic dataset adapted to real domains and a small-scale real-world dataset.
2. Related Work
2.1. Depth Estimation
2.2. Semantic Segmentation
2.3. Multi-Task Learning
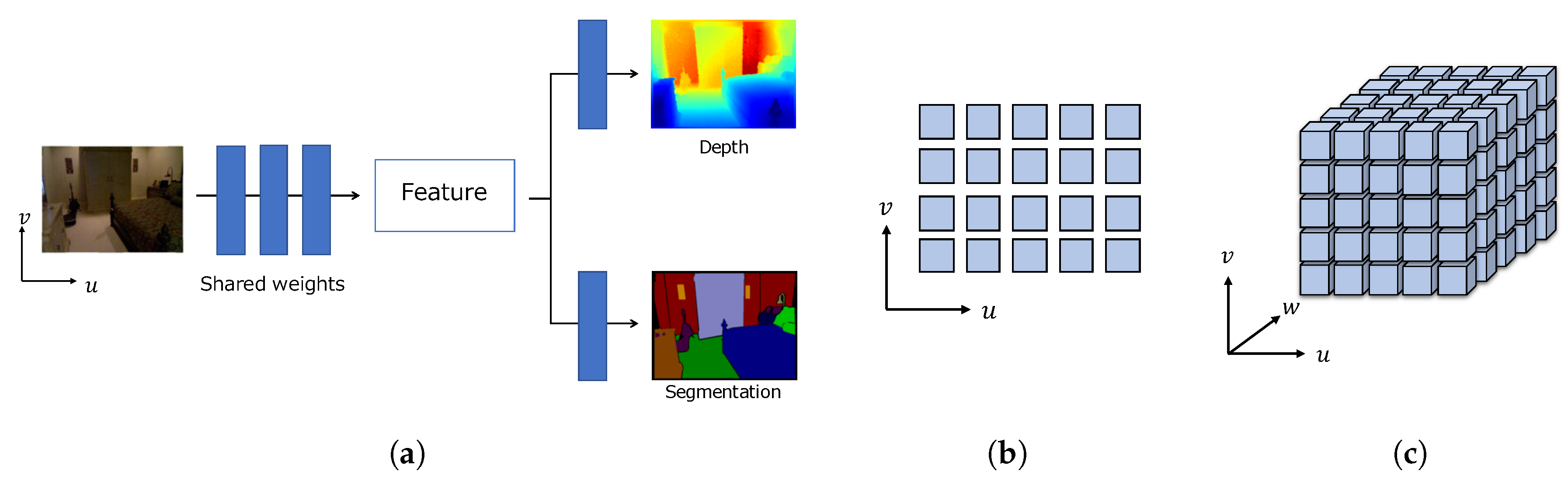
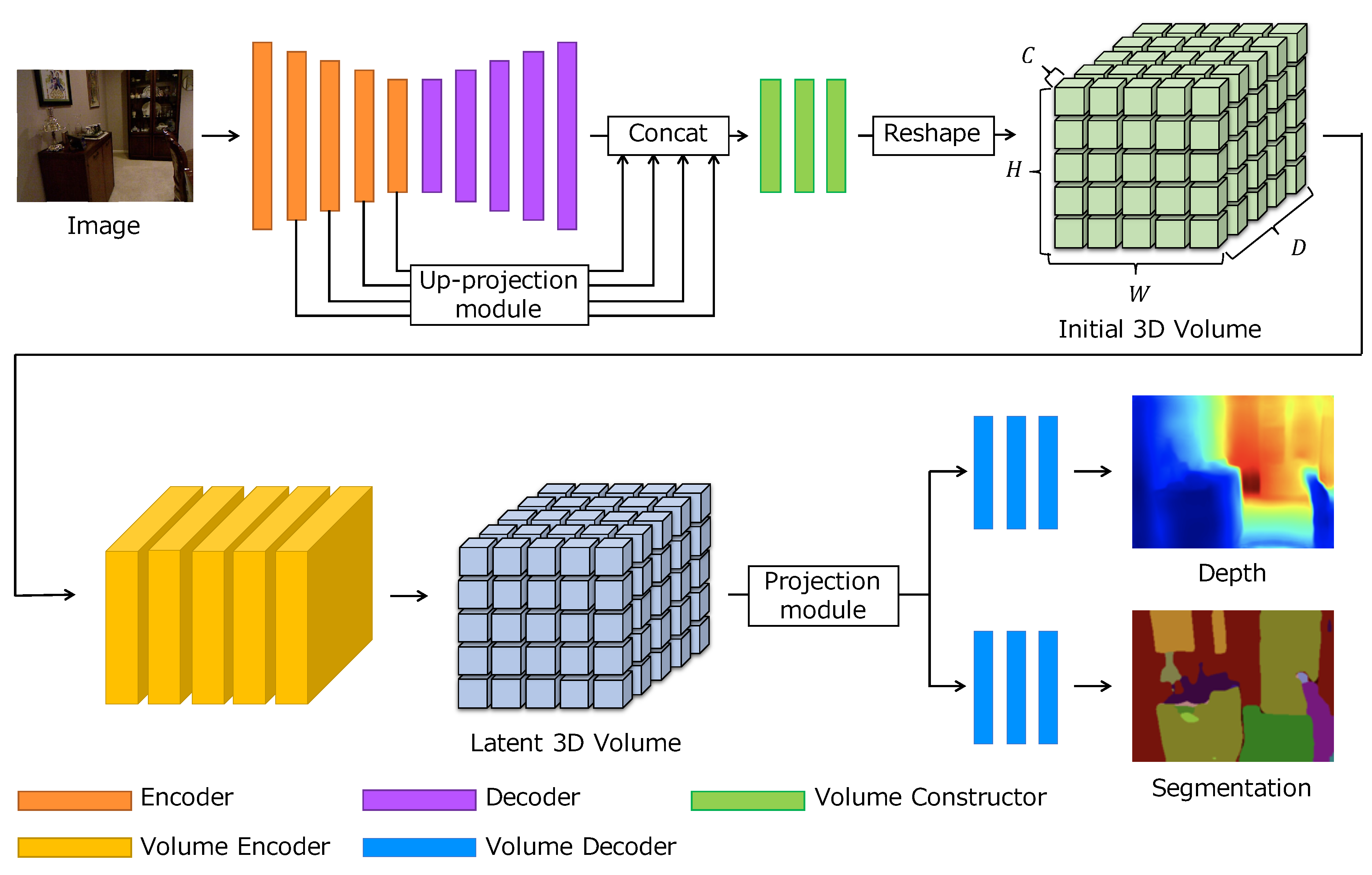
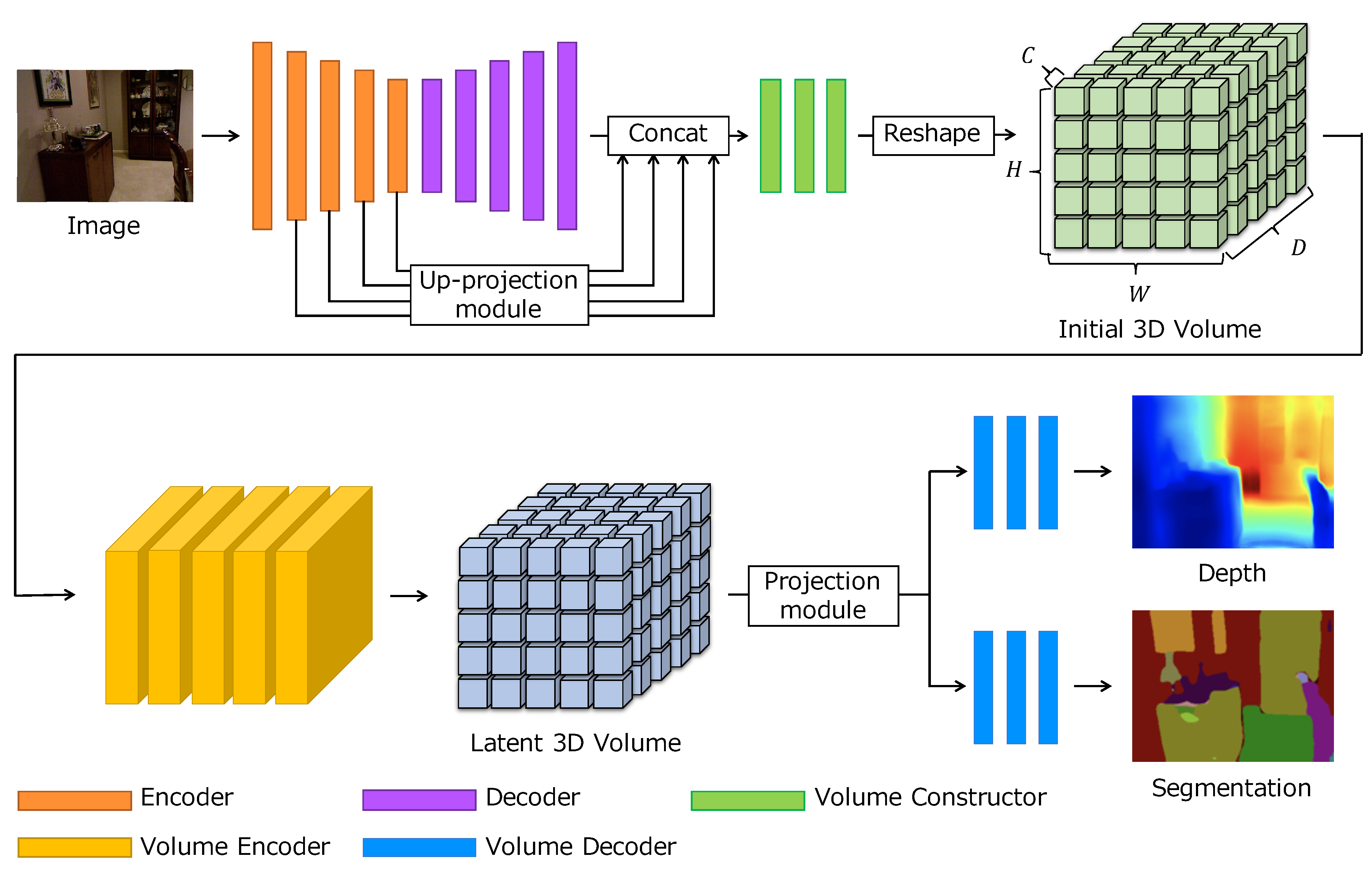
3. Latent 3D Volume
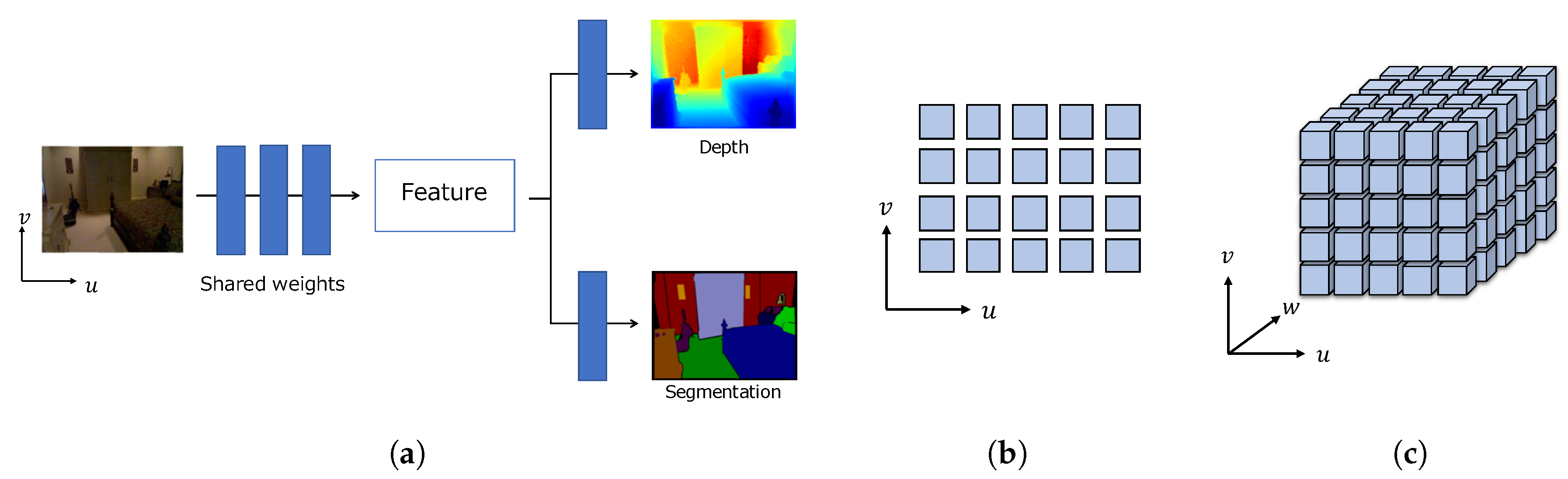
3.1. Overview
3.2. Image Features
3.3. Latent Volume Generation
3.4. Depth Regression and Classification
3.5. Loss Functions
3.5.1. Depth Estimation
3.5.2. Semantic Segmentation
3.5.3. Overall Losses
4. Datasets and Training
4.1. NYU Depth v2 Dataset
4.2. SUNCG Dataset
4.3. Training Protocol
- Rotation. The RGB image, depth, and segmentation mask are rotated by degrees.
- Flip. The RGB image, depth, and segmentation mask are horizontally flipped with 0.5 probability.
- Color jitters. Brightness, contrast, and saturation values of the RGB image are randomly scaled by .
5. Experiments
5.1. Metrics
- Mean absolute relative difference (REL):
- Root mean square error (RMSE):
- Mean error (log10):
- Thresholded accuracy ():where
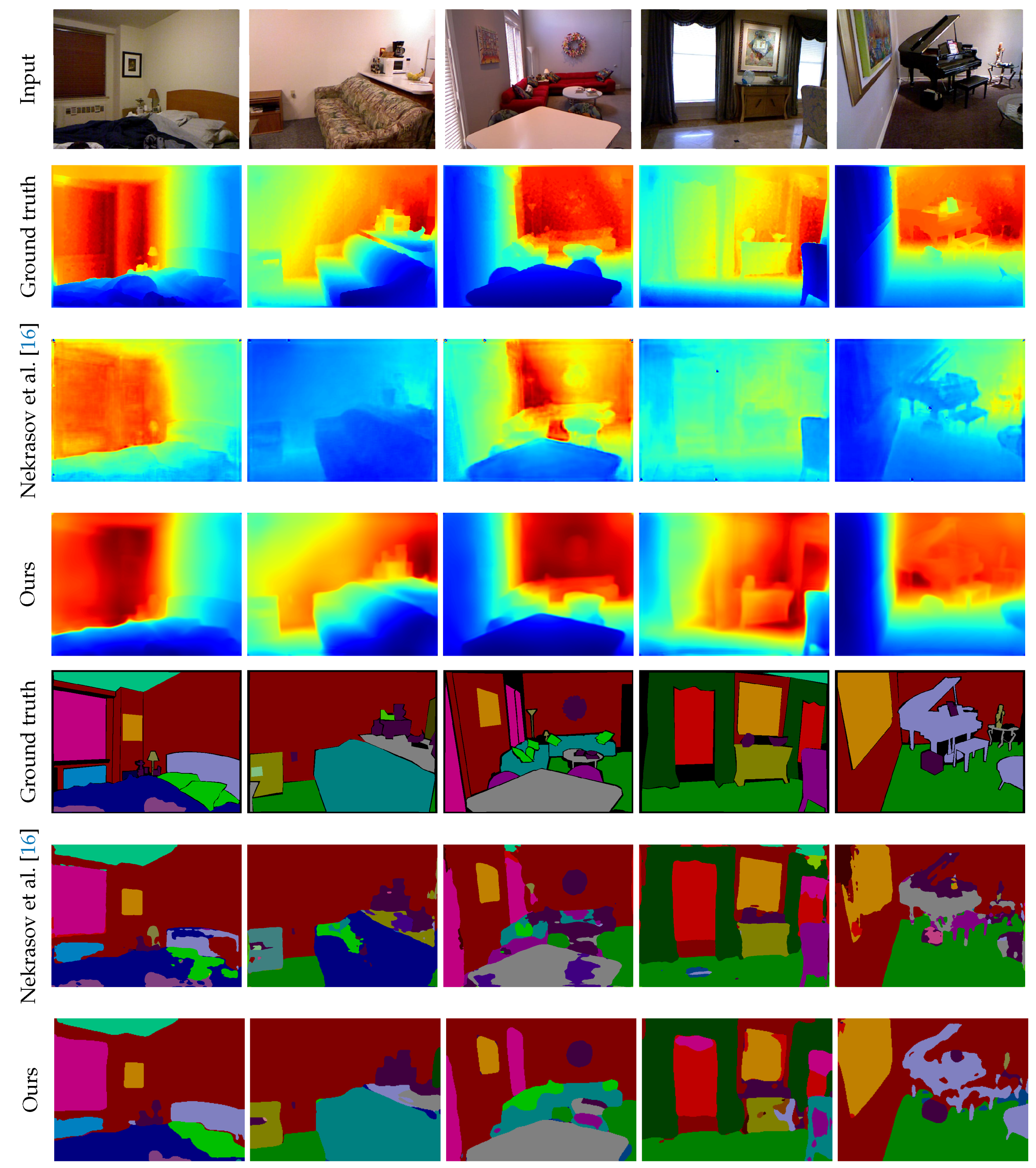
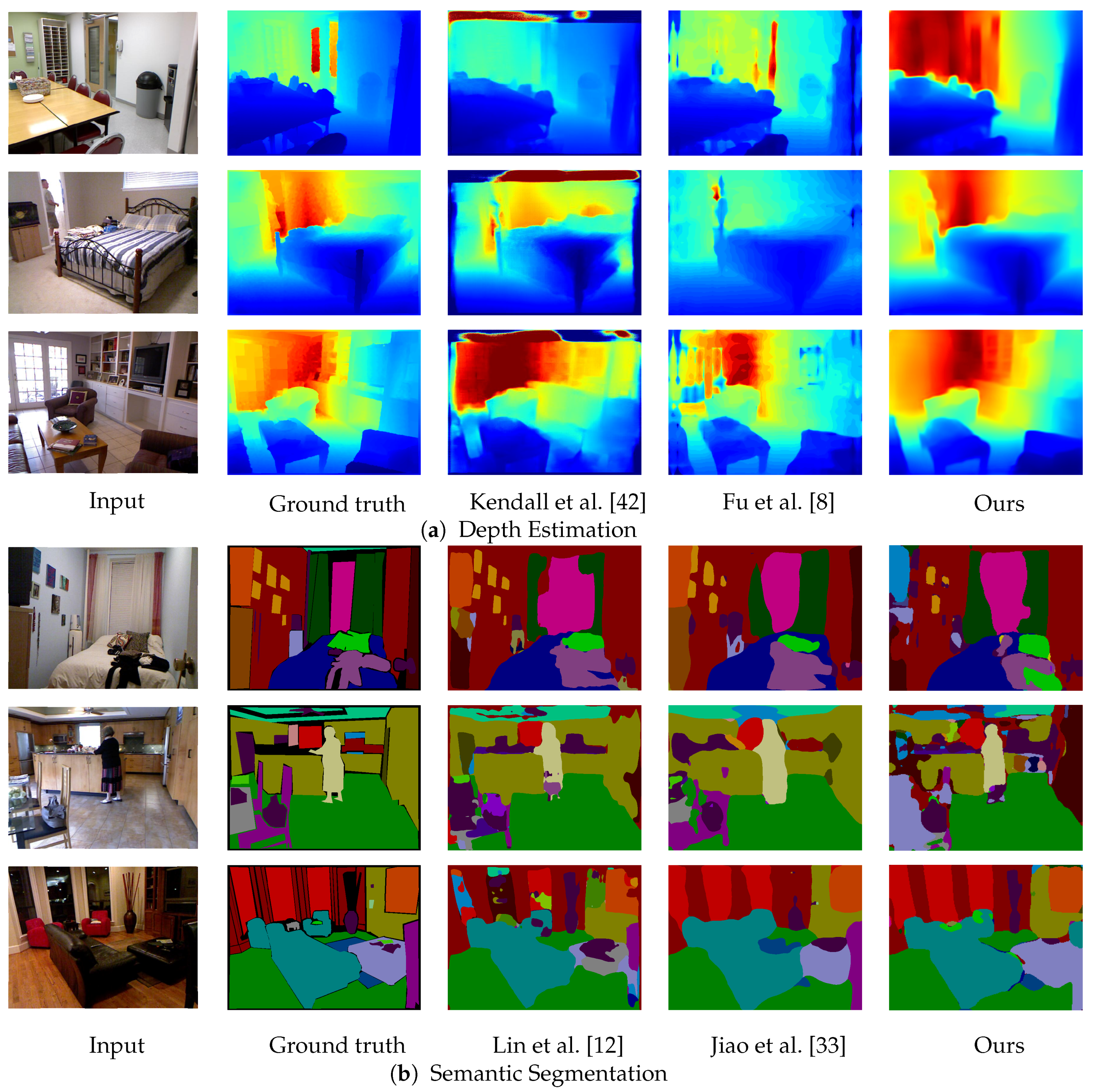
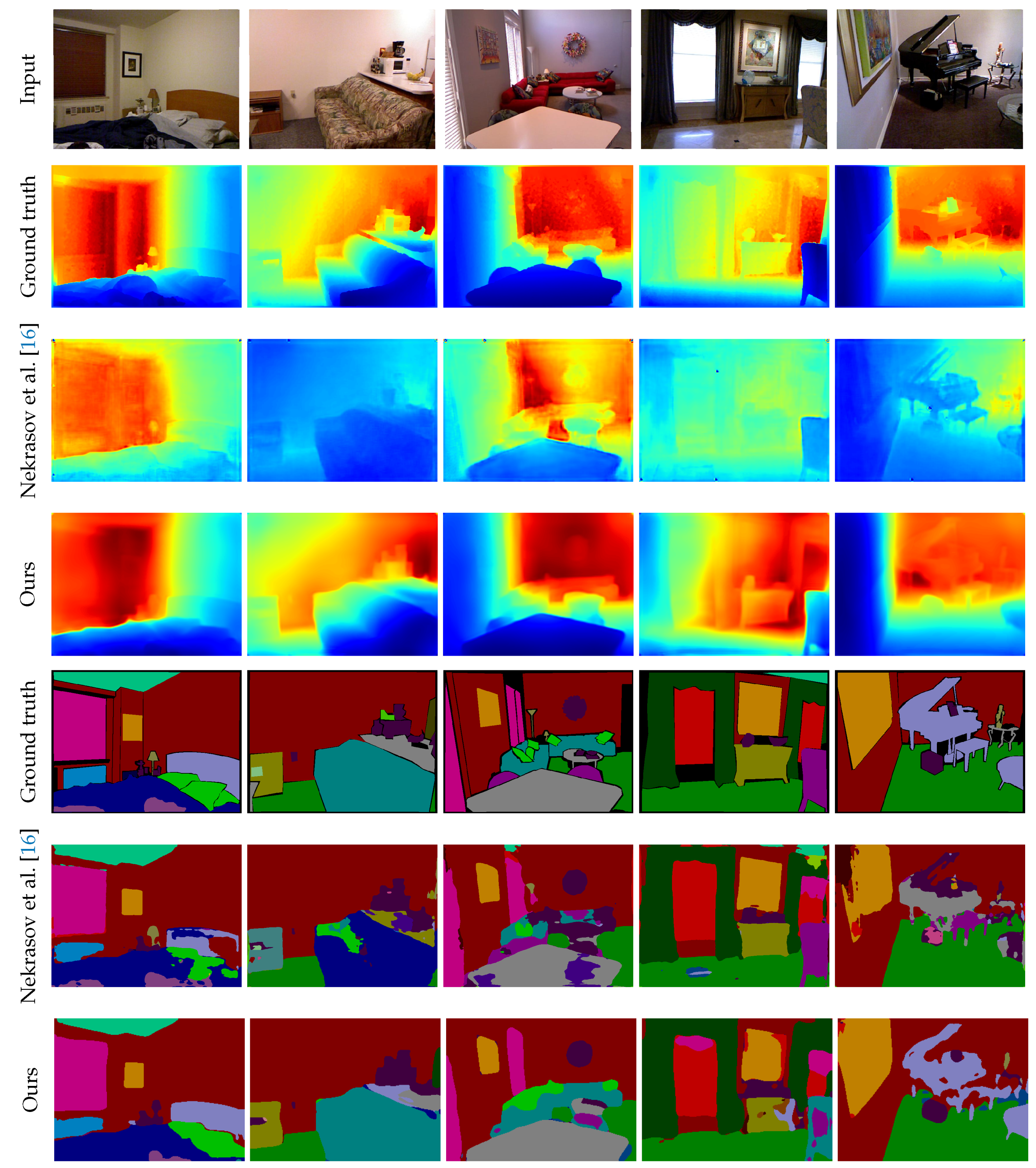
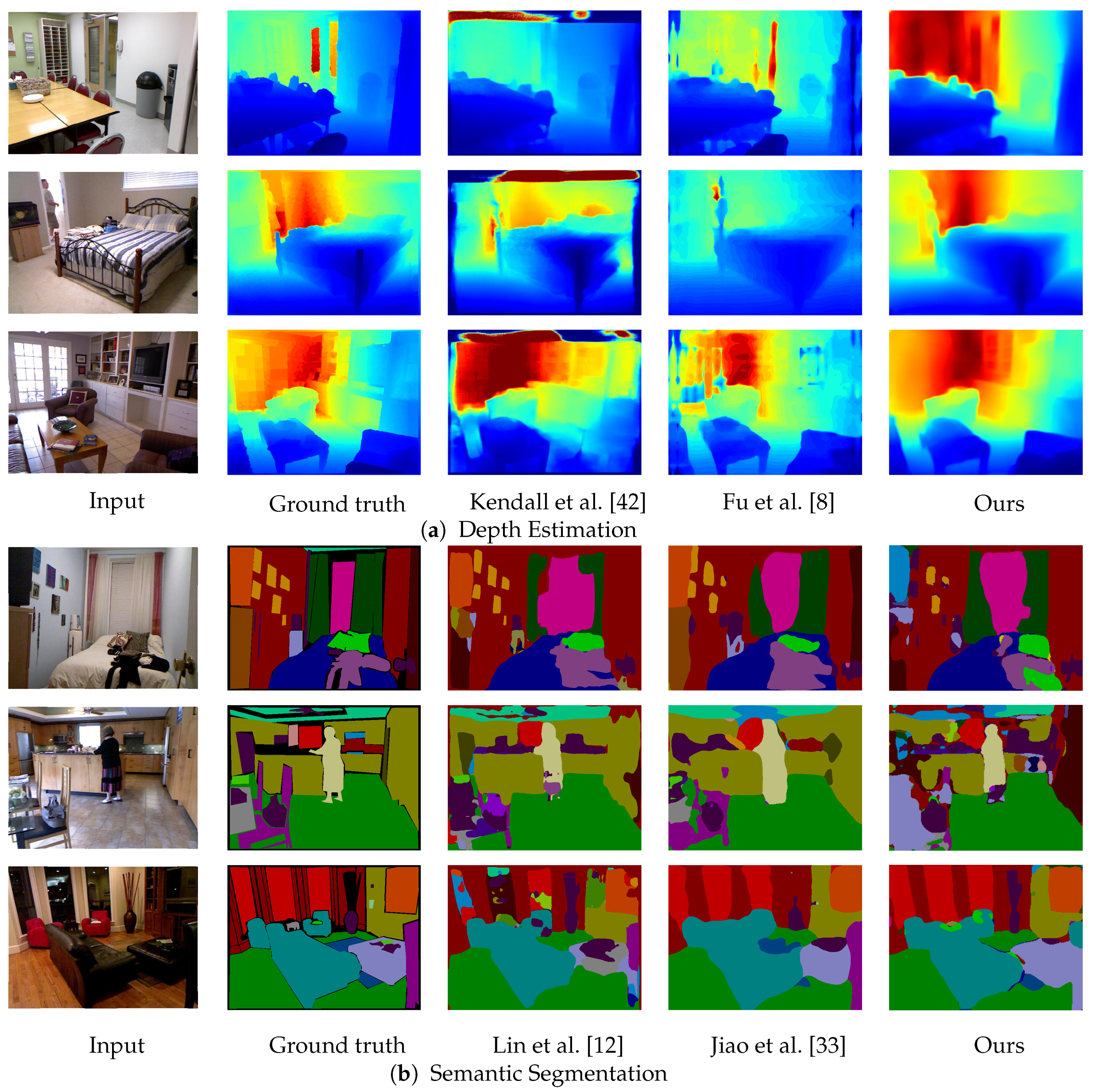
5.2. Results on the NYU Depth v2 Dataset
5.3. Ablation Study
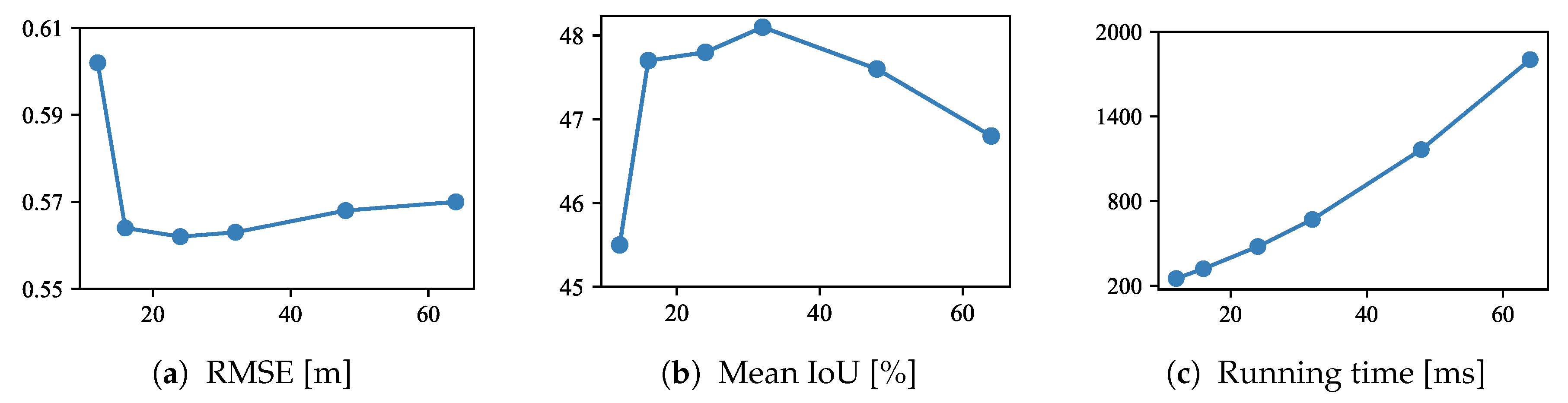
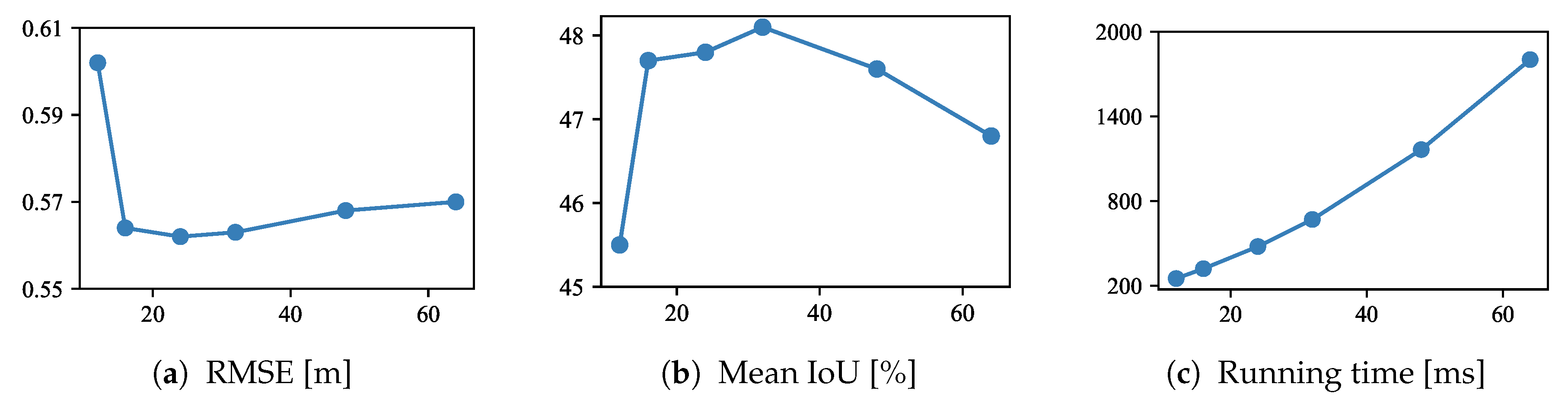
5.3.1. Number of Depth Samples
5.3.2. Network Architecture
5.3.3. Pre-Training
5.3.4. Single Tasks
6. Discussion
- Hard parameter sharing. For the joint task of depth estimation and semantic segmentation, the typical design choice is hard parameter sharing. Although dimensionality of feature representations is an important aspect, it has been overlooked in previous studies [15,16,17,18,19,20,41]. In this study, considering the real world is three-dimensional, we proposed a latent 3D volume representation.
- Comparison against state-of-the-art methods. We evaluated our method on the NYU Depth v2 dataset [22]. As shown in Section 5.2, the proposed method achieves the best performance in both depth estimation and semantic segmentation compared to previous joint task methods [15,16,17]. The main difference between our method and previous methods is the representation of shared features in terms of dimensionality. While 2D representation has one feature vector for each pixel, the proposed representation assumes multiple depth planes and can maintain feature vectors for each depth. Having multiple feature vectors can enhance the 3D spatial context, which leads to dealing with ambiguity in depth and semantics. In other words, the proposed representation complements each other in geometric and semantic contexts. The experimental results show that the proposed latent 3D volume is superior to 2D feature representation for the joint task of depth estimation and semantic segmentation. One concern about the proposed method is running time and memory consumption. Although our new attempt is the use of 3D CNNs, it requires more running time and memory than 2D CNNs. Especially, the method by Nekrasov et al. [16] is much better than our method in terms of time and memory efficiency. A more compact representation of 3D features is required to reduce running time and memory consumption for practical use.
- Network architecture. Our network builds the initial volume using the 2D feature maps from 2D CNNs and then feeds it into 3D CNNs to obtain the latent 3D volume. While the initial volume is obtained by reshaping the 2D feature maps, our network can produce a latent 3D volume with 3D spatial contextual information. By training the network in an end-to-end manner, the 2D CNNs are trained to output the feature maps to have the 3D structure in the channel dimension. We examine how the network structure affects the learning of latent 3D volume. As shown in Section 5.3, multi-scale features from 2D CNNs are most effective to build a latent 3D volume. In contrast, the comparison of 3D CNNs shows that there is only a slight difference in performance between the residual and hourglass modules. In other words, multi-scale feature extraction in 3D CNNs has little effect.
- Projection module. The latent 3D volume is used for inferring depth and semantic segmentation. We design the projection module to have two branches to decompose the latent 3D volume into geometric and semantic features. The outputs of the branches are fed into task-specific layers. We show that concatenating the outputs of the two branches improves performance. In addition, the combination of latent 3D volume and projection module achieves promising results.
- Training strategy. We train the network in two stages using a large-scale synthetic dataset and a small-scale real-world dataset. Our experimental results show that pre-training using synthetic images is effective for learning the latent 3D volume. In addition, we use the domain adaptation to fill the gap between synthetic and real images. One of the advantages of synthetic data is accurate annotation. As real data sometimes suffers from inter-sensor distortions, calibration may be required. In contrast, synthetic data and its annotations are always aligned. We show that the performance of depth and semantic segmentation can be improved by using domain-adapted synthetic data.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hane, C.; Zach, C.; Cohen, A.; Angst, R.; Pollefeys, M. Joint 3D Scene Reconstruction and Class Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 97–104. [Google Scholar]
- Sengupta, S.; Greveson, E.; Shahrokni, A.; Torr, P.H.S. Urban 3D semantic modelling using stereo vision. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 580–585. [Google Scholar]
- Kundu, A.; Li, Y.; Dellaert, F.; Li, F.; Rehg, J.M. Joint Semantic Segmentation and 3D Reconstruction from Monocular Video. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 703–718. [Google Scholar]
- Hane, C.; Zach, C.; Cohen, A.; Pollefeys, M. Dense Semantic 3D Reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 39, 1730–1743. [Google Scholar] [CrossRef] [PubMed]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper Depth Prediction with Fully Convolutional Residual Networks. In Proceedings of the International Conference on 3D Vision (3DV), Palo Alto, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep Ordinal Regression Network for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I.D. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Mousavian, A.; Pirsiavash, H.; Kosecka, J. Joint Semantic Segmentation and Depth Estimation with Deep Convolutional Networks. In Proceedings of the International Conference on 3D Vision (3DV), Palo Alto, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar]
- Nekrasov, V.; Dharmasiri, T.; Spek, A.; Drummond, T.; Shen, C.; Reid, I.D. Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7101–7107. [Google Scholar]
- Lin, X.; Sánchez-Escobedo, D.; Casas, J.R.; Pardàs, M. Depth Estimation and Semantic Segmentation from a Single RGB Image Using a Hybrid Convolutional Neural Network. Sensors 2019, 19, 1795. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, L.; Xu, C.; Cui, Z.; Yang, J. KIL: Knowledge Interactiveness Learning for Joint Depth Estimation and Semantic Segmentation. In Proceedings of the Asian Conference on Pattern Recognition (ACPR), Auckland, New Zealand, 26–29 November 2019; pp. 835–848. [Google Scholar]
- Zhou, L.; Cui, Z.; Xu, C.; Zhang, Z.; Wang, C.; Zhang, T.; Yang, J. Pattern-Structure Diffusion for Multi-Task Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4513–4522. [Google Scholar]
- Jiao, J.; Cao, Y.; Song, Y.; Lau, R.W.H. Look Deeper into Depth: Monocular Depth Estimation with Semantic Booster and Attention-Driven Loss. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 55–71. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 238–255. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T.A. Semantic Scene Completion from a Single Depth Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 190–198. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning Depth from Single Monocular Images. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 5–8 December 2005; pp. 1161–1168. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D Scene Structure from a Single Still Image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, B.; Gould, S.; Koller, D. Single image depth estimation from predicted semantic labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1253–1260. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Automatic Photo Pop-up. ACM Trans. Graph. 2005, 24, 577–584. [Google Scholar] [CrossRef]
- Li, B.; Shen, C.; Dai, Y.; van den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Roy, A.; Todorovic, S. Monocular Depth Estimation Using Neural Regression Forest. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5506–5514. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Jiao, J.; Wei, Y.; Jie, Z.; Shi, H.; Lau, R.W.H.; Huang, T.S. Geometry-Aware Distillation for Indoor Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2869–2878. [Google Scholar]
- Gupta, S.; Girshick, R.B.; Arbeláez, P.A.; Malik, J. Learning Rich Features from RGB-D Images for Object Detection and Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 345–360. [Google Scholar]
- Cheng, Y.; Cai, R.; Li, Z.; Zhao, X.; Huang, K. Locality-Sensitive Deconvolution Networks with Gated Fusion for RGB-D Indoor Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1475–1483. [Google Scholar]
- Park, S.; Lee, S.; Hong, K. RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4990–4999. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Gool, L.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar]
- Caruana, R. Multitask Learning: A Knowledge-Based Source of Inductive Bias. In Proceedings of the 35th International Conference Machine Learning (ICML), Amherst, MA, USA, 27–29 June 1993; pp. 41–48. [Google Scholar]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A.L. Towards unified depth and semantic prediction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2800–2809. [Google Scholar]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5574–5584. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Chen, P.; Liu, A.H.; Liu, Y.; Wang, Y.F. Towards Scene Understanding: Unsupervised Monocular Depth Estimation With Semantic-Aware Representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2624–2632. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P. End-to-End Learning of Geometry and Context for Deep Stereo Regression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Im, S.; Jeon, H.; Lin, S.; Kweon, I.S. DPSNet: End-to-end Deep Plane Sweep Stereo. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. Available online: https://openreview.net/forum?id=ryeYHi0ctQ (accessed on 10 August 2020).
- Ma, F.; Karaman, S. Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 1–8. [Google Scholar]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting Single Image Depth Estimation: Toward Higher Resolution Maps With Accurate Object Boundaries. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1043–1051. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual Organization and Recognition of Indoor Scenes from RGB-D Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 564–571. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid Stereo Matching Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.A.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 165–174. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 1994–2003. [Google Scholar]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Luo, Z.; Wang, J. Structured Knowledge Distillation for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2604–2613. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Depth Estimation | Sem. Segm. | |||||
|---|---|---|---|---|---|---|---|
| Method | Depth | Sem. Segm. | REL ↓ | RMSE ↓ | log10 ↓ | ↑ | MIoU↑ |
| Laina et al. [6] | ✓ | 0.127 | 0.573 | 0.055 | 0.811 | ||
| Fu et al. [8] | ✓ | 0.115 | 0.509 | 0.051 | 0.828 | ||
| Lin et al. [12] | ✓ | 46.5 | |||||
| Jiao et al. [33] | ✓ | 59.6 | |||||
| † Eigen & Fergus [13] | ✓ | ✓ | 0.158 | 0.641 | - | 0.769 | 34.1 |
| † Kendall & Gal [42] | ✓ | ✓ | 0.110 | 0.506 | - | 0.817 | 37.3 |
| ‡ Mousavian et al. [15] | ✓ | ✓ | 0.200 | 0.816 | - | 0.568 | 39.2 |
| ‡ Zhang et al. [21] | ✓ | ✓ | 0.144 | 0.501 | - | 0.815 | 46.4 |
| ‡ Lin et al. [17] | ✓ | ✓ | 0.279 | 0.942 | - | 0.501 | 36.5 |
| ‡ Nekrasov et al. [16] | ✓ | ✓ | 0.149 | 0.565 | - | 0.790 | 42.2 |
| ‡ Ours | ✓ | ✓ | 0.139 | 0.564 | 0.059 | 0.819 | 47.7 |
| Task | General | |||
|---|---|---|---|---|
| Method | Depth | Sem. Segm. | Params [M] | Running Time [ms] |
| Laina et al. [6] | ✓ | 63.57 | ||
| Fu et al. [8] | ✓ | N/A | ||
| Lin et al. [12] | ✓ | 118.10 | ||
| Jiao et al. [33] | ✓ | 103.46 | N/A | |
| Nekrasov et al. [16] | ✓ | ✓ | 3.07 | |
| Ours | ✓ | ✓ | 77.43 | |
| Method | Wall | Floor | Cabinet | Bed | Chair | Sofa | Table | Door |
|---|---|---|---|---|---|---|---|---|
| FCN [9] | 69.9 | 79.4 | 50.3 | 66.0 | 47.5 | 53.2 | 32.8 | 22.1 |
| Gupta et al. [34] | 68.0 | 81.3 | 44.9 | 65.0 | 47.9 | 47.9 | 29.9 | 20.3 |
| Cheng et al. [35] | 78.5 | 87.1 | 56.6 | 70.1 | 65.2 | 63.9 | 46.9 | 35.9 |
| Park et al. [36] | 79.7 | 87.0 | 60.9 | 73.4 | 64.6 | 65.4 | 50.7 | 39.9 |
| * Jiao et al. [33] | 71.4 | 75.2 | 71.3 | 77.1 | 53.3 | 69.5 | 51.4 | 63.7 |
| * Ours | 79.0 | 84.8 | 62.4 | 69.9 | 61.5 | 67.0 | 46.1 | 47.1 |
| Window | Bookshelf | Picture | Counter | Blinds | Desk | Shelves | Curtain | |
| FCN [9] | 39.0 | 36.1 | 50.5 | 54.2 | 45.8 | 11.9 | 8.6 | 32.5 |
| Gupta et al. [34] | 32.6 | 18.1 | 40.3 | 51.3 | 42.0 | 11.3 | 3.5 | 29.1 |
| Cheng et al. [35] | 47.1 | 48.9 | 54.3 | 66.3 | 51.7 | 20.6 | 13.7 | 49.8 |
| Park et al. [36] | 49.6 | 44.9 | 61.2 | 67.1 | 63.9 | 28.6 | 14.2 | 59.7 |
| * Jiao et al. [33] | 68.2 | 57.3 | 61.4 | 53.1 | 77.1 | 55.2 | 52.5 | 70.4 |
| * Ours | 53.3 | 52.1 | 62.0 | 53.1 | 62.6 | 36.7 | 26.4 | 60.0 |
| Dresser | Pillow | Mirror | Floormat | Clothes | Ceiling | Books | Fridge | |
| FCN [9] | 31.0 | 37.5 | 22.4 | 13.6 | 18.3 | 59.1 | 27.3 | 27.0 |
| Gupta et al. [34] | 34.8 | 34.4 | 16.4 | 28.0 | 4.7 | 60.5 | 6.4 | 14.5 |
| Cheng et al. [35] | 43.2 | 50.4 | 48.5 | 32.2 | 24.7 | 62.0 | 34.2 | 45.3 |
| Park et al. [36] | 49.0 | 49.9 | 54.3 | 39.4 | 26.9 | 69.1 | 35.0 | 58.9 |
| * Jiao et al. [33] | 64.2 | 51.6 | 68.3 | 61.3 | 53.1 | 58.1 | 42.9 | 62.2 |
| * Ours | 59.9 | 46.8 | 52.0 | 49.1 | 38.8 | 71.1 | 34.6 | 37.3 |
| TV | Paper | Towel | Shower | Box | Board | Person | Nightstand | |
| FCN [9] | 41.9 | 15.9 | 26.1 | 14.1 | 6.5 | 12.9 | 57.6 | 30.1 |
| Gupta et al. [34] | 31.0 | 14.3 | 16.3 | 4.2 | 2.1 | 14.2 | 0.2 | 27.2 |
| Cheng et al. [35] | 53.4 | 27.7 | 42.6 | 23.9 | 11.2 | 58.8 | 53.2 | 54.1 |
| Park et al. [36] | 63.8 | 34.1 | 41.6 | 38.5 | 11.6 | 54.0 | 80.0 | 45.3 |
| * Jiao et al. [33] | 71.7 | 40.0 | 58.2 | 79.2 | 44.1 | 72.6 | 55.9 | 55.0 |
| * Ours | 68.5 | 22.3 | 44.1 | 29.8 | 4.7 | 42.7 | 64.1 | 23.4 |
| Toilet | Sink | Lamp | Bathtub | Bag | Ot. Struct. | Ot. Furn. | Ot. Props. | |
| FCN [9] | 61.3 | 44.8 | 32.1 | 39.2 | 4.8 | 15.2 | 7.7 | 30.0 |
| Gupta et al. [34] | 55.1 | 37.5 | 34.8 | 38.2 | 0.2 | 7.1 | 6.1 | 23.1 |
| Cheng et al. [35] | 80.4 | 59.2 | 45.5 | 52.6 | 15.9 | 12.7 | 16.4 | 29.3 |
| Park et al. [36] | 65.7 | 62.1 | 47.1 | 57.3 | 19.1 | 30.7 | 20.6 | 39.0 |
| * Jiao et al. [33] | 72.5 | 50.8 | 33.6 | 72.3 | 46.3 | 50.6 | 54.1 | 37.8 |
| * Ours | 67.7 | 47.8 | 35.3 | 35.1 | 6.7 | 33.4 | 30.2 | 38.5 |
| Method | REL | RMSE | MIoU |
|---|---|---|---|
| (a) Straightforward projection module | 0.143 | 0.548 | 43.3 |
| (b) Two different branches | 0.130 | 0.563 | 45.7 |
| (c) w/o Decoder | 0.151 | 0.581 | 45.8 |
| (d) w/o Up-projection module | 0.154 | 0.583 | 43.1 |
| (e) Stacked hourglass | 0.132 | 0.567 | 47.2 |
| (f) Depth domain | 0.146 | 0.573 | 47.2 |
| (g) w/o Pre-training | 0.151 | 0.583 | 41.8 |
| (h) Pre-training w/o Domain Adaptation | 0.125 | 0.561 | 43.5 |
| (i) Single tasks | 0.127 | 0.559 | 44.8 |
| (j) Ours | 0.139 | 0.564 | 47.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ito, S.; Kaneko, N.; Sumi, K. Latent 3D Volume for Joint Depth Estimation and Semantic Segmentation from a Single Image. Sensors 2020, 20, 5765. https://doi.org/10.3390/s20205765
Ito S, Kaneko N, Sumi K. Latent 3D Volume for Joint Depth Estimation and Semantic Segmentation from a Single Image. Sensors. 2020; 20(20):5765. https://doi.org/10.3390/s20205765
Chicago/Turabian StyleIto, Seiya, Naoshi Kaneko, and Kazuhiko Sumi. 2020. "Latent 3D Volume for Joint Depth Estimation and Semantic Segmentation from a Single Image" Sensors 20, no. 20: 5765. https://doi.org/10.3390/s20205765
APA StyleIto, S., Kaneko, N., & Sumi, K. (2020). Latent 3D Volume for Joint Depth Estimation and Semantic Segmentation from a Single Image. Sensors, 20(20), 5765. https://doi.org/10.3390/s20205765